openchatbi
OpenChatBI 是一款基于大语言模型的开源智能对话式 BI 工具,旨在通过自然语言对话帮助用户轻松查询、分析和可视化数据。它消除了传统数据分析中编写 SQL 代码的门槛,让业务人员也能直接获取数据洞察,同时为开发者提供了灵活可扩展的分析框架。
OpenChatBI 特别适合数据分析师、后端开发人员以及对数据应用感兴趣的研究者。它基于 LangGraph 和 LangChain 生态构建,核心亮点包括将自然语言自动转换为 SQL 语句、生成直观的图表、执行 Python 代码进行深度分析,甚至支持时间序列预测。此外,OpenChatBI 还具备强大的知识库管理和持久化记忆能力,能结合外部知识回答复杂问题,并支持 MCP 工具集成。无论是搭建内部数据平台还是探索 AI 数据分析,OpenChatBI 都提供了一个开箱即用的强大起点。
使用场景
某电商公司运营经理需要在早会前快速复盘昨日各区域的销售表现及用户活跃度,以往高度依赖数据分析师协助取数。
没有 openchatbi 时
- 每次提取销售明细都需要向数据团队提交工单,响应周期通常超过 4 小时,延误决策时机。
- 业务人员不懂 SQL 语法,面对复杂的表结构关联往往无从下手,只能等待技术人员处理。
- 获取原始数据后需手动导入 Excel 制作图表,耗时且容易在复制粘贴过程中出现数据错误。
- 缺乏上下文记忆,无法基于上一轮分析结果进行连续的深度追问,分析过程碎片化。
使用 openchatbi 后
- 直接在界面输入“展示昨日华东区 Top10 商品销量”,openchatbi 自动完成 Text2SQL 转换并执行查询。
- openchatbi 根据数据特征自动调用 Plotly 生成可视化报表,直观呈现趋势变化,无需手动绘图。
- 利用 openchatbi 内置数据目录管理功能,自动识别业务术语与数据库字段的映射关系,降低理解门槛。
- 基于 openchatbi 的持久化记忆支持多轮对话,可随时追问“剔除促销因素后的真实增长率”进行归因分析。
openchatbi 通过自然语言交互打通了业务需求与底层数据之间的壁垒,让非技术人员也能独立高效地完成复杂的数据分析任务。
运行环境要求
- Linux
- macOS
未说明
未说明
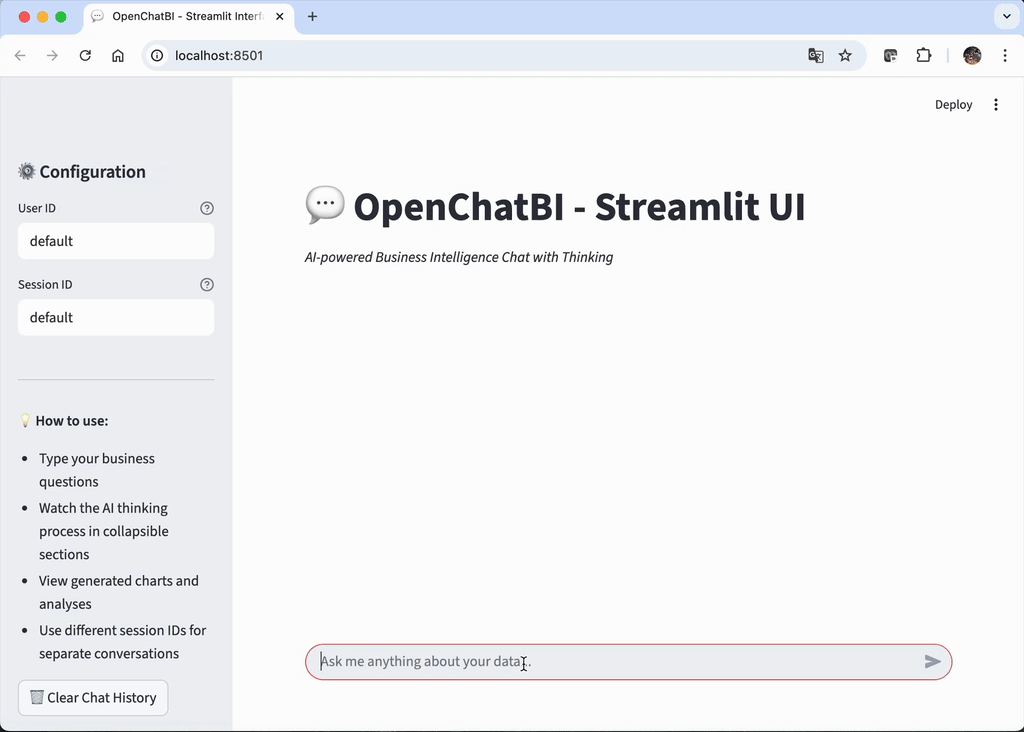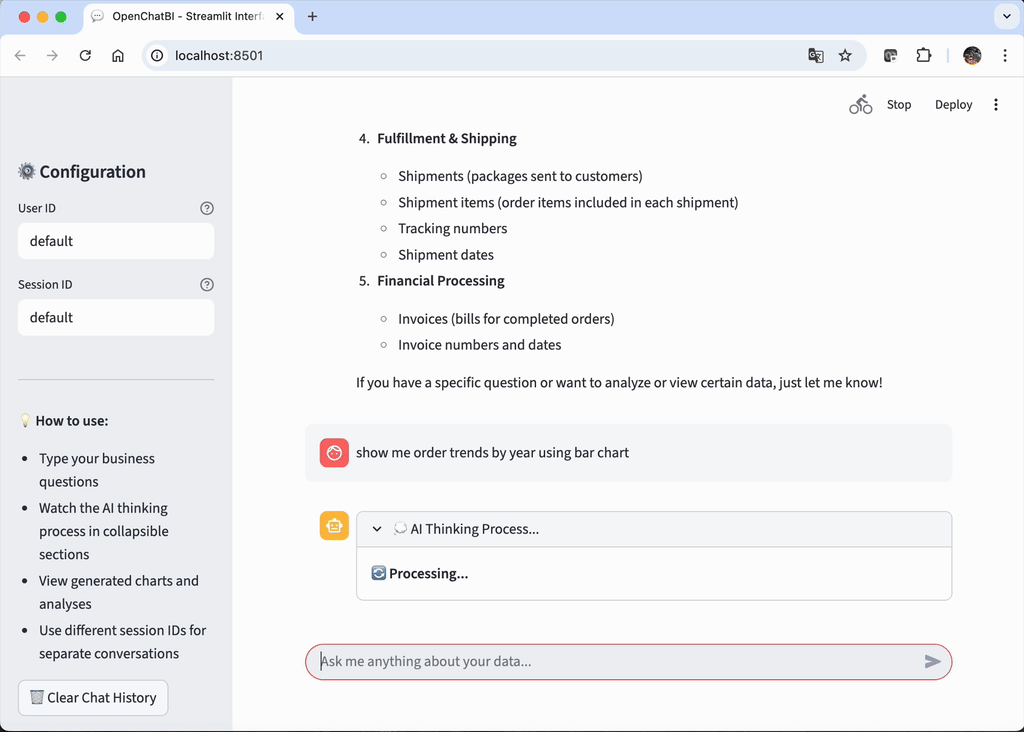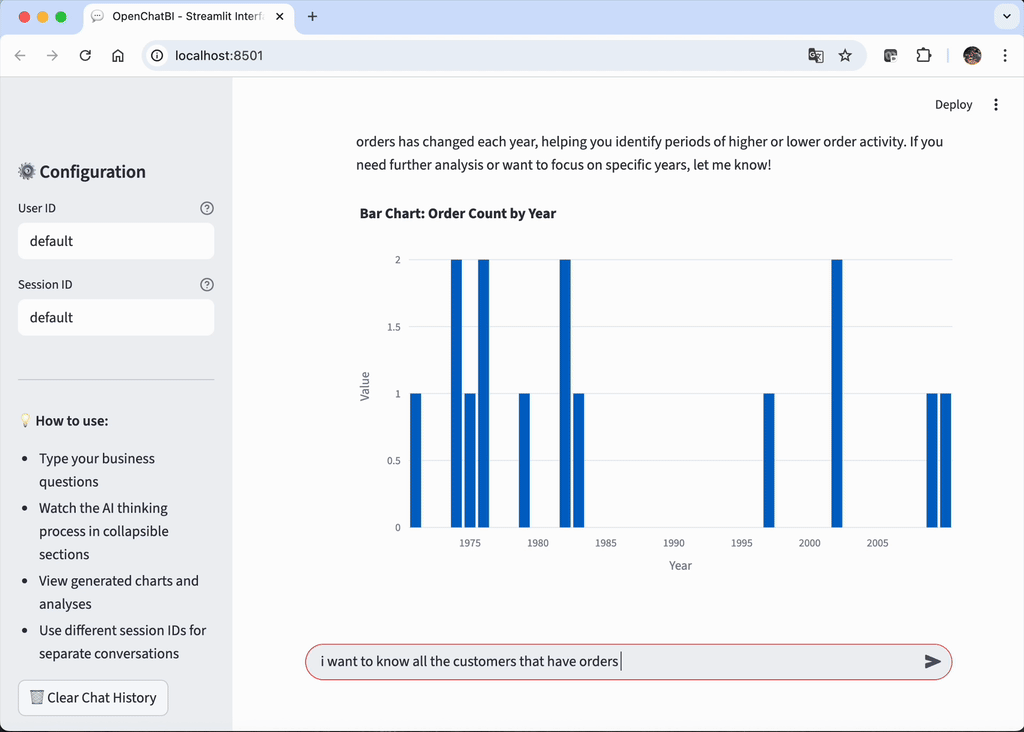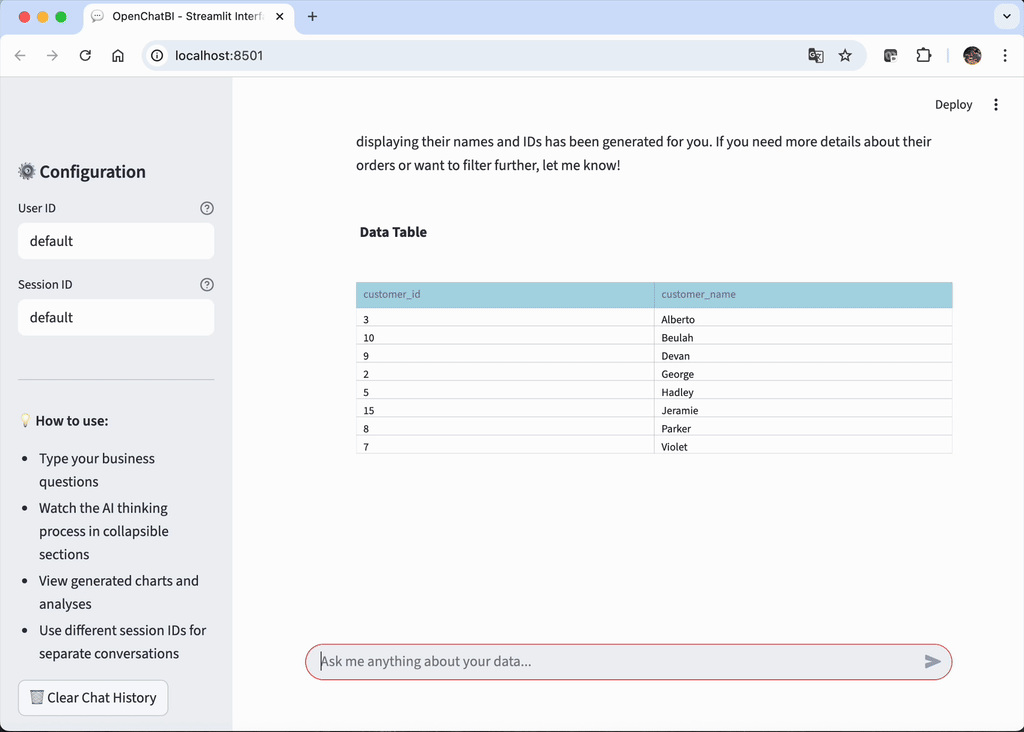
快速开始
OpenChatBI
OpenChatBI 是一个开源的、基于聊天的智能商业智能(BI)工具,由大语言模型(LLM)驱动,旨在帮助用户通过自然语言对话来查询、分析和可视化数据。它构建在 LangGraph 和 LangChain 生态系统之上,提供聊天代理和工作流,支持自然语言到 SQL 的转换以及简化的数据分析。
加入 Slack 频道进行讨论:https://join.slack.com/t/openchatbicommunity/shared_invite/zt-3jpzpx9mv-Sk88RxpO4Up0L~YTZYf4GQ
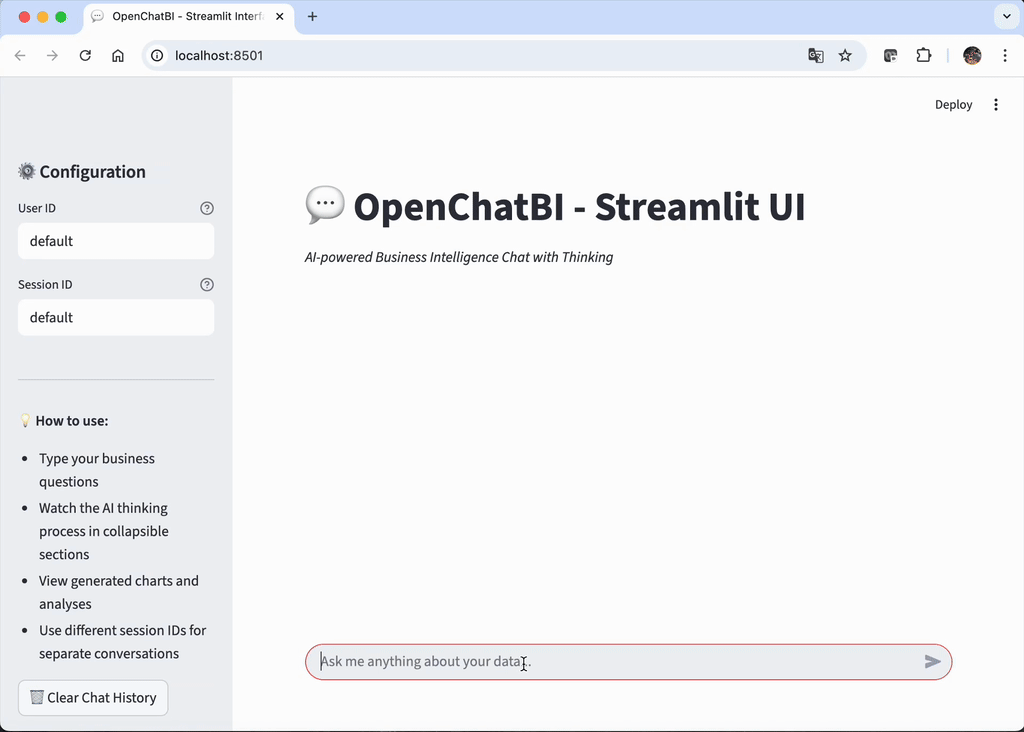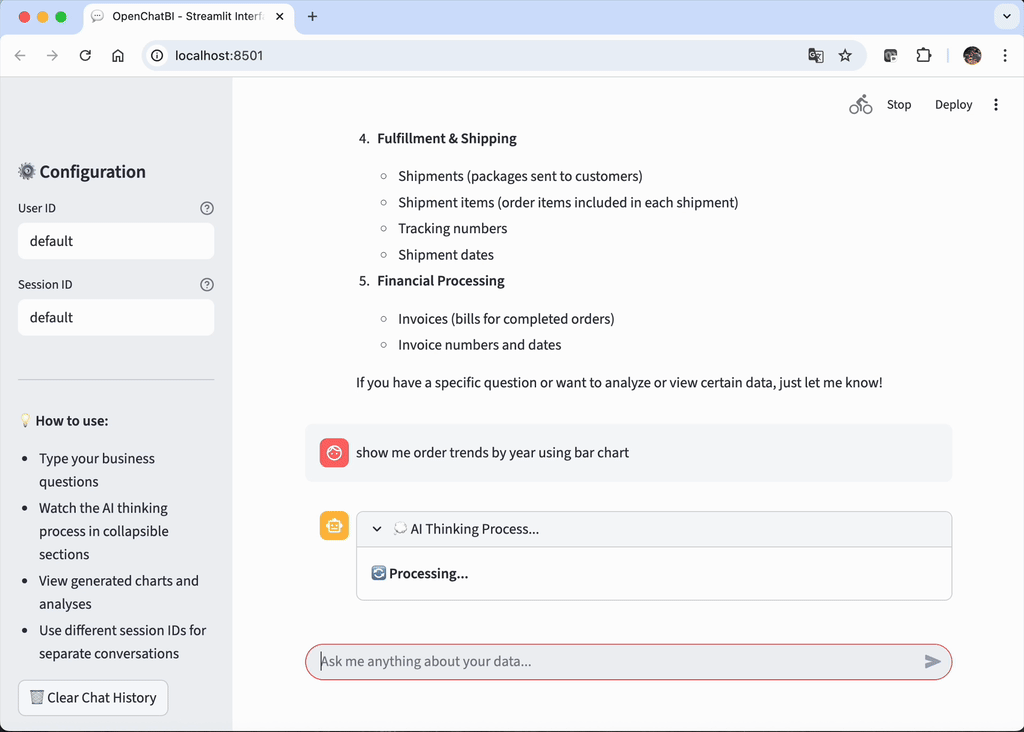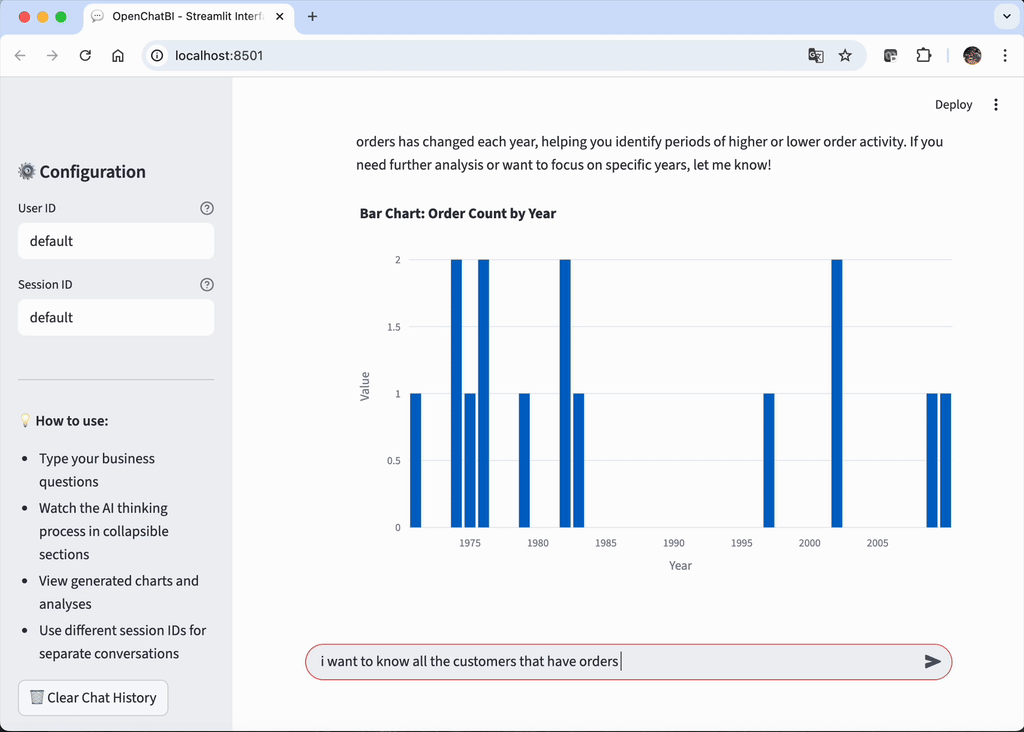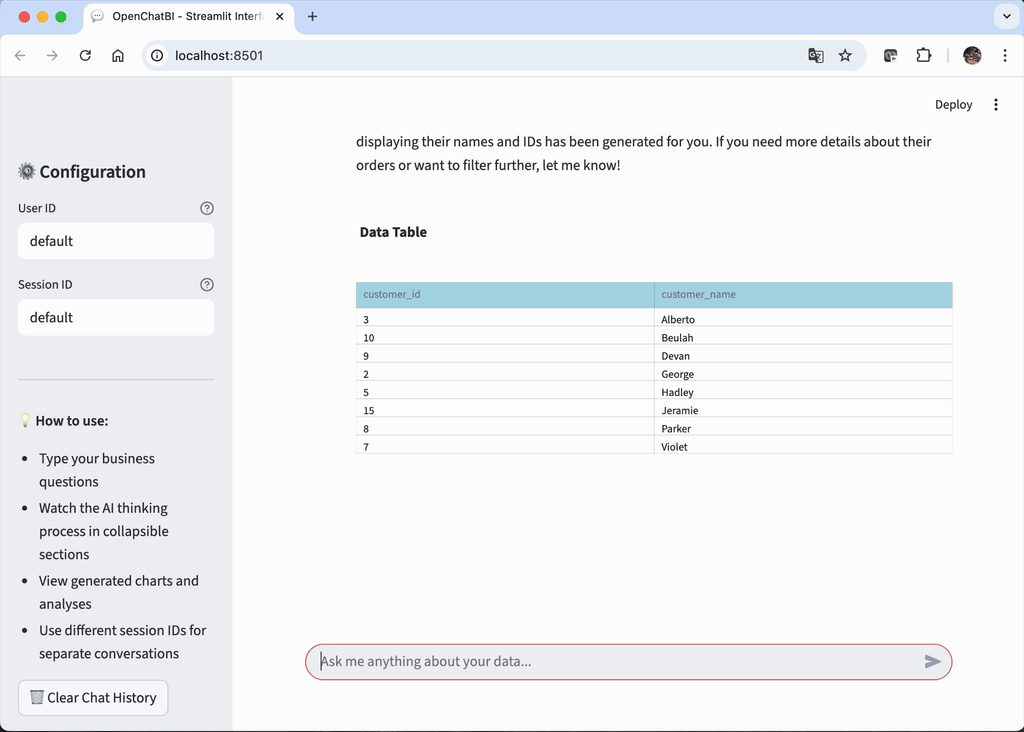
核心功能
- 自然语言交互:通过自然语言提问获取数据分析结果
- 自动 SQL 生成:利用高级 text2sql 工作流,结合 Schema 链接和精心组织的提示工程(Prompt Engineering),将自然语言查询转换为 SQL 语句
- 数据可视化:生成直观的数据可视化图表(通过 Plotly)
- 数据目录管理:自动发现并索引数据库表结构,支持灵活的目录存储后端,具备基于向量或 BM25 的检索能力,并可轻松维护表和列的业务解释以及优化提示词(Prompts)。
- 时间序列预测:内部部署的预测模型可作为工具被调用
- 代码执行:执行 Python 代码以进行数据分析和可视化
- 交互式问题解决:当信息不完整时,主动询问用户获取更多上下文
- 持久化记忆:基于 LangGraph 检查点机制(Checkpointing)的对话管理和用户特征记忆
- MCP 支持:通过配置集成 MCP 工具
- 知识库集成:结合基于目录的知识检索和外部知识库检索(通过 MCP 工具)来回答复杂问题
- Web UI 界面:提供 2 个示例 UI:使用 Gradio 和 Streamlit 构建的简单和流式 Web 界面,易于与其他 Web 应用集成
路线图
- 异常检测算法:时间序列异常检测
- 根本原因分析算法:用于异常调查的多维下钻能力
开始使用
安装与设置
前置条件
- Python 3.11 或更高版本
- 访问支持的 LLM 提供商(OpenAI, Anthropic 等)
- 数据仓库(数据库)凭证(如 Presto, PostgreSQL, MySQL 等)
- (可选)用于基于向量检索的嵌入模型(Embedding model)- 如果不可用,将使用基于 BM25 的检索
- (可选)Docker - 仅在
docker执行器模式下需要
中文文本分词说明:为了更好的中文文本检索,系统使用 jieba 进行分词。然而,jieba 与 Python 3.12+ 不兼容。在 Python 3.12 及更高版本上,系统会自动回退到基于简单标点的中文文本分词。
安装
- 使用 uv(推荐):
git clone git@github.com:zhongyu09/openchatbi
uv sync
- 使用 pip:
pip install openchatbi
- 用于开发:
git clone git@github.com:zhongyu09/openchatbi
uv sync --group dev
可选:如果你想使用 pysqlite3(较新的 SQLite 构建版本),可以手动安装它。如果构建失败,请先安装 SQLite:
在 macOS 上,尝试使用 Homebrew 安装 sqlite:
brew install sqlite
brew info sqlite
export LDFLAGS="-L/opt/homebrew/opt/sqlite/lib"
export CPPFLAGS="-I/opt/homebrew/opt/sqlite/include"
在 Amazon Linux / RHEL / CentOS 上:
sudo yum install sqlite-devel
在 Ubuntu / Debian 上:
sudo apt-get update
sudo apt-get install libsqlite3-dev
运行演示
使用 spider 数据集的示例数据集运行演示。你需要提供 "YOUR OPENAI API KEY" 或更改配置以使用其他 LLM 提供商。
注意:演示示例包含嵌入模型配置。如果你想在不使用嵌入模型的情况下运行,可以从配置中删除 embedding_model 部分 - 系统将自动使用 BM25 检索。
cp example/config.yaml openchatbi/config.yaml
sed -i 's/YOUR_API_KEY_HERE/[YOUR OPENAI API KEY]/g' openchatbi/config.yaml
python run_streamlit_ui.py
配置
- 创建配置文件
复制配置模板:
cp openchatbi/config.yaml.template openchatbi/config.yaml
或者创建一个空的 YAML 文件。
- 配置你的 LLMs:
# Select which provider to use
default_llm: openai
# Define one or more providers
llm_providers:
openai:
default_llm:
class: langchain_openai.ChatOpenAI
params:
api_key: YOUR_API_KEY_HERE
model: gpt-4.1
temperature: 0.02
max_tokens: 8192
# Optional: Embedding model for vector-based retrieval and memory tools
# If not configured, BM25-based retrieval will be used, and the memory tools will not work
embedding_model:
class: langchain_openai.OpenAIEmbeddings
params:
api_key: YOUR_API_KEY_HERE
model: text-embedding-3-large
chunk_size: 1024
- 配置你的数据仓库:
organization: Your Company
dialect: presto
data_warehouse_config:
uri: "presto://user@host:8080/catalog/schema"
include_tables:
- your_table_name
database_name: "catalog.schema"
运行应用程序
- 调用 LangGraph:
export CONFIG_FILE=YOUR_CONFIG_FILE_PATH
from openchatbi import get_default_graph
graph = get_default_graph()
graph.invoke({"messages": [{"role": "user", "content": "Show me ctr trends for the past 7 days"}]},
config={"configurable": {"thread_id": "1"}})
# System-generated SQL
SELECT date, SUM(clicks)/SUM(impression) AS ctr
FROM ad_performance
WHERE date >= CURRENT_DATE - 7 DAYS
GROUP BY date
ORDER BY date;
- 示例 Web UI:
基于 Streamlit 的 UI:
streamlit run sample_ui streamlit_ui.py
运行基于 Gradio 的 UI:
python sample_ui/streaming_ui.py
配置说明
配置模板位于 config.yaml.template。主要配置部分包括:
基本设置
organization:组织名称(例如:"Your Company")dialect:数据库方言(例如:"presto")bi_config_file:BI 配置文件路径(例如:"example/bi.yaml")
目录存储配置
catalog_store:数据目录存储配置store_type:存储类型(例如:"file_system")data_path:文件系统存储的目录数据路径(例如:"./example")
数据仓库配置
data_warehouse_config: 数据库连接设置uri: 数据库的连接字符串include_tables: 要包含在目录中的表列表,留空则包含所有表database_name: 目录的数据库名称token_service: Token 服务 URL(适用于需要 Token 认证的数据仓库,如 Presto)user_name/password: Token 服务凭证
LLM (大型语言模型) 配置
基于 LangChain 支持多种 LLM,详见 LangChain API 文档 (https://python.langchain.com/api_reference/reference.html#integrations) 以获取完整的支持 chat_models 列表。您可以为不同任务配置不同的 LLM:
default_llm: 用于一般任务的主要语言模型embedding_model: (可选)用于生成嵌入 (embedding) 的模型。如果未配置,将使用基于 BM25 的文本检索作为回退,且记忆工具将无法工作text2sql_llm: (可选)用于 SQL 生成的专用模型。如果未配置,则使用default_llm
多提供商配置(可选):
- 在
llm_providers下配置多个提供商,并通过default_llm: <provider_name>进行选择。 - 在
sample_ui/streamlit_ui.py中,当配置了llm_providers时会出现提供商下拉菜单。 - 在
sample_api/async_api.py中,在/chat/stream请求体中传递provider。
常用 LLM 提供商及其对应的类和安装命令:
- Anthropic:
langchain_anthropic.ChatAnthropic,pip install langchain-anthropic - OpenAI:
langchain_openai.ChatOpenAI,pip install langchain-openai - Azure OpenAI:
langchain_openai.AzureChatOpenAI,pip install langchain-openai - Google Vertex AI:
langchain_google_vertexai.ChatVertexAI,pip install langchain-google-vertexai - Bedrock:
langchain_aws.ChatBedrock,pip install langchain-aws - Huggingface:
langchain_huggingface.ChatHuggingFace,pip install langchain-huggingface - Deepseek:
langchain_deepseek.ChatDeepSeek,pip install langchain-deepseek - Ollama:
langchain_ollama.ChatOllama,pip install langchain-ollama
高级配置
OpenChatBI 通过提示工程 (Prompt Engineering) 和目录管理功能支持复杂的自定义:
- 提示工程配置:自定义系统提示词、业务术语表和数据库介绍
- 数据目录管理:配置表元数据、列描述和 SQL 生成规则
- 业务规则:定义表选择标准和特定领域的 SQL 约束
- 预测服务:根据您的部署配置预测服务 URL 和提示词
有关详细的配置选项和示例,请参阅 高级功能 部分。
架构概览
OpenChatBI 采用模块化架构构建,职责分离清晰:
- LangGraph 工作流:使用状态机 (State Machines) 进行核心编排,处理复杂的多步骤流程
- 目录管理:灵活的数据目录系统,支持智能检索(基于向量或 BM25 回退)
- Text2SQL 管道:带有模式链接 (Schema Linking) 的高级自然语言到 SQL 转换
- 代码执行:用于数据分析的沙箱 (Sandboxed) Python 执行环境
- 工具集成:可扩展的工具系统,用于人机交互和知识搜索
- 持久化记忆:基于 SQLite 的对话状态检查点 (Checkpointing) 管理
技术栈
- 框架:LangGraph, LangChain, FastAPI, Gradio/Streamlit
- 大语言模型:Azure OpenAI (GPT-4), Anthropic Claude, OpenAI GPT 模型
- 文本检索:基于向量 (Vector-based)(带嵌入模型)或基于 BM25(无嵌入时的回退)
- 数据库:Presto, Trino, MySQL,支持 SQLAlchemy
- 代码执行:本地 Python, RestrictedPython, Docker 容器化
- 开发:Python 3.11+,使用现代工具链(Black, Ruff, MyPy, Pytest)
- 存储:SQLite 用于对话检查点,文件系统目录存储
代理图
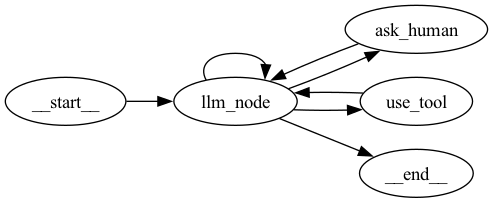
Text2SQL 图

项目结构
openchatbi/
├── README.md # Project documentation
├── pyproject.toml # Modern Python project configuration
├── Dockerfile.python-executor # Docker image for isolated code execution
├── run_tests.py # Test runner script
├── run_streamlit_ui.py # Streamlit UI launcher
├── openchatbi/ # Core application code
│ ├── __init__.py # Package initialization
│ ├── config.yaml.template # Configuration template
│ ├── config_loader.py # Configuration management
│ ├── constants.py # Application constants
│ ├── agent_graph.py # Main LangGraph workflow
│ ├── graph_state.py # State definition for workflows
│ ├── context_config.py # Context management configuration
│ ├── context_manager.py # Context window and token management
│ ├── text_segmenter.py # Text segmentation with jieba support
│ ├── utils.py # Utility functions and SimpleStore (BM25-based retrieval)
│ ├── catalog/ # Data catalog management
│ │ ├── __init__.py # Package initialization
│ │ ├── catalog_loader.py # Catalog loading logic
│ │ ├── catalog_store.py # Catalog storage interface
│ │ ├── factory.py # Catalog factory patterns
│ │ ├── helper.py # Catalog helper functions
│ │ ├── retrival_helper.py # Retrieval helper utilities
│ │ ├── schema_retrival.py # Schema retrieval logic
│ │ ├── token_service.py # Token service integration
│ │ └── store/ # Catalog storage implementations
│ │ └── file_system.py # File system-based catalog storage
│ ├── code/ # Code execution framework
│ │ ├── __init__.py # Package initialization
│ │ ├── executor_base.py # Base executor interface
│ │ ├── local_executor.py # Local Python execution
│ │ ├── restricted_local_executor.py # RestrictedPython execution
│ │ └── docker_executor.py # Docker-based isolated execution
│ ├── llm/ # LLM integration layer
│ │ ├── __init__.py # Package initialization
│ │ └── llm.py # LLM management and retry logic
│ ├── prompts/ # Prompt templates and engineering
│ │ ├── __init__.py # Package initialization
│ │ ├── agent_prompt.md # Main agent prompts
│ │ ├── extraction_prompt.md # Information extraction prompts
│ │ ├── system_prompt.py # System prompt management
│ │ ├── summary_prompt.md # Summary conversation prompts
│ │ ├── table_selection_prompt.md # Table selection prompts
│ │ ├── text2sql_prompt.md # Text-to-SQL prompts
│ │ └── sql_dialect/ # SQL dialect-specific prompts
│ ├── text2sql/ # Text-to-SQL conversion pipeline
│ │ ├── __init__.py # Package initialization
│ │ ├── data.py # Data and retriever for Text-to-SQL
│ │ ├── extraction.py # Information extraction
│ │ ├── generate_sql.py # SQL generation and execution logic
│ │ ├── schema_linking.py # Schema linking process
│ │ ├── sql_graph.py # SQL generation LangGraph workflow
│ │ ├── text2sql_utils.py # Text2SQL utilities
│ │ └── visualization.py # Data visualization functions
│ └── tool/ # LangGraph tools and functions
│ ├── ask_human.py # Human-in-the-loop interactions
│ ├── memory.py # Memory management tool
│ ├── mcp_tools.py # MCP (Model Context Protocol) integration
│ ├── run_python_code.py # Configurable Python code execution
│ ├── save_report.py # Report saving functionality
│ ├── search_knowledge.py # Knowledge base search
│ └── timeseries_forecast.py # Time series forecasting tool
├── sample_api/ # API implementations
│ └── async_api.py # Asynchronous FastAPI example
├── sample_ui/ # Web interface implementations
│ ├── memory_ui.py # Memory-enhanced UI interface
│ ├── plotly_utils.py # Plotly utilities and helpers
│ ├── simple_ui.py # Simple non-streaming Gradio UI
│ ├── streaming_ui.py # Streaming Gradio UI with real-time updates
│ ├── streamlit_ui.py # Streaming Streamlit UI with enhanced features
│ └── style.py # UI styling and CSS
├── example/ # Example configurations and data
│ ├── bi.yaml # BI configuration example
│ ├── config.yaml # Application config example
│ ├── table_info.yaml # Table information
│ ├── table_columns.csv # Table column registry
│ ├── common_columns.csv # Common column definitions
│ ├── sql_example.yaml # SQL examples for retrieval
│ ├── table_selection_example.csv # Table selection examples
│ └── tracking_orders.sqlite # Sample SQLite database
├── timeseries_forecasting/ # Time series forecasting service
│ ├── README.md # Forecasting service documentation
│ └── ... # Forecasting service implementation
├── tests/ # Test suite
│ ├── __init__.py # Package initialization
│ ├── conftest.py # Test configuration
│ ├── test_*.py # Test modules for various components
│ └── README.md # Testing documentation
├── docs/ # Documentation
│ ├── source/ # Sphinx documentation source
│ ├── build/ # Built documentation
│ ├── Makefile # Documentation build scripts
│ └── make.bat # Windows build script
└── .github/ # GitHub workflows and templates
└── workflows/ # CI/CD workflows
高级功能
可视化配置
您可以选择基于规则的、基于 LLM (大语言模型) 的可视化,或者禁用可视化。
# Options: "rule" (rule-based), "llm" (LLM-based), or null (skip visualization)
visualization_mode: llm
提示工程
基础知识与术语表
您可以在 example/bi.yaml 中定义基础知识和术语表,例如:
basic_knowledge_glossary: |
# Basic Knowledge Introduction
The basic knowledge about your company and its business, including key concepts, metrics, and processes.
# Glossary
Common terms and their definitions used in your business context.
数据仓库介绍
您可以在 example/bi.yaml 中提供数据仓库的简要介绍,例如:
data_warehouse_introduction: |
# Data Warehouse Introduction
This data warehouse is built on Presto and contains various tables related to XXXXX.
The main fact tables include XXXX metrics, while dimension tables include XXXXX.
The data is updated hourly and is used for reporting and analysis purposes.
表选择规则
您可以在 example/bi.yaml 中配置表选择规则,例如:
table_selection_extra_rule: |
- All tables with is_valid can support both valid and invalid traffics
自定义 SQL 规则
您可以在 example/table_info.yaml 中定义针对表的额外 SQL 生成规则,例如:
sql_rule: |
### SQL Rules
- All event_date in the table are stored in **UTC**. If the user specifies a timezone (e.g., CET, PST), convert between timezones accordingly.
目录管理
简介
高质量的目录数据对于准确的 Text2SQL(文本转 SQL)生成和数据分析至关重要。OpenChatBI 自动发现并索引数据仓库表结构,同时为业务元数据、列描述和查询优化规则提供灵活的管理。
目录结构
目录系统以分层结构组织元数据:
数据库级别
- 所有表和模式的顶层容器
表级别
description: 表的功能和业务目的selection_rule: 在查询中使用此表的时机和方法指南sql_rule: 此表特定的 SQL 生成规则和约束
列级别
- 必填字段:启用有效 Text2SQL 生成所需的每列关键元数据
column_name: 技术数据库列名display_name: 供业务用户阅读的易读名称alias: 替代名称或缩写type: 数据类型(字符串、整数、日期等)category: 业务类别、维度或指标tag: 用于过滤和组织的附加标签description: 列用途和用法的详细解释
- 两种类型的列
- 通用列:跨表共享标准化业务含义的列
- 特定于表的列:具有上下文相关含义且在不同表之间变化的列
- 衍生指标:使用 SQL 公式从现有列计算的虚拟指标
- 在查询执行期间动态计算,而不是作为物理列存储
- 示例:CTR(点击量/展示量)、转化率、利润率
- 无需预计算值即可实现复杂的业务计算
从数据库加载目录
OpenChatBI 可以自动发现并从您的数据仓库加载表结构:
- 自动发现:连接到您配置的数据仓库并扫描表模式 (Schema)
- 元数据提取:提取列名、数据类型和基本结构信息
- 增量更新:支持随着数据库模式演变而更新目录数据
在您的 config.yaml 中配置自动目录加载:
catalog_store:
store_type: file_system
data_path: ./catalog_data
data_warehouse_config:
include_tables:
- your_table_pattern
# Leave empty to include all accessible tables
文件系统目录存储
文件系统目录存储将元数据组织在多个文件中,以便于维护和版本控制:
核心表信息
table_info.yaml: 分层组织的综合表元数据(数据库 → 表 → 信息)type: 表分类(例如:"fact" 表示事实表,"dimension" 表示维度表)description: 业务功能和目的selection_rule: 使用指南,采用 markdown 列表格式(每行以-开头)sql_rule: SQL 生成规则,采用 markdown 标题格式(每条规则以####开头)derived_metric: 带有计算公式的虚拟指标,按组组织:#### Derived Ratio Metrics Click-through Rate (alias CTR): SUM(clicks) / SUM(impression) Conversion Rate (alias CVR): SUM(conversions) / SUM(clicks)
列管理
table_columns.csv: 基本列注册表,模式为db_name,table_name,column_nametable_spec_columns.csv: 特定于表的列元数据,完整模式为:db_name,table_name,column_name,display_name,alias,type,category,tag,descriptioncommon_columns.csv: 跨表共享的列定义,模式为:column_name,display_name,alias,type,category,tag,description
查询示例和训练数据
table_selection_example.csv: 表选择训练示例,模式为question,selected_tablessql_example.yaml: 按数据库和表结构组织的查询示例:your_database: ad_performance: | Q: Show me CTR trends for the past 7 days A: SELECT date, SUM(clicks)/SUM(impressions) AS ctr FROM ad_performance WHERE date >= CURRENT_DATE - INTERVAL 7 DAY GROUP BY date ORDER BY date;
时间序列预测服务设置
OpenChatBI 可以与时间序列预测服务集成,以实现高级预测分析。请按照以下步骤设置服务:
1. 构建并运行预测服务
详见 timeseries_forecasting/README.md 中的详细说明
快速开始:
cd timeseries_forecasting
./build_and_run.sh
2. 配置工具使用规则
在您的 bi.yaml 中,为 timeseries_forecast 工具添加约束,例如如果您使用的是 timer-base-84m 模型:
extra_tool_use_rule: |
- timeseries_forecast tool requires at least 96 time points in input data. If no enough input data, set input_len to 96 to pad with zeros.
3. 配置服务 URL
在您的 config.yaml 中:
# Time Series Forecasting Service Configuration
timeseries_forecasting_service_url: "http://localhost:8765"
重要:根据您的部署场景调整 URL:
- 本地开发(OpenChatBI 在主机上,预测服务在 Docker 中):
http://localhost:8765 - 远程服务:
http://your-service-host:8765
4. 验证服务健康状态
测试服务是否可访问:
curl http://localhost:8765/health
预期响应:
{
"status": "healthy",
"model_initialized": true,
"uptime_seconds": 123.45
}
Python 代码执行配置
OpenChatBI 支持多种执行环境 (Execution Environments),用于运行具有不同安全性和性能特征的 Python 代码:
# Python Code Execution Configuration
python_executor: local # Options: "local", "restricted_local", "docker"
执行器类型 (Executor Types)
local(默认)- 性能:执行速度最快
- 安全性:安全性最低(代码在当前 Python 进程中运行)
- 能力:完整的 Python 功能及库访问权限
- 适用场景:开发环境、可信代码执行
restricted_local- 性能:中等执行速度
- 安全性:中等安全性,使用 RestrictedPython 沙箱隔离 (sandboxing)
- 能力:有限的 Python 功能(无导入、文件访问等)
- 适用场景:半可信环境下的受控执行
docker- 性能:由于容器开销导致较慢
- 安全性:最高安全性,具备完整的进程隔离
- 能力:在隔离容器内拥有完整的 Python 功能
- 适用场景:生产环境、不可信代码执行
- 要求:必须安装并运行 Docker (容器引擎)
Docker 执行器设置
对于生产部署或运行不可信代码时,Docker 执行器提供完全隔离:
- 安装 Docker:下载并安装 Docker Desktop 或 Docker Engine
- 配置执行器:在配置中设置
python_executor: docker - 自动设置:OpenChatBI 将自动构建所需的 Docker 镜像
- 回退行为:如果 Docker 不可用,则自动回退到本地执行器
Docker 执行器特性:
- 预装数据科学库(pandas, numpy, matplotlib, seaborn)
- 网络隔离以保障安全
- 自动清理容器
- 与主机系统的资源隔离
开发与测试
代码质量工具
本项目使用现代 Python 工具链进行代码质量控制(例如 uv Python 运行时、black 代码格式化工具、ruff 代码检查工具等):
# Format code
uv run black .
# Lint code
uv run ruff check .
# Type checking
uv run mypy openchatbi/
# Security scanning
uv run bandit -r openchatbi/
测试
运行测试套件(pytest 测试框架):
# Run all tests
uv run pytest
# Run with coverage
uv run pytest --cov=openchatbi --cov-report=html
# Run specific test files
uv run pytest test/test_generate_sql.py
uv run pytest test/test_agent_graph.py
前置提交钩子 (pre-commit hooks)
安装前置提交钩子以进行自动代码质量检查:
uv run pre-commit install
贡献指南
- Fork (仓库分叉) 该仓库
- 创建功能分支 (
git checkout -b feature/fooBar) - 提交你的更改 (
git commit -am 'Add some fooBar') - 推送到分支 (
git push origin feature/fooBar) - 创建新的拉取请求 (Pull Request)
许可证
本项目采用 MIT 许可证授权 - 详见 LICENSE 文件
联系与支持
- 作者:Yu Zhong (zhongyu8@gmail.com)
- 仓库:github.com/zhongyu09/openchatbi
- 问题反馈:报告错误和功能请求
版本历史
v0.2.22026/03/02v0.2.12025/12/03v0.2.02025/11/21v0.1.12025/10/09v0.1.02025/10/09v0.0.12025/09/25常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。