comfyui_controlnet_aux
comfyui_controlnet_aux 是专为 ComfyUI 设计的一套即插即用节点集合,旨在帮助用户快速生成 ControlNet 所需的“提示图像”(hint images)。在利用 AI 进行图像创作时,用户往往需要精确控制画面的线条、边缘或结构,而原始图片通常无法直接满足这一需求。comfyui_controlnet_aux 通过集成多种先进的预处理算法(如 Canny 边缘检测、HED 软边缘提取、各类线稿风格转换及涂鸦识别等),能自动将普通图片转化为适合 ControlNet 理解的结构图,从而让 AI 更精准地遵循用户的构图意图。
这套工具特别适合使用 ComfyUI 进行创作的数字艺术家、设计师以及 AI 绘画爱好者。无论是想将照片转为动漫线稿,还是从草图生成精细成品,它都能大幅降低手动处理素材的门槛。其核心亮点在于高度的集成化:除了需要微调阈值的特殊场景外,绝大多数功能都被整合在一个"AIO Aux Preprocessor"通用节点中,让用户无需连接繁琐的节点链即可一键调用。此外,它直接对接 Hugging Face 模型库,确保了预处理器算法与官方 ControlNet 项目保持同步,为用户提供了稳定且丰富的创作辅助能力。
使用场景
一位独立游戏开发者正在为赛博朋克风格的项目批量生成角色概念图,需要严格保持人物姿势和线条结构的一致性。
没有 comfyui_controlnet_aux 时
- 开发者必须手动切换多个外部插件或脚本来提取线稿、边缘和骨架,工作流支离破碎且容易报错。
- 无法在 ComfyUI 原生界面中精细调节 Canny 阈值或 HED 软边缘参数,导致生成的控制图噪点过多或细节丢失。
- 针对动漫风格的角色,缺乏专用的
Anime Lineart预处理节点,通用算法难以准确识别二次元特有的简洁线条。 - 每次尝试不同风格的控制图(如从硬边缘切换到涂鸦风格)都需要重新搭建复杂的节点组,严重拖慢迭代速度。
使用 comfyui_controlnet_aux 后
- 所有预处理功能(如 Canny、HED、MLSD 等)均以原生节点形式集成,开发者可在同一工作流中一键调用,无需跳转外部环境。
- 每个预处理器都提供独立的阈值调节滑块,能精准控制线条粗细与细节保留度,直接获得高质量的提示图像。
- 内置专为二次元优化的
Anime Lineart和Manga Lineart节点,完美适配粉色头发、金色眼睛等动漫特征的结构提取。 - 通过
AIO Aux Preprocessor节点可快速预览多种效果,或利用分类节点灵活组合,将原本数小时的调试过程缩短至几分钟。
comfyui_controlnet_aux 通过将专业的 ControlNet 预处理能力无缝融入 ComfyUI,让创作者能以前所未有的精度和效率掌控 AI 绘图的构图与结构。
运行环境要求
- Linux
- Windows
未说明 (作为 ComfyUI 插件,通常依赖宿主环境的 GPU 配置以运行 ControlNet 模型)
未说明

快速开始
ComfyUI 的 ControlNet 辅助预处理器
即插即用的 ComfyUI 节点集,用于生成 ControlNet 提示图。
“动漫风格,街头抗议场景,赛博朋克城市,一位粉色头发、金色眼睛的女性(正注视着观众)手持标语,上面用粗体霓虹粉字写着‘ComfyUI ControlNet Aux’”——基于 Flux.1 Dev 模型。

代码直接从 https://github.com/lllyasviel/ControlNet/tree/main/annotator 中相应文件夹复制而来,并与 Hugging Face Hub 相连。
所有版权及署名权归 https://github.com/lllyasviel 所有。
更新
请前往 更新页面 查看最新动态。
安装:
使用 ComfyUI 管理器(推荐):
安装 ComfyUI 管理器,并按照其说明步骤安装本仓库。
其他方式:
如果您使用的是 Linux 系统,或在 Windows 上以非管理员账户运行,请确保 /ComfyUI/custom_nodes 和 comfyui_controlnet_aux 文件夹具有写入权限。
现在提供了一个 install.bat 脚本,若检测到便携式安装环境,则会自动执行便携式安装;否则将默认为系统安装,并假定您已按照 ComfyUI 的手动安装步骤操作。
如果您无法运行 install.bat(例如,您是 Linux 用户),请打开终端或命令行,执行以下操作:
- 导航至您的
/ComfyUI/custom_nodes/文件夹。 - 运行
git clone https://github.com/Fannovel16/comfyui_controlnet_aux/。 - 进入
comfyui_controlnet_aux文件夹:- 对于便携式或虚拟环境:
- 运行
path/to/ComfUI/python_embeded/python.exe -s -m pip install -r requirements.txt。
- 运行
- 对于系统 Python:
- 运行
pip install -r requirements.txt。
- 运行
- 对于便携式或虚拟环境:
- 启动 ComfyUI。
节点
请注意,本仓库仅支持用于生成提示图的预处理器(如人体轮廓、Canny 边缘等)。除 Inpaint 外的所有预处理器均已集成到 AIO 辅助预处理器 节点中。该节点可快速获取预处理结果,但无法设置预处理器自身的阈值参数。如需调整阈值,需直接使用对应的预处理器节点。
节点(分类按 Comfy 菜单中的类别划分)
线条提取器
| 预处理器节点 | sd-webui-controlnet/其他 | ControlNet/T2I-Adapter |
|---|---|---|
| 二值线条 | binary | control_scribble |
| Canny 边缘 | canny | control_v11p_sd15_canny control_canny t2iadapter_canny |
| HED 软边缘线条 | hed | control_v11p_sd15_softedge control_hed |
| 标准线稿 | standard_lineart | control_v11p_sd15_lineart |
| 写实线稿 | lineart(若启用 coarse 模式则为 lineart_coarse) |
control_v11p_sd15_lineart |
| 动漫线稿 | lineart_anime | control_v11p_sd15s2_lineart_anime |
| 漫画线稿 | lineart_anime_denoise | control_v11p_sd15s2_lineart_anime |
| M-LSD 线条 | mlsd | control_v11p_sd15_mlsd control_mlsd |
| PiDiNet 软边缘线条 | pidinet | control_v11p_sd15_softedge control_scribble |
| 涂鸦线条 | scribble | control_v11p_sd15_scribble control_scribble |
| XDoG 涂鸦线条 | scribble_xdog | control_v11p_sd15_scribble control_scribble |
| 假涂鸦线条 | scribble_hed | control_v11p_sd15_scribble control_scribble |
| TEED 软边缘线条 | teed | controlnet-sd-xl-1.0-softedge-dexined control_v11p_sd15_softedge(理论上) |
| PiDiNet 涂鸦线条 | scribble_pidinet | control_v11p_sd15_scribble control_scribble |
| AnyLine 线稿 | mistoLine_fp16.safetensors mistoLine_rank256 control_v11p_sd15s2_lineart_anime control_v11p_sd15_lineart |
法线与深度估计器
| 预处理器节点 | sd-webui-controlnet/其他 | ControlNet/T2I-Adapter |
|---|---|---|
| MiDaS 深度图 | (法线)depth | control_v11f1p_sd15_depth control_depth t2iadapter_depth |
| LeReS 深度图 | depth_leres | control_v11f1p_sd15_depth control_depth t2iadapter_depth |
| Zoe 深度图 | depth_zoe | control_v11f1p_sd15_depth control_depth t2iadapter_depth |
| MiDaS 法线图 | normal_map | control_normal |
| BAE 法线图 | normal_bae | control_v11p_sd15_normalbae |
| MeshGraphormer 手部精修器(HandRefiner) | depth_hand_refiner | control_sd15_inpaint_depth_hand_fp16 |
| Depth Anything | depth_anything | Depth-Anything |
| Zoe Depth Anything (本质上是 Zoe,但编码器被 DepthAnything 替换) |
depth_anything | Depth-Anything |
| Normal DSINE | control_normal/control_v11p_sd15_normalbae | |
| Metric3D 深度 | control_v11f1p_sd15_depth control_depth t2iadapter_depth |
|
| Metric3D 法线 | control_v11p_sd15_normalbae | |
| Depth Anything V2 | Depth-Anything |
人脸与姿态估计器
| 预处理节点 | sd-webui-controlnet/other | ControlNet/T2I-Adapter |
|---|---|---|
| DWPose 姿态估计器 | dw_openpose_full | control_v11p_sd15_openpose control_openpose t2iadapter_openpose |
| OpenPose 姿态估计器 | openpose (detect_body) openpose_hand (detect_body + detect_hand) openpose_faceonly (detect_face) openpose_full (detect_hand + detect_body + detect_face) |
control_v11p_sd15_openpose control_openpose t2iadapter_openpose |
| MediaPipe 人脸网格 | mediapipe_face | controlnet_sd21_laion_face_v2 |
| 动物姿态估计器 | animal_openpose | control_sd15_animal_openpose_fp16 |
光流估计器
| 预处理节点 | sd-webui-controlnet/other | ControlNet/T2I-Adapter |
|---|---|---|
| Unimatch 光流 | DragNUWA |
如何获取 OpenPose 格式的 JSON?
用户端
此工作流会将图像保存到 ComfyUI 的输出文件夹(与输出图像相同的位置)。如果您没有找到 Save Pose Keypoints 节点,请更新此扩展。
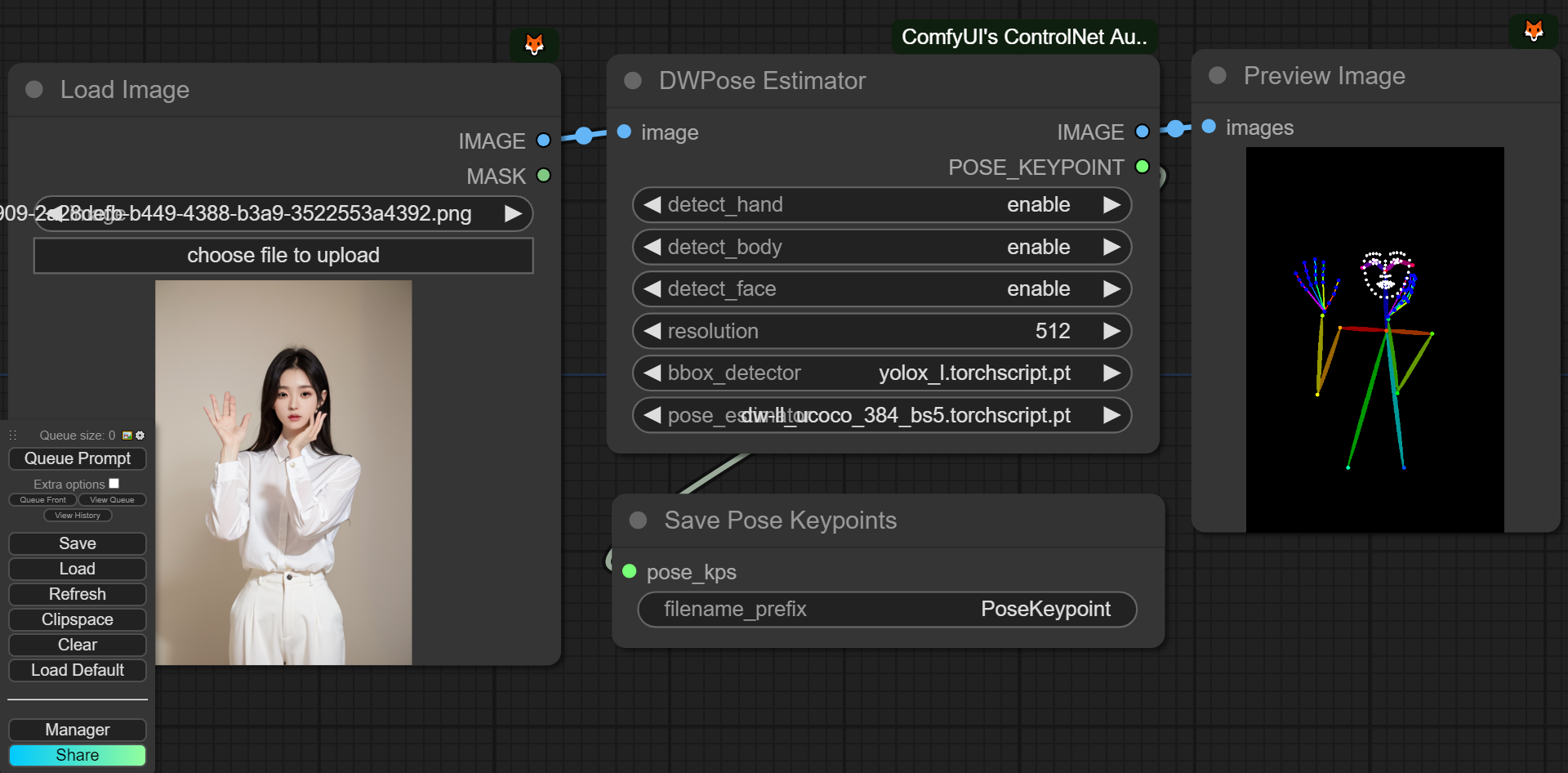
开发者端
对于 IMAGE 批次中的每一帧,可以使用 UI 上的 app.nodeOutputs 或 /history API 端点,从 DWPose 和 OpenPose 中获取对应于每帧的 OpenPose 格式 JSON 数组。AnimalPose 的 JSON 输出格式与 OpenPose JSON 类似:
[
{
"version": "ap10k",
"animals": [
[[x1, y1, 1], [x2, y2, 1],..., [x17, y17, 1]],
[[x1, y1, 1], [x2, y2, 1],..., [x17, y17, 1]],
...
],
"canvas_height": 512,
"canvas_width": 768
},
...
]
对于扩展开发者(例如 Openpose 编辑器):
const poseNodes = app.graph._nodes.filter(node => ["OpenposePreprocessor", "DWPreprocessor", "AnimalPosePreprocessor"].includes(node.type))
for (const poseNode of poseNodes) {
const openposeResults = JSON.parse(app.nodeOutputs[poseNode.id].openpose_json[0])
console.log(openposeResults) //包含每帧 OpenPose JSON 的数组
}
对于 API 用户: JavaScript
import fetch from "node-fetch" //请确保在 "package.json" 中添加 "type": "module"
async function main() {
const promptId = '792c1905-ecfe-41f4-8114-83e6a4a09a9f' //懒得 POST /queue
let history = await fetch(`http://127.0.0.1:8188/history/${promptId}`).then(re => re.json())
history = history[promptId]
const nodeOutputs = Object.values(history.outputs).filter(output => output.openpose_json)
for (const nodeOutput of nodeOutputs) {
const openposeResults = JSON.parse(nodeOutput.openpose_json[0])
console.log(openposeResults) //包含每帧 OpenPose JSON 的数组
}
}
main()
Python
import json, urllib.request
server_address = "127.0.0.1:8188"
prompt_id = '' #懒得 POST /queue
def get_history(prompt_id):
with urllib.request.urlopen("http://{}/history/{}".format(server_address, prompt_id)) as response:
return json.loads(response.read())
history = get_history(prompt_id)[prompt_id]
for o in history['outputs']:
for node_id in history['outputs']:
node_output = history['outputs'][node_id]
if 'openpose_json' in node_output:
print(json.loads(node_output['openpose_json'][0])) #包含每帧 OpenPose JSON 的列表
语义分割
| 预处理节点 | sd-webui-controlnet/other | ControlNet/T2I-Adapter |
|---|---|---|
| OneFormer ADE20K 分割器 | oneformer_ade20k | control_v11p_sd15_seg |
| OneFormer COCO 分割器 | oneformer_coco | control_v11p_sd15_seg |
| UniFormer 分割器 | segmentation | control_sd15_seg control_v11p_sd15_seg |
仅 T2IAdapter
| 预处理节点 | sd-webui-controlnet/other | ControlNet/T2I-Adapter |
|---|---|---|
| 色彩调色板 | color | t2iadapter_color |
| 内容打乱 | shuffle | t2iadapter_style |
重新着色
| 预处理节点 | sd-webui-controlnet/other | ControlNet/T2I-Adapter |
|---|---|---|
| 图像亮度 | recolor_luminance | ioclab_sd15_recolor sai_xl_recolor_256lora bdsqlsz_controlllite_xl_recolor_luminance |
| 图像强度 | recolor_intensity | 不清楚。也许和上面一样? |
示例
一张图片胜过千言万语


测试工作流
https://github.com/Fannovel16/comfyui_controlnet_aux/blob/main/examples/ExecuteAll.png 输入图像:https://github.com/Fannovel16/comfyui_controlnet_aux/blob/main/examples/comfyui-controlnet-aux-logo.png
{kind=link}
{kind=link}
问答:
为什么安装了这个仓库后有些节点没有出现?
该仓库采用了一种新机制,会跳过无法导入的自定义节点。如果遇到这种情况,请在 Issues 标签页 上提交问题,并附上命令行日志。
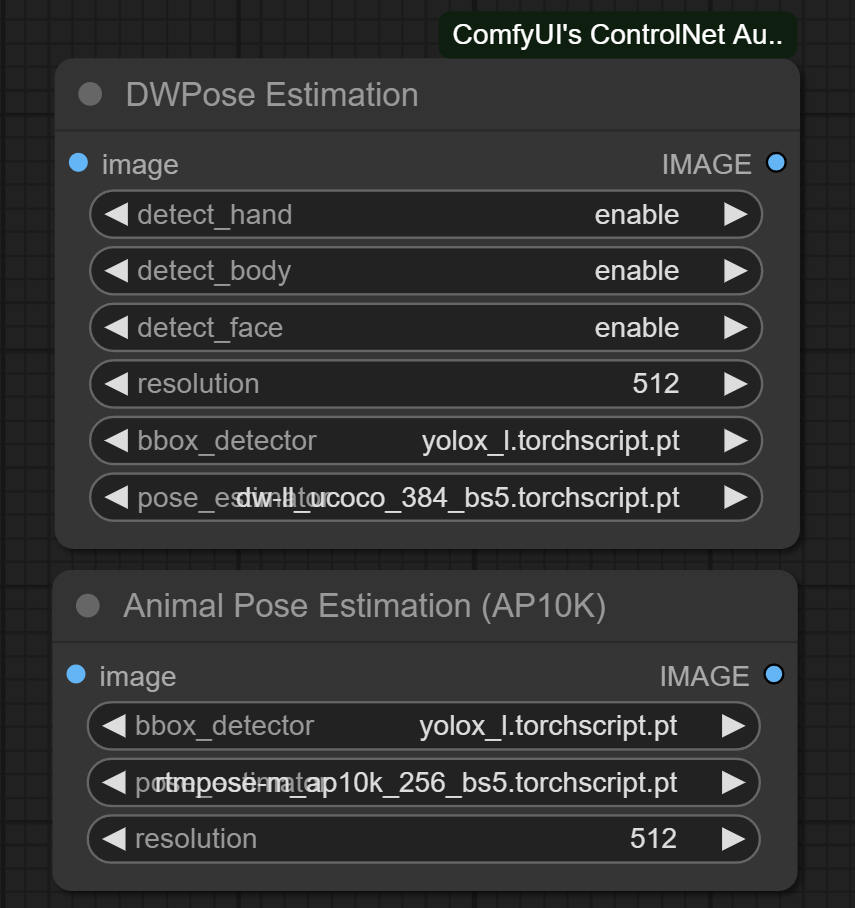
DWPose/AnimalPose 只使用 CPU,速度很慢。如何让它使用 GPU?
加速 DWPose 的方法有两种:使用 TorchScript 检查点(.torchscript.pt)或 ONNXRuntime(.onnx)。TorchScript 方法比 ONNXRuntime 略慢,但不需要额外的库,而且仍然比 CPU 快得多。
TorchScript 边界框检测器与 ONNX 姿态估计器是兼容的,反之亦然。
TorchScript
按照这张图设置 bbox_detector 和 pose_estimator。如果输入图像质量较好,可以尝试使用以 .torchscript.pt 结尾的其他边界框检测器,以缩短边界框检测时间。
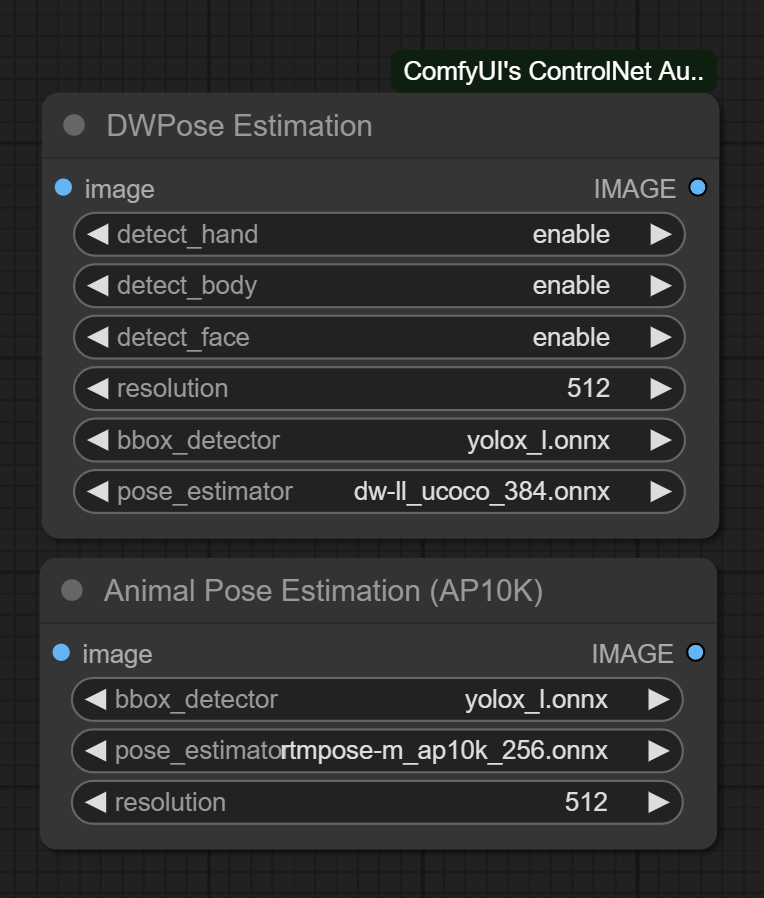
ONNXRuntime
如果 ONNXRuntime 已成功安装,并且所使用的检查点文件名以 .onnx 结尾,则会替换默认的 OpenCV 后端,从而利用 GPU 加速。请注意,如果您使用的是 NVIDIA 显卡,目前此方法仅适用于 CUDA 11.8 版本(ComfyUI_windows_portable_nvidia_cu118_or_cpu.7z),除非您自行编译 ONNXRuntime。
- 确认您的 ONNXRuntime 构建版本:
- NVIDIA CUDA 11.x 或更低版本/AMD GPU:
onnxruntime-gpu - NVIDIA CUDA 12.x:
onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/ - DirectML:
onnxruntime-directml - OpenVINO:
onnxruntime-openvino
- NVIDIA CUDA 11.x 或更低版本/AMD GPU:
请注意,如果您是首次使用 ComfyUI,请先测试其是否能在您的设备上正常运行,再进行后续步骤。
将其添加到
requirements.txt文件中。运行
install.bat脚本,或按照安装说明中的 pip 命令进行安装。
预处理工具的资产文件
- anime_face_segment: bdsqlsz/qinglong_controlnet-lllite/Annotators/UNet.pth, anime-seg/isnetis.ckpt
- densepose: LayerNorm/DensePose-TorchScript-with-hint-image/densepose_r50_fpn_dl.torchscript
- dwpose:
- animal_pose (ap10k):
- hed: lllyasviel/Annotators/ControlNetHED.pth
- leres: lllyasviel/Annotators/res101.pth, lllyasviel/Annotators/latest_net_G.pth
- lineart: lllyasviel/Annotators/sk_model.pth, lllyasviel/Annotators/sk_model2.pth
- lineart_anime: lllyasviel/Annotators/netG.pth
- manga_line: lllyasviel/Annotators/erika.pth
- mesh_graphormer: hr16/ControlNet-HandRefiner-pruned/graphormer_hand_state_dict.bin, hr16/ControlNet-HandRefiner-pruned/hrnetv2_w64_imagenet_pretrained.pth
- midas: lllyasviel/Annotators/dpt_hybrid-midas-501f0c75.pt
- mlsd: lllyasviel/Annotators/mlsd_large_512_fp32.pth
- normalbae: lllyasviel/Annotators/scannet.pt
- oneformer: lllyasviel/Annotators/250_16_swin_l_oneformer_ade20k_160k.pth
- open_pose: lllyasviel/Annotators/body_pose_model.pth, lllyasviel/Annotators/hand_pose_model.pth, lllyasviel/Annotators/facenet.pth
- pidi: lllyasviel/Annotators/table5_pidinet.pth
- sam: dhkim2810/MobileSAM/mobile_sam.pt
- uniformer: lllyasviel/Annotators/upernet_global_small.pth
- zoe: lllyasviel/Annotators/ZoeD_M12_N.pt
- teed: bdsqlsz/qinglong_controlnet-lllite/7_model.pth
- depth_anything: 可以是 LiheYoung/Depth-Anything/checkpoints/depth_anything_vitl14.pth、LiheYoung/Depth-Anything/checkpoints/depth_anything_vitb14.pth 或者 LiheYoung/Depth-Anything/checkpoints/depth_anything_vits14.pth
- diffusion_edge: 可以是 hr16/Diffusion-Edge/diffusion_edge_indoor.pt、hr16/Diffusion-Edge/diffusion_edge_urban.pt 或者 hr16/Diffusion-Edge/diffusion_edge_natrual.pt
- unimatch: 可以是 hr16/Unimatch/gmflow-scale2-regrefine6-mixdata.pth、hr16/Unimatch/gmflow-scale2-mixdata.pth 或者 hr16/Unimatch/gmflow-scale1-mixdata.pth
- zoe_depth_anything: 可以是 LiheYoung/Depth-Anything/checkpoints_metric_depth/depth_anything_metric_depth_indoor.pt 或者 LiheYoung/Depth-Anything/checkpoints_metric_depth/depth_anything_metric_depth_outdoor.pt
2000 颗星 😄

感谢大家的支持!真没想到星星数量的增长会这么线性,哈哈。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。