Skill_Seekers
Skill_Seekers 是一款专为 AI 系统打造的数据层工具,旨在将分散的知识源高效转化为结构化技能资产。它能自动抓取并处理文档网站、GitHub 仓库、PDF 文件、视频教程及笔记等多种格式的内容,将其快速封装为适用于 Claude、Gemini 等主流大模型的“技能包”,或直接接入 RAG(检索增强生成)流水线与 AI 编程助手。
在开发自定义 AI 应用时,用户常面临数据源格式杂乱、内容冲突难以识别以及预处理耗时过长等痛点。Skill_Seekers 通过内置的自动冲突检测机制,智能识别并解决不同来源间的信息矛盾,确保知识库的准确性与一致性,将原本需要数小时的手工整理工作缩短至几分钟。
这款工具特别适合开发者、AI 研究人员及技术团队使用。无论是希望为项目构建专属知识库的工程师,还是试图让 AI 助手深入理解特定技术栈的创作者,都能从中获益。其核心亮点在于支持超过 10 种数据源类型,提供丰富的预设配置,并原生集成 MCP(模型上下文协议),能够无缝嵌入现有的 LangChain、LlamaIndex 等工作流中。作为一个开源项目,Skill_Seekers 以简洁的命令行界面和灵活的扩展性,帮助用户轻松打通从原始数据到智能应用的“最后一公里”。
使用场景
某初创公司的后端团队急需将分散在官方文档站、GitHub 私有仓库及内部 PDF 规范中的微服务架构知识,快速转化为 Claude AI 可理解的专属技能,以辅助新入职工程师进行代码开发。
没有 Skill_Seekers 时
- 人工整理耗时极长:开发人员需手动复制粘贴网页内容、下载 PDF 并清洗格式,耗费数天才能拼凑出一份完整的知识库。
- 信息冲突难以察觉:不同来源的文档(如旧版 PDF 与新版 GitHub README)存在逻辑矛盾,人工核对极易遗漏,导致 AI 学习到错误指令。
- 知识更新滞后:一旦上游代码或文档变更,重新同步数据需要重复繁琐的手工流程,AI 助手往往基于过时的信息进行回答。
- 非结构化数据难利用:视频演示、Jupyter Notebook 等多模态资料无法直接被 AI 读取,大量高价值技术细节被闲置。
使用 Skill_Seekers 后
- 分钟级自动构建:只需配置源地址,Skill_Seekers 即可自动抓取网站、仓库和 PDF,并在几分钟内将其转换为结构化的 AI 技能资产。
- 智能冲突检测:工具内置算法自动识别并标记不同来源间的内容冲突,确保输入给 AI 的知识库逻辑一致且准确。
- 实时同步机制:结合 CI/CD 流水线,当源代码或文档更新时,Skill_Seekers 自动触发重新索引,保证 AI 始终掌握最新技术规范。
- 多源异构支持:轻松处理视频、Wiki、Notebook 等 10+ 种复杂数据源,将原本沉睡的非结构化资料全部转化为可调用的 AI 能力。
Skill_Seekers 通过将杂乱的多源技术文档瞬间转化为高质量、无冲突的结构化知识,让企业构建专属 AI 助手的时间从数天缩短至数分钟。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 仅在使用视频处理功能(skill-seekers[video])时可能需要 GPU 加速,具体型号和显存未说明
未说明

快速开始

技能探索者
English | 简体中文 | 日本語 | 한국어 | Español | Français | Deutsch | Português | Türkçe | العربية | हिन्दी | Русский
![]()
![]()
![]()
![]()
![]()
![]()
![]()


![]()




🧠 人工智能系统的数据层。 Skill Seekers 可以将文档网站、GitHub 仓库、PDF 文件、视频、笔记本、维基以及其他 10 多种来源类型转化为结构化的知识资产,从而在几分钟内而非几小时内为 AI 技能(Claude、Gemini、OpenAI)、RAG 流水线(LangChain、LlamaIndex、Pinecone)以及 AI 编码助手(Cursor、Windsurf、Cline)提供支持。
🌐 访问 SkillSeekersWeb.com - 浏览 24 种以上的预设配置,分享您的配置,并获取完整的文档!
📋 查看开发路线图与任务 - 10 个类别中共有 134 项任务,您可以选择任意一项参与贡献!
🌐 生态系统
Skill Seekers 是一个多仓库项目。以下是各个项目的存放位置:
| 仓库 | 描述 | 链接 |
|---|---|---|
| Skill_Seekers | 核心 CLI 和 MCP 服务器(本仓库) | PyPI |
| skillseekersweb | 网站和文档 | 在线 |
| skill-seekers-configs | 社区配置仓库 | |
| skill-seekers-action | 用于 CI/CD 的 GitHub Action | |
| skill-seekers-plugin | Claude Code 插件 | |
| homebrew-skill-seekers | macOS 的 Homebrew tap |
想参与贡献吗? 网站和配置仓库是新贡献者的好起点!
🧠 人工智能系统的数据层
Skill Seekers 是通用的预处理层,位于原始文档和所有消费这些文档的人工智能系统之间。无论您是在构建 Claude 技能、LangChain RAG 流水线,还是一份 Cursor .cursorrules 文件——数据准备过程都是相同的。您只需进行一次准备,即可导出到所有目标平台。
# 一条命令 → 结构化知识资产
skill-seekers create https://docs.react.dev/
# 或:skill-seekers create facebook/react
# 或:skill-seekers create ./my-project
# 导出到任何人工智能系统
skill-seekers package output/react --target claude # → Claude AI 技能 (ZIP)
skill-seekers package output/react --target langchain # → LangChain 文档
skill-seekers package output/react --target llama-index # → LlamaIndex TextNodes
skill-seekers package output/react --target cursor # → .cursorrules
构建的内容
| 输出 | 目标 | 支持的内容 |
|---|---|---|
| Claude 技能(ZIP + YAML) | --target claude |
Claude Code, Claude API |
| Gemini 技能(tar.gz) | --target gemini |
Google Gemini |
| OpenAI / 自定义 GPT(ZIP) | --target openai |
GPT-4o、自定义助手 |
| LangChain 文档 | --target langchain |
QA 链、代理、检索器 |
| LlamaIndex TextNodes | --target llama-index |
查询引擎、聊天引擎 |
| Haystack 文档 | --target haystack |
企业级 RAG 流水线 |
| Pinecone 就绪(Markdown) | --target markdown |
向量插入 |
| ChromaDB / FAISS / Qdrant | --format chroma/faiss/qdrant |
本地向量数据库 |
Cursor .cursorrules |
--target claude → 复制 |
Cursor IDE 的 AI 上下文 |
| Windsurf / Cline / Continue | --target claude → 复制 |
VS Code、IntelliJ、Vim |
为什么重要
- ⚡ 快 99% — 数天的手动数据准备 → 15–45 分钟
- 🎯 AI 技能质量 — 500 多行的 SKILL.md 文件,包含示例、模式和指南
- 📊 适合 RAG 的分块 — 智能分块保留代码块并维持上下文
- 🎬 视频 — 从 YouTube 和本地视频中提取代码、字幕和结构化的知识
- 🔄 多源整合 — 将 17 种来源类型(文档、GitHub、PDF、视频、笔记本、维基等)合并为一个知识资产
- 🌐 一次准备,多平台适用 — 将同一资产导出到 16 个平台,无需重新抓取
- ✅ 经过实战检验 — 2,540 多项测试、24 多种框架预设,可直接投入生产
🚀 快速入门(3 条命令)
# 1. 安装
pip install skill-seekers
# 2. 从任何来源创建技能
skill-seekers create https://docs.django.com/
# 3. 打包以供您的 AI 平台使用
skill-seekers package output/django --target claude
就是这样! 您现在拥有了 output/django-claude.zip,可以立即使用。
# 使用不同的 AI 代理进行增强(默认:claude)
skill-seekers create https://docs.django.com/ --agent kimi
skill-seekers create https://docs.django.com/ --agent codex
skill-seekers create https://docs.django.com/ --agent-cmd "my-custom-agent run"
其他来源(支持 17 种)
# GitHub 仓库
skill-seekers create facebook/react
# 本地项目
skill-seekers create ./my-project
# PDF 文档
skill-seekers create manual.pdf
# Word 文档
skill-seekers create report.docx
# EPUB 电子书
skill-seekers create book.epub
# Jupyter Notebook
skill-seekers create notebook.ipynb
# OpenAPI 规范
skill-seekers create openapi.yaml
# PowerPoint 演示文稿
skill-seekers create presentation.pptx
# AsciiDoc 文档
skill-seekers create guide.adoc
# 本地 HTML 文件
skill-seekers create page.html
# RSS/Atom 订阅源
skill-seekers create feed.rss
# 手册页
skill-seekers create curl.1
# 视频(YouTube、Vimeo 或本地文件 — 需要 skill-seekers[video])
skill-seekers video --url https://www.youtube.com/watch?v=... --name mytutorial
# 第一次使用?自动安装支持 GPU 的可视化依赖:
skill-seekers video --setup
# Confluence 维基
skill-seekers confluence --space TEAM --name wiki
# Notion 页面
skill-seekers notion --database-id ... --name docs
# Slack/Discord 聊天记录导出
skill-seekers chat --export-dir ./slack-export --name team-chat
导出到各平台
# 针对多个平台的打包
for platform in claude gemini openai langchain; do
skill-seekers package output/django --target $platform
done
Skill Seekers 是什么?
Skill Seekers 是 AI 系统的数据层。它能够将 17 种来源类型——文档网站、GitHub 仓库、PDF、视频、Jupyter Notebook、Word/EPUB/AsciiDoc 文档、OpenAPI 规范、PowerPoint 演示文稿、RSS 订阅源、手册页、Confluence 维基、Notion 页面、Slack/Discord 导出等——转化为结构化的知识资产,供各类 AI 目标使用:
| 使用场景 | 输出内容 | 示例 |
|---|---|---|
| AI 技能 | 全面的 SKILL.md + 引用 | Claude Code、Gemini、GPT |
| RAG 流水线 | 带有丰富元数据的分块文档 | LangChain、LlamaIndex、Haystack |
| 向量数据库 | 已格式化并可直接插入的数据 | Pinecone、Chroma、Weaviate、FAISS |
| AI 编程助手 | IDE 中的 AI 可自动读取的上下文文件 | Cursor、Windsurf、Cline、Continue.dev |
📚 文档
| 我想... | 阅读这篇 |
|---|---|
| 快速入门 | 快速入门 - 3 条命令即可获得首个技能 |
| 理解概念 | 核心概念 - 工作原理 |
| 抓取源数据 | 抓取指南 - 所有源类型 |
| 增强技能 | 增强指南 - AI 增强 |
| 导出技能 | 打包指南 - 平台导出 |
| 查找命令 | CLI 参考 - 所有 20 条命令 |
| 配置 | 配置格式 - JSON 规范 |
| 故障排除 | 故障排除 - 常见问题 |
完整文档: docs/README.md
与其花费数天进行手动预处理,Skill Seekers 能够:
- 摄取 — 文档、GitHub 仓库、本地代码库、PDF、视频、Notebook、维基等 10 多种来源
- 分析 — 深度 AST 解析、模式检测、API 提取
- 结构化 — 分类参考文件与元数据
- 增强 — AI 驱动的 SKILL.md 生成(Claude、Gemini 或本地模型)
- 导出 — 从一份资产中导出 16 种平台特定的格式
为什么使用它?
对于 AI 技能构建者(Claude、Gemini、OpenAI)
- 🎯 生产级技能 — 500 行以上的 SKILL.md 文件,包含代码示例、模式和指南
- 🔄 增强工作流 — 应用
security-focus、architecture-comprehensive或自定义 YAML 预设 - 🎮 任意领域 — 游戏引擎(Godot、Unity)、框架(React、Django)、内部工具
- 🔧 团队 — 将内部文档与代码整合为单一的事实来源
- 📚 高质量 — AI 增强,附带示例、快速参考和导航指引
对于 RAG 构建者及 AI 工程师
- 🤖 适合 RAG 的数据 — 预先分块的 LangChain
Documents、LlamaIndexTextNodes、HaystackDocuments - 🚀 快 99% — 数天的预处理 → 15–45 分钟
- 📊 智能元数据 — 分类、来源、类型 → 更高的检索准确率
- 🔄 多源整合 — 将文档、GitHub、PDF 和视频整合到一条流水线中
- 🌐 平台无关 — 可导出至任何向量数据库或框架,无需重新抓取
对于 AI 编程助手用户
- 💻 Cursor / Windsurf / Cline — 自动生成
.cursorrules/.windsurfrules/.clinerules - 🎯 持久上下文 — AI“了解”你的框架,无需反复提示
- 📚 始终最新 — 当文档更新时,可在几分钟内更新上下文
核心功能
🌐 文档抓取
- ✅ 智能 SPA 发现 - 三层发现机制,适用于 JavaScript SPA 网站(sitemap.xml → llms.txt → 无头浏览器渲染)
- ✅ llms.txt 支持 - 自动检测并使用 LLM 就绪的文档文件(速度提升 10 倍)
- ✅ 通用抓取器 - 适用于任何文档网站
- ✅ 智能分类 - 自动按主题组织内容
- ✅ 代码语言检测 - 识别 Python、JavaScript、C++、GDScript 等
- ✅ 24+ 即用预设 - Godot、React、Vue、Django、FastAPI 等
📄 PDF 支持
- ✅ 基础 PDF 提取 - 从 PDF 文件中提取文本、代码和图片
- ✅ 扫描 PDF 的 OCR - 从扫描文档中提取文本
- ✅ 密码保护的 PDF - 处理加密 PDF
- ✅ 表格提取 - 从 PDF 中提取复杂表格
- ✅ 并行处理 - 大型 PDF 处理速度提升 3 倍
- ✅ 智能缓存 - 再次运行时速度提升 50%
🎬 视频提取
- ✅ YouTube 和本地视频 - 从视频中提取字幕、屏幕上的代码以及结构化知识
- ✅ 视觉帧分析 - 从代码编辑器、终端、幻灯片和图表中提取 OCR 数据
- ✅ GPU 自动检测 - 自动安装正确的 PyTorch 版本(CUDA/ROCm/MPS/CPU)
- ✅ AI 增强 - 两步流程:清除 OCR 杂质 + 生成精炼的 SKILL.md
- ✅ 时间剪辑 - 使用
--start-time和--end-time提取特定片段 - ✅ 播放列表支持 - 批量处理 YouTube 播放列表中的所有视频
- ✅ Vision API 备用 - 在 OCR 置信度较低时使用 Claude Vision
🐙 GitHub 仓库分析
- ✅ 深度代码分析 - 对 Python、JavaScript、TypeScript、Java、C++、Go 进行 AST 解析
- ✅ API 提取 - 函数、类、方法及其参数和类型
- ✅ 仓库元数据 - README、文件树、语言分布、星标/分支数
- ✅ GitHub 问题和 PR - 获取已关闭和未解决的问题,附带标签和里程碑
- ✅ CHANGELOG 和发布 - 自动提取版本历史
- ✅ 冲突检测 - 比较文档中的 API 与实际代码实现
- ✅ MCP 集成 - 自然语言输入:“抓取 GitHub 仓库 facebook/react”
🔄 统一多源抓取
- ✅ 整合多个来源 - 将文档、GitHub 和 PDF 混合到一个技能中
- ✅ 冲突检测 - 自动发现文档与代码之间的不一致
- ✅ 智能合并 - 基于规则或 AI 驱动的冲突解决
- ✅ 透明报告 - 并排对比,并附带 ⚠️ 警告
- ✅ 文档缺口分析 - 识别过时的文档和未记录的功能
- ✅ 单一事实来源 - 一个技能同时展示意图(文档)和现实(代码)
- ✅ 向后兼容 - 旧版单源配置仍可正常工作
🤖 多 LLM 平台支持
- ✅ 12 个 LLM 平台 - Claude AI、Google Gemini、OpenAI ChatGPT、MiniMax AI、通用 Markdown、OpenCode、Kimi(Moonshot AI)、DeepSeek AI、Qwen(阿里巴巴)、OpenRouter、Together AI、Fireworks AI
- ✅ 通用抓取 - 同一份文档适用于所有平台
- ✅ 平台特定打包 - 针对每个 LLM 优化格式
- ✅ 一键导出 - 使用
--target标志选择平台 - ✅ 可选依赖 - 只安装你需要的部分
- ✅ 100% 向后兼容 - 现有 Claude 工作流无需更改
| 平台 | 格式 | 上传 | 增强 | API 密钥 | 自定义端点 |
|---|---|---|---|---|---|
| Claude AI | ZIP + YAML | ✅ 自动 | ✅ 是 | ANTHROPIC_API_KEY | ANTHROPIC_BASE_URL |
| Google Gemini | tar.gz | ✅ 自动 | ✅ 是 | GOOGLE_API_KEY | - |
| OpenAI ChatGPT | ZIP + 向量存储 | ✅ 自动 | ✅ 是 | OPENAI_API_KEY | - |
| MiniMax AI | ZIP + 知识文件 | ✅ 自动 | ✅ 是 | MINIMAX_API_KEY | - |
| 通用 Markdown | ZIP | ❌ 手动 | ❌ 否 | - | - |
# Claude(默认,无需更改!)
skill-seekers package output/react/
skill-seekers upload react.zip
# Google Gemini
pip install skill-seekers[gemini]
skill-seekers package output/react/ --target gemini
skill-seekers upload react-gemini.tar.gz --target gemini
# OpenAI ChatGPT
pip install skill-seekers[openai]
skill-seekers package output/react/ --target openai
skill-seekers upload react-openai.zip --target openai
# MiniMax AI
pip install skill-seekers[minimax]
skill-seekers package output/react/ --target minimax
skill-seekers upload react-minimax.zip --target minimax
# 通用 Markdown(通用导出)
skill-seekers package output/react/ --target markdown
# 直接在任何 LLM 中使用这些 Markdown 文件
🔧 Claude 兼容 API 的环境变量(例如 GLM-4.7)
Skill Seekers 支持任何 Claude 兼容的 API 端点:
# 选项 1:官方 Anthropic API(默认)
export ANTHROPIC_API_KEY=sk-ant-...
# 选项 2:GLM-4.7 Claude 兼容 API
export ANTHROPIC_API_KEY=your-glm-47-api-key
export ANTHROPIC_BASE_URL=https://glm-4-7-endpoint.com/v1
# 所有 AI 增强功能都将使用配置的端点
skill-seekers enhance output/react/
skill-seekers analyze --directory . --enhance
注意:设置 ANTHROPIC_BASE_URL 允许你使用任何 Claude 兼容的 API 端点,比如 GLM-4.7(智谱 AI)或其他兼容服务。
安装:
# 安装支持 Gemini 的版本
pip install skill-seekers[gemini]
# 安装支持 OpenAI 的版本
pip install skill-seekers[openai]
# 安装支持 MiniMax 的版本
pip install skill-seekers[minimax]
# 安装支持所有 LLM 平台的版本
pip install skill-seekers[all-llms]
🔗 RAG 框架集成
✅ LangChain Documents - 直接导出为
Document格式,包含page_content和元数据- 非常适合:问答链、检索器、向量存储、代理
- 示例:LangChain RAG 流程
- 指南:LangChain 集成
✅ LlamaIndex TextNodes - 导出为
TextNode格式,带有唯一 ID 和嵌入- 非常适合:查询引擎、聊天引擎、存储上下文
- 示例:LlamaIndex 查询引擎
- 指南:LlamaIndex 集成
✅ Pinecone 就绪格式 - 优化用于向量数据库的插入更新操作
- 非常适合:生产级向量搜索、语义搜索、混合搜索
- 示例:Pinecone 插入更新
- 指南:Pinecone 集成
快速导出:
# LangChain Documents(JSON)
skill-seekers package output/django --target langchain
# → output/django-langchain.json
# LlamaIndex TextNodes(JSON)
skill-seekers package output/django --target llama-index
# → output/django-llama-index.json
# Markdown(通用)
skill-seekers package output/django --target markdown
# → output/django-markdown/SKILL.md + references/
完整的 RAG 流程指南:RAG 流程文档
🧠 AI 编码助手集成
将任何框架的文档转化为专家级编码上下文,供 4 种以上的 AI 助手使用:
✅ Cursor IDE - 生成
.cursorrules文件,用于 AI 驱动的代码建议- 非常适合:框架特定的代码生成、一致性模式
- 适用:Cursor IDE(VS Code 分支)
- 指南:Cursor 集成
- 示例:Cursor React 技能
✅ Windsurf - 使用
.windsurfrules自定义 Windsurf 的 AI 助手上下文- 非常适合:IDE 原生 AI 辅助、基于流程的编码
- 适用:Codeium 的 Windsurf IDE
- 指南:Windsurf 集成
- 示例:Windsurf FastAPI 上下文
✅ Cline(VS Code) - 系统提示 + MCP,用于 VS Code 代理
- 非常适合:在 VS Code 中进行代理式代码生成
- 适用:Cline 扩展(VS Code)
- 指南:Cline 集成
- 示例:Cline Django 助手
✅ Continue.dev - 为跨 IDE 的 AI 提供上下文服务器
- 非常适合:多 IDE 环境(VS Code、JetBrains、Vim),自定义 LLM 提供者
- 适用:任何安装了 Continue.dev 插件的 IDE
- 指南:Continue 集成
- 示例:Continue 通用上下文
针对 AI 编码工具的快速导出:
# 适用于任何 AI 编码助手(Cursor、Windsurf、Cline、Continue.dev)
skill-seekers scrape --config configs/django.json
skill-seekers package output/django --target claude # 或 --target markdown
# 复制到你的项目中(以 Cursor 为例)
cp output/django-claude/SKILL.md my-project/.cursorrules
# 或者用于 Windsurf
cp output/django-claude/SKILL.md my-project/.windsurf/rules/django.md
# 或者用于 Cline
cp output/django-claude/SKILL.md my-project/.clinerules
# 或者用于 Continue.dev(HTTP 服务器)
python examples/continue-dev-universal/context_server.py
# 在 ~/.continue/config.json 中进行配置
集成中心:所有 AI 系统集成
🌊 三流 GitHub 架构
- ✅ 三重流分析 - 将 GitHub 仓库拆分为代码、文档和洞察三个流
- ✅ 统一代码库分析器 - 支持 GitHub URL 和本地路径
- ✅ C3.x 作为分析深度 - 可选择“basic”(1-2 分钟)或“c3x”(20-60 分钟)分析
- ✅ 增强的路由生成 - 包含 GitHub 元数据、README 快速入门指南及常见问题
- ✅ 问题集成 - 从 GitHub 问题中提取顶级问题及其解决方案
- ✅ 智能路由关键词 - GitHub 标签权重提升 2 倍,以更好地检测主题
三流详解:
- 流 1:代码 - 深度 C3.x 分析(模式、示例、指南、配置、架构)
- 流 2:文档 - 仓库文档(README、CONTRIBUTING、docs/*.md)
- 流 3:洞察 - 社区知识(问题、标签、星标、分支)
from skill_seekers.cli.unified_codebase_analyzer import UnifiedCodebaseAnalyzer
# 使用所有三流分析 GitHub 仓库
analyzer = UnifiedCodebaseAnalyzer()
result = analyzer.analyze(
source="https://github.com/facebook/react",
depth="c3x", # 或 "basic" 进行快速分析
fetch_github_metadata=True
)
# 访问代码流(C3.x 分析)
print(f"设计模式: {len(result.code_analysis['c3_1_patterns'])}")
print(f"测试示例: {result.code_analysis['c3_2_examples_count']}")
# 访问文档流(仓库文档)
print(f"README: {result.github_docs['readme'][:100]}")
# 访问洞察流(GitHub 元数据)
print(f"星标数: {result.github_insights['metadata']['stars']}")
print(f"常见问题: {len(result.github_insights['common_problems'])}")
查看完整文档:三流实现摘要
🔐 智能速率限制管理与配置
- ✅ 多令牌配置系统 - 管理多个 GitHub 账户(个人、工作、开源项目)
- 安全配置存储于
~/.config/skill-seekers/config.json(权限 600) - 每个账户的速率限制策略:提示、等待、切换、失败
- 可配置每个账户的超时时间(默认 30 分钟,防止无限等待)
- 智能回退链:CLI 参数 → 环境变量 → 配置文件 → 提示
- 支持 Claude、Gemini、OpenAI 的 API 密钥管理
- 安全配置存储于
- ✅ 交互式配置向导 - 美观的终端 UI,便于设置
- 浏览器集成用于创建令牌(自动打开 GitHub 等)
- 令牌验证和连接测试
- 带颜色编码的可视化状态显示
- ✅ 智能速率限制处理器 - 再也不用无限等待了!
- 提前警告速率限制情况(60/小时 vs 5000/小时)
- 实时从 GitHub API 响应中检测
- 带进度的倒计时定时器
- 当达到速率限制时自动切换账户
- 四种策略:提示(询问)、等待(倒计时)、切换(尝试其他账户)、失败(终止)
- ✅ 恢复功能 - 继续中断的任务
- 按可配置间隔自动保存进度(默认 60 秒)
- 列出所有可恢复任务及其进度详情
- 自动清理旧任务(默认 7 天)
- ✅ CI/CD 支持 - 非交互模式,适用于自动化
--non-interactive标志会快速失败,不弹出提示--profile标志用于选择特定 GitHub 账户- 清晰的错误信息,便于流水线日志记录
快速设置:
# 一次性配置(5 分钟)
skill-seekers config --github
# 使用特定账户访问私有仓库
skill-seekers github --repo mycompany/private-repo --profile work
# CI/CD 模式(快速失败,无提示)
skill-seekers github --repo owner/repo --non-interactive
# 恢复中断的任务
skill-seekers resume --list
skill-seekers resume github_react_20260117_143022
速率限制策略说明:
- prompt(默认) - 当达到速率限制时询问如何处理(等待、切换、设置令牌、取消)
- wait - 自动等待并显示倒计时(尊重超时设置)
- switch - 自动尝试下一个可用账户(适用于多账户设置)
- fail - 立即失败并给出明确错误信息(非常适合 CI/CD)
🎯 引导技能 - 自托管
将 skill-seekers 打包为技能,以便在您的 AI 代理(Claude Code、Kimi、Codex 等)中使用:
# 生成技能
./scripts/bootstrap_skill.sh
# 安装到 Claude Code
cp -r output/skill-seekers ~/.claude/skills/
您将获得:
- ✅ 完整的技能文档 - 所有 CLI 命令和使用模式
- ✅ CLI 命令参考 - 记录了每个工具及其选项
- ✅ 快速入门示例 - 常见工作流程和最佳实践
- ✅ 自动生成的 API 文档 - 包括代码分析、模式和示例
🔐 私有配置仓库
- ✅ 基于 Git 的配置源 - 从私有/团队 Git 仓库获取配置
- ✅ 多源管理 - 注册不限数量的 GitHub、GitLab、Bitbucket 仓库
- ✅ 团队协作 - 在 3-5 人团队内共享自定义配置
- ✅ 企业支持 - 可扩展至 500 多名开发者,并提供优先级解决机制
- ✅ 安全认证 - 使用环境变量令牌(GITHUB_TOKEN、GITLAB_TOKEN)
- ✅ 智能缓存 - 克隆一次,自动拉取更新
- ✅ 离线模式 - 即使离线也能使用缓存配置
🤖 代码库分析(C3.x)
C3.4:AI 增强的配置模式提取
- ✅ 9 种配置格式 - JSON、YAML、TOML、ENV、INI、Python、JavaScript、Dockerfile、Docker Compose
- ✅ 7 种模式类型 - 数据库、API、日志、缓存、邮件、认证、服务器配置
- ✅ AI 增强 - 可选双模 AI 分析(API + LOCAL)
- 解释每种配置的作用
- 提供建议和改进建议
- 安全分析 - 查找硬编码的秘密和暴露的凭据
- ✅ 自动文档化 - 生成所有配置的 JSON + Markdown 文档
- ✅ MCP 集成 -
extract_config_patterns工具支持增强功能
C3.3:AI 增强的教程指南
- ✅ 全面的 AI 增强 - 将基础指南转化为专业教程
- ✅ 5 项自动改进 - 步骤描述、故障排除、先决条件、后续步骤、使用场景
- ✅ 双模支持 - API 模式(Claude API)或 LOCAL 模式(Claude Code CLI)
- ✅ LOCAL 模式无需 API 费用 - 使用您的 Claude Code Max 方案即可免费增强
- ✅ 质量飞跃 - 75 行模板 → 500+ 行综合指南
使用方法:
# 快速分析(1-2 分钟,仅基础功能)
skill-seekers analyze --directory tests/ --quick
# 全面分析(20-60 分钟,所有功能)
skill-seekers analyze --directory tests/ --comprehensive
# 含 AI 增强
skill-seekers analyze --directory tests/ --enhance
🔄 增强工作流预设
可重用的 YAML 定义增强流水线,控制 AI 如何将您的原始文档转换为完善的技能。
- ✅ 5 个捆绑预设 —
default、minimal、security-focus、architecture-comprehensive、api-documentation - ✅ 用户自定义预设 — 将自定义工作流添加到
~/.config/skill-seekers/workflows/ - ✅ 多工作流 — 在一个命令中串联两个或多个工作流
- ✅ 完全管理的 CLI — 列出、检查、复制、添加、删除和验证工作流
# 应用单个工作流
skill-seekers create ./my-project --enhance-workflow security-focus
# 串联多个工作流(按顺序应用)
skill-seekers create ./my-project \
--enhance-workflow security-focus \
--enhance-workflow minimal
# 管理预设
skill-seekers workflows list # 列出所有(捆绑 + 用户)
skill-seekers workflows show security-focus # 打印 YAML 内容
skill-seekers workflows copy security-focus # 复制到用户目录以便编辑
skill-seekers workflows add ./my-workflow.yaml # 安装自定义预设
skill-seekers workflows remove my-workflow # 删除用户预设
skill-seekers workflows validate security-focus # 验证预设结构
# 一次性复制多个
skill-seekers workflows copy security-focus minimal api-documentation
# 一次性添加多个文件
skill-seekers workflows add ./wf-a.yaml ./wf-b.yaml
# 一次性删除多个
skill-seekers workflows remove my-wf-a my-wf-b
YAML 预设格式:
name: security-focus
description: "以安全为重点的审查:漏洞、认证、数据处理"
version: "1.0"
stages:
- name: vulnerabilities
type: custom
prompt: "审查 OWASP 十大常见安全漏洞..."
- name: auth-review
type: custom
prompt: "检查身份验证和授权模式..."
uses_history: true
⚡ 性能与规模
- ✅ 异步模式 - 使用 async/await 可使抓取速度提升 2-3 倍(使用
--async标志) - ✅ 大型文档支持 - 通过智能拆分,可处理 1 万至 4 万页以上的文档
- ✅ 路由器/集线器技能 - 智能路由至专业子技能
- ✅ 并行抓取 - 同时处理多个技能
- ✅ 断点续传 - 长时间抓取任务不会丢失进度
- ✅ 缓存系统 - 抓取一次,即可立即重建
🤖 代理无关的技能生成
- ✅ 多代理支持 - 可为 Claude、Kimi、Codex、Copilot、OpenCode 或任何自定义代理生成技能,只需使用
--agent标志 - ✅ 自定义代理命令 - 使用
--agent-cmd指定用于增强的自定义代理 CLI 命令 - ✅ 通用标志 -
--agent和--agent-cmd适用于所有命令(创建、抓取、GitHub、PDF 等)
📦 市场管道
- ✅ 发布到市场 - 将技能发布到 Claude Code 插件市场仓库
- ✅ 端到端管道 - 从文档源到已发布的市场条目
✅ 质量保证
- ✅ 全面测试 - 2,540 多项测试,覆盖全面
📦 安装
# 基本安装(文档抓取、GitHub 分析、PDF、打包)
pip install skill-seekers
# 包含所有 LLM 平台支持
pip install skill-seekers[all-llms]
# 包含 MCP 服务器
pip install skill-seekers[mcp]
# 全部功能
pip install skill-seekers[all]
需要帮助选择吗? 运行设置向导:
skill-seekers-setup
安装选项
| 安装 | 功能 |
|---|---|
pip install skill-seekers |
抓取、GitHub 分析、PDF、所有平台 |
pip install skill-seekers[gemini] |
+ Google Gemini 支持 |
pip install skill-seekers[openai] |
+ OpenAI ChatGPT 支持 |
pip install skill-seekers[all-llms] |
+ 所有 LLM 平台 |
pip install skill-seekers[mcp] |
+ MCP 服务器,适用于 Claude Code、Cursor 等 |
pip install skill-seekers[video] |
+ YouTube/Vimeo 字幕及元数据提取 |
pip install skill-seekers[video-full] |
+ Whisper 转录及视觉帧提取 |
pip install skill-seekers[jupyter] |
+ Jupyter Notebook 支持 |
pip install skill-seekers[pptx] |
+ PowerPoint 支持 |
pip install skill-seekers[confluence] |
+ Confluence Wiki 支持 |
pip install skill-seekers[notion] |
+ Notion 页面支持 |
pip install skill-seekers[rss] |
+ RSS/Atom 订阅支持 |
pip install skill-seekers[chat] |
+ Slack/Discord 聊天记录导出支持 |
pip install skill-seekers[asciidoc] |
+ AsciiDoc 文档支持 |
pip install skill-seekers[all] |
启用所有功能 |
视频视觉依赖(GPU 感知): 安装
skill-seekers[video-full]后,运行skill-seekers video --setup自动检测您的 GPU 并安装正确的 PyTorch 版本 + easyocr。这是安装视觉提取依赖的推荐方式。
🚀 一键安装流程
从配置到上传技能的最快方式——完全自动化:
# 从官方配置安装 React 技能(自动上传至 Claude)
skill-seekers install --config react
# 从本地配置文件安装
skill-seekers install --config configs/custom.json
# 不上传(仅打包)
skill-seekers install --config django --no-upload
# 预览工作流而不执行
skill-seekers install --config react --dry-run
耗时: 总共 20-45 分钟 | 质量: 生产就绪(9/10)| 成本: 免费
执行阶段:
📥 第 1 阶段:获取配置(如果提供了配置名称)
📖 第 2 阶段:抓取文档
✨ 第 3 阶段:AI 增强(强制性——不可跳过)
📦 第 4 阶段:打包技能
☁️ 第 5 阶段:上传至 Claude(可选,需 API 密钥)
要求:
- ANTHROPIC_API_KEY 环境变量(用于自动上传)
- Claude Code Max 方案(用于本地 AI 增强),或使用
--agent选择其他 AI 代理
📊 功能矩阵
Skill Seekers 支持 12 个 LLM 平台、17 种来源类型,并在所有目标上实现功能对等。
平台: Claude AI、Google Gemini、OpenAI ChatGPT、MiniMax AI、通用 Markdown、OpenCode、Kimi(Moonshot AI)、DeepSeek AI、Qwen(Alibaba)、OpenRouter、Together AI、Fireworks AI
来源类型: 文档网站、GitHub 仓库、PDF、Word (.docx)、EPUB、视频、本地代码库、Jupyter 笔记books、本地 HTML、OpenAPI/Swagger、AsciiDoc、PowerPoint (.pptx)、RSS/Atom 订阅、Man 页面、Confluence 维基、Notion 页面、Slack/Discord 聊天记录导出
详细平台和功能支持,请参阅 完整功能矩阵。
快速平台比较
| 功能 | Claude | Gemini | OpenAI | MiniMax | Markdown |
|---|---|---|---|---|---|
| 格式 | ZIP + YAML | tar.gz | ZIP + Vector | ZIP + Knowledge | ZIP |
| 上传 | ✅ API | ✅ API | ✅ API | ✅ API | ❌ 手动 |
| 增强 | ✅ Sonnet 4 | ✅ 2.0 Flash | ✅ GPT-4o | ✅ M2.7 | ❌ 无 |
| 所有技能模式 | ✅ | ✅ | ✅ | ✅ | ✅ |
使用示例
文档抓取
# 抓取文档网站
skill-seekers scrape --config configs/react.json
# 无需配置的快速抓取
skill-seekers scrape --url https://react.dev --name react
# 使用异步模式(速度提升3倍)
skill-seekers scrape --config configs/godot.json --async --workers 8
# 使用特定的AI智能体进行增强
skill-seekers scrape --config configs/react.json --agent kimi
PDF 提取
# 基本PDF提取
skill-seekers pdf --pdf docs/manual.pdf --name myskill
# 高级功能
skill-seekers pdf --pdf docs/manual.pdf --name myskill \
--extract-tables \ # 提取表格
--parallel \ # 快速并行处理
--workers 8 # 使用8个CPU核心
# 扫描版PDF(需安装:pip install pytesseract Pillow)
skill-seekers pdf --pdf docs/scanned.pdf --name myskill --ocr
视频提取
# 安装视频支持
pip install skill-seekers[video] # 提供字幕和元数据
pip install skill-seekers[video-full] # 包含Whisper和视觉帧提取
# 自动检测GPU并安装视觉依赖项(PyTorch + easyocr)
skill-seekers video --setup
# 从YouTube视频中提取内容
skill-seekers video --url https://www.youtube.com/watch?v=dQw4w9WgXcQ --name mytutorial
# 从YouTube播放列表中提取内容
skill-seekers video --playlist https://www.youtube.com/playlist?list=... --name myplaylist
# 从本地视频文件中提取内容
skill-seekers video --video-file recording.mp4 --name myrecording
# 带视觉帧分析的提取(需安装video-full依赖)
skill-seekers video --url https://www.youtube.com/watch?v=... --name mytutorial --visual
# 使用AI增强(清理OCR文本并生成精美的SKILL.md)
skill-seekers video --url https://www.youtube.com/watch?v=... --visual --enhance-level 2
# 截取视频的特定片段(支持秒数、MM:SS、HH:MM:SS格式)
skill-seekers video --url https://www.youtube.com/watch?v=... --start-time 1:30 --end-time 5:00
# 对低置信度OCR帧使用Vision API(需设置ANTHROPIC_API_KEY)
skill-seekers video --url https://www.youtube.com/watch?v=... --visual --vision-ocr
# 从先前提取的数据重建技能(跳过下载步骤)
skill-seekers video --from-json output/mytutorial/video_data/extracted_data.json --name mytutorial
完整指南: 请参阅 docs/VIDEO_GUIDE.md,了解完整的CLI参考、视觉流程细节、AI增强选项以及故障排除方法。
GitHub 仓库分析
# 基本仓库抓取
skill-seekers github --repo facebook/react
# 使用认证(提高速率限制)
export GITHUB_TOKEN=ghp_your_token_here
skill-seekers github --repo facebook/react
# 自定义包含内容
skill-seekers github --repo django/django \
--include-issues \ # 提取GitHub Issues
--max-issues 100 \ # 限制Issue数量
--include-changelog # 提取CHANGELOG.md
统一多源抓取
将文档、GitHub和PDF整合为一个统一的技能,并自动检测冲突:
# 使用现有的统一配置
skill-seekers unified --config configs/react_unified.json
skill-seekers unified --config configs/django_unified.json
# 或者创建统一配置
cat > configs/myframework_unified.json << 'EOF'
{
"name": "myframework",
"merge_mode": "rule-based",
"sources": [
{
"type": "documentation",
"base_url": "https://docs.myframework.com/",
"max_pages": 200
},
{
"type": "github",
"repo": "owner/myframework",
"code_analysis_depth": "surface"
}
]
}
EOF
skill-seekers unified --config configs/myframework_unified.json
冲突检测会自动识别:
- 🔴 代码中缺失(高优先级):文档中有但代码中未实现
- 🟡 文档中缺失(中优先级):代码中已实现但文档未记录
- ⚠️ 签名不匹配:参数或类型不同
- ℹ️ 描述不匹配:解释内容不一致
完整指南: 请参阅 docs/UNIFIED_SCRAPING.md 获取完整说明。
私有配置仓库
通过私有Git仓库在团队间共享自定义配置:
# 选项1:使用MCP工具(推荐)
# 注册团队的私有仓库
add_config_source(
name="team",
git_url="https://github.com/mycompany/skill-configs.git",
token_env="GITHUB_TOKEN"
)
# 从团队仓库获取配置
fetch_config(source="team", config_name="internal-api")
支持的平台:
- GitHub (
GITHUB_TOKEN)、GitLab (GITLAB_TOKEN)、Gitea (GITEA_TOKEN)、Bitbucket (BITBUCKET_TOKEN)
完整指南: 请参阅 docs/GIT_CONFIG_SOURCES.md 获取完整说明。
工作原理
graph LR
A[文档网站] --> B[Skill Seekers]
B --> C[抓取器]
B --> D[AI增强]
B --> E[打包器]
C --> F[整理后的参考资料]
D --> F
F --> E
E --> G[AI技能.zip]
G --> H[上传至AI平台]
- 检测llms.txt - 首先检查llms-full.txt、llms.txt、llms-small.txt(属于Smart SPA Discovery的一部分)
- 抓取:提取文档中的所有页面
- 分类:将内容组织成主题(API、指南、教程等)
- 增强:AI分析文档并创建包含示例的全面SKILL.md文件(可通过
--agent参数支持多种智能体) - 打包:将所有内容打包成适合平台使用的
.zip文件
架构
系统由8个核心模块和5个工具模块组成(总计约200个类):
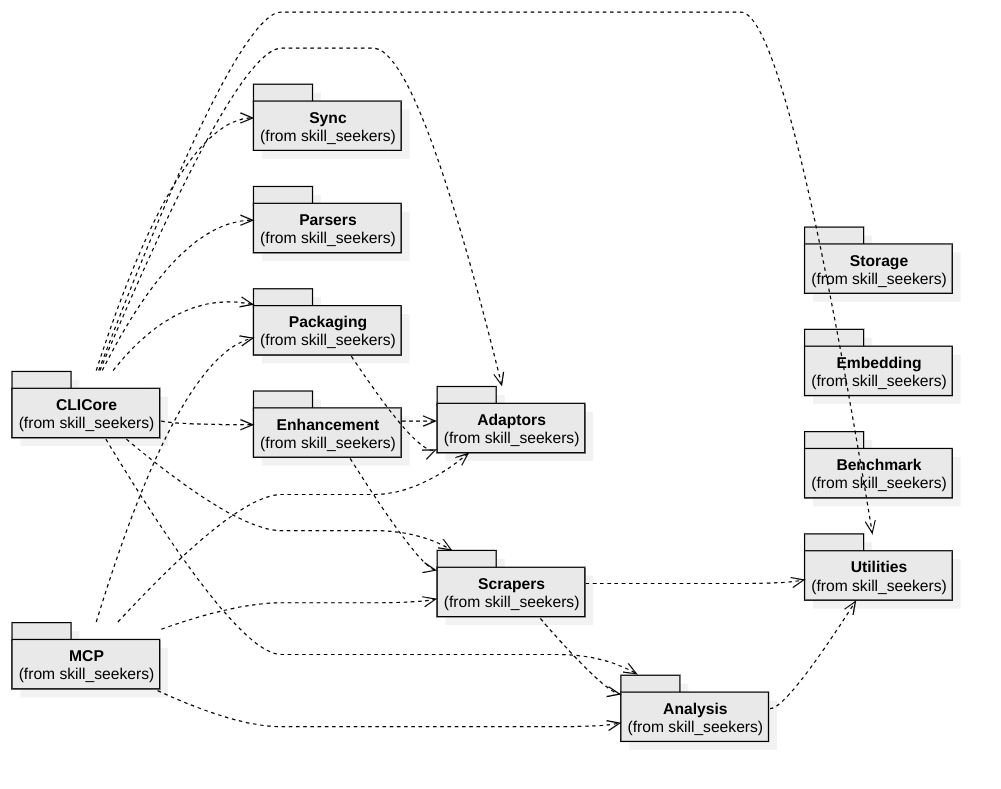
| 模块 | 目的 | 关键类 |
|---|---|---|
| CLICore | Git风格的命令分发器 | CLIDispatcher、SourceDetector、CreateCommand |
| Scrapers | 17种来源类型的提取器 | DocToSkillConverter、GitHubScraper、UnifiedScraper |
| Adaptors | 20多种输出平台格式 | SkillAdaptor(ABC)、ClaudeAdaptor、LangChainAdaptor |
| Analysis | C3.x代码库分析流水线 | UnifiedCodebaseAnalyzer、PatternRecognizer、10种GoF检测器 |
| Enhancement | 基于AI的技能改进,通过AgentClient实现 |
AgentClient、AIEnhancer、UnifiedEnhancer、WorkflowEngine |
| Packaging | 打包、上传、安装技能 | PackageSkill、InstallAgent |
| MCP | FastMCP服务器(40种工具) | SkillSeekerMCPServer、10个工具模块 |
| Sync | 文档变更检测 | ChangeDetector、SyncMonitor、Notifier |
工具模块:解析器(28种CLI解析器)、存储(S3/GCS/Azure)、嵌入(多提供商向量)、基准测试(性能)、实用工具(16种共享助手)。
完整UML图:docs/UML_ARCHITECTURE.md | StarUML项目:docs/UML/skill_seekers.mdj | HTML API参考:docs/UML/html/
📋 前置条件
在开始之前,请确保您已具备以下内容:
首次使用? → 从这里开始:防弹快速入门指南 🎯
📤 将技能上传至 Claude
当您的技能打包完成后,需要将其上传至 Claude:
选项 1:自动上传(基于 API)
# 设置您的 API 密钥(仅需一次)
export ANTHROPIC_API_KEY=sk-ant-...
# 自动打包并上传
skill-seekers package output/react/ --upload
# 或者上传现有的 .zip 文件
skill-seekers upload output/react.zip
选项 2:手动上传(无需 API 密钥)
# 打包技能
skill-seekers package output/react/
# → 生成 output/react.zip
# 然后手动上传:
# - 访问 https://claude.ai/skills
# - 点击“上传技能”
# - 选择 output/react.zip
选项 3:MCP(Claude Code)
在 Claude Code 中,只需询问:
“打包并上传 React 技能”
🤖 安装到 AI 代理
Skill Seekers 可以自动将技能安装到 18 种 AI 编程代理中。
# 安装到特定代理
skill-seekers install-agent output/react/ --agent cursor
# 一次性安装到所有代理
skill-seekers install-agent output/react/ --agent all
# 预览而不安装
skill-seekers install-agent output/react/ --agent cursor --dry-run
支持的代理
| 代理 | 路径 | 类型 |
|---|---|---|
| Claude Code | ~/.claude/skills/ |
全局 |
| Cursor | .cursor/skills/ |
项目 |
| VS Code / Copilot | .github/skills/ |
项目 |
| Amp | ~/.amp/skills/ |
全局 |
| Goose | ~/.config/goose/skills/ |
全局 |
| OpenCode | ~/.opencode/skills/ |
全局 |
| Windsurf | ~/.windsurf/skills/ |
全局 |
| Roo Code | .roo/skills/ |
项目 |
| Cline | .cline/skills/ |
项目 |
| Aider | ~/.aider/skills/ |
全局 |
| Bolt | .bolt/skills/ |
项目 |
| Kilo Code | .kilo/skills/ |
项目 |
| Continue | ~/.continue/skills/ |
全局 |
| Kimi Code | ~/.kimi/skills/ |
全局 |
🔌 MCP 集成(26 种工具)
Skill Seekers 提供了一个 MCP 服务器,可用于 Claude Code、Cursor、Windsurf、VS Code + Cline 或 IntelliJ IDEA。
# stdio 模式(Claude Code、VS Code + Cline)
python -m skill_seekers.mcp.server_fastmcp
# HTTP 模式(Cursor、Windsurf、IntelliJ)
python -m skill_seekers.mcp.server_fastmcp --transport http --port 8765
# 一次性自动配置所有代理
./setup_mcp.sh
所有 26 种工具可用:
- 核心(9):
list_configs、generate_config、validate_config、estimate_pages、scrape_docs、package_skill、upload_skill、enhance_skill、install_skill - 扩展(10):
scrape_github、scrape_pdf、unified_scrape、merge_sources、detect_conflicts、add_config_source、fetch_config、list_config_sources、remove_config_source、split_config - 向量数据库(4):
export_to_chroma、export_to_weaviate、export_to_faiss、export_to_qdrant - 云服务(3):
cloud_upload、cloud_download、cloud_list
完整指南: docs/MCP_SETUP.md
⚙️ 配置
可用预设(24+)
# 列出所有预设
skill-seekers list-configs
| 类别 | 预设 |
|---|---|
| Web 框架 | react、vue、angular、svelte、nextjs |
| Python | django、flask、fastapi、sqlalchemy、pytest |
| 游戏开发 | godot、pygame、unity |
| 工具与 DevOps | docker、kubernetes、terraform、ansible |
| 统一版(文档 + GitHub) | react-unified、vue-unified、nextjs-unified 等等 |
创建您自己的配置
# 选项 1:交互式
skill-seekers scrape --interactive
# 选项 2:复制并编辑预设
cp configs/react.json configs/myframework.json
nano configs/myframework.json
skill-seekers scrape --config configs/myframework.json
配置文件结构
{
"name": "myframework",
"description": "何时使用此技能",
"base_url": "https://docs.myframework.com/",
"selectors": {
"main_content": "article",
"title": "h1",
"code_blocks": "pre code"
},
"url_patterns": {
"include": ["/docs", "/guide"],
"exclude": ["/blog", "/about"]
},
"categories": {
"getting_started": ["intro", "quickstart"],
"api": ["api", "reference"]
},
"rate_limit": 0.5,
"max_pages": 500
}
配置存储位置
该工具会按以下顺序搜索配置:
- 提供的确切路径
./configs/(当前目录)~/.config/skill-seekers/configs/(用户配置目录)- SkillSeekersWeb.com API(预设配置)
📊 生成的内容
output/
├── godot_data/ # 抓取的原始数据
│ ├── pages/ # JSON 文件(每页一个)
│ └── summary.json # 概述
│
└── godot/ # 生成的技能
├── SKILL.md # 使用真实示例增强
├── references/ # 分类后的文档
│ ├── index.md
│ ├── getting_started.md
│ ├── scripting.md
│ └── ...
├── scripts/ # 空的(可自行添加)
└── assets/ # 空的(可自行添加)
🐛 故障排除
没有提取到内容?
- 检查您的
main_content选择器 - 尝试:
article、main、div[role="main"]
数据存在但不被使用?
# 强制重新抓取
rm -rf output/myframework_data/
skill-seekers scrape --config configs/myframework.json
分类不够好?
编辑配置中的 categories 部分,使用更合适的关键词。
想更新文档?
# 删除旧数据并重新抓取
rm -rf output/godot_data/
skill-seekers scrape --config configs/godot.json
增强功能不起作用?
# 检查是否设置了 API 密钥
echo $ANTHROPIC_API_KEY
# 尝试使用 LOCAL 模式(使用 Claude Code Max,无需 API 密钥)
skill-seekers enhance output/react/ --mode LOCAL
# 监控后台增强状态
skill-seekers enhance-status output/react/ --watch
GitHub 速率限制问题?
# 设置 GitHub 令牌(5000 请求/小时 vs 匿名用户的 60 请求/小时)
export GITHUB_TOKEN=ghp_your_token_here
# 或者配置多个个人资料
skill-seekers config --github
📈 性能
| 任务 | 时间 | 备注 |
|---|---|---|
| 抓取(同步) | 15-45 分钟 | 仅首次执行,基于线程 |
| 抓取(异步) | 5-15 分钟 | 使用 --async 标志时速度提升 2-3 倍 |
| 构建 | 1-3 分钟 | 从缓存快速重建 |
| 重新构建 | <1 分钟 | 使用 --skip-scrape 标志 |
| 增强(LOCAL) | 30-60 秒 | 使用 Claude Code Max |
| 增强(API) | 20-40 秒 | 需要 API 密钥 |
| 视频(转录本) | 1-3 分钟 | 仅 YouTube/本地视频的转录本 |
| 视频(视觉内容) | 5-15 分钟 | + OCR 帧提取 |
| 打包 | 5-10 秒 | 最终生成 .zip 文件 |
📚 文档
入门
- BULLETPROOF_QUICKSTART.md - 🎯 如果你是新手,请从这里开始!
- QUICKSTART.md - 高级用户的快速入门
- TROUBLESHOOTING.md - 常见问题及解决方案
- docs/QUICK_REFERENCE.md - 一页纸的速查表
架构
- docs/UML_ARCHITECTURE.md - 包含14张图的UML架构概览
- docs/UML/exports/ - PNG格式的图表导出文件(包概述 + 13张类图)
- docs/UML/html/ - 完整的HTML API参考文档(所有类、操作和属性)
- docs/UML/skill_seekers.mdj - StarUML项目文件(可用StarUML打开)
指南
- docs/LARGE_DOCUMENTATION.md - 处理1万至4万页以上的文档
- ASYNC_SUPPORT.md - 异步模式指南(爬取速度提升2至3倍)
- docs/ENHANCEMENT_MODES.md - AI增强模式指南
- docs/MCP_SETUP.md - MCP集成设置
- docs/UNIFIED_SCRAPING.md - 多源数据抓取
- docs/VIDEO_GUIDE.md - 视频提取指南
集成指南
- docs/integrations/LANGCHAIN.md - LangChain RAG
- docs/integrations/CURSOR.md - Cursor IDE
- docs/integrations/WINDSURF.md - Windsurf IDE
- docs/integrations/CLINE.md - Cline(VS Code)
- docs/integrations/RAG_PIPELINES.md - 所有RAG管道
📝 许可证
MIT许可证 - 详情请参阅LICENSE文件
祝你技能提升愉快!🚀
🔒 安全性

版本历史
v3.4.02026/03/25v3.3.02026/03/15v3.2.02026/03/02v3.1.32026/02/24v3.1.22026/02/24v3.1.12026/02/23v3.1.02026/02/22v3.0.02026/02/08v2.9.02026/02/02v2.8.02026/02/02v2.7.42026/01/21v2.7.32026/01/21v2.7.22026/01/21v2.7.12026/01/18v2.7.02026/01/18v2.6.02026/01/13v2.5.12025/12/30v2.5.02025/12/28v2.4.02025/12/25v2.2.02025/12/21常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。