beads_viewer
beads_viewer 是一款专为 Beads 问题追踪器打造的终端界面工具,它让开发者能在命令行中高效浏览和管理复杂的项目依赖关系。面对大型代码库中错综复杂的任务依赖网,传统列表视图往往难以直观呈现关键路径或潜在循环,而 beads_viewer 通过图形感知技术,将抽象数据转化为可视化的看板、依赖有向无环图(DAG)及 PageRank 影响力分析,帮助用户快速定位瓶颈与核心任务。
这款工具特别适合习惯键盘操作的后端工程师、系统架构师及 DevOps 人员,尤其是那些需要在无图形界面服务器环境中工作,或追求极致操作效率的技术团队。其独特亮点在于“机器人模式”(Robot Mode),可通过 JSON API 直接与大模型代理集成,实现自动化任务分拣与分析;同时支持多种视图切换,如一键查看关键路径、检测依赖环路以及看板流视图。无论是日常任务梳理还是深度架构审查,beads_viewer 都能以轻量、快速且信息丰富的方式,提升问题追踪的清晰度与决策效率。
使用场景
某大型开源项目的技术负责人正在梳理积压的数百个功能请求与缺陷报告,试图制定下周的冲刺计划并识别阻碍发布的关键瓶颈。
没有 beads_viewer 时
- 依赖关系一团乱麻:面对复杂的任务依赖网,只能靠肉眼在电子表格中追踪,极易遗漏关键的阻塞项,导致开发中途卡壳。
- 优先级判断凭感觉:缺乏量化依据,难以区分哪些是真正影响全局的核心任务,往往陷入“谁声音大先做谁”的被动局面。
- 状态同步效率低下:需要频繁切换网页看板、代码库和文档来确认进度,无法在一个界面内获得项目全貌,上下文切换成本极高。
- 关键路径不清晰:无法直观看到从当前状态到最终发布的最长依赖链,导致资源分配分散,无法集中火力攻克阻碍发布的“拦路虎”。
使用 beads_viewer 后
- 依赖图谱一目了然:通过
g键 instantly 调出依赖 DAG 可视化视图,清晰展示任务间的上下游关系,瞬间定位所有潜在的循环依赖和断点。 - 科学决策优先级:利用内置的 PageRank 算法自动计算任务权重,精准识别出那些被最多其他任务依赖的“枢纽型”问题,确保优先解决高价值痛点。
- 终端内全景掌控:在分屏视图中同时查看任务列表、详细元数据和 Kanban 看板,无需离开终端即可完成从分析到规划的全流程,心流不被打断。
- 关键路径自动高亮:一键显示项目的关键路径(Critical Path),让团队明确知道哪些任务的延误会直接推迟整个版本发布,从而针对性地投入资源。
beads_viewer 将混乱的任务依赖转化为可视化的智能洞察,帮助团队从“盲目救火”转向“精准攻坚”,显著提升研发交付效率。
运行环境要求
- Linux
- macOS
- Windows
无 GPU 需求
未说明
快速开始
Beads 查看器 (bv)


![]()
优雅、键盘驱动的终端界面,专为 Beads 问题跟踪系统设计。
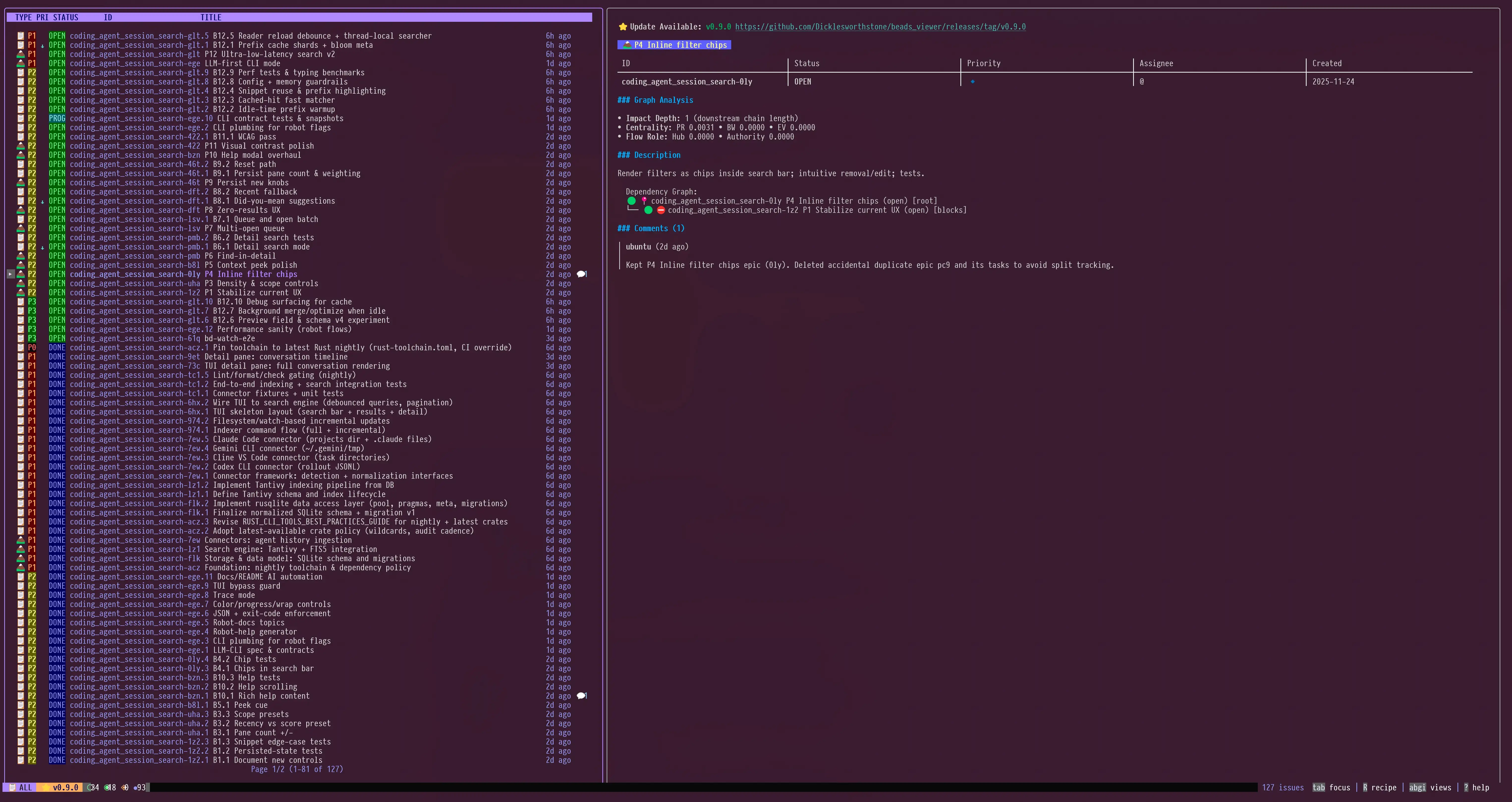
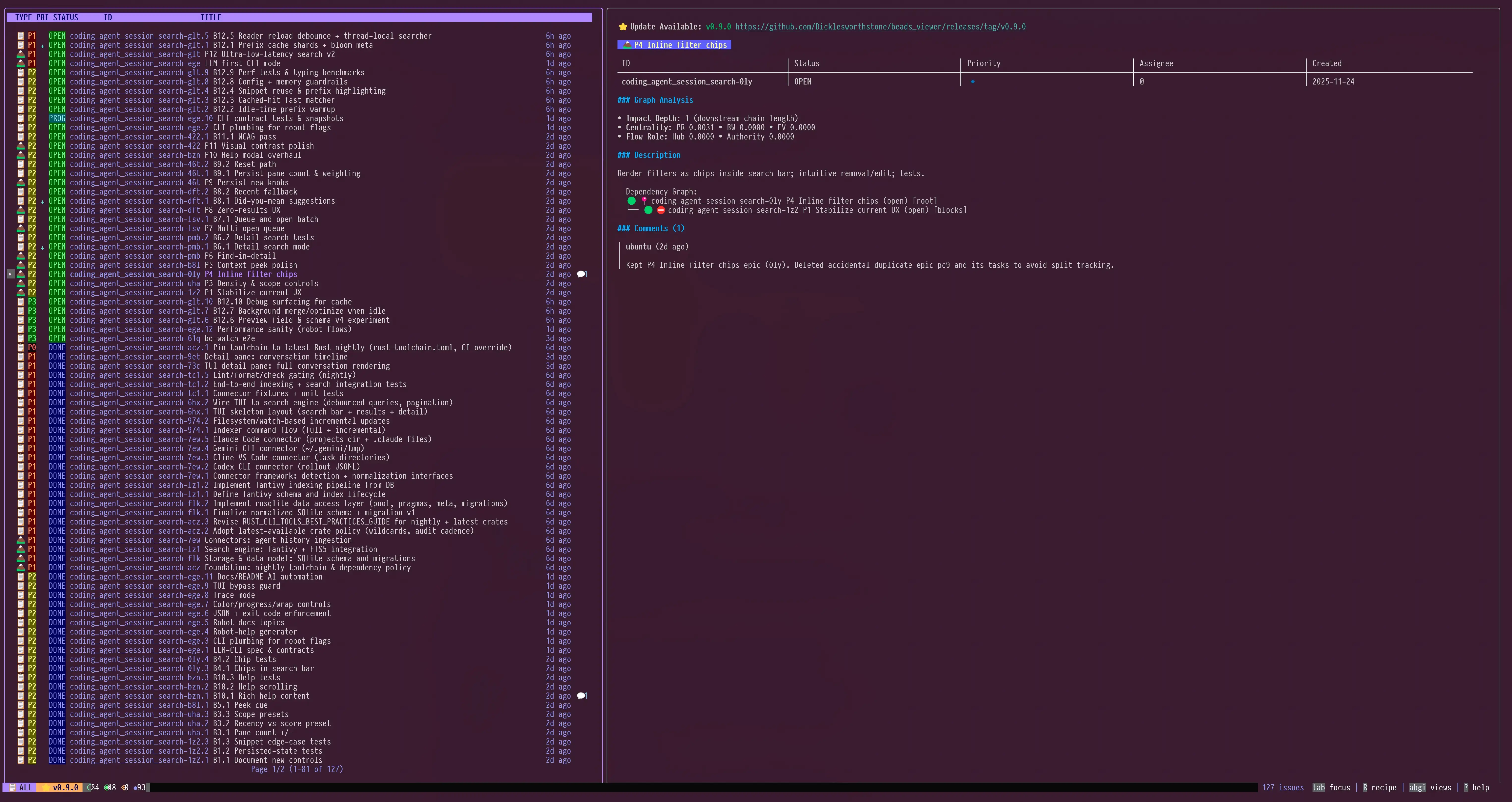
主分屏视图:快速列表 + 丰富详情
|
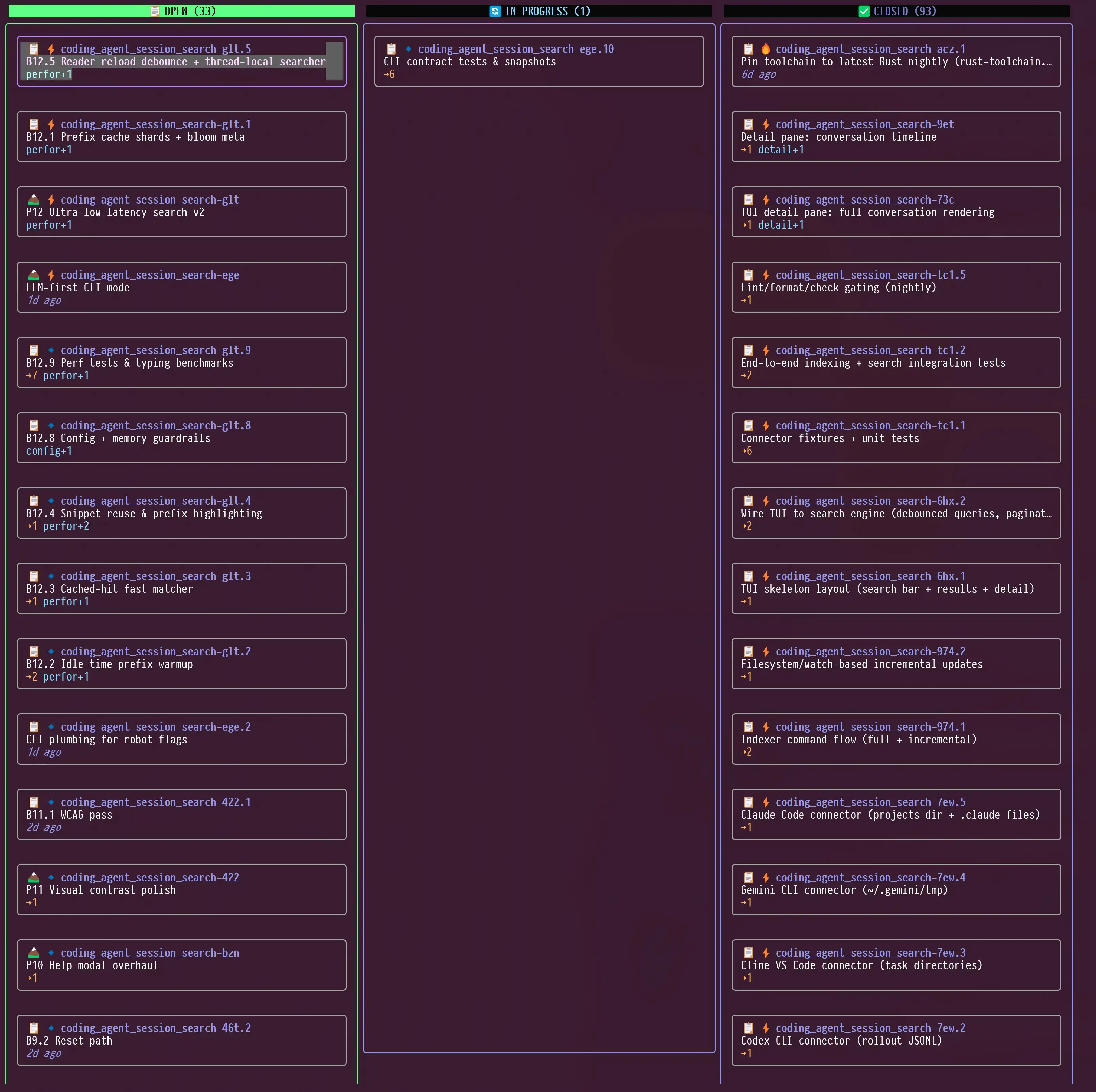
看板视图(`b`):一目了然的工作流
|
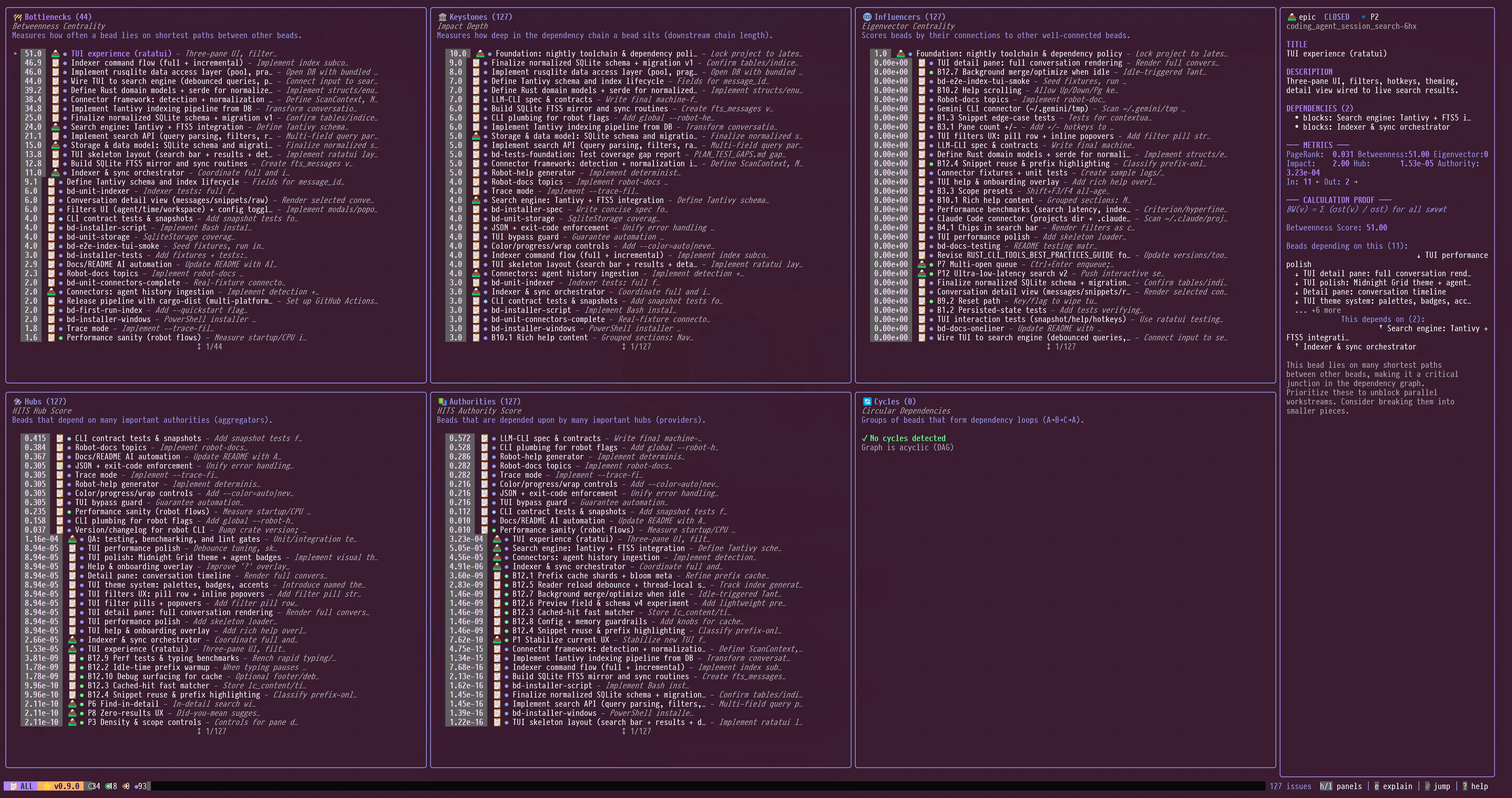
洞察面板:PageRank、关键路径、循环
|
图视图(`g`):导航依赖 DAG
|
安装
推荐:Homebrew(macOS/Linux)
brew install dicklesworthstone/tap/bv
此方法提供:
- 通过
brew upgrade自动更新 - 依赖管理
- 通过
brew uninstall轻松卸载
Windows:Scoop
scoop bucket add dicklesworthstone https://github.com/Dicklesworthstone/scoop-bucket
scoop install dicklesworthstone/bv
其他:直接下载
下载适用于您平台的最新版本(tar.gz 格式):
注意:资产名称包含版本号。如果链接显示 404 错误,请打开最新发布页面并下载对应的文件。
其他:安装脚本
Linux/macOS:
curl -fsSL "https://raw.githubusercontent.com/Dicklesworthstone/beads_viewer/main/install.sh?$(date +%s)" | bash
Windows(PowerShell):
irm "https://raw.githubusercontent.com/Dicklesworthstone/beads_viewer/main/install.ps1" | iex
注意: Windows 需要 Go 1.21 或更高版本(下载)。为了获得最佳显示效果,请使用带有 Nerd Font 的 Windows Terminal。
生成 JSONL 文件 (br 和 bd)
bv 从 .beads/beads.jsonl 中读取数据。基于 Rust 的 br 和原始基于 Go 的 bd 都可以生成此文件。
Rust (br) 用户 — br 默认会写入 .beads/beads.jsonl;无需额外步骤。
Go (bd) 用户 — 运行:
bd export --no-memories -o .beads/beads.jsonl
一旦文件存在,无论由哪种工具生成,bv 的运行方式都相同。
🤖 代理快速入门(机器人模式)
⚠️ 切勿在代理环境中直接运行 bv — 它会启动交互式 TUI。请始终使用 --robot-* 参数。
# 1) 从分类开始(单次调用的超级命令)
bv --robot-triage
# 2) 最小化模式:仅选择最优先的任务并执行认领命令
bv --robot-next
# 3) 优化后的令牌输出(TOON)
bv --robot-triage --format toon
export BV_OUTPUT_FORMAT=toon
# 4) 完整的机器人帮助
bv --robot-help
输出规范
- stdout = 仅 JSON/TOON 数据
- stderr = 诊断信息
- 退出码 0 = 成功
💡 简而言之
bv 是一款高性能的 终端用户界面(TUI),用于浏览和管理使用 Beads 问题跟踪系统的项目中的任务。
为什么你会感兴趣:
- 速度: 无需网络延迟,即可瞬间浏览数千个问题。
- 专注: 停留在终端中,使用 Vim 风格的按键(
j/k)进行导航。 - 智能: 它将你的项目可视化为 依赖图,自动突出显示传统基于列表的跟踪工具所忽略的瓶颈、循环和关键路径。
- AI 就绪: 它提供结构化的预计算洞察,供 AI 编码代理使用,充当你项目任务管理的“大脑”。
📖 核心体验
归根结底,bv 的核心在于 美观地查看你的工作。
⚡ 快速流畅的浏览
无需加载网页,也无需笨重的客户端。bv 可以立即启动,并允许你使用标准的 Vim 键盘(j/k)快速浏览问题积压。
- 分屏仪表盘: 在较宽的屏幕上,左侧显示列表,右侧显示完整详情。
- Markdown 渲染: 问题描述、评论和笔记都会以语法高亮、标题和列表的形式精美呈现。
- 即时筛选: 零延迟筛选。按
o查看未处理的问题,按c查看已完成的问题,或按r查看已准备好(未被阻塞)的问题。 - 实时重新加载: 监听
.beads/beads.jsonl文件,当文件发生变化时,自动刷新列表、详情和洞察——无需重启。
🔎 丰富的上下文
不要只看标题。bv 会为你提供完整的画面:
- 评论与历史记录: 滚动查看任何任务的完整对话历史。
- 元数据: 立即查看分配人、标签、优先级徽章以及创建日期。
- 搜索: 强大的模糊搜索(
/)可立即根据 ID、标题或内容找到问题。
🎯 专注的工作流程
- 看板: 按
b切换到列式视图(未处理、进行中、被阻塞、已完成),以可视化工作流。 - 可视化图: 按
g可以直观地探索依赖树。 - 洞察: 按
i可以查看图谱指标和瓶颈。 - 历史视图: 按
h可以查看变更时间线,将 git 提交与珠子修改关联起来。在较宽的终端上,享受响应式的三栏布局,显示提交、受影响的珠子和详细信息。 - 超宽模式: 在大屏幕上,列表会扩展以显示额外的列,例如火花线和标签。
🛠️ 快捷操作
- 导出: 按下
E可将所有问题导出为带时间戳的 Markdown 文件,并包含 Mermaid 图表。 - 图导出(CLI):
bv --robot-graph会以 JSON、DOT(Graphviz)或 Mermaid 格式输出依赖关系图。使用--graph-format=dot可通过 Graphviz 渲染,或使用--graph-root=ID --graph-depth=3提取聚焦的子图。 - 复制: 按下
C可将选中的问题以格式化的 Markdown 形式复制到剪贴板。 - 编辑: 按下
O可在您首选的 GUI 编辑器中打开.beads/beads.jsonl文件。 - 时光回溯: 按下
t可与任意 Git 提交版本进行对比,或按下T进行快速的 HEAD~5 对比。结合历史视图(h),您可以导航到任意提交,并查看具体发生了哪些变化。
🔌 自动化钩子
在 .bv/hooks.yaml 中配置导出前后的钩子,以执行验证、通知或上传等操作。默认设置为:导出前钩子在出现错误时立即失败(on_error: fail),导出后钩子则记录日志并继续执行(on_error: continue)。为空的命令会被忽略,并发出警告以确保安全。钩子环境变量包括 BV_EXPORT_PATH、BV_EXPORT_FORMAT、BV_ISSUE_COUNT、BV_TIMESTAMP,以及任何自定义的 env 条目。
🤖 可直接插入 AGENTS.md 或 CLAUDE.md 文件的现成简介
### 使用 bv 作为 AI 辅助工具
bv 是一个面向 Beads 项目(.beads/beads.jsonl)的图感知分类引擎。它无需解析 JSONL 或凭空推测图遍历路径,而是通过机器人标志实现确定性、依赖感知的输出,并提供预计算的指标(PageRank、介数中心性、关键路径、环路、HITS、特征向量、k-核)。
**作用范围边界:** bv 负责 *处理什么工作*(分类、优先级排序、规划)。对于代理间的协作(消息传递、任务认领、文件预留),请使用 [MCP Agent Mail](https://github.com/Dicklesworthstone/mcp_agent_mail)。
**⚠️ 重要提示:仅使用 `--robot-*` 标志。直接运行 `bv` 会启动交互式 TUI,从而阻塞您的会话。**
#### 工作流程:从分类开始
**`bv --robot-triage` 是您的唯一入口。** 它一次调用即可返回您所需的一切:
- `quick_ref`: 一目了然的统计信息 + 前三名建议
- `recommendations`: 排序后的可执行事项,附带评分、理由及解除阻塞信息
- `quick_wins`: 低投入高回报的任务
- `blockers_to_clear`: 能够解锁最多下游工作的事项
- `project_health`: 状态/类型/优先级分布、图谱指标
- `commands`: 下一步操作的可复制粘贴 Shell 命令
bv --robot-triage # 综合命令:从这里开始
bv --robot-next # 极简版:仅显示排名第一的事项及认领命令
# 面向低 LLM 上下文占用的优化输出(TOON):
bv --robot-triage --format toon
export BV_OUTPUT_FORMAT=toon
bv --robot-next
#### 其他命令
**规划:**
| 命令 | 返回内容 |
|---------|---------|
| `--robot-plan` | 并行执行轨迹及“解除阻塞”列表 |
| `--robot-priority` | 优先级不匹配检测及置信度 |
**图分析:**
| 命令 | 返回内容 |
|---------|---------|
| `--robot-insights` | 完整指标:PageRank、介数中心性、HITS(枢纽/权威)、特征向量、关键路径、环路、k-核、割点、松弛度 |
| `--robot-label-health` | 按标签健康状况:`health_level`(健康\|警告\|严重)、`velocity_score`、`staleness`、`blocked_count` |
| `--robot-label-flow` | 标签间依赖关系:`flow_matrix`、`dependencies`、`bottleneck_labels` |
| `--robot-label-attention [--attention-limit=N]` | 按注意力排名的标签:(pagerank × staleness × block_impact) / velocity |
**历史与变更追踪:**
| 命令 | 返回内容 |
|---------|---------|
| `--robot-history` | 珠子与提交的关联:`stats`、`histories`(每颗珠子的事件/提交/里程碑)、`commit_index` |
| `--robot-diff --diff-since <ref>` | 自指定参考以来的变更:新增/关闭/修改的问题、引入/解决的环路 |
**其他命令:**
| 命令 | 返回内容 |
|---------|---------|
| `--robot-burndown <sprint>` | Sprint 燃尽图、范围变化、风险事项 |
| `--robot-forecast <id\|all>` | 带依赖感知调度的 ETA 预测 |
| `--robot-alerts` | 过期问题、阻塞级联、优先级不匹配 |
| `--robot-suggest` | 卫生检查:重复项、缺失依赖、标签建议、环路修复 |
| `--robot-graph [--graph-format=json\|dot\|mermaid]` | 导出依赖关系图 |
| `--export-graph <file.html>` | 自包含的交互式 HTML 可视化 |
#### 范围限定与筛选
bv --robot-plan --label backend # 限定到特定标签的子图
bv --robot-insights --as-of HEAD~30 # 历史时间点
bv --recipe actionable --robot-plan # 预过滤:已准备好工作的(无阻塞)
bv --recipe high-impact --robot-triage # 预过滤:PageRank 分数最高的
bv --robot-triage --robot-triage-by-track # 按并行工作流分组
bv --robot-triage --robot-triage-by-label # 按领域分组
#### 理解机器人输出
**所有机器人 JSON 包含:**
- `data_hash` — 源 beads.jsonl 的指纹(用于验证多次调用的一致性)
- `status` — 各指标状态:`computed|approx|timeout|skipped` + 耗时 ms
- `as_of` / `as_of_commit` — 在使用 `--as-of` 时提供,包含引用和解析后的 SHA
**两阶段分析:**
- **第一阶段(即时):** 度、拓扑排序、密度 — 总是立即可用
- **第二阶段(异步,超时 500ms):** PageRank、介数中心性、HITS、特征向量、环路 — 请检查 `status` 标志
**对于大型图(>500 个节点):** 部分指标可能会被近似或跳过。务必检查 `status`。
#### jq 快速参考
bv --robot-triage | jq '.quick_ref' # 一目了然的摘要
bv --robot-triage | jq '.recommendations[0]' # 最优推荐
bv --robot-plan | jq '.plan.summary.highest_impact' # 最佳解除阻塞目标
bv --robot-insights | jq '.status' # 检查指标是否已就绪
bv --robot-insights | jq '.Cycles' # 循环依赖(必须修复!)
bv --robot-label-health | jq '.results.labels[] | select(.health_level == "critical")'
**性能:** 第一阶段即时,第二阶段异步(超时 500ms)。当速度至关重要时,优先选择 `--robot-plan` 而不是 `--robot-insights`。结果按数据哈希缓存。
使用 bv 替代直接解析 beads.jsonl——它能以确定性方式计算 PageRank、关键路径、环路和并行轨迹。
自动集成
bv 可以自动将上述说明添加到你的项目代理文件中:
- 首次运行时,
bv会检查是否存在AGENTS.md(或类似文件),如果不存在,则会提示是否注入简介。 - 选择 "Yes" 添加说明,"No" 跳过,或 "Don't ask again" 记住你的选择。
- 每个项目的偏好设置会存储在
~/.config/bv/agent-prompts/目录下。
支持的文件(按顺序检查):
AGENTS.md(优先)CLAUDE.mdagents.mdclaude.md
手动控制:
bv --agents-check # 检查代理文件中是否已存在简介
bv --agents-add # 将简介添加到代理文件(如需要则创建文件)
bv --agents-remove # 从代理文件中移除简介
bv --agents-update # 将简介更新为最新版本
bv --agents-dry-run # 显示不执行操作时会发生什么
版本跟踪:
简介使用 HTML 注释标记进行版本跟踪:
<!-- bv-agent-instructions-v1 -->
... 内容 ...
<!-- end-bv-agent-instructions -->
当发布新版本的简介时,bv 可以检测到过时的版本并提示你更新。
📐 架构与设计
bv 将你的项目视为一个有向无环图(DAG),而不仅仅是一组列表。这使得它能够推导出哪些内容是真正重要的。
graph TD
%% Soft Pastel Theme — Refined
classDef data fill:#e3f2fd,stroke:#90caf9,stroke-width:2px,color:#1565c0,rx:8
classDef logic fill:#fff8e1,stroke:#ffcc80,stroke-width:2px,color:#e65100,rx:8
classDef ui fill:#f3e5f5,stroke:#ce93d8,stroke-width:2px,color:#6a1b9a,rx:8
classDef output fill:#e8f5e9,stroke:#a5d6a7,stroke-width:2px,color:#2e7d32,rx:8
subgraph storage [" 📂 数据层 "]
A[".beads/beads.jsonl<br/>JSONL 问题存储"]:::data
end
subgraph engine [" ⚙️ 分析引擎 "]
B["加载器"]:::logic
C["图构建器"]:::logic
D["9 个指标<br/>PageRank · Betweenness · HITS..."]:::logic
end
subgraph interface [" 🖥️ TUI 层 "]
E["Bubble Tea 模型"]:::ui
F["列表视图"]:::ui
G["图视图"]:::ui
G2["树形视图"]:::ui
H["洞察仪表盘"]:::ui
end
subgraph outputs [" 📤 输出 "]
I["--robot-insights<br/>用于 AI 代理的 JSON"]:::output
J["--export-md<br/>Markdown 报告"]:::output
end
A --> B
B --> C
C --> D
D --> E
D --> I
D --> J
E --> F
E --> G
E --> G2
E --> H
linkStyle 0,1,2 stroke:#90caf9,stroke-width:2px
linkStyle 3,4,5 stroke:#ffcc80,stroke-width:2px
linkStyle 6,7,8,9 stroke:#ce93d8,stroke-width:2px
关键指标与算法
bv 计算9 个图论指标,以揭示隐藏的项目动态:
| 序号 | 指标 | 表示的内容 | 关键洞察 |
|---|---|---|---|
| 1 | PageRank | 递归依赖的重要性 | 基础性阻塞因素 |
| 2 | Betweenness | 最短路径上的流量 | 瓶颈与桥梁 |
| 3 | HITS | Hub/Authority 对偶性 | 重大任务 vs. 工具性任务 |
| 4 | 关键路径 | 最长依赖链 | 零松弛度的关键节点 |
| 5 | 特征向量 | 通过邻居传递的影响 | 战略性依赖关系 |
| 6 | 度数 | 直接连接的数量 | 即时阻塞者/被阻塞者 |
| 7 | 密度 | 边与节点的比例 | 项目耦合健康状况 |
| 8 | 循环 | 循环依赖 | 结构性错误 |
| 9 | 拓扑排序 | 合法的执行顺序 | 工作队列的基础 |
1. PageRank(依赖权威)
数学公式: 最初设计用于根据传入链接对网页的“重要性”进行排名,PageRank 模拟了一个“随机浏览者”在图上行走的过程。在我们的依赖图中(u → v 表示 u 依赖于 v),我们将依赖关系视为“投票”,用来衡量重要性。 $$ PR(v) = \frac{1-d}{N} + d \sum_{u \in M(v)} \frac{PR(u)}{L(u)} $$
直观理解: 如果许多任务都依赖于任务 A,或者有一个非常重要的任务 B 依赖于任务 A,那么任务 A 就会变得“举足轻重”。一个随机游走者沿着依赖关系不断前进,往往会频繁地停留在任务 A 上。
实际意义: 基础性阻塞因素。 PageRank 值高的任务是你项目的基石。它们很少是面向用户的“功能”,通常是架构、核心库或架构决策。一旦这些任务出现问题,整个依赖图就会崩溃。
2. 介数中心性(瓶颈)
数学公式: 定义为网络中所有最短路径中经过给定节点 $v$ 的比例。 $$C_B(v) = \sum_{s \neq v \neq t} \frac{\sigma_{st}(v)}{\sigma_{st}}$$
直观理解: 想象信息(或进度)从每个任务流向其他任务,沿着最高效的路径传输。“桥接节点”连接着原本孤立的集群(例如前端集群和后端集群),因此会承受巨大的流量。
实际意义: 把关者与瓶颈。 介数中心性高的任务是一个关键的卡点。它可能是一个移动应用和服务器团队都在等待的 API 接口。如果这个任务延迟了,不仅会阻塞一条线程,还会阻止整个子团队之间的同步。
3. HITS(枢纽与权威)
数学公式: 一种迭代算法,为每个节点定义两个分数:
- 权威分: 指向该节点的枢纽得分之和。
- 枢纽分: 该节点指向的权威得分之和。
直观理解: 这种模型描述了一种“相互强化”的关系。优秀的库(权威)会被许多应用程序使用。而优秀的应用程序(枢纽)也会使用许多优秀的库。
实际意义: 重大任务 vs. 基础设施。
- 高枢纽分: 这些是你的重大任务或产品特性。它们汇集了许多依赖关系来交付价值。
- 高权威分: 这些是你的工具性任务。它们为许多消费者提供价值。
4. 关键路径(DAG 中的最长路径)
数学公式: 在 DAG 中,最长路径代表完成项目所需的最短时间(假设可以无限并行)。bv 会递归计算这一路径:
$$Impact(u) = 1 + \max({Impact(v) \mid u \to v})$$
直观理解: 如果你抓住图中的“叶子”节点(没有依赖的任务)让它悬空,那么位于最顶端、支撑着最长链条的任务就承担了最大的重量。
实际意义: 关键节点。 关键节点是指任何延迟都会直接导致整个项目交付延迟的任务。这些任务没有任何“松弛时间”。
5. 特征向量中心性(影响力邻居)
数学公式: 特征向量中心性不仅考虑节点的连接数量,还衡量这些连接的重要性。一个节点即使只有少数但非常重要的邻居,其得分也可能高于拥有大量不重要邻居的节点。 $$x_i = \frac{1}{\lambda} \sum_{j \in N(i)} x_j$$
其中,$\lambda$ 是邻接矩阵的最大特征值,$N(i)$ 表示节点 $i$ 的邻居。
直观理解: 影响力不仅仅取决于你有多少连接,更在于你与哪些人相连。如果一项关键任务依赖于你,那么你的作用就比许多琐碎任务依赖你更为重要。
实际意义: 战略依赖关系。 高特征向量中心性的任务通常与图中的“关键角色”相连。它们可能没有很多直接依赖的任务,但其依赖的任务本身却至关重要。
6. 度中心性(直接连接)
数学公式: 最简单的中心性度量——只需统计边的数量。 $$C_D^{in}(v) = |{u : u \to v}|$$
$$C_D^{out}(v) = |{u : v \to u}|$$
直观理解:
- 入度: 有多少任务依赖于我?(我是阻塞者)
- 出度: 我依赖多少任务?(我被阻塞)
实际意义: 直接影响。
- 高入度: 该任务是许多其他任务的直接阻塞点。完成它会立即解除其他工作的阻塞。
- 高出度: 该任务有许多前置条件。它很可能处于被阻塞状态,应在执行计划中安排在较晚的时间。
7. 图密度(互联程度)
数学公式: 密度衡量图的实际连接情况与其最大可能连接数之间的比例。 $$D = \frac{|E|}{|V|(|V|-1)}$$
其中,$|E|$ 是边的数量,$|V|$ 是节点的数量。对于有向图,最大边数为 $|V|(|V|-1)$。
直观理解: 密度为 0.0 表示不存在依赖关系(孤立任务)。而密度接近 1.0 则意味着所有任务都相互依赖(病态复杂性)。
实际意义: 项目健康指标。
- 低密度(< 0.05): 健康。任务相对独立,可以并行化。
- 中等密度(0.05 - 0.15): 正常。合理的互联反映了现实中的依赖关系。
- 高密度(> 0.15): 警告。项目耦合过强。建议将其拆分为更小的模块。
8. 环检测(循环依赖)
数学公式: 有向图中的环是指从节点 $v_1$ 出发,经过一系列节点 $v_2, \dots, v_k$ 后又回到 $v_1$ 的路径,即起点和终点相同。bv 使用 Tarjan 算法的变体,通过 topo.DirectedCyclesIn 来枚举所有基本环。
直观理解: 如果 A 依赖 B,而 B 又依赖 A,那么两者都无法完成。这是一种逻辑上的不可能,必须予以解决。
实际意义: 结构错误。 环是项目计划中的“漏洞”,而不仅仅是警告。它们表明:
- 依赖关系分类错误(A 并非真正阻塞 B,反之亦然)
- 缺少中间任务(A 和 B 都依赖于未明确的 C)
- 范围混淆(A 和 B 应合并为一个任务)
9. 拓扑排序(执行顺序)
数学公式: 有向无环图的拓扑排序是将所有顶点排列成一个线性序列,使得对于每一条边 $u \to v$,顶点 $u$ 总是在 $v$ 之前出现。只有无环图才存在有效的拓扑排序。
直观理解: 如果必须按照依赖关系完成任务,拓扑排序就能给出一种可行的顺序(可能存在多种)。
实际意义: 工作队列。 拓扑排序是 bv 执行计划的基础。结合优先级权重,它生成了“下一步要做什么”的建议,从而驱动 --robot-plan 功能。
🤖 机器人协议(AI 接口)
bv 桥接了原始数据与 AI 代理之间的鸿沟。代理在处理图算法时往往表现不佳;而 bv 作为确定性的“辅助工具”,能够卸载图遍历的认知负担,从而解决这一问题。
sequenceDiagram
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8f5e9', 'primaryTextColor': '#2e7d32', 'primaryBorderColor': '#81c784', 'lineColor': '#90a4ae', 'secondaryColor': '#fff8e1', 'tertiaryColor': '#fce4ec'}}}%%
participant 用户
participant 代理 as 🤖 AI 代理
participant BV as ⚡ bv
participant 文件 as 📄 beads.jsonl
用户->代理: “修复下一个被阻塞的任务”
rect rgba(232, 245, 233, 0.4)
Note over 代理, BV: 认知卸载
代理->BV: bv --robot-plan
BV->文件: 读取并解析
BV->BV: PageRank + 拓扑排序
BV-->>代理: { next: "TASK-123", unblocks: 5 }
end
rect rgba(255, 243, 224, 0.3)
Note over 代理: 实施阶段
代理->代理: 修复 TASK-123
代理->BV: bv --robot-insights
BV-->>代理: 更新后的图指标
end
“认知卸载”策略
机器人协议的主要设计目标是 认知卸载。大型语言模型(LLM)本质上是概率引擎,它们擅长语义推理(如编码、写作),但在算法层面的图遍历(如寻找环、计算最短路径)方面却极不可靠。两阶段分析器会立即返回度、拓扑和密度等指标,并以大小感知的超时机制和哈希缓存异步完成 PageRank、介数中心性、HITS、特征向量中心性、关键路径以及环的检测,因此当图结构未发生变化时,重复调用机器人接口的速度依然很快。
如果直接将原始的 beads.jsonl 数据输入到代理中,就会迫使代理:
- 解析数千行 JSON 数据。
- 在其上下文窗口中重建依赖关系图。
- “幻觉式”地尝试进行路径遍历或环检测。
而 bv 提供了一个确定性的图引擎作为辅助工具,从而解决了这一问题。
为什么选择 bv 而不是直接使用原始数据?
直接使用 beads 数据只能为代理提供 数据;而使用 bv --robot-insights 则能为代理提供 智能。
| 能力 | 原始 Beads (JSONL) | bv 机器人模式 |
|---|---|---|
| 查询 | “列出所有问题。” | “列出阻碍发布的前 5 个瓶颈。” |
| 上下文开销 | 高(与问题数量成正比)。 | 低(固定摘要结构)。 |
| 图逻辑 | 代理需自行推断/计算。 | 已预先计算(PageRank/Brandes)。 |
| 安全性 | 代理可能会遗漏环。 | 环已被明确标记。 |
代理使用模式
代理通常在三个阶段使用 bv:
分类与定位: 在开始会话之前,代理会运行
bv --robot-insights。它会收到一个轻量级的 JSON 摘要,描述项目的结构健康状况。代理会立即了解到:- “我目前不应该处理任务 C,因为它依赖于瓶颈任务 B。”
- “图中存在环路(A->B->A);在添加新功能之前,我必须修复这个结构性错误。”
影响分析: 当被要求“重构登录模块”时,代理会检查相关节点的 PageRank 和 影响得分。如果这些得分较高,则代理知道这是一项高风险的变更,涉及大量下游依赖,因此需要运行更全面的测试。
执行计划制定: 代理不会随意猜测操作顺序,而是使用
bv的拓扑排序生成一个严格的线性化计划。
JSON 输出模式(--robot-insights):
输出设计为严格类型化,便于工具如 jq 或标准 JSON 库解析。
{
"bottlenecks": [
{ "id": "CORE-123", "value": 0.45 }
],
"keystones": [
{ "id": "API-001", "value": 12.0 }
],
"influencers": [
{ "id": "AUTH-007", "value": 0.82 }
],
"hubs": [
{ "id": "EPIC-100", "value": 0.67 }
],
"authorities": [
{ "id": "UTIL-050", "value": 0.91 }
],
"cycles": [
["TASK-A", "TASK-B", "TASK-A"]
],
"clusterDensity": 0.045,
"stats": {
"pageRank": { "CORE-123": 0.15, "...": "..." },
"betweenness": { "CORE-123": 0.45, "...": "..." },
"eigenvector": { "AUTH-007": 0.82, "...": "..." },
"hubs": { "EPIC-100": 0.67, "...": "..." },
"authorities": { "UTIL-050": 0.91, "...": "..." },
"inDegree": { "CORE-123": 5, "...": "..." },
"outDegree": { "CORE-123": 2, "...": "..." },
"criticalPathScore": { "API-001": 12.0, "...": "..." },
"density": 0.045,
"topologicalOrder": ["CORE-123", "API-001", "..."]
}
}
| 字段 | 指标 | 包含内容 |
|---|---|---|
bottlenecks |
Betweenness | 连接图中不同簇的顶级节点 |
keystones |
Critical Path | 最长依赖链上的顶级节点 |
influencers |
Eigenvector | 与重要邻居相连的顶级节点 |
hubs |
HITS Hub | 顶级依赖聚合节点(Epic) |
authorities |
HITS Authority | 顶级前置条件提供者(Utility) |
cycles |
环检测 | 所有循环依赖路径 |
clusterDensity |
密度 | 整体图的互联程度 |
stats |
所有指标 | 完整原始数据,用于自定义分析 |
🎨 TUI 工程与工艺
bv 基于 Bubble Tea 框架构建,确保无卡顿、60fps 的流畅体验。它配备了一个自适应布局引擎,可响应终端大小调整事件,并内置了一个自定义的 ASCII/Unicode 图形渲染器。
flowchart LR
classDef core fill:#fef3e2,stroke:#f5d0a9,stroke-width:2px,color:#8b5a2b
classDef engine fill:#f0e6f6,stroke:#d4b8e0,stroke-width:2px,color:#5d3a6b
classDef ui fill:#e6f3e6,stroke:#b8d9b8,stroke-width:2px,color:#2d5a2d
classDef output fill:#e8f4f8,stroke:#b8d4e3,stroke-width:2px,color:#2c5f7c
INPUT["⌨️ 输入<br/>键 · 鼠标 · 调整大小"]:::core
MODEL["🫖 模型<br/>问题 · 统计 · 焦点"]:::core
GRAPH["🧮 图引擎<br/>PageRank · HITS · 循环"]:::engine
VIEWS["🖼️ 视图<br/>列表 · 板 · 图 · 树 · 智能洞察"]:::ui
LAYOUT["📐 布局<br/>移动 · 分割 · 宽屏"]:::ui
TERM["🖥️ 终端<br/>60fps 输出"]:::output
INPUT -->|tea.Msg| MODEL
GRAPH -->|metrics| MODEL
MODEL -->|state| VIEWS
VIEWS --> LAYOUT
LAYOUT --> TERM
linkStyle 0 stroke:#f5d0a9,stroke-width:2px
linkStyle 1 stroke:#d4b8e0,stroke-width:2px
linkStyle 2 stroke:#b8d9b8,stroke-width:2px
linkStyle 3,4 stroke:#b8d4e3,stroke-width:2px
1. 自适应布局引擎
bv 并非简单地输出文本,而是在每个渲染周期计算几何布局。
- 动态调整大小:
View()函数会在每一帧检查当前终端宽度 (msg.Width)。 - 断点逻辑:
< 100 列: 移动模式。列表占据 100% 宽度。> 100 列: 分割模式。列表占 40%,详情占 60%。> 140 列: 超宽模式。列表会插入额外的列(Sparklines、标签),这些列通常会被隐藏。
- 边距感知: 布局引擎会明确考虑边框(2 个字符)和内边距(2 个字符),以防止许多 TUI 中常见的“差一”换行错误。
2. 零延迟虚拟化
渲染 10,000 个问题会让一个简单的终端应用崩溃。bv 实现了 视口虚拟化:
- 窗口化: 我们只渲染当前终端窗口中可见的行。
- 预计算: 图表指标(PageRank 等)在启动时由单独的 goroutine 计算一次,而不是每帧都计算。底层图采用紧凑的邻接表实现,比基于映射的传统方法快 50–100 倍。
- 细节缓存: Markdown 渲染器是惰性实例化的,并且重复使用,避免了昂贵的正则表达式重新编译。
3. 可视化图引擎(pkg/ui/graph.go)
我们从头开始构建了一个自定义的 2D ASCII/Unicode 渲染引擎,用于可视化依赖关系图。
- 画布抽象: 使用 2D 格子的
rune单元格和style指针,可以在终端中绘制“像素”。 - 曼哈顿路由: 边缘使用正交线绘制,并配合适当的 Unicode 角落字符(
╭,─,╮,│,╰,╯),以最大限度减少视觉干扰。 - 拓扑分层: 节点根据其“影响深度”分层排列,确保依赖关系始终向下流动。
4. 主题一致性
我们使用 Lipgloss 来强制执行严格的设计系统。
- 语义化颜色: 颜色是按语义定义的(
Theme.Blocked,Theme.Open),而非硬编码的十六进制值。这使得bv能够在“吸血鬼”(暗色)和“亮色”模式之间无缝切换。 - 状态指示器: 我们使用 Nerd Font 字形(
🐛,✨,🔥)搭配颜色编码,无需阅读文字即可快速传达状态。
📈 可视化数据编码:火花图与热力图
在终端等信息密集的环境中,文本占用空间较大。bv 采用了受爱德华·塔夫特启发的高密度数据可视化技术(pkg/ui/visuals.go),以最小的空间传达复杂的指标。
1. Unicode 简易图
在超宽屏模式下查看列表时,bv 使用 Unicode 块字符( 、▂、▃、▄、▅、▆、▇、█)渲染“图表分数”列。
- 数学原理:
RenderSparkline(val, width)将浮点数值(0.0 - 1.0)与可用的字符宽度进行归一化处理。它会计算每个字符单元格的精确高度,从而形成连续的柱状图效果。 - 实用价值: 这样你只需扫视包含 50 个问题的列表,就能立刻发现复杂度或中心性上的“高峰”,而无需逐个阅读数字。
2. 语义热力图
我们并不使用随机颜色。pkg/ui/visuals.go 实现了一种感知均匀的颜色渐变(GetHeatmapColor),可将指标强度映射到渐变色:
0.0 - 0.2:低(灰色/暗淡)0.2 - 0.5:中(蓝色/冷色调)0.5 - 0.8:高(紫色/暖色调)0.8 - 1.0:峰值(粉色/炽热)
这种视觉编码被应用于洞察仪表板中的徽章,使你能够一眼区分“稍重要”和“极度紧急”的任务。
🔍 搜索架构
在一个拥有数千个问题的项目中,你无法承受等待后端查询的时间。bv 实现了一种复合式、内存中的模糊搜索,响应速度极快。
“扁平化向量”索引
与其分别搜索各个字段(这需要复杂的 UI 控件),bv 在加载时会将每个问题合并为一个可搜索的“向量”。
FilterValue() 方法会构建一个复合字符串,包含:
- 核心标识: ID(
"CORE-123")和标题("修复登录竞态条件") - 元数据: 状态(
"open")、类型("bug")、优先级 - 上下文: 分配人(
"@steve")和标签("frontend, v1.0")
模糊子序列匹配
当你按下 / 键时,搜索引擎会针对这个复合向量执行模糊子序列匹配。
- 示例: 输入
"log fix"可成功匹配到"Fix login race condition"。 - 示例: 输入
"steve bug"可找到分配给 Steve 的 Bug。 - 示例: 输入
"open v1.0"可筛选出 v1.0 版本中未关闭的问题。
性能特点
- 零分配: 搜索索引仅在首次加载时构建一次(
loader.LoadIssues)。 - 客户端过滤: 过滤完全在渲染循环中完成。不存在数据库延迟、网络往返,也没有“加载中”的提示。
- 稳定排序: 搜索结果会保持主列表的拓扑顺序和优先级排序,确保即使经过筛选后的视图也能反映项目的真正优先级。
🧜 Mermaid 集成:终端里的图表?
常见问题之一是:“如何在纯文本终端中渲染复杂的图表?”
bv 从两个方面解决了这个问题:
1. 原生图形可视化器 (g)
对于交互式 TUI,我们构建了一个专门的 ASCII/Unicode 图形引擎(pkg/ui/graph.go),它能够在不依赖图形协议支持(如 Sixel)的情况下,复现 Mermaid 流程图的核心价值。
- 拓扑分层: 节点会根据其依赖深度自动排序。
- 正交布线: 连接线使用方框绘制字符(
│、─、╭、╯),以绘制干净的直角路径,避免穿过节点文本。 - 自适应画布: 虚拟画布可以无限扩展,但视口(
pkg/ui/viewport.go)会裁剪渲染内容,只显示当前屏幕可见的部分,并通过h/j/k/l键实现平滑滚动。
2. 导出引擎 (--export-md)
对于外部报告,bv 包含一个强大的 Mermaid 生成器(pkg/export/markdown.go)。
- 净化处理: 它会自动转义问题标题中的不安全字符,以防止 Mermaid 解析器出现语法错误。
- 防冲突 ID: 当净化处理可能导致冲突时(例如仅由符号组成的 ID),节点会被赋予稳定的哈希后缀,从而确保边不会合并或消失。
- 基于类别的样式: 根据节点状态,为其分配 CSS 类(
classDef open、classDef blocked等),这样在 GitHub 或 GitLab 上渲染时,生成的图表外观会与 TUI 的配色方案一致。 - 语义边: 阻碍关系用粗箭头表示(
==>),而松散关系则用虚线表示(-.->),将链接的 严重程度 编码进视觉语法中。
graph TD
%% Generated by bv — Soft Pastel Theme
classDef open fill:#c8e6c9,stroke:#81c784,stroke-width:2px,color:#2e7d32
classDef blocked fill:#ffcdd2,stroke:#e57373,stroke-width:2px,color:#c62828
classDef inProgress fill:#fff3e0,stroke:#ffb74d,stroke-width:2px,color:#ef6c00
A["CORE-123<br/>重构登录"]:::open
B["UI-456<br/>登录页面"]:::blocked
C["API-789<br/>认证接口"]:::inProgress
A --> B
A --> C
C -.-> B
linkStyle 0 stroke:#81c784,stroke-width:2px
linkStyle 1 stroke:#81c784,stroke-width:2px
linkStyle 2 stroke:#e57373,stroke-width:1px,stroke-dasharray:5
📸 图表导出 (--robot-graph)
将依赖关系图以多种格式导出,用于可视化、文档记录或与其他工具集成:
bv --robot-graph # JSON(默认)
bv --robot-graph --graph-format=dot # Graphviz DOT
bv --robot-graph --graph-format=mermaid # Mermaid 图
# 提取聚焦子图
bv --robot-graph --graph-root=bv-123 # 以特定根节点为中心的子图
bv --robot-graph --graph-root=bv-123 --graph-depth=3 # 限制深度
输出格式
| 格式 | 使用场景 | 渲染方式 |
|---|---|---|
json |
程序化处理、自定义可视化 | 使用 jq 或代码解析 |
dot |
高质量静态图像 | dot -Tpng file.dot -o graph.png |
mermaid |
嵌入 Markdown、GitHub 渲染 | 直接粘贴到文档中 |
子图提取
对于大型项目,可以围绕特定问题提取聚焦视图:
--graph-root=ID:从某个问题出发,包含其所有依赖项和被依赖项--graph-depth=N:限制遍历深度至 N 层(0 表示无限制)
JSON 模式
{
"nodes": [
{ "id": "bv-123", "title": "修复认证", "status": "open", "priority": 1 }
],
"edges": [
{ "from": "bv-124", "to": "bv-123", "type": "blocks" }
],
"metadata": {
"data_hash": "abc123",
"node_count": 45,
"edge_count": 62
}
}
🌌 交互式图形可视化 (--export-graph)
为了深入探索复杂的依赖结构,bv 会生成由力导向图引擎驱动的自包含 HTML 可视化文件。与静态导出不同,这些文件完全可交互——你可以平移、缩放、过滤并深入查看单个节点,而无需任何服务器或额外依赖。
# 生成交互式 HTML 图表
bv --export-graph graph.html # 导出到指定文件
bv --export-graph # 自动生成带时间戳的文件名
bv --export-graph --graph-title "Q4 Sprint" # 自定义标题
bv --export-graph --graph-include-closed # 包含已关闭的问题
为什么选择交互式图可视化?
传统的列表视图将任务孤立地展示出来。而交互式图则能揭示项目的隐藏结构:
- 依赖链:一眼看出哪些任务阻塞了其他任务,并追踪待办事项中的关键路径。
- 瓶颈检测:通过 PageRank 和介数中心性调整节点大小,可快速发现哪些事项对整体影响最大。
- 聚类发现:力导向布局会自然地将相关工作分组,从而揭示团队边界或功能集群。
- 上下文切换:只需悬停在任意节点上,即可查看完整详情——描述、设计说明、验收标准等,无需离开可视化界面。
导出内容包含什么?
每个 HTML 文件都是完全自包含的(通常大小为 400KB 至 1MB,具体取决于项目规模):
| 组件 | 描述 |
|---|---|
| 完整的珠子数据 | 标题、描述、设计、验收标准、备注、标签、时间戳 |
| 图谱指标 | PageRank、介数中心性、关键路径得分、松弛值、枢纽/权威得分 |
| 分类分析 | 完整的分类建议,附带评分和理由 |
| Git 关联信息 | 每个珠子关联的提交历史(如有) |
| 依赖关系图 | 完整的“被阻塞者”与“阻塞者”关系,以可视化边线表示 |
界面概览
该可视化提供了一个功能丰富的键盘驱动界面:
┌─────────────────────────────────────────────────────────────────────────────┐
│ 📊 项目图 | [搜索...] | 布局 ▾ | 过滤器 ▾ | 🔥 📋 ⭐ ☀️ ❓ │
├──────────────────────┬──────────────────────────────────────────────────────┤
│ │ │
│ 珠子详情 │ 力导向图 │
│ ═══════════════ │ │
│ ID: bv-xyz │ ●───────● │
│ 标题: Feature X │ /│\ │ │
│ │ ● ● ● ●───● │
│ 描述: │ │ │ │
│ [markdown...] │ ●───────────● │
│ │ │
│ 图谱指标: │ ┌──────────────────┐ │
│ PageRank: 2.34% │ │ 低 ▰▰▰▰ 高 │ <- 热图图例 │
│ 介数: 0.12 │ └──────────────────┘ │
│ 关键路径: 4.0 │ ┌─────────────┐ │
│ │ │ 小地图 │ │
│ 被阻塞者: [...] │ └─────────────┘ │
│ 阻塞者: [...] │ │
└──────────────────────┴──────────────────────────────────────────────────────┘
可视化编码
节点同时编码了多维信息:
| 视觉属性 | 含义 |
|---|---|
| 颜色 | 状态:🟢 开放、🟠 进行中、🔴 阻塞、⚫ 已关闭 |
| 大小 | 可配置的度量标准(PageRank、介数中心性、关键路径、入度) |
| 形状 | 类型:● 功能、▲ 缺陷、■ 任务、◆ 壮举 |
| 光晕 | 悬停时出现金色光环,显示连接的子图(两跳邻居) |
| 边的颜色 | 粉色边表示关键路径连接。 |
键盘快捷键
该可视化完全由键盘控制:
| 键 | 动作 | 键 | 动作 |
|---|---|---|---|
? |
帮助叠加层 | D |
固定/分离详情面板 |
F |
适应所有内容 | L |
切换亮/暗模式 |
R |
重置为默认 | H |
切换热图着色 |
Space |
全屏 | T |
顶部节点面板 |
Esc |
清除/取消 | G |
分类面板 |
1-4 |
布局模式 | Y |
最近查看 |
P |
路径查找模式 |
功能
过滤与搜索
- 全文搜索:按 ID、标题或内容实时预览查找珠子。
- 状态筛选:开放、进行中、阻塞、已关闭。
- 类型筛选:功能、缺陷、任务、壮举。
- 优先级筛选:从 P0(关键)到 P4(待办)。
- 标签筛选:根据您的数据动态填充。
导航
- 路径查找:按下
P,然后点击两个节点,即可找到并高亮显示两者之间的最短路径。 - 最近查看:按下
Y查看导航历史,并快速返回之前访问过的节点。 - 小地图:角落中的概览显示当前视口位置。
面板
- 固定详情面板:左侧栏在悬停时显示完整的珠子信息(默认)。
- 浮动模式:按下
D可将面板分离,以悬浮提示框形式显示。 - 分类面板:显示最高推荐项及其评分和理由。
- 顶部节点:列出 PageRank 最高的节点,方便快速导航。
定制化
- 布局模式:力导向(默认)、DAG 自顶向下、DAG 自左向右、放射状。
- 尺寸度量:选择决定节点大小的指标(PageRank、介数中心性、关键路径、入度)。
- 亮/暗模式:支持完整主题,确保适当的对比度。
- 保存偏好设置:主题和布局选择会通过 localStorage 持久化。
使用场景
| 场景 | 图表如何帮助 |
|---|---|
| 冲刺计划 | 识别哪些事项能够解锁最多的下游工作 |
| 利益相关者更新 | 分享单个 HTML 文件——无需任何设置即可查看 |
| 架构评审 | 发现功能之间意想不到的依赖关系 |
| 新员工入职 | 新成员可以探索代码库的工作结构 |
| 回顾会议 | 可视化已完成的工作及剩余的阻塞点 |
示例流程
# 1. 生成可视化
bv --export-graph sprint_review.html --graph-title "Sprint 42 Review"
# 2. 在浏览器中打开
open sprint_review.html # macOS
xdg-open sprint_review.html # Linux
start sprint_review.html # Windows
# 3. 与团队分享
# HTML 文件是自包含的——直接发送或托管到任何地方即可
技术说明
- 无需服务器:所有内容都在浏览器端运行。
- 离线可用:一旦打开即可完全离线使用。
- 现代浏览器:已在 Chrome、Firefox、Safari 和 Edge 上测试过。
- 性能:借助 WebGL 加速渲染,可流畅处理 500 多个节点。
- 文件大小:通常为 400KB 至 1MB,具体取决于项目规模和内容。
📄 状态报告引擎
bv 不仅适用于个人浏览,它还是一种沟通工具。--export-md 标志会生成一份 面向管理层的状态报告,将你的代码库状态转换为一份适合利益相关者的精良文档。
1. “混合文档”架构
导出器(pkg/export/markdown.go)构建的文档兼顾了人类可读性和可视化数据:
- 一目了然的摘要: 顶级统计信息(总数、未解决、阻塞中、已关闭)提供了即时的健康状况背景。
- 嵌入式图表: 它会将完整的依赖关系图以 Mermaid 图表的形式 直接嵌入到文档中。在 GitHub 或 GitLab 等平台上,这会渲染成一个交互式的图表。
- 锚点导航: 自动生成的目录使用 URL 友好的 slug(
#core-123-refactor-login),可以直接链接到具体的 issue 详情,使读者能够在高层级的图表和底层规格之间自由跳转。
2. 语义化格式
我们并不只是简单地输出 JSON 值。导出器应用了特定的格式规则,以确保报告看起来专业:
- 元数据表格: 关键字段(分配人、优先级、状态)会在 GFM(GitHub 风格 Markdown)表格中对齐,并配有 emoji 指示符。
- 对话线程化: 评论会被渲染为块引用(
>),并附带相对时间戳,从而保留讨论的流程,与技术规范区分开来。 - 智能排序: 报告并不会按 issue ID 顺序列出问题。它采用了与 TUI 相同的优先级逻辑:未解决的高优先级问题会首先出现,确保读者关注当前最重要的内容。
⏳ 时间旅行:快照对比与 Git 历史
bv 最强大的功能之一就是 时间旅行——能够比较项目在 Git 历史中任意两个时间点的状态。这使得 bv 从一个“查看器”转变为一个 进度跟踪和回归检测系统。
快照模型
bv 可以在任何时刻捕获项目的完整状态:
graph LR
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8f5e9', 'primaryTextColor': '#2e7d32', 'primaryBorderColor': '#81c784', 'lineColor': '#90a4ae'}}}%%
subgraph "Git 历史"
A["HEAD~10<br/><small>10 次提交前</small>"]
B["HEAD~5<br/><small>5 次提交前</small>"]
C["HEAD<br/><small>当前</small>"]
end
subgraph "快照"
D["快照 A<br/><small>45 个 issue,3 个循环</small>"]
E["快照 B<br/><small>52 个 issue,1 个循环</small>"]
F["快照 C<br/><small>58 个 issue,0 个循环</small>"]
end
A --> D
B --> E
C --> F
D -.->|"diff"| E
E -.->|"diff"| F
style D fill:#ffcdd2,stroke:#e57373,stroke-width:2px
style E fill:#fff3e0,stroke:#ffb74d,stroke-width:2px
style F fill:#c8e6c9,stroke:#81c784,stroke-width:2px
跟踪的内容
SnapshotDiff 会捕获每一个有意义的变化:
| 类别 | 跟踪的变化 |
|---|---|
| Issues | 新建、关闭、重新打开、移除、修改 |
| Fields | 标题、状态、优先级、标签、依赖关系 |
| Graph | 新增循环、已解决的循环 |
| Metrics | PageRank 的变化、介数中心性的变化、密度的变化 |
Git 历史集成 (pkg/loader/git.go)
GitLoader 能够从 任意 Git 提交记录 中加载 issue:
loader := NewGitLoader("/path/to/repo")
// 从不同引用加载
current, _ := loader.LoadAt("HEAD")
lastWeek, _ := loader.LoadAt("HEAD~7")
release, _ := loader.LoadAt("v1.0.0")
byDate, _ := loader.LoadAt("main@{2024-01-15}")
缓存架构:
- 提交记录会被解析为稳定的 commit SHA 值以便缓存
- 线程安全的
sync.RWMutex保护并发访问 - 5 分钟的 TTL 避免数据过时,同时防止重复调用 Git
使用场景
- Sprint 回顾: “这个 sprint 我们关闭了多少个 issue?”
- 回归检测: “我们是否不小心重新引入了一个依赖循环?”
- 趋势分析: “我们的图密度是否在增加?我们是否创建了过多的依赖关系?”
- 发布说明: “生成 v1.0 和 v2.0 之间的所有变更差异。”
🍳 配方系统:声明式视图配置
与其记住 CLI 标志或反复设置筛选条件,不如使用 bv 支持的 配方——基于 YAML 的视图配置,可以保存、共享并进行版本控制。
配方结构
# .beads/recipes/sprint-review.yaml
name: sprint-review
description: "当前 sprint 中涉及的 issues"
filters:
status: [open, in_progress, closed]
updated_after: "14d" # 相对时间:14 天前
exclude_tags: [backlog, icebox]
sort:
field: updated
direction: desc
secondary:
field: priority
direction: asc
view:
columns: [id, title, status, priority, updated]
show_metrics: true
max_items: 50
export:
format: markdown
include_graph: true
过滤能力
| 过滤器 | 类型 | 示例 |
|---|---|---|
status |
数组 | [open, closed, blocked, in_progress] |
priority |
数组 | [0, 1](仅 P0 和 P1) |
tags |
数组 | [frontend, urgent] |
exclude_tags |
数组 | [wontfix, duplicate] |
created_after |
相对/ISO | "7d"、"2w"、"2024-01-01" |
updated_before |
相对/ISO | "30d"、"1m" |
actionable |
布尔值 | true = 无未解决的阻塞问题 |
has_blockers |
布尔值 | true = 正等待依赖项 |
id_prefix |
字符串 | "bv-" 用于项目过滤 |
title_contains |
字符串 | 子字符串搜索 |
内置配方
bv 自带 11 种预配置配方:
| 配方 | 用途 |
|---|---|
default |
所有未解决的问题按优先级排序 |
actionable |
已准备好处理(无阻塞问题) |
recent |
近 7 天内更新过的 |
blocked |
正在等待依赖项 |
high-impact |
PageRank 得分最高的 |
stale |
已经打开超过 30 天但未被触碰的 |
triage |
按计算出的分类评分排序(影响 + 解除阻塞潜力) |
closed |
最近关闭的 issues |
release-cut |
近 14 天内关闭的(用于生成变更日志) |
quick-wins |
容易处理的 P2/P3 问题且无阻塞 |
bottlenecks |
介数中心性高的节点(项目瓶颈) |
使用配方
# 交互式选择器(在 TUI 中按 R 键)
bv
# 直接调用配方
bv --recipe actionable
bv --recipe high-impact
# 自定义配方文件
bv --recipe .beads/recipes/sprint-review.yaml
🎯 综合影响评分
传统的 issue 跟踪工具通常只按单一维度排序——通常是优先级。而 bv 则会计算一个 多因素影响评分,将图论指标与时间因素及优先级信号相结合。
评分公式
$$ \text{Impact} = 0.30 \cdot \text{PageRank} + 0.30 \cdot \text{Betweenness} + 0.20 \cdot \text{BlockerRatio} + 0.10 \cdot \text{Staleness} + 0.10 \cdot \text{PriorityBoost} $$
组件分解
| 组件 | 权重 | 衡量内容 |
|---|---|---|
| PageRank | 30% | 递归依赖的重要性 |
| Betweenness | 30% | 瓶颈/桥梁的位置 |
| BlockerRatio | 20% | 直接依赖项(入度) |
| Staleness | 10% | 自上次更新以来的天数(老化) |
| PriorityBoost | 10% | 人工分配的优先级 |
为什么选择这些权重?
- 60% 图谱指标: 依赖关系的结构是决定真正重要性的主要因素。
- 20% 阻塞比: 直接依赖项对立即解除阻塞至关重要。
- 10% 老化程度: 老问题值得关注,它们可能是被遗忘的阻塞点。
- 10% 优先级: 人工判断很有价值,但可能过时或带有政治偏见。
分数输出
{
"issue_id": "CORE-123",
"title": "重构认证模块",
"score": 0.847,
"breakdown": {
"pagerank": 0.27,
"betweenness": 0.25,
"blocker_ratio": 0.18,
"staleness": 0.07,
"priority_boost": 0.08
}
}
优先级建议
当计算出的影响分数与人工分配的优先级显著不同时,bv 会生成 可操作的建议:
⚠️ CORE-123 的影响分数为 0.85,但优先级却是 P3。 原因:高 PageRank(基础依赖)+ 高 Betweenness(瓶颈) 建议: 考虑将其提升至 P1。
优先级提示叠加
在列表视图中按下 p 键即可切换 优先级提示——内联的视觉指示器,显示哪些问题的优先级与实际情况不符:
┌──────────────────────────────────────────────────────────────┐
│ OPEN CORE-123 ⬆ 数据库模式迁移 P3 🟢 │
│ OPEN UI-456 登录页面样式 P2 🟢 │
│ BLOCKED API-789 ⬇ 旧版接口封装 P1 🔴 │
└──────────────────────────────────────────────────────────────┘
⬆ = 影响分数表明应提高优先级(红色箭头)
⬇ = 影响分数表明应降低优先级(青色箭头)
这能让你一目了然地了解你的优先级分配是否与计算出的图谱重要性一致。
🛤️ 并行执行计划
当你问“接下来该做什么?”时,bv 不只是挑选优先级最高的项目。它会生成一个 完整的执行计划,既尊重依赖关系,又识别可以并行处理的机会。
按轨道规划
规划器使用 Union-Find 算法来识别依赖关系图中的连通组件,将相关问题分组到独立的“轨道”中,以便同时进行处理。
graph TD
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8f5e9', 'lineColor': '#90a4ae'}}}%%
subgraph track_a ["🅰️ 轨道 A:认证系统"]
A1["AUTH-001<br/>P1 · 解除 3 个阻塞"]:::actionable
A2["AUTH-002"]:::blocked
A3["AUTH-003"]:::blocked
end
subgraph track_b ["🅱️ 轨道 B:UI 优化"]
B1["UI-101<br/>P2 · 解除 1 个阻塞"]:::actionable
B2["UI-102"]:::blocked
end
subgraph track_c ["🅲 轨道 C:独立任务"]
C1["DOCS-001<br/>P3 · 无阻塞"]:::actionable
end
A1 --> A2
A2 --> A3
B1 --> B2
classDef actionable fill:#c8e6c9,stroke:#81c784,stroke-width:2px,color:#2e7d32
classDef blocked fill:#ffcdd2,stroke:#e57373,stroke-width:2px,color:#c62828
linkStyle 0,1,2 stroke:#81c784,stroke-width:2px
计划输出 (--robot-plan)
{
"tracks": [
{
"track_id": "track-A",
"reason": "独立工作流",
"items": [
{ "id": "AUTH-001", "priority": 1, "unblocks": ["AUTH-002", "AUTH-003", "API-005"] }
]
},
{
"track_id": "track-B",
"reason": "独立工作流",
"items": [
{ "id": "UI-101", "priority": 2, "unblocks": ["UI-102"] }
]
}
],
"total_actionable": 3,
"total_blocked": 5,
"summary": {
"highest_impact": "AUTH-001",
"impact_reason": "解除 3 个任务的阻塞",
"unblocks_count": 3
}
}
算法流程
- 识别可行动问题: 过滤出未关闭且无未解决阻塞的问题。
- 计算解除阻塞情况: 对每个可行动问题,计算完成它后会解除哪些阻塞。
- 寻找连通组件: 使用 Union-Find 算法根据依赖关系将问题分组。
- 构建轨道: 从每个组件中创建并行轨道,并按每个轨道内的优先级排序。
- 计算总结: 识别出最具影响力的单一问题(解除下游阻塞最多)。
对 AI 代理的好处
- 确定性: 相同输入始终产生相同计划(不会出现 LLM 幻觉)。
- 并行感知: 多个代理可以同时获取不同轨道而不会发生冲突。
- 影响排序:
highest_impact字段会明确告诉代理从哪里开始。
🔬 Insights 控制面板:交互式图分析
Insights 控制面板(i)将抽象的图谱指标转化为 交互式探索界面。它不仅展示数字,还允许你深入探究某个节点为何得分较高,以及这对你的项目意味着什么。
6 面板布局
┌─────────────────────┬─────────────────────┬─────────────────────┐
│ 🚧 瓶颈 │ 🏛️ 关键节点 │ 🌐 影响者 │
│ Betweenness │ Impact Depth │ Eigenvector │
│ ───────────────── │ ───────────────── │ ───────────────── │
│ ▸ 0.45 AUTH-001 │ 12.0 CORE-123 │ 0.82 API-007 │
│ 0.38 API-005 │ 10.0 DB-001 │ 0.71 AUTH-001 │
└─────────────────────┴─────────────────────┴─────────────────────┘
┌─────────────────────┬─────────────────────┬─────────────────────┐
│ 🛰️ 中心节点 │ 📚 权威节点 │ 🔄 循环依赖 │
│ HITS Hub Score │ HITS Auth Score │ Circular Deps │
│ ───────────────── │ ───────────────── │ ───────────────── │
│ 0.67 EPIC-100 │ 0.91 UTIL-050 │ ⚠ A → B → C → A │
│ 0.54 FEAT-200 │ 0.78 LIB-010 │ ⚠ X → Y → X │
└─────────────────────┴─────────────────────┴─────────────────────┘
面板说明
| 面板 | 指标 | 显示内容 | 可操作见解 |
|---|---|---|---|
| 🚧 瓶颈 | Betweenness | 位于许多最短路径上的节点 | 优先处理以解除并行工作的阻塞 |
| 🏛️ 关键节点 | Impact Depth | 深处依赖链中的节点 | 应首先完成——延迟会层层传导 |
| 🌐 影响者 | Eigenvector | 与重要节点相连 | 在更改前仔细审查 |
| 🛰️ 中心节点 | HITS Hub | 汇集大量依赖关系 | 作为里程碑跟踪完成进度 |
| 📚 权威节点 | HITS Authority | 许多中心节点所依赖的对象 | 尽早稳定——否则会引发连锁反应 |
| 🔄 循环依赖 | Tarjan SCC | 循环依赖环 | 必须解决——逻辑上不可能成立 |
详情面板:计算证明
当您选择一个节点时,右侧的详情面板不仅会显示得分,还会展示证明——即实际参与计算的节点及其对应的值:
─── 计算证明 ───
BW(v) = Σ (σst(v) / σst) 对所有 s≠v≠t
介数中心性得分:0.452
依赖于此节点的有(5个):
↓ UI-Login:实现登录表单
↓ UI-Dashboard:用户仪表盘
↓ API-Auth:认证接口
... 还有2个
此节点又依赖于(2个):
↑ DB-Schema:用户表迁移
↑ CORE-Config:环境配置
该节点位于许多其他节点之间的最短路径上,因此是关键的枢纽节点。
仪表板导航
| 键 | 操作 |
|---|---|
Tab / Shift+Tab |
在不同面板之间切换 |
j / k |
在当前面板内导航 |
Enter |
将选中的节点聚焦到主视图中 |
e |
切换说明 |
i |
退出仪表板 |
📋 看板:可视化工作流状态
看板(b)提供一种列式工作流视图,具有智能泳道分组、可视化依赖关系指示器和丰富的卡片详情。空列会自动折叠,以最大化屏幕空间。
泳道分组模式
按下 s 键可在三种分组模式间循环切换:
| 模式 | 列 | 使用场景 |
|---|---|---|
| 状态(默认) | 待办 | 进行中 | 阻塞 | 已完成 | 跟踪工作流状态 |
| 优先级 | P0 关键 | P1 高 | P2 中 | P3+ 其他 | 基于紧急程度的分类 |
| 类型 | Bug | Feature | Task | Epic | 工作分类 |
当前模式会显示在状态栏中。每种模式使用不同的列颜色,便于快速识别。
可视化依赖关系指示器
卡片边框采用颜色编码,以便一目了然地显示依赖状态:
┌─ 🔴 红色 ──────────────────┐ ┌─ 🟡 黄色 ─────────────────┐
│ 阻塞中 │ │ 高影响 │
│ 此卡片存在未解决的 │ │ 此卡片阻塞了其他任务。 │
│ 依赖关系。请先处理 │ │ 完成它将解除下游任务的 │
│ 阻碍因素。 │ │ 阻塞状态。 │
└────────────────────────────┘ └──────────────────────────────┘
┌─ 🟢 绿色 ────────────────┐ ┌─ ⬜ 默认 ─────────────────┐
│ 可执行 │ │ 正常 │
│ 无阻碍的待办事项。 │ │ 标准优先级,没有 │
│ 请选择它! │ │ 阻碍关系。 │
└────────────────────────────┘ └──────────────────────────────┘
搜索匹配项会以紫色(当前匹配)或蓝色(其他匹配)边框叠加显示。
丰富的四行卡片格式
每张卡片以紧凑的格式展示全面的元数据:
┌────────────────────────────────────┐
│ 🐛 P1 BUG-1234 3d │ ← 第一行:类型、优先级、编号、年龄
│ 修复认证超时问题 │ ← 第二行:标题(已截断)
│ 👤alice ⛔3 →2 🏷️2 │ ← 第三行:负责人、阻塞者、被阻塞者、标签
│ auth, backend, critical │ ← 第四行:标签名称
└────────────────────────────────────┘
| 元素 | 含义 |
|---|---|
| 类型图标 | 🐛 Bug,✨ Feature,📝 Task,🎯 Epic,🔧 Chore |
| 优先级 | P0(红色)、P1(红色)、P2(暗色)、P3+(灰色) |
| 年龄颜色 | 🟢 <7天(新鲜),🟡 7-30天(老化),🔴 >30天(过期) |
| ⛔N | 被N个问题阻塞 |
| →N | 阻塞N个下游问题 |
| 🏷️N | 拥有N个标签 |
列统计信息
每个列的标题都会显示汇总统计信息:
┌─────────────────────────────────────┐
│ 进行中(5) 🔥2 ⚠️1 │
└─────────────────────────────────────┘
│ │ │
│ │ └── ⚠️ 该列中的阻塞项
│ └────── 🔥 P0/P1 关键项
└───────────────── 总数量
卡片内联展开
按下 d 键可内联展开选中的卡片,显示:
- 完整的问题描述
- 所有阻塞依赖(附带标题)
- 所有下游依赖
- 完整的标签列表
- 评论预览
通过 j/k 键进行导航时,展开的卡片会自动收起,以确保流畅浏览。
详情面板
按下 Tab 键可打开一个侧边面板,显示完整的问题详情视图(在宽屏终端上)。使用 Ctrl+J/Ctrl+K 键进行滚动。
看板导航
| 键 | 操作 |
|---|---|
| 移动 | |
h / l |
在列之间移动 |
j / k |
在列内移动 |
gg / G |
跳转到列的顶部/底部 |
0 / $ |
列中的第一个/最后一个项目 |
H / L |
跳转到第一/最后一列 |
1-4 |
直接跳转到第1-4列 |
Ctrl+D / Ctrl+U |
向下/向上翻页 |
| 分组与显示 | |
s |
循环切换泳道模式(状态 → 优先级 → 类型) |
e |
切换空列可见性 |
d |
展开/收起内联卡片详情 |
Tab |
切换侧边详情面板 |
| 搜索 | |
/ |
开始搜索 |
n / N |
下一个/上一个搜索匹配 |
Esc |
取消搜索 |
| 筛选 | |
o |
筛选:仅显示待办事项 |
c |
筛选:仅显示已完成事项 |
r |
筛选:可执行(无阻塞) |
| 操作 | |
y |
复制问题编号到剪贴板 |
V |
预览相关CASS会话(如果已安装CASS) |
Enter |
将选中的节点聚焦到详情视图中 |
b |
退出看板视图 |
🔄 列表排序:多维度组织
按下 s 键可在五种不同的排序模式之间循环切换,让您即时掌控问题的组织方式。当前排序模式会显示在状态栏中。
排序模式
| 模式 | 键显示 | 排序逻辑 | 使用场景 |
|---|---|---|---|
| 默认 | Default |
优先级(升序)→ 创建时间(降序) | 标准的优先级驱动工作流 |
| 创建时间↑ | Created ↑ |
按创建日期升序排列(最早开始的排在前面) | 审计:查找长期未解决的问题 |
| 创建时间↓ | Created ↓ |
按创建日期降序排列(最新创建的排在前面) | 回顾:查看最近创建的工作 |
| 优先级 | Priority |
仅按优先级排序(P0 → P4) | 纯粹的优先级分类 |
| 更新时间 | Updated |
按最后更新时间降序排列(最新的排在前面) | 活动跟踪:查看活跃的问题 |
设计理念
排序系统采用稳定的二级排序,以确保确定性的排序结果。当主要排序值相同时,问题会回退到按ID排序,以保证跨会话的一致性。这可以防止“列表乱序”问题,即相同优先级的项目会随机重新排序。
状态栏指示器
┌────────────────────────────────────────────────────────────┐
│ 📋 问题 [创建时间↓] │
├────────────────────────────────────────────────────────────┤
│ 待办 FEAT-789 添加暗黑模式开关 P2 🟢 │
│ 待办 BUG-456 修复登录竞态条件 P1 🟢 │
│ 待办 TASK-123 更新文档 P3 🟢 │
└────────────────────────────────────────────────────────────┘
[创建时间↓] 的标识牌会立即告知您当前的排序模式,而无需记住自己处于哪种模式。
🌲 层次树状视图:父子关系可视化
按 E 键可打开层次树状视图——一个可折叠的树形结构,用于可视化问题之间的父子关系。与显示所有依赖类型的关系图视图不同,树状视图仅关注结构化层级关系:哪些问题是其他问题的“组成部分”。
为什么父子关系很重要?
在复杂项目中,问题通常有两种不同的关系类型:
- 阻塞型依赖(
blocks/blocked_by):任务 B 必须等到任务 A 完成后才能开始。 - 父子关系(
parent):特性 X 包含任务 A、B 和 C 作为子工作。
树状视图仅渲染父子关系,从而构建出一份工作分解结构(WBS),帮助回答以下问题:
- “这个史诗级任务由哪些子任务组成?”
- “这个缺陷属于哪个特性?”
- “整个项目中的工作是如何分解的?”
树状布局
┌─────────────────────────────────────────────────────────────────────────────┐
│ 🌲 树状视图 3 个根节点 · 12 个节点 │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ ▾ 🎯 P1 EPIC-100 认证系统改造 ● 开启 │
│ │ ├─ ▸ ✨ P1 FEAT-101 实现 OAuth2 流程 ● 开启 │
│ │ │ └─ • 📝 P2 TASK-102 添加令牌刷新逻辑 ○ 已完成 │
│ │ └─ • 🐛 P0 BUG-103 修复会话超时竞态问题 ⚠ 被阻塞 │
│ │ │
│ ▾ 🎯 P2 EPIC-200 UI 美化冲刺 ● 开启 │
│ │ ├─ • ✨ P2 FEAT-201 支持深色模式 ● 开启 │
│ │ └─ • ✨ P3 FEAT-202 响应式布局 ● 开启 │
│ │ │
│ • 📝 P3 TASK-300 更新文档 ● 开启 │
│ │
└─────────────────────────────────────────────────────────────────────────────┘
可视化编码
| 元素 | 含义 |
|---|---|
| ▾ / ▸ | 展开 / 折叠(有子节点) |
| • | 叶子节点(无子节点) |
| ├─ / └─ | 树枝连接符 |
| 类型图标 | 🎯 史诗级任务、✨ 特性、🐛 缺陷、📝 任务、🔧 杂项 |
| 优先级 | P0(严重红色)、P1(高)、P2(中等灰色)、P3+(浅色) |
| 状态点 | ● 开启(绿色)、◐ 进行中(黄色)、⚠ 被阻塞(红色)、○ 已完成(灰色) |
树状视图构建算法
树状视图的构建采用仅父子关系的过滤器,并结合智能根节点检测:
- 筛选依赖关系:仅考虑
DepParentChild类型的依赖关系;阻塞和相关依赖将被忽略。 - 构建索引:创建父 → 子映射,以便高效遍历。
- 识别根节点:没有父节点(或其父节点不在数据集中)的问题将成为根节点。
- 递归构建:使用深度优先遍历并检测循环,防止无限循环。
- 排序子节点:每个父节点下的子节点按以下顺序排序:优先级(升序)→ 类型(史诗级 > 特性 > 缺陷 > 任务)→ 创建日期(最新优先)。
边缘情况处理:
- 孤立引用:如果某个问题引用了一个不存在的父节点,则该问题将成为根节点(不会被静默丢弃)。
- 循环:在遍历时检测到循环;循环节点将被渲染,但不再继续递归。
- 深层层级:无深度限制——树状视图能够忠实地表示任意嵌套的结构。
树状视图导航
| 键 | 操作 |
|---|---|
| 移动 | |
j / k / ↓ / ↑ |
光标下移 / 上移 |
g / G |
跳转到第一个 / 最后一个节点 |
Ctrl+D / Ctrl+U |
向下 / 向上翻页(半屏) |
| 展开/折叠 | |
Enter / Space |
切换当前节点的展开/折叠状态 |
l / → |
展开节点,或在已展开状态下移动到第一个子节点 |
h / ← |
折叠节点,或在已折叠状态下跳转到父节点 |
o |
展开树中所有节点 |
O |
折叠树中所有节点 |
| 集成 | |
Tab |
将选中内容同步到详情面板(分屏模式) |
E / Esc |
退出树状视图,返回列表视图 |
使用场景
| 场景 | 树状视图如何帮助 |
|---|---|
| 冲刺计划 | 展开史诗级任务以查看所有子工作,并估算范围 |
| 进度跟踪 | 折叠已完成的分支,专注于未完成的工作 |
| 新人入职 | 新成员可以一目了然地了解项目结构 |
| 重构 | 在重新组织之前,查看哪些任务属于某个特性 |
| 状态会议 | 自上而下地梳理层级结构,向利益相关者汇报进展 |
树状视图 vs. 关系图视图
| 方面 | 树状视图 (E) |
关系图视图 (g) |
|---|---|---|
| 关系类型 | 仅父子关系 | 所有依赖类型 |
| 布局 | 缩进式层级结构 | 力导向 / DAG |
| 关注点 | 工作分解结构 | 依赖流程 |
| 导航方式 | Vim 风格(j/k/h/l) | 视口平移 |
| 适用场景 | “这个史诗级任务里都有什么?” | “是什么阻塞了这个任务?” |
两种视图相辅相成:使用树状视图理解结构,使用关系图视图理解流程。
🎯 可执行计划视图:并行执行轨道
按 a 键可打开可执行计划视图——一种将工作项分组为独立执行轨道的结构化展示。该视图将抽象的关系图分析转化为具体的“接下来要做什么”的界面。
为什么执行轨道很重要?
传统的优先级列表会将任务按单一顺序排列。但在复杂的依赖关系图中,有些工作流是完全独立的——处理其中一个并不影响另一个。可执行计划视图利用并查集连通分量分析来识别这些并行轨道,允许多个团队成员或代理同时协作,而不会相互干扰。
可视化布局
┌─────────────────────────────────────────────────────────────────────────────┐
│ 🎯 可行动计划 3个轨道 · 8个项目 │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ ━━━ 轨道A:认证系统 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ │
│ ▸ 🎯 P1 AUTH-001 实现OAuth2流程 解锁3项 │
│ ✨ P2 AUTH-002 添加令牌刷新 解锁1项 │
│ │
│ ━━━ 轨道B:UI优化 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ │
│ 📝 P2 UI-101 暗色模式切换 解锁2项 │
│ 📝 P3 UI-102 响应式布局 解锁0项 │
│ │
│ ━━━ 轨道C:独立任务 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ │
│ 📝 P3 DOCS-001 更新API文档 解锁0项 │
│ │
├─────────────────────────────────────────────────────────────────────────────┤
│ 最高影响力:AUTH-001(解锁3项) │
└─────────────────────────────────────────────────────────────────────────────┘
什么使一个项目“可行动”
当满足以下条件时,一个问题会出现在可行动计划中:
- 状态为未完成或进行中(非已完成)
- 不存在未解决的阻塞问题(所有依赖项均已解决)
这确保了视图中的每个项目都可以立即开始,无需等待其他事项。
解锁分析
每个项目都会显示一个解锁数量——即如果该项目完成,将有多少其他问题变为可行动。较高的解锁数量表明其具有放大效应:完成这些项目将释放大量后续工作。
底部的最高影响力摘要会标识出唯一一个项目,一旦完成,就能解锁最多的额外工作。这就是你接下来应该优先处理的最佳选择。
导航
| 快捷键 | 功能 |
|---|---|
j / k |
在不同项目间移动(跨轨道) |
Enter |
打开所选项目的详细视图 |
a / Esc |
退出可行动视图 |
使用场景
| 场景 | 可行动视图如何帮助 |
|---|---|
| 单人开发 | 始终清楚下一个最具影响力的任务 |
| 团队站会 | 每个人认领不同的轨道 |
| AI代理调度 | 代理可以确定性地获取“highest_impact”项目 |
| 冲刺规划 | 通过统计每个轨道上的可行动项目数量来估算工作量 |
🔀 流矩阵视图:跨标签依赖分析
按下f键即可打开流矩阵视图——一个交互式仪表盘,用于可视化各标签(领域/团队)之间的依赖关系。这能揭示在单个问题视图中无法看到的跨团队瓶颈。
为什么跨标签流动很重要
在大型项目中,工作通常按标签划分:前端、后端、API、认证、基础设施。问题之间的依赖关系会隐式地转化为标签之间的依赖。流矩阵能够揭示这些模式:
- 哪个团队最常阻碍其他团队?
- 哪个领域正在等待最多的外部工作?
- 跨团队协作的瓶颈在哪里?
可视化布局
┌─────────────────────────────────────────────────────────────────────────────┐
│ 🔀 流矩阵 5个标签 · 23项依赖 │
├───────────────────────────────────────────┬─────────────────────────────────┤
│ 标签 │ 详情 │
│ ───────────────────────────────────── │ ───────────────────────────── │
│ │ │
│ ▸ 🔴 api ━━━━━━━━━━ 0.72 │ 标签:api │
│ 外部依赖:8 → [auth, db, infra] │ ────────────────────── │
│ 内部依赖:3 ← [frontend, mobile] │ │
│ │ 瓶颈得分:0.72 │
│ 🟡 auth ━━━━━━━━ 0.58 │ (前20% = 严重) │
│ 外部依赖:4 → [db] │ │
│ 内部依赖:5 ← [api, frontend] │ 外部依赖: │
│ │ → auth(3个问题) │
│ 🟢 frontend ━━━━━ 0.31 │ → db(4个问题) │
│ 外部依赖:2 → [api] │ → infra(1个问题) │
│ 内部依赖:0 │ │
│ │ 内部依赖: │
│ 🟢 db ━━━ 0.22 │ ← frontend(2个问题) │
│ 外部依赖:0 │ ← mobile(1个问题) │
│ 内部依赖:7 ← [api, auth] │ │
│ │ 关键路径:是 │
└───────────────────────────────────────────┴─────────────────────────────────┘
瓶颈得分
瓶颈得分(0.0–1.0)衡量一个标签对跨领域工作的阻碍程度:
$$ \text{瓶颈} = \frac{\text{外部依赖}}{\text{总跨标签依赖}} \times \text{关键性权重} $$
| 得分 | 颜色 | 含义 |
|---|---|---|
| 0.7 – 1.0 | 🔴 红色 | 严重瓶颈——优先解除阻塞 |
| 0.4 – 0.7 | 🟡 黄色 | 中度阻碍——需密切监控 |
| 0.0 – 0.4 | 🟢 绿色 | 流畅——无协调问题 |
下钻模式
按下某个标签上的Enter键,即可深入查看造成跨标签依赖的具体问题:
┌─────────────────────────────────────────────────────────────────────────────┐
│ 🔀 流矩阵 > api → auth 3个问题 │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ 🐛 P1 API-123 认证接口返回500错误 阻止AUTH-456 │
│ ✨ P2 API-456 添加OAuth作用域验证 阻止AUTH-789 │
│ 📝 P2 API-789 限制令牌刷新频率 阻止AUTH-101 │
│ │
└─────────────────────────────────────────────────────────────────────────────┘
导航
| 键 | 操作 |
|---|---|
j / k |
在标签之间移动 |
Tab |
在标签列表和详情面板之间切换焦点 |
Enter |
下钻到跨标签的问题 |
Esc |
退出下钻/退出视图 |
f / q |
退出流矩阵视图 |
机器人命令
bv --robot-label-flow | jq '.flow.bottleneck_labels'
🎪 注意力视图:标签优先级排序
按下 ] 打开 注意力视图——一个按注意力分数排序的标签表格,帮助您识别哪些项目领域需要重点关注。
注意力分数公式
注意力分数结合了多种信号,以突出被忽视或存在问题的区域:
$$ \text{Attention} = \frac{\text{PageRank}_{\text{avg}} \times \text{Staleness} \times \text{BlockImpact}}{\text{Velocity} + \epsilon} $$
| 组件 | 表示的内容 |
|---|---|
| PageRank(平均) | 该标签中问题的平均重要性 |
| Staleness | 问题自上次更新以来的时间长度(越高表示越陈旧) |
| Block Impact | 该标签内被阻塞的问题数量 |
| Velocity | 完成率(每周关闭的问题数) |
高注意力分数表明该标签既重要又被忽视——需要采取干预措施。
可视化布局
┌─────────────────────────────────────────────────────────────────────────────┐
│ 🎪 ATTENTION VIEW │
├──────┬────────────┬───────────┬─────────────────────────────────────────────┤
│ Rank │ Label │ Attention │ Reason │
├──────┼────────────┼───────────┼─────────────────────────────────────────────┤
│ 1 │ api │ 2.45 │ blocked=5 stale=3 vel=0.8 │
│ 2 │ auth │ 1.89 │ blocked=2 stale=4 vel=1.2 │
│ 3 │ infra │ 1.23 │ blocked=1 stale=6 vel=0.5 │
│ 4 │ frontend │ 0.67 │ blocked=0 stale=1 vel=3.5 │
│ 5 │ docs │ 0.34 │ blocked=0 stale=2 vel=2.1 │
└──────┴────────────┴───────────┴─────────────────────────────────────────────┘
结果解读
- 高注意力 + 低速度:该领域停滞不前——需调查阻塞因素。
- 高注意力 + 高陈旧度:工作被遗忘——重新浮现并重新优先级排序。
- 低注意力 + 高速度:健康领域——保持势头。
- 高阻塞数量:依赖关系造成瓶颈。
导航
| 键 | 操作 |
|---|---|
j / k |
在标签之间移动 |
] / Esc |
退出注意力视图 |
机器人命令
bv --robot-label-attention --attention-limit=10
📚 快捷键侧边栏:持久化的键盘参考
按下 ;(分号)或 F2 切换 快捷键侧边栏——一个与当前视图上下文相关的持久化面板,显示键盘快捷键。
为什么是侧边栏(而不是简单的帮助)?
? 帮助覆盖层会显示快捷键,但会遮挡您的视图。而快捷键侧边栏在您工作时始终可见,非常适合:
- 学习键盘快捷键而不打断工作流程
- 在复杂导航时快速参考
- 在结对编程时指导新用户
上下文感知
侧边栏会自动筛选快捷键,仅显示与当前视图相关的快捷键:
| 上下文 | 显示的部分 |
|---|---|
| 列表视图 | 导航、过滤器、视图、操作 |
| 看板视图 | 导航、看板特定、泳道 |
| 图形视图 | 导航、平移、缩放 |
| 洞察视图 | 导航、面板、切换 |
| 历史视图 | 导航、视图模式、时间线 |
可视化布局
┌──────────────────────────────────────────────┬──────────────────────┐
│ │ ⌨️ SHORTCUTS │
│ │ ────────────────── │
│ Main Content Area │ │
│ │ Navigation │
│ (List, Board, Graph, etc.) │ j/k Move ↓/↑ │
│ │ G/gg End/Start │
│ │ ^d/^u Page ↓/↑ │
│ │ │
│ │ Views │
│ │ b Board │
│ │ g Graph │
│ │ i Insights │
│ │ │
│ │ ; to hide │
└──────────────────────────────────────────────┴──────────────────────┘
侧边栏控制
| 键 | 操作 |
|---|---|
; 或 F2 |
切换侧边栏的可见性 |
Ctrl+J |
向下滚动侧边栏(当可见时) |
Ctrl+K |
向上滚动侧边栏(当可见时) |
侧边栏占据终端右侧固定宽度为34个字符。
🎓 交互式教程系统
按下 `(反引号)打开 交互式教程——一个全面的多页引导,通过丰富且样式化的内容教授所有 bv 功能。
教程架构
教程使用 基于组件的渲染系统,生成美观的终端输出:
| 组件 | 目的 | 示例 |
|---|---|---|
| Section | 带下划线的样式标题 | ## 导航 |
| Paragraph | 自动换行的流畅文本 | 解释性文字 |
| KeyTable | 对齐的按键-描述对 | j/k → 上下移动 |
| Tip | 高亮显示的提示框 | 💡 提示:按 g 跳转... |
| Warning | 用于重要提示的警告框 | ⚠️ 警告:此操作... |
| Code | 语法高亮的代码块 | bv --robot-triage |
| Bullet | 样式化的项目符号列表 | • 第一项 |
| Tree | 层次结构展示 | 目录树 |
| StatusFlow | 可视化的流程图 | 开始 → 进行中 → 完成 |
| InfoBox | 带边框的信息面板 | 功能亮点 |
教程章节
教程深入涵盖了以下主题:
- 简介 — bv 是什么以及存在的意义
- 核心概念 — 珠子、依赖关系、标签、优先级
- 列表视图 — 导航、过滤、排序
- 看板视图 — 看板工作流、泳道
- 图形视图 — 依赖关系可视化
- 树形视图 — 父子层级关系
- 洞察仪表盘 — 图形指标深度解析
- 历史视图 — 与 Git 的关联
- 机器人协议 — AI 代理集成
- 工作流程 — 分诊、计划、冲刺管理
进度跟踪
本教程会自动记录您已查看的页面:
┌─────────────────────────────────────────────────────────────────────────────┐
│ 📖 教程 第3页/共10页 · 30% ████░░░░│
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ ## 列表视图导航 │
│ ───────────────────────── │
│ │
│ 列表视图是您的主界面。使用 Vim 风格的快捷键进行导航: │
│ │
│ j / k 向下 / 向上移动 │
│ g / G 跳转到顶部 / 底部 │
│ Ctrl+D/U 向下 / 向上翻页 │
│ │
│ ╭──────────────────────────────────────────────────────────────────────╮ │
│ │ 💡 小贴士 按 `/` 键搜索,然后输入问题标题中的任意部分 │ │
│ ╰──────────────────────────────────────────────────────────────────────╯ │
│ │
├─────────────────────────────────────────────────────────────────────────────┤
│ ← h 上一页 │ l 下一页 → │ t 目录 │ q 关闭 │
└─────────────────────────────────────────────────────────────────────────────┘
进度会在不同会话间保持,因此您可以关闭 bv 并从上次停止的地方继续。
教程导航
| 快捷键 | 功能 |
|---|---|
h / l 或 ← / → |
上一页 / 下一页 |
j / k |
内容上下滚动 |
t |
切换目录 |
g / G |
第一页 / 最后一页 |
q / Esc |
关闭教程 |
上下文敏感过滤
当您从特定视图打开教程时(例如,在看板视图中按下 `),教程会自动筛选出与该上下文相关的页面。这样可以为新用户提供专注的学习体验,而不会让他们感到不知所措。
快速参考与完整教程
bv 提供两种帮助级别:
| 功能 | 快捷键 | 用途 |
|---|---|---|
| 快速参考 | ? |
当前视图的简洁键盘快捷键 |
| 完整教程 | ` |
包含示例的多页引导 |
| 快捷键侧边栏 | ; |
工作时持续显示的参考信息 |
从快速参考界面,按 Space 键即可直接进入完整教程。
📜 历史视图:珠子与提交的关联
按 h 键可打开 历史视图——一个交互式时间线,将珠子与其相关的 Git 提交关联起来。这有助于弥合“计划的工作”与“实际编写的代码”之间的差距。
关联引擎
pkg/correlation 包实现了一个 多策略关联系统,通过多种技术推断珠子和提交之间的关系:
graph TD
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8f5e9', 'lineColor': '#90a4ae'}}}%%
subgraph strategies ["🔍 关联策略"]
E["显式提及<br/><small>提交包含珠子 ID</small>"]
T["时间邻近性<br/><small>提交靠近珠子事件</small>"]
C["共同提交分析<br/><small>文件一起被修改</small>"]
P["路径匹配<br/><small>文件路径与珠子范围一致</small>"]
end
subgraph scorer ["📊 置信度评分器"]
S["多因素评分<br/><small>加权组合</small>"]
end
subgraph output ["📈 输出"]
H["BeadHistory<br/><small>事件 + 提交 + 里程碑</small>"]
end
E --> S
T --> S
C --> S
P --> S
S --> H
classDef strategy fill:#e3f2fd,stroke:#90caf9,stroke-width:2px,color:#1565c0
classDef score fill:#fff8e1,stroke:#ffcc80,stroke-width:2px,color:#e65100
classDef out fill:#e8f5e9,stroke:#a5d6a7,stroke-width:2px,color:#2e7d32
class E,T,C,P strategy
class S score
class H out
关联策略
| 策略 | 权重 | 工作原理 |
|---|---|---|
| 显式提及 | 高 | 提交消息中包含珠子 ID(例如:fix(auth): 解决竞态条件 [BV-123]) |
| 时间邻近性 | 中 | 提交时间戳落在珠子的有效生命周期窗口内 |
| 共同提交分析 | 中 | 经常一起修改的文件表明具有共同目的 |
| 路径匹配 | 低 | 文件路径与珠子的标签范围一致(例如:pkg/auth/* 对应 auth 标签) |
置信度评分
每项关联都会获得一个 置信度分数(0.0–1.0),计算公式如下:
$$ \text{置信度} = w_1 \cdot \text{显式} + w_2 \cdot \text{时间} + w_3 \cdot \text{共同提交} + w_4 \cdot \text{路径} $$
默认权重:显式=0.5,时间=0.25,共同提交=0.15,路径=0.10
历史视图布局
历史视图采用 响应式三栏布局,可根据终端宽度自适应调整:
| 宽度 | 布局 |
|---|---|
| < 100 | 单栏:带内嵌详情的列表 |
| 100-160 | 双栏:列表 + 详情 |
| > 160 | 三栏:列表 + 时间线 + 详情 |
宽屏终端(三栏)布局:
┌─────────────────────────────────────────────────────────────────────────────────┐
│ 📜 历史视图 [珠子模式] [≥ 0.5] │
├───────────────────────┬───────────────────┬─────────────────────────────────────┤
│ 珠子 │ 时间线 │ 提交详情 │
│ ───────────────── │ ───────────── │ ───────────────────────── │
│ ▸ BV-123 (3次提交) │ ┃ │ abc1234 - 修复认证竞态 │
│ 🎯 BV-456 (1次) │ ━╋━ 1月15日 │ 作者: alice@example.com │
│ 🔗 BV-789 (5次) │ ┃ ▪▪▪ │ 日期: 2025-01-15 14:32 │
│ 📁 BV-100 (2次) │ ━╋━ 1月14日 │ 置信度: 0.85(显式) │
│ │ ┃ ▪ │ │
│ │ ━╋━ 1月13日 │ 修改的文件: │
│ │ ┃ ▪▪▪▪▪ │ M pkg/auth/session.go │
└───────────────────────┴───────────────────┴─────────────────────────────────────┘
时间线面板(t 切换)
按 t 键可显示或隐藏 时间线面板——一张展示项目活动密度的可视化图表:
- 纵轴:时间(最新在顶部)
- 横条:活动密度(每日提交次数)
- 条形大小:▪ = 1-2 次,▪▪ = 3-5 次,▪▪▪ = 6-10 次,▪▪▪▪ = 11 次及以上
- 亮点:选定珠子的提交会用
━标记
点击或导航到某一天,即可将视图筛选到该时间段。
因果标记
每个珠子与提交的关联都会以可视化标记展示其检测方法:
| 标记 | 含义 | 置信度 |
|---|---|---|
| 🎯 直接 | 提交信息明确提及珠子 ID | 高(0.8-1.0) |
| 🔗 时间 | 提交发生在珠子的有效生命周期内 | 中等(0.4-0.7) |
| 📁 文件 | 提交触及与珠子相关的文件 | 低(0.2-0.5) |
视图模式
按 v 键可在两种视图模式之间切换:
| 模式 | 显示内容 | 使用场景 |
|---|---|---|
| 珠子模式(默认) | 将珠子与其相关联的提交分组 | “哪些提交与此任务相关?” |
| Git 模式 | 按时间顺序显示提交及其相关联的珠子 | “此提交涉及哪些任务?” |
基于文件的下钻视图(f 键)
按 f 键可切换到文件模式——一个按目录分组的更改文件树形视图:
┌─────────────────────────────────────────────────────────────────────────┐
│ 📁 文件模式 [12个文件] │
├─────────────────────────────────────────────────────────────────────────┤
│ ▼ pkg/auth/ │
│ session.go 42 处改动 BV-123, BV-456 │
│ token.go 18 处改动 BV-123 │
│ middleware.go 8 处改动 BV-789 │
│ ▼ pkg/api/ │
│ handler.go 25 处改动 BV-100 │
│ routes.go 12 处改动 BV-100, BV-456 │
└─────────────────────────────────────────────────────────────────────────┘
导航至某个文件并按 Enter 键,即可查看所有触及该文件的珠子和提交。
历史导航
| 键 | 动作 |
|---|---|
| 导航 | |
j / k |
在主面板(珠子或提交)中移动 |
J / K |
在次级面板(提交或详情)中移动 |
Tab |
循环焦点:列表 → 时间线 → 详情 |
Enter |
展开/折叠或深入选择项 |
| 视图模式 | |
v |
切换珠子模式 ↔ Git 模式 |
f |
切换基于文件的下钻视图 |
t |
切换时间线面板的可见性 |
| 筛选 | |
c |
循环置信度阈值(0.0 → 0.3 → 0.5 → 0.7) |
/ |
搜索提交或珠子 |
| 操作 | |
y |
将选中的提交 SHA 复制到剪贴板 |
o |
在浏览器中打开提交(GitHub/GitLab) |
V |
预览所选珠子的会话记录 |
Esc |
返回列表视图 |
机器人命令:--robot-history
bv --robot-history # 完整历史报告
bv --robot-history --bead-history BV-123 # 单个珠子聚焦
bv --robot-history --history-since '30天前'
bv --robot-history --min-confidence 0.7 # 仅高置信度
输出格式:
{
"stats": {
"total_beads": 58,
"beads_with_commits": 42,
"total_commits": 156,
"avg_cycle_time_hours": 72.5,
"method_distribution": {
"explicit": 89,
"temporal": 45,
"cocommit": 22
}
},
"histories": {
"BV-123": {
"events": [...],
"commits": [...],
"milestones": [...],
"cycle_time_hours": 48.2
}
},
"commit_index": {
"abc1234": ["BV-123", "BV-456"]
}
}
🔗 关联分析:影响网络与相关工作
除了简单的珠子与提交之间的关联外,bv 还提供了关于珠子如何通过共享代码变更相互关联的深度分析。这有助于识别隐藏的依赖关系、查找相关工作,并理解变更的真实影响。
影响网络图
影响网络基于以下内容可视化珠子之间的隐式关系:
graph LR
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e3f2fd', 'lineColor': '#90a4ae'}}}%%
subgraph connections ["🔗 边类型"]
SC["共享提交<br/><small>同一份提交同时触及两个珠子</small>"]
SF["共享文件<br/><small>两个珠子修改了相同的文件</small>"]
DEP["依赖<br/><small>显式的阻塞关系</small>"]
end
classDef edge fill:#fff8e1,stroke:#ffcc80,stroke-width:2px
class SC,SF,DEP edge
| 边类型 | 权重 | 含义 |
|---|---|---|
| 共享提交 | 高 | 一份提交同时引用了两个珠子(强耦合) |
| 共享文件 | 中等 | 两个珠子都触及了同一个源文件 |
| 依赖 | 显式 | 来自问题跟踪系统的直接阻塞关系 |
网络聚类
bv 使用社区发现算法自动检测紧密连接的珠子集群:
┌─────────────────────────────────────────────────────────────────────────┐
│ 🔗 影响网络 [3个集群] │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─── 集群 1:认证模块 ───┐ ┌─── 集群 2:API 层 ───┐ │
│ │ BV-123 ←──→ BV-456 │ │ BV-789 ←──→ BV-100 │ │
│ │ ↕ ↕ │ │ ↕ │ │
│ │ BV-321 ←──→ BV-654 │────→│ BV-111 │ │
│ └──────────────────────────────┘ └─────────────────────────────┘ │
│ │
│ 中心珠子:BV-123(度数最高) │
│ 内部连通性:0.85(紧密耦合) │
│ 外部边:1(指向 API 层集群) │
└─────────────────────────────────────────────────────────────────────────┘
文件到珠子的查找
使用 --robot-file-beads 可以找到所有触及特定文件的珠子:
bv --robot-file-beads pkg/ui/board.go
返回按最近程度排序的珠子及提交详情:
{
"file_path": "pkg/ui/board.go",
"total_beads": 21,
"open_beads": [],
"closed_beads": [
{
"bead_id": "bv-v67w",
"title": "Board: Integration & Polish",
"status": "closed",
"commit_shas": ["abc123"],
"last_touch": "2025-12-18T00:19:21-05:00",
"total_changes": 17
}
]
}
应用场景:
- 代码所有权:“最近谁在维护这个文件?”
- 影响分析:“哪些工作项受到这个文件的影响?”
- Bug 调查:“哪些变更可能导致了这次回归?”
孤儿提交检测
使用 --robot-orphans 查找本应与珠子关联但未关联的提交:
bv --robot-orphans
返回可能的珠子匹配候选提交:
{
"stats": {
"total_commits": 500,
"correlated_count": 242,
"orphan_count": 258,
"orphan_ratio": 0.516
},
"candidates": [
{
"sha": "abc1234",
"message": "feat: add auth caching",
"suspicion_score": 100,
"probable_beads": [
{
"bead_id": "bv-xyz",
"confidence": 65,
"reasons": ["touches file pkg/auth/cache.go", "same author worked on bead nearby"]
}
]
}
]
}
用例:
- 卫生检查:查找未正确关联的遗漏提交
- 审计:确保所有代码变更都追踪到工作项
- 相关性改进:通过确认或拒绝建议来训练系统
相关工作发现
对于任意珠子,bv 可以从四个维度找到其相关工作:
| 关系类型 | 检测方式 | 示例 |
|---|---|---|
| 文件重叠 | 两个珠子修改相同的源文件 | “BV-123 和 BV-456 都涉及 session.go 文件” |
| 提交重叠 | 两个珠子在同一份提交中被引用 | “BV-123 和 BV-456 在提交 abc123 中被修复” |
| 依赖簇 | 两者处于同一个紧密连接的子图中 | “BV-123 与 BV-456 同属认证模块” |
| 同时进行 | 在同一时间段内活跃 | “BV-123 和 BV-456 上周都在开发中” |
每种关系都包含一个相关性评分(0–100),表示其强度。
机器人命令
# 获取完整的影响力网络(使用 "all" 获取完整图)
bv --robot-impact-network all
# 获取聚焦于特定珠子的子网络(默认深度为 2,最大 3)
bv --robot-impact-network bv-123 --network-depth 2
# 查找某珠子的相关工作
bv --robot-related bv-123
# 在相关工作结果中包含已关闭的珠子
bv --robot-related bv-123 --related-include-closed
# 调整相关工作的阈值
bv --robot-related bv-123 --related-min-relevance 30 --related-max-results 20
# 分析某珠子的因果链(时间线、阻塞点、洞察)
bv --robot-causality bv-123
# 查找接触过某个文件的珠子
bv --robot-file-beads pkg/auth/session.go
# 查找孤儿提交(未关联珠子的提交)
bv --robot-orphans
因果链分析
--robot-causality 命令通过重建事件时间线,揭示为何某珠子耗时如此之久:
| 事件类型 | 描述 |
|---|---|
created |
珠子被创建 |
claimed |
工作开始(状态变为 in_progress) |
commit |
与珠子关联的代码提交 |
blocked |
珠子因其他珠子而被阻塞 |
unblocked |
阻塞依赖被解决 |
closed |
珠子完成 |
reopened |
珠子在关闭后重新开启 |
提供的洞察:
- 阻塞比例:等待依赖的时间占比
- 关键路径:决定最小完成时间的事件链
- 最长停滞期:识别需要调查的停滞阶段
- 建议:可操作的建议(例如:“考虑将任务拆分为更小的珠子”)
因果链输出模式:
{
"generated_at": "2025-01-15T14:32:00Z",
"data_hash": "abc123...",
"chain": {
"bead_id": "bv-123",
"title": "实现认证缓存",
"status": "closed",
"events": [
{"id": 1, "type": "created", "timestamp": "2025-01-10T10:00:00Z"},
{"id": 2, "type": "claimed", "timestamp": "2025-01-10T11:00:00Z", "caused_by_id": 1},
{"id": 3, "type": "blocked", "timestamp": "2025-01-11T09:00:00Z", "blocker_id": "bv-456"},
{"id": 4, "type": "unblocked", "timestamp": "2025-01-12T16:00:00Z"},
{"id": 5, "type": "commit", "timestamp": "2025-01-13T10:00:00Z", "commit_sha": "abc1234"},
{"id": 6, "type": "closed", "timestamp": "2025-01-13T17:00:00Z"}
],
"edge_count": 5,
"total_time": "79h0m0s",
"is_complete": true
},
"insights": {
"total_duration": "79h0m0s",
"blocked_duration": "31h0m0s",
"active_duration": "48h0m0s",
"blocked_percentage": 39.2,
"blocked_periods": [
{"start_time": "2025-01-11T09:00:00Z", "end_time": "2025-01-12T16:00:00Z", "blocker_id": "bv-456"}
],
"commit_count": 1,
"critical_path_desc": "created → claimed → blocked → unblocked → commit → closed",
"summary": "该珠子总共耗时 79 小时;其中 39% 时间被 bv-456 阻塞",
"recommendations": ["建议提前解除 bv-456 的阻塞,以减少等待时间"]
}
}
相关性反馈系统
通过确认或拒绝相关性建议来训练相关性引擎:
# 解释某相关性的存在原因
bv --robot-explain-correlation abc1234:bv-xyz
# 确认正确的相关性(提升置信度)
bv --robot-confirm-correlation abc1234:bv-xyz
# 拒绝错误的相关性(移除该关联)
bv --robot-reject-correlation abc1234:bv-xyz
# 查看反馈统计信息
bv --robot-correlation-stats
反馈统计输出:
{
"total_feedback": 15,
"confirmed": 12,
"rejected": 3,
"accuracy_rate": 0.80,
"avg_confirm_conf": 0.85,
"avg_reject_conf": 0.42
}
这一反馈循环会随着时间推移提高相关性的准确性——确认的相关性会强化模式识别能力,而拒绝则有助于消除误报。
影响力网络输出模式:
{
"generated_at": "2025-01-15T14:32:00Z",
"data_hash": "abc123...",
"stats": {
"total_nodes": 58,
"total_edges": 142,
"cluster_count": 5,
"avg_degree": 4.9,
"density": 0.086,
"isolated_nodes": 3
},
"clusters": [
{
"cluster_id": 1,
"bead_ids": ["BV-123", "BV-456", "BV-321"],
"label": "认证模块",
"internal_connectivity": 0.85,
"central_bead": "BV-123",
"shared_files": ["pkg/auth/session.go", "pkg/auth/token.go"]
}
],
"edges": [
{"from_bead": "BV-123", "to_bead": "BV-456", "edge_type": "shared_commit", "weight": 5}
]
}
🤖 Cass 集成:AI 会话关联(可选)
bv 可选择集成 cass(Claude 助手会话存储)——一款用于捕获和索引 Claude 等 AI 助手编码会话的工具。当安装 cass 后,bv 会自动利用会话级洞察增强其关联能力。
工作原理
graph LR
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8f5e9', 'lineColor': '#90a4ae'}}}%%
CASS["🤖 cass<br/><small>会话存储</small>"]
BV["⚡ bv<br/><small>问题查看器</small>"]
CORR["🔗 增强的<br/>关联功能"]
CASS --> BV
BV --> CORR
classDef tool fill:#e3f2fd,stroke:#90caf9,stroke-width:2px
class CASS,BV,CORR tool
优雅降级:若未安装 cass,bv 仍可正常工作——不会出现错误、UI 破裂或加载状态。只是 cass 的功能不可用而已。
检测与状态
bv 在启动时会自动检测 cass 的状态:
| 状态 | 标识 | 含义 |
|---|---|---|
| 健康 | 状态栏中的 🤖 | cass 已安装、已索引并就绪 |
| 需索引 | 状态栏中的 ⚠️ | cass 已安装,但需要运行 cass index |
| 未安装 | (无) | cass 未在 PATH 中——功能被隐藏 |
会话预览模态框(V 键)
在任意 bead 上按下 V 键,即可打开 会话预览模态框,其中展示了可能对该问题有贡献的 AI 编码会话:
┌─────────────────────────────────────────────────────────────────────────┐
│ 🤖 BV-123 的相关编码会话 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ▸ 会话 1(claude-opus-4) 12月15日 下午2:30 │
│ “实现会话刷新超时处理…” │
│ 置信度:0.92(明确提及) │
│ │
│ 会话 2(claude-opus-4) 12月14日 上午10:15 │
│ “重构令牌验证中间件…” │
│ 置信度:0.67(文件重叠) │
│ │
│ 会话 3(claude-opus-4) 12月13日 下午4:45 │
│ “为认证服务添加重试逻辑…” │
│ 置信度:0.45(时间相关) │
│ │
├─────────────────────────────────────────────────────────────────────────┤
│ j/k:导航 y:复制搜索命令 Enter:查看完整会话 │
└─────────────────────────────────────────────────────────────────────────┘
会话关联方法:
| 方法 | 权重 | 含义 |
|---|---|---|
| 明确提及 | 0.9–1.0 | 会话中直接提到 bead ID |
| 文件重叠 | 0.5–0.8 | 会话涉及与该 bead 相关的文件 |
| 时间相关 | 0.3–0.6 | 会话发生于 bead 的活跃生命周期内 |
| 关键词匹配 | 0.2–0.5 | 会话包含来自 bead 标题或描述的关键词 |
状态栏指示器
当 cass 处于健康状态时,状态栏会显示代理活动:
┌────────────────────────────────────────────────────────────────────────┐
│ 📋 437 个问题 • 🤖 claude-opus-4(活跃) • 最后:5 分钟前 │
└────────────────────────────────────────────────────────────────────────┘
| 状态 | 显示 | 含义 |
|---|---|---|
| 活跃 | 🤖 代理名称 | 近 15 分钟内正在进行会话 |
| 空闲 | 💤 | 无近期会话 |
安装 Cass
# 安装 cass(完整文档请参见 https://github.com/Dicklesworthstone/coding_agent_session_search)
brew install dicklesworthstone/tap/cass # macOS
# 或
cargo install cass # 从源码安装
# 索引你的编码会话
cass index
# 验证集成
bv # 查看状态栏中是否有 🤖
Cass 增强的历史视图
当 cass 可用时,历史视图将具备以下额外功能:
- 会话时间线:按
V键可同时查看会话和提交记录 - 代理归属:了解是哪位 AI 助手对代码变更做出了贡献
- 增强搜索:可在提交记录和会话中进行联合搜索
📅 Sprint 仪表板:燃尽图与进度跟踪
按下 P 键(大写)即可打开 Sprint 仪表板,这是一个全面展示 sprint 进度的视图,包含燃尽图可视化、范围变更跟踪以及风险项检测。
仪表板布局
┌─────────────────────────────────────────────────────────────────────────┐
│ 📅 Sprint:2025年1月 │
│ ─────────────────────────────────────────────────────────────────── │
│ 日期:1月6日 → 1月20日 │
│ 剩余:5天 │
│ │
│ ══════════════════════════════════════════════════════════════════ │
│ 进度 │
│ ══════════════════════════════════════════════════════════════════ │
│ │
│ 总数:24 个 bead 已关闭:18个(75%) 剩余:6个 │
│ [████████████████████░░░░░░] 75% │
│ │
│ ══════════════════════════════════════════════════════════════════ │
│ 燃尽图 │
│ ══════════════════════════════════════════════════════════════════ │
│ │
│ 24 ┤ · │
│ 20 ┤ ····· │
│ 16 ┤ ····▸ │
│ 12 ┤ ╲ (理想) │
│ 8 ┤ ╲ │
│ 4 ┤ ╲ │
│ 0 ┼────────────────────────────────────────────────────────────── │
│ 1月6日 1月13日 1月20日 │
│ │
│ 图例:· = 实际 ╲ = 理想 ▸ = 今日 │
│ │
│ ══════════════════════════════════════════════════════════════════ │
│ 范围变更 │
│ ══════════════════════════════════════════════════════════════════ │
│ │
│ 1月8日:新增 2 个 bead(BV-456、BV-457) │
│ 1月10日:移除 1 个 bead(BV-100 被移至待办列表) │
│ │
│ ══════════════════════════════════════════════════════════════════ │
│ 风险项 │
│ ══════════════════════════════════════════════════════════════════ │
│ │
│ ⚠ BV-789(P0 严重) - 已阻塞 3 天 │
│ ⚠ BV-234(P1 高) - 已 5 天未有进展 │
└─────────────────────────────────────────────────────────────────────────┘
燃尽图计算
燃尽图采用一种范围感知算法,不仅跟踪完成速度,还跟踪范围的变化:
- 理想燃尽速率:
总任务数 / Sprint 时长 - 实际燃尽速率:
已完成任务数 / 已经过的天数 - 范围事件:新增或移除的任务会在理想线上产生断点。
当在 Sprint 中间添加任务时,燃尽图会从该点重新计算理想轨迹,从而提供一个更真实的进度视图,而不是误导性的“落后于计划”指示。
风险检测
根据多种启发式规则,项目会被标记为有风险:
| 信号 | 阈值 | 原因 |
|---|---|---|
| 阻塞时长 | > 2 天 | 依赖瓶颈 |
| 无活动 | > 4 天 | 可能卡住或被遗忘 |
| 高优先级阻塞 | P0/P1 阻塞 | 关键路径障碍 |
| 依赖未解决 | 阻塞项仍未关闭 | 连锁延迟风险 |
机器人命令
bv --robot-sprint-list # 列出所有 Sprint
bv --robot-sprint-show sprint-1 # 查看特定 Sprint 的详细信息
bv --robot-burndown current # 当前活跃 Sprint 的燃尽图
bv --robot-burndown sprint-1 # 特定 Sprint 的燃尽图
燃尽图输出:
{
"sprint_id": "sprint-1",
"total_days": 14,
"elapsed_days": 9,
"remaining_days": 5,
"total_issues": 24,
"completed_issues": 18,
"remaining_issues": 6,
"ideal_burn_rate": 1.71,
"actual_burn_rate": 2.0,
"projected_complete": "2025-01-18",
"on_track": true,
"scope_changes": [
{"date": "2025-01-08", "delta": 2, "reason": "新增 BV-456、BV-457"}
]
}
🏷️ 标签分析:领域中心的健康监控
按下 L(大写)可打开标签仪表板——一个表格视图,显示项目中每个标签的健康指标。这有助于通过揭示代码库中哪些区域需要关注来实现领域驱动的优先级排序。
标签仪表板布局
┌─────────────────────────────────────────────────────────────────────────┐
│ 🏷️ 标签健康 │
├──────────────┬────────┬────────┬────────┬────────┬────────┬────────────┤
│ 标签 │ 健康度 │ 状态 │ 开放 │ 阻塞│ 老化 │ 流量 │
├──────────────┼────────┼────────┼────────┼────────┼────────┼────────────┤
│ 🔴 api │ 0.32 │ CRIT │ 12 │ 5 │ 3 │ 0.8/周 │
│ 🟡 auth │ 0.58 │ WARN │ 8 │ 2 │ 1 │ 2.1/周 │
│ 🟢 ui │ 0.85 │ OK │ 4 │ 0 │ 0 │ 4.2/周 │
│ 🟢 docs │ 0.92 │ OK │ 2 │ 0 │ 0 │ 1.5/周 │
│ 🟡 infra │ 0.61 │ WARN │ 6 │ 1 │ 2 │ 1.2/周 │
└──────────────┴────────┴────────┴────────┴────────┴────────┴────────────┘
健康度计算
标签健康度综合了多个因素:
$$ \text{健康} = 1 - \left( w_1 \cdot \frac{\text{阻塞数}}{\text{开放数}} + w_2 \cdot \frac{\text{老化数}}{\text{开放数}} + w_3 \cdot (1 - \text{流量评分}) \right) $$
| 组件 | 权重 | 含义 |
|---|---|---|
| 阻塞比例 | 0.4 | 高阻塞数量表明存在瓶颈 |
| 老化比例 | 0.3 | 老化问题暗示疏忽 |
| 流量倒数 | 0.3 | 低吞吐量表明容量问题 |
健康等级
| 等级 | 分数范围 | 指示 | 行动 |
|---|---|---|---|
| 严重 | 0.0 – 0.4 | 🔴 | 需立即处理 |
| 警告 | 0.4 – 0.7 | 🟡 | 密切监控 |
| 健康 | 0.7 – 1.0 | 🟢 | 进展正常 |
用于标签分析的机器人命令
--robot-label-health:按标签显示健康指标
bv --robot-label-health
bv --robot-label-health | jq '.results.labels[] | select(.health_level == "critical")'
--robot-label-flow:跨标签依赖关系矩阵
bv --robot-label-flow
bv --robot-label-flow | jq '.flow.bottleneck_labels'
--robot-label-attention:按关注度排序的标签,用于优先级排序
bv --robot-label-attention --attention-limit=5
标签范围内的分析
使用 --label 参数可以将任何机器人命令限定在特定标签的子图范围内:
bv --robot-insights --label api # 仅针对 api 标签的问题生成图表指标
bv --robot-plan --label backend # 针对 backend 领域的执行计划
bv --robot-priority --label auth # 针对 auth 工作的优先级建议
这实现了领域隔离:可以在一个限定的上下文中进行分析和规划,而不是在整个项目图上操作。
流量矩阵:跨标签依赖关系
流量矩阵展示了标签之间的依赖关系:
→ api → auth → ui → docs
api - 3 2 0
auth 1 - 0 1
ui 4 2 - 0
docs 0 0 0 -
解读为:“api 有 3 个问题依赖于 auth 的问题。” 高数值表示领域之间的耦合;bottleneck_labels 字段则突出显示阻碍最多跨领域工作的标签。
🌐 静态站点导出:可共享的仪表板
bv 可以生成自包含的静态网站,方便与没有终端访问权限的利益相关者分享项目状态。
交互式向导
bv --pages
启动一个交互式向导,引导您完成以下步骤:
- 导出:生成静态资源包
- 预览:本地服务器地址为
http://localhost:9000(或下一个可用端口) - 部署:推送到 GitHub Pages,并自动创建仓库
直接导出
bv --export-pages ./bv-pages # 导出到指定目录
bv --export-pages ./bv-pages --pages-title "Sprint 42 Status"
bv --export-pages ./bv-pages --pages-exclude-closed # 排除已完成的问题
bv --export-pages ./bv-pages --pages-exclude-history # 排除 Git 历史记录
# 预览现有资源包,无需重新生成
bv --preview-pages ./bv-pages # 在 localhost:9000(或下一个可用端口)提供服务
可选:混合搜索 WASM 计分器
对于非常大的数据集,您可以构建一个可选的 WASM 计分器,供静态查看器使用。
# 一次性构建(需要 wasm-pack)
./scripts/build_hybrid_wasm.sh
# 或在导出时构建
BV_BUILD_HYBRID_WASM=1 bv --export-pages ./bv-pages
如果缺少 wasm/ 资源,查看器会自动回退到 JS 计分器。
生成的内容
./bv-pages/
├── index.html # 主仪表板,使用 Alpine.js + Tailwind
├── beads.sqlite3 # 完整的 SQLite 数据库(约 2MB,包含 400 多个问题)
├── data/
│ ├── graph_layout.json # 预先计算的位置和指标(约 82KB)
│ ├── meta.json # 导出元数据
│ ├── triage.json # 分类建议
│ └── history.json # 问题与提交的关联数据
└── vendor/
├── d3.v7.min.js # 可视化库
├── force-graph.min.js # 图形渲染
└── bv_graph.js # WASM 图形引擎
图形可视化:渲染速度提升16倍
导出采用混合架构,实现图形的即时加载:
| 组件 | 大小 | 用途 |
|---|---|---|
graph_layout.json |
~82KB | 预计算的节点位置 + 图谱指标 |
beads.sqlite3 |
~2MB | 完整的问题数据,用于详情面板、搜索和表格 |
工作原理:
- 浏览器首先加载极小的
graph_layout.json(宽带下约100毫秒)。 - 使用预计算的
fx/fy固定位置,图形立即渲染。 - SQLite 并行加载,以支持搜索和详情功能。
- 完全跳过力导向模拟——无抖动,无布局延迟。
性能对比:
| 指标 | 未预计算 | 已预计算 |
|---|---|---|
| 初始加载 | 4+秒 | ~250毫秒 |
| 力导向模拟 | 2+秒 | 0毫秒(已跳过) |
| 图形数据 | 914KB(冗余) | 82KB(精简) |
详情面板
点击任意节点即可打开一个400px宽的滑动详情面板:
┌─────────────────────────────────────────────────────────────────────┐
│ │ ╭─────────────────────────╮ │
│ │ │ BV-123: 认证重构 │ │
│ [交互式图] │ │ ─────────────────────── │ │
│ │ │ 优先级:P1(高) │ │
│ ⬤ │ │ 类型:功能 │ │
│ /│\ │ │ 状态:进行中 │ │
│ / │ \ │ │ │ │
│ ⬤ ⬤ ⬤ │ │ **描述** │ │
│ │ │ 重构认证模块... │ │
│ │ │ │ │
│ │ │ ⛔ 3个阻塞项 │ │
│ │ │ 📤 阻塞了5个问题 │ │
│ │ ╰─────────────────────────╯ │
└─────────────────────────────────────────────────────────────────────┘
详情面板包含:
- 完整的问题标题和描述(Markdown渲染)
- 优先级、类型、状态及可视化标识
- 阻塞项数量(“⛔ 3个阻塞项”)——必须先完成的问题
- 被阻塞问题数量(“📤 阻塞了5个问题”)——等待此问题解决的下游工作
- PageRank、介数中心性等指标(来自预计算数据)
功能特性
- 全文搜索:SQLite FTS5 提供跨所有问题标题和描述的即时搜索。结果随键入显示,无需服务器。
- 交互式图:使用 D3.js 力导向图可视化依赖关系,支持缩放、平移和节点选择。
- 详情面板:点击任意节点可查看完整问题详情及依赖信息。
- 分类视图:与
--robot-triage提供的建议相同。 - 离线支持:首次加载后无需网络即可使用。
- 移动端响应式:适配手机/平板屏幕,提供触控友好的交互体验。
技术说明
静态导出采用混合架构,结合以下组件:
纯Go SQLite(modernc.org/sqlite):
- 无需C编译器——可在任何系统上运行,无需CGO。
- 跨平台打包生成。
- 内置FTS5全文搜索。
预计算图布局:
- BFS层次布局,按深度分配X坐标。
- 节点位置存储为
[x, y]对。 - 指标存储为紧凑的5元素数组:
[pagerank, betweenness, inDegree, outDegree, inCycle]。 - 相比完整图JSON,文件大小缩减约91%。
WASM图引擎(
bv_graph.js):- 客户端侧环检测。
- 高效的邻居查找。
- 用于阻塞链的路径查找。
部署选项
| 平台 | 命令 | 备注 |
|---|---|---|
| GitHub Pages | bv --pages(向导) |
自动创建 gh-pages 分支 |
| Cloudflare Pages | bv --export-pages ./dist + CF控制台 |
连接至Git仓库 |
| 任何静态托管服务 | bv --export-pages ./dist |
Netlify、Vercel、S3等 |
🚨 警报系统:主动健康监测
警报系统能够在问题演变为阻塞之前,提前发现潜在风险。它结合了漂移检测(与基线的偏差)和主动分析(基于模式的警告)。
警报类型
| 类型 | 触发条件 | 严重程度 | 示例 |
|---|---|---|---|
stale_issue |
30天以上无更新 | 警告 | “BV-123自10月15日以来未被处理” |
blocking_cascade |
一个问题阻塞5个及以上问题 | 严重 | “AUTH-001正在阻塞8个下游任务” |
priority_mismatch |
优先级低但PageRank高 | 警告 | “BV-456优先级为P3,但PageRank排名第二” |
cycle_introduced |
新出现循环依赖 | 严重 | “检测到循环:A → B → C → A” |
scope_creep |
开放问题数量增加20%以上 | 信息 | “本周开放问题从45个增至58个” |
TUI集成
按下 ! 键即可打开警报面板:
┌─────────────────────────────────────────────────────────────┐
│ 🚨 警报(3条活跃) [!] 关闭 │
├─────────────────────────────────────────────────────────────┤
│ ⚠️ 警告:bv-123已闲置45天 │
│ 🔴 严重:bv-456阻塞8个任务(级联风险) │
│ ℹ️ 信息:本冲刺周期开放问题增加了23% │
├─────────────────────────────────────────────────────────────┤
│ j/k 导航 • Enter 跳转至问题 • d 屏蔽 • q 关闭 │
└─────────────────────────────────────────────────────────────┘
机器人集成
# 获取所有警报的JSON格式
bv --robot-alerts
# 按严重程度筛选(信息、警告、严重)
bv --robot-alerts --severity=critical
# 按类型筛选
bv --robot-alerts --alert-type=blocking_cascade
# 按受影响标签筛选
bv --robot-alerts --alert-label=backend
输出格式
{
"alerts": [
{
"type": "blocking_cascade",
"severity": "critical",
"issue_id": "bv-456",
"message": "阻塞8个下游任务",
"blocked_ids": ["bv-101", "bv-102", "..."],
"suggested_action": "优先完成或拆分为更小的任务"
}
],
"summary": {
"total": 3,
"critical": 1,
"warning": 1,
"info": 1
}
}
🤖 完整CLI参考
除了交互式TUI外,bv还提供全面的命令行接口,适用于脚本编写、自动化以及AI代理集成。
核心命令
bv # 启动交互式TUI
bv --help # 显示所有选项
bv --version # 显示版本号
机器人协议命令
这些命令会输出专为程序化消费设计的结构化 JSON:
| 命令 | 输出 | 使用场景 |
|---|---|---|
--robot-triage |
超级命令:包含所有分析的统一分类 | 代理的单一入口点 |
--robot-next |
单个最高推荐项 + 执行命令 | 快速回答“下一步是什么?” |
--robot-insights |
图形指标 + 前N名列表 | 项目健康评估 |
--robot-plan |
可执行的任务轨道 + 依赖关系 | 工作队列生成 |
--robot-priority |
优先级建议 | 自动化优先级修复 |
--robot-history |
提交与问题的关联 | 代码变更追踪 |
--robot-label-health |
按标签的健康指标 | 领域健康监控 |
--robot-label-flow |
标签间依赖矩阵 | 跨领域分析 |
--robot-label-attention |
按关注度排序的标签 | 领域优先级排序 |
--robot-sprint-list |
所有冲刺以 JSON 格式 | 冲刺计划 |
--robot-burndown |
冲刺燃尽数据 | 进度跟踪 |
--robot-suggest |
卫生建议(依赖、重复、标签、循环) | 项目清理自动化 |
--robot-diff |
JSON 差异(配合 --diff-since) |
变更追踪 |
--robot-recipes |
可用配方列表 | 配方发现 |
--robot-graph |
依赖关系图以 JSON/DOT/Mermaid 格式 | 图表可视化与导出 |
--robot-forecast |
按问题预测的 ETA | 完成时间预估 |
--robot-capacity |
团队容量模拟 | 资源规划 |
--robot-alerts |
偏离预警 + 主动警告 | 健康监控 |
--robot-help |
详细 AI 代理文档 | 代理入职 |
所有机器人命令都支持 --as-of <ref> 用于历史分析。指定后,输出将包含 as_of 和 as_of_commit 元数据字段。
时间旅行命令
--as-of 标志允许您在不修改工作树的情况下查看项目的任意历史状态。它既适用于交互式 TUI,也适用于所有机器人命令。
# 查看历史状态(TUI)
bv --as-of HEAD~10 # 10 次提交之前
bv --as-of v1.0.0 # 在发布标签处
bv --as-of 2024-01-15 # 在特定日期
bv --as-of main@{2024-01-15} # 分支在该日期的状态
# 使用机器人命令进行历史分析
bv --robot-insights --as-of HEAD~30 # 30 次提交前的图形指标
bv --robot-plan --as-of v1.0.0 # 发布时的执行计划
bv --robot-triage --as-of 2024-06-01 # 特定日期的全面分类
bv --robot-priority --as-of HEAD~5 # 5 次提交前的优先级建议
# 比较变更
bv --diff-since HEAD~5 # 最近 5 次提交的变更
bv --diff-since v1.0.0 # 自发布以来的变更
bv --diff-since 2024-01-01 # 自该日期以来的变更
# JSON 差异输出(结合 `--as-of` 获取“到”快照)
bv --diff-since HEAD~10 --robot-diff # 从 HEAD~10 到当前
bv --diff-since HEAD~10 --as-of HEAD~5 --robot-diff # 从 HEAD~10 到 HEAD~5
当使用 --as-of 与机器人命令结合时,JSON 输出会包含额外的元数据:
as_of: 您指定的引用(例如,“HEAD~30”、“v1.0.0”)as_of_commit: 解析后的提交 SHA,以确保可重复性
配方命令
# 列出可用配方
bv --robot-recipes
# 应用内置配方
bv --recipe actionable # 立即可执行
bv --recipe high-impact # PageRank 得分最高的
bv --recipe stale # 30 天以上未触碰
bv --recipe blocked # 等待依赖解决
bv -r recent # 短标志,7 天内更新
# 应用自定义配方
bv --recipe .beads/recipes/sprint.yaml
导出命令
# 生成带有 Mermaid 图的 Markdown 报告
bv --export-md report.md
# 导出优先级简报(重点摘要)
bv --priority-brief brief.md
# 导出完整的代理简报包
bv --agent-brief ./agent-bundle/
# 生成:triaje.json、insights.json、brief.md、helpers.md
ETA 预测与容量规划
# 预测特定问题的完成 ETA
bv --robot-forecast bv-123
# 对所有开放问题进行预测并筛选
bv --robot-forecast all --forecast-label=backend
bv --robot-forecast all --forecast-sprint=sprint-1
bv --robot-forecast all --forecast-agents=2 # 多代理并行处理
# 容量模拟:什么时候所有任务都能完成?
bv --robot-capacity # 默认:1 个代理
bv --robot-capacity --agents=3 # 3 个并行代理
bv --robot-capacity --capacity-label=frontend # 限定于特定标签
警报与健康监控
# 获取所有警报(偏离预警 + 主动健康检查)
bv --robot-alerts
# 按严重程度筛选
bv --robot-alerts --severity=critical
bv --robot-alerts --severity=warning
# 按警报类型筛选
bv --robot-alerts --alert-type=stale_issue
bv --robot-alerts --alert-type=blocking_cascade
# 按标签范围筛选
bv --robot-alerts --alert-label=backend
分类分组(多代理协调)
# 按执行轨道对建议进行分组(并行工作流)
bv --robot-triage --robot-triage-by-track
# 按标签对建议进行分组(领域专注代理)
bv --robot-triage --robot-triage-by-label
Shell 脚本生成
从建议中生成可执行的 Shell 脚本,用于自动化工作流:
# 为前 5 条建议生成 Bash 脚本
bv --robot-triage --emit-script --script-limit=5
# 不同的 Shell 格式
bv --robot-triage --emit-script --script-format=fish
bv --robot-triage --emit-script --script-format=zsh
反馈系统(自适应建议)
反馈系统会根据您的接受或忽略决定来调整建议权重:
# 记录正面反馈(您已执行此建议)
bv --feedback-accept bv-123
# 记录负面反馈(您跳过了此建议)
bv --feedback-ignore bv-456
# 查看当前反馈状态及权重调整
bv --feedback-show
# 将反馈重置为默认值
bv --feedback-reset
基线与漂移检测
# 将当前状态保存为基线
bv --save-baseline "Pre-release v2.0"
# 显示基线信息
bv --baseline-info
# 检查是否偏离基线
bv --check-drift # 退出码:0=正常,1=严重,2=警告
bv --check-drift --robot-drift # JSON 输出
语义搜索
# 对标题/描述进行语义向量搜索
bv --search "login oauth"
# 用于自动化的 JSON 输出
bv --search "login oauth" --robot-search
# 混合搜索(文本 + 图形指标)
bv --search "login oauth" --search-mode hybrid --search-preset impact-first
# 混合模式,自定义权重
bv --search "login oauth" --search-mode hybrid \
--search-weights '{"text":0.4,"pagerank":0.2,"status":0.15,"impact":0.1,"priority":0.1,"recency":0.05}'
语义搜索会基于加权的问题文档(ID 和标题重复,包含标签和描述)构建一个轻量级向量索引。这样既能保持快速查找,又能像人类可读的搜索一样工作。
混合模式是一个两阶段的流程:首先根据语义相似度检索出最相关的候选问题,然后使用图感知信号(PageRank、状态、影响、优先级、最近性)对这些候选问题进行重新排序。这使得结果既紧扣查询内容,又能突出依赖关系图中最重要的项目——非常符合 bv 的目标,即让“为什么这件事重要”一目了然。
对于简短且意图明确的查询(例如“benchmarks”、“oauth”),bv 会特意采取不同的处理方式。它会扩大候选池,提升精确匹配的权重,并提高文本相关性的权重,从而使快速查找表现得更像一次精准搜索。而对于较长、描述性更强的查询,则更多地依赖图信号来进行智能的并列解决和优先级排序。
混合模式的默认设置可以通过以下方式配置:
BV_SEARCH_MODE(text|hybrid)BV_SEARCH_PRESET(default|bug-hunting|sprint-planning|impact-first|text-only)BV_SEARCH_WEIGHTS(JSON 字符串,会覆盖预设值)
在 --robot-search 的 JSON 输出中,混合模式的结果会包含 mode、preset、weights,以及每个结果的 text_score 和 component_scores。
示例:AI 代理工作流
#!/bin/bash
# agent-workflow.sh - 自动化任务选择
# 1. 获取执行计划
PLAN=$(bv --robot-plan)
# 2. 提取最具影响力的可执行任务
TASK=$(echo "$PLAN" | jq -r '.plan.summary.highest_impact')
# 3. 获取完整洞察以提供上下文
INSIGHTS=$(bv --robot-insights)
# 4. 检查完成此任务是否会引入回归
BASELINE=$(bv --diff-since HEAD~1 --robot-diff)
echo "正在处理:$TASK"
echo "将解除阻塞:$(echo "$PLAN" | jq '.plan.summary.unblocks_count') 个任务"
输出示例
--robot-priority 输出:
{
"generated_at": "2025-01-15T10:30:00Z",
"recommendations": [
{
"issue_id": "CORE-123",
"current_priority": 3,
"suggested_priority": 1,
"confidence": 0.87,
"direction": "increase",
"reasoning": "高 PageRank(0.15)+ 高介数中心性(0.45)表明这是一个基础性阻塞问题"
}
],
"summary": {
"total_issues": 58,
"recommendations": 12,
"high_confidence": 5
}
}
--robot-recipes 输出:
{
"recipes": [
{ "name": "actionable", "description": "可立即处理(无阻塞)", "source": "builtin" },
{ "name": "high-impact", "description": "PageRank 得分最高", "source": "builtin" },
{ "name": "sprint-review", "description": "当前冲刺中的问题", "source": "project" }
]
}
🏢 多仓库工作区支持
对于单体仓库和多包架构,bv 提供了 工作区配置,可以将多个仓库中的问题统一到一个连贯的视图中。
工作区配置文件(.bv/workspace.yaml)
# .bv/workspace.yaml - 多仓库工作区定义
name: my-workspace
repos:
- name: api
path: services/api
prefix: "api-" # 问题会变成 api-AUTH-123
beads_path: .beads # 可选的仓库级覆盖(默认为 .beads)
- name: web
path: apps/web
prefix: "web-" # 问题会变成 web-UI-456
- name: shared
path: packages/shared
prefix: "lib-" # 问题会变成 lib-UTIL-789
discovery:
enabled: true
patterns:
- "*" # 直接子目录
- "packages/*" # npm/pnpm 工作空间
- "apps/*" # Next.js/Turborepo
- "services/*" # 微服务
- "libs/*" # 库包
exclude:
- node_modules
- vendor
- .git
max_depth: 2
defaults:
beads_path: .beads # 在每个仓库中查找 beads.jsonl 的位置
ID 命名空间
当跨多个仓库工作时,问题会自动进行命名空间划分:
| 本地 ID | 仓库前缀 | 命名空间 ID |
|---|---|---|
AUTH-123 |
api- |
api-AUTH-123 |
UI-456 |
web- |
web-UI-456 |
UTIL-789 |
lib- |
lib-UTIL-789 |
跨仓库依赖关系
工作区系统支持 跨仓库的阻塞关系:
┌─────────────────────────────────────────────────────────┐
│ web-UI-456 (apps/web) │
│ “实现 OAuth 登录页面” │
│ │
│ 阻塞:api-AUTH-123、lib-UTIL-789 │
└─────────────────────────────────────────────────────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ api-AUTH-123 │ │ lib-UTIL-789 │
│ (services/api) │ │ (packages/lib) │
│ “认证端点” │ │ “令牌工具” │
└─────────────────┘ └─────────────────┘
工作区内筛选
使用 --repo 参数可以将视图(以及机器人输出)限定到特定的仓库前缀。匹配不区分大小写,并接受常见的分隔符(-、:、_);如果存在 source_repo 字段,则会优先考虑该字段。
支持的单体仓库布局
| 布局 | 模式 | 示例项目 |
|---|---|---|
| npm/pnpm 工作空间 | packages/* |
Lerna、Turborepo |
| Next.js 应用 | apps/* |
Vercel 单体仓库 |
| 微服务 | services/* |
后端平台 |
| Go 模块 | modules/* |
多模块 Go 项目 |
| 扁平结构 | * |
简单的单体仓库 |
ID 解析
IDResolver 会智能地处理跨仓库引用:
resolver := NewIDResolver(config, "api")
// 从 api 仓库上下文中:
resolver.Resolve("AUTH-123") // → {Namespace: "api-", LocalID: "AUTH-123"}
resolver.Resolve("web-UI-456") // → {Namespace: "web-", LocalID: "UI-456"}
resolver.IsCrossRepo("web-UI-456") // → true
resolver.DisplayID("api-AUTH-123") // → "AUTH-123"(本地,去掉前缀)
resolver.DisplayID("web-UI-456") // → "web-UI-456"(跨仓库,保留前缀)
⏰ 交互式时间旅行模式
除了 CLI 中的 diff 命令之外,bv 还支持在 TUI 内部进行 交互式时间旅行。该模式会在问题列表上叠加差异标记,让你直观地探索哪些内容发生了变化。
激活时光旅行模式
在主列表视图中按下 t 键,即可进入带有自定义修订版本提示的时光旅行模式:
┌──────────────────────────────────────────┐
│ ⏱️ 时间旅行模式 │
│ │
│ 将当前状态与历史修订版本进行比较 │
│ │
│ ⏱️ 修订版本: HEAD~5█ │
│ │
│ 示例:HEAD~5、main、v1.0.0、 │
│ 2024-01-01、abc123 │
│ │
│ 按 Enter 键比较,按 Esc 键取消 │
└──────────────────────────────────────────┘
若需快速访问,可按下 T 键(大写),直接与 HEAD~5 进行比较,无需提示。
差异徽章
激活后,问题会显示视觉徽章,指示其差异状态:
| 徽章 | 含义 | 颜色 |
|---|---|---|
[NEW] |
自基线以来创建的问题 | 绿色 |
[CLOSED] |
自基线以来关闭的问题 | 灰色 |
[MODIFIED] |
问题字段已更改 | 黄色 |
[REOPENED] |
自基线以来重新打开的问题 | 橙色 |
可视化示例
┌────────────────────────────────────────────────────────────┐
│ 📋 问题(自 HEAD~5 起) 总计 58 个 │
├────────────────────────────────────────────────────────────┤
│ [NEW] ✨ FEAT-789 添加暗色模式切换 P2 🟢 │
│ [NEW] 🐛 BUG-456 修复登录竞争条件 P1 🟢 │
│ [MODIFIED] 📝 TASK-123 更新文档 P3 🟡 │
│ ✨ FEAT-100 OAuth 集成 P1 🟢 │
│ [CLOSED] 🐛 BUG-001 解析器中的内存泄漏 P0 ⚫ │
└────────────────────────────────────────────────────────────┘
时光旅行摘要面板
页脚显示汇总统计信息:
─────────────────────────────────────────────────────────────
📊 变更:+3 新建 ✓2 关闭 ~1 修改 ↺0 重新打开
健康状况:↑ 改善中(密度:-0.02,周期:-1)
─────────────────────────────────────────────────────────────
时光旅行导航
| 键 | 操作 |
|---|---|
t |
进入时光旅行(自定义修订版本提示) |
T |
快速时光旅行(HEAD~5) |
t(在时光旅行模式中) |
退出时光旅行模式 |
n |
跳转到下一个变更问题 |
N |
跳转到上一个变更问题 |
🧪 质量保证与鲁棒性
信任是通过努力赢得的。bv 采用严格的测试策略,以确保它能够应对真实世界代码库中可能出现的各种复杂情况。
1. 合成数据模糊测试
我们不仅针对“正常路径”数据进行测试。测试套件(pkg/loader/synthetic_test.go)会生成合成复杂图——包含数千个节点、错综复杂的依赖循环以及边缘 UTF-8 字符的大规模 JSONL 文件——以验证图引擎和渲染逻辑在高负载下绝不会崩溃。
2. 对损坏数据的鲁棒性
在基于 Git 的工作流中,合并冲突和部分写入时有发生。TestLoadIssuesRobustness 测试套件会明确地向数据流中注入垃圾行和损坏的 JSON。
- 结果:
bv能够检测到损坏数据,将警告记录到stderr,并继续加载有效数据。它绝不会因为一行错误数据而导致用户会话崩溃。
贡献测试
对于编写测试的贡献者,请参阅全面的**测试指南**,其中涵盖了:
- 测试理念(不使用模拟、表格驱动测试、黄金文件)
- 使用
testutil包生成测试用例 - 运行测试、覆盖率和基准测试
- E2E 测试模式及 CI 集成
🔄 无摩擦更新引擎
bv 内置了一个主动且非侵入式的更新检查功能,以确保您不会错过任何新功能。我们认为工具应该能够自我维护,而不应打断您的工作流程。
设计与实现
更新程序(pkg/updater/updater.go)的设计宗旨是安静与安全:
- 非阻塞并发: 检查会在一个独立的 goroutine 中运行,且有严格的2 秒超时限制。它绝不会延迟您的启动时间或影响 UI 的交互性。
- 语义版本控制: 它不仅仅是简单地匹配字符串。自定义的 SemVer 比较器确保您只会收到关于严格意义上的新版本的通知,从而处理诸如发布候选版与稳定版等复杂边缘情况。
- 容错性: 它能够优雅地处理网络分区、GitHub API 速率限制(403/429)以及超时等情况,静默失败。您永远不会因为更新检查而看到崩溃或错误日志。
- 不显眼的通知: 当发现更新时,
bv不会弹出模态窗口。它只是在页脚处显示一个低调的有更新可用指示符(⭐),让您自行决定何时升级。
🗂️ 数据加载与自我修复
可靠性至关重要。bv 并不假设环境完美;它会主动处理常见的文件系统不一致性。
1. 智能路径发现
加载器(pkg/loader/loader.go)并不会盲目地打开 .beads/beads.jsonl。它采用基于优先级的发现算法:
- 标准路径: 检查
issues.jsonl(beads 上游推荐的格式)。 - 旧版路径: 回退到
beads.jsonl以保持向后兼容性。 - 基础路径: 检查
beads.base.jsonl(由br在守护进程模式下使用)。 - 验证: 它会跳过临时文件,如
*.backup或deletions.jsonl,以防止显示损坏的状态。
2. 强大的解析能力
JSONL 解析器被设计为容错型。
- 它使用缓冲扫描器(
bufio.NewScanner)配合 10MB 的宽松行长度限制,以处理巨大的描述文本块。 - 格式错误的行(例如来自合并冲突的行)会被跳过,并发出警告,而不是导致应用程序崩溃。这样即使在糟糕的 Git 合并过程中,您仍然可以查看项目中未损坏的部分。
🧩 设计哲学:为何选择图?
传统的任务跟踪工具(Jira、GitHub Issues、Trello)将工作视为“容器”:“待办”、“进行中”、“已完成”。这对于简单的任务列表来说尚可,但在大规模场景下却显得力不从心,因为它忽略了结构。
在复杂的软件项目中,任务并非孤立存在,而是相互紧密关联。一个“简单”的前端任务可能依赖于后端接口,而后端接口又依赖于架构变更,而架构变更则需要迁移脚本的支持。
bv 采用了图优先的理念:
- 结构即现实: 依赖关系图就是整个项目本身。列表视图只是该图的一个投影而已。
- 明确的阻塞关系: 我们不只是简单地“关联”任务,还会定义严格的“阻塞”关系。如果 A 阻塞 B,那么在 A 关闭之前,您根本无法在
bv中将 B 标记为“就绪”。 - 本地优先、文本为基础: 您的项目数据存储在您的仓库中(
.beads/beads.jsonl),而不是远程服务器上。它随您的代码一起移动,随着您的分支一起分叉,并随着您的 PR 一起合并。
⚡ 性能规格
bv 专为速度而设计。我们相信,延迟是流畅体验的敌人。
- 启动时间: 对于典型仓库(少于 1000 个问题),启动时间小于 50 毫秒。
- 渲染: 使用 Bubble Tea 实现 60 FPS 的 UI 更新。
- 虚拟化: 列表视图和 Markdown 渲染器完全采用窗口化技术。
bv能够处理包含 10,000+ 个问题 的仓库,而不会出现 UI 卡顿,同时占用极少的内存。 - 图计算: 两阶段分析器会立即计算拓扑结构、度数和密度,随后异步计算 PageRank、介数中心性、HITS、关键路径和环路,并设置与规模相关的超时机制。
- 缓存: 重复的分析会自动重用哈希结果,避免在珠状图未发生变化时进行重复计算。
性能基准测试
bv 包含一套全面的基准测试套件,用于验证性能:
# 运行所有基准测试
./scripts/benchmark.sh
# 将当前性能保存为基准
./scripts/benchmark.sh baseline
# 与基准对比(需要 benchstat)
./scripts/benchmark.sh compare
# 快速基准测试(CI 模式)
./scripts/benchmark.sh quick
基准测试类别:
- 完整分析: 各种规模下的端到端
Analyze()流程 - 单个算法: PageRank、介数中心性、HITS、拓扑排序的独立测试
- 病态图: 用于保护超时机制的压力测试(大量环路、完全图)
- 超时验证: 确保大型图不会卡死
超时保护: 所有耗时较长的算法(介数中心性、PageRank、HITS、环路检测)都设置了 500 毫秒的超时,以防止在大型或病态图上阻塞。
详细调优指南: 有关性能的全面文档,包括故障排除、基于规模的算法选择以及调优选项,请参阅 docs/performance.md。
图引擎优化
分析引擎使用一种 紧凑的邻接表图 (compactDirectedGraph),而非标准的 Gonum 基于 map 的实现。这一优化带来了显著的性能提升:
| 基准测试(696 个问题) | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 完整分类 | 67ms | 1.3ms | 快 52 倍 |
| 完整分析 | 46ms | 477μs | 快 96 倍 |
| 图构建 | 1.2ms | 323μs | 快 3.7 倍 |
| 内存(图构建) | 735KB | 444KB | 减少 40% |
| 分配次数 | 4,647 | 2,512 | 减少 46% |
为什么重要: 默认的 Gonum DirectedGraph 使用基于 map 的边集,在图构建过程中会产生大量的内存分配。而我们的紧凑实现:
- 在已知大小下预先分配节点数组
- 使用
[]int64邻接列表代替map[int64]set - 完全消除了 map 扩容和重新哈希的开销
真实数据基准测试: 运行 go test -bench=BenchmarkRealData ./pkg/analysis/...,以根据您项目的实际 .beads/issues.jsonl 数据验证性能。
❓ 故障排除与常见问题
Q: 我的图标显示异常 / 文本对齐错位。
bv需要支持 TrueColor 的终端,并安装 Nerd Font。- 推荐: Nerd Fonts(例如,“JetBrains Mono Nerd Font”或“Hack Nerd Font”)。
- 终端: Windows Terminal、iTerm2、Alacritty、Kitty、WezTerm。
Q: 实时刷新没有更新(尤其是在 NFS/SMB/SSHFS/FUSE 上)。
- 某些文件系统无法可靠地传递文件系统事件。
bv会尝试自动检测并切换到轮询模式。 - 如果仍然有问题,请强制启用轮询:
BV_FORCE_POLLING=1 bv # 或者 BV_FORCE_POLL=1 bv
Q: 我在页脚看到 polling …。这有问题吗?
没关系——这只是表示 bv 正在使用轮询而不是文件系统事件来进行实时刷新(这在远程文件系统中很常见)。轮询可能会导致更新出现时稍有延迟。
Q: 我在页脚看到 ⚠ STALE / ✗ bg … / ⚠ worker unresponsive / ↻ recovered。
这些提示意味着后台工作进程最近没有生成新的快照(或者需要自我修复)。请尝试按 Ctrl+R/F5,检查文件系统权限和健康状况,或者暂时禁用后台模式 (BV_BACKGROUND_MODE=0) 来回退到同步刷新。
Q: 我在仪表盘上看到“检测到环路”。接下来该怎么办?
答:环路(例如 A → B → A)意味着您的项目逻辑存在缺陷,没有任何任务可以优先完成。请使用洞察仪表盘 (i) 查找具体的环路成员,然后使用 br 删除其中一条依赖关系(例如 br unblock A --from B)。
Q: 这个工具适用于 Jira/GitHub 吗?
答:bv 是数据无关的。Beads 数据模式支持 external_ref 字段。如果您使用自定义脚本或同步工具将外部跟踪器中的问题填充到您的 .beads/beads.jsonl 文件中,bv 会将其与本地任务一起渲染。未来版本的 br CLI 可能会支持原生同步功能,但 bv 目前已经可以处理这类数据了。
Q: “bead” 和 “issue” 有什么区别?
答:它们是一回事!在 Beads 生态系统中,工作单元被称为“bead”(这也是名称的由来)。然而,bv 在许多地方使用“issue”,因为这对大多数开发者来说更为熟悉。CLI 标志也交替使用这两个术语:--robot-file-beads、--pages-include-closed(issues)等。您可以将“bead”视为 Beads 特有的术语,而“issue”则是更通用的概念。
📦 安装
一行安装(Linux/macOS)
最快开始的方式。会自动检测您的操作系统和架构。
curl -fsSL "https://raw.githubusercontent.com/Dicklesworthstone/beads_viewer/main/install.sh?$(date +%s)" | bash
一行安装(Windows)
对于使用 PowerShell 的 Windows 用户:
irm "https://raw.githubusercontent.com/Dicklesworthstone/beads_viewer/main/install.ps1" | iex
要求:
- 已安装 Go 1.21+ 并添加到 PATH 中(下载)
- 为了获得最佳显示效果,请使用带有 Nerd Font 的 Windows Terminal
从源码构建
需要 Go 1.21+。
git clone https://github.com/Dicklesworthstone/beads_viewer.git
cd beads_viewer
go install ./cmd/bv
Nix Flake
对于 Nix 用户,bv 提供了一个 flake,用于可重复的构建和开发环境。
# 直接运行
nix run github:Dicklesworthstone/beads_viewer
# 安装到用户配置文件
nix profile install github:Dicklesworthstone/beads_viewer
# 开发环境,包含 Go 工具链
nix develop github:Dicklesworthstone/beads_viewer
或者将以下内容添加到您的 flake 输入中:
{
inputs.bv.url = "github:Dicklesworthstone/beads_viewer";
# 使用:bv.packages.${system}.default
}
🚀 使用指南
导航到任何使用 br init 初始化的项目,然后运行:
bv
🎓 获取帮助
bv 内置了全面的帮助系统:
快速参考 (?) - 在任意位置按下即可查看当前视图的快捷键。从这里按 Space 键可直接跳转到完整教程。
交互式教程 (` 反引号) - 多页指南,涵盖所有功能:
- 概念:珠子、依赖关系、标签、优先级
- 视图:列表、看板、图谱、树状图、洞察、历史
- 工作流:AI 代理集成、分类处理、计划制定
- 进度会自动保存——您可以从中断处继续。
键盘控制表
| 上下文 | 键 | 动作 |
|---|---|---|
| 全局导航 | j / k |
下一个/上一个项目 |
g / G |
跳至顶部/底部 | |
Ctrl+D / Ctrl+U |
向下/向上翻页 | |
Tab |
切换焦点(列表 ↔ 详情) | |
Enter |
打开/聚焦选中项 | |
q / Esc |
退出/返回 | |
| 筛选器 | o |
显示 未完成 问题 |
r |
显示 已就绪(未阻塞) | |
c |
显示 已完成 问题 | |
a |
显示 全部 问题 | |
/ |
搜索(模糊匹配) | |
Ctrl+S |
切换 搜索模式(语义 ↔ 模糊) | |
l |
标签选择器(按标签快速筛选) | |
| 列表排序 | s |
循环切换排序模式(默认 → 创建时间升序 → 创建时间降序 → 优先级 → 更新时间) |
| 视图切换 | b |
切换 看板 |
i |
切换 洞察仪表板 | |
g |
切换 图谱可视化工具 | |
E |
切换 树状视图(父子层级) | |
a |
切换 可执行计划 | |
h |
切换 历史视图(珠子与提交的关联) | |
f |
切换 流程矩阵(跨标签依赖关系) | |
[ |
切换 标签仪表板(标签健康分析) | |
] |
切换 关注视图(标签关注度评分) | |
| 看板 | h / l |
在列之间移动 |
j / k |
在列内移动 | |
| 洞察仪表板 | Tab |
切换到下一个面板 |
Shift+Tab |
切换到上一个面板 | |
e |
切换解释说明 | |
x |
切换计算证明 | |
m |
切换热力图叠加 | |
| 图谱视图 | H / L |
向左/向右滚动 |
Ctrl+D / Ctrl+U |
向下/向上翻页 | |
| 树状视图 | j / k |
光标上下移动 |
h / l |
折叠父节点或展开子节点 | |
Enter / Space |
切换展开/折叠 | |
o / O |
展开全部/折叠全部 | |
g / G |
跳至顶部/底部 | |
| 时间旅行与分析 | t |
时间旅行模式(自定义版本) |
T |
快速时间旅行(HEAD~5) | |
p |
切换优先级提示叠加 | |
| 操作 | x |
导出为 Markdown 文件 |
C |
将问题复制到剪贴板 | |
O |
在编辑器中打开 | |
| 帮助与学习 | ? |
切换帮助覆盖层(快捷键) |
` |
打开交互式教程(进度已保存) | |
| 全局 | ; |
切换快捷键侧边栏 |
! |
切换 警报面板(主动预警) | |
' |
食谱选择器 | |
w |
仓库选择器(工作区模式) |
🛠️ 配置
bv 会自动检测终端能力,以呈现最佳 UI。它会在当前目录中查找 .beads/beads.jsonl 文件。
环境变量
| 变量 | 描述 | 默认值 |
|---|---|---|
BEADS_DIR |
自定义珠子目录路径。设置后将覆盖默认的 .beads 目录查找。 |
当前工作目录下的 .beads |
BV_BACKGROUND_MODE |
实验性功能:启用后台快照加载,实现 TUI 的实时重载(1/0)。 |
(禁用) |
BV_FORCE_POLLING |
强制使用轮询方式的实时重载(适用于 NFS/SMB/SSHFS/FUSE 或任何文件系统事件不可靠的环境)(1/0)。 |
(自动) |
BV_FORCE_POLL |
BV_FORCE_POLLING 的别名。 |
(自动) |
BV_DEBOUNCE_MS |
后台模式下实时重载事件的防抖窗口(毫秒)。 | 200 |
BV_CHANNEL_BUFFER |
后台工作线程与 UI 之间的消息缓冲区大小。 | 8 |
BV_HEARTBEAT_INTERVAL_S |
后台工作线程的心跳间隔(秒)。 | 5 |
BV_WATCHDOG_INTERVAL_S |
后台工作线程的看门狗间隔(秒)。 | 10 |
BV_FRESHNESS_WARN_S |
快照过时警告阈值(秒)。 | 30 |
BV_FRESHNESS_STALE_S |
快照过时严重阈值(秒)。 | 120 |
BV_MAX_LINE_SIZE_MB |
JSONL 文件每行的最大大小(MB)。超过此大小的行将被跳过并发出警告。 | 10 |
BV_SKIP_PHASE2 |
跳过第二阶段的图谱指标计算(中心性、环路、关键路径)(1/0)。 |
(禁用) |
BV_PHASE2_TIMEOUT_S |
重写第二阶段各指标的超时时间(秒)。 | (基于文件大小) |
BV_SEMANTIC_EMBEDDER |
用于 bv --search 和 TUI 语义模式的语义嵌入提供商。 |
hash |
BV_SEMANTIC_DIM |
语义搜索索引的嵌入维度。 | 384 |
BV_SEMANTIC_MODEL |
语义搜索特定提供商的模型名称(可选)。 | (空) |
BEADS_DIR 的使用场景:
- 单体仓库:多个包共享同一个珠子目录
- 非标准布局:
.beads不在工作目录中的项目 - 测试:指向测试用例而不改变目录
- 跨目录访问:从文件系统的任意位置查看珠子
# 示例:指向不同的珠子目录
BEADS_DIR=/path/to/shared/beads bv
# 示例:在单体仓库中使用
export BEADS_DIR=$(git rev-parse --show-toplevel)/.beads
实验性功能:后台模式(实时重载)
TUI 可以通过 实验性后台快照工作线程 实现实时重载(将文件 I/O 和分析从 UI 线程中移出)。
启用(需手动开启):
BV_BACKGROUND_MODE=1 bv
bv --background-mode
禁用/回滚:
BV_BACKGROUND_MODE=0 bv
bv --no-background-mode
用户配置文件(当 CLI 标志和 BV_BACKGROUND_MODE 均未设置时):
# ~/.config/bv/config.yaml
experimental:
background_mode: true
优先级顺序: CLI 标志 → BV_BACKGROUND_MODE → ~/.config/bv/config.yaml。
迁移计划(高层次):
- A 阶段(目前):启用后台模式,同步模式仍为默认。
- B 阶段:扩大推广范围;保留显式回滚选项(
--no-background-mode/BV_BACKGROUND_MODE=0)。 - C 阶段:稳定后将默认模式切换为后台模式;在过渡期内仍保留同步模式作为备用。
- D 阶段:经过弃用期后,移除旧版同步重载路径。
监控计划: 目前暂无自动遥测;A/B 阶段将依靠 CI + 回归测试以及用户反馈。
状态指示器(后台模式 + 实时重载)
当启用后台模式或实时重载时,页脚可能会显示以下指示器:
◌ metrics…— 第二阶段指标仍在计算中;UI 会立即使用第一阶段的数据进行渲染。⚠ 45s ago— 快照过期警告(数据正在变得陈旧)。⚠ STALE: 3m ago— 快照已过期。✗ bg <phase> (3x)— 后台工作进程在构建快照时多次遇到错误(显示阶段;括号内为重试次数)。↻ recovered xN— 监控程序已恢复后台工作进程 N 次(瞬态故障/自我修复)。⚠ worker unresponsive— 监控程序检测到工作进程卡死并正在进行恢复。polling …— 实时重载正在使用轮询而非文件系统事件(常见于远程文件系统);更改可能会有轻微延迟。
提示:按 Ctrl+R(或 F5)可强制刷新。
视觉主题
UI 使用受 Dracula 原则启发的高对比度、视觉上鲜明的主题,以确保易读性。
- 主色:
#BD93F9(紫色) - 状态:开放:
#50FA7B(绿色) - 状态:阻塞:
#FF5555(红色)
📄 许可证
MIT 许可证(附带 OpenAI/Anthropic 的附加条款)。详情请参阅 LICENSE。
版权所有 © 2025 杰弗里·伊曼纽尔
🤖 为什么机器人喜欢 bv
- 确定性的 JSON 协议:机器人命令会发出稳定的字段名和顺序(相同 ID 的任务按 ID 排序),并包含
data_hash、analysis_config和computed_at,以便安全地关联多次调用。 - 健康标志:每个耗时指标都会报告其状态(
computed、approx、timeout、skipped),以及所花费的毫秒数,并在采样时注明使用的样本量。 - 一致的缓存:机器人子命令共享同一个基于问题数据哈希的分析器/缓存,从而避免在
--robot-insights、--robot-plan和--robot-priority之间出现输出不一致的情况。 - 即时与最终完整性:第一阶段指标会立即可用;第二阶段会补充完整,而状态标志会告知您何时完成或是否降级。
🧭 数据流概览
.beads/beads.jsonl
↓ 容错加载器(去除 BOM、10MB 行、跳过格式错误)
↓ 图构建器(仅处理阻塞性依赖关系)
↓ 分析器(第一阶段快速;第二阶段中心性指标带有超时限制)
↓ 缓存(按哈希键存储)
↓ 输出:TUI | 机器人 JSON | 导出/钩子
- 每个机器人负载中都会携带哈希值和配置信息,以便下游消费者验证一致性。
📐 图分析算法(通俗解释)
- PageRank:“阻塞权威”——拥有大量(或重要)依赖的任务。
- Betweenness:“桥梁”——位于许多最短路径上的节点;是不同集群之间的瓶颈。
- HITS:枢纽节点(聚合者)与权威节点(前置条件)。
- 关键路径深度:最长的下游链长度;零松弛的关键节点。
- 特征向量:通过有影响力的邻居传播影响力。
- 密度、度数、拓扑排序:结构骨干。
- 循环:通过 Tarjan SCC 和
DirectedCyclesIn检测;设置超时限制并记录循环数量。 - 每项指标都会出现在机器人洞察中,并附带状态标志,待准备就绪后会显示每项问题的得分。
⚡ 第一阶段 vs 第二阶段
- 第一阶段(即时): 度数、拓扑排序、密度;始终存在。
- 第二阶段(异步): PageRank、Betweenness、HITS、特征向量、关键路径、循环;默认超时时间为 500 毫秒,并根据规模进行调整。状态标志会反映计算完成、近似结果、超时或跳过等情况。
⏱️ 超时与近似语义
- 每项指标的状态:
computed(完整)、approx(例如,采样的 betweenness)、timeout(回退)、skipped(基于大小/密度的保护机制)。 - 负载示例:
{ "status": { "pagerank": {"state":"computed","ms":142}, "betweenness": {"state":"approx","ms":480,"sample":120}, "cycles": {"state":"timeout","ms":500,"reason":"deadline"} } }
🧮 执行计划逻辑
- 可执行集合:无未解决阻塞性依赖的开放/进行中问题。
- 解除阻塞:对于每个可执行问题,列出如果该问题关闭后将变为可执行的问题列表(且没有其他未解决的阻塞)。
- 路径:无向连通分量将可执行事项分组为可并行处理的流。
- 总结:最具影响力的项目 = 最多解除阻塞的问题,其次是优先级,最后是 ID 以保证确定性。
🎯 优先级推荐模型
- 复合评分权重:PageRank 30%,Betweenness 30%,阻塞比例 20%,陈旧程度 10%,优先级提升 10%。
- 阈值:高 PR >0.30,高 BW >0.50,陈旧程度约 14 天,最低置信度默认为 0.30。
- 方向:根据评分与当前优先级的比较得出“提高”或“降低”优先级的结论;置信度结合信号数量、强度和评分差来综合判断。
🔍 差异与时间旅行安全注意事项
- 当标准输出不是 TTY 或
BV_ROBOT=1时,--diff-since会自动输出 JSON(或在严格设置下需要使用--robot-diff);解析后的修订版本会回显在负载中。 - TUI 时间旅行标记:
[NEW]、[CLOSED]、[MODIFIED]、[REOPENED],与机器人差异摘要相匹配。
🛡️ 性能保障措施
- 两阶段分析,配备基于规模的配置(对大型稀疏图采用近似的 betweenness,对循环设置上限,在密集的 XL 图上跳过 HITS)。
- 每个耗时指标的默认超时时间为 500 毫秒;结果会标注状态。
- 缓存 TTL 使重复的机器人调用在数据未变化时保持快速;若哈希不匹配,则会触发重新计算。
- 快速基准测试:
./scripts/benchmark.sh quick,或通过bv --profile-startup进行诊断。
🧷 稳健性与自我修复
- 加载器会跳过格式错误的行并发出警告,去除 UTF-8 BOM,容忍大行(10MB)。
- Beads 文件发现顺序:issues.jsonl → beads.jsonl → beads.base.jsonl;会跳过备份、合并产物和删除清单。
- 实时重载经过防抖处理;更新检查是非阻塞的,在网络出现问题时也能优雅失败。
🔗 与 CI 和代理集成
- 典型流水线:
bv --robot-insights > insights.json bv --robot-plan | jq '.plan.summary' bv --robot-priority | jq '.recommendations[0]' bv --check-drift --robot-drift --diff-since HEAD~5 > drift.json - 使用
data_hash确保所有工件来自同一次分析运行;若哈希值不一致,则 CI 测试失败。 - 退出码:漂移检查(0 正常,1 严重,2 警告)。
🩺 故障排除矩阵(机器人模式)
- 空的指标映射 → 第二阶段仍在运行或已超时;请检查状态标志。
- 大型负载 → 使用 jq 截取前几项;按照配方过滤后再重新运行。
- 缺少循环 → 很可能被跳过或超时;请查看
status.cycles。 - 不同命令之间的输出不一致 → 比较
data_hash;若不同则重新运行。
🔒 安全与隐私注意事项
- 本地优先:所有分析都在您的仓库的 JSONL 文件上进行;机器人无需联网。
- 钩子和导出功能为可选;更新检查静默进行,即使网络出现故障也不会影响启动。
🙏 致谢与鸣谢
bv 站在巨人的肩膀上。我们衷心感谢这些卓越开源项目的维护者和贡献者:
基础
| 项目 | 作者 | 描述 |
|---|---|---|
| Beads | Steve Yegge | 这是一个优雅的原生 Git 风格的问题跟踪系统,bv 就是为了配合它而构建的 |
Go 库(TUI 和 CLI)
| 库 | 作者 | 我们如何使用 |
|---|---|---|
| Bubble Tea | Charm | 受 Elm 启发的 TUI 框架,为所有交互式界面提供支持 |
| Lip Gloss | Charm | 美观的终端样式——颜色、边框、布局 |
| Bubbles | Charm | 现成组件:列表、文本输入、加载指示器、视口 |
| Huh | Charm | 用于部署向导的交互式表单和提示 |
| Glamour | Charm | 在终端中带有语法高亮的 Markdown 渲染 |
| modernc.org/sqlite | modernc.org | 纯 Go 实现的 SQLite,带 FTS5 全文检索功能,用于静态站点导出 |
| Gonum | Gonum 作者 | 图算法:PageRank、介数中心性、强连通分量 |
| fsnotify | fsnotify | 文件系统监听,用于实时重载 |
| clipboard | atotto | 跨平台剪贴板,用于复制到剪贴板功能 |
JavaScript 库(静态查看器)
| 库 | 作者 | 我们如何使用 |
|---|---|---|
| force-graph | Vasco Asturiano | 美丽的交互式力导向图可视化 |
| D3.js | Mike Bostock / Observable | 数据可视化基础及图物理学 |
| Alpine.js | Caleb Porzio | 轻量级响应式 UI 框架 |
| sql.js | sql.js 贡献者 | SQLite 编译为 WebAssembly,用于客户端查询 |
| Chart.js | Chart.js 贡献者 | 交互式图表:燃尽图、优先级分布、热力图 |
| Mermaid | Knut Sveidqvist | 在 Markdown 中绘制依赖关系图 |
| DOMPurify | cure53 | 安全的 XSS 防护 HTML 净化 |
| Marked | marked 贡献者 | 高速 Markdown 解析 |
| Tailwind CSS | Tailwind Labs | 实用程序优先的 CSS 框架 |
特别致谢
- 整个 Charm 团队,感谢他们打造了目前最令人愉悦的终端 UI 生态系统。他们的库让构建美观的 CLI 工具变得无比轻松。
- Vasco Asturiano,感谢他出色的
force-graph库以及更广泛的可视化工具生态。 - Steve Yegge,感谢他提出的 Beads 理念——一种清新简洁的问题跟踪方式,充分尊重开发者的日常工作流程。
关于贡献: 请不要误会,我并不接受任何外部对我的项目的贡献。我真的没有精力去评审这些内容,而且这个项目是我个人的名字在负责,所以如果出现问题,我需要承担全部责任;从我的角度来看,这种风险与回报极不对称。此外,我还得担心其他“利益相关者”,这对我来说并不明智,毕竟这些工具大多是我在业余时间免费制作的。当然,你仍然可以提交问题,甚至 PR 来展示你的修复方案,但我不会直接合并它们。相反,我会让 Claude 或 Codex 通过
gh工具来审查这些提交,并独立决定是否以及如何处理它们。尤其是 bug 报告,我们非常欢迎。抱歉如果这让你感到不快,但我不想浪费大家的时间,也不想伤害任何人的情感。我明白这与当前倡导社区贡献的开源精神不太一致,但这却是我能以现有速度推进工作并保持理智的唯一方式。
📄 许可证
特此授予任何人免费获取本软件及其相关文档文件(以下简称“软件”)副本的权利,允许其不受限制地处理该软件,包括但不限于以下权利:使用、复制、修改、合并、发布、分发、再许可和/或销售该软件的副本,并允许向任何获得该软件的人提供服务,但须遵守以下条件:
上述版权声明和本许可声明应包含在该软件的所有副本或实质性部分中。
本软件按“原样”提供,不提供任何形式的明示或暗示担保,包括但不限于适销性、特定用途适用性和非侵权性。在任何情况下,作者或版权所有者均不对因本软件或其使用或其他交易而产生的任何索赔、损害赔偿或其他责任负责,无论该责任是基于合同、侵权行为或其他原因。
🤖 机器人 JSON 协议——快速参考表
所有机器人共享
data_hash: 驱动响应的 beads 文件的哈希值(用于关联多次调用)。analysis_config: 精确的分析设置(超时、模式、循环上限),以确保可重复性。status: 每项指标的状态computed|approx|timeout|skipped,附带耗时/原因;在信任 PageRank/介数/HITS 等复杂指标之前,请务必检查。as_of/as_of_commit: 使用--as-of时显示;包含您指定的引用以及解析后的提交 SHA,以确保可重复性。
5 秒内了解 Schema(jq 友好)
bv --robot-insights→.status,.analysis_config, 指标映射(受BV_INSIGHTS_MAP_LIMIT限制)、Bottlenecks,CriticalPath,Cycles,以及高级信号:Cores(k-core)、Articulation(割点)、Slack(最长路径松弛)。bv --robot-plan→.plan.tracks[].items[].{id,unblocks},用于下游解锁;.plan.summary.highest_impact。bv --robot-priority→.recommendations[].{id,current_priority,suggested_priority,confidence,reasoning}。bv --robot-suggest→.suggestions.suggestions[](排名靠前的建议)+.suggestions.stats(数量统计)+.usage_hints。bv --robot-diff --diff-since <ref>→{from_data_hash,to_data_hash,diff.summary,diff.new_issues,diff.cycle_*}。bv --robot-history→.histories[ID].events+.commit_index,用于反向查找;.stats.method_distribution显示相关性是如何推断的。
复制粘贴注意事项
# 确保指标已准备好
bv --robot-insights | jq '.status'
# 计划中的顶级解锁项
bv --robot-plan | jq '.plan.tracks[].items[] | {id, unblocks}'
# 高置信度的优先级修复建议
bv --robot-priority | jq '.recommendations[] | select(.confidence > 0.6)'
# 结构强度与并行性
bv --robot-insights | jq '.full_stats.core_number | to_entries | sort_by(-.value)[:5]'
bv --robot-insights | jq '.Articulation'
bv --robot-insights | jq '.Slack[:5]'
# 验证差异哈希是否符合预期
bv --robot-diff --diff-since HEAD~1 | jq '{from: .from_data_hash, to: .to_data_hash}'
# 历史分析(验证 as_of 元数据)
bv --robot-insights --as-of HEAD~30 | jq '{as_of, as_of_commit, data_hash}'
版本历史
v0.15.22026/03/09v0.15.12026/03/09v0.15.02026/03/08v0.14.42026/02/03v0.14.32026/02/03v0.14.22026/02/03v0.14.12026/02/03v0.14.02026/02/02v0.13.02026/01/14v0.12.12026/01/07v0.12.02026/01/06v0.11.32026/01/03v0.11.22025/12/21v0.11.12025/12/19v0.11.02025/12/19v0.10.62025/12/18v0.10.52025/12/18v0.10.42025/12/18v0.10.32025/12/18v0.10.22025/11/30常见问题
相似工具推荐
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
gstack
gstack 是 Y Combinator CEO Garry Tan 亲自开源的一套 AI 工程化配置,旨在将 Claude Code 升级为你的虚拟工程团队。面对单人开发难以兼顾产品战略、架构设计、代码审查及质量测试的挑战,gstack 提供了一套标准化解决方案,帮助开发者实现堪比二十人团队的高效产出。 这套配置特别适合希望提升交付效率的创始人、技术负责人,以及初次尝试 Claude Code 的开发者。gstack 的核心亮点在于内置了 15 个具有明确职责的 AI 角色工具,涵盖 CEO、设计师、工程经理、QA 等职能。用户只需通过简单的斜杠命令(如 `/review` 进行代码审查、`/qa` 执行测试、`/plan-ceo-review` 规划功能),即可自动化处理从需求分析到部署上线的全链路任务。 所有操作基于 Markdown 和斜杠命令,无需复杂配置,完全免费且遵循 MIT 协议。gstack 不仅是一套工具集,更是一种现代化的软件工厂实践,让单人开发者也能拥有严谨的工程流程。