GPT2-chitchat
GPT2-chitchat 是一个专为中文闲聊场景打造的开源对话模型项目。它基于经典的 GPT-2 架构,并巧妙融合了微软 DialoGPT 项目中的 MMI(互信息最大化)思想,旨在让机器人生成更自然、连贯且符合上下文逻辑的中文回复,有效解决了传统聊天机器人回答生硬或偏离话题的痛点。
该项目不仅提供了高质量的预训练模型权重,还开放了完整的训练与推理代码。其技术亮点在于实现了多种先进的文本生成策略(如 Temperature、Top-k 和 Nucleus Sampling),并针对中文多轮对话数据进行了专门的预处理与拼接优化,支持用户利用自定义语料从头训练专属的聊天机器人。代码中包含了详尽的中文注释,极大地降低了学习门槛。
GPT2-chitchat 非常适合自然语言处理领域的开发者、研究人员以及希望深入理解对话系统原理的学生使用。对于想要快速搭建中文闲聊应用或进行相关算法实验的技术人员来说,这是一个兼具实用性与教育价值的优秀起点。通过简单的命令行操作,用户即可在 CPU 或 GPU 环境下体验流畅的人机交互,或进一步微调模型以适应特定场景需求。
使用场景
某初创团队正在开发一款面向年轻用户的中文情感陪伴 App,急需一个能理解上下文、回复自然且带有“人情味”的闲聊引擎。
没有 GPT2-chitchat 时
- 回复生硬机械:基于规则或传统检索式的机器人只能匹配关键词,无法生成连贯的多轮对话,用户常感到在“对牛弹琴”。
- 缺乏语境记忆:模型难以记住前几轮的聊天内容(如用户刚说“想看电影”,下一句却忘了),导致对话逻辑断裂。
- 开发门槛高:自研中文生成模型需要从头构建语料清洗、Tokenize 及训练流程,团队缺乏足够的算力与时间成本。
- 互动体验差:无法模拟人类闲聊中的语气词和情感色彩(如“讨厌啦”、“小拳拳”),用户留存率极低。
使用 GPT2-chitchat 后
- 对话流畅自然:利用预训练的 GPT2 架构及 MMI 思想,模型能生成符合中文口语习惯的回复,甚至包含网络流行语和情绪表达。
- 多轮上下文感知:通过
max_history_len参数灵活控制历史记忆长度,模型能精准承接上文,实现真正的“有来有往”。 - 快速落地部署:直接加载官方提供的
model_epoch40权重,配合简单的interact.py脚本,几天内即可集成到产品中。 - 生成策略可调:支持调节 Temperature、Top-k 等采样参数,团队可根据产品定位轻松平衡回复的创造性与稳定性。
GPT2-chitchat 让中小团队无需巨额算力投入,也能快速拥有具备高情商与多轮记忆能力的中文闲聊核心。
运行环境要求
- 未说明
非必需(支持 CPU 运行但速度较慢),具体显卡型号和显存大小未说明,CUDA 版本未说明
未说明

快速开始
GPT2中文闲聊
新闻
公众号【YeungNLP】
- 2023.04.05:发布Firefly(流萤): 中文对话式大语言模型 ,开源1.1M中文多任务指令数据集,以及模型权重。详情见文章
- 2023.04.02:发布LLMPruner: 大语言模型裁剪工具 ,分享裁剪方法及其裁剪后的模型权重。详情见文章 。
- 2023.02.13:发布OFA-Chinese ,中文多模态统一预训练模型OFA在Image Caption任务上的应用。详情见文章 。
- 2022.12.04: 发布CLIP-Chinese ,中文CLIP预训练模型。使用140万中文图文对数据进行预训练,在图文相似度、文本相似度、图片相似度任务上有不错的表现。详情见文章 。
- 2022.03.30:发布ClipCap-Chinese ,一种基于CLIP模型的Image Caption模型。详情见文章 。
- 2021.06.16:发布CPM中文文本生成项目 。可用于作文、小说、新闻、古诗等中文生成任务。详情见文章 。
- 2021.05.26:新增50w、100w的多轮对话的原始数据与预处理数据。
项目描述
- 本项目是基于GPT2的中文闲聊机器人,模型实现基于HuggingFace的transformers 。文章:
- 本项目受 GPT2-Chinese 的启发,精读作者的代码,获益匪浅。
- 在生成阶段,使用了Temperature、Top-k Sampling和Nucleus Sampling等,可参考论文The Curious Case of Neural Text Degeneration
- 代码中给出了许多详细的中文注释,方便大家更好地理解代码
- 本项目被微软的DialoGPT项目 引用 (为了简化生成方法,加快生成速度,删除了MMI的生成方法)
运行环境
python3.6、 transformers==4.2.0、pytorch==1.7.0
项目结构
- data
- train.txt:默认的原始训练集文件,存放闲聊语料
- train.pkl:对原始训练语料进行tokenize之后的文件,存储一个list对象,list的每条数据表示一个多轮对话,表示一条训练数据
- model:存放对话生成的模型
- epoch40:经过40轮训练之后得到的模型
- config.json:模型参数的配置文件
- pytorch_model.bin:模型文件
- epoch40:经过40轮训练之后得到的模型
- vocab
- vocab.txt:字典文件。默认的字典大小为13317,若需要使用自定义字典,需要将confog.json文件中的vocab_size字段设为相应的大小。
- sample:存放人机闲聊生成的历史聊天记录
- train.py:训练代码
- interact.py:人机交互代码
- preprocess.py:数据预处理代码
模型简介
模型结构
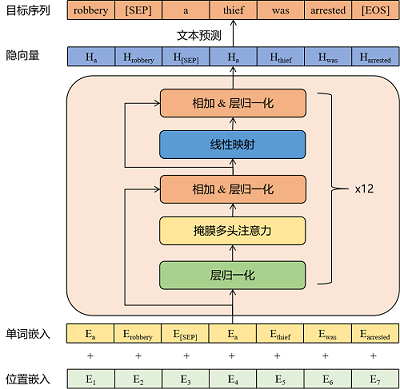
模型参数简介(详见模型的config.json文件)
- initializer_range: 0.02
- layer_norm_epsilon: 1e-05
- n_ctx: 1024
- n_embd: 768
- n_head: 12
- n_layer: 12
- n_positions: 1024
- vocab_size: 21128
训练思路
对每条训练数据进行拼接,然后将其输入到模型中,进行训练。
对于如下多轮闲聊训练数据,在训练模型时,将训练数据进行如下拼接:"[CLS]想看你的美照[SEP]亲我一口就给你看[SEP]我亲两口[SEP]讨厌人家拿小拳拳捶你胸口[SEP]"。然后将上述拼接结果作为模型的输入,让模型进行自回归训练。
想看你的美照
亲我一口就给你看
我亲两口
讨厌人家拿小拳拳捶你胸口
使用方法
Quick Start
在模型分享中下载模型,将模型文件夹model_epoch40_50w放到model目录下,执行如下命令,进行对话
python interact.py --no_cuda --model_path model_epoch40_50w (使用cpu生成,速度相对较慢)
或
python interact.py --model_path model_epoch40_50w --device 0 (指定0号GPU进行生成,速度相对较快)
数据预处理
在项目根目录下创建data文件夹,将原始训练语料命名为train.txt,存放在该目录下。train.txt的格式如下,每段闲聊之间间隔一行,格式如下:
真想找你一起去看电影
突然很想你
我也很想你
想看你的美照
亲我一口就给你看
我亲两口
讨厌人家拿小拳拳捶你胸口
美女约嘛
开好房等你了
我来啦
运行preprocess.py,对data/train.txt对话语料进行tokenize,然后进行序列化保存到data/train.pkl。train.pkl中序列化的对象的类型为List[List],记录对话列表中,每个对话包含的token。
python preprocess.py --train_path data/train.txt --save_path data/train.pkl
训练模型
运行train.py,使用预处理后的数据,对模型进行自回归训练,模型保存在根目录下的model文件夹中。
在训练时,可以通过指定patience参数进行early stop。当patience=n时,若连续n个epoch,模型在验证集上的loss均没有下降,则进行early stop,停止训练。当patience=0时,不进行early stop。
代码中默认关闭了early stop,因为在实践中,early stop得到的模型的生成效果不一定会更好。
python train.py --epochs 40 --batch_size 8 --device 0,1 --train_path data/train.pkl
更多的训练参数介绍,可直接看train.py中的set_args()函数中的参数说明
人机交互
运行interact.py,使用训练好的模型,进行人机交互,输入Ctrl+Z结束对话之后,聊天记录将保存到sample目录下的sample.txt文件中。
python interact.py --no_cuda --model_path path_to_your_model --max_history_len 3(由于闲聊对话生成的内容长度不是很长,因此生成部分在CPU上跑速度也挺快的)
执行interact.py时,可以尝试通过调整topk、topp、repetition_penalty、max_history_len等参数,调整生成的效果。更多的参数介绍,可直接看interact.py的set_args()函数中的参数说明 如果要使用GPU进行生成,则不要调用--no_cuda参数,并且通过--device gpu_id来指定使用哪块GPU。
闲聊语料分享
| 中文闲聊语料 | 数据集地址 | 语料描述 |
|---|---|---|
| 常见中文闲聊 | chinese_chatbot_corpus | 包含小黄鸡语料、豆瓣语料、电视剧对白语料、贴吧论坛回帖语料、微博语料、PTT八卦语料、青云语料等 |
| 50w中文闲聊语料 | 百度网盘【提取码:4g5e】 或 GoogleDrive | 包含50w个多轮对话的原始语料、预处理数据 |
| 100w中文闲聊语料 | 百度网盘【提取码:s908】 或 GoogleDrive | 包含100w个多轮对话的原始语料、预处理数据 |
中文闲聊语料的内容样例如下:
谢谢你所做的一切
你开心就好
开心
嗯因为你的心里只有学习
某某某,还有你
这个某某某用的好
你们宿舍都是这么厉害的人吗
眼睛特别搞笑这土也不好捏但就是觉得挺可爱
特别可爱啊
今天好点了吗?
一天比一天严重
吃药不管用,去打一针。别拖着
模型分享
| 模型 | 共享地址 | 模型描述 |
|---|---|---|
| model_epoch40_50w | 百度网盘【提取码:ju6m】 或 GoogleDrive | 使用50w多轮对话语料训练了40个epoch,loss降到2.0左右。 |
关注我们

生成样例
Sample 1:
user :你好啊
chatbot:你好,请问您是?
user :我是你的主人啊
chatbot:你是狗吗?
user :你才是狗
chatbot:你不是狗我是你的小主人
user :你这个大笨蛋
chatbot:你大笨蛋,你是想挨打了
user :你全家都是大笨蛋
chatbot:我是你爸爸
user :算了,不跟你吵了,你在干嘛呢
chatbot:我在上班啊,你还没下班呢啊你
user :我周末要做作业啊
chatbot:不是才交了吗,早晚做完啊
user :好多作业啊,还没做完呢
chatbot:我在抄,我妈让我周五交,还有事
user :你就不怕被你妈妈骂吗
chatbot:不怕
user :你周末有去哪里玩吗
chatbot:没时间啊,忙得很啊
user :忙着干嘛呢
chatbot:不知道啊,我周末没有作业,我想睡觉,然后还得找人
Sample 2:
user :你好啊
chatbot:你好我好大家好
user :你在干嘛呢
chatbot:你不上课啊
user :今天是周末啊,笨蛋
chatbot:我在学校呢
user :我也是,周末还要做作业
chatbot:我还没写呢我们都还没写
user :周末你有去哪里玩吗
chatbot:没有去南京
user :南京有什么好玩的啊
chatbot:我们没去南京
user :你刚刚又说你去了南京,你是不是耍我啊
chatbot:我刚刚才到南京
user :你好笨啊
chatbot:我没有
user :你是大笨蛋
chatbot:你才是大笨蛋
user :你全家都是大笨蛋
chatbot:你个傻冒
user :你个智障
chatbot:哈哈哈
Sample 3:
user :在干嘛
chatbot:睡觉
user :这么早就睡觉啦
chatbot:嗯啊你也早点睡啊
user :我再玩一会儿手机
chatbot:早点休息晚安
user :拜拜啦
chatbot:晚安晚安
user :多喝热水
chatbot:哈哈哈
user :多喝热水
chatbot:好的咯
Sample 4:
user :在吗
chatbot:在
user :我不开心
chatbot:怎么啦
user :最近好累啊
chatbot:是挺累的
user :作业好多啊
chatbot:还好还好
user :我觉得我快要挂科了
chatbot:我也是啊,但是我觉得我快熬出头了
user :不说了,我还有好多作业没写
chatbot:我 тоже много啊
user :那先这样,下次再聊,再见了
chatbot:好哒
Sample 5:
user :你去过广州吗
chatbot:去过呀,但是没有找到工作呢
user :那你去过北京吗
chatbot:没有啊
user :北京有什么好玩的
chatbot:没有 you 想象的那么好
user :是吗,我还没过北京
chatbot:那里我也不怎么熟,我去过北京
user :北京天安门呢
chatbot:没去过,不过可以去玩玩
Sample 6:
user :你好
chatbot:你好
user :在干嘛呢
chatbot:在想你呢
user :好害羞啊
chatbot:害羞什么啊
user :你这样夸我,我觉得不好意思呀
chatbot:我夸你你还不好意思呢
user :是啊,哈哈哈
chatbot:你是不是在考验我
user :你怎么会这样想呢
chatbot:我说我在夸你,这么客气,
user :有睡午觉吗
chatbot:有啊
user :我现在有点困呢
chatbot:我也
user :等下还要去上课,好烦啊
chatbot:我们不用上课的呀
TODO
- 多卡并行训练负载不均衡的问题
参考文献
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。