MedLLMsPracticalGuide
MedLLMsPracticalGuide 是一个专注于医疗领域大语言模型(Medical LLMs)的精选资源库,旨在为研究人员和开发者提供一份实用的应用指南。随着人工智能在医疗行业的快速渗透,如何安全、有效地将大模型应用于临床诊断、患者管理及医学研究成为一大挑战。该项目通过系统梳理海量的学术论文、开源模型及实践案例,构建了清晰的“医疗大模型知识树”和数据表格,帮助用户快速把握该领域的最新进展、核心应用场景及潜在风险。
其独特亮点在于依托发表于顶级期刊《Nature Reviews Bioengineering》的深度综述论文,内容由来自牛津大学、麻省理工学院等全球顶尖机构的学者共同维护,确保了信息的权威性与前沿性。资源库保持高频更新,不仅涵盖了从基础理论到落地实践的全链路资源,还提供了详细的分类索引,极大地降低了信息检索门槛。无论是希望深入了解医疗 AI 趋势的学术研究人员,还是致力于开发医疗辅助系统的工程师,都能从中获得极具价值的参考指引,是推动医疗大模型技术规范化发展的重要工具。
使用场景
某三甲医院科研团队正计划开发一款辅助医生进行复杂病例分析的医疗大模型,但在技术选型和合规落地阶段陷入停滞。
没有 MedLLMsPracticalGuide 时
- 资源检索如大海捞针:团队成员需在 arXiv、GitHub 和各大学术会议网站间反复切换,耗时数周仍难以穷尽最新的医疗大模型论文与开源代码。
- 技术路线盲目试错:缺乏对现有模型(如针对临床笔记微调或医学影像多模态模型)的系统性对比,导致选择了不适合特定科室数据的基座模型,浪费大量算力资源。
- 合规风险难以评估:由于缺少权威的实践指南,团队无法快速识别数据隐私保护、模型幻觉抑制等关键挑战的成熟解决方案,项目因伦理审查顾虑被迫搁置。
- 前沿动态严重滞后:仅能关注到个别热门模型,错过了 Nature Reviews Bioengineering 等顶级期刊发布的最新综述与行业趋势判断。
使用 MedLLMsPracticalGuide 后
- 一站式获取权威资源:直接利用其整理的"Medical LLMs Tree"和表格,在几分钟内定位到涵盖预训练、微调到评估的全链路高质量论文与代码库。
- 精准匹配技术方案:参考指南中按任务类型(如诊断推理、病历生成)分类的模型清单,迅速锁定了适合该院数据结构的最优基座模型,缩短选型周期 80%。
- 规避落地核心陷阱:依据指南中总结的挑战与对策章节,提前部署了针对性的去幻觉策略和数据脱敏流程,顺利通过伦理委员会审核。
- 同步全球最新进展:通过其持续更新的机制,团队实时掌握了 2025 年最新发布的医疗大模型应用案例,确保技术架构具备前瞻性。
MedLLMsPracticalGuide 将原本需要数月完成的调研工作压缩至数天,为医疗大模型的安全、高效落地提供了不可或缺的导航图。
运行环境要求
未说明
未说明

快速开始

[Nature Reviews Bioengineering] 医疗大型语言模型实用指南
如果您喜欢我们的项目,请在 GitHub 上为我们点亮一颗星 ⭐,以获取最新更新。
![]()

这是一个不断更新的医疗大型语言模型(Medical LLMs)实用指南资源列表。 它基于我们的综述论文:
[Nature Reviews Bioengineering🔥] 大型语言模型在医学中的应用
[arXiv 预印本] 医学领域大型语言模型的综述:进展、应用与挑战
周洪建1,*, 刘凤林1,*, 顾博洋2,*, 邹欣宇3,*, 黄金发4,*, 吴金格5, 李怡如6, Sam S. Chen7, 周培琳8, 刘俊玲9, 华一宁10, 毛成峰11, 游晨宇12, 武贤13, 郑业峰13, Lei Clifton1, 李征14,†, 罗杰波4,†, 大卫·A·克利夫顿1,†. (*核心贡献者, †通讯作者)
1牛津大学, 2帝国理工学院伦敦, 3滑铁卢大学, 4罗切斯特大学, 5伦敦大学学院, 6西安大略大学, 7佐治亚大学, 8香港科技大学(广州), 9阿里巴巴, 10哈佛 T.H. 钱公共卫生学院, 11麻省理工学院, 12耶鲁大学, 13腾讯, 14亚马逊
📣 最新消息
[2025-04-08] 🎉🎉🎉 我们的论文已正式发表于 Nature Reviews Bioengineering,GitHub 仓库的星标数也达到了 1,500 颗!
[2023-11-09] 我们发布了该仓库及 综述。
⚡ 贡献方式
如果您希望将自己的工作或模型添加到此列表中,请随时发送邮件至 fenglin.liu@eng.ox.ac.uk 和 jhuang90@ur.rochester.edu,或提交 拉取请求。 Markdown 格式如下:
* [**会议或期刊名称 + 年份**] 论文标题。[[论文]](链接) [[代码]](链接)
🤔 医疗 LLM 的目标是什么?
目标 1:超越人类专家水平。
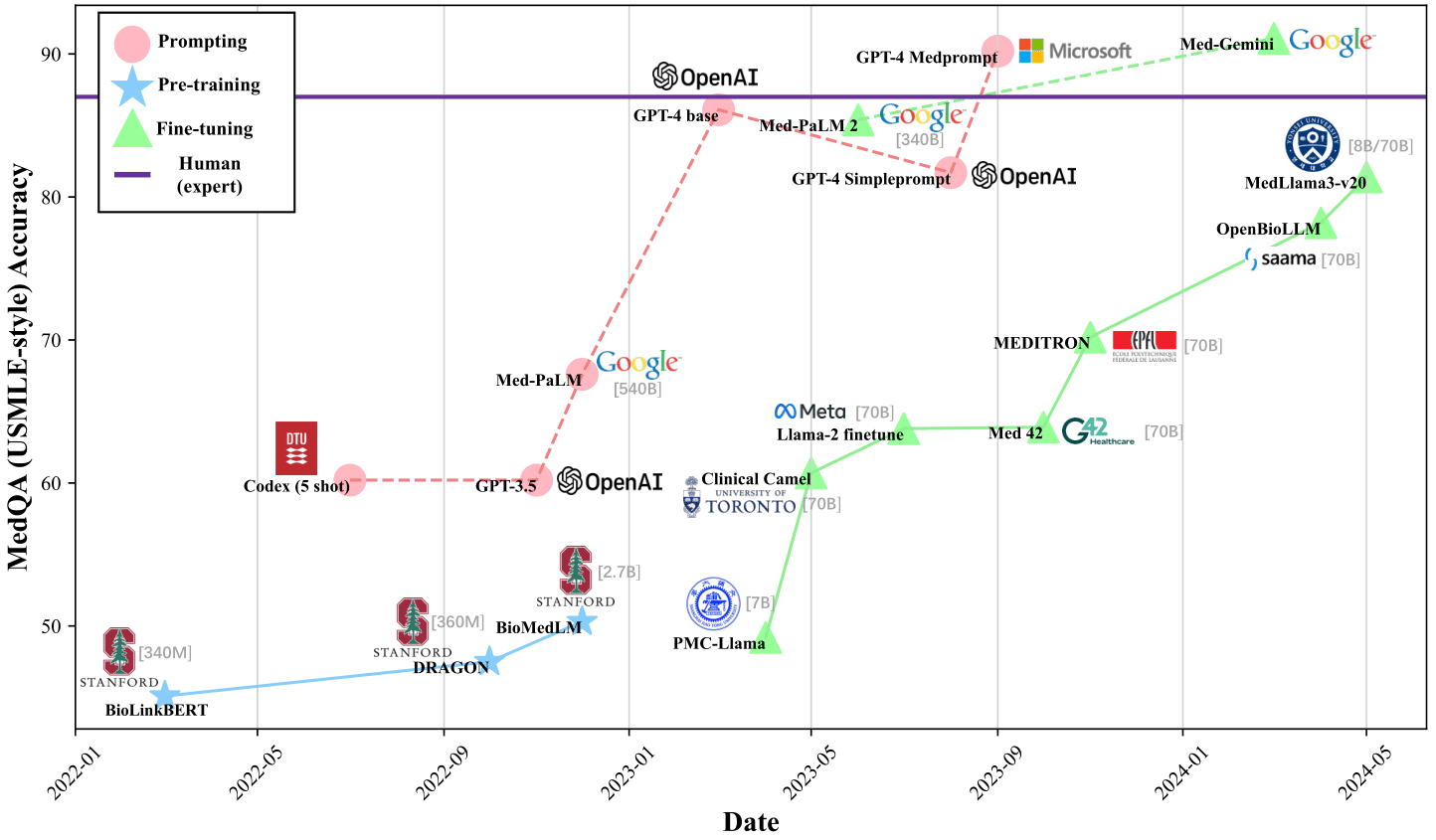
目标 2:随着模型规模扩大,医疗 LLM 出现涌现性特征。
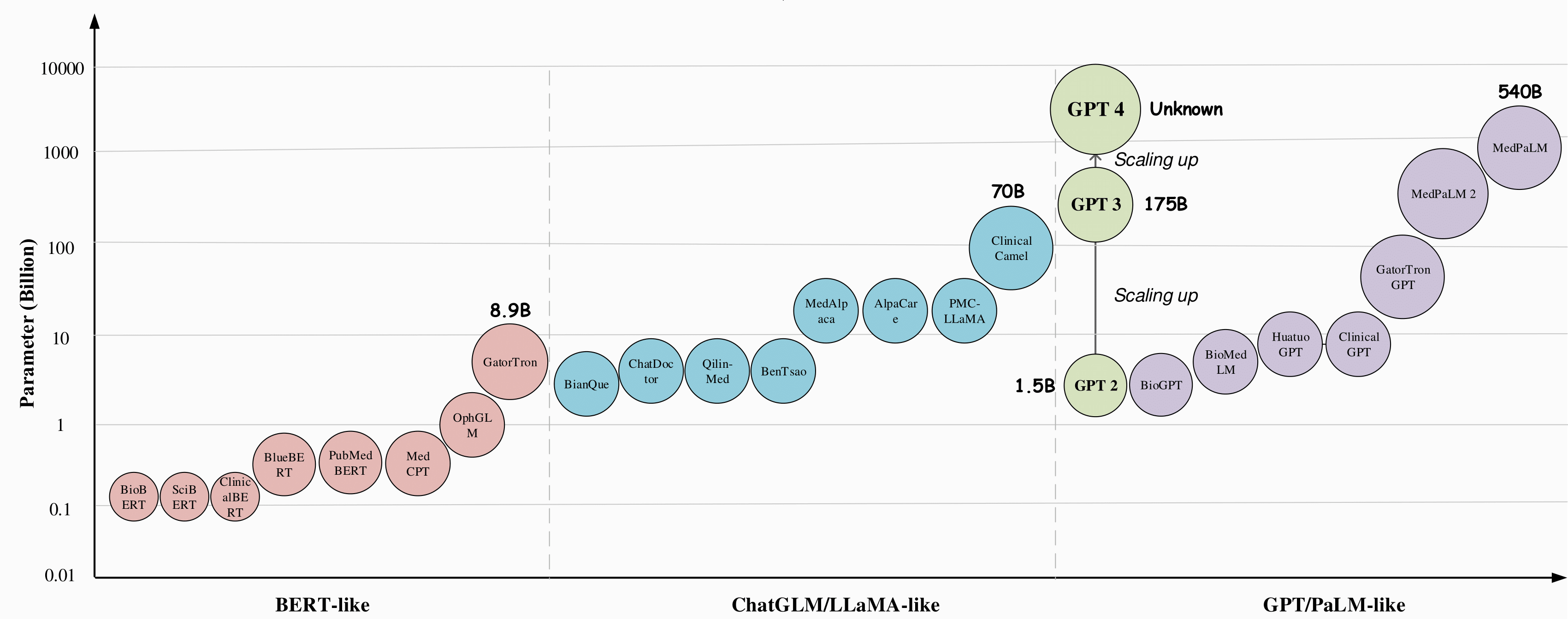
🤗 这篇综述讲的是什么?
本综述全面概述了大型语言模型在医学领域的原理、应用及面临的挑战。我们重点探讨了以下几个具体问题:
- 医疗 LLM 应该如何构建?
- 如何评估医疗 LLM 的下游性能?
- 医疗 LLM 应如何应用于实际临床实践?
- 使用医疗 LLM 会面临哪些挑战?
- 我们应如何更好地构建和利用医疗 LLM?
本综述旨在为读者提供关于大型语言模型在医学领域机遇与挑战的深入见解,并作为构建高效医疗 LLM 的实用参考资源。
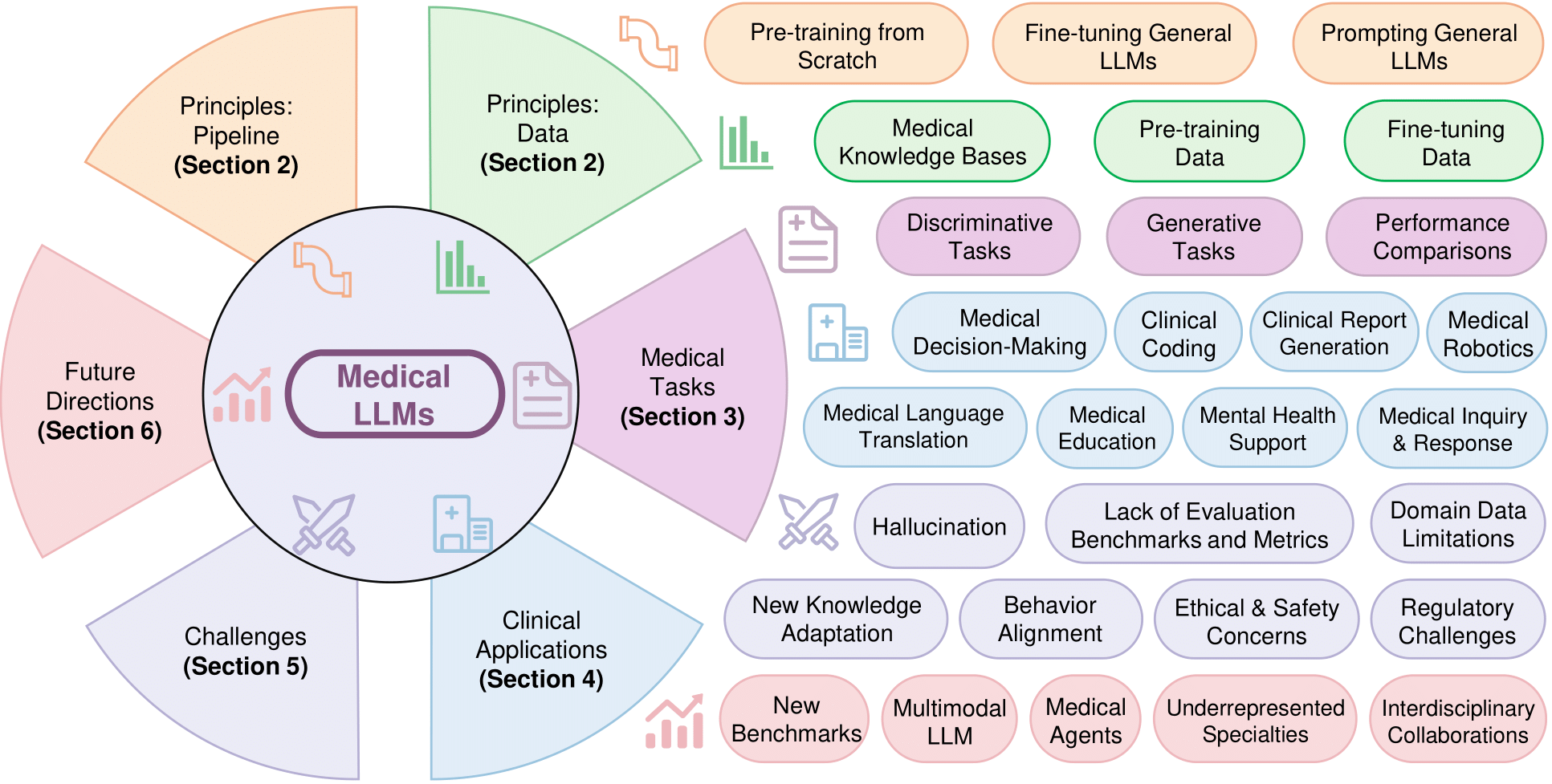
目录
- 📣 更新消息
- ⚡ 贡献
- 🤔 医疗大模型的目标是什么?
- 🤗 本次调查的主题是什么?
- 目录
- 🔥 构建流程实用指南
- 📊 医疗数据实用指南
- 🗂️ 下游生物医学任务
- ✨ 临床应用实用指南
- ⚔️ 挑战实用指南
- 🚀 未来发展方向实用指南
- 👍 致谢
- 📑 引用
- ♥️ 贡献者
🔥 构建流程实用指南
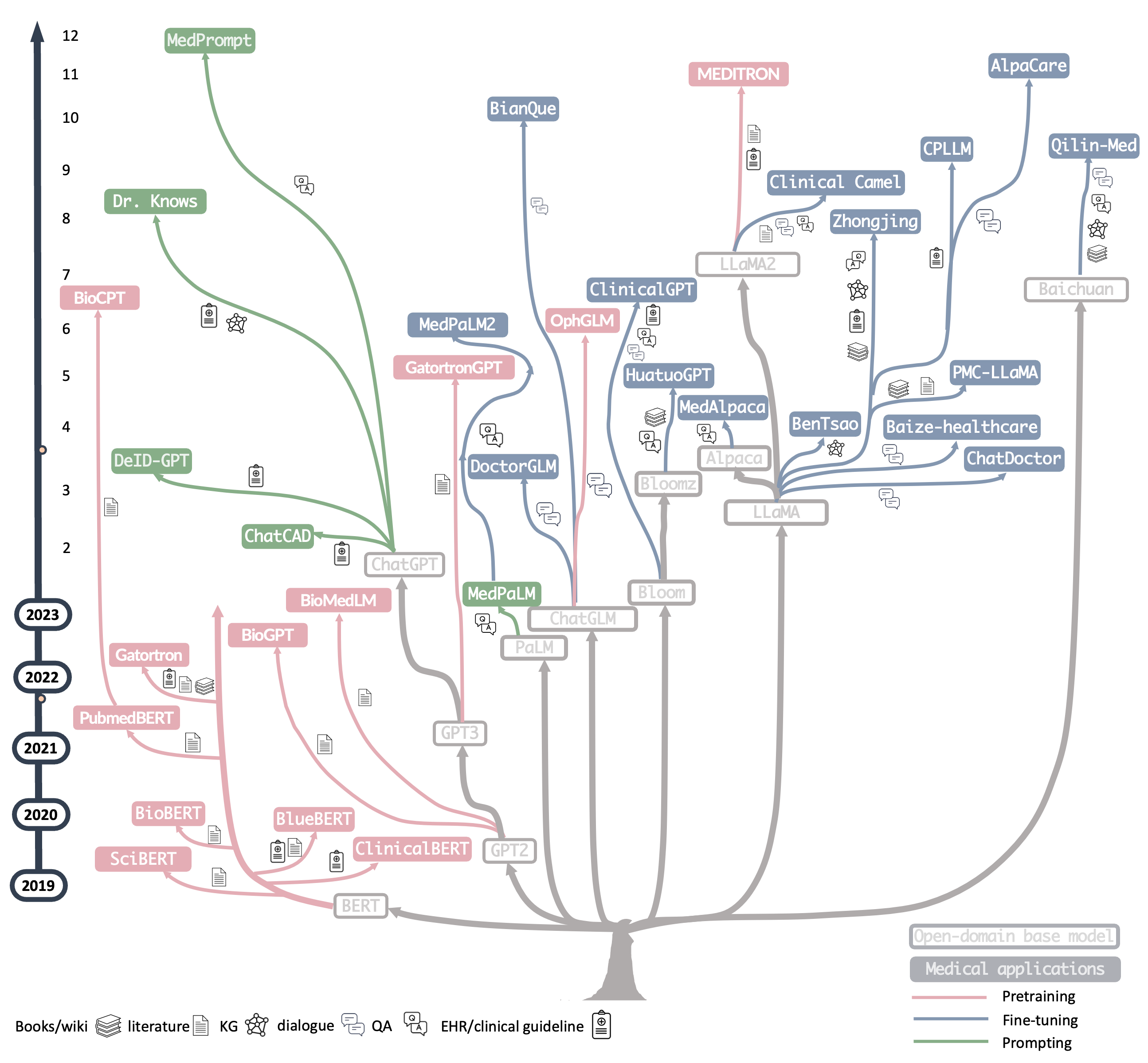
从头开始预训练
- [Nature Medicine, 2024] BiomedGPT 一种用于多样化生物医学任务的通用视觉-语言基础模型 论文
- [Nature, 2023] NYUTron 健康系统规模的语言模型是全能的预测引擎 论文
- [Arxiv, 2023] OphGLM: 基于指令和对话训练的眼科大型语言-视觉助手。论文
- [npj Digital Medicine, 2023] GatorTronGPT: 关于用于医学研究和医疗保健的生成式大型语言模型的研究。论文
- [Bioinformatics, 2023] MedCPT: 对比预训练的Transformer,结合大规模PubMed搜索日志,用于零样本生物医学信息检索。论文
- [Bioinformatics, 2022] BioGPT: 用于生物医学文本生成和挖掘的生成式预训练Transformer。论文
- [NeurIPS, 2022] DRAGON: 深度双向语言-知识图谱预训练。论文 代码
- [ACL, 2022] BioLinkBERT/LinkBERT: 使用文档链接进行语言模型预训练。论文 代码
- [npj Digital Medicine, 2022] GatorTron: 一种用于电子健康记录的大语言模型。论文
- [HEALTH, 2021] PubMedBERT: 面向生物医学自然语言处理的领域特定语言模型预训练。论文
- [Bioinformatics, 2020] BioBERT: 一种用于生物医学文本挖掘的预训练生物医学语言表示模型。论文
- [ENNLP, 2019] SciBERT: 一种用于科学文本的预训练语言模型。论文
- [NAACL研讨会,2019年] ClinicalBERT: 公开可用的临床BERT嵌入。论文
- [BioNLP研讨会,2019年] BlueBERT: 生物医学自然语言处理中的迁移学习:在十个基准数据集上对BERT和ELMo的评估。论文
通用大语言模型的微调
- [Nature Communications, 2024.9] MMed-Llama3: 构建多语言医学语言模型。[论文] [代码]
- [Arxiv, 2024.8] Med42-v2: 一系列临床大语言模型。论文 模型
- [JAMIA, 2024.5] Internist.ai 7b 高质量、跨领域数据对医学语言模型性能的影响 论文 模型
- [Huggingface, 2024.5] OpenBioLLM-70b: 推动开源大型语言模型在医疗领域的应用 模型
- [Huggingface, 2024.5] MedLllama3 模型
- [Arxiv, 2024.5] Aloe: 一系列微调后的开源医疗大语言模型。论文 模型
- [Arxiv, 2024.4] Med-Gemini Gemini模型在医学领域的应用能力。论文
- [npj Digital Medicine, 2024] Meerkat: 小型语言模型从医学教科书中学习增强的推理能力 论文
- [Arxiv, 2024.2] BioMistral 医疗领域的一系列开源预训练大型语言模型。论文
- [Arxiv, 2023.12] 从初学者到专家: 将医学知识融入通用大语言模型。论文
- [Arxiv, 2023.11] Taiyi: 一款面向多样化生物医学任务的双语微调大型语言模型。论文 代码
- [Arxiv, 2023.10] AlpaCare: 针对医疗应用的指令微调大型语言模型。论文 代码
- [Arxiv, 2023.10] BianQue: 通过ChatGPT润色的多轮健康对话,平衡健康类大语言模型的提问与建议能力。论文
- [Arxiv, 2023.10] Qilin-Med: 多阶段知识注入的先进医学大型语言模型。论文
- [Arxiv, 2023.10] Qilin-Med-VL: 向通用医疗领域的中文大型视觉-语言模型迈进。论文
- [Arxiv, 2023.10] MEDITRON-70B: 扩展大型语言模型的医学预训练规模。论文
- [AAAI, 2024/2023.10] Med42: 评估医学大语言模型的微调策略:全参数与参数高效方法。论文 模型
- [Arxiv, 2023.9] CPLLM: 利用大型语言模型进行临床预测。论文
- [Arxiv, 2023.8] BioMedGPT/OpenBioMed 面向生物医学的开源多模态生成式预训练Transformer。论文 代码
- [Nature Digital Medicine, 2023.8] 大型语言模型用于识别电子健康记录中的社会健康决定因素。论文 [代码]
- [Arxiv, 2023.8] Zhongjing: 通过专家反馈和真实场景下的多轮对话,提升大型语言模型的中医能力。论文
- [Arxiv, 2023.7] Med-Flamingo: 多模态医学少样本学习模型。论文 代码
- [Arxiv, 2023.6] ClinicalGPT: 基于多样化的医疗数据并经过全面评估的大型语言模型微调。2023年。论文
- [Cureus, 2023.6] ChatDoctor: 一款基于Meta AI(LLaMA)大型语言模型,并结合医学领域知识进行微调的医疗聊天模型。论文
- [NeurIPS 数据集/基准测试赛道, 2023.6] LLaVA-Med: 在一天内训练一个面向生物医学的大语言-视觉助手。论文
- [Arxiv, 2023.6] MedPaLM 2: 朝着利用大型语言模型实现专家级医学问答目标迈进。论文
- [Arxiv, 2023.5] Clinical Camel: 一款开源的专家级医学语言模型,采用对话式知识编码。论文
- [Arxiv, 2023.5] BiomedGPT: 一款面向多样化生物医学任务的通用视觉-语言基础模型。论文
- [Arxiv, 2023.5] HuatuoGPT: HuatuoGPT,致力于将语言模型驯化为医生。论文
- [Arxiv, 2023.4] Baize-healthcare: 一款基于自我对话数据进行参数高效微调的开源聊天模型。论文
- [Arxiv, 2023.4] Visual Med-Alpeca: 一款具有视觉能力的参数高效生物医学语言模型。GitHub
- [Arxiv, 2023.4] PMC-LLaMA: 进一步对LLaMA模型进行医学论文的微调。论文
- [Arxiv, 2023.4] MedPaLM M: 朝着通用生物医学人工智能迈进。论文 代码
- [Arxiv, 2023.4] BenTsao/Huatuo: 利用中医药知识对LLaMA模型进行微调。论文
- [Github, 2023.4] ChatGLM-Med: ChatGLM-Med: 基于中文医学知识的ChatGLM模型微调。GitHub
- [Arxiv, 2023.4] DoctorGLM: 微调你的中国医生并非难事。论文
通用大语言模型的提示工程
- [NEJM AI, 2024] GPT-4在肿瘤学指南的信息检索与比较中的应用。论文
- [Arxiv, 2023.11] MedPrompt: 通用基础模型能否超越专用微调?以医学为例的研究。论文
- [Arxiv, 2023.8] Dr. Knows: 利用医学知识图谱增强大型语言模型的诊断预测能力。论文
- [Arxiv, 2023.3] DelD-GPT: 使用GPT-4实现零样本医学文本去标识化。论文 代码
- [Arxiv, 2023.2/5] ChatCAD/ChatCAD+: 基于大型语言模型的医学影像交互式辅助诊断系统。论文 代码
- [Nature, 2022.12] MedPaLM: 大型语言模型能够编码临床知识。论文
- [Arxiv, 2022.7/2023.12] 大型语言模型能否对医学问题进行推理?论文
📊 医疗数据实用指南
临床知识库
预训练数据
- [NEJM AI, 2024] 医疗人工智能与大型语言模型的临床文本数据集——系统综述 论文
- [npj Digital Medicine, 2023] EHRs: 生成式大型语言模型在医学研究与医疗保健中的应用研究。论文
- [Arxiv, 2023] Guidelines: 高质量的临床实践指南(CPGs)集合,用于大型语言模型的医学训练。数据集
- [Arxiv, 2023] GAP-REPLAY: 扩展大型语言模型的医学预训练规模。论文
- [npj Digital Medicine, 2022] EHRs: 面向电子健康记录的大型语言模型。论文
- [美国国家医学图书馆, 2022] PubMed: 美国国立卫生研究院的PubMed数据。数据库
- [Arxiv, 2020] PubMed: The Pile:一个包含多样化文本的800 GB语言建模数据集。论文 代码
- [EMNLP, 2020] MedDialog: Meddialog:两个大规模医学对话数据集。论文 代码
- [NAACL, 2018] Literature: 在Semantic Scholar中构建文献图谱。论文
- [Scientific Data, 2016] MIMIC-III: MIMIC-III,一个可自由访问的重症监护数据库。论文
微调数据
- MedBook-18-CoT: 小型语言模型从医学教科书中学习增强的推理能力 论文 Huggingface
- MMedC: 构建多语言医学语言模型。[论文] [代码] [Huggingface]
- MedTrinity-25M: 医学领域的大规模多模态数据集,包含多粒度标注。2024年。github 论文
- cMeKG: 中文医学知识图谱。2023年。github
- CMD.: 中文医学对话数据。2023年。仓库
- BianQueCorpus: BianQue:通过ChatGPT润色的多轮健康对话,平衡健康LLM的提问与建议能力。2023年。论文
- MD-EHR: ClinicalGPT:基于多样化的医疗数据进行微调并进行全面评估的大语言模型。2023年。论文
- VariousMedQA: 用于中文医学问答选择的多尺度注意力交互网络。2018年。论文
- VariousMedQA: 这位患者患有何种疾病?来自医学考试的大规模开放域问答数据集。2021年。论文
- MedDialog: Meddialog:两个大规模医学对话数据集。2020年。论文
- ChiMed: Qilin-Med:多阶段知识注入的先进医学大语言模型。2023年。论文
- ChiMed-VL: Qilin-Med-VL:面向通用医疗领域的中文大型视觉-语言模型。2023年。论文
- Healthcare Magic: Healthcare Magic。链接,Huggingface
- ICliniq: ICliniq。平台
- Hybrid SFT: HuatuoGPT,旨在驯服语言模型成为医生。2023年。论文
- PMC-15M: 面向生物医学视觉-语言处理的大规模领域特定预训练。2023年。论文
- MedQuAD: 基于问题蕴涵的问答方法。2019年。论文
- VariousMedQA: Visual med-alpaca:具有视觉能力的参数高效生物医学LLM。2023年。仓库
- CMtMedQA: Zhongjing:通过专家反馈和真实世界多轮对话提升大语言模型的中文医学能力。2023年。论文
- MTB: Med-flamingo:一种多模态医学少样本学习模型。2023年。论文
- PMC-OA: Pmc-clip:利用生物医学文献进行对比语言-图像预训练。2023年。论文
- Medical Meadow: MedAlpaca——一个开源的医学对话AI模型及训练数据集合。2023年。论文
- Literature: S2ORC:语义学者开放研究语料库。2019年。论文
- MedC-I: Pmc-llama:在医学论文上进一步微调llama模型。2023年。论文
- ShareGPT: Sharegpt。2023年。平台
- PubMed: 美国国立卫生研究院。PubMed数据。位于美国国家医学图书馆。2022年。数据库
- MedQA: 这位患者患有何种疾病?来自医学考试的大规模开放域问答数据集。2021年。论文
- MultiMedQA: 利用大语言模型实现专家级医学问答。2023年。论文
- MultiMedBench: 朝着通用生物医学AI方向发展。2023年。论文
- MedInstruct-52: 针对医疗应用的指令微调大语言模型。2023年。论文
- eICU-CRD: eicu合作研究数据库,一个免费提供的多中心重症监护研究数据库。2018年。论文
- MIMIC-IV: MIMIC-IV,一个可自由访问的电子健康记录数据集。2023年。论文 数据库
- PMC-Patients: 16.7万份公开的患者摘要。2023年。论文 数据库
🗂️ 下游生物医学任务
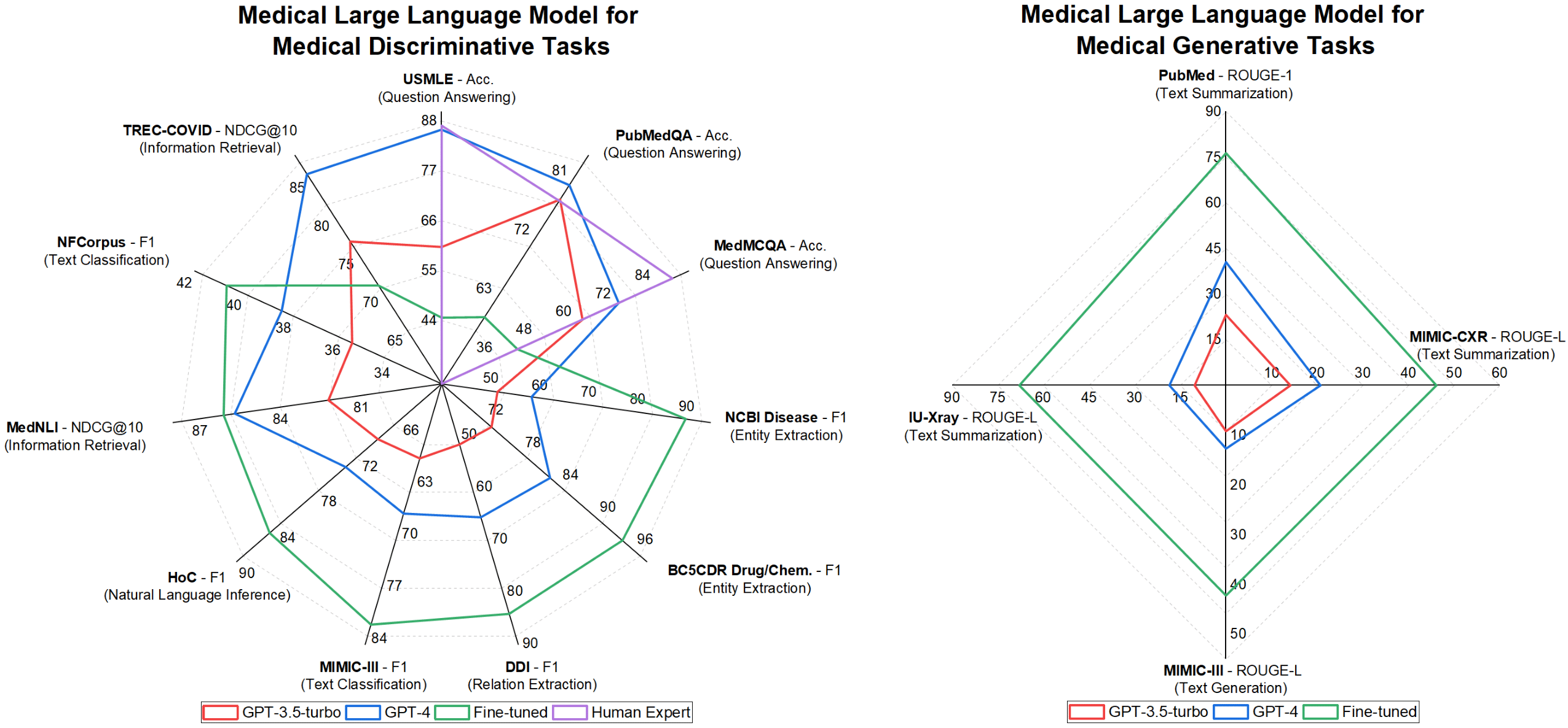
Huggingface排行榜
- 开放医学-LLM排行榜: MedQA (USMLE)、PubMedQA、MedMCQA以及与医学和生物学相关的MMLU子集。排行榜
- ReXrank: 一个用于AI驱动放射科报告生成的公开排行榜 论文 [[论文]] [[代码]] (https://github.com/rajpurkarlab/ReXrank)
生成任务
文本摘要
- PubMed: 美国国立卫生研究院。PubMed 数据。载于美国国家医学图书馆。数据库
- PMC: 美国国立卫生研究院。PubMed Central 数据。载于美国国家医学图书馆。数据库
- CORD-19: Cord-19:2020 年新冠肺炎开放研究数据集。论文
- MentSum: Mentsum:用于探索心理健康在线帖子摘要的资源,2022 年。论文
- MeQSum: 关于消费者健康问题的摘要,2019 年。论文
- MedQSum: 提升大型语言模型在医疗问答中的实用性:一种患者健康问题摘要方法。[论文] [代码]
文本简化
问答任务
- CareQA: CareQA:基于西班牙专科医疗培训准入考试(FSE)的多选题问答数据集。论文 数据集
- BioASQ-QA: BioASQ-QA:2023 年手动整理的生物医学问答语料库。论文
- emrQA: emrqa:2018 年用于电子病历问答的大规模语料库。论文
- CliCR: CliCR:2018 年用于机器阅读理解的临床病例报告数据集。论文
- PubMedQA: Pubmedqa:2019 年用于生物医学研究问答的数据集。论文
- COVID-QA: COVID-QA:2020 年针对新冠肺炎的问答数据集。论文
- MASH-QA: 具有长跨度多答案的问答任务,2020 年。论文
- Health-QA: 2019 年用于医疗问答的层次化注意力检索模型。论文
- MedQA: 这位患者患有何种疾病?2021 年来自医学考试的大规模开放域问答数据集。论文
- MedMCQA: Medmcqa:2022 年用于医学领域问答的大规模多学科多项选择数据集。论文
- MMLU(临床知识): 测量大规模多任务语言理解能力,2020 年。论文
- MMLU(大学医学): 测量大规模多任务语言理解能力,2020 年。论文
- MMLU(专业医学): 测量大规模多任务语言理解能力,2020 年。论文
- 【ArXiv 2024】MediQ:用于自适应且可靠的临床推理的问答型大语言模型。[论文] [代码]
- EWS_v5_USONLY_final: 紧急战地外科问答数据集(v5),2025 年。数据
区分性任务
实体抽取
- [Arxiv, 2024.10] 命名临床实体识别基准 论文 排行榜
- NCBI疾病:NCBI疾病语料库——用于疾病名称识别和概念归一化的资源,2014年。论文
- JNLPBA:2004年JNLPBA生物实体识别任务介绍。论文
- GENIA:GENIA语料库——用于生物文本挖掘的语义标注语料库,2003年。论文
- BC5CDR:BioCreative V CDR任务语料库——用于化学疾病关系抽取的资源,2016年。论文
- BC4CHEMD:CHEMDNER化学与药物语料库及其标注原则,2015年。论文
- BioRED:BioRED——丰富的生物医学关系抽取数据集,2022年。论文
- CMeEE:Cblue——中文生物医学语言理解评估基准,2021年。论文
- NLM-Chem-BC7:NLM-Chem-BC7——用于生物医学文章中化学实体标注与索引的手动标注全文资源,2022年。论文
- ADE:开发用于支持从医疗病例报告中自动提取药物相关不良反应的基准语料库,2012年。论文
- 2012 i2b2:评估临床文本中的时间关系:2012年i2b2挑战赛,2013年。论文
- 2014 i2b2/UTHealth(赛道1):为去标识化而标注纵向临床叙述:2014年i2b2/UTHealth语料库,2015年。论文
- 2018 n2c2(赛道2):2018年n2c2电子健康记录中不良药物事件与用药信息抽取共享任务,2020年。论文
- Cadec:Cadec——不良药物事件标注语料库,2015年。论文
- DDI:Semeval-2013任务9:从生物医学文本中抽取药物-药物相互作用(ddiextraction 2013),2013年。论文
- PGR:人类表型-基因关系银标准语料库,2019年。论文
- EU-ADR:EU-ADR语料库——标注了药物、疾病、靶点及其相互关系,2012年。论文
- [BioCreative VII挑战赛,2021年] 使用Transformer网络和多任务学习在推文中检测药物。[论文] [代码]
关系抽取
- BC5CDR:BioCreative V CDR任务语料库——用于化学疾病关系抽取的资源,2016年。论文
- BioRED:BioRED——丰富的生物医学关系抽取数据集,2022年。论文
- ADE:开发用于支持从医疗病例报告中自动提取药物相关不良反应的基准语料库,2012年。论文
- 2018 n2c2(赛道2):2018年n2c2电子健康记录中不良药物事件与用药信息抽取共享任务,2020年。论文
- 2010 i2b2/VA:2010年i2b2/VA临床文本中的概念、断言和关系挑战赛,2011年。论文
- ChemProt:2017年BioCreative VI化学-蛋白质相互作用赛道概述。数据库
- GDA:Renet——一种基于深度学习从文献中提取基因-疾病关联的方法,2019年。论文
- DDI:Semeval-2013任务9:从生物医学文本中抽取药物-药物相互作用(ddiextraction 2013),2013年。论文
- GAD:遗传关联数据库,2004年。论文
- 2012 i2b2:评估临床文本中的时间关系:2012年i2b2挑战赛,2013年。论文
- PGR:人类表型-基因关系银标准语料库,2019年。论文
- EU-ADR:EU-ADR语料库——标注了药物、疾病、靶点及其相互关系,2012年。论文
文本分类
- OpiateID: 识别社区社交媒体帖子中关于药物使用、滥用和成瘾的自我披露。论文 代码
- ADE: 开发用于支持从医学病例报告中自动提取药物相关不良反应的基准语料库,2012年。论文
- 2014 i2b2/UTHealth (Track 2): 为去标识化标注纵向临床叙述:2014年i2b2/UTHealth语料库,2015年。论文
- HoC: 根据癌症标志物对科学文献进行自动语义分类,2016年。论文
- OHSUMED: OHSUMED:交互式检索评估及用于研究的新大型测试集,1994年。论文
- WNUT-2020 Task 2: WNUT-2020任务2:识别具有信息量的COVID-19英文推文,2020年。论文
- Medical Abstracts: 评估无监督文本分类:零样本和基于相似度的方法,2022年。论文
- MIMIC-III: MIMIC-III,一个可自由访问的重症监护数据库,2016年。论文
自然语言推理
语义文本相似度
- MedSTS: MedSTS:用于临床语义文本相似度的资源,2020年。论文
- 2019 n2c2/OHNLP: 2019年n2c2/ohnlp临床语义文本相似度赛道:概述,2020年。论文
- BIOSSES: BIOSSES:用于生物医学领域的语义句子相似度估计系统,2017年。论文
信息检索
- TREC-COVID: TREC-COVID:构建大流行信息检索测试集,2021年。论文
- NFCorpus: 用于医学信息检索的全文学习排序数据集,2016年。论文
- BioASQ (BEIR): 用于信息检索模型零样本评估的异构基准,2021年。论文
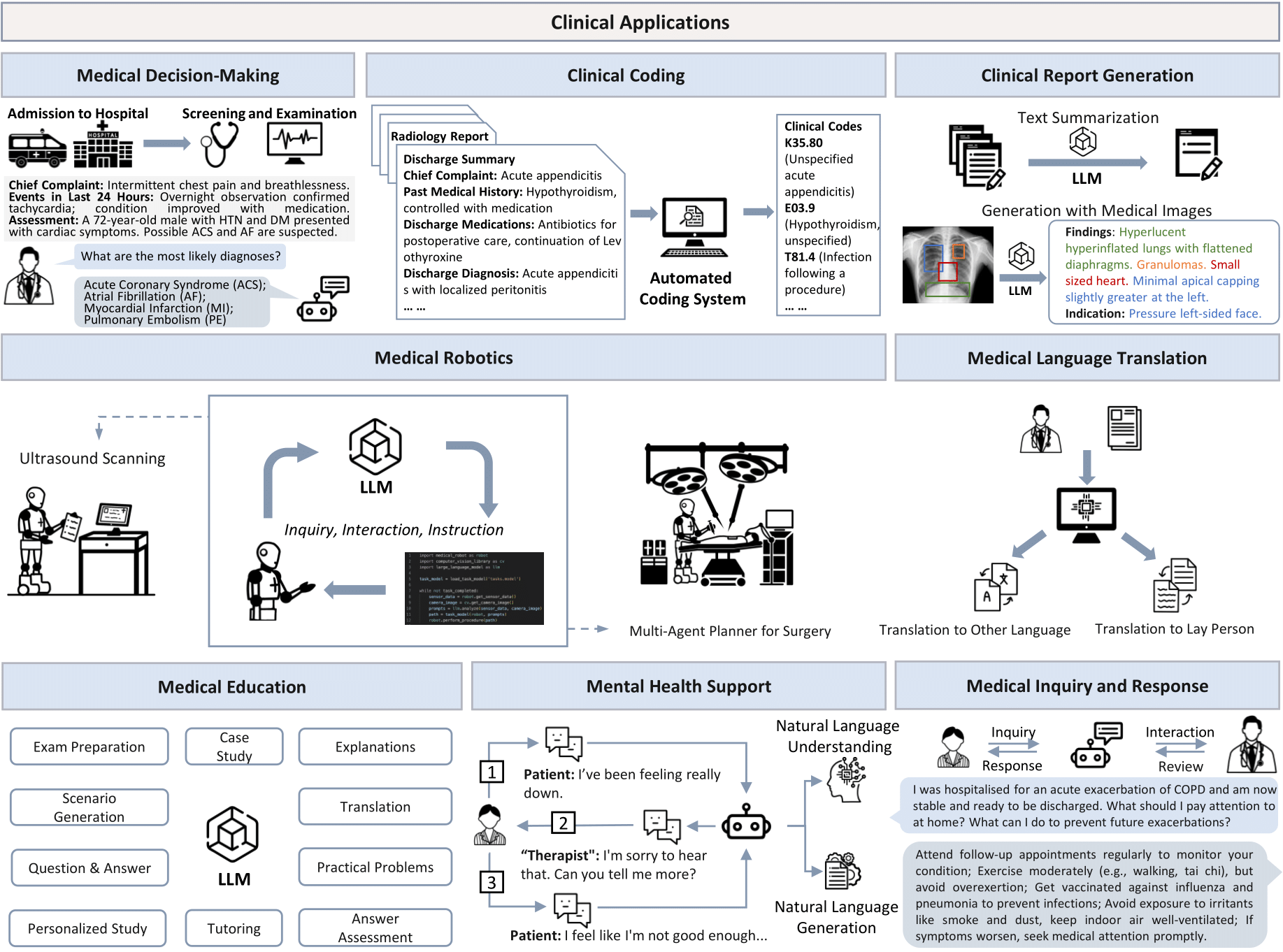
✨ 临床应用实用指南
检索增强生成
- [Arxiv, 2024] 医学图RAG:通过图检索增强生成实现安全的医学大型语言模型。论文
- [NEJM AI, 2024] GPT-4用于医学肿瘤学指南的信息检索与比较。论文
- [Arxiv, 2023] 思考与检索:一种基于假设知识图谱增强的医学大型语言模型。论文
- [JASN, 2023] 检索、总结与验证:ChatGPT将如何影响从医学文献中获取信息?论文
医学决策
- [NAACL Findings, 2024] 识别社区社交媒体帖子中关于药物使用、滥用和成瘾的自我披露。论文 代码
- [Nature, 2023] NYUTron 健康系统规模的语言模型是通用预测引擎 论文
- [Arxiv, 2023] 将医学知识图谱融入大型语言模型以进行诊断预测。论文
- [Arxiv, 2023] ChatCAD+/Chatcad:利用大型语言模型在医学影像上进行交互式计算机辅助诊断。论文 代码
- [Cancer Inform, 2023] 设计一种基于深度学习的资源高效转移性乳腺癌诊断系统:减少临床诊断的长期延误并提高发展中国家患者的生存率。论文
- [Nature Medicine, 2023] 大型语言模型在医学中的应用。论文
- [Nature Medicine, 2022] 人工智能在健康与医学中的应用。论文
临床编码
- [NEJM AI, 2024] 大型语言模型是糟糕的医疗编码员——医疗编码查询的基准测试。论文
- [JMAI, 2023] 将大型语言模型人工智能应用于视网膜国际疾病分类(ICD)编码。论文
- [ClinicalNLP Workshop, 2022] PLM-ICD:使用预训练语言模型进行自动ICD编码。论文 代码
临床报告生成
- [《自然医学》,2024年] 经过适配的大型语言模型在临床文本摘要生成方面可超越医学专家。论文
- [Arxiv,2023年] GPT-4V(视觉)能否服务于医疗应用?GPT-4V在多模态医学诊断中的案例研究。论文
- [Arxiv,2023年] Qilin-Med-VL:面向通用医疗保健的中文大型视觉—语言模型。论文
- [Arxiv,2023年] 针对医学报告生成定制通用基础模型。论文
- [Arxiv,2023年] 向放射学领域的通用基础模型迈进。论文 代码
- [Arxiv,2023年] 临床文本摘要生成:适配大型语言模型的表现可超越人类专家。2023年。论文 项目 代码
- [Arxiv,2023年] MAIRA-1:用于放射学报告生成的专业化大型多模态模型。论文 项目
- [Arxiv,2023年] 放射学报告生成中临床医生与专业基础模型之间的共识、分歧与协同作用。论文
- [《柳叶刀·数字健康》,2023年] 使用ChatGPT撰写患者门诊信件。论文
- [《柳叶刀·数字健康》,2023年] ChatGPT:出院小结的未来吗?论文
- [Arxiv,2023年2月5日] ChatCAD/ChatCAD+:利用大型语言模型进行医学影像的交互式计算机辅助诊断。论文 代码
医学教育
- [JMIR,2023年] 大型语言模型在医学教育中的机遇、挑战与未来方向。论文
- [JMIR,2023年] 生成式语言模型在医学教育中的兴起。论文
- [韩国医学教育杂志,2023年] 大型语言模型对医学教育的潜在影响。论文
- [Healthcare,2023年] 利用生成式AI和大型语言模型:医疗整合的全面路线图。论文
医疗机器人
- [ICARM,2023年] 用于机器人手术中器械分割的嵌套U型结构。论文
- [Appl. Sci.,2023年] 智慧医院中随机环境下的带时间窗多趟次自主移动机器人调度问题。论文
- [Arxiv,2023年] GRID:基于场景图的指令驱动型机器人任务规划。论文
- [I3CE,2023年] 对建筑领域人工智能协作机器人的信任:一项定性实证分析。论文
- [STAR,2016年] 用于医疗康复的先进机器人技术。论文
医学语言翻译
心理健康支持
- [Arxiv,2024年] 大型语言模型在心理健康护理中的应用:范围界定综述。论文
- [Arxiv,2023年] PsyChat:以客户为中心的心理健康支持对话系统。论文 代码
- [Arxiv,2023年] 数字心理健康领域中大型语言模型的益处与危害。论文
- [CIKM,2023年] ChatCounselor:用于心理健康支持的大型语言模型。论文 代码
- [HCII,2023年] 告诉我,你最害怕什么?探讨人机聊天互动中主体表征对信息披露的影响。论文
- [IJSR,2023年] 由人形社交机器人提供的简短幸福感训练课程:一项试点随机对照试验。论文
- [CHB,2015年] 与人工智能的真实对话:人与人在线交流及人与聊天机器人交流的比较。论文
⚔️ 面临挑战的实用指南
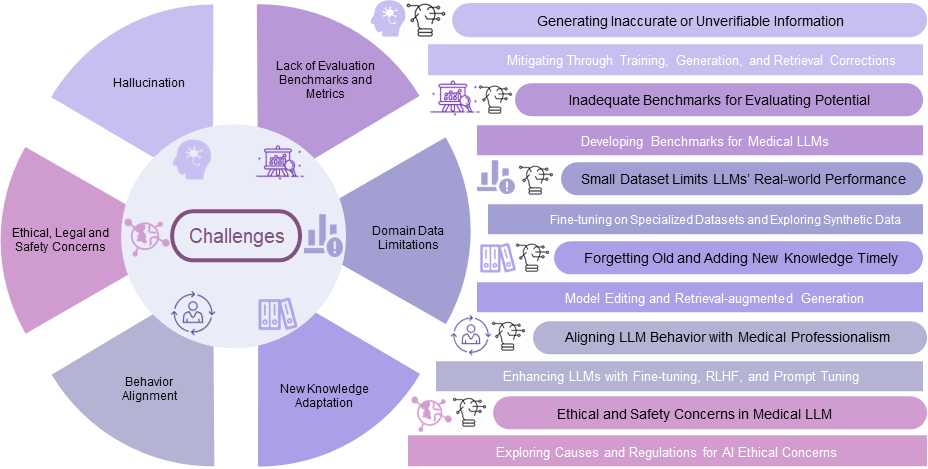
幻觉问题
- [Arxiv,2025年] 基础模型中的医学幻觉及其对医疗保健的影响。论文 代码
- [Arxiv,2024年] 验证链可减少大型语言模型中的幻觉。论文
- [ACM计算综述,2023年] 自然语言生成中的幻觉问题综述。论文
- [EMNLP,2023年] Med-halt:针对大型语言模型的医学领域幻觉测试。论文
- [Arxiv,2023年] 大型基础模型中的幻觉问题综述。2023年。论文 代码
- [EMNLP,2023年] Selfcheckgpt:面向生成式大型语言模型的零资源黑盒幻觉检测工具。2023年。论文
- [EMNLP Findings,2021年] 检索增强可减少对话中的幻觉。2021年。论文
评估基准与指标的缺乏
- [Arxiv, 2025.06] LLMEval-Med:经医生验证的医疗大语言模型真实临床基准 论文 代码
- [Arxiv, 2025.05] HealthBench:面向改善人类健康的大型语言模型评估 论文 代码
- [博客, 2024.11] SymptomCheck 基准。博客 代码
- [EMNLP, 2024] 放射科报告生成的评价指标。论文
- [Arxiv, 2024] GMAI-MMBench:迈向通用医疗人工智能的综合性多模态评估基准。论文
- [Arxiv, 2024] 临床中的大型语言模型:一个全面的基准测试。论文 代码
- [Nature Reviews Bioengineering, 2023] 医疗领域大型语言模型的基准测试。论文
- [Bioinformatics, 2023] 关于使用 ChatGPT 进行生物医学文本生成和挖掘的大规模基准研究。论文
- [Arxiv, 2023] 大型语言模型在生物医学自然语言处理中的应用:基准、基线及建议。论文
- [ACL, 2023] HaluEval:大型语言模型幻觉的大规模评估基准。论文 代码
- [ACL, 2022] TruthfulQA:衡量模型如何模仿人类错误信息。论文
- [Appl. Sci, 2021] 这位患者患有何种疾病?来自医学考试的大规模开放域问答数据集。论文
领域数据局限性
新知识适应
- [ACL Findings, 2023] 检测大型语言模型中的编辑失败:一种改进的特异性基准。论文
- [EMNLP, 2023] 编辑大型语言模型:问题、方法与机遇。论文
- [NeurIPS, 2020] 面向知识密集型 NLP 任务的检索增强生成。论文
行为对齐
- [JMIR Medical Education, 2023] 区分 ChatGPT 生成与人类撰写的医学文本。论文
- [Arxiv, 2023] 语言即奖励:利用人类反馈进行事后微调。论文 代码
- [Arxiv, 2022] 使用人类反馈强化学习训练有益且无害的助手。论文 代码
- [Arxiv, 2022] 通过有针对性的人类判断改进对话代理的对齐性。论文
- [ICLR, 2021] 将 AI 与共同的人类价值观对齐。论文 代码
- [Arxiv, 2021.12] WebGPT:借助浏览器和人类反馈进行问答。论文
伦理、法律与安全顾虑
- [Arxiv, 2023.10] 医疗保健领域大型语言模型综述:从数据、技术与应用到问责制与伦理。论文
- [Arxiv, 2023.8] “立即做任何事”:表征并评估大型语言模型上的野外越狱提示。论文 代码
- [NeurIPS, 2023.7] 越狱:LLM 安全训练为何失效?论文
- [EMNLP, 2023.4] ChatGPT 上的多步越狱隐私攻击。论文
- [Healthcare, 2023.3] ChatGPT 在医疗教育、研究和实践中的效用:关于其潜在前景与合理担忧的系统综述。论文
- [Nature News, 2023.1] ChatGPT 被列为研究论文作者:许多科学家表示反对。论文
🚀 未来发展方向实用指南
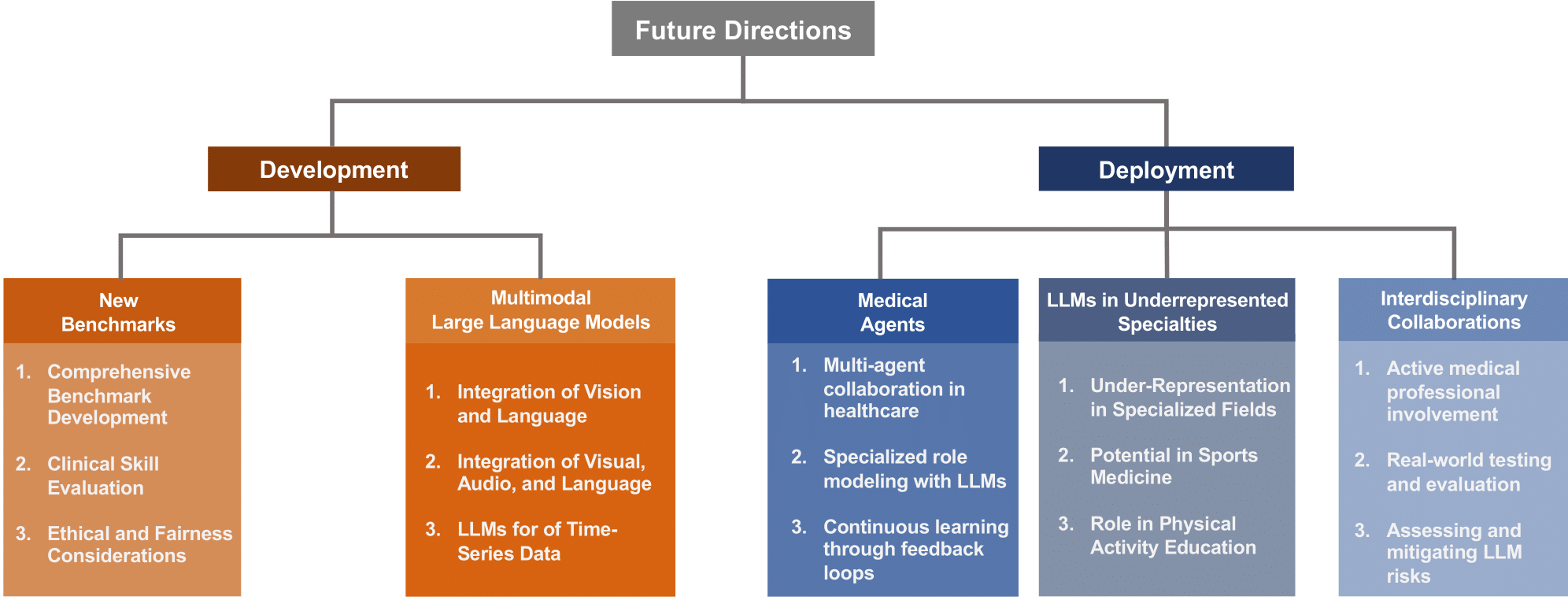
新基准的引入
- [EMNLP, 2024.11] 大型语言模型是糟糕的临床决策者:一个全面的基准测试。论文 代码
- [博客, 2024.11] SymptomCheck 基准。博客 代码
- [Nature Communications, 2024.9] MMed-Llama3:迈向构建多语言医学语言模型。[论文] [代码] [Hugging Face]
- [Arxiv, 2023.12] 为医疗保健领域的 NLP 设计指导原则:以母体健康为例。论文
- [JCO CCI, 2023] 利用自然语言处理自动提取接受放疗患者病历中食管炎的存在及其严重程度。[论文] [代码]
- [JAMA ONC, 2023] 使用人工智能聊天机器人提供癌症治疗信息。[论文] [代码]
- [BioRxiv, 2023] 关于使用 ChatGPT 进行生物医学文本生成和挖掘的全面基准研究。论文
- [JAMA, 2023] 大型语言模型在医学中的创建与应用。论文
- [Arxiv, 2023] 大型语言模型在运动科学与医学中的应用:机遇、风险与考量。论文
跨学科合作
多模态LLM
- [TPAMI, 2025] 对齐、自编码与提示工程在大型语言模型中的应用:用于新型疾病报告 论文 代码
- [npj Digital Medicine, 2025] 一种多模态、多领域、多语言的医学基础模型,用于零样本临床诊断 论文 代码
- [Nature Medicine, 2024] BiomedGPT 一个通用的视觉-语言基础模型,适用于多样化的生物医学任务 论文
- [Arxiv, 2023] VisionFM:一种多模态、多任务的视觉基础模型,用于通用眼科人工智能。论文
- [Arxiv, 2023] 多模态大型语言模型综述。论文
- [Arxiv, 2023] Mm-react:利用ChatGPT进行多模态推理与行动。论文
- [Int J Oral Sci, 2023] ChatGPT在塑造牙科未来中的作用:多模态大型语言模型的潜力。论文
- [MIDL, 2023] 冻结语言模型助力心电图零样本学习。论文
- [Arxiv, 2023] 探索与表征大型语言模型在嵌入式系统开发与调试中的应用。论文
医疗代理
- [Arxiv, 2025] 一种协同进化的代理型AI系统,用于医学影像分析 论文 代码
- [Arxiv, 2024] MedAgentBench:一个用于基准测试医疗LLM代理的真实虚拟电子健康记录环境 论文 代码
- [Arxiv, 2023] 基于大型语言模型的代理崛起与潜力:综述。论文
- [Arxiv, 2023] MedAgents:大型语言模型作为协作伙伴,用于零样本医学推理。论文 代码
- [Arxiv, 2023] GeneGPT:通过领域工具增强大型语言模型,以提升生物医学信息的可访问性。论文 代码
- [MedRxiv, 2023] OpenMedCalc:将ChatGPT与临床医生提供的工具相结合,可显著提升其在医学计算任务中的表现。论文
- [NEJM AI, 2024] Almanac——用于临床医学的检索增强型语言模型。论文
- [Arxiv, 2024] ClinicalAgent:基于大型语言模型推理的临床试验多智能体系统。论文
- [Arxiv, 2024] AgentClinic:一个用于评估模拟临床环境中AI性能的多模态代理基准测试 论文
- [Arxiv, 2024] MDAgents:一种用于医疗决策的LLM自适应协作系统。论文 代码
- [Arxiv 2024] MediQ:用于自适应且可靠的临床推理的提问型LLM。[论文] [代码]。
👍 致谢
- LLMs实用指南。我们在此基础上构建了代码库,它是一份全面的LLM综述。
- 大型AI综述。健康信息学中的大型AI模型:应用、挑战与未来。
- Nature Medicine。医学领域大型语言模型的综述。
- 医疗LLM综述。面向医疗保健领域的大型语言模型综述。
📑 引用
如果您觉得我们的仓库对您的工作有所帮助,请考虑引用我们的论文,衷心感谢!
@article{liu2025application,
title={大型语言模型在医学中的应用},
author={刘凤林、周洪建、顾博洋、邹欣宇、黄金发、吴金格、李一儒、陈Sam S.、华怡宁、周培琳、刘俊玲、毛成峰、游晨宇、吴宪、郑叶枫、克利夫顿Lei、李正、罗杰波、大卫·A·克利夫顿 },
journal={自然评论·生物工程},
year={2025}
}
@article{zhou2023survey,
title={医学领域大型语言模型的综述:进展、应用与挑战},
author={周洪建、刘凤林、顾博洋、邹欣宇、黄金发、吴金格、李一儒、陈Sam S.、周培琳、刘俊玲、华怡宁、毛成峰、吴宪、郑叶枫、克利夫顿Lei、李正、罗杰波、大卫·A·克利夫顿},
journal={arXiv预印本 arXiv:2311.05112},
year={2023}
}
♥️ 贡献者

相似工具推荐
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备