super-gradients
super-gradients 是一个专为计算机视觉打造的开源训练库,旨在帮助开发者轻松构建、训练及微调达到业界最先进水平(SOTA)的深度学习模型。它有效解决了传统模型训练流程复杂、配置繁琐以及难以在精度与速度之间取得平衡的痛点,让用户能够通过统一的接口快速复现高性能模型。
该工具非常适合人工智能工程师、算法研究人员以及希望将视觉模型落地到生产环境的技术团队使用。无论是图像分类、目标检测、语义分割还是姿态估计任务,super-gradients 都能提供完善的支持。其核心亮点在于内置了包括 YOLO-NAS 和 YOLO-NAS-POSE 在内的 34 种预训练模型架构。特别是 YOLO-NAS 系列,在保持极高推理速度的同时实现了超越 YOLOv5 至 v8 等主流模型的检测精度,提供了卓越的性价比。基于 PyTorch 构建,super-gradients 不仅支持 Python 3.7 及以上版本,还配备了详尽的文档与社区支持,让从实验探索到模型部署的全过程变得更加高效顺畅。
使用场景
某智慧物流团队正致力于升级其自动化分拣系统,需要训练一个能精准识别各类包裹并检测姿态的 AI 模型,以适配高速传送带环境。
没有 super-gradients 时
- 模型选型困难:团队需在 YOLOv5、v7、v8 等多个独立仓库间反复对比,难以确定哪个模型能在现有硬件上平衡速度与精度。
- 复现成本高昂:不同模型的代码结构、数据预处理逻辑差异巨大,工程师花费数周时间清洗数据和调整配置,却仍难复现论文中的 SOTA 效果。
- 训练流程繁琐:缺乏统一的训练接口,每次切换架构都要重写训练脚本,且难以快速进行迁移学习或微调。
- 部署风险未知:自行训练的模型缺乏生产级验证,上线后常出现推理延迟波动大或特定场景漏检的问题。
使用 super-gradients 后
- 一键获取最优架构:直接调用库中集成的 YOLO-NAS 系列模型,该模型在官方基准测试中已证明在同等速度下精度超越主流 YOLO 版本。
- 标准化训练流程:利用统一的 API 加载预训练权重并启动微调,无需关心底层细节,将原本数周的准备工作缩短至几天。
- 高效任务覆盖:通过同一套代码库轻松同时处理物体检测(包裹定位)和姿态估计(包裹朝向),大幅降低多任务维护成本。
- 生产级性能保障:直接使用经过严格验证的预训练模型,确保在边缘设备上的推理延迟稳定,显著降低上线后的调试风险。
super-gradients 通过提供统一且高性能的训练框架,让团队从繁琐的模型工程中解放出来,专注于业务逻辑优化,实现了从算法实验到生产部署的无缝衔接。
运行环境要求
- 未说明
生产环境部署支持 TensorRT (Nvidia) 和 OpenVINO (Intel),具体显存和 CUDA 版本未在 README 中明确说明,但涉及深度学习训练通常建议配备 NVIDIA GPU。
未说明

快速开始

构建、训练并微调生产就绪的深度学习 SOTA 视觉模型

版本 3.5 已发布!Notebook 已更新!


使用 SuperGradients 构建
支持多种计算机视觉任务



随时可部署的 SOTA 预训练模型
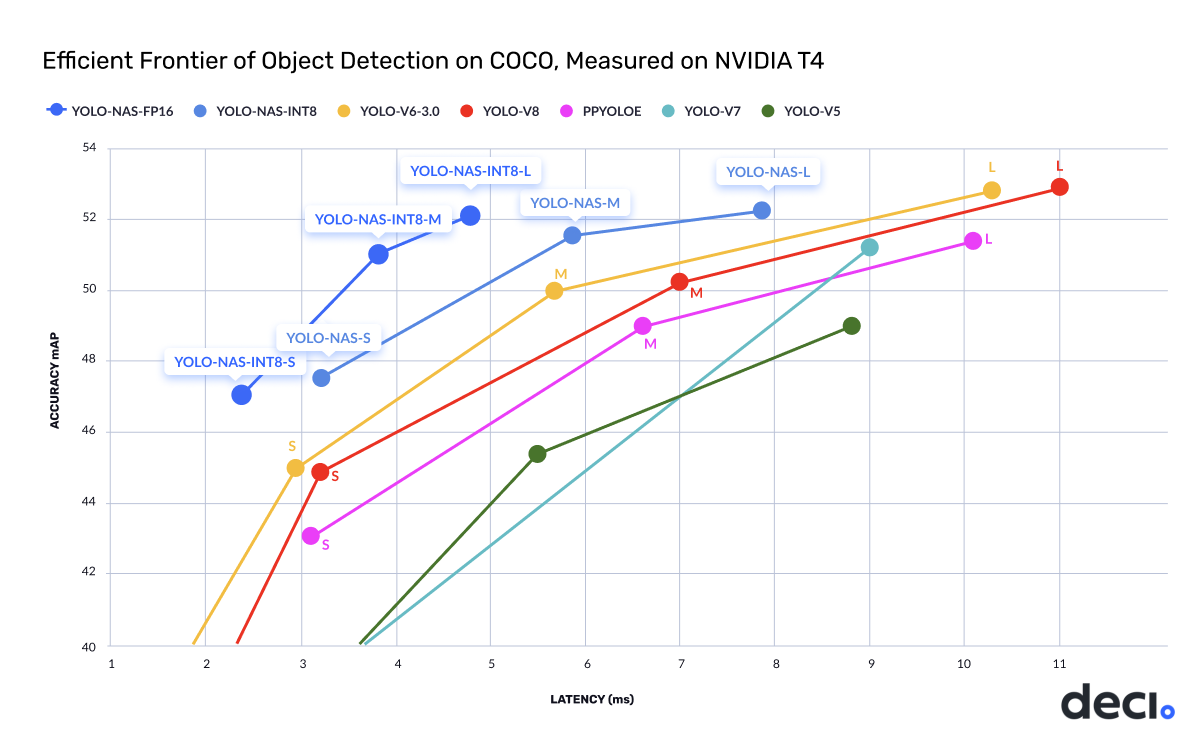
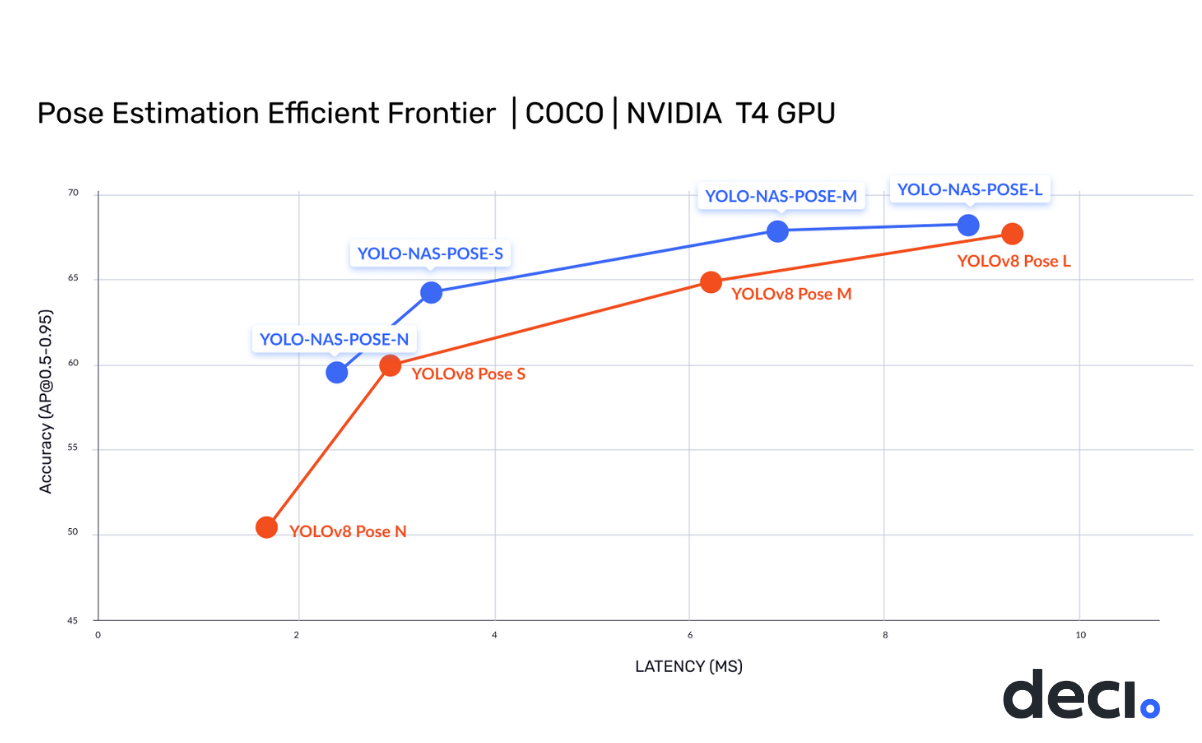
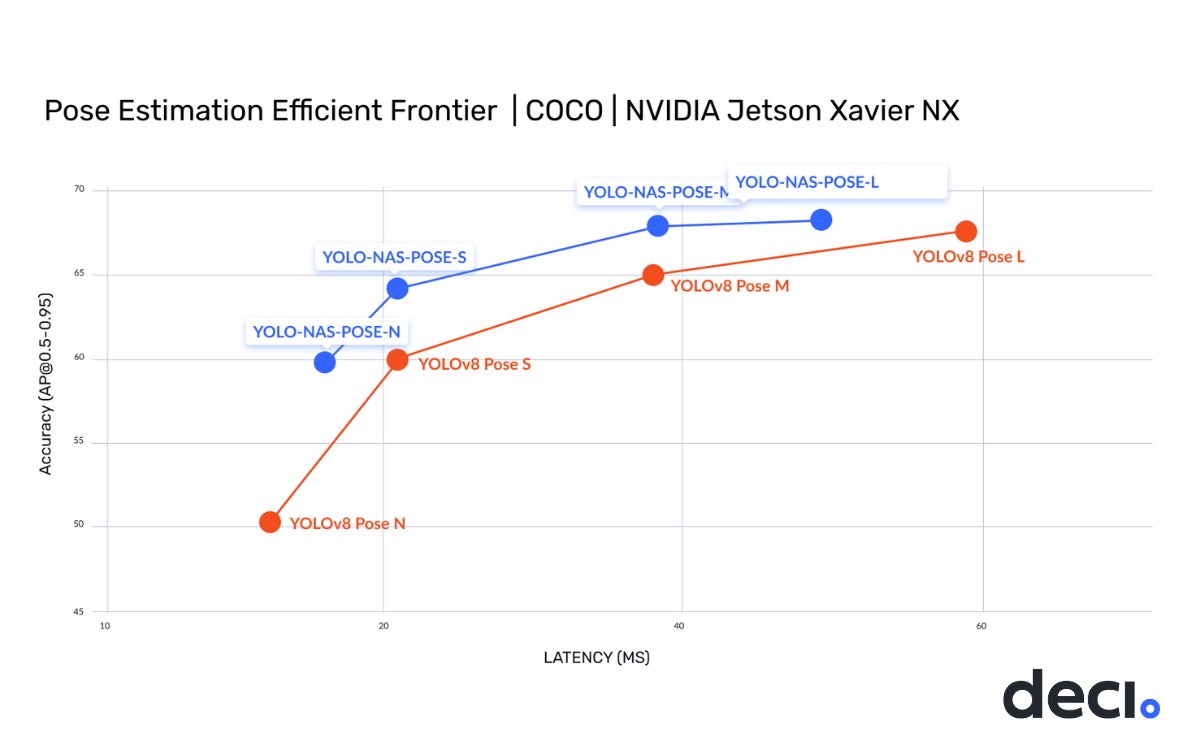
YOLO-NAS 和 YOLO-NAS-POSE 架构现已推出!全新的 YOLO-NAS 在精度与速度方面表现出色,超越了 YOLOv5、YOLOv6、YOLOv7 和 YOLOv8 等其他模型。同时,还提供用于姿态估计的 YOLO-NAS-POSE 模型,实现了最先进的精度与性能平衡。
请在此处查看:YOLO-NAS 和 YOLO-NAS-POSE。
# 加载带有预训练权重的模型
from super_gradients.training import models
from super_gradients.common.object_names import Models
model = models.get(Models.YOLO_NAS_M, pretrained_weights="coco")
所有计算机视觉模型的预训练检查点均可在 Model Zoo 中找到
分类
语义分割
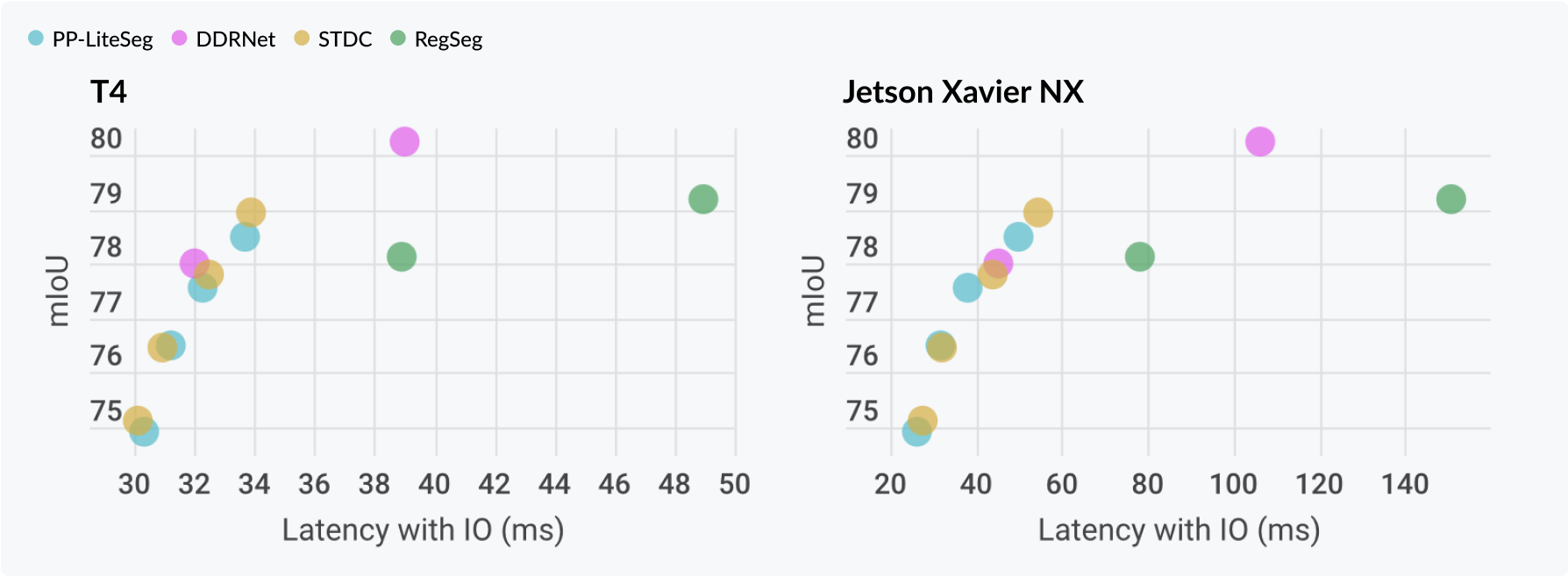
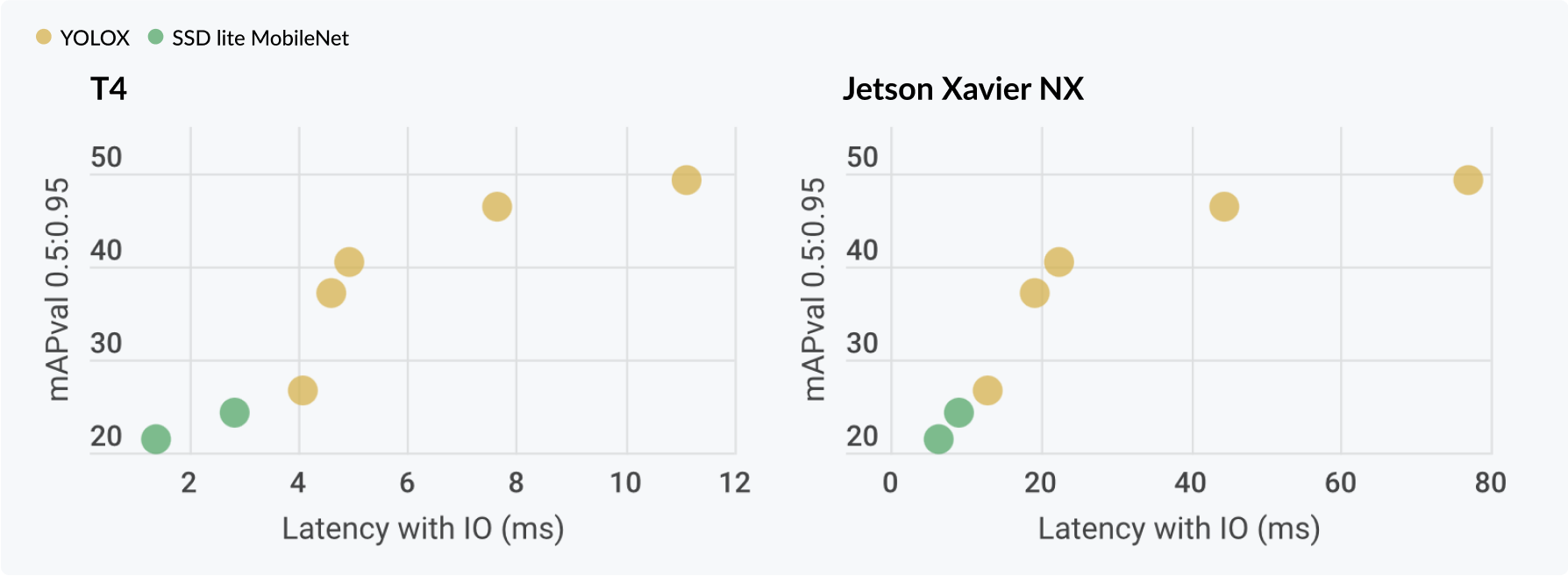
目标检测
姿态估计
轻松训练 SOTA 模型
您可以轻松加载并微调生产就绪的 SOTA 预训练模型,这些模型采用了最佳实践和经过验证的超参数,以实现一流的准确率。有关如何操作的更多信息,请参阅 开始使用。
即插即用的配方
python -m super_gradients.train_from_recipe architecture=regnetY800 dataset_interface.data_dir=<YOUR_Imagenet_LOCAL_PATH> ckpt_root_dir=<CHEKPOINT_DIRECTORY>
更多关于如何以及为何使用配方的示例,请参阅 Recipes。
生产就绪
所有 SuperGradients 模型都具备生产就绪性,这意味着它们兼容 TensorRT(Nvidia)和 OpenVINO(Intel)等部署工具,可以轻松投入生产。只需几行代码,您就可以将模型集成到您的代码库中。
# 加载带有预训练权重的模型
from super_gradients.training import models
from super_gradients.common.object_names import Models
model = models.get(Models.YOLO_NAS_M, pretrained_weights="coco")
# 准备模型进行转换
# 输入尺寸格式为 [Batch x Channels x Width x Height],其中 640 是标准 COCO 数据集的尺寸
model.eval()
model.prep_model_for_conversion(input_size=[1, 3, 640, 640])
# 创建虚拟输入
# 将模型转换为 ONNX 格式
torch.onnx.export(model, dummy_input, "yolo_nas_m.onnx")
有关如何将您的模型投入生产的更多信息,请参阅 开始使用 的 Notebook。
快速安装
pip install super-gradients
新增内容
版本 3.4.0(2023年11月6日)
- 发布 YoloNAS-Pose 模型——姿态估计领域的新前沿
- 增加了将配方导出为单个 YAML 文件或独立 train.py 文件的选项
- 其他错误修复及小幅改进。完整发布说明请见此处
版本 3.1.3(2023年7月19日)
- 支持姿态估计任务——请查看微调笔记本示例
- 预训练的修改版 DEKR 姿态估计模型(兼容 TensorRT)
- 支持 Python 3.10
- 支持 torch.compile
- 其他还原修复及小幅改进。请参阅发布说明
5月30日
版本 3.1.1(5月3日)
- YOLO-NAS
- 新增 predict 函数(可对任意图像、视频、URL、路径或流进行预测)
- 集成 RoboFlow100 数据集
- 新建 文档中心
- 与 DagsHub 实验监控平台 集成
- 支持 Darknet/Yolo 格式检测数据集(被 Yolo v5、v6、v7、v8 使用)
- Segformer 模型及配方
- 训练后量化与量化感知训练——相关笔记本
请查阅 SG 完整的发布说明。
目录
快速入门
仅需一条命令即可开始训练
使用 SuperGradients 可复现的配方,以最简单直接的方式开始训练 SOTA 性能模型。只需指定数据集路径和检查点保存位置,即可从终端启动训练!
请确保按照配方中指定的数据目录设置好您的数据集。
python -m super_gradients.train_from_recipe --config-name=imagenet_regnetY architecture=regnetY800 dataset_interface.data_dir=<YOUR_Imagenet_LOCAL_PATH> ckpt_root_dir=<CHEKPOINT_DIRECTORY>
快速加载您所需模型的预训练权重
想在本地尝试我们的预训练模型吗?导入 SuperGradients,初始化 Trainer,并从我们的 SOTA 模型库 加载您想要的架构和预训练权重。
# pretrained_weights 参数会加载在给定数据集上预训练好的架构
import super_gradients
model = models.get("model-name", pretrained_weights="pretrained-model-name")
分类
语义分割
姿态估计
目标检测
如何使用预训练模型进行预测
Albumentations 集成
高级功能
训练后量化与量化感知训练
量化是指以较低的精度表示权重和偏置,从而减少内存和计算需求,这使得它在资源有限的设备上部署模型时非常有用。 该过程可以在训练期间进行,称为量化感知训练,也可以在训练之后进行,称为训练后量化。 完整的教程可以在这里找到 here。
在自定义数据集上对 YoloNAS 进行量化感知训练
本教程提供了关于如何使用自定义数据集对 YoloNAS 模型进行微调的全面指南。 它还演示了如何利用 SG 的 QAT(量化感知训练)支持。此外,它还提供了部署模型和进行基准测试的分步说明。
知识蒸馏训练
知识蒸馏是一种训练技术,它利用一个大型模型(教师模型)来提升小型模型(学生模型)的性能。 通过我们在 Google Colab 上提供的 CIFAR10 示例笔记本,使用预训练的 BEiT 基础教师模型和 Resnet18 学生模型,您可以了解 SuperGradients 的知识蒸馏训练,并获得一个易于使用的教程,同时还能免费使用 GPU 硬件。
配方
要训练一个模型,需要配置四个主要组件。
这些组件被汇总到一个名为“main”的配方 .yaml 文件中,该文件继承了上述的数据集、架构、训练和检查点参数。
为了灵活性,也可以(并且建议)用自定义设置覆盖默认设置。
所有配方都可以在这里找到 here。
配方开箱即用地支持 SuperGradients 中实现的每一种模型、指标或损失函数,但您也可以通过“注册”轻松将其扩展到任何所需的自定义对象。有关更多信息,请参阅 this 教程。
使用分布式数据并行(DDP)
为什么使用 DDP?
近年来,深度学习模型变得越来越大,以至于在单个 GPU 上训练可能需要数周时间。 为了及时训练模型,必须使用多个 GPU 进行训练。 使用数百个 GPU 可以将模型的训练时间从一周缩短到不到一小时。
它是如何工作的?
每个 GPU 都有自己的进程,该进程控制着模型的一个副本,并从磁盘加载自己的小批量数据,在训练过程中将其发送到对应的 GPU。在每个 GPU 上完成前向传播后,梯度会在所有 GPU 之间进行归约,从而使所有 GPU 在本地拥有相同的梯度。这导致在反向传播之后,所有 GPU 上的模型权重保持同步。
如何使用它?
您只需几行代码就可以使用 SuperGradients 通过 DDP 训练您的模型。
main.py
from super_gradients import init_trainer, Trainer
from super_gradients.common import MultiGPUMode
from super_gradients.training.utils.distributed_training_utils import setup_device
# 初始化环境
init_trainer()
# 在 4 个 GPU 上启动 DDP
setup_device(multi_gpu=MultiGPUMode.DISTRIBUTED_DATA_PARALLEL, num_gpus=4)
# 调用训练器
Trainer(expriment_name=...)
# 您在下方执行的所有操作都将在4个GPU上运行
...
Trainer.train(...)
最后,您可以通过一个简单的Python命令启动分布式训练。
python main.py
请注意,如果您使用的是torch<1.9.0(已弃用),则必须使用torch.distributed.launch或torchrun来启动训练,在这种情况下,nproc_per_node会覆盖通过gpu_mode设置的值:
python -m torch.distributed.launch --nproc_per_node=4 main.py
torchrun --nproc_per_node=4 main.py
在单节点上调用函数
在DDP训练中,我们通常希望在主进程(即rank 0)上执行代码。在SG中,用户通常通过触发“阶段回调”来执行自己的代码(参见下文“使用阶段回调”部分)。可以使用ddp_silent_mode或multi_process_safe装饰器来确保所需代码仅在rank 0上运行。例如,考虑下面的简单阶段回调,它会在训练过程中将每个批次的前3张图像上传到TensorBoard:
from super_gradients.training.utils.callbacks import PhaseCallback、PhaseContext和Phase
from super_gradients.common.environment.env_helpers import multi_process_safe
class Upload3TrainImagesCalbback(PhaseCallback):
def __init__(
self,
):
super().__init__(phase=Phase.TRAIN_BATCH_END)
@multi_process_safe
def __call__(self, context: PhaseContext):
batch_imgs = context.inputs.cpu().detach().numpy()
tag = "batch_" + str(context.batch_idx) + "_images"
context.sg_logger.add_images(tag=tag, images=batch_imgs[: 3], global_step=context.epoch)
@multi_process_safe装饰器确保该回调仅由rank 0触发。或者,也可以通过SG训练器的布尔属性ddp_silent_mode来实现,该属性在当前进程排名为零时设置为False(即使在进程组被终止后仍然如此):
from super_gradients.training.utils.callbacks import PhaseCallback、PhaseContext和Phase
class Upload3TrainImagesCalbback(PhaseCallback):
def __init__(
self,
):
super().__init__(phase=Phase.TRAIN_BATCH_END)
def __call__(self, context: PhaseContext):
if not context.ddp_silent_mode:
batch_imgs = context.inputs.cpu().detach().numpy()
tag = "batch_" + str(context.batch_idx) + "_images"
context.sg_logger.add_images(tag=tag, images=batch_imgs[: 3], global_step=context.epoch)
请注意,可以通过SgTrainer.ddp_silent_mode访问ddp_silent_mode。因此,在调用SgTrainer.train()之后,如果脚本中的某些部分只需要在rank 0上运行,则可以使用它。
需要了解的事项
您的总批量大小将是(GPU数量×批量大小),因此您可能需要增加学习率。虽然没有明确的规则,但一个经验法则是根据GPU数量线性增加学习率。
轻松更改架构参数
from super_gradients.training import models
# 实例化默认的预训练resnet18
default_resnet18 = models.get(model_name="resnet18", num_classes=100, pretrained_weights="imagenet")
# 实例化预训练resnet18,开启DropPath,概率为0.5
droppath_resnet18 = models.get(model_name="resnet18", arch_params={"droppath_prob": 0.5}, num_classes=100, pretrained_weights="imagenet")
# 实例化预训练resnet18,不带分类头。输出将来自全局池化之前的最后一个阶段
backbone_resnet18 = models.get(model_name="resnet18", arch_params={"backbone_mode": True}, pretrained_weights="imagenet")
使用阶段回调
from super_gradients import Trainer
from torch.optim.lr_scheduler import ReduceLROnPlateau
from super_gradients.training.utils.callbacks import Phase、LRSchedulerCallback
from super_gradients.training.metrics.classification_metrics import Accuracy
# 定义PyTorch的训练和验证数据加载器以及优化器
# 定义回调中要调用的内容
rop_lr_scheduler = ReduceLROnPlateau(optimizer, mode="max", patience=10, verbose=True)
# 定义阶段回调,它们将按照Phase中定义的方式触发
phase_callbacks = [LRSchedulerCallback(scheduler=rop_lr_scheduler,
phase=Phase.VALIDATION_EPOCH_END,
metric_name="Accuracy")]
# 创建一个训练器对象,更多参数请参阅声明
trainer = Trainer("experiment_name")
# 将phase_callbacks定义为训练参数的一部分
train_params = {"phase_callbacks": phase_callbacks}
集成到DagsHub
![]()
from super_gradients import Trainer
trainer = Trainer("experiment_name")
model = ...
training_params = { ... # 您的训练参数
"sg_logger": "dagshub_sg_logger", # DagsHub日志记录器,详情请参阅super_gradients.common.sg_loggers.dagshub_sg_logger.DagsHubSGLogger类
"sg_logger_params": # 将传递给日志记录器super_gradients.common.sg_loggers.dagshub_sg_logger.DagsHubSGLogger初始化方法的参数
{
"dagshub_repository": "<REPO_OWNER>/<REPO_NAME>", # 可选:您的DagsHub项目名称,由所有者名称、斜杠和仓库名称组成。如果留空,您将在运行时被提示手动填写。
"log_mlflow_only": False, # 可选:设置为true以跳过DVC日志记录,仅将所有工件记录到MLflow
"save_checkpoints_remote": True,
"save_tensorboard_remote": True,
"save_logs_remote": True,
}
}
集成到Weights and Biases
from super_gradients import Trainer
# 创建一个训练器对象,更多参数请查看声明
trainer = Trainer("experiment_name")
train_params = { ... # 训练参数
"sg_logger": "wandb_sg_logger", # Weights&Biases 日志记录器,详情请参阅 WandBSGLogger 类
"sg_logger_params": # 将传递给日志记录器 __init__ 方法的参数
{
"project_name": "project_name", # W&B 项目名称
"save_checkpoints_remote": True,
"save_tensorboard_remote": True,
"save_logs_remote": True,
}
}
集成到 ClearML
from super_gradients import Trainer
# 创建一个训练器对象,更多参数请查看声明
trainer = Trainer("experiment_name")
train_params = { ... # 训练参数
"sg_logger": "clearml_sg_logger", # ClearML 日志记录器,详情请参阅 ClearMLSGLogger 类
"sg_logger_params": # 将传递给日志记录器 __init__ 方法的参数
{
"project_name": "project_name", # ClearML 项目名称
"save_checkpoints_remote": True,
"save_tensorboard_remote": True,
"save_logs_remote": True,
}
}
集成到 Voxel51
您可以使用 apply_model() 方法将 SuperGradients YOLO-NAS 模型直接应用于您的 FiftyOne 数据集:
import fiftyone as fo
import fiftyone.zoo as foz
from super_gradients.training import models
dataset = foz.load_zoo_dataset("quickstart", max_samples=25)
dataset.select_fields().keep_fields()
model = models.get("yolo_nas_m", pretrained_weights="coco")
dataset.apply_model(model, label_field="yolo_nas", confidence_thresh=0.7)
session = fo.launch_app(dataset)
SuperGradients YOLO-NAS 模型可以直接从 FiftyOne Model Zoo 获取:
import fiftyone as fo
import五十one.zoo as foz
model = foz.load_zoo_model("yolo-nas-torch")
dataset = foz.load_zoo_dataset("quickstart")
dataset.apply_model(model, label_field="yolo_nas")
session = fo.launch_app(dataset)
安装方法
前提条件
一般要求
- 已安装 Python 3.7、3.8 或 3.9。
- 1.9.0 <= torch < 1.14
- requirements.txt 中指定的 Python 包;
在 NVIDIA GPU 上进行训练
- NVIDIA CUDA Toolkit >= 11.2
- CuDNN >= 8.1.x
- 支持 CUDA >= 11.2 的 NVIDIA 驱动程序(≥460.x)
快速安装
使用 GitHub 安装
pip install git+https://github.com/Deci-AI/super-gradients.git@stable
已实现的模型架构
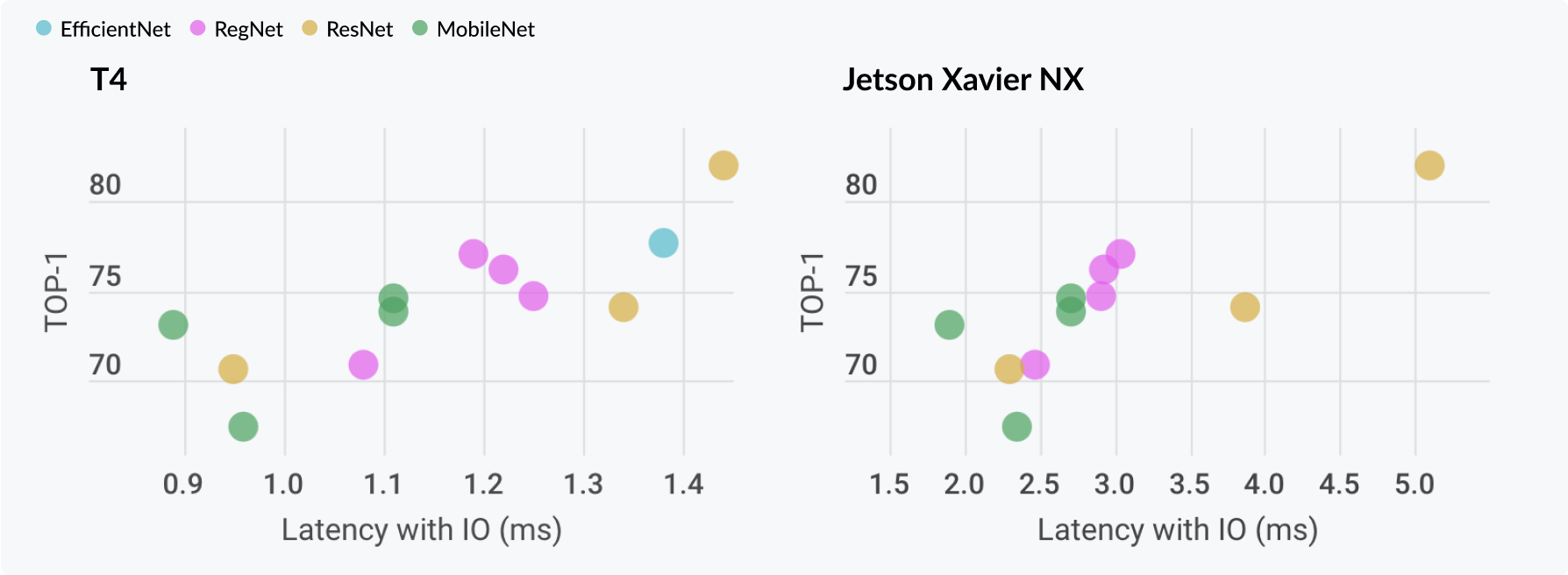
所有计算机视觉模型及其预训练检查点均可在 Model Zoo 中找到。
图像分类
- DenseNet(密集连接卷积网络)
- DPN
- EfficientNet
- LeNet
- MobileNet
- MobileNet v2
- MobileNet v3
- PNASNet
- 预激活 ResNet
- RegNet
- RepVGG
- ResNet
- ResNeXt
- SENet
- ShuffleNet
- ShuffleNet v2
- VGG
语义分割
目标检测
姿态估计
已实现的数据集
Deci 提供了多种数据集的实现。如果您需要下载其中的任何数据集,可以 查看说明。
图像分类
语义分割
目标检测
姿态估计
文档
请访问 SuperGradients 的 文档,获取完整的文档、用户指南和示例。
贡献
如需了解如何为 SuperGradients 做出贡献,请参阅我们的 贡献页面。
我们优秀的贡献者:

由 contrib.rocks 制作。
引用
如果您在研究中使用了 SuperGradients 库或基准测试,请引用 SuperGradients 深度学习训练库。
社区
如果您想加入 SuperGradients 不断壮大的社区,了解所有令人兴奋的新闻和更新,需要帮助、请求高级功能, 或者想要提交错误报告或问题反馈,我们都热烈欢迎您的加入!
Discord 是讨论 SuperGradients 和获得支持的最佳场所。点击此处加入我们的 Discord 社区
如需报告错误,请在 GitHub 上 提交问题。
加入 SG 新闻通讯 以随时了解新功能和模型、重要公告以及即将举行的活动。
如需与我们简短会面,请使用此 链接 并选择您方便的时间。
许可证
本项目采用 Apache 2.0 许可证 发布。
引用
BibTeX
@misc{supergradients,
doi = {10.5281/ZENODO.7789328},
url = {https://zenodo.org/record/7789328},
author = {Aharon, Shay 和 {Louis-Dupont} 以及 {Ofri Masad} 和 Yurkova, Kate 和 {Lotem Fridman} 以及 {Lkdci} 以及 Khvedchenya, Eugene 和 Rubin, Ran 和 Bagrov, Natan 和 Tymchenko, Borys 和 Keren, Tomer 和 Zhilko, Alexander 和 {Eran-Deci}},
title = {Super-Gradients},
publisher = {GitHub},
journal = {GitHub 仓库},
year = {2021},
}
最新 DOI
![]()
ֿ
在此处申请免费试用 这里
版本历史
3.7.12024/04/083.7.02024/04/013.6.12024/03/083.6.02024/01/253.5.02023/11/233.4.12023/11/123.4.02023/11/063.3.12023/10/263.3.02023/10/153.2.12023/09/043.2.02023/08/153.1.32023/07/193.1.22023/06/073.1.12023/05/033.1.02023/05/023.0.92023/04/193.0.82023/04/023.0.72023/02/013.0.62023/01/113.0.52022/12/28常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器