DeepMimic
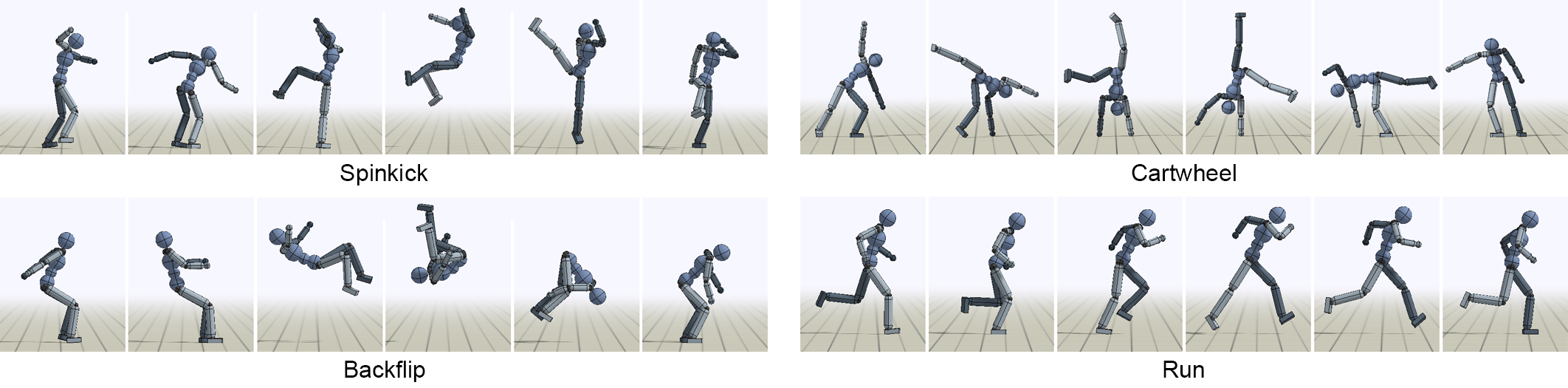
DeepMimic 是一个基于深度强化学习的开源框架,旨在让虚拟角色在物理仿真环境中精准模仿真实的人类动作。它主要解决了传统动画技术中动作僵硬、缺乏物理真实感以及难以适应复杂交互环境的难题。通过输入动作捕捉(MoCap)数据,DeepMimic 能训练出具备高度平衡感和协调性的智能体,使其不仅能复现后空翻、踢腿等高难度技巧,还能在受到外力干扰时自动调整姿态以防摔倒。
该项目的核心技术亮点在于将示例引导的深度强化学习与物理引擎紧密结合,并衍生出了对抗性运动先验(AMP)等先进方法,实现了风格化且鲁棒的角色控制。需要注意的是,原始代码库目前已标记为弃用,官方推荐开发者转向其继任项目 MimicKit 以获得更高效、易用的实现版本。
DeepMimic 非常适合从事计算机图形学、机器人控制算法研究的研究人员,以及需要开发高保真物理角色动画的游戏开发者或工程师使用。由于涉及复杂的 C++ 环境配置、依赖项编译及强化学习模型训练,它要求使用者具备较强的编程基础和算法背景,并不适合普通终端用户直接操作。
使用场景
某游戏工作室的动作程序员正致力于为一款写实风格格斗游戏开发高难度的空中连招,需要角色在保持物理平衡的同时精准复现专业武术家的动作捕捉数据。
没有 DeepMimic 时
- 动作僵硬失真:传统逆向运动学(IK)难以处理高速旋转踢腿等复杂动态,导致角色脚部滑步或肢体穿透地面,缺乏真实打击感。
- 平衡控制困难:手动编写维持平衡的物理反馈代码耗时极长,角色在执行大幅度过招时极易摔倒,需反复微调参数。
- 开发效率低下:每新增一个招式都需要美术与程序紧密配合进行长达数周的手工调优,无法快速迭代大量技能库。
- 物理交互割裂:预设动画无法实时响应环境碰撞,角色被击中或在崎岖地形移动时,动作显得像“播放录像”而非物理模拟。
使用 DeepMimic 后
- 动作自然流畅:利用深度强化学习,角色能完美复刻动作捕捉中的高难度旋踢,自动解决脚部滑步问题,动作具备真实的惯性质感。
- 自适应平衡:模型在训练中学会了物理平衡策略,即使受到外力干扰或处于单脚着地状态,也能自动调整姿态避免摔倒。
- 自动化技能生成:只需导入新的动作捕捉片段作为参考,DeepMimic 即可自动训练出对应的控制策略,将新招式开发周期从数周缩短至数小时。
- 动态物理响应:生成的技能基于物理引擎运行,角色能根据实时碰撞和地形变化动态调整动作细节,实现真正的“活”的角色控制。
DeepMimic 通过将动作捕捉数据与物理仿真深度融合,让虚拟角色在拥有电影级动作表现力的同时,具备了适应复杂环境的真实物理智能。
运行环境要求
- Linux
- Windows
未说明 (依赖 OpenGL >= 3.2 进行渲染,深度学习框架为 TensorFlow 1.13.1,通常建议 NVIDIA GPU 但未明确指定型号或 CUDA 版本)
未说明
快速开始
简介
此代码库现已弃用。 请查看 MimicKit,其中包含了我们方法的更快速且易于使用的实现。
以下论文配套的代码:
“DeepMimic:基于示例引导的物理角色技能深度强化学习”
(https://xbpeng.github.io/projects/DeepMimic/index.html) 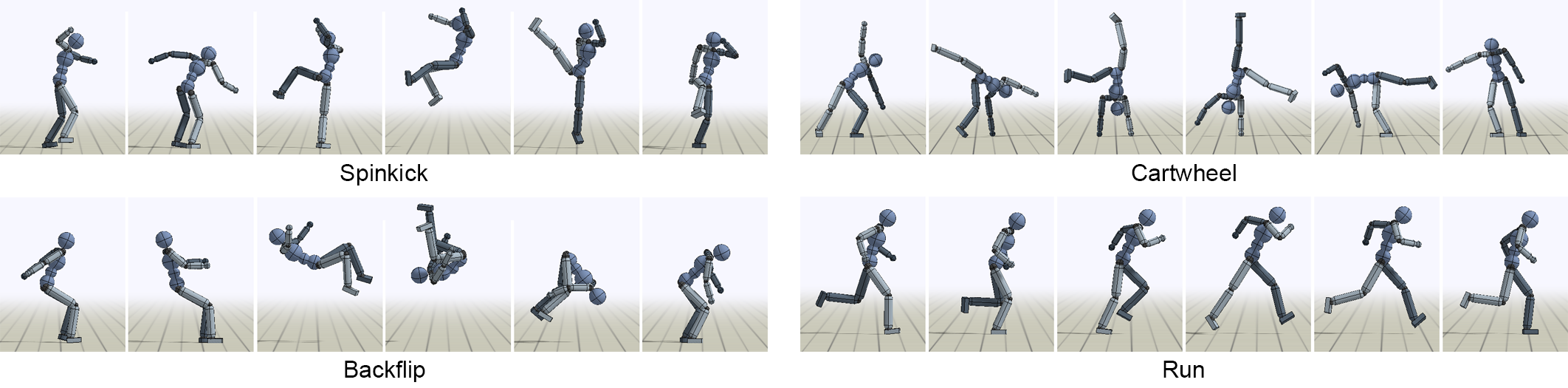
“AMP:用于风格化物理角色控制的对抗性运动先验”
(https://xbpeng.github.io/projects/AMP/index.html) 
该框架使用强化学习训练一个模拟人形角色,以模仿来自动作捕捉数据的各种运动技能。
依赖项
sudo apt install libgl1-mesa-dev libx11-dev libxrandr-dev libxi-dev
sudo apt install mesa-utils
sudo apt install clang
sudo apt install cmake
C++:
Bullet 2.88 (https://github.com/bulletphysics/bullet3/releases)
从上述链接下载 Bullet 2.88,并使用以下命令进行安装。
./build_cmake_pybullet_double.shcd build_cmakesudo make installEigen (http://www.eigen.tuxfamily.org/index.php?title=Main_Page)(版本:3.3.7)
mkdir build && cd buildcmake ..sudo make installOpenGL ≥ 3.2
freeglut (http://freeglut.sourceforge.net/)(版本:3.0.0)
cmake .makesudo make installglew (http://glew.sourceforge.net/)(版本:2.1.0)
makesudo make installmake clean
其他:
SWIG (http://www.swig.org/)(版本:4.0.0)
./configure --without-pcremakesudo make installMPI
- Windows:https://docs.microsoft.com/en-us/message-passing-interface/microsoft-mpi
- Linux:
sudo apt install libopenmpi-dev
Python:
- Python 3
- PyOpenGL (http://pyopengl.sourceforge.net/)
pip install PyOpenGL PyOpenGL_accelerate
- Tensorflow (https://www.tensorflow.org/)(版本:1.13.1)
pip install tensorflow
pip install mpi4py
构建
模拟环境是用 C++ 编写的,Python 封装器则是使用 SWIG 构建的。
请注意,在安装 MPI4Py 之前必须先安装 MPI。在构建 Bullet 时,请务必通过编译标志 USE_DOUBLE_PRECISION=OFF 禁用双精度计算。
Windows
封装器使用 DeepMimicCore.sln 进行构建。
在配置管理器中选择
x64配置。在
DeepMimicCore项目的属性中,修改Additional Include Directories以指定:- Bullet 源代码目录
- Eigen 头文件目录
- Python 头文件目录
修改
Additional Library Directories以指定:- Bullet 库目录
- Python 库目录
使用
Release_Swig配置构建DeepMimicCore项目,这将生成DeepMimicCore.py文件,位于DeepMimicCore/目录下。
Linux
修改
DeepMimicCore/中的Makefile,指定以下内容:EIGEN_DIR:Eigen 头文件目录BULLET_INC_DIR:Bullet 源代码目录PYTHON_INC:Python 头文件目录PYTHON_LIB:Python 库目录
构建封装器,
make python
这将生成 DeepMimicCore.py 文件,位于 DeepMimicCore/ 目录下。
使用方法
一旦 Python 封装器构建完成,训练完全在 Python 中使用 Tensorflow 进行。
DeepMimic.py 运行用于查看模拟的可视化工具。训练则使用 mpi_run.py,它利用 MPI 在多个进程之间并行化训练。
运行 DeepMimic.py 时,需指定一个参数文件,该文件提供场景的配置信息。例如,
python DeepMimic.py --arg_file args/run_humanoid3d_spinkick_args.txt
将运行一个预先训练好的旋转踢腿策略。类似地,
python DeepMimic.py --arg_file args/play_motion_humanoid3d_args.txt
将加载并播放一段动作捕捉片段。要运行一个模拟狗的预训练策略,可使用以下命令:
python DeepMimic.py --arg_file args/run_dog3d_pace_args.txt
要训练一个策略,可以使用 mpi_run.py,指定参数文件和工作进程的数量。例如,
python mpi_run.py --arg_file args/train_humanoid3d_spinkick_args.txt --num_workers 16
将使用 16 个工作进程训练一个执行旋转踢腿的动作策略。随着训练的进行,系统会定期打印统计数据,并将其记录到 output/ 目录中,同时保存最新的策略检查点文件(.ckpt)。通常需要约 6000 万次采样才能训练出一个策略,而在 16 个工作进程的情况下,这可能需要一天时间。16 个工作进程可能是该框架所能支持的最大数量,如果使用过多的工作进程,系统可能会不堪重负。
args/ 目录中已经提供了多种不同技能的参数文件。train_[something]_args.txt 文件用于 mpi_run.py 训练策略,而 run_[something]_args.txt 文件则用于 DeepMimic.py 运行预训练策略。要运行您自己的策略,可以选取其中一个 run_[something]_args.txt 文件,并通过 --model_file 指定您想要运行的策略。请确保参考动作文件 --motion_file 与您的策略所训练的动作相匹配,否则策略将无法正常运行。
同样,要使用 AMP 训练策略,可以使用相应的参数文件运行:
python mpi_run.py --arg_file args/train_amp_target_humanoid3d_locomotion_args.txt --num_workers 16
预训练的 AMP 模型可以通过以下方式评估:
python DeepMimic.py --arg_file args/run_amp_target_humanoid3d_locomotion_args.txt
界面
- 右上角的图表显示价值函数的预测值
- 右键拖动可平移相机
- 左键拖动可在角色的特定位置施加力
- 滚轮可缩放视图
- 按下 'r' 键可重置当前回合
- 按下 'l' 键可重新加载参数文件并重建所有内容
- 按下 'x' 键可向角色投掷随机方块
- 按下空格键可暂停或恢复模拟
- 按下 '>' 键可逐帧推进模拟
动作捕捉数据
动作捕捉片段位于 data/motions/ 目录下。要播放一个片段,首先修改
args/play_motion_humanoid3d_args.txt 文件,并使用 --motion_file 指定要播放的文件,然后运行:
python DeepMimic.py --arg_file args/play_motion_humanoid3d_args.txt
动作文件采用 JSON 格式。"Loop" 字段用于指定该动作是否为循环动作。
"wrap" 表示循环动作会在结束时自动回到起点,而 "none" 则表示非循环动作,会在到达动作末尾时停止。"Frames" 列表中的每个向量代表动作中的一个关键帧。每个关键帧的格式如下:
[
该帧持续时间(秒,1D),
根节点位置(3D),
根节点旋转(4D),
胸部旋转(4D),
颈部旋转(4D),
右髋关节旋转(4D),
右膝关节旋转(1D),
右踝关节旋转(4D),
右肩关节旋转(4D),
右肘关节旋转(1D),
左髋关节旋转(4D),
左膝关节旋转(1D),
左踝关节旋转(4D),
左肩关节旋转(4D),
左肘关节旋转(1D)
]
位置以米为单位,球形关节的 3D 旋转用四元数表示 (w, x, y, z),而转动关节(如膝盖和肘部)的 1D 旋转则用弧度表示的标量值。根节点的位置和旋转使用世界坐标系,其他所有关节的旋转则使用各自局部坐标系。若要使用您自己的动作片段,需将其转换为类似风格的 JSON 文件。
可能的问题及解决方案
ImportError: libGLEW.so.2.1: 无法打开共享对象文件:没有这样的文件或目录
请查找 libGLEW.so.2.1 文件,并根据路径执行以下命令:
ln /path/to/libGLEW.so.2.1 /usr/lib/x86----/libGLEW.so.2.1
ln /path/to/libGLEW.so.2.1.0 /usr/lib/x86----/libGLEW.so.2.1.0
ImportError: libBulletDynamics.so.2.88: 无法打开共享对象文件:没有这样的文件或目录
可临时在终端中运行以下命令设置环境变量:
export LD_LIBRARY_PATH=/usr/local/lib/
(该路径下存在 Bullet 库文件——在安装 Bullet 时执行 sudo make install 命令后会将其安装到该路径)
其他
- 一份兼容 ROS 的人形机器人 URDF 文件可在此获取:https://github.com/EricVoll/amp_motion_conversion
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。