End-to-end-ASR-Pytorch
End-to-end-ASR-Pytorch 是一个基于 PyTorch 构建的开源端到端自动语音识别(ASR)项目,前身是著名的“听、关注并拼写”(Listen, Attend and Spell)实现。它致力于解决将原始音频直接转换为文本的核心难题,支持从特征提取到模型训练及解码的全流程开发。
该工具特别适合人工智能研究人员和深度学习开发者使用,尤其是那些希望复现经典算法或探索最新语音识别技术的团队。普通用户若无编程基础则较难直接上手。其技术亮点在于高度的灵活性与模块化:不仅实现了基于 Seq2seq 和 CTC 的多种主流架构,还支持两者混合建模;提供在线特征提取、子词编码以及束搜索解码等高级功能。此外,项目采用 YAML 配置文件管理超参数,并集成 TensorBoard 可视化训练过程与注意力对齐效果,极大提升了实验效率与可解释性。无论是学术研究还是工程原型验证,End-to-end-ASR-Pytorch 都是一个功能完备且易于扩展的理想起点。
使用场景
某初创团队正在为医疗问诊系统开发定制化的语音转文字引擎,需处理大量带有专业术语的医生口述录音。
没有 End-to-end-ASR-Pytorch 时
- 团队需从零搭建复杂的序列到序列模型,手动编写编码器、注意力机制及 CTC 损失函数,开发周期长达数月且极易出错。
- 缺乏统一的配置文件管理,每次调整超参数或切换模型结构(如从纯 Attention 改为混合 CTC-Attention)都需要修改大量底层代码,实验迭代效率极低。
- 训练过程如同“黑盒”,无法直观查看注意力对齐效果或损失曲线,难以定位模型为何无法识别特定的医学术语。
- 解码策略单一,仅支持简单的贪婪搜索,导致在噪音环境下识别准确率大幅下降,且难以集成外部语言模型进行优化。
使用 End-to-end-ASR-Pytorch 后
- 直接复用基于 Listen, Attend and Spell 架构的成熟代码,利用内置的多种编码器和注意力模块,将核心模型搭建时间缩短至几天。
- 通过 YAML 文件即可灵活定义模型结构和超参数,轻松实现混合 CTC-Attention 模型的快速切换与对比实验,大幅提升研发迭代速度。
- 集成 TensorBoard 可视化面板,实时监控训练进度并观察注意力对齐图,迅速发现并修正模型对长尾医学词汇的关注偏差。
- 启用束搜索(Beam Search)及联合 CTC-注意力解码功能,并结合 RNN 语言模型进行联合推理,显著提升了复杂医疗场景下的识别鲁棒性。
End-to-end-ASR-Pytorch 通过提供模块化、可配置且可视化的全链路解决方案,让团队能以最低成本快速构建出高精度的垂直领域语音识别系统。
运行环境要求
- 未说明
必需(训练自有模型时极度重要),具体型号和显存大小未说明,需支持 PyTorch CUDA 后端
未说明(文中强调训练时 RAM 和 GPU 显存空间极度重要,解码时增加线程数会消耗更多 RAM)

快速开始
端到端自动语音识别系统 - PyTorch 实现
这是一个开源项目(原名 Listen, Attend and Spell - PyTorch Implementation),由 Tzu-Wei Sung 和我共同开发的端到端 ASR 项目。
实现主要基于广为人知的深度学习框架 PyTorch。
该端到端 ASR 的基础是 Listen, Attend and Spell1。此外,我们还实现了近年来提出的多种技术,作为插件以提升性能。已实现的技术列表请参阅 亮点、配置文件 和 参考文献。
欢迎使用或修改这些代码,任何 bug 报告或改进建议都将不胜感激。如果您觉得本项目对您的研究有所帮助,请考虑引用我们的论文[Citation],谢谢!
亮点
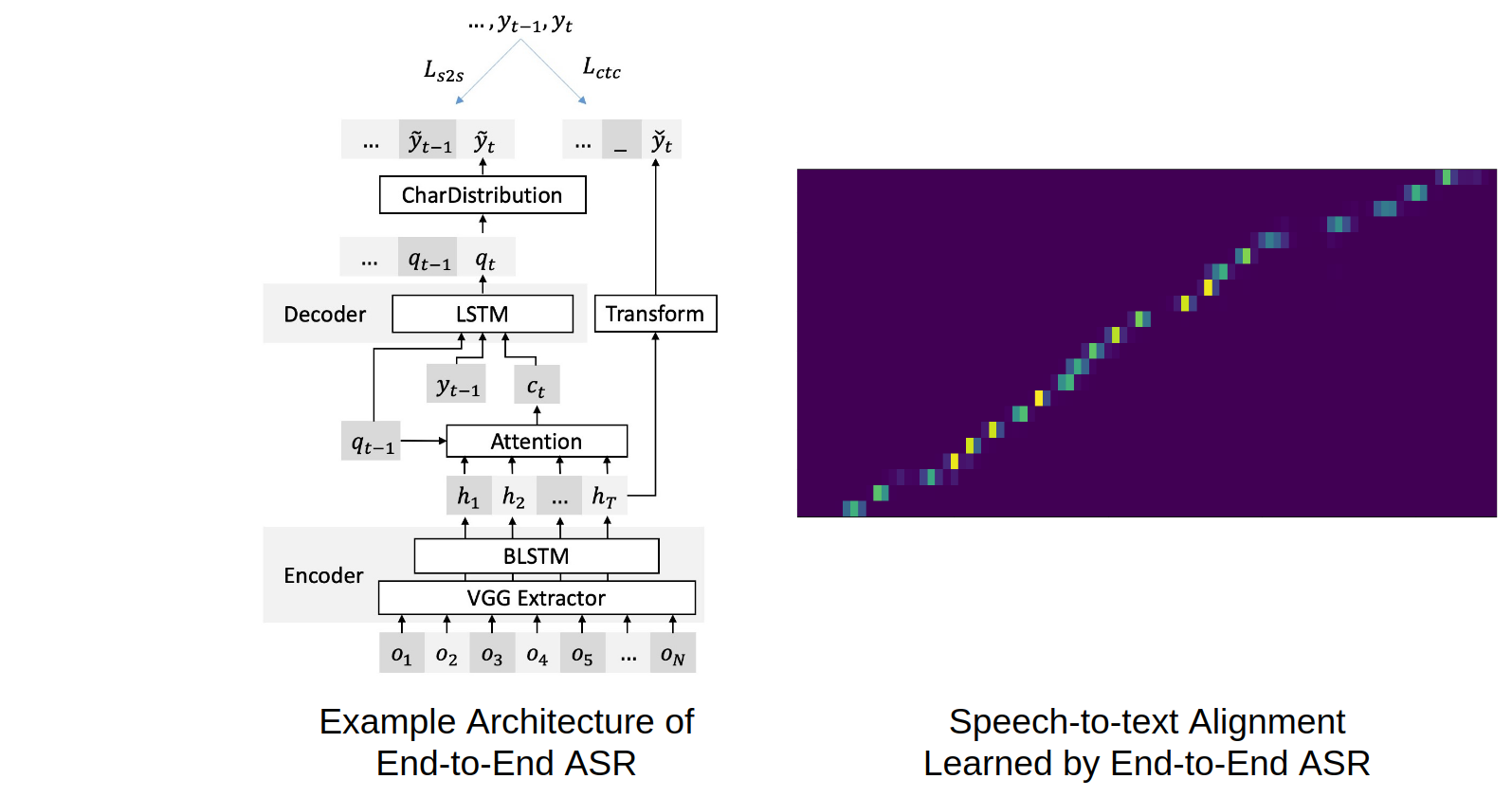
特征提取
- 使用 torchaudio 作为后端进行实时特征提取
- 文本的字符/子词2/词编码
训练端到端 ASR
- 具有不同编码器/注意力机制3的序列到序列 ASR
- 基于 CTC 的 ASR4,也可与前者混合5
- yaml 风格的模型构建和超参数设置
- 使用 TensorBoard 可视化训练过程,包括注意力对齐
使用端到端 ASR 进行语音识别(即解码)
- 波束搜索解码
- RNN 语言模型训练及与 ASR 的联合解码6
- 联合 CTC-注意力机制的解码6
- 贪心解码和 CTC 波束搜索由 Heng-Jui (Harry) Chang 贡献
您可以通过下载 coming soon 中的示例日志文件,使用 TensorBoard 查看相关可视化内容
依赖项
- Python 3
- 如果您想训练自己的模型,计算能力(高端 GPU)和内存空间(RAM 和 GPU 显存)都至关重要。
- 所需的软件包及其用途列在 requirements.txt 中。
使用说明
步骤 0. 预处理 - 生成文本编码器
您可以直接使用 tests/sample_data/ 目录下提供的文本编码器,跳过此步骤。
子词模型使用 sentencepiece 训练。对于字符/词模型,您需要逐行生成包含词汇表的文件。也可以使用 util/generate_vocab_file.py 脚本,只需准备一个文本文件,其中包含所有用于生成词汇表或子词模型的文本即可。如果要更改模式或词汇表文件,请更新配置文件中的 data.text.* 字段。对于子词模型,应使用以 .model 结尾的文件作为 vocab_file。
python3 util/generate_vocab_file.py --input_file TEXT_FILE \
--output_file OUTPUT_FILE \
--vocab_size VOCAB_SIZE \
--mode MODE
更多详细信息请参阅 python3 util/generate_vocab_file.py -h。
步骤 1. 配置 - 模型设计与超参数设置
所有与训练/解码相关的参数都将存储在一个 yaml 文件中。通过这种方式可以轻松管理超参数调优和实验。具体格式请参阅 文档和示例。请注意,提供的示例配置并未经过精细调优,为了获得最佳性能,建议您编写自己的配置文件。
步骤 2. 训练(端到端 ASR 或 RNN-LM)
配置文件准备好后,运行以下命令即可开始训练端到端 ASR(或语言模型):
python3 main.py --config <配置文件路径>
例如,在 LibriSpeech 数据集上训练一个 ASR,并使用以下命令查看日志:
# 查看可用选项
python3 main.py -h
# 使用特定配置开始训练
python3 main.py --config config/libri/asr_example.yaml
# 打开 TensorBoard 查看日志
tensorboard --logdir log/
# 训练外部语言模型
python3 main.py --config config/libri/lm_example.yaml --lm
所有设置将自动从配置文件中解析并开始训练,训练日志可通过 TensorBoard 查看。请注意,TensorBoard 上显示的错误率存在偏差(见 issue #10),您应运行测试阶段以获得模型的真实性能。
本阶段可用的选项包括:
| 选项 | 描述 |
|---|---|
| config | 配置文件路径。 |
| seed | 随机种子,请注意,此选项会影响结果 |
| name | 用于记录和保存模型的实验名称。 默认为 |
| logdir | 存储训练日志(TensorBoard 日志文件)的路径,默认为 log/。 |
| ckpdir | 存放模型的目录,默认为 ckpt/。 |
| njobs | 数据加载器使用的工作者数量,如果发现数据预处理占用了大部分训练时间,可适当增加,默认使用 6。 |
| no-ping | 禁用 PyTorch 数据加载器的固定内存选项。 |
| cpu | 仅 CPU 模式,不推荐使用,可用于调试。 |
| no-msg | 隐藏所有标准输出消息。 |
| lm | 切换到 RNNLM 训练模式。 |
| test | 切换到解码模式(请勿在训练阶段使用) |
| cudnn-ctc | 使用 CuDNN 作为 PyTorch CTC 的后端。不稳定,详见 此问题,不确定是否已在 最新版本的 PyTorch 中修复,且 cuDNN 版本 > 7.6 |
步骤 3. 语音识别与性能评估
要测试模型,请运行以下命令:
python3 main.py --config <配置文件路径> --test --njobs <整数>
请注意,解码过程不采用批处理方式,因此需要使用更多的工作者来加快速度,但这会消耗更多内存。
默认情况下,识别结果将存储在 result/<name>/ 目录下,以两个 CSV 文件的形式保存,并根据解码配置文件自动命名。output.csv 将存储 ASR 提供的最佳假设,而 beam.csv 将记录波束搜索过程中的前几条假设。结果文件可以使用 eval.py 进行评估。例如,测试在 LibriSpeech 上训练的示例 ASR,并检查其性能:
python3 main.py --config config/libri/decode_example.yaml --test --njobs 8
# 检查 WER/CER
python3 eval.py --file result/asr_example_sd0_dev_output.csv
大多数选项与训练阶段类似,除了以下几点:
| 选项 | 描述 |
|---|---|
| test | 必须启用 |
| config | 解码配置文件的路径。 |
| outdir | 存储解码结果的路径。 |
| njobs | 用于解码的线程数,对效率非常重要。数值越大,解码速度越快,但会占用更多的内存/GPU显存。 |
故障排除
训练刚开始时损失就变为
nan对于 CTC 损失,
len(pred)>len(label)是必要的条件。此外,可以考虑将torch.nn.CTCLoss的zero_infinity参数设置为True。
待办事项
- 提供示例
- 纯 CTC 训练 / CTC 束搜索解码中的问题(候选列表外)
- 贪心解码
- 自定义数据集
- 工具脚本
- 完成 CLM 的迁移和参考实现
- 将预处理后的数据集存储在内存中
致谢
- 部分实现参考了 ESPnet,这是一款由 Watanabe 等人开发的强大端到端语音处理工具包。
- 特别感谢 LAS 的第一作者 William Chan,他在实现过程中解答了我的疑问。
- 感谢 xiaoming、Odie Ko、b-etienne、Jinserk Baik 和 Zhong-Yi Li,他们指出了我们实现中的几个问题。
参考文献
- Listen, Attend and Spell,W Chan 等人。
- Neural Machine Translation of Rare Words with Subword Units,R Sennrich 等人。
- Attention-Based Models for Speech Recognition,J Chorowski 等人。
- Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks,A Graves 等人。
- Joint CTC-Attention based End-to-End Speech Recognition using Multi-task Learning,S Kim 等人。
- Advances in Joint CTC-Attention based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM,T Hori 等人。
引用
@inproceedings{liu2019adversarial,
title={Adversarial Training of End-to-end Speech Recognition Using a Criticizing Language Model},
author={Liu, Alexander and Lee, Hung-yi and Lee, Lin-shan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP)},
year={2019},
organization={IEEE}
}
@misc{alex2019sequencetosequence,
title={Sequence-to-sequence Automatic Speech Recognition with Word Embedding Regularization and Fused Decoding},
author={Alexander H. Liu and Tzu-Wei Sung and Shun-Po Chuang and Hung-yi Lee and Lin-shan Lee},
year={2019},
eprint={1910.12740},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
GPT-SoVITS
GPT-SoVITS 是一款强大的开源语音合成与声音克隆工具,旨在让用户仅需极少量的音频数据即可训练出高质量的个性化语音模型。它核心解决了传统语音合成技术依赖海量录音数据、门槛高且成本大的痛点,实现了“零样本”和“少样本”的快速建模:用户只需提供 5 秒参考音频即可即时生成语音,或使用 1 分钟数据进行微调,从而获得高度逼真且相似度极佳的声音效果。 该工具特别适合内容创作者、独立开发者、研究人员以及希望为角色配音的普通用户使用。其内置的友好 WebUI 界面集成了人声伴奏分离、自动数据集切片、中文语音识别及文本标注等辅助功能,极大地降低了数据准备和模型训练的技术门槛,让非专业人士也能轻松上手。 在技术亮点方面,GPT-SoVITS 不仅支持中、英、日、韩、粤语等多语言跨语种合成,还具备卓越的推理速度,在主流显卡上可实现实时甚至超实时的生成效率。无论是需要快速制作视频配音,还是进行多语言语音交互研究,GPT-SoVITS 都能以极低的数据成本提供专业级的语音合成体验。
TTS
🐸TTS 是一款功能强大的深度学习文本转语音(Text-to-Speech)开源库,旨在将文字自然流畅地转化为逼真的人声。它解决了传统语音合成技术中声音机械生硬、多语言支持不足以及定制门槛高等痛点,让高质量的语音生成变得触手可及。 无论是希望快速集成语音功能的开发者,还是致力于探索前沿算法的研究人员,亦或是需要定制专属声音的数据科学家,🐸TTS 都能提供得力支持。它不仅预置了覆盖全球 1100 多种语言的训练模型,让用户能够即刻上手,还提供了完善的工具链,支持用户利用自有数据训练新模型或对现有模型进行微调,轻松实现特定风格的声音克隆。 在技术亮点方面,🐸TTS 表现卓越。其最新的 ⓍTTSv2 模型支持 16 种语言,并在整体性能上大幅提升,实现了低于 200 毫秒的超低延迟流式输出,极大提升了实时交互体验。此外,它还无缝集成了 🐶Bark、🐢Tortoise 等社区热门模型,并支持调用上千个 Fairseq 模型,展现了极强的兼容性与扩展性。配合丰富的数据集分析与整理工具,🐸TTS 已成为科研与生产环境中备受信赖的语音合成解决方案。
LocalAI
LocalAI 是一款开源的本地人工智能引擎,旨在让用户在任意硬件上轻松运行各类 AI 模型,包括大语言模型、图像生成、语音识别及视频处理等。它的核心优势在于彻底打破了高性能计算的门槛,无需昂贵的专用 GPU,仅凭普通 CPU 或常见的消费级显卡(如 NVIDIA、AMD、Intel 及 Apple Silicon)即可部署和运行复杂的 AI 任务。 对于担心数据隐私的用户而言,LocalAI 提供了“隐私优先”的解决方案,确保所有数据处理均在本地基础设施内完成,无需上传至云端。同时,它完美兼容 OpenAI、Anthropic 等主流 API 接口,这意味着开发者可以无缝迁移现有应用,直接利用本地资源替代云服务,既降低了成本又提升了可控性。 LocalAI 内置了超过 35 种后端支持(如 llama.cpp、vLLM、Whisper 等),并集成了自主 AI 代理、工具调用及检索增强生成(RAG)等高级功能,且具备多用户管理与权限控制能力。无论是希望保护敏感数据的企业开发者、进行算法实验的研究人员,还是想要在个人电脑上体验最新 AI 技术的极客玩家,都能通过 LocalAI 获
bark
Bark 是由 Suno 推出的开源生成式音频模型,能够根据文本提示创造出高度逼真的多语言语音、音乐、背景噪音及简单音效。与传统仅能朗读文字的语音合成工具不同,Bark 基于 Transformer 架构,不仅能模拟说话,还能生成笑声、叹息、哭泣等非语言声音,甚至能处理带有情感色彩和语气停顿的复杂文本,极大地丰富了音频表达的可能性。 它主要解决了传统语音合成声音机械、缺乏情感以及无法生成非语音类音效的痛点,让创作者能通过简单的文字描述获得生动自然的音频素材。无论是需要为视频配音的内容创作者、探索多模态生成的研究人员,还是希望快速原型设计的开发者,都能从中受益。普通用户也可通过集成的演示页面轻松体验其神奇效果。 技术亮点方面,Bark 支持商业使用(MIT 许可),并在近期更新中实现了显著的推理速度提升,同时提供了适配低显存 GPU 的版本,降低了使用门槛。此外,社区还建立了丰富的提示词库,帮助用户更好地驾驭模型生成特定风格的声音。只需几行 Python 代码,即可将创意文本转化为高质量音频,是连接文字与声音世界的强大桥梁。
ChatTTS
ChatTTS 是一款专为日常对话场景打造的生成式语音模型,特别适用于大语言模型助手等交互式应用。它主要解决了传统文本转语音(TTS)技术在对话中缺乏自然感、情感表达单一以及难以处理停顿、笑声等细微语气的问题,让机器生成的语音听起来更像真人在聊天。 这款工具非常适合开发者、研究人员以及希望为应用增添自然语音交互功能的设计师使用。普通用户也可以通过社区开发的衍生产品体验其能力。ChatTTS 的核心亮点在于其对对话任务的深度优化:它不仅支持中英文双语,还能精准控制韵律细节,自动生成自然的 laughter(笑声)、pauses(停顿)和 interjections(插入语),从而实现多说话人的互动对话效果。在韵律表现上,ChatTTS 超越了大多数开源 TTS 模型。目前开源版本基于 4 万小时数据预训练而成,虽主要用于学术研究与教育目的,但已展现出强大的潜力,并支持流式音频生成与零样本推理,为后续的多情绪控制等进阶功能奠定了基础。