Grad-CAM.pytorch
Grad-CAM.pytorch 是一个基于 PyTorch 框架开发的开源工具,旨在为深度学习分类网络和目标检测模型提供直观的可视化解释。它核心解决了神经网络“黑盒”决策过程不透明的问题,通过生成类激活映射图(CAM),清晰展示模型在判断图像类别或定位物体时,具体关注了图片中的哪些区域。
该工具不仅完整复现了经典的 Grad-CAM 及其改进版 Grad-CAM++ 算法,还具备极强的通用性,支持包括 ResNet、VGG、DenseNet 在内的多种主流自定义分类网络,以及 Faster R-CNN、RetinaNet 和 FCOS 等复杂的目标检测架构。其独特的技术亮点在于能够灵活指定网络层级和类别 ID,并融合了引导反向传播(Guided Backpropagation)技术,从而生成更高分辨率、细节更丰富的热力图,帮助用户精准分析模型的注意力机制。
Grad-CAM.pytorch 非常适合 AI 研究人员、算法工程师及深度学习开发者使用。无论是需要调试模型性能、验证数据偏差,还是希望向非技术人员展示模型决策依据,这款工具都能提供强有力的支持。它安装简便,命令行操作友好,是深入理解卷积神经网络内部运作机制的实用助手。
使用场景
某医疗 AI 研发团队正在开发基于深度学习的肺部 CT 影像辅助诊断系统,急需验证模型是否真正关注病灶区域而非背景噪声。
没有 Grad-CAM.pytorch 时
- 决策过程如“黑盒”:医生无法理解模型为何将某张片子判定为“肺炎”,只能盲目信任或拒绝结果,难以建立临床信任。
- 错误归因难排查:当模型误判时,开发者无法确定是模型学到了错误的特征(如关注到了影像角落的标记文字),还是数据标注本身有误。
- 模型优化无方向:在调整网络结构(如从 ResNet50 切换到 DenseNet121)时,缺乏直观依据来判断哪种架构更能精准聚焦病灶。
- 合规审查受阻:医疗器械审批需要提供算法的可解释性证明,缺乏可视化证据导致项目无法通过伦理和安全审查。
使用 Grad-CAM.pytorch 后
- 可视化决策依据:利用 Grad-CAM 生成热力图,清晰叠加显示模型高亮关注的肺部区域,让医生直观看到“模型看到了什么”,显著提升信任度。
- 快速定位误判根源:通过对比不同网络(如 VGG16 与 MobileNetV2)的热力图,迅速发现旧模型错误地关注了肋骨纹理而非炎症区域,从而针对性清洗数据。
- 科学选型网络架构:借助 Grad-CAM++ 对多类目标的精细定位能力,量化评估各主干网络对微小病灶的覆盖准确度,选出最优模型部署。
- 满足监管合规要求:直接输出带有热力图解释的诊断报告作为技术文档,有力证明了算法的逻辑合理性,加速产品上市进程。
Grad-CAM.pytorch 将抽象的神经网络梯度转化为直观的视觉证据,彻底打破了深度学习在关键领域的“黑盒”壁垒。
运行环境要求
- 未说明
未说明 (支持 CPU 运行,示例命令中包含 MODEL.DEVICE cpu)
未说明
快速开始
Grad-CAM.pytorch
使用 PyTorch 实现 Grad-CAM: 通过基于梯度的定位从深度网络获得视觉解释 和
- 依赖
- 使用方法
- 样例分析
3.1 单个对象
3.3 多个对象 - 总结
- 目标检测-faster-r-cnn
5.1 detectron2安装
5.2 测试
5.3 Grad-CAM结果
5.4 总结 - 目标检测-retinanet
6.1 detectron2安装
6.2 测试
6.3 Grad-CAM结果
6.4 总结 - 目标检测-fcos
7.1 AdelaiDet安装
7.2 测试
7.3 Grad-CAM结果
7.4 总结
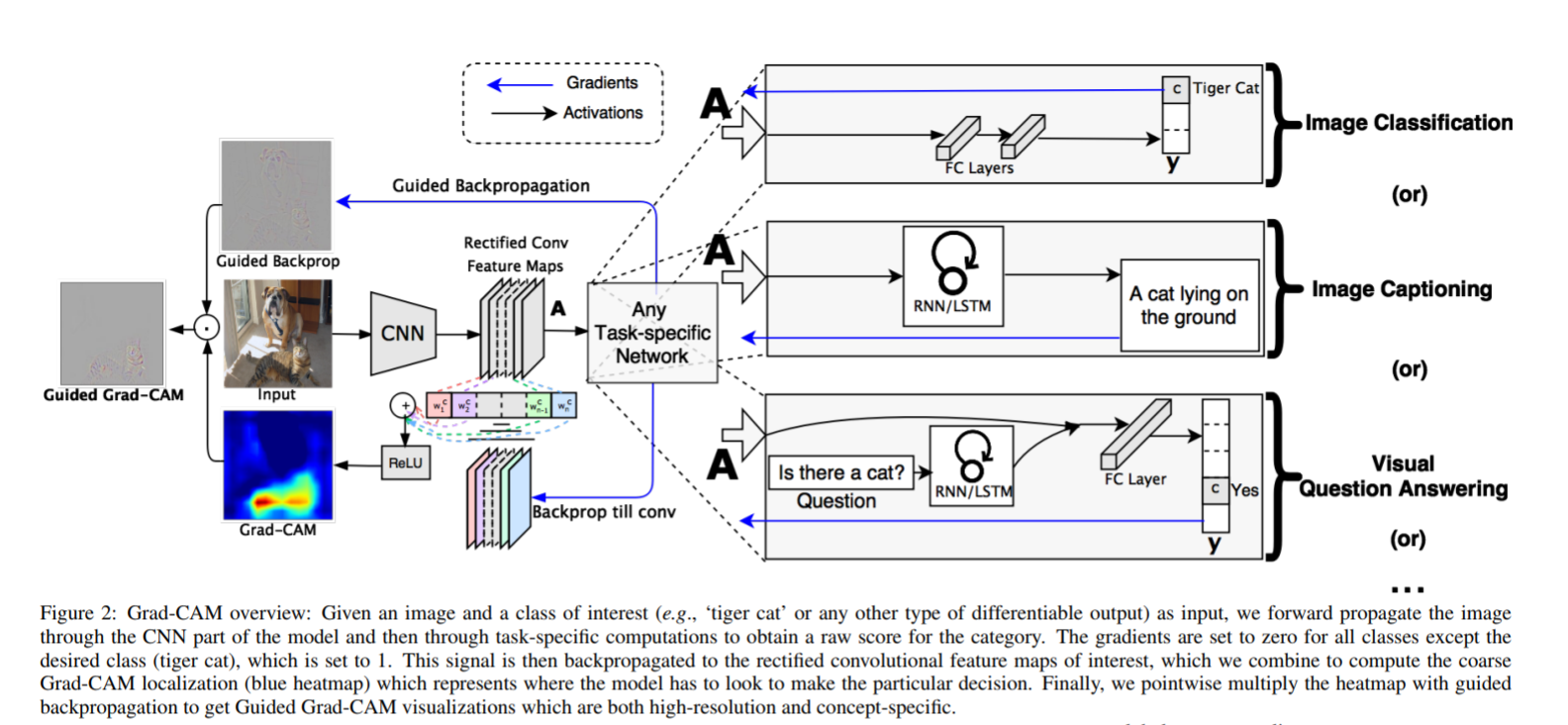
Grad-CAM整体架构
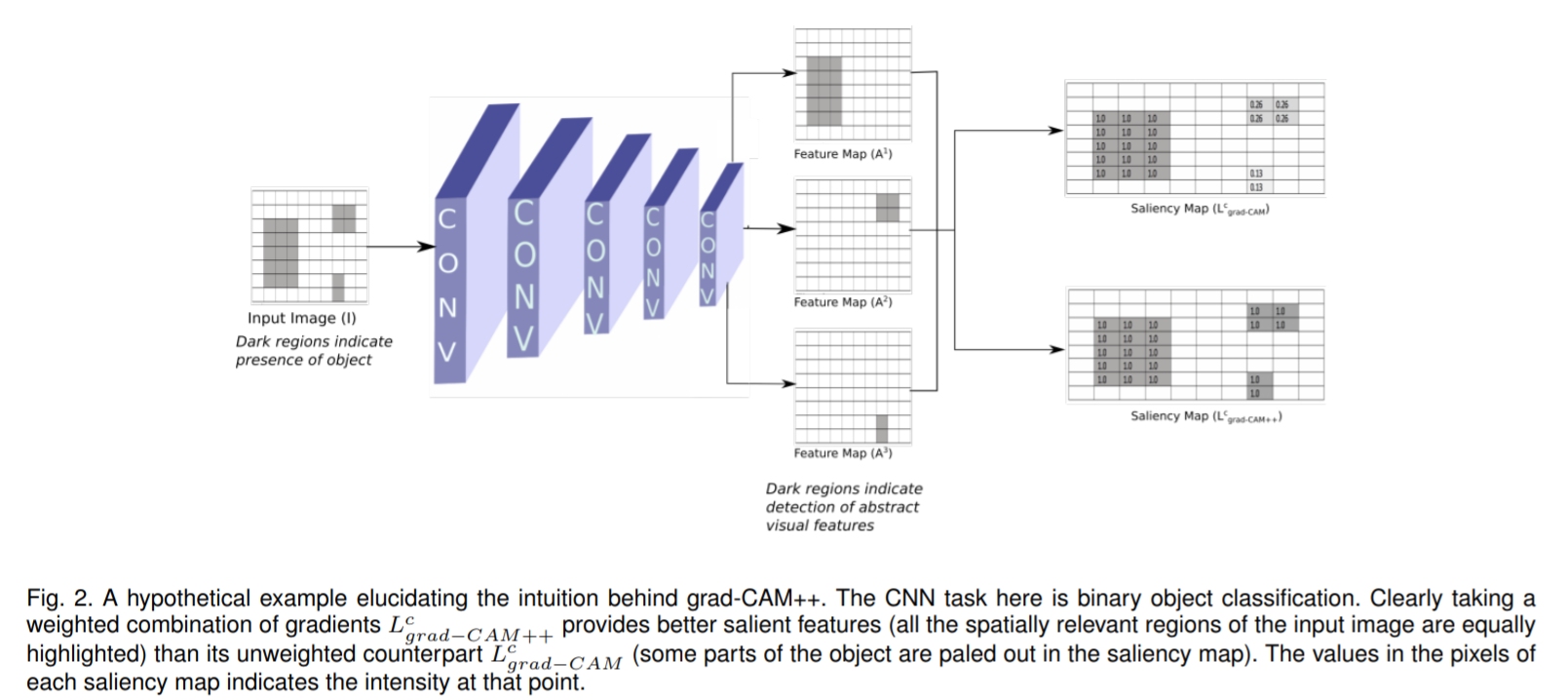
Grad-CAM++与Grad-CAM的异同
依赖
python 3.6.x
pytoch 1.0.1+
torchvision 0.2.2
opencv-python
matplotlib
scikit-image
numpy
使用方法
python main.py --image-path examples/pic1.jpg \
--network densenet121 \
--weight-path /opt/pretrained_model/densenet121-a639ec97.pth
参数说明:
image-path:需要可视化的图像路径(可选,默认
.https://oss.gittoolsai.com/images/yizt_Grad-CAM.pytorch_readme_ccf4bb08e27b.jpg)network: 网络名称(可选,默认
resnet50)weight-path: 网络对应的与训练参数权重路径(可选,默认从pytorch官网下载对应的预训练权重)
layer-name: Grad-CAM使用的层名(可选,默认最后一个卷积层)
class-id:Grad-CAM和Guided Back Propagation反向传播使用的类别id(可选,默认网络预测的类别)
output-dir:可视化结果图像保存目录(可选,默认
results目录)
样例分析
单个对象
原始图像

效果
| network | HeatMap | Grad-CAM | HeatMap++ | Grad-CAM++ | Guided backpropagation | Guided Grad-CAM |
|---|---|---|---|---|---|---|
| vgg16 |  |
 |
 |
 |
 |
 |
| vgg19 |  |
 |
 |
 |
 |
 |
| resnet50 | 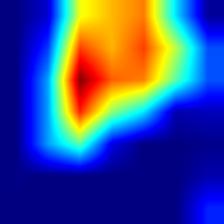 |
 |
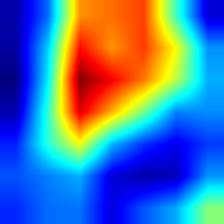 |
 |
 |
 |
| resnet101 |  |
 |
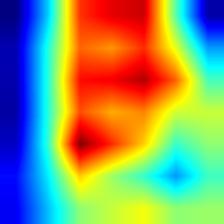 |
 |
 |
 |
| densenet121 |  |
 |
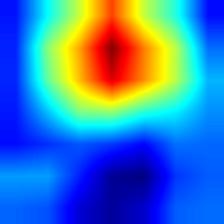 |
 |
 |
 |
| inception_v3 |  |
 |
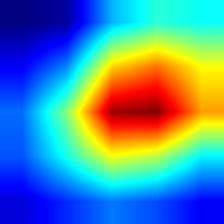 |
 |
 |
 |
| mobilenet_v2 | 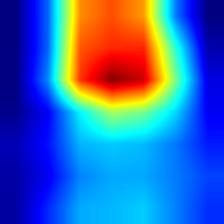 |
 |
 |
 |
 |
 |
| shufflenet_v2 |  |
 |
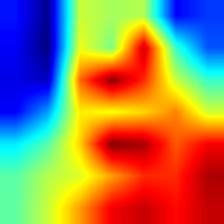 |
 |
 |
 |
多个对象
对应多个图像时,Grad-CAM++的覆盖范围比Grad-CAM更为全面,这也是Grad-CAM++最主要的优点。
原始图像

效果
| 网络 | 热力图 | Grad-CAM | 热力图++ | Grad-CAM++ | 引导反向传播 | 引导Grad-CAM |
|---|---|---|---|---|---|---|
| vgg16 |  |
 |
 |
 |
 |
 |
| vgg19 | 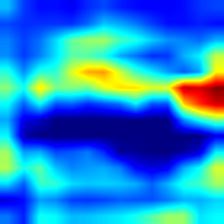 |
 |
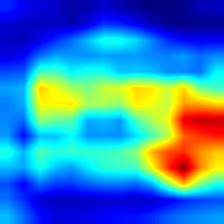 |
 |
 |
 |
| resnet50 | 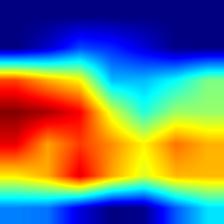 |
 |
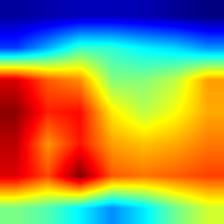 |
 |
 |
 |
| resnet101 | 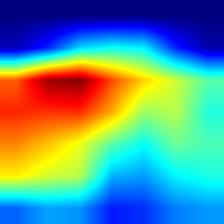 |
 |
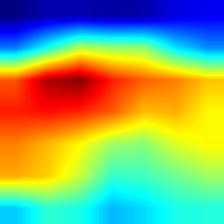 |
|
 |
 |
| densenet121 | 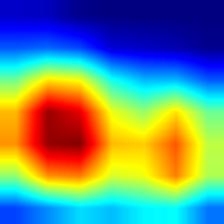 |
 |
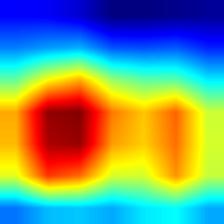 |
 |
 |
 |
| inception_v3 | 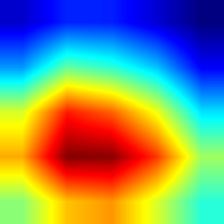 |
 |
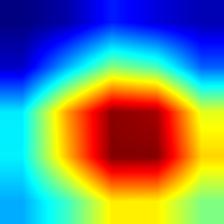 |
 |
 |
 |
| mobilenet_v2 | 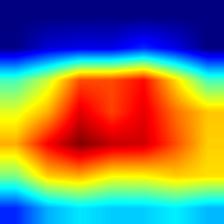 |
 |
 |
 |
 |
 |
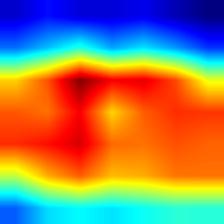
| shufflenet_v2 |  |
 |
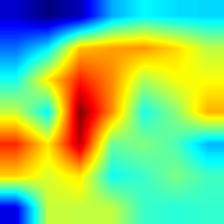 |
 |
 |
 |
总结
- VGG模型的Grad-CAM并未完全覆盖整个目标,相比之下,ResNet和DenseNet的覆盖更加全面,尤其是DenseNet;这从侧面说明,在模型的泛化能力和鲁棒性方面,DenseNet > ResNet > VGG。
- 相较于Grad-CAM,Grad-CAM++对目标的覆盖也更为全面,特别是在同一类别存在多个实例的情况下,Grad-CAM可能只覆盖部分目标,而Grad-CAM++则基本能够覆盖所有目标。不过,这一点仅在VGG模型中表现明显,对于DenseNet而言,直接使用Grad-CAM也能基本覆盖所有目标。
- MobileNet V2的Grad-CAM覆盖同样非常全面。
- Inception V3和MobileNet V2的引导反向传播图轮廓较为模糊,而ShuffleNet V2的轮廓则相对清晰。
目标检测——Faster R-CNN
有位网友SHAOSIHAN询问如何在目标检测中使用Grad-CAM;然而,在Grad-CAM和Grad-CAM++的相关论文中,并未提及针对目标检测生成CAM图的方法。我认为主要有以下两个原因:
a) 目标检测与分类任务不同:分类网络通常只有一个分类损失,且各网络的最后一层结构一致(根据类别数决定神经元数量),最终的预测输出为单一的类别得分分布。而目标检测的输出则复杂得多,不同网络如Faster R-CNN、CornerNet、CenterNet、FCOS等,其建模方式各异,输出的意义也不相同。因此,不存在一种统一的方法来生成Grad-CAM图。
b) 分类任务属于弱监督学习,通过CAM图可以了解网络在预测时主要关注的空间位置,即“它在看哪里”,这对分析问题具有实际价值。而目标检测本身是强监督学习,预测出的边界框已经直接指明了“应该关注的位置”。
这里以Detectron2中的Faster R-CNN网络为例,介绍如何生成Grad-CAM图。其核心思路是:首先获取预测分数最高的边界框,然后将该边界框的预测分数对应的梯度反向传播到与其对应的proposal边界框的特征图上,从而生成该特征图的CAM图。
Detectron2安装
a) 下载
git clone https://github.com/facebookresearch/detectron2.git
b) 修改detectron2/modeling/roi_heads/fast_rcnn.py文件中的fast_rcnn_inference_single_image函数,主要是增加索引号,记录分值高的预测边框是由第几个proposal边框生成的;修改后的fast_rcnn_inference_single_image函数如下:
def fast_rcnn_inference_single_image(
boxes, scores, image_shape, score_thresh, nms_thresh, topk_per_image
):
"""
单张图片推理。通过对得分进行阈值筛选并应用非极大值抑制(NMS)来返回边界框检测结果。
参数:
与 `fast_rcnn_inference` 相同,但针对每张图片分别提供边界框、得分和图像尺寸。
返回值:
与 `fast_rcnn_inference` 相同,但仅适用于一张图片。
"""
valid_mask = torch.isfinite(boxes).all(dim=1) & torch.isfinite(scores).all(dim=1)
indices = torch.arange(start=0, end=scores.shape[0], dtype=int)
indices = indices.expand((scores.shape[1], scores.shape[0])).T
if not valid_mask.all():
boxes = boxes[valid_mask]
scores = scores[valid_mask]
indices = indices[valid_mask]
scores = scores[:, :-1]
indices = indices[:, :-1]
num_bbox_reg_classes = boxes.shape[1] // 4
# 转换为 Boxes 格式以便使用 `clip` 函数 ...
boxes = Boxes(boxes.reshape(-1, 4))
boxes.clip(image_shape)
boxes = boxes.tensor.view(-1, num_bbox_reg_classes, 4) # R x C x 4
# 根据检测得分过滤结果
filter_mask = scores > score_thresh # R x K
# R' x 2。第一列包含 R 个预测的索引;
# 第二列包含类别的索引。
filter_inds = filter_mask.nonzero()
if num_bbox_reg_classes == 1:
boxes = boxes[filter_inds[:, 0], 0]
else:
boxes = boxes[filter_mask]
scores = scores[filter_mask]
indices = indices[filter_mask]
# 对每个类别分别应用 NMS
keep = batched_nms(boxes, scores, filter_inds[:, 1], nms_thresh)
if topk_per_image >= 0:
keep = keep[:topk_per_image]
boxes, scores, filter_inds = boxes[keep], scores[keep], filter_inds[keep]
indices = indices[keep]
result = Instances(image_shape)
result.pred_boxes = Boxes(boxes)
result.scores = scores
result.pred_classes = filter_inds[:, 1
result.indices = indices
return result, filter_inds[:, 0]
c) 安装;如遇到问题,请参考detectron2;不同操作系统安装方法有所不同
cd detectron2
pip install -e .
测试
a) 预训练模型下载
wget https://dl.fbaipublicfiles.com/detectron2/PascalVOC-Detection/faster_rcnn_R_50_C4/142202221/model_final_b1acc2.pkl
b) 测试Grad-CAM图像生成
在本工程目录下执行如下命令
export KMP_DUPLICATE_LIB_OK=TRUE
python detection/demo.py --config-file detection/faster_rcnn_R_50_C4.yaml \
--input .https://oss.gittoolsai.com/images/yizt_Grad-CAM.pytorch_readme_ccf4bb08e27b.jpg \
--opts MODEL.WEIGHTS /Users/yizuotian/pretrained_model/model_final_b1acc2.pkl MODEL.DEVICE cpu
Grad-CAM结果
| 原始图像 | 检测边框 | Grad-CAM HeatMap | Grad-CAM++ HeatMap | 边框预测类别 |
|---|---|---|---|---|
 |
 |
 |
 |
Dog |
 |
 |
 |
 |
Aeroplane |
 |
 |
 |
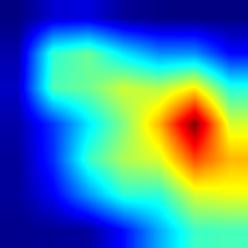 |
Person |
 |
 |
 |
 |
Horse |
总结
对于目标检测Grad-CAM++的效果并没有比Grad-CAM效果好,推测目标检测中预测边框已经是单个对象了,Grad-CAM++在多个对象的情况下优于Grad-CAM
目标检测-retinanet
在目标检测网络faster r-cnn的Grad-CAM完成后,有两位网友abhigoku10 、wangzyon问道怎样在retinanet中实现Grad-CAM。retinanet与faster r-cnn网络结构不同,CAM的生成也有一些差异;以下是详细的过程:
detectron2安装
a) 下载
git clone https://github.com/facebookresearch/detectron2.git
b) 修改detectron2/modeling/meta_arch/retinanet.py 文件中的inference_single_image函数,主要是增加feature level 索引,记录分值高的预测边框是由第几层feature map生成的;修改后的inference_single_image函数如下:
def inference_single_image(self, box_cls, box_delta, anchors, image_size):
"""
Single-image inference. Return bounding-box detection results by thresholding
on scores and applying non-maximum suppression (NMS).
Arguments:
box_cls (list[Tensor]): list of #feature levels. Each entry contains
tensor of size (H x W x A, K)
box_delta (list[Tensor]): Same shape as 'box_cls' except that K becomes 4.
anchors (list[Boxes]): list of #feature levels. Each entry contains
a Boxes object, which contains all the anchors for that
image in that feature level.
image_size (tuple(H, W)): a tuple of the image height and width.
Returns:
Same as `inference`, but for only one image.
"""
boxes_all = []
scores_all = []
class_idxs_all = []
feature_level_all = []
# Iterate over every feature level
for i, (box_cls_i, box_reg_i, anchors_i) in enumerate(zip(box_cls, box_delta, anchors)):
# (HxWxAxK,)
box_cls_i = box_cls_i.flatten().sigmoid_()
# Keep top k top scoring indices only.
num_topk = min(self.topk_candidates, box_reg_i.size(0))
# torch.sort is actually faster than .topk (at least on GPUs)
predicted_prob, topk_idxs = box_cls_i.sort(descending=True)
predicted_prob = predicted_prob[:num_topk]
topk_idxs = topk_idxs[:num_topk]
# filter out the proposals with low confidence score
keep_idxs = predicted_prob > self.score_threshold
predicted_prob = predicted_prob[keep_idxs]
topk_idxs = topk_idxs[keep_idxs]
anchor_idxs = topk_idxs // self.num_classes
classes_idxs = topk_idxs % self.num_classes
box_reg_i = box_reg_i[anchor_idxs]
anchors_i = anchors_i[anchor_idxs]
# predict boxes
predicted_boxes = self.box2box_transform.apply_deltas(box_reg_i, anchors_i.tensor)
boxes_all.append(predicted_boxes)
scores_all.append(predicted_prob)
class_idxs_all.append(classes_idxs)
feature_level_all.append(torch.ones_like(classes_idxs) * i)
boxes_all, scores_all, class_idxs_all, feature_level_all = [
cat(x) for x in [boxes_all, scores_all, class_idxs_all, feature_level_all]
]
keep = batched_nms(boxes_all, scores_all, class_idxs_all, self.nms_threshold)
keep = keep[: self.max_detections_per_image]
result = Instances(image_size)
result.pred_boxes = Boxes(boxes_all[keep])
result.scores = scores_all[keep]
result.pred_classes = class_idxs_all[keep]
result.feature_levels = feature_level_all[keep]
return result
c) 修改detectron2/modeling/meta_arch/retinanet.py 文件增加predict函数,具体如下:
def predict(self, batched_inputs):
"""
Args:
batched_inputs: a list, batched outputs of :class:`DatasetMapper` .
Each item in the list contains the inputs for one image.
For now, each item in the list is a dict that contains:
* image: Tensor, image in (C, H, W) format.
* instances: Instances
Other information that's included in the original dicts, such as:
* "height", "width" (int): the output resolution of the model, used in inference.
See :meth:`postprocess` for details.
Returns:
dict[str: Tensor]:
mapping from a named loss to a tensor storing the loss. Used during training only.
"""
images = self.preprocess_image(batched_inputs)
features = self.backbone(images.tensor)
features = [features[f] for f in self.in_features]
box_cls, box_delta = self.head(features)
anchors = self.anchor_generator(features)
results = self.inference(box_cls, box_delta, anchors, images.image_sizes)
processed_results = []
for results_per_image, input_per_image, image_size in zip(
results, batched_inputs, images.image_sizes
):
height = input_per_image.get("height", image_size[0])
width = input_per_image.get("width", image_size[1])
r = detector_postprocess(results_per_image, height, width)
processed_results.append({"instances": r})
return processed_results
d) 安装;如遇到问题,请参考detectron2;不同操作系统安装有差异
cd detectron2
pip install -e .
测试
a) 预训练模型下载
wget https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_3x/137849486/model_final_4cafe0.pkl
b) 测试Grad-CAM图像生成
在本工程目录下执行如下命令:
export KMP_DUPLICATE_LIB_OK=TRUE
python detection/demo_retinanet.py --config-file detection/retinanet_R_50_FPN_3x.yaml \
--input .https://oss.gittoolsai.com/images/yizt_Grad-CAM.pytorch_readme_ccf4bb08e27b.jpg \
--layer-name head.cls_subnet.0 \
--opts MODEL.WEIGHTS /Users/yizuotian/pretrained_model/model_final_4cafe0.pkl MODEL.DEVICE cpu
Grad-CAM结果
| 图像1 | 图像2 | 图像3 | 图像4 | |
|---|---|---|---|---|
| 原图 | |
|
|
|
| 预测边框 |  |
 |
 |
 |
| GradCAM-cls_subnet.0 |  |
 |
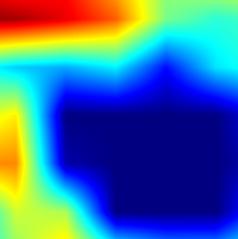 |
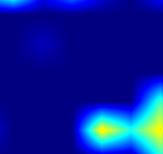 |
| GradCAM-cls_subnet.1 |  |
 |
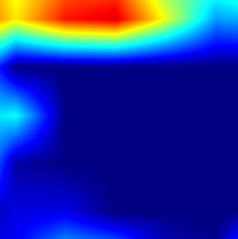 |
 |
| GradCAM-cls_subnet.2 | 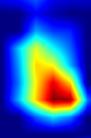 |
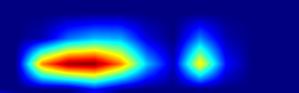 |
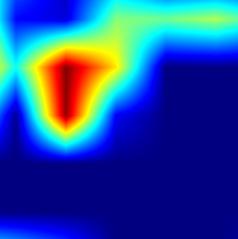 |
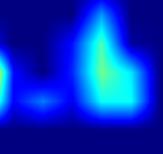 |
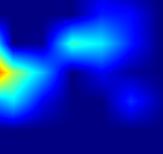
| GradCAM-cls_subnet.3 |  |
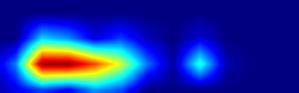 |
 |
 |
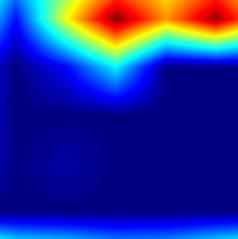
| GradCAM-cls_subnet.4 |  |
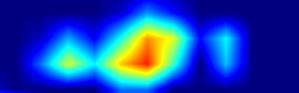 |
 |
 |
| GradCAM-cls_subnet.5 |  |
 |
 |
 |
| GradCAM-cls_subnet.6 |  |
 |
 |
 |
| GradCAM-cls_subnet.7 |  |
 |
 |
 |
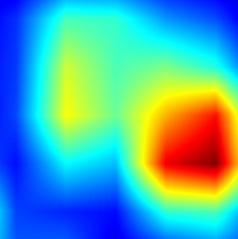
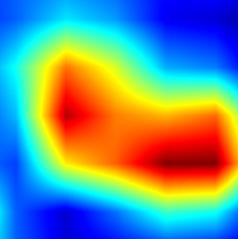
| GradCAM++-cls_subnet.0 |  |
 |
 |
 |
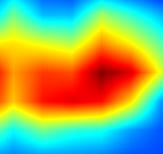
| GradCAM++-cls_subnet.1 |  |
 |
 |
 |
| GradCAM++-cls_subnet.2 | 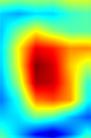 |
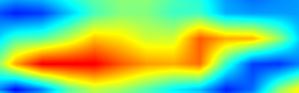 |
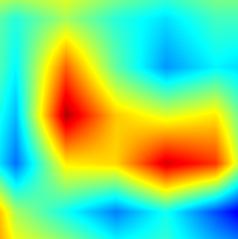 |
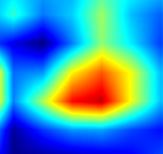 |
| GradCAM++-cls_subnet.3 |  |
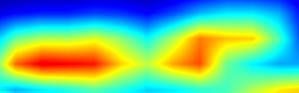 |
 |
 |
| GradCAM++-cls_subnet.4 |  |
 |
 |
 |
| GradCAM++-cls_subnet.5 |  |
 |
 |
 |
| GradCAM++-cls_subnet.6 |  |
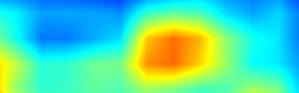 |
 |
 |
| GradCAM++-cls_subnet.7 |  |
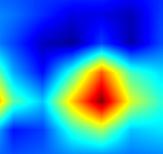
 |
 |
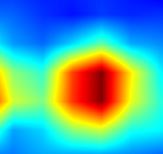 |
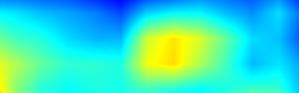
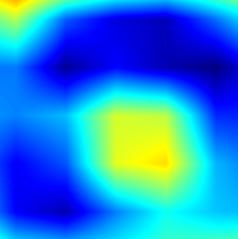
注:以上分别对head.cls_subnet.0~head.cls_subnet.7共8个层生成Grad-CAM图,这8层分别对应retinanet分类子网络的4层卷积feature map及ReLu激活后的feature map
总结
a) retinanet的Grad-CAM图效果都不算好,相对来说中间层head.cls_subnet.2~head.cls_subnet.4相对好一点
b) 个人认为retinanet效果不要的原因是,retinanet最后的分类是卷积层,卷积核实3*3,也就是说反向传播到最后一个卷积层的feature map上,只有3*3个单元有梯度。而分类网络或者faster r-cnn分类都是全连接层,感受全局信息,最后一个卷积层的feature map上所有单元都有梯度。
c) 反向传播到浅层的feature map上,有梯度的单元会逐渐增加,但是就像Grad-CAM论文中说的,越浅层的feature map语义信息越弱,所以可以看到head.cls_subnet.0的CAM图效果很差。
目标检测-fcos
在目标检测网络faster r-cnn和retinanet的Grad-CAM完成后,有位网友linsy-ai 问道怎样在fcos中实现Grad-CAM。fcos与retinanet基本类似,因为它们整体网络结构类似;这里使用AdelaiDet 工程中的fcos网络,以下是详细的过程:
AdelaiDet 安装
a) 下载
git clone https://github.com/aim-uofa/AdelaiDet.git
b) 安装
cd AdelaiDet
python setup.py build develop
注意:1. AdelaiDet安装依赖detectron2,需要首先安装$\color{red}{detectron2}$
2. fcos的不支持CPU,只支持GPU,请确保在$\color{red}{GPU环境}$下安装和测试
测试
a) 预训练模型下载
wget https://cloudstor.aarnet.edu.au/plus/s/glqFc13cCoEyHYy/download -O fcos_R_50_1x.pth
b) 测试Grad-CAM图像生成
在本工程目录下执行如下命令:
export CUDA_DEVICE_ORDER="PCI_BUS_ID"
export CUDA_VISIBLE_DEVICES="0"
python AdelaiDet/demo_fcos.py --config-file AdelaiDet/R_50_1x.yaml \
--input .https://oss.gittoolsai.com/images/yizt_Grad-CAM.pytorch_readme_ccf4bb08e27b.jpg \
--layer-name proposal_generator.fcos_head.cls_tower.8 \
--opts MODEL.WEIGHTS /path/to/fcos_R_50_1x.pth MODEL.DEVICE cuda
Grad-CAM结果
| 图像1 | 图像2 | 图像3 | 图像4 | |
|---|---|---|---|---|
| 原图 | |
|
|
|
| 预测边框 |  |
 |
 |
 |
| GradCAM-cls_tower.0 |  |
 |
 |
 |
| GradCAM-cls_tower.1 |  |
 |
 |
 |
| GradCAM-cls_tower.2 |  |
 |
 |
 |
| GradCAM-cls_tower.3 | 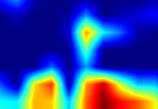 |
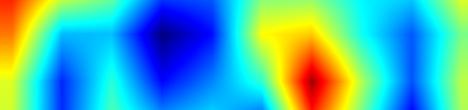 |
 |
 |
| GradCAM-cls_tower.4 |  |
 |
 |
 |
| GradCAM-cls_tower.5 | 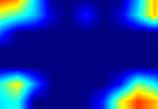 |
 |
 |
 |
| GradCAM-cls_tower.6 |  |
 |
 |
 |
| GradCAM-cls_tower.7 |  |
 |
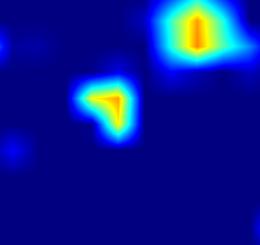 |
 |
| GradCAM-cls_tower.8 |  |
 |
 |
 |
| GradCAM-cls_tower.9 |  |
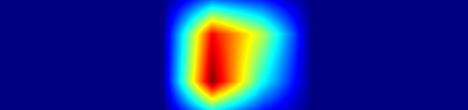 |
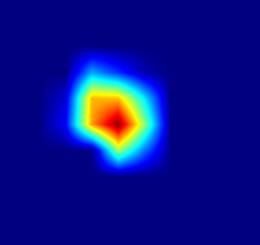 |
 |
| GradCAM-cls_tower.10 |  |
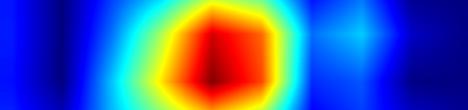 |
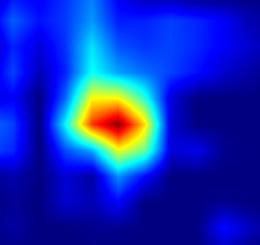 |
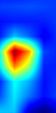 |
| GradCAM-cls_tower.11 |  |
 |
 |
 |
| GradCAM++-cls_tower.0 |  |
 |
 |
 |
| GradCAM++-cls_tower.1 |  |
 |
 |
 |
| GradCAM++-cls_tower.2 |  |
 |
 |
 |
| GradCAM++-cls_tower.3 |  |
 |
 |
 |
| GradCAM++-cls_tower.4 |  |
 |
 |
 |
| GradCAM++-cls_tower.5 |  |
 |
 |
 |
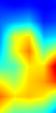
| GradCAM++-cls_tower.6 | 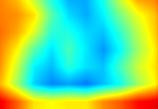 |
 |
 |
 |
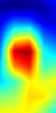
| GradCAM++-cls_tower.7 | 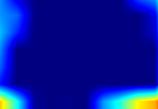 |
 |
 |
 |
| GradCAM++-cls_tower.8 |  |
 |
 |
 |
| GradCAM++-cls_tower.9 |  |
 |
 |
 |
| GradCAM++-cls_tower.10 |  |
 |
 |
 |
| GradCAM++-cls_tower.11 |  |
 |
 |
 |
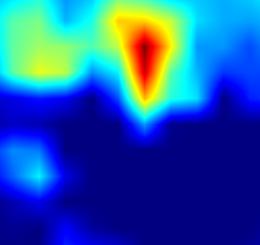
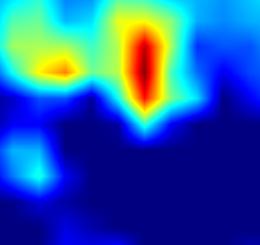
注:以上分别对proposal_generator.fcos_head.cls_tower..0~head.cls_subnet.11共12个层生成Grad-CAM图,这12层分别对应fcos分类子网络的4层卷积feature map、组标准化后的feature map及ReLu激活后的feature map
总结
不总结了,看图效果吧!
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。