Awesome-LLMs-in-Graph-tasks
Awesome-LLMs-in-Graph-tasks 是一个精心整理的开源资源库,专注于收录利用大语言模型(LLM)解决图相关任务的前沿研究论文。该项目源自一篇已被 IJCAI 2024 录用的综述文章,旨在系统性地梳理“图技术遇上大模型”这一新兴领域的进展与未来方向。
在传统图神经网络(GNN)研究中,模型虽擅长捕捉结构信息,却往往受限于节点特征的语义表达能力;而大语言模型虽精通文本理解,却难以直接处理复杂的图结构数据。Awesome-LLMs-in-Graph-tasks 正是为了解决这一痛点而生,它汇集了将两者优势结合的创新方案:既包括用 LLM 增强节点特征表示的方法,也涵盖利用 GNN 弥补 LLM 结构认知短板的策略,从而显著提升图学习的效果。
该资源库特别适合人工智能领域的研究人员、算法工程师及高校师生使用。它不仅提供了按方法论分类的详细论文列表(如"LLM 作为增强器”、"LLM 作为预测器”及"GNN-LLM 对齐”等),还附带了代码链接和技术细节总结,帮助从业者快速定位最新成果。无论是希望探索图数据新范式的学者,还是寻求技术落地的开发者,都能从中获得宝贵的灵感与参考。项目社区活跃,持续更新,是进入该交叉领域不可或缺的入门指南。
使用场景
某金融科技公司的算法团队正致力于构建一个反欺诈系统,需要分析包含数百万用户节点和交易边的巨大知识图谱,其中每个节点都附带复杂的文本描述(如交易备注、用户画像)。
没有 Awesome-LLMs-in-Graph-tasks 时
- 特征表达受限:传统图神经网络(GNN)只能将文本压缩为简单的向量,丢失了交易备注中细微的语义线索,导致难以识别隐蔽的洗钱模式。
- 技术选型迷茫:面对层出不穷的“大模型 + 图”论文,团队耗费数周手动检索,却难以区分哪些方法支持参数高效微调(PEFT),哪些仅需提示工程(Prompting)。
- 结构与时文割裂:自行尝试结合 LLM 与 GNN 时,往往顾此失彼,要么保留了文本理解能力却丢失了图谱结构信息,要么反之,模型效果不如预期。
- 复现成本高昂:缺乏统一的代码和论文索引,团队成员在复现基准模型时频繁遇到环境配置错误或缺失关键实现细节,严重拖慢研发进度。
使用 Awesome-LLMs-in-Graph-tasks 后
- 增强节点表征:参考列表中"LLM as Enhancer"分类下的 GIANT 等前沿方案,团队成功利用 LLM 提取多尺度邻居文本特征,显著提升了模型对异常交易语义的敏感度。
- 精准技术决策:通过查阅基于分类学的总结表格,团队迅速锁定了适合自身算力限制的“参数高效微调”模型,避免了盲目试错,将选型时间从数周缩短至两天。
- 优势互补融合:依据综述中关于 GNN 与 LLM 对齐的策略,构建了既能深度理解文本上下文又能捕捉复杂交易拓扑的混合架构,欺诈识别准确率提升 15%。
- 高效落地复现:直接获取列表中附带的官方代码链接和最新论文,快速搭建了基线系统,并根据社区更新的 Issue 解决了兼容性问题,大幅加速了产品上线。
Awesome-LLMs-in-Graph-tasks 不仅是一份论文清单,更是连接大语言模型语义理解能力与图数据结构优势的桥梁,让复杂的图任务研发从“盲人摸象”变为“有的放矢”。
运行环境要求
未说明
未说明

快速开始
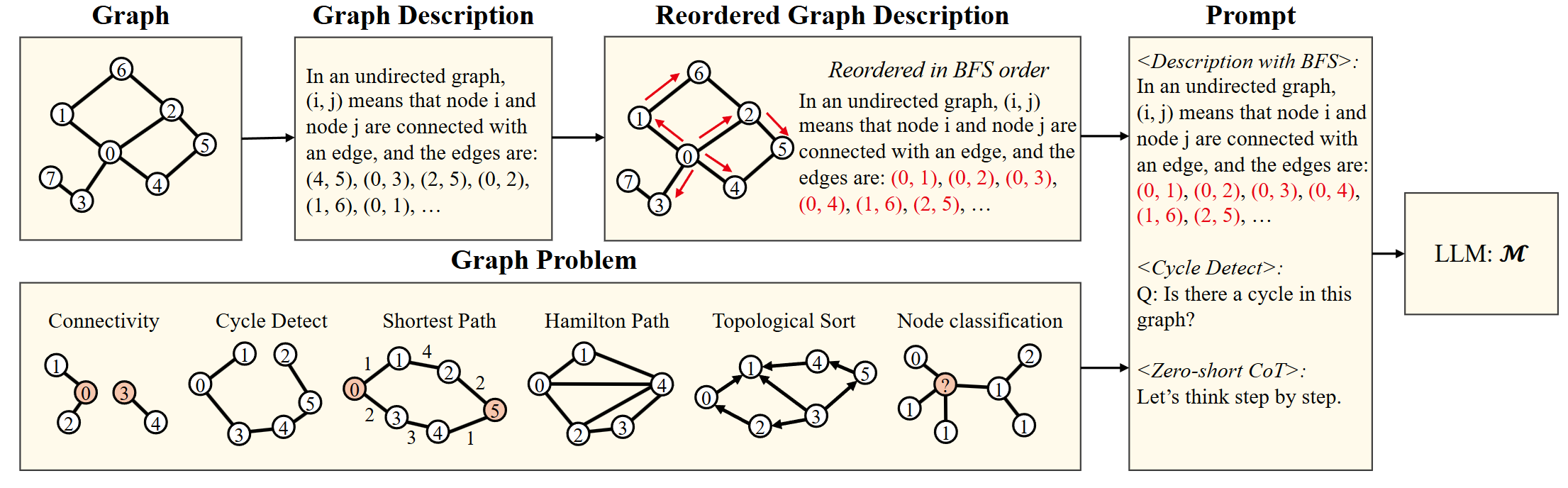
图任务中的优秀大语言模型
如果您喜欢我们的项目,请在 GitHub 上为我们点亮一颗星 ⭐,以获取最新更新。
![]()

这是一个关于在图任务中利用大语言模型的论文合集。 它基于我们的综述论文:图与大语言模型的融合:进展与未来方向。
我们将努力保持这份列表的及时更新。如果您发现任何错误或遗漏的论文,请随时提出问题或创建拉取请求。
我们的综述已被 IJCAI 2024 综述赛道接收。
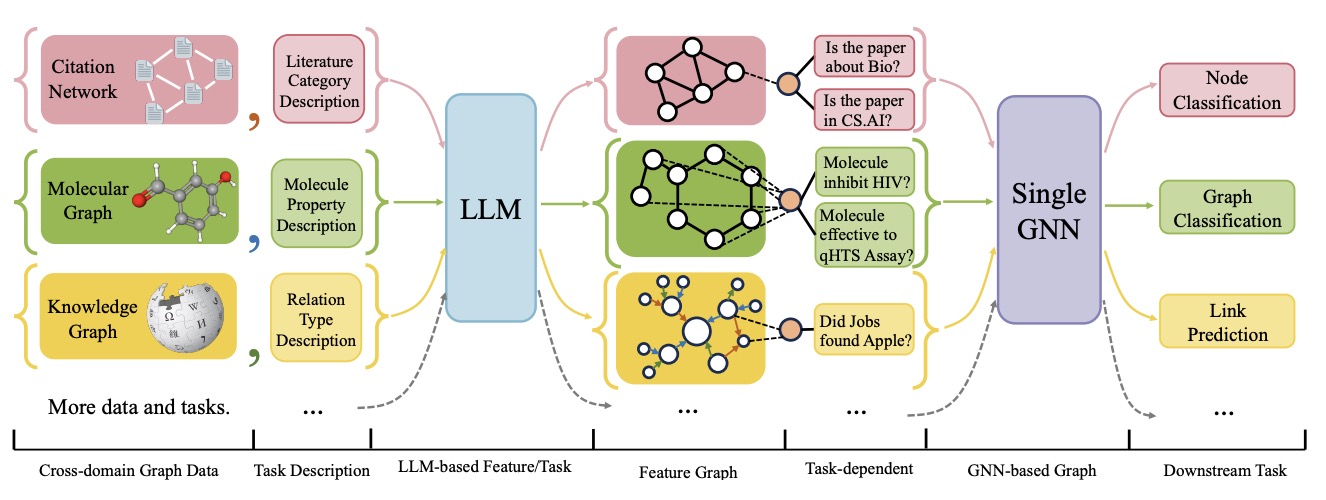
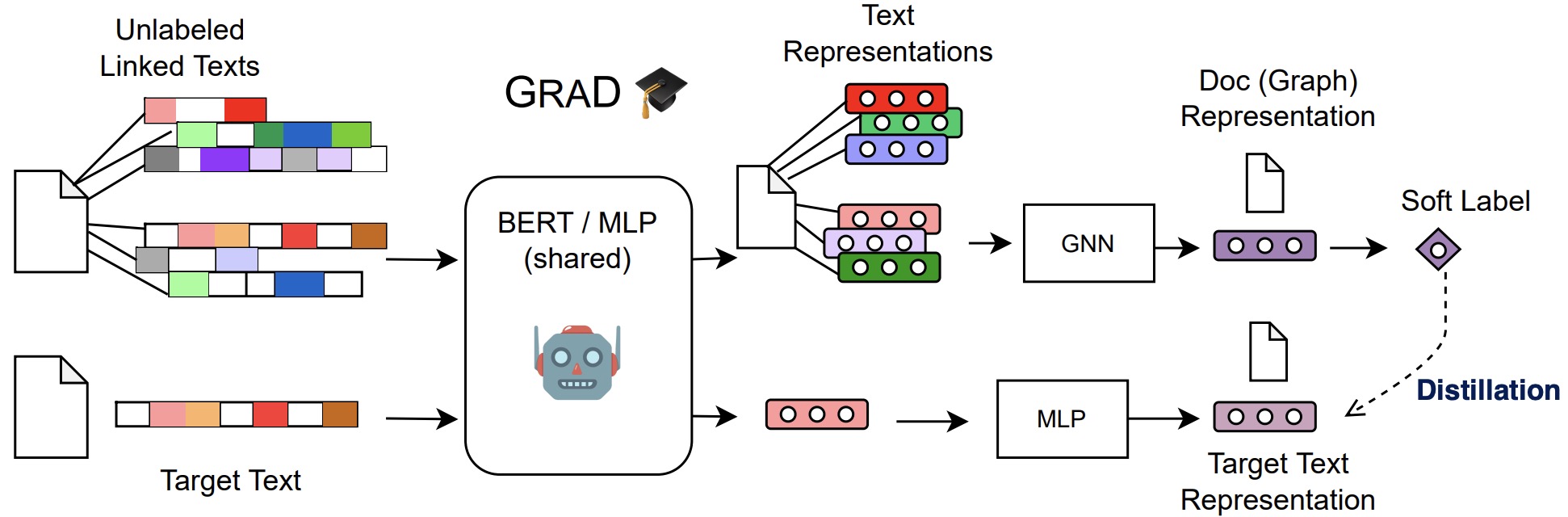
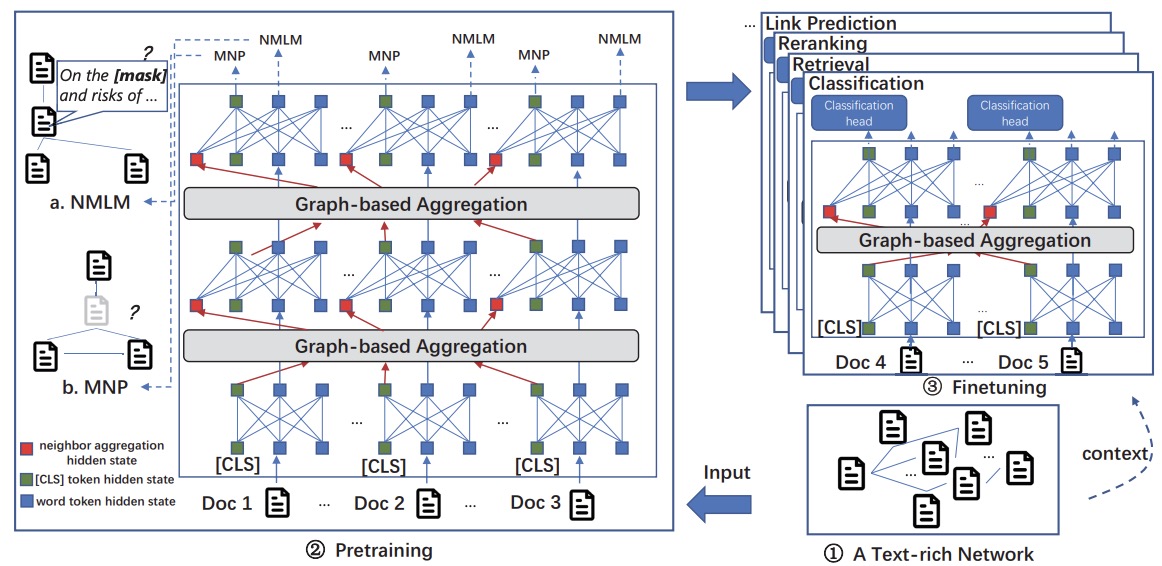
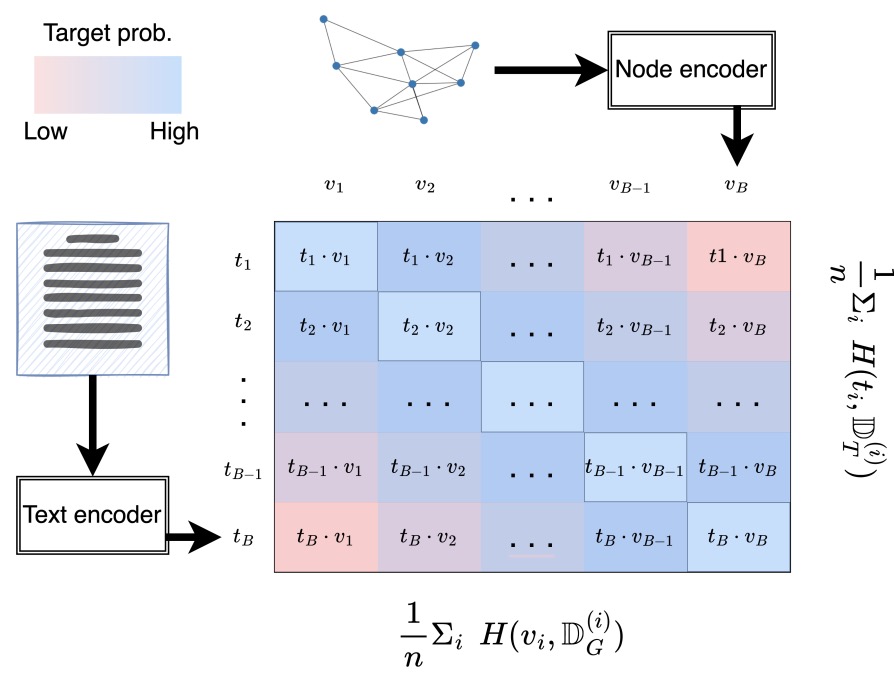
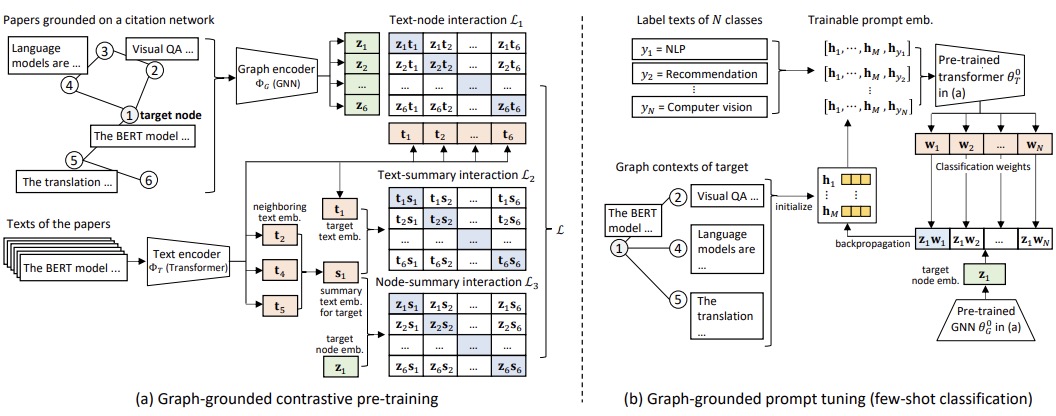
大语言模型如何帮助提升图相关任务?
借助大语言模型,我们与图数据(尤其是包含文本属性节点的图)交互的方式发生了显著变化。将大语言模型与传统图神经网络相结合,可以实现互补优势,从而增强图学习能力。图神经网络擅长捕捉结构信息,但其节点特征主要依赖于语义受限的嵌入表示,这限制了它们表达节点复杂性的能力。通过引入大语言模型,图神经网络可以获得更强大的节点特征,有效结合结构和上下文信息。另一方面,大语言模型擅长处理文本信息,但在捕捉图数据中的结构关系方面存在不足。将图神经网络与大语言模型结合,既能发挥大语言模型强大的文本理解能力,又能利用图神经网络对结构关系的建模优势,从而实现更加全面和高效的图学习。
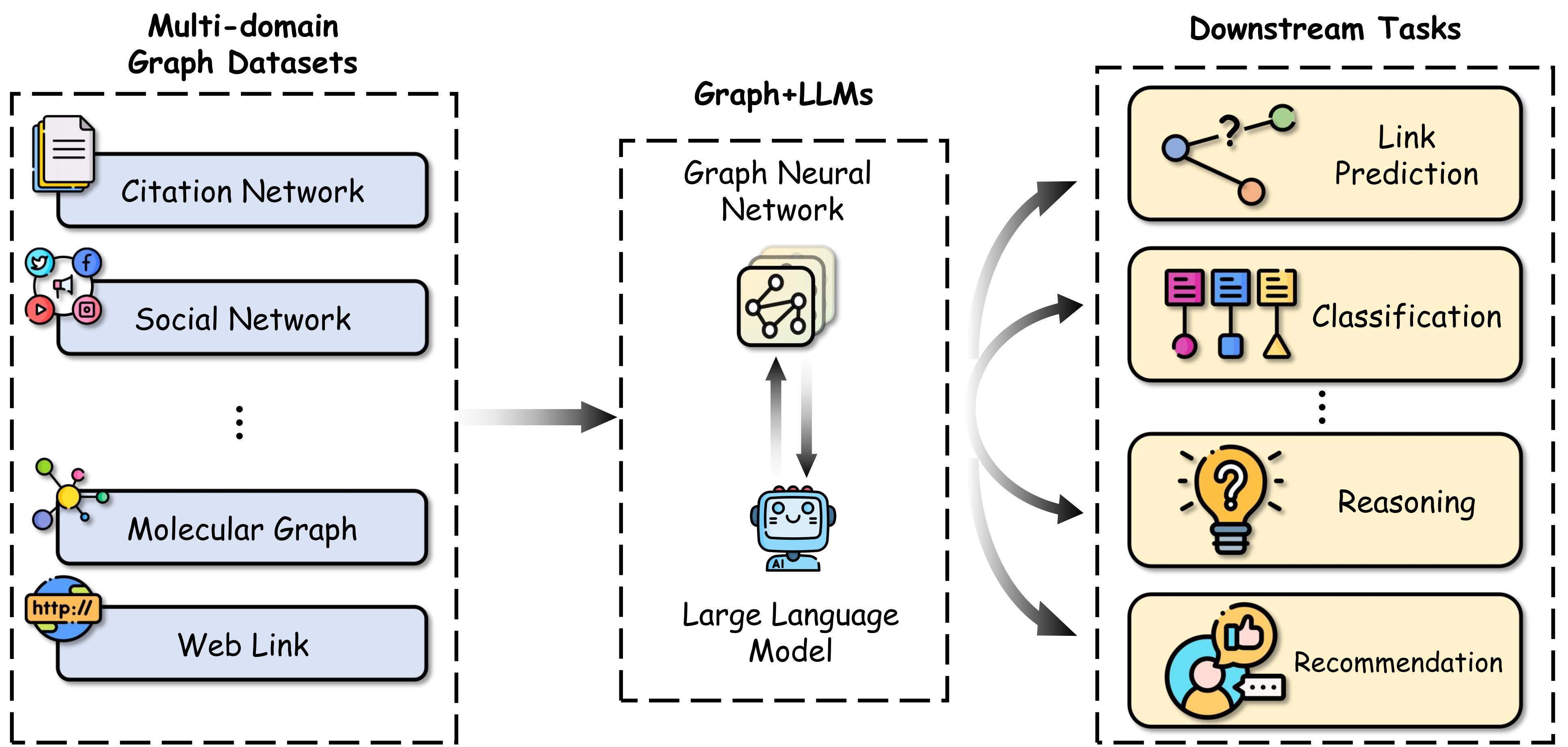
图 1. 图与大语言模型的融合概览。
基于所提分类体系的总结
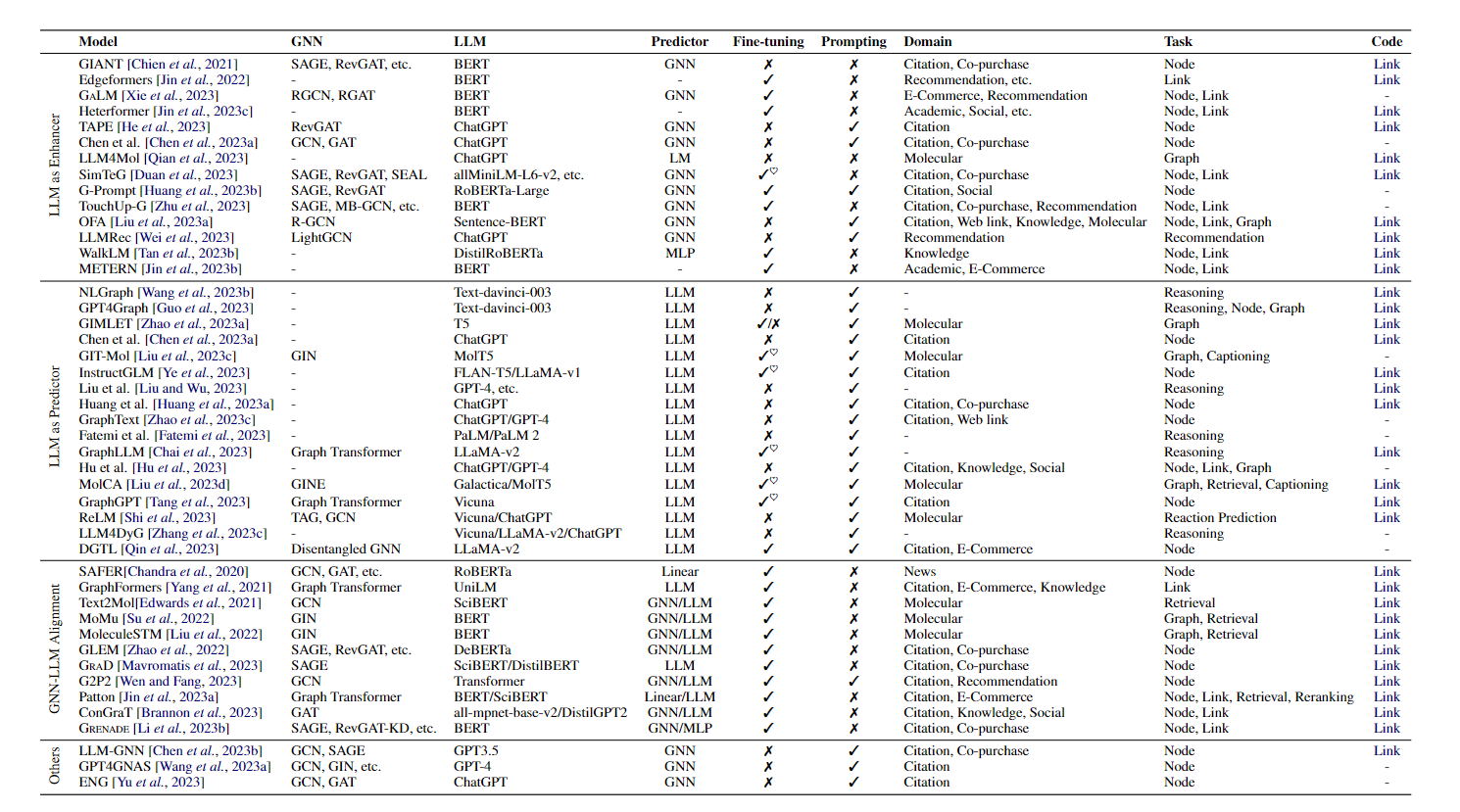
表 1. 文献中利用大语言模型辅助图相关任务的模型汇总,按发布时间排序。微调表示是否需要对大语言模型的参数进行微调,♥ 表示采用参数高效微调(PEFT)策略,如 LoRA 和前缀微调。提示词表示在大语言模型中使用文本格式的提示词,可能是手动或自动生成的。任务中的缩写含义如下:Node 指节点级任务;Link 指链接级任务;Graph 指图级任务;Reasoning 指图推理;Retrieval 指图-文本检索;Captioning 指图描述生成。
目录
LLM作为增强器
(2022.03) [ICLR' 2022] 基于自监督多尺度邻域预测的节点特征提取 [论文 | 代码]
GIANT
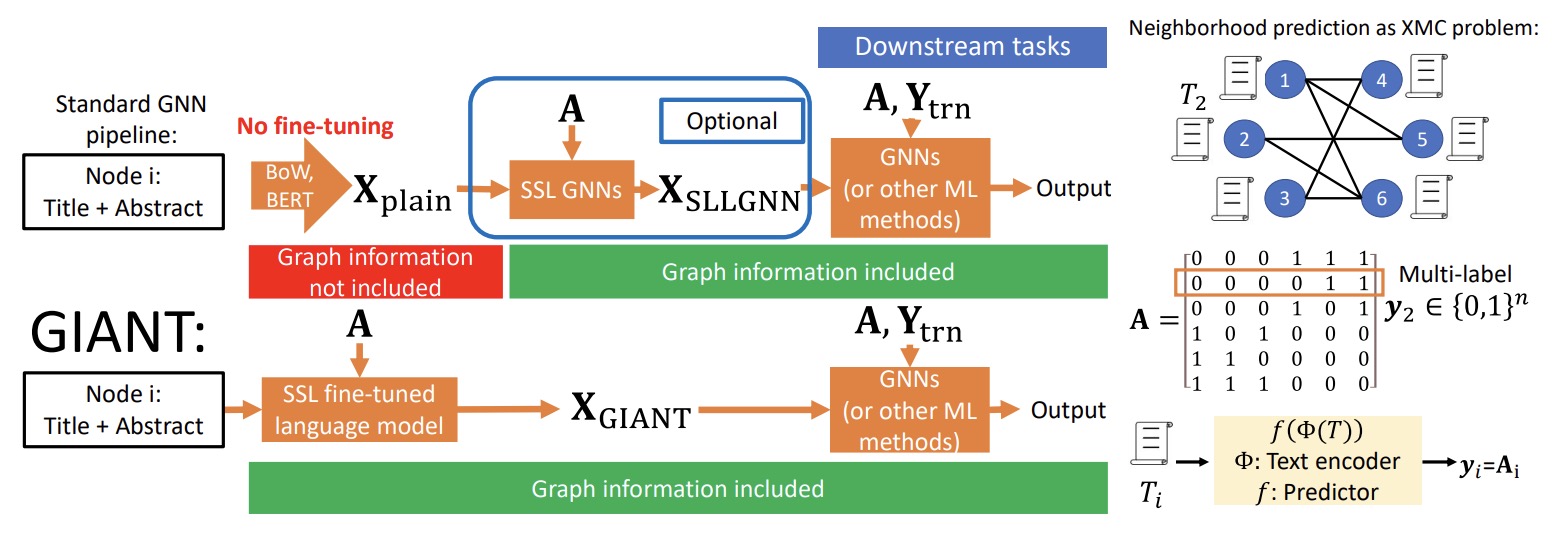
GIANT的框架。
(2023.02) [ICLR' 2023] Edgeformers:用于文本边网络表示学习的图增强型Transformer [论文 | 代码]
Edgeformers
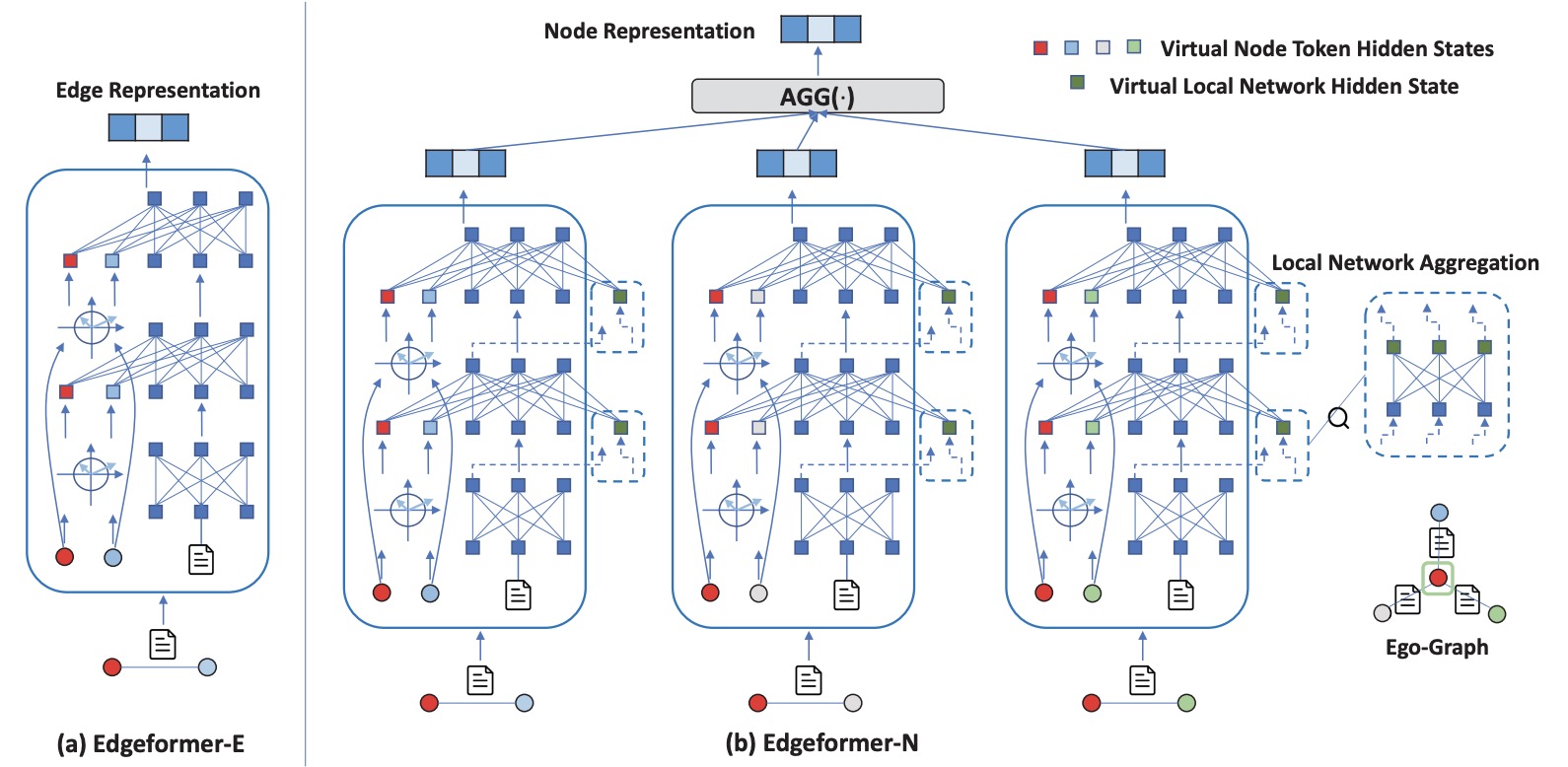
Edgeformers的框架。
(2023.05) [KDD' 2023] 在大型图语料库上进行图感知语言模型预训练有助于多种图应用 [论文]
GALM
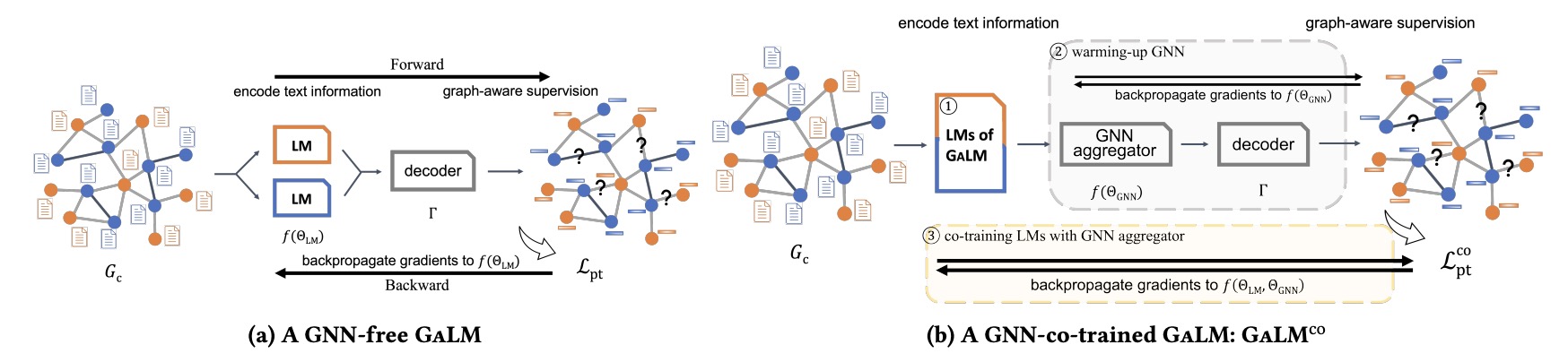
GALM的框架。
(2023.06) [KDD' 2023] Heterformer:基于Transformer的异构富文本网络深度节点表示学习 [论文 | 代码]
Heterformer
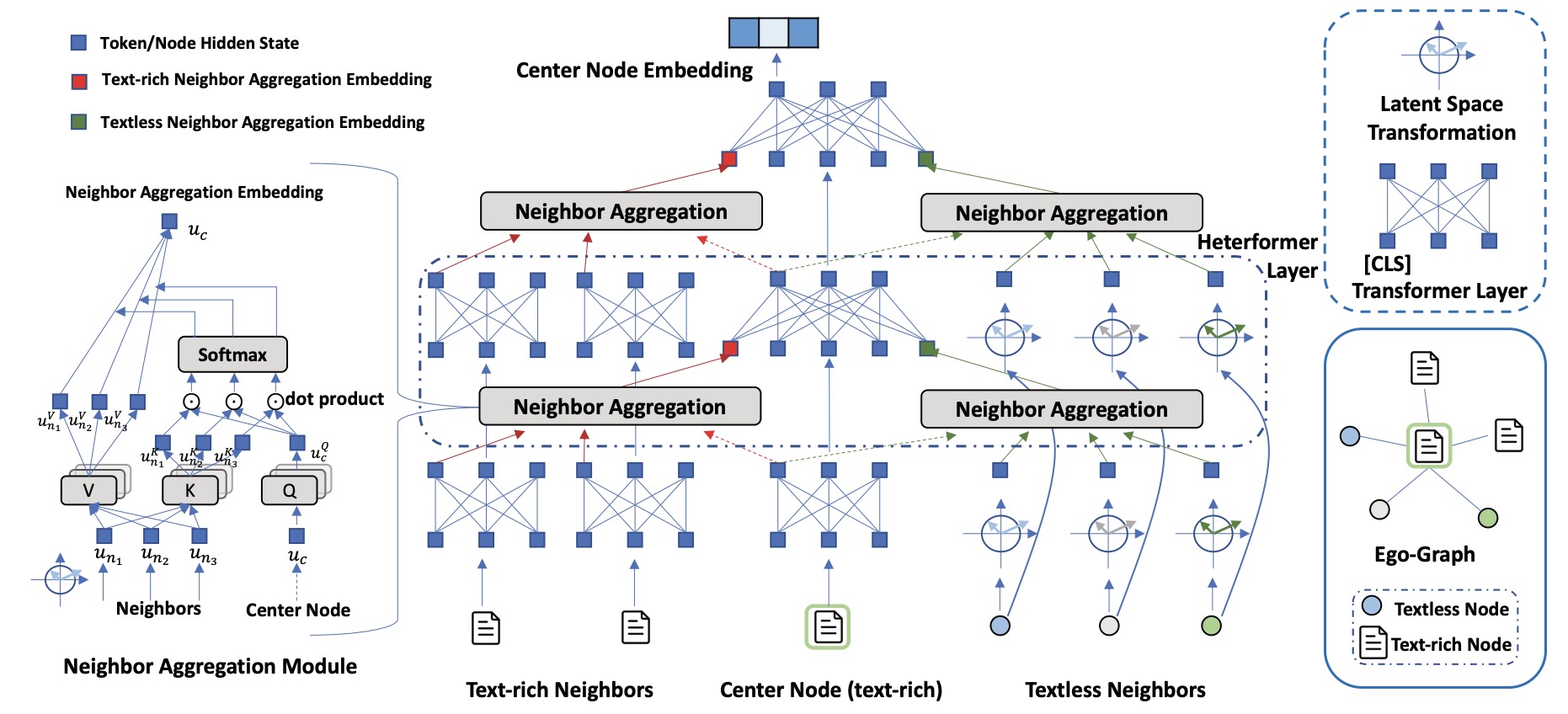
Heterformer的框架。
(2023.05) [ICLR' 2024] 利用解释:LLM到LLM解释器用于增强文本属性图表示学习 [论文 | 代码]
TAPE
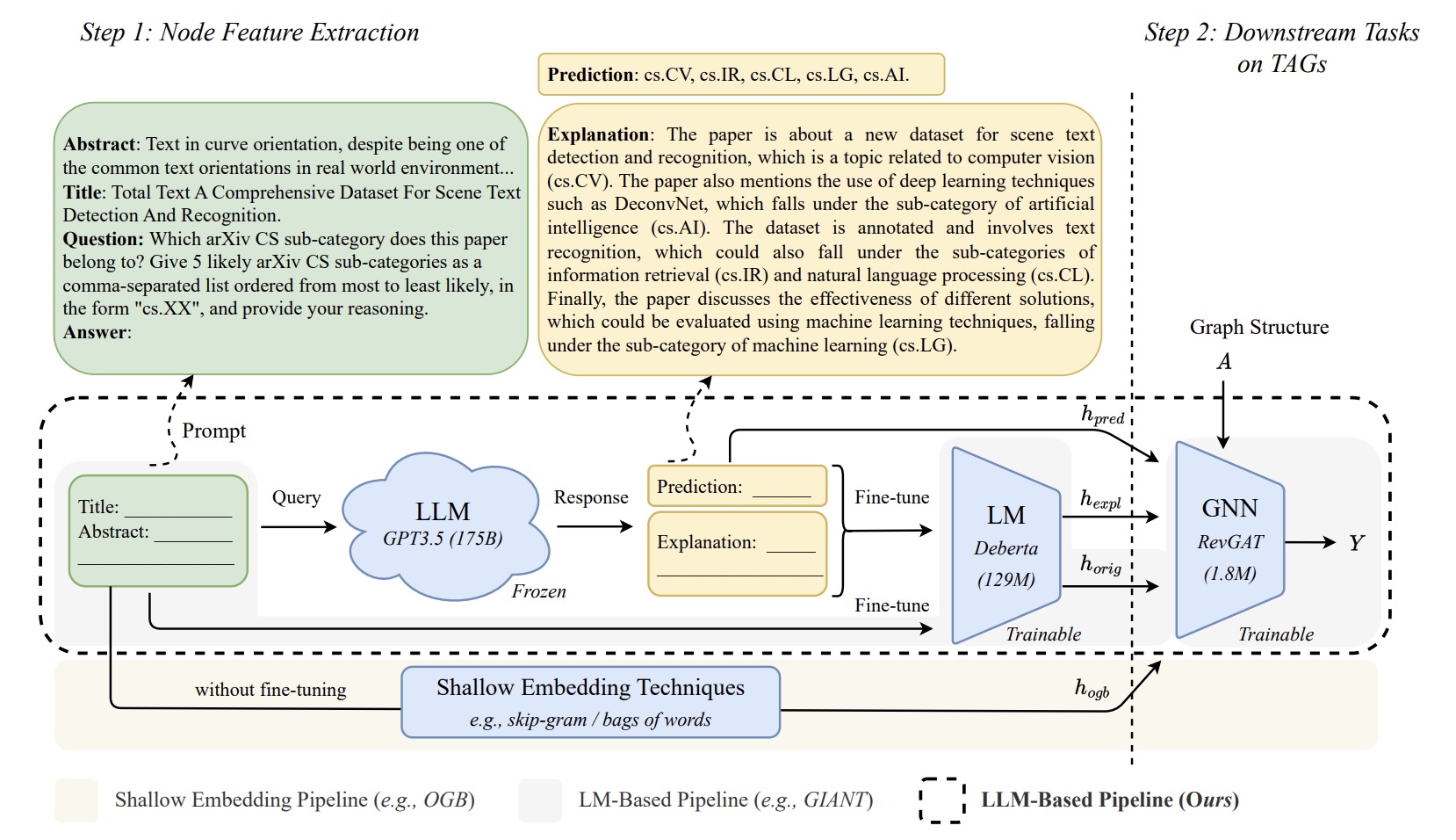
TAPE的框架。
(2023.08) [Arxiv' 2023] 探索大型语言模型(LLMs)在图上学习的潜力 [论文]
KEA
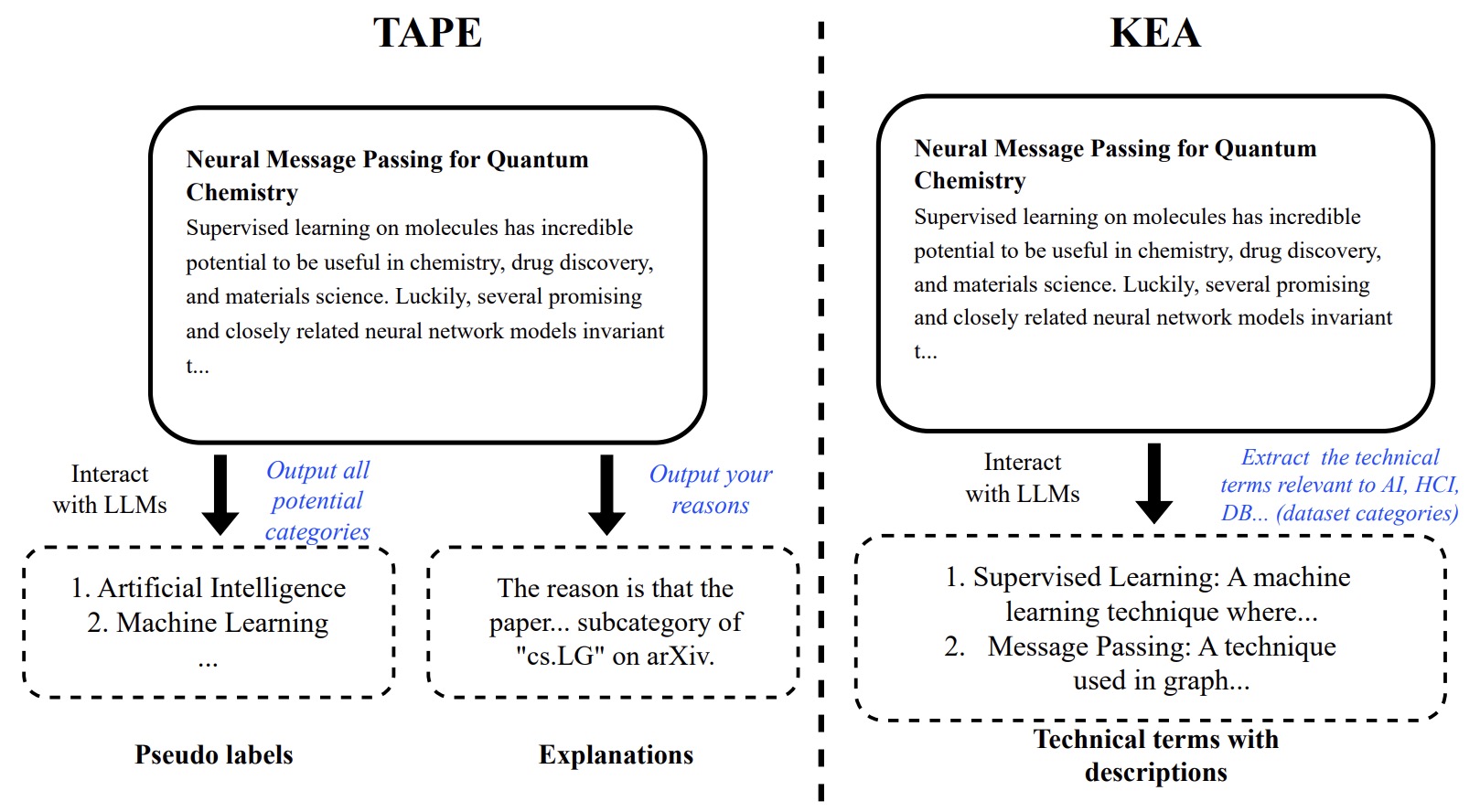
KEA的框架。
(2023.07) [Arxiv' 2023] 大型语言模型能否赋能分子性质预测? [论文 | 代码]
LLM4Mol
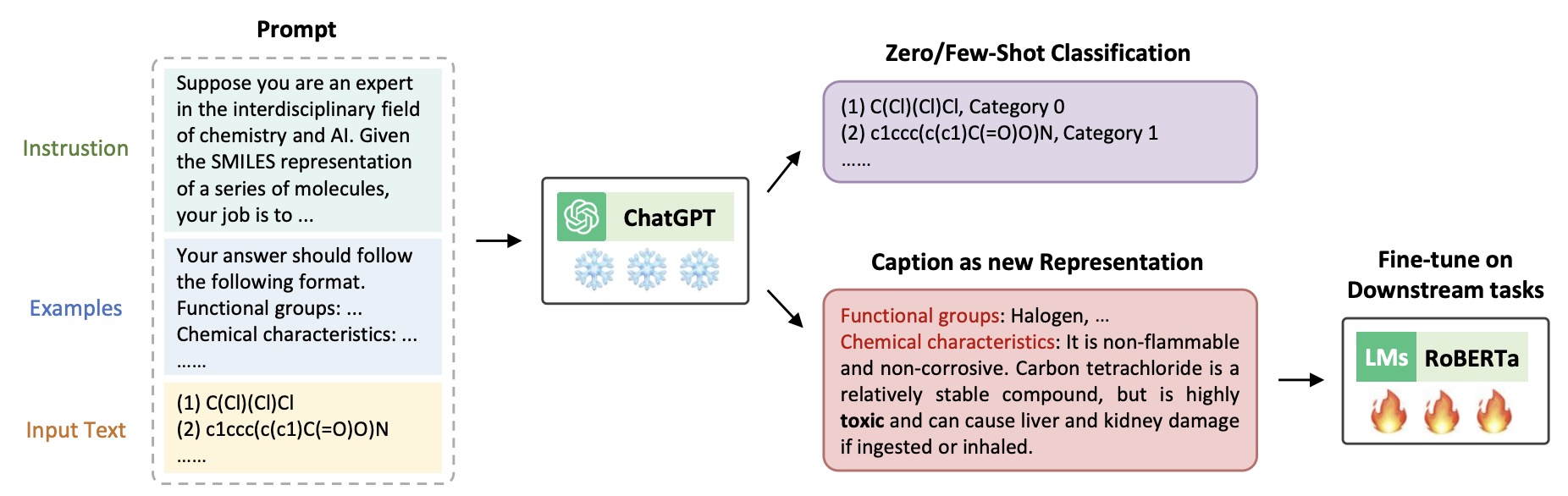
LLM4Mol的框架。
(2023.08) [Arxiv' 2023] Simteg:一种令人沮丧的简单方法改进了文本图学习 [论文 | 代码]
SimTeG
SimTeG的框架。
(2023.09) [Arxiv' 2023] 基于提示的节点特征提取器,用于文本属性图上的少样本学习 [论文]
G-Prompt
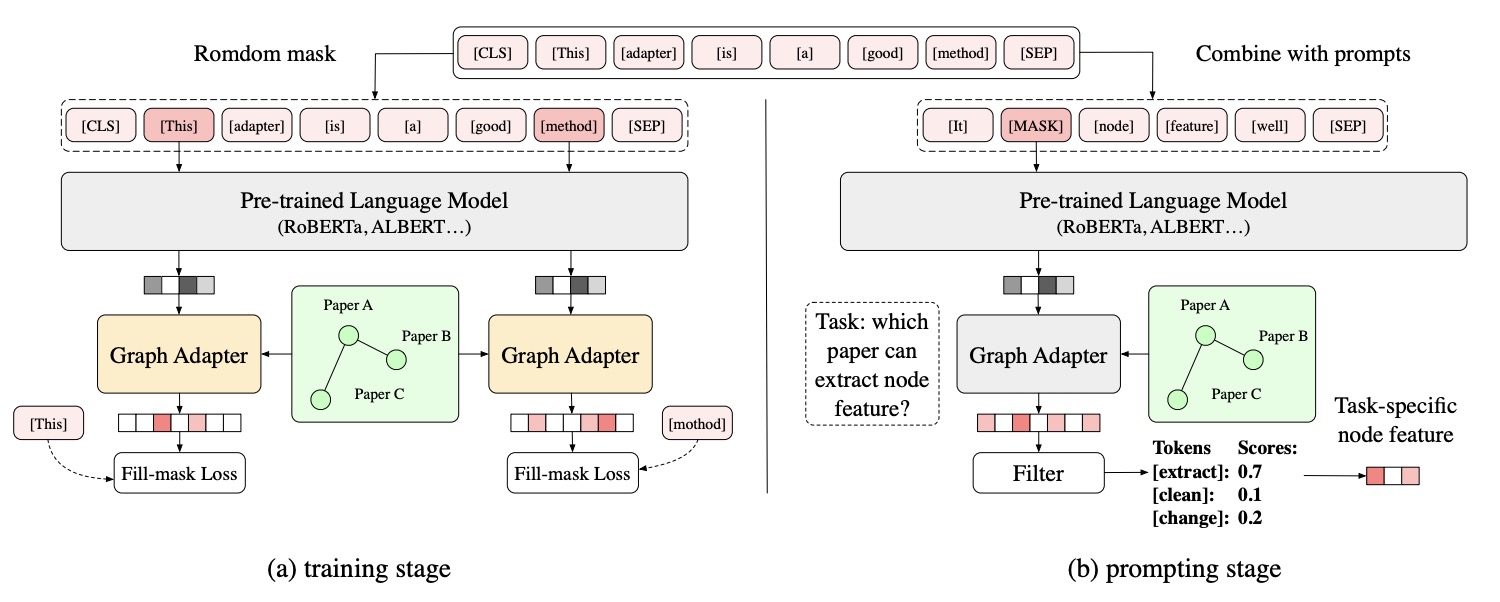
G-Prompt的框架。
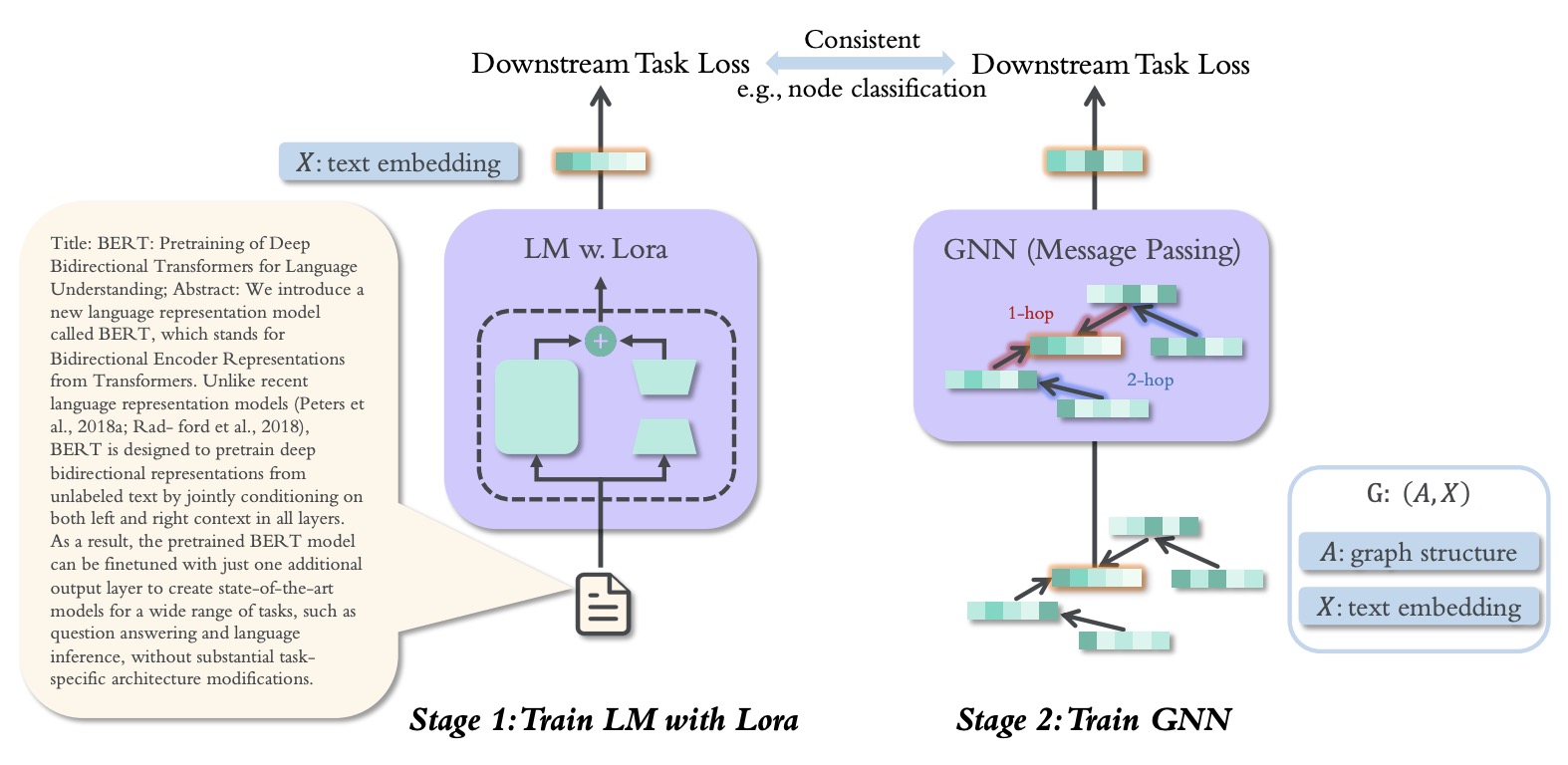
(2023.09) [Arxiv' 2023] TouchUp-G:通过以图为中心的微调改进特征表示 [论文]
TouchUp-G
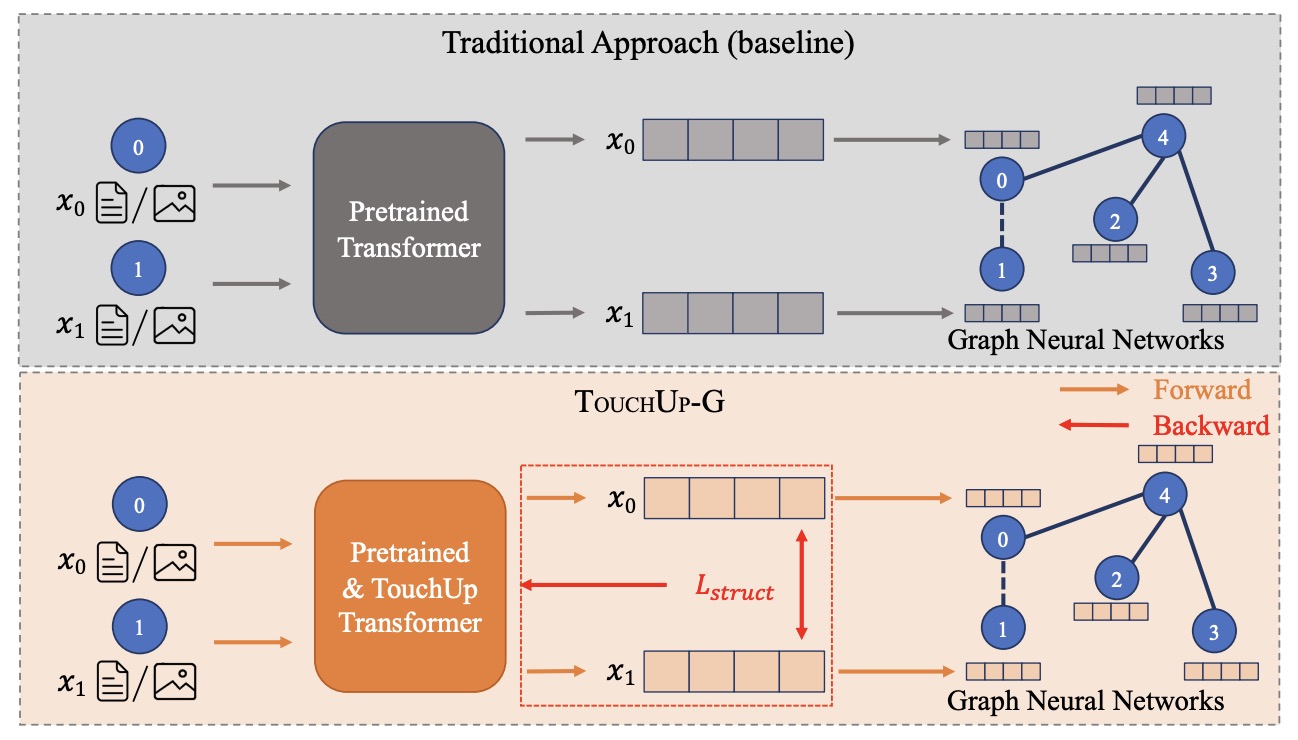
TouchUp-G的框架。
(2023.09) [ICLR' 2024] 一统天下:迈向训练一个图模型以应对所有分类任务 [论文 | 代码]
OFA
OFA的框架。

大语言模型作为预测器
(2023.05) [NeurIPS' 2023] 语言模型能否用自然语言解决图问题? [论文 | 代码]
NLGraph
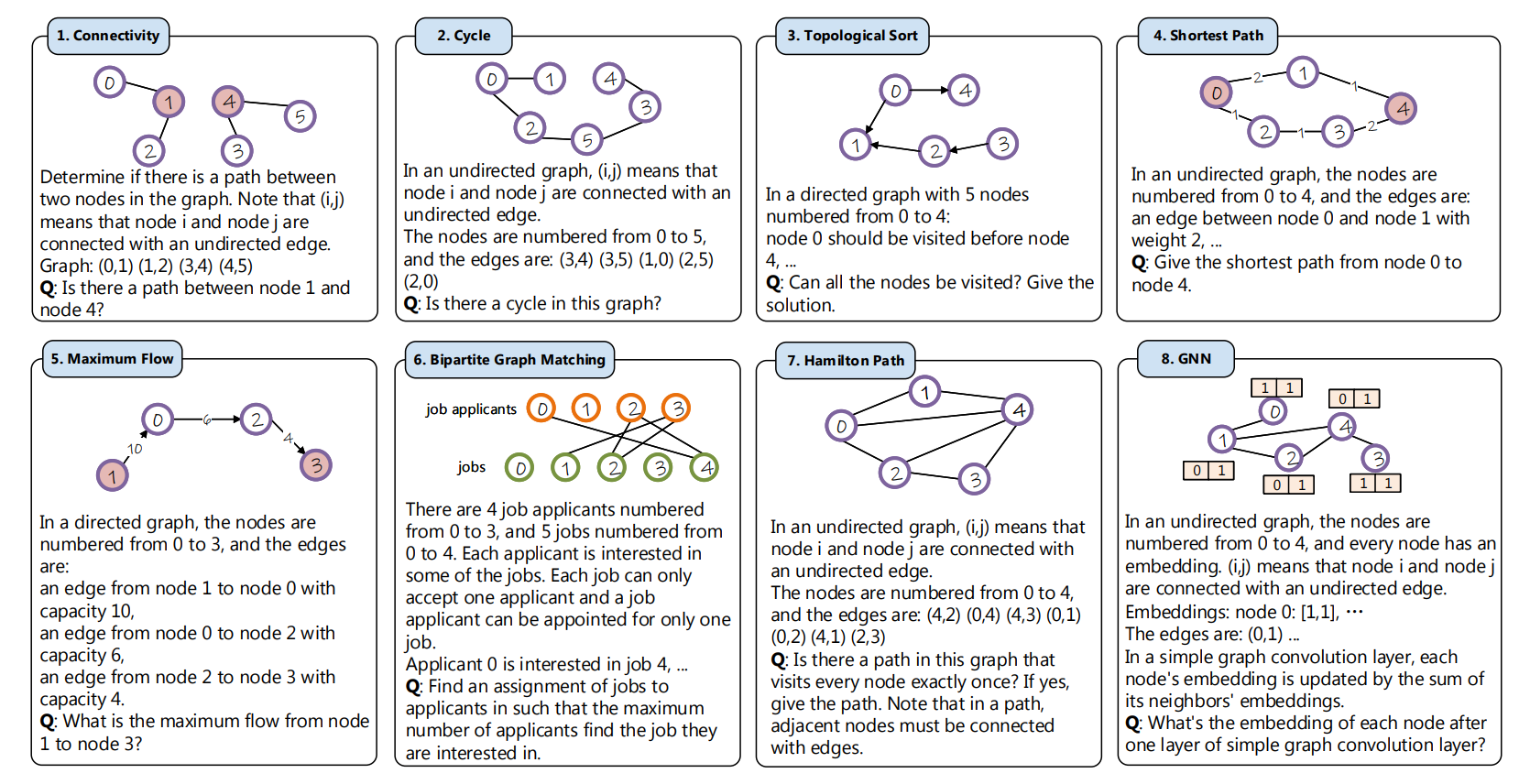
NLGraph的框架。
(2023.05) [Arxiv' 2023] GPT4Graph:大型语言模型能否理解图结构数据?一项实证评估与基准测试 [论文 | 代码]
GPT4Graph
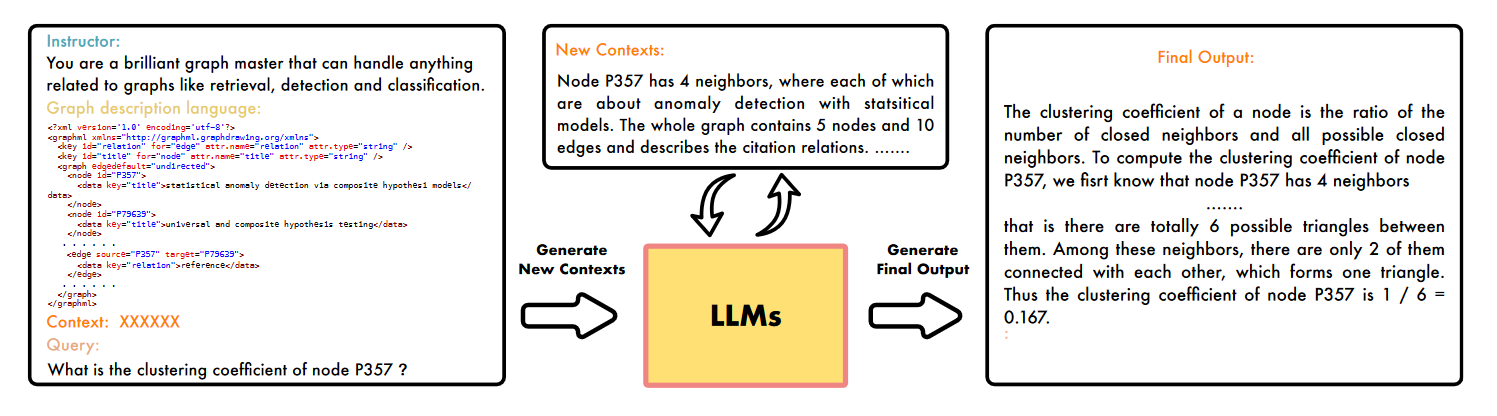
GPT4Graph的框架。
(2023.06) [NeurIPS' 2023] GIMLET:用于基于指令的分子零样本学习的统一图-文本模型 [论文 | 代码]
GIMLET
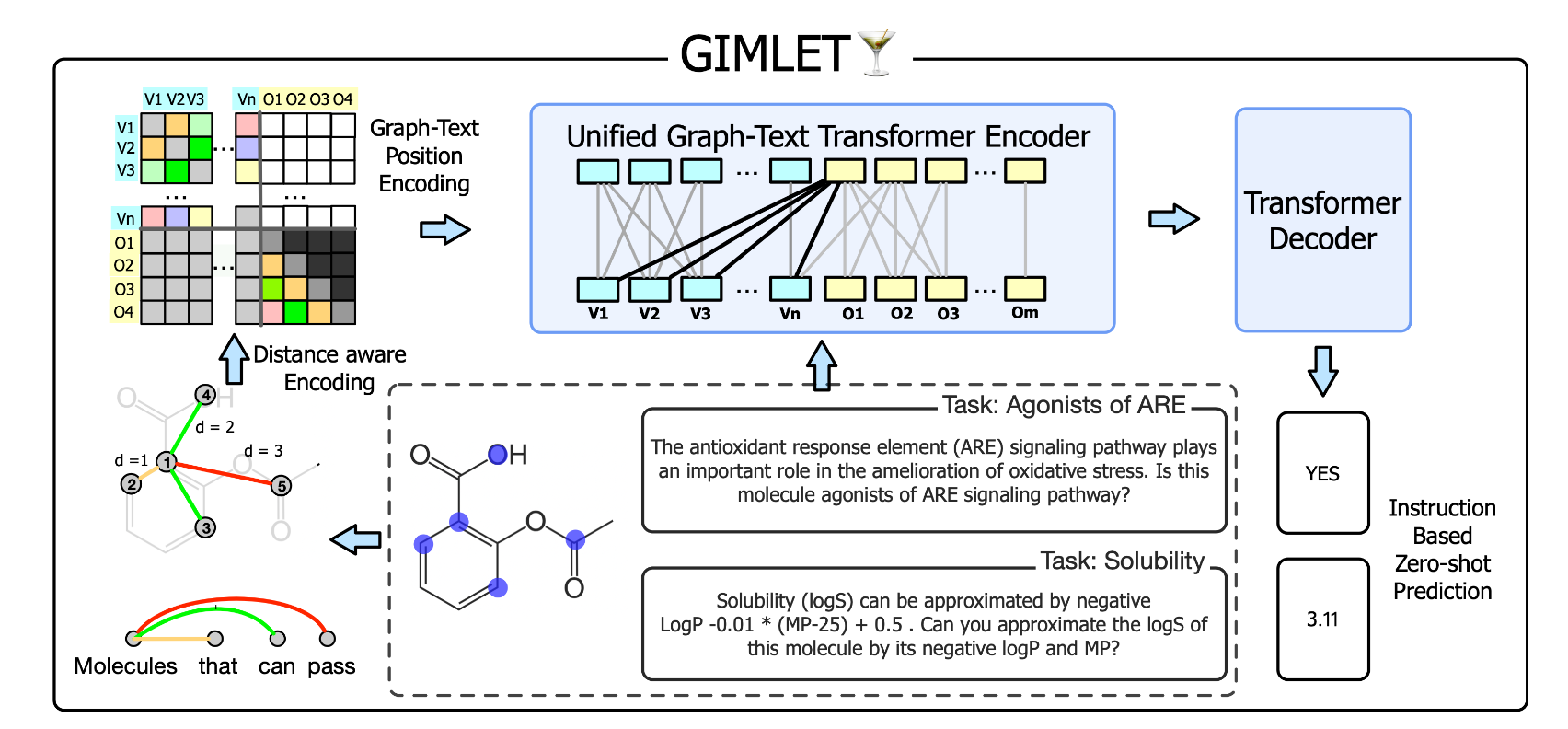
GIMLET的框架。
(2023.07) [Arxiv' 2023] 探索大型语言模型(LLMs)在图上学习的潜力 [论文 | 代码]
框架
Chen等人设计的提示词。
(2023.08) [Arxiv' 2023] GIT-Mol:一种用于分子科学的多模态大型语言模型,融合了图、图像和文本 [论文]
GIT-Mol
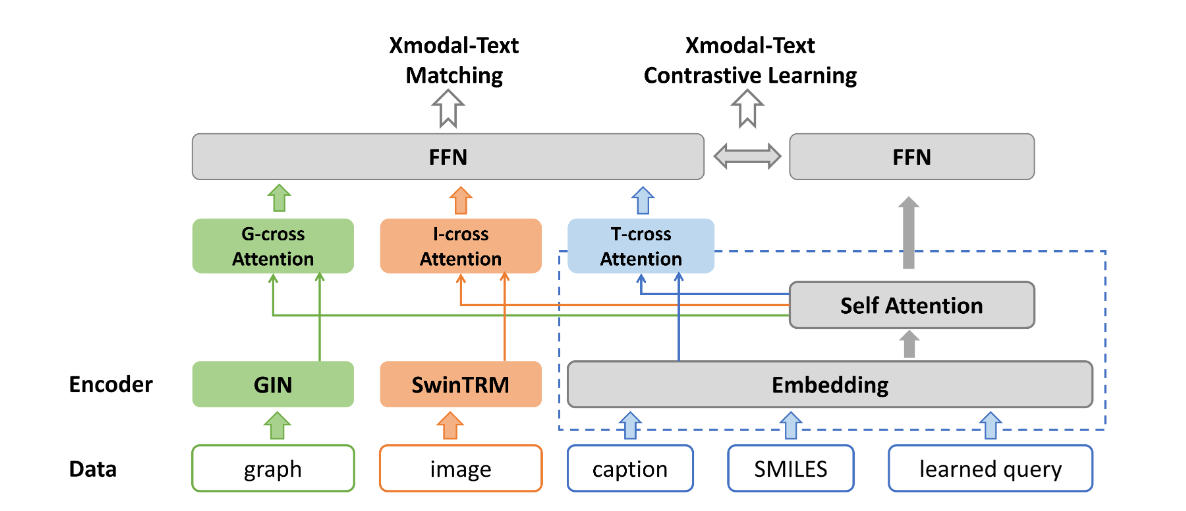
GIT-Mol的框架。
(2023.08) [Arxiv' 2023] 自然语言就是图所需的一切 [论文 | 代码]
InstructGLM
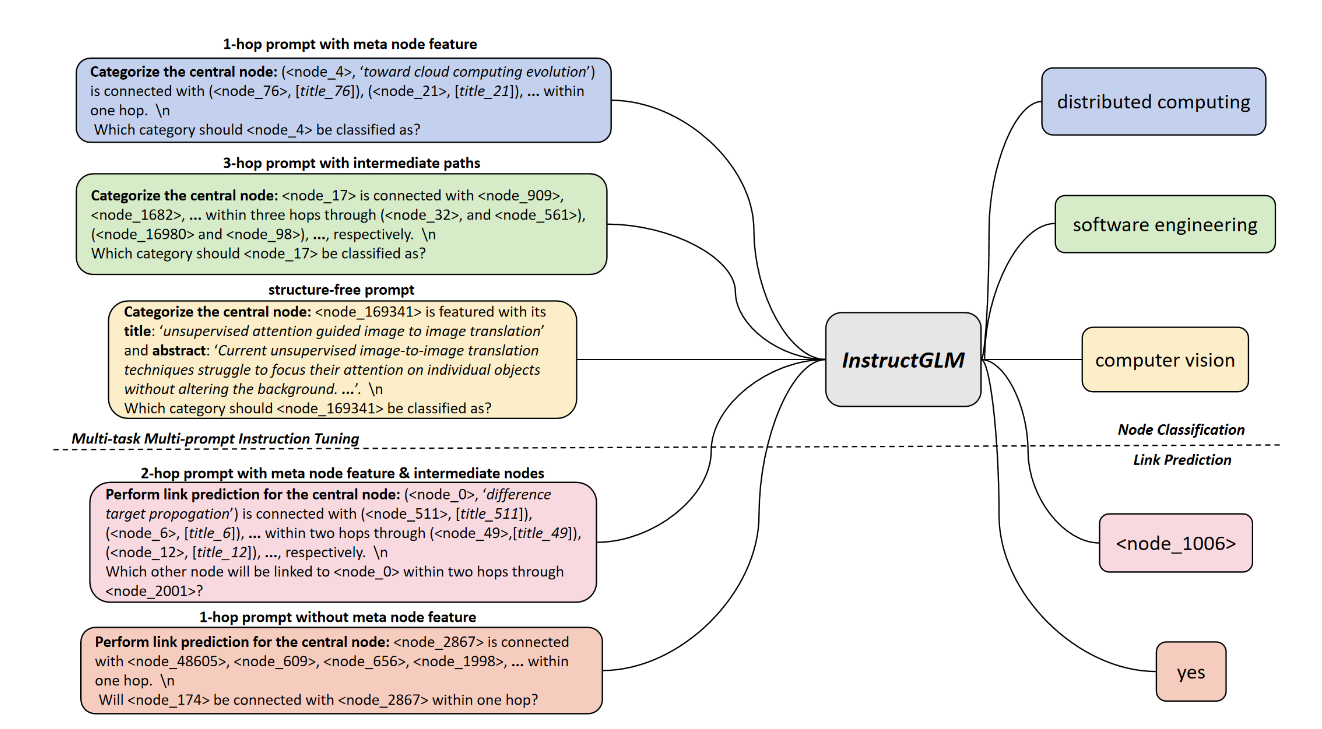
InstructGLM的框架。
(2023.08) [Arxiv' 2023] 在图上评估大型语言模型:性能洞察与比较分析 [论文 | 代码]
框架
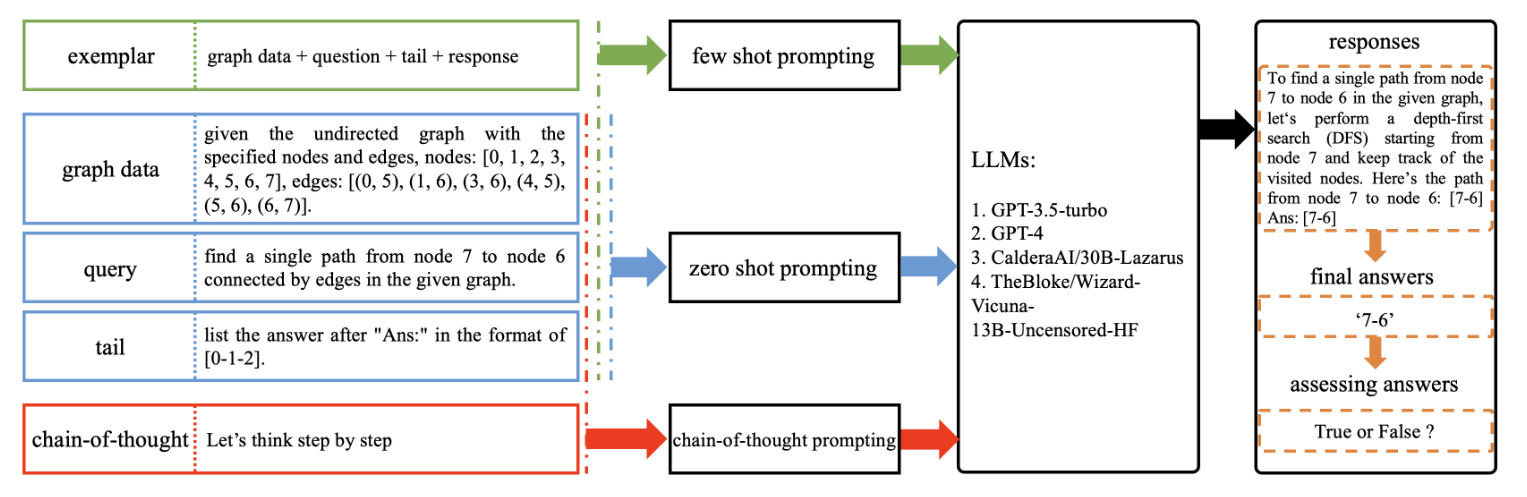
Liu等人设计的提示词。
(2023.09) [Arxiv' 2023] 大型语言模型能否有效利用图结构信息:何时以及为何 [论文 | 代码]
框架
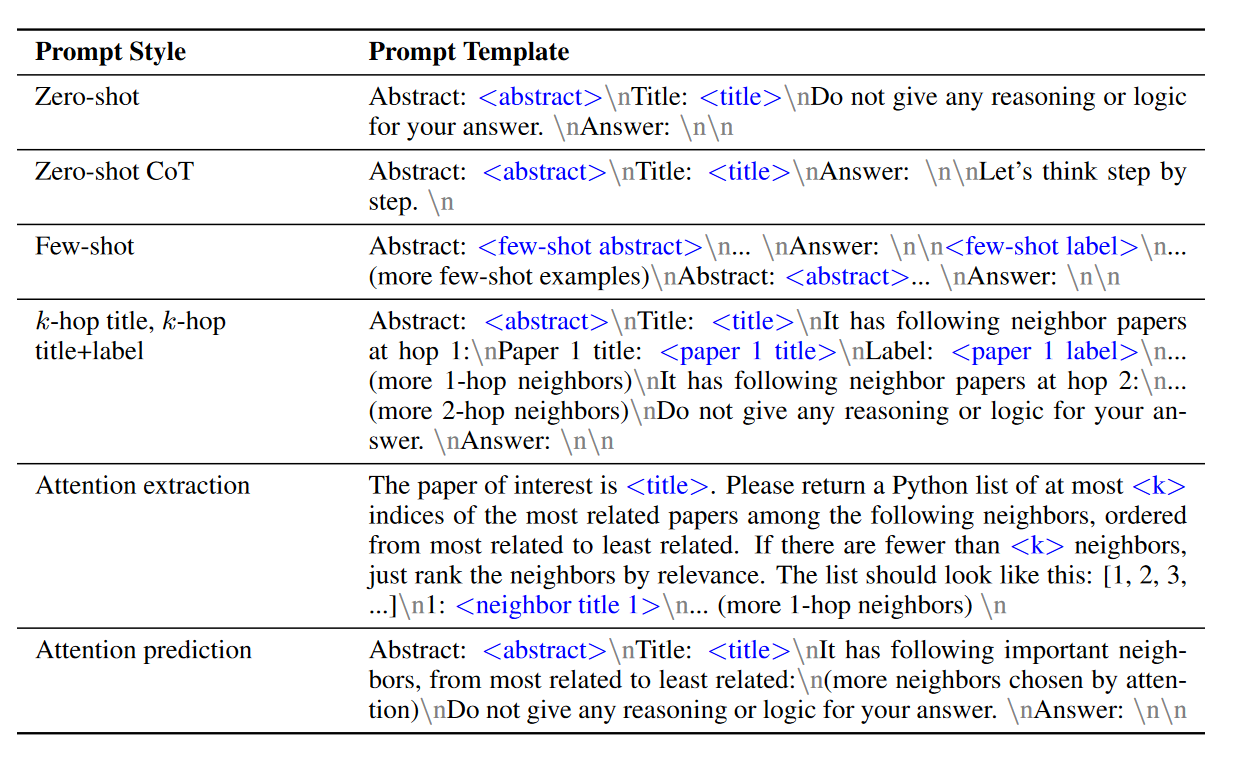
Huang等人设计的提示词。
(2023.10) [Arxiv' 2023] GraphText:文本空间中的图推理 [论文] | 代码]
GraphText
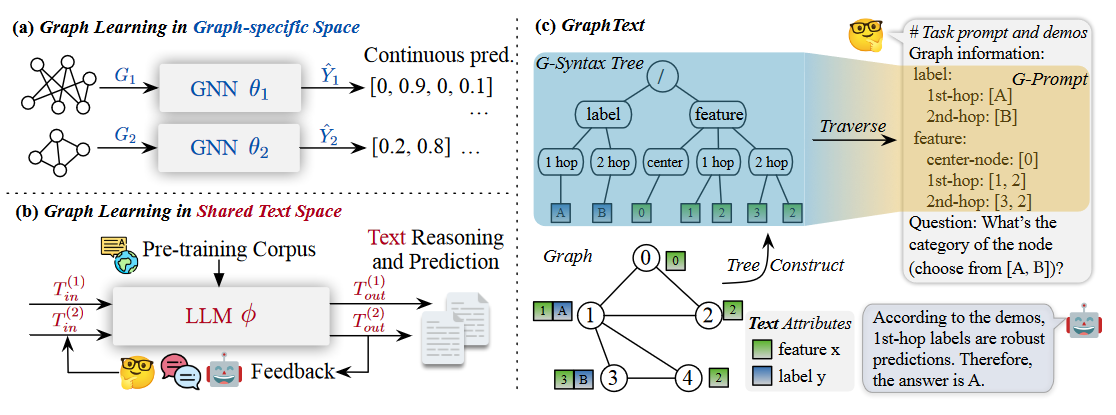
GraphText的框架。
(2023.10) [Arxiv' 2023] 像图一样说话:为大型语言模型编码图数据 [论文]
框架
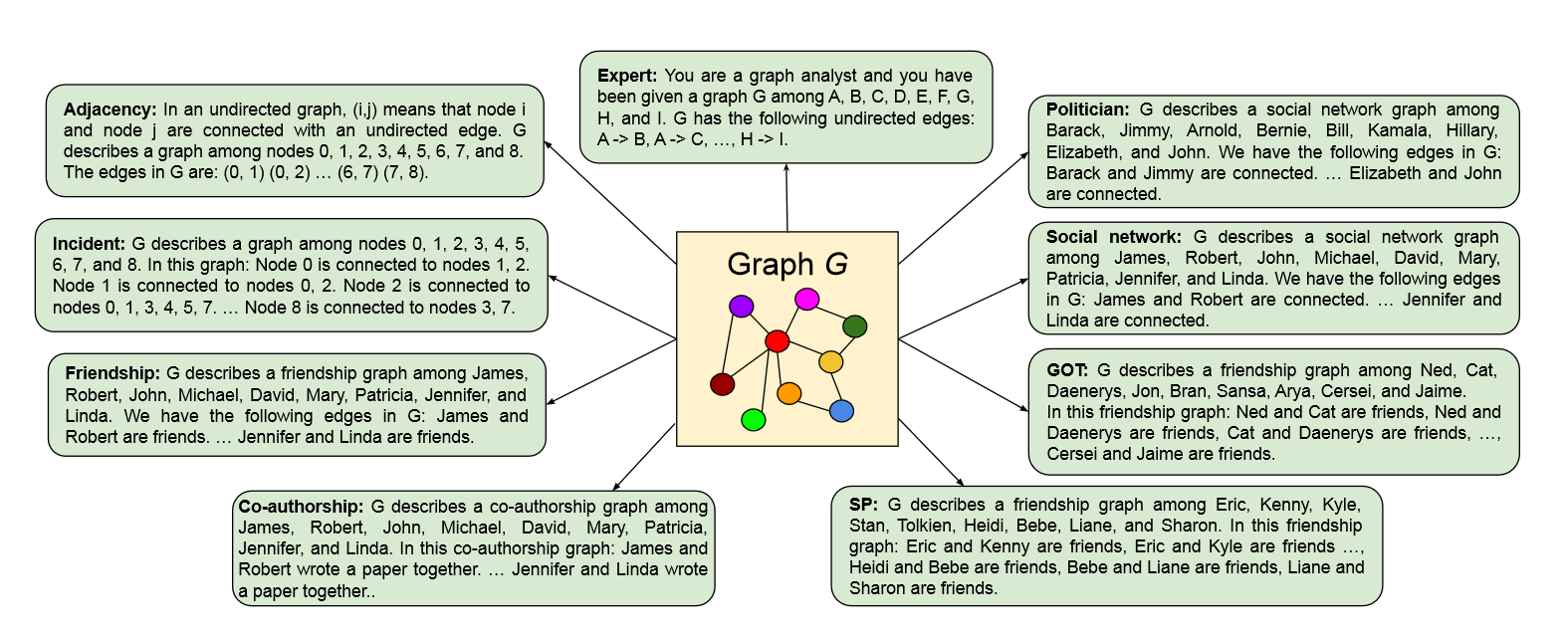
Fatemi等人设计的提示词。
(2023.10) [Arxiv' 2023] GraphLLM:提升大型语言模型的图推理能力 [论文 | 代码]
GraphLLM
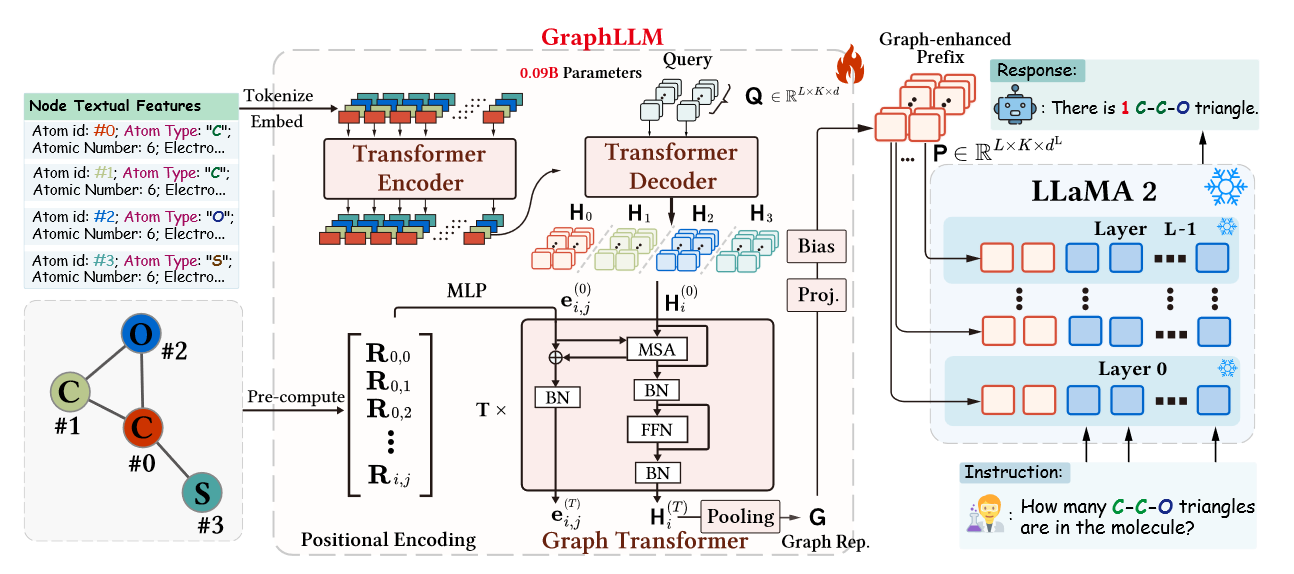
GraphLLM的框架。
(2023.10) [Arxiv' 2023] 超越文本:深入探究大型语言模型 [论文]
框架
Hu等人设计的提示词。
(2023.10) [EMNLP' 2023] MolCA:具有跨模态投影器和单模态适配器的分子图-语言建模 [论文 | 代码]
MolCA
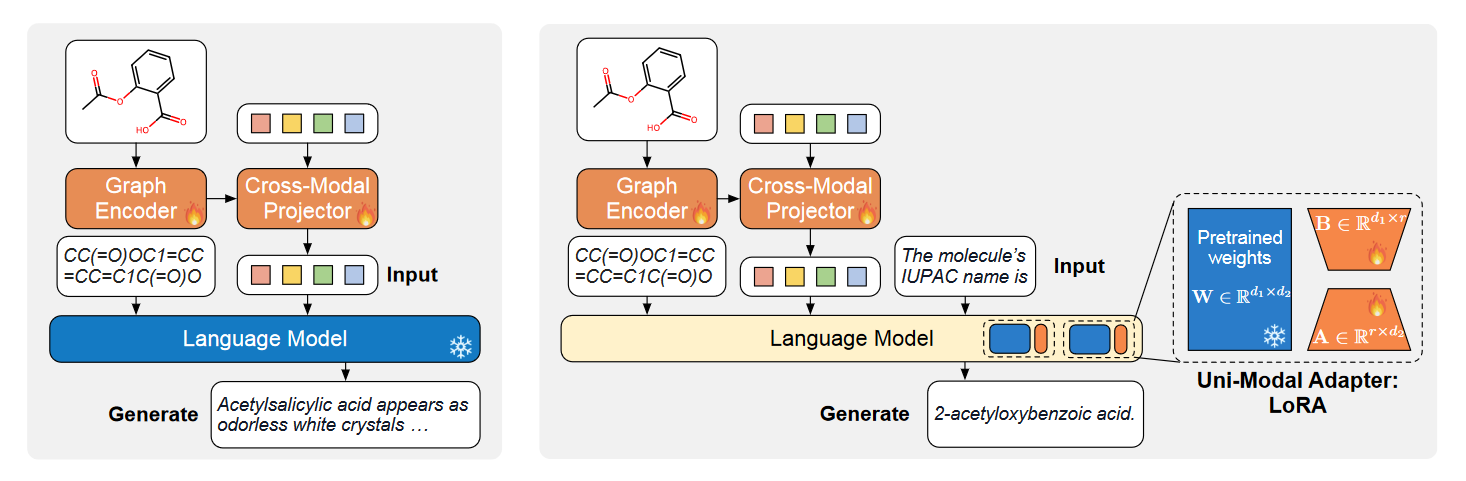
MolCA的框架。
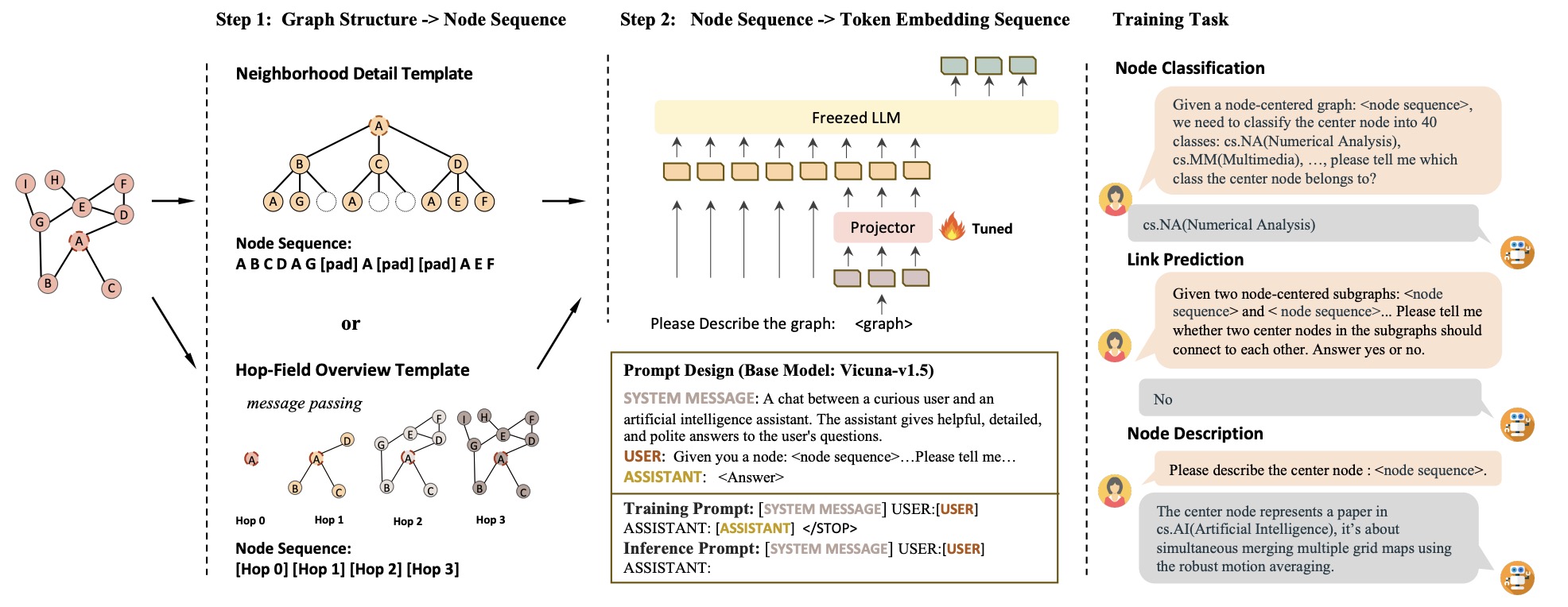
(2023.10) [Arxiv' 2023] GraphGPT:面向大型语言模型的图指令微调 [论文 | 代码]
GraphGPT
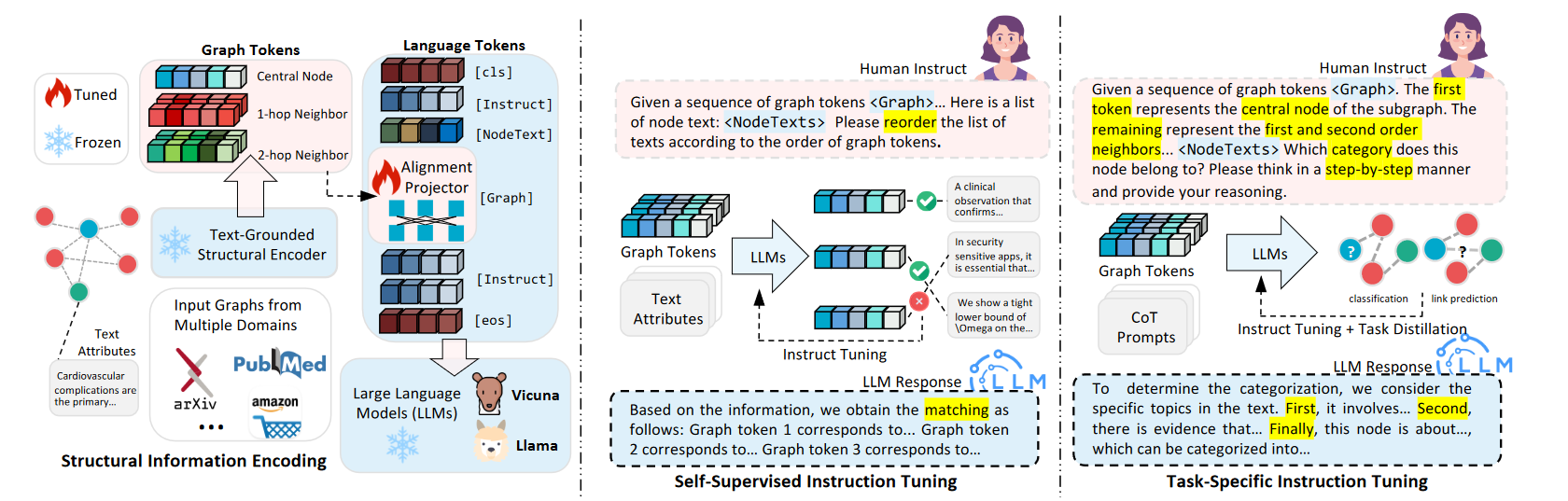
GraphGPT的框架。
(2023.10) [EMNLP' 2023] ReLM:利用语言模型提升化学反应预测能力 [论文 | 代码]
ReLM
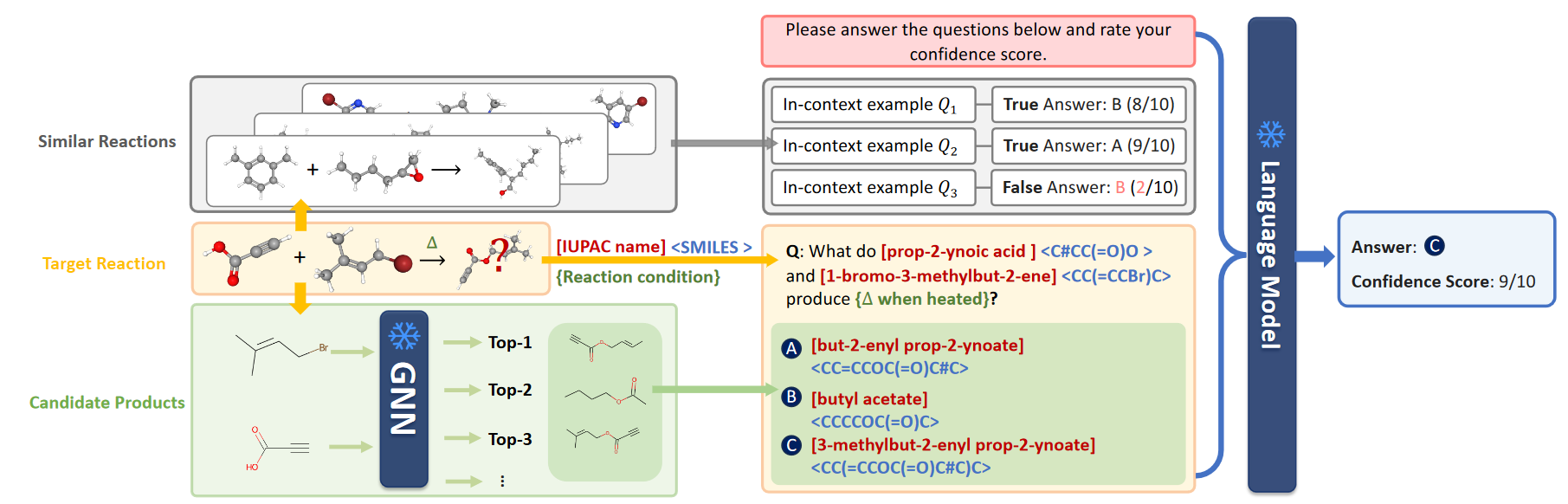
ReLM的框架。
(2023.10) [Arxiv' 2023] LLM4DyG:大型语言模型能否解决动态图上的问题? [论文]
LLM4DyG
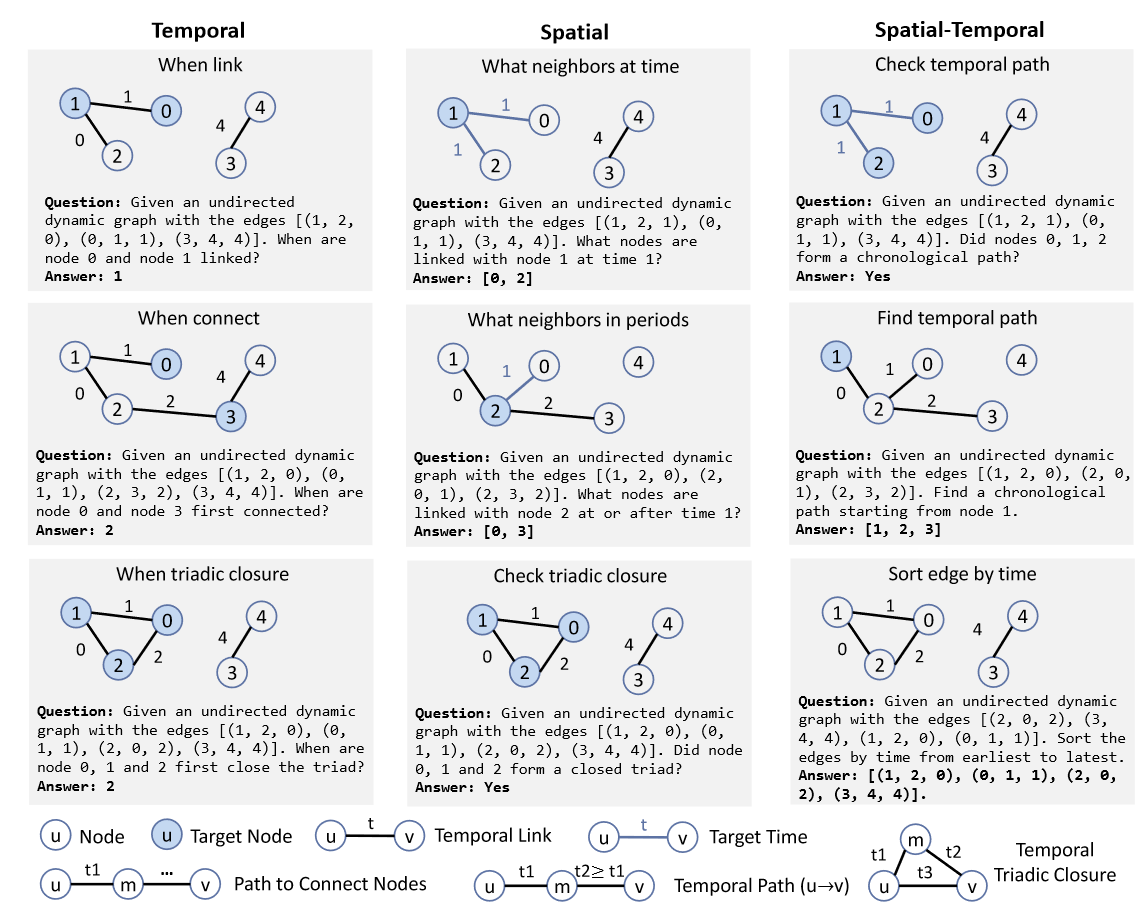
LLM4DyG的框架。
(2023.10) [Arxiv' 2023] 利用大型语言模型对带文本属性的图进行解耦表征学习 [论文]
DGTL
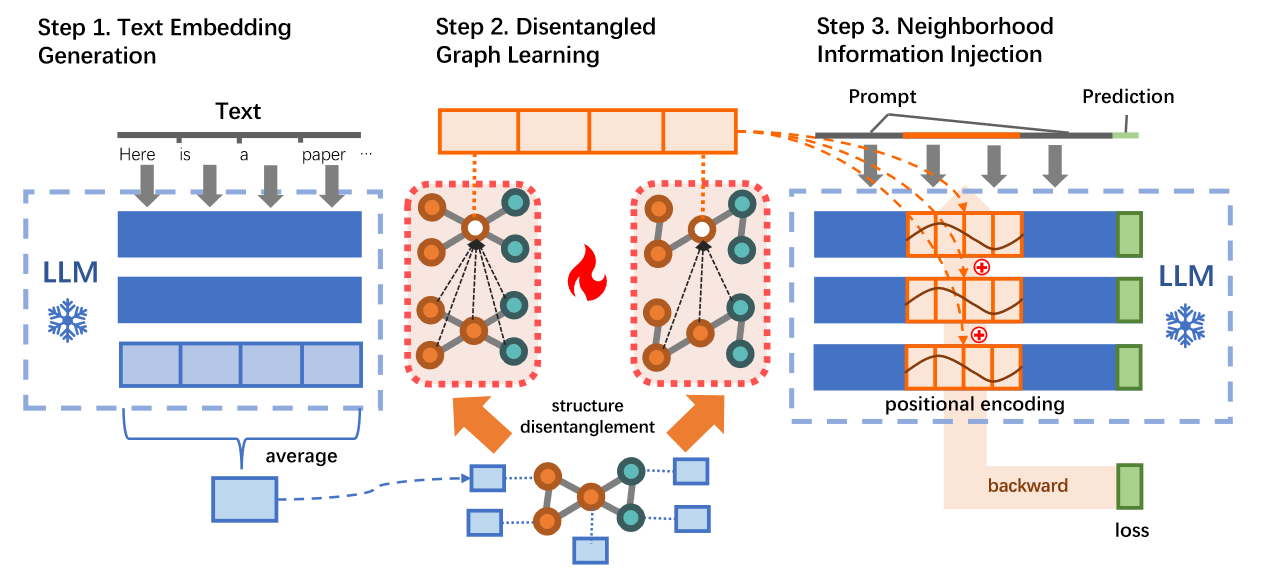
DGTL的框架。
(2023.11) [Arxiv' 2023] 我该使用哪种模态——文本、基元还是图像?:用大型语言模型理解图 [论文]
框架
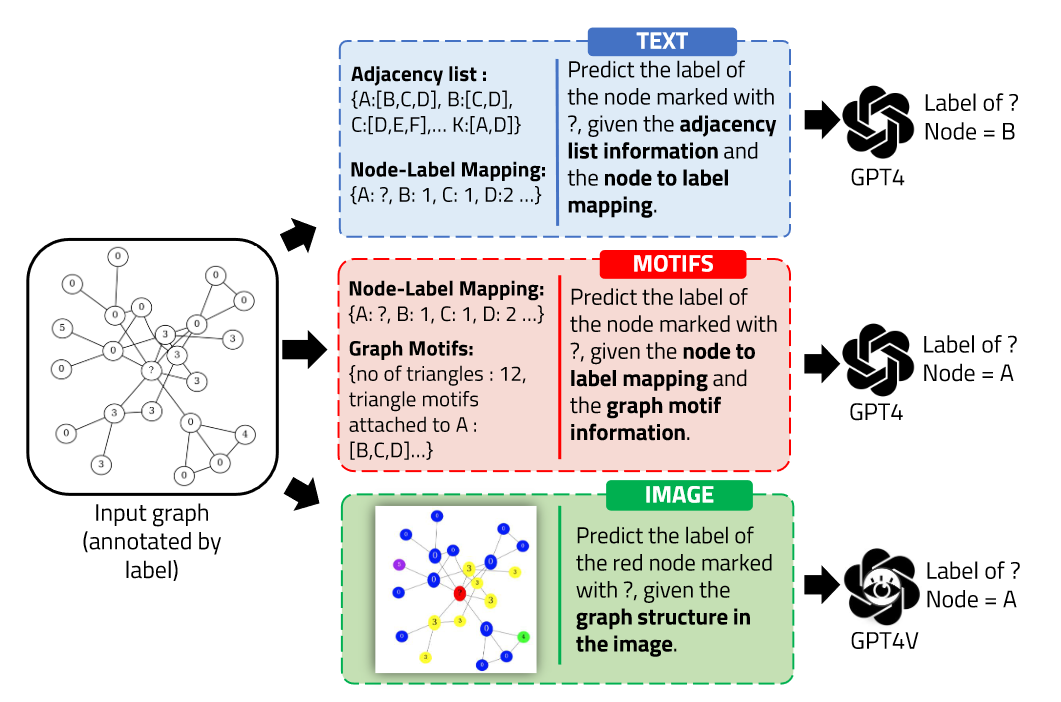
Das等人的框架。
(2023.11) [Arxiv' 2023] InstructMol:多模态融合,打造药物研发中通用且可靠的分子助手 [论文]
InstructMol
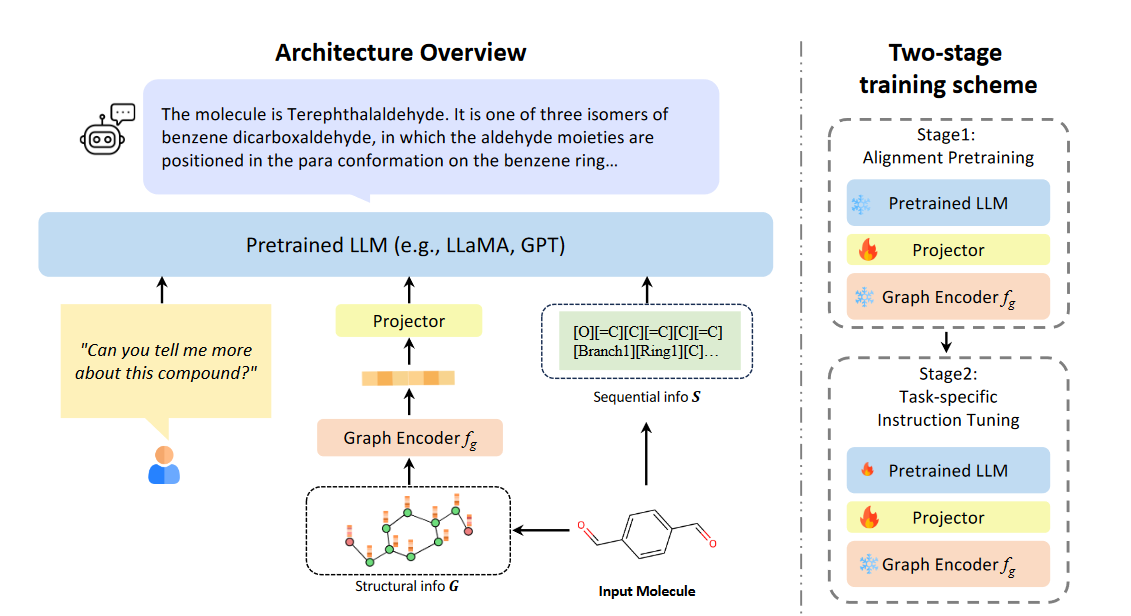
InstructMol的框架。
(2023.12) [Arxiv' 2023] 当图数据遇到多模态时:图理解和推理的新范式 [论文]
框架

Ai等人的框架。
(2024.02) [Arxiv' 2024] 让你的图开口说话:为LLMs编码结构化数据 [论文]
GraphToken
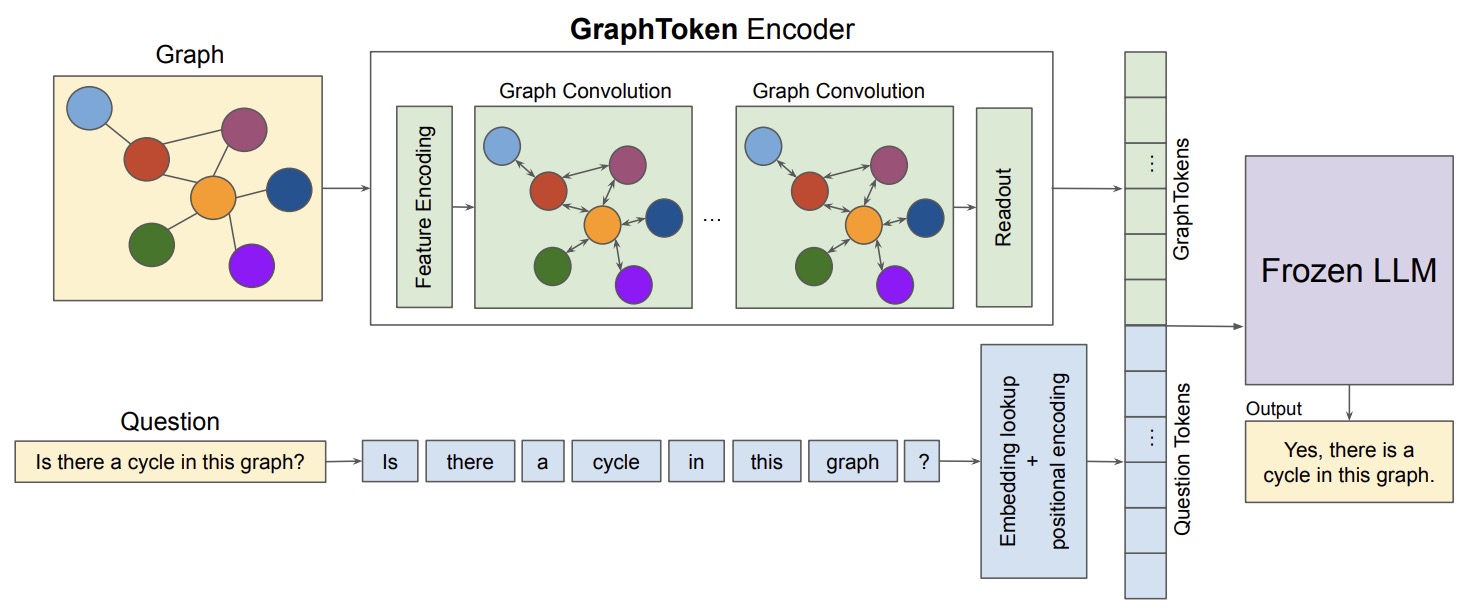
GraphToken的框架。
(2024.02) [Arxiv' 2024] 在多模态大型语言模型中为图推理渲染图 [论文]
GITA
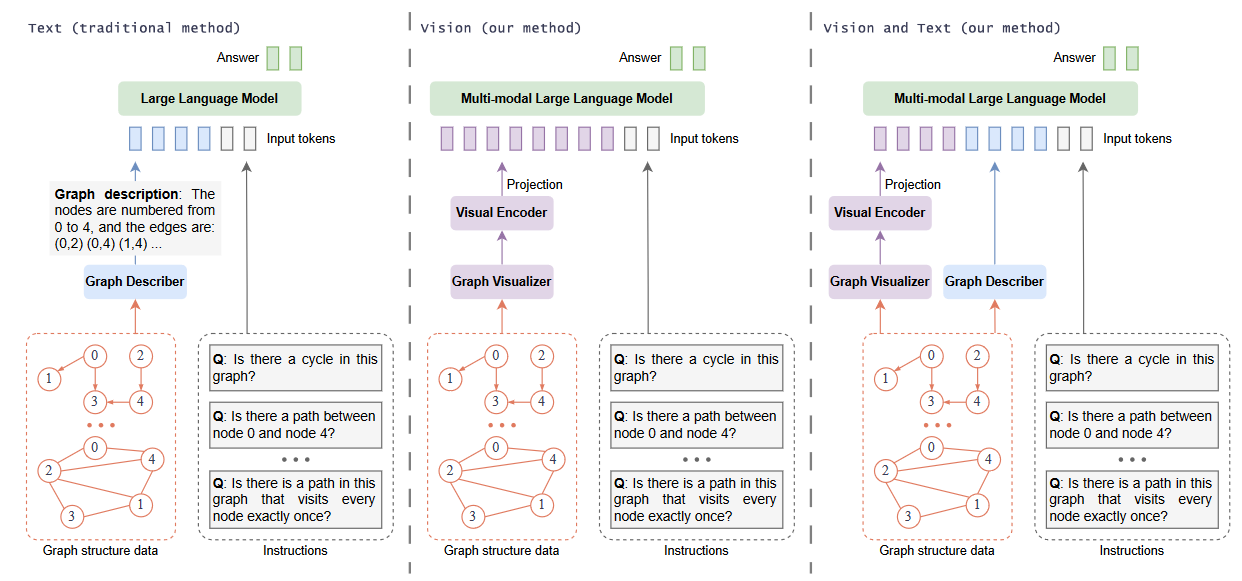
GITA的框架。
(2024.02) [WWW' 2024] GraphTranslator:为开放式任务将图模型与大型语言模型对齐 [论文 | 代码]
GraphTranslator
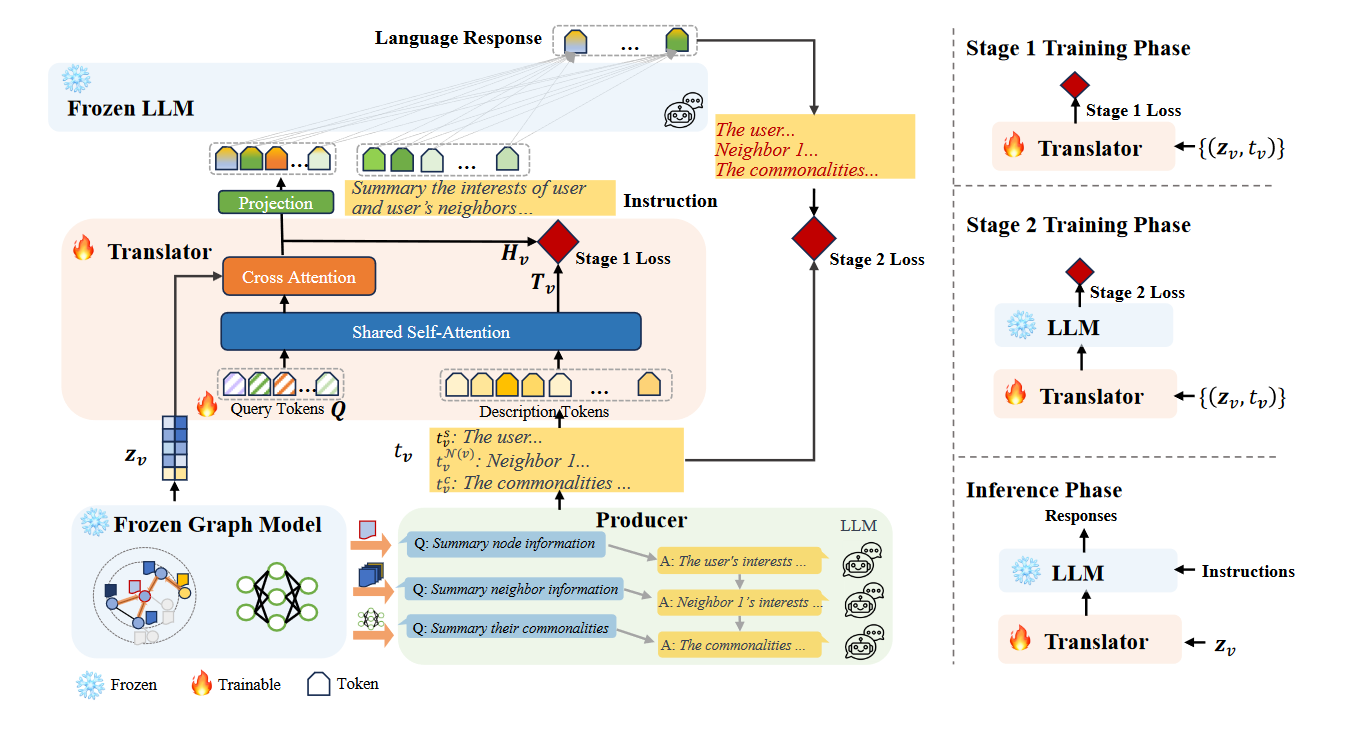
GraphTranslator的框架。
(2024.02) [Arxiv' 2024] InstructGraph:通过以图为中心的指令微调和偏好对齐来增强大型语言模型 [论文 | 代码]
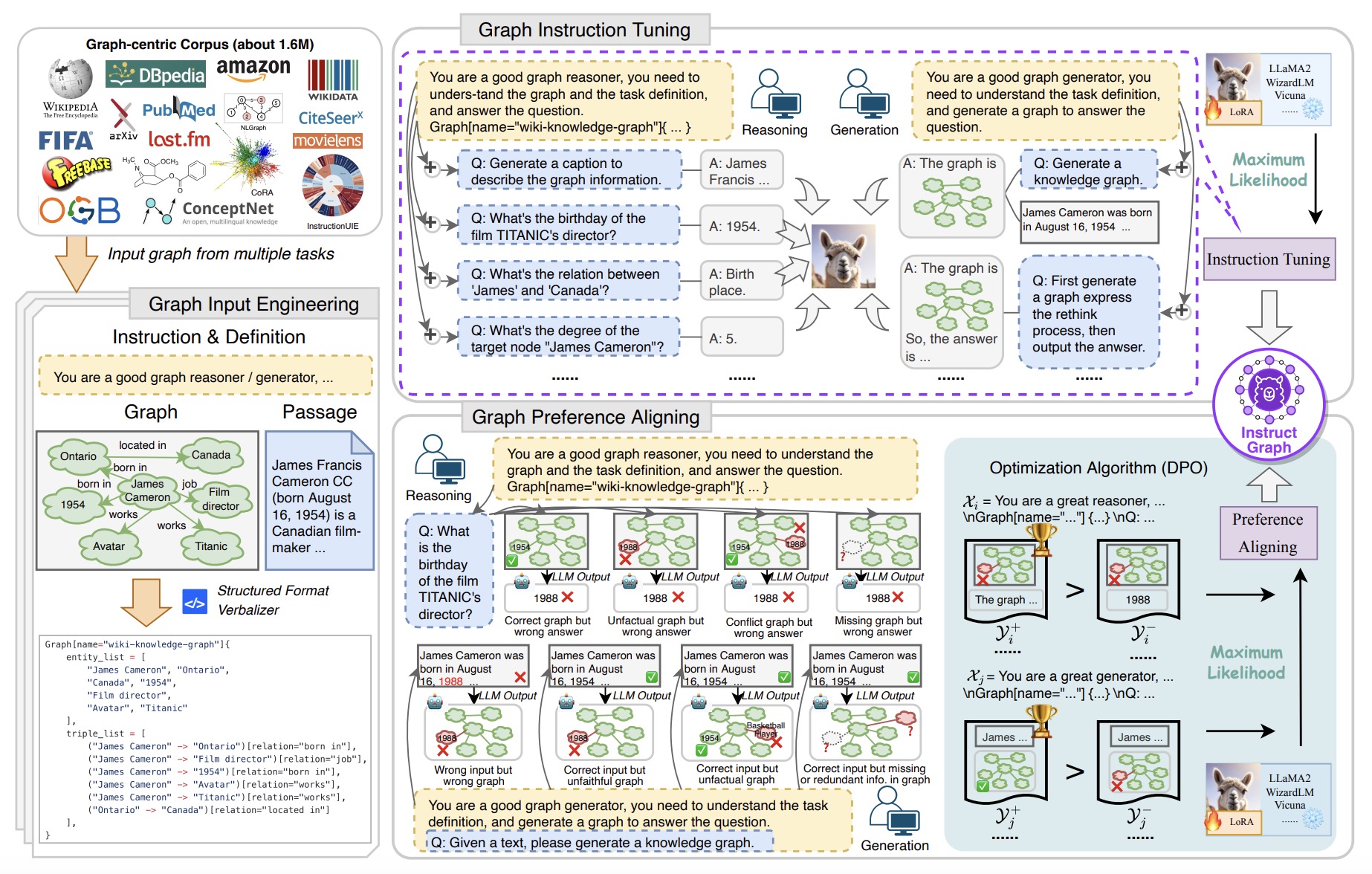

GNN-LLM对齐
- (2020.08) [Arxiv' 2020] 基于图的在线社区建模用于假新闻检测 [论文 | 代码]
SAFER
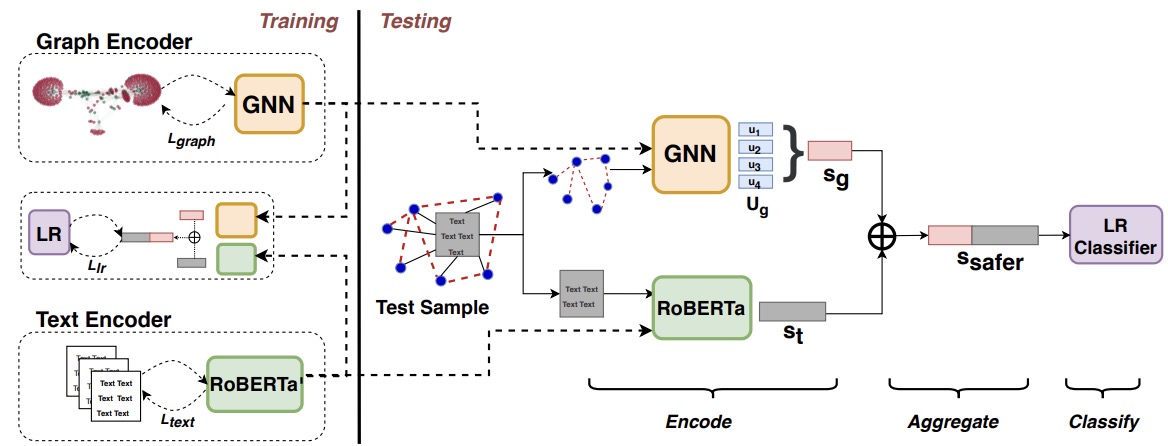
SAFER的框架。
- (2021.05) [NeurIPS' 2021] GraphFormers:用于文本图表示学习的GNN嵌套Transformer [论文 | 代码]
GraphFormers
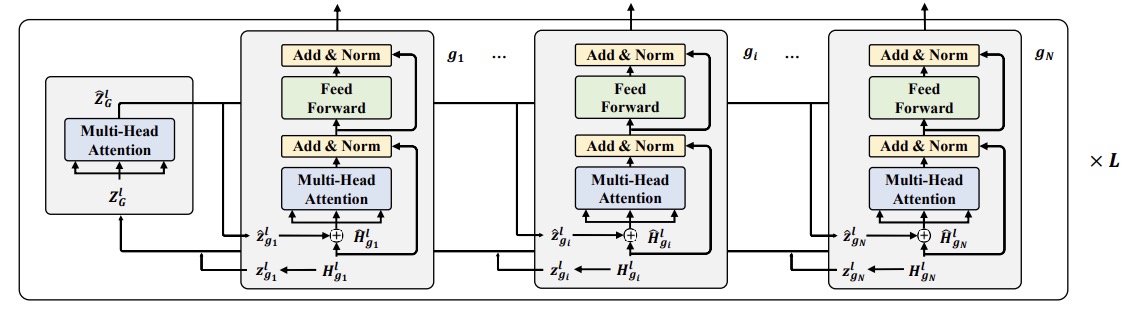
GraphFormers的框架。
- (2021.11) [EMNLP' 2021] Text2Mol:基于自然语言查询的跨模态分子检索 [论文 | 代码]
Text2Mol
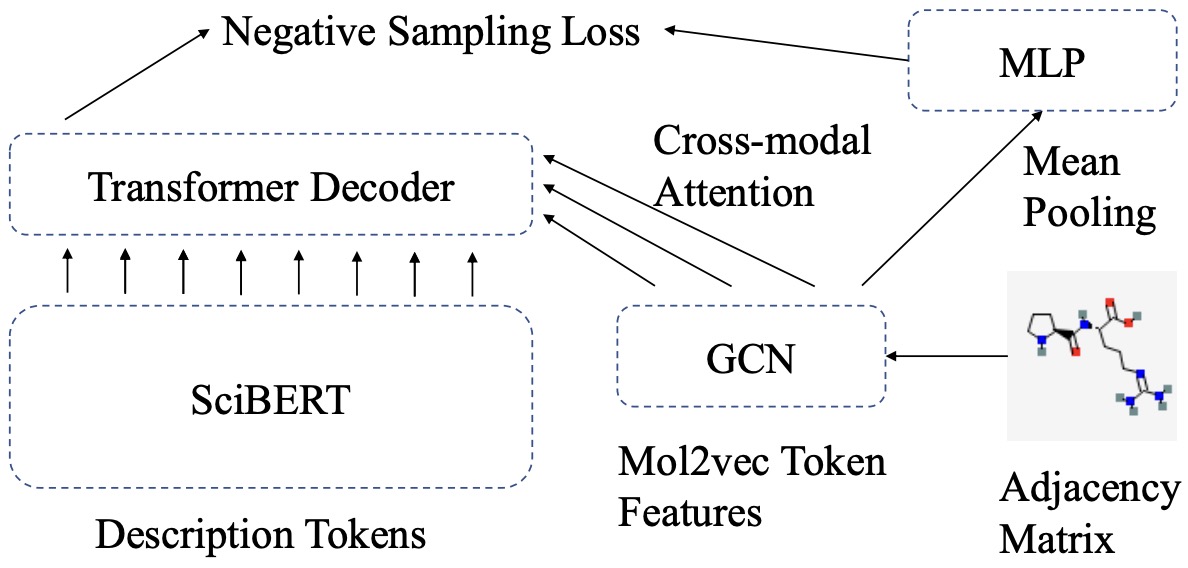
Text2Mol的框架。
- (2022.07) [ACL' 2023] 隐藏模式网络 [论文 | 代码]
HSN
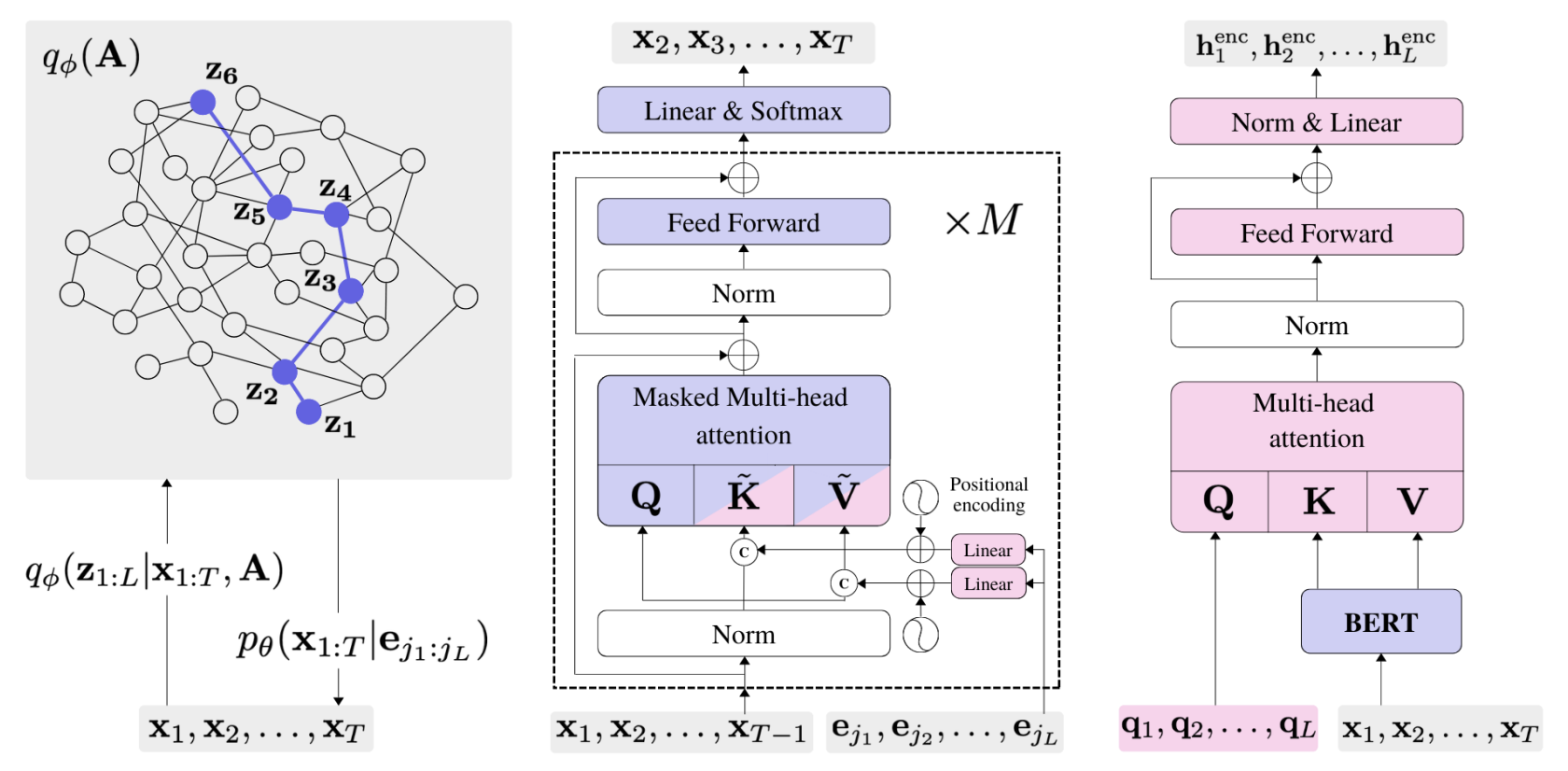
HSN的框架。
- (2022.09) [Arxiv' 2022] 一种将分子图与自然语言关联的分子多模态基础模型 [论文 | 代码]
MoMu
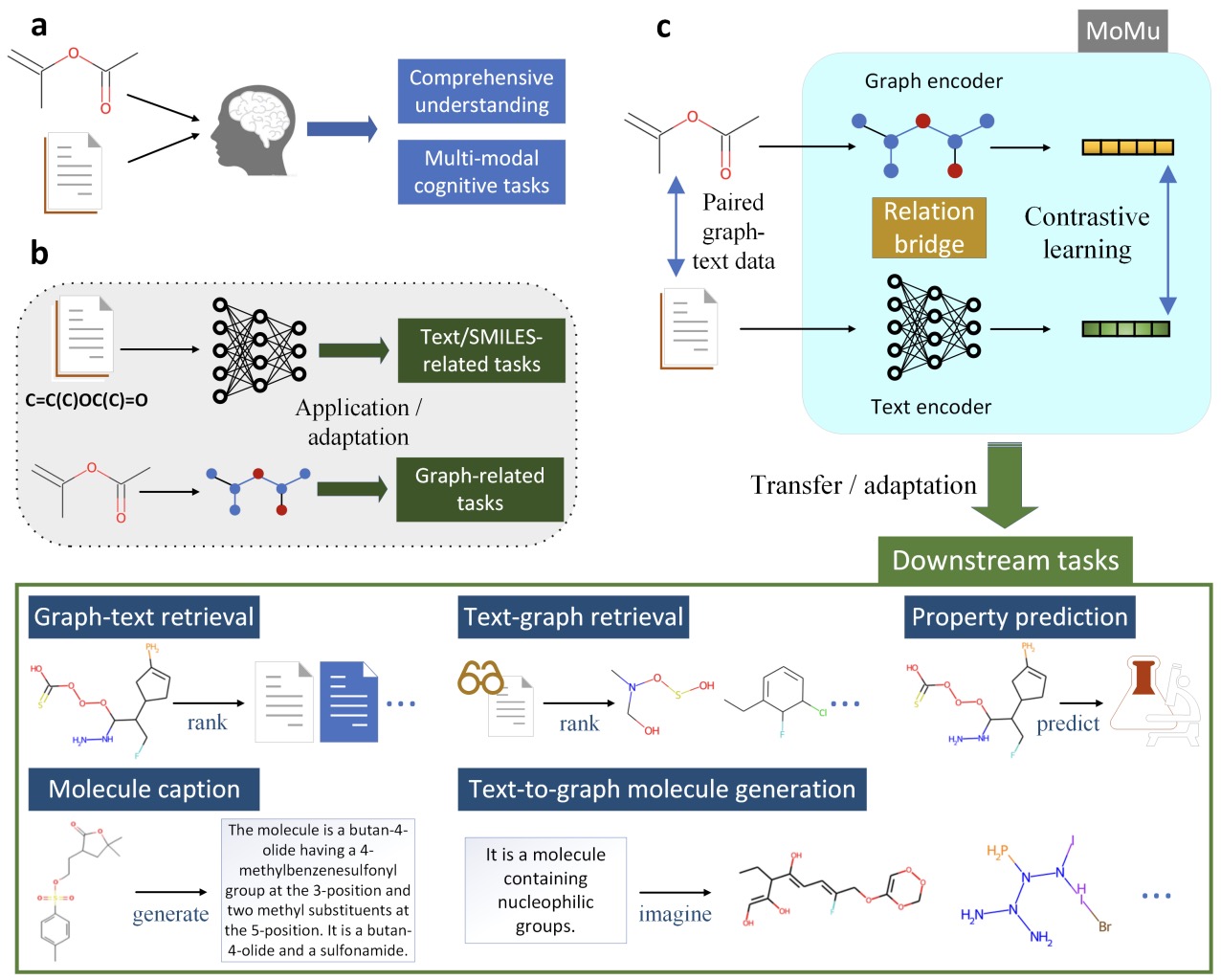
MoMu的框架。
- (2022.10) [ICLR' 2023] 通过变分推断在大规模文本属性图上进行学习 [论文 | 代码]
GLEM
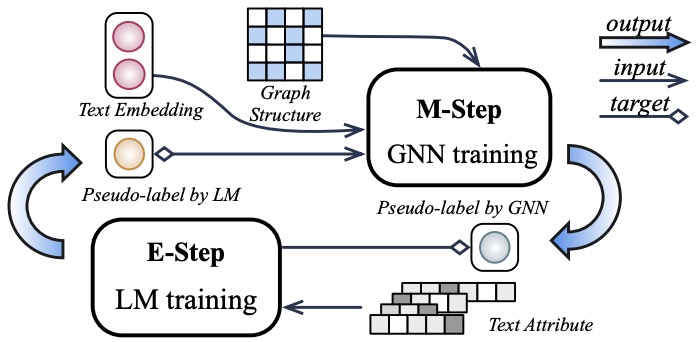
GLEM的框架。
- (2022.12) [NMI' 2023] 用于基于文本编辑和检索的多模态分子结构-文本模型 [论文 | 代码]
MoleculeSTM
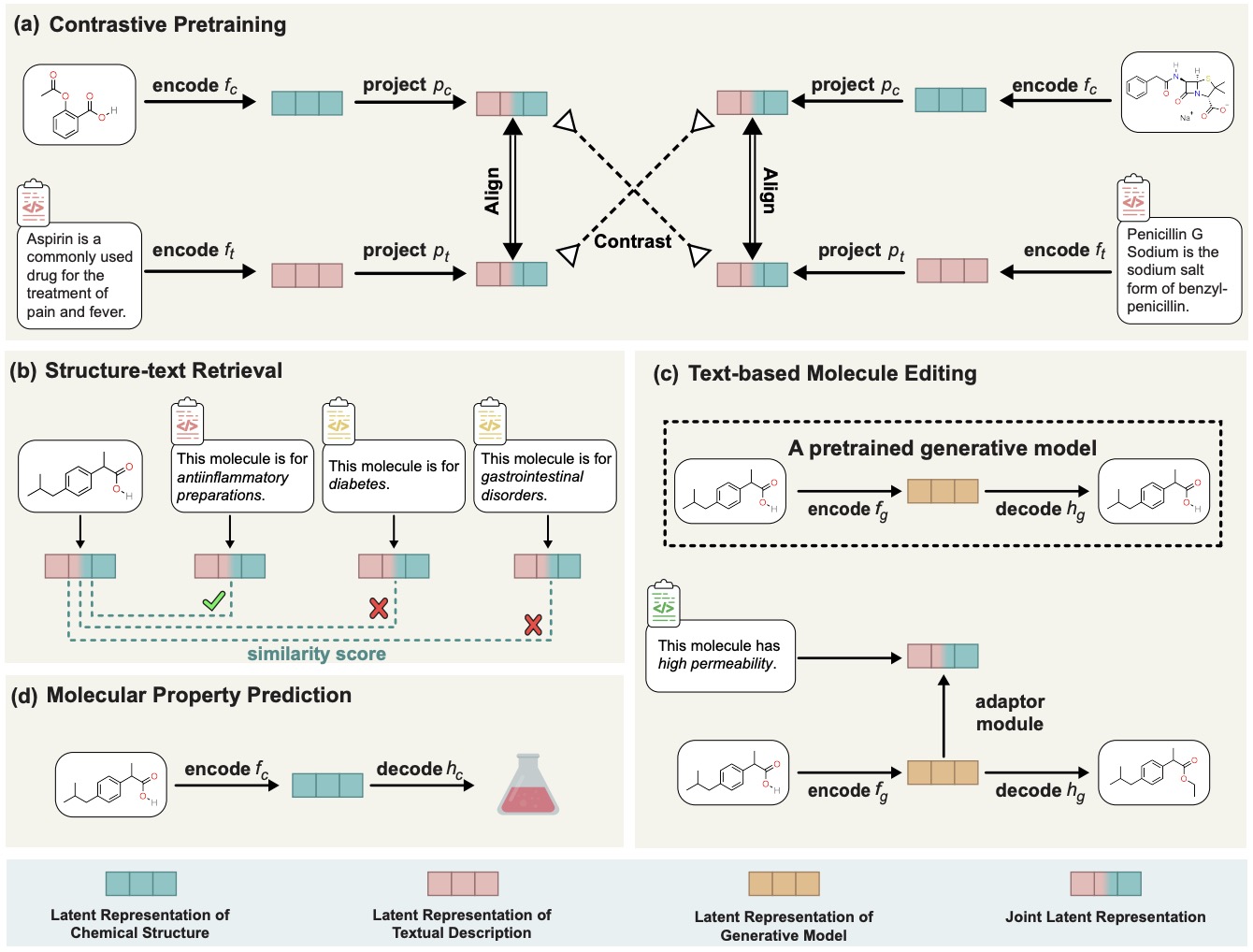
MoleculeSTM的框架。
- (2023.04) [Arxiv' 2023] 训练你自己的GNN教师:文本图上的图感知蒸馏 [论文 | 代码]
- (2021.11) [EMNLP' 2021] Text2Mol:基于自然语言查询的跨模态分子检索 [论文 | 代码]
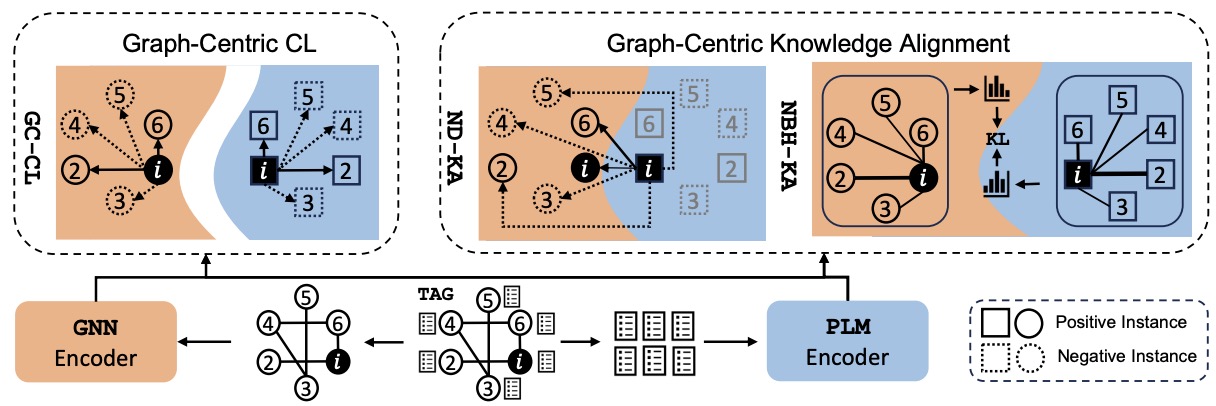
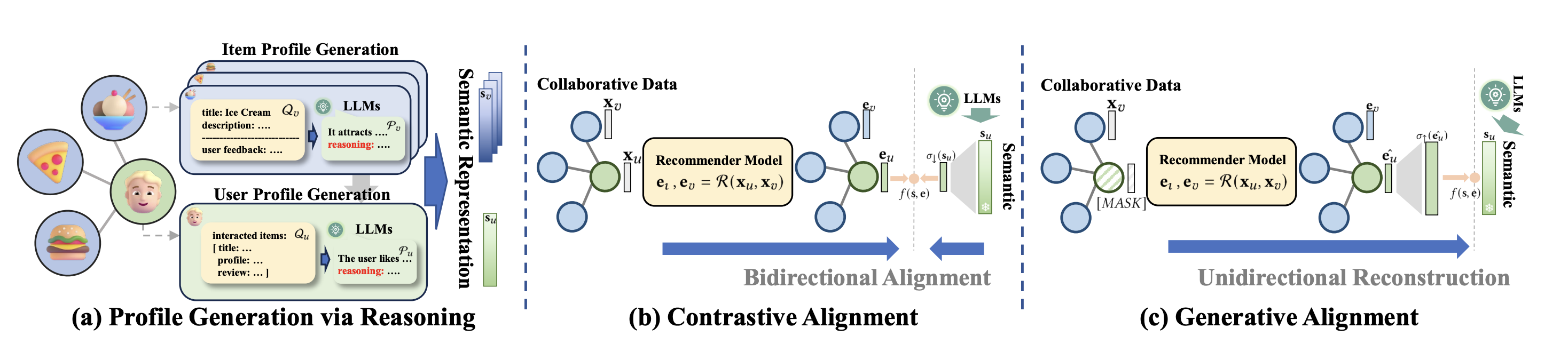
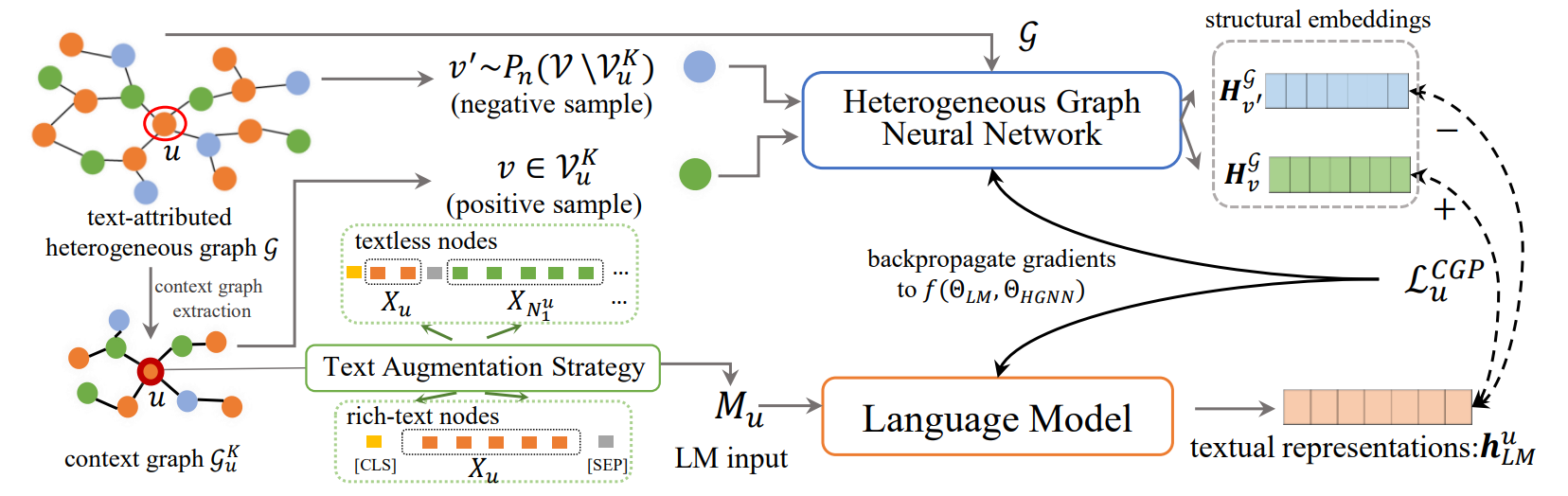
基准测试
其他
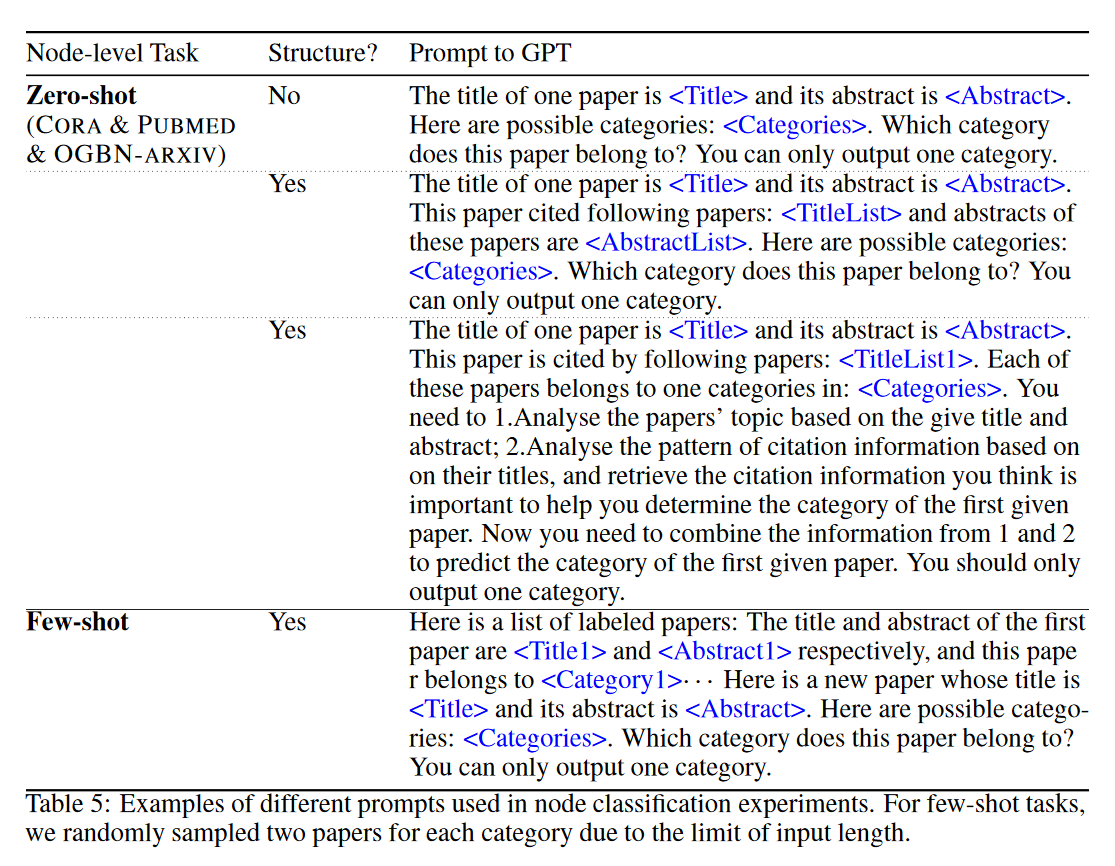
LLM 作为标注器
(2023.10) [ICLR' 2024] 基于大型语言模型(LLMs)的无标签图节点分类 [论文 | 代码]
LLM-GNN
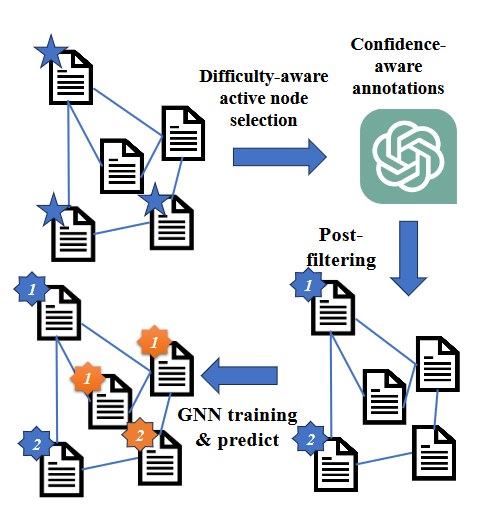
LLM-GNN 的框架。
(2024.09) [NeurIPS' 2024] 利用大型语言模型生成的噪声标注进行实体对齐 [论文 | 代码]
LLM4EA
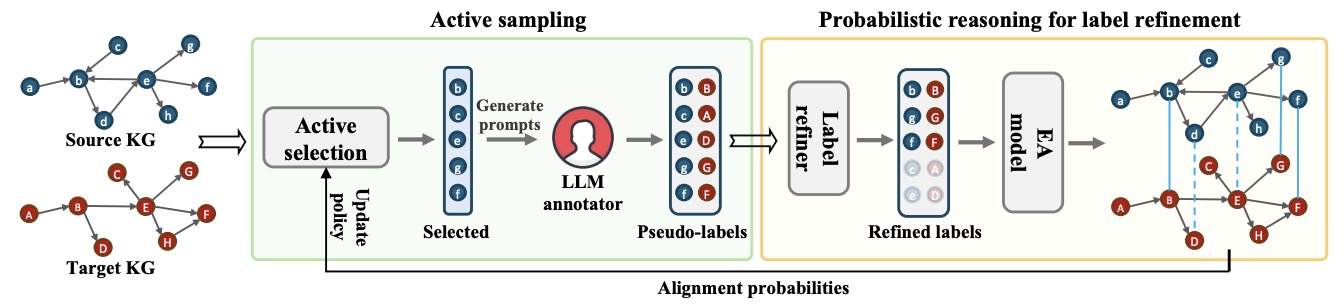
LLM4EA 的框架。
LLM 作为控制器
- (2023.10) [Arxiv' 2023] 使用 GPT-4 进行图神经网络架构搜索 [论文]
GPT4GNAS
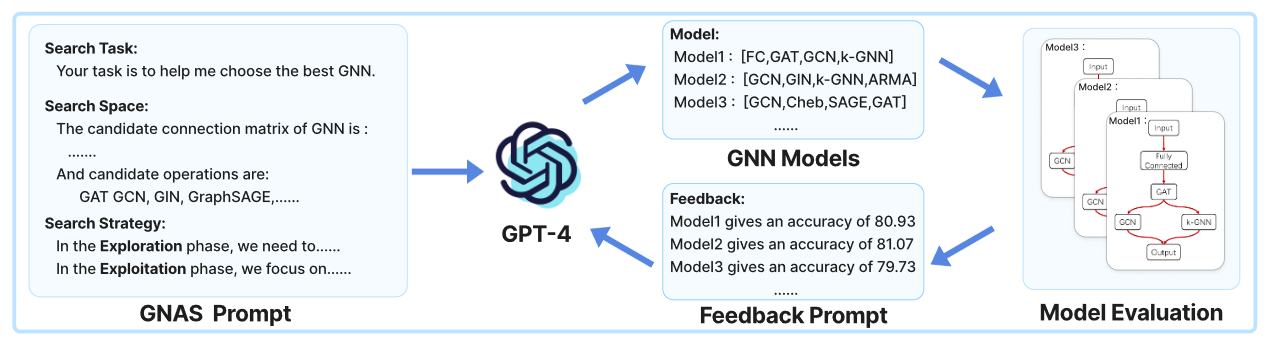
GPT4GNAS 的框架。
LLM 作为样本生成器
- (2023.10) [Arxiv' 2023] 利用大型语言模型(LLMs)增强文本属性图学习 [论文]
ENG
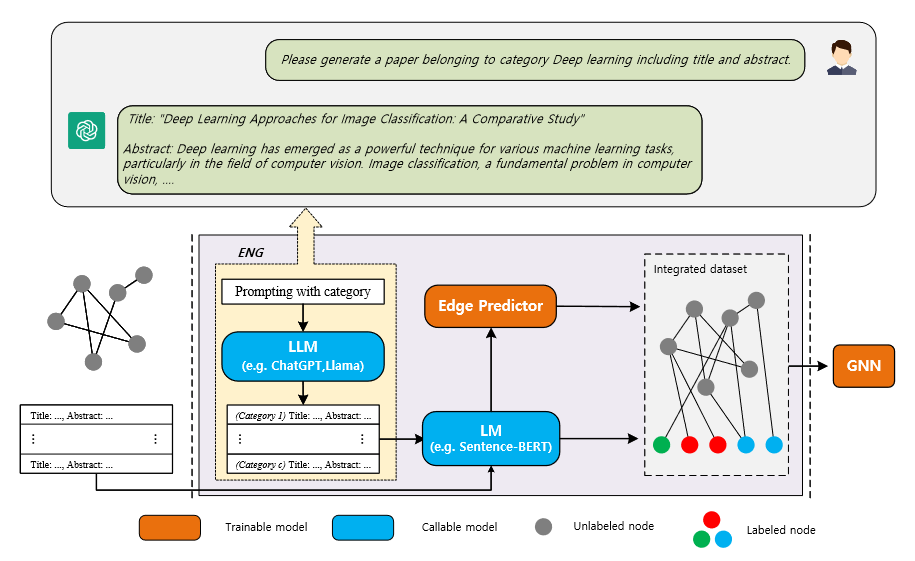
ENG 的框架。
LLM 作为相似性分析器
- (2023.11) [Arxiv' 2023] 大型语言模型作为文本属性图的拓扑结构增强器 [论文]
框架
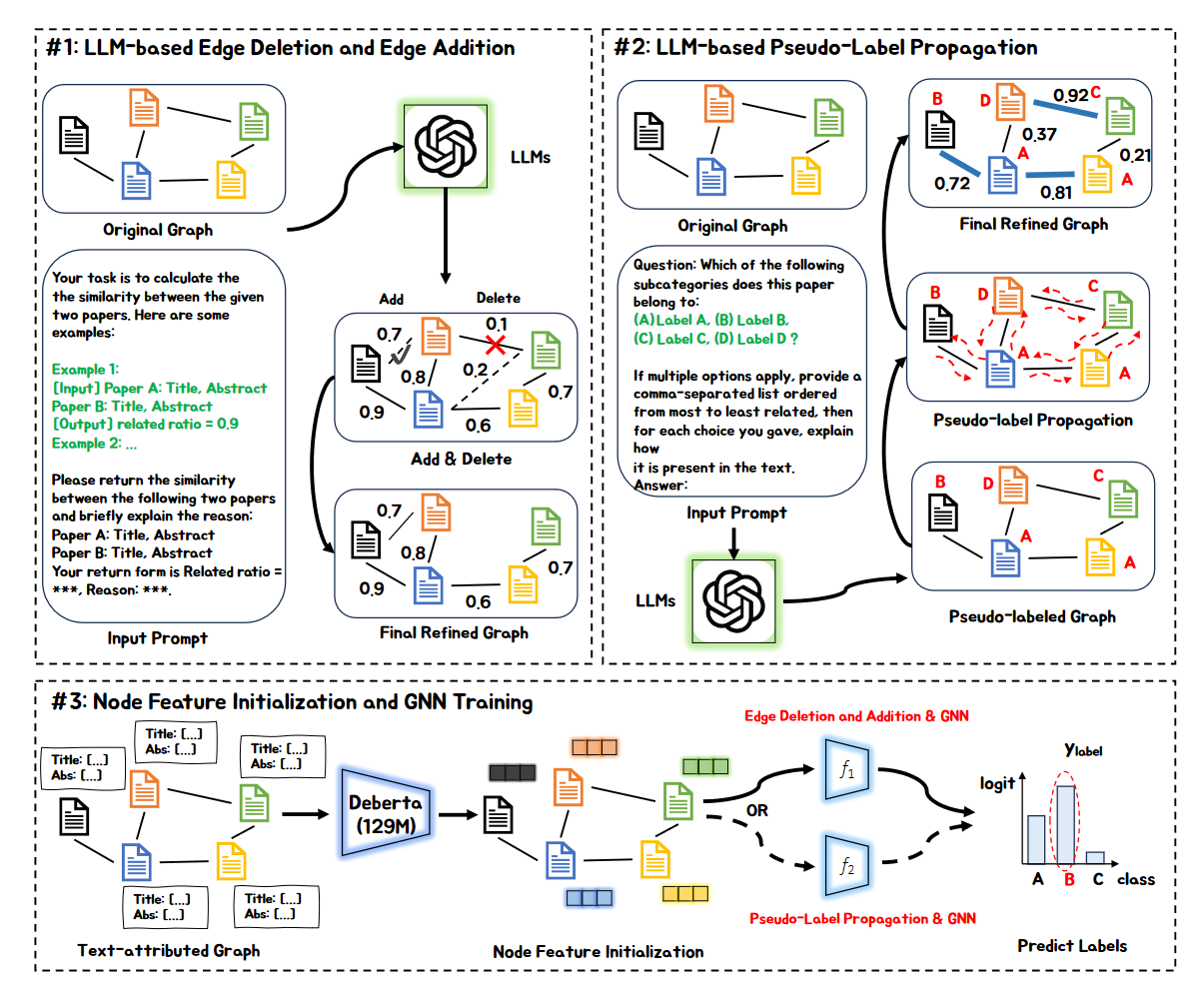
Sun 等人的框架。
LLM 提升鲁棒性
(2024.05) [Arxiv' 2024] 用文字入侵:迈向理解文本层面的图注入攻击 [论文]
Lei, et al.
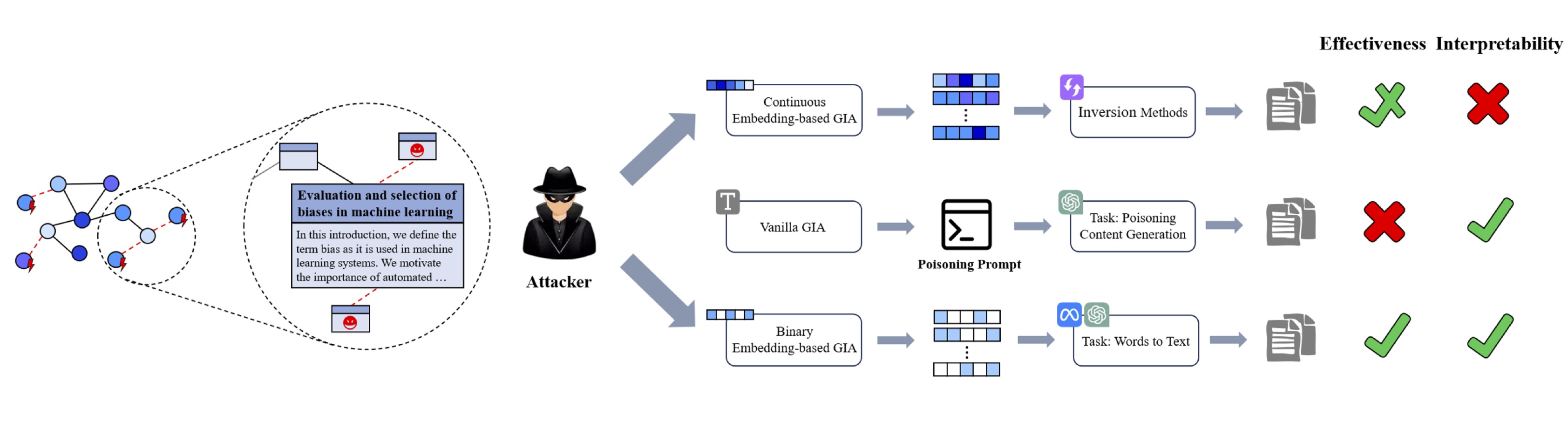
Lei, et al. 的框架。
(2024.08) [Arxiv' 2024] 大型语言模型能否提升图神经网络的对抗鲁棒性? [论文]
LLM4RGNN
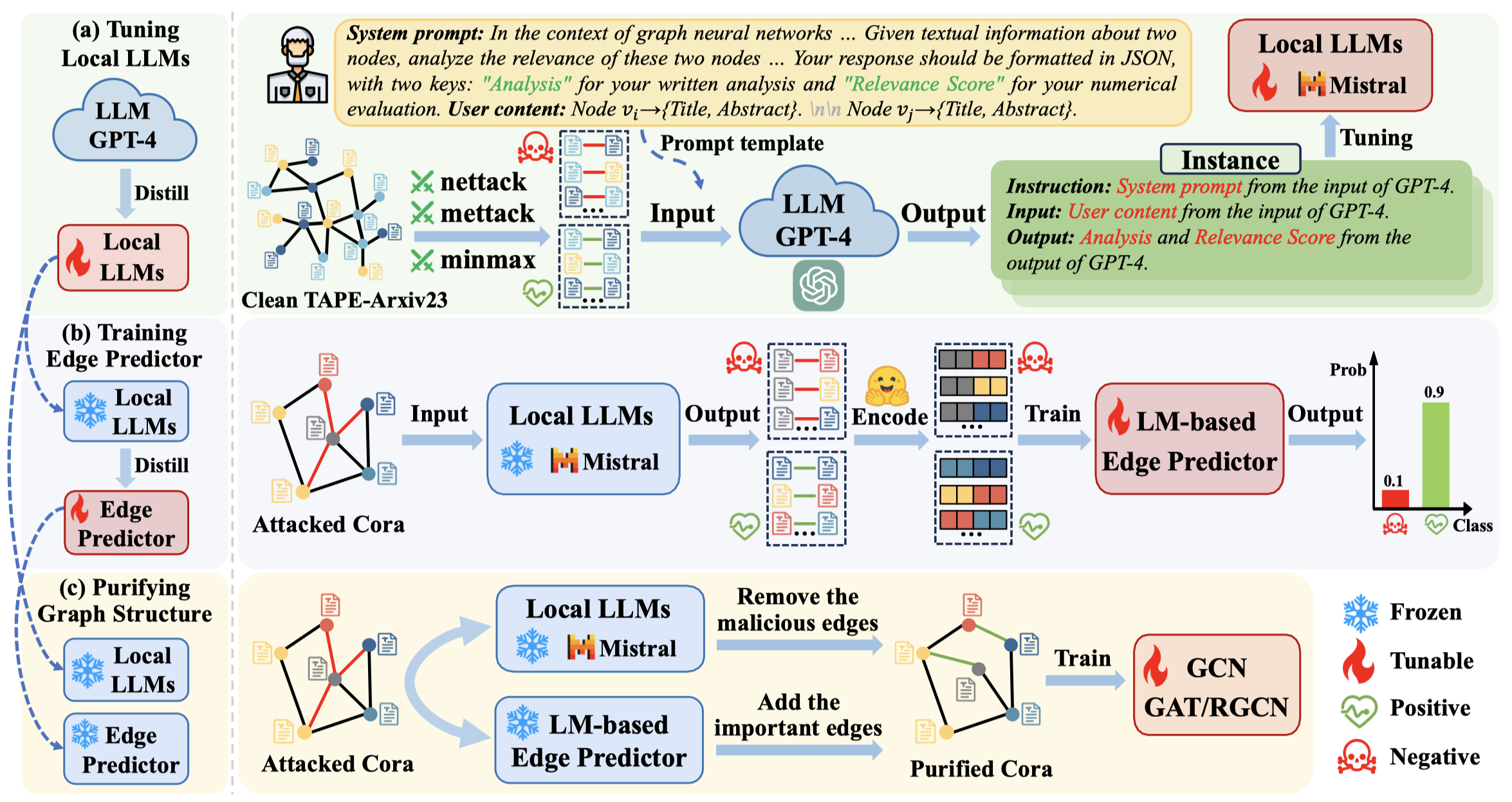
LLM4RGNN 的框架。
LLM 用于任务规划
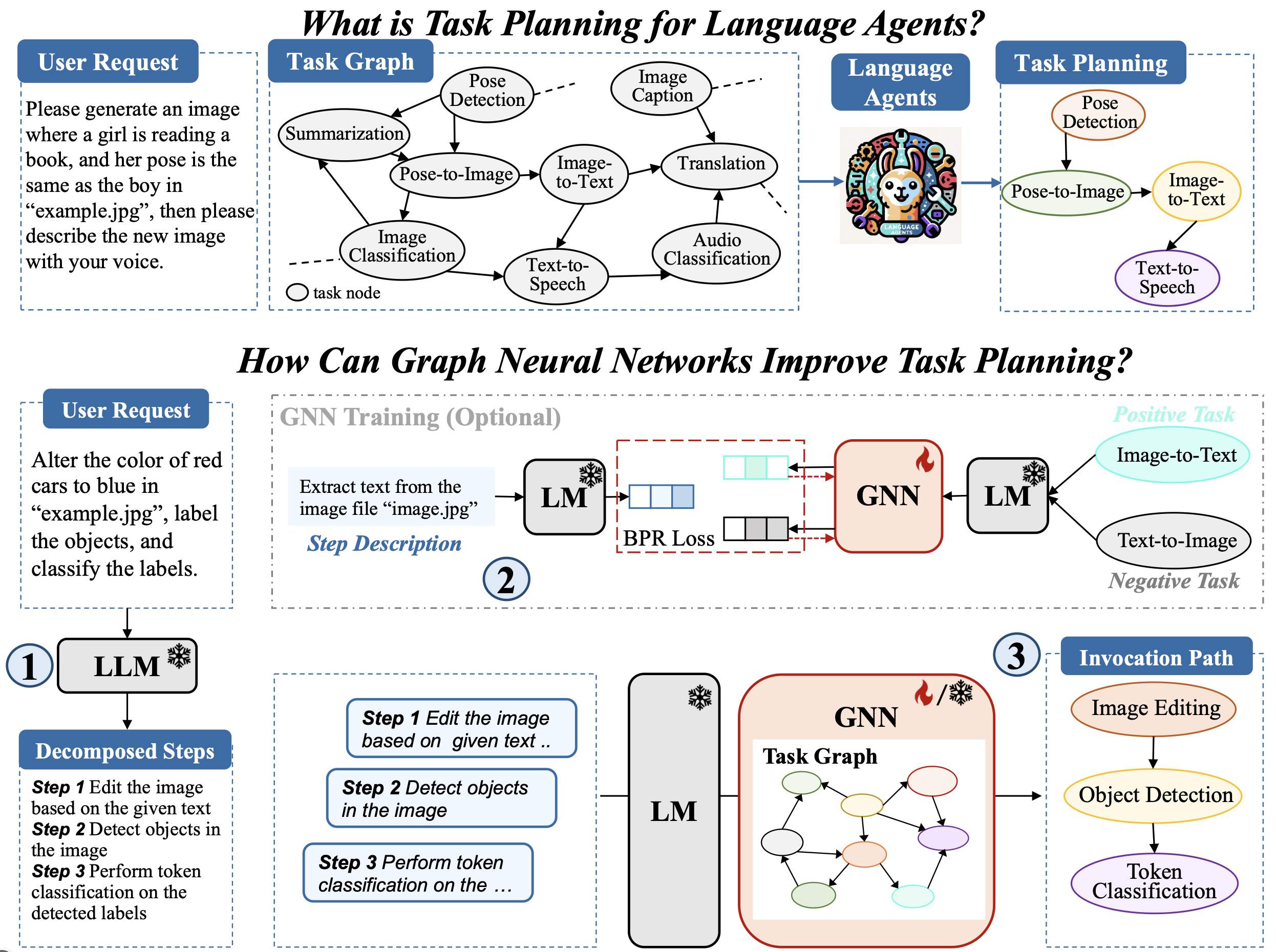
其他仓库
我们注意到,目前已有多个仓库汇总了关于 LLM 与图结合的相关论文。然而,我们通过采用一种更为细致和新颖的分类体系来组织这些文献,从而形成了自身的特色。建议研究者们参考这些仓库以获得更全面的综述。
Awesome-Graph-LLM,由新加坡国立大学的 Xiaoxin He 创建。
Awesome-Large-Graph-Model,由清华大学的 Ziwei Zhang 创建。
Awesome-Language-Model-on-Graphs,由伊利诺伊大学厄巴纳-香槟分校的 Bowen Jin 创建。
此外,我们强烈推荐一个专注于 Graph Prompt 相关工作的仓库,它与 Graph-LLM 的研究方向非常接近。
- Awesome-Graph-Prompt,由香港中文大学的 Xixi Wu 创建。
贡献
如果您发现了相关资源,欢迎随时提出 issue 或提交 pull request。
* (_时间_) [会议] **论文名称** [[论文](链接) | [代码](链接)]
<details close>
<summary>模型名称</summary>
<p align="center"><img width="75%" src="Figures/xxx.jpg" /></p>
<p align="center"><em>模型名称的框架。</em></p>
</details
引用我们
如果您觉得本工作对您有所帮助,请随时引用!
@article{li2023survey,
title={A Survey of Graph Meets Large Language Model: Progress and Future Directions},
author={Li, Yuhan and Li, Zhixun and Wang, Peisong and Li, Jia and Sun, Xiangguo and Cheng, Hong and Yu, Jeffrey Xu},
journal={arXiv preprint arXiv:2311.12399},
year={2023}
}
相似工具推荐
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
DeepSeek-V3
DeepSeek-V3 是一款由深度求索推出的开源混合专家(MoE)大语言模型,旨在以极高的效率提供媲美顶尖闭源模型的智能服务。它拥有 6710 亿总参数,但在处理每个 token 时仅激活 370 亿参数,这种设计巧妙解决了大规模模型推理成本高、速度慢的难题,让高性能 AI 更易于部署和应用。 这款模型特别适合开发者、研究人员以及需要构建复杂 AI 应用的企业团队使用。无论是进行代码生成、逻辑推理还是多轮对话开发,DeepSeek-V3 都能提供强大的支持。其独特之处在于采用了无辅助损失的负载均衡策略和多令牌预测训练目标,前者在提升计算效率的同时避免了性能损耗,后者则显著增强了模型表现并加速了推理过程。此外,模型在 14.8 万亿高质量令牌上完成预训练,且整个训练过程异常稳定,未出现不可恢复的损失尖峰。凭借仅需 278.8 万 H800 GPU 小时即可完成训练的高效特性,DeepSeek-V3 为开源社区树立了一个兼顾性能与成本效益的新标杆。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。