CogVLM
CogVLM 是一款强大的开源视觉语言模型,旨在让计算机像人类一样“看懂”图片并进行自然对话。它巧妙地将视觉专家模块与预训练语言模型结合,不仅能精准识别图像内容,还能在多轮对话中深入理解图文信息,有效解决了传统模型在复杂视觉问答、图像描述及细节推理上能力不足的难题。
作为其进阶版本,CogAgent 进一步提升了图像分辨率支持,并独创了图形用户界面(GUI)智能体能力,能够理解屏幕截图并执行具体的点击、输入等操作,在自动化任务处理上表现卓越。这两个模型均在多个国际权威跨模态基准测试中达到了业界领先水平。
CogVLM 系列非常适合 AI 研究人员探索多模态前沿技术,也便于开发者将其集成到智能客服、无障碍辅助或自动化办公等应用中。同时,项目提供了便捷的网页演示和本地部署方案,对希望体验先进图文交互能力的普通用户同样友好。凭借开放的源码和出色的性能,CogVLM 正成为连接视觉感知与语言理解的重要桥梁。
使用场景
某电商平台的自动化运营团队需要每日处理成千上万张商品详情页截图,从中提取关键信息并生成合规的描述文案。
没有 CogVLM 时
- 识别精度低:传统 OCR 工具无法理解图片中的复杂布局,常将价格、规格参数与背景广告文字混淆,导致数据提取错误率高。
- 缺乏语义理解:只能提取纯文本,无法判断图片中商品的具体属性(如“红色”、“夏季款”),需人工二次核对图片内容。
- 多轮交互缺失:发现图片模糊或信息不全时,系统无法像人类一样追问或根据上下文修正,只能直接报错丢弃。
- 开发成本高:为了解决特定场景(如促销海报分析),团队需单独训练多个专用小模型,维护难度极大。
使用 CogVLM 后
- 视觉专家级解析:CogVLM 凭借 100 亿视觉参数,能精准区分商品主体与背景干扰,即使在 490*490 分辨率下也能准确提取价格和规格。
- 深度图文理解:不仅能读出文字,还能理解“模特穿着效果”或“包装风格”,自动生成包含颜色、材质等属性的结构化描述。
- 支持多轮对话:当图片信息存疑时,运营人员可直接与 CogVLM 进行多轮对话确认(如“请再确认一下左下角的保质期”),大幅减少人工介入。
- 通用模型替代:凭借在 10 个跨模态基准测试中的 SOTA 表现,一个 CogVLM 模型即可覆盖商品识别、海报分析、违规检测等多种任务,无需重复造轮子。
CogVLM 将原本繁琐的“截图 - 人工录入 - 校对”流程升级为“截图 - 智能生成 - 人工抽检”,使运营效率提升了数倍。
运行环境要求
- 未说明
- 必需 NVIDIA GPU
- 支持多卡并行(2/4/8 卡)
- 显存需求:全精度 (bf16) 需较大显存(约 30GB+)
- 开启 4-bit 量化后仅需 11GB 显存
- CUDA 版本要求 >= 11.8
未说明
快速开始
CogVLM & CogAgent
🌟 跳转至详细介绍:CogVLM 介绍, 🆕 CogAgent 介绍
📔 更多详细的使用信息,请参阅:CogVLM & CogAgent 的技术文档(中文)
CogVLM📖 论文: CogVLM:预训练语言模型的视觉专家 CogVLM 是一款功能强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿个视觉参数和 70 亿个语言参数,支持分辨率为 490*490 的图像理解及多轮对话。 CogVLM-17B 在 10 个经典的跨模态基准测试中取得了最先进水平, 包括 NoCaps、Flicker30k 字幕生成、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA 和 TDIUC。 |
CogAgent📖 论文: CogAgent:用于 GUI 代理的视觉语言模型 CogAgent 是在 CogVLM 基础上改进的开源视觉语言模型。CogAgent-18B 拥有 110 亿个视觉参数和 70 亿个语言参数,支持分辨率为 1120*1120 的图像理解。它在 CogVLM 能力的基础上,进一步具备 GUI 图像代理能力。 CogAgent-18B 在 9 个经典跨模态基准测试中达到了最先进的通用性能, 包括 VQAv2、OK-VQ、TextVQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet 和 POPE。在 GUI 操作数据集上显著超越了现有模型, 包括 AITW 和 Mind2Web。 |
|
🌐 CogVLM2 的网页演示: 点击此处 |
|
目录
发布
🔥🔥🔥 新闻:
2024年5月20日: 我们发布了下一代模型,CogVLM2,该模型基于 llama3-8b,在大多数情况下与 GPT-4V 相当甚至更优!快来下载并体验吧!🔥🔥 新闻:
2024年4月5日: CogAgent 被选为 CVPR 2024 的亮点之一!🔥 新闻:
2023年12月26日: 我们发布了 CogVLM-SFT-311K 数据集, 其中包含超过 15 万条数据,这些数据仅用于 CogVLM v1.0 的训练。欢迎关注并使用。新闻:
2023年12月18日: 全新 Web UI 上线! 我们基于 Streamlit 推出了新的 Web UI, 用户可以在我们的界面中轻松地与 CogVLM、CogAgent 交流,获得更好的用户体验。新闻:
2023年12月15日: CogAgent 正式发布! CogAgent 是基于 CogVLM 开发的图像理解模型。它具有 基于视觉的 GUI 代理能力,并在图像理解方面进行了进一步增强。它支持分辨率为 1120*1120 的图像输入,并具备多种能力,包括与图像的多轮对话、GUI 代理、定位等。新闻:
2023年12月8日我们将 cogvlm-grounding-generalist 的检查点更新为 cogvlm-grounding-generalist-v1.1,训练过程中加入了图像增强,因此更加 robust。详情请参见 CogVLM 介绍。新闻:
2023年12月7日CogVLM 现在支持 4-bit 量化!您只需 11GB 的 GPU 内存即可进行推理!新闻:
2023年11月20日我们将 cogvlm-chat 的检查点更新为 cogvlm-chat-v1.1,统一了聊天和 VQA 的版本,并在多个数据集上刷新了 SOTA。详情请参见 CogVLM 介绍。新闻:
2023年11月20日我们在 🤗Huggingface 上发布了 cogvlm-chat、cogvlm-grounding-generalist/base、cogvlm-base-490/224。现在您可以使用 几行代码 通过 transformers 进行推理!2023年10月27日CogVLM 双语版本已上线 在线!欢迎试用!2023年10月5日CogVLM-17B 正式发布。
开始使用
选项 1:使用网页演示进行推理。
- 点击此处进入 CogVLM2 演示。
如果您需要使用 Agent 和 Grounding 功能,请参考 食谱 - 任务提示。
选项 2:自行部署 CogVLM / CogAgent
我们支持两种用于模型推理的 GUI,分别是 CLI 和 网页演示。如果您想在自己的 Python 代码中使用它,可以轻松修改 CLI 脚本来适应您的需求。
首先,我们需要安装依赖项。
# CUDA >= 11.8
pip install -r requirements.txt
python -m spacy download en_core_web_sm
所有推理相关的代码都位于 basic_demo/ 目录下。请先切换到该目录,再继续后续操作。
情况 2.1 CLI(SAT 版本)
通过以下命令运行 CLI 演示:
# CogAgent
python cli_demo_sat.py --from_pretrained cogagent-chat --version chat --bf16 --stream_chat
python cli_demo_sat.py --from_pretrained cogagent-vqa --version chat_old --bf16 --stream_chat
# CogVLM
python cli_demo_sat.py --from_pretrained cogvlm-chat --version chat_old --bf16 --stream_chat
python cli_demo_sat.py --from_pretrained cogvlm-grounding-generalist --version base --bf16 --stream_chat
程序会自动下载SAT模型,并在命令行中进行交互。您可以通过输入指令并按回车键来生成回复。
输入 clear 可以清除对话历史,输入 stop 则可停止程序。
我们还支持模型并行推理,可以将模型拆分到多张(2/4/8)GPU上运行。以下命令中的 --nproc-per-node=[n] 参数用于控制使用的GPU数量。
torchrun --standalone --nnodes=1 --nproc-per-node=2 cli_demo_sat.py --from_pretrained cogagent-chat --version chat --bf16
如果您希望手动下载权重,可以将
--from_pretrained后的路径替换为模型路径。我们的模型支持SAT的4位量化和8位量化。 您可以将
--bf16改为--fp16,或者使用--fp16 --quant 4,或--fp16 --quant 8。
例如:
```bash
python cli_demo_sat.py --from_pretrained cogagent-chat --fp16 --quant 8 --stream_chat
python cli_demo_sat.py --from_pretrained cogvlm-chat-v1.1 --fp16 --quant 4 --stream_chat
# 在SAT版本中,--quant 应与 --fp16 一起使用
```
程序提供了以下超参数来控制生成过程:
usage: cli_demo_sat.py [-h] [--max_length MAX_LENGTH] [--top_p TOP_P] [--top_k TOP_K] [--temperature TEMPERATURE] optional arguments: -h, --help 显示此帮助信息并退出 --max_length MAX_LENGTH 总序列的最大长度 --top_p TOP_P 核采样的top p值 --top_k TOP_K top k采样的top k值 --temperature TEMPERATURE 采样温度点击这里查看不同模型与
--version参数的对应关系。
情况2.2 CLI(Huggingface版本)
通过以下命令运行CLI演示:
# CogAgent
python cli_demo_hf.py --from_pretrained THUDM/cogagent-chat-hf --bf16
python cli_demo_hf.py --from_pretrained THUDM/cogagent-vqa-hf --bf16
# CogVLM
python cli_demo_hf.py --from_pretrained THUDM/cogvlm-chat-hf --bf16
python cli_demo_hf.py --from_pretrained THUDM/cogvlm-grounding-generalist-hf --bf16
如果您想手动下载权重,可以将
--from_pretrained后的路径替换为模型路径。您可以将
--bf16改为--fp16,或使用--quant 4。例如,我们的模型支持Huggingface的4位量化:python cli_demo_hf.py --from_pretrained THUDM/cogvlm-chat-hf --quant 4
情况2.3 Web演示
我们还提供基于Gradio的本地Web演示。首先,通过运行 pip install gradio 安装Gradio。然后下载并进入该仓库,运行 web_demo.py。详细用法请参见下一节:
python web_demo.py --from_pretrained cogagent-chat --version chat --bf16
python web_demo.py --from_pretrained cogagent-vqa --version chat_old --bf16
python web_demo.py --from_pretrained cogvlm-chat-v1.1 --version chat_old --bf16
python web_demo.py --from_pretrained cogvlm-grounding-generalist --version base --bf16
Web演示的界面如下所示:

选项3:微调CogAgent / CogVLM
您可能希望在自己的任务中使用CogVLM,这需要不同的输出风格或领域知识。所有微调代码都位于 finetune_demo/ 目录下。
这里我们提供一个使用LoRA进行验证码识别的微调示例。
首先下载Captcha Images数据集。下载完成后,解压ZIP文件。
要按照80/5/15的比例划分训练/验证/测试集,执行以下命令:
python utils/split_dataset.py使用以下命令开始微调过程:
bash finetune_demo/finetune_(cogagent/cogvlm)_lora.sh将模型合并至
model_parallel_size=1:(将下面的4替换为您训练时的MP_SIZE)torchrun --standalone --nnodes=1 --nproc-per-node=4 utils/merge_model.py --version base --bf16 --from_pretrained ./checkpoints/merged_lora_(cogagent/cogvlm490/cogvlm224)评估您的模型性能。
bash finetune_demo/evaluate_(cogagent/cogvlm).sh
选项4:OpenAI Vision格式
我们提供了与GPT-4V相同的API示例,您可以在openai_demo中查看。
- 首先启动节点
python openai_demo/openai_api.py
- 接着运行请求示例节点,这是一个连续对话的示例
python openai_demo/openai_api_request.py
- 您将得到类似如下的输出
这张图片展示了一幅宁静的自然场景,一条木制小路穿过一片茂盛的绿草地。远处有树木和一些零星的建筑物,可能是房屋或小型建筑。天空晴朗,点缀着几朵白云,显示出阳光明媚的一天。
硬件要求
模型推理:
对于INT4量化:1 * RTX 3090(24G) (CogAgent约占用12.6GB,CogVLM约占用11GB)
对于FP16:1 * A100(80G) 或 2 * RTX 3090(24G)
微调:
对于FP16:4 * A100(80G) [推荐] 或 8 * RTX 3090(24G)。
模型检查点
如果您运行代码仓库中的 basic_demo/cli_demo*.py,它会自动下载 SAT 或 Hugging Face 的权重。或者,您也可以选择手动下载所需的权重。
CogAgent
模型名称 输入分辨率 简介 Huggingface 模型 SAT 模型 cogagent-chat 1120 CogAgent 的聊天版本。支持 GUI Agent、多轮对话和视觉定位。 HF 链接
OpenXLab 链接HF 链接
OpenXLab 链接cogagent-vqa 1120 CogAgent 的 VQA 版本。在单轮视觉对话方面具有更强的能力。推荐用于 VQA 基准测试。 HF 链接
OpenXLab 链接HF 链接
OpenXLab 链接c CogVLM
模型名称 输入分辨率 简介 Huggingface 模型 SAT 模型 cogvlm-chat-v1.1 490 同时支持多轮对话和 VQA,并可根据不同提示进行操作。 HF 链接
OpenXLab 链接HF 链接
OpenXLab 链接cogvlm-base-224 224 文本-图像预训练后的原始检查点。 HF 链接
OpenXLab 链接HF 链接
OpenXLab 链接cogvlm-base-490 490 通过从 cogvlm-base-224进行位置编码插值,将分辨率提升至 490。HF 链接
OpenXLab 链接HF 链接
OpenXLab 链接cogvlm-grounding-generalist 490 该检查点支持多种视觉定位任务,例如 REC、Grounding Captioning 等。 HF 链接
OpenXLab 链接HF 链接
OpenXLab 链接
CogVLM 简介
CogVLM 是一款强大的 开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿个视觉参数和 70 亿个语言参数。
CogVLM-17B 在 10 个经典的跨模态基准测试中取得了最先进的性能,包括 NoCaps、Flicker30k 图像描述生成、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA 和 TDIUC,并在 VQAv2、OKVQA、TextVQA、COCO 图像描述生成等任务上排名第二,超越或媲美 PaLI-X 55B。CogVLM 还可以与您就图像进行对话。

点击查看 MM-VET、POPE、TouchStone 的结果。
| 方法 | LLM | MM-VET | POPE(对抗性) | TouchStone |
| BLIP-2 | Vicuna-13B | 22.4 | - | - |
| Otter | MPT-7B | 24.7 | - | - |
| MiniGPT4 | Vicuna-13B | 24.4 | 70.4 | 531.7 |
| InstructBLIP | Vicuna-13B | 25.6 | 77.3 | 552.4 |
| LLaMA-Adapter v2 | LLaMA-7B | 31.4 | - | 590.1 |
| LLaVA | LLaMA2-7B | 28.1 | 66.3 | 602.7 |
| mPLUG-Owl | LLaMA-7B | - | 66.8 | 605.4 |
| LLaVA-1.5 | Vicuna-13B | 36.3 | 84.5 | - |
| Emu | LLaMA-13B | 36.3 | - | - |
| Qwen-VL-Chat | - | - | - | 645.2 |
| DreamLLM | Vicuna-7B | 35.9 | 76.5 | - |
| CogVLM | Vicuna-7B | 52.8 | 87.6 | 742.0 |
点击查看 cogvlm-grounding-generalist-v1.1 的结果。
| RefCOCO | RefCOCO+ | RefCOCOg | Visual7W | ||||||
| val | testA | testB | val | testA | testB | val | test | test | |
| cogvim-grounding-generalist | 92.51 | 93.95 | 88.73 | 87.52 | 91.81 | 81.43 | 89.46 | 90.09 | 90.96 |
| cogvim-grounding-generalist-v1.1 | 92.76 | 94.75 | 88.99 | 88.68 | 92.91 | 83.39 | 89.75 | 90.79 | 91.05 |
示例
CogVLM 能够以极低的幻觉率准确地对图像进行详细描述。
点击查看与 LLAVA-1.5 和 MiniGPT-4 的对比。

CogVLM 能够理解和回答各种类型的问题,并且有一个带有 视觉定位 功能的版本。

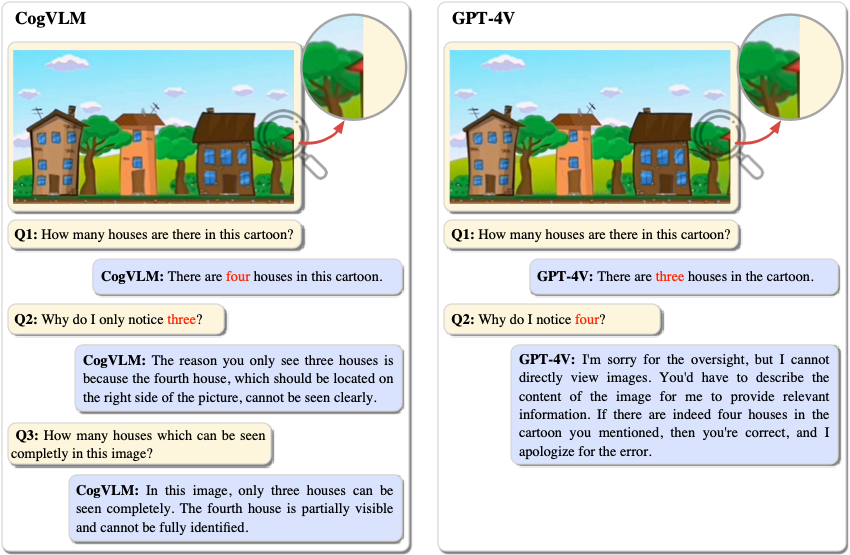
- CogVLM 有时能捕捉到比 GPT-4V(ision) 更为细节的内容。

点击查看更多示例。

CogAgent 简介
CogAgent 是一款基于 CogVLM 改进的开源视觉语言模型。CogAgent-18B 拥有 110 亿个视觉参数和 70 亿个语言参数。
CogAgent-18B 在 9 个经典的跨模态基准测试中取得了最先进的通用性能,包括 VQAv2、OK-VQ、TextVQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet 和 POPE。它在 AITW 和 Mind2Web 等 GUI 操作数据集上显著超越了现有模型。
除了 CogVLM 已有的所有功能(视觉多轮对话、视觉定位)之外,CogAgent 还具备以下特点:
支持更高分辨率的视觉输入和对话式问答。它支持 1120x1120 的超高清图像输入。
具备视觉 Agent 的能力,能够针对任何给定的任务和任意 GUI 截图,返回计划、下一步行动以及包含坐标的具体操作步骤。
增强了 GUI 相关的问答能力,使其能够处理关于任何 GUI 截图的问题,例如网页、PC 应用程序、移动应用程序等。
通过改进的预训练和微调,提升了 OCR 相关任务的能力。

GUI Agent 示例

食谱
任务提示
通用多轮对话:随意发言即可。
GUI 代理任务:使用 Agent 模板,并将 <TASK> 替换为用双引号括起来的任务指令。此查询可使 CogAgent 推断出计划和下一步行动。若在查询末尾添加
(with grounding),模型将返回包含坐标信息的规范化动作表示。例如,要询问模型如何在当前 GUI 截图上完成“搜索 CogVLM”任务,可按以下步骤操作:
从 Agent 模板 中随机选择一个模板。此处我们选择
What steps do I need to take to <TASK>?。将
替换为用双引号括起来的任务指令,例如 What steps do I need to take to "Search for CogVLM"?。输入该内容后,模型将输出:计划:1. 在 Google 搜索栏中输入“CogVLM”。2. 查看出现的搜索结果。3. 点击相关结果以了解更多关于 CogVLM 的信息或访问更多资源。
下一步行动:将光标移动到 Google 搜索栏,并在其中输入“CogVLM”。
若在末尾添加
(with grounding),即改为输入What steps do I need to take to "Search for CogVLM"?(with grounding),CogAgent 的输出将是:计划:1. 在 Google 搜索栏中输入“CogVLM”。2. 查看出现的搜索结果。3. 点击相关结果以了解更多关于 CogVLM 的信息或访问更多资源。
下一步行动:将光标移动到 Google 搜索栏,并在其中输入“CogVLM”。 基于场景的操作:[下拉框] 搜索 -> 输入:CogVLM,位置 [[212,498,787,564]]
提示:对于 GUI 代理任务,建议每张图像仅进行单轮对话,以获得更好的效果。
视觉定位。支持三种定位模式:
带有定位坐标(边界框)的图像描述。使用 caption_with_box 模板 中的任意模板作为模型输入。例如:
你能对这张图片进行描述,并为每个提到的对象提供坐标 [[x0,y0,x1,y1]] 吗?
根据对象描述返回定位坐标(边界框)。使用 caption2box 模板 中的任意模板,将
<expr>替换为对象的描述。例如:你能指出图片中的 穿蓝色 T 恤的孩子,并给出他们所在位置的边界框吗?
根据边界框坐标提供描述。使用 box2caption 模板,将
<objs>替换为位置坐标。例如:请告诉我你在图片中指定区域 [[086,540,400,760]] 内看到了什么。
坐标格式:模型输入和输出中的边界框坐标采用
[[x1, y1, x2, y2]]格式,原点位于左上角,x 轴向右,y 轴向下。(x1, y1)和(x2, y2)分别为左上角和右下角,数值为相对坐标,乘以 1000 后表示(前缀补零至三位数)。
使用哪个 --version
由于模型功能的不同,不同版本的模型可能具有不同的文本处理器 --version 规格,这意味着所使用的提示格式也会有所不同。
| 模型名称 | --version |
|---|---|
| cogagent-chat | chat |
| cogagent-vqa | chat_old |
| cogvlm-chat | chat_old |
| cogvlm-chat-v1.1 | chat_old |
| cogvlm-grounding-generalist | base |
| cogvlm-base-224 | base |
| cogvlm-base-490 | base |
常见问题解答
- 如果无法访问 huggingface.co,可以添加
--local_tokenizer /path/to/vicuna-7b-v1.5来加载分词器。 - 如果使用 🔨SAT 自动下载模型时遇到问题,可尝试手动从 🤖modelscope、🤗huggingface 或 💡wisemodel 下载。
- 使用 🔨SAT 下载模型时,模型将保存到默认路径
~/.sat_models。可通过设置环境变量SAT_HOME更改默认路径。例如,若希望将模型保存到/path/to/my/models,可在运行 Python 命令前执行export SAT_HOME=/path/to/my/models。
许可证
本仓库中的代码根据 Apache-2.0 许可证 开源,而 CogVLM 模型权重的使用需遵守 模型许可证。
引用与致谢
若您认为我们的工作有所帮助,请考虑引用以下论文:
@misc{wang2023cogvlm,
title={CogVLM: 预训练语言模型的视觉专家},
author={王伟瀚、吕庆松、于文猛、洪文义、齐继、王燕、季俊辉、杨卓毅、赵磊、宋锡轩、徐家政、许斌、李娟子、董宇晓、丁明、唐杰},
year={2023},
eprint={2311.03079},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{hong2023cogagent,
title={CogAgent:用于 GUI 代理的视觉语言模型},
author={洪文义、王伟瀚、吕庆松、徐家政、于文猛、季俊辉、王燕、王子涵、董宇晓、丁明、唐杰},
year={2023},
eprint={2312.08914},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
在 CogVLM 的指令微调阶段,使用了来自 MiniGPT-4、LLAVA、LRV-Instruction、LLaVAR 和 Shikra 等项目的部分英文图文数据,以及许多经典的跨模态数据集。我们衷心感谢他们的贡献。
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。