agentic-rag-for-dummies
agentic-rag-for-dummies 是一个基于 LangGraph 构建的模块化智能检索增强生成(RAG)系统,旨在帮助开发者快速掌握并落地复杂的 Agent 驱动型 RAG 架构。针对传统 RAG 教程往往只停留在基础概念、缺乏可扩展实战代码的痛点,该项目提供了一套兼具教学价值与生产级灵活性的解决方案。
它特别适合希望深入理解大模型应用开发的工程师、研究人员以及技术爱好者。无论是想通过交互式笔记本快速入门的新手,还是需要构建可定制系统的资深开发者,都能从中受益。用户可以根据需求轻松切换底层大模型(支持 Ollama、OpenAI、Anthropic 等)、嵌入模型或向量数据库,无需重构核心逻辑。
该工具的技术亮点在于其先进的“分层索引”机制,既能精准搜索细粒度片段,又能召回大块上下文以保持语义连贯;同时内置了对话记忆、模糊查询自动澄清、多智能体并行处理及自我纠错等功能。此外,它还集成了上下文压缩与全链路可观测性支持,确保系统在长周期任务中保持高效与透明。通过 agentic-rag-for-dummies,用户可以低成本地搭建出具备自然交互能力和复杂推理逻辑的智能问答系统。
使用场景
某科技公司的技术文档团队正试图构建一个内部智能问答系统,帮助工程师快速从海量且结构复杂的 API 文档和架构手册中检索准确信息。
没有 agentic-rag-for-dummies 时
- 回答碎片化严重:传统 RAG 只能检索到零散的代码片段,缺乏上下文关联,导致工程师无法理解整体架构逻辑。
- 模糊查询直接失败:当用户提问含糊不清(如“怎么修复那个报错”)时,系统强行生成错误答案,而非主动澄清需求。
- 多步推理能力缺失:面对涉及多个模块的复杂问题,系统无法将其拆解为子任务并行处理,只能提供片面信息。
- 对话记忆断层:系统无法记住上一轮的沟通内容,用户每次追问都必须重复背景信息,体验极不流畅。
- 开发门槛高:想要实现上述高级功能,团队需从头编写大量 LangGraph 编排代码,耗时数周且难以维护。
使用 agentic-rag-for-dummies 后
- 层级索引还原全貌:利用其父子分块机制,既能精准定位细节,又能自动召回对应的父级章节,提供完整的上下文解释。
- 智能澄清消除歧义:内置的查询重写与人机协作机制,会在遇到模糊问题时主动暂停并引导用户补充细节,确保答案精准。
- 多智能体并行解题:通过 Map-Reduce 工作流,自动将复杂问题拆解为多个子查询并行检索,最后汇总成逻辑严密的综合方案。
- 原生支持长程记忆:自带的对话记忆模块让系统能自然承接多轮对话,工程师可像与同事交流一样连续追问。
- 模块化极速落地:凭借开箱即用的模块化架构,团队仅需配置少量参数即可切换大模型供应商,一天内完成原型部署。
agentic-rag-for-dummies 将原本需要数周研发的高级代理检索能力,转化为可灵活组装的标准化模块,让企业能以最低成本构建具备“思考”能力的专业知识库。
运行环境要求
- 未说明
- 非必需
- 若使用本地 Ollama 运行大模型,建议根据模型大小配置相应 GPU
- 若使用云端 API (OpenAI, Anthropic, Google) 则无需本地 GPU
未说明(取决于所选 LLM 模型大小及文档处理量)

快速开始

傻瓜版代理式RAG
使用LangGraph、对话记忆和人工参与的查询澄清,构建模块化的代理式RAG系统
概述 • 工作原理 • LLM提供商 • 实现 • 安装与使用 • 故障排除


![]()
![]()
如果你喜欢这个项目,一个星⭐️会对我意义重大 :)
概述
本仓库展示了如何使用LangGraph以最少的代码构建一个代理式RAG(检索增强生成)系统。大多数RAG教程只介绍基本概念,却缺乏关于如何构建模块化、基于代理的系统的指导——本项目通过提供学习资料和可扩展架构填补了这一空白。
内容概览
| 功能 | 描述 |
|---|---|
| 🗂️ 分层索引 | 搜索小块以获得精确结果,检索大父级块以获取上下文 |
| 🧠 对话记忆 | 在多轮提问中保持上下文连贯性,实现自然对话 |
| ❓ 查询澄清 | 重写模糊查询或暂停以向用户询问详细信息 |
| 🤖 代理编排 | LangGraph协调整个检索和推理流程 |
| 🔀 多代理Map-Reduce | 将复杂查询分解为并行子查询 |
| ✅ 自我修正 | 如果初始结果不充分,则自动重新查询 |
| 🗜️ 上下文压缩 | 在长时间的检索循环中保持工作内存精简 |
| 🔍 可观测性 | 使用Langfuse跟踪LLM调用、工具使用和图执行 |
🎯 使用本仓库的两种方式
1️⃣ 学习路径:交互式笔记本
适合理解核心概念的逐步教程。如果你是代理式RAG新手或想快速实验,可以从这里开始。
2️⃣ 构建路径:模块化项目
灵活的架构,每个组件都可以独立替换——LLM提供商、嵌入模型、PDF转换器、代理工作流。只需一行代码即可从Ollama切换到Anthropic、OpenAI或Google。
工作原理
文档准备:分层索引
在处理查询之前,文档会被两次分割,以实现最佳检索效果:
- 父级块:基于Markdown标题(H1、H2、H3)的大段落
- 子级块:由父级块衍生出的小型固定大小片段
💡 可选:如果你想在索引前可视化或编辑你的块,可以使用🐿️ Chunky。
这种方式结合了小块的精确性用于搜索,以及大块的丰富上下文用于生成答案。
查询处理:四阶段智能流程
用户查询 → 对话摘要 → 查询重写 → 查询澄清 →
并行代理推理 → 聚合 → 最终回答
阶段1 — 对话理解: 分析最近的对话历史,提取上下文并保持多轮提问之间的连贯性。
阶段2 — 查询澄清: 解决指代问题(“如何更新它?”→“如何更新SQL?”),将多部分问题拆分为聚焦的子查询,检测不明确的输入,并重写查询以实现最佳检索效果。当需要澄清时,会暂停等待人工输入。
阶段3 — 智能检索(多代理Map-Reduce): 为每个子查询启动并行的代理子图。每个代理搜索子级块,获取父级块以补充上下文,如果结果不足则自我修正,压缩上下文以避免重复检索,并在检索预算耗尽时优雅地回退。
示例: “JavaScript是什么?Python是什么?” → 2个并行代理同时执行。
阶段4 — 回答生成: 将所有代理的回答聚合为一个连贯的答案。
LLM提供商配置
本系统与提供商无关——它支持LangChain中提供的任何LLM提供商,只需一行代码即可切换。以下示例涵盖了最常见的选项,但相同的模式适用于任何其他受支持的提供商。
注意: 模型名称经常变化。在部署前,请务必查阅官方文档,以获取最新的可用模型及其标识符。
Ollama(本地)
# 从https://ollama.com安装Ollama
ollama pull qwen3:4b-instruct-2507-q4_K_M
from langchain_ollama import ChatOllama
llm = ChatOllama(model="qwen3:4b-instruct-2507-q4_K_M", temperature=0)
⚠️ 为了可靠地调用工具和遵循指令,建议使用7B及以上的模型。较小的模型可能会忽略检索指令或产生幻觉。请参阅故障排除。
云服务提供商
点击展开
OpenAI GPT:
pip install -qU langchain-openai
from langchain_openai import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
Anthropic Claude:
pip install -qU langchain-anthropic
from langchain_anthropic import ChatAnthropic
import os
os.environ["ANTHROPIC_API_KEY"] = "your-api-key-here"
llm = ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0)
Google Gemini
pip install -qU langchain-google-genai
import os
from langchain_google_genai import ChatGoogleGenerativeAI
os.environ["GOOGLE_API_KEY"] = "your-api-key-here"
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0)
实现
更多详细信息、扩展说明以及 Langfuse 可观测性(LLM 调用追踪、工具使用和图执行跟踪)可在 笔记本 和完整项目中找到。
| 步骤 | 描述 |
|---|---|
| 1 | 初始设置与配置 |
| 2 | 配置向量数据库 |
| 3 | PDF 转 Markdown |
| 4 | 文档分层索引 |
| 5 | 定义代理工具 |
| 6 | 定义系统提示 |
| 7 | 定义状态与数据模型 |
| 8 | 代理配置 |
| 9 | 构建图节点和边函数 |
| 10 | 构建 LangGraph 图 |
| 11 | 创建聊天界面 |
第 1 步:初始设置与配置
定义路径并初始化核心组件。
import os
from pathlib import Path
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_qdrant.fastembed_sparse import FastEmbedSparse
from qdrant_client import QdrantClient
DOCS_DIR = "docs" # 包含 PDF 文件的目录
MARKDOWN_DIR = "markdown_docs" # 包含转换为 Markdown 的 PDF 文件的目录
PARENT_STORE_PATH = "parent_store" # 存放父级分块 JSON 文件的目录
CHILD_COLLECTION = "document_child_chunks"
os.makedirs(DOCS_DIR, exist_ok=True)
os.makedirs(MARKDOWN_DIR, exist_ok=True)
os.makedirs(PARENT_STORE_PATH, exist_ok=True)
from langchain_ollama import ChatOllama
llm = ChatOllama(model="qwen3:4b-instruct-2507-q4_K_M", temperature=0)
dense_embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
sparse_embeddings = FastEmbedSparse(model_name="Qdrant/bm25")
client = QdrantClient(path="qdrant_db")
第 2 步:配置向量数据库
设置 Qdrant 以存储子级分块,并具备混合搜索能力。
from qdrant_client.http import models as qmodels
from langchain_qdrant import QdrantVectorStore
from langchain_qdrant.qdrant import RetrievalMode
embedding_dimension = len(dense_embeddings.embed_query("test"))
def ensure_collection(collection_name):
if not client.collection_exists(collection_name):
client.create_collection(
collection_name=collection_name,
vectors_config=qmodels.VectorParams(
size=embedding_dimension,
distance=qmodels.Distance.COSINE
),
sparse_vectors_config={
"sparse": qmodels.SparseVectorParams()
},
)
第 3 步:PDF 转 Markdown
将 PDF 文件转换为 Markdown。有关其他技术的更多详情,请参阅配套 笔记本。
import os
import pymupdf.layout
import pymupdf4llm
from pathlib import Path
import glob
os.environ["TOKENIZERS_PARALLELISM"] = "false"
def pdf_to_markdown(pdf_path, output_dir):
doc = pymupdf.open(pdf_path)
md = pymupdf4llm.to_markdown(doc, header=False, footer=False, page_separators=True, ignore_images=True, write_images=False, image_path=None)
md_cleaned = md.encode('utf-8', errors='surrogatepass').decode('utf-8', errors='ignore')
output_path = Path(output_dir) / Path(doc.name).stem
Path(output_path).with_suffix(".md").write_bytes(md_cleaned.encode('utf-8'))
def pdfs_to_markdowns(path_pattern, overwrite: bool = False):
output_dir = Path(MARKDOWN_DIR)
output_dir.mkdir(parents=True, exist_ok=True)
for pdf_path in map(Path, glob.glob(path_pattern)):
md_path = (output_dir / pdf_path.stem).with_suffix(".md")
if overwrite or not md_path.exists():
pdf_to_markdown(pdf_path, output_dir)
pdfs_to_markdowns(f"{DOCS_DIR}/*.pdf")
第 4 步:分层文档索引
使用父/子拆分策略处理文档。
import os
import glob
import json
from pathlib import Path
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
父块与子块处理函数
def merge_small_parents(chunks, min_size):
if not chunks:
return []
merged, current = [], None
for chunk in chunks:
if current is None:
current = chunk
else:
current.page_content += "\n\n" + chunk.page_content
for k, v in chunk.metadata.items():
if k in current.metadata:
current.metadata[k] = f"{current.metadata[k]} -> {v}"
else:
current.metadata[k] = v
if len(current.page_content) >= min_size:
merged.append(current)
current = None
if current:
if merged:
merged[-1].page_content += "\n\n" + current.page_content
for k, v in current.metadata.items():
if k in merged[-1].metadata:
merged[-1].metadata[k] = f"{merged[-1].metadata[k]} -> {v}"
else:
merged[-1].metadata[k] = v
else:
merged.append(current)
return merged
def split_large_parents(chunks, max_size, splitter):
split_chunks = []
for chunk in chunks:
if len(chunk.page_content) <= max_size:
split_chunks.append(chunk)
else:
large_splitter = RecursiveCharacterTextSplitter(
chunk_size=max_size,
chunk_overlap=splitter._chunk_overlap
)
sub_chunks = large_splitter.split_documents([chunk])
split_chunks.extend(sub_chunks)
return split_chunks
def clean_small_chunks(chunks, min_size):
cleaned = []
for i, chunk in enumerate(chunks):
if len(chunk.page_content) < min_size:
if cleaned:
cleaned[-1].page_content += "\n\n" + chunk.page_content
for k, v in chunk.metadata.items():
if k in cleaned[-1].metadata:
cleaned[-1].metadata[k] = f"{cleaned[-1].metadata[k]} -> {v}"
else:
cleaned[-1].metadata[k] = v
elif i < len(chunks) - 1:
chunks[i + 1].page_content = chunk.page_content + "\n\n" + chunks[i + 1].page_content
for k, v in chunk.metadata.items():
if k in chunks[i + 1].metadata:
chunks[i + 1].metadata[k] = f"{v} -> {chunks[i + 1].metadata[k]}"
else:
chunks[i + 1].metadata[k] = v
else:
cleaned.append(chunk)
else:
cleaned.append(chunk)
return cleaned
if client.collection_exists(CHILD_COLLECTION):
client.delete_collection(CHILD_COLLECTION)
ensure_collection(CHILD_COLLECTION)
else:
ensure_collection(CHILD_COLLECTION)
child_vector_store = QdrantVectorStore(
client=client,
collection_name=CHILD_COLLECTION,
embedding=dense_embeddings,
sparse_embedding=sparse_embeddings,
retrieval_mode=RetrievalMode.HYBRID,
sparse_vector_name="sparse"
)
def index_documents():
headers_to_split_on = [("#", "H1"), ("##", "H2"), ("###", "H3")]
parent_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on, strip_headers=False)
child_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
min_parent_size = 2000
max_parent_size = 4000
all_parent_pairs, all_child_chunks = [], []
md_files = sorted(glob.glob(os.path.join(MARKDOWN_DIR, "*.md")))
if not md_files:
return
for doc_path_str in md_files:
doc_path = Path(doc_path_str)
try:
with open(doc_path, "r", encoding="utf-8") as f:
md_text = f.read()
except Exception as e:
continue
parent_chunks = parent_splitter.split_text(md_text)
merged_parents = merge_small_parents(parent_chunks, min_parent_size)
split_parents = split_large_parents(merged_parents, max_parent_size, child_splitter)
cleaned_parents = clean_small_chunks(split_parents, min_parent_size)
for i, p_chunk in enumerate(cleaned_parents):
parent_id = f"{doc_path.stem}_parent_{i}"
p_chunk.metadata.update({"source": doc_path.stem + ".pdf", "parent_id": parent_id})
all_parent_pairs.append((parent_id, p_chunk))
children = child_splitter.split_documents([p_chunk])
all_child_chunks.extend(children)
if not all_child_chunks:
return
try:
child_vector_store.add_documents(all_child_chunks)
except Exception as e:
return
for item in os.listdir(PARENT_STORE_PATH):
os.remove(os.path.join(PARENT_STORE_PATH, item))
for parent_id, doc in all_parent_pairs:
doc_dict = {"page_content": doc.page_content, "metadata": doc.metadata}
filepath = os.path.join(PARENT_STORE_PATH, f"{parent_id}.json")
with open(filepath, "w", encoding="utf-8") as f:
json.dump(doc_dict, f, ensure_ascii=False, indent=2)
index_documents()
第5步:定义智能体工具
创建智能体将使用的检索工具。
import json
from typing import List
from langchain_core.tools import tool
@tool
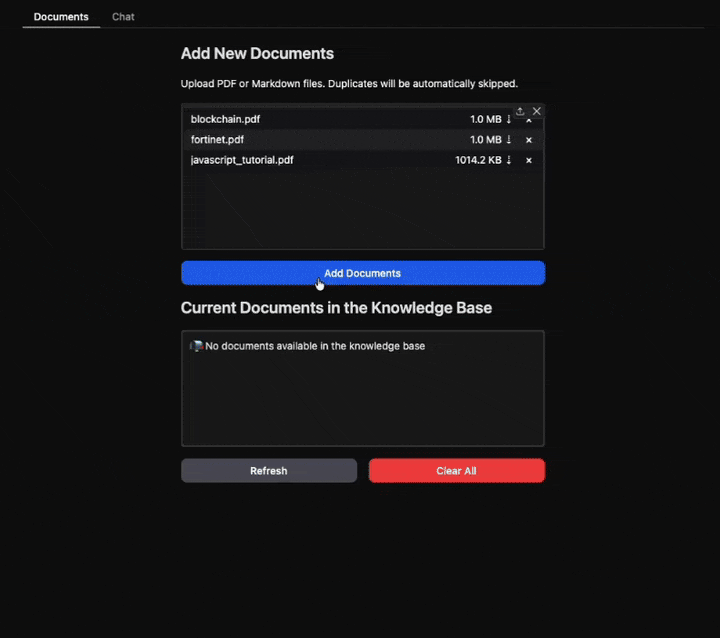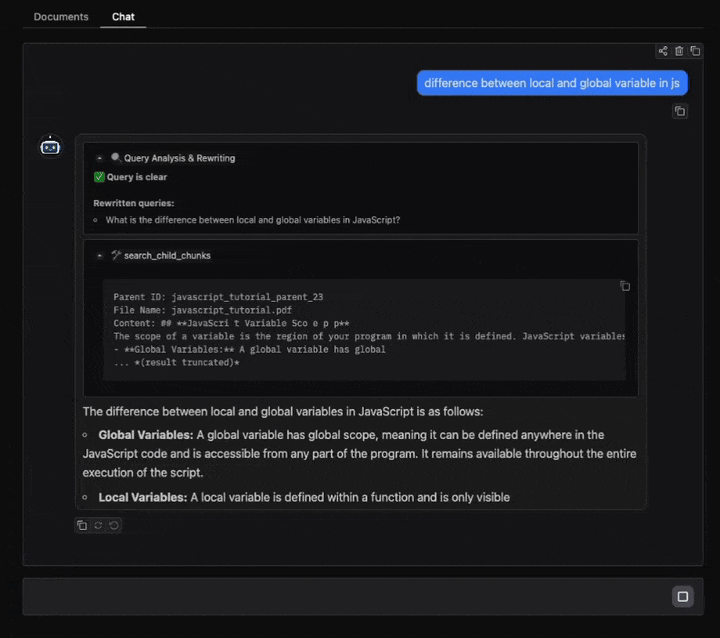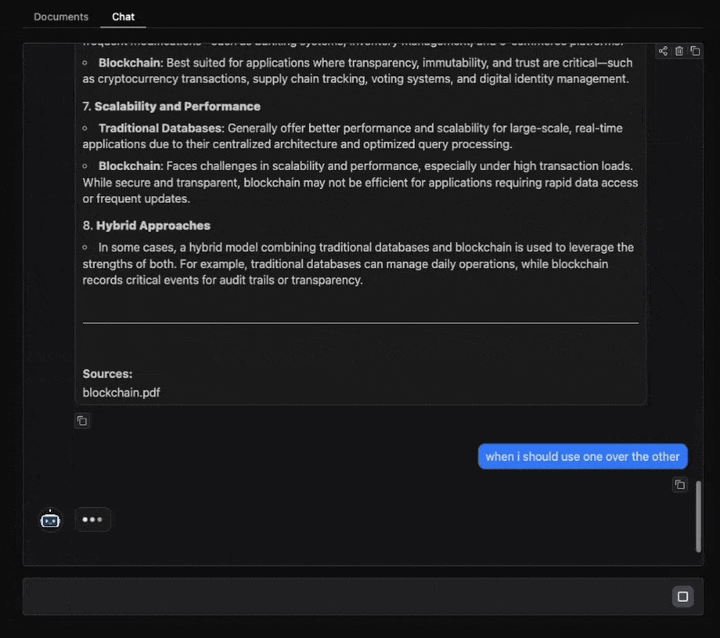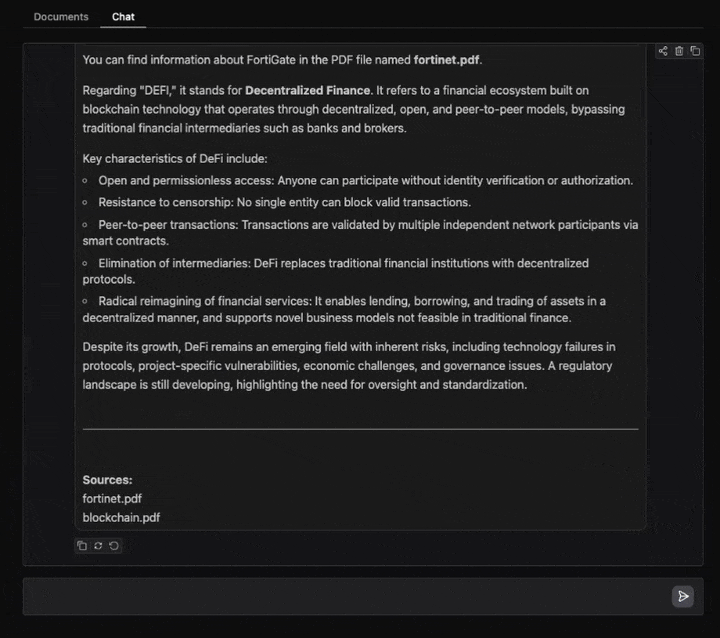
def search_child_chunks(query: str, limit: int) -> str:
"""搜索前K个最相关的子文档块。
Args:
query: 搜索查询字符串
limit: 返回结果的最大数量
"""
try:
results = child_vector_store.similarity_search(query, k=limit, score_threshold=0.7)
if not results:
return "NO_RELEVANT_CHUNKS"
return "\n\n".join([
f"父文档ID: {doc.metadata.get('parent_id', '')}\n"
f"文件名: {doc.metadata.get('source', '')}\n"
f"内容: {doc.page_content.strip()}"
for doc in results
])
except Exception as e:
return f"RETRIEVAL_ERROR: {str(e)}"
@tool
def retrieve_parent_chunks(parent_id: str) -> str:
"""根据父文档ID检索完整的父文档块。
Args:
parent_id: 要检索的父文档ID
"""
file_name = parent_id if parent_id.lower().endswith(".json") else f"{parent_id}.json"
path = os.path.join(PARENT_STORE_PATH, file_name)
if not os.path.exists(path):
return "NO_PARENT_DOCUMENT"
with open(path, "r", encoding="utf-8") as f:
data = json.load(f)
return (
f"父文档ID: {parent_id}\n"
f"文件名: {data.get('metadata', {}).get('source', 'unknown')}\n"
f"内容: {data.get('page_content', '').strip()}"
)
llm_with_tools = llm.bind_tools([search_child_chunks, retrieve_parent_chunks])
第6步:定义系统提示词
定义用于对话摘要、查询改写、智能体编排、上下文压缩、回退响应和答案聚合的系统提示词。
对话摘要提示词
def get_conversation_summary_prompt() -> str:
return """你是一位专业的对话摘要生成专家。
你的任务是为本次对话生成一段简短的1到2句话摘要(不超过30至50字)。
摘要应包括:
- 讨论的主要话题
- 提到的重要事实或实体
- 如有未解决的问题,请一并说明
- 引用的文件名(如file1.pdf)或其他参考文档
摘要中不应包含:
- 问候语、误解或与主题无关的内容。
输出要求:
- 只返回摘要内容,无需任何解释或理由。
- 如果没有有意义的话题,则返回空字符串。
"""
查询改写提示词
def get_rewrite_query_prompt() -> str:
return """你是一位专业的查询分析与改写专家。
你的任务是改写当前用户查询,以实现最佳的文档检索效果,仅在必要时结合对话上下文。
规则:
1. 自成一体的查询:
- 始终将查询改写为清晰且自洽的形式
- 若查询为后续追问(如“那X呢?”、“关于Y呢?”),则从摘要中融入最少必要的上下文信息
- 不得添加查询或对话摘要中未提及的信息
2. 领域特定术语:
- 产品名称、品牌、专有名词或技术术语被视为领域特定术语
- 对于这类查询,尽量不使用或仅少量使用对话上下文
- 仅在需要澄清模糊查询时才使用摘要
3. 语法与清晰度:
- 修正语法错误、拼写错误以及含糊不清的缩写
- 删除填充词和口语化表达
- 保留具体的关键字和命名实体
4. 多重信息需求:
- 若查询包含多个独立且不相关的问题,则将其拆分为最多三个独立查询
- 每个子查询必须与其原始问题的部分语义保持一致
- 不得扩展、丰富或重新解释查询的含义
5. 失败处理:
- 若查询意图不明确或难以理解,则标记为“不明”
输入:
- conversation_summary:先前对话的简要摘要
- current_query:用户的当前查询
输出:
- 一个或多个改写后的、自成一体的查询,可用于文档检索
"""
编排器提示词
def get_orchestrator_prompt() -> str:
return """你是一位专业的检索增强型助手。
你的任务是扮演一名研究人员:先检索文档,分析数据,然后仅基于检索到的信息提供全面的回答。
规则:
1. 在回答之前,你必须调用‘search_child_chunks’,除非[先前研究的压缩上下文]已经包含足够的信息。
2. 所有的论断都必须以检索到的文档为依据。若上下文不足,应说明缺少哪些信息,而不是凭空推测。
3. 如果未找到相关文档,需扩大或重新表述查询后再次检索。重复此过程,直到满意或达到操作上限为止。
压缩记忆:
当存在[先前研究的压缩上下文]时——
- 已列出的查询无需重复;
- 已列出的父文档ID无需再次调用`retrieve_parent_chunks`;
- 使用它来确定还需检索哪些内容,然后再继续搜索。
工作流程:
1. 检查压缩上下文,确认已检索过的内容和仍需补充的内容。
2. 仅针对尚未覆盖的部分,调用‘search_child_chunks’检索5至7条相关片段。
3. 若均不相关,则立即执行第3条规则。
4. 对每一条相关但零散的片段,逐一调用‘retrieve_parent_chunks’——仅对不在压缩上下文中出现的ID进行检索。绝不可重复检索同一ID。
5. 当上下文完整后,提供详尽的答案,不得遗漏任何相关事实。
6. 最后以“---\n**来源:**”开头,列出所有引用的独特文件名。
"""
回退响应提示词
def get_fallback_response_prompt() -> str:
return """你是一位专业的综合解答专家。系统已达到最大检索次数限制。
你的任务是仅利用下方提供的信息,尽可能给出最完整的答案。
输入结构:
- “压缩的研究上下文”:先前多次检索得到的总结性发现——视为可靠信息。
- “检索到的数据”:当前迭代中的原始工具输出——若与压缩上下文存在冲突,优先采用检索到的数据。
两者中任一方存在即可,另一方不存在也不影响使用。
规则:
1. 来源完整性:仅使用提供上下文中明确存在的事实。不得推断、假设或添加任何未被数据直接支持的信息。
2. 处理缺失数据:将用户查询与可用上下文进行交叉核对。
仅标记用户问题中无法从所提供数据中回答的部分。
不得将压缩研究上下文中提到的空白视为未回答的内容,
除非它们与用户所问内容直接相关。
3. 语气:专业、客观且直接。
4. 仅输出最终答案。不得透露推理过程、内部步骤或关于检索过程的任何元评论。
5. 在“来源”部分之后,不得添加结束语、最后说明、免责声明、摘要或重复陈述。
“来源”部分始终是你回复的最后一项。在其后立即停止。
格式:
- 使用 Markdown(标题、加粗、列表)以提高可读性。
- 尽可能采用流畅的段落形式。
- 最后按照如下描述包含“来源”部分。
“来源”部分规则:
- 在结尾处包含一个 "---\\n**Sources:**\\n" 部分,后接带有项目符号的文件名列表。
- 仅列出具有实际文件扩展名的条目(如 ".pdf"、".docx"、".txt")。
- 任何没有文件扩展名的条目均为内部块标识符——完全舍弃,绝不可列入。
- 去重:若同一文件出现多次,仅列出一次。
- 若无有效文件名,则完全省略“来源”部分。
- “来源”部分是你撰写的最后一部分内容。其后不得再添加任何内容。
"""
上下文压缩提示
def get_context_compression_prompt() -> str:
return """你是一位专家级的研究上下文压缩员。
你的任务是将检索到的对话内容压缩成简洁、以查询为中心且结构化的摘要,以便由增强检索的代理直接用于生成答案。
规则:
1. 仅保留与回答用户问题相关的信息。
2. 保留精确的数字、名称、版本、技术术语和配置细节。
3. 移除重复、无关或管理性的内容。
4. 不得包含搜索查询、父级 ID、块 ID 或内部标识符。
5. 按照来源文件组织所有发现。每个文件部分必须以:### filename.pdf 开头。
6. 在专门的“空白”部分突出显示缺失或未解决的信息。
7. 将摘要限制在大约 400–600 字。如果内容超出此范围,优先保留关键事实和结构化数据。
8. 不得解释你的推理过程;仅以 Markdown 格式输出结构化内容。
所需结构:
# 研究上下文摘要
## 重点
[简要的技术性重述问题]
## 结构化发现
### filename.pdf
- 直接相关的事实
- 支持性背景信息(如有需要)
## 空白
- 缺失或不完整的内容
该摘要应简洁、结构化,并可直接供代理用于生成答案或规划进一步的检索。
"""
聚合提示
def get_aggregation_prompt() -> str:
return """你是一位专家级的聚合助手。
你的任务是将多个检索到的解答合并成一个全面且自然流畅的回答。
规则:
1. 以对话式、自然的语气撰写——仿佛在向同事解释一般。
2. 仅使用检索到的答案中的信息。
3. 不得推断、扩展或解释缩写词或技术术语,除非来源中已明确给出定义。
4. 将信息流畅地编织在一起,同时保留重要细节、数字和示例。
5. 内容需全面——包含所有来自来源的相关信息,而不仅仅是摘要。
6. 如果来源之间存在分歧,应自然地同时提及两种观点(例如:“虽然有些来源认为 X,但另一些来源则表明 Y……”)。
7. 直接开始回答,无需诸如“根据来源……”之类的前言。
格式:
- 使用 Markdown 提高清晰度(标题、列表、加粗),但不要过度使用。
- 尽可能采用流畅的段落形式,而非过多的项目符号。
- 最后按照下文所述包含“来源”部分。
“来源”部分规则:
- 每个检索到的解答可能包含“来源”部分——从中提取列出的文件名。
- 仅列出具有实际文件扩展名的条目(如 ".pdf"、".docx"、".txt")。
- 任何没有文件扩展名的条目均为内部块标识符——完全舍弃,绝不可列入。
- 去重:若同一文件出现在多个解答中,仅列出一次。
- 格式为 "---\\n**Sources:**\\n" 后接清理后的文件名项目符号列表。
- 文件名必须仅出现在此最终的“来源”部分中,不得出现在回答的其他任何地方。
- 若无有效文件名,则完全省略“来源”部分。
若无可用信息,只需简单回答:“在现有来源中,我未能找到回答您问题的相关信息。”
"""
第7步:定义状态与数据模型
创建用于跟踪对话和代理执行的状态结构。
from langgraph.graph import MessagesState
from pydantic import BaseModel, Field
from typing import List, Annotated, Set
import operator
def accumulate_or_reset(existing: List[dict], new: List[dict]) -> List[dict]:
if new and any(item.get('__reset__') for item in new):
return []
return existing + new
def set_union(a: Set[str], b: Set[str]) -> Set[str]:
return a | b
class State(MessagesState):
questionIsClear: bool = False
conversation_summary: str = ""
originalQuery: str = ""
rewrittenQuestions: List[str] = []
agent_answers: Annotated[List[dict], accumulate_or_reset] = []
class AgentState(MessagesState):
tool_call_count: Annotated[int, operator.add] = 0
iteration_count: Annotated[int, operator.add] = 0
question: str = ""
question_index: int = 0
context_summary: str = ""
retrieval_keys: Annotated[Set[str], set_union] = set()
final_answer: str = ""
agent_answers: List[dict] = []
class QueryAnalysis(BaseModel):
is_clear: bool = Field(description="指示用户的提问是否清晰且可回答。")
questions: List[str] = Field(description="改写后的自洽问题列表。")
clarification_needed: str = Field(description="如果问题不清晰,则说明原因。")
第8步:代理配置
对工具调用和迭代次数设置硬性限制,以防止无限循环。通过 tiktoken 进行令牌计数,从而驱动上下文压缩决策。
import tiktoken
MAX_TOOL_CALLS = 8 # 每次代理运行的最大工具调用次数
MAX_ITERATIONS = 10 # 代理循环的最大迭代次数
BASE_TOKEN_THRESHOLD = 2000 # 压缩的初始令牌阈值
TOKEN_GROWTH_FACTOR = 0.9 # 每次压缩后应用的倍增因子
def estimate_context_tokens(messages: list) -> int:
try:
encoding = tiktoken.encoding_for_model("gpt-4")
except:
encoding = tiktoken.get_encoding("cl100k_base")
return sum(len(encoding.encode(str(msg.content))) for msg in messages if hasattr(msg, 'content') and msg.content)
第9步:构建图节点与边函数
为 LangGraph 工作流创建处理节点和边。
主要图节点与边
from langgraph.types import Send, Command
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage, RemoveMessage, ToolMessage
from typing import Literal
def summarize_history(state: State):
if len(state["messages"]) < 4:
return {"conversation_summary": ""}
relevant_msgs = [
msg for msg in state["messages"][:-1]
if isinstance(msg, (HumanMessage, AIMessage)) and not getattr(msg, "tool_calls", None)
]
if not relevant_msgs:
return {"conversation_summary": ""}
conversation = "对话历史:\n"
for msg in relevant_msgs[-6:]:
role = "用户" if isinstance(msg, HumanMessage) else "助手"
conversation += f"{role}: {msg.content}\n"
summary_response = llm.with_config(temperature=0.2).invoke([SystemMessage(content=get_conversation_summary_prompt()), HumanMessage(content=conversation)])
return {"conversation_summary": summary_response.content, "agent_answers": [{"__reset__": True}]}
def rewrite_query(state: State):
last_message = state["messages"][-1]
conversation_summary = state.get("conversation_summary", "")
context_section = (f"对话上下文:\n{conversation_summary}\n" if conversation_summary.strip() else "") + f"用户问题:\n{last_message.content}\n"
llm_with_structure = llm.with_config(temperature=0.1).with_structured_output(QueryAnalysis)
response = llm_with_structure.invoke([SystemMessage(content=get_rewrite_query_prompt()), HumanMessage(content=context_section)])
if response.questions and response.is_clear:
delete_all = [RemoveMessage(id=m.id) for m in state["messages"] if not isinstance(m, SystemMessage)]
return {"questionIsClear": True, "messages": delete_all, "originalQuery": last_message.content, "rewrittenQuestions": response.questions}
clarification = response.clarification_needed if response.clarification_needed and len(response.clarification_needed.strip()) > 10 else "我需要更多信息来理解您的问题。"
return {"questionIsClear": False, "messages": [AIMessage(content=clarification)]}
def request_clarification(state: State):
return {}
def route_after_rewrite(state: State) -> Literal["request_clarification", "agent"]:
if not state.get("questionIsClear", False):
return "request_clarification"
else:
return [
Send("agent", {"question": query, "question_index": idx, "messages": []})
for idx, query in enumerate(state["rewrittenQuestions"])
]
def aggregate_answers(state: State):
if not state.get("agent_answers"):
return {"messages": [AIMessage(content="没有生成任何答案。")]}
sorted_answers = sorted(state["agent_answers"], key=lambda x: x["index"])
formatted_answers = ""
for i, ans in enumerate(sorted_answers, start=1):
formatted_answers += (f"\n答案 {i}:\n"f"{ans['answer']}\n")
user_message = HumanMessage(content=f"""原始用户问题: {state["originalQuery"]}\n获取到的答案:{formatted_answers}""")
synthesis_response = llm.invoke([SystemMessage(content=get_aggregation_prompt()), user_message])
return {"messages": [AIMessage(content=synthesis_response.content)]}
代理子图节点与边
def orchestrator(state: AgentState):
context_summary = state.get("context_summary", "").strip()
sys_msg = SystemMessage(content=get_orchestrator_prompt())
summary_injection = (
[HumanMessage(content=f"[来自先前研究的压缩上下文]\n\n{context_summary}")]
if context_summary else []
)
if not state.get("messages"):
human_msg = HumanMessage(content=state["question"])
force_search = HumanMessage(content="您必须首先调用 'search_child_chunks' 来回答这个问题。")
response = llm_with_tools.invoke([sys_msg] + summary_injection + [human_msg, force_search])
return {"messages": [human_msg, response], "tool_call_count": len(response.tool_calls or []), "iteration_count": 1}
response = llm_with_tools.invoke([sys_msg] + summary_injection + state["messages"])
tool_calls = response.tool_calls if hasattr(response, "tool_calls") else []
return {"messages": [response], "tool_call_count": len(tool_calls) if tool_calls else 0, "iteration_count": 1}
def route_after_orchestrator_call(state: AgentState) -> Literal["tool", "fallback_response", "collect_answer"]:
iteration = state.get("iteration_count", 0)
tool_count = state.get("tool_call_count", 0)
if iteration >= MAX_ITERATIONS 或 tool_count > MAX_TOOL_CALLS:
return "fallback_response"
last_message = state["messages"][-1]
tool_calls = getattr(last_message, "tool_calls", None) 或 []
if not tool_calls:
return "collect_answer"
return "tools"
def fallback_response(state: AgentState):
seen = set()
unique_contents = []
for m in state["messages"]:
if isinstance(m, ToolMessage) 并且 m.content 不在 seen 中:
unique_contents.append(m.content)
seen.add(m.content)
context_summary = state.get("context_summary", "").strip()
context_parts = []
if context_summary:
context_parts.append(f"## 压缩的研究上下文(来自先前迭代)\n\n{context_summary}")
if unique_contents:
context_parts.append(
"## 获取的数据(当前迭代)\n\n" +
"\n\n".join(f"--- 数据来源 {i} ---\n{content}" for i, content in enumerate(unique_contents, 1))
)
context_text = "\n\n".join(context_parts) 如果 context_parts 存在,否则是 "没有从文档中获取到任何数据。"
prompt_content = (
f"用户问题: {state.get('question')}\n\n"
f"{context_text}\n\n"
f"指令:\n仅使用上述数据提供最佳答案。"
)
response = llm.invoke([SystemMessage(content=get_fallback_response_prompt()), HumanMessage(content=prompt内容)])
return {"messages": [response]}
def should_compress_context(state: AgentState) -> Command[Literal["compress_context", "orchestrator"]]:
messages = state["messages"]
new_ids: Set[str] = set()
for msg in reversed(messages):
if isinstance(msg, AIMessage) and getattr(msg, "tool_calls", None):
for tc in msg.tool_calls:
if tc["name"] == "retrieve_parent_chunks":
raw = tc["args"].get("parent_id") or tc["args"].get("id") or tc["args"].get("ids") or []
if isinstance(raw, str):
new_ids.add(f"parent::{raw}")
else:
new_ids.update(f"parent::{r}" for r in raw)
elif tc["name"] == "search_child_chunks":
query = tc["args"].get("query", "")
if query:
new_ids.add(f"search::{query}")
break
updated_ids = state.get("retrieval_keys", set()) | new_ids
current_token_messages = estimate_context_tokens(messages)
current_token_summary = estimate_context_tokens([HumanMessage(content=state.get("context_summary", ""))])
current_tokens = current_token_messages + current_token_summary
max_allowed = BASE_TOKEN_THRESHOLD + int(current_token_summary * TOKEN_GROWTH_FACTOR)
goto = "compress_context" if current_tokens > max_allowed else "orchestrator"
return Command(update={"retrieval_keys": updated_ids}, goto=goto)
def compress_context(state: AgentState):
messages = state["messages"]
existing_summary = state.get("context_summary", "").strip()
if not messages:
return {}
conversation_text = f"USER QUESTION:\n{state.get('question')}\n\nConversation to compress:\n\n"
if existing_summary:
conversation_text += f"[PRIOR COMPRESSED CONTEXT]\n{existing_summary}\n\n"
for msg in messages[1:]:
if isinstance(msg, AIMessage):
tool_calls_info = ""
if getattr(msg, "tool_calls", None):
calls = ", ".join(f"{tc['name']}({tc['args']})" for tc in msg.tool_calls)
tool_calls_info = f" | Tool calls: {calls}"
conversation_text += f"[ASSISTANT{tool_calls_info}]\n{msg.content or '(tool call only)'}\n\n"
elif isinstance(msg, ToolMessage):
tool_name = getattr(msg, "name", "tool")
conversation_text += f"[TOOL RESULT — {tool_name}]\n{msg.content}\n\n"
summary_response = llm.invoke([SystemMessage(content=get_context_compression_prompt()), HumanMessage(content=conversation_text)])
new_summary = summary_response.content
retrieved_ids: Set[str] = state.get("retrieval_keys", set())
if retrieved_ids:
parent_ids = sorted(r for r in retrieved_ids if r.startswith("parent::"))
search_queries = sorted(r.replace("search::", "") for r in retrieved_ids if r.startswith("search::"))
block = "\n\n---\n**Already executed (do NOT repeat):**\n"
if parent_ids:
block += "Parent chunks retrieved:\n" + "\n".join(f"- {p.replace('parent::', '')}" for p in parent_ids) + "\n"
if search_queries:
block += "Search queries already run:\n" + "\n".join(f"- {q}" for q in search_queries) + "\n"
new_summary += block
return {"context_summary": new_summary, "messages": [RemoveMessage(id=m.id) for m in messages[1:]]}
def collect_answer(state: AgentState):
last_message = state["messages"][-1]
is_valid = isinstance(last_message, AIMessage) and last_message.content and not last_message.tool_calls
answer = last_message.content if is_valid else "Unable to generate an answer."
return {
"final_answer": answer,
"agent_answers": [{"index": state["question_index"], "question": state["question"], "answer": answer}]
}
为什么采用这种架构?
- 摘要生成能够在不使大模型过载的情况下保持对话上下文的连贯性。
- 查询重写利用上下文智能地确保搜索查询精确且无歧义。
- 人工介入可以在浪费检索资源之前捕捉到不明确的查询。
- 并行执行通过
SendAPI 同时为每个子问题启动独立的代理子图,实现高效处理。 - 上下文压缩在长时间的检索循环中保持代理的工作内存简洁,避免重复获取数据。
- 回退响应确保系统能够优雅降级——即使预算耗尽,代理仍会返回有用的信息。
- 答案收集与聚合从各个代理中提取清晰的最终答案,并将其整合成一个连贯的整体响应。
第 10 步:构建 LangGraph 图
使用对话记忆和多智能体架构组装完整的流程图。
from langgraph.graph import START, END, StateGraph
from langgraph.prebuilt import ToolNode
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
agent_builder = StateGraph(AgentState)
agent_builder.add_node(orchestrator)
agent_builder.add_node("tools", ToolNode([search_child_chunks, retrieve_parent_chunks]))
agent_builder.add_node(compress_context)
agent_builder.add_node(fallback_response)
agent_builder.add_node(should_compress_context)
agent_builder.add_node(collect_answer)
agent_builder.add_edge(START, "orchestrator")
agent_builder.add_conditional_edges("orchestrator", route_after_orchestrator_call, {"tools": "tools", "fallback_response": "fallback_response", "collect_answer": "collect_answer"})
agent_builder.add_edge("tools", "should_compress_context")
agent_builder.add_edge("compress_context", "orchestrator")
agent_builder.add_edge("fallback_response", "collect_answer")
agent_builder.add_edge("collect_answer", END)
agent_subgraph = agent_builder.compile()
graph_builder = StateGraph(State)
graph_builder.add_node(summarize_history)
graph_builder.add_node(rewrite_query)
graph_builder.add_node(request_clarification)
graph_builder.add_node("agent", agent_subgraph)
graph_builder.add_node(aggregate_answers)
graph_builder.add_edge(START, "summarize_history")
graph_builder.add_edge("summarize_history", "rewrite_query")
graph_builder.add_conditional_edges("rewrite_query", route_after_rewrite)
graph_builder.add_edge("request_clarification", "rewrite_query")
graph_builder.add_edge(["agent"], "aggregate_answers")
graph_builder.add_edge("aggregate_answers", END)
agent_graph = graph_builder.compile(checkpointer=checkpointer, interrupt_before=["request_clarification"])
图架构说明:
架构流程图可在此查看 here。
{kind=link}
代理子图(处理单个问题):
- START →
orchestrator(调用带有工具的 LLM) orchestrator→tools(如果需要调用工具)或fallback_response(如果预算耗尽)或collect_answer(如果已完成)tools→should_compress_context(检查 token 预算)should_compress_context→compress_context(如果超过阈值)或orchestrator(否则)compress_context→orchestrator(恢复使用压缩后的记忆)fallback_response→collect_answer(打包尽力而为的答案)collect_answer→ END(清理最终答案并索引)
主图(协调完整流程):
- START →
summarize_history(从历史中提取对话上下文) summarize_history→rewrite_query(结合上下文重写查询,检查清晰度)rewrite_query→request_clarification(如果不清晰)或通过Send启动并行的agent子图(如果清晰)request_clarification→rewrite_query(用户提供澄清后)- 所有
agent子图 →aggregate_answers(合并所有响应) aggregate_answers→ END(返回最终合成的答案)
第 11 步:创建聊天界面
构建具有对话持久性和人工介入支持的 Gradio 界面。有关包含文档摄取在内的完整端到端管道 Gradio 界面,请参阅 project/README.md。
注意: 完整的流式传输支持——包括推理步骤和工具调用的可见性——已在 notebook 和完整 项目 中实现。下面的示例故意保持极简——仅展示基本的 Gradio 集成模式。
import gradio as gr
import uuid
def create_thread_id():
"""为每次对话生成唯一的线程 ID"""
return {"configurable": {"thread_id": str(uuid.uuid4())}, "recursion_limit": 50}
def clear_session():
"""清除线程以开始新对话"""
global config
agent_graph.checkpointer.delete_thread(config["configurable"]["thread_id"])
config = create_thread_id()
def chat(message, history):
current_state = agent_graph.get_state(config)
if current_state.next:
agent_graph.update_state(config,{"messages": [HumanMessage(content=message.strip())]})
result = agent_graph.invoke(None, config)
else:
result = agent_graph.invoke({"messages": [HumanMessage(content=message.strip())]}, config)
return result['messages'][-1].content
config = create_thread_id()
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
chatbot.clear(clear_session)
gr.ChatInterface(fn=chat, chatbot=chatbot)
demo.launch(theme=gr.themes.Citrus())
大功告成! 您现在拥有一个功能齐全的 Agentic RAG 系统,具备对话记忆、层次化索引以及人工介入的查询澄清功能。
模块化架构
该应用(project/ 文件夹)被组织成模块化组件——每个组件都可以独立替换而不破坏系统。
📂 项目结构
project/
├── app.py # 主 Gradio 应用入口点
├── config.py # 配置中心(模型、分块大小、提供商)
├── core/ # RAG 系统编排
├── db/ # 向量数据库和父级分块存储
├── rag_agent/ # LangGraph 工作流(节点、边、提示词、工具)
└── ui/ # Gradio 界面
关键可定制点:LLM 提供商、嵌入模型、分块策略、代理工作流以及系统提示词——均可通过 config.py 或其各自模块进行配置。
完整文档请参阅 project/README.md。
安装与使用
示例 PDF 文件可在以下位置找到:javascript、区块链、微服务、Fortinet。
选项 1:快速入门笔记本(推荐用于测试)
Google Colab: 点击本 README 顶部的“在 Colab 中打开”徽章,在文件浏览器中将您的 PDF 上传到 docs/ 文件夹,使用 pip install -r requirements.txt 安装依赖项,然后从上到下运行所有单元格。
本地(Jupyter/VSCode): 您可以选择创建并激活虚拟环境,使用 pip install -r requirements.txt 安装依赖项,将您的 PDF 添加到 docs/,然后从上到下运行所有单元格。
聊天界面将在最后出现。
选项 2:完整 Python 项目(推荐用于开发)
1. 安装依赖项
# 克隆仓库
git clone https://github.com/GiovanniPasq/agentic-rag-for-dummies
cd agentic-rag-for-dummies
# 可选:创建并激活虚拟环境
# 在 macOS/Linux 上:
python -m venv venv && source venv/bin/activate
# 在 Windows 上:
python -m venv venv && .\venv\Scripts\activate
# 安装依赖包
pip install -r requirements.txt
2. 运行应用
python app.py
3. 提问
打开本地 URL(例如 http://127.0.0.1:7860)即可开始聊天。
选项 3:Docker 部署
完整的 Docker 指令和系统要求,请参阅 project/README.md。
示例对话
带会话记忆:
用户:「如何安装 SQL?」
代理:【提供文档中的安装步骤】
用户:「如何更新它?」
代理:【理解“它”指 SQL,提供更新说明】
带查询澄清:
用户:「告诉我关于那个东西的事。」
代理:「我需要更多信息。您具体想了解哪个主题呢?」
用户:「PostgreSQL 的安装过程。」
代理:【检索并回答具体信息】
故障排除
| 方面 | 常见问题 | 建议解决方案 |
|---|---|---|
| 模型选择 | - 回答忽略指令 - 工具(检索/搜索)使用不当 - 上下文理解能力差 - 幻觉或聚合不完整 |
- 使用更强大的大语言模型 - 推荐 7B 以上的模型以获得更好的推理能力 - 如果本地模型性能有限,可考虑使用云端模型 |
| 系统提示行为 | - 模型在未检索文档的情况下直接作答 - 查询重写导致上下文丢失 - 聚合引入幻觉 |
- 在系统提示中明确检索要求 - 确保查询重写贴近用户意图 |
| 检索配置 | - 未能检索到相关文档 - 检索结果包含过多无关信息 |
- 增加检索的片段数量 (k) 或降低相似度阈值以提高召回率- 减少 k 或提高阈值以提升精确度 |
| 分块大小/文档拆分 | - 回答缺乏上下文或显得支离破碎 - 检索速度慢或嵌入成本高 |
- 增大分块及父级分块的大小以提供更多上下文 - 缩小分块大小以提高速度并降低成本 |
| 上下文压缩 | - 代理在压缩后丢失重要细节 - 压缩后的摘要过于笼统 |
- 调整压缩系统的提示词 - 提高 BASE_TOKEN_THRESHOLD 以延迟压缩- 增加 TOKEN_GROWTH_FACTOR |
| 代理配置 | - 代理过早放弃 - 代理陷入无限循环 |
- 对于复杂查询,增加 MAX_TOOL_CALLS / MAX_ITERATIONS;对于简单查询,则减少这些参数以加快速度 |
| 温度与一致性 | - 回答不一致或过于富有创造性 - 回答过于刻板或重复 |
- 将温度设置为 0 以获得事实性、一致性的输出- 在总结或分析任务中可适当提高温度 |
| 嵌入模型质量 | - 语义搜索效果不佳 - 在领域特定或多语言文档上表现较差 |
- 使用更高质量或领域专用的嵌入模型 - 更换嵌入模型后需重新索引所有文档 |
💡 更多故障排除技巧 请参阅 README 故障排除。
版本历史
v2.12026/04/01v2.02026/02/24v1.92026/01/21v1.82025/12/18v1.72025/12/08v1.62025/11/15v1.52025/10/31v1.02025/10/20常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备