Awesome-Model-Quantization
Awesome-Model-Quantization 是一个专注于模型量化领域的开源资源聚合库,旨在为研究者和开发者提供一站式的学术与工程支持。随着大语言模型(LLM)和多模态模型规模的不断扩大,如何在保持性能的同时降低计算成本和存储需求成为关键挑战,而模型量化正是解决这一问题的核心技术。该仓库系统地收集并整理了从早期经典到 2026 年最新的量化相关论文、技术文档、基准测试(如 BiBench、LLaMA3 及 Qwen3 量化实证研究)以及开源代码实现。
通过持续更新的分类目录,Awesome-Model-Quantization 帮助用户快速定位特定年份的研究成果或具体的实验工具,极大地降低了文献调研和复现算法的门槛。它不仅涵盖了理论综述,还包含了针对主流模型(如 LLaMA 系列、Qwen 系列)的实战基准分析,为评估不同量化策略的效果提供了权威参考。无论是希望深入探索量化算法前沿的科研人员,还是致力于将大模型部署到边缘设备的工程师,都能从中获得宝贵的灵感与实用工具。该项目鼓励社区协作,欢迎用户提交遗漏的优秀工作,共同推动高效人工智能技术的发展。
使用场景
某边缘计算团队正试图将最新的 Qwen3 大语言模型部署到资源受限的工业手持终端上,急需通过模型量化技术在保持精度的同时大幅降低显存占用。
没有 Awesome-Model-Quantization 时
- 文献检索如大海捞针:工程师需手动在 arXiv、GitHub 和各大会议网站分散搜索"Qwen3 量化”或"LLM 二值化”相关论文,耗时数天仍可能遗漏关键成果(如 ICML 2023 的 BiBench)。
- 代码复现门槛极高:找到论文后,往往找不到官方开源代码,或仓库已归档失效,导致算法验证无法启动,项目进度严重受阻。
- 缺乏权威基准对比:团队自行设计的量化方案缺乏统一的评估标准,无法判断其效果是否优于业界现有的 LLaMA3 或 Qwen3 实证研究结果。
- 技术选型盲目试错:面对众多量化策略(如权重量化、激活量化),因缺乏系统的综述论文(Survey Papers)指导,只能凭经验盲目尝试,浪费大量算力资源。
使用 Awesome-Model-Quantization 后
- 一站式获取前沿资源:直接查阅按年份(2022-2026)分类的论文列表,瞬间定位到《An Empirical Study of Qwen3 Quantization》等最新实证研究与对应代码链接。
- 快速复用成熟方案:通过收录的"Related Repositories"直接获取经过验证的量化工具箱(如 LightCompress),将环境搭建与代码调试时间从周缩短至小时级。
- 依托标准基准评估:利用项目中整理的 BiBench 等权威基准测试集,快速量化评估模型性能,确保优化后的模型在精度损失可控范围内。
- 系统化技术决策:参考收录的综述论文理清技术脉络,迅速选定最适合工业终端的二值化或低比特量化路径,避免无效探索。
Awesome-Model-Quantization 将原本分散、高门槛的量化 research 转化为结构化的知识资产,让团队能专注于业务落地而非重复造轮子。
运行环境要求
未说明
未说明
快速开始
令人惊叹的模型量化 
本仓库收集了关于模型量化的论文、文档和代码,供所有希望研究这一领域的人员参考。我们正在持续改进该项目。欢迎提交该仓库尚未收录的相关工作(论文、代码库)。
基准测试
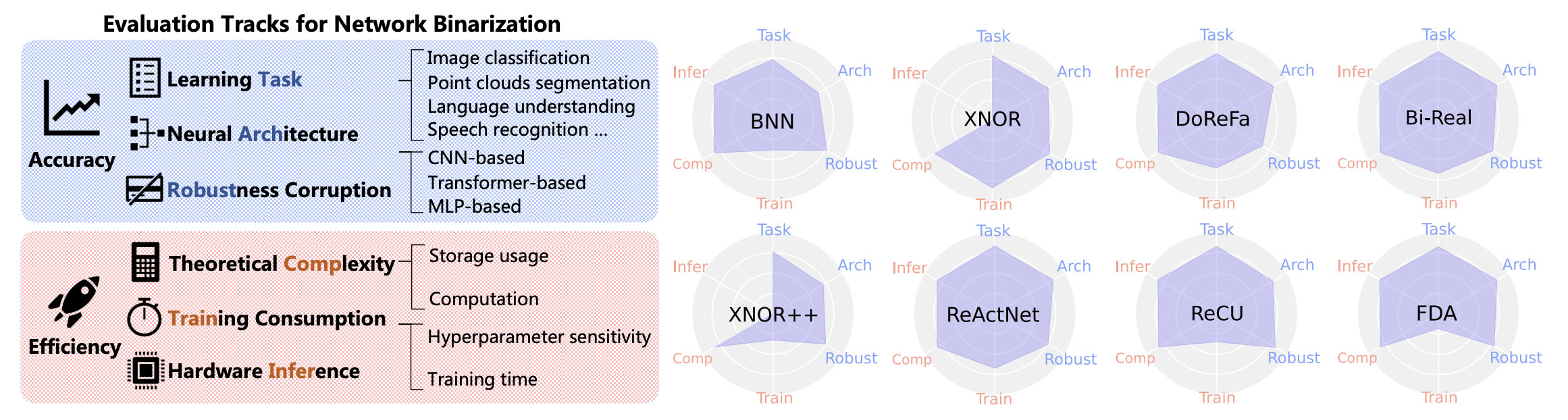
1. BiBench:网络二值化的基准测试与分析 [论文] [代码]

会议: ICML 2023
作者: 秦浩桐、张明远、丁一夫、李傲宇、蔡中刚、刘子威、费舍尔·余、刘向龙。
Bibtex
@inproceedings{qin2023bibench,
title={BiBench: Benchmarking and Analyzing Network Binarization},
author={Qin, Haotong and Zhang, Mingyuan and Ding, Yifu and Li, Aoyu and Cai, Zhongang and Liu, Ziwei and Yu, Fisher and Liu, Xianglong},
booktitle={International Conference on Machine Learning (ICML)},
year={2023}
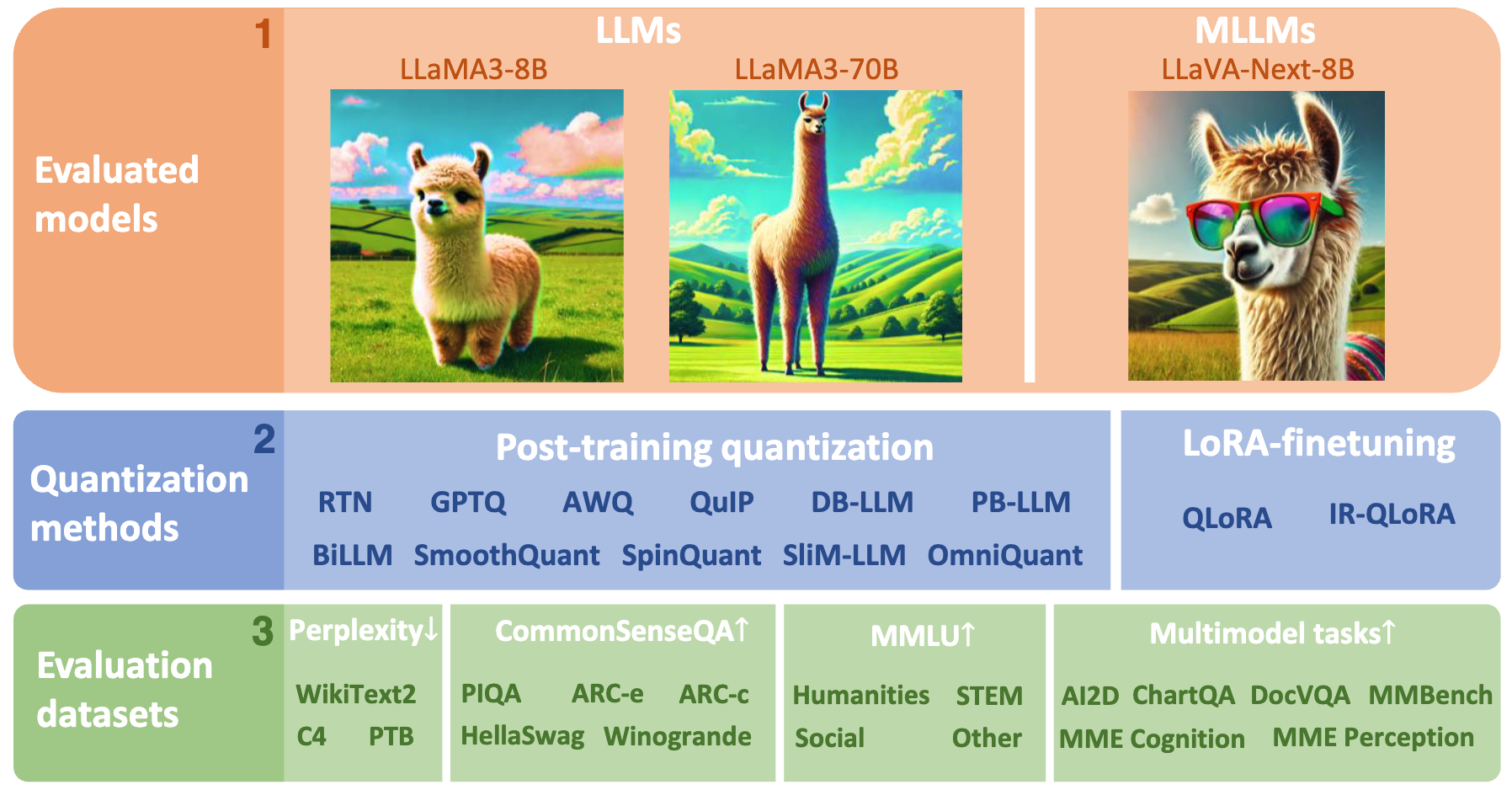
}2. LLaMA3 量化实证研究:从 LLM 到 MLLM [论文] [代码]

会议: Visual Intelligence 2024
作者: 黄伟、郑星宇、马旭东、秦浩桐、吕成涛、陈宏、罗杰、齐晓娟、刘向龙、米凯莱·马尼奥。
Bibtex
@article{huang2024empirical,
title={An empirical study of llama3 quantization: From llms to mllms},
author={Huang, Wei and Zheng, Xingyu and Ma, Xudong and Qin, Haotong and Lv, Chengtao and Chen, Hong and Luo, Jie and Qi, Xiaojuan and Liu, Xianglong and Magno, Michele},
journal={Visual Intelligence},
volume={2},
number={1},
pages={36},
year={2024},
publisher={Springer}
}
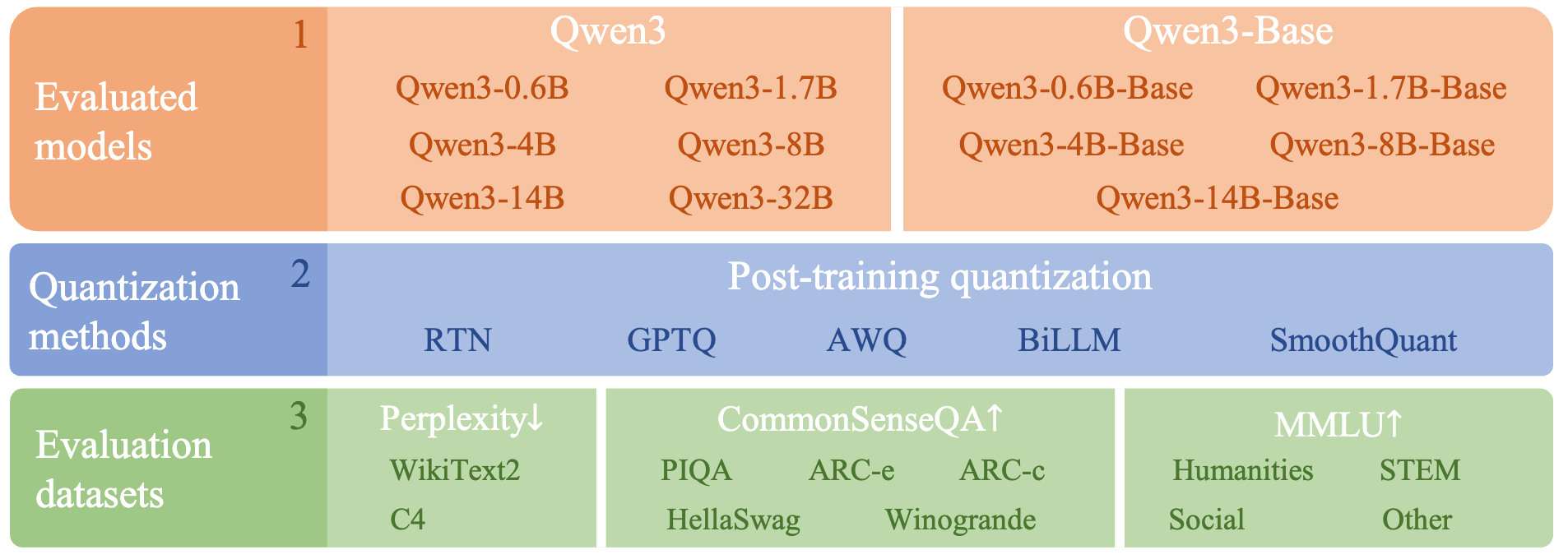
会议: Visual Intelligence 2026
作者: 郑星宇、李雨叶、楚浩然、冯岳、马旭东、罗杰、郭金阳、秦浩桐、米凯莱·马尼奥、刘向龙。
Bibtex
@article{zheng2025empirical,
title={An empirical study of qwen3 quantization},
author={Zheng, Xingyu and Li, Yuye and Chu, Haoran and Feng, Yue and Ma, Xudong and Luo, Jie and Guo, Jinyang and Qin, Haotong and Magno, Michele and Liu, Xianglong},
journal={arXiv preprint arXiv:2505.02214},
year={2025}
}4. LLMC:使用多功能压缩工具包对大型语言模型量化进行基准测试 [论文] [代码]

会议: EMNLP 2024 行业专场
作者: 龚瑞豪、杨勇、顾世桥、黄宇诗、吕成涛、张云晨、刘向龙、陶大成。
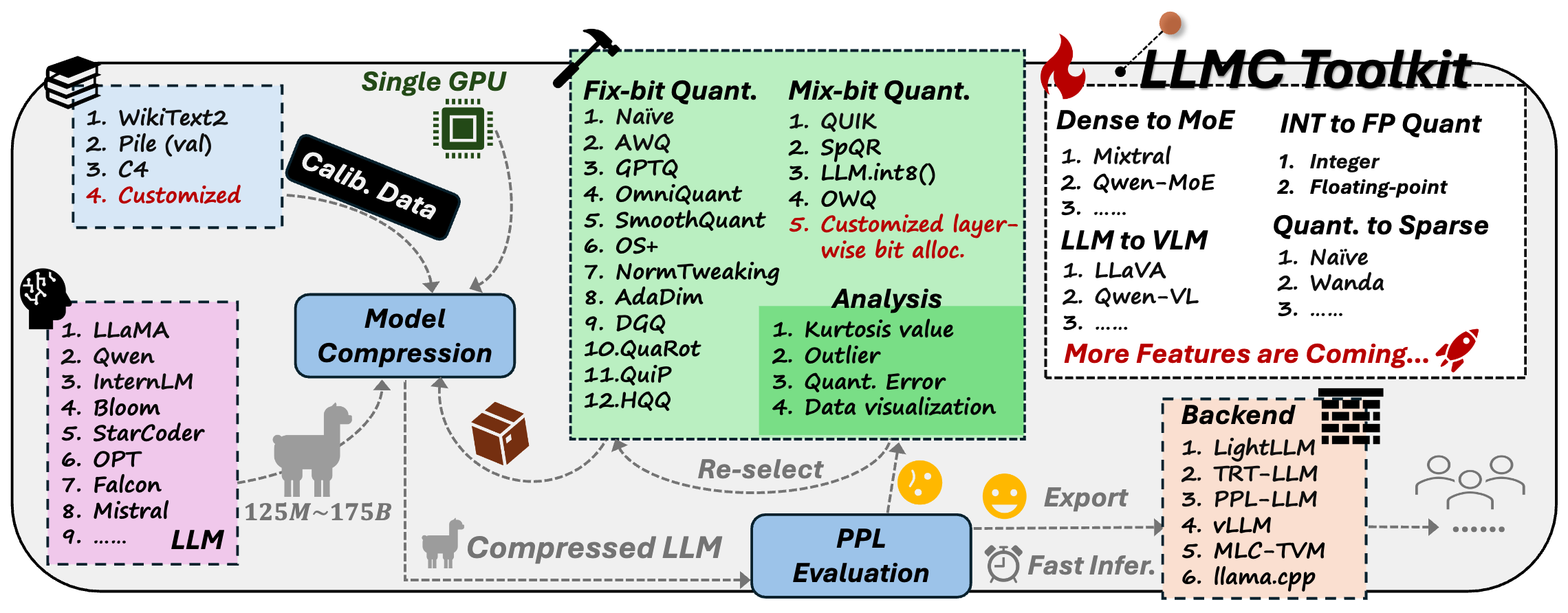
Bibtex
@inproceedings{gong2024llmc,
title={Llmc: Benchmarking large language model quantization with a versatile compression toolkit},
author={Gong, Ruihao and Yong, Yang and Gu, Shiqiao and Huang, Yushi and Lv, Chengtao and Zhang, Yunchen and Tao, Dacheng and Liu, Xianglong},
booktitle={Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track},
pages={132--152},
year={2024}
}5. RobustMQ:量化模型鲁棒性基准测试 [论文]
会议: Visual Intelligence 2023
作者: 肖义松、刘爱珊、张天元、秦浩桐、郭金阳、刘向龙。
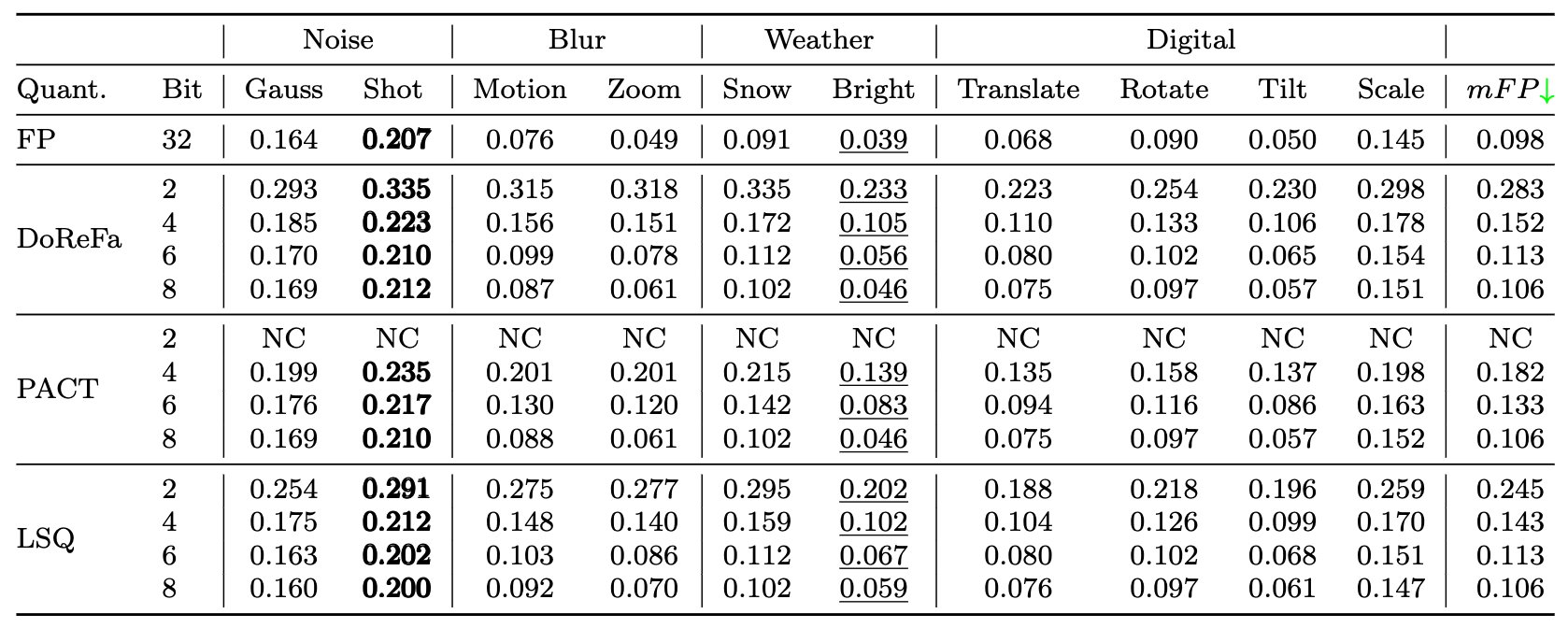
Bibtex
@article{xiao2023robustmq,
title={Robustmq: benchmarking robustness of quantized models},
author={Xiao, Yisong and Liu, Aishan and Zhang, Tianyuan and Qin, Haotong and Guo, Jinyang and Liu, Xianglong},
journal={Visual Intelligence},
volume={1},
number={1},
pages={30},
year={2023},
publisher={Springer}
}综述论文
会议/期刊:模式识别 2020
作者:Haotong Qin、Ruihao Gong、Xianglong Liu、Xiao Bai、Jingkuan Song、Nicu Sebe。

Bibtex
@article{Qin:pr20_bnn_survey,
title = "Binary neural networks: A survey",
author = "Haotong Qin and Ruihao Gong and Xianglong Liu and Xiao Bai and Jingkuan Song and Nicu Sebe",
journal = "Pattern Recognition",
volume = "105",
pages = "107281",
year = "2020"
}2. 低比特大语言模型综述:基础、系统与算法 [论文]
会议/期刊:神经网络 2025
作者:Ruihao Gong、Yifu Ding、Zining Wang、Chengtao Lv、Xingyu Zheng、Jinyang Du、Yang Yong、Shiqiao Gu、Haotong Qin、Jinyang Guo、Dahua Lin、Michele Magno、Xianglong Liu。
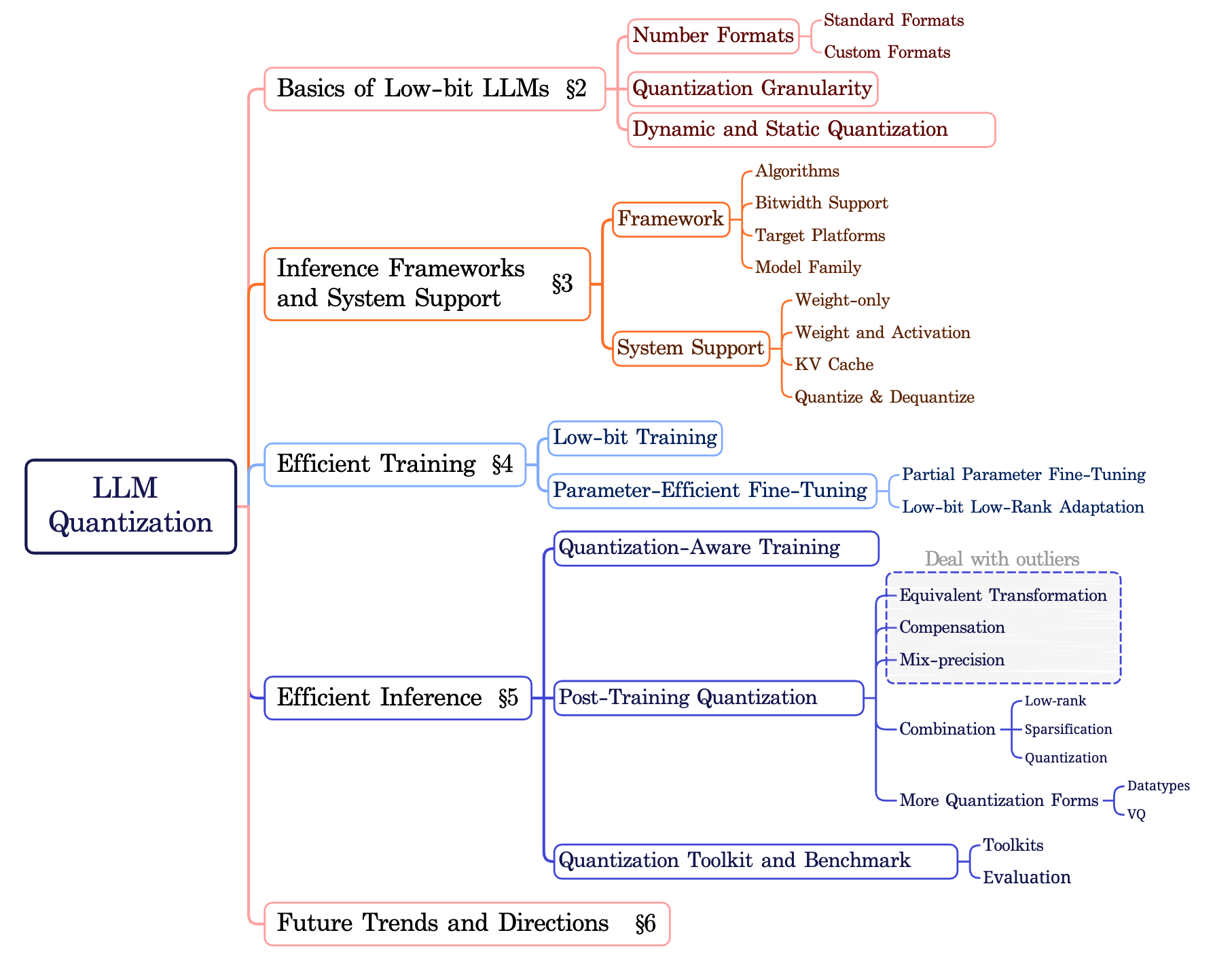
Bibtex
@article{gong2025survey,
title={A survey of low-bit large language models: Basics, systems, and algorithms},
author={Gong, Ruihao and Ding, Yifu and Wang, Zining and Lv, Chengtao and Zheng, Xingyu and Du, Jinyang and Yong, Yang and Gu, Shiqiao and Qin, Haotong and Guo, Jinyang and others},
journal={Neural networks},
pages={107856},
year={2025},
publisher={Elsevier}
}3. 深度神经网络的低比特模型量化:综述 [论文]
会议/期刊:arXiv 2025
作者:Kai Liu、Qian Zheng、Kaiwen Tao、Zhiteng Li、Haotong Qin、Wenbo Li、Yong Guo、Xianglong Liu、Linghe Kong、Guihai Chen、Yulun Zhang、Xiaokang Yang。

Bibtex
@article{liu2025low,
title={Low-bit model quantization for deep neural networks: A survey},
author={Liu, Kai and Zheng, Qian and Tao, Kaiwen and Li, Zhiteng and Qin, Haotong and Li, Wenbo and Guo, Yong and Liu, Xianglong and Kong, Linghe and Chen, Guihai and others},
journal={arXiv preprint arXiv:2505.05530},
year={2025}
}论文
2026
- [ICLR] PT²-LLM:面向大型语言模型的后训练三值化 [代码]
- [ICLR] Quant-dLLM:面向扩散型大型语言模型的后训练极低比特量化
- [ICLR] DVD-Quant:无数据视频扩散Transformer量化
- [ICLR] Q&C:高效生成中量化与缓存的结合
- [CVPR Findings] Q-MambaIR:用于高效图像修复的高精度量化Mamba模型
- [ICLR] 量化视觉几何基础Transformer
- [ICLR] 视频抠图的后训练量化
- [ICLR] QVGen:推动量化视频生成模型的极限
- [ICLR] QuantSparse:通过模型量化和注意力稀疏化全面压缩视频扩散Transformer [代码]
- [AAAI] 一阶误差很重要:对量化大型语言模型的精确补偿 [代码]
- [AAAI] TR-DQ:时间-旋转扩散量化
- [ICLR] TurboQuant:近似最优失真率的在线向量量化
- [ICLR] 面向LLM联合量化与稀疏化的最优大脑恢复 [代码]
- [ICLR] AnyBCQ:面向多精度LLM的硬件高效灵活二进制编码量化 [代码]
- [ICLR] Tequila:无死区的大型语言模型三值量化
- [ICLR] LogART:推动高效对数后训练量化的极限 [代码]
- [ICLR] ParoQuant:面向高效推理LLM推理的成对旋转量化 [代码]
- [ICLR] 通过4位广义正态浮点格式提升分块式LLM量化
- [arXiv] D²Quant:LLM的高精度低比特后训练权重量化
- [arXiv] QuantLRM:通过微调信号对大型推理模型进行量化
- [arXiv] SliderQuant:LLM的高精度后训练量化
- [arXiv] 什么使低比特量化感知训练在推理LLM中有效?一项系统性研究
- [ICLR] 面向高效长上下文推理的通道感知混合精度量化
- [ICLR] CodeQuant:统一聚类与量化,以增强低精度专家混合模型中的异常平滑
- [ICLR] QeRL:超越效率——面向LLM的量化增强强化学习 [代码]
- [ICLR] AutoQVLA:视觉-语言-行动模型量化中并非所有通道都同等重要
- [ICLR] 通过子空间保持和网格量化实现低比特缪子
- [ICLR] 面向视觉自回归模型的移位求和量化
- [ICLR] 面向目标检测模型的内点中心后训练量化
- [ICLR] 在理论泛化保证下高效量化专家混合模型
- [ICLR] BBQ:通过贝尔盒量化提升量化熵
- [ICLR] 通过4位块优化浮点(BOF4)提升分块式LLM量化:分析与变体 [代码]
- [ICLR] 高维线性回归下的量化学习
- [ICLR] 即时适应量化:面向高效微调量化LLM的配置感知LoRA
- [ICLR] 拉开FP4量化承诺与实际性能之间的差距 [代码]
- [ICLR] KBVQ-MoE:面向MoE大型语言模型的KLT引导SVD与偏置校正向量量化 [代码]
- [ICLR] UniQL:面向自适应边缘LLM的统一量化与低秩压缩 [代码]
- [ICLR] 神经网络量化中的格子几何:GPTQ与Babai算法等价性的简短证明
- [ICLR] DPQuant:通过动态量化调度实现高效且私密的模型训练
- [ICLR] 朝着超低比特推理LLM的量化感知训练迈进
- [ICLR] 浮点量化下自适应优化器的收敛性分析
- [ICLR] 训练动态影响后训练量化鲁棒性 [代码]
- [ICLR] SSDi8:面向状态空间对偶的准确高效8比特量化
- [ICLR] LLM量化的几何:GPTQ即Babai最近平面算法
- [ICLR] PTQ4ARVG:面向自回归视觉生成模型的后训练量化 [代码]
- [ICLR] QWHA:面向大型语言模型参数高效微调的量化感知沃尔什-哈达玛适配 [代码]
- [ICLR] 扩散模型后训练量化的梯度对齐校准
- [ICLR] SERQ:面向LLM量化的显著性感知低秩误差重构
- [ICLR] 计算最优的量化感知训练
- [ICLR] PM-KVQ:面向长上下文LLM的渐进式混合精度KV缓存量化 [代码]
- [ICLR] 超越异常值:量化下优化器的研究
- [ICLR] Qronos:通过塑造未来来修正过去……在后训练量化中
- [ICLR] MicroMix:面向大型语言模型的高效混合精度量化,采用微缩格式 [代码]
- [ICLR] TurboBoA:无需反向传播即可实现更快、更精确的注意力感知量化
- [ICLR] 超越均匀性:扩散模型后训练量化的样本与频率元加权
- [ICLR] 重新思考基于补偿的LLM量化的残差误差
- [ICLR] SPR²Q:面向图像超分辨率的静态优先级整流路由量化 [代码]
- [ICLR] STaMP:序列转换与混合精度,用于低精度激活量化


















2025年
- [ICML] Q-VDiT:迈向视频生成扩散Transformer的精确量化与蒸馏 [代码]
- [AAAI] MPQ-DM:面向极低比特扩散模型的混合精度量化
- [ICML] SliM-LLM:基于显著性驱动的大型语言模型混合精度量化 [代码]
- [TPAMI] BiVM:用于高效视频抠图的精确二值化神经网络
- [NeurIPS] S²Q-VDiT:基于显著性数据与稀疏令牌蒸馏的精确量化视频扩散Transformer [代码]
- [CVPR] PassionSR:基于单步扩散的图像超分辨率中的自适应尺度后训练量化 [代码]
- [ICLR] ARB-LLM:大型语言模型的交替精炼二值化 [代码]
- [ICLR] BinaryDM:面向高效扩散模型的精确权重二值化 [代码]
- [ICML] FlatQuant:对于LLM量化而言,平坦性至关重要 [代码]
- [ICML] RoSTE:一种高效的量化感知监督微调方法,适用于大型语言模型 [代码]
- [ICML] GANQ:面向大型语言模型的GPU自适应非均匀量化
- [ICML] 调制扩散:通过调制量化加速生成式建模 [代码]
- [NeurIPS] DartQuant:用于LLM量化的高效旋转分布校准 [代码]
- [AAAI] JAQ:高效架构设计与低比特量化相结合
- [AAAI] OAC:输出自适应校准,实现LLM后训练量化的精准性
- [AAAI] 通过衰减时间步长感知损失进行蒸馏,优化量化扩散模型
- [AAAI] 扩散模型的可量化敏感度
- [AAAI] TCAQ-DM:面向扩散模型的时间步-通道自适应量化
- [ACL] EfficientQAT:面向大型语言模型的高效量化感知训练 [代码]
- [ACL] L4Q:在大型语言模型上进行参数高效的量化感知微调
- [ACL] MoQAE:通过量化感知专家混合实现长上下文LLM推理的混合精度量化
- [ACL] 面向大型语言模型稳健4比特量化之异常值安全预训练
- [ACL] PTQ1.61:推动极低比特后训练量化方法的实际极限 [代码]
- [ACL] 统一均匀与二进制编码量化,实现大型语言模型的精准压缩
- [ACL] “给我BF16,否则就让我死”?LLM量化中的准确率与性能权衡
- [ACM MM] DilateQuant:通过权重扩张实现扩散模型的精准高效量化感知训练
- [ACM MM] 利用伪正向蒸馏学习二值化表示
- [ACM MM] MQuant:通过后训练量化释放多模态大型语言模型的推理潜力
- [ACM MM] 推动二值化神经网络在图像超分辨率中的极限,实现信息的平滑传输
- [ACM MM] 量化遇见OOD:从平坦性视角看可泛化的量化感知训练
- [EMNLP] AMQ:为大型语言模型的混合精度仅权重量化提供AutoML支持
- [EMNLP] 量化是否会影响模型在长输入和长输出任务上的表现?
- [ICLR] CBQ:面向大型语言模型的跨块量化
- [ICLR] DGQ:面向文本到图像扩散模型的分布感知分组量化
- [ICLR] LeanQuant:具有损失误差感知网格的精准且可扩展大型语言模型量化
- [ICLR] OSTQuant:通过正交与缩放变换优化大型语言模型量化,以更好地拟合分布 [代码]
- [ICLR] QERA:一种用于量化误差重建的分析框架 [代码]
- [ICLR] SpinQuant:利用学习到的旋转进行LLM量化
- [ICLR] SVDQuant:通过低秩成分吸收异常值,适用于4比特扩散模型
- [ICLR] ViDiT-Q:面向图像和视频生成的扩散Transformer的高效精准量化
- [ICML] GuidedQuant:通过利用末端损失指导实现大型语言模型量化 [代码]
- [ICML] ResQ:采用低秩残差的大型语言模型混合精度量化 [代码]
- [NeurIPS] 一种无需校准的低比特KV缓存量化双归一化方法
- [NeurIPS] 二元二次量化:超越一阶量化,用于实值矩阵压缩
- [NeurIPS] 学习分组格子向量量化器,用于低比特大型语言模型
- [NeurIPS] LittleBit:通过潜在因子分解实现超低比特量化
- [NeurIPS] ParetoQ:在极低比特LLM量化中改进规模法则
- [NeurIPS] Q-Palette:面向最优仅权重后训练量化的分数比特量化器
- [NeurIPS] 为LLM增强小波的高保真1比特量化
- [ACL Findings] 通过后训练量化实现LLM的二值权重与激活
- [EMNLP Findings] KurTail:基于峰度的LLM量化
- [SIGMOD] 面向近似最近邻搜索的欧几里得空间中高维向量的实用且渐近最优量化 [代码]
- [NeurIPS] QBasicVSR:面向视频超分辨率的时间感知适应量化
- [NeurIPS] 量化误差传播:重新审视逐层后训练量化
- [NeurIPS] Point4Bit:点云3D检测的后训练4比特量化
- [NeurIPS] PMQ-VE:面向视频增强的渐进式多帧量化 [代码]
- [NeurIPS] VETA-DiT:方差均衡且时间自适应的量化,用于高效的4比特扩散Transformer
- [NeurIPS] LoTA-QAF:无损三值适应,用于量化感知微调 [代码]
- [NeurIPS] 通过权重偏置校正和位级核心集采样,实现高效多比特量化网络训练
- [NeurIPS] 通过拓扑熵实现高效且可泛化的混合精度量化
- [NeurIPS] QSCA:用于单目深度估计的自补偿辅助量化
- [ICCV] 为量化感知训练安排权重过渡 [代码]
- [ICCV] 面向目标检测的任务特定零样本量化感知训练 [代码]
- [ICCV] OuroMamba:面向Vision Mamba的无数据量化框架
- [ICCV] FedWSQ:通过权重标准化和分布感知的非均匀量化实现高效联邦学习 [代码]
- [ICCV] 视觉Transformer无数据量化的语义对齐与强化 [代码]
- [ICCV] QuantCache:面向视频生成的自适应重要性引导量化,结合层次化潜伏层与层缓存 [代码]
- [ICCV] MixA-Q:从混合精度量化视角重新审视视觉Transformer的激活稀疏性
- [ICCV] DMQ:剖析扩散模型的异常值,用于后训练量化 [代码]
- [ICCV] AHCPTQ:面向Segment Anything Model的精准且硬件兼容后训练量化
- [ICCV] MSQ:内存高效的比特稀疏化量化
- [ICCV] QuEST:通过高效的选择性微调实现低比特扩散模型量化 [代码]
- [ICML] MxMoE:兼具准确性和性能的MoE混合精度量化 [代码]
- [ICML] 从损失景观中学习:通过自适应尖锐度感知梯度对齐实现可泛化的混合精度量化
- [ICML] PARQ:分段仿射正则化量化 [代码]
- [ICML] Quamba2:面向选择性状态空间模型的稳健且可扩展后训练量化框架 [代码]
- [ICML] LRA-QViT:将低秩近似与量化相结合,打造稳健高效的视觉Transformer
- [ICML] BoA:注意力感知后训练量化,无需反向传播
- [ICML] MoEQuant:通过专家平衡采样和亲和力引导,提升混合专家大型语言模型的量化效果 [代码]
- [ICML] NestQuant:嵌套格子量化,适用于矩阵乘积和LLM
- [ICML] Q-resafe:评估量化大型语言模型的安全风险及量化感知安全补丁 [代码]
- [ICML] SLiM:一次性的量化与稀疏化,结合低秩近似压缩LLM权重 [代码]
- [ICML] QT-DoG:面向领域泛化的量化感知训练 [代码]
- [ICML] 套娃量化
- [ICML] 适合合并的多目标领域适应后训练量化 [代码]
- [ICML] 面向量化乐观对偶平均的逐层量化
- [ICML] 面向离散图扩散模型的异常值感知后训练量化
- [ICML] BlockDialect:面向节能LLM推理的按块细粒度混合格式量化
- [ICML] GPTAQ:采用非对称校准的高效免微调量化 [代码]
- [ICML] 使用FP4量化优化大型语言模型训练
- [ICML] SKIM:任何比特量化,突破后训练量化的极限
- [ICML] SageAttention2:高效注意力机制,彻底平滑异常值并采用线程级INT4量化 [代码]
- [AAAI] 以粒度思考:通过引人入胜的多粒度线索实现图像超分辨率的动态量化 [代码]
- [AAAI] D2-DPM:面向量化扩散概率模型的双重去噪 [代码]
- [CVPR] 无痛量化
- [CVPR] APHQ-ViT:基于平均扰动海森矩阵重构的视觉Transformer后训练量化 [代码]
- [ICLR] SynQ:通过合成感知微调实现精准零样本量化 [代码]








































2024年
- [ICML] BiLLM:推动大语言模型后训练量化极限 [代码]
- [ICML] 通过联合稀疏化与量化压缩大型语言模型
- [NeurIPS] BiDM:推动扩散模型量化极限
- [ACL Findings] DB-LLM:高效大语言模型的精确双二值化
- [NeurIPS] 用于图像超分辨率的二值化扩散模型 [代码]
- [NeurIPS] 2DQuant:面向图像超分辨率的低比特后训练量化 [代码]
- [ICML] 基于信息保留的大语言模型LoRA微调量化 [代码]
- [ICML] 面向图像超分辨率的灵活残差二值化
- [AAAI] Agile-Quant:激活引导量化,加速边缘端大语言模型推理
- [AAAI] AQ-DETR:具有辅助查询的低比特量化检测Transformer
- [AAAI] Bi-ViT:推动视觉Transformer量化极限
- [AAAI] 从全面研究到低秩补偿:探索大语言模型的后训练量化
- [AAAI] 再次提升RepVGG性能:一种量化感知方法
- [AAAI] MetaMix:面向混合精度激活量化的元状态精度搜索器
- [AAAI] 范数调整:高性能低比特量化大型语言模型
- [AAAI] OWQ:面向高效微调与推理的异常值感知权重量化大型语言模型
- [AAAI] PTMQ:神经网络的后训练多比特量化
- [AAAI] 鲁棒性引导的数据无依赖量化图像合成
- [AAAI] 大型语言模型量化为何困难?基于扰动视角的实证研究
- [ACL] 通过直接偏好对齐提升量化大语言模型的对话能力
- [ACM MM] 基于预热的量化感知尺度学习推进多模态大语言模型
- [CVPR] 通过伪标签过滤实现数据无依赖量化
- [CVPR] 通过对比学习提升后训练量化校准
- [CVPR] 视觉Transformer的实例感知分组量化
- [CVPR] 面向资源受限异构设备的联邦学习混合精度量化
- [CVPR] PTQ4SAM:Segment Anything的后训练量化
- [CVPR] Reg-PTQ:面向全量化目标检测器的回归专用后训练量化
- [CVPR] 无需重训的模型量化:一次性权重耦合学习
- [CVPR] TFMQ-DM:扩散模型的时间特征保持量化
- [CVPR] 向更准确的扩散模型后训练量化迈进
- [ECCV] AdaLog:带有自适应对数量化器的视觉Transformer后训练量化
- [ECCV] CLAMP-ViT:对比式数据无依赖学习,用于ViT的自适应后训练量化
- [ECCV] 量化扩散模型的内存高效微调
- [ECCV] MetaAug:面向后训练量化的元数据增强
- [ECCV] MixDQ:内存高效的几步文本到图像扩散模型,采用度量解耦的混合精度量化
- [ECCV] 文本到图像扩散模型的渐进式校准与激活放松后训练量化
- [ECCV] PQ-SAM:Segment Anything模型的后训练量化
- [ECCV] 量化扩散模型的时间步长感知修正
- [ECCV] 向稳健的超分辨率网络全低比特量化迈进
- [EMNLP] ApiQ:2比特量化大型语言模型的微调
- [EMNLP] 在注意力层前添加sink可缓解大型语言模型量化中的激活异常值
- [EMNLP] VPTQ:极端低比特的大型语言模型向量后训练量化
- [ICLR] AffineQuant:大型语言模型的仿射变换量化 [代码]
- [ICLR] EfficientDM:低比特扩散模型的高效量化感知微调
- [ICLR] LiDAR-PTQ:点云三维目标检测的后训练量化
- [ICLR] LoftQ:面向大型语言模型的LoRA微调感知量化 [代码]
- [ICLR] LUT-GEMM:基于查找表的量化矩阵乘法,用于大规模生成式语言模型的高效推理
- [ICLR] OmniQuant:全方位校准的大型语言模型量化 [代码]
- [ICLR] PB-LLM:部分二值化大型语言模型 [代码]
- [ICLR] QA-LoRA:面向大型语言模型的量化感知低秩适配 [代码]
- [ICLR] QLLM:大型语言模型的精准高效低比特量化
- [ICLR] 重新思考通道维度以隔离异常值,用于大型语言模型的低比特权重量化
- [ICLR] SpQR:近无损LLM权重压缩的稀疏量化表示 [代码]
- [ICML] A2Q+:改进累积器感知权重量化
- [ICML] BiE:大型语言模型量化的双指数块浮点数
- [ICML] ERQ:视觉Transformer后训练量化的误差降低
- [ICML] 量化大型语言模型的评估
- [ICML] 通过加性量化实现大型语言模型的极致压缩
- [ICML] FrameQuant:面向Transformer的灵活低比特量化
- [ICML] KIVI:无需调优的KV缓存非对称2比特量化 [代码]
- [ICML] LQER:面向LLM的低秩量化误差重构
- [ICML] 异常值感知切片用于视觉Transformer的后训练量化
- [ICML] 锐度感知数据生成用于零样本量化
- [ICML] SqueezeLLM:密集与稀疏量化 [代码]
- [MLSys] AWQ:面向设备端LLM压缩与加速的激活感知权重量化 [代码]
- [NeurIPS] BitsFusion:扩散模型的1.99比特权重量化
- [NeurIPS] DuQuant:通过双重变换分散异常值,打造更强的量化LLM
- [NeurIPS] KV缓存每通道1比特:耦合量化实现高效大语言模型推理
- [NeurIPS] KVQuant:迈向KV缓存量化下1000万上下文长度的LLM推理
- [NeurIPS] PTQ4DiT:扩散Transformer的后训练量化
- [NeurIPS] Q-VLM:大型视觉-语言模型的后训练量化
- [NeurIPS] QBB:面向LLM的二进制基量化
- [NeurIPS] ZipCache:精准高效的KV缓存量化,结合显著token识别
- [ACL Findings] 大型语言模型量化策略的全面评估
- [ACL Findings] AFPQ:面向LLM的非对称浮点量化 [代码]
- [ACL Findings] LLM-QAT:面向大型语言模型的数据无依赖量化感知训练
- [EMNLP Findings] ATQ:激活转换用于LLM的权重-激活量化
- [EMNLP Findings] 微调旋转后的无异常值LLM,以实现有效的权重-激活量化
- [EMNLP Findings] 量化如何影响多语言LLM?
- [EMNLP Findings] MobileQuant:面向设备端语言模型的移动友好量化
- [EMNLP Findings] QEFT:面向LLM高效微调的量化
- [EMNLP Industry] LLMC:使用多功能压缩工具包基准测试大型语言模型量化
- [arXiv] APTQ:面向大型语言模型的注意力感知后训练混合精度量化
- [arXiv] EasyQuant:一种高效的LLM数据无依赖量化算法
- [arXiv] EdgeQAT:熵与分布引导的量化感知训练,用于加速边缘端轻量级LLM [代码]
- [arXiv] FlattenQuant:通过逐张量量化突破大型语言模型的推理计算瓶颈
- [arXiv] GPTVQ:维度优势助力LLM量化 [代码]
- [arXiv] IntactKV:通过保留枢轴token提升大型语言模型量化
- [arXiv] OneBit:迈向极低比特大型语言模型
- [arXiv] QuaRot:旋转后的LLM实现无异常值的4比特推理 [代码]
- [arXiv] RepQuant:通过规模再参数化迈向大型Transformer模型的精准后训练量化
- [SIGMOD] RaBitQ:为近似最近邻搜索提供理论误差上限的高维向量量化 [代码]
- [AAAI] 一步向前,一步回溯:克服损失感知量化训练中的锯齿状波动
- [ICML] 向学生学习:应用t分布探索LLM的精准高效格式 [代码]
- [ICML] Jetfire:采用INT8数据流和逐块量化,实现高效精准的Transformer预训练
- [ICML] RAOQ:重塑与适配用于输出量化,面向内存计算系统的量化感知训练
- [ICML] QuIP#:借助哈达玛不相干性和格码本,实现更优秀的LLM量化 [代码]
- [NeurIPS] 向超大规模Transformer的下一代后训练量化迈进 [代码]
- [NeurIPS] MagR:通过减少权重幅度提升后训练量化效果 [代码]
- [NeurIPS] 探索LLM量化
- [NeurIPS] 面向多个LoRA适配器的高效多任务LLM量化与服务
- [NeurIPS] QTIP:基于网格与不相干性处理的量化 [代码]
- [NeurIPS] 将CNN泛化至图结构,采用可学习的邻域量化 [代码]
- [NeurIPS] SDP4Bit:迈向LLM训练中分片数据并行下的4比特通信量化 [代码]
- [NeurIPS] 最优与近似的自适应随机量化 [代码]
- [NeurIPS] 点睛之笔:大型语言模型中的参数异质性与量化
- [NeurIPS] StepbaQ:作为修正措施,量化扩散模型的退步操作


























2023年
- [ICML] BiBench:网络二值化的基准测试与分析 [代码]
- [IJCV] 面向准确二值神经网络的分布敏感信息保留
- [NeurIPS] BiMatting:通过二值化实现高效的视频抠图 [代码]
- [NeurIPS] QuantSR:用于高效图像超分辨率的高精度低比特量化 [代码]
- [TPAMI] 多样化样本生成:突破无数据量化生成能力的极限 [代码]
- [TNNLS] BiFSMNv2:将用于关键词检测的二值神经网络性能提升至真实网络水平 [代码]
- [AAAI] 基于深度-宽度重塑的快速且精确的二值神经网络
- [AAAI] OMPQ:正交混合精度量化
- [AAAI] 用于网络量化的量化特征蒸馏
- [AAAI] 鲁棒二值神经网络
- [AAAI] 将无数据量化重新思考为零和博弈
- [ACL] 利用适合GPU的稀疏性和量化技术提升基于Transformer的语言模型
- [ACL] PreQuant:一种适用于预训练语言模型的任务无关量化方法
- [CVPR] ABCD:任意位系数去量化
- [CVPR] 自适应无数据量化
- [CVPR] 减比特:限制瞬时锐度以改进训练后量化
- [CVPR] 利用适合GPU的稀疏性和量化技术提升视觉Transformer
- [CVPR] GENIE:为量化提供数据 [代码]
- [CVPR] 硬样本在零样本量化中至关重要
- [CVPR] NIPQ:基于噪声代理的集成伪量化
- [CVPR] NoisyQuant:面向视觉Transformer的噪声增强型训练后激活量化
- [CVPR] 混合精度量化的单次模型
- [CVPR] PD-Quant:基于预测差异指标的训练后量化 [代码]
- [CVPR] 扩散模型上的训练后量化 [代码]
- [CVPR] Q-DETR:一种高效的低比特量化检测Transformer [代码]
- [CVPR] 正则化向量量化用于标记化图像合成
- [CVPR] 从理论角度解决训练后量化中的振荡问题 [代码]
- [CVPR] 朝着图像超分辨率的准确训练后量化迈进
- [EMNLP] LLM-FP4:4位浮点数量化Transformer [代码]
- [EMNLP] 异常值抑制+:通过等效且最优的移位和缩放实现大型语言模型的准确量化
- [EMNLP] 重新审视基于块的量化:对于低于8比特的LLM推理,什么才是关键?
- [EMNLP] 利用量化解码为LLM添加水印 [代码]
- [EMNLP] 预训练语言模型的零样本锐度感知量化
- [ICCV] A2Q:具有保证溢出避免功能的累加器感知量化
- [ICCV] BiViT:极度压缩的二值视觉Transformer
- [ICCV] Causal-DFQ:因果导向的无数据网络量化 [代码]
- [ICCV] DenseShift:迈向准确且高效的低比特二的幂次量化
- [ICCV] EMQ:用于自动混合精度量化的不断进化训练无依赖代理
- [ICCV] EQ-Net:弹性量化神经网络 [代码]
- [ICCV] 估计器与均衡视角相遇:用于二值神经网络训练的修正直通估计器 [代码]
- [ICCV] I-ViT:仅整数量化以实现高效的视觉Transformer推理 [代码]
- [ICCV] 跨越局部极小值:视觉Transformer损失景观中的量化
- [ICCV] 克服量化感知训练中的遗忘灾难
- [ICCV] Q-diffusion:量化扩散模型 [代码]
- [ICCV] QD-BEV:面向多视角3D目标检测的视图引导式量化感知蒸馏
- [ICCV] RepQ-ViT:用于视觉Transformer训练后量化的尺度重参数化 [代码]
- [ICCV] 统一的无数据压缩:无需微调的剪枝和量化
- [ICLR] 模拟比特:利用自条件扩散模型生成离散数据
- [ICLR] GPTQ:面向生成式预训练Transformer的准确训练后量化 [代码]
- [ICML] 少比特反向:用于减少内存占用的激活函数量化梯度 [代码]
- [ICML] FlexRound:基于逐元素除法的可学习四舍五入,用于训练后量化 [代码]
- [ICML] GPT-Zip:对微调后的大型语言模型进行深度压缩
- [ICML] 无振荡量化:面向低比特视觉Transformer
- [ICML] QIGen:为大型语言模型的量化推理生成高效内核 [代码]
- [ICML] 具有收敛保证的大规模模型量化分布式训练
- [ICML] SmoothQuant:面向大型语言模型的准确且高效的训练后量化 [代码]
- [ICML] 支持4位精度的理由:k位推理缩放法则
- [ICML] 理解面向语言模型的INT4量化:延迟加速、可组合性及失败案例
- [ICML] 理解面向Transformer模型的INT4量化:延迟加速、可组合性及失败案例 [代码]
- [NeurIPS] 二值化光谱压缩成像 [代码]
- [NeurIPS] 通过低于4比特的整数量化实现压缩大型语言模型的内存高效微调
- [NeurIPS] PackQViT:通过移动端上的完整和打包量化,加速低于8比特的视觉Transformer
- [NeurIPS] PTQD:面向扩散模型的准确训练后量化 [代码]
- [NeurIPS] Q-DM:一种高效的低比特量化扩散模型
- [NeurIPS] QLoRA:面向量化LLM的高效微调 [代码]
- [NeurIPS] QuIP:带有保证的大型语言模型2比特量化 [代码]
- [NeurIPS] 面向扩散模型的时序动态量化
- [NeurIPS] TexQ:通过纹理特征分布校准实现零样本网络量化
- [NeurIPS] 使用前向和后向近似量化器理解神经网络二值化
- [TIP] MBFQuant:一种针对移动CNN应用的乘法位宽固定、混合精度量化方法
- [TPAMI] 基于优化的训练后量化:采用比特拆分与拼接
- [TPAMI] 单路径比特共享:自动实现损失感知的模型压缩
- [arXiv] Atom:面向高效且准确LLM服务的低比特量化 [代码]
- [arXiv] 使用FP8格式的高效训练后量化 [代码]
- [arXiv] QFT:以经济实惠的资源实现LLM的全参数量化
- [arXiv] QMoE:面向万亿参数模型的实用低于1比特压缩
- [arXiv] RPTQ:基于重新排序的大型语言模型训练后量化 [代码]
- [arXiv] ZeroQuant-HERO:面向W8A8 Transformer的硬件增强型鲁棒优化训练后量化框架
- [AAAI] 量化感知区间传播:用于训练可认证鲁棒量化神经网络 [代码]
- [ICLR] PowerQuant:非均匀量化中的自同构搜索
- [ICLR] 块与子词缩放浮点数(BSFP):一种面向低精度推理的高效非均匀量化
- [NeurIPS] REx:无数据残差量化误差扩展
- [NeurIPS] 大规模量化中的有趣特性
- [NeurIPS] 用4位整数训练Transformer [代码]
- [NeurIPS] 通过完全量化迈向高效且准确的Winograd卷积
- [NeurIPS] 剪枝 vs 量化:哪个更好? [代码]
- [ICLR] A^2Q:面向图神经网络的聚合感知量化































2022年
- [ICLR] BiBERT: 精确的全二值化BERT。代码
- [IJCAI] BiFSMN: 用于关键词检测的二值神经网络 [代码]
- [ACM MM] 面向视觉Transformer的高精度训练后量化
- [ACL] 通过量化压缩生成式预训练语言模型
- [ACM Trans. Des. Autom. Electron. Syst.] 针对深度神经网络的结构化动态精度量化
- [ASE] QVIP: 一种基于整数线性规划的量化神经网络形式化验证方法
- [Applied Soft Computing] 基于知识蒸馏和参数量化的一种轴承故障诊断神经网络压缩方法
- [CCF Transactions on High Performance Computing] 面向图神经网络的高效分段量化
- [CVPR] 一种内存占用极低的量化神经网络,用于超稀疏飞行时间深度图的深度补全
- [CVPR] BppAttack: 基于图像量化和对比对抗学习的隐蔽高效后门攻击 [代码]
- [CVPR] 基于参数化非均匀混合精度量化的无数据网络压缩
- [CVPR] 实例感知的动态神经网络量化
- [CVPR] IntraQ: 学习类内异质性的合成图像,用于零样本网络量化 [代码]
- [CVPR] 全在教师身上:让零样本量化更接近教师 [代码]
- [CVPR] 神经网络量化中的可学习查找表 [代码]
- [CVPR] Mr.BiQ: 基于最小化重建误差的训练后非均匀量化
- [CVPR] 非均匀到均匀量化:通过广义直通估计实现精确量化 [代码]
- [CVPR] RecDis-SNN: 修正膜电位分布,以直接训练脉冲神经网络
- [CVPR] 模拟量化,真正节省功耗
- [EANN] 一种鲁棒的光子神经网络量化感知训练方法
- [ECCV] BASQ: 面向4比特以下神经网络的分支级激活裁剪搜索量化 [代码]
- [ECCV] 基于学习的逐层重要性进行混合精度神经网络量化 [代码]
- [ECCV] 用于训练脉冲神经网络的神经形态数据增强。[代码]
- [ECCV] 非均匀步长量化,用于精确的训练后量化
- [ECCV] 面向视觉Transformer的补丁相似性感知无数据量化 [代码]
- [ECCV] PTQ4ViT: 面向视觉Transformer的双均匀量化训练后量化 [代码]
- [ECCV] RDO-Q: 基于率失真优化的极细粒度通道级量化
- [ECCV] 对称性正则化和饱和非线性,用于鲁棒量化
- [ECCV] 通过等效平滑正则化实现精确的网络量化
- [ECCV] 固定权重网络。[代码]
- [ESE] DiverGet: 一种基于搜索的软件测试方法,用于评估深度神经网络量化
- [Electronics] 关于高效卷积神经网络及其硬件加速的综述
- [FPGA] FILM-QNN: 基于层内混合精度量化的高效FPGA加速深度神经网络
- [ICCRD] 神经网络训练后的量化
- [ICLR] 基于块状量化的8位优化器 [代码]
- [ICLR] F8Net: 仅使用定点8位乘法进行网络量化
- [ICLR] 信息瓶颈:对(量化)神经网络的精确分析 [代码]
- [ICLR] 高精度、超低延迟脉冲神经网络的最佳ANN-SNN转换
- [ICLR] QDrop: 随机丢弃量化,实现极低比特的训练后量化 [代码]
- [ICLR] SQuant: 基于对角海森矩阵近似的即时无数据量化。代码
- [ICLR] 朝着高效的低精度训练迈进:数据格式优化和迟滞量化
- [ICLR] 过参数化 regime 下部分量化神经网络的VC维
- [ICML] 在深度神经网络中寻找任务最优的低比特子分布 [代码]
- [ICML] GACT: 针对通用网络架构的激活压缩训练 [代码]
- [ICML] 克服量化感知训练中的振荡 [代码]
- [ICML] SDQ: 混合精度的随机可微量化
- [ICPR] 分层无数据CNN压缩
- [IEEE Internet of Things Journal] FedQNN: 一种面向物联网的计算-通信效率高的联邦学习框架,采用低带宽神经网络量化
- [IJCAI] FQ-ViT: 全量化视觉Transformer的训练后量化 [代码]
- [IJCAI] MultiQuant: 一次训练即可实现神经网络的多比特量化
- [IJCAI] RAPQ: 挽救二的幂次低比特训练后量化的准确性 [代码]
- [IJCNN] 转置卷积基量化神经网络的准确度评估
- [IJCV] 面向精确二值神经网络的分布敏感信息保留
- [IJNS] 带有注意力机制的卷积神经网络量化
- [ITSM] 边缘—人工智能赋能的停车场监控,采用量化神经网络
- [Intelligent Automation & Soft Computing] 一种资源高效的卷积神经网络加速器,采用细粒度对数量化
- [LNAI] ECQ$^x$: 以解释性为导向的低比特和稀疏DNN量化
- [MICRO] ANT: 利用自适应数值类型进行低比特深度神经网络量化
- [NeurIPS] BiMLP: 面向视觉多层感知器的紧凑二值架构 [代码]
- [NeurIPS] BiT: 鲁棒的二值化多蒸馏Transformer [代码]
- [NeurIPS] ClimbQ: 类别不平衡量化,提升高效推理的鲁棒性
- [NeurIPS] 熵驱动的混合精度量化,用于深度网络设计
- [NeurIPS] FP8量化:指数的力量 [代码]
- [NeurIPS] 利用层间依赖关系进行训练后量化
- [NeurIPS] LLM.int8(): 大规模Transformer的8位矩阵乘法 [代码]
- [NeurIPS] 最优大脑压缩:一种用于精确训练后量化和剪枝的框架 [代码]
- [NeurIPS] Q-ViT: 精确且完全量化的小比特视觉Transformer [代码]
- [NeurIPS] 为AdderNet量化重新分配权重和激活
- [NeurIPS] 理论上更好、数值上更快的分布式优化,结合平滑感知量化技术
- [NeurIPS] 朝着高效训练后量化预训练语言模型的方向迈进
- [NeurIPS] ZeroQuant: 面向大规模Transformer的高效且经济的训练后量化 [代码]
- [Neural Networks] 低精度光子神经网络的量化感知训练
- [Neurocomputing] EPQuant: 一种基于产品量化的图神经网络压缩方法
- [Ocean Engineering] 基于神经网络的自适应滑模跟踪控制,用于输入量化和饱和的自主水面航行器
- [PPoPP] QGTC: 通过GPU张量核心加速量化图神经网络
- [TCCN] 用于无线干扰识别的低带宽卷积神经网络
- [TCSVT] 在FPGA上使用CLIP-Q量化实现高效的卷积神经网络
- [TGARS] 通过逐步激活量化加速基于卷积神经网络的高光谱图像分类
- [TODAES] 模拟内存中神经网络加速的动态量化范围控制
- [arXiv] 使用完全可微的量化混合精度神经网络进行边缘推理
- [arXiv] 使用AI模型效率工具包(AIMET)进行神经网络量化
- [arXiv] Q-ViT: 视觉Transformer的完全可微量化
- [arXiv] QONNX: 表示任意精度的量化神经网络
- [arXiv] Quantune: 使用极端梯度提升快速部署的卷积神经网络训练后量化
- [arXiv] SmoothQuant: 面向大型语言模型的精确高效训练后量化 [代码]
- [arXiv] 面向8位神经网络加速器的子8比特量化感知训练,支持设备端语音识别
- [tinyML Research Symposium] 二的幂次量化,适用于低比特且符合硬件要求的神经网络
- [ECCV] CADyQ: 面向图像超分辨率的内容感知动态量化
- [ECCV] 基于比特宽度自适应的量化感知神经网络训练:一种元学习方法 [代码]
- [ECCV] 细粒度数据分布对齐,用于训练后量化 [代码]
- [ICML] 最佳裁剪和幅度感知微分,以改善量化感知训练

























2021年
- [CVPR] 用于精确无数据量化的小样本多样性生成
- [ICLR] BiPointNet:面向点云的二值神经网络 [代码]
- [ICML] Adam优化器与训练策略如何助力二值神经网络优化? [代码]
- [AAAI] 通过堆叠低维二值卷积滤波器压缩深度卷积神经网络
- [AAAI] 面向CNN训练的分布自适应INT8量化
- [AAAI] FracBits:基于分数比特宽度的混合精度量化
- [AAAI] 基于二值嵌入和三值系数的内存与计算高效核SVM
- [AAAI] OPQ:通过一次性剪枝-量化压缩深度神经网络
- [AAAI] 针对高效混合精度激活量化的信息论基比特瓶颈优化
- [AAAI] 多点后训练量化:无需混合精度的混合精度
- [AAAI] 可扩展的量化神经网络验证 [代码]
- [AAAI] 随机精度集成:面向量化深度神经网络的自知识蒸馏
- [AAAI] TRQ:带有残差量化的三值神经网络
- [AAAI] 通过凸神经网络自助法进行CNN中的不确定性量化
- [AAAI] 面向数据流的向量量化贝叶斯神经网络推断
- [ACL] 关于Transformer中注意力值的分布、稀疏性及推理时量化
- [ACM MM] 全量化图像超分辨率网络 [代码]
- [ACM MM] VQMG:用于显式表征学习的分层向量量化与多跳图推理
- [CVPR] 二值图神经网络 [代码]
- [CVPR] 用于高精度低比特神经网络的可学习压缩量化
- [CVPR] 基于逐元素梯度缩放的网络量化 [代码]
- [CVPR] 置换、量化与微调:高效的神经网络压缩 [代码]
- [CVPR] PokeBNN:追求轻量级精度的二值网络 [代码]
- [CVPR] S2-bnn:通过引导式分布校准弥合自监督真实网络与1比特网络之间的差距 [代码]
- [CVPR] 零样本对抗量化 [代码]
- [ECCV] PAMS:基于参数化最大尺度的量化超分辨率 [代码]
- [ICCV] MixMix:实现无数据压缩只需特征与数据混合
- [ICLR] BRECQ:通过块重建突破后训练量化极限 [代码]
- [ICLR] BSQ:探索位级稀疏性以实现混合精度神经网络量化 [代码]
- [ICLR] Degree-Quant:面向图神经网络的量化感知训练
- [ICLR] 高容量专家二值网络 [代码]
- [ICLR] 基于深度嵌入空间中向量量化的增量式小样本学习
- [ICLR] 多奖彩票假说:通过修剪随机加权网络寻找高精度二值神经网络 [代码]
- [ICLR] 神经网络梯度接近对数正态分布:改进量化与稀疏训练
- [ICLR] 使用二值神经网络降低深度生成模型的计算成本
- [ICLR] 简单增强大有裨益:用于DNN量化的ADRL
- [ICLR] 稀疏量化谱聚类
- [ICLR] 带有量化噪声的训练以实现极端模型压缩 [代码]
- [ICLR] WrapNet:采用超低分辨率算术的神经网络推断
- [ICML] ActNN:通过2比特激活压缩训练降低训练内存占用 [代码]
- [ICML] Auto-NBA:在网络、比特宽度与加速器联合空间中高效且有效地搜索 [代码]
- [ICML] 混合精度与自适应分辨率的可微动态量化
- [ICML] HAWQ-V3:二进制神经网络量化 [代码]
- [ICML] I-BERT:纯整数BERT量化 [代码]
- [NeurIPS] 胜利之手:压缩深度网络可提升分布外鲁棒性 [代码]
- [NeurIPS] 生成模型的散度边界:样本复杂度、量化效应与边界积分
- [NeurIPS] 视觉Transformer的后训练量化
- [NeurIPS] 后训练稀疏感知量化 [代码]
- [NeurIPS] Qimera:利用合成边界支持样本实现无数据量化 [代码]
- [NeurIPS] Qu-ANTI-zation:利用量化伪影达成对抗性结果
- [NeurIPS] VQ-GNN:一种使用向量量化扩展图神经网络的通用框架
- [arXiv] 面向高效神经网络推断的量化方法综述
- [arXiv] 神经网络量化白皮书
- [arXiv] 任意精度深度神经网络 [代码]
- [arXiv] ReCU:复活二值神经网络中的死亡权重 [代码]
- [AAAI] 不使用批归一化训练二值神经网络用于图像超分辨率
- [AAAI] SA-BNN:状态感知二值神经网络
- [CVPR] 低成本深度神经网络的自动化对数尺度量化
- [CVPR] QPP:深度神经网络的实时量化参数预测
- [ICLR] 改善后训练神经网络量化:逐层校准与整数规划 [代码]
- [ICML] 使用小型校准集实现精确的后训练量化
- [NeurIPS] BatchQuant:具有稳健量化器的全量化解析架构搜索

























2020年
- [CVPR] 用于精确二值神经网络的前向与后向信息保留 [代码]
- [PR] 二值神经网络:综述
- [AAAI] HLHLp:为在损失曲面上达到平坦极小值而训练的量化神经网络
- [AAAI] Q-BERT:基于海森矩阵的 BERT 超低精度量化
- [AAAI] 引入稀疏性的二值化神经网络
- [AAAI] 基于多阶段自适应的高精度低比特量化
- [ACL] 用于文本分类的端到端二值化神经网络
- [COOL CHIPS] 面向二值神经网络的新型 DRAM 内加速器架构
- [CVPR] APQ:网络架构、剪枝与量化策略的联合搜索 [代码]
- [CVPR] BiDet:一种高效的二值化目标检测器。[代码]
- [CVPR] 定点反向传播训练
- [CVPR] GhostNet:以低成本操作获得更多特征
- [CVPR] 低比特量化需要良好的分布
- [CVPR] 旋转一致性间隔损失用于高效低比特人脸识别
- [arXiv] 使用贝叶斯学习规则训练二值神经网络
- [DATE] BNNsplit:面向嵌入式分布式 FPGA 计算系统的二值神经网络
- [DATE] OrthrusPE:面向二值神经网络的运行时可重构处理单元
- [DATE] PhoneBit:面向手机的高效 GPU 加速二值神经网络推理引擎
- [ECCV] BATS:二值架构搜索
- [ECCV] 针对硬件效率的可微分联合剪枝与量化
- [ECCV] 生成式无数据低比特量化 [代码]
- [ECCV] 用于二值网络的学习架构 [代码]
- [ECCV] PROFIT:一种针对 4 比特以下 MobileNet 模型的新型训练方法
- [ECCV] ProxyBNN:通过代理矩阵学习二值神经网络
- [ECCV] ReActNet:具有广义激活函数的高精度二值神经网络 [代码]
- [EMNLP] 用于机器翻译的全量化 Transformer
- [EMNLP] TernaryBERT:蒸馏感知的超低比特 BERT [代码]
- [ICASSP] 带门控残差的平衡二值神经网络
- [ICET] 一种节能的袋装二值神经网络加速器
- [ICLR] BinaryDuo:通过耦合二值激活减少二值激活网络中的梯度不匹配 [代码]
- [ICLR] DMS:二值神经网络的可微维度搜索
- [ICLR] 学习步长量化
- [ICLR] 混合精度 DNN:你所需要的只是一个好的参数化 [代码]
- [ICLR] 使用实数到二进制卷积训练二值神经网络
- [ICML] 利用各向异性向量量化加速大规模推理
- [ICML] LSQ+:通过可学习偏移和更好的初始化改进低比特量化
- [ICML] 通过带噪声监督的学习训练二值神经网络
- [ICML] 向上还是向下?训练后量化中的自适应四舍五入
- [IEEE Access] 一种节能且高吞吐的内存内计算位单元,具有出色的工艺变异鲁棒性,适用于二值神经网络
- [IEEE TCS.I] IMAC:在 6T SRAM 阵列中实现内存内多比特乘累加
- [IEEE TCS.II] 一种资源高效的二值卷积神经网络推理加速器
- [IEEE Trans. Electron Devices] 基于二值忆阻器的高鲁棒性 BNN 推理加速器设计
- [IEEE Trans. Magn] SIMBA:一种基于斯格明子的内存内二值神经网络加速器
- [IJCAI] CP-NAS:面向二值神经网络的父子架构搜索
- [IJCAI] 直接量化用于训练高精度低比特深度神经网络
- [IJCAI] 全嵌套神经网络用于自适应压缩与量化
- [IJCAI] 溢出感知量化:通过低比特乘累加操作加速神经网络推理
- [IJCAI] 软阈值三值网络
- [IJCAI] 朝着 Transformer 模型的完全 8 位整数推理迈进
- [IJCV] 面向高效目标识别的二值化神经架构搜索
- [ISCAS] MuBiNN:用于 EEG 信号分类的多级二值递归神经网络
- [ISQED] BNN 剪枝:基于权重翻转频率指导的二值神经网络剪枝 [代码]
- [MICRO] GOBO:为低延迟和节能推理量化基于注意力的 NLP 模型
- [MLST] 使用 HLS4ML 将 FPGA 上的深度神经网络压缩至二值和三值精度
- [NN] 使用完整的 8 位整数训练高性能和大规模深度神经网络
- [NeurIPS] 数据并行 SGD 的自适应梯度量化 [代码]
- [NeurIPS] 贝叶斯比特:统一量化与剪枝
- [NeurIPS] 缩小去量化差距:PixelCNN 作为单层流 [代码]
- [NeurIPS] 高效精确地验证二值神经网络 [代码]
- [NeurIPS] FleXOR:可训练的分数量化
- [NeurIPS] HAWQ-V2:海森矩阵感知的迹加权神经网络量化
- [NeurIPS] 随机二值网络的路径样本分析梯度估计器 [代码]
- [NeurIPS] 基于位置的缩放梯度用于模型量化和剪枝 [代码]
- [NeurIPS] 鲁棒量化:一个模型统治一切
- [NeurIPS] 旋转二值神经网络 [代码]
- [NeurIPS] 在量化神经网络中寻找低比特权重 [代码]
- [NeurIPS] 普遍量化的神经压缩
- [Neurocomputing] 基于权重二值化级联卷积神经网络的眼部定位
- [PR Letters] 控制二值神经网络的信息容量
- [SysML] Riptide:快速端到端二值神经网络 [代码]
- [TPAMI] 通过并行剪枝-量化压缩深度神经网络
- [TPAMI] 面向资源有限情况下的地标定位的层次化二值 CNN [代码]
- [TPAMI] 朝着高效 U-Net 迈进:一种耦合与量化的方法
- [TVLSI] Phoenix:一种面向卷积神经网络的低精度浮点量化导向架构
- [WACV] MoBiNet:一款用于图像分类的移动二值网络
- [arXiv] 通过 Turing GPU 中的位张量核心加速二值神经网络 [代码]
- [arXiv] 二值图神经网络
- [arXiv] BinaryBERT:突破 BERT 量化极限 [代码]
- [arXiv] 蒸馏引导的二值卷积神经网络残差学习
- [arXiv] 批量归一化如何帮助二值训练?
- [arXiv] MeliusNet:二值神经网络能否达到 MobileNet 级别的精度?[代码]
- [arXiv] RPR:用于训练的随机分区松弛;二值和三值权重神经网络
- [arXiv] 通过量化噪声进行极端模型压缩的训练 [代码]
- [arXiv] 通过信息瓶颈理解二值神经网络的学习动力学
- [论文] 采用分段逼近实现无损二值卷积神经网络
- [CVPR] ZeroQ:一种新型零样本量化框架 [代码]
- [CVPR] AdaBits:具有自适应比特宽度的神经网络量化 [代码]
- [CVPR] 多比特网络的自适应损失感知量化 [代码]
- [ECCV] HMQ:面向 CNN 的硬件友好型混合精度量化模块 [代码]























2019年
- [AAAI] 具有二值权重和低比特激活的神经网络高效量化
- [AAAI] 基于离散反向传播的1位CNN的投影卷积神经网络
- [APCCAS] 利用神经进化二值神经网络求解强化学习环境 [代码]
- [BMVC] 带有训练后二值化的精确且紧凑的卷积神经网络
- [BMVC] XNOR-Net++:改进的二值神经网络
- [CVPR] 用于简化二值神经网络的主辅网络框架
- [CVPR] 二值集成神经网络:每个网络更多位,还是每比特更多网络?
- [CVPR] 循环二值卷积网络:通过循环反向传播提升1位DCNN性能
- [CVPR] 用于目标检测的全量化网络
- [CVPR] HAQ:具有混合精度的硬件感知自动化量化 [代码]
- [CVPR] 学习二值卷积神经网络中的通道间交互
- [CVPR] 通过优化量化区间并结合任务损失来学习深度网络的量化方法
- [CVPR] 量化网络 [代码]
- [CVPR] 正则化激活分布以训练二值化深度网络
- [CVPR] SeerNet:通过低比特量化预测卷积神经网络特征图稀疏性
- [CVPR] 用于准确图像分类和语义分割的结构化二值神经网络
- [arXiv] 回归简单:如何从头开始训练精确的BNN? [代码]
- [arXiv] 二值化神经架构搜索
- [arXiv] 改进的人体姿态估计和图像识别中二值网络的训练方法
- [arXiv] 用于训练二值神经网络的矩阵与张量分解
- [arXiv] RBCN:整流二值卷积网络,用于提升1位DCNN性能
- [arXiv] TentacleNet:用于精确二值卷积神经网络的伪集成模板
- [FPGA] 向FPGA上快速且节能的二值化神经网络推理迈进
- [GLSVLSI] 用于FPGA中目标跟踪的二值化深度可分离神经网络
- [ICCV] 贝叶斯优化的1位CNN
- [ICCV] 无数据量化:通过权重均衡和偏置校正实现 [代码]
- [ICCV] 可微软量化:连接全精度与低比特神经网络
- [ICCV] DSConv:高效的卷积算子
- [ICCV] HAWQ:混合精度下基于海森矩阵的神经网络量化
- [ICCV] 寻找精确的二值神经架构
- [ICIP] 从零开始训练精确的二值神经网络 [代码]
- [ICLR] 二值神经网络优化的实证研究
- [ICLR] ProxQuant:基于近端算子的量化神经网络 [代码]
- [ICML] Transformer神经机器翻译模型的高效8位量化
- [ICUS] 平衡的循环二值卷积网络
- [IEEE J. Emerg. Sel. Topics Circuits Syst.] Hyperdrive:多芯片、可流水线扩展的二值权重CNN推理引擎
- [IEEE J. Solid-State Circuits] 一种面向二值及三值权重神经网络、具有灵活数据位宽的节能可重构处理器
- [IEEE JETC] Eyeriss v2:一款适用于移动设备上新兴深度神经网络的灵活加速器
- [IEEE TCS.I] 递归式二值神经网络训练模型,以高效利用片上内存
- [IEEE TCS.I] Xcel-RAM:在高吞吐SRAM计算阵列中加速二值神经网络
- [IJCAI] 带有蒸馏图卷积网络的二值协同过滤
- [IJCAI] 用于资源高效哈希且最小化量化损失的二值神经网络
- [ISOCC] 双路径二值神经网络
- [MDPI Electronics] 二值神经网络综述
- [NeurIPS] 全量化Transformer以提升翻译效果
- [NeurIPS] 隐含权重不存在:重新思考二值神经网络优化 [代码]
- [NeurIPS] MetaQuant:通过学习穿透不可微量化来掌握量化技巧 [代码]
- [NeurIPS] 带有对抗鲁棒性的模型压缩:统一的优化框架
- [NeurIPS] 归一化有助于量化LSTM的训练
- [NeurIPS] Q8BERT:量化后的8位BERT
- [NeurIPS] 正则化二值网络训练
- [RoEduNet] PXNOR:扰动式二值神经网络 [代码]
- [SiPS] 知识蒸馏用于优化量化深度神经网络
- [TMM] 使用二值深度神经网络进行紧凑哈希码学习
- [TMM] 深度二值重建用于跨模态哈希
- [VLSI-SoC] 一种利用电阻式存储器实现二值神经网络节能执行的产品引擎
- [arXiv] daBNN:一款适用于ARM设备的超快速二值神经网络推理框架 [代码]
- [arXiv] 通过可微神经架构搜索实现混合精度的卷积网络量化
- [arXiv] QKD:量化感知的知识蒸馏
- [arXiv] 自二值化网络
- [arXiv] 朝着卷积神经网络统一INT8训练的目标迈进
- [论文] BNN+:改进的二值网络训练









2018年
- [AAAI] 极低比特神经网络:利用ADMM榨取最后一滴性能 [代码]
- [AAAI] 从哈希到CNN:通过哈希训练二值权重网络
- [CAAI] 基于二值深度卷积神经网络的快速目标检测
- [CVPR] 使用低比特权重和激活的有效卷积神经网络训练
- [CVPR] 针对低比特深度神经网络的显式损失误差感知量化
- [CVPR] 调制卷积网络
- [CVPR] 用于高效仅整数运算推理的神经网络量化与训练
- [CVPR] SYQ:为高效深度神经网络学习对称量化 [代码]
- [CVPR] 向高效的低比特卷积神经网络迈进
- [CVPR] 低比特神经网络的两步量化
- [arXiv] BinaryRelax:一种用于训练量化权重深度神经网络的松弛方法
- [arXiv] LightNN:弥合传统深度神经网络与二值化网络之间的差距
- [ECCV] Bi-Real Net:通过提升表示能力和先进的训练算法增强1比特CNN性能 [代码]
- [ECCV] LQ-Nets:用于高精度、紧凑型深度神经网络的可学习量化 [代码]
- [ECCV] 量化模拟:迈向用于目标检测的超小型CNN
- [ECCV] TBN:具有三值输入和二值权重的卷积神经网络 [代码]
- [ECCV] 通过半二值分解训练二值权重网络
- [FCCM] ReBNet:残差二值化神经网络 [代码]
- [FPL] FBNA:全二值化神经网络加速器
- [ICLR] 量化模型分析
- [ICLR] Apprentice:利用知识蒸馏技术提升低精度网络精度
- [ICLR] 深度网络的损失感知权重量化 [代码]
- [ICLR] 通过蒸馏和量化进行模型压缩 [代码]
- [ICLR] PACT:量化神经网络的参数化裁剪激活
- [ICLR] WRPN:宽广的低精度网络
- [IEEE J. Solid-State Circuits] BRein Memory:单芯片二值/三值可重构片上深度神经网络加速器,在0.6W功耗下实现1.4 TOPS
- [IJCAI] 卷积神经网络的确定性二值滤波器
- [IJCAI] 利用学习到的二值神经网络转移模型在因子化状态和动作空间中进行规划
- [IJCNN] 简单动态二值神经网络的分析与实现
- [IPDPS] BitFlow:在CPU上利用向量并行性加速二值神经网络
- [MM] BitStream:用于在CPU上实时低功耗推理二值神经网络的高效计算架构
- [NCA] 基于FPGA的卷积神经网络加速器综述
- [NeurIPS] 神经网络8位训练的可扩展方法 [代码]
- [NeurIPS] 使用8位浮点数训练深度神经网络
- [Res Math Sci] 混合粗粒度梯度下降法,用于深度神经网络的完全量化
- [TCAD] XNOR神经引擎:用于21.6-fJ/op二值神经网络推理的硬件加速器IP
- [TRETS] FINN-R:一个端到端的深度学习框架,用于快速探索量化神经网络
- [TVLSI] 一种面向二值权重卷积神经网络的节能架构
- [arXiv] 联合神经架构搜索与量化 [代码]
- [arXiv] 从零开始训练具有竞争力的二值神经网络 [代码]








2017年
- [CVPR] 通过半波高斯量化实现低精度深度学习 [代码]
- [CVPR] 局部二值卷积神经网络 [代码]
- [arXiv] BMXNet:基于 MXNet 的开源二值神经网络实现 [代码]
- [FPGA] FINN:一种用于快速、可扩展的二值神经网络推理的框架
- [ICASSP] 具有自适应步长再训练的深度神经网络定点优化
- [ICCV] 面向资源受限场景的人体姿态估计与人脸对齐的二值卷积地标定位器 [代码]
- [ICCV] 基于高阶残差量化的性能保障型网络加速
- [ICLR] 渐进式网络量化:迈向使用低精度权重的无损 CNN [代码]
- [ICLR] 损失感知的深度网络二值化 [代码]
- [ICLR] 用于神经网络压缩的软权值共享
- [ICLR] 训练得到的三值量化 [代码]
- [IPDPSW] 基于片上存储的二值卷积深度神经网络,在 FPGA 上应用无批归一化技术
- [InterSpeech] 用于语音识别的二值深度神经网络
- [JETC] 一种超越 GPU 性能的 FPGA 加速器架构,适用于二值卷积神经网络
- [MWSCAS] 在 FPGA 上实现的深度学习二值神经网络
- [NeurIPS] 向精确的二值卷积神经网络迈进 [代码]
- [Neurocomputing] FP-BNN:在 FPGA 上实现的二值神经网络
- [arXiv] ShiftCNN:面向卷积神经网络推理的通用低精度架构 [代码]
- [arXiv] 具有细粒度量化的三值神经网络







2016年
- [CVPR] 用于移动设备的量化卷积神经网络。代码
- [arXiv] DoReFa-Net:使用低比特梯度训练低比特宽度卷积神经网络 [代码]
- [ECCV] XNOR-Net:使用二值卷积神经网络进行 ImageNet 分类 [代码]
- [ICASSP] 循环神经网络的定点性能分析
- [NeurIPS] 二值神经网络:在权重和激活值被约束为 +1 或 -1 的情况下训练深度神经网络 [代码]
- [NeurIPS] 三值权重网络 [代码]




2015年

相关仓库
星标历史

常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备