Segment-and-Track-Anything
Segment-and-Track-Anything 是一款专注于视频对象分割与追踪的开源项目,旨在帮助用户轻松提取视频中任意目标的轮廓并持续锁定其运动轨迹。它有效解决了传统方法在处理复杂动态场景时难以兼顾精度与效率的难题,无论是自动检测新出现的目标,还是通过人工交互指定特定物体,都能实现高精度的逐帧处理。
该项目特别适合计算机视觉研究人员、视频处理开发者以及需要精细视频分析内容创作者使用。其核心亮点在于巧妙融合了两大前沿算法:利用 Segment Anything Model (SAM) 在关键帧上进行强大的自动或交互式分割,再结合 DeAOT 技术高效地将掩码传播至整个视频序列,实现多目标稳定追踪。此外,它还支持独特的“声音定位”功能,能根据音频线索自动追踪发声物体,并允许用户通过点击、画笔涂抹甚至文本提示等多种灵活方式与系统互动。配合友好的 Web 界面和 Colab 在线演示,用户无需深厚的编程背景也能快速上手,探索视频智能分析的无限可能。
使用场景
某野生动物保护团队正在处理数千小时红外相机拍摄的森林监控视频,需要统计特定珍稀动物的活动轨迹与种群数量。
没有 Segment-and-Track-Anything 时
- 人工标注成本极高:分析师必须逐帧手动勾勒动物轮廓,一段几分钟的视频需耗费数小时,面对海量数据几乎无法完成。
- 目标丢失频繁:当动物被树枝遮挡或快速移动时,传统追踪算法极易跟丢目标,导致轨迹断裂,后续需人工反复修正。
- 新目标识别困难:视频中突然闯入的新个体无法被自动发现,往往需要人工全程盯守屏幕才能捕捉,漏检率高。
- 多模态分析缺失:仅凭视觉难以区分隐蔽在草丛中的动物,无法利用叫声等音频线索辅助定位发声源。
使用 Segment-and-Track-Anything 后
- 自动化高效分割:利用 SAM 模型自动在关键帧生成高精度掩码,并通过 DeAOT 算法将结果传播至全视频,将处理时间从小时级缩短至分钟级。
- 鲁棒性显著增强:即使动物长时间被植被遮挡或发生剧烈形变,长短期记忆机制也能确保持续稳定追踪,无需人工干预修补轨迹。
- 动态新增目标检测:结合 Grounding-DINO,系统能自动识别并分割视频中后期新出现的动物个体,实现全天候无人值守监测。
- 音画协同定位:启用音频接地功能后,系统可直接根据动物叫声锁定并追踪发声主体,有效解决视觉盲区下的目标捕获难题。
Segment-and-Track-Anything 通过将顶尖的分割与追踪算法深度融合,把原本耗时数周的视频分析工作压缩至瞬间完成,让科研人员能从繁琐的标注中解放出来专注于生态研究本身。
运行环境要求
- 未说明
需要 NVIDIA GPU (基于 PyTorch 和 DeAOT/SAM 架构推断),具体显存大小和 CUDA 版本未在片段中明确说明
未说明

快速开始
任意对象分割与追踪(SAM-Track)
在线演示:![]() 技术报告:
技术报告:
教程:tutorial-v1.6(音频)、tutorial-v1.5(文本)、tutorial-v1.0(点击与涂抹)

Segment and Track Anything 是一个开源项目,专注于视频中任意对象的分割与追踪,支持自动和交互式两种方式。主要算法包括用于关键帧自动/交互式分割的 SAM(Segment Anything Models),以及用于高效多目标追踪与传播的 DeAOT(Decoupling features in Associating Objects with Transformers)(NeurIPS2022)。SAM-Track 流程能够通过 SAM 动态且自动地检测并分割新对象,而 DeAOT 则负责跟踪所有已识别的对象。
:loudspeaker:新功能
[2024/4/23] 我们新增了音频定位功能,可追踪视频配乐中的发声物体。
[2023/5/12] 我们撰写了 SAM-Track 的技术报告。
[2023/5/7] 我们添加了
demo_instseg.ipynb,该脚本利用 Grounding-DINO 在视频的关键帧中检测新对象,可用于智慧城市和自动驾驶等领域。[2023/4/29] 我们为 AOT-L 增加了高级参数:
long_term_memory_gap和max_len_long_term。long_term_memory_gap控制 AOT 模型向其长期记忆库添加新参考帧的频率。在掩码传播过程中,AOT 会将当前帧与长期记忆库中的参考帧进行匹配。- 合理设置间隔值有助于获得更好的性能。为避免在长视频中内存占用过大,我们还设置了长期记忆存储的最大长度
max_len_long_term,即当记忆帧数达到该值时,最旧的帧将被丢弃,并加入新的帧。
[2023/4/26] 交互式 WebUI 1.5 版:我们在交互式 WebUI 1.0 版的基础上新增了多项功能。
- 我们为 SAMTrack 新增了一种交互方式——文本提示。
- 从现在起,用户可以交互式地添加多个需要追踪的对象。
- 请参阅 教程 了解交互式 WebUI 1.5 版的使用方法。未来几天还将发布更多演示。
[2023/4/26] 图像序列输入:WebUI 现在新增了图像序列输入功能,可用于测试视频分割数据集。请参阅 教程 了解如何使用图像序列输入功能。
[2023/4/25] 在线演示:您可以在 Colab 中轻松使用 SAMTrack 进行视觉追踪任务。
[2023/4/23] 交互式 WebUI:我们推出了全新的 WebUI,支持通过涂抹和点击实现交互式用户分割。欢迎体验并观看 教程!
- [2023/4/24] 教程 V1.0:请查看我们的全新视频教程!
- YouTube 链接:教程:交互式修改视频第一帧的单个对象掩码、教程:通过点击交互式添加对象、教程:通过涂抹交互式添加对象。
- Bilibili 视频链接:教程:交互式修改视频第一帧的单个对象掩码、教程:通过点击交互式添加对象、教程:通过涂抹交互式添加对象。
- 1.0 版本为开发者版本,如果您遇到任何问题,请随时联系我们 :bug:。
- [2023/4/24] 教程 V1.0:请查看我们的全新视频教程!
[2023/4/17] SAMTrack:自动分割并追踪视频中的任何对象!
:fire:演示视频

本视频展示了 SAM-Track 在多种场景下的分割与追踪能力,例如街景、增强现实、细胞、动画、航拍等。
:calendar:待办事项
- Colab 笔记本:2023年4月25日完成。
- 1.0版本交互式WebUI:2023年4月23日完成。
- 1.5版本交互式WebUI:2023年4月26日完成。
- 2.x版本交互式WebUI
Demo1 展示了 SAM-Track 能够以物体类别作为提示的能力。用户输入类别文本“panda”,即可实现对该类别下所有目标的实例级分割与跟踪。

Demo2 展示了 SAM-Track 能够以文本描述作为提示的能力。只需输入“最左边的熊猫”,SAM-Track 就能分割并跟踪目标对象。

Demo3 展示了 SAM-Track 同时跟踪多个目标的能力。它还能自动检测新出现的对象。

Demo4 展示了 SAM-Track 能够接受多种交互方式作为提示的能力。用户分别用点击和笔刷标注了人和滑板。

Demo5 展示了 SAM-Track 能够对“分割一切”的结果进行优化。用户只需单击一下,就能将电车合并为一个整体。

Demo6 展示了 SAM-Track 在跟踪过程中添加新对象的能力。用户通过回退到中间帧,标注了另一辆汽车。

Demo7 展示了 SAM-Track 在跟踪过程中不断优化预测的能力。这一特性对于复杂环境下的分割与跟踪尤为有利。
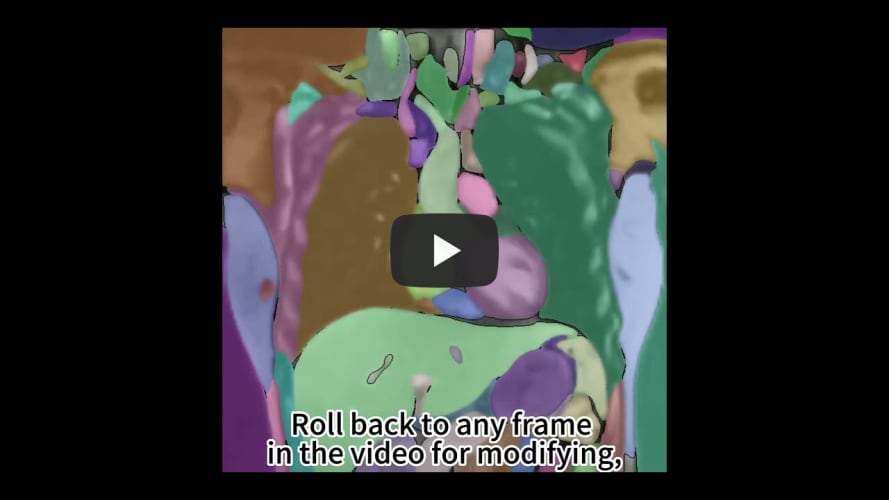
Demo8 展示了 SAM-Track 能够交互式地分割并跟踪单个目标。用户指定 SAM-Track 跟踪一名正在打街头篮球的男子。

Demo9 展示了 SAM-Track 能够交互式地添加指定目标进行跟踪。用户在使用 SAM-Track 对场景中的所有内容进行分割的基础上,自定义了需要跟踪的对象。

:computer:开始使用
:bookmark_tabs:要求
已克隆并重命名为 sam 的 Segment-Anything 仓库,以及已克隆并重命名为 aot 的 aot-benchmark 仓库。
该实现已在 Python 3.9、PyTorch 1.10 和 torchvision 0.11 下进行了测试。建议使用相同或更高版本的 PyTorch。
使用 install.sh 脚本来安装 SAM-Track 所需的库:
bash script/install.sh
:star:模型准备
- 下载SAM模型到ckpt文件夹以运行代码
SAM vit_b(默认):https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
SAM vit_l:https://dl.fbaipublicfiles.com/segment_anything/sam_vit_l_0b3195.pth
SAM vit_h:https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
- 下载DEAOT模型到ckpt文件夹以运行代码
| 模型 | 参数(M) | PRE_YTB_DAV |
|---|---|---|
| DeAOTT | 7.2 | gdrive |
| DeAOTS | 10.2 | gdrive |
| DeAOTB | 13.2 | gdrive |
| DeAOTL | 13.2 | gdrive |
| R50-DeAOTL | 19.8 | gdrive |
| SwinB-DeAOTL | 70.3 | gdrive |
下载Grounding-DINO模型到ckpt文件夹
| 名称 | 主干网络 | 训练数据 | 边框AP(COCO) | 检查点 |
|---|---|---|---|---|
| GroundingDINO-T | Swin-T | O365、GoldG、Cap4M | 48.4(零样本)/ 57.2(微调) | 下载 |
| GroundingDINO-B | Swin-B | COCO、O365、GoldG、Cap4M、OpenImages、ODinW-35、RefCOCO | 56.7 | 下载 |
下载AST模型到ast_master/pretrained_models,克隆AST仓库后
Speechcommands V2-35,10 tstride,10 fstride,不带权重平均,模型(在评估集上准确率98.12%),默认模型是audioset_0.4593(audioset_0.4593.pth))。
您可以通过以下命令行下载默认权重。 $$ bash script/download_ckpt.sh $$
运行docker文件
- docker build -f docker/Dockerfile -t myimage .
- docker run myimage
:heart:运行演示
- 待处理的视频可以放在./assets中。
- 然后逐步运行demo.ipynb以生成结果。
- 结果将保存为每帧的掩码以及用于可视化的gif文件。
SAM-Track、DeAOT和SAM的参数可以在model_args.py中手动修改,以便使用其他模型或控制各模型的行为。
:muscle:WebUI应用
我们友好的可视化界面使您能够轻松获得实验结果。只需通过命令行启动即可。
python app.py
用户可以直接在界面上上传视频,并使用SegTracker对视频中的物体进行自动或交互式跟踪。我们以一段男子打篮球的视频为例。
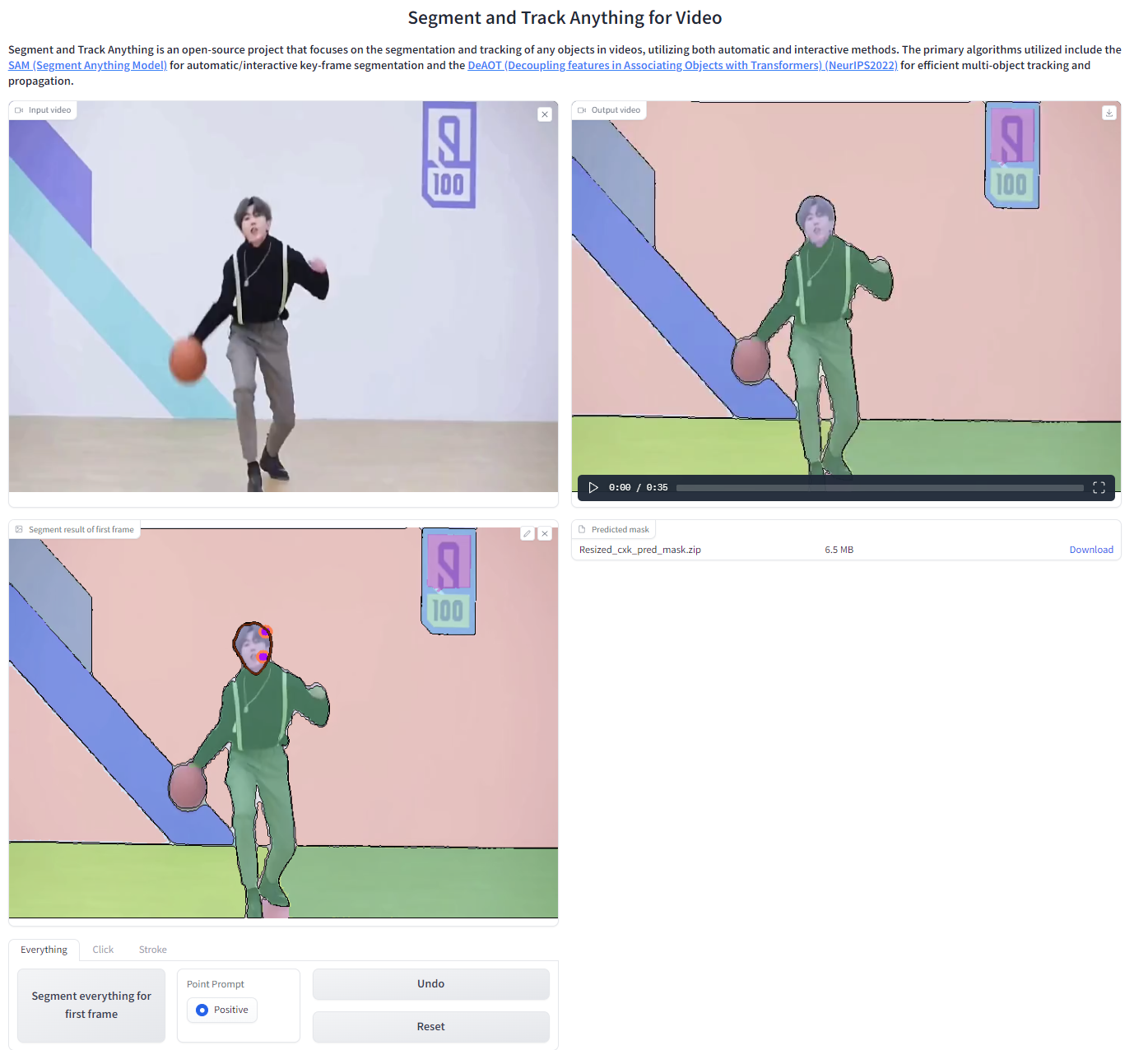
SegTracker参数:
- aot_model:用于选择使用哪个版本的DeAOT/AOT进行跟踪和传播。
- sam_gap:用于控制SAM在指定帧间隔内添加新出现物体的频率。增加该值可降低发现新目标的频率,但会显著提高推理速度。
- points_per_side:用于控制在图像上采样网格以生成掩码时每边使用的点数。增大该值可提高检测小物体的能力,但较大目标可能会被分割得更细。
- max_obj_num:用于限制SAM-Track能够检测和跟踪的最大物体数量。物体数量越多,所需的内存也越大,大约16GB内存最多可处理255个物体。
用法:欲了解更多细节,请参阅1.0版本WebUI教程。
:school:关于我们
感谢您对本项目的关注。该项目由浙江大学计算机科学与技术学院的ReLER实验室指导。ReLER由浙江大学求是特聘教授杨毅创立。我们的贡献团队包括程阳明、胡继元、徐远优、李柳磊、李晓迪、杨宗欣、王文冠以及杨毅。
:full_moon_with_face:致谢
借用代码的许可证可在licenses.md文件中找到。
- DeAOT/AOT - https://github.com/yoxu515/aot-benchmark
- SAM - https://github.com/facebookresearch/segment-anything
- Gradio(用于构建WebUI) - https://github.com/gradio-app/gradio
- Grounding-Dino - https://github.com/yamy-cheng/GroundingDINO
- AST - https://github.com/YuanGongND/ast
许可协议
本项目采用 AGPL-3.0 许可协议进行授权。如需将本项目用于商业用途或以专有方式进一步开发,必须获得我们的许可(以及任何借用代码的版权所有者的许可)。
引用
如果您认为相关论文对您的研究有所帮助,请在您的出版物中引用这些论文。
@article{cheng2023segment,
title={Segment and Track Anything},
author={Cheng, Yangming and Li, Liulei and Xu, Yuanyou and Li, Xiaodi and Yang, Zongxin and Wang, Wenguan and Yang, Yi},
journal={arXiv preprint arXiv:2305.06558},
year={2023}
}
@article{kirillov2023segment,
title={Segment anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C and Lo, Wan-Yen and others},
journal={arXiv preprint arXiv:2304.02643},
year={2023}
}
@inproceedings{yang2022deaot,
title={Decoupling Features in Hierarchical Propagation for Video Object Segmentation},
author={Yang, Zongxin and Yang, Yi},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{yang2021aot,
title={Associating Objects with Transformers for Video Object Segmentation},
author={Yang, Zongxin and Wei, Yunchao and Yang, Yi},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2021}
}
@article{yang2024scalable,
title={Scalable video object segmentation with identification mechanism},
author={Yang, Zongxin and Miao, Jiaxu and Wei, Yunchao and Wang, Wenguan and Wang, Xiaohan and Yang, Yi},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
volume={46},
number={9},
pages={6247--6262},
year={2024},
publisher={IEEE}
}
@article{liu2023grounding,
title={Grounding dino: Marrying dino with grounded pre-training for open-set object detection},
author={Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others},
journal={arXiv preprint arXiv:2303.05499},
year={2023}
}
@inproceedings{gong21b_interspeech,
author={Yuan Gong and Yu-An Chung and James Glass},
title={AST: Audio Spectrogram Transformer},
booktitle={Proc. Interspeech 2021},
pages={571--575},
doi={10.21437/Interspeech.2021-698}
year={2021}
}
版本历史
v1.62024/04/25v1.52023/04/28v1.02023/04/25v0.52023/04/19常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
tesseract
Tesseract 是一款历史悠久且备受推崇的开源光学字符识别(OCR)引擎,最初由惠普实验室开发,后由 Google 维护,目前由全球社区共同贡献。它的核心功能是将图片中的文字转化为可编辑、可搜索的文本数据,有效解决了从扫描件、照片或 PDF 文档中提取文字信息的难题,是数字化归档和信息自动化的重要基础工具。 在技术层面,Tesseract 展现了强大的适应能力。从版本 4 开始,它引入了基于长短期记忆网络(LSTM)的神经网络 OCR 引擎,显著提升了行识别的准确率;同时,为了兼顾旧有需求,它依然支持传统的字符模式识别引擎。Tesseract 原生支持 UTF-8 编码,开箱即用即可识别超过 100 种语言,并兼容 PNG、JPEG、TIFF 等多种常见图像格式。输出方面,它灵活支持纯文本、hOCR、PDF、TSV 等多种格式,方便后续数据处理。 Tesseract 主要面向开发者、研究人员以及需要构建文档处理流程的企业用户。由于它本身是一个命令行工具和库(libtesseract),不包含图形用户界面(GUI),因此最适合具备一定编程能力的技术人员集成到自动化脚本或应用程序中