docutranslate
DocuTranslate 是一款支持多种文档格式的本地翻译工具,可轻松翻译 PDF、Word、Excel、EPUB、字幕文件(SRT/ASS)和 JSON 等常见文件,无需上传至云端,保障隐私与安全。它特别解决了学术论文、小说、技术文档等复杂内容翻译时格式丢失、术语不一致、公式表格无法识别的难题,能智能保留原文排版结构,并自动构建术语表确保专业词汇统一。支持调用多种 AI 平台接口,实现高并发翻译,还提供简洁的网页界面和 REST API,方便个人或团队协作使用。其亮点在于内置 PDF 解析引擎(如 docling 和 minerU),可准确识别并翻译表格、数学公式和代码片段,同时支持通过 JSONPath 精准指定需翻译的字段。适合研究人员、译者、学生、技术写作者以及希望本地化处理多语言文档的普通用户。Windows 和 macOS 提供免安装的轻量版(小于 40MB),开箱即用,无需复杂配置。
使用场景
一位中国高校研究者正在撰写一篇英文论文,准备投稿至国际期刊,但需要将中文初稿中的图表说明、参考文献和公式注释完整翻译为专业英文,同时保留原有 Word 格式与排版结构。
没有 docutranslate 时
- 手动复制粘贴内容到翻译软件,极易遗漏公式、表格中的文字,导致论文关键信息丢失。
- 每次翻译后需重新调整 Word 格式,耗费数小时,还常出现字体错乱、段落错位。
- 专业术语如“卷积神经网络”“反向传播”缺乏统一译法,不同段落翻译不一致,被审稿人质疑专业性。
- 多次使用在线翻译平台存在数据泄露风险,敏感研究数据可能被第三方截取。
- 翻译过程中无法批量处理附录中的 JSON 配置文件和参考文献的 BibTeX 条目,必须单独处理,效率极低。
使用 docutranslate 后
- 直接上传 Word 文档,自动识别并翻译表格、公式标注和代码片段,保留原始排版,无需手动重制。
- 自动构建术语表,首次翻译“Transformer架构”后,全文其余出现均统一译为“Transformer architecture”,确保术语一致性。
- 支持本地部署,所有翻译在内网完成,研究数据零外传,符合学术机构数据安全规范。
- 一键翻译附录中的 JSON 文件,通过 jsonpath-ng 指定仅翻译
"description"字段,其余结构完全保留。 - Web 界面支持多人协作,合作者可同时查看翻译进度,实时同步术语库,团队协作效率提升 70%。
docutranslate 让学术文档翻译从繁琐的手工劳动,变成安全、精准、高效的自动化流程。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
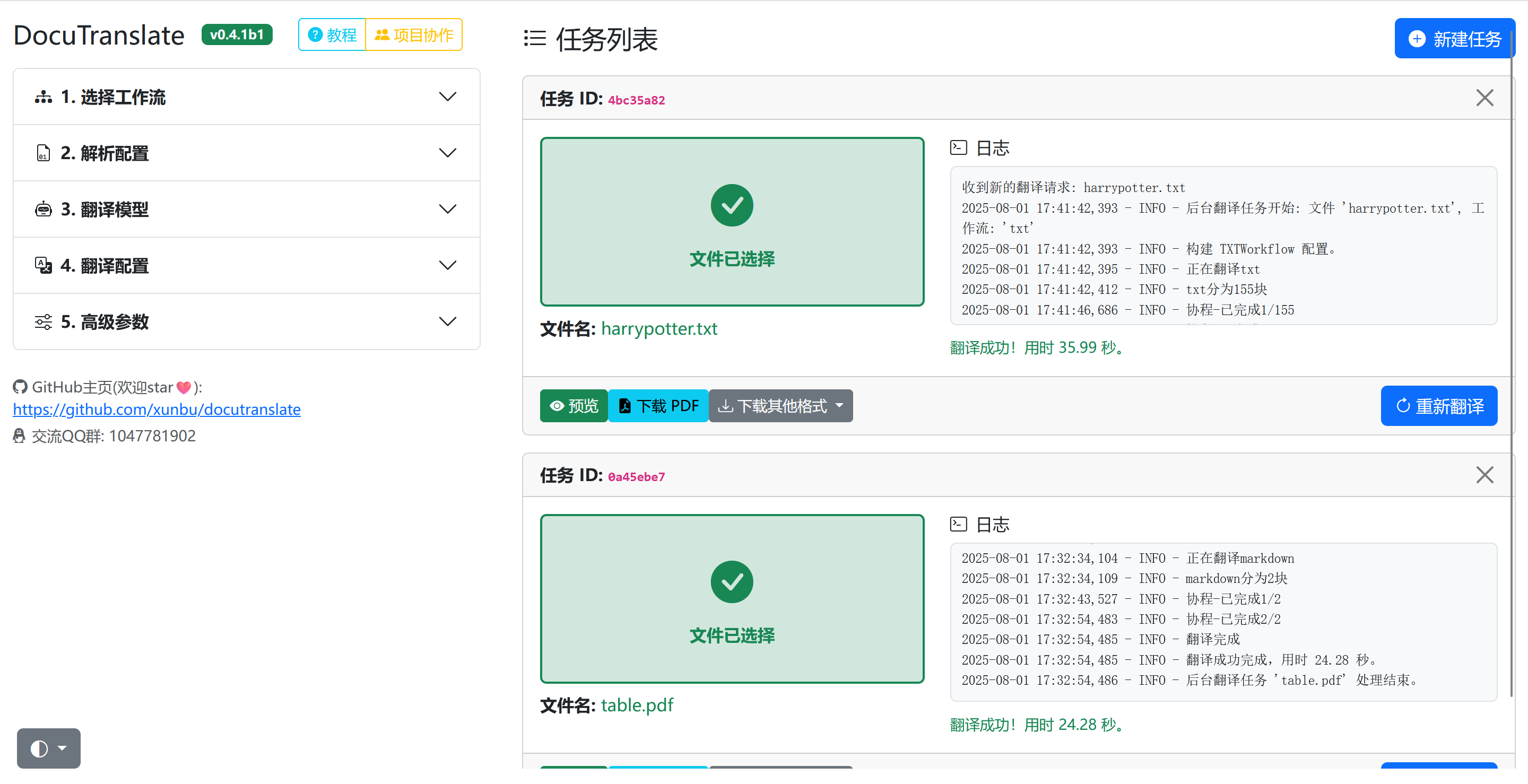
快速开始

DocuTranslate



简体中文 / English / 日本語 / Tiếng Việt
一款基于大语言模型的轻量级本地文件翻译工具。
- ✅ 支持多种格式:可翻译
pdf、docx、xlsx、md、txt、json、epub、srt、ass等文件。 - ✅ 自动生成术语表:支持自动生成术语表,确保术语一致性。
- ✅ PDF表格、公式、代码识别:利用
docling和mineruPDF解析引擎,识别并翻译学术论文中常见的表格、公式和代码。 - ✅ JSON翻译:支持通过路径(
jsonpath-ng语法)指定要翻译的JSON值。 - ✅ 保留Word/Excel格式:支持
docx和xlsx文件(暂不支持doc或xls),同时保持原有格式。 - ✅ 多AI平台支持:支持大多数AI平台,可实现高性能并发AI翻译,并支持自定义提示词。
- ✅ 异步支持:专为高性能场景设计,提供完整的异步支持和接口,实现多任务并行处理。
- ✅ 局域网与多用户支持:支持局域网内多用户同时使用。
- ✅ 交互式Web界面:提供开箱即用的Web UI和RESTful API,方便集成与使用。
- ✅ 小巧便携的软件包:Windows和Mac便携版软件包小于40MB(不使用
docling进行本地PDF解析的版本)。
翻译
QQ社区群:1047781902 1081128602
UI界面:
![]()
论文翻译:
![]()
小说翻译:
![]()
集成包
对于希望快速上手的用户,我们在GitHub发布页面提供了集成包。只需下载、解压,输入AI平台API-Key即可开始使用。
- DocuTranslate:标准版。使用
minerU(在线或本地部署)进行PDF解析。支持本地minerU API调用。(推荐) - DocuTranslate_full:完整版。内置
docling本地PDF解析引擎。如果需要离线PDF解析且无需minerU,请选择此版本。
快速开始
使用pip
# 基本安装
pip install docutranslate
# 安装mcp扩展
pip install docutranslate[mcp]
# 安装docling扩展
pip install docutranslate[docling]
docutranslate -i
#docutranslate -i --with-mcp
使用uv
# 初始化环境
uv init
# 基本安装
uv add docutranslate
# 安装mcp扩展
uv add docutranslate[mcp]
# 安装docling扩展
uv add docutranslate[docling]
uv run --no-dev docutranslate -i
#uv run --no-dev docutranslate -i --with-mcp
使用git
# 初始化环境
git clone https://github.com/xunbu/docutranslate.git
cd docutranslate
uv sync --no-dev
# uv sync --no-dev --extra mcp
# uv sync --no-dev --extra docling
# uv sync --no-dev --all-extras
使用docker
docker run -d -p 8010:8010 xunbu/docutranslate:latest #不支持docling
# docker run -it -p 8010:8010 xunbu/docutranslate:latest
# docker run -it -p 8010:8010 xunbu/docutranslate:v1.5.4
启动Web UI与API服务
为了便于使用,DocuTranslate提供了功能完备的Web界面和RESTful API。
启动服务:
docutranslate -i (启动GUI,默认本地访问)
docutranslate -i --host 0.0.0.0 (允许局域网内其他设备访问)
docutranslate -i -p 8081 (指定端口号)
docutranslate -i --cors (启用默认CORS设置)
docutranslate -i --with-mcp (启动GUI并附带MCP SSE端点、共享队列、共享端口)
docutranslate --mcp (启动MCP服务器,stdio模式)
docutranslate --mcp --transport sse (启动MCP服务器,SSE模式)
docutranslate --mcp --transport sse --mcp-host MCP_HOST --mcp-port MCP_PORT (启动MCP服务器,SSE模式)
docutranslate --mcp --transport streamable-http (启动MCP服务器,Streamable HTTP模式)
- 交互式界面:服务启动后,请在浏览器中访问
http://127.0.0.1:8010(或您指定的端口)。 - API文档:完整的API文档(Swagger UI)位于
http://127.0.0.1:8010/docs。 - MCP:SSE服务端点位于
http://127.0.0.1:8010/mcp/sse(使用--with-mcp启动)或http://127.0.0.1:8000/mcp/sse(使用--mcp启动)
MCP配置
DocuTranslate可用作MCP(模型上下文协议)服务器。详细文档请参阅MCP文档。
支持的环境变量
| 环境变量 | 描述 | 必需 |
|---|---|---|
DOCUTRANSLATE_API_KEY |
AI平台API密钥 | 是 |
DOCUTRANSLATE_BASE_URL |
AI平台基础URL | 是 |
DOCUTRANSLATE_MODEL_ID |
模型ID | 是 |
DOCUTRANSLATE_TO_LANG |
目标语言(默认:中文) | 否 |
DOCUTRANSLATE_CONCURRENT |
并发请求数(默认:10) | 否 |
DOCUTRANSLATE_CONVERT_ENGINE |
PDF转换引擎 | 否 |
DOCUTRANSLATE_MINERU_TOKEN |
MinerU API Token | 否 |
uvx 配置(无需安装)
{
"mcpServers": {
"docutranslate": {
"command": "uvx",
"args": ["--from", "docutranslate[mcp]", "docutranslate", "--mcp"],
"env": {
"DOCUTRANSLATE_API_KEY": "sk-xxxxxx",
"DOCUTRANSLATE_BASE_URL": "https://api.openai.com/v1",
"DOCUTRANSLATE_MODEL_ID": "gpt-4o",
"DOCUTRANSLATE_TO_LANG": "中文",
"DOCUTRANSLATE_CONCURRENT": "10",
"DOCUTRANSLATE_CONVERT_ENGINE": "mineru",
"DOCUTRANSLATE_MINERU_TOKEN": "your-mineru-token"
}
}
}
}
SSE 模式配置
首先以 SSE 模式启动 MCP 服务器:
docutranslate --mcp --transport sse --mcp-host 127.0.0.1 --mcp-port 8000
然后在客户端配置 SSE 端点:http://127.0.0.1:8000/mcp/sse
使用示例
使用简单客户端 SDK(推荐)
最简便的入门方式是使用 Client 类,它提供了简单直观的翻译 API:
from docutranslate.sdk import Client
# 使用您的 AI 平台设置初始化客户端
client = Client(
api_key="YOUR_OPENAI_API_KEY", # 或其他任何 AI 平台的 API 密钥
base_url="https://api.openai.com/v1/",
model_id="gpt-4o",
to_lang="中文",
concurrent=10, # 并发请求数量
)
# 示例 1:翻译纯文本文件(无需 PDF 解析引擎)
result = client.translate("path/to/your/document.txt")
print(f"翻译完成!保存到:{result.save()}")
# 示例 2:翻译 PDF 文件(需要 mineru_token 或本地部署)
# 选项 A:使用在线 MinerU(需 token:https://mineru.net/apiManage/token)
result = client.translate(
"path/to/your/document.pdf",
convert_engine="mineru",
mineru_token="YOUR_MINERU_TOKEN", # 替换为您自己的 MinerU Token
formula_ocr=True, # 开启公式识别
)
result.save(fmt="html")
# 选项 B:使用本地部署的 MinerU(推荐用于内网或离线环境)
# 首先启动本地 MinerU 服务,参考:https://github.com/opendatalab/MinerU
result = client.translate(
"path/to/your/document.pdf",
convert_engine="mineru_deploy",
mineru_deploy_base_url="http://127.0.0.1:8000", # 您的本地 MinerU 地址
mineru_deploy_backend="hybrid-auto-engine", # 后端类型
)
result.save(fmt="markdown")
# 示例 3:翻译 Docx 文件(保留格式)
result = client.translate(
"path/to/your/document.docx",
insert_mode="replace", # replace/append/prepend
)
result.save(fmt="docx") # 保存为 docx 格式
# 示例 4:导出为 base64 编码字符串(用于 API 传输)
base64_content = result.export(fmt="html")
print(f"导出内容长度:{len(base64_content)}")
# 您也可以访问底层工作流进行高级操作
# 工作流 = 结果.工作流
客户端功能:
- 自动检测:自动检测文件类型并选择合适的工作流
- 灵活配置:可在每次翻译调用时覆盖任何默认设置
- 多种输出选项:保存到磁盘或导出为Base64字符串
- 异步支持:使用
translate_async()进行并发翻译任务
客户端SDK参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| api_key | str |
- | AI平台API密钥 |
| base_url | str |
- | AI平台基础URL(例如:https://api.openai.com/v1/) |
| model_id | str |
- | 用于翻译的模型ID |
| to_lang | str |
- | 目标语言(例如:“中文”、“英语”、“日语”) |
| concurrent | int |
10 | 并发LLM请求数量 |
| convert_engine | str |
"mineru" |
PDF解析引擎:“mineru”、“docling”、“mineru_deploy” |
| md2docx_engine | str |
"auto" |
Markdown转Docx引擎:“python”(纯Python)、“pandoc”(使用Pandoc)、“auto”(若安装Pandoc则使用Pandoc,否则使用Python)、null(不生成Docx) |
| mineru_deploy_base_url | str |
- | 本地minerU API地址(当convert_engine="mineru_deploy"时) |
| mineru_deploy_parse_method | str |
"auto" |
本地minerU解析方法:“auto”、“txt”、“ocr” |
| mineru_deploy_table_enable | bool |
True |
启用本地minerU表格识别 |
| mineru_token | str |
- | minerU API令牌(当使用在线minerU时) |
| skip_translate | bool |
False |
跳过翻译,仅解析文档 |
| output_dir | str |
"./output" |
save()的默认输出目录 |
| chunk_size | int |
3000 | LLM处理的文本分块大小 |
| temperature | float |
0.3 | LLM温度参数 |
| timeout | int |
60 | 请求超时时间,单位为秒 |
| retry | int |
3 | 失败时重试次数 |
| provider | str |
"auto" |
AI提供商类型(auto、openai、azure等) |
| force_json | bool |
False |
强制JSON输出模式 |
| rpm | int |
- | 每分钟请求数限制 |
| tpm | int |
- | 每分钟令牌数限制 |
| extra_body | str |
- | 额外请求体参数,以JSON字符串格式传递,将合并到API请求中 |
| thinking | str |
"auto" |
思考模式:“auto”、“none”、“block” |
| custom_prompt | str |
- | 自定义翻译提示 |
| system_proxy_enable | bool |
False |
启用系统代理 |
| insert_mode | str |
"replace" |
Docx/Xlsx/Txt插入模式:“replace”、“append”、“prepend” |
| separator | str |
"\n" |
append/prepend模式下的文本分隔符 |
| segment_mode | str |
"line" |
分段模式:“line”、“paragraph”、“none” |
| translate_regions | list |
- | Excel翻译区域(例如:“Sheet1!A1:B10”) |
| model_version | str |
"vlm" |
MinerU模型版本:“pipeline”、“vlm” |
| formula_ocr | bool |
True |
启用PDF解析中的公式OCR |
| code_ocr | bool |
True |
启用PDF解析中的代码OCR |
| mineru_deploy_backend | str |
"hybrid-auto-engine" |
MinerU本地后端:“pipeline”、“vlm-auto-engine”、“vlm-http-client”、“hybrid-auto-engine”、“hybrid-http-client” |
| mineru_deploy_formula_enable | bool |
True |
启用本地MinerU的公式识别 |
| mineru_deploy_start_page_id | int |
0 | 本地MinerU解析的起始页码 |
| mineru_deploy_end_page_id | int |
99999 | 本地MinerU解析的结束页码 |
| mineru_deploy_lang_list | list |
- | 本地MinerU解析的语言列表 |
| mineru_deploy_server_url | str |
- | MinerU本地服务器URL |
| json_paths | list |
- | JSONPath表达式,用于JSON翻译(例如:“$.data.*”) |
| glossary_generate_enable | bool |
- | 启用自动术语表生成 |
| glossary_dict | dict |
- | 术语表字典(例如:{"Jobs": "史蒂夫·乔布斯"}) |
| glossary_agent_config | dict |
- | 术语表代理配置 |
结果方法
| 方法 | 参数 | 描述 |
|---|---|---|
| save() | output_dir、name、fmt |
将翻译结果保存到磁盘 |
| export() | fmt |
导出为Base64编码字符串 |
| supported_formats | - | 获取支持的输出格式列表 |
| workflow | - | 访问底层工作流对象 |
import asyncio
from docutranslate.sdk import Client
async def translate_multiple():
client = Client(
api_key="YOUR_API_KEY",
base_url="https://api.openai.com/v1/",
model_id="gpt-4o",
to_lang="中文",
)
# 并发翻译多个文件
files = ["doc1.pdf", "doc2.docx", "notes.txt"]
results = await asyncio.gather(
*[client.translate_async(f) for f in files]
)
for r in results:
print(f"已保存:{r.save()}")
asyncio.run(translate_multiple())
使用工作流API(用于高级控制)
如需更多控制,可直接使用工作流API。每个工作流遵循相同的模式:
# 模式:
# 1. 创建TranslatorConfig(LLM设置)
# 2. 创建WorkflowConfig(工作流设置)
# 3. 创建工作流实例
# 4. workflow.read_path(文件)
# 5. await workflow.translate_async()
# 6. workflow.save_as_*(name=...) 或 export_to_*(...)
可用工作流与输出方法
| 工作流 | 输入 | save_as_* | export_to_* | 关键配置选项 |
|---|---|---|---|---|
| MarkdownBasedWorkflow | .pdf, .docx, .md, .png, .jpg |
html, markdown, markdown_zip, docx |
html, markdown, markdown_zip, docx |
convert_engine, md2docx_engine, translator_config |
| TXTWorkflow | .txt |
txt, html |
txt, html |
translator_config |
| JsonWorkflow | .json |
json, html |
json, html |
translator_config, json_paths |
| DocxWorkflow | .docx |
docx, html |
docx, html |
translator_config, insert_mode |
| XlsxWorkflow | .xlsx, .csv |
xlsx, html |
xlsx, html |
translator_config, insert_mode |
| SrtWorkflow | .srt |
srt, html |
srt, html |
translator_config |
| EpubWorkflow | .epub |
epub, html |
epub, html |
translator_config, insert_mode |
| HtmlWorkflow | .html, .htm |
html |
html |
translator_config, insert_mode |
| AssWorkflow | .ass |
ass, html |
ass, html |
translator_config |
关键配置选项
通用TranslatorConfig选项:
| 选项 | 类型 | 默认值 | 描述 |
|---|---|---|---|
base_url |
str |
- | AI平台基础URL |
api_key |
str |
- | AI平台API密钥 |
model_id |
str |
- | 模型ID |
to_lang |
str |
- | 目标语言 |
chunk_size |
int |
3000 | 文本分块大小 |
concurrent |
int |
10 | 并发请求数 |
temperature |
float |
0.3 | 大语言模型温度 |
timeout |
int |
60 | 请求超时时间(秒) |
retry |
int |
3 | 重试次数 |
格式特定选项:
| 选项 | 适用工作流 | 描述 |
|---|---|---|
insert_mode |
Docx, Xlsx, Html, Epub | "replace"(默认)、"append"、"prepend" |
json_paths |
Json | JSONPath表达式(例如:["$.*", "$.name"]) |
separator |
Docx, Xlsx, Html, Epub | 用于append/prepend模式的文本分隔符 |
convert_engine |
MarkdownBased | "mineru"(默认)、"docling"、"mineru_deploy" |
示例1:翻译PDF文件(使用MarkdownBasedWorkflow)
这是最常见的使用场景。我们将使用minerU引擎将PDF转换为Markdown,然后通过大语言模型进行翻译。本示例采用异步执行。
import asyncio
from docutranslate.workflow.md_based_workflow import MarkdownBasedWorkflow, MarkdownBasedWorkflowConfig
from docutranslate.converter.x2md.converter_mineru import ConverterMineruConfig
from docutranslate.translator.ai_translator.md_translator import MDTranslatorConfig
from docutranslate.exporter.md.md2html_exporter import MD2HTMLExporterConfig
async def main():
# 1. 构建翻译器配置
translator_config = MDTranslatorConfig(
base_url="https://open.bigmodel.cn/api/paas/v4", # AI平台基础URL
api_key="YOUR_ZHIPU_API_KEY", # AI平台API密钥
model_id="glm-4-air", # 模型ID
to_lang="English", # 目标语言
chunk_size=3000, # 文本分块大小
concurrent=10, # 并发级别
# glossary_generate_enable=True, # 启用自动术语表生成
# glossary_dict={"Jobs":"Steve Jobs"}, # 传入术语表字典
# system_proxy_enable=True, # 启用系统代理
)
# 2. 构建转换器配置(使用minerU)
converter_config = ConverterMineruConfig(
mineru_token="YOUR_MINERU_TOKEN", # 您的minerU Token
formula_ocr=True # 启用公式识别
)
# 3. 构建主工作流配置
workflow_config = MarkdownBasedWorkflowConfig(
convert_engine="mineru", # 指定解析引擎
converter_config=converter_config, # 传入转换器配置
translator_config=translator_config, # 传入翻译器配置
html_exporter_config=MD2HTMLExporterConfig(cdn=True) # HTML导出配置
)
# 4. 实例化工作流
workflow = MarkdownBasedWorkflow(config=workflow_config)
# 5. 读取文件并执行翻译
print("开始读取并翻译文件...")
workflow.read_path("path/to/your/document.pdf")
await workflow.translate_async()
# 或者使用同步方法
# workflow.translate()
print("翻译完成!")
# 6. 保存结果
workflow.save_as_html(name="translated_document.html")
workflow.save_as_markdown_zip(name="translated_document.zip")
workflow.save_as_markdown(name="translated_document.md") # 带内嵌图片的Markdown
print("文件已保存到./output文件夹。")
# 或者直接获取内容字符串
html_content = workflow.export_to_html()
html_content = workflow.export_to_markdown()
# print(html_content)
if __name__ == "__main__":
asyncio.run(main())
其他工作流
所有工作流都遵循相同的模式。导入对应的配置和工作流,然后进行配置:
# TXT:from docutranslate.workflow.txt_workflow import TXTWorkflow, TXTWorkflowConfig
# JSON:from docutranslate.workflow.json_workflow import JsonWorkflow, JsonWorkflowConfig
# DOCX:from docutranslate.workflow.docx_workflow import DocxWorkflow, DocxWorkflowConfig
# XLSX:from docutranslate.workflow.xlsx_workflow import XlsxWorkflow, XlsxWorkflowConfig
# EPUB:from docutranslate.workflow.epub_workflow import EpubWorkflow, EpubWorkflowConfig
# HTML:from docutranslate.workflow.html_workflow import HtmlWorkflow, HtmlWorkflowConfig
# SRT:from docutranslate.workflow.srt_workflow import SrtWorkflow, SrtWorkflowConfig
# ASS:from docutranslate.workflow.ass_workflow import AssWorkflow, AssWorkflowConfig
关键配置选项:
- insert_mode:
"replace"、"append"或"prepend"(适用于docx/xlsx/html/epub) - json_paths:JSON翻译的JSONPath表达式(例如:
["$.*", "$.name"]) - separator:用于
"append"/"prepend"模式的文本分隔符
前提条件与详细配置
1. 获取大模型 API 密钥
翻译功能依赖于大型语言模型。您需要从相应的 AI 平台获取 base_url、api_key 和 model_id。
推荐模型:火山引擎的
doubao-seed-1-6-flash、doubao-seed-1-6系列,智谱的glm-4-flash,阿里云的qwen-plus、qwen-flash,Deepseek 的deepseek-chat等。
302.AI 👈 通过此链接注册即可获得 1 美元免费额度。
| 平台名称 | 获取 API 密钥 | Base URL |
|---|---|---|
| ollama | http://127.0.0.1:11434/v1 | |
| lm studio | http://127.0.0.1:1234/v1 | |
| 302.AI | 点击获取 | https://api.302.ai/v1 |
| openrouter | 点击获取 | https://openrouter.ai/api/v1 |
| openai | 点击获取 | https://api.openai.com/v1/ |
| gemini | 点击获取 | https://generativelanguage.googleapis.com/v1beta/openai/ |
| deepseek | 点击获取 | https://api.deepseek.com/v1 |
| 智谱 AI | 点击获取 | https://open.bigmodel.cn/api/paas/v4 |
| 腾讯混元 | 点击获取 | https://api.hunyuan.cloud.tencent.com/v1 |
| 阿里百炼 | 点击获取 | https://dashscope.aliyuncs.com/compatible-mode/v1 |
| 火山引擎 | 点击获取 | https://ark.cn-beijing.volces.com/api/v3 |
| SiliconFlow | 点击获取 | https://api.siliconflow.cn/v1 |
| DMXAPI | 点击获取 | https://www.dmxapi.cn/v1 |
| 居光 AI | 点击获取 | https://ai.juguang.chat/v1 |
2. PDF 解析引擎(如无需翻译 PDF,请跳过)
2.1 获取 minerU Token(在线 PDF 解析,免费,推荐)
如果您选择 mineru 作为文档解析引擎(convert_engine="mineru"),则需要申请一个免费的 Token。
- 访问 minerU 官网 注册并申请 API。
- 在 API Token 管理界面 创建一个新的 API Token。
注意:minerU Token 有效期为 14 天,到期后请重新生成。
2.2 docling 引擎配置(本地 PDF 解析)
如果您选择 docling 作为文档解析引擎(convert_engine="docling"),它会在首次使用时从 Hugging Face 下载所需的模型。
更好的选择是从 GitHub Releases 下载
docling_artifact.zip,并解压到您的工作目录中。
解决 docling 模型下载网络问题的方案:
- 设置 Hugging Face 镜像(推荐):
- 方法 A(环境变量):设置系统环境变量
HF_ENDPOINT,并重启您的 IDE 或终端。HF_ENDPOINT=https://hf-mirror.com - 方法 B(代码中):在 Python 脚本开头添加以下代码。
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
- 离线使用(提前下载模型包):
- 从 GitHub Releases 下载
docling_artifact.zip。 - 解压到您的项目目录。
- 在配置中指定模型路径(如果模型与脚本不在同一目录):
from docutranslate.converter.x2md.converter_docling import ConverterDoclingConfig
converter_config = ConverterDoclingConfig(
artifact="./docling_artifact", # 指向解压后的文件夹
code_ocr=True,
formula_ocr=True
)
2.3 本地部署 minerU 服务
对于离线/内网环境,可本地部署启用 API 的 minerU。将 mineru_deploy_base_url 设置为您 minerU 的 API 地址。
客户端 SDK:
from docutranslate.sdk import Client
client = Client(
api_key="YOUR_LLM_API_KEY",
model_id="llama3",
to_lang="中文",
convert_engine="mineru_deploy",
mineru_deploy_base_url="http://127.0.0.1:8000", # 您的 minerU API 地址
)
result = client.translate("document.pdf")
result.save(fmt="markdown")
常见问题
问:输出是原文语言? 答:检查日志是否有错误。通常是由于 API 积分耗尽或网络问题。
问:端口 8010 被占用?
答:使用 docutranslate -i -p 8011 或设置 DOCUTRANSLATE_PORT=8011。
问:支持扫描的 PDF?
答:是的,使用具备 OCR 功能的 mineru 引擎。
问:第一次翻译 PDF 较慢?
答:docling 首次运行时需要下载模型。可使用 Hugging Face 镜像或提前下载 artifact。
问:用于内网/离线环境? 答:可以。使用本地 LLM(Ollama/LM Studio)和本地 minerU 或 docling。
问:PDF 缓存机制?
答:MarkdownBasedWorkflow 会将解析结果缓存在内存中(最近 10 次解析)。可通过 DOCUTRANSLATE_CACHE_NUM 进行配置。
问:启用代理?
答:在 TranslatorConfig 中设置 system_proxy_enable=True。
星数历史

捐赠支持
欢迎支持作者。请在评论中注明捐赠用途!
![]()
版本历史
整合包v1.7.12026/03/07整合包v1.7.02026/03/02整合包v1.6.32026/01/19整合包v1.6.22026/01/11整合包v1.6.02025/12/31整合包v1.5.62025/12/17整合包v1.5.42025/12/12整合包v1.5.32025/12/04整合包v1.5.12025/11/10整合包v1.4.182025/11/03整合包v1.4.172025/10/26整合包v1.4.162025/10/20整合包v1.4.152025/10/19整合包v1.4.142025/10/19整合包v1.4.122025/10/15整合包v1.4.112025/10/14整合包v1.4.102025/10/13整合包v1.4.92025/10/10整合包v1.4.82025/10/04整合包v1.4.72025/09/29常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。