HumanML3D
HumanML3D 是一个大规模且多样化的 3D 人体运动与语言配对数据集,旨在搭建自然语言描述与三维人体动作之间的桥梁。它整合了 HumanAct12 和 AMASS 等权威数据源,涵盖了从日常行走、跳跃到游泳、高尔夫等体育运动,乃至杂技和艺术舞蹈等丰富场景。
该数据集主要解决了当前 AI 领域缺乏高质量“文本 - 动作”配对数据的痛点,为训练能够理解文字指令并生成对应 3D 动作的模型提供了坚实基础。通过众包标注,每个动作片段都配有 3-4 句精准的英文描述,并经过镜像翻转和关键词替换等增强处理,显著提升了数据的规模与鲁棒性。
HumanML3D 特别适合人工智能研究人员、计算机图形学开发者以及动画设计师使用。无论是从事文本生成动作(Text-to-Motion)、动作检索,还是开发虚拟数字人交互系统,都能从中获益。其独特的技术亮点在于标准化的数据处理流程(统一降采样至 20fps)以及配套的完整复现脚本,支持基于 SMPL+H 模型快速构建本地数据环境。作为多个前沿生成模型(如 T2M、MoMask)的基石,HumanML3D 正推动着 3D 内容创作向更智能化、自然化的方向迈进。
使用场景
一家游戏开发团队正在为一款开放世界 RPG 制作 NPC 的自然行为系统,希望实现通过文本指令直接生成多样化的 3D 人物动作。
没有 HumanML3D 时
- 数据获取困难:缺乏大规模且带有详细文本标注的 3D 动作数据,团队需手动录制动作并逐帧编写描述,耗时数月仅能积累少量样本。
- 动作与语言割裂:现有数据集(如纯动作库 AMASS)缺少自然语言描述,导致训练出的模型无法理解“向左翻滚”或“悲伤地行走”等复杂语义指令。
- 多样性严重不足:自建数据集覆盖场景有限,NPC 动作重复单调,难以涵盖从日常散步到高难度杂技等广泛行为,玩家极易产生审美疲劳。
- 研发成本高昂:由于缺乏标准基准,团队需自行设计评估指标和数据增强策略,算法迭代周期长且效果难以量化。
使用 HumanML3D 后
- 数据即刻可用:直接利用包含 1.4 万段动作和 4.5 万条描述的现成数据集,涵盖日常、运动、舞蹈等多领域,几天内即可启动模型训练。
- 语义精准对齐:依托其高质量的动作 - 语言配对数据,模型能准确解析文本指令,生成符合“顺时针旋转”或“快速冲刺”等细微语义差别的流畅动作。
- 行为丰富自然:借助数据集内置的镜像增强处理和广泛的动作类别,NPC 展现出极高的行为多样性,显著提升了游戏世界的沉浸感。
- 研发效率倍增:基于统一的数据标准和官方提供的评估脚本,团队可快速复现 T2M、MoMask 等前沿算法,将开发重心从数据清洗转向业务逻辑优化。
HumanML3D 通过提供大规模、高精度的动作 - 语言配对数据,彻底打通了从自然语言文本到高质量 3D 人物动作生成的自动化链路。
运行环境要求
- 未说明
未说明
未说明
快速开始
HumanML3D:3D人体动作-文本数据集
HumanML3D是一个3D人体动作-文本数据集,由HumanAct12和Amass数据集合并而成。它涵盖了广泛的人体动作,包括日常活动(如“走路”、“跳跃”)、体育运动(如“游泳”、“打高尔夫球”)、杂技动作(如“空翻”)以及艺术性动作(如“跳舞”)。
HumanML3D数据集统计信息
:bar_chart: 统计数据
HumanML3D中的每个动作片段都配有3到4条在Amazon Mechanical Turk平台上标注的单句描述。动作数据被下采样至20帧/秒,每个片段时长为2至10秒。
总体而言,HumanML3D数据集包含14,616个动作片段和44,970条描述,这些描述由5,371个不同的词汇组成。动作总时长达到28.59小时。平均每个动作片段时长为7.1秒,而平均每条描述则包含12个词。
:chart_with_upwards_trend: 数据增强
我们通过镜像所有动作并适当替换描述中的某些关键词(例如,“left”替换为“right”,“clockwise”替换为“counterclockwise”),使HumanML3D数据集规模扩大了一倍。
KIT-ML数据集
KIT动作-文本数据集(KIT-ML)也是一个相关数据集,包含3,911个动作片段和6,278条描述。我们按照与HumanML3D数据集相同的流程处理了KIT-ML数据集,并在此仓库中提供访问。然而,如果您希望使用KIT-ML数据集,请务必引用其原始论文。
如果这个数据集对您的项目有所帮助,我们非常感谢您为本代码库点亮星标。😆😆
查看我们在HumanML3D上的研究成果
:ok_woman: T2M - 首个基于HumanML3D的研究,利用时间变分自编码器学习从文本描述生成3D动作。 :running: TM2T - 通过离散的动作标记学习文本与动作之间的双向映射。 :dancer: TM2D - 根据文本指令生成舞蹈动作。 :honeybee: MoMask - 利用残差量化和生成式掩码建模实现更高水平的文本到动作生成。
如何获取数据
对于KIT-ML数据集,您可以直接从[这里]下载。由于AMASS数据集的分发政策限制,我们无法直接分发该数据。因此,我们提供了一系列脚本,可帮助您从AMASS数据集重新构建我们的HumanML3D数据集。
您需要克隆此仓库并安装虚拟环境。
[2022/12/15] 更新:安装matplotlib=3.3.4可以避免生成的数据与参考数据之间出现微小偏差。详情请参阅问题
Python虚拟环境
conda env create -f environment.yaml
conda activate torch_render
若安装失败,您也可以手动安装以下依赖:
- Python==3.7.10
- Numpy
- Scipy
- PyTorch
- Tqdm
- Pandas
- Matplotlib==3.3.4 // 仅用于动画
- ffmpeg==4.3.1 // 仅用于动画
- Spacy==2.3.4 // 仅用于文本处理
下载SMPL+H和DMPL模型
请从SMPL+H下载SMPL+H模型(选择AMASS项目中使用的扩展版SMPL+H模型),并从DMPL下载DMPL模型(选择与SMPL兼容的版本)。然后将所有模型放置在“./body_model/”目录下。
数据提取与处理
您需要按顺序运行以下脚本以获得HumanML3D数据集:
- raw_pose_processing.ipynb
- motion_representation.ipynb
- cal_mean_variance.ipynb
这一步是可选的,如果您需要生成动画,可以运行第4步:
- animation.ipynb
请务必仔细检查每一步,以确保您正朝着正确方向构建HumanML3D数据集。最终,您所需要的全部数据都在“./HumanML3D”文件夹中。
数据结构
<DATA-DIR>
./animations.rar // 所有动作片段的MP4格式动画。
./new_joint_vecs.rar // 从3D运动位置中提取的旋转不变特征和旋转特征向量。
./new_joints.rar // 3D运动位置数据。
./texts.rar // 动作数据的描述文本。
./Mean.npy // new_joint_vecs中所有数据的均值。
./Std.npy // new_joint_vecs中所有数据的标准差。
./all.txt // 所有数据的文件名列表。
./train.txt // 训练数据的文件名列表。
./test.txt // 测试数据的文件名列表。
./train_val.txt // 训练和验证数据的文件名列表。
./val.txt // 验证数据的文件名列表。
./all.txt // 所有数据的文件名列表。
HumanML3D数据遵循具有22个关节的SMPL骨骼结构。KIT-ML则包含21个骨骼关节。详细的运动学链请参考paraUtils。
以“MXXXXXX.*”命名的文件(例如‘M000000.npy’)是对应名称为“XXXXXX.*”的文件(例如‘000000.npy’)的镜像版本。文本文件和动作文件采用相同的命名规则,即“./texts/XXXXXX.txt”(例如‘000000.txt’)中的文本准确描述了“./new_joints(或new_joint_vecs)/XXXXXX.npy”(例如‘000000.npy’)中的人体动作。
每个文本文件的格式如下:
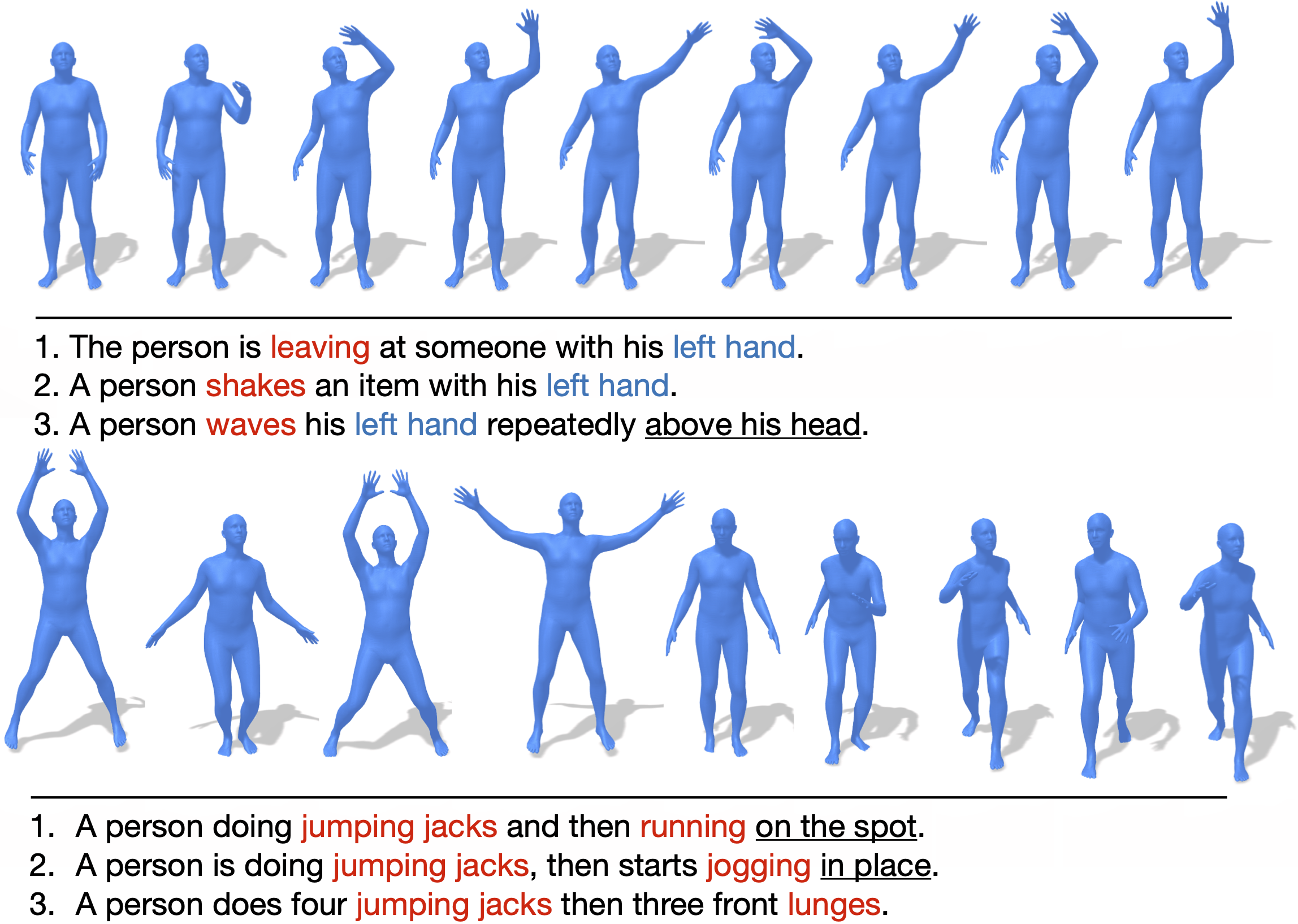
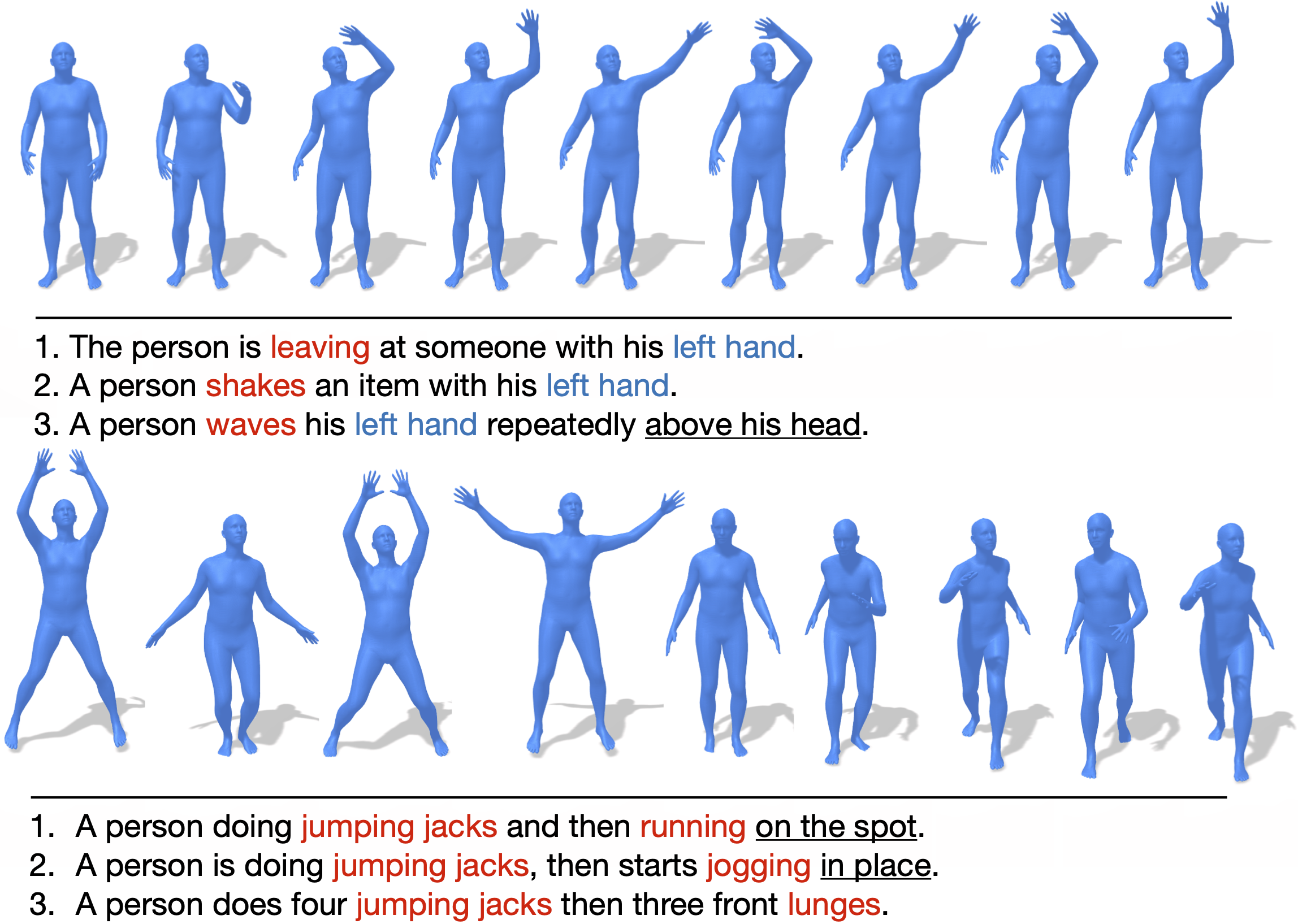
一个男人用左腿踢某物或某人。#a/DET man/NOUN kick/VERB something/PRON or/CCONJ someone/PRON with/ADP his/DET left/ADJ leg/NOUN#0.0#0.0
站立的人先用左脚踢一下,然后回到原来的姿势。#the/DET stand/VERB person/NOUN kick/VERB with/ADP their/DET left/ADJ foot/NOUN before/ADP go/VERB back/ADV to/ADP their/DET original/ADJ stance/NOUN#0.0#0.0
一个男人用左腿踢某物或某人。#a/DET man/NOUN kick/VERB with/ADP something/PRON or/CCONJ someone/PRON with/ADP his/DET left/ADJ leg/NOUN#0.0#0.0
他正在用左腿进行飞踢。#he/PRON is/AUX fly/VERB kick/NOUN with/ADP his/DET left/ADJ leg/NOUN#0.0#0.0
每行都是一个独立的文本注释,由四部分组成:原始描述(小写)、处理后的句子、开始时间(s)、结束时间(s),各部分之间用“#”分隔。
由于某些动作过于复杂而难以完整描述,我们允许标注者在必要时只对动作的某一部分进行描述。在这种情况下,*开始时间(s)和结束时间(s)*将指明被标注的动作片段。不过,我们观察到这种情况在HumanML3D数据集中所占比例很小。默认情况下,*开始时间(s)和结束时间(s)*会被设置为0,这意味着该文本是对整个动作序列的描述。
如果您无法安装ffmpeg,可以将视频转换为’.gif’格式而非’.mp4’格式来生成动画。然而,生成GIF文件通常需要更长的时间和更多的内存资源。
引用
如果您使用KIT-ML数据集,请考虑引用以下论文:
@article{Plappert2016,
author = {Matthias Plappert和Christian Mandery和Tamim Asfour},
title = {The {KIT} Motion-Language Dataset},
journal = {Big Data}
publisher = {Mary Ann Liebert Inc},
year = 2016,
month = {dec},
volume = {4},
number = {4},
pages = {236--252},
url = {http://dx.doi.org/10.1089/big.2016.0028},
doi = {10.1089/big.2016.0028},
}
如果您使用HumanML3D数据集,请考虑引用以下论文:
@InProceedings{Guo_2022_CVPR,
author = {Guo, Chuan和Zou, Shihao和Zuo, Xinxin和Wang, Sen和Ji, Wei和Li, Xingyu和Cheng, Li},
title = {Generating Diverse and Natural 3D Human Motions From Text},
booktitle = {IEEE/CVF计算机视觉与模式识别会议(CVPR)论文集},
month = {June},
year = {2022},
pages = {5152-5161}
}
其他
如有任何问题或意见,请联系Guo Chuan,邮箱:cguo2@ualberta.ca。
点赞历史

常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备