awesome-deep-learning-music
awesome-deep-learning-music 是一个专注于深度学习与音乐领域交叉研究的开源资源库,通过系统整理学术论文、技术报告和代码资源,为研究者提供一站式参考。它解决了音乐信息处理领域研究资料分散、检索成本高的问题,尤其针对音乐生成、音源分离、乐器识别等任务,覆盖从1988年至今的重要研究成果。
该资源库适合人工智能、音乐技术领域的研究人员和开发者使用,尤其对需要跟踪前沿算法、验证模型效果的研究者具有较高价值。其独特优势在于提供结构化数据:每项研究均附带论文标题、PDF链接、代码地址,并通过表格和Bib文件格式呈现元数据,方便学术引用。项目还包含统计可视化模块,可直观展示研究趋势和热点分布。
尽管项目当前处于无人维护状态,但作者保留了完整的技术文档和贡献指南,鼓励社区协作更新。对于开发者而言,这里不仅是文献检索工具,更是了解音乐AI技术演进脉络的窗口。普通用户若对AI音乐创作原理感兴趣,也可通过摘要部分获取基础认知。
使用场景
音乐科技初创公司的一名研发工程师正在开发AI作曲工具,需要快速了解深度学习在音乐生成领域的最新研究进展和技术方案。
没有 awesome-deep-learning-music 时
- 需要手动在arXiv、Google Scholar等平台搜索"deep learning music generation",每天耗费2小时仍难以覆盖所有相关文献
- 遇到1995年提出的源识别算法与2023年的Transformer变体难以对比,研究演进脉络不清晰
- 找到的论文中仅30%提供可复现的代码仓库,且代码质量参差不齐
- 面对"Music Information Retrieval"等跨学科术语时,需要额外查阅领域专有名词解释
- 无法判断哪些研究已被后续工作改进,存在重复研究风险
使用 awesome-deep-learning-music 后
- 通过按年份/任务分类的表格,30分钟内即可掌握从1988年神经网络建模到2023年扩散模型的完整发展脉络
- 每篇条目附带论文摘要、代码链接和关键创新点说明,可直接定位到2021年提出的MusicLM等里程碑工作
- 代码仓库标注了"PyTorch实现"或"Colab可运行"等标签,优先选择验证过的高质量实现方案
- 术语表解释了"Monophonic Source Identification"等专业概念,降低跨学科理解门槛
- 通过引用关系图谱发现某篇2018年论文已被2022年研究改进,避免重复开发相似方案
这个工具将音乐领域深度学习研究的检索效率提升了70%,使工程师能将80%精力集中在技术验证而非文献筛选上,显著加速了AI作曲产品的原型开发周期。
运行环境要求
- 未说明
未说明
未说明

快速开始
⚠️ 本仓库已停止维护。虽然信息仍然相关,但欢迎贡献以保持其更新!一个不错的起点是此处引用的文章:https://github.com/ybayle/awesome-deep-learning-music/issues/5

音乐领域的深度学习(DL4M)
由 Yann Bayle(个人网站,GitHub)来自 LaBRI(官网,Twitter)、Univ. Bordeaux(官网,Twitter)、CNRS(官网,Twitter)和 SCRIME(官网)。
TL;DR 音乐领域深度学习的非详尽科学论文列表:摘要(论文标题、PDF链接和代码),详情(表格 - 更多信息),详情(参考文献格式 - 所有信息)
本精选列表旨在汇总使用深度学习(Deep Learning)方法应用于音乐的科学论文、博士论文和报告。 该列表仍在建设中,欢迎补充缺失字段或添加其他资源!请参见如何贡献部分了解具体方式。 此处提供的资源来源于我为博士论文撰写的综述文章,目前相关论文正在撰写中。 目前已有关于深度学习在音乐生成、语音分离和说话人识别方面的综述。 然而,这些综述未涵盖本仓库包含的音乐信息检索(Music Information Retrieval)任务。
目录
DL4M 摘要
DL4M 详细信息
一个可读性更强的表格汇总版本显示在文件 dl4m.tsv 中。每篇文章的完整细节存储在对应的 BibTeX 条目(bib entry)中,位于 dl4m.bib。每个条目包含标准的 bib 字段:
authoryeartitlejournal或booktitle
dl4m.bib 中的每个条目还包含额外信息:
link- PDF 文件的 HTML 链接code- 可用的源代码链接archi- 神经网络架构(Neural Network Architecture)layer- 层数task- 文章中研究的提出任务dataset- 使用的数据集名称dataaugmentation- 使用的数据增强技术类型time- 计算时间hardware- 使用的硬件note- 额外说明和信息repro- 实验可重复性的程度说明
无关联论文的代码项目
- 使用卷积神经网络(Convolutional Neural Network, CNN)的音频分类器(Keras 实现)
- 使用 Keras & Theano 的爵士乐生成深度学习模型
- 大规模音乐音频标签的端到端学习
- 使用 CNN 在 GTZAN 数据集上的音乐流派分类
- 基于深度学习策略的合唱音乐音高估计:从独唱到齐唱录音
- 使用 LSTM 的音乐流派分类
- 使用 TensorFlow 的基于 CNN 的音乐情感分类
- 基于 Tensorflow 的深度神经网络实现的歌声人声分离
- 使用 CRNN 的音乐标签分类模型
- 使用深度学习确定歌曲流派
- 使用神经网络作曲
- Performance-RNN-PyTorch
统计数据与可视化
- 引用了 167 篇论文。详情见 dl4m.bib。
2017 年的论文数量超过其他年份的总和。
按年份划分的文章数量:
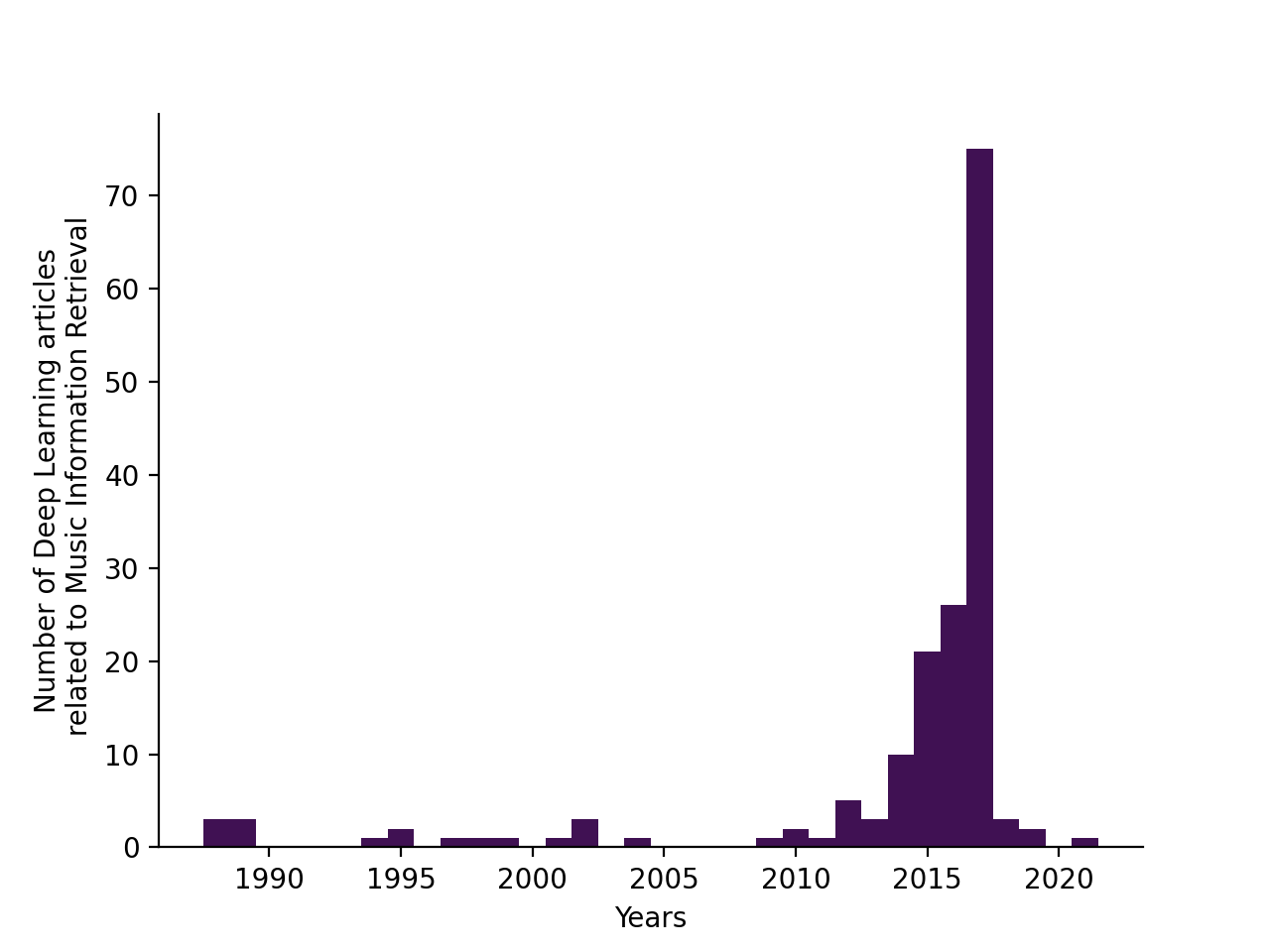
- 如果你正在应用深度学习(Deep Learning, DL)进行音乐研究,那么还有 364 位其他研究者 在这个领域。
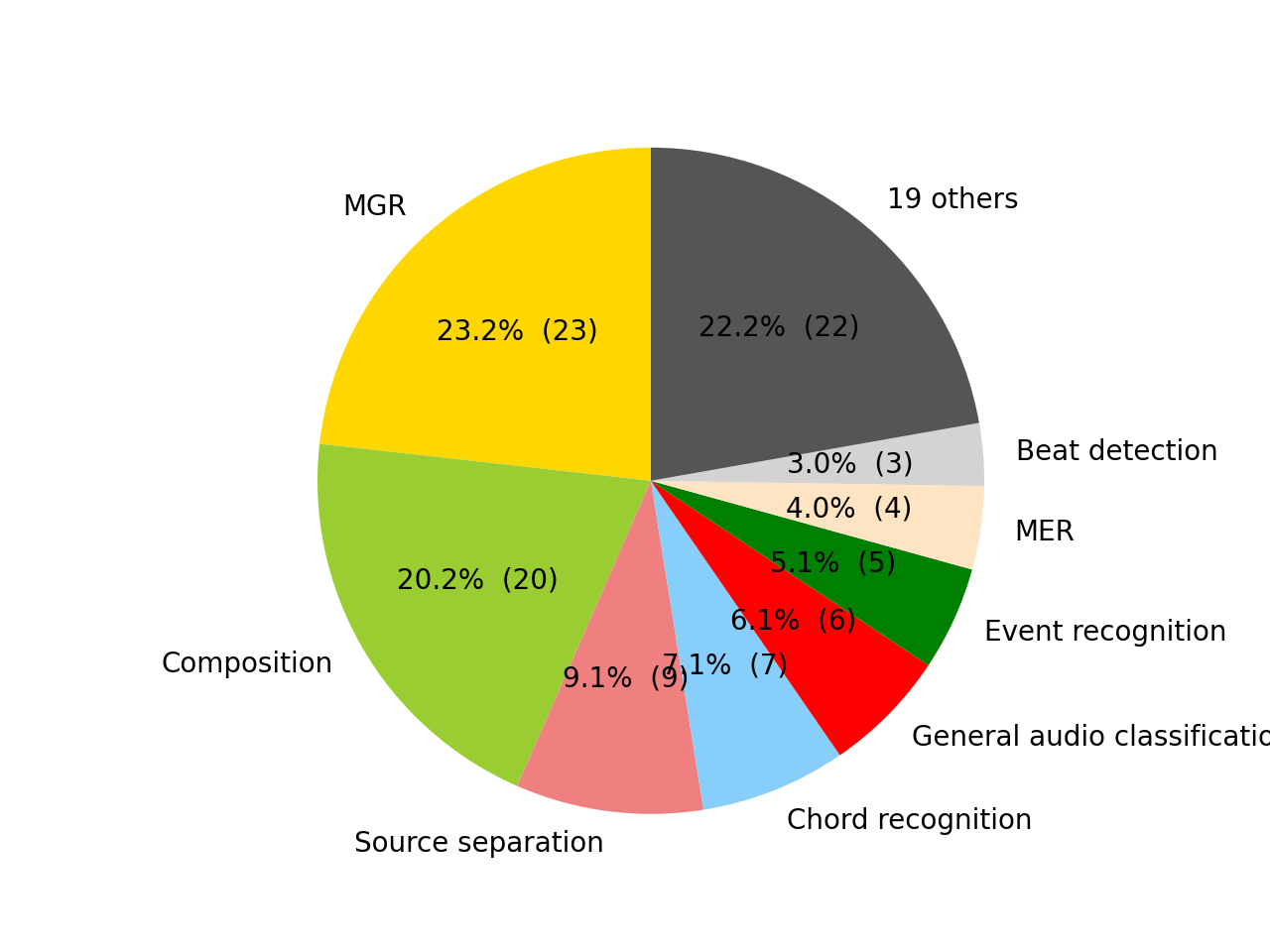
- 调查了 34 项任务。任务列表见 tasks。
任务饼图:
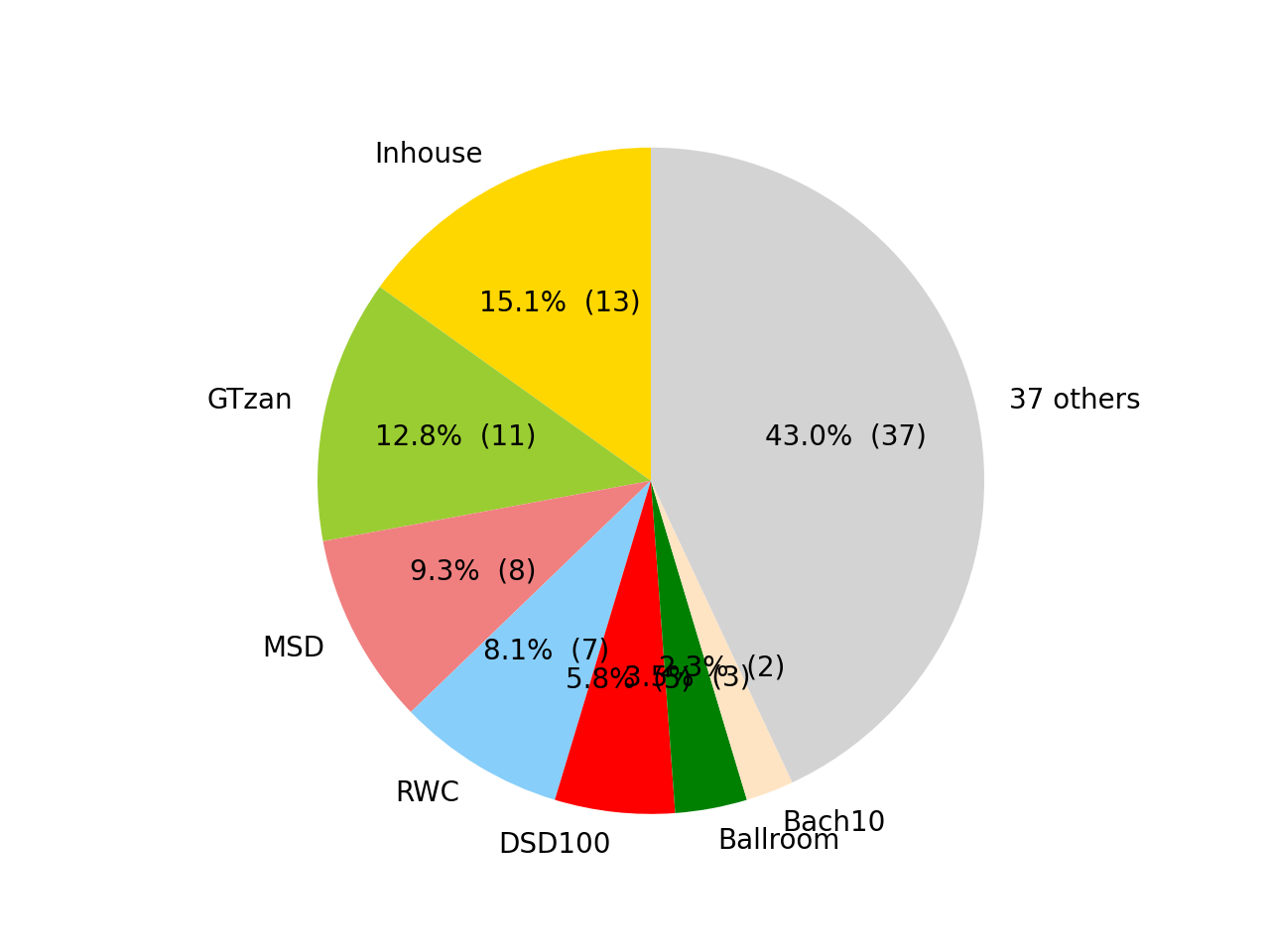
- 使用了 55 个数据集。数据集列表见 datasets。
数据集饼图:
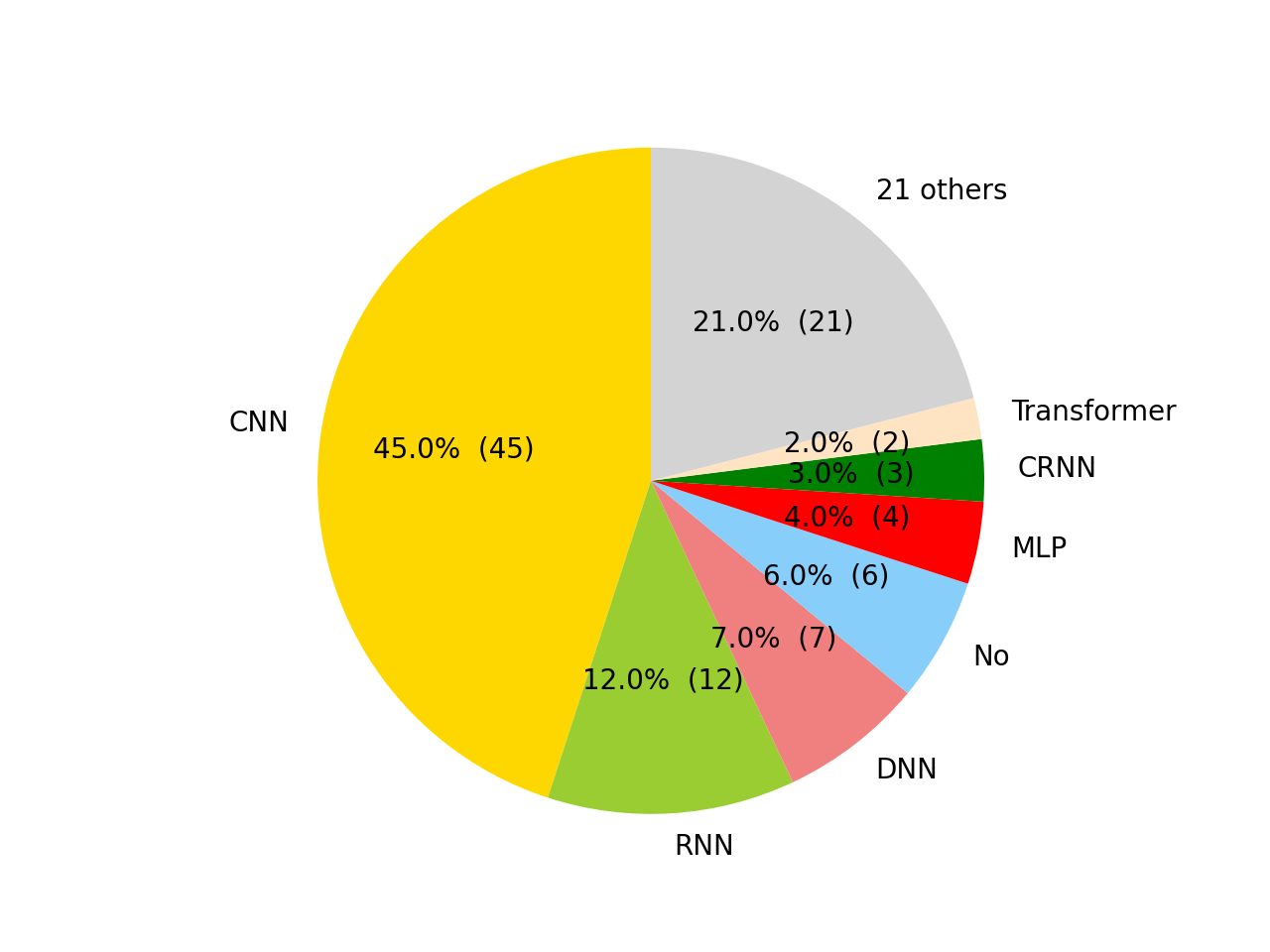
- 使用了 30 种架构。架构列表见 architectures。
架构饼图:
- 使用了 9 种框架。框架列表见 frameworks。
框架饼图:
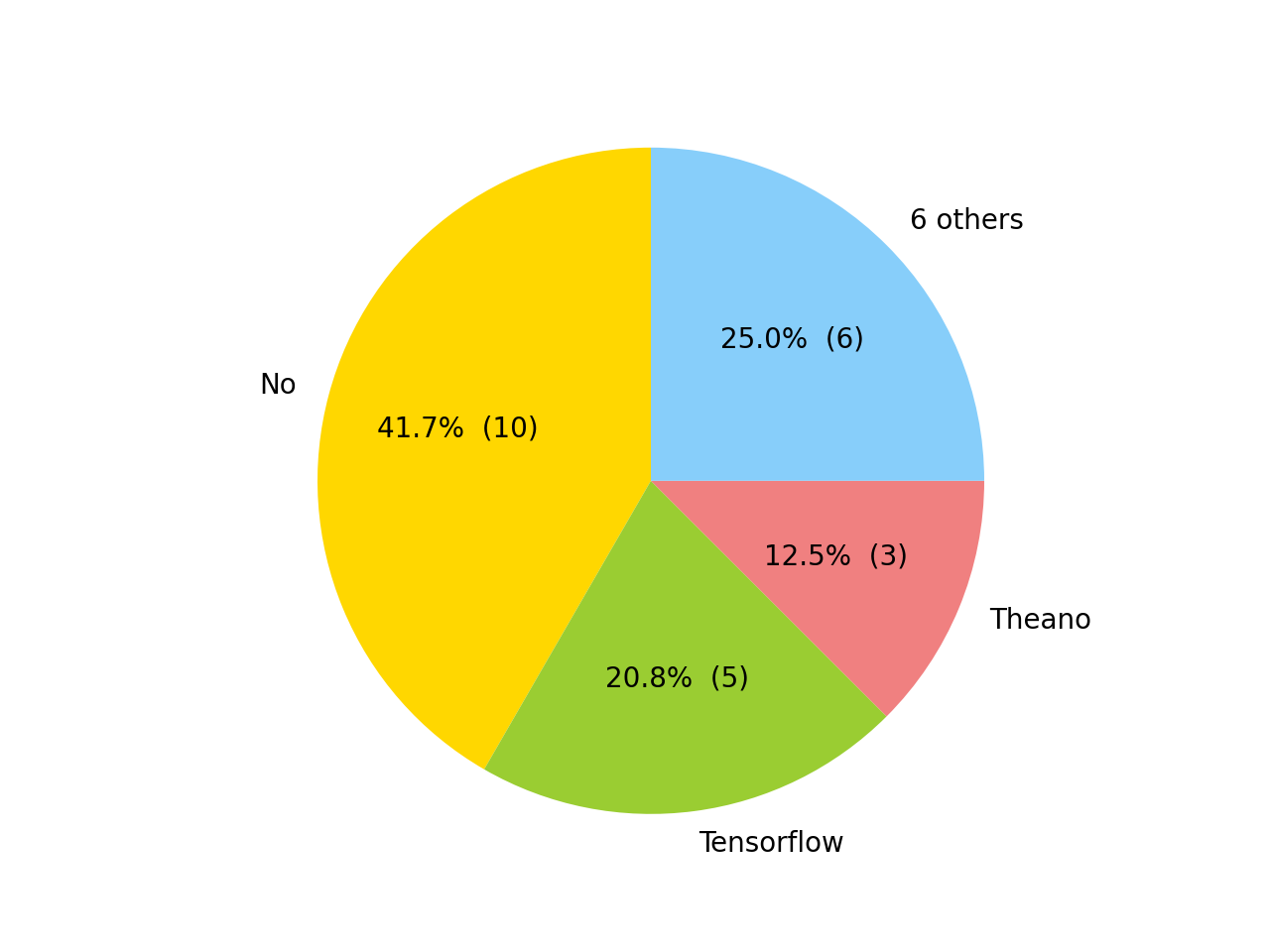
- 仅有 47 篇文章(28%)提供了源代码。 可重复性是科学的关键,因此请查看 MIR 和 ML 领域可重复性的有用资源列表。
dl4m 论文审阅建议
请参考 advice_review.md 文件。
如何贡献
欢迎贡献! 请参考 CONTRIBUTING.md 文件。
常见问题
文章是如何排序的?
文章首先按年份降序排列(以便紧跟最新动态),然后按主要作者的姓氏字母顺序排列。
为什么 arXiv 的预印本包含在列表中?
我希望对 DL4M 进行全面研究并获取最新动态。然而,应注意当前处于评审中的文章信息。如果可能,请等待最终被接受并经过同行评审的版本后再引用 arXiv 论文。我会定期更新 arXiv 链接为已发表的论文链接(如果可用)。
我能信任文章中发表的结果吗?
此处提供的列表不保证文章的质量。您应尝试重现描述的实验,或向 ReScience 提交请求。使用一篇文章的结论需自行承担风险。
使用的缩写
深度学习和音乐领域常用缩写列表存储在 acronyms.md 中。
来源
用于收集所列材料的会议、期刊和聚合器列表存储在 sources.md 中。
贡献者
- Yann Bayle (GitHub) - 发起人和主要维护者
- Vincent Lostanlen (GitHub)
- Keunwoo Choi (GitHub)
- Bob L. Sturm (GitHub)
- Stefan Balke (GitHub)
- Jordi Pons (GitHub)
- Mirza Zulfan (GitHub) 为项目设计了标志
- Devin Walters
- https://github.com/LegendJ
其他有用的列表和资源
音频
- 使用Keras的DL4MIR教程 - 由Thomas Lidy提供的音乐信息检索(MIR)深度学习(Deep Learning)教程
- Ron Weiss的视频演讲 - Ron Weiss(Google)关于在波形(waveforms)上训练神经网络声学模型(Acoustic models)的演讲
- DL4M幻灯片 - Jordi Pons对当前技术的个人(重新)审视
- DL4MIR教程 - Python教程,学习使用深度学习解决MIR任务
- Awesome Python科学音频 - 音频与机器学习的Python资源
- ISMIR资源 - 社区维护的资源列表
- ISMIR Google群组 - 每日MIR通用话题
- Awesome Python - Python资源中的音频部分
- Awesome Web Audio - WebAudio包和资源
- Awesome Music - 音乐软件
- Awesome Music Production - 音乐创作
- Asimov研究所 - 6个用于音乐生成的深度学习工具
- DLM Google群组 - 音乐领域的深度学习群组
- Slack上的MIR社区 - 订阅MIR社区Slack的链接
- 未分类的MIR相关链接列表 - Cory McKay整理的深度学习、MIR等各类链接
- MIRDL - Jordi Pons整理的MIR深度学习文章列表(已不再维护)
- WWW 2018挑战赛 - 在FMA数据集上学习识别音乐流派
- 使用深度学习的音乐生成 - 深度学习音乐生成资源列表
- 听觉场景分析(Auditory Scene Analysis) - 由Albert Bregman撰写的关于声音感知组织的书籍,他是“听觉场景分析(Auditory Scene Analysis)”的奠基人。
- 听觉场景分析演示 - 展示听觉感知组织示例的音频演示
音乐数据集
深度学习
- DLPaper2Code: 从深度学习研究论文中自动生成代码(Auto-generation of Code from Deep Learning Research Papers)
- Model Convertors - 深度学习框架和后端的模型转换工具(Convertors for DL frameworks and backend)
- Deep architecture genealogy - 深度学习架构的谱系图(Genealogy of DL architectures)
- Deep Learning as an Engineer - Jan Schlüter 的演讲幻灯片(Slides from Jan Schlüter)
- Awesome Deep Learning - 通用深度学习资源(General deep learning resources)
- Awesome Deep Learning Resources - 关于深度学习和深度强化学习的论文(Papers regarding deep learning and deep reinforcement learning)
- Awesome RNNs - 循环神经网络(RNNs)的代码、理论和应用(RNNs code, theory and applications)
- Cheatsheets AI - Keras、神经网络、scikit-learn 等速查表(Cheat Sheets for Keras, neural networks, scikit-learn,...)
- DL PaperNotes - 通用深度学习研究论文的摘要和笔记(Summaries and notes on general deep learning research papers)
- 通用 资源列表(General
lists)
- Echo State Network
- DL in NLP - 使用神经网络的最佳实践(Best practices for using neural networks by Sebastian Ruder)
- CNN overview - 斯坦福课程(Stanford Course)
- Dilated Recurrent Neural Networks - 如何改进循环神经网络(RNNs)?(How to improve RNNs?)
- Encoder-Decoder in RNNs(编码器-解码器在 RNNs 中的应用) - 编码器-解码器循环神经网络中的注意力机制(How Does Attention Work in Encoder-Decoder Recurrent Neural Networks)
- On the use of DL - 关于深度学习的趣味内容(Misc fun around DL)
- ML from scratch - 从数据挖掘到深度学习的机器学习模型和算法的 Python 实现(Python implementations of ML models and algorithms from scratch from Data Mining to DL)
- Comparison of DL frameworks - 描述现有深度学习框架的演示文稿(Presentation describing the different existing frameworks for DL)
- ELU > ReLU - 描述 ELU 和 ReLU 之间差异的文章(Article describing the differences between ELU and ReLU)
- Reinforcement Learning: An Introduction - 强化学习入门书籍(Book about reinforcement learning)
- Estimating Optimal Learning Rate - 关于学习率优化的博客文章(Blog post on the learning rate optimisation)
- GitHub repo for sklearn add-on for imbalanced learning - 处理不平衡数据集的机器学习(ML in uneven datasets)
- Video on DL from Nando de Freitas, Scott Reed and Oriol Vinyals - 深度学习:实践与趋势(NIPS 2017 教程,第一部分和第二部分)(Deep Learning: Practice and Trends (NIPS 2017 Tutorial, parts I & II))
- Article "Are GANs Created Equal? A Large-Scale Study" - 对比深度学习算法的实际研究(Actually comparing DL algorithms)
- Battle of the Deep Learning frameworks - 深度学习框架的对比与演进(DL frameworks comparison and evolution)
- Black-box optimization - 除了梯度下降之外的其他优化算法(There are other optimization algorithms than just gradient descent)
被引用情况(Cited by)
如果您使用了本仓库中的信息,请告知我们!本仓库已被以下内容引用:
- Alexander Schindler
- Meinard Müller, Christof Weiss, Stefan Balke
- WWW 2018 Challenge: Learning to Recognize Musical Genre
- Awesome Deep Learning
- AINewsFeed
许可证(License)
您可以在 MIT 许可证条款下自由复制、修改和分发 Deep Learning for Music(DL4M),并需注明来源。详情请参阅 LICENSE 文件。
本项目使用了其他项目,请参考以下项目以获取相应的许可证信息:
- Readme checklist - 用于构建通用 Readme
- Pylint - 用于清理 Python 代码
- Numpy - 用于管理 Python 数据结构
- Matplotlib - 用于绘制图表
- Bibtexparser - 用于处理 BibTeX 条目
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。