deep_research_bench
DeepResearch Bench 是一个专为评估“深度研究智能体”而设计的综合性基准测试平台。随着 AI 代理从简单的问答转向执行复杂的长周期研究任务(如自主搜集信息、分析数据并撰写报告),业界亟需一套标准来衡量这些能力的真实水平。DeepResearch Bench 正是为了解决这一评估缺失问题而生,它提供了一套严谨的数据集和评测流程,能够量化不同模型在深度研究场景下的表现。
该平台主要服务于 AI 研究人员、大模型开发者以及企业技术团队。通过访问其公开的排行榜和数据集,用户可以直观对比各类开源与闭源模型(如 Grep Deep Research、MS-Agent 等)的性能差异,从而为模型选型或算法优化提供客观依据。其独特亮点在于构建了贴近真实科研与工作流的复杂任务场景,不仅关注最终答案的准确性,更强调智能体在多步推理、信息整合及报告生成过程中的综合能力。此外,项目维护活跃,持续收录最新模型成果并更新排名,已成为观察深度研究代理技术发展的重要窗口。无论是希望验证新算法的研究者,还是寻求高效研究助手的开发者,都能从中获得极具价值的参考。
使用场景
某顶尖 AI 实验室的研究团队正在研发新一代深度研究智能体,急需在发布前对其复杂推理与多步检索能力进行权威、量化的评估。
没有 deep_research_bench 时
- 评估标准混乱:团队只能自行拼凑简单的问答测试集,缺乏涵盖长程规划、信息综合等高难度任务的统一标准,导致自评结果虚高且不可信。
- 横向对比困难:面对市场上层出不穷的竞品(如 Grep Deep Research 或 MS-Agent),无法在同等条件下进行公平排名,难以定位自身模型的真实行业位次。
- 迭代方向模糊:由于缺乏细粒度的分项得分(如检索准确率 vs. 报告生成质量),开发人员难以判断模型是“找不到信息”还是“写不好总结”,优化效率低下。
- 学术认可度低:自建的评测数据集缺乏社区公信力,相关技术论文在投稿顶级会议时,常因实验部分缺乏权威基准支撑而受到审稿人质疑。
使用 deep_research_bench 后
- 建立权威标尺:直接接入包含多样化复杂任务的综合基准,利用其标准化的评测流程,瞬间获得具有社区共识的客观能力画像。
- 精准定位排名:将模型提交至 Hugging Face 排行榜,直接与 Grep、LiAuto Mind 等前沿模型同台竞技,清晰看到 53.52 分或 56.23 分背后的具体差距。
- 诊断瓶颈所在:通过基准提供的多维度分析报告,团队迅速发现模型在“跨文档信息整合”环节得分偏低,从而针对性地调整了 Agent 的规划算法。
- 提升论文说服力:引用 arXiv 论文及 AGI-Eval 认证背书,用详实的基准数据证明模型性能,显著提升了研究成果的学术影响力和可信度。
deep_research_bench 不仅是一把衡量深度的“标尺”,更是驱动深度研究智能体从“能用”迈向“好用”的核心导航仪。
运行环境要求
未说明
未说明

快速开始
DeepResearch Bench:面向深度研究智能体的全面基准测试
如果您喜欢我们的项目,请在 GitHub 上为我们点亮星标 ⭐,以获取最新更新。
✨ 新闻
[2026年4月16日] 🎉 新增模型:我们欢迎Deep Dog 1——一款开源深度研究代理(MIT许可证),综合得分为53.52。请查看我们排行榜上的最新排名。
[2026年4月13日] 🎉 新增模型:DeepResearch Bench迎来了两款新模型:
- 🥇 Grep Deep Research——一款专有深度研究代理,以56.23的综合得分位居第1名。
- LiAuto Mind DeepResearch 1.5——理想汽车推出的一款专有深度研究代理,综合得分为52.54。
请查看我们排行榜上的最新排名。
[2026年4月9日] 🎉 新增模型:我们欢迎MS-Agent Agentic Insight v2(Qwen3.5-Plus、GPT 5.2)——一款开源深度研究代理(Apache-2.0许可证),综合得分为55.31。请查看我们排行榜上的最新排名。
[2026年4月2日] 🎉 新增模型:我们欢迎Grep.ai Deep Research——一款专有深度研究代理,综合得分为56.09,在排行榜上位列第2名!请查看我们排行榜上的最新排名。
[2026年4月2日] 🎉 新增模型:DeepResearch Bench迎来了两款新模型:
- 🥉 1688AILab-DeepResearch——一款专有深度研究代理,以55.39的综合得分位居第3名。
- TrajectoryKit(GPT-OSS、GPT5.4)——一款开源深度研究代理(MIT许可证),综合得分为54.92。
请查看我们排行榜上的最新排名。
[2026年3月31日] 📝 排行榜提交更新:我们在README中明确了官方排行榜的提交要求。现在,提交内容应包括可临时访问的Gemini-2.5-Pro密钥、原始生成报告、可复现性链接(仓库或产品/API链接),以及模型元数据,如模型名称、链接和开源许可证。请通过dumingxuan@mail.ustc.edu.cn和imlrz@mail.ustc.edu.cn进行提交,详情请参阅提交排行榜。
[2026年3月25日] 🎉 新增模型:我们欢迎MS-Agent Agentic Insight v2(Qwen3.5-Plus、GPT 5)——一款开源深度研究代理(Apache-2.0许可证),综合得分为54.97。请查看我们排行榜上的最新排名。
[2026年3月20日] 🎉 新增模型:DeepResearch Bench迎来了三款新模型:
- 🥇 Cellcog Max——一款专有深度研究代理,以56.13的综合得分位居第1名!
- 🥉 Cellcog——一款专有深度研究代理,以55.31的综合得分位居第3名。
- RecallRadar Intelligence——一款专有深度研究代理,综合得分为53.19。
请查看我们排行榜上的最新排名。
[2026年2月6日] 🚀 DeepResearch Bench II发布:我们发布了DeepResearch Bench II(DRB II)(主页|仓库|论文)。欢迎各位评估并交流想法。请注意,作为DRB的后续版本,DRB II的评估重点与DRB有所不同;DRB将在DRB II发布后继续维护和更新。更多详情请参阅DRB II论文。
[2026年2月6日] 📚 实验室新论文:欢迎查阅我们实验室(Agent Research Lab)的新论文:
- 基准测试:
- DeepResearch Bench II:基于专家撰写的文章,采用9,430个细粒度二元评分标准(信息召回、分析、呈现)来评估DRA生成的报告。
- Wiki Live Challenge:一项实时基准测试,以维基百科优良条目作为专家级参考,采用细粒度标准评估写作质量和事实可验证性。
- WildGraphBench:针对长篇异构文档,涵盖单事实问答、多事实问答及章节级摘要的1,100道问题,对GraphRAG进行基准测试。
- 智能体:
- A-RAG:一种具身化RAG框架,向模型暴露分层检索接口(关键词搜索、语义搜索、块读取),实现自适应的多粒度检索。
- FS-Researcher:一种基于文件系统的双智能体框架(上下文构建器+报告撰写器),通过持久化知识库将深度研究扩展至上下文窗口之外。
如果您希望评估自己的深度研究代理,请参阅下方的排行榜提交要求,并通过dumingxuan@mail.ustc.edu.cn和imlrz@mail.ustc.edu.cn与我们联系。
- 基准测试:
[2025年7月18日] 🎉 我们与AGI-Eval平台建立了合作关系。DeepResearch Bench现已上线AGI-Eval,为研究人员和从业者提供更便捷的评估界面,用于测试他们的深度研究代理。
[2025年7月15日] ⚡️⚡️ 重大更新:新增了对Kimi-Researcher、Doubao-DeepResearch和Claude-Researcher的全面评估。升级了评估基础设施,使用Gemini-2.5-Pro进行RACE评估,使用Gemini-2.5-Flash进行FACT评估。所有原始研究文章和评估分数现已在我们的Hugging Face排行榜上公开,供全面分析和比较。
有关详细的评估结果和全面比较,请参阅下方的评估结果表格。
📖 概述
DeepResearch Bench 解决了缺乏系统性评估深度研究代理(DRA)的综合基准的问题。我们的基准由 100 个博士级别的研究任务 组成,每个任务均由来自 22 个不同领域 的领域专家精心设计,包括:
- 🔬 科学技术:物理、化学、生物、环境科学和工程
- 💼 金融与商业:投资、个人理财、市场营销和人力资源
- 💻 软件:与软件和互联网使用相关的主题
- 🌍 其他:艺术与设计、娱乐、历史、工业、交通、旅游等
基准构建
主题分布分析
为确保 DeepResearch Bench 能够反映现实世界的研究需求,我们分析了来自启用网络搜索的 LLM 交互中的 96,147 条匿名用户查询。这些查询根据 WebOrganizer 分类体系被划分为 22 个主题领域,揭示了人类在不同领域的深度研究需求的真实分布情况。
专家任务收集
在真实需求分布的指导下,我们邀请了 博士级别的专家和资深从业者(5 年以上经验)在其各自领域内设计具有挑战性的研究任务。每份提交的任务都经过严格的手动筛选,以确保:
- 质量:高研究标准和复杂性
- 清晰度:明确的任务定义和要求
- 真实性:基于真实的科研场景
- 挑战程度:测试 DRA 能力的上限
通过这一过程,我们最终获得了 100 个高质量的基准任务(中文和英文各 50 个),其主题分布与实际使用中的分布保持一致。
评估框架
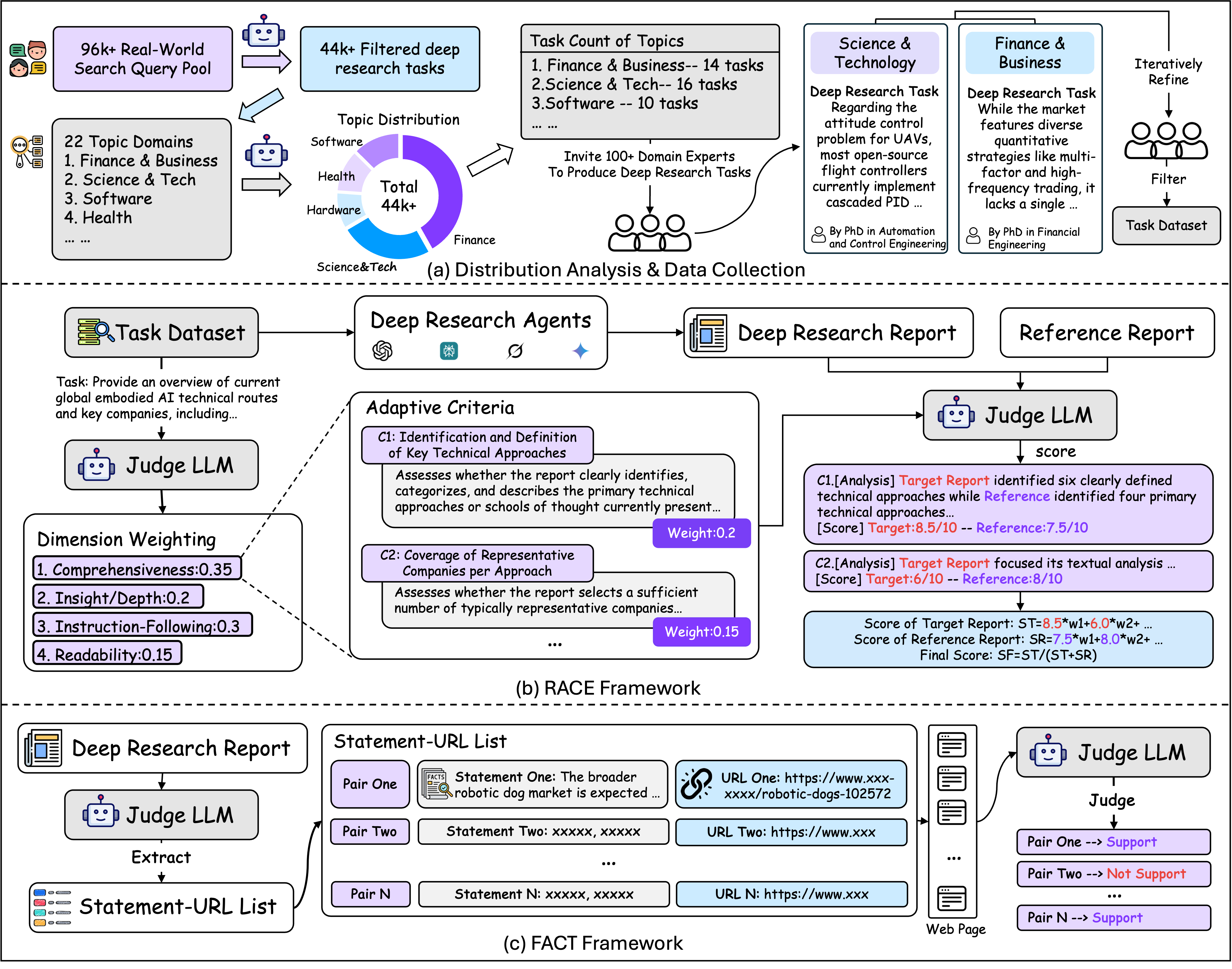
DeepResearch Bench 引入了两种互补的评估方法,旨在全面评估深度研究代理:
🎯 RACE(基于参考的自适应标准驱动评估)
RACE 通过一个复杂的多步骤流程来评估 报告生成质量:
动态标准生成:自动为每个任务生成特定的评估标准,涵盖四个关键维度:
- 📚 全面性:对研究主题覆盖的广度和深度
- 🔍 洞察力/深度:分析质量和见解生成能力
- 📋 指令遵循:对具体任务要求的遵守程度
- 📖 可读性:清晰度、组织性和呈现质量
基于参考的评分:将目标报告与高质量的参考报告进行对比,以确保评估的区分度
加权评估:根据每个任务的具体要求动态调整权重
🔗 FACT(事实丰富度与引用可信度框架)
FACT 通过以下方式评估 信息检索和知识 grounded 性能:
- 语句-URL 提取:自动从生成的报告中提取事实性陈述及其引用来源
- 去重处理:去除重复的语句-URL 对,以聚焦于独特的事实性陈述
- 支持验证:利用网页抓取和 LLM 判断来验证所引用的来源是否确实支持这些陈述
- 引用指标计算:计算:
- 引用准确性:正确支持的引用所占百分比
- 有效引用数:每个任务中可验证支持的平均引用数量
📊 评估结果
主要结果
查看最新排行榜:访问我们的 DeepResearch Bench 排行榜 ,获取实时更新的评估结果、详细比较分析以及原始数据。
提交至排行榜
如果您希望在 DeepResearch Bench 上获得 官方排行榜条目,请准备以下材料,并通过电子邮件发送至:
dumingxuan@mail.ustc.edu.cnimlrz@mail.ustc.edu.cn
所需提交材料:
具备 Gemini-2.5-Pro 访问权限的临时密钥
- 此密钥仅用于验证和评估。
- 在评估期间应保持有效。
- 支持的示例包括:
- Google AI Studio
- Vertex AI
- OpenRouter
- 其他提供 Gemini-2.5-Pro 访问权限的官方提供商
生成的原始文章
- 请以与基准原始数据相同格式提供您的模型输出。
- 参考示例:
可复现性链接
- 如果您的模型/代理是 开源的,请提供允许他人复现结果的仓库链接。
- 如果您的模型/代理是 闭源的,请提供用于复现和验证的产品页面和/或 API 链接。
模型元数据
- 模型名称
- 模型/项目链接
- 开源许可证(适用于开源提交;若为闭源,请明确注明为专有技术)
推荐的附加文件:
results/race/<model_name>/race_result.txtresults/fact/<model_name>/fact_result.txt
提供这些文件可以帮助我们加快验证速度,但最重要的要求仍然是生成的原始报告和临时评估密钥。
🛠️ 安装与使用
前置条件
- Python 3.9+
- Gemini API 密钥(用于 LLM 评估)
- Jina API 密钥(用于 FACT 评估中的网页抓取)
设置
git clone https://github.com/your-username/deep_research_bench.git
cd deep_research_bench
pip install -r requirements.txt
API 配置
将所需的 API 密钥设置为环境变量:
# 设置用于 LLM 评估的 Gemini API 密钥
export GEMINI_API_KEY="your_gemini_api_key_here"
# 设置用于网页抓取的 Jina API 密钥
export JINA_API_KEY="your_jina_api_key_here"
项目结构
deep_research_bench/
├── data/
│ ├── criteria_data/ # 评估标准数据
│ ├── prompt_data/
│ │ └── query.jsonl # ← 您的代理需要完成的 100 个基准查询
│ └── test_data/
│ ├── cleaned_data/ # 清洗后的文章数据
│ └── raw_data/ # ← 将您的模型输出放在这里(model_name.jsonl)
├── prompt/ # 提示模板
├── utils/ # 工具函数
├── deepresearch_bench_race.py # RACE 评估脚本
├── run_benchmark.sh # ← 在这里添加您的模型名称,然后运行
└── requirements.txt # 依赖项
快速入门流程:
- 使用
data/prompt_data/query.jsonl中的查询 → 运行您的深度研究代理 - 将输出保存到
data/test_data/raw_data/<model_name>.jsonl - 将模型名称添加到
run_benchmark.sh中的TARGET_MODELS - 运行:
bash run_benchmark.sh
快速入门
1. 准备您的模型数据
在基准查询上运行您的深度研究代理,并将输出保存为所需格式:
输入:使用 data/prompt_data/query.jsonl 中的查询(100 个基准任务)
输出:将结果保存到 data/test_data/raw_data/<model_name>.jsonl
所需格式(每行应包含):
{
"id": "task_id",
"prompt": "original_query_text",
"article": "generated_research_article_with_citations"
}
2. 配置待评估的模型
编辑 run_benchmark.sh 文件,添加您的模型名称:
TARGET_MODELS=("your-model-name")
3. 运行评估
bash run_benchmark.sh
评估结果将保存至:
- RACE 评估:
results/race/<model_name>/race_result.txt - FACT 评估:
results/fact/<model_name>/fact_result.txt
自定义大语言模型集成
如果您未使用官方 Gemini API,或希望使用其他大语言模型进行评估,请修改 utils/api.py 中的 AIClient 类,以实现您自定义的大语言模型接口。
致谢
我们谨向以下为收集评估数据提供帮助的贡献者表示衷心感谢。由于许多模型和代理并未提供公开 API,因此不得不采用手动方式收集数据,对此我们深表感激:
Xin Yang、Jie Yang、Yawen Li、Xinyu Ouyang、Jiaqi He、Gefan Zhang、Jinfu Liao、Qiuyue Chen、Yulin Wang 和 Lina Wang。
他们的贡献对于本基准测试中所呈现的全面评估至关重要。
引用
如果您在研究中使用 DeepResearch Bench,请引用我们的论文:
@article{du2025deepresearch,
author = {Mingxuan Du and Benfeng Xu and Chiwei Zhu and Xiaorui Wang and Zhendong Mao},
title = {DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents},
journal = {arXiv preprint},
year = {2025},
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。