FireRedASR
FireRedASR 是一套开源的工业级自动语音识别(ASR)模型家族,专为高精度处理普通话、中文方言及英语而设计。它不仅刷新了公开中文语音识别基准的最佳性能记录,还具备出色的歌曲歌词识别能力,有效解决了传统模型在复杂声学环境、多语言混合及歌唱场景下识别率低的技术难题。
该工具特别适合开发者、算法研究人员以及需要构建高质量语音交互应用的企业团队使用。无论是开发智能客服、会议转录系统,还是进行多语言语音数据分析,FireRedASR 都能提供强有力的支持。
其核心技术亮点在于提供了两种差异化架构以满足不同需求:FireRedASR-LLM 版本结合大语言模型能力,实现了端到端的流畅语音交互,适合追求极致效果的场景;FireRedASR-AED 版本则基于注意力编码器 - 解码器架构,在保持高性能的同时大幅优化了计算效率。此外,最新推出的 FireRedASR2S 系统更是集成了语音活动检测(VAD)、语言识别(LID)和标点恢复(Punc)模块,所有组件均达到业界领先水平,为用户提供了一站式的高效解决方案。
使用场景
某大型在线音乐平台的内容审核团队,每天需要处理数万小时的用户上传音频,涵盖普通话、各地方言翻唱及英文歌曲,亟需自动化提取歌词以进行版权比对和内容合规审查。
没有 FireRedASR 时
- 方言与歌声识别率低:传统模型对粤语、四川话等方言翻唱几乎无法识别,且将歌唱语音误判为普通说话,导致大量歌词提取失败或乱码。
- 多模型切换繁琐:团队需分别部署语音检测(VAD)、语言识别(LID)和标点恢复模块,不同模型间数据格式不兼容,维护成本极高。
- 长音频处理效率差:面对长达数小时的直播录音或专辑串烧,现有方案常出现截断或延迟,无法满足实时审核需求。
- 人工复核成本高:由于自动转写错误率高,审核员需花费 70% 的时间手动修正字幕,严重拖慢内容上线速度。
使用 FireRedASR 后
- 歌声与方言精准识别:FireRedASR 凭借卓越的唱歌歌词识别能力,能准确转录带有浓重口音的方言翻唱,即使是高音部分也能保持高准确率。
- 一站式全链路解决:FireRedASR2S 集成了 VAD、LID、ASR 和标点模块,单一模型即可输出带时间戳和标点的完整文本,大幅简化了技术架构。
- 工业级高效推理:得益于优化的 AED 架构,FireRedASR 在处理长音频时流式响应迅速,资源占用更低,实现了近实时的内容审核流程。
- 人工干预大幅减少:转写准确率提升至行业新标杆(SOTA),人工复核工作量降低至 15% 以下,审核团队得以专注于复杂的版权判定工作。
FireRedASR 通过其对方言、歌声的卓越理解力及“多合一”的工业级架构,将音乐平台的音频内容处理效率提升了数倍,真正实现了从“听得见”到“听得懂”的跨越。
运行环境要求
- Linux
- 可选(代码示例中 use_gpu=1),具体型号和显存未说明
- FireRedASR-LLM 基于 Qwen2-7B,建议显存 16GB+
- FireRedASR-AED 参数量较小,需求较低
- CUDA 版本未说明
未说明(FireRedASR-LLM 包含 7B+ 参数模型,建议 16GB+)

快速开始
FireRedASR:开源工业级
自动语音识别模型
FireRedASR2S 已开源!欢迎试用!https://github.com/FireRedTeam/FireRedASR2S
FireRedASR2S 是一款最先进的、工业级的多合一 ASR 系统,包含 ASR、VAD、LID 和 Punc 模块。所有模块均达到 SOTA 性能。
FireRedASR 是一系列开源的工业级自动语音识别(ASR)模型,支持普通话、汉语方言和英语,在公开的普通话 ASR 基准测试中达到了新的 SOTA 水平,同时还具备出色的歌曲歌词识别能力。
🔥 最新消息
- [2026.02.25] 我们发布了 FireRedASR2-LLM 模型权重。🤗 🤖
- [2026.02.12] 我们发布了 FireRedASR2S(FireRedASR2-AED、FireRedVAD、FireRedLID 和 FireRedPunc),附带模型权重和推理代码。详情请见 https://github.com/FireRedTeam/FireRedASR2S
- [2025.02.17] 我们发布了 FireRedASR-LLM-L 模型权重。
- [2025.01.24] 我们发布了 技术报告,博客以及 FireRedASR-AED-L 模型权重。
方法
FireRedASR 旨在满足各种应用场景下对卓越性能和最佳效率的多样化需求。它包含两个变体:
- FireRedASR-LLM:旨在实现最先进的(SOTA)性能,并支持无缝的端到端语音交互。该模型采用基于大语言模型(LLM)能力的编码器-适配器-LLM 架构。
- FireRedASR-AED:旨在平衡高性能与计算效率,作为基于 LLM 的语音模型中的有效语音表示模块。它使用基于注意力的编码器-解码器(AED)架构。
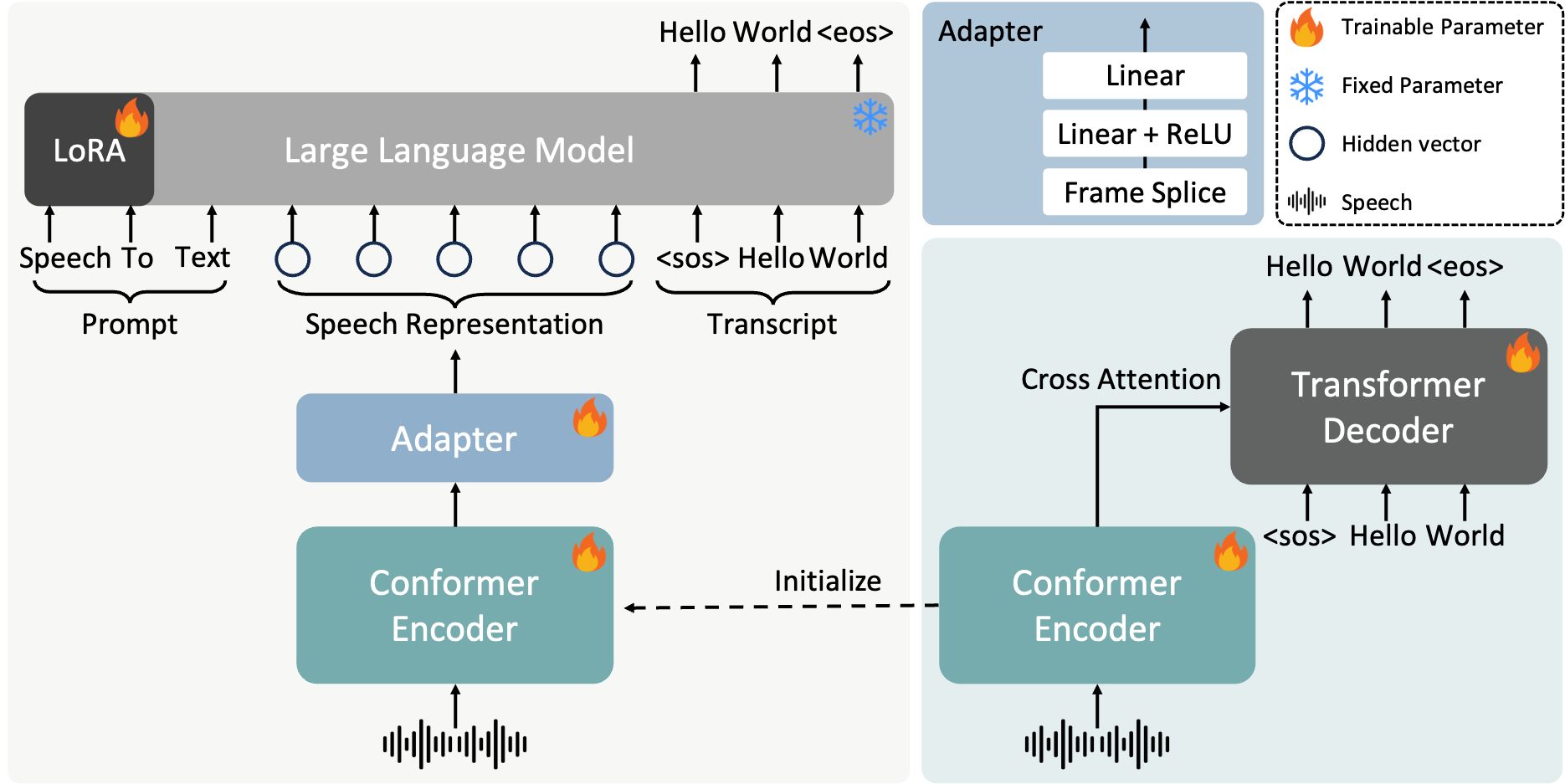
评估
结果以中文的字符错误率(CER%)和英文的词错误率(WER%)来报告。
公开普通话 ASR 基准测试评估
| 模型 | 参数量 | aishell1 | aishell2 | ws_net | ws_meeting | 平均-4 |
|---|---|---|---|---|---|---|
| FireRedASR-LLM | 8.3B | 0.76 | 2.15 | 4.60 | 4.67 | 3.05 |
| FireRedASR-AED | 1.1B | 0.55 | 2.52 | 4.88 | 4.76 | 3.18 |
| Seed-ASR | 12B+ | 0.68 | 2.27 | 4.66 | 5.69 | 3.33 |
| Qwen-Audio | 8.4B | 1.30 | 3.10 | 9.50 | 10.87 | 6.19 |
| SenseVoice-L | 1.6B | 2.09 | 3.04 | 6.01 | 6.73 | 4.47 |
| Whisper-Large-v3 | 1.6B | 5.14 | 4.96 | 10.48 | 18.87 | 9.86 |
| Paraformer-Large | 0.2B | 1.68 | 2.85 | 6.74 | 6.97 | 4.56 |
ws 表示 WenetSpeech。
公开汉语方言及英语 ASR 基准测试评估
| 测试集 | KeSpeech | LibriSpeech test-clean | LibriSpeech test-other |
|---|---|---|---|
| FireRedASR-LLM | 3.56 | 1.73 | 3.67 |
| FireRedASR-AED | 4.48 | 1.93 | 4.44 |
| 之前的 SOTA 结果 | 6.70 | 1.82 | 3.50 |
使用方法
从 huggingface 下载模型文件,并将其放置在 pretrained_models 文件夹中。
如果您想使用 FireRedASR-LLM-L,还需要下载 Qwen2-7B-Instruct 并将其放入 pretrained_models 文件夹中。然后,进入 FireRedASR-LLM-L 文件夹并运行 $ ln -s ../Qwen2-7B-Instruct
设置
创建 Python 环境并安装依赖项
$ git clone https://github.com/FireRedTeam/FireRedASR.git
$ conda create --name fireredasr python=3.10
$ conda activate fireredasr
$ pip install -r requirements.txt
设置 Linux PATH 和 PYTHONPATH
$ export PATH=$PWD/fireredasr/:$PWD/fireredasr/utils/:$PATH
$ export PYTHONPATH=$PWD/:$PYTHONPATH
将音频转换为 16kHz 16 位 PCM 格式
ffmpeg -i input_audio -ar 16000 -ac 1 -acodec pcm_s16le -f wav output.wav
快速入门
$ cd examples
$ bash inference_fireredasr_aed.sh
$ bash inference_fireredasr_llm.sh
命令行使用
$ speech2text.py --help
$ speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "aed" --model_dir pretrained_models/FireRedASR-AED-L
$ speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "llm" --model_dir pretrained_models/FireRedASR-LLM-L
Python 使用
from fireredasr.models.fireredasr import FireRedAsr
batch_uttid = ["BAC009S0764W0121"]
batch_wav_path = ["examples/wav/BAC009S0764W0121.wav"]
# FireRedASR-AED
model = FireRedAsr.from_pretrained("aed", "pretrained_models/FireRedASR-AED-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 1,
"beam_size": 3,
"nbest": 1,
"decode_max_len": 0,
"softmax_smoothing": 1.25,
"aed_length_penalty": 0.6,
"eos_penalty": 1.0
}
)
print(results)
# FireRedASR-LLM
model = FireRedAsr.from_pretrained("llm", "pretrained_models/FireRedASR-LLM-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 1,
"beam_size": 3,
"decode_max_len": 0,
"decode_min_len": 0,
"repetition_penalty": 3.0,
"llm_length_penalty": 1.0,
"temperature": 1.0
}
)
print(results)
使用提示
批量束搜索
- 使用 FireRedASR-LLM 进行批量束搜索时,请确保输入话语的长度相近。如果话语长度差异较大,较短的话语可能会出现重复问题。您可以按长度对数据集进行排序,或者将
batch_size设置为 1,以避免重复问题。
输入长度限制
- FireRedASR-AED 支持最长 60 秒的音频输入。超过 60 秒的输入可能会导致幻觉问题,而超过 200 秒的输入则会触发位置编码错误。
- FireRedASR-LLM 支持最长 30 秒的音频输入。对于更长的输入,其行为目前尚不清楚。
致谢
感谢以下开源项目:
引用
@article{xu2025fireredasr,
title={FireRedASR:从编码器-解码器到大语言模型集成的开源工业级中文语音识别模型},
author={徐凯拓和谢丰龙和唐旭和胡尧},
journal={arXiv预印本 arXiv:2501.14350},
year={2025}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器