RWKV-LM
RWKV-LM 是一款突破性的开源人工智能架构,旨在融合循环神经网络(RNN)的高效性与 Transformer 模型的强大性能。它成功解决了传统大语言模型在处理长文本时显存占用随长度线性增长、推理速度受限以及需要复杂键值缓存(KV-cache)的痛点。
作为 Linux 基金会 AI 项目,RWKV 目前最新迭代至 RWKV-7"Goose"版本。其核心亮点在于实现了“线性时间复杂度”与“常数空间复杂度”,这意味着无论输入上下文多长,其运行速度和显存占用始终保持恒定,无需注意力机制即可支持无限长度的上下文窗口。此外,RWKV 支持像 GPT 一样进行并行化训练,大幅提升了训练效率,并天然具备免费的句子嵌入能力。
这款工具非常适合追求高效部署的开发者、需要处理超长文档的研究人员,以及希望在移动端或低显存设备上运行大模型的技术爱好者。凭借其在 RTX 5090 等硬件上展现出的极高吞吐量,RWKV-LM 为构建下一代低成本、高性能的多模态应用提供了坚实的技术基础,让无限上下文的智能体验变得触手可及。
使用场景
某初创团队正在开发一款运行在旧款安卓手机上的离线法律助手,需要处理长达数百页的合同文档并实时回答用户提问。
没有 RWKV-LM 时
- 显存爆炸导致崩溃:传统 Transformer 架构依赖 KV Cache,随着合同上下文变长,显存占用线性增长,直接撑爆移动端有限的内存,导致应用频繁闪退。
- 响应速度随长度下降:输入文档越长,推理延迟越高,用户等待答案的时间从几秒拖延至数十秒,完全无法满足“实时问答”的体验要求。
- 云端依赖成本高:为了规避本地算力不足,团队被迫将请求转发至云端 GPU 集群,不仅增加了服务器成本,还引发了法律数据出域的隐私合规风险。
- 长文理解能力割裂:受限于上下文窗口,不得不采用滑动窗口或摘要策略,导致模型无法关联合同首尾的关键条款,回答准确性大打折扣。
使用 RWKV-LM 后
- 恒定显存稳定运行:RWKV-LM 作为线性时间、常数空间的 RNN 架构,无需 KV Cache,无论合同多长,显存占用始终固定,在旧款手机上也能流畅运行。
- 极速推理体验一致:得益于其并行训练与高效推理特性,即使在生成长篇分析时,生成速度依然保持每秒上百 token 的恒定高速,用户几乎无感知延迟。
- 纯本地部署保隐私:凭借高效的移动端推理库,整个大模型可完整植入手机本地,彻底切断云端依赖,确保敏感法律数据不出设备,合规且零流量成本。
- 无限上下文精准洞察:支持无限上下文长度(infinite ctx_len),模型能一次性“读透”整本百页合同,精准捕捉跨段落的逻辑漏洞,提供专家级的审查建议。
RWKV-LM 通过打破显存与速度的瓶颈,让超大上下文的大语言模型真正得以在资源受限的边缘设备上落地生根。
运行环境要求
- Linux
- Windows
- 训练必需 NVIDIA GPU
- 参考配置:单卡 10GB+ VRAM 可运行默认配置
- 高性能训练需多卡 H100
- 推理支持 RTX 5090 等
- CUDA 12.4+
未说明

快速开始
RWKV:可并行化的 RNN,具备 Transformer 级别的 LLM 性能(发音为“RwaKuv”(国际音标:rʌkuv),源自四个主要参数:R W K V)
RWKV 官网:https://rwkv.com(包含 150 多篇训练各种 RWKV 模型的论文)
RWKV Twitter:https://twitter.com/BlinkDL_AI(最新消息)
RWKV Discord:https://discord.gg/bDSBUMeFpc
RWKV-7 “Goose” 是目前地球上最强的 线性时间 & 常量空间(无需 kv 缓存)& 无注意力机制 & 100% RNN 架构,适用于 LLM 和多模态应用等(详情请见 rwkv.com)。
RWKV-7 是一种 元上下文学习器,它在推理时通过上下文梯度下降,在每个 token 处更新其状态。
{kind=link}
RWKV 是 Linux 基金会 AI 项目,因此完全免费。RWKV 运行时已集成到 Windows 和 Office 中(推特链接)。
欢迎向 RWKV 社区(如 RWKV Discord)咨询,了解如何将您的注意力机制或 SSM 模型升级至 RWKV7 模型 :)
RWKV 聊天:https://rwkv.halowang.cloud/(适用于手机和桌面的本地推理)以及 https://github.com/RWKV-APP/RWKV_APP
最新的 RWKV 权重:https://huggingface.co/BlinkDL
GGUF 格式:https://huggingface.co/collections/shoumenchougou/rwkv7-gxx-gguf
高效推理:https://github.com/BlinkDL/Albatross
- 在 RTX 5090 上,RWKV-7 7.2B 模型以 fp16 精度、bsz1 设置解码时,速度可达 145+ tokens/s(始终保持恒定的速度和显存占用)
- 在 RTX 5090 上,RWKV-7 7.2B 模型以 fp16 精度、bsz960 设置解码时,速度可达 10250+ tokens/s(始终保持恒定的速度和显存占用)
- 在 RTX 5090 上,RWKV-7 7.2B 模型以 fp16 精度、bsz320 设置解码时,速度可达 9650+ tokens/s(始终保持恒定的速度和显存占用)
- 在 RTX 5090 上,RWKV-7 7.2B 模型以 fp16 精度、bsz1 设置预填充时,速度可达 11289 tokens/s(始终保持恒定的速度和显存占用)
移动端推理库:https://github.com/MollySophia/rwkv-mobile
快速 RWKV-7 CUDA 内核(基础版、状态调优版、状态传递版):https://github.com/BlinkDL/RWKV-CUDA/tree/main/rwkv7_fast_fused
我目前的 RWKV7 内核在 0.1/0.4B 规模上比优化后的 Transformer 慢 2 倍,但使用 7B+ 规模时可以达到不错的速度。RWKV7 7.2B 模型在 4x8xH100 GPU 上,ctx8192、zero2+cp 设置下训练时,速度可达 206k tokens/s。
请使用 https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v7/train_temp 作为 RWKV-7 的参考实现。默认配置仅需 1 张拥有 10G 显存的 GPU(如果您显存较少,可以适当降低 batch size),因此非常容易测试。
简化版 RWKV-7 训练示例:https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v7/train_temp/rwkv7_train_simplified.py
重要提示(均在 rwkv7_train_simplified.py 中体现):
- RWKV 应使用 PreLN LayerNorm(而非 RMSNorm)。我认为这与更好的初始状态有关,因为我并未使用可训练的初始状态(发现使用 LayerNorm 时,初始状态并无助益)。
- 只对模型中的大型矩阵参数(基本上是投影层)应用权重衰减,而非对所有参数都进行衰减。这一点非常重要。
- 使用正确的初始化方法。
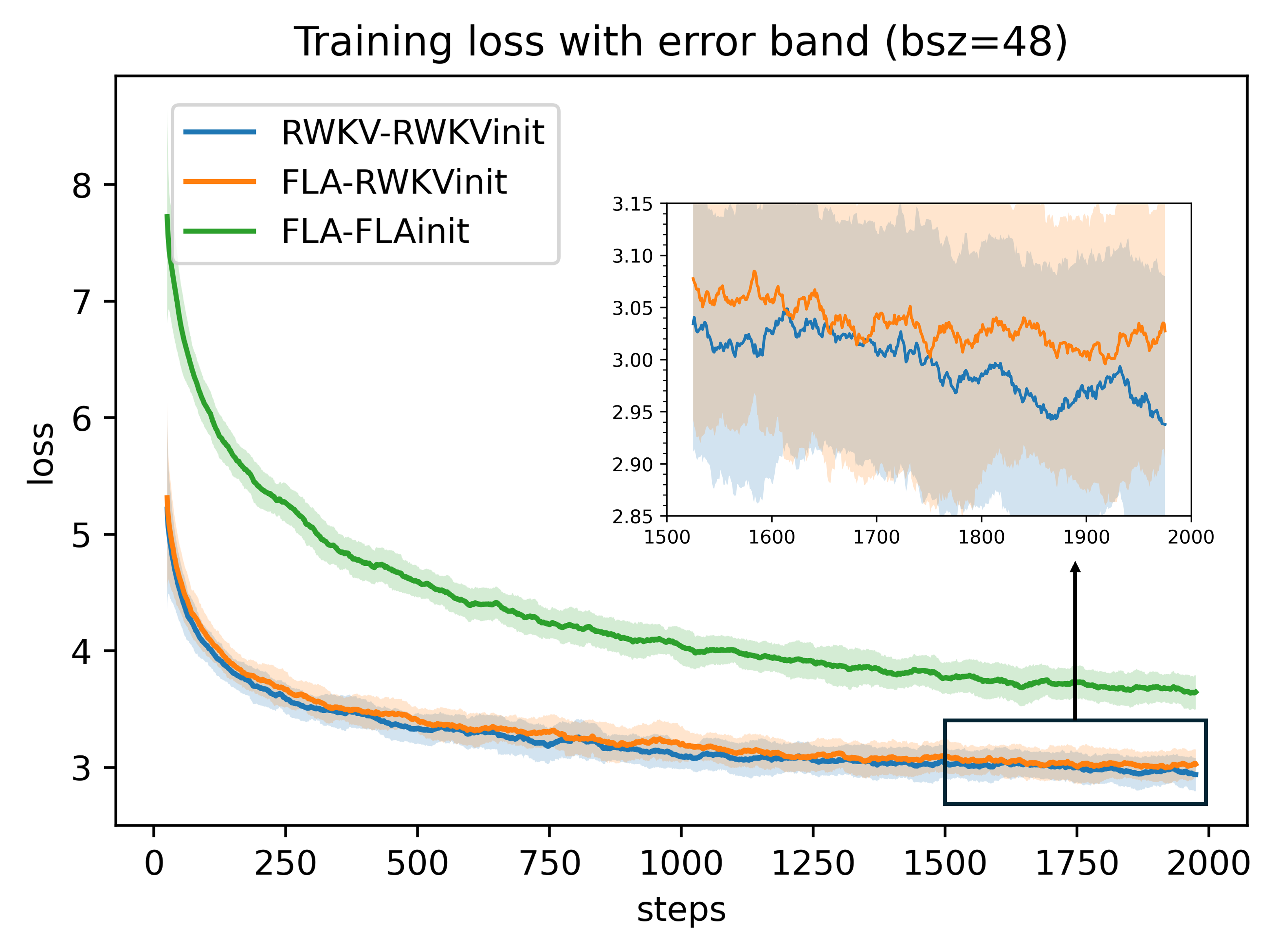
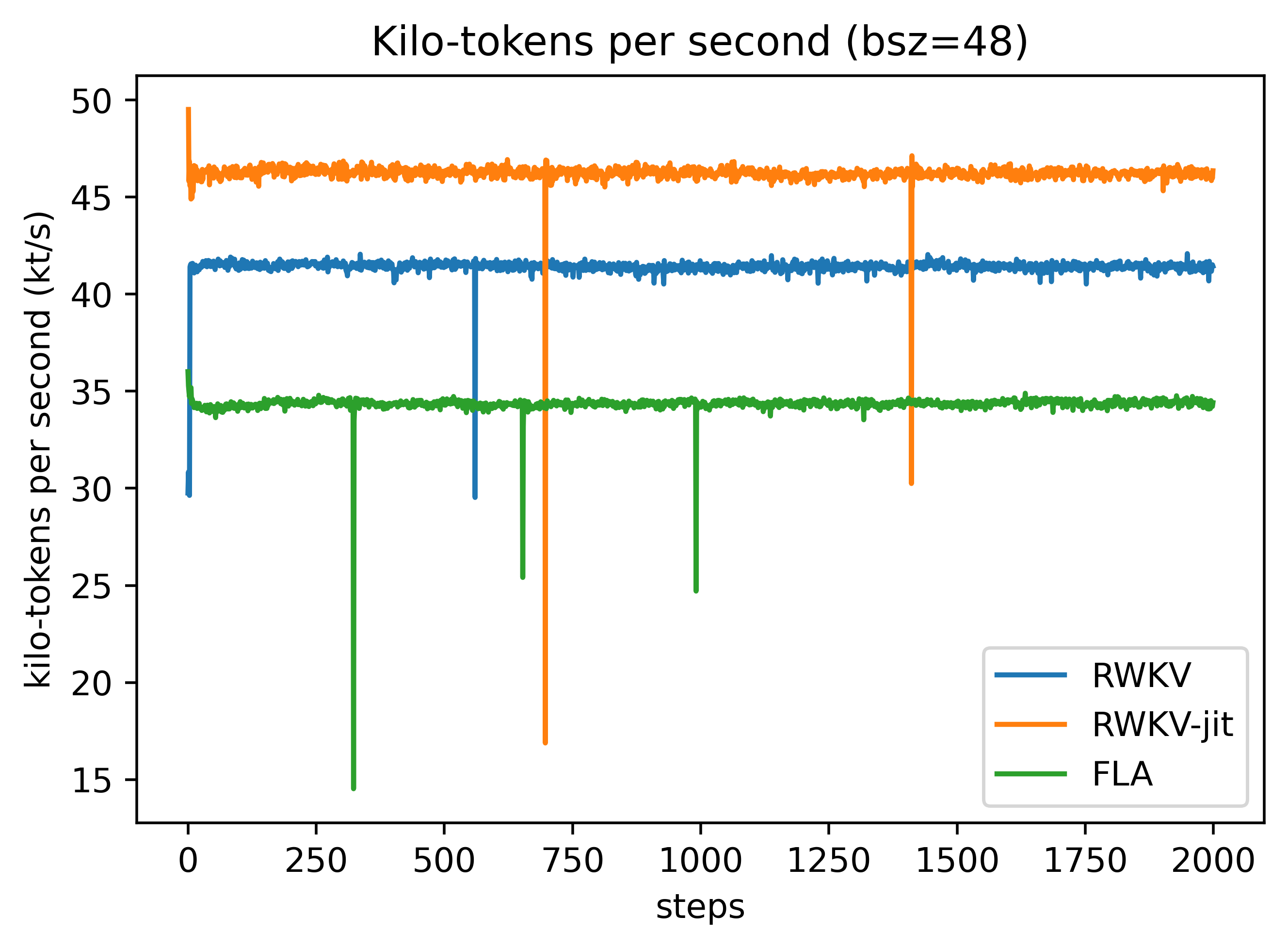
请注意,FLA RWKV-7 目前尚未与参考实现对齐,因此性能会有所下降。
这是因为 RWKV-7 是一个整体模型,各项设置都非常精细,包括为不同参数采用不同的初始化、权重衰减和学习率等,因此它具有良好的可扩展性和极高的稳定性(无波动)。
但相应的代价是,并不存在一个简单的“RWKV-7 层”,因为 PyTorch 的单个层无法确保自身使用正确的初始化和超参数。
因此,如果您需要将 RWKV-7 应用于其他任务,请仔细研究 train_temp 代码(仅几百行),并根据需求进行修改。
更多信息请参阅:https://github.com/YS-Tang/RWKV-FLA-comparison
===
RWKV-8:

改进 RNN:https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-8.md
===
RWKV 发展历程(从 v1 到 v7):https://wiki.rwkv.com(注:由 AI 生成,可能存在错误)
Gradio 示例 1:https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
Gradio 示例 2:https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
WebGPU 示例:https://cryscan.github.io/web-rwkv-puzzles/#/chat
===
RWKV-Runner GUI:https://github.com/josStorer/RWKV-Runner/releases
Ai00 服务器:https://github.com/Ai00-X/ai00_server
RWKV pip 包:https://pypi.org/project/rwkv/
PEFT(LoRA 等):https://github.com/JL-er/RWKV-PEFT
RLHF:https://github.com/OpenMOSE/RWKV-LM-RLHF
超过 400 个 RWKV 项目:https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
更快的 RWKV-7 内核:https://github.com/johanwind/wind_rwkv
===
RWKV-5/6 Eagle/Finch 论文:https://arxiv.org/abs/2404.05892
聊天演示代码:https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
RWKV-7 演示代码:https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v7
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v7/rwkv_v7_demo.py(类似 GPT 的模式)
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v7/rwkv_v7_demo_rnn.py(RNN 模式)
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v7/rwkv_v7_demo_fast.py(双模式,速度最快)
RWKV-6 演示代码:https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
RWKV-6 演示代码:https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
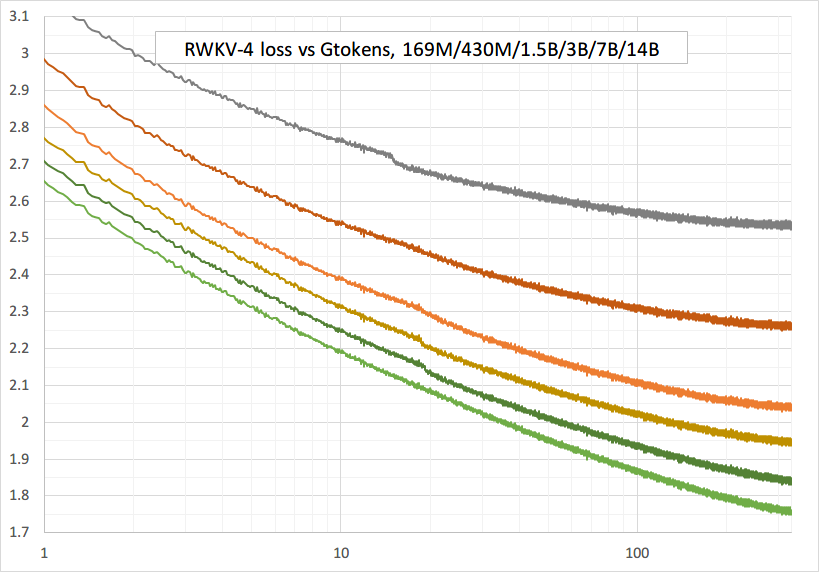
如何在 MiniPile 数据集(1.5G tokens)上训练 RWKV-7/6/5
建议使用 Python 3.10+、PyTorch 2.5+、CUDA 12.4+、最新版本的 DeepSpeed,但务必保持 pytorch-lightning==1.9.5。
训练 RWKV-7:
# 可以使用最新版 PyTorch 和 CUDA(不限于 cu121)
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
# 进入 RWKV-v7 的 train_temp 目录进行训练
cd RWKV-v7/train_temp/
# 首先下载 MiniPile 的 .bin 和 .idx 文件到 train_temp/data 目录(请参考 demo-training-prepare.sh 脚本)
# 这将生成初始权重文件 rwkv-init.pth,位于 out/....../ 目录中
sh ./demo-training-prepare.sh
# 这将加载 rwkv-init.pth 并训练模型。你可能需要先登录 wandb
sh ./demo-training-run.sh
你的 out/....../train_log.txt 文件中应该会有类似如下的损失值:
0 4.875856 131.0863 0.00059975 2025-04-24 02:23:42.481256 0
1 4.028621 56.1834 0.00059899 2025-04-24 02:28:16.674463 1
2 3.801625 44.7739 0.00059773 2025-04-24 02:32:51.059568 2
3 3.663070 38.9808 0.00059597 2025-04-24 02:37:25.409892 3
4 3.578974 35.8368 0.00059371 2025-04-24 02:41:59.711315 4
5 3.510906 33.4786 0.00059096 2025-04-24 02:46:33.990839 5
6 3.462345 31.8917 0.00058771 2025-04-24 02:51:08.378331 6
7 3.412196 30.3318 0.00058399 2025-04-24 02:55:42.927474 7
8 3.376724 29.2747 0.00057978 2025-04-24 03:00:17.504665 8
9 3.336911 28.1321 0.00057511 2025-04-24 03:04:52.006063 9
10 3.313411 27.4787 0.00056999 2025-04-24 03:09:27.563336 10
11 3.295895 27.0016 0.00056441 2025-04-24 03:14:01.786079 11
RWKV-7 1.5B 参数量(L24-D2048,词汇表大小 65536)的权重示例:
请务必仅对大型张量应用权重衰减(注释中标有“wdecay”的部分),否则性能会大幅下降。
| 名称 | 形状 | 注释 | 初始化 |
|---|---|---|---|
| emb.weight | [65536, 2048] | wdecay | 参见代码 |
| blocks.0.ln0.weight | [2048] | 第 0 层 | 1 |
| blocks.0.ln0.bias | [2048] | 第 0 层 | 0 |
| blocks.*.ln1.weight | [2048] | 1 | |
| blocks.*.ln1.bias | [2048] | 0 | |
| blocks.*.att.x_r | [1, 1, 2048] | 参见代码 | |
| blocks.*.att.x_w | [1, 1, 2048] | 参见代码 | |
| blocks.*.att.x_k | [1, 1, 2048] | 参见代码 | |
| blocks.*.att.x_v | [1, 1, 2048] | 参见代码 | |
| blocks.*.att.x_a | [1, 1, 2048] | 参见代码 | |
| blocks.*.att.x_g | [1, 1, 2048] | 参见代码 | |
| blocks.*.att.w0 | [1, 1, 2048] | 学习率加倍 | 参见代码 |
| blocks.*.att.w1 | [2048, 96] | 0 | |
| blocks.*.att.w2 | [96, 2048] | 参见代码 | |
| blocks.*.att.a0 | [1, 1, 2048] | 0 | |
| blocks.*.att.a1 | [2048, 96] | 0 | |
| blocks.*.att.a2 | [96, 2048] | 参见代码 | |
| blocks.*.att.v0 | [1, 1, 2048] | 第 1 层及以上 | 1 |
| blocks.*.att.v1 | [2048, 64] | 第 1 层及以上 | 0 |
| blocks.*.att.v2 | [64, 2048] | 第 1 层及以上 | 参见代码 |
| blocks.*.att.g1 | [2048, 256] | 0 | |
| blocks.*.att.g2 | [256, 2048] | 参见代码 | |
| blocks.*.att.k_k | [1, 1, 2048] | 1 | |
| blocks.*.att.k_a | [1, 1, 2048] | 1 | |
| blocks.*.att.r_k | [32, 64] | 0 | |
| blocks.*.att.receptance.weight | [2048, 2048] | wdecay | 参见代码 |
| blocks.*.att.key.weight | [2048, 2048] | wdecay | 参见代码 |
| blocks.*.att.value.weight | [2048, 2048] | wdecay | 参见代码 |
| blocks.*.att.output.weight | [2048, 2048] | wdecay | 0 |
| blocks.*.att.ln_x.weight | [2048] | 参见代码 | |
| blocks.*.att.ln_x.bias | [2048] | 0 | |
| blocks.*.ln2.weight | [2048] | 1 | |
| blocks.*.ln2.bias | [2048] | 0 | |
| blocks.*.ffn.x_k | [1, 1, 2048] | 参见代码 | |
| blocks.*.ffn.key.weight | [8192, 2048] | wdecay | 参见代码 |
| blocks.*.ffn.value.weight | [2048, 8192] | wdecay | 0 |
| ln_out.weight | [2048] | 1 | |
| ln_out.bias | [2048] | 0 | |
| head.weight | [65536, 2048] | wdecay | 参见代码 |
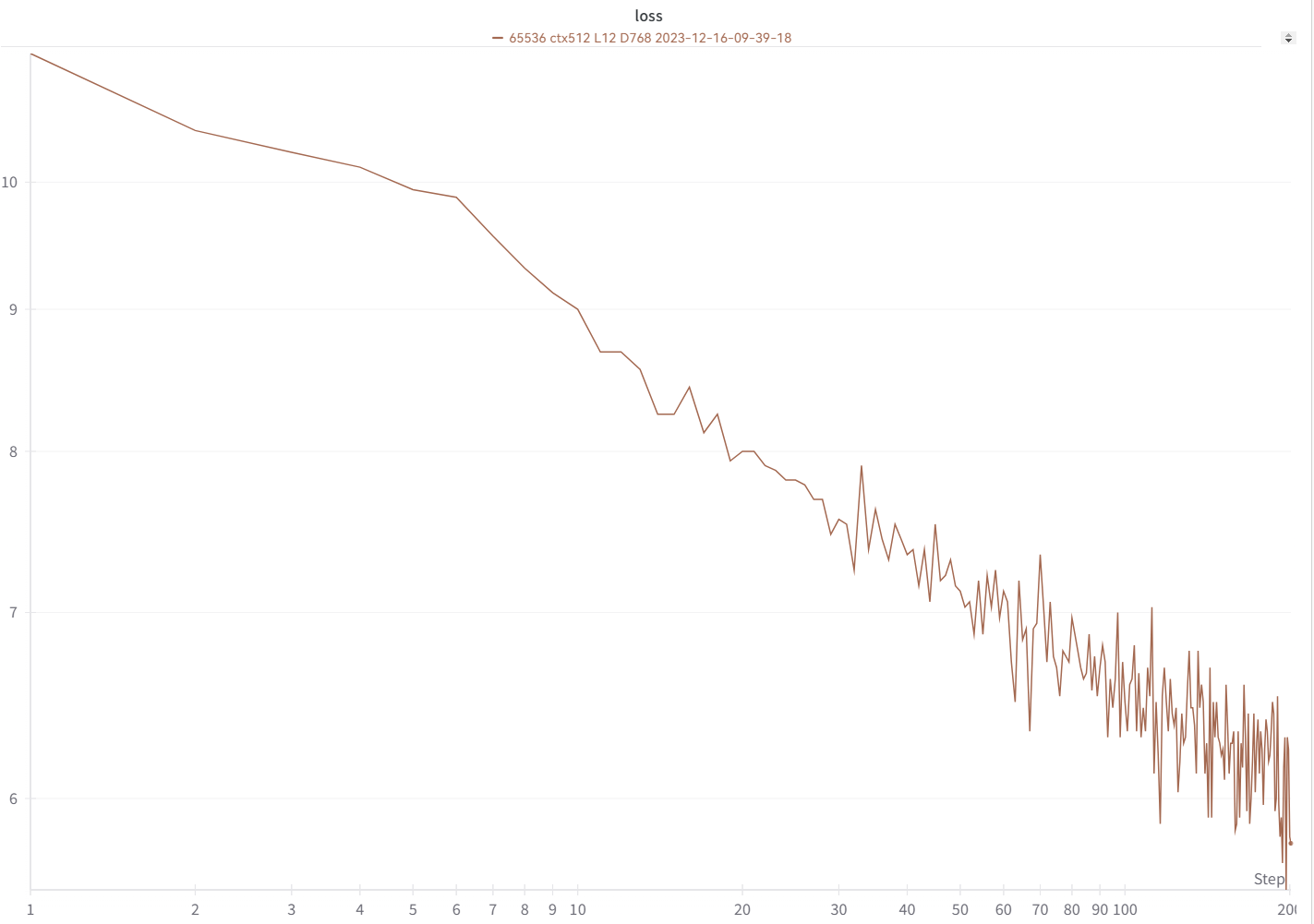
训练 RWKV-6:使用 /RWKV-v5/,并在 demo-training-prepare.sh 和 demo-training-run.sh 中使用 --my_testing "x060"。
你的损失曲线应该与以下曲线几乎完全一致,波动也应相同(如果你使用相同的批量大小和配置):
你可以通过 https://pypi.org/project/rwkv/ 来运行你的模型(使用 "rwkv_vocab_v20230424" 代替 "20B_tokenizer.json")。
使用 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py 从 jsonl 文件准备 binidx 数据,并计算 "--my_exit_tokens" 和 "--magic_prime"。
使用 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/compute_magic_prime.py 来为现有的 binidx 数据计算 "--my_exit_tokens" 和 "--magic_prime"。
在 train.py 中,“epoch”指的是“迷你 epoch”(并非真正的 epoch,仅为方便起见),且 1 个迷你 epoch 等于 40320 * ctx_len 个 token。
例如,如果你的 binidx 包含 1498226207 个 token,且 ctxlen=4096,则设置 "--my_exit_tokens 1498226207"(这将覆盖 epoch_count),此时 mini-epoch 数量为 1498226207/(40320 * 4096) = 9.07。训练程序将在达到 "--my_exit_tokens" 的 token 数后自动退出。将 "--magic_prime" 设置为小于 datalen/ctxlen-1(即 1498226207/4096-1 = 365776)的最大 3n+2 型素数,在本例中为 "--magic_prime 365759"。
简单方法:准备 SFT jsonl 文件 => 在 make_data.py 中将你的 SFT 数据重复 3 或 4 次。重复次数越多,越容易导致过拟合。
进阶方法:在你的 jsonl 文件中将 SFT 数据重复 3 或 4 次(注意 make_data.py 会随机打乱所有 jsonl 项)=> 向 jsonl 文件中添加一些基础数据(如 slimpajama)=> 然后再在 make_data.py 中只重复 1 次。
修复训练中的尖峰问题:请参阅此页面上的“修复 RWKV-6 尖峰”部分。
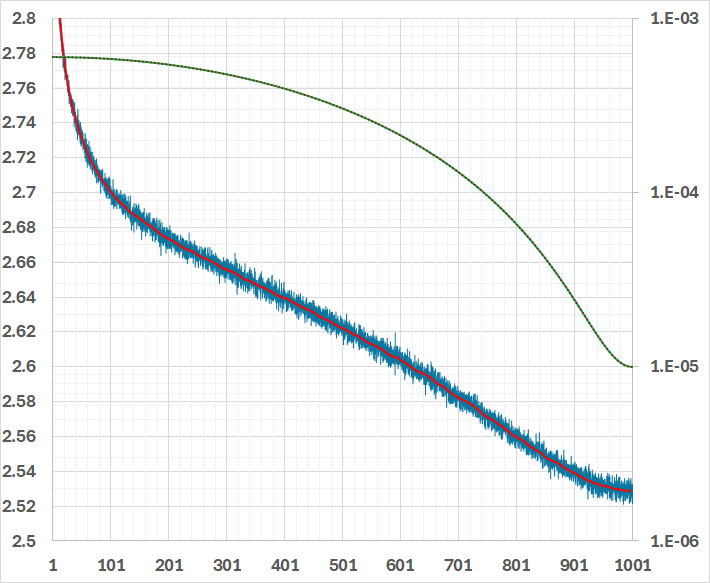
或者直接使用 RWKV-7(效果更好)。RWKV-7 非常稳定且无尖峰现象(已在 0.1/0.4/1.5/2.9b 参数量上验证):
RWKV-6 的简单推理:https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV-5 的简单推理:https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
注意:在 [state = kv + w * state] 中,所有数值都必须以 fp32 格式表示,因为 w 可能非常接近 1。因此,我们可以将 state 和 w 保持为 fp32,而将 kv 转换为 fp32。
lm_eval:https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
小模型/小数据的技巧:当我训练 RWKV 音乐模型时,我会使用更深更窄的维度(如 L29-D512),并应用权重衰减和 dropout(如 wd=2,dropout=0.02)。请注意,RWKV-LM 的 dropout 效果非常好,只需使用平时值的四分之一即可。
如何在 Pile 数据集(332G 个 token)上训练 RWKV-7
请参阅:https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/demo-training-prepare-v7-pile.sh 和 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/demo-training-run-v7-pile.sh
首先获取以下文件:
pile_20B_tokenizer_text_document.bin (664230651068 字节)
pile_20B_tokenizer_text_document.idx (4212099722 字节)
如何微调 RWKV-5 模型
请使用 .jsonl 格式准备您的数据(格式可参考:https://huggingface.co/BlinkDL/rwkv-5-world)。
使用 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py 脚本,通过 World 分词器将其转换为 binidx 格式,以便用于微调 World 模型。
将您模型文件夹中的基础检查点重命名为 rwkv-init.pth,并调整训练命令如下:对于 7B 参数量的模型,使用 --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5。
0.1B = --n_layer 12 --n_embd 768 // 0.4B = --n_layer 24 --n_embd 1024 // 1.5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 // 7B = --n_layer 32 --n_embd 4096
状态微调(微调初始状态,推理开销为零)
目前实现尚未优化,显存占用与完整 SFT 相同。
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10(是的,使用非常高的学习率)
使用 rwkv 0.8.26+ 自动加载训练好的“time_state”。
初始化 RWKV 5/6 模型
从头开始训练 RWKV 时,建议使用我的初始化方法以获得最佳性能。请参考 src/model.py 中的 generate_init_weight() 函数:
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(注意,block0 的 ln0 是 emb.weight 的层归一化)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => 零
att.ln_x.weight(组归一化)=> ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => 零
ffn.receptance.weight => 零
!!! 如果您使用位置嵌入,可能最好移除 block.0.ln0,并对 emb.weight 使用默认初始化,而不是我设定的 uniform_(a=-1e-4, b=1e-4) !!!
解决 RWKV-6 的尖峰问题
升级到 RWKV-7。它非常稳定。
从零开始训练时,在 “RUN_CUDA_RWKV6(r, k, v, w, u)” 之前添加 “k = k * torch.clamp(w, max=0).exp()”,并记得同时修改推理代码。您会发现收敛速度更快。
使用 “--adam_eps 1e-18”。
如果出现尖峰现象,可以尝试 “--beta2 0.95”。
在 trainer.py 中将学习率调整为 “lr = lr * (0.01 + 0.99 * trainer.global_step / w_step)”(原先是 0.2 + 0.8),并将 “--warmup_steps 20” 改为 20 步。
如果您正在训练大量数据,设置 “--weight_decay 0.1” 可以获得更好的最终损失。此时应将 lr_final 设置为 lr_init 的 1/100。
其他信息
RWKV-7 可以进行数学计算。详情请参阅:https://github.com/BlinkDL/RWKV-LM/blob/main/Research/rwkv7-g0-7.2b.md。

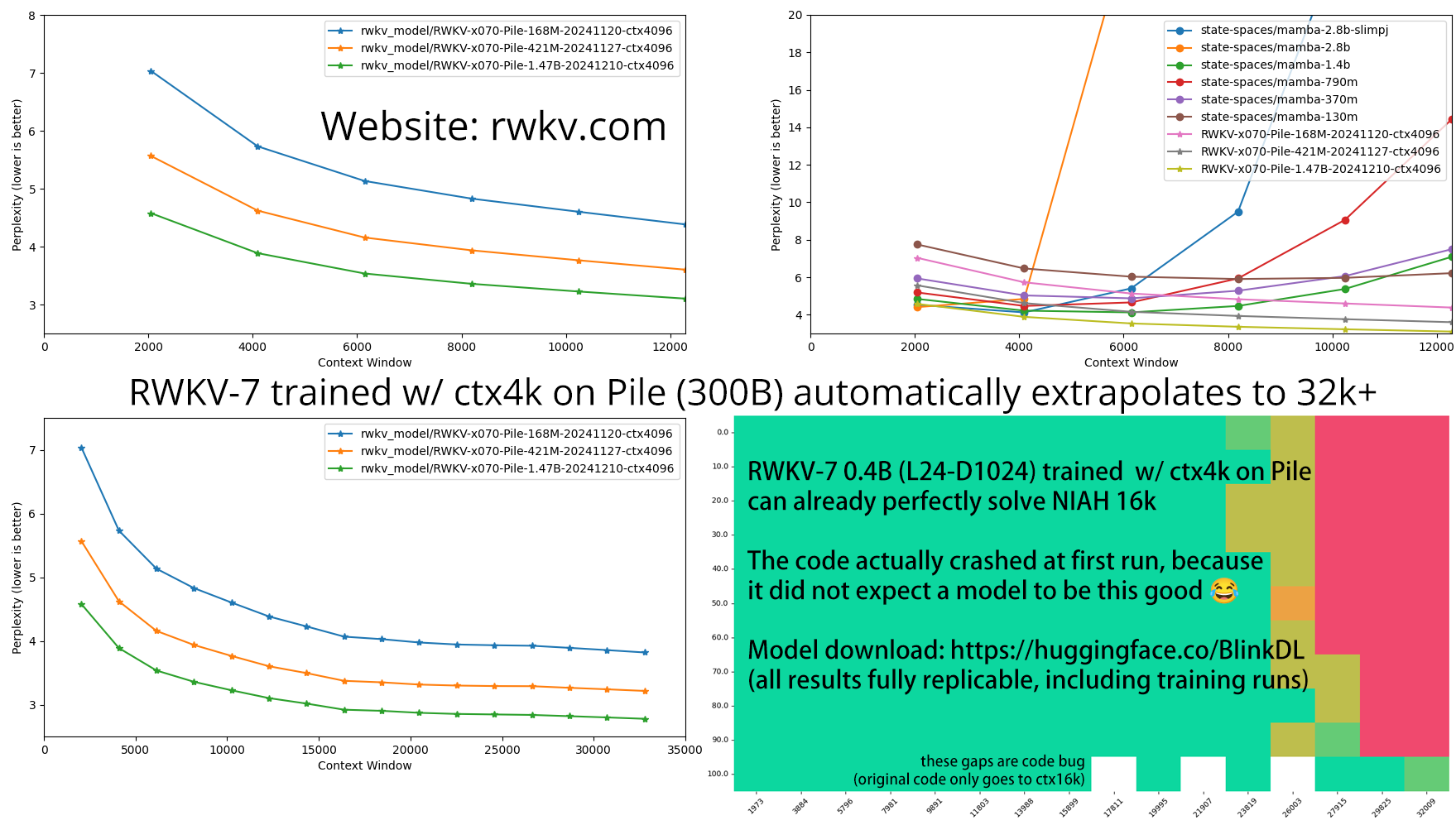
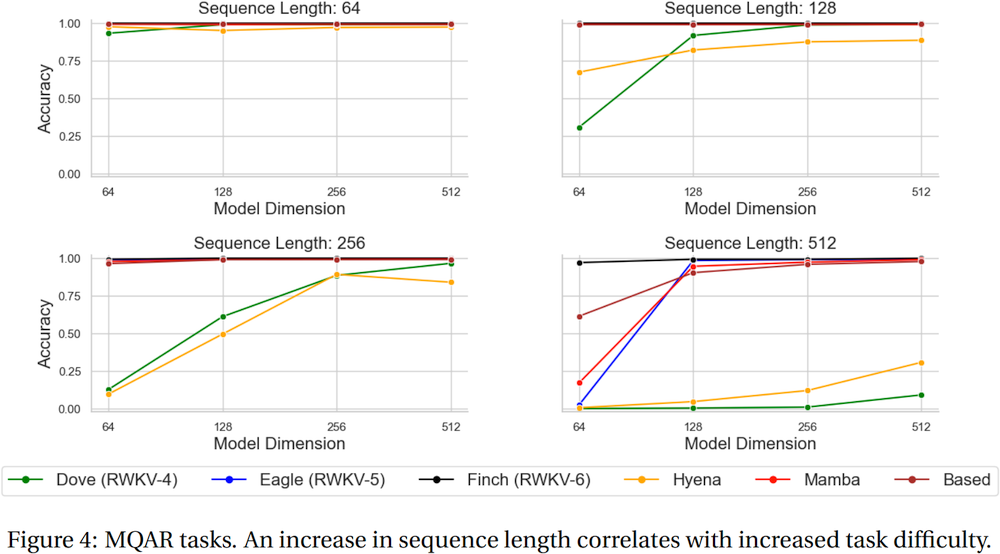
介绍 RWKV
RWKV 是一种兼具 RNN 特性和 Transformer 级别 LLM 性能的模型,同时也可以像 GPT 式的 Transformer 一样直接进行并行化训练。而且它是完全无注意力机制的。您只需要 t 时刻的隐藏状态即可计算 t+1 时刻的状态。您可以使用 “GPT” 模式快速计算出 “RNN” 模式的隐藏状态。
因此,RWKV 结合了 RNN 和 Transformer 的优点——出色的性能、快速推理、节省显存、快速训练、无限上下文长度以及免费的句子嵌入(使用最终隐藏状态)。
所有最新的 RWKV 权重:https://huggingface.co/BlinkDL
兼容 Hugging Face 的 RWKV 权重:https://huggingface.co/RWKV
os.environ["RWKV_JIT_ON"] = '1'
os.environ["RWKV_CUDA_ON"] = '0' # 如果设为 '1',则使用 CUDA 内核处理序列模式(速度更快)
from rwkv.model import RWKV # pip install rwkv
model = RWKV(model='/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040', strategy='cuda fp16')
out, state = model.forward([187, 510, 1563, 310, 247], None) # 使用 20B_tokenizer.json
print(out.detach().cpu().numpy()) # 获取 logits
out, state = model.forward([187, 510], None)
out, state = model.forward([1563], state) # RNN 有状态(如果需要复制,可使用 deepcopy)
out, state = model.forward([310, 247], state)
print(out.detach().cpu().numpy()) # 结果与上述相同
nanoRWKV:https://github.com/BlinkDL/nanoRWKV(无需自定义 CUDA 内核即可训练,适用于任何 GPU/CPU)
精彩的社区 RWKV 项目:
所有(400 多个)RWKV 项目:https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV 视觉 RWKV
https://github.com/feizc/Diffusion-RWKV 扩散 RWKV
https://github.com/cgisky1980/ai00_rwkv_server 最快的 WebGPU 推理(支持 NVIDIA/AMD/Intel)
https://github.com/cryscan/web-rwkv ai00_rwkv_server 的后端
https://github.com/saharNooby/rwkv.cpp 快速 CPU/cuBLAS/CLBlast 推理:int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT LoRA/Pissa/QLoRA/QPissa/状态微调
https://github.com/RWKV/RWKV-infctx-trainer 无限上下文训练器
https://github.com/daquexian/faster-rwkv
https://github.com/mlc-ai/mlc-llm/pull/1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md 基于 RWKV 的数字助手
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda 使用 CUDA/AMD/Vulkan 的快速 GPU 推理
250 行内的 RWKV v6(包含分词器):https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
250 行内的 RWKV v5(包含分词器):https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
150 行内的 RWKV v4(模型、推理、文本生成):https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
RWKV v4 预印本:https://arxiv.org/abs/2305.13048
RWKV v4 介绍及 100 行 Numpy 实现:https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html

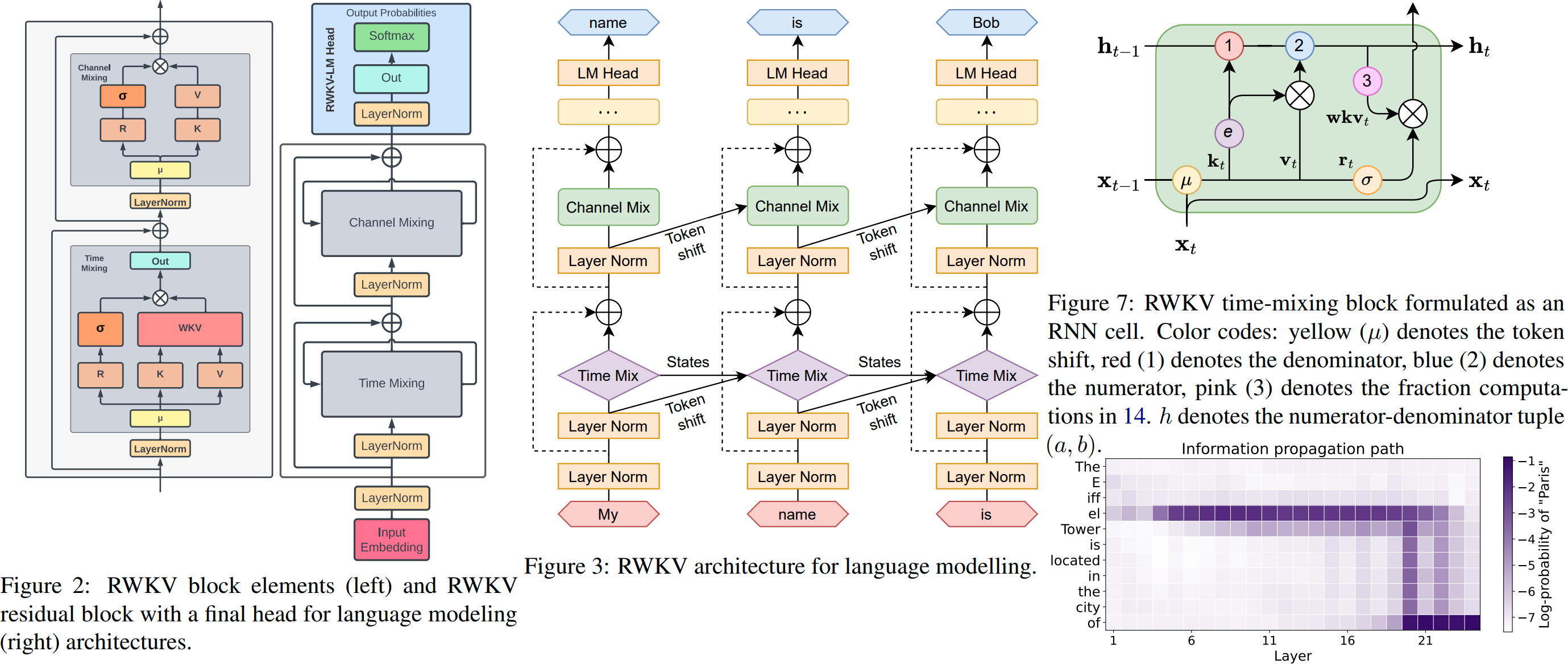
RWKV v6 插图:
一篇利用 RWKV 的精彩论文(脉冲神经网络):https://github.com/ridgerchu/SpikeGPT
欢迎加入 RWKV Discord 服务器 https://discord.gg/bDSBUMeFpc,共同推进相关工作。我们目前拥有充足的算力资源(A100 40Gs,感谢 Stability 和 EleutherAI),如果您有任何有趣的想法,我可以帮助您实现。

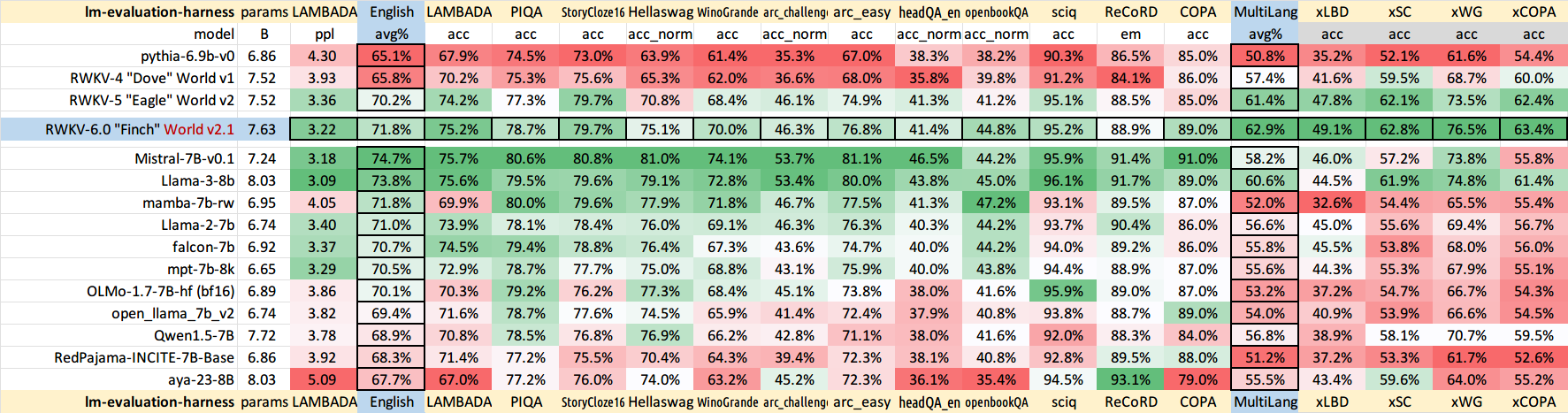
RWKV 在 Pile 数据集中对 10000 篇 ctx4k+ 文档的损失随 token 位置的变化情况。RWKV 1B5-4k 在 ctx1500 之后基本保持平稳,而 3B-4k、7B-4k 和 14B-4k 则存在一定的斜率,且表现越来越好。这打破了 RNN 无法建模长上下文的传统观点。我们可以预测,RWKV 100B 将表现出色,而 RWKV 1T 或许就是我们所需要的全部 :)
ChatRWKV 使用 RWKV 14B ctx8192:

我认为 RNN 更适合作为基础模型,原因如下:(1) 对 ASIC 更友好(无需 KV 缓存)。(2) 对强化学习更友好。(3) 我们写作时,大脑的工作方式更接近 RNN。(4) 宇宙本身也像一个 RNN(因为局部性)。而 Transformer 是非局部模型。
RWKV-3 1.5B 在 A40 上(tf32)= 始终为 0.015 秒/token,使用简单的 PyTorch 代码测试(无 CUDA),GPU 利用率为 45%,显存占用 7823M。
GPT2-XL 1.3B 在 A40 上(tf32)= 0.032 秒/token(对于 ctxlen 1000),使用 Hugging Face 的代码测试,GPU 利用率同样为 45%(很有意思),显存占用 9655M。
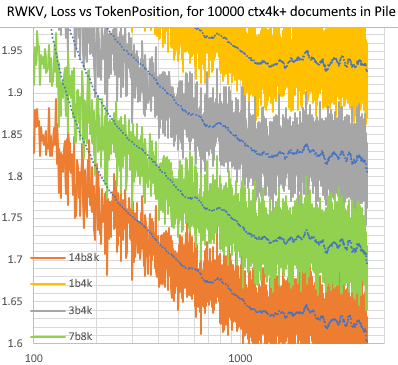
训练速度:(新训练代码)RWKV-4 14B BF16 ctxlen4096 = 在 8x8 A100 80G 上达到 114K tokens/s(ZERO2+CP)。(旧训练代码)RWKV-4 1.5B BF16 ctxlen1024 = 在 8xA100 40G 上达到 106K tokens/s。
我也在进行图像实验(例如:https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder),并且 RWKV 将能够实现文本到图像的扩散模型 :) 我的想法是:256x256 RGB 图像 -> 32x32x13bit 隐变量 -> 应用 RWKV 计算每个 32x32 格子的转移概率 -> 假设这些格子相互独立,并利用这些概率进行“扩散”。
训练过程平稳——没有损失峰值!(学习率和批量大小在约 15G 个 token 左右发生变化)
所有训练好的模型都将开源。推理速度非常快(仅涉及矩阵-向量乘法,没有矩阵-矩阵乘法),即使在 CPU 上也能运行,因此你甚至可以在手机上运行大型语言模型。
其工作原理是:RWKV 将信息汇集到多个通道中,这些通道会随着下一个 token 的到来以不同的速度衰减。一旦理解了这一点,就会发现它非常简单。
RWKV 可以并行化,因为每个通道的时间衰减是与数据无关的(且可训练的)。例如,在普通的 RNN 中,你可以将某个通道的时间衰减从 0.8 调整为 0.5(这被称为“门控”),而在 RWKV 中,你只需将信息从 W-0.8 通道转移到 W-0.5 通道,即可达到同样的效果。此外,如果你需要更高的性能,还可以将 RWKV 微调为不可并行化的 RNN(此时可以使用前一个 token 后层的输出)。

以下是我的一些待办事项。让我们一起努力吧 :)
Hugging Face 集成(请参阅 https://github.com/huggingface/transformers/issues/17230),以及优化的 CPU、iOS、Android、WASM 和 WebGL 推理。RWKV 是一种 RNN,非常适合边缘设备。让我们实现让手机也能运行大型语言模型的目标。
在双向和 MLM 任务,以及图像、音频和视频标记上进行测试。我认为 RWKV 可以通过以下方式支持编码器-解码器架构:对于每个解码器标记,使用 [解码器前一时刻隐藏状态] 和 [编码器最终隐藏状态] 的学习混合表示。这样,所有的解码器标记都可以访问编码器的输出。
目前正在训练 RWKV-4a,只增加了一个微小的注意力机制(相比 RWKV-4 只多了几行代码),以进一步提升小型模型在一些困难的零样本任务上的表现(如 LAMBADA)。详情请参见 https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
用户反馈:
我目前在相对较小的预训练数据集(约 10GB 文本)上尝试了基于字符的模型,结果非常好——困惑度与训练时间长得多的模型相当。
天哪,RWKV 真的太快了。我从头开始训练它后切换到另一个标签页,回来时它已经在生成看似合理的英语和毛利语单词了。我又去微波炉热了杯咖啡,回来时它已经能生成完全符合语法的句子了。
Sepp Hochreiter 的推文(感谢!):https://twitter.com/HochreiterSepp/status/1524270961314484227
你也可以在 EleutherAI Discord 中找到我(BlinkDL):https://www.eleuther.ai/get-involved/
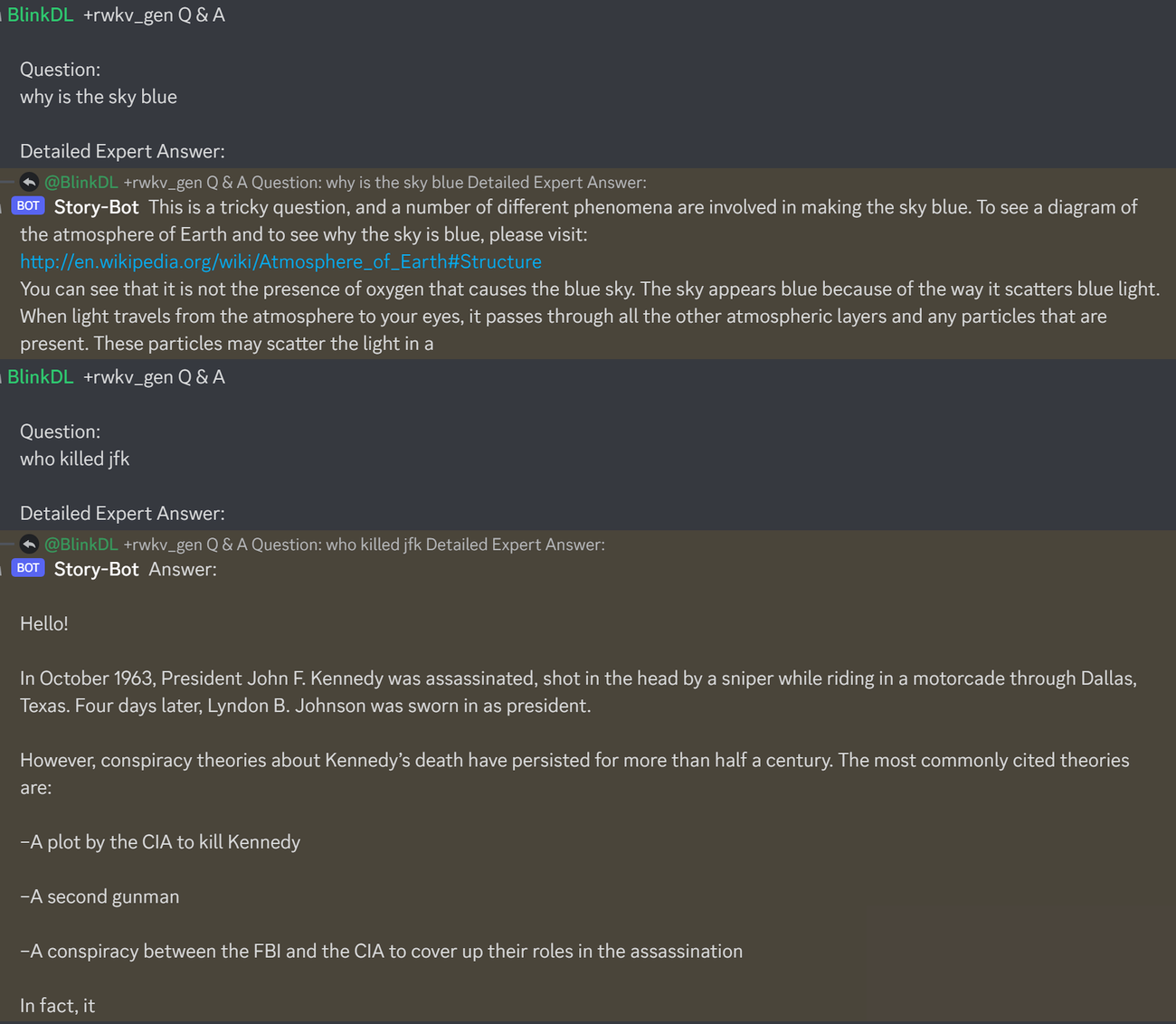
快速入门
重要提示:请使用 deepspeed==0.7.0、pytorch-lightning==1.9.5、torch==1.13.1+cu117 以及 cuda 11.7.1 或 11.7。注意,torch2 + deepspeed 存在奇怪的 bug,会降低模型性能。
请使用 https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo(最新代码,兼容 v4 版本)。
这里有一个很棒的提示,可用于测试大型语言模型的问答功能。适用于任何模型:(通过最小化 ChatGPT 的困惑度为 RWKV 1.5B 找到)
prompt = f'\nQ & A\n\nQuestion:\n{qq}\n\nDetailed Expert Answer:\n' # 让模型在此之后生成内容
推理
运行 RWKV-4 Pile 模型: 从 https://huggingface.co/BlinkDL 下载模型。在 run.py 中设置 TOKEN_MODE = 'pile',然后运行。即使在 CPU 上也能快速运行(默认模式)。
RWKV-4 Pile 1.5B 的 Colab 笔记本: https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
在浏览器中运行 RWKV-4 Pile 模型(以及 ONNX 版本):请参阅此问题 https://github.com/BlinkDL/RWKV-LM/issues/7
RWKV-4 Web 演示:https://josephrocca.github.io/rwkv-v4-web/demo/(注:目前仅支持贪婪采样)
对于旧版 RWKV-2:请参阅此处发布的 enwik8 数据集上 27M 参数模型,其开发集 BPC 为 0.72。在 https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN 中运行 run.py 即可。你甚至可以在浏览器中运行它:https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/(这是使用 tf.js WASM 单线程模式)。
训练/微调
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // torch 1.13.1+cu117
注意:在少量数据上训练时,应加入权重衰减(0.1 或 0.01)和 Dropout(0.1 或 0.01)。可以尝试以下组合:x=x+dropout(att(x))、x=x+dropout(ffn(x))、x=dropout(x+att(x))、x=dropout(x+ffn(x)) 等。
从头开始训练 RWKV-4: 运行 train.py,默认使用 enwik8 数据集(解压 https://data.deepai.org/enwik8.zip)。
您将训练的是“GPT”版本,因为它可以并行化且训练速度更快。RWKV-4 具有外推能力,因此使用 ctxLen 1024 训练的模型也可以很好地处理 ctxLen 为 2500+ 的情况。您可以使用更长的 ctxLen 对模型进行微调,使其快速适应更长的上下文长度。
微调 RWKV-4 Pile 模型: 使用 https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 中的 'prepare-data.py' 将 .txt 文件分词并转换为 train.npy 数据。然后使用 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py 来训练该模型。
阅读 src/model.py 中的推理代码,并尝试将最终隐藏状态(.xx、.aa、.bb)用作其他任务的忠实句子嵌入。建议从 .xx 和 .aa/.bb 开始(.aa 除以 .bb)。
用于微调 RWKV-4 Pile 模型的 Colab 笔记本:https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
大型语料库: 使用 https://github.com/Abel2076/json2binidx_tool 将 .jsonl 文件转换为 .bin 和 .idx 文件。
.jsonl 格式示例(每行为一个文档):
{"text": "这是第一篇文档。"}
{"text": "你好\n世界"}
{"text": "1+1=2\n1+2=3\n2+2=4"}
可通过如下代码生成:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "\n")
无限上下文长度训练(开发中): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
如何将 RWKV 隐藏状态用作文本嵌入
以 RWKV 14B 为例,其状态包含 200 个向量,即每个块有 5 个向量:fp16(xx)、fp32(aa)、fp32(bb)、fp32(pp)、fp16(xx)。
不要进行平均池化,因为状态中的不同向量(xx、aa、bb、pp、xx)具有非常不同的含义和范围。您可能可以移除 pp。
我建议首先收集每个向量各通道的均值和标准差统计信息,并对它们进行归一化处理(注意:归一化应与数据无关,需从多种文本中收集)。然后训练一个线性分类器。
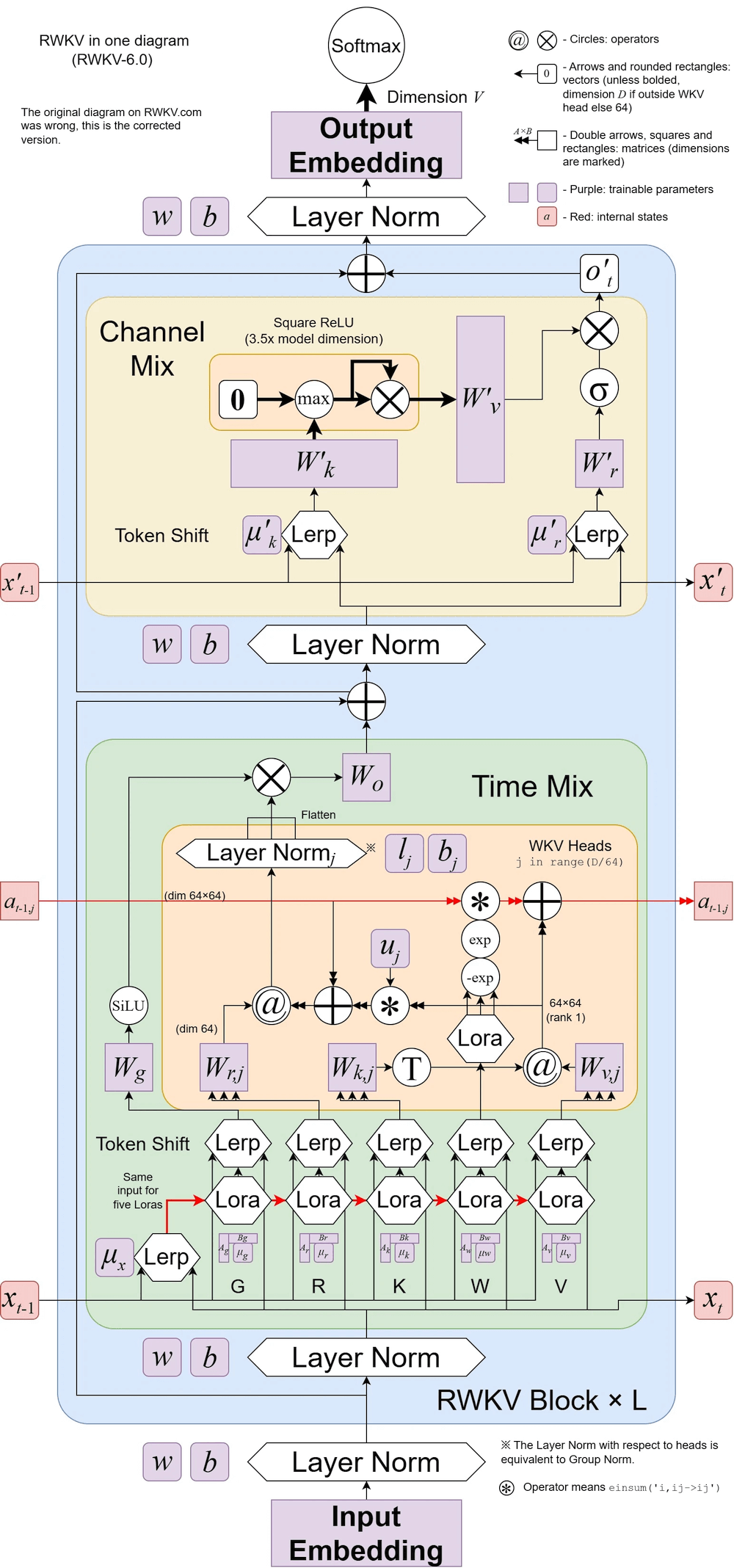
向 RWKV-5 发展(仅记录一些新想法)
最新设计
RWKV-5 是多头架构,此处展示的是其中的一个头。每个头还配备了一个 LayerNorm(实际上是 GroupNorm)。
$ \begin{array}{|l|l|l|} \hline & \text { RWKV-4,使用实数值 } k \,\&\, v \,\&\, u \,\&\, w & \text { RWKV-5,使用矩阵值 } \mathrm{k}^{\dagger} \mathrm{v} \,\&\, \mathrm{u} \,\&\, \mathrm{w} \\ \hline \mathrm{y}_0 & \mathrm{r}_0 \frac{\mathrm{uk}_0 \mathrm{v}_0}{\mathrm{uk}_0} & \mathrm{r}_0\left(\mathrm{uk}_0^{\dagger} \mathrm{v}_0\right) \\ \hline \mathrm{y}_1 & \mathrm{r}_1 \frac{\mathrm{uk}_1 \mathrm{v}_1+\mathrm{k}_0 \mathrm{v}_0}{\mathrm{uk}_1+\mathrm{k}_0} & \mathrm{r}_1\left(\mathrm{uk}_1^{\dagger} \mathrm{v}_1+\mathrm{k}_0^{\dagger} \mathrm{v}_0\right) \\ \hline \mathrm{y}_2 & \mathrm{r}_2 \frac{\mathrm{uk}_2 \mathrm{v}_2+\mathrm{k}_1 \mathrm{v}_1+\mathrm{wk}_0 \mathrm{v}_0}{\mathrm{uk}_2+\mathrm{k}_1+\mathrm{wk}_0} & \mathrm{r}_2\left(\mathrm{uk}_2^{\dagger} \mathrm{v}_2+\mathrm{k}_1^{\dagger} \mathrm{v}_1+\mathrm{wk}_0^{\dagger} \mathrm{v}_0\right) \\ \hline \mathrm{y}_3 & \mathrm{r}_3 \frac{\mathrm{uk}_3 \mathrm{v}_3+\mathrm{k}_2 \mathrm{v}_2+\mathrm{wk}_1 \mathrm{v}_1+\mathrm{w}^2 \mathrm{k}_0 \mathrm{v}_0}{\mathrm{uk}_3+\mathrm{k}_2+\mathrm{wk}_1+\mathrm{w}^2 \mathrm{k}_0} & \mathrm{r}_3\left(\mathrm{uk}_3^{\dagger} \mathrm{v}_3+\mathrm{k}_2^{\dagger} \mathrm{v}_2+\mathrm{wk}_1^{\dagger} \mathrm{v}_1+\mathrm{w}^2 \mathrm{k}_0^{\dagger} \mathrm{v}_0\right) \\ \hline \end{array}$
$\left[\begin{array}{ll} \mathrm{y}_{20} & \cdots \mathrm{y}_{2 \mathrm{c}} \end{array}\right]=\left[\begin{array}{lll} \mathrm{r}_{20} & \cdots & \mathrm{r}_{2 \mathrm{c}} \end{array}\right]$
$`\left(\left[\begin{array}{ccc}
\mathrm{u}{00} & \cdots & \mathrm{u}{0 \mathrm{c}} \
\vdots & \ddots & \vdots \
\mathrm{u}{\mathrm{c} 0} & \cdots & \mathrm{u}{\mathrm{cc}}
\end{array}\right]\left[\begin{array}{ccc}
\mathrm{k}{20} \mathrm{v}{20} & \cdots & \mathrm{k}{20} \mathrm{v}{2 \mathrm{c}} \
\vdots & \ddots & \vdots \
\mathrm{k}{2 \mathrm{c}} \mathrm{v}{20} & \cdots & \mathrm{k}{2 \mathrm{c}} \mathrm{v}{2 \mathrm{c}}
\end{array}\right]+\left[\begin{array}{ccc}
\mathrm{k}{10} \mathrm{v}{10} & \cdots & \mathrm{k}{10} \mathrm{v}{1 \mathrm{c}} \
\vdots & \ddots & \vdots \
\mathrm{k}{1 \mathrm{c}} \mathrm{v}{10} & \cdots & \mathrmk_{1 \mathrm{c}} \mathrm{v}{1 \mathrm{c}}
\end{array}\right]+\left[\begin{array}{ccc}
\mathrm{w}{00} & \cdots & \mathrm{w}{0 \mathrm{c}} \
\vdots & \dders & \vdols \
\mathrm{w}{\mathrm{c} 0} & \cds & the w ccc
\end{array}\right]\left[\begin{array}{ccc}
\mathrm{k}{00} \mathrm{v}{00} & \cds & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v00,
\vdols & dders & the k00 v0......### 训练/微调
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // torch 1.13.1+cu117
注意:在少量数据上训练时,建议加入权重衰减(0.1 或 0.01)和 Dropout(0.1 或 0.01)。可以尝试以下组合:x=x+dropout(att(x))、x=x+dropout(ffn(x))、x=dropout(x+att(x))、x=dropout(x+ffn(x)) 等。
从零开始训练 RWKV-4: 运行 train.py,默认使用 enwik8 数据集(解压 https://data.deepai.org/enwik8.zip)。
你将训练的是“GPT”版本,因为它可以并行化且训练速度更快。RWKV-4 具有外推能力,因此使用 ctxLen 1024 训练的模型也可以很好地处理 ctxLen 为 2500+ 的情况。你可以用更长的 ctxLen 对模型进行微调,它会迅速适应更长的上下文长度。
微调 RWKV-4 Pile 模型: 使用 https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 中的 ‘prepare-data.py’ 将 .txt 文件分词并转换为 train.npy 数据。然后使用 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py 来训练该模型。
阅读 src/model.py 中的推理代码,并尝试将最终隐藏状态(.xx、.aa、.bb)作为其他任务的忠实句子嵌入。建议从 .xx 和 .aa/.bb 开始(即 .aa 除以 .bb)。
用于微调 RWKV-4 Pile 模型的 Colab 笔记本:https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
大型语料库: 使用 https://github.com/Abel2076/json2binidx_tool 将 .jsonl 文件转换为 .bin 和 .idx 格式。
.jsonl 格式的示例(每行为一个文档):
{"text": "这是第一篇文档。"}
{"text": "你好\n世界"}
{"text": "1+1=2\n1+2=3\n2+2=4"}
生成代码如下:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "\n")
无限上下文长度训练(开发中): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
如何将 RWKV 隐藏状态用作文本嵌入
以 RWKV 14B 为例,其状态包含 200 个向量,即每个块有 5 个向量:fp16 (.xx)、fp32 (.aa)、fp32 (.bb)、fp32 (.pp)、fp16 (.xx)。
不要进行平均池化,因为状态中的不同向量(.xx、.aa、.bb、.pp、.xx)具有非常不同的含义和范围。你可能需要移除 .pp。
我建议首先收集每个向量各通道的均值和标准差统计信息,并对所有向量进行归一化处理(注意:归一化应与具体数据无关,需基于多种文本数据进行统计)。然后训练一个线性分类器。
向 RWKV-5 发展(仅记录一些新想法)
最新设计
RWKV-5 采用多头机制,此处展示的是其中的一个头。每个头还配备了一个 LayerNorm(实际上是 GroupNorm)。
$ \begin{array}{|l|l|l|} \hline & \text { RWKV-4,使用实数值 } k \,\&\, v \,\&\, u \,\&\, w & \text { RWKV-5,使用矩阵值 } \mathrm{k}^{\dagger} \mathrm{v} \,\&\, \mathrm{u} \,\&\, \mathrm{w} \\ \hline \mathrm{y}_0 & \mathrm{r}_0 \frac{\mathrm{uk}_0 \mathrm{v}_0}{\mathrm{uk}_0} & \mathrm{r}_0\left(\mathrm{uk}_0^{\dagger} \mathrm{v}_0\right) \\ \hline \mathrm{y}_1 & \mathrm{r}_1 \frac{\mathrm{uk}_1 \mathrm{v}_1+\mathrm{k}_0 \mathrm{v}_0}{\mathrm{uk}_1+\mathrm{k}_0} & \mathrm{r}_1\left(\mathrm{uk}_1^{\dagger} \mathrm{v}_1+\mathrm{k}_0^{\dagger} \mathrm{v}_0\right) \\ \hline \mathrm{y}_2 & \mathrm{r}_2 \frac{\mathrm{uk}_2 \mathrm{v}_2+\mathrm{k}_1 \mathrm{v}_1+\mathrm{wk}_0 \mathrm{v}_0}{\mathrm{uk}_2+\mathrm{k}_1+\mathrm{wk}_0} & \mathrm{r}_2\left(\mathrm{uk}_2^{\dagger} \mathrm{v}_2+\mathrm{k}_1^{\dagger} \mathrm{v}_1+\mathrm{wk}_0^{\dagger} \mathrm{v}_0\right) \\ \hline \mathrm{y}_3 & \mathrm{r}_3 \frac{\mathrm{uk}_3 \mathrm{v}_3+\mathrm{k}_2 \mathrm{v}_2+\mathrm{wk}_1 \mathrm{v}_1+\mathrm{w}^2 \mathrm{k}_0 \mathrm{v}_0}{\mathrm{uk}_3+\mathrm{k}_2+\mathrm{wk}_1+\mathrm{w}^2 \mathrm{k}_0} & \mathrm{r}_3\left(\mathrm{uk}_3^{\dagger} \mathrm{v}_3+\mathrm{k}_2^{\dagger} \mathrm{v}_2+\mathrm{wk}_1^{\dagger} \mathrm{v}_1+\mathrm{w}^2 \mathrm{k}_0^{\dagger} \mathrm{v}_0\right) \\ \hline \end{array}$
$\left[\begin{array}{ll} \mathrm{y}_{20} & \cdots \mathrm{y}_{2 \mathrm{c}} \end{array}\right]=\left[\begin{array}{lll} \mathrm{r}_{20} & \cdots & \mathrm{r}_{2 \mathrm{c}} \end{array}\right]$
$`\left(\left[\begin{array}{ccc}
\mathrm{u}{00} & \cdots & \mathrm{u}{0 \mathrm{c}} \
\vdots & \ddots & \vdots \
\mathrm{u}{\mathrm{c} 0} & \cdots & \mathrm{u}{\mathrm{cc}}
\end{array}\right]\left[\begin{array}{ccc}
\mathrm{k}{20} \mathrm{v}{20} & \cdots & \mathrm{k}{20} \mathrm{v}{2 \mathrm{c}} \
\vdots & \ddots & \vdots \
\mathrm{k}{2 \mathrm{c}} \mathrm{v}{20} & \cdots & \mathrm{k}{2 \mathrm{c}} \mathrm{v}{2 \mathrm{c}}
\end{array}\right]+\left[\begin{array}{ccc}
\mathrm{k}{10} \mathrm{v}{10} & \cdots & \mathrm{k}{10} \mathrm{v}{1 \mathrm{c}} \
\vdots & \ddots & \vdotedit
### 一些旧想法
1. 目前的时间衰减是 0.999^T(0.999 可学习)。可以将其改为类似 (0.999^T + 0.1) 的形式,其中 0.1 也是可学习的。这样 0.1 部分将永远保留下来。或者,使用 A^T + B^T + C 的形式,分别代表快速衰减、慢速衰减和常数项。甚至可以采用不同的衰减公式,比如用 K^2 替代 e^K 作为衰减成分,或者不进行归一化。
2. 在某些通道中使用复数值衰减(即旋转而非单纯的衰减)。
3. 是否可以注入一些可训练且可外推的位置编码?
4. 除了二维旋转之外,还可以尝试其他李群,例如三维旋转(SO(3))。非交换的 RWKV 哈哈。
5. RWKV 在模拟设备上可能会非常出色(可搜索“模拟矩阵-向量乘法”和“光子矩阵-向量乘法”)。RNN 模式对硬件非常友好(存内计算)。它也可以作为脉冲神经网络(SNN)实现(https://github.com/ridgerchu/SpikeGPT)。我想知道它是否能被优化以用于量子计算。
6. 可训练的初始隐藏状态(xx aa bb pp xx)。
7. 使用逐层(甚至逐行/逐列、逐元素)的学习率,并测试 Lion 优化器。
### 视觉任务
1. 我发现添加二维位置编码效果不错:
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd))) self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd))) ... x = x + pos_emb_x + pos_emb_y
2. 在基于 BPE 的语言模型中,最好使用 [偏移 1 个 token] 的方式(在字符级英语模型中可以混合更多 token)。然而,如果图像大小为 N×N,也可以尝试 [偏移 N 个(或 N-1 个、N+1 个)token],因为这相当于将 [当前位置上方的 token(或待预测位置上方的 token)] 与 [当前 token] 混合。可以在 “ATT” 和 “FFN” 中尝试不同的偏移风格,或者混合多种偏移方式——例如将 [token A] 与 [token A-1] 和 [token A-(N-1)] 等混合起来。
### 杂项
也许我们可以通过简单地重复上下文来提升记忆能力(我猜重复两次就足够了)。示例:参考 -> 参考(再次)-> 问题 -> 答案
#### 想法:字节感知嵌入
这个想法是让词汇表中的每个 token 都了解自身的长度及其原始 UTF-8 字节表示。
设 a = 词汇表中所有 token 的最大长度。定义 AA : float[a][d_emb]
设 b = 词汇表中所有 token 的最大 UTF-8 字节长度。定义 BB : float[b][256][d_emb]
对于词汇表中的每个 token X,设 [x0, x1, ..., xn] 为其原始 UTF-8 字节。我们将为其嵌入 EMB(X) 添加一些额外的值:
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn](注:AA 和 BB 是可学习的权重)
* 我们也可以对最终的 Linear(d_emb, n_vocab) 投影层这样做。
* 可以使用一些小型网络来生成 AA 和 BB,以增加正则化效果(例如,BB[m][xi] 和 BB[n][xi] 应该具有一定的关联性)。
#### 旧想法
我有一个改进分词的想法。我们可以硬编码一些通道来赋予其特定含义。例如:
通道 0 = “空格”
通道 1 = “首字母大写”
通道 2 = “全部字母大写”
因此:
“abc”的嵌入:[0, 0, 0, x0, x1, x2, ..]
“ abc”的嵌入:[1, 0, 0, x0, x1, x2, ..]
“ Abc”的嵌入:[1, 1, 0, x0, x1, x2, ..]
“ABC”的嵌入:[0, 0, 1, x0, x1, x2, ...]
......
这样它们就可以共享大部分嵌入。并且我们可以快速计算出 “abc” 所有变体的输出概率。
注意:上述方法假设 p(" xyz") / p("xyz") 对任何 "xyz" 都相同,但这可能是错误的。
更好的做法是:将 emb_space、emb_capitalize_first、emb_capitalize_all 定义为 emb 的函数。
也许最好的办法是让 ‘abc’、‘ abc’ 等共享其嵌入的最后 90%。
目前,我们的所有分词器都花费了大量的条目来表示 ‘abc’、‘ abc’、‘ Abc’ 等的所有变体。此外,如果这些变体在数据集中很少出现,模型也无法发现它们实际上是相似的。这里的方法可以改善这一点。我计划在 RWKV 的新版本中进行测试。
#### 想法:更好的初始状态
单轮问答示例:
1. 生成所有维基文档的最终状态。
2. 对于任何用户的问题,找到最佳的维基文档,并将其最终状态作为初始状态。
3. 训练一个模型,直接为任何用户的问题生成最优的初始状态。
不过,对于多轮问答来说,这可能会稍微复杂一些 :)
## 工作原理
RWKV 受苹果公司 AFT(https://arxiv.org/abs/2105.14103)的启发。
此外,它还使用了我提出的多项技巧,例如:
* SmallInitEmb:https://github.com/BlinkDL/SmallInitEmb(适用于所有 Transformer),有助于提高嵌入质量,并稳定 Post-LN(这是我正在使用的)。
* Token-shift:https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing(适用于所有 Transformer),尤其对字符级模型很有帮助。
* Head-QK:https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens(适用于所有 Transformer)。注意:虽然有用,但我为了保持 Pile 模型 100% RNN 特性,已将其禁用。
* FFN 中的额外 R-gate(适用于所有 Transformer)。我还使用了 Primer 中的 reluSquared。
* 更好的初始化:我将大多数矩阵初始化为 ZERO(参见 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py 中的 RWKV_Init)。
* 可以将参数从小模型迁移到大模型中(注意:我还会对其进行排序和平滑处理),以加快并提高收敛速度(参见 https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with/)。
* 我的 CUDA 内核:https://github.com/BlinkDL/RWKV-CUDA,用于加速训练。
## 伪代码(从上到下执行):

a、b、c、d 四个因子共同作用,构建时间衰减曲线:[X, 1, W, W^2, W^3, ...]。
写出 “位置 2 的 token” 和 “位置 3 的 token” 的公式,你就能明白其中的原理:
* a 和 b:分别是 kv 和 k 的指数移动平均值。
* c 和 d:是 a 和 b 与自注意力机制结合后的结果。
kv / k 是记忆机制。如果通道中的 W 接近 1,那么 k 值较高的 token 就可以被长期记住。
R-gate 对性能至关重要。k 表示该 token 的信息强度(传递给后续 token),而 r 则决定是否将该信息应用到当前 token 上。
## RWKV-3 的改进
在 SA 和 FF 层中,分别为 R / K / V 使用不同的可训练 TimeMix 因子。示例:
```python
xx = self.time_shift(x)
xk = x * self.time_mix_k + xx * (1 - self.time_mix_k)
xv = x * self.time_mix_v + xx * (1 - self.time_mix_v)
xr = x * self.time_mix_r + xx * (1 - self.time_mix_r)
使用 preLN 而不是 postLN(更稳定且收敛更快):
if self.layer_id == 0:
x = self.ln0(x)
x = x + self.att(self.ln1(x))
x = x + self.ffn(self.ln2(x))
解释 RWKV-3 GPT 模式的代码
GPT 模式 - 概述
RWKV-3 GPT 模式的构建模块与普通的 preLN GPT 类似。
唯一的区别是在嵌入之后多了一个 Layer Normalization 层。请注意,在训练完成后,可以将这个 Layer Normalization 层合并到嵌入层中。
x = self.emb(idx) # 输入:idx = token 索引
x = self.ln_emb(x) # 嵌入后的额外 Layer Normalization
x = x + self.att_0(self.ln_att_0(x)) # preLN
x = x + self.ffn_0(self.ln_ffn_0(x))
...
x = x + self.att_n(self.ln_att_n(x))
x = x + self.ffn_n(self.ln_ffn_n(x))
x = self.ln_head(x) # 投影前的最终 Layer Normalization
x = self.head(x) # 输出:x = logits
重要的是要将嵌入层初始化为非常小的值,例如 nn.init.uniform_(a=-1e-4, b=1e-4),以便利用我的技巧 https://github.com/BlinkDL/SmallInitEmb。
对于 15 亿参数的 RWKV-3 模型,我使用 Adam 优化器(无权重衰减,无 dropout)在 8 张 A100 40G 显卡上进行训练。
batchSz = 32 * 896,ctxLen = 896。由于我使用的是 tf32 精度,因此 batchSz 稍微偏小。
在前 150 亿个 token 的训练中,学习率固定为 3e-4,动量参数 beta=(0.9, 0.99)。
随后我将 beta 调整为 (0.9, 0.999),并采用指数衰减的学习率策略,最终在训练到 3320 亿个 token 时将学习率降至 1e-5。
GPT 模式 - ATT 块
RWKV-3 并没有传统意义上的注意力机制,但我们仍然称这一模块为 ATT。
B, T, C = x.size() # x = (Batch,Time,Channel)
# 将当前时间步的 x 与前一个时间步的 x 混合,生成 xk、xv 和 xr
xx = self.time_shift(x) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self.time_mix_k + xx * (1 - self.time_mix_k)
xv = x * self.time_mix_v + xx * (1 - self.time_mix_v)
xr = x * self.time_mix_r + xx * (1 - self.time_mix_r)
# 使用 xk、xv 和 xr 生成 k、v 和 r
k = self.key(xk).transpose(-1, -2)
v = self.value(xv).transpose(-1, -2)
r = self.receptance(xr)
k = torch.clamp(k, max=60) # 限制 k 的值以防止溢出
k = torch.exp(k)
kv = k * v
# 计算 W 曲线 = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self.time_w = torch.cat([torch.exp(self.time_decay) * self.time_curve.to(x.device), self.time_first], dim=-1)
w = torch.exp(self.time_w)
# 使用 W 分别混合 kv 和 k。为避免除零错误,在 wk 中加入 K_EPS
if RUN_DEVICE == 'cuda':
wkv = TimeX.apply(w, kv, B,C,T, 0)
wk = TimeX.apply(w, k, B,C,T, K_EPS)
else:
w = w[:,-T:].unsqueeze(1)
wkv = F.conv1d(nn.ZeroPad2d((T-1, 0, 0, 0))(kv), w, groups=C)
wk = F.conv1d(nn.ZeroPad2d((T-1, 0, 0, 0))(k), w, groups=C) + K_EPS
# RWKV 公式
rwkv = torch.sigmoid(r) * (wkv / wk).transpose(-1, -2)
rwkv = self.output(rwkv) # 最终输出投影
self.key、self.receptance 和 self.output 矩阵均初始化为零。
time_mix、time_decay 和 time_first 向量则从一个较小的已训练模型中迁移而来(注意:我还对这些向量进行了排序和平滑处理)。
GPT 模式 - FFN 块
FFN 块相比普通 GPT 有三个创新点:
我的时间混合技巧。
来自 Primer 论文的 sqReLU。
额外的受容门(类似于 ATT 块中的受容门)。
# 将当前时间步的 x 与前一个时间步的 x 混合,生成 xk 和 xr
xx = self.time_shift(x)
xk = x * self.time_mix_k + xx * (1 - self.time_mix_k)
xr = x * self.time_mix_r + xx * (1 - self.time_mix_r)
# 普通的 FFN 操作
k = self.key(xk)
k = torch.square(torch.relu(k)) # 来自 Primer 论文
kv = self.value(k)
# 对 kv 应用额外的受容门
rkv = torch.sigmoid(self.receptance(xr)) * kv
return rkv
self.value 和 self.receptance 矩阵均初始化为零。
RWKV-4 改进

从GPT到RWKV(公式)
设F[t]为时刻t时的系统状态。
设x[t]为时刻t时的新外部输入。
在GPT中,预测F[t+1]需要考虑F[0], F[1], .. F[t]。因此,生成长度为T的序列需要O(T^2)的时间复杂度。
GPT的简化公式如下:
理论上它非常强大,然而这并不意味着我们能够用常规优化器充分发挥其能力。我怀疑当前的方法难以应对如此复杂的损失景观。
相比之下,RWKV的简化公式(并行模式,与苹果的AFT类似)如下:
其中,R、K、V是可训练的矩阵,而W是一个可训练的向量(用于每个通道的时间衰减因子)。
在GPT中,F[i]对F[t+1]的贡献由 权重决定。
而在RWKV-2中,F[i]对F[t+1]的贡献则由 权重决定。
- 其中的
是一个非线性激活函数,我们可以使用Sigmoid。
- 注意
并不在分母中,我称R为“接受度”。
- 而
则是时间衰减因子。我在2020年8月就提出了同样的想法(按距离缩放注意力),并称之为“时间加权”(请查看 https://github.com/BlinkDL/minGPT-tuned 的提交历史)。
关键在于:我们可以将其改写成一个RNN(递归公式)。注意:
因此,很容易验证以下关系:
其中,A[t]和B[t]分别是上一步的分子和分母。
我认为RWKV之所以性能优异,是因为W的作用类似于反复应用一个对角矩阵。注意(P^{-1} D P)^n = P^{-1} D^n P,因此它等同于反复应用一个可对角化的矩阵。
此外,它还可以被转化为连续的常微分方程(有点类似于状态空间模型)。这一点我将在后续文章中详细说明。
星标历史

多模态想法
我有一个关于[文本 --> 32x32 RGB图像]的想法,使用语言模型(Transformer、RWKV等)来实现。我很快就会进行测试。
首先,使用语言模型的损失函数(而不是L2损失),这样生成的图像就不会模糊。
其次,进行颜色量化。例如,只允许R/G/B每个通道有8个等级。这样一来,图像的词汇表大小就是8×8×8=512(针对每个像素),而不是2^24。因此,一张32x32的RGB图像就可以表示为一个长度为1024、词汇表大小为512的序列(图像标记),这正是普通语言模型的典型输入格式。 (之后我们可以使用扩散模型来上采样并生成RGB888图像。也许我们也可以用语言模型来做这件事。)
第三,使用易于模型理解的二维位置嵌入。 例如,在前64个(=32+32)通道中加入独热编码的X和Y坐标。假设某个像素位于x=8,y=20,那么就在第8个通道和第52个通道(=32+20)中分别加1。 此外,我们还可以将归一化到0~1范围的浮点X和Y坐标添加到另外两个通道中。其他周期性的位置编码也可能有所帮助(我会进一步测试)。
最后,在DataLoader中进行颜色量化时使用随机四舍五入。 例如,如果某个像素的浮点值是4.578,那么就有57.8%的概率取5,而42.2%的概率取4。 在预测时,我们可以同时考虑4和5这两种可能性,但如果预测结果是4,损失会更高。
多任务训练也可能有所帮助。我将尝试以下数据格式: [TxtFirst] [图像描述(文本标记)] [图像] [图像标记] 以及有时 [ImgFirst] [图像标记] [文本] [图像描述(文本标记)] ……在DataLoader中应随机打乱图像的顺序,而[TxtFirst]、[ImgFirst]、[Img]、[Txt]则是特殊标记。 同时对整个数据集进行随机采样。这样,有时模型会先看到图像标记,再看到对应的文本标记,这就构成了一个[图像 -> 文本]的任务。此外,模型还会看到一些部分的图像和部分的文本。我认为,基于字符级别的语言模型可能会帮助模型在图像上生成正确的文字。
如何从大型数据集中采样(用于训练)
我使用一个小技巧来以确定性但又足够随机的方式从Pile数据集中采样。
假设Pile数据集有x个块(一个块等于ctx_len个标记)。
选择一个比x略小的素数p,并确保p ≡ 2 (mod 3)。
使用(step * step * step) mod p来进行采样。为了增加随机性,可以在step中加入一些偏置。
top-p-x采样方法(用于推理)
我们提出了一种新的采样方法,称为top-p-x:
它类似于top-p,唯一的区别在于你还会保留所有概率大于x的标记。 可以先尝试x=0.01。
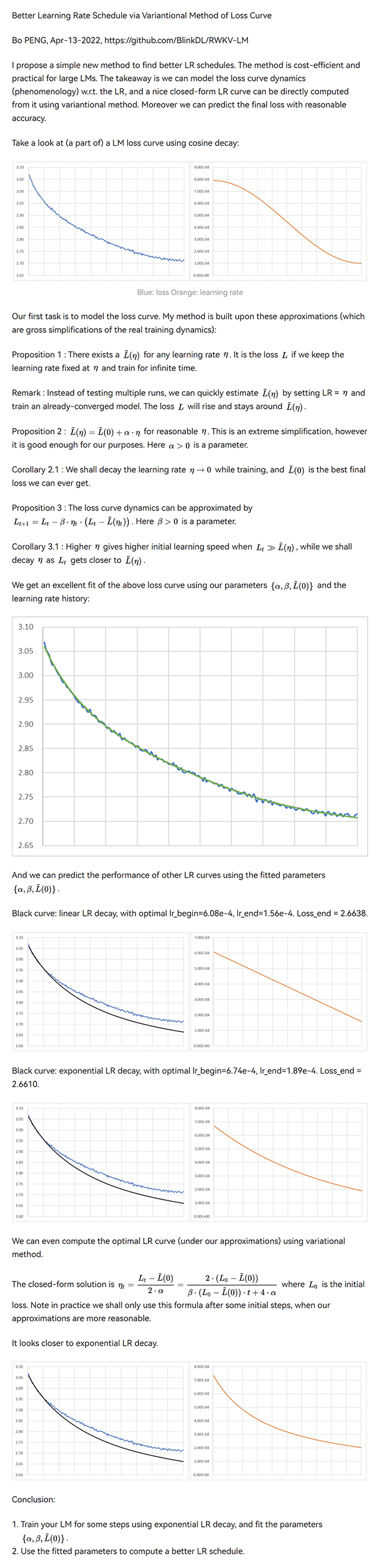
基于变分法的损失曲线优化学习率调度方案
我提出了一种简单的新方法来寻找更好的学习率调度方案。这种方法成本效益高,且适用于大型语言模型。其核心思想是,我们可以对损失曲线随学习率变化的动力学(现象学)进行建模,并利用变分法直接计算出一个优美的闭式解学习率曲线。此外,我们还可以相当准确地预测最终的损失。
更新:在“结论1”中,使用最佳拟合区间(忽略初始阶段我们的近似失效的部分)来拟合参数。
尝试如下方案:固定学习率为1小时,然后在12小时内指数衰减至0.2倍的学习率,并选择t=[1小时, 13小时]这段区间。
在最后三张图中,黑色代表新学习率调度方案的预测损失曲线,蓝色代表原始(未优化)的实际损失曲线,橙色代表新的学习率调度方案。
RWKV v1
我们提出了RWKV语言模型,该模型交替使用时间混合层和通道混合层:
R、K、V是由输入经过线性变换生成的,而W则是可学习的参数。RWKV的核心思想是将注意力分解为R(目标)* W(源与目标)* K(源)。因此,我们可以将R称为“接受度”,而sigmoid函数则表明它的取值范围在0到1之间。
时间混合层类似于AFT(https://arxiv.org/abs/2105.14103)。两者有两个不同之处。
(1) 我们改变了归一化方式(分母)。对于掩码语言模型,我们定义:
(更新:我们在v2版本中使用了原始的AFT归一化方式)
为了快速且稳定的收敛,我们将K和R矩阵(以及输出投影矩阵)初始化为零。
(2) 我们将W_{t,u,c}分解,并引入多头W(这里h是c对应的头):
此外,我们还在时间混合层的最终输出上乘以γ(t)。引入α、β、γ这些因子的原因是,当t较小时,上下文的规模较小,可以通过这些因子来弥补。
(更新:我们在v2-RNN版本中去除了α、β、γ因子,将W限制为一种简单的形式,从而可以将其重写为RNN)
通道混合层类似于GeGLU(https://arxiv.org/abs/2002.05202),只是额外增加了一个R因子。为了快速且稳定的收敛,我们将R和W矩阵初始化为零。
最后,我们还加入了额外的标记移位(时间移位混合),就像(https://github.com/BlinkDL/minGPT-tuned)中那样。
令牌移位(时间移位混合)
令牌移位显式地使用(该令牌的一半通道)与(前一个令牌的一半通道),来生成所有的向量(QKV、RWKV 等)。
self.time_shift = nn.ZeroPad2d((0,0,1,-1))
x = torch.cat([self.time_shift(x[:, :, :C//2]), x[:, :, C//2:]], dim = -1)
将通道数减半并进行一次移位,在字符级别的英语和中文语言模型中效果非常好。
然而,对于 BPE 级别的英语语言模型,只有当你的嵌入维度足够大时(至少 1024 维——因此常见的小型 L12-D768 模型并不够用)才会有效。
我对令牌移位有效性的理解如下:
当我们训练 GPT 时,一个标记的隐藏表示需要完成两个不同的任务:
- 预测下一个标记。有时这很容易(下一个标记很明显)。
- 收集所有之前的上下文信息,以便后续标记可以利用这些信息。这一点总是很困难。
移位后的通道可以专注于第 2 个任务,从而实现良好的信息传播。这就像是某种残差连接,或者是在 Transformer 内部加入了一个小型 RNN。
你也可以在普通的 QKV 自注意力机制中使用令牌移位。我查看了权重,发现 V 很喜欢移位后的通道,而 Q 则不太依赖。仔细想想也确实有道理。此外,我还发现高层层中可能需要减少混合的程度。
附注:这个仓库中有一个名为 MHA_pro 的模型,性能非常出色。不妨试一试 :)
Head-QK 技巧:学习复制和避免特定标记
在普通的 Transformer 中,小型模型很难复制上下文中出现的特定标记(如人名)。我们通过在最终输出中添加额外的 Q 和 K,使模型可以直接复制(或避免)上下文中的特定标记。之后,如果你观察学习到的权重,会发现模型实际上已经学会了命名实体识别(NER)。
q = self.head_q(x)[:,:T,:] # 投影到 256 维
k = self.head_k(x)[:,:T,:] # 投影到 256 维
c = (q @ k.transpose(-2, -1)) * (1.0 / 256)
c = c.masked_fill(self.copy_mask[:T,:T] == 0, 0)
c = c @ F.one_hot(idx, num_classes = self.config.vocab_size).float()
x = self.head(x) + c
注意:当某个标记在上下文中多次出现时,使用最大概率而不是总概率可能会更好。
Top-a 采样方法
我们还提出了一种新的采样方法,称为 top-a(见 src/utils.py):
(1) 找到 softmax 后的最大概率 p_max。
(2) 移除所有概率低于 0.2 * pow(p_max, 2) 的条目。因此它是自适应的,这就是“top-a”的由来。
(3) 你可以自由调整 0.2 和 2 这两个系数。建议先从调整 0.2 开始。
Top-a 的思路是:
- 如果 max_prob=0.9,则移除所有概率 < 0.162 的标记(即排除所有其他选择)。
- 如果 max_prob=0.5,则移除所有概率 < 0.05 的标记(即允许更多选择)。
- 如果 max_prob=0.1,则移除所有概率 < 0.002 的标记(即保留大量可能性)。
probs = F.softmax(logits, dim=-1)
limit = torch.pow(torch.max(probs), 2) * 0.02
logits[probs < limit] = -float('Inf')
性能
SimpleBooks-92 数据集上的字符级别损失 https://dldata-public.s3.us-east-2.amazonaws.com/simplebooks.zip
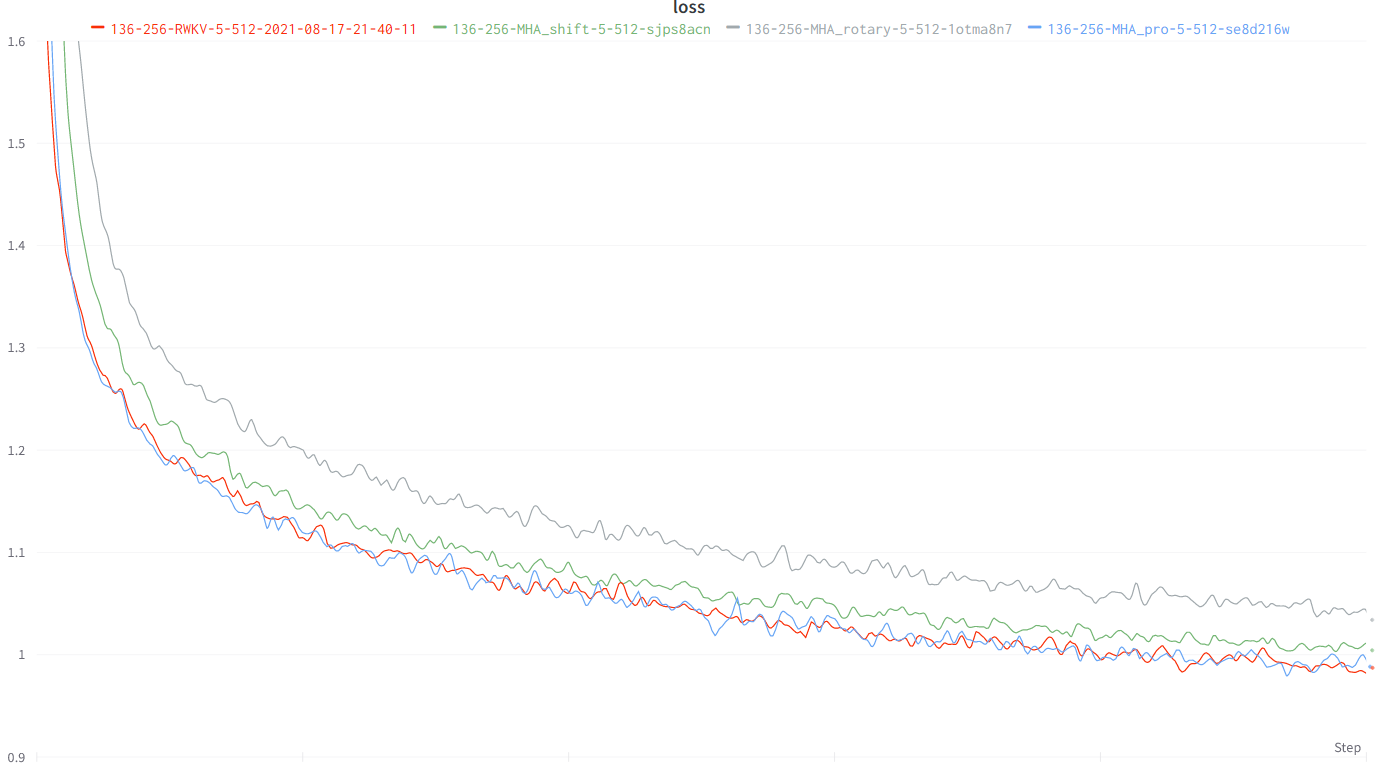
灰色:普通 MHA+Rotary+GeGLU——性能一般。17.2M 参数。
红色:RWKV(“线性”注意力)——显存友好——在长上下文窗口时速度更快——性能良好。16.6M 参数。
绿色:MHA+Rotary+GeGLU+Token_shift。17.2M 参数。
蓝色:MHA_pro(带有各种改进和 RWKV 类型 FFN 的 MHA)——速度较慢——需要更多显存——性能不错。16.6M 参数。
@software{peng_bo_2021_5196578,
author = {PENG Bo},
title = {BlinkDL/RWKV-LM: 0.01},
month = aug,
year = 2021,
publisher = {Zenodo},
version = {0.01},
doi = {10.5281/zenodo.5196577},
url = {https://doi.org/10.5281/zenodo.5196577}
}
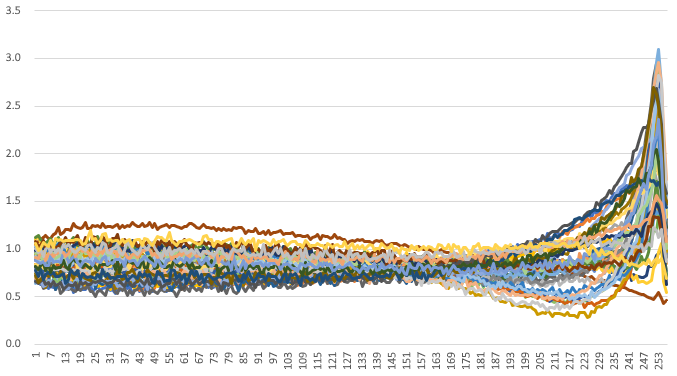
初始化
我们对 RWKV 使用了精心设计的初始化方法,以实现快速收敛——采用适当缩放的正交矩阵,并结合特殊的 time_w 曲线。详细信息请参阅 model.py 文件。
一些学习到的 time_w 示例:
版本历史
5.002023/12/164.002022/12/062.002022/03/250.022021/08/250.012021/08/13常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器