PatchTST
PatchTST 是一个基于 Transformer 的时间序列长期预测模型,灵感来源于论文《A Time Series is Worth 64 Words》(ICLR 2023)。它通过将时间序列切分为“片段”(patches),把每个片段当作类似自然语言中的“词”输入到 Transformer 中,从而更有效地捕捉长时间依赖关系。传统 Transformer 在处理长序列时容易受噪声干扰且计算效率低,而 PatchTST 通过“分片”和“通道独立”设计显著提升了预测精度与稳定性。在多个公开数据集上,PatchTST 不仅优于其他 Transformer 变体(如 Autoformer、Informer),还超越了非 Transformer 模型(如 DLinear),尤其在回看窗口较长时表现更佳。此外,它还支持自监督预训练,可迁移到下游任务。PatchTST 已被集成到 GluonTS、NeuralForecast 和 tsai 等主流时间序列库中,适合从事时间序列建模的研究人员和开发者使用,尤其适用于电力负荷、气象、交通等需要高精度长期预测的场景。项目提供清晰的训练脚本和示例,便于快速复现与实验。
使用场景
某省级电网调度中心需对全省未来7天的电力负荷进行高精度预测,以优化发电计划和跨区调度,数据包含数百个变电站的小时级负荷序列,具有强周期性和长期依赖特征。
没有 PatchTST 时
- 采用传统LSTM或早期Transformer模型(如Informer),在720小时(30天)回看窗口下训练不稳定,预测误差显著上升。
- 长期预测(如168步)时,模型难以捕捉跨周季节模式,MAE高达8.2%,导致备用容量预留过多,增加运营成本。
- 多变量联合建模导致参数爆炸,训练耗时长达数天,且不同站点间性能差异大,需逐站调参。
- 自监督预训练效果有限,无法有效迁移到新接入的变电站数据上。
使用 PatchTST 后
- 利用“分片”(patching)机制将长序列切分为语义子序列,使Transformer能稳定处理长达720小时的输入,MSE降低21%。
- 在相同硬件条件下,168步预测MAE降至6.8%,显著提升跨周负荷趋势把握能力,减少冗余备用约5%。
- 采用通道独立设计,共享权重建模所有变电站,训练时间缩短40%,且新站点只需微调即可获得可靠预测。
- 基于自监督预训练的PatchTST模型可直接迁移到新增站点,在无标签数据下仍优于监督训练的基线模型。
PatchTST通过创新的序列分片与通道独立架构,在真实电力系统中实现了更准、更快、更具扩展性的长期时序预测。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始
PatchTST (ICLR 2023)
这是论文《PatchTST: A Time Series is Worth 64 Words: Long-term Forecasting with Transformers》(arXiv 链接)的官方实现。
:triangular_flag_on_post: 我们的模型已被集成到 GluonTS 中。特别感谢贡献者 @kashif!
:triangular_flag_on_post: 我们的模型已被集成到 NeuralForecast 中。特别感谢贡献者 @kdgutier 和 @cchallu!
:triangular_flag_on_post: 我们的模型已被集成到 timeseriesAI(tsai) 中。特别感谢贡献者 @oguiza!
我们提供了一个视频,为希望快速理解论文内容的读者提供简洁概述:https://www.youtube.com/watch?v=Z3-NrohddJw
核心设计
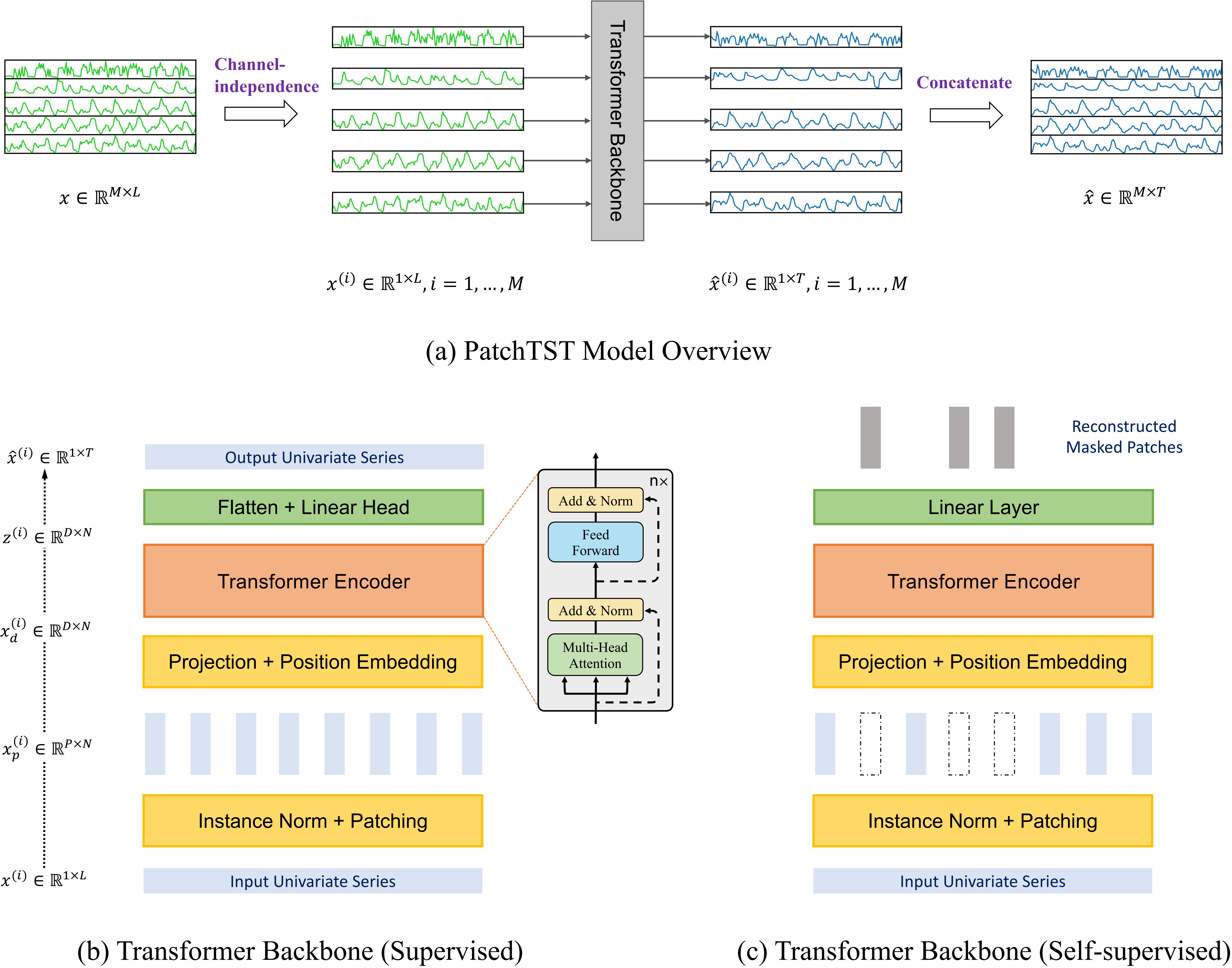
:star2: 分块(Patching):将时间序列分割成子序列级别的“块”(patches),这些块作为 Transformer 的输入 token。
:star2: 通道独立性(Channel-independence):每个通道包含一个单变量时间序列,所有序列共享相同的嵌入(embedding)和 Transformer 权重。
实验结果
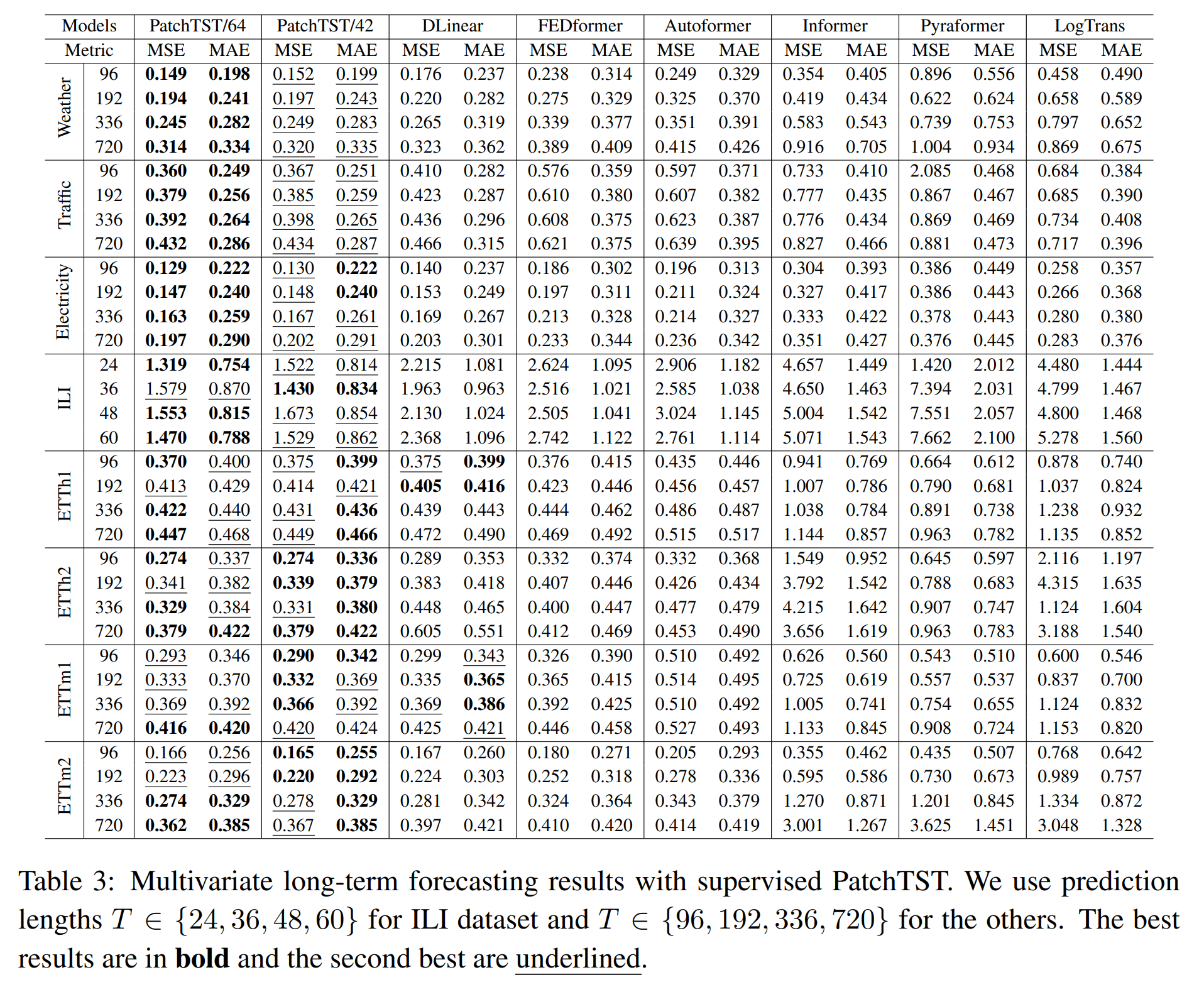
有监督学习(Supervised Learning)
与基于 Transformer 模型所能达到的最佳结果相比,PatchTST/64 在 MSE 上整体降低了 21.0%,在 MAE 上整体降低了 16.7%;而 PatchTST/42 在 MSE 上整体降低了 20.2%,在 MAE 上整体降低了 16.4%。它也优于其他非 Transformer 模型,如 DLinear。
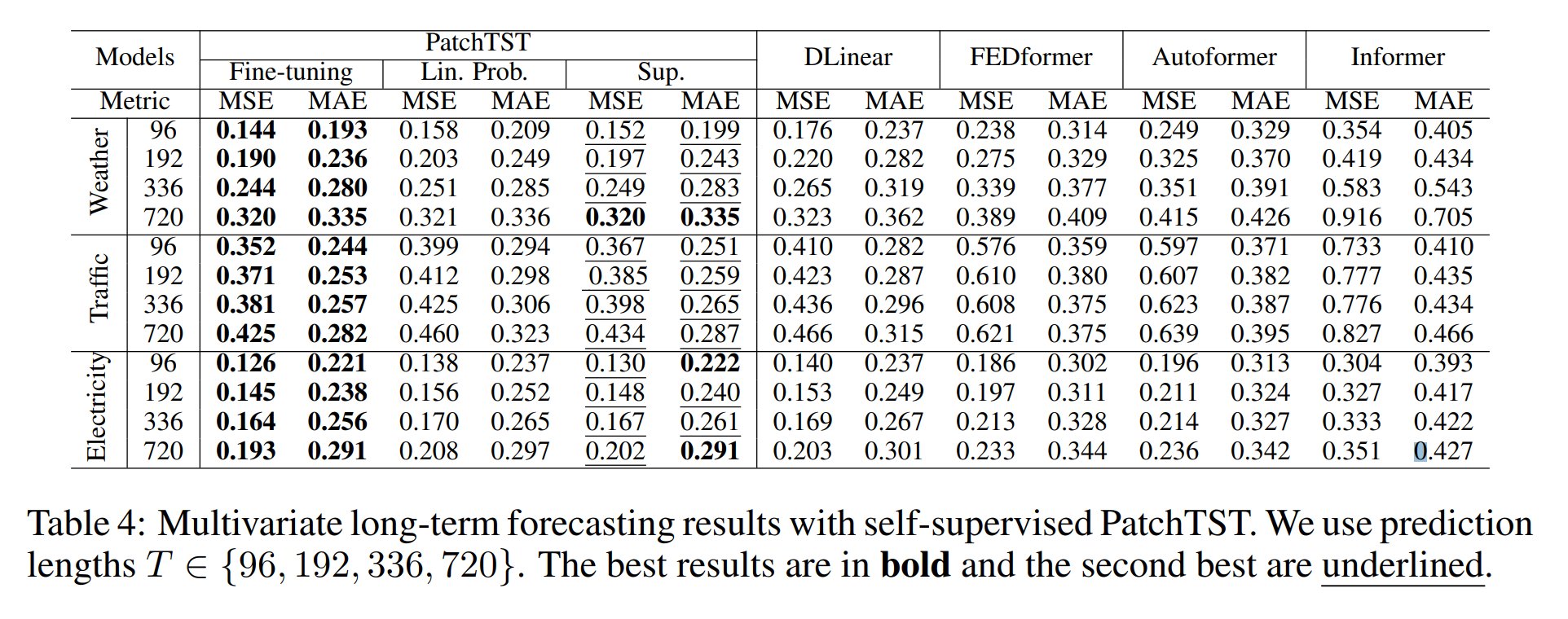
自监督学习(Self-supervised Learning)
我们将自监督版本的 PatchTST 与其他有监督和自监督模型进行了比较,结果表明自监督 PatchTST 能够超越所有基线模型。
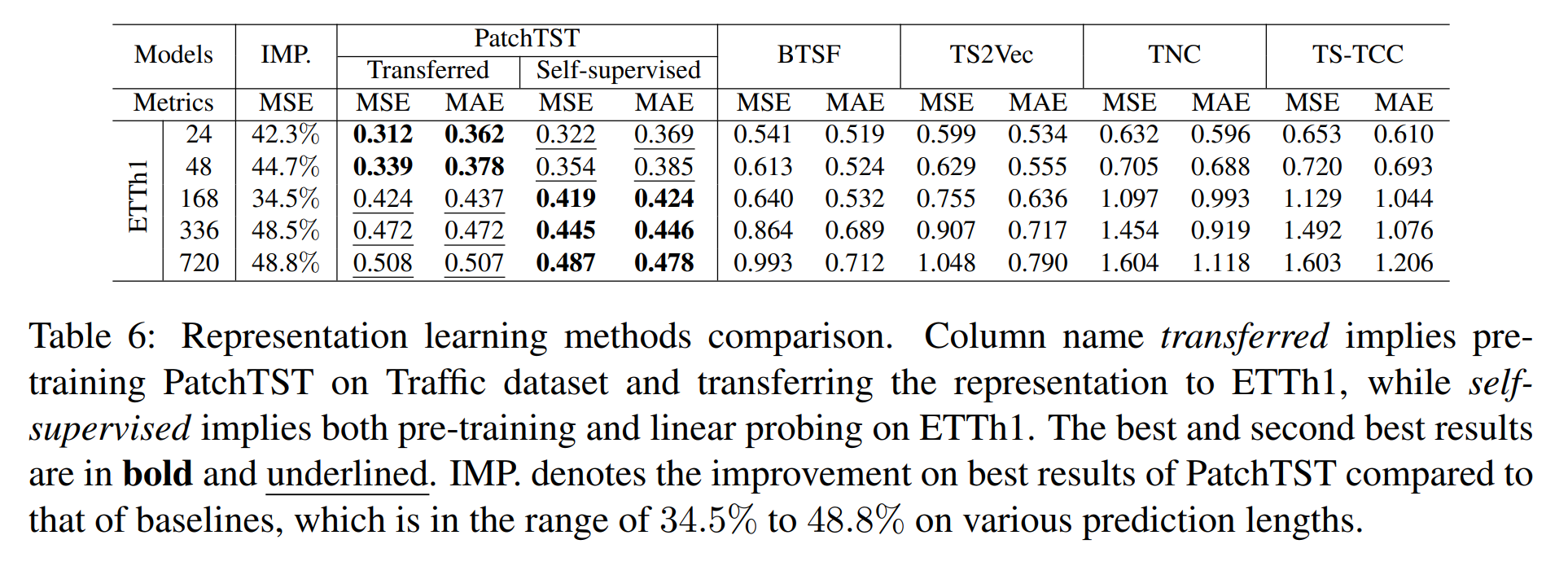
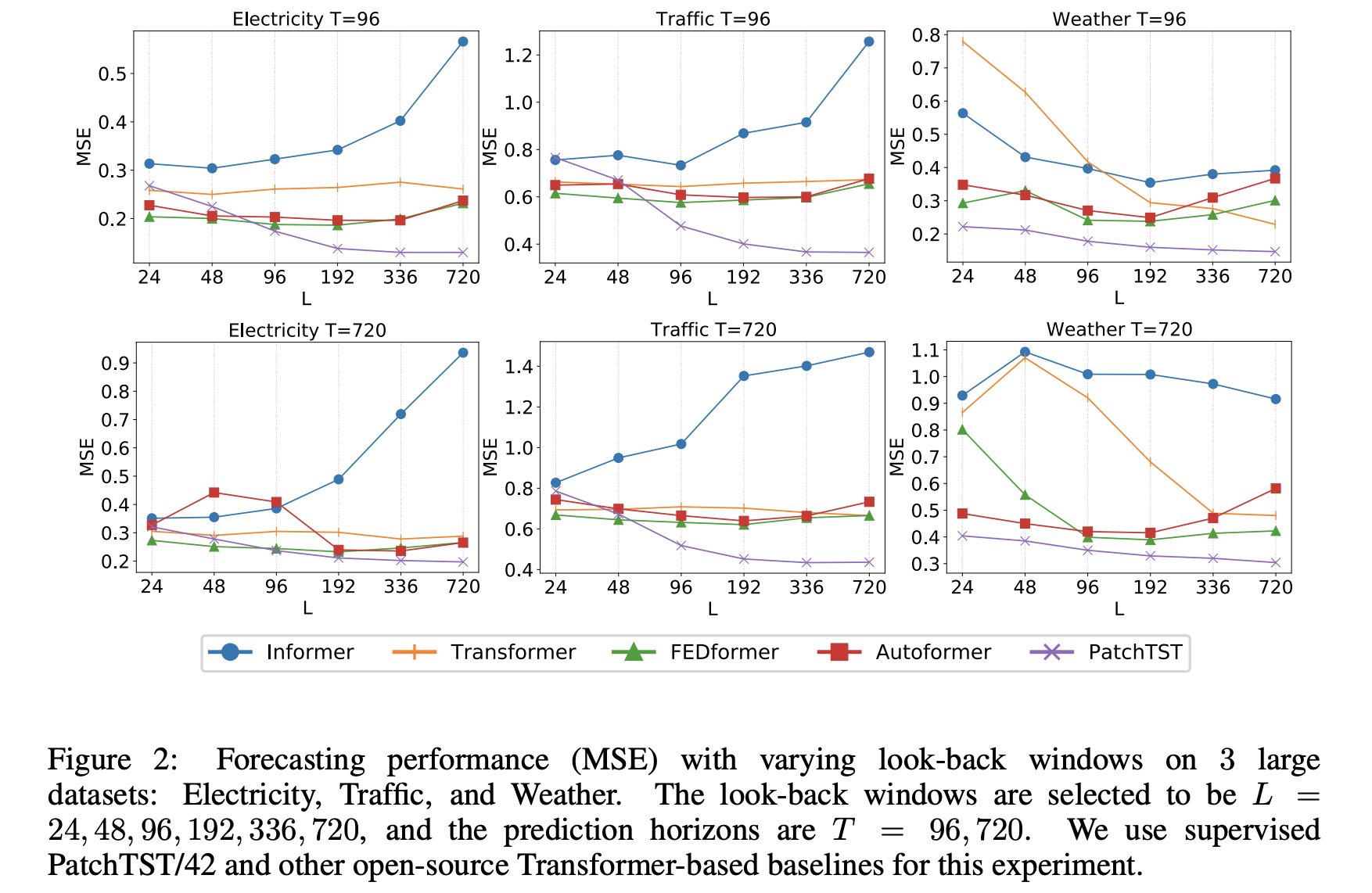
我们还测试了将预训练模型迁移到下游任务的能力。
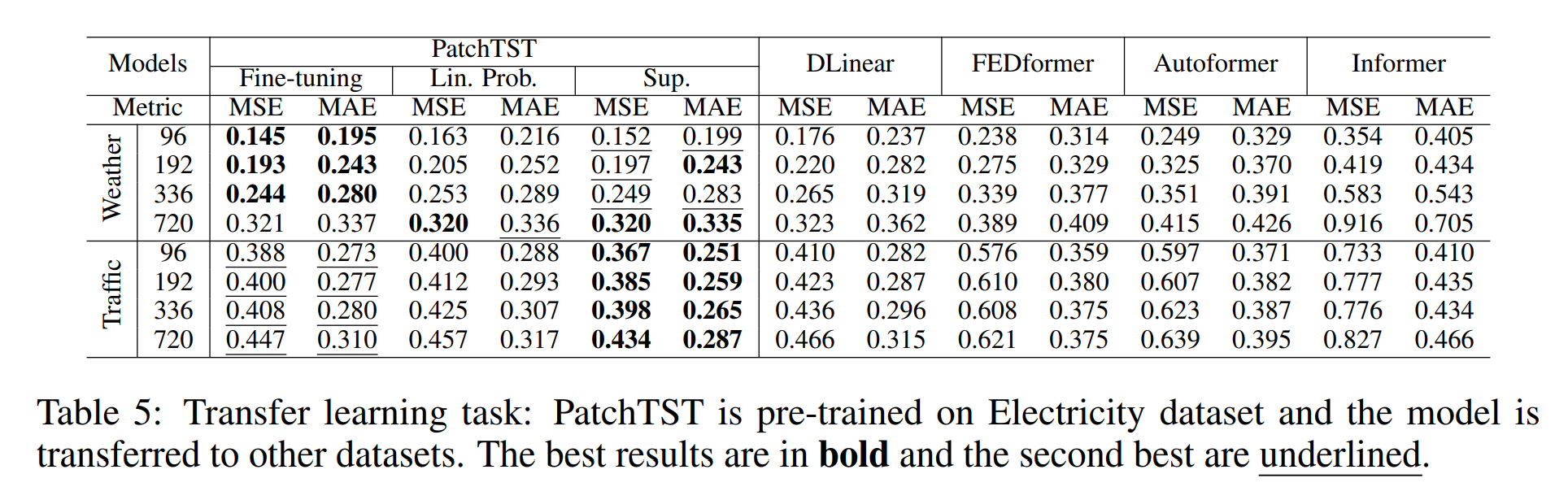
在长回看窗口(Long Look-back Windows)下的效率
随着回看窗口(look-back window)长度的增加,我们的 PatchTST 能够持续 降低 MSE 分数,这验证了模型从更长感受野(receptive field)中学习的能力。
快速开始
我们将有监督学习和自监督学习的代码分别放在两个文件夹中:PatchTST_supervised 和 PatchTST_self_supervised。请根据你的需求选择对应的文件夹。
有监督学习
安装依赖:
pip install -r requirements.txt下载数据:你可以从 Autoformer 下载所有数据集。创建一个独立的文件夹
./dataset,并将所有 CSV 文件放入该目录。训练:所有脚本位于
./scripts/PatchTST目录下。默认模型为 PatchTST/42。例如,如果你想获取 weather 数据集的多变量预测结果,只需运行以下命令。训练完成后,你可以打开./result.txt查看结果:
sh ./scripts/PatchTST/weather.sh
你可以根据需要调整超参数(例如不同的 patch 长度、不同的回看窗口长度和预测长度)。我们也提供了基线模型的代码。
自监督学习
完成上述前两步
预训练:脚本
patchtst_pretrain.py用于训练 PatchTST/64。若要在单个 GPU 上对 ettm1 数据集运行代码,请执行以下命令:
python patchtst_pretrain.py --dset ettm1 --mask_ratio 0.4
模型将被保存到 saved_model 文件夹中,供下游任务使用。你还可以在 patchtst_pretrain.py 脚本中设置其他参数。
- 微调(Fine-tuning):脚本
patchtst_finetune.py用于微调步骤,支持线性探测(linear probing)或对整个网络进行微调:
python patchtst_finetune.py --dset ettm1 --pretrained_model <model_name>
致谢
我们非常感谢以下 GitHub 仓库提供的宝贵代码库和数据集:
https://github.com/cure-lab/LTSF-Linear
https://github.com/zhouhaoyi/Informer2020
https://github.com/thuml/Autoformer
https://github.com/MAZiqing/FEDformer
https://github.com/alipay/Pyraformer
https://github.com/ts-kim/RevIN
https://github.com/timeseriesAI/tsai
联系方式
如有任何问题或建议,请联系我们:ynie@princeton.edu 或 nnguyen@us.ibm.com,或提交 issue。
引用
如果你在研究中使用了本仓库,请考虑引用我们的论文:
@inproceedings{Yuqietal-2023-PatchTST,
title = {A Time Series is Worth 64 Words: Long-term Forecasting with Transformers},
author = {Nie, Yuqi and
H. Nguyen, Nam and
Sinthong, Phanwadee and
Kalagnanam, Jayant},
booktitle = {International Conference on Learning Representations},
year = {2023}
}
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。