gpudrive
gpudrive 是一款基于 C++ 构建的超高速数据驱动驾驶模拟器,专为多智能体自动驾驶研发而设计。它核心解决了传统仿真环境运行速度慢、难以支撑大规模并行训练与评估的痛点,借助 Madrona 引擎的强大算力,实现了惊人的每秒 100 万帧(1M FPS)模拟速度。
这款工具非常适合自动驾驶算法研究人员、强化学习开发者以及需要处理海量场景数据的工程师使用。gpudrive 不仅兼容包含超过 10 万个真实人类驾驶场景的 Waymo 开放数据集,还支持车辆、骑行者和行人等多种智能体类型的混合仿真,让模型训练更贴近复杂现实路况。
在技术亮点方面,gpudrive 提供了便捷的 Python 接口,并原生支持 PyTorch 和 JAX 框架,能够无缝对接 Gymnasium 标准。用户可以直接利用 Stable-Baselines3、CleanRL 或 Pufferlib 等主流库快速部署 PPO 等强化学习算法,无需从零搭建训练基础设施。此外,它还允许灵活配置模拟器状态与智能体观测视角,帮助开发者高效调试策略。无论是进行大规模算法预训练,还是对现有模型进行严谨评估,gpudrive 都能以极高的效率加速研发进程,是推动自动驾驶技术落地的重要利器。
使用场景
某自动驾驶算法团队正在基于 Waymo 开放数据集,训练一个能同时处理车辆、行人和骑行者的复杂多智能体决策模型。
没有 gpudrive 时
- 仿真速度极慢:传统 CPU 模拟器每秒仅能运行几十帧,训练百万步策略需数周时间,严重拖慢迭代节奏。
- 场景覆盖不足:难以高效复用 Waymo 数据集中超过 10 万种真实人类驾驶场景,导致模型在长尾案例(如突发横穿马路)上表现不佳。
- 多智能体支持弱:同时模拟大量异构代理(车、人、自行车)时计算负载过高,常被迫简化交通密度,无法还原真实路况。
- 框架适配繁琐:将仿真环境对接 PyTorch 或 JAX 等深度学习框架需要大量自定义代码,容易引入 Bug 且维护成本高。
使用 gpudrive 后
- 百万级帧率加速:借助 Madrona 引擎的 GPU 并行能力,gpudrive 实现每秒 100 万帧的仿真速度,将原本数周的训练周期压缩至数小时。
- 数据驱动无缝集成:直接加载 Waymo 开源数据集中的 10 万 + 真实场景,让模型在丰富的人类驾驶演示中快速学习复杂交互逻辑。
- 高密度异构模拟:轻松在同一场景中渲染并计算数千个车辆、行人和骑行者的动态,显著提升模型应对拥堵和混合交通的能力。
- 主流框架即插即用:提供原生的 Gymnasium 封装及 Stable-Baselines3、CleanRL 等 PPO 算法实现,研究人员可立即开始实验而无需编写底层接口。
gpudrive 通过极致的 GPU 加速仿真,让自动驾驶多智能体训练从“等待结果”转变为“即时验证”,极大提升了算法研发效率。
运行环境要求
- Linux
- macOS
- Windows
需要 NVIDIA GPU,CUDA Toolkit 版本需在 12.2 到 12.4 之间(不支持 12.5+),显存大小未说明
未说明(Docker 运行建议共享内存 20GB)
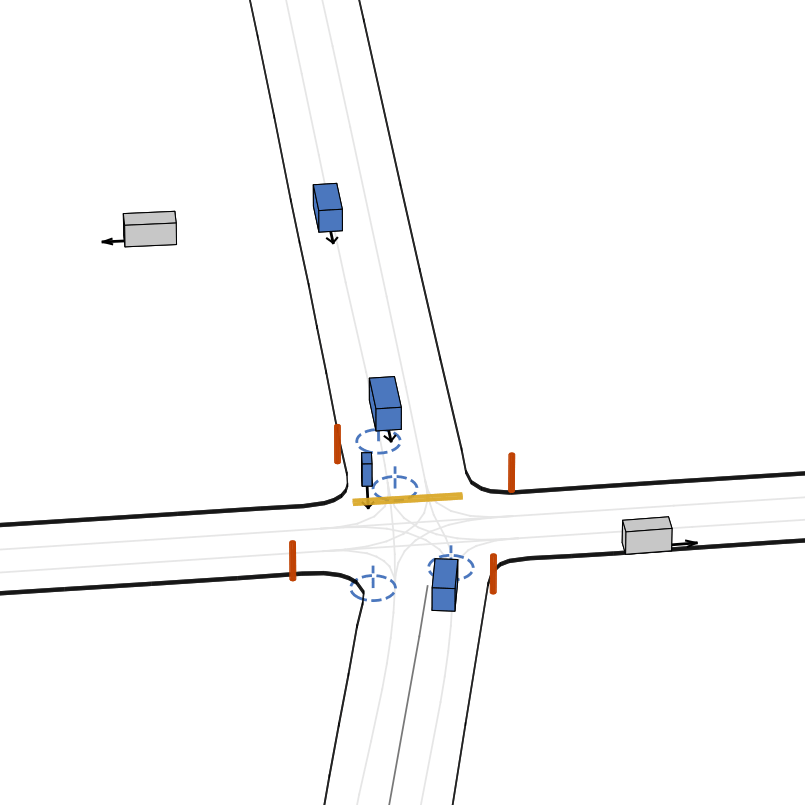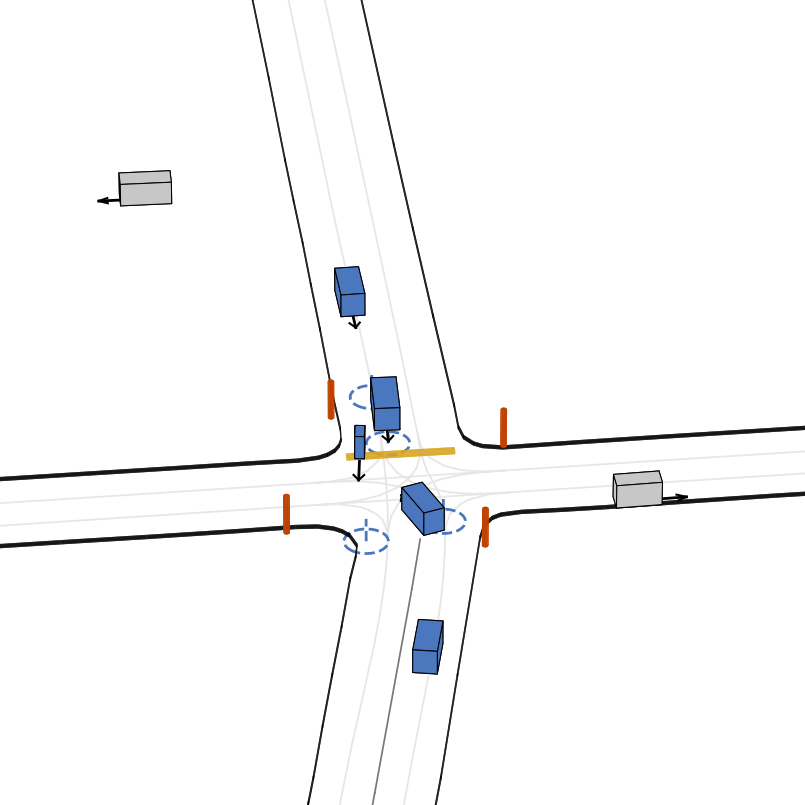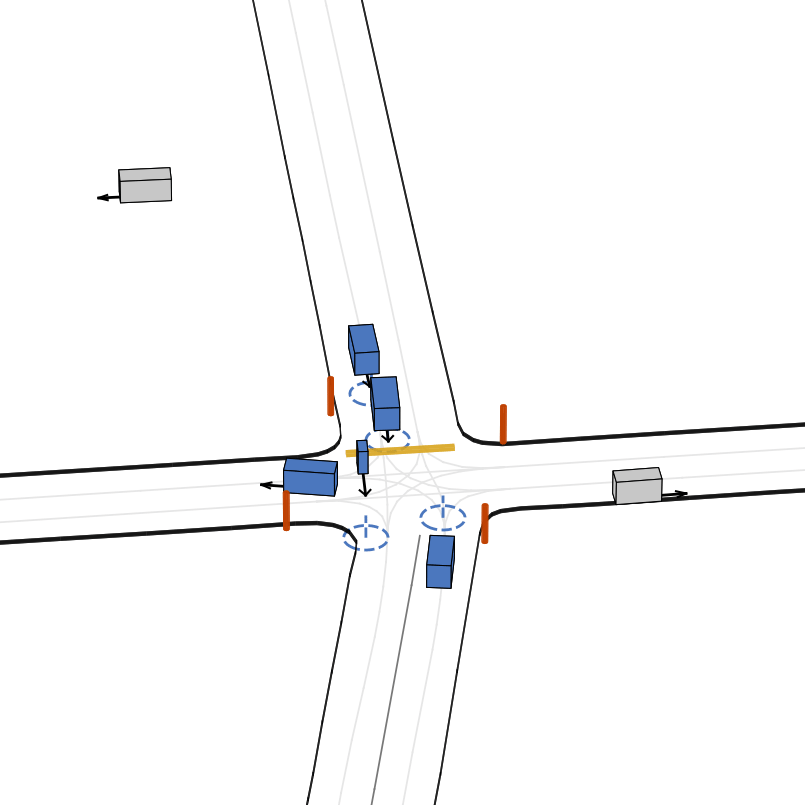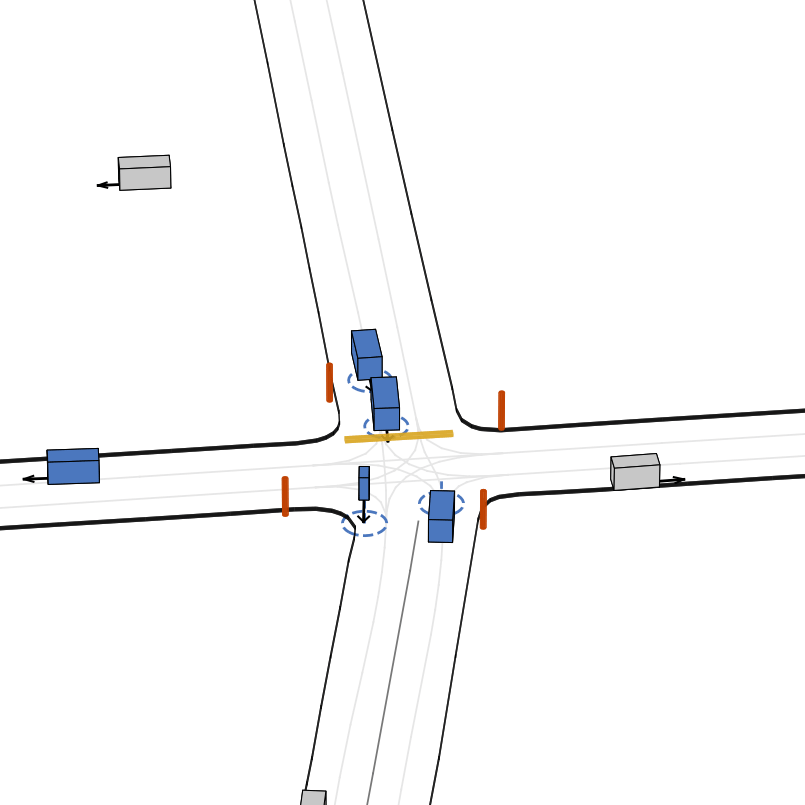
快速开始
GPUDrive
![]()
![]()

一款用C++编写的极速、数据驱动的自动驾驶仿真器。
亮点
- ⚡️ 通过Madrona引擎实现每秒100万帧的高速仿真,适用于智能体开发与评估。
- 🐍 提供Python绑定及基于
torch和jax的gymnasium封装。 - 🏃➡️ 兼容Waymo开放运动数据集,包含超过10万个由人类驾驶演示的场景。
- 📜 可通过SB3和CleanRL / Pufferlib轻松获取现成的PPO实现。
- 👀 轻松配置仿真器和智能体视角。
- 🎨 多样化的智能体类型:车辆、骑行者和行人。
| 仿真器状态 | 智能体观测 |
|---|---|
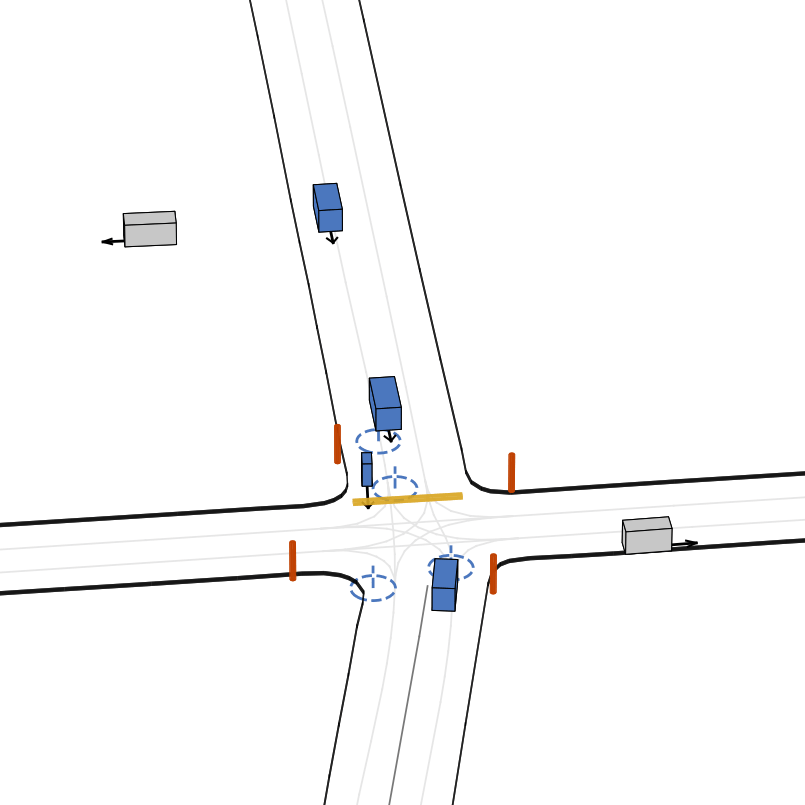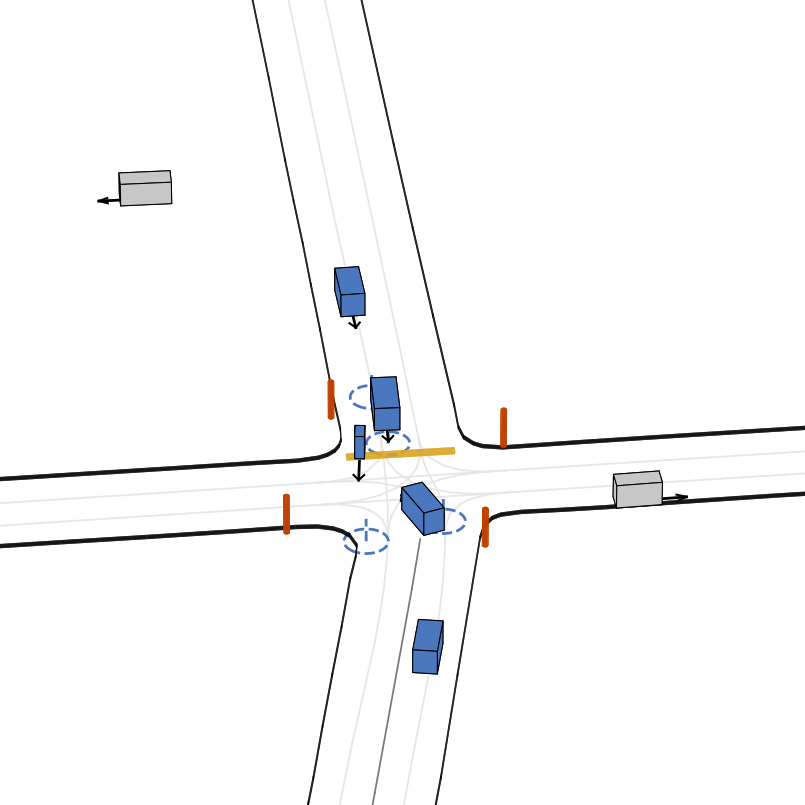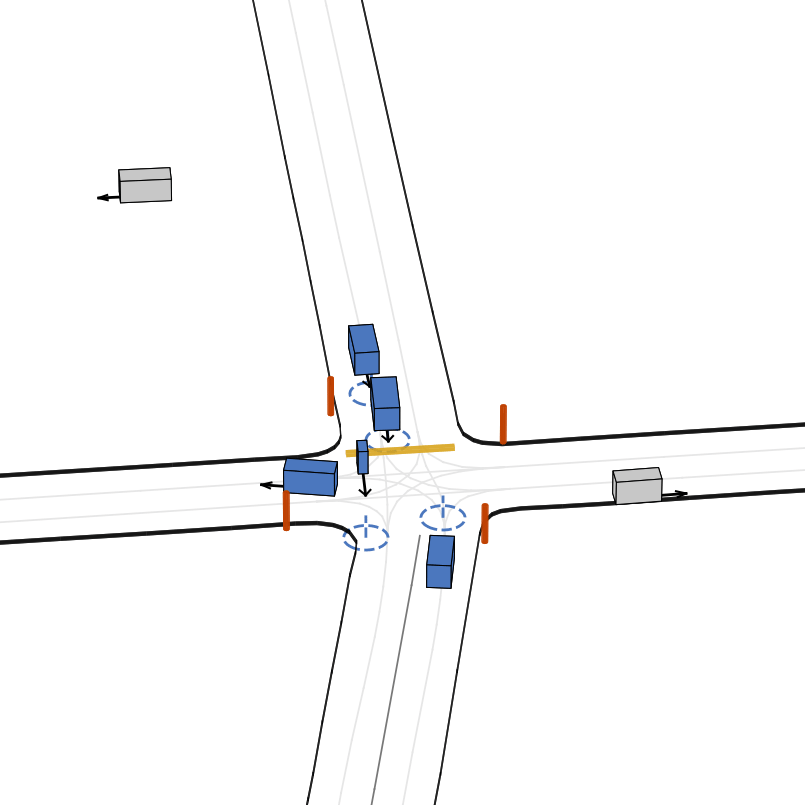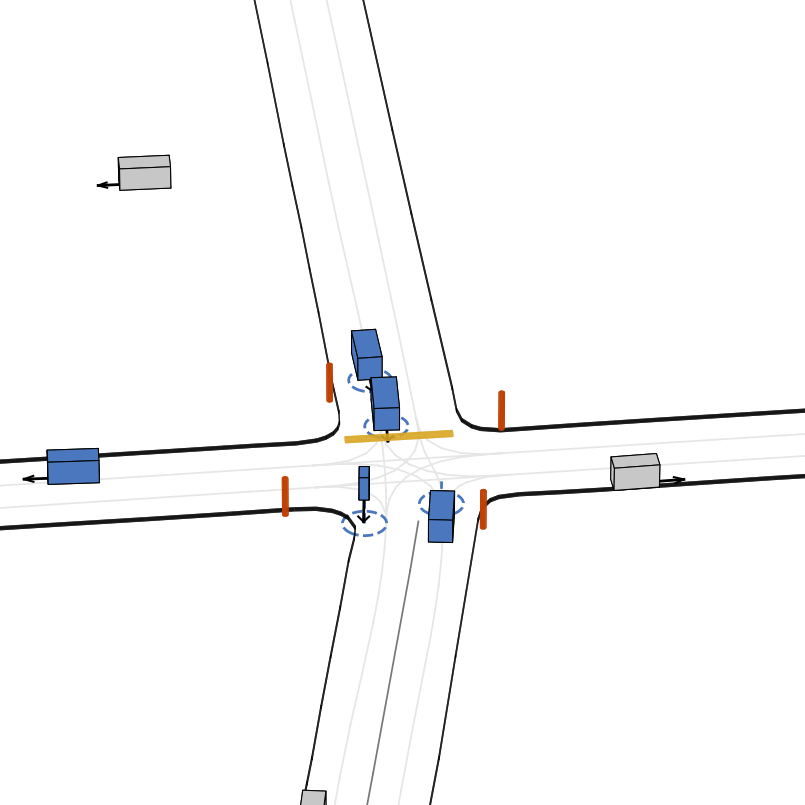 |
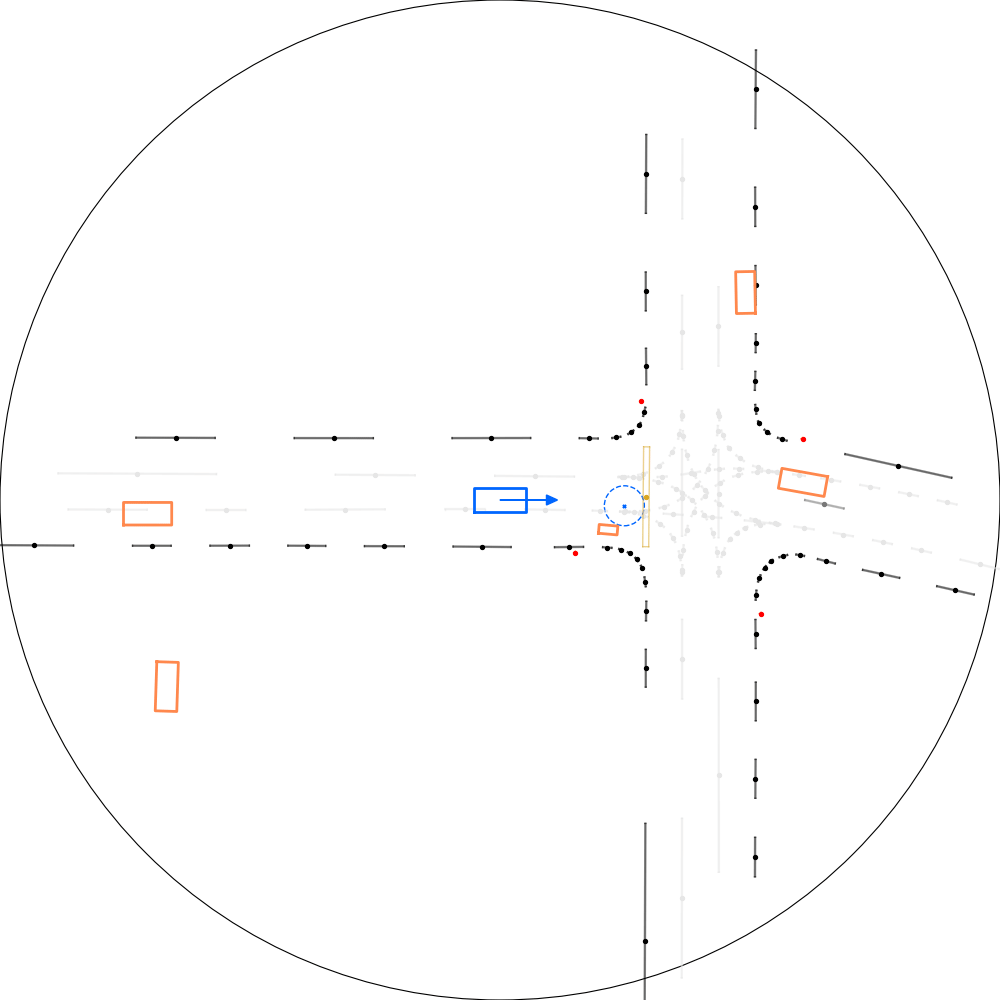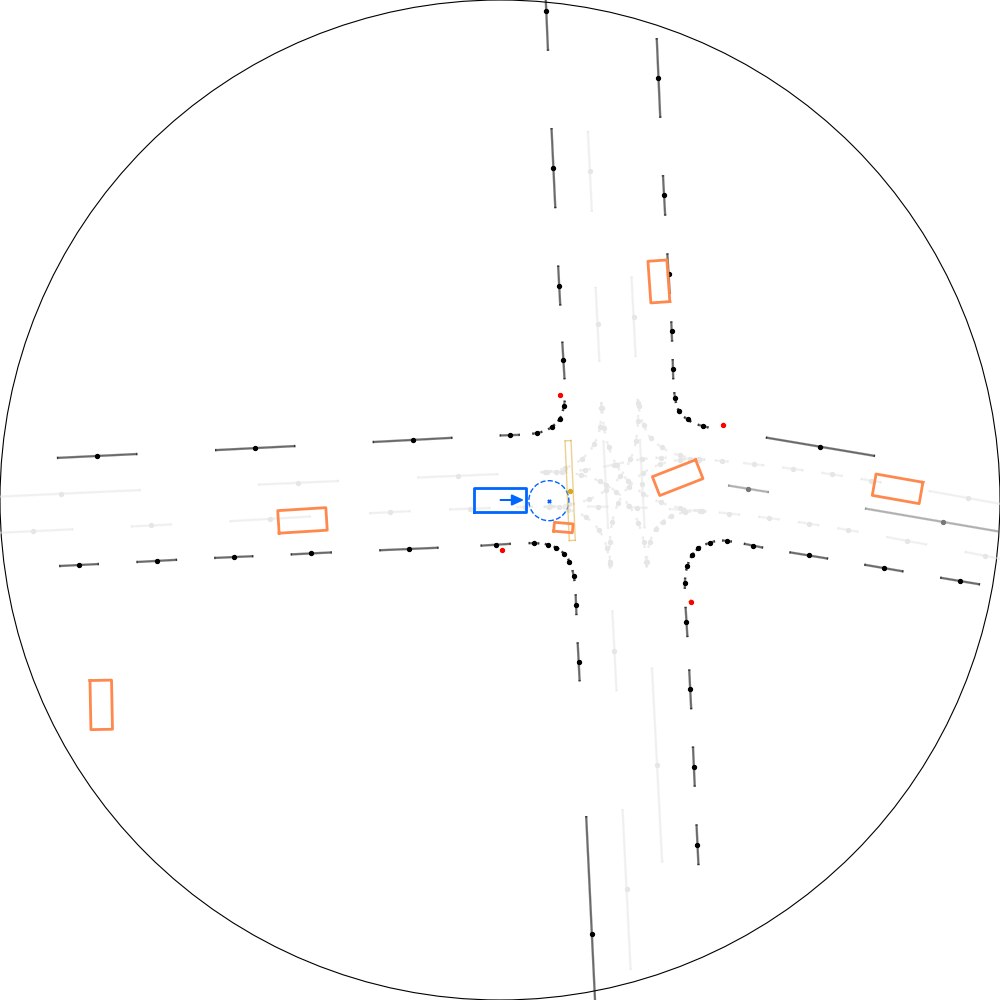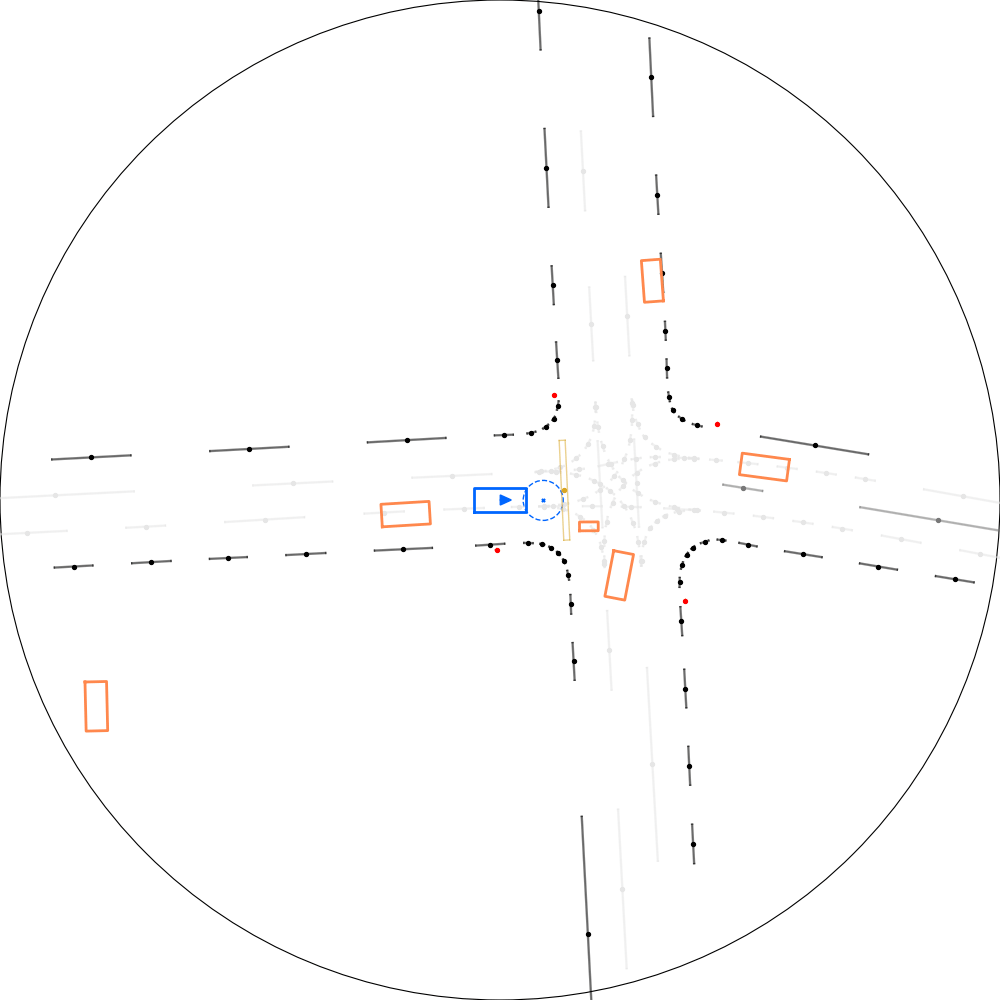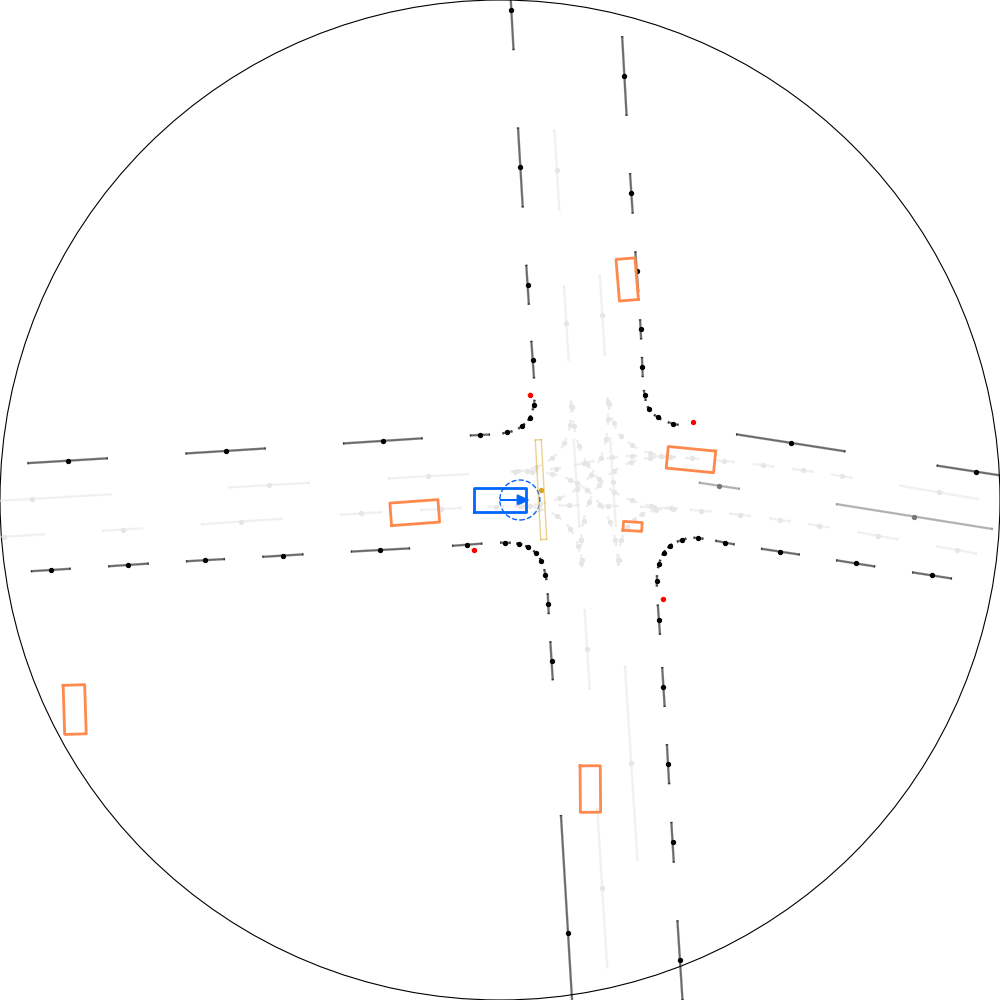 |
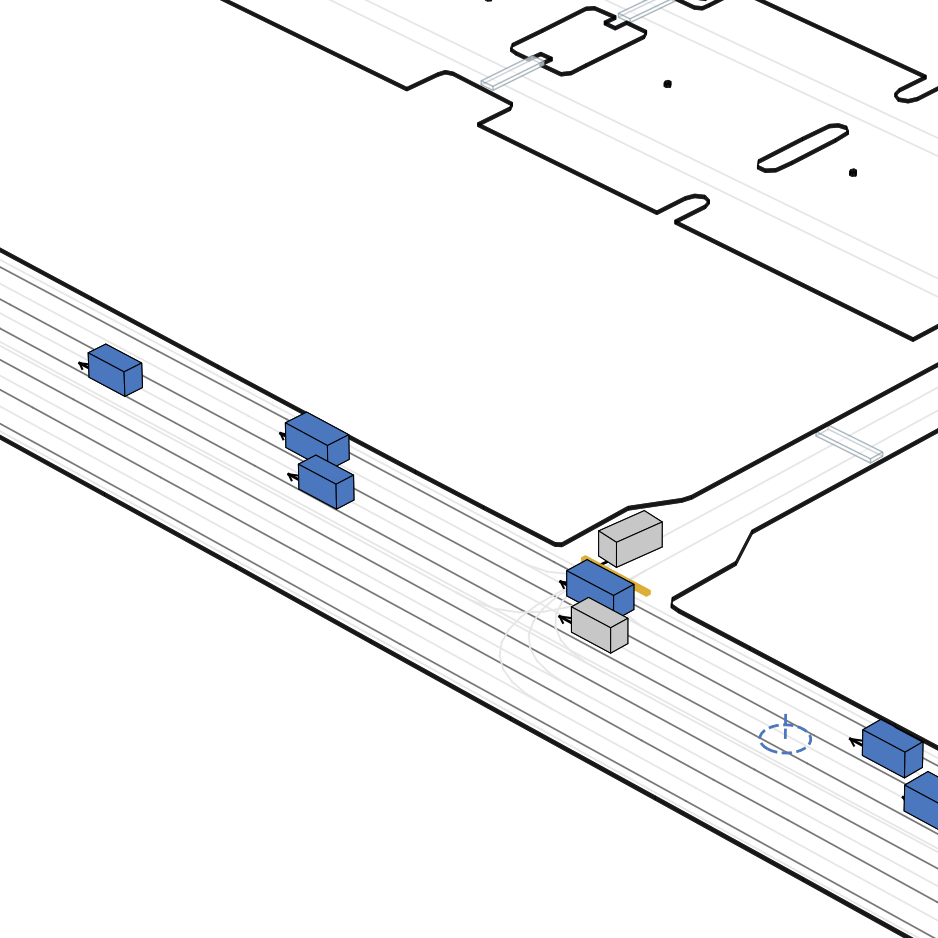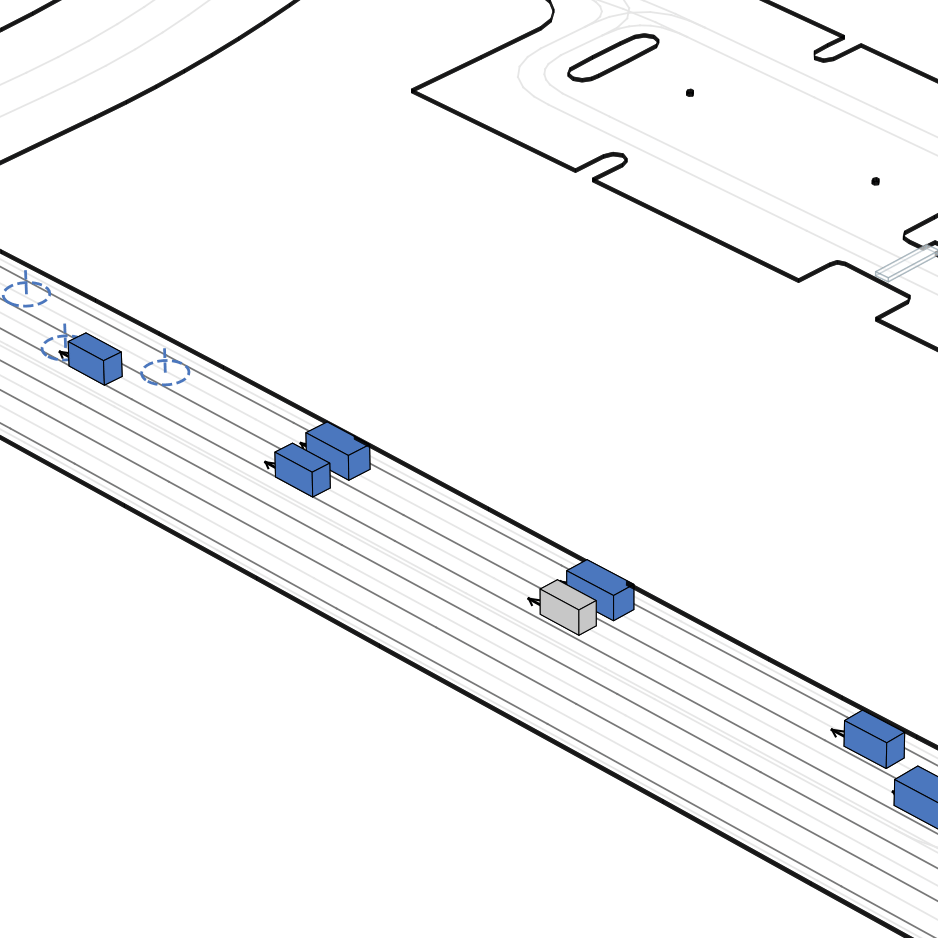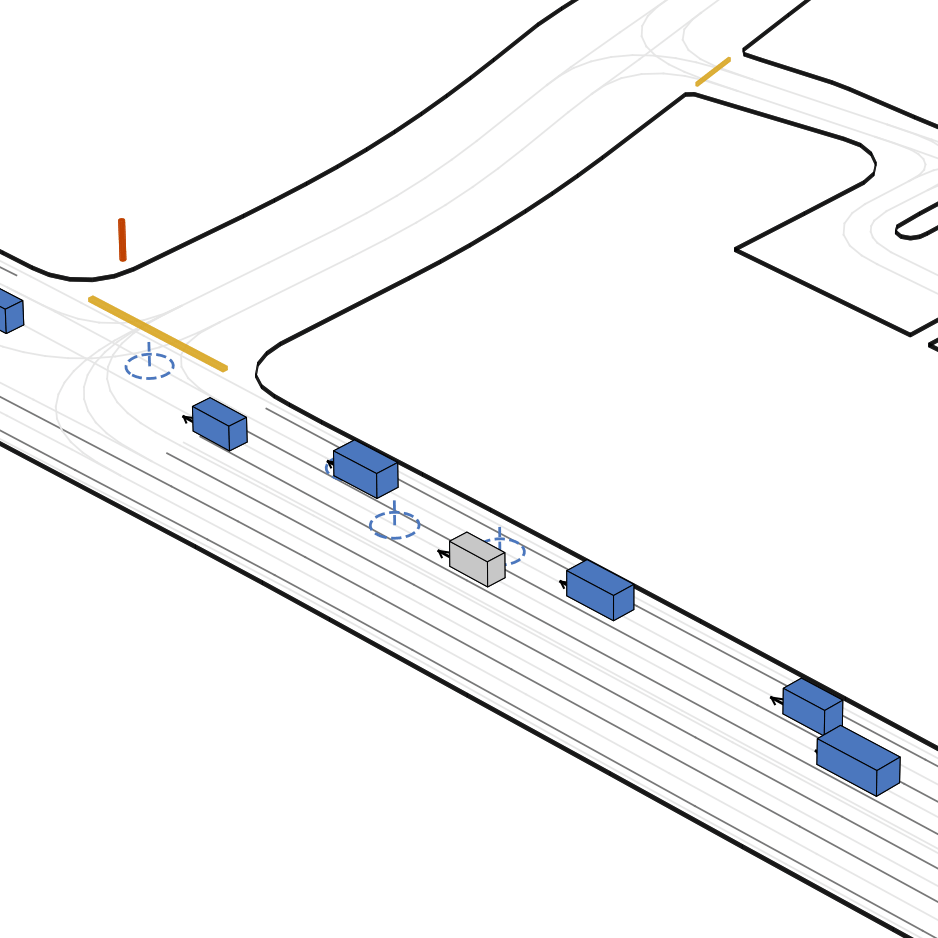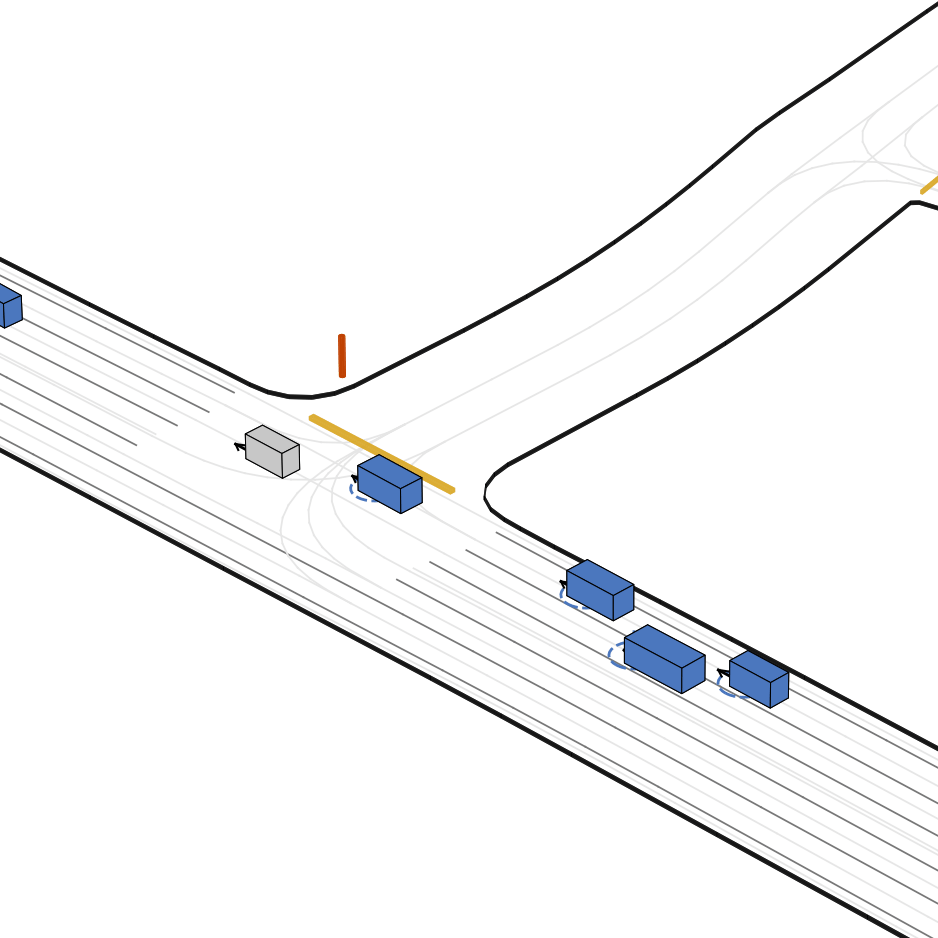 |
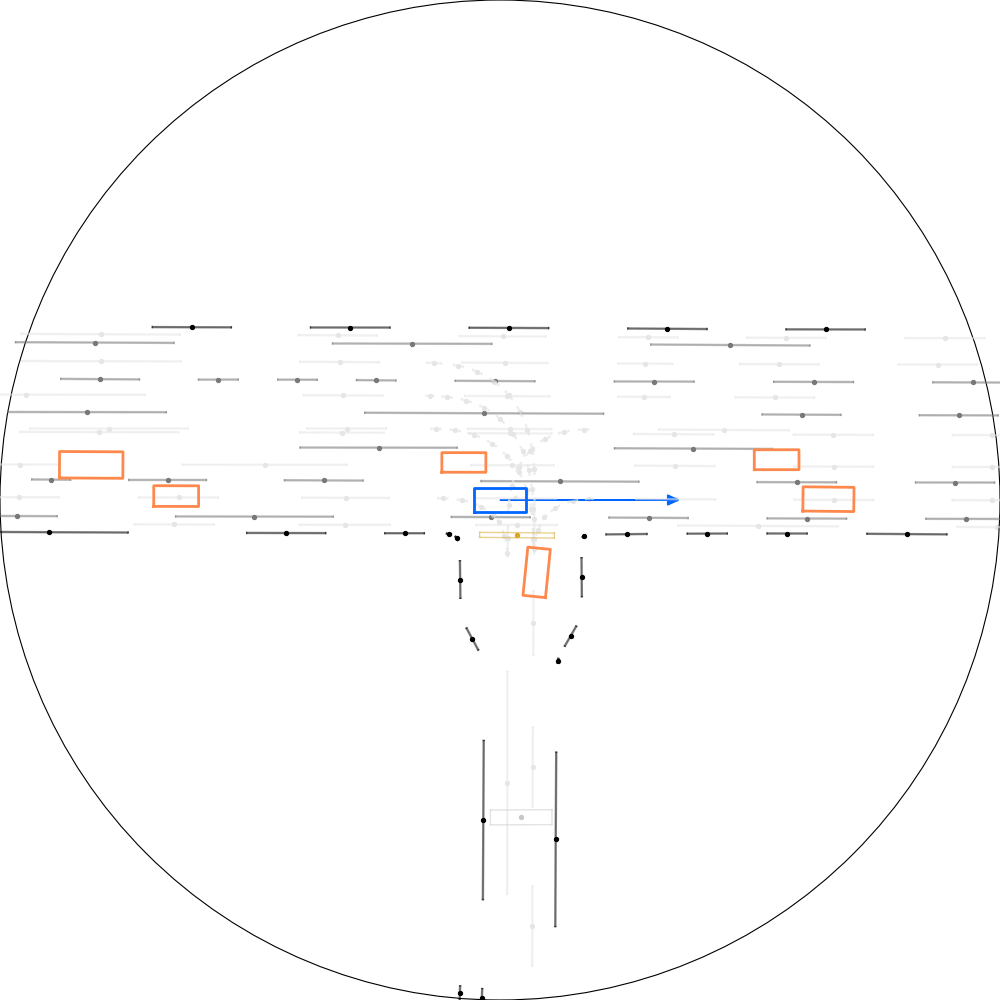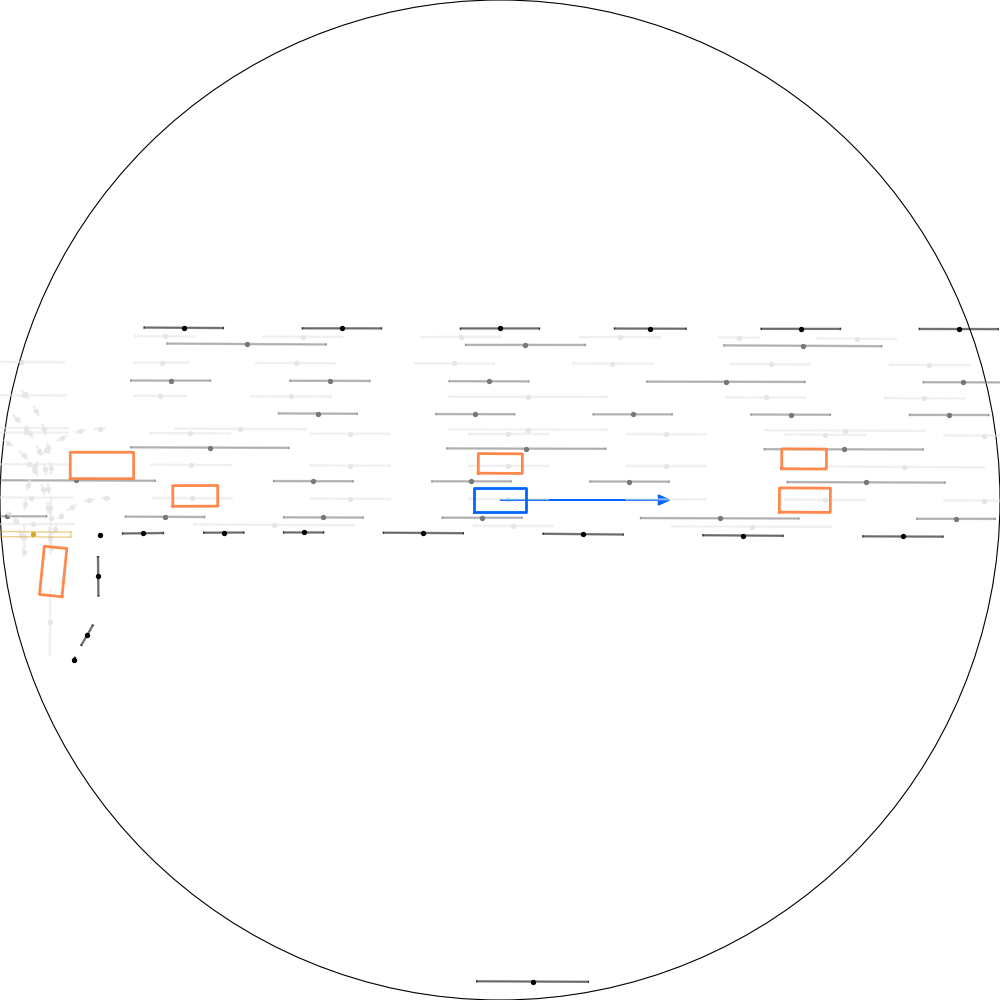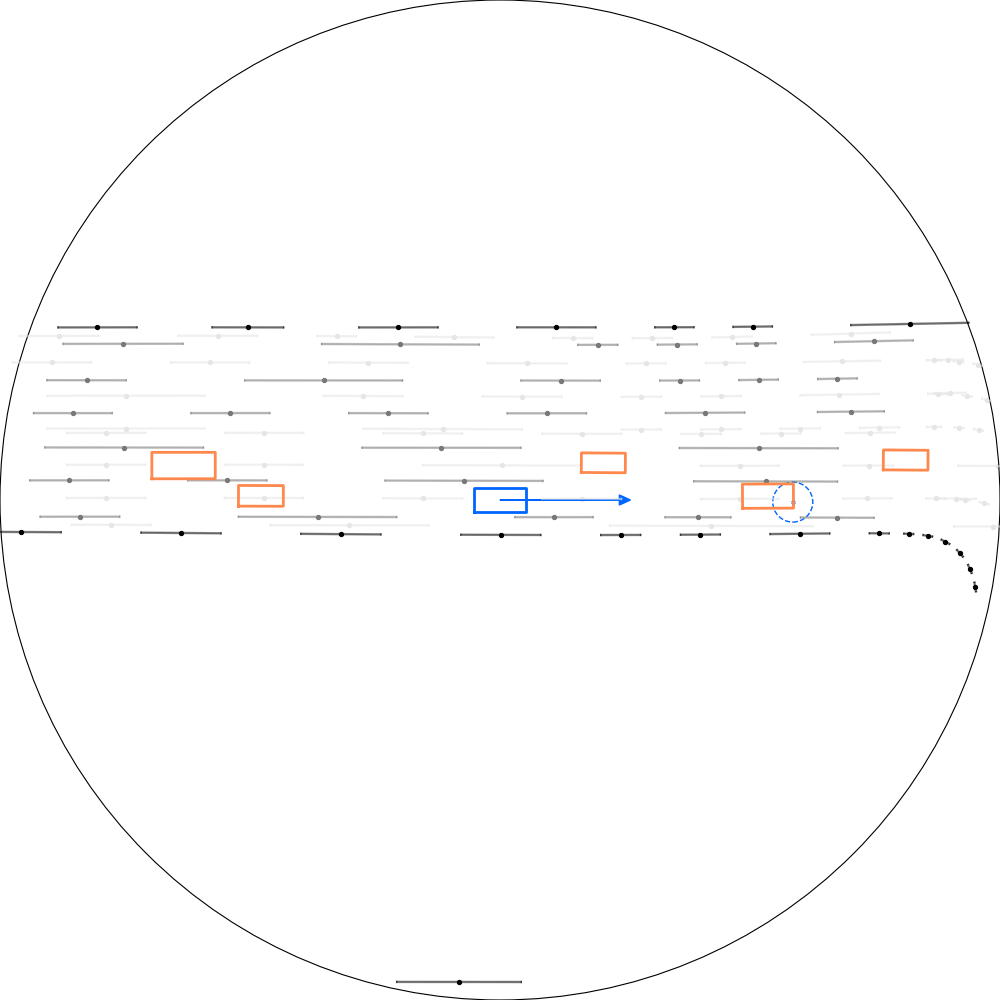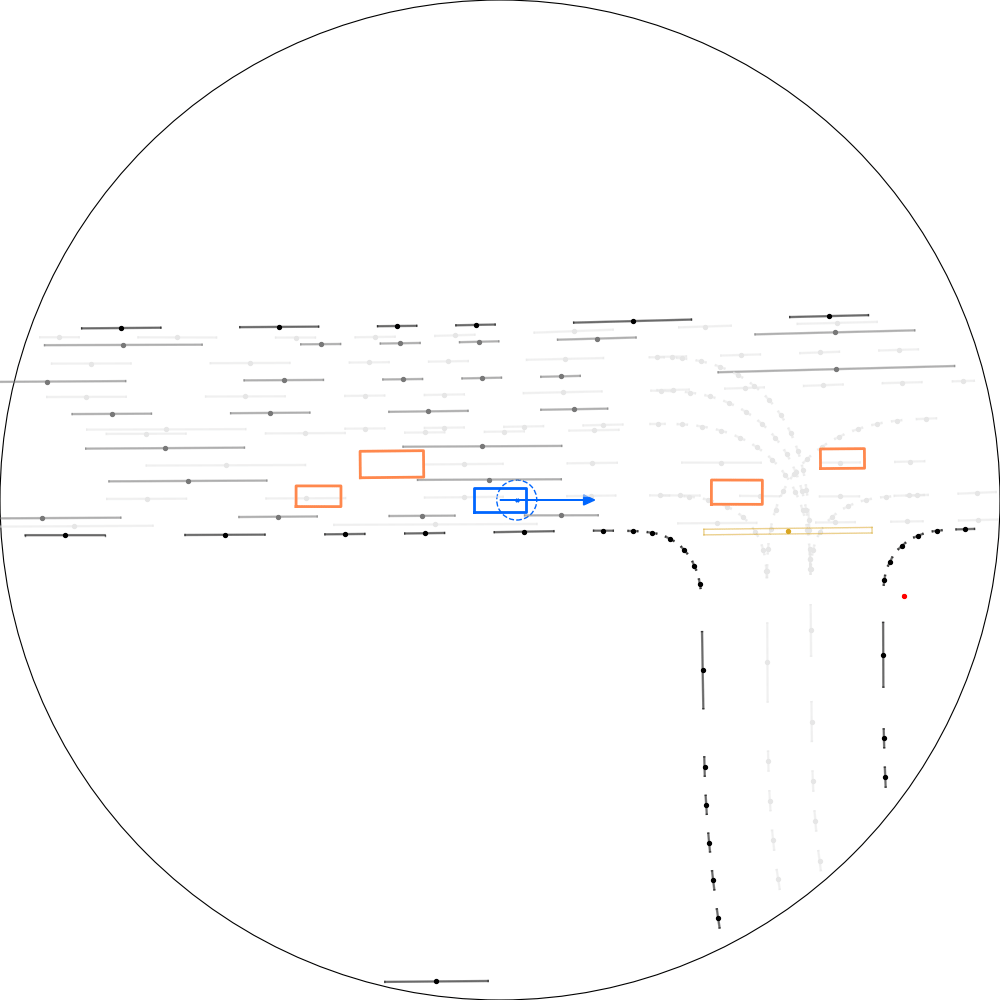 |
更多详情请参阅我们的论文以及入门教程,其中将引导您完成基本使用。
安装
要构建GPUDrive,请确保已安装所有必需的依赖项,这些依赖项列于此处,包括CMake、Python和CUDA工具包。具体步骤如下。
依赖项
- CMake >= 3.24
- Python >= 3.11
- CUDA工具包 >= 12.2且<= 12.4(目前我们不支持12.5及以上版本的CUDA。请使用nvcc --version验证您的CUDA版本。)
- 在macOS和Windows上,分别安装XCode和Visual Studio C++工具所需的依赖项。
安装完必要依赖后,克隆仓库(别忘了加上--recursive标志!):
git clone --recursive https://github.com/Emerge-Lab/gpudrive.git
cd gpudrive
随后有两种方式来构建仿真器:
🔧 选项1:手动安装
对于Linux和macOS,使用以下命令:
mkdir build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j # 核心数,例如32
cd ..
对于Windows,打开克隆的仓库到Visual Studio中,并使用内置的cmake功能构建项目。
接下来,设置Python环境
使用uv(推荐)
创建虚拟环境并安装仓库中的Python组件:
uv sync --frozen
使用pyenv
创建虚拟环境:
pyenv virtualenv 3.11 gpudrive
pyenv activate gpudrive
将其设置为当前项目目录(可选):
pyenv local gpudrive
使用conda
conda env create -f ./environment.yml
conda activate gpudrive
安装Python包
最后,使用pip安装仓库中的Python组件(此步骤对uv安装无需执行):
# macOS和Linux。
pip install -e .
依赖组包括pufferlib、sb3、vbd和tests。
# Windows。
pip install -e . -Cpackages.madrona_escape_room.ext-out-dir=<PATH_TO_YOUR_BUILD_DIR on Windows>
🐳 选项2:Docker
为了快速上手,我们在根目录下提供了Dockerfile。
前提条件
请确保已安装以下内容:
构建Docker镜像
安装完成后,您可以使用以下命令构建容器:
DOCKER_BUILDKIT=1 docker build --build-arg USE_CUDA=true --tag gpudrive:latest --progress=plain .
运行容器
要以GPU支持和共享内存的方式运行容器:
docker run --gpus all -it --rm --shm-size=20G -v ${PWD}:/workspace gpudrive:latest /bin/bash
通过导入仿真器来测试安装是否成功:
import madrona_gpudrive
为避免每次都在GPU模式下编译,可以设置以下环境变量,并指定自定义路径。例如,您可以将编译后的程序存储在名为gpudrive_cache的缓存中:
export MADRONA_MWGPU_KERNEL_CACHE=./gpudrive_cache
请注意,如果对C++代码进行任何更改,都需要删除缓存并重新编译。
可选:如果您想使用C++中的Madrona查看器
使用Madrona查看器所需的额外依赖
若要在Linux上构建带有可视化支持的仿真器(build/viewer),您需要安装X11和OpenGL开发库。而在macOS上,这些依赖项已由Xcode自动安装。例如,在Ubuntu系统上:
sudo apt install libx11-dev libxrandr-dev libxinerama-dev libxcursor-dev libxi-dev mesa-common-dev libc++1
集成
| 项目 | 信息 | 运行命令 | 训练步数 |
|---|---|---|---|
| IPPO 实现 SB3 | IPPO, PufferLib, 实现 | python baselines/ppo/ppo_sb3.py |
25 - 50K |
| IPPO 实现 PufferLib 🐡 | PPO | python baselines/ppo/ppo_pufferlib.py |
100 - 300K |
入门指南
要开始使用,请参考以下入门资源:
预训练策略
通过 🤗 huggingface_hub 中的 PyTorchModelHubMixin 类,提供了若干预训练策略。
最佳策略(10,000 场景)。来自论文《通过扩展自我博弈构建可靠的自动驾驶代理》的最佳策略在此处提供:链接。该策略基于 WOMD 训练数据集中随机采样的 10,000 个场景进行训练。
备选策略(1,000 场景)。一个基于 1,000 个场景训练的策略可在此处找到:链接
注意:这些模型是在
examples/experimental/config/reliable_agents_params.yaml中定义的环境配置下训练的,更改环境或观测配置将影响性能。
使用方法
要加载预训练策略,可以使用以下代码:
from gpudrive.networks.late_fusion import NeuralNet
# 通过 huggingface_hub 加载预训练模型
agent = NeuralNet.from_pretrained("daphne-cornelisse/policy_S10_000_02_27")
更多详细信息请参阅教程 04。
数据集
下载数据集
- 数据集有两个版本:一个包含 1,000 个训练文件和 300 个测试/验证文件的迷你版,以及一个包含 10 万个唯一场景的大型数据集。
- 如果您希望下载完整数据集,请将下方路径中的“GPUDrive_mini”替换为“GPUDrive”。
下载数据集
下载数据集需要安装 huggingface_hub 库:
pip install huggingface_hub
然后您可以使用 Python 或 huggingface-cli 下载数据集。
- 选项 1:使用 Python
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="EMERGE-lab/GPUDrive_mini", repo_type="dataset", local_dir="data/processed")
- 选项 2:使用 huggingface-cli
- 登录您的 Hugging Face 账户:
huggingface-cli login
- 下载数据集:
huggingface-cli download EMERGE-lab/GPUDrive_mini --local-dir data/processed --repo-type "dataset"
- 选项 3:手动下载
- 访问 https://huggingface.co/datasets/EMERGE-lab/GPUDrive_mini
- 进入“Files and versions”选项卡。
- 下载所需的文件或目录。
注意:如果您下载的是完整数据集,它会按照 Hugging Face 的限制被分成每 10,000 个文件一个子目录。为了使路径能够与 GPUDrive 正常配合使用,您需要运行:
python data_utils/post_processing.py # 如果您使用了自定义下载路径,请使用 --help 参数
重新构建数据集
如果您希望手动生成数据集,GPUDrive 兼容完整的 Waymo 开放运动数据集,该数据集包含超过 10 万个场景。要下载新文件并为模拟器创建场景,请按照以下步骤操作。
分三步重新构建数据集
- 首先,访问 https://waymo.com/open/ 并点击顶部的“下载”按钮。注册后,选择
v1.2.1 March 2024版本的文件,这是撰写本文时(2024年10月)最新的数据集版本。这将引导您进入 Google Cloud 页面。在此页面上,您应会看到如下文件夹结构:
waymo_open_dataset_motion_v_1_2_1/
│
├── uncompressed/
│ ├── lidar_and_camera/
│ ├── scenario/
│ │ ├── testing_interactive/
│ │ ├── testing/
│ │ ├── training_20s/
│ │ ├── training/
│ │ ├── validation_interactive/
│ │ └── validation/
│ └── tf_example/
- 现在,从
scenario文件夹中下载测试、训练和/或验证数据集文件。一种简便的方法是使用gsutil。首先通过以下命令进行登录:
gcloud auth login
然后运行以下命令来下载您所需的数据集。例如,下载验证数据集:
gsutil -m cp -r gs://waymo_open_dataset_motion_v_1_2_1/uncompressed/scenario/validation/ data/raw
其中 data/raw 是您的本地存储文件夹。请注意,根据您下载的数据集大小,此过程可能需要较长时间。
- 最后一步是将原始数据转换为与模拟器兼容的格式,使用以下命令:
python data_utils/process_waymo_files.py '<raw-data-path>' '<storage-path>' '<dataset>'
注意:由于存在一个未解决的 问题,在 Python 3.11 中安装 waymo-open-dataset-tf-2.12.0 会失败。为了使用该脚本,请在单独的 Python 3.10 环境中运行:
pip install waymo-open-dataset-tf-2-12-0 trimesh[easy] python-fcl
然后,例如,如果您想处理验证数据集,可以运行:
python data_utils/process_waymo_files.py 'data/raw/' 'data/processed/' 'validation'
>>>
Processing Waymo files: 100%|████████████████████████████████████████████████████████████████| 150/150 [00:05<00:00, 28.18it/s]
INFO:root:Done!
这样就完成了!
🧐 注意事项:单个 Waymo tfrecord 文件大约包含 500 个交通场景。在 16 核 CPU 上,处理速度约为每分钟 250 个场景。例如,尝试处理整个验证数据集(150 个 tfrecord 文件)将耗费大量时间。
后处理
- 运行
python data_utils/postprocessing.py可以过滤掉损坏的文件,并取消 Hugging Face 的目录分组。
📜 引用 GPUDrive
如果您在研究中使用了 GPUDrive,请引用我们即将发表于 ICLR 2025 的论文:
@inproceedings{kazemkhani2025gpudrive,
title={GPUDrive: Data-driven, multi-agent driving simulation at 1 million FPS},
author={Saman Kazemkhani and Aarav Pandya and Daphne Cornelisse and Brennan Shacklett and Eugene Vinitsky},
booktitle={Proceedings of the International Conference on Learning Representations (ICLR)},
year={2025},
url={https://arxiv.org/abs/2408.01584},
eprint={2408.01584},
archivePrefix={arXiv},
primaryClass={cs.AI},
}
贡献
如果您遇到 bug、发现缺少功能,或希望参与贡献,请随时创建 issue 或联系我们!我们非常期待您的加入!
版本历史
v0.4.02025/02/20v0.32024/12/19v0.22024/08/06v0.12024/06/13常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备