DeepSearchAgent-Demo
DeepSearchAgent-Demo 是一款从零构建的轻量级深度搜索 AI 代理,旨在通过多轮自主搜索与反思机制,生成高质量的结构化研究报告。它解决了传统搜索工具信息碎片化、缺乏深度整合以及过度依赖重型框架导致难以定制的问题。
这款工具特别适合开发者、研究人员及希望深入理解 AI Agent 内部运作原理的技术爱好者使用。其核心亮点在于“无框架”设计,不依赖 LangChain 等复杂库,代码简洁清晰,便于学习与二次开发。同时,它集成了 Tavily 搜索引擎与 DeepSeek、OpenAI 等主流大模型,采用独特的“反思循环”机制:在生成报告初稿后,系统会自动评估内容缺失并发起补充搜索,经过多轮迭代优化,确保最终输出的 Markdown 报告既全面又深入。
除了支持命令行和 Python 编程调用外,DeepSearchAgent-Demo 还提供了友好的 Streamlit Web 界面,让用户无需配置环境即可直接输入课题获取研报。无论是用于技术调研、市场分析还是学术辅助,它都能帮助用户高效完成从信息检索到深度总结的全过程。
使用场景
某科技咨询公司的分析师需要在半天内为重要客户输出一份关于"2025 年全球量子计算商业化落地路径”的深度研究报告,要求数据详实、逻辑严密且覆盖最新行业动态。
没有 DeepSearchAgent-Demo 时
- 信息搜集碎片化:分析师需手动在多个搜索引擎反复切换关键词,耗时数小时筛选低质网页,难以确保信息的全面性与时效性。
- 深度挖掘不足:面对复杂议题,人工很难自发进行多轮“搜索 - 反思 - 再搜索”的闭环,导致报告往往停留在表面现象,缺乏对技术瓶颈和产业链深层逻辑的剖析。
- 结构整合困难:将零散的搜索结果整理成逻辑连贯的大纲并撰写初稿极易出错,常出现段落间逻辑断层或关键数据遗漏,反复修改耗费大量精力。
- 过程不可追溯:研究过程依赖个人笔记,一旦中途打断或需要调整方向,之前的搜索状态和思路难以恢复,协作效率低下。
使用 DeepSearchAgent-Demo 后
- 智能全量检索:DeepSearchAgent-Demo 自动集成 Tavily 引擎,根据查询生成结构化大纲,并针对每个段落自动执行多轮高精度搜索,瞬间聚合全球最新权威信源。
- 自主反思深化:内置的反思机制让代理能像资深专家一样自我审视,主动发现初稿中的逻辑漏洞或信息缺失,自动发起补充搜索并优化总结,确保洞察深度。
- 自动化报告生成:从大纲构建到最终 Markdown 格式输出全流程自动化,直接生成结构清晰、引证规范的高质量研报草稿,分析师仅需做最后润色。
- 状态全程可控:完整的状态管理功能支持研究过程随时暂停与恢复,所有中间搜索数据和思考路径均被记录,便于团队复盘或二次迭代。
DeepSearchAgent-Demo 通过将繁琐的信息搜集与逻辑推演自动化,把分析师从低效的“搬运工”解放为高价值的“决策者”,实现了深度研究效率的质的飞跃。
运行环境要求
- 未说明
未说明
未说明
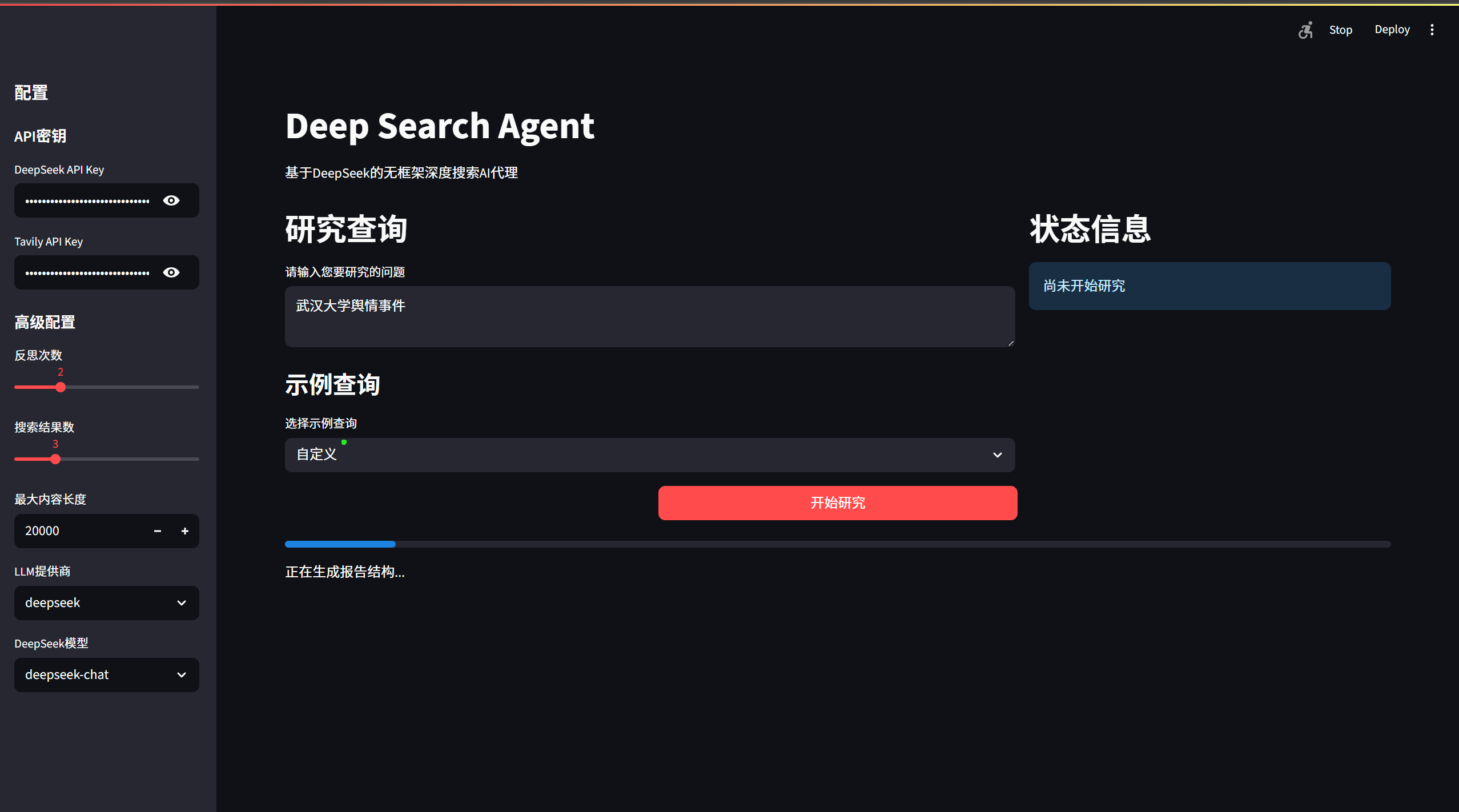
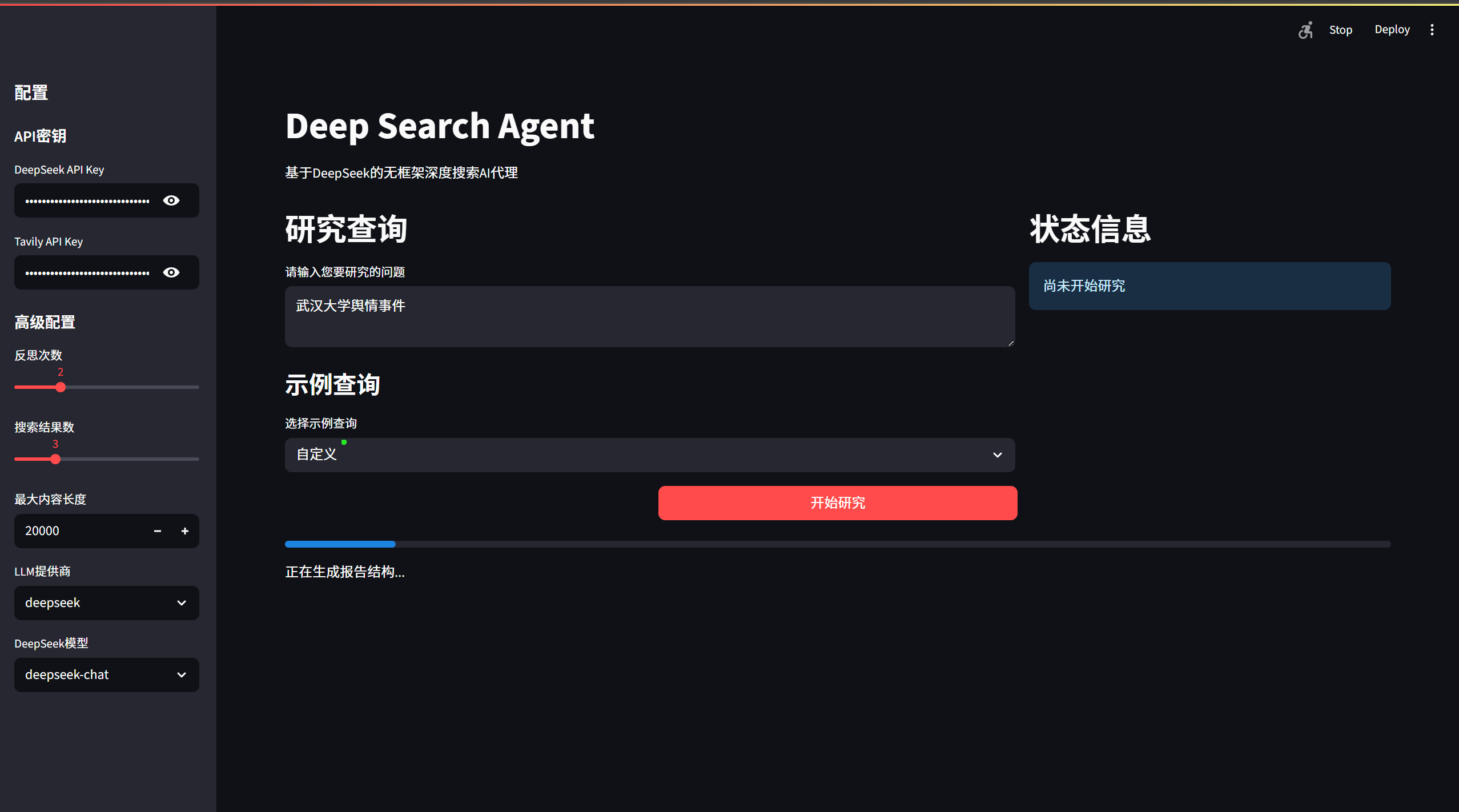
快速开始
深度搜索代理
![]()
![]()
![]()
![]()
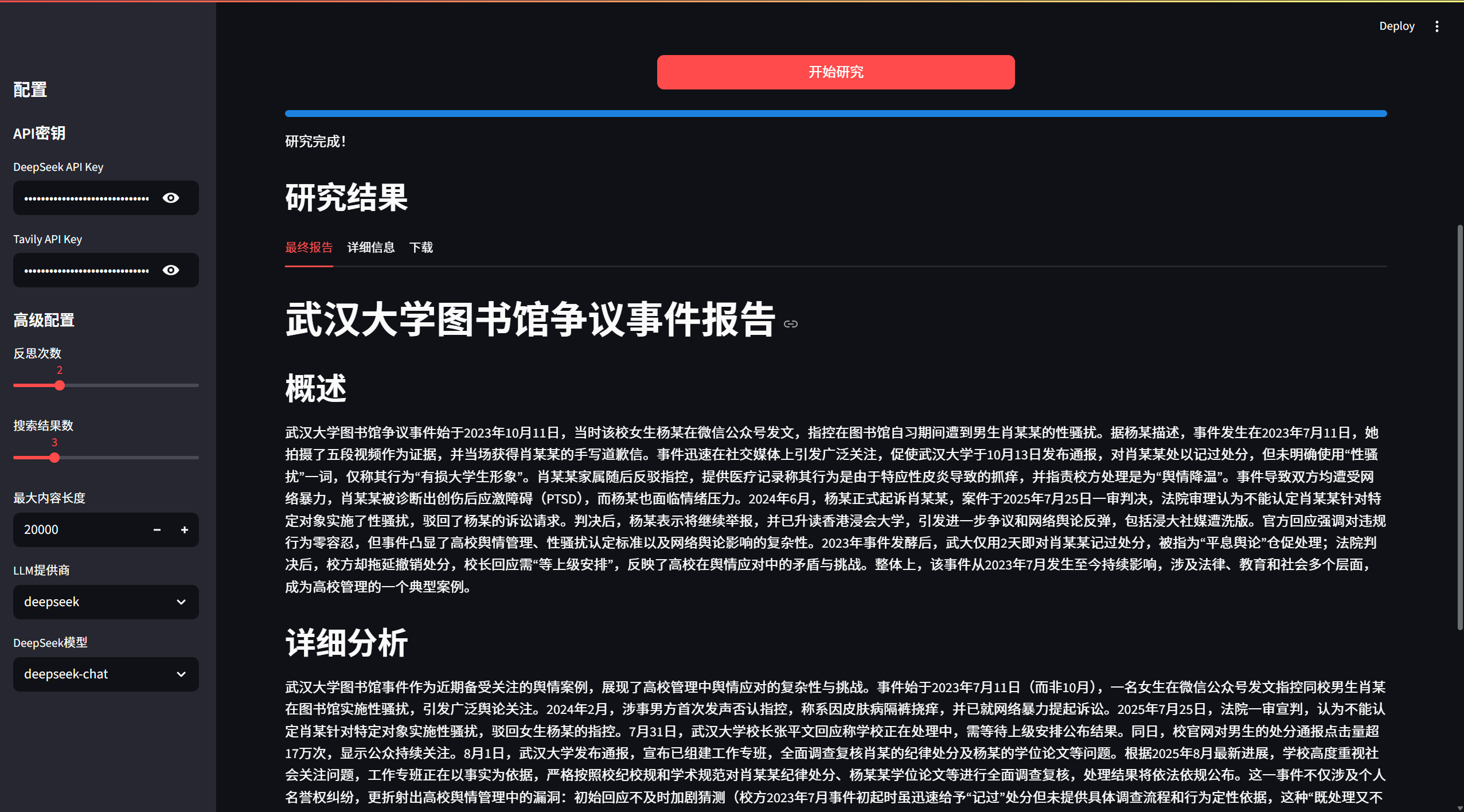
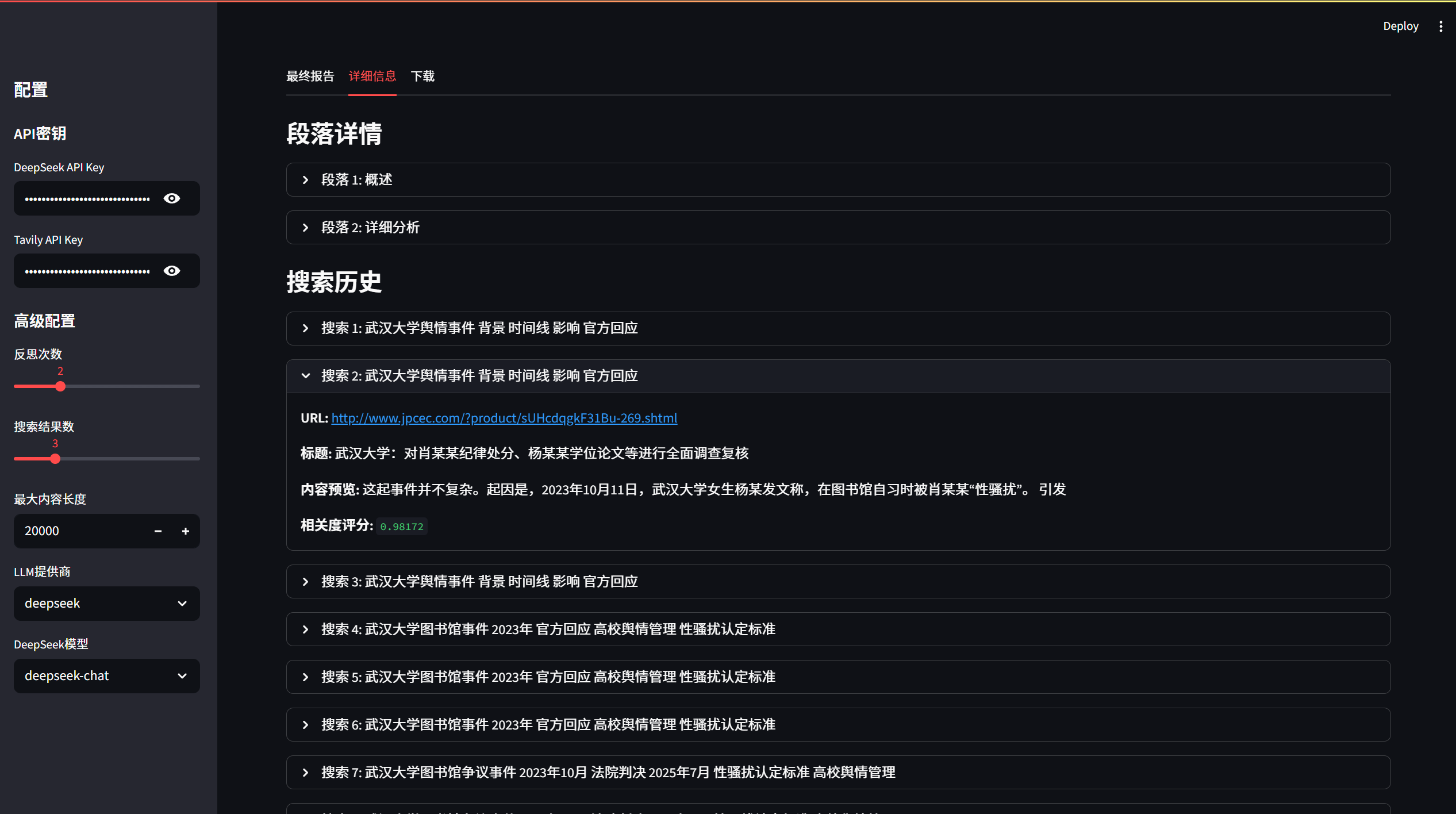
一个无框架的深度搜索AI代理实现,能够通过多轮搜索和反思生成高质量的研究报告。
特性
- 无框架设计: 从零实现,不依赖LangChain等重型框架
- 多LLM支持: 支持DeepSeek、OpenAI等主流大语言模型
- 智能搜索: 集成Tavily搜索引擎,提供高质量网络搜索
- 反思机制: 多轮反思优化,确保研究深度和完整性
- 状态管理: 完整的研究过程状态跟踪和恢复
- Web界面: Streamlit友好界面,易于使用
- Markdown输出: 美观的Markdown格式研究报告
工作原理
Deep Search Agent采用分阶段的研究方法:
graph TD
A[用户查询] --> B[生成报告结构]
B --> C[遍历每个段落]
C --> D[初始搜索]
D --> E[生成初始总结]
E --> F[反思循环]
F --> G[反思搜索]
G --> H[更新总结]
H --> I{达到反思次数?}
I -->|否| F
I -->|是| J{所有段落完成?}
J -->|否| C
J -->|是| K[格式化最终报告]
K --> L[输出报告]
核心流程
- 结构生成: 根据查询生成报告大纲和段落结构
- 初始研究: 为每个段落生成搜索查询并获取相关信息
- 初始总结: 基于搜索结果生成段落初稿
- 反思优化: 多轮反思,发现遗漏并补充搜索
- 最终整合: 将所有段落整合为完整的Markdown报告
快速开始
1. 环境准备
确保您的系统安装了Python 3.9或更高版本:
python --version
2. 克隆项目
git clone <your-repo-url>
cd Demo\ DeepSearch\ Agent
3. 安装依赖
# 激活虚拟环境(推荐)
conda activate pytorch_python11 # 或者使用其他虚拟环境
# 安装依赖
pip install -r requirements.txt
4. 配置API密钥
项目根目录下已有config.py配置文件,请直接编辑此文件设置您的API密钥:
# Deep Search Agent 配置文件
# 请在这里填入您的API密钥
# DeepSeek API Key
DEEPSEEK_API_KEY = "your_deepseek_api_key_here"
# OpenAI API Key (可选)
OPENAI_API_KEY = "your_openai_api_key_here"
# Tavily搜索API Key
TAVILY_API_KEY = "your_tavily_api_key_here"
# 配置参数
DEFAULT_LLM_PROVIDER = "deepseek"
DEEPSEEK_MODEL = "deepseek-chat"
OPENAI_MODEL = "gpt-4o-mini"
MAX_REFLECTIONS = 2
SEARCH_RESULTS_PER_QUERY = 3
SEARCH_CONTENT_MAX_LENGTH = 20000
OUTPUT_DIR = "reports"
SAVE_INTERMEDIATE_STATES = True
5. 开始使用
现在您可以开始使用Deep Search Agent了!
使用方法
方式一:运行示例脚本
基本使用示例:
python examples/basic_usage.py
这个示例展示了最简单的使用方式,执行一个预设的研究查询并显示结果。
高级使用示例:
python examples/advanced_usage.py
这个示例展示了更复杂的使用场景,包括:
- 自定义配置参数
- 执行多个研究任务
- 状态管理和恢复
- 不同模型的使用
方式二:Web界面
启动Streamlit Web界面:
streamlit run examples/streamlit_app.py
Web界面无需配置文件,直接在界面中输入API密钥即可使用。
方式三:编程方式
from src import DeepSearchAgent, load_config
# 加载配置
config = load_config()
# 创建Agent
agent = DeepSearchAgent(config)
# 执行研究
query = "2025年人工智能发展趋势"
final_report = agent.research(query, save_report=True)
print(final_report)
方式四:自定义配置(编程方式)
如果需要在代码中动态设置配置,可以使用以下方式:
from src import DeepSearchAgent, Config
# 自定义配置
config = Config(
default_llm_provider="deepseek",
deepseek_model="deepseek-chat",
max_reflections=3, # 增加反思次数
max_search_results=5, # 增加搜索结果数
output_dir="my_reports" # 自定义输出目录
)
# 设置API密钥
config.deepseek_api_key = "your_api_key"
config.tavily_api_key = "your_tavily_key"
agent = DeepSearchAgent(config)
项目结构
Demo DeepSearch Agent/
├── src/ # 核心代码
│ ├── llms/ # LLM调用模块
│ │ ├── base.py # LLM基类
│ │ ├── deepseek.py # DeepSeek实现
│ │ └── openai_llm.py # OpenAI实现
│ ├── nodes/ # 处理节点
│ │ ├── base_node.py # 节点基类
│ │ ├── report_structure_node.py # 结构生成
│ │ ├── search_node.py # 搜索节点
│ │ ├── summary_node.py # 总结节点
│ │ └── formatting_node.py # 格式化节点
│ ├── prompts/ # 提示词模块
│ │ └── prompts.py # 所有提示词定义
│ ├── state/ # 状态管理
│ │ └── state.py # 状态数据结构
│ ├── tools/ # 工具调用
│ │ └── search.py # 搜索工具
│ ├── utils/ # 工具函数
│ │ ├── config.py # 配置管理
│ │ └── text_processing.py # 文本处理
│ └── agent.py # 主Agent类
├── examples/ # 使用示例
│ ├── basic_usage.py # 基本使用示例
│ ├── advanced_usage.py # 高级使用示例
│ └── streamlit_app.py # Web界面
├── reports/ # 输出报告目录
├── requirements.txt # 依赖列表
├── config.py # 配置文件
└── README.md # 项目文档
代码结构
graph TB
subgraph "用户层"
A[用户查询]
B[Web界面]
C[命令行接口]
end
subgraph "主控制层"
D[DeepSearchAgent]
end
subgraph "处理节点层"
E[ReportStructureNode<br/>报告结构生成]
F[FirstSearchNode<br/>初始搜索]
G[FirstSummaryNode<br/>初始总结]
H[ReflectionNode<br/>反思搜索]
I[ReflectionSummaryNode<br/>反思总结]
J[ReportFormattingNode<br/>报告格式化]
end
subgraph "LLM层"
K[DeepSeekLLM]
L[OpenAILLM]
M[BaseLLM抽象类]
end
subgraph "工具层"
N[Tavily搜索]
O[文本处理工具]
P[配置管理]
end
subgraph "状态管理层"
Q[State状态对象]
R[Paragraph段落对象]
S[Research研究对象]
T[Search搜索记录]
end
subgraph "数据持久化"
U[JSON状态文件]
V[Markdown报告]
W[日志文件]
end
A --> D
B --> D
C --> D
D --> E
D --> F
D --> G
D --> H
D --> I
D --> J
E --> K
E --> L
F --> K
F --> L
G --> K
G --> L
H --> K
H --> L
I --> K
I --> L
J --> K
J --> L
K --> M
L --> M
F --> N
H --> N
D --> O
D --> P
D --> Q
Q --> R
R --> S
S --> T
Q --> U
D --> V
D --> W
style A fill:#e1f5fe
style D fill:#f3e5f5
style E fill:#fff3e0
style F fill:#fff3e0
style G fill:#fff3e0
style H fill:#fff3e0
style I fill:#fff3e0
style J fill:#fff3e0
style K fill:#e8f5e8
style L fill:#e8f5e8
style N fill:#fce4ec
style Q fill:#f1f8e9
API 参考
DeepSearchAgent
主要的Agent类,提供完整的深度搜索功能。
class DeepSearchAgent:
def __init__(self, config: Optional[Config] = None)
def research(self, query: str, save_report: bool = True) -> str
def get_progress_summary(self) -> Dict[str, Any]
def load_state(self, filepath: str)
def save_state(self, filepath: str)
配置
配置管理类,控制Agent的行为参数。
class Config:
# API密钥
deepseek_api_key: Optional[str]
openai_api_key: Optional[str]
tavily_api_key: Optional[str]
# 模型配置
default_llm_provider: str = "deepseek"
deepseek_model: str = "deepseek-chat"
openai_model: str = "gpt-4o-mini"
# 搜索配置
max_search_results: int = 3
search_timeout: int = 240
max_content_length: int = 20000
# Agent配置
max_reflections: int = 2
max_paragraphs: int = 5
示例
示例1:基本研究
from src import create_agent
# 快速创建Agent
agent = create_agent()
# 执行研究
report = agent.research("量子计算的发展现状")
print(report)
示例2:自定义研究参数
from src import DeepSearchAgent, Config
config = Config(
max_reflections=4, // 更深度的反思
max_search_results=8, // 更多搜索结果
max_paragraphs=6 // 更长的报告
)
agent = DeepSearchAgent(config)
report = agent.research("人工智能的伦理问题")
示例3:状态管理
# 开始研究
agent = DeepSearchAgent()
report = agent.research("区块链技术应用")
// 保存状态
agent.save_state("blockchain_research.json")
// 稍后恢复状态
new_agent = DeepSearchAgent()
new_agent.load_state("blockchain_research.json")
// 检查进度
progress = new_agent.get_progress_summary()
print(f"研究进度: {progress['progress_percentage']}%")
高级功能
多模型支持
// 使用DeepSeek
config = Config(default_llm_provider="deepseek")
// 使用OpenAI
config = Config(default_llm_provider="openai", openai_model="gpt-4o")
自定义输出
config = Config(
output_dir="custom_reports", // 自定义输出目录
save_intermediate_states=True // 保存中间状态
)
常见问题
Q: 支持哪些LLM?
A: 目前支持:
- DeepSeek: 推荐使用,性价比高
- OpenAI: GPT-4o、GPT-4o-mini等
- 可以通过继承
BaseLLM类轻松添加其他模型
Q: 如何获取API密钥?
A:
- DeepSeek: 访问 DeepSeek平台 注册获取
- Tavily: 访问 Tavily 注册获取(每月1000次免费)
- OpenAI: 访问 OpenAI平台 获取
获取密钥后,直接编辑项目根目录的config.py文件填入即可。
Q: 研究报告质量如何提升?
A: 可以通过以下方式优化:
- 增加
max_reflections参数(更多反思轮次) - 增加
max_search_results参数(更多搜索结果) - 调整
max_content_length参数(更长的搜索内容) - 使用更强大的LLM模型
Q: 如何自定义提示词?
A: 修改src/prompts/prompts.py文件中的系统提示词,可以根据需要调整Agent的行为。
Q: 支持其他搜索引擎吗?
A: 当前主要支持Tavily,但可以通过修改src/tools/search.py添加其他搜索引擎支持。
贡献
欢迎贡献代码!请遵循以下步骤:
- Fork本项目
- 创建特性分支 (
git checkout -b feature/AmazingFeature) - 提交更改 (
git commit -m 'Add some AmazingFeature') - 推送到分支 (
git push origin feature/AmazingFeature) - 开启Pull Request
许可证
本项目采用MIT许可证 - 查看 LICENSE 文件了解详情。
致谢
如果这个项目对您有帮助,请给个Star!
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备