transdim
transdim 是一款专为交通时空数据设计的机器学习开源工具。面对现实世界中传感器数据常因故障或传输问题而缺失的挑战,transdim 致力于提供精准的数据补全与时空预测解决方案。它不仅能修复随机、非随机及块状等多种模式的缺失数据,还能在数据不完整的情况下依然保持高预测精度。
技术层面,transdim 引入了张量完成框架,核心采用低秩自回归张量完成(LATC)方法,有效捕捉交通流的时间与空间相关性。这使得它在处理复杂的时空任务时表现优异,无论是基础的数据清洗还是高精度的未来交通状态预报,都能胜任。
transdim 基于 Python 开发并遵循 MIT 协议,代码结构清晰,文档完善。它非常适合交通领域的科研人员、算法工程师以及需要处理大规模时空数据的开发者使用。借助 transdim,团队可以更高效地构建鲁棒的智能交通系统,无需从零开始搭建复杂的数据预处理流程。
使用场景
某市智慧交通运营中心的数据团队负责监控全市主干道流量,但在设备维护期间常面临传感器数据大面积丢失的问题。
没有 transdim 时
- 传感器网络不稳定导致时间序列出现大量随机空洞,简单的线性插值无法还原真实的拥堵突变。
- 遇到连续数小时断网的“块状缺失”时,传统算法直接报错,导致早高峰预测任务完全中断。
- 因数据不全强行训练模型,使得神经网络过拟合噪声,预测结果与实际路况偏差超过 30%。
- 运维人员需手动清洗数据,耗费大量人力且难以保证多源异构数据的时空一致性。
使用 transdim 后
- transdim 基于低秩张量补全框架,能自动识别并修复随机、非随机及块状等多种缺失模式。
- 即使部分路段传感器持续离线,系统也能利用周边路网的空间相关性精准还原缺失时刻的车流状态。
- 内置的预测器支持在观测值不完整的情况下直接输出未来短时流量趋势,无需先完美补全再预测。
- 大幅降低了人工干预成本,将数据可用性从不足 70% 提升至接近 100%,保障了信号调控的实时性。
transdim 通过解决时空数据缺失难题,让残缺的交通监测数据具备了高可用的预测能力。
运行环境要求
- 未说明
未说明
未说明

快速开始
transdim
![]()
![]()


由陈新宇制作 • :globe_with_meridians: https://xinychen.github.io
![]()
Transportation data imputation(即 transdim,交通数据补全)。
机器学习模型在时空数据(spatiotemporal data)建模领域取得了重要进展——例如如何预测路网近期的交通状态。但是,当这些模型建立在从现实世界系统(如交通系统)中普遍收集的不完整数据之上时,会发生什么呢?
目录
关于本项目
在 transdim 项目中,我们开发机器学习模型以帮助解决时空数据建模的一些最严峻挑战——从缺失数据补全(missing data imputation)到时间序列预测(time series prediction)。本项目的战略目标是为时空交通数据补全和预测任务创建准确且高效的解决方案。
赶时间吗?请查看以下内容。
任务与挑战
缺失数据就在那里,无论我们是否喜欢它们。真正有趣的问题是如何处理不完整的数据。
![]()
图 1: 时空设置下的两种经典缺失模式。
我们在真实世界数据上创建了三种缺失数据机制。
缺失数据补全 🔥
- 随机缺失 (Random Missing, RM): 每个传感器完全随机地丢失观测值。(★★★)
- 非随机缺失 (Non-random Missing, NM): 每个传感器在几天内丢失观测值。(★★★★)
- 阻断缺失 (Blockout Missing, BM): 所有传感器在几个连续时间点丢失观测值。(★★★★)
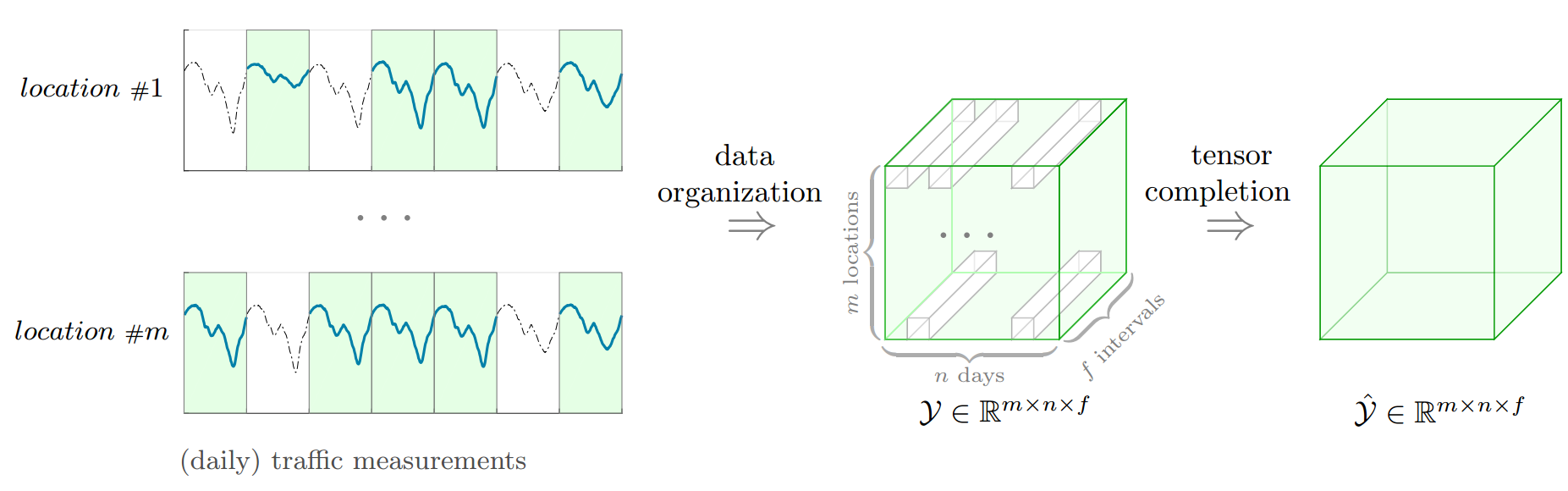
图 2: 用于时空缺失交通数据补全的张量补全(Tensor Completion)框架。
- 时空预测 🔥
- 无缺失值预测。(★★★)
- 基于不完整观测值的预测。(★★★★★)
![]()
图 3: 我们提出的低秩自回归张量补全(Low-Rank Autoregressive Tensor Completion, LATC)补全器/预测器的示意图(绿色节点:观测值;白色节点:缺失值;红色节点/面板:预测;蓝色面板:用于构建张量的训练数据)。
实现
公开数据
在本项目中,我们将一些公开可用的数据集适配到了我们的实验中。这些数据的原始链接总结如下,
- 多元时间序列 (Multivariate time series)
- 伯明翰停车数据集
- 加州 PeMS 交通速度数据集 (大规模)
- 广州城市交通速度数据集
- 杭州地铁客流数据集
- 伦敦城市移动速度数据集 (其他城市的数据也可在 Uber Movement 项目 获取)
- 波特兰高速公路交通数据集 (包括交通流量/速度/占有率,参见 数据文档)
- 西雅图高速公路交通速度数据集
- 多维时间序列 (Multidimensional time series)
例如,如果您想查看或使用这些数据集,请提前在 ../datasets/ 文件夹中下载它们,然后在您的 Python 控制台中运行以下代码:
import scipy.io
tensor = scipy.io.loadmat('../datasets/Guangzhou-data-set/tensor.mat')
tensor = tensor['tensor']
特别是,如果您对大规模交通数据感兴趣,我们推荐 PeMS-4W/8W/12W 和 UTD19。对于 PeMS 数据,您可以从 Zenodo 下载数据并将其放置在 datasets 文件夹中(数据路径示例:../datasets/California-data-set/pems-4w.csv)。然后您可以使用 Pandas 打开数据:
import pandas as pd
data = pd.read_csv('../datasets/California-data-set/pems-4w.csv', header = None)
对于模型评估,我们将“观测”数据中的某些条目掩码为缺失值,然后对这些“缺失”值执行补全操作。
模型实现
在我们的实验中,我们主要在 Numpy 上实现了一些机器学习模型,并使用 Jupyter Notebook 编写了这些 Python 代码。如果您想评估这些模型,请直接下载并运行这些笔记本(前提:提前下载数据集)。在下方的实现中,我们在可读性和效率方面改进了 Python 代码(在 Jupyter Notebook 中)。
我们提出的模型以粗体显示。
- imputer(插补模型)
| Notebook | 广州 | 伯明翰 | 杭州 | 西雅图 | 伦敦 | 纽约 | 太平洋 |
|---|---|---|---|---|---|---|---|
| BPMF | ✅ | ✅ | ✅ | ✅ | ✅ | 🔶 | 🔶 |
| TRMF | ✅ | 🔶 | ✅ | ✅ | ✅ | 🔶 | 🔶 |
| BTRMF | ✅ | 🔶 | ✅ | ✅ | ✅ | 🔶 | 🔶 |
| BTMF | ✅ | ✅ | ✅ | ✅ | ✅ | 🔶 | 🔶 |
| BGCP | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| BATF | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| BTTF | 🔶 | 🔶 | 🔶 | 🔶 | 🔶 | ✅ | ✅ |
| HaLRTC | ✅ | 🔶 | ✅ | ✅ | ✅ | ✅ | ✅ |
| LRTC-TNN | ✅ | 🔶 | ✅ | ✅ | 🔶 | 🔶 | 🔶 |
- predictor(预测模型)
| Notebook | 广州 | 伯明翰 | 杭州 | 西雅图 | 伦敦 | 纽约 | 太平洋 |
|---|---|---|---|---|---|---|---|
| TRMF | ✅ | 🔶 | ✅ | ✅ | ✅ | 🔶 | 🔶 |
| BTRMF | ✅ | 🔶 | ✅ | ✅ | ✅ | 🔶 | 🔶 |
| BTRTF | 🔶 | 🔶 | 🔶 | 🔶 | 🔶 | ✅ | ✅ |
| BTMF | ✅ | 🔶 | ✅ | ✅ | ✅ | ✅ | ✅ |
| BTTF | 🔶 | 🔶 | 🔶 | 🔶 | 🔶 | ✅ | ✅ |
- ✅ — 覆盖
- 🔶 — 未覆盖
- 🚧 — 开发中
对于这些模型的实现,我们同时使用
dense_mat(稠密矩阵)和sparse_mat(稀疏矩阵)(或dense_tensor(稠密张量)和sparse_tensor(稀疏张量))作为输入。但是,如果您不希望看到迭代过程中的插补/预测性能,则无需如此操作,您可以从这些算法的输入中移除dense_mat(或dense_tensor)。
插补/预测性能
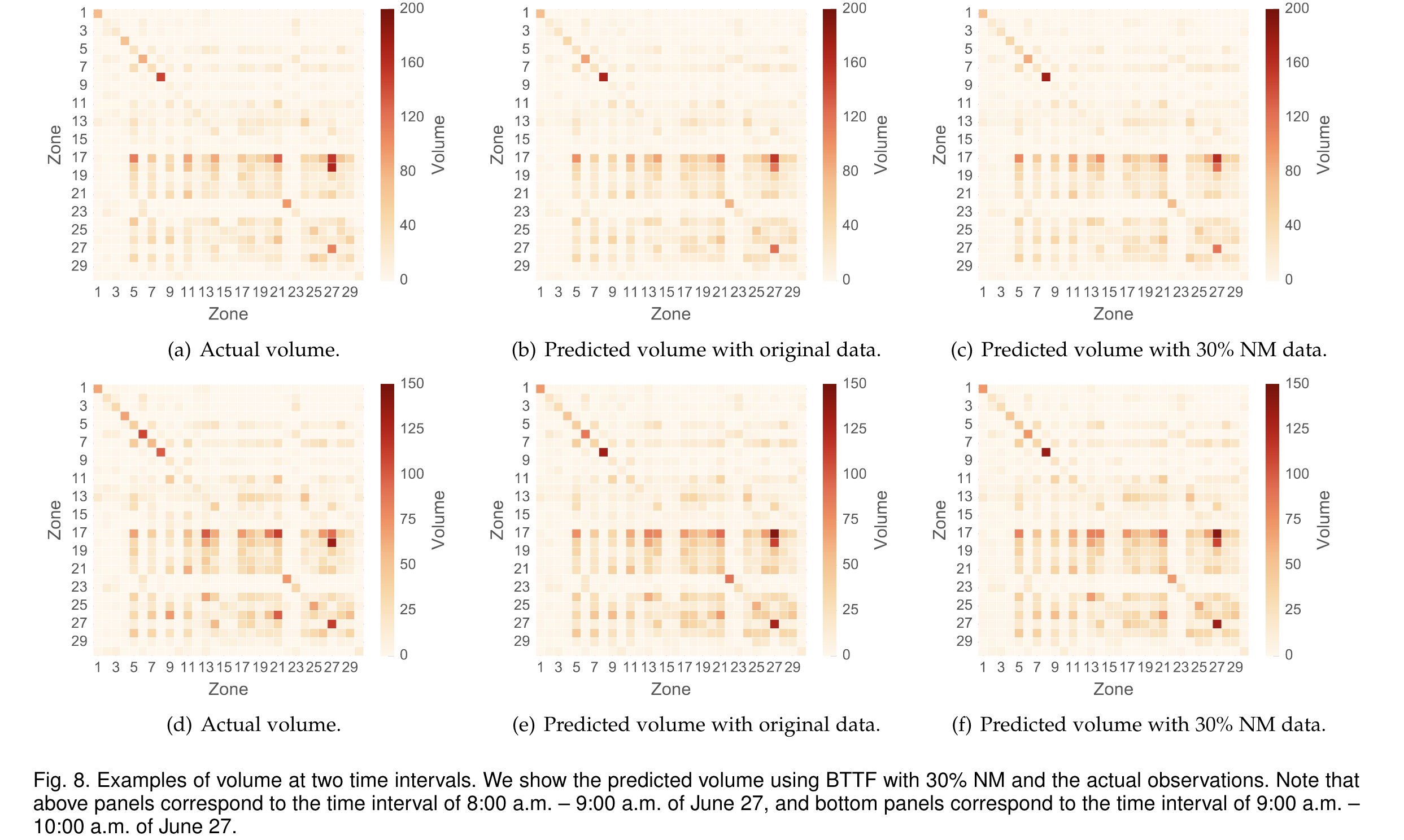
- 插补示例(基于广州数据)
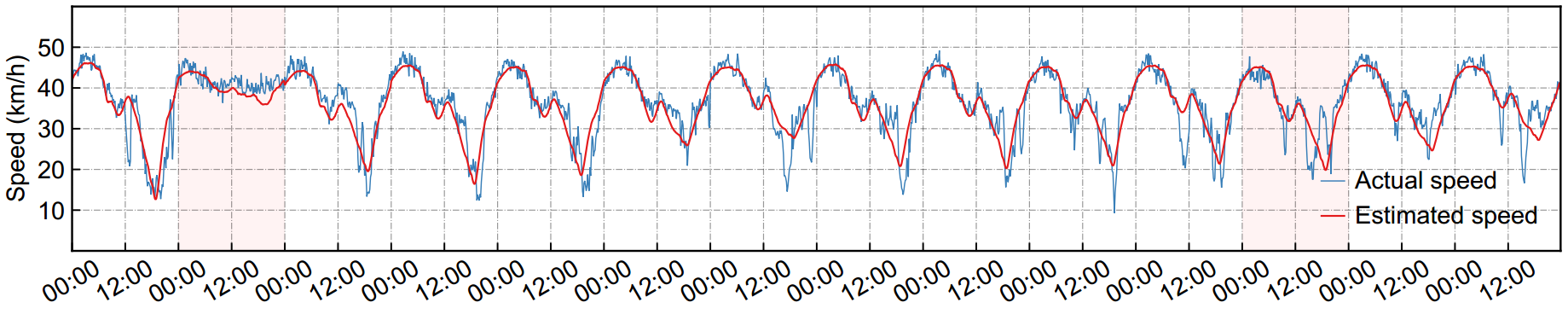 (a) 8 月 1 日至 14 日两周内实际与估计速度的时间序列。
(a) 8 月 1 日至 14 日两周内实际与估计速度的时间序列。
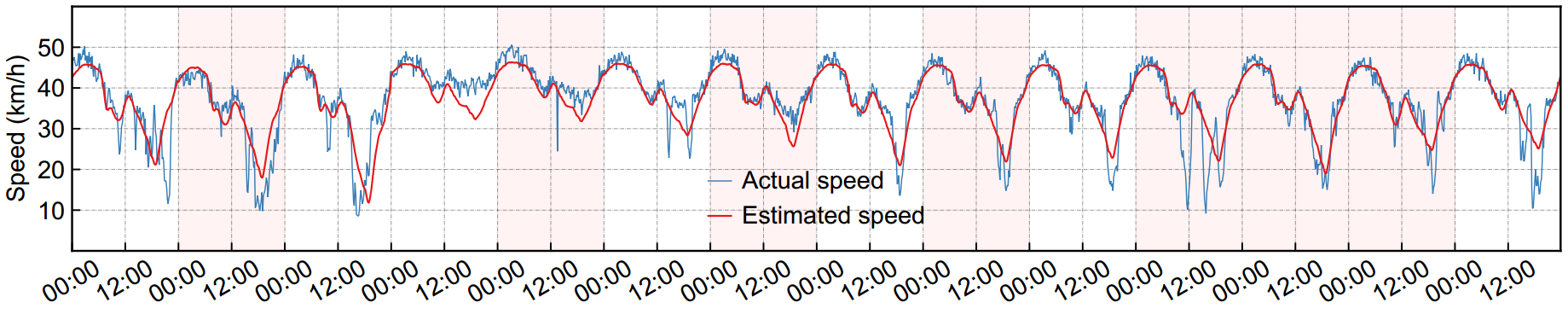 (b) 9 月 12 日至 25 日两周内实际与估计速度的时间序列。
(b) 9 月 12 日至 25 日两周内实际与估计速度的时间序列。
BGCP 的插补性能(CP rank r=15 且缺失率α=30%),在三阶张量表示下的纤维缺失场景中,选取路段 #1 的估计结果作为示例。在这两个面板中,红色矩形代表纤维缺失(即全天速度观测值丢失)。
- 预测示例

快速开始
这是一个低秩张量补全与截断核范数最小化 (LRTC-TNN) 的插补示例。值得注意的是,与我们论文中的复杂公式不同,我们的 Python 实现非常容易使用。
- 首先,导入一些必要的包:
import numpy as np
from numpy.linalg import inv as inv
- 使用
Numpy定义张量展开 (ten2mat) 和矩阵折叠 (mat2ten) 算子:
def ten2mat(tensor, mode):
return np.reshape(np.moveaxis(tensor, mode, 0), (tensor.shape[mode], -1), order = 'F')
def mat2ten(mat, tensor_size, mode):
index = list()
index.append(mode)
for i in range(tensor_size.shape[0]):
if i != mode:
index.append(i)
return np.moveaxis(np.reshape(mat, list(tensor_size[index]), order = 'F'), 0, mode)
- 为截断核范数 (TNN) 最小化定义奇异值阈值处理 (SVT):
def svt_tnn(mat, tau, theta):
[m, n] = mat.shape
if 2 * m < n:
u, s, v = np.linalg.svd(mat @ mat.T, full_matrices = 0)
s = np.sqrt(s)
idx = np.sum(s > tau)
mid = np.zeros(idx)
mid[:theta] = 1
mid[theta:idx] = (s[theta:idx] - tau) / s[theta:idx]
return (u[:,:idx] @ np.diag(mid)) @ (u[:,:idx].T @ mat)
elif m > 2 * n:
return svt_tnn(mat.T, tau, theta).T
u, s, v = np.linalg.svd(mat, full_matrices = 0)
idx = np.sum(s > tau)
vec = s[:idx].copy()
vec[theta:] = s[theta:] - tau
return u[:,:idx] @ np.diag(vec) @ v[:idx,:]
- 定义性能指标(即 RMSE, MAPE):
def compute_rmse(var, var_hat):
return np.sqrt(np.sum((var - var_hat) ** 2) / var.shape[0])
def compute_mape(var, var_hat):
return np.sum(np.abs(var - var_hat) / var) / var.shape[0]
- 定义 LRTC-TNN:
def LRTC(dense_tensor, sparse_tensor, alpha, rho, theta, epsilon, maxiter):
"""Low-Rank Tensor Completion with Truncated Nuclear Norm, LRTC-TNN."""
dim = np.array(sparse_tensor.shape)
pos_missing = np.where(sparse_tensor == 0)
pos_test = np.where((dense_tensor != 0) & (sparse_tensor == 0))
dense_test = dense_tensor[pos_test]
del dense_tensor
X = np.zeros(np.insert(dim, 0, len(dim))) # \boldsymbol{\mathcal{X}}
T = np.zeros(np.insert(dim, 0, len(dim))) # \boldsymbol{\mathcal{T}}
Z = sparse_tensor.copy()
last_tensor = sparse_tensor.copy()
snorm = np.sqrt(np.sum(sparse_tensor ** 2))
it = 0
while True:
rho = min(rho * 1.05, 1e5)
for k in range(len(dim)):
X[k] = mat2ten(svt_tnn(ten2mat(Z - T[k] / rho, k), alpha[k] / rho, int(np.ceil(theta * dim[k]))), dim, k)
Z[pos_missing] = np.mean(X + T / rho, axis = 0)[pos_missing]
T = T + rho * (X - np.broadcast_to(Z, np.insert(dim, 0, len(dim))))
tensor_hat = np.einsum('k, kmnt -> mnt', alpha, X)
tol = np.sqrt(np.sum((tensor_hat - last_tensor) ** 2)) / snorm
last_tensor = tensor_hat.copy()
it += 1
if (it + 1) % 50 == 0:
print('Iter: {}'.format(it + 1))
print('MAPE: {:.6}'.format(compute_mape(dense_test, tensor_hat[pos_test])))
print('RMSE: {:.6}'.format(compute_rmse(dense_test, tensor_hat[pos_test])))
print()
if (tol < epsilon) or (it >= maxiter):
break
print('Imputation MAPE: {:.6}'.format(compute_mape(dense_test, tensor_hat[pos_test])))
print('Imputation RMSE: {:.6}'.format(compute_rmse(dense_test, tensor_hat[pos_test])))
print()
return tensor_hat
- 让我们尝试在广州城市交通速度数据集上运行:
import scipy.io
import scipy.io
import numpy as np
np.random.seed(1000)
dense_tensor = scipy.io.loadmat('../datasets/Guangzhou-data-set/tensor.mat')['tensor']
dim = dense_tensor.shape
missing_rate = 0.2 # Random missing (RM)
sparse_tensor = dense_tensor * np.round(np.random.rand(dim[0], dim[1], dim[2]) + 0.5 - missing_rate)
- 运行补全 (Imputation) 实验:
import time
start = time.time()
alpha = np.ones(3) / 3
rho = 1e-5
theta = 0.30
epsilon = 1e-4
maxiter = 200
tensor_hat = LRTC(dense_tensor, sparse_tensor, alpha, rho, theta, epsilon, maxiter)
end = time.time()
print('Running time: %d seconds'%(end - start))
此示例来自 ../imputer/LRTC-TNN.ipynb,您可以查看该 Jupyter Notebook 以获取详细信息。
Documentation
- 随机奇异值分解的直观理解 (Intuitive Understanding of Randomized Singular Value Decomposition). 2020 年 7 月 1 日。
- Matlab 和 Numpy 中生成随机数和数组 (Generating Random Numbers and Arrays in Matlab and Numpy). 2021 年 10 月 9 日。
- 用于高维时间序列预测的低秩向量自回归模型 (Reduced-Rank Vector Autoregressive Model for High-Dimensional Time Series Forecasting). 2021 年 10 月 16 日。
- 西雅图高速公路时空交通速度时间序列的动态模态分解 (Dynamic Mode Decomposition for Spatiotemporal Traffic Speed Time Series in Seattle Freeway). 2021 年 10 月 29 日。
- 分析 Uber 移动速度数据中的缺失数据问题 (Analyzing Missing Data Problem in Uber Movement Speed Data). 2022 年 2 月 14 日。
- 使用共轭梯度法求解矩阵方程 (Using Conjugate Gradient to Solve Matrix Equations). 2022 年 2 月 23 日。
- 使用张量分解进行流体动力学修复 (NumPy) (Inpainting Fluid Dynamics with Tensor Decomposition (NumPy)). 2022 年 3 月 15 日。
- 用于多元时间序列预测的时间矩阵分解 (Temporal Matrix Factorization for Multivariate Time Series Forecasting). 2022 年 3 月 20 日。
- 使用非平稳时间矩阵分解预测多元时间序列 (Forecasting Multivariate Time Series with Nonstationary Temporal Matrix Factorization). 2022 年 4 月 25 日。
- 使用 NumPy 实现克罗内克积分解 (Implementing Kronecker Product Decomposition with NumPy). 2022 年 6 月 20 日。
- 张量自回归:一种多维时间序列模型 (Tensor Autoregression: A Multidimensional Time Series Model). 2022 年 9 月 3 日。
- 在 Python 中复现流体流动数据的动态模态分解 (Reproducing Dynamic Mode Decomposition on Fluid Flow Data in Python). 2022 年 9 月 6 日。
- 用于时间序列建模的卷积核范数最小化 (Convolution Nuclear Norm Minimization for Time Series Modeling). 2022 年 10 月 3 日。
- 强化矩阵因子化用于时间序列建模:概率顺序矩阵因子化 (Reinforce Matrix Factorization for Time Series Modeling: Probabilistic Sequential Matrix Factorization). 2022 年 10 月 5 日。
- 离散卷积和快速傅里叶变换逐步解释与实现 (Discrete Convolution and Fast Fourier Transform Explained and Implemented Step by Step). 2022 年 10 月 19 日。
- Python 中用于图像修复的矩阵因子化 (Matrix Factorization for Image Inpainting in Python). 2022 年 12 月 8 日。
- Python 中用于图像修复的循环矩阵核范数最小化 (Circulant Matrix Nuclear Norm Minimization for Image Inpainting in Python). 2022 年 12 月 9 日。
- 用于时间序列补全和图像修复的低秩拉普拉斯卷积模型 (Low-Rank Laplacian Convolution Model for Time Series Imputation and Image Inpainting). 2022 年 12 月 10 日。
- 用于彩色图像修复的低秩拉普拉斯卷积模型 (Low-Rank Laplacian Convolution Model for Color Image Inpainting). 2022 年 12 月 17 日。
- 机器学习张量的直观理解 (Intuitive Understanding of Tensors in Machine Learning). 2023 年 1 月 20 日。
- 用于速度场重建的低秩矩阵和张量因子化 (Low-Rank Matrix and Tensor Factorization for Speed Field Reconstruction). 2023 年 3 月 9 日。
- 贝叶斯向量自回归预测 (Bayesian Vector Autoregression Forecasting)
- 结构化低秩矩阵补全 (Structured Low-Rank Matrix Completion)
Publications
Xinyu Chen, Zhanhong Cheng, HanQin Cai, Nicolas Saunier, Lijun Sun (2024). 用于交通时间序列补全的拉普拉斯卷积表示 (Laplacian Convolutional Representation for Traffic Time Series Imputation). IEEE Transactions on Knowledge and Data Engineering. 36 (11): 6490-6502. [DOI] [幻灯片] [数据与 Python 代码]
Xinyu Chen, Lijun Sun (2022). 用于多维时间序列预测的贝叶斯时间因子分解。IEEE 模式分析与机器智能汇刊,44 (9): 4659-4673。[预印本] [DOI] [演示文稿] [数据与 Python 代码]
Xinyu Chen, Mengying Lei, Nicolas Saunier, Lijun Sun (2022). 用于时空交通数据填补的低秩自回归张量补全。IEEE 智能交通系统汇刊,23 (8): 12301-12310。[预印本] [DOI] [数据与 Python 代码] (亦被 KDD 2021 的 MiLeTS 研讨会 部分接收,参见 研讨会论文)
Xinyu Chen, Yixian Chen, Nicolas Saunier, Lijun Sun (2021). 用于时空交通数据填补的可扩展低秩张量学习。交通运输研究 C 辑:新兴技术,129: 103226。[预印本] [DOI] [数据] [Python 代码]
Xinyu Chen, Jinming Yang, Lijun Sun (2020). 用于时空交通数据填补的非凸低秩张量补全模型。交通运输研究 C 辑:新兴技术,117: 102673。[预印本] [DOI] [数据与 Python 代码]
Xinyu Chen, Zhaocheng He, Yixian Chen, Yuhuan Lu, Jiawei Wang (2019). 基于贝叶斯增强张量因子分解模型的缺失交通数据填补与模式发现。交通运输研究 C 辑:新兴技术,104: 66-77。[DOI] [演示文稿] [数据] [Matlab 代码] [Python 代码]
Xinyu Chen, Zhaocheng He, Lijun Sun (2019). 一种用于时空交通数据填补的贝叶斯张量分解方法。交通运输研究 C 辑:新兴技术,98: 73-84。[预印本] [DOI] [数据] [Matlab 代码] [Python 代码]
Xinyu Chen, Zhaocheng He, Jiawei Wang (2018). 通过 SVD 结合张量分解进行时空交通速度模式发现与不完整数据恢复。交通运输研究 C 辑:新兴技术,86: 59-77。[DOI] [数据]
本项目源自上述论文,如果它们对您的研究有帮助,请引用这些论文。
合作者
 Xinyu Chen 💻 |
 Jinming Yang 💻 |
 Yixian Chen 💻 |
 Mengying Lei 💻 |
- 指导委员会
 Lijun Sun 💻 |
 Nicolas Saunier 💻 |
查看参与本项目的 贡献者 列表。
支持单位


许可证
本作品采用 MIT 许可证发布。
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。