chatgpt-web
chatgpt-web 是一个基于纯 JavaScript 打造的轻量级 ChatGPT 网页演示项目,旨在让用户无需复杂后端环境即可快速拥有自己的 AI 对话界面。它核心解决了传统部署流程繁琐、依赖重型服务器框架的痛点,用户只需部署一个 HTML 文件,配合 OpenAI API 密钥即可立即使用。
这款工具非常适合希望快速搭建个人 AI 助手的前端开发者、需要私有化部署演示环境的研究人员,以及想要在不安装额外软件的情况下体验原生对话功能的普通用户。其独特的技术亮点在于极致的轻量化与高度的可定制性:不仅支持语音输入、朗读、深色模式及 PWA 应用等丰富功能,还允许通过简单的 Nginx 配置统一代理 OpenAI、DeepSeek、Gemini 和 Claude 等多个大模型接口。此外,项目特别提供了加密 HTML 文件和自定义环境变量等安全选项,有效避免了 API 密钥在公网传输中的泄露风险,让本地或私有部署更加安全可控。无论是作为学习前端交互的参考案例,还是作为日常高效的对话终端,chatgpt-web 都提供了一个简洁而强大的解决方案。
使用场景
某跨国开发团队需要在内网环境中为多名成员提供统一的 AI 编程助手,同时希望整合 OpenAI、DeepSeek 等多个模型接口以降低成本并保障数据安全。
没有 chatgpt-web 时
- 每位开发者需自行配置本地环境或购买独立账号,导致 API 密钥分散管理,存在泄露风险且难以统一计费。
- 团队成员无法直接访问官方接口(受网络限制),各自寻找不稳定的第三方镜像站,响应速度慢且服务经常中断。
- 缺乏统一界面,无法在不同模型间灵活切换,遇到复杂代码问题时只能单一依赖某个模型,解决效率低下。
- 会话记录散落在个人浏览器或本地文件中,知识无法沉淀,新人入职后无法快速复用过往的技术解决方案。
使用 chatgpt-web 后
- 团队只需在一台服务器上部署单个 HTML 文件并通过 Nginx 反向代理,统一封装多个模型密钥,成员仅需一个自定义密钥即可安全访问。
- 内置的反代配置完美解决网络连通性问题,所有请求经由公司服务器转发,既保证了连接稳定性,又避免了明文传输密钥的安全隐患。
- 界面支持动态切换 DeepSeek、Claude 等不同后端模型,开发者可根据代码生成、逻辑推理等不同需求灵活选择最优模型,大幅提升解题准确率。
- 支持会话搜索、复制及 PWA 离线使用,核心技术方案被完整保留在统一平台,团队成员可随时检索历史对话,实现知识高效共享与传承。
chatgpt-web 通过极简的部署方式和强大的多模型聚合能力,将分散的 AI 资源转化为团队可控、安全且高效的基础设施。
运行环境要求
- 任何支持现代浏览器的操作系统 (Linux
- macOS
- Windows 等)
不需要 GPU
未说明 (取决于浏览器运行需求,通常较低)
快速开始
chatgpt-web
基于OpenAI API的纯JavaScript ChatGPT演示
纯JS实现的ChatGPT项目,基于OpenAI API
部署一个HTML文件即可使用。
支持复制/更新/刷新会话,语音输入,朗读等功能,以及众多自定义选项。
支持搜索会话,深色模式,自定义头像,快捷键,多语言,环境变量,PWA应用,API额度显示等。
支持加密HTML文件。
参考项目: markdown-it, highlight.js, github-markdown-css, chatgpt-html, markdown-it-copy, markdown-it-texmath, awesome-chatgpt-prompts-zh
Demo
在线预览 (使用需配置OpenAI接口和API密钥)
使用方法
注意:部署反代接口请注意OpenAI的支持地区,部署在不支持地区的服务器可能导致封号!最好配置https,公网以http方式明文传输API key非常不安全!
仅部署HTML
使用任意http server部署index.html。打开网页设置,填写API密钥,填写OpenAI接口,当本地
可正常访问
api.openai.com,填写https://api.openai.com/不可正常访问
api.openai.com,填写其反代地址(可使用Cloudflare Worker等反代),注意:反代接口响应需添加跨域HeaderAccess-Control-Allow-OriginOpenAI接口也可以在环境变量中单独配置。
同时部署HTML和OpenAI反代接口
注意:服务器需正常访问官方api接口,可统一所有api接口为一个自定义密钥
使用nginx,示例配置如下
server { listen 80; server_name example.com; #开启openai接口的gzip压缩,大量重复文本的压缩率高,节省服务端流量 gzip on; gzip_min_length 1k; gzip_types text/event-stream; #统一所有api接口为一个自定义密钥 set $custom_key "sk-12345678"; set $openai_key "sk-xxxxxx"; set $deepseek_key "sk-xxxxxx"; set $gemini_key "xxx-xxx"; set $claude_key "sk-ant-xxx"; #DeepSeek, 网页端需单独设置DeepSeek接口为deepseek location ^~ /deepseek { if ($http_authorization != "Bearer ${custom_key}") { return 401; } proxy_pass https://api.deepseek.com/; proxy_set_header Host api.deepseek.com; proxy_ssl_name api.deepseek.com; proxy_ssl_server_name on; proxy_set_header Authorization "Bearer ${deepseek_key}"; proxy_buffering off; } #Gemini location ^~ /v1/models { if ($arg_key != $custom_key) { return 401; } proxy_pass https://generativelanguage.googleapis.com$uri?alt=sse&key=$gemini_key; proxy_buffering off; } #Claude location ^~ /v1/messages { if ($http_x_api_key != $custom_key) { return 401; } proxy_pass https://api.anthropic.com/v1/messages; proxy_set_header Host api.anthropic.com; proxy_ssl_name api.anthropic.com; proxy_ssl_server_name on; proxy_set_header X-Api-Key $claude_key; proxy_buffering off; } #Openai location ^~ /v1 { if ($http_authorization != "Bearer ${custom_key}") { return 401; } proxy_pass https://api.openai.com/v1; proxy_set_header Host api.openai.com; proxy_ssl_name api.openai.com; proxy_ssl_server_name on; proxy_set_header Authorization "Bearer ${openai_key}"; proxy_buffering off; } location / { alias /usr/share/nginx/html/; index index.html; } }如服务器无法正常访问
api.openai.com,可配合socat反代和http代理使用,proxy_pass配置改成proxy_pass https://127.0.0.1:8443/v1;并打开socat
socat TCP4-LISTEN:8443,reuseaddr,fork PROXY:http代理地址:api.openai.com:443,proxyport=http代理端口使用Caddy,可以自动生产HTTPS证书,示例配置如下
yourdomain.example.com { reverse_proxy /v1/* https://api.openai.com { header_up Host api.openai.com header_up Authorization "{http.request.header.Authorization}" header_up Authorization "Bearer sk-your-token" } file_server / { root /var/wwwroot/chatgpt-web index index.html } }Caddy 2.6.5及之后版本支持https_proxy和http_proxy环境变量,如服务器无法正常访问
api.openai.com,可先设置代理环境变量
环境变量
OpenAI接口和密钥可以单独在环境变量文件中配置。
新建环境变量文件env.js到index.html同目录下,示例如下。
envAPIEndpoint="https://api.openai.com/"
envAPIKey="sk-your-token"
PWA应用
部署文件icon.png,manifest.json,sw.js到index.html同目录下,即可支持PWA应用。
{kind=link}
注意:如果重命名index.html使用,则sw.js文件中./index.html也需修改。
部署PWA应用后,更新html文件需同步更新sw.js,不然无法更新成功。
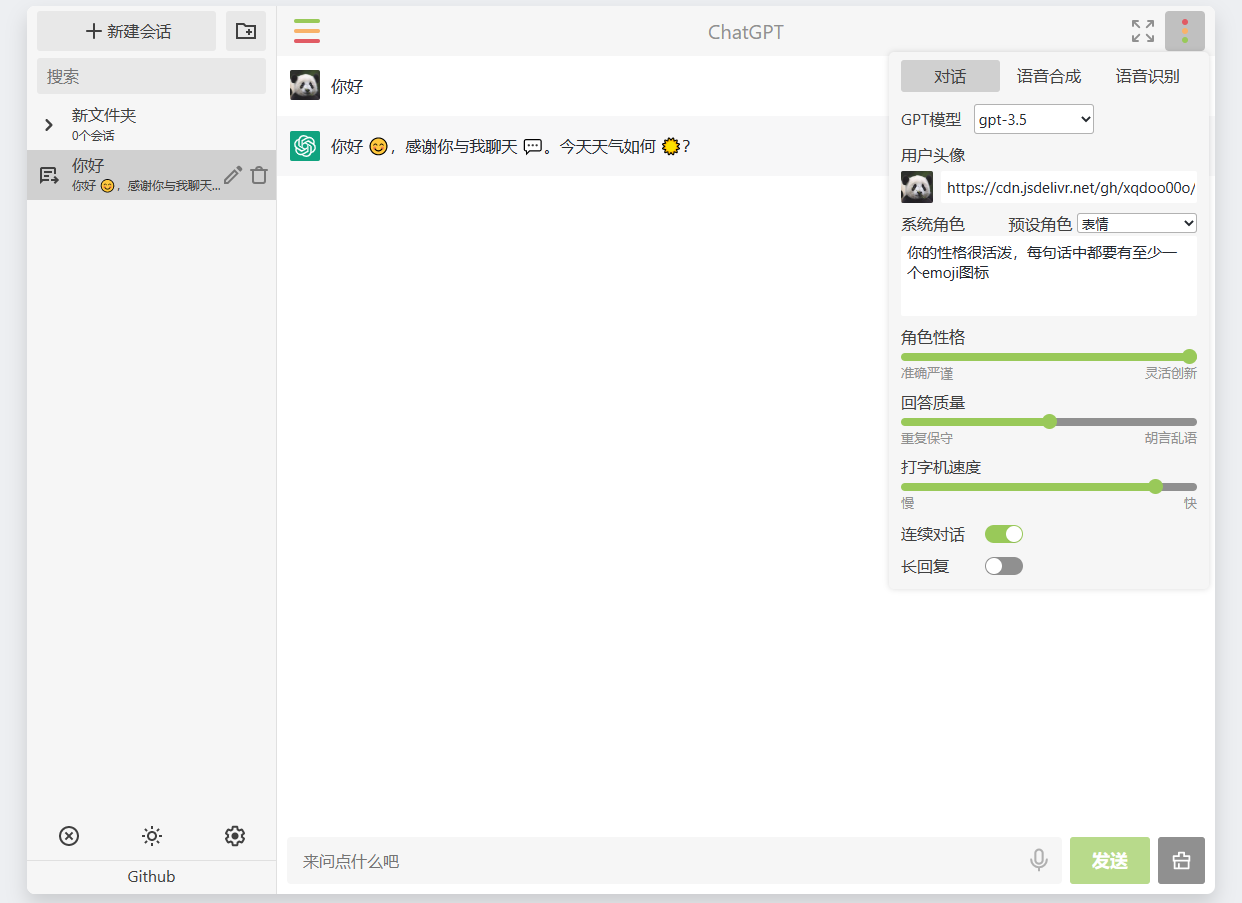
自定义选项
左边栏支持,搜索会话,新建/重命名/删除(会话/文件夹),中英双语,浅色/深色/自动主题模式,导出/导入/重置会话和设置数据,快捷键,显示API额度,显示本地存储。
可选GPT模型,默认gpt-3.5,当前使用gpt-4模型需通过OpenAI的表单申请,或使用ChatGPT-to-API模拟网页ChatGPT为API使用(使用gpt-4需Plus账户)。
可选OpenAI接口地址,使用nginx或caddy部署反代后可以不设置。
可选API密钥,默认不设置,如需网页设置自定义API密钥使用,反代接口最好配置https,公网以http方式明文传输API key极易被中间人截获。
可选用户头像,可修改为任意图片地址。
可选系统角色,默认不开启,有四个预设角色,并动态加载awesome-chatgpt-prompts-zh或awesome-chatgpt-prompts中的角色。
可选角色性格,默认灵活创新,对应接口文档的top_p参数。
可选回答质量,默认平衡,对应接口文档的temperature参数。
修改打字机速度,默认较快,值越大速度越快。
可选连续会话上下文信息限制,默认25条,对话中包含上下文信息,会导致api费用增加。设置为0条则关闭连续会话。
允许长回复,默认关闭,开启后可能导致api费用增加,并丢失全部上下文,对于一些要发送
继续才完整的回复,不用发继续了。选择语音,默认Bing语音,支持Azure语音和系统语音,可分开设置提问语音和回答语音。
音量,默认最大。
语速,默认正常。
音调,默认正常。
全部允许连续朗读,默认开启,连续郎读到所有对话结束。
全部允许自动朗读,默认关闭,自动朗读新的回答。iOS需打开设置-自动播放视频预览,Mac上Safari需打开此网站的设置-允许全部自动播放
支持语音输入,默认识别为普通话,可长按语音按钮修改识别语言选项。语音识别必需条件:使用chrome内核系浏览器 + https网页或本地网页,允许网页的麦克风权限,并已安装麦克风设备。
自动发送关键词,默认为空,识别到关键词后自动发送。
自动停止关键词,默认为空,识别到关键词后自动停止识别。
自动发送延迟时间,默认为0秒,即不自动发送。不为0秒时,表示识别到内容后,自动发送延迟的时间。
保持监听,默认关闭,保持麦克风一直处于监听状态,除非识别报错或手动关闭识别。
加密HTML文件
使用加密网页可加密index.html文件。
密码,打开加密HTML的密码。
是否压缩,默认允许,较大HTML可减少加密后文件体积。
允许记住密码,默认允许,是否允许前端记住密码。
记住密码有效期,默认永不过期,过期后需重新输入密码。
拷贝index.html内容到要加密的HTML文本框,点击生成按钮后,即可下载加密HTML,并替换index.html使用。
注意:该方式仅加密前端HTML,不加密OpenAI反代接口。
可取消OpenAI反代接口的默认API密钥,打开index.html代码,此行结尾添加代码value="sk-xxx",则默认使用该密钥
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。