flymyai-lora-trainer
flymyai-lora-trainer 是一款开源的 AI 模型微调工具,专为 Qwen-Image、Qwen-Image-Edit 及 FLUX.1-dev 等主流文生图模型设计。它核心解决了用户希望以低成本、高效率的方式定制专属图像生成风格或角色的难题。通过训练 LoRA(低秩适应)层,用户无需重新训练庞大的基础模型,仅需少量数据集即可让模型学会特定的画风、人物特征或编辑逻辑。
这款工具特别适合具备一定技术基础的开发者、AI 研究人员以及需要批量定制模型内容的设计团队使用。其技术亮点在于全面兼容 Hugging Face diffusers 生态,支持通过简单的 YAML 文件进行配置,大幅降低了操作门槛。此外,它针对显存资源有限的场景进行了优化,支持在小于 24GB 显存的 GPU 上运行训练流程,并提供了完善的数据集验证脚本,确保训练数据的规范性。对于需要进行可控图像编辑(如基于参考图修改)的用户,flymyai-lora-trainer 也提供了专门的支持路径,是实现高质量人像与角色定制的理想选择。
使用场景
一家独立游戏工作室急需为新作生成风格统一的角色立绘,但现有通用模型无法还原其独特的手绘美术风格。
没有 flymyai-lora-trainer 时
- 风格割裂严重:直接使用原生 Qwen-Image 或 FLUX.1-dev 模型生成的角色,虽然细节丰富,但完全丢失了工作室特有的笔触和上色风格,导致素材无法直接商用。
- 微调门槛极高:尝试自行编写训练代码时,面临显存优化难题,普通消费级显卡(<24GiB)频繁爆显存,且缺乏针对 Qwen-Image-Edit 的控制编辑支持。
- 数据整理繁琐:手动构建数据集极易出错,缺乏自动验证脚本,常因图片与文本标签不匹配导致训练中途失败,浪费数小时算力。
- 迭代周期漫长:每次调整风格都需要重新配置复杂的训练环境,从准备数据到产出可用模型往往耗时数天,严重拖慢美术迭代进度。
使用 flymyai-lora-trainer 后
- 风格完美复刻:利用其对 Qwen-Image 和 FLUX.1-dev 的全量训练支持,仅用少量样本即可训练出高度还原手绘质感的 LoRA 模型,生成图可直接融入游戏管线。
- 低显存友好:借助专为 <24GiB GPU 优化的训练管道,开发者在单张 RTX 3090 上也能流畅运行全流程,无需昂贵的高端集群。
- 流程自动化:通过内置的数据集验证脚本(
validate_dataset.py)和清晰的 YAML 配置,自动检查图文对应关系,将数据准备时间从数小时缩短至几分钟。 - 高效可控迭代:支持基于控制图的图像编辑训练,美术人员可快速调整角色姿态或局部细节,实现“上午提需求,下午出成品”的敏捷开发。
flymyai-lora-trainer 将高门槛的模型定制化训练转化为标准化的工作流,让中小团队也能低成本拥有专属的 AI 美术资产生产线。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 支持显存小于 24GB 的显卡(如 RTX 4090),官方测试环境为 NVIDIA H200
- 需支持 CUDA(具体版本未说明,通常需配合 PyTorch 版本)
未说明

快速开始
LoRA 训练:适用于 Qwen-Image、Qwen-Image-Edit 和 FLUX.1-dev
由 FlyMy.AI 提供的开源实现,用于训练 Qwen/Qwen-Image、Qwen/Qwen-Image-Edit 以及 FLUX.1-dev 模型的 LoRA(低秩适应)层。

星标历史

🌟 关于 FlyMy.AI
面向生成式 AI 的代理基础设施。FlyMy.AI 是一家面向 B2B 的基础设施提供商,致力于构建和运行生成式 AI 媒体代理。
🔗 有用链接:
- 🌐 官方网站
- 📚 文档
- 💬 Discord 社区
- 🤗 预训练的 Qwen LoRA 模型
- 🤗 预训练的 FLUX LoRA 模型
- 🚀 训练您自己的 FLUX LoRA
- 🐦 X (Twitter)
- 📺 YouTube
🚀 特性
- 基于 LoRA 的微调,实现高效训练
- 支持 Qwen-Image、Qwen-Image-Edit 和 FLUX.1-dev 模型
- 兼容 Hugging Face
diffusers - 通过 YAML 文件轻松配置
- 利用 LoRA 进行基于控制的图像编辑
- LoRA 训练的开源实现
- 完整支持 Qwen-Image 的训练
- 高质量的人像与角色训练,适用于 FLUX 模型
📅 更新
2025年10月16日
- ✅ 添加了 FLUX.1-dev 的 LoRA 训练支持
- ✅ 添加了预训练的 FLUX LoRA 模型示例
2025年9月2日
- ✅ 添加了 Qwen-Image 和 Qwen-Image-Edit 的完整训练功能
2025年8月20日
- ✅ 添加了 Qwen-Image-Edit 的 LoRA 训练支持
2025年8月9日
- ✅ 添加了适用于显存小于 24GiB GPU 的训练流程
2025年8月8日
- ✅ 添加了全面的数据集准备说明
- ✅ 添加了数据集验证脚本 (
utils/validate_dataset.py) - ✅ 在训练过程中冻结模型权重
⚠️ 项目状态
🚧 开发中: 我们正在积极改进代码并增加测试覆盖率。该项目目前处于优化阶段,但已可投入使用。
📋 开发计划:
- ✅ 基础代码已可用
- ✅ 已实现训练功能
- ✅ 已添加 FLUX.1-dev 支持
- 🔄 正在进行性能优化
- 🔜 测试覆盖率即将推出
📦 安装
要求:
- Python 3.10
克隆仓库并进入目录:
git clone https://github.com/FlyMyAI/flymyai-lora-trainer cd flymyai-lora-trainer安装所需依赖包:
pip install -r requirements.txt从 GitHub 安装最新版
diffusers:pip install git+https://github.com/huggingface/diffusers下载预训练的 LoRA 权重(可选):
# Qwen LoRA 权重 git clone https://huggingface.co/flymy-ai/qwen-image-realism-lora # FLUX LoRA 权重 git clone https://huggingface.co/flymy-ai/flux-dev-anne-hathaway-lora # 或者直接下载特定文件 wget https://huggingface.co/flymy-ai/qwen-image-realism-lora/resolve/main/flymy_realism.safetensors wget https://huggingface.co/flymy-ai/flux-dev-anne-hathaway-lora/resolve/main/pytorch_lora_weights.safetensors
📁 数据准备
训练用数据集结构
无论是 Qwen 还是 FLUX 模型,训练数据都应遵循相同的格式:每张图片都对应一个同名的文本文件。
dataset/
├── img1.png
├── img1.txt
├── img2.jpg
├── img2.txt
├── img3.png
├── img3.txt
└── ...
Qwen-Image-Edit 训练用数据集结构
对于基于控制的图像编辑,数据集应分为目标图像及描述和控制图像两个独立目录:
dataset/
├── images/ # 目标图像及其描述
│ ├── image_001.jpg
│ ├── image_001.txt
│ ├── image_002.jpg
│ ├── image_002.txt
│ └── ...
└── control/ # 控制图像
├── image_001.jpg
├── image_002.jpg
└── ...
数据格式要求
- 图像:支持常见格式(PNG、JPG、JPEG、WEBP)
- 文本文件:包含图像描述的纯文本文件
- 文件命名:每张图像必须有一个与其同名的文本文件
示例数据结构
my_training_data/
├── portrait_001.png
├── portrait_001.txt
├── landscape_042.jpg
├── landscape_042.txt
├── abstract_design.png
├── abstract_design.txt
└── style_reference.jpg
└── style_reference.txt
文本文件内容示例
针对 FLUX 角色训练(portrait_001.txt):
ohwx 女性,专业人像照,影棚灯光,优雅姿势,直视镜头
针对 Qwen 风景训练(landscape_042.txt):
日落时分的山地景观,壮丽云海,金色时刻的光线,广角视角
针对 FLUX 人像训练(abstract_design.txt):
ohwx 女性,现代人像风格,柔和光线,艺术构图
数据准备提示
- 图像质量:使用高分辨率图像(建议 1024×1024 或更高)
- 描述质量:撰写详细且准确的图像描述
- 一致性:确保数据集中风格和质量的一致性
- 数据集规模:为获得良好效果,建议至少使用 10–50 组图像-文本对
- 触发词:
- 对于 FLUX 角色训练:使用“ohwx 女性”或“ohwx 男性”作为触发词
- 对于 Qwen 训练:无需特定触发词
- 自动生成描述:您可以使用 Florence-2 自动生成功能来生成图像描述。
快速数据验证
您可以使用附带的验证工具来检查数据结构:
python utils/validate_dataset.py --path path/to/your/dataset
该工具将检查:
- 每张图像是否都有对应的文本文件
- 所有文件是否遵循正确的命名规范
- 报告任何缺失的文件或不一致之处
🏁 在显存小于 24GB 的设备上开始训练
要使用您的配置文件(例如 train_lora_4090.yaml)开始训练,请运行:
accelerate launch train_4090.py --config ./train_configs/train_lora_4090.yaml

🏁 训练
Qwen 模型训练
Qwen-Image LoRA 训练
要使用您的配置文件(例如 train_lora.yaml)开始训练,请运行:
accelerate launch train.py --config ./train_configs/train_lora.yaml
请确保 train_lora.yaml 已正确设置好数据集路径、模型路径、输出目录及其他参数。
Qwen-Image 全模型训练
要使用你的配置文件(例如 train_full_qwen_image.yaml)开始训练,请运行:
accelerate launch train_full_qwen_image.py --config ./train_configs/train_full_qwen_image.yaml
请确保 train_full_qwen_image.yaml 已正确设置,包含数据集、模型、输出目录及其他参数的路径。
所提出的方法在 NVIDIA H200 GPU 环境上进行了测试。
加载训练好的全模型
训练完成后,你可以从检查点目录加载训练好的模型以进行推理。
简单示例:
from diffusers import QwenImagePipeline, QwenImageTransformer2DModel, AutoencoderKLQwenImage
import torch
from omegaconf import OmegaConf
import os
def load_trained_model(checkpoint_path):
"""从检查点加载训练好的模型"""
print(f"从 {checkpoint_path} 加载训练好的模型")
# 加载配置文件以获取原始模型路径
config_path = os.path.join(checkpoint_path, "config.yaml")
config = OmegaConf.load(config_path)
original_model_path = config.pretrained_model_name_or_path
# 加载训练好的 Transformer
transformer_path = os.path.join(checkpoint_path, "transformer")
transformer = QwenImageTransformer2DModel.from_pretrained(
transformer_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True
)
transformer.to("cuda")
transformer.eval()
# 从原始模型加载 VAE
vae = AutoencoderKLQwenImage.from_pretrained(
original_model_path,
subfolder="vae",
torch_dtype=torch.bfloat16
)
vae.to("cuda")
vae.eval()
# 创建管道
pipe = QwenImagePipeline.from_pretrained(
original_model_path,
transformer=transformer,
vae=vae,
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
print("模型加载成功!")
return pipe
# 使用方法
checkpoint_path = "/path/to/your/checkpoint"
pipe = load_trained_model(checkpoint_path)
# 生成图像
prompt = "一幅美丽的山水风景画"
image = pipe(
prompt=prompt,
width=768,
height=768,
num_inference_steps=30,
true_cfg_scale=5,
generator=torch.Generator(device="cuda").manual_seed(42)
)
# 保存结果
output_image = image.images[0]
output_image.save("generated_image.png")
完整示例脚本:
python inference_trained_model_gpu_optimized.py
检查点结构:
训练好的模型以如下结构保存:
checkpoint/
├── config.yaml # 训练配置文件
└── transformer/ # 训练好的 Transformer 权重
├── config.json
├── diffusion_pytorch_model.safetensors.index.json
└── diffusion_pytorch_model-00001-of-00005.safetensors
└── ... (多个分片文件)
Qwen-Image-Edit LoRA 训练
对于基于控制的图像编辑训练,使用专门的训练脚本:
accelerate launch train_qwen_edit_lora.py --config ./train_configs/train_lora_qwen_edit.yaml
Qwen-Image-Edit 的配置
配置文件 train_lora_qwen_edit.yaml 应包含以下内容:
img_dir: 目标图像和说明文字目录的路径(例如./extracted_dataset/train/images)control_dir: 控制图像目录的路径(例如./extracted_dataset/train/control)- 其他标准的 LoRA 训练参数
🧪 使用方法
Qwen-Image-Edit 全模型训练
要使用你的配置文件(例如 train_full_qwen_edit.yaml)开始训练,请运行:
accelerate launch train_full_qwen_edit.py --config ./train_configs/train_full_qwen_edit.yaml
🔧 Qwen-Image 初始化
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
# 加载管道
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.float32
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
🔧 Qwen-Image-Edit 初始化
from diffusers import QwenImageEditPipeline
import torch
from PIL import Image
# 加载管道
pipeline = QwenImageEditPipeline.from_pretrained("Qwen/Qwen-Image-Edit")
pipeline.to(torch.bfloat16)
pipeline.to("cuda")
🔌 加载 LoRA 权重
对于 Qwen-Image:
# 加载 LoRA 权重
pipe.load_lora_weights('flymy-ai/qwen-image-realism-lora', adapter_name="lora")
对于 Qwen-Image-Edit:
# 加载训练好的 LoRA 权重
pipeline.load_lora_weights("/path/to/your/trained/lora/pytorch_lora_weights.safetensors")
🎨 使用 Qwen-Image LoRA 生成图像
你可以在 这里 找到 LoRA 权重。
无需触发词
prompt = '''一位非洲裔青少年女性的超写实肖像,神情宁静安详,双臂交叉,被戏剧性的影棚灯光照亮,背景是阳光明媚的公园,佩戴精致的珠宝,四分之三侧面像,肌肤晒得健康自然,带有天然瑕疵,披散着及肩的卷发,眼睛微微眯起,环境为街头人像,T恤上印有“FLYMY AI”字样。'''
negative_prompt = " "
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=1024,
height=1024,
num_inference_steps=50,
true_cfg_scale=5,
generator=torch.Generator(device="cuda").manual_seed(346346)
)
# 显示图像(在 Jupyter 中或保存到文件)
image.show()
# 或
image.save("output.png")
🎨 使用 Qwen-Image-Edit LoRA 编辑图像
# 加载输入图像
image = Image.open("/path/to/your/input/image.jpg").convert("RGB")
# 定义编辑提示
prompt = "在同一场景中拍摄一张画面,人物逐渐远离相机,保持相机稳定以聚焦于主体,同时镜头慢慢拉远,捕捉更多周围环境,远处的人物细节逐渐模糊。"
# 生成编辑后的图像
inputs = {
"image": image,
"prompt": prompt,
"generator": torch.manual_seed(0),
"true_cfg_scale": 4.0,
"negative_prompt": " ",
"num_inference_steps": 50,
}
with torch.inference_mode():
output = pipeline(**inputs)
output_image = output.images[0]
output_image.save("edited_image.png")
🖼️ 示例输出 - Qwen-Image
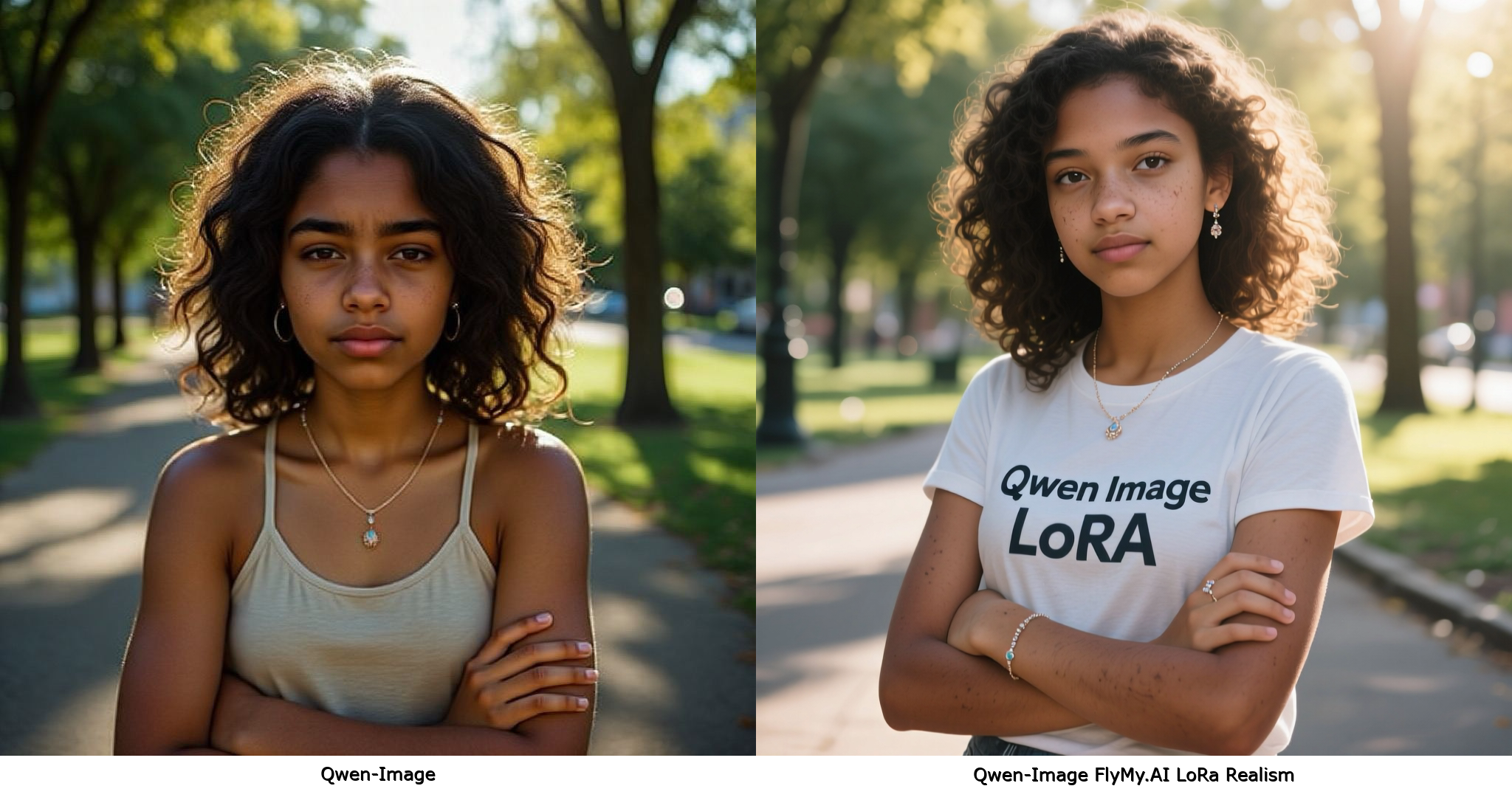
🖼️ 示例输出 - Qwen-Image-Edit
输入图像:

提示: “在同一场景中拍摄一张画面,左手固定砧板边缘,右手倾斜砧板,使切碎的番茄滑入锅中,摄像机角度略微向左移动,以便更集中地拍摄锅中的食材。”
无 LoRA 输出:
LoRA 输出:

FLUX.1-dev 模型训练
FLUX.1-dev LoRA 训练
FLUX.1-dev 是一款功能强大的文生图模型,特别擅长生成高质量的人像和角色图像。我们的 LoRA 训练实现允许您针对特定角色或风格对 FLUX 进行微调。
开始 FLUX 训练
要使用您的配置文件开始 FLUX LoRA 训练,请运行:
accelerate launch train_flux_lora.py --config ./train_configs/train_flux_config.yaml
请确保 train_flux_config.yaml 已正确设置,包含数据集、模型、输出目录等路径及其他参数。
🔧 FLUX.1-dev 初始化
from diffusers import DiffusionPipeline
import torch
model_name = "black-forest-labs/FLUX.1-dev"
# 加载管道
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.float32
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
🔌 加载 FLUX LoRA 权重
# 加载 LoRA 权重
pipe.load_lora_weights('flymy-ai/flux-dev-anne-hathaway-lora', adapter_name="lora")
🎨 使用 FLUX LoRA 生成图像
您可以在此处找到我们预训练的 FLUX LoRA 权重:https://huggingface.co/flymy-ai/flux-dev-anne-hathaway-lora
需要触发词:“ohwx woman”
prompt = '''ohwx 女性的肖像,专业头像,影棚灯光,优雅姿势,直视镜头,柔和阴影,高质量,细致面部特征,电影级灯光,85mm 镜头,浅景深'''
negative_prompt = "模糊,低质量,扭曲,解剖结构错误"
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
宽度=1024,
高度=1024,
推理步数=30,
引导系数=3.5,
生成器=torch.Generator(device="cuda").manual_seed(346346)
)
# 显示图像(在 Jupyter 中)或保存到文件
image.images[0].show()
# 或
image.images[0].save("output.png")
🖼️ FLUX 输出示例
🎨 FLUX 生成示例
以下是使用我们的 FLUX Anne Hathaway LoRA 模型生成的图像示例:
休闲人像自拍
提示词:“ohwx 女性肖像自拍”

艺术双曝光
提示词:“ohwx 女性完美对称的年轻女性脸部特写,以双曝光叠加呈现,融合树叶和水等自然纹理”

黄金时段微距人像
提示词:“ohwx 女性微距摄影风格的女性脸部特写,化着淡妆,重点突出眼睛和嘴唇,在黄金时段阳光下呈现出温暖色调”

温馨熊猫人像
提示词:“ohwx 女性身穿棕色针织高领毛衣的特写。她与一只黑白相间的胖熊猫依偎在一起,抱着它,直视镜头”

🚀 训练您自己的 FLUX LoRA
想训练属于您自己的 FLUX LoRA 模型吗?请使用我们的在线训练平台:
🚀 在 FlyMy.AI 上训练您自己的 FLUX LoRA
特点:
- ✅ 简单易用的网页界面
- ✅ 无需本地 GPU
- ✅ 优化的训练流程
- ✅ 快速训练时间
- ✅ 专业级效果
🎛️ 与 ComfyUI 结合使用
我们提供了开箱即用的 ComfyUI 工作流,可同时用于我们训练的 Qwen 和 FLUX LoRA 模型。请按照以下步骤设置并使用这些工作流:
设置说明
下载最新版 ComfyUI:
- 访问 ComfyUI GitHub 仓库
- 克隆或下载最新版本
安装 ComfyUI:
- 按照 ComfyUI 仓库 中的安装说明操作
- 确保所有依赖项均已正确安装
下载模型权重:
对于 Qwen-Image:
- 前往 Qwen-Image ComfyUI 权重
- 下载所有模型文件
对于 FLUX.1-dev:
- 前往 FLUX.1-dev 模型
- 下载所有模型文件
将模型权重放入 ComfyUI:
- 将下载的模型文件复制到
ComfyUI/models/中的相应文件夹 - 按照模型仓库中指定的文件夹结构进行操作
- 将下载的模型文件复制到
下载我们预训练的 LoRA 权重:
- Qwen LoRA: flymy-ai/qwen-image-realism-lora
- FLUX LoRA: flymy-ai/flux-dev-anne-hathaway-lora
- 下载 LoRA 的
.safetensors文件
将 LoRA 权重放入 ComfyUI:
- 将 LoRA 文件复制到
ComfyUI/models/loras/目录中
- 将 LoRA 文件复制到
加载工作流:
- 在浏览器中打开 ComfyUI
- 对于 Qwen: 加载
qwen_image_lora_example.json - 对于 FLUX: 加载
flux_anne_hathaway_lora_example.json - 这些工作流已预先配置好,可与我们的 LoRA 模型配合使用
工作流特点
- ✅ 预先配置用于 Qwen-Image + LoRA 推理
- ✅ 预先配置用于 FLUX.1-dev + LoRA 推理
- ✅ 优化的设置以获得最佳画质
- ✅ 方便调整提示词和参数
- ✅ 兼容我们训练的所有 LoRA 模型
ComfyUI 工作流提供了一个用户友好的界面,让您无需编写 Python 代码即可使用我们训练好的 LoRA 模型生成图像。
🖼️ 工作流截图
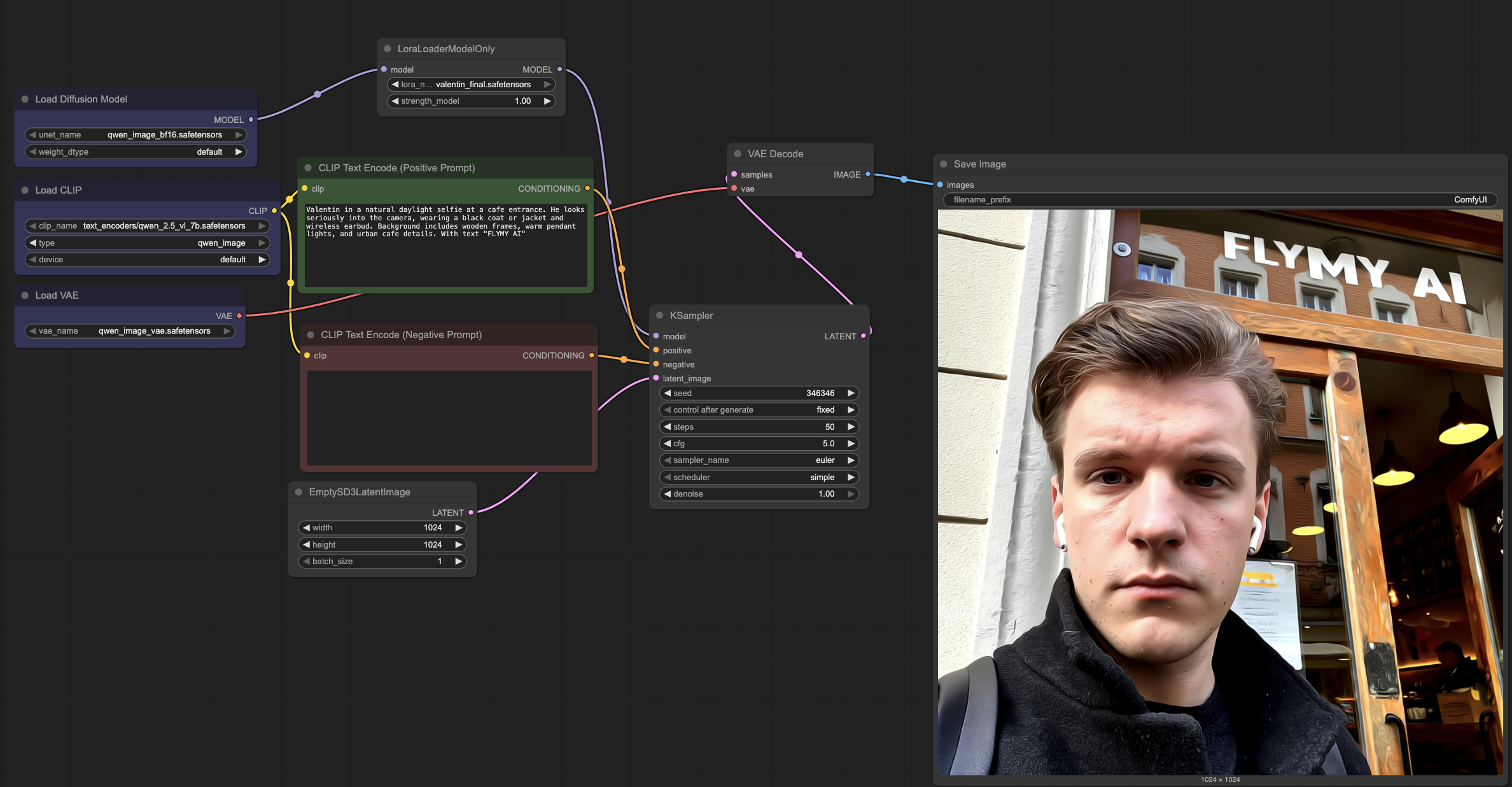
🤝 支持
如果您有任何问题或建议,请加入我们的社区:
- 🌐 FlyMy.AI
- 💬 Discord 社区
- 🐦 在 X 上关注我们
- 💼 在 LinkedIn 上联系我们
- 📧 支持邮箱
⭐ 如果您喜欢这个项目,请别忘了给仓库点个赞!
版本历史
1.0.02025/08/09常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备