TextGAN-PyTorch
TextGAN-PyTorch 是一个基于 PyTorch 深度学习框架的开源文本生成工具,专门用于实现基于生成对抗网络(GAN)的各种文本生成模型。简单来说,它能帮助计算机学习如何“写”出自然流畅的文字。
这个项目解决了两个主要问题:首先,很多先进的文本生成技术都是用 TensorFlow 实现的,但如果你更熟悉 PyTorch,学习成本会比较高;其次,TextGAN-PyTorch 整合了多种主流的 GAN 文本生成模型(如 SeqGAN、LeakGAN、RelGAN 等),并提供了统一的代码框架,相当于为研究者搭建了一个便捷的实验平台。
TextGAN-PyTorch 特别适合以下用户:机器学习和自然语言处理领域的研究人员、想学习 GAN 文本生成技术的学生、以及需要在项目中快速实验不同文本生成模型的开发者。对于需要生成特定类别文本(如情感文本、新闻文章等)的应用场景,它也提供了专门的类别文本生成模型支持。
技术上,TextGAN-PyTorch 的亮点在于它同时支持通用文本生成和类别感知的文本生成,并且实现了超过 10 种不同的 GAN 变体。此外,项目还提供了完整的数据集和预训练模型,方便用户直接上手实验。如果你想在 PyTorch 生态中开展文本生成相关的研究或应用,这个开源项目是一个不错的起点。
使用场景
某高校 NLP 实验室的研究生小李正在从事文本生成研究,需要复现多篇顶会论文中的 GAN 文本生成模型并进行比较实验。
没有 TextGAN-PyTorch 时
- 小李 发现大多数 GAN 文本生成论文(SeqGAN、LeakGAN、SentiGAN 等)都是用 TensorFlow 实现的,而她习惯使用 PyTorch,需要额外花费数周时间学习 TensorFlow 语法和 API
- 每篇论文的代码实现细节各不相同,小李 需要从零开始手写整个生成器和判别器,光是调试就耗费了数月时间
- 由于各模型代码风格不一致,小李 很难进行公平的对比实验,无法准确评估哪个模型在特定数据集上表现更好
- 安装配置过程繁琐,需要手动安装 KenLM、Boost 等依赖库,且不同模型的环境配置方式差异很大
- 训练过程中缺乏统一的可视化和日志工具,小李 只能自己编写代码来监控生成文本的质量
使用 TextGAN-PyTorch 后
- TextGAN-PyTorch 提供了统一的 PyTorch 实现框架,小李 可以直接用自己熟悉的 PyTorch 代码进行实验,无需切换技术栈
- 框架内置了 10+ 种主流 GAN 文本生成模型的完整实现,下载后只需运行一条命令即可开始训练,如
python3 run_seqgan.py 0 0 - 所有模型使用统一的训练接口和评估指标,小李 可以轻松在 Image COCO、EMNLP NEWS、Movie Review 等数据集上进行公平对比
- 项目提供了详细的依赖安装说明和 requirements.txt,PyTorch >= 1.1.0、nltk、tqdm 等依赖一键安装,KenLM 也有清晰的编译指南
- 内置的 Instructor 类封装了完整的训练流程和可视化功能,小李 可以专注于模型调优而非重复造轮子
TextGAN-PyTorch 大幅降低了 GAN 文本生成模型的研究门槛,让研究者能够快速复现论文结果并进行公平的性能对比。
运行环境要求
- Linux
- macOS
- Windows
需要 NVIDIA GPU,CUDA 7.5+(未说明具体显存要求)
未说明
快速开始
TextGAN-PyTorch
TextGAN 是一个基于 PyTorch 的生成对抗网络(GANs)文本生成模型框架,包括通用文本生成模型和类别文本生成模型。TextGAN 作为基准测试平台,支持基于 GAN 的文本生成模型研究。由于大多数基于 GAN 的文本生成模型都是用 Tensorflow 实现的,TextGAN 可以帮助习惯使用 PyTorch 的研究者更快地进入文本生成领域。
如果您发现我的实现中有任何错误,请告诉我!此外,如果您想添加其他模型,欢迎为此仓库做出贡献。

![]()
依赖环境
- PyTorch >= 1.1.0
- Python 3.6
- Numpy 1.14.5
- CUDA 7.5+ (用于 GPU)
- nltk 3.4
- tqdm 4.32.1
- KenLM (https://github.com/kpu/kenlm)
安装依赖请运行 pip install -r requirements.txt。如遇到 CUDA 问题,请查阅官方 PyTorch 入门指南。
KenLM 安装
下载稳定版本并解压:http://kheafield.com/code/kenlm.tar.gz
需要 Boost >= 1.42.0 和 bjam
- Ubuntu:
sudo apt-get install libboost-all-dev - Mac:
brew install boost; brew install bjam
- Ubuntu:
在 kenlm 目录下运行:
mkdir -p build cd build cmake .. make -j 4pip install https://github.com/kpu/kenlm/archive/master.zip更多信息请查看:https://github.com/kpu/kenlm 和 http://kheafield.com/code/kenlm/
已实现的模型及原始论文
通用文本生成
- SeqGAN - SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
- LeakGAN - Long Text Generation via Adversarial Training with Leaked Information
- MaliGAN - Maximum-Likelihood Augmented Discrete Generative Adversarial Networks
- JSDGAN - Adversarial Discrete Sequence Generation without Explicit Neural Networks as Discriminators
- RelGAN - RelGAN: Relational Generative Adversarial Networks for Text Generation
- DPGAN - DP-GAN: Diversity-Promoting Generative Adversarial Network for Generating Informative and Diversified Text
- DGSAN - DGSAN: Discrete Generative Self-Adversarial Network
- CoT - CoT: Cooperative Training for Generative Modeling of Discrete Data
类别文本生成
- SentiGAN - SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks
- CatGAN (我们的模型) - CatGAN: Category-aware Generative Adversarial Networks with Hierarchical Evolutionary Learning for Category Text Generation
快速开始
- 快速开始
git clone https://github.com/williamSYSU/TextGAN-PyTorch.git
cd TextGAN-PyTorch
- 对于真实数据实验,所有数据集(
Image COCO、EMNLP NEWs、Movie Review、Amazon Review)都可以从这里下载。 - 运行特定模型
cd run
python3 run_[model_name].py 0 0 # 第一个 0 是 job_id,第二个 0 是 gpu_id
# 例如
python3 run_seqgan.py 0 0
功能特性
训练器(Instructor)
对于每个模型,整个运行过程都定义在
instructor/oracle_data/seqgan_instructor.py中(以合成数据实验中的 SeqGAN 为例)。一些基本函数如init_model()和optimize()定义在基类BasicInstructor的instructor.py中。如果您想添加新的基于 GAN 的文本生成模型,请在instructor/oracle_data下创建新的训练器并定义模型的训练过程。可视化(Visualization)
使用
utils/visualization.py可视化日志文件,包括模型损失和评估指标分数。在log_file_list中自定义您的日志文件,数量不超过len(color_list)。日志文件名应去掉.txt后缀。日志记录(Logging)
TextGAN-PyTorch 使用 Python 的
logging模块记录运行过程,如生成器的损失和评估指标分数。为了便于可视化,会有两个相同的日志文件分别保存在log/log_****_****.txt和save/**/log.txt中。此外,代码会自动将模型的状态字典和一批生成器样本保存在./save/**/models和./save/**/samples中(每 log 一步保存一次),其中**取决于您的超参数。运行信号(Running Signal)
您可以使用
Signal类(请参考utils/helpers.py)基于字典文件run_signal.txt轻松控制训练过程。使用
Signal时,只需编辑本地文件run_signal.txt并将pre_sig设置为False(例如),程序将停止预训练并进入下一训练阶段。如果您认为当前训练已经足够,这可以方便地提前停止训练。自动选择 GPU
在
config.py中,程序会自动选择nvidia-smi中 GPU 使用率(GPU-Util)最低的 GPU 设备。此功能默认启用。如果您想手动选择 GPU 设备,请在run_[run_model].py中取消注释--device参数并通过命令指定 GPU 设备。
实现细节
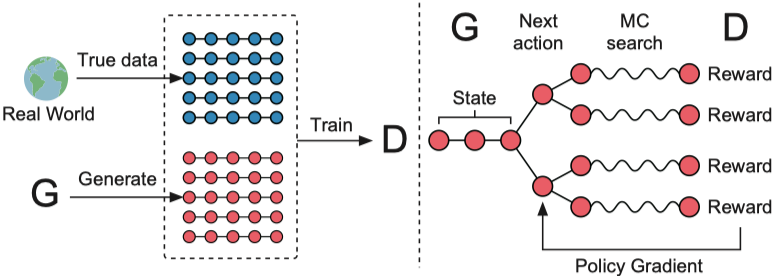
SeqGAN
运行文件:run_seqgan.py
训练器:oracle_data,real_data
结构图(来自 SeqGAN)
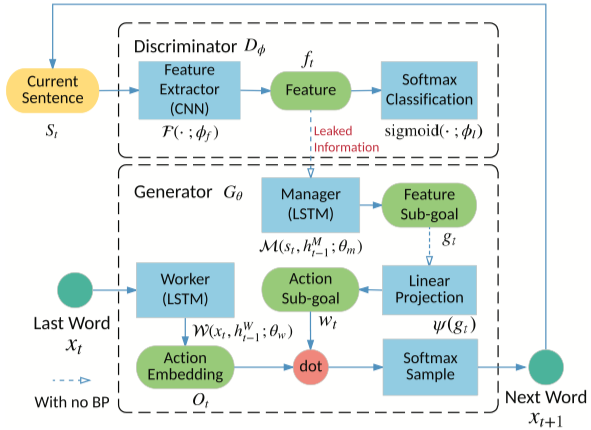
LeakGAN
运行文件:run_leakgan.py
训练器:oracle_data,real_data
结构图(来自 LeakGAN)
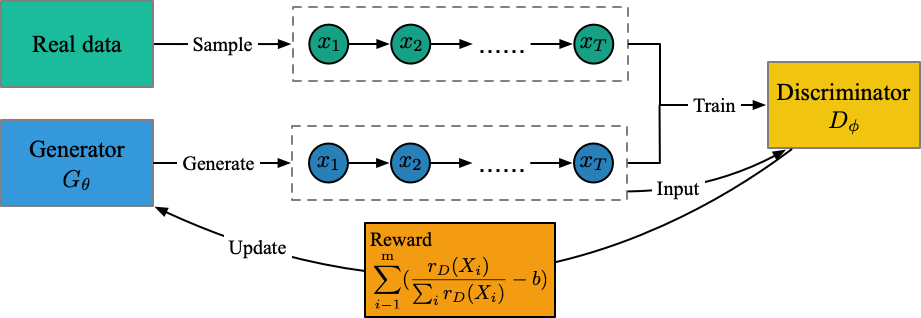
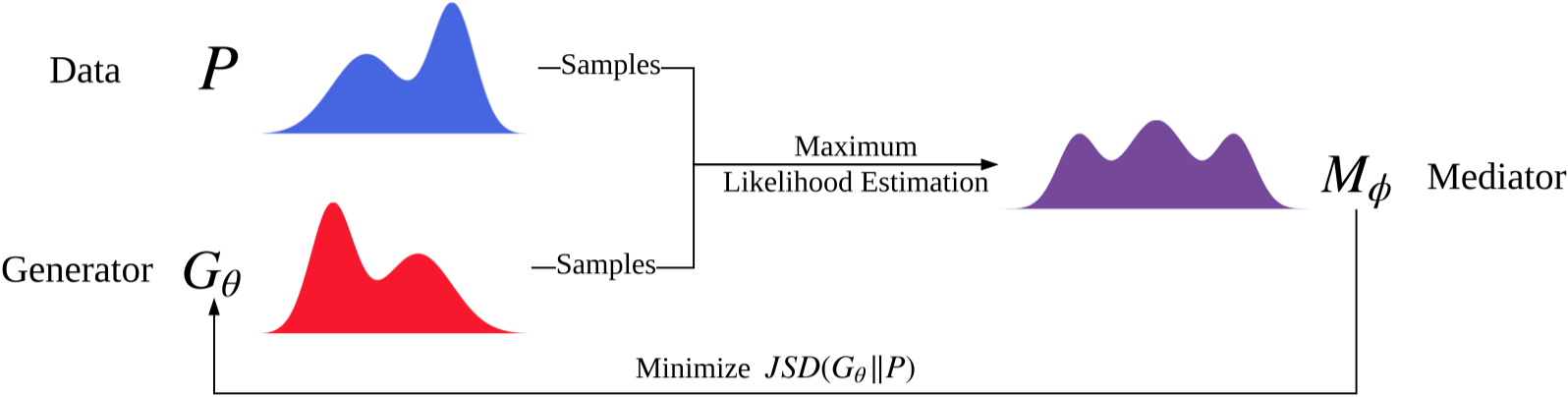
MaliGAN
运行文件:run_maligan.py
训练器:oracle_data,real_data
结构图(来自我的理解)
JSDGAN
运行文件:run_jsdgan.py
指导器:oracle_data、real_data
模型:generator(无判别器,discriminator)
结构(根据我的理解)
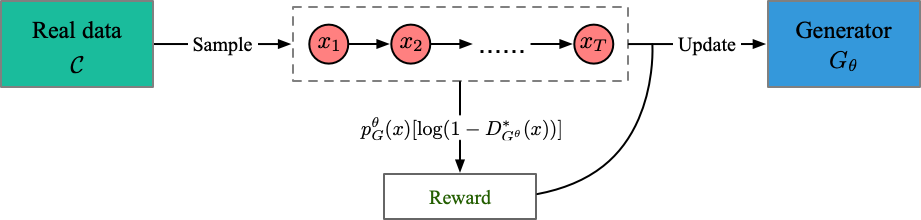
RelGAN
运行文件:run_relgan.py
指导器:oracle_data、real_data
结构(根据我的理解)
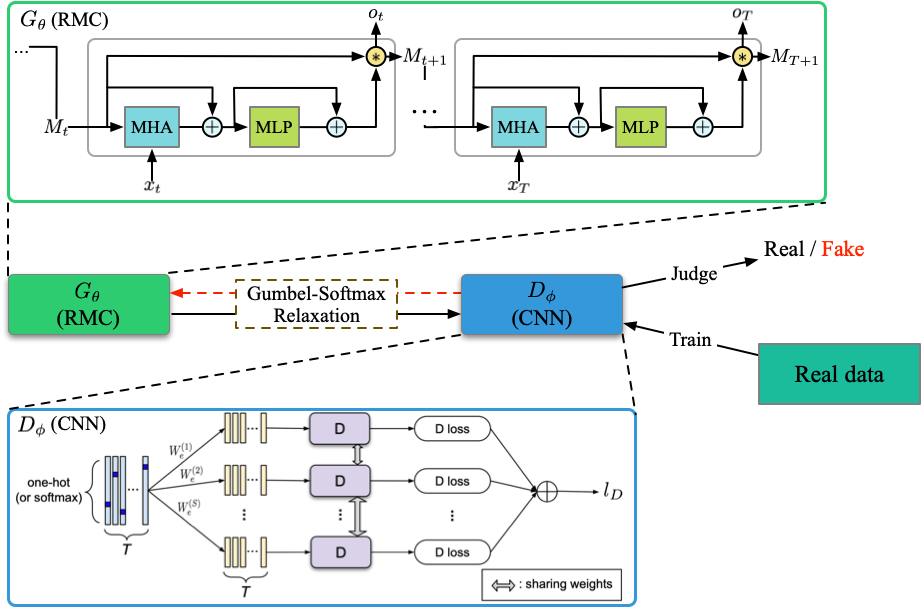
DPGAN
运行文件:run_dpgan.py
指导器:oracle_data、real_data
结构(来自 DPGAN)
DGSAN
运行文件:run_dgsan.py
指导器:oracle_data、real_data
CoT
运行文件:run_cot.py
指导器:oracle_data、real_data
结构(来自 CoT)
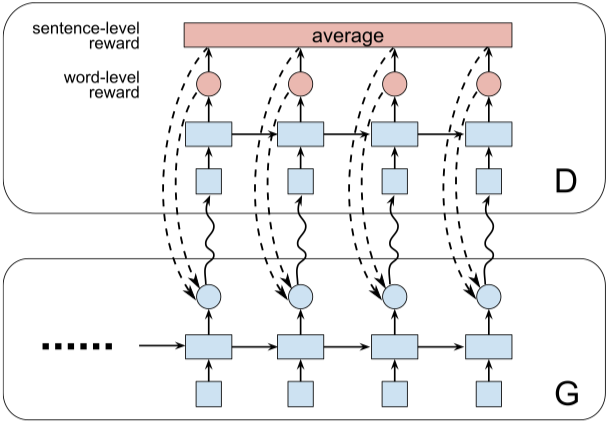
SentiGAN
运行文件:run_sentigan.py
指导器:oracle_data、real_data
结构(来自 SentiGAN)
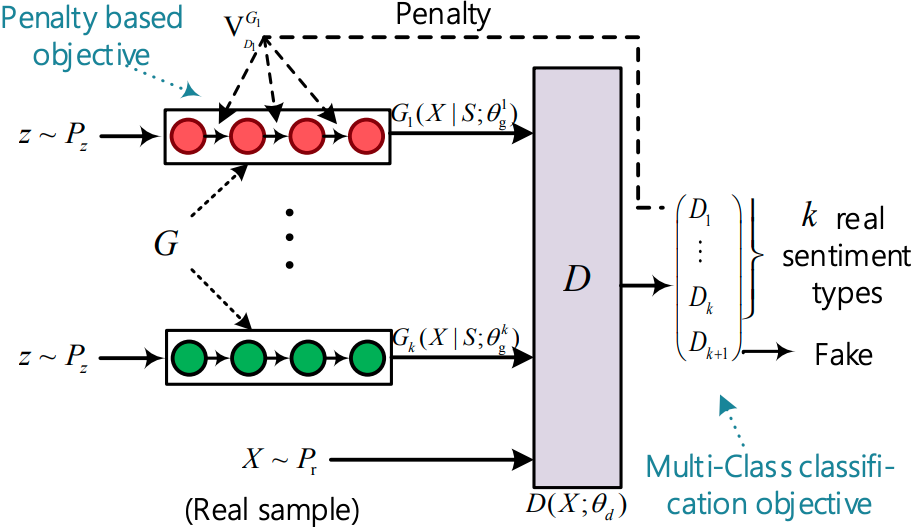
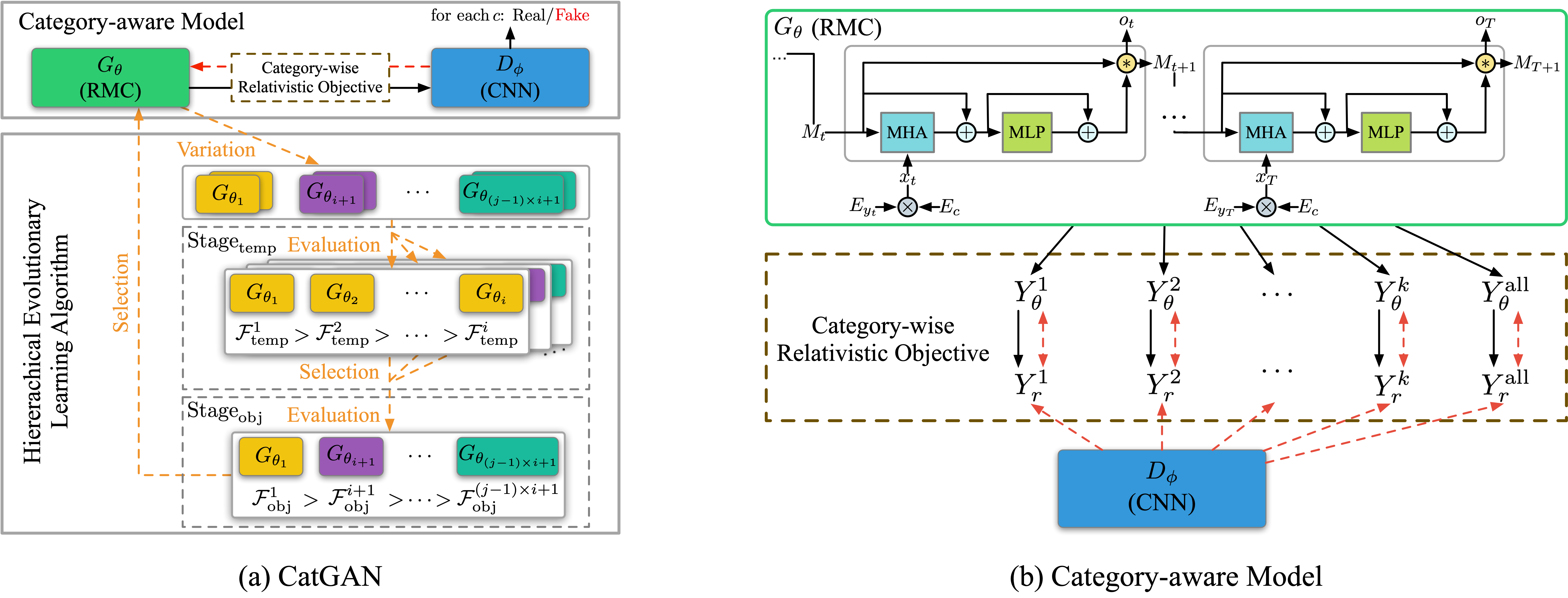
CatGAN
运行文件:run_catgan.py
指导器:oracle_data、real_data
结构(来自 CatGAN)
许可证
MIT 许可证
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。