HVI-CIDNet
HVI-CIDNet 是一款专为低光照图像增强设计的开源 AI 模型,其核心成果已入选计算机视觉顶会 CVPR 2025。它主要解决在极暗环境下拍摄的照片噪点多、色彩失真及细节丢失等难题,能够将昏暗模糊的影像还原为明亮清晰的高质量图片。
该工具最大的技术亮点在于提出了一种全新的色彩空间——HVI。不同于传统方法直接在 RGB 空间处理,HVI 色彩空间能更有效地分离亮度与色彩信息,配合高效的网络架构,在大幅提升图像亮度的同时,精准保留自然色彩与纹理细节,避免了常见的过曝或色偏现象。此外,该项目还在 NTIRE 2025 低光照增强挑战赛中荣获冠军,证明了其卓越的性能。
HVI-CIDNet 非常适合多类人群使用:研究人员可基于其开源代码探索新的色彩空间理论;开发者能将其集成到监控、自动驾驶或移动摄影应用中;设计师和普通用户则可通过集成的 Gradio 演示界面,一键修复夜景照片或欠曝素材,无需具备深厚的编程背景。项目团队公开了完整的训练代码、预训练模型及数据集,致力于推动低光照视觉技术的进一步发展。
使用场景
某安防监控团队在夜间处理城市街道的低照度视频流时,面临图像昏暗、噪点严重且色彩失真的难题,急需提升画面质量以辅助人工研判。
没有 HVI-CIDNet 时
- 细节丢失严重:传统增强算法在提亮暗部时,往往导致阴影区域的纹理(如车牌号、行人面部)完全糊成一片,无法辨识。
- 色彩还原偏差:常规方法容易将夜间灯光下的物体渲染成诡异的偏色(如过度饱和的橙色或惨白的蓝色),干扰对现场环境的真实判断。
- 噪点放大明显:强行增加曝光度会同时放大传感器噪声,使画面布满彩色噪点,严重影响后续的人脸识别或车辆检测算法精度。
- 处理效率低下:为了平衡画质与速度,工程师不得不手动调整多组参数进行试错,难以满足实时监控的低延迟要求。
使用 HVI-CIDNet 后
- 暗部纹理清晰重现:基于全新的 HVI 色彩空间,HVI-CIDNet 能精准分离亮度与色彩信息,在显著提亮画面的同时,完整保留街道招牌和行人衣物的细微纹理。
- 自然色彩高保真:工具有效校正了低光环境下的色偏问题,还原出接近人眼所见的自然色调,确保监控人员能准确判断物体原本的颜色。
- 智能抑制噪声:在增强过程中同步去除高频噪声,输出画面干净纯净,大幅提升了下游 AI 识别模型在夜间场景的准确率。
- 端到端高效部署:无需繁琐的参数调优,HVI-CIDNet 可直接集成至视频流处理管道,以极低的计算开销实现实时的画质增强。
HVI-CIDNet 通过重构色彩空间底层逻辑,从根本上解决了低照度图像“亮不起来、彩不准、噪点多”的三大顽疾,让夜间监控真正具备实战价值。
运行环境要求
- 未说明
未说明 (项目为低光图像增强深度学习模型,通常需 NVIDIA GPU 加速,但 README 未明确具体型号或显存要求)
未说明
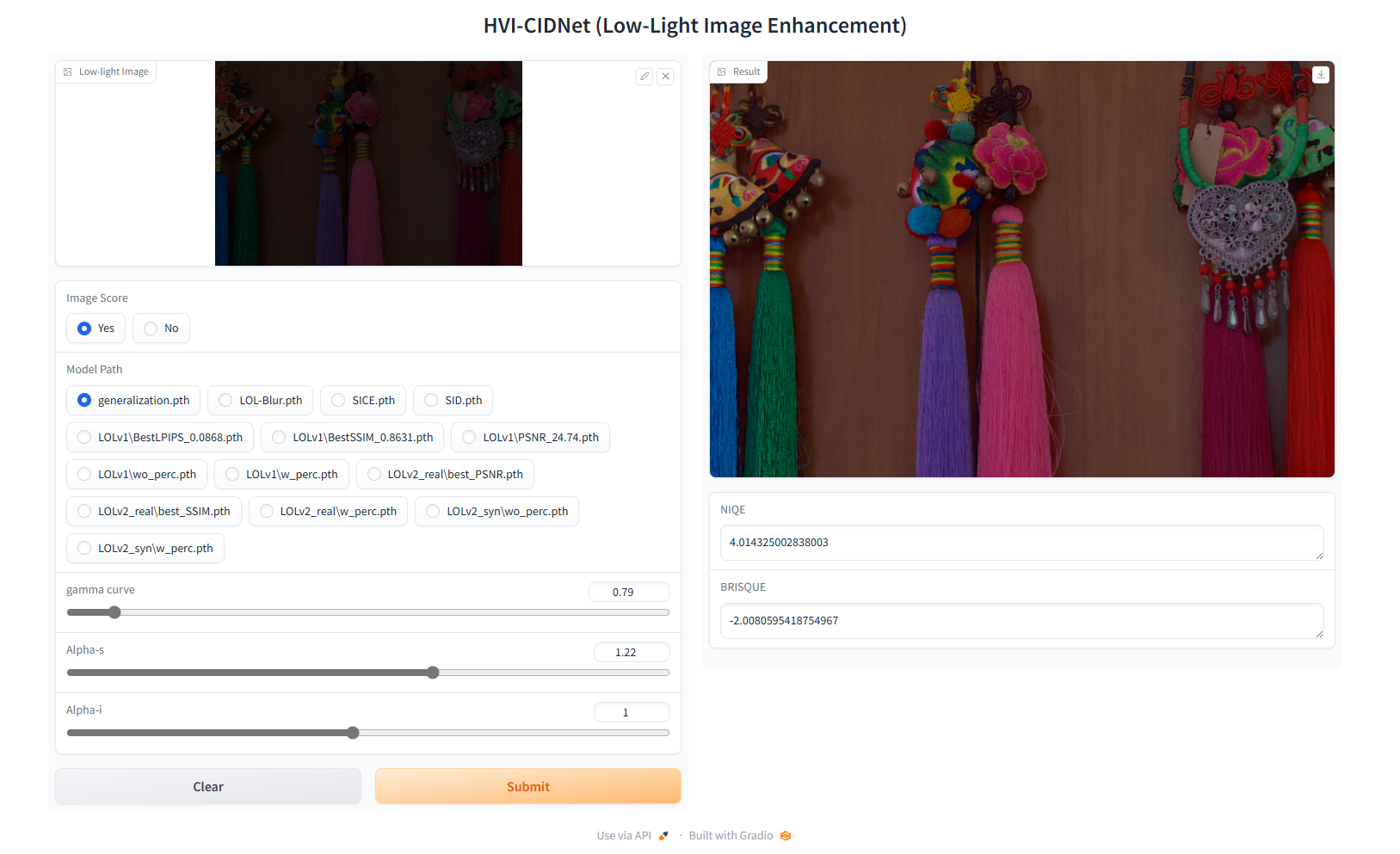
快速开始

[CVPR2025] HVI:一种用于低光图像增强的新色彩空间
Yan Qingsen∗ , Feng Yixu∗ , Zhang Cheng, Pang Guansong, Shi Kangbiao, Wu Peng, Dong Wei, Sun Jinqiu, Zhang Yanning
![]()
HVI-CIDNet演示:
新闻 🆕
2025.10.27 感谢shade233帮助我修复了冲突和argparser的错误使用。
2025.07.11 升级版论文为“HVI-CIDNet+:超越极端黑暗的低光图像增强”,发表于Arxiv。新的代码、模型和结果将很快上传。(代码链接:Github)
2025.06.03 特别感谢Shi Kangbiao,他在FiveK数据集上按照retinexformer的方法训练了HVI-CIDNet。训练代码和模型现已可用。 🔆
2025.05.01 我们的NTIRE2025 LLIE赛道冠军方案FusionNet现已在Arxiv上公开!📝
2025.03.27 恭喜!我们的团队在比赛中获得了第一名:NTIRE 2025低光图像增强挑战赛(如对我们的NTIRE方法有任何疑问,请联系:Shi Kangbiao,邮箱:18334840904@163.com)。我们把HVI-CIDNet与去年的冠亚军模型融合,以获得最佳效果。我们将在报告中详细解释融合方法,供后续参考。🚀
2025.03.10 所有权重已在Hugging Face上公开。特别感谢Niels Rogge、Wauplin和hysts。🔆
2025.02.26 恭喜!我们的最终版论文“HVI:一种用于低光图像增强的新色彩空间”已被CVPR 2025接受。🔥
2025.02.20 我们的模型测试demo已在Hugging Face上可用。🤗
2025.01.31 更新训练代码。使用随机gamma函数(增强曲线)来提高跨数据集的泛化能力。 🔆
2024.06.19 在Arxiv上更新了最新版本的论文。📝
2024.05.12 更新LOLv1上的同行对比结果。🤝
2024.04.28 将所有百度网盘的数据集、输出和权重同步到One Drive。🌎
2024.04.18 完整版代码、模型和可视化对比已发布。我们承诺所有权重均仅在训练集上训练,并且每份权重均可复现。希望这能对您的未来工作有所帮助。如果您训练出了更好的结果,请联系我们。我们期待基于HVI色彩“空间”的后续工作!💎
2024.04.14 更新LOLv1数据集上的微调结果和权重。🧾
2024.03.04 更新五个非配对数据集(DICM、LIME、MEF、NPE、VV)的可视化结果。✨
2024.03.03 使用百度网盘更新HVI-CIDNet的预训练权重和输出结果。🧾
2024.02.08 将HVI-CIDNet原始版本论文更新为“你只需要一个色彩空间:用于低光图像增强的高效网络”,发表于Arxiv。新的代码、模型和结果即将上传。🎈
提出的HVI-CIDNet ⚙
动机:
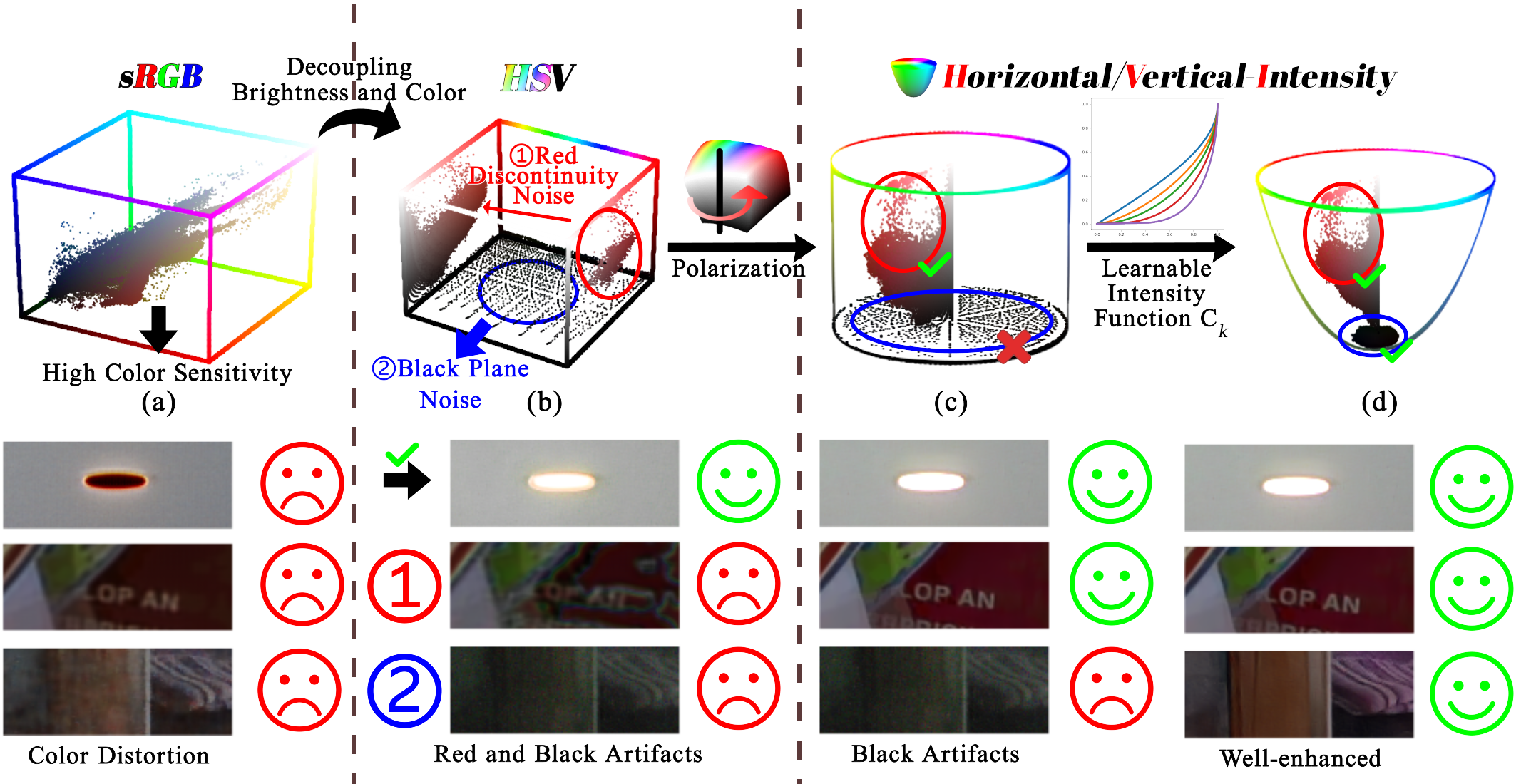
HVI-CIDNet流程:
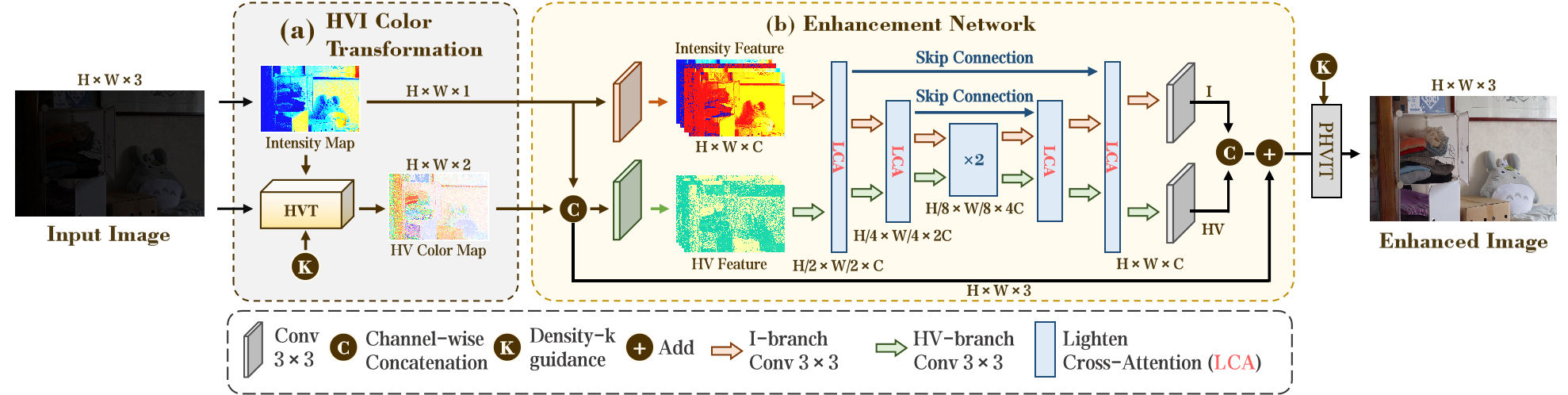
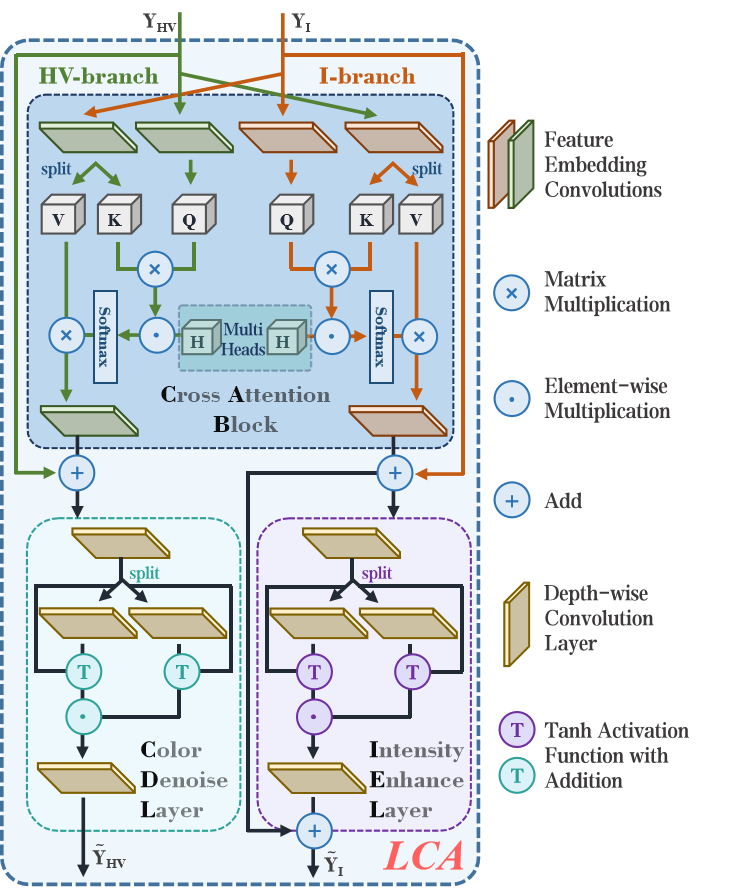
轻量化交叉注意力(LCA)模块结构:
可视化对比 🖼
LOL-v1、LOLv2-real和LOLv2-synthetic:

DICM、LIME、MEF、NPE和VV:

LOL-Blur:

权重和结果 🧾
我们在不同数据集上训练的所有权重均可在[百度网盘](密码:yixu)和[One Drive](密码:yixu)上获取。DICM、LIME、MEF、NPE和VV数据集的结果可从[百度网盘](密码:yixu)和[One Drive](密码:yixu)下载。
加粗字体表示优异的指标。
HVI-CIDNet在配对数据集上的指标如下表所示:
所有链接密码均为yixu。
| 文件夹(测试数据集) | PSNR | SSIM | LPIPS | GT均值 | 结果 | 权重路径 |
|---|---|---|---|---|---|---|
| (LOLv1) v1 使用感知损失/不使用GT均值 |
23.8091 | 0.8574 | 0.0856 | 百度网盘 和 One Drive | LOLv1/w_perc.pth | |
| (LOLv1) v1 使用感知损失/使用GT均值 |
27.7146 | 0.8760 | 0.0791 | √ | 同上 | LOLv1/w_perc.pth |
| (LOLv1) v1 不使用感知损失/不使用GT均值 |
23.5000 | 0.8703 | 0.1053 | 百度网盘 和 One Drive | LOLv1/wo_perc.pth | |
| (LOLv1) v1 不使用感知损失/使用GT均值 |
28.1405 | 0.8887 | 0.0988 | √ | 同上 | LOLv1/wo_perc.pth |
| (LOLv2_real) v2 不使用感知损失/不使用GT均值 |
23.4269 | 0.8622 | 0.1691 | 百度网盘 和 One Drive | (丢失) | |
| (LOLv2_real) v2 不使用感知损失/使用GT均值 |
27.7619 | 0.8812 | 0.1649 | √ | 同上 | (丢失) |
| (LOLv2_real) v2 最佳GT均值 |
28.1387 | 0.8920 | 0.1008 | √ | 百度网盘 和 One Drive | LOLv2_real/w_prec.pth |
| (LOLv2_real) v2 最佳Normal |
24.1106 | 0.8675 | 0.1162 | 百度网盘 和 One Drive | (丢失) | |
| (LOLv2_real) v2 最佳PSNR |
23.9040 | 0.8656 | 0.1219 | 百度网盘 和 One Drive | LOLv2_real/best_PSNR.pth | |
| (LOLv2_real) v2 最佳SSIM |
23.8975 | 0.8705 | 0.1185 | 百度网盘 和 One Drive | LOLv2_real/best_SSIM.pth | |
| (LOLv2_real) v2 最佳SSIM/使用GT均值 |
28.3926 | 0.8873 | 0.1136 | √ | 无 | LOLv2_real/best_SSIM.pth |
| (LOLv2_syn) 合成数据不使用感知损失/不使用GT均值 |
25.7048 | 0.9419 | 0.0471 | 百度网盘 和 One Drive | LOLv2_syn/wo_perc.pth | |
| (LOLv2_syn) 合成数据不使用感知损失/使用GT均值 |
29.5663 | 0.9497 | 0.0437 | √ | 同上 | LOLv2_syn/wo_perc.pth |
| (LOLv2_syn) 合成数据使用感知损失/不使用GT均值 |
25.1294 | 0.9388 | 0.0450 | 百度网盘 和 One Drive | LOLv2_syn/w_perc.pth | |
| (LOLv2_syn) 合成数据使用感知损失/使用GT均值 |
29.3666 | 0.9500 | 0.0403 | √ | 同上 | LOLv2_syn/w_perc.pth |
| Sony_Total_Dark | 22.9039 | 0.6763 | 0.4109 | 百度网盘 和 One Drive | SID.pth | |
| LOL-Blur | 26.5719 | 0.8903 | 0.1203 | 百度网盘 和 One Drive | LOL-Blur.pth | |
| SICE-Mix | 13.4235 | 0.6360 | 0.3624 | √ | 百度网盘 和 One Drive | SICE.pth |
| SICE-Grad | 13.4453 | 0.6477 | 0.3181 | √ | 百度网盘 和 One Drive | SICE.pth |
| FiveK 遵循Retinexformer |
24.4587 | 0.8769 | 0.0851 | 百度网盘 和 One Drive | fivek.pth |
以下表格展示了在五个未配对数据集上的性能:
| 指标 | DICM | LIME | MEF | NPE | VV |
|---|---|---|---|---|---|
| NIQE | 3.79 | 4.13 | 3.56 | 3.74 | 3.21 |
| BRISQUE | 21.47 | 16.25 | 13.77 | 18.92 | 30.63 |
此外,我们发现,在训练过程中使用随机伽马函数可以提升CIDNet的泛化能力。 详细信息请参见 train.py 第53–55行;您也可以在训练时通过将 data/options.py 第60行的随机伽马模式开启来启用该功能。
我们使用随机伽马模式在LOLv2-Syn数据集上进行了训练,并将权重保存为 LOLv2_syn/generalization.pth(可在链接中找到)。下表展示了其性能,其中7项指标均有提升:
| 指标 | DICM | LIME | MEF | NPE | VV | 结果 |
|---|---|---|---|---|---|---|
| NIQE | 3.55 | 3.85 | 3.46 | 3.82 | 3.24 | 百度网盘 和 One Drive |
| BRISQUE | 25.62 | 16.02 | 13.08 | 18.90 | 29.55 | 同上 |
我们在 Hugging Face 网站上的 HVI-CIDNet 演示中使用了具有“最强”泛化能力的权重,强烈推荐大家尝试。以下是该模型在五个无配对数据集上的 NIQE 指标,您可以在 Hugging Face 上轻松复现:
| 指标 | DICM | LIME | MEF | NPE | VV | 平均 |
|---|---|---|---|---|---|---|
| NIQE | 3.36 | 3.03 | 3.11 | 3.33 | 2.49 | 3.13 |
测试微调:
- 虽然我们不建议您在测试集上进行微调,但为了展示我们模型的有效性,我们也在此提供了在 LOLv1 数据集上进行测试微调训练的结果。在测试集上使用微调技术确实会使 PSNR 指标更高,但在 CIDNet 上其他指标并未发现显著变化,这可能会导致模型的泛化能力下降,因此我们不建议您这样做。
| 文件夹(测试数据集) | PSNR | SSIM | LPIPS | GT 均值 | 结果 | 权重路径 |
|---|---|---|---|---|---|---|
| (LOLv1) v1 测试微调 |
25.4036 | 0.8652 | 0.0897 | 百度网盘 和 One Drive | LOLv1/test_finetuning.pth | |
| (LOLv1) v1 测试微调 |
27.5969 | 0.8696 | 0.0869 | √ | 同上 | 同上 |
其他同行的贡献:
- 本节展示了其他同行使用我们的模型训练出的更优权重版本,我们将在此处同时展示他们的权重和结果。如果您也训练出了更好的权重,请通过电子邮件联系我们或提交问题。
| 数据集 | PSNR | SSIM | LPIPS | GT 均值 | 结果 | 权重路径 | 贡献者详情 | GPU |
|---|---|---|---|---|---|---|---|---|
| LOLv1 | 24.7401 | 0.8604 | 0.0896 | 百度网盘 和 One Drive | LOLv1/other/PSNR_24.74.pth | [西安工程大学] Yingjian Li |
NVIDIA 4070 |
1. 开始使用 🌑
依赖与安装
- Python 3.7.0
- Pytorch 1.13.1
(1) 创建 Conda 环境
conda create --name CIDNet python=3.7.0
conda activate CIDNet
(2) 克隆仓库
git clone git@github.com:Fediory/HVI-CIDNet.git
(3) 安装依赖
cd HVI-CIDNet
pip install -r requirements.txt
数据准备
您可以参考以下链接下载数据集。请注意,我们仅使用 LOL-Blur 数据集中 low_blur 和 high_sharp_scaled 子集。
- LOLv1
- LOLv2:百度网盘(密码:
yixu)和 One Drive(密码:yixu) - LOL-Blur:百度网盘(密码:
yixu)和 One Drive(密码:yixu) - DICM、LIME、MEF、NPE、VV:百度网盘(密码:
yixu)和 One Drive(密码:yixu) - SICE:百度网盘(密码:
yixu)和 One Drive(密码:yixu) - Sony-Total-Dark(SID):百度网盘(密码:
yixu)和 One Drive(密码:yixu) - FiveK(参照 Retinexformer):百度网盘(密码:
cyh2),Google Drive
然后,将这些数据放入以下文件夹中:
datasets(点击展开)
├── datasets
├── DICM
├── FiveK
├── test
├──input
├──target
├── train
├──input
├──target
├── LIME
├── LOLdataset
├── our485
├──low
├──high
├── eval15
├──low
├──high
├── LOLv2
├── Real_captured
├── Train
├── Low
├── Normal
├── Test
├── Low
├── Normal
├── Synthetic
├── Train
├── Low
├── Normal
├── Test
├── Low
├── Normal
├── LOL_blur
├── eval
├── high_sharp_scaled
├── low_blur
├── test
├── high_sharp_scaled
├── 0012
├── 0017
...
├── low_blur
├── 0012
├── 0017
...
├── train
├── high_sharp_scaled
├── 0000
├── 0001
...
├── low_blur
├── 0000
├── 0001
...
├── MEF
├── NPE
├── SICE
├── Dataset
├── eval
├── target
├── test
├── label
├── train
├── 1
├── 2
...
├── SICE_Grad
├── SICE_Mix
├── SICE_Reshape
├── Sony_total_dark
├── eval
├── long
├── short
├── test
├── long
├── 10003
├── 10006
...
├── short
├── 10003
├── 10006
...
├── train
├── long
├── 00001
├── 00002
...
├── short
├── 00001
├── 00002
...
├── VV
2. 测试 🌒
从 [百度网盘](密码:yixu)下载我们的权重,并将其放入 weights 文件夹中:
weights(点击展开)
├── weights
├── LOLv1
├── w_perc.pth
├── wo_perc.pth
├── test_finetuning.pth
├── LOLv2_real
├── best_PSNR.pth
├── best_SSIM.pth
├── w_perc.pth
├── LOLv2_syn
├── generalization.pth
├── w_perc.pth
├── wo_perc.pth
├── LOL-Blur.pth
├── SICE.pth
├── SID.pth
- 您可以通过运行
python app.py的 Bash 命令在我们的 Gradio 演示中测试我们的方法,并访问 URL 链接 “http://127.0.0.1:7862” 来体验演示。(添加--cpu可以仅使用 CPU 进行推理) - 或者,您也可以使用
huggingface_hub下载并测试我们的方法,如下所示:
# 您可以在 https://huggingface.co/papers/2502.20272 找到所有权重
python eval_hf.py --path fediory/our_model_path --input_img your/img/path --alpha_s 1.0 --alpha_i 1.0 --gamma 1.0
# 例如
python eval_hf.py --path fediory/HVI-CIDNet-LOLv1-wperc --input_img ./datasets/DICM/01.JPG --alpha_s 1.0 --alpha_i 1.0 --gamma 1.0
您的增强图像将保存在 ./output_hf 目录下。
- 或者 您可以按照以下步骤测试我们的方法,所有结果都将保存在
./output文件夹中:
(点击展开)
# LOLv1
python eval.py --lol --perc # 使用感知损失训练的权重
python eval.py --lol # 不使用感知损失训练的权重
# LOLv2-real
python eval.py --lol_v2_real --best_GT_mean # 您可以选择 best_GT_mean、best_PSNR 或 best_SSIM
# LOLv2-syn
python eval.py --lol_v2_syn --perc # 使用感知损失训练的权重
python eval.py --lol_v2_syn # 不使用感知损失训练的权重
# SICE
python eval.py --SICE_grad # 输出 SICE_grad
python eval.py --SICE_mix # 输出 SICE_mix
# FiveK
python eval.py --fivek # 输出遵循 Retinexformer 的 FiveK 结果
# Sony-Total-Dark
python eval_SID_blur --SID
# LOL-Blur
python eval_SID_blur --Blur
# 五个非配对数据集:DICM、LIME、MEF、NPE、VV。
# 注意:您可以从 ./weights 文件夹中选择一种权重,并设置光照缩放系数 alpha(默认为 1.0)。gamma 表示伽马函数(曲线),请参阅 eval.py 第 59 行。
# 您可以将 "--DICM" 替换为其他非配对数据集 "LIME、MEF、NPE、VV"。
python eval.py --unpaired --DICM --unpaired_weights --alpha
# 例如:
python eval.py --unpaired --DICM --unpaired_weights ./weights/LOLv2_syn/w_perc.pth --alpha 0.9 --gamma 0.9
# 自定义数据集:alpha 和 gamma 是可选的。
python eval.py --unpaired --custome --custome_path ./您自定义数据集路径 --unpaired_weights ./weights/LOLv2_syn/w_perc.pth --alpha 0.9 --gamma 0.9
- 此外,您还可以按照以下方式测试我们论文中提到的所有评价指标:
(点击展开)
# LOLv1
python measure.py --lol
# LOLv2-real
python measure.py --lol_v2_real
# LOLv2-syn
python measure.py --lol_v2_syn
# Sony-Total-Dark
python measure_SID_blur.py --SID
# LOL-Blur
python measure_SID_blur.py --Blur
# SICE-Grad
python measure.py --SICE_grad
# SICE-Mix
python measure.py --SICE_mix
# fivek
python measure.py --fivek
# 五个非配对数据集:DICM、LIME、MEF、NPE、VV。
# 您可以将 "--DICM" 替换为其他非配对数据集 "LIME、MEF、NPE、VV"。
python measure_niqe_bris.py --DICM
# 注意:参照 LLFlow、KinD 和 Retinxformer 的做法,我们也根据 GroundTruth (GT) 的平均值调整了网络输出图像的亮度。此操作仅适用于配对数据集。如果您想进行测量,请添加 "--use_GT_mean"。
#
# 例如:
python measure.py --lol --use_GT_mean
- 评估 HVI-CIDNet 的参数量、FLOPs 和运行时间:
python net_test.py
3. 训练 🌓
- 我们将所有需要调整的配置都放在
./data/options.py文件中,并在文件中进行了详细说明。对于部分训练参数,我们很遗憾无法继续提供和分享给您,但我们保证所有权重都可以通过参数调优进行训练。您可以通过以下方式训练我们的 HVI-CIDNet:
# 您可以设置 --start_warmup True/False 来决定是否在训练阶段启用预热。
# 您可以选择以下数据集进行训练:lol_v1、lolv2_real、lolv2_syn、lol_blur、SID、SICE_mix、SICE_grad、fivek。
# 以下是示例。
python train.py --dataset lol_v1
- 所有权重都会保存到
./weights/train文件夹中,并以epoch_*.pth的形式按options.py中设置的检查点步长保存,其中*表示当前的 epoch 数。 - 此外,每保存一个权重时,都会对验证集进行指标测量,并将结果打印到命令行。最终,所有权重在验证集上的测试指标以及
./data/options.py中的配置信息,都将被保存到./results/training/metrics-YYYY-mm-dd-HHMMSS.md文件中。 - 在每个 epoch 中,我们会将一次输出(测试)图像和 GT 图像保存到
./results/training文件夹,以便于可视化每次训练的结果和进度,同时也能提前检测梯度爆炸现象。 - 每个检查点完成后,我们都会将此次验证集的所有输出保存到
./results文件夹中的相应子文件夹中。需要注意的是,针对不同数据集,我们采用了替换策略,即不会保存所有检查点的图表,而只保留每个检查点的权重文件。
4. 联系方式 🌔
如果您有任何问题,请随时联系我们或在仓库中提交 issue!
Yixu Feng (yixu-nwpu@mail.nwpu.edu.cn)
5. 引用 🌕
如果您认为我们的工作对您的研究有所帮助,请引用我们的论文:
@article{yan2025hvi,
title={HVI: A New color space for Low-light Image Enhancement},
author={Yan, Qingsen and Feng, Yixu and Zhang, Cheng and Pang, Guansong and Shi, Kangbiao and Wu, Peng and Dong, Wei and Sun, Jinqiu and Zhang, Yanning},
journal={arXiv preprint arXiv:2502.20272},
year={2025}
}
@misc{feng2024hvi,
title={You Only Need One Color Space: An Efficient Network for Low-light Image Enhancement},
author={Yixu Feng and Cheng Zhang and Pei Wang and Peng Wu and Qingsen Yan and Yanning Zhang},
year={2024},
eprint={2402.05809},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备