GalTransl
GalTransl 是一款专为视觉小说(Galgame)打造的自动化翻译解决方案,旨在帮助用户高效制作高质量的内嵌式汉化补丁。它巧妙结合了基础功能创新与大语言模型提示工程技术,有效解决了传统机翻在人名、代词及专有名词上翻译不准、上下文断裂等痛点,显著提升了译文的可读性与准确性。
该工具不仅支持 GPT-4、Claude、Deepseek 等主流云端大模型,还首创了"GPT 字典”功能,能让模型“记住”角色设定与术语,确保翻译风格统一。此外,GalTransl 具备自动断点续翻、实时缓存保存以及灵活的译前译后字典系统,大幅降低了操作门槛。近期更新更推出了专为视觉小说优化的本地模型(如 GalTransl-7B/14B),让用户无需依赖云端 API 即可在本地显卡上运行,同时支持字幕、电子书等多种文件格式的翻译。
GalTransl 非常适合希望尝试制作游戏汉化的普通爱好者、字幕组人员,以及需要批量处理文本的开发者。无论是想快速生成机翻补丁体验剧情,还是以此为基础进行精细化人工润色,它都能提供完整的工作流支持,让汉化制作变得更加简单可控。使用时请注意,若发布未经人工校对的版本,建议明确标注为"AI 翻译补丁”,以保持透明与尊重。
使用场景
独立汉化组“樱雨社”正计划将一款经典的日本悬疑视觉小说引入中文社区,需要在两周内完成十万字剧本的初步本地化工作。
没有 GalTransl 时
- 人名与术语混乱:通用翻译模型无法识别游戏特有的人物关系和生造词,导致主角名字在文中忽男忽女,关键道具名称前后不一,严重破坏剧情逻辑。
- 人工校对成本极高:成员需逐句对照日文原文修正机翻错误,处理断点续翻困难,一旦中途报错需手动排查进度,耗时占整个项目的 80%。
- 技术门槛劝退新人:从解包游戏资源、提取文本到重新注入封包,需要掌握多种命令行工具和脚本编写,非技术背景的翻译人员难以独立完成全流程。
- 上下文缺失:传统机翻缺乏对长对话上下文的记忆,导致代词指代错误频发,译文读起来支离破碎,缺乏视觉小说应有的沉浸感。
使用 GalTransl 后
- 专属 GPT 字典精准控词:利用 GalTransl 首创的 GPT 字典功能,预先录入人设表和术语库,模型能自动锁定人名性别与专用词汇,确保全文称呼与概念高度统一。
- 自动化流程高效流转:依托实时缓存与自动断点续翻机制,即使网络波动也能无缝继续;结合一键解包注入插件,将原本数天的技术预处理压缩至几小时。
- 提示工程提升译文质感:通过深度优化的 Prompt 策略,GalTransl 让大模型理解视觉小说的语境,输出的译文语气自然流畅,大幅减少了后期人工润色的工作量。
- 多格式与本地模型支持:不仅支持主流大模型,还能部署 GalTransl-7B/14B 等本地专项模型,在保护隐私的同时低成本处理大量文本,甚至可直接翻译字幕和 EPUB 文件。
GalTransl 通过将提示工程与自动化工作流深度融合,把视觉小说汉化的核心精力从繁琐的技术操作中解放出来,真正回归到内容本身的打磨上。
运行环境要求
- Windows
- 可选
- 若使用本地模型 GalTransl-7B-v3.5 需显存 6GB+
- GalTransl-14B-v3 需更大显存(未说明具体数值)
- 云端 API 模式无需本地 GPU
未说明

快速开始
GalTransl
支持GPT-4/Claude/Deepseek/Sakura等大语言模型的Galgame自动化翻译解决方案
GalTransl是一套将数个基础功能上的微小创新与对GPT提示工程(Prompt Engineering)的深度利用相结合的Galgame自动化翻译工具,用于制作内嵌式翻译补丁。
前言
GalTransl的核心是一组自动化翻译脚本,解决了使用ChatGPT自动化翻译Gal过程中已知的大部分问题,并提高了整体的翻译质量。同时,通过与其他项目的组合,打通了制作补丁的完整流程,一定程度降低了上手门槛。对此感兴趣的朋友可以通过本项目更容易的构建具有一定质量的机翻补丁,并(或许)可以尝试在此框架的基础上高效的构建更高质量的汉化补丁。
- 特性:
- 支持GPT-4/Claude/Deepseek/Sakura等大语言模型,并通过提示工程提高了GPT的翻译质量
- 首创GPT字典,让GPT了解人设,准确翻译人名、人称代词与生词
- 通过译前、译后字典与条件字典实现灵活的自动化字典系统
- 实时保存缓存、自动断点续翻
- 结合其他项目支持多引擎脚本一键解包与注入,提供完整教程降低上手难度
- (新)现在也支持直接翻译srt、lrc、vtt字幕文件,mtool json文件,t++ excel文件,epub文件
- (2025.5新)🤗 Galtransl-7B-v3.5是为视觉小说翻译任务专项优化的本地模型,可在6G VRAM以上显卡部署,由sakuraumi和xd2333共同构建。
- (2025.4新)🤗GalTransl-14B-v3是GalTransl-v3模型的14b版本,得益于更大的底模及改进的对齐训练,GalTransl-14B-v3整体质量好于GalTransl-7B-v3
❗❗使用本工具翻译并在未做全文校对/润色的前提下发布时,请在最显眼的位置标注"GPT翻译/AI翻译补丁",而不是"个人汉化"或"AI汉化"补丁。
近期更新
- 2025.5: 更新v6,新增翻译模板ForGal、新增GalTransl-14B-v3模型
- 2024.5:更新v5,新增GalTransl-7B模型,新增多种文件类型支持
- 2024.2:更新v4版,主要支持了插件系统
- 2023.12:更新v3版,支持基于文件的多线程 by @ryank231231
- 2023.7:更新v2版,主要重构了代码 by @ryank231231
- 2023.6:v1初版发布
导航
- 环境准备:环境与软件的安装
- 上手教程:全流程介绍如何制作一个机翻补丁,只想看怎么使用本工具的话,可以直接跳转第2章的2.2节
- 配置文件与翻译引擎设置:本篇详细介绍各个翻译引擎API的调用与配置方式。
- GalTransl核心功能介绍:介绍GPT字典、缓存、普通字典、找问题等功能。
- 后续教程已经转移至Wiki
环境准备
免环境版
现在release里有winexe版本,不需要安装运行环境和依赖。下载本项目
解压到任意位置,例如D:\GalTranslPython
安装 Python 3.11.9。 下载
安装时勾选下方 add Python to path安装Python依赖
安装 Python 后
可以直接双击安装、更新依赖.bat来安装本项目需要的依赖。
实用工具
| 名称 | 说明 |
|---|---|
| GARbro | 引擎工具:神一样的解包工具。下载 |
| KirikiriTools | 引擎工具:Krkr、krkrz 提取、注入工具 |
| UniversalInjectorFramework | 引擎工具:sjis隧道、sjis替换模式通用注入框架 |
| VNTextProxy | 引擎工具:sjis隧道模式通用注入框架 |
| GalTransl_DumpInjector | 脚本工具:VNTextPatch的图形化界面,综合脚本文本提取导入工具 |
| SExtractor | 脚本工具:综合脚本文本提取导入工具 |
| msg-tool | 脚本工具:综合脚本文本提取导入工具 |
| DBTXT2Json_jp | 脚本工具:双行文本与json_jp互转脚本 |
| EmEditor | 文本工具:神一样的文本编辑器,主语用于修缓存文件。 |
| VSCode | 文本工具:神一样的文本编辑器,主语用于修缓存文件。 |
| KeywordGacha | 文本工具:使用 OpenAI 兼容接口自动生词语表 |
上手教程
做一个gal内嵌翻译补丁的大致流程是:
- 识别引擎 -> 解包资源包拿到脚本 -> 接2.
- 解包脚本为日文文本 -> 翻译为中文文本 -> 构建中文脚本 -> 接3.
- 封包为资源包/免封包 -> 接4.
- 引擎支持unicode的话,直接玩 -> 引擎是shift jis的,尝试2种路线使其支持显示中文
我会分成以上4个模块分步讲解,这个段落为了让没做过的朋友也能有机会上手,会写的更照顾小白一些。
- 建议先只跑开头一个文件的翻译,或先随便添加一些中文,导回游戏确认可以正常显示再全部翻译
(点击展开详细说明)
第一章 识别与解包
识别引擎其实很简单,通常来说,使用GARbro打开游戏目录内的任意资源包,在左下方的状态栏中就会显示引擎名称:
或者,参考资源包后缀表,比较资源包的后缀。
剧情脚本一般在一些有明显关键字的资源包,或在资源包中明显关键字的目录内,例如:scene、scenario、message、script等字样。并且脚本通常是由许多明显分章节、分人物,有的还分出了剧情和hs(例如带_h),通常多翻找几个资源包就能找到。
或者,参考Dir-A佬的教程
特别的,针对新的krkrz引擎,GARbro已经无法打开资源包,可以用KrkrzExtract项目,将游戏拖到exe上启动。然后下一个全cg存档,直接把所有剧情ctrl一遍,也可以获取到脚本文件。
第二章 提取与翻译
- 【2.1. 提取脚本文本】
通常情况下,本项目是结合VNTextPatch工具来解包脚本的。 VNTextPatch是由外国大佬arcusmaximus开发的支持许多引擎脚本的提取与注入的通用工具。(但并不是这些引擎都能搞定了,实测有的游戏是会提取失败的)
VNTextPatch是使用cmd操作的,为了降低上手难度,我搓了一个图形化的界面,你可以在项目的useful_tools/GalTransl_DumpInjector内找到,点击GalTransl_DumpInjector.exe运行。
现在,你只需要选择日文脚本目录,然后选择保存提取的日文json的目录,这里一般将日文脚本放到叫script_jp的文件夹,再新建一个gt_input目录,用于存储提取出的脚本:![]() 需要注意GalTransl全程是使用name-message格式的JSON输入、处理和输出的。JSON是什么
需要注意GalTransl全程是使用name-message格式的JSON输入、处理和输出的。JSON是什么
提取出来的json文件可以用emeditor打开,一般是这个样子的:
[
{
"name": "咲來",
"message": "「ってか、白鷺学園だったらあたしと一緒じゃん。\r\nセンパイだったんですねー」"
}
]
其中,每个{object(对象)}是一句话,message是消息内容,如果object还带了name,说明是对话。不过可能并不是所有类型的脚本都可以带name提取,当可以正确提取name时,GalTransl的翻译质量会 better.
PS. GalTransl只支持指定格式的json文件输入,但并不是说GalTransl就与VNTextPatch工具绑定了,也可以使用SExtractor工具,现在也支持导出GalTransl需要的name-message format JSON.
- 【2.2. GalTransl启动】
将本项目下载下来解压到任意位置(示例中默认为D盘根目录),在项目示例文件夹sampleProject中,找到示例配置文件config.inc.yaml,将其重命名为config.yaml。另外,也将sampleProject文件夹改个名字,一般是游戏的名字.
本教程使用deepseek API来举例,其他模型同理,对应修改示例项目的config.yaml即可调用.
先将所有提取出的日文json文件放入示例文件夹内的gt_input文件夹中,然后用任意 text editor 编辑config.yaml文件,按注释修改以下内容:
# 翻译后端相关设置
backendSpecific:
OpenAI-Compatible: # (ForGal/ForNovel/r1/Gendic)OpenAI API兼容接口通用
tokens:
- token: sk-example-key1
endpoint: https://api.deepseek.com # 请求地址,加不加v1都可以
modelName: deepseek-chat
- token: sk-example-key2
endpoint: https://openrouter.ai/api/v1/chat/completions # /chat/completions结尾则不自动补v1
modelName: deepseek/deepseek-chat-v3-0324:free
stream: true # 支持为单个token设置流式请求
- 一些收费api转发项目,例如:硅基流动(modelName: "deepseek-ai/DeepSeek-V3.1-Terminus")、oaipro等等,以上只是举例,更多中转可以谷歌,本项目不担保它们的稳定性及可用性。
但要注意这里获取的key填入的同时要修改endpoint地址,一般在对应平台的说明里能找到:
- token: sk-example-key1
endpoint: https://api.siliconflow.cn # 请求地址,加不加v1都可以
修改好项目设置后,确保你已经安装了需要的依赖(见环境准备),然后双击run.bat(免环境版双击exe),首先输入拖入项目配置文件,例如D:\GalTransl-main\sampleProject\config.inc.yaml
接着选择第一个翻译选项(现在是ForGal-json,可能与图片不对应):
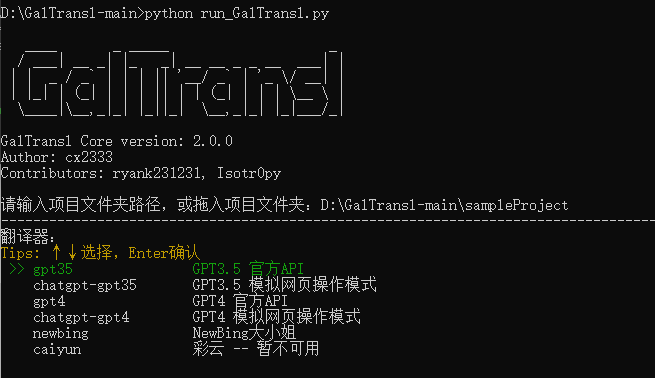
程序就会启动并开始翻译:
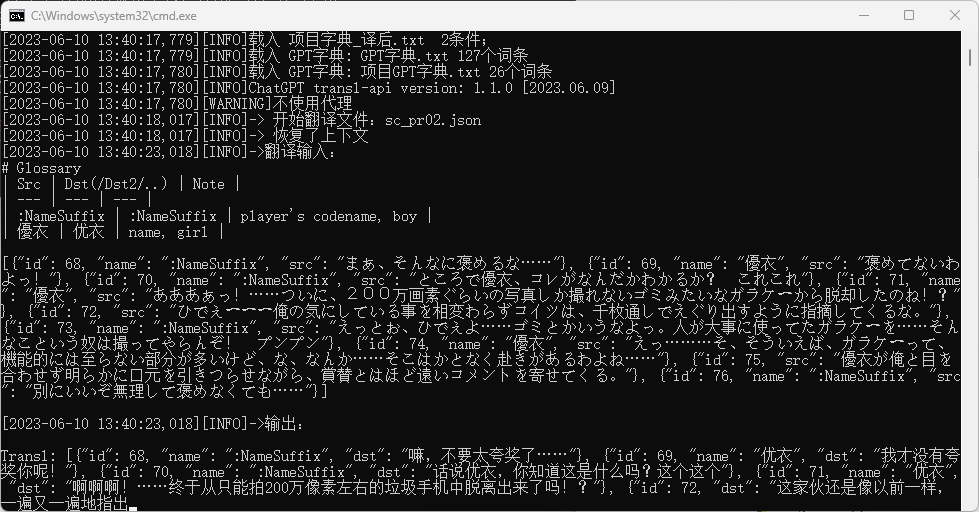
但是,不建议就这样开始翻译了,请至少要先学会GPT字典的使用,或者选择GenDic来生成一个人名字典,为你要翻译的gal设定好各角色的人名字典,这样才能保证基本的翻译质量。
翻译完成后,记得修修缓存,因为大模型经常会犯错。GalTransl会自动查找一些常见问题并记录于缓存中。可以对缓存进行修正,并重新运行程序来基于缓存重新生成结果json,见自动化找错章节和翻译缓存章节
- 【2.3. 构建中文脚本】
如果你是使用GalTransl提取注入工具提取的脚本,构建同理,选择日文脚本目录、中文json目录、中文脚本保存目录,然后点'注入',即可将文本注入回脚本。但这里面有一些坑,第四章会提到。
注:
- 这里一般把中文脚本保存目录叫script_cn,因为日文脚本目录叫script_jp
- 一般使用什么工具导出,就用什么工具导入。所以要先尝试导入导出是否都正常再开始翻译。
第三章 封包或免封
构建好中文脚本后,下一步就是想办法让游戏读取。首先目前主流引擎基本都是支持免封包读取的,可以继续参考Dir-A佬的教程,看看你要搞的引擎支不支持免封包读取。
特别的,针对krkr/krkrz引擎,可以使用arcusmaximus大佬的KirikiriTools工具,下载里面的version.dll,丢到游戏目录里,然后在游戏目录里新建一个"unencrypted"文件夹,将脚本直接丢进去(不用新建二级目录),就可以让krkr读取
第四章 引擎与编码
在这一章首先需要了解一下unicode、sjis(shift jis)、gbk编码的基础知识,为了偷懒在这里我还是放Dir-A佬的文章,如果你对这块不了解的话,先去读一下。
如果你在做的引擎支持unicode编码,例如krkr、Artemis引擎等,一般就可以直接玩了。但如果引擎是使用sjis编码的话,直接打开会是乱码,这时候需要通过2种路线尝试使其可以正常显示中文:
路线1:使用GBK编码注入脚本,然后修改引擎程序使其支持GBK编码
路线2:仍然使用jis编码注入脚本,但通过jis隧道或jis替换(推荐)2种方式,结合通用注入dll在运行过程中通过动态替换来显示中文
GalTransl提取注入工具的VNTextPatch模式注入脚本时默认是以sjis或unicode(utf8)编码注入的,这取决于引擎类型。
使用路线1
(注:这个模式现在有bug,有的引擎会卡死)在注入前勾选"GBK编码注入",在这个模式下所有GBK编码不支持的字符将被替换成空白,例如音符♪
然后需要ollydbg或windbg工具,在这里下载,用于修改引擎。
最后还是去看Dir-A佬的教程,里面有教如何下断点、修改,完全没接触过逆向的话这可能很难,但没办法,照着视频多试试。使用路线2
在注入脚本时先什么都不勾选,如果有提示"sjis_ext.bin包含文字:xxx"的话,说明程序是以sjis编码注入的,并把这些不支持显示的字符放到script_cn目录内的sjis_ext.bin里供sjis隧道模式调用了。
jis隧道:仍然来自arcusmaximus大佬的VNTranslationTools项目中的VNTextProxy组件。VNTextPatch在将文本注入回脚本时,会将sjis编码不支持的字符临时替换为sjis编码中未定义的字符,VNTextProxy通过DLL劫持技术HOOK游戏,并在遇到这些字符时再把它还原回去。
当使用sjis隧道模式时,将script_cn内的sjis_ext.bin文件移动到游戏目录内,然后将useful_tools\VNTextProxy内的所有dll逐个丢到游戏目录内(一般推荐先试version.dll,或使用PEID/DIE等工具查输入表),运行游戏,看有没有哪个DLL可以正确的hook游戏并让不显示的文本可以正常显示(不正常的话那些地方会是空的)。不正常的话,删掉这个DLL,换下一个。详细设置见此
jis替换:来自AtomCrafty大佬的UniversalInjectorFramework(通用注入框架)项目,也是通过DLL劫持技术HOOK游戏,并可以将某个字符根据设置替换成指定的另一个字符,不限编码。我建立了一套替换字典,按一些规则梳理了jis编码内不支持的简中汉字与jis支持的日文汉字的映射关系,可以满足99.99%常用简体中文汉字的正常显示(见hanzi2kanji_table.txt),并将替换功能写在了GalTransl提取注入工具内(新:现在SExtractor也支持替换,并且更好用)。在替换后结合UniversalInjectorFramework的动态Hook替换功能在游戏中将这些日文汉字替换回简中文字,实现游戏的正常显示。
当使用 sjis 替换模式时,可以先运行一遍 GalTransl 提取注入工具的注入文本,获取游戏不支持的文字列表(注入后会提示“sjis_ext.bin 包含文字:xxx”),然后,勾选“sjis 替换模式注入”,把这些文字复制到右边的文本框内,再点击注入。注入后会获得一个 sjis 替换模式配置。
打开 useful_tools/UniversalInjectorFramework 文件夹,里面也是很多 dll,也是逐个尝试,一般推荐先试 winmm.dll,把目录内的 uif_config.json 一并复制到游戏目录,然后编辑这个 json,按 GalTransl 提取注入工具提供的配置填写 source_characters 和 target_characters。
然后运行游戏,如果游戏可以正常运行,并且弹出了一个像这样的控制台: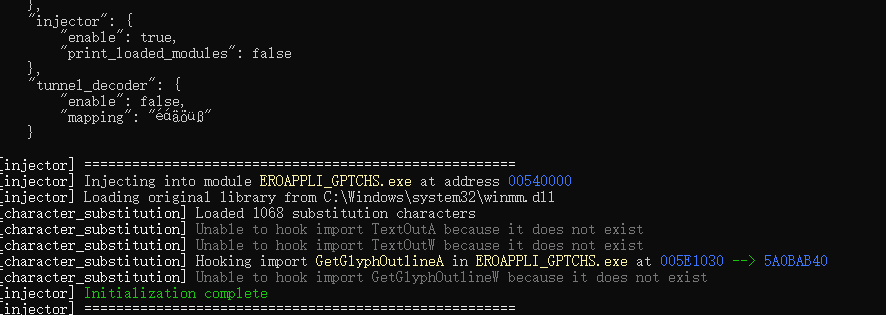 那多半就搞定了。如果不正常的话,删掉这个 DLL,尝试换下一个。
那多半就搞定了。如果不正常的话,删掉这个 DLL,尝试换下一个。
注:UniversalInjectorFramework 也支持 sjis 隧道模式,可以设置 tunnel_decoder 为 True 然后在 mapping 里填入 sjis_ext.bin 包含文字。
注:UniversalInjectorFramework 的控制台窗口可以隐藏,详细配置文件设置见此
GalTransl核心功能介绍
介绍GPT字典、缓存、普通字典、找问题等功能。
(点击展开详细说明)
GPT字典
GPT字典系统是使用GalTransl翻译时想提高质量的关键功能,通过补充设定的方式大幅提高翻译质量,是GPT翻译区别于传统机翻的核心。适用于gpt35、gpt4、newbing。
在程序目录中,Dict文件夹内有"通用GPT字典.txt",在项目文件夹内可以新建"项目GPT字典.txt",一般人名定义写进项目字典,通用提高翻译质量的词汇写进通用字典。
在程序目录中,
Dict文件夹内有"通用GPT字典.txt",在项目文件夹内可以新建"项目GPT字典.txt",一般人名定义写进项目字典,通用提高翻译质量的词汇写进通用字典。 - 举例来说,你可以提前在这里对每个角色名的中文翻译进行定义,并说明这个角色的设定,例如性别、大致年龄、职业等。通过自动给GPT喂这些设定,可以自动调整合适的人称代词他/她、称谓等,并固定人名为假名时的中文翻译。
- 再比如,可以在这里为GPT补充一些它总是翻不对的词语,如果提供一定的解释,它会理解的更好。
- 通过下面这个例子认识GPT字典喂人物设定的用法,每行的格式为
日文[Tab]中文[Tab]解释(可不写),注意中间的连接符为TAB
フラン 芙兰 name, lady, teacher
笠間 笠间 笠間 陽菜乃’s lastname, girl
陽菜乃 阳菜乃 笠間 陽菜乃's firstname, girl
张三 张三 player's name, boy
$str20 $str20 player's codename, boy
这几条字典都是定义角色用的:
- 第一条可以理解为我想告诉GPT:“假名フラン的翻译是芙兰,这是人名,是位女士,是老师”。这样GPT在翻译フラン先生的时候就会翻译成芙兰老师而不会是芙兰医生。
- 二三条是同一个人的日本姓和名,经测试姓名必须拆成两行写,不然GPT3.5会不认识。
- 第四条是设定主角的推荐写法。注意即使日文和中文相同,也要再重复一遍
- 第五条是主角在脚本中使用占位符而不是名字时的推荐写法。
- 设定不要太复杂,否则会让GPT多很多奇怪脑补。
- 通过下面这个例子认识GPT字典喂生词的用法,每行的格式亦为
日文[Tab]中文[Tab]解释(可不写),注意中间的连接符为TAB
大家さん 房东
あたし 我/人家 use '人家' when being cute
- 当你发现GPT不太认识这个词,例如“大家さん”,并且这个词含义比较唯一,那么就可以像这样加进通用GPT字典里,解释不是必要的。
- 第二行的中文写了一个多义词“我/人家”,并且在解释中写了“当扮可爱时用人家”。GPT3.5没那么聪明,但GPT4基本可以灵活运用。
- 想让GPT更瑟?自己加字典(
在程序目录中,Dict文件夹内有"通用GPT字典.txt",在sampleProject文件夹内会有"项目GPT字典.txt",一般人名定义写进项目字典,通用提高翻译质量的词汇写进通用字典。
只有当本次发送给GPT的人名和句子中有这个词,这个词的解释才会被送进本轮的对话中。
但不要什么词都往里加,什么都往里加只会害了你,推荐只写各角色的设定和总是会翻错的词。
运行时字典会动态的展示在每一次请求里:
常规字典
在GalTransl中,常规字典分为“译前字典”和“译后字典”。译前字典用于在翻译前对日文进行a到b的替换处理,而译后字典则用于对翻译后的中文进行a到b的替换处理。
译前字典多用于矫正发音不清的情况,或者当多个词表示相同意思时,可以通过译前字典先统一处理,从而减少GPT字典的输入量。
译后字典则是比较常见的字典用法,即在翻译完成后将某个词替换成另一个词。不过在这里,我改进了一种称为“条件字典”的功能。条件字典实际上是在替换之前增加了一步判断,以避免误替换或过度替换等情况。
每行格式为pre_jp/post_jp[tab]判断词[tab]查找词[tab]替换词
- pre_jp/post_jp代表判断词查找的位置,定义在“翻译缓存”章节中说明
- 判断词:如果在查找位置(pre_jp/post_jp)中找到判断词,才会激活后面的替换。
- 判断词可以在开头加“!”代表“不存在则替换”,否则一般是代表“存在则替换”。
- 判断词可以使用
[or]或[and]关键字连接,多个[or]连接代表“有一个条件满足就进入替换”,多个[and]连接代表“条件都满足才进入替换”。 - 查找词、替换词,同普通字典,将a替换成b。
翻译缓存
开始翻译后,可以在transl_cache目录内找到翻译缓存。
翻译缓存与json_jp是一一对应的,在翻译过程中,翻译结果会优先写进缓存里,当一个文件被翻译完成后,才会出现在json_cn里。
首先,总结一些要点:
- 当你想重翻某句时,打开对应的翻译缓存文件,删掉该句的pre_zh整行(不要留空行)
- 当你想整段重翻时,直接删对应的数个object块,重翻某文件时,直接删对应的翻译缓存文件。
- 当GalTransl正在翻译时,不要修改正在翻译的文件的缓存,改了也会被覆写回去。
- json_cn结果文件 = 翻译缓存内的pre_zh/proofread_zh + 译后字典替换 + 恢复对话框
- 当新的post_jp与缓存内的post_jp不一致时,会触发重翻,一般发生在添加了新的译前字典时。
下面是翻译缓存的典型样例:
{
"index": 4,
"name": "",
"pre_jp": "欠品していたコーヒー豆を受け取ったまでは良かったが、\r\n帰り道を歩いていると汗が吹き出してくる。",
"post_jp": "欠品していたコーヒー豆を受け取ったまでは良かったが、\r\n帰り道を歩いていると汗が吹き出してくる。",
"pre_zh": "领取了缺货的咖啡豆还好,\r\n但是走在回去的路上就汗流浃背了。",
"proofread_zh": "领了缺货的咖啡豆倒是没问题,\r\n可是走在回去的路上,汗水就冒了出来。",
"trans_by": "NewBing",
"proofread_by": "NewBing",
},
解释一下每个字段的含义:
基本参数:
index序号name人名pre_jp原始日文post_jp处理后日文。一般来讲,post_jp = pre_jp 去除对话框 + 译前字典替换。你会代码的话也可以在此处加入自己的处理pre_zh原始中文proofread_zh校对的中文
(没有post_zh,post_zh在结果文件夹里。)trans_by翻译引擎/翻译者proofread_by校对引擎/校对者problem存储问题。见下方自动化找错。post_zh_preview用于预览json_cn,但对它的修改并不会应用到json_cn,要修改pre_jp/proofread_zh简单讲下如何用Emeditor修缓存:选中一个文件,先右键-Emeditor打开,然后把transl_cache内所有文件全选拖进去。
这时候标签可能会占很大位置,右键标签-自定义标签页,将“标签不合适时”改成“无”,这样标签就只会在一行了(需要使用Emeditor专业版)。
接着ctrl+f搜索,搜索你感兴趣的关键字(如problem、doub_content),勾选“搜索组群中所有文档”,即可快速在所有文件中搜索,或点提取快速预览所有的问题。VSCode也是非常好的修缓存工具,只要使用VsCode打开缓存文件夹,然后全局搜索如problem,就可以快速定位所有问题。
在确定需要修改的内容后,直接修改对应句子的
pre_zh,或proofread_zh,然后重新跑一遍Galtransl,很快就会生成新的json_cn。
自动化找错
GalTransl根据长期对翻译结果的观察建立了一套根据规则自动找问题的系统。
找问题系统的开启是在各个项目的`config.yaml`里,默认配置是这样的
# 自动问题分析配置,在-前面加#号可以禁用
problemAnalyze:
problemList: # 要发现的问题清单
- 词频过高 # 重复大于20次
- 标点错漏 # 标点符号多加或漏加
- 残留日文 # 日文平假名片假名残留
- 丢失换行 # 缺少换行符,一般没事
- 多加换行 # 换行符比原句多,可能导致溢出屏幕
- 比日文长 # 比日文长1.3倍以上
- 字典使用 # 没有按GPT字典要求翻译
- 语言不通 # 疑似没有被翻译成目标语言,翻译为中文时检查是否包含非GBK字符
#- 引入英文 # 本来没有英文,译文引入了英文
#- 比日文长严格 # 严格查找,不能比日文长
目前支持找以上问题,有的项目被#号注释,可以取消来开启,或手动加上#号关闭对应问题的查找。
找到问题后会存在翻译缓存里,见翻译缓存章节,使用Emeditor批量提取problem关键字就可以看到目前所有的问题了,并通过修改缓存的pre_jp来修正问题。
(新) 现在还可以通过在config.yaml中配置retranslKey来批量重翻某个问题,例如 retranslKey: “残留日文”。
配置文件与翻译引擎设置
2025.9:详细设置项可以直接阅读配置文件注释,目前已经比较详细,此处不再重复
版本历史
6.7.32025/10/036.7.22025/09/306.6.62025/09/076.6.52025/07/226.6.42025/07/146.6.32025/07/126.6.22025/07/066.6.12025/07/046.6.02025/06/306.5.12025/06/126.5.02025/06/116.4.12025/06/096.4.02025/06/066.3.12025/06/066.3.02025/05/306.2.12025/05/156.2.02025/05/136.1.02025/05/056.0.52025/05/046.8.02025/12/20常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。