Awesome-Backbones
Awesome-Backbones 是一个专为图像分类任务打造的深度学习模型集成项目,旨在帮助开发者轻松对比、训练和修改各类主流骨干网络(Backbone)。它解决了研究人员在复现经典模型时面临的环境配置繁琐、代码风格不统一以及超参数调整困难等痛点,提供了一个标准化的 PyTorch 实现框架。
该项目非常适合计算机视觉领域的研究人员、算法工程师以及希望深入理解模型原理的开发者使用。无论是需要快速验证新想法,还是希望在特定数据集上微调现有模型,Awesome-Backbones 都能提供高效支持。其独特亮点在于不仅集成了从 MobileNet、EfficientNet 到 ViT、Swin Transformer 等数十种前沿架构,还贴心地提供了详细的训练调优指南,例如针对小数据集如何关闭可能污染数据的图像增强策略。此外,项目持续更新,近期已支持模型转 ONNX 格式、生成类别激活图(CAM)可视化,并能自动输出完整的训练与验证指标(如准确率、损失值等),极大地便利了实验分析与结果复现。通过统一的接口和清晰的文档,Awesome-Backbones 让模型探索变得更加简单高效。
使用场景
某初创团队正在开发一款基于移动端的花卉识别应用,需要在有限的算力下快速验证多种主流骨干网络(Backbone)的精度与速度平衡。
没有 Awesome-Backbones 时
- 模型复现成本高:工程师需手动从不同论文仓库扒取代码,花费数天时间统一数据加载、训练循环和评估接口,极易因版本不兼容导致环境崩溃。
- 调参盲目且低效:面对小数据集训练效果差的问题,缺乏系统性的排查指引,往往在错误的图像增强策略上浪费大量时间,不知如何关闭干扰项。
- 性能对比困难:难以在同一框架下公平对比 MobileNet、EfficientNet 或 ViT 等不同架构的 FLOPs 与准确率,每次切换模型都需重写配置文件。
- 可视化功能缺失:想要分析模型“关注”花朵的哪个部位以优化误判,需额外编写复杂的类别激活图(CAM)脚本,开发周期被拉长。
使用 Awesome-Backbones 后
- 开箱即用的集成:直接调用内置的 MobileViT、EfficientNetV2 等 30+ 种预置模型,统一了 PyTorch 接口,将模型验证周期从数天缩短至几小时。
- 精准的调试指引:利用官方提供的“训练失败排查指南”,快速定位并关闭了不适合小样本的增强操作,显著提升了收敛速度和最终精度。
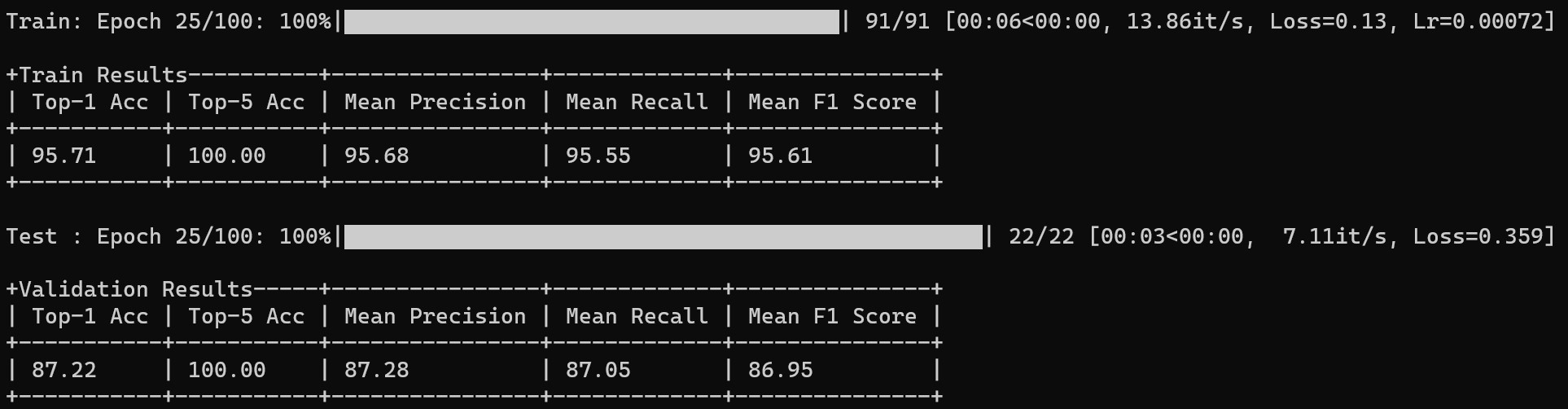
- 一键式基准测试:通过修改简单配置文件即可自动输出 Train/Val 的 Loss、Accuracy 及 F1-score 报表,并自动计算参数量,轻松选出最适合移动端的模型。
- 内置可解释性工具:直接运行自带脚本即可生成类别激活图,直观展示模型决策依据,帮助团队迅速迭代优化特征提取能力。
Awesome-Backbones 通过标准化流程与丰富的预置组件,让开发者从繁琐的代码整合中解放出来,专注于核心算法的选型与优化。
运行环境要求
- 未说明
未说明 (基于 PyTorch,通常建议配备 NVIDIA GPU 以加速训练,具体显存需求取决于模型大小)
未说明

快速开始
用于图像分类的优秀骨干网络



写在前面
- 若训练效果不佳,首先需要调整学习率和Batch size,这俩超参很大程度上影响收敛。其次,从关闭图像增强手段(尤其小数据集)开始,有的图像增强方法会污染数据,如


如何去除增强?如efficientnetv2-b0配置文件中train_pipeline可更改为如下
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='RandomResizedCrop',
size=192,
efficientnet_style=True,
interpolation='bicubic'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]
若你的数据集提前已经将shape更改为网络要求的尺寸,那么Resize操作也可以去除。
更新日志
2025.01.17
2024.09.06
- 修复高频反馈的评估时结果浮动大的问题
2023.12.02
新增Issue中多人提及的输出Train Acc与Val loss
metrics_outputs.csv保存每周期train_loss, train_acc, train_precision, train_recall, train_f1-score, val_loss, val_acc, val_precision, val_recall, val_f1-score方便各位绘图- 终端由原先仅输出Val相关metrics升级为Train与Val都输出
2023.08.05
- 新增TinyViT(预训练权重不匹配)、DeiT3、EdgeNeXt、RevVisionTransformer
2023.03.07
- 新增MobileViT、DaViT、RepLKNet、BEiT、EVA、MixMIM、EfficientNetV2
测试环境
- Pytorch 1.7.1+
- Python 3.6+
资料
| 数据集 | 视频教程 | 人工智能技术探讨群 |
|---|---|---|
花卉数据集 提取码:0zat |
点我跳转 | 1群:78174903 3群:584723646 |
快速开始
- 遵循环境搭建完成配置
- 下载MobileNetV3-Small权重至datas下
- Awesome-Backbones文件夹下终端输入
python tools/single_test.py datas/cat-dog.png models/mobilenet/mobilenet_v3_small.py --classes-map datas/imageNet1kAnnotation.txt
教程
模型
- LeNet5
- AlexNet
- VGG
- DenseNet
- ResNet
- Wide-ResNet
- ResNeXt
- SEResNet
- SEResNeXt
- RegNet
- MobileNetV2
- MobileNetV3
- ShuffleNetV1
- ShuffleNetV2
- EfficientNet
- RepVGG
- Res2Net
- ConvNeXt
- HRNet
- ConvMixer
- CSPNet
- Swin-Transformer
- Vision-Transformer
- Transformer-in-Transformer
- MLP-Mixer
- DeiT
- Conformer
- T2T-ViT
- Twins
- PoolFormer
- VAN
- HorNet
- EfficientFormer
- Swin Transformer V2
- MViT V2
- MobileViT
- DaViT
- replknet
- BEiT
- EVA
- MixMIM
- EfficientNetV2
预训练权重
我维护的其他项目




参考
@repo{2020mmclassification,
title={OpenMMLab 的图像分类工具箱及基准测试},
author={MMClassification 贡献者},
howpublished = {\url{https://github.com/open-mmlab/mmclassification}},
year={2020}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备