wenda
闻达是一个专为个人用户和中小企业打造的大规模语言模型(LLM)调用平台。它致力于在有限的计算资源下,实现高效、安全且私密的内容生成,解决了本地部署大模型门槛高、数据隐私难保障以及通用模型缺乏特定领域知识等痛点。
闻达的核心优势在于其高度的灵活性与安全性。它支持多种主流开源模型(如 ChatGLM、RWKV、Baichuan 等)的本地离线部署,确保敏感数据不出内网;同时内置强大的知识库功能,可对接本地向量库或搜索引擎,让模型能基于私有文档进行精准回答。此外,闻达独特的"Auto 脚本”机制允许用户通过 JavaScript 插件自定义对话流程、调用外部 API 或动态切换模型,极大地扩展了应用场景。
该平台非常适合希望私有化部署 AI 能力的中小企业主、关注数据安全的机构人员,以及具备一定技术基础的开发者。无论是用于构建企业内部智能助手、搭建专属知识库问答系统,还是进行大模型应用的原型开发,闻达都提供了一个功能全面且易于上手的解决方案,让用户能在保护隐私的前提下,轻松享受大语言模型带来的效率提升。
使用场景
某中型法律科技公司的内部团队,需要在完全隔离的内网环境中,利用私有法律法规文档构建一个智能问答助手,以辅助律师快速检索案例和条款。
没有 wenda 时
- 数据安全风险高:若使用公有云大模型 API,必须将敏感的案情描述和客户合同上传至外部服务器,严重违反行业合规要求。
- 硬件资源门槛高:部署主流开源模型通常需要多张高端显卡,公司现有的单卡消费级 GPU 服务器无法运行,导致项目搁置。
- 知识更新滞后:模型训练数据截止于过去,无法回答最新的地方法规或公司内部新发布的办案指引,回答往往“一本正经地胡说八道”。
- 定制开发困难:缺乏统一平台整合本地搜索与模型推理,开发人员需从零编写复杂的向量检索和接口对接代码,耗时数月。
使用 wenda 后
- 实现纯内网私有化:利用 wenda 的本地离线向量库功能,将所有法律文档存储在本地,配合 ChatGLM-6B 等离线模型,确保数据不出内网,完美解决隐私顾虑。
- 低资源高效运行:借助 wenda 对量化技术和多种轻量模型(如 RWKV、Baichuan-LoRA)的优化支持,成功在单张 6G 显存的旧显卡上流畅运行服务。
- 精准结合私有知识:通过挂载本地知识库,系统能先检索内部文档再生成答案,准确引用最新条款,大幅降低了模型幻觉,提升了回答的可信度。
- 快速落地与扩展:利用内置的 Auto 脚本功能,团队仅用少量 JavaScript 代码就实现了自定义的案情分析流程,将原本数月的开发周期缩短至几天。
wenda 让资源有限的中小企业也能在保障绝对数据安全的前提下,低成本、高效率地拥有专属的行业大模型应用。
运行环境要求
- Windows
- Linux
- 非必需(支持 CPU 运行)
- 若使用 GPU,推荐 NVIDIA 显卡
- 默认参数在 GTX1660Ti (6GB 显存) 上运行良好
- 部分模式建议显存小于 12GB 时使用 CPU
- 需安装 CUDA 11.8(懒人包提及)
未说明
快速开始
闻达:一个大规模语言模型调用平台
本项目设计目标为实现针对特定环境的高效内容生成,同时考虑个人和中小企业的计算资源局限性,以及知识安全和私密性问题。为达目标,平台化集成了以下能力:
- 知识库:支持对接本地离线向量库、本地搜索引擎、在线搜索引擎等。
- 多种大语言模型:目前支持离线部署模型有
chatGLM-6B\chatGLM2-6B、chatRWKV、llama系列(不推荐中文用户)、moss(不推荐)、baichuan(需配合lora使用,否则效果差)、Aquila-7B、InternLM,在线API访问openai api和chatGLM-130b api。 - Auto脚本:通过开发插件形式的JavaScript脚本,为平台附件功能,实现包括但不限于自定义对话流程、访问外部API、在线切换LoRA模型。
- 其他实用化所需能力:对话历史管理、内网部署、多用户同时使用等。
交流QQ群:LLM使用和综合讨论群162451840;知识库使用讨论群241773574(已满,请去QQ频道讨论);Auto开发交流群744842245;QQ频道
安装部署
各模型功能说明
| 功能 | 多用户并行 | 流式输出 | CPU | GPU | 量化 | 外挂LoRa |
|---|---|---|---|---|---|---|
| chatGLM-6B/chatGLM2-6B | √ | √ | 需安装编译器 | √ | 预先量化和在线量化 | √ |
| RWKV torch | √ | √ | √ | √ | 预先量化和在线量化 | |
| RWKV.cpp | √ | √ | 可用指令集加速 | 预先量化 | ||
| Baichuan-7B | √ | √ | √ | √ | √ | |
| Baichuan-7B (GPTQ) | √ | √ | √ | 预先量化 | ||
| Aquila-7B | 官方未实现 | √ | √ | |||
| replit | √ | √ | ||||
| chatglm130b api | √ | |||||
| openai api | √ | √ | ||||
| llama.cpp | √ | √ | 可用指令集加速 | 预先量化 | ||
| llama torch | √ | √ | √ | √ | 预先量化和在线量化 | |
| InternLM | √ | √ | √ | √ | 在线量化 |
懒人包
百度云
https://pan.baidu.com/s/1idvot-XhEvLLKCbjDQuhyg?pwd=wdai
夸克
链接:https://pan.quark.cn/s/c4cb08de666e 提取码:4b4R
介绍
默认参数在6G显存设备上运行良好。最新版懒人版已集成一键更新功能,建议使用前更新。
使用步骤(以glm6b模型为例):
- 下载懒人版主体和模型,模型可以用内置脚本从HF下载,也可以从网盘下载。
- 如果没有安装
CUDA11.8,从网盘下载并安装。 - 双击运行
运行GLM6B.bat。 - 如果需要生成离线知识库,参考 知识库。
自行安装
PS:一定要看example.config.yml,里面对各功能有更详细的说明!!!
1.安装库
通用依赖:pip install -r requirements/requirements.txt
根据使用的 知识库进行相应配置
2.下载模型
根据需要,下载对应模型。
建议使用chatRWKV的RWKV-4-Raven-7B-v11,或chatGLM-6B。
3.参数设置
把example.config.yml重命名为config.yml,根据里面的参数说明,填写你的模型下载位置等信息
Auto
auto功能通过JavaScript脚本实现,使用油猴脚本或直接放到autos目录的方式注入至程序,为闻达附加各种自动化功能。
Auto 开发函数列表
| 函数 (皆为异步调用) | 功能 | 说明 |
|---|---|---|
| send(s,keyword = "",show=true) | 发送信息至LLM,返回字符串为模型返回值 | s:输入模型文本;keyword:聊天界面显示文本;show:是否在聊天界面显示 |
| add_conversation(role, content) | 添加会话信息 | role:'AI'、'user';content:字符串 |
| save_history() | 保存会话历史 | 对话完成后会自动保存,但手动添加的对话须手动保存 |
| find(s, step = 1) | 从知识库查找 | 返回json数组 |
| find_dynamic(s,step=1,paraJson) | 从动态知识库查找;参考闻达笔记Auto | paraJson:{libraryStategy:"sogowx:3",maxItmes:2} |
| zsk(b=true) | 开关知识库 | |
| lsdh(b=true) | 开关历史对话 | 打开知识库时应关闭历史 |
| speak(s) | 使用TTS引擎朗读文本。 | 调用系统引擎 |
| copy(s) | 使用浏览器clipboard-write复制文本 |
需要相关权限 |
Auto 开发涉及代码段
在左侧功能栏添加内容:
func.push({
name: "名称",
question: async () => {
let answer=await send(app.question)
alert(answer)
},
})
在下方选项卡添加内容:
app.plugins.push({ icon: 'note-edit-outline', url: "/static/wdnote/index.html" })
在指定RTST知识库查找:
find_in_memory = async (s, step, memory_name) => {
response = await fetch("/api/find_rtst_in_memory", {
method: 'post',
body: JSON.stringify({
prompt: s,
step: step,
memory_name: memory_name
}),
headers: {
'Content-Type': 'application/json'
}
})
let json = await response.json()
console.table(json)
app.zhishiku = json
return json
}
上传至指定RTST知识库:
upload_rtst_zhishiku = async (title, txt,memory_name) => {
response = await fetch("/api/upload_rtst_zhishiku", {
method: 'post',
body: JSON.stringify({
title: title,
txt: txt,
memory_name: memory_name
}),
headers: { 'Content-Type': 'application/json' }
})
alert(await response.text())
}
保存指定RTST知识库:
save_rtst = async (memory_name) => {
response = await fetch("/api/save_rtst_zhishiku", {
method: 'post',
body: JSON.stringify({
memory_name: memory_name
}),
headers: { 'Content-Type': 'application/json' }
})
alert(await response.text())
}
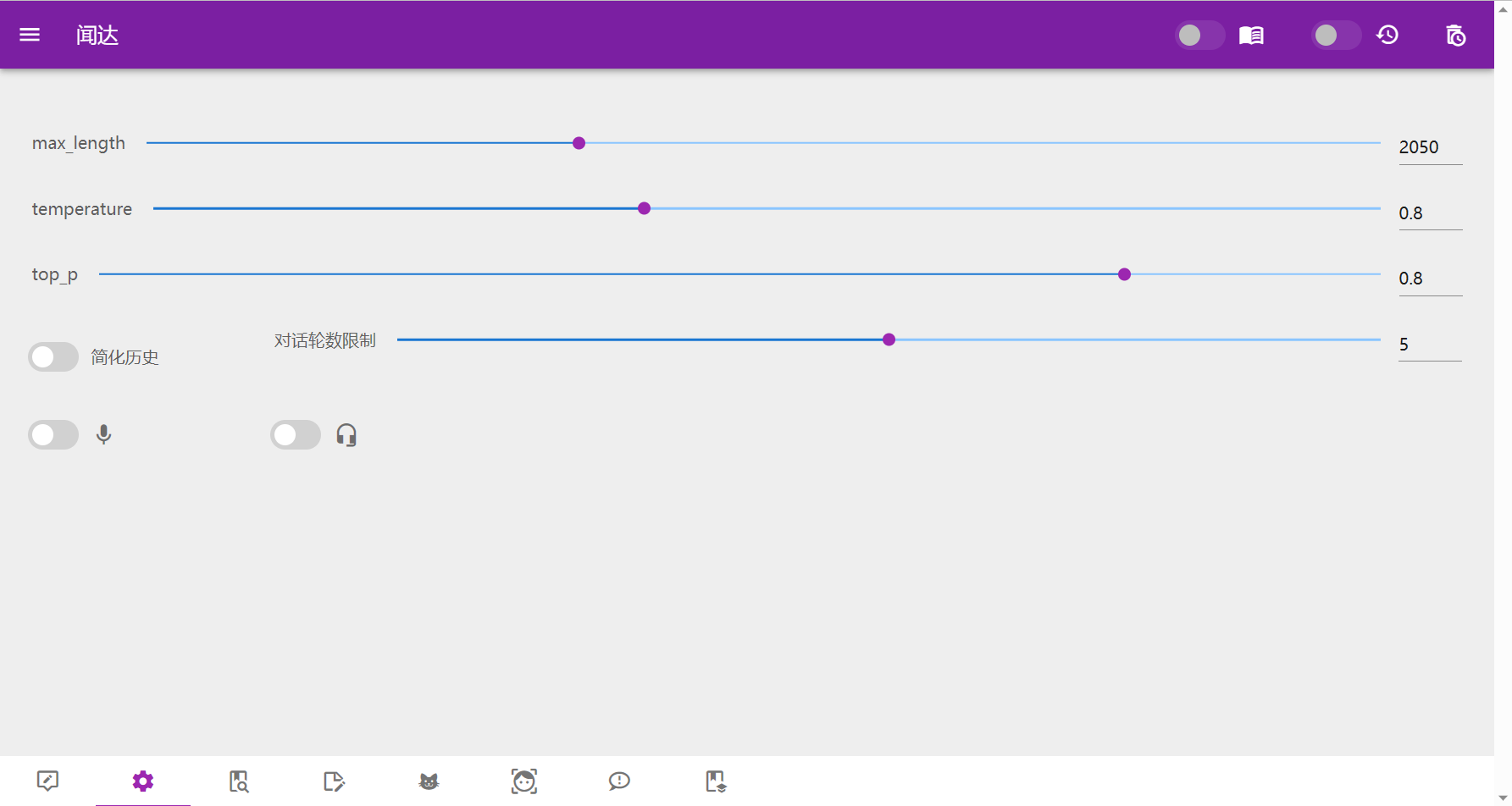
访问SD_agent:
response = await fetch("/api/sd_agent", {
method: 'post',
body: JSON.stringify({
prompt: `((masterpiece, best quality)), photorealistic,` + Q,
steps: 20,
// sampler_name: "DPM++ SDE Karras",
negative_prompt: `paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans`
}),
headers: {
'Content-Type': 'application/json'
}
})
try {
let json = await response.json()
add_conversation("AI", '")
} catch (error) {
alert("连接SD API失败,请确认已开启agents库,并将SD API地址设置为127.0.0.1:786")
}
部分内置 Auto 使用说明
| 文件名 | 功能 |
|---|---|
| 0-write_article.js | 写论文:根据题目或提纲写论文 |
| 0-zsk.js | 知识库增强和管理 |
| face-recognition.js | 纯浏览器端人脸检测:通过识别嘴巴开合,控制语音输入。因浏览器限制,仅本地或TLS下可用 |
| QQ.js | QQ机器人:配置过程见文件开头注释 |
| block_programming.js | 猫猫也会的图块化编程:通过拖动图块实现简单Auto功能 |
| 1-draw_use_SD_api.js | 通过agents模块(见example.config.yml<Library>)调用Stable Diffusion接口绘图 |
以上功能主要用于展示auto用法,进一步能力有待广大用户进一步发掘。

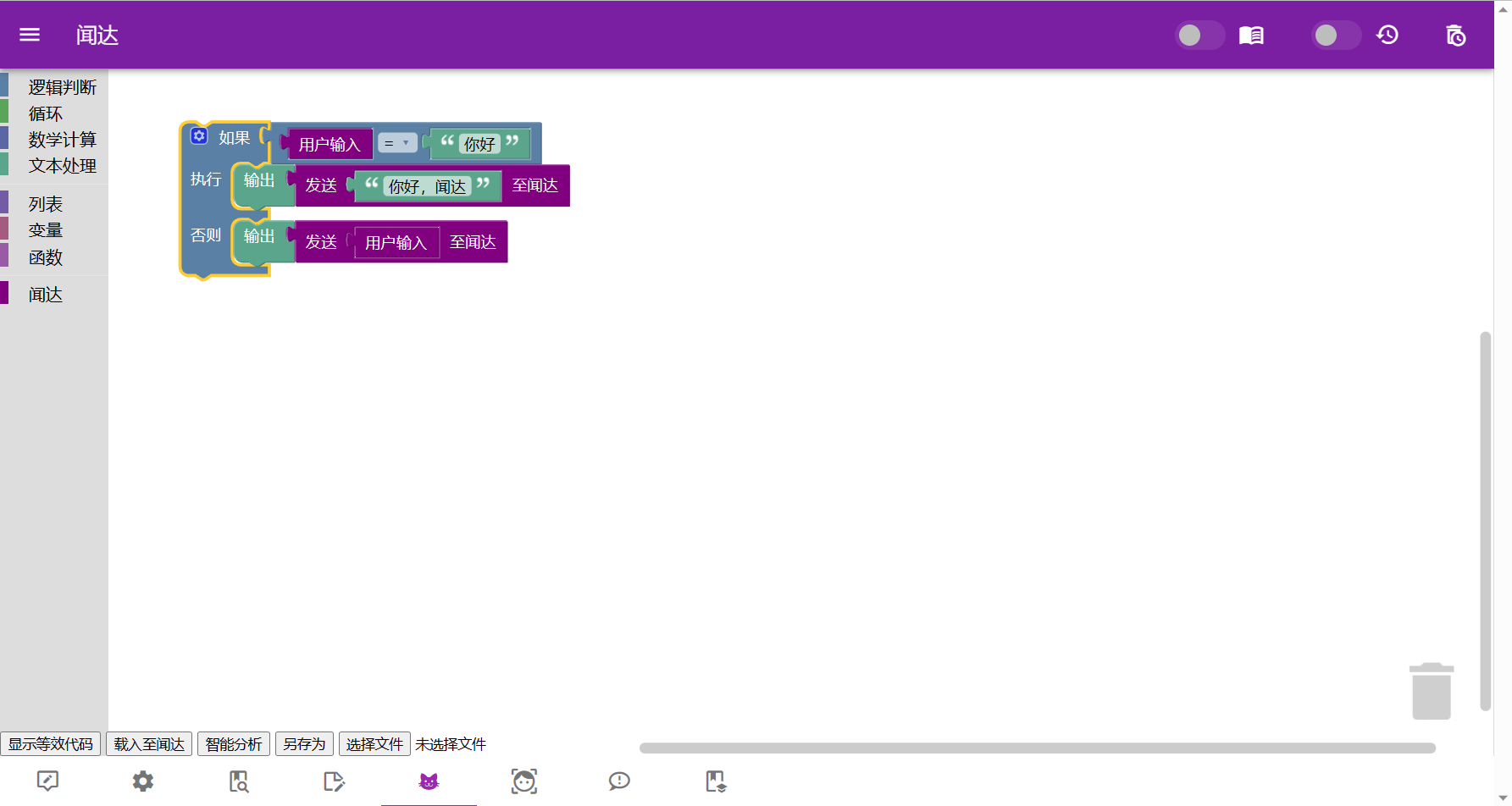
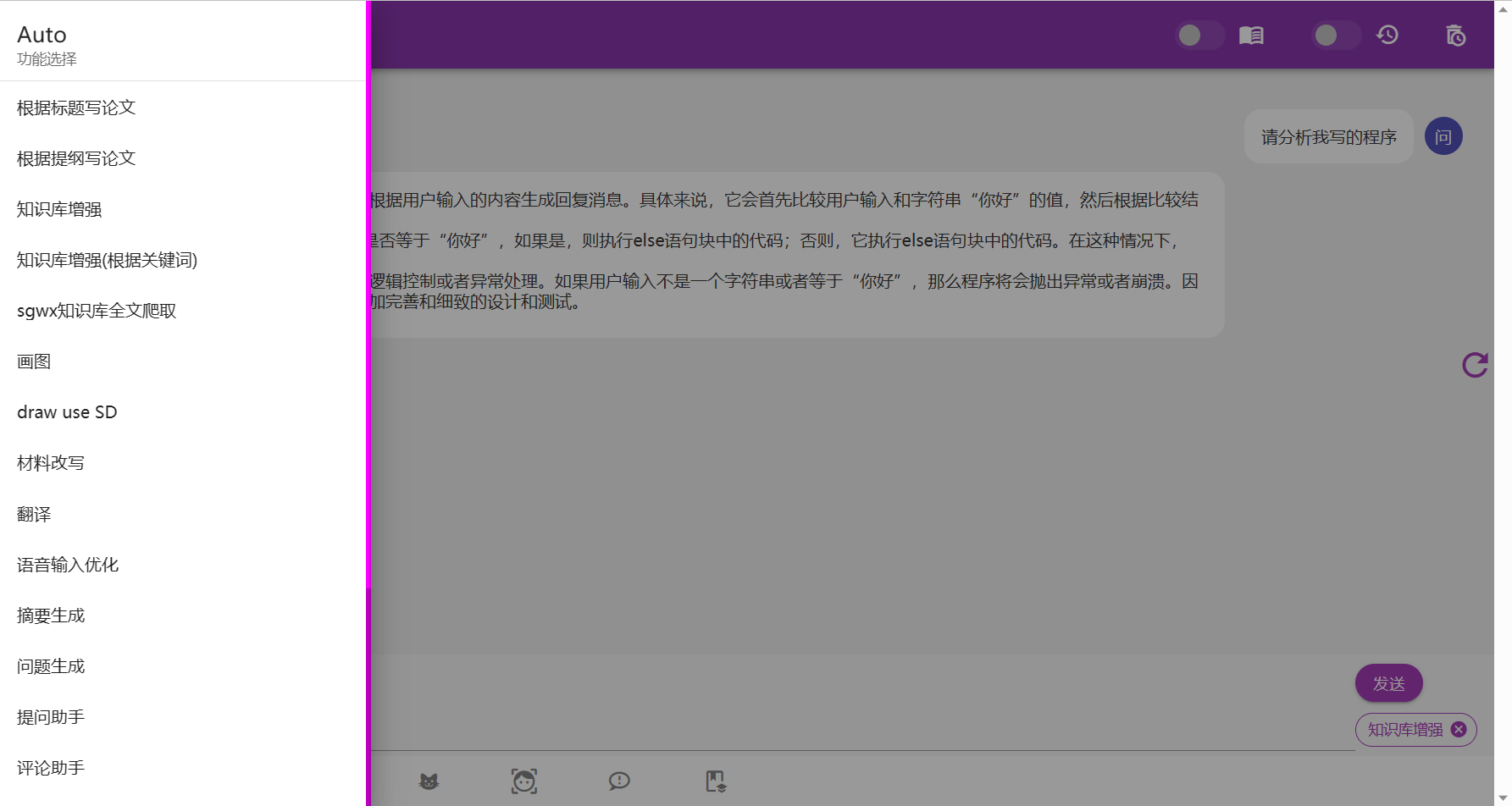
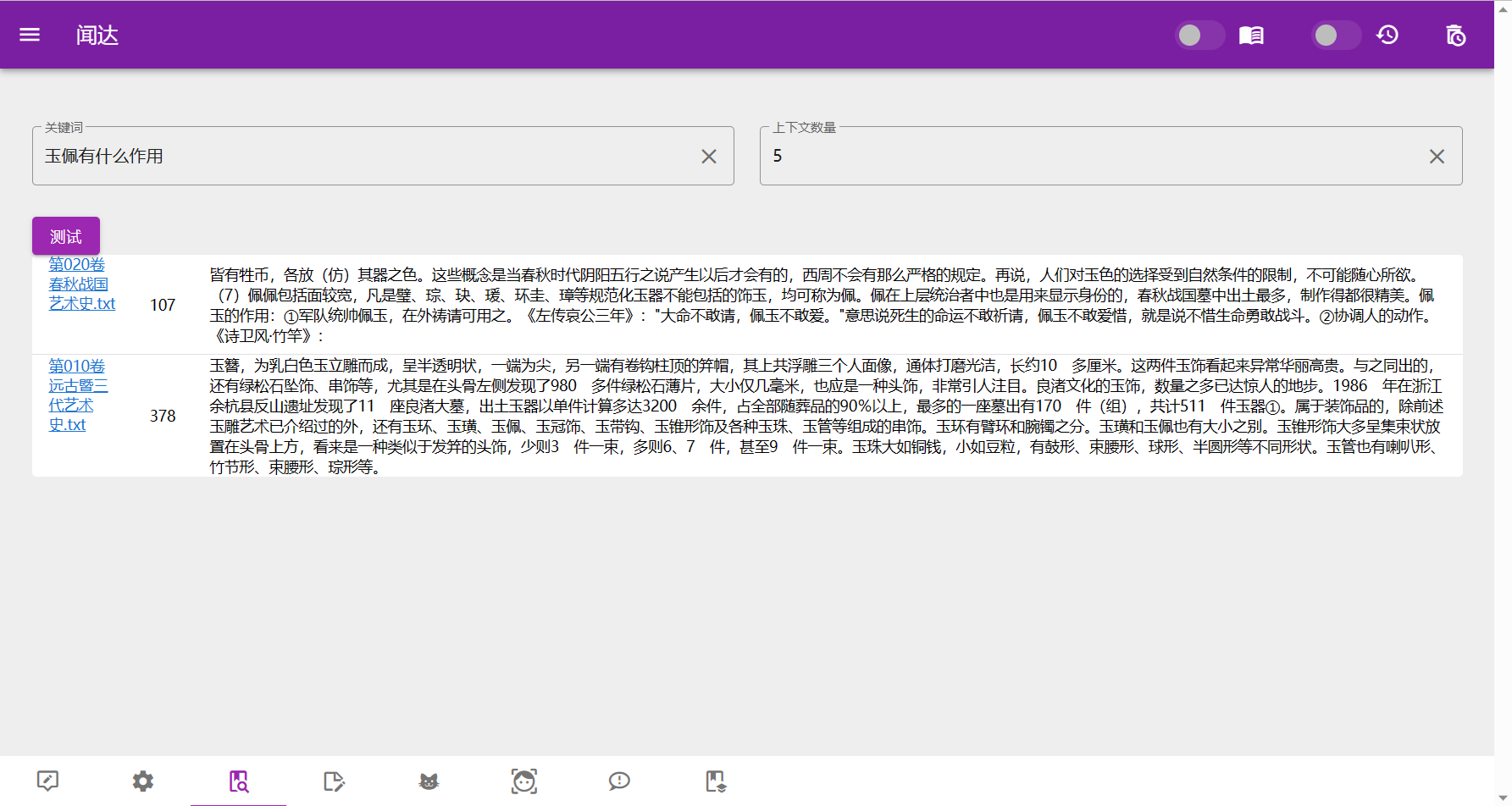
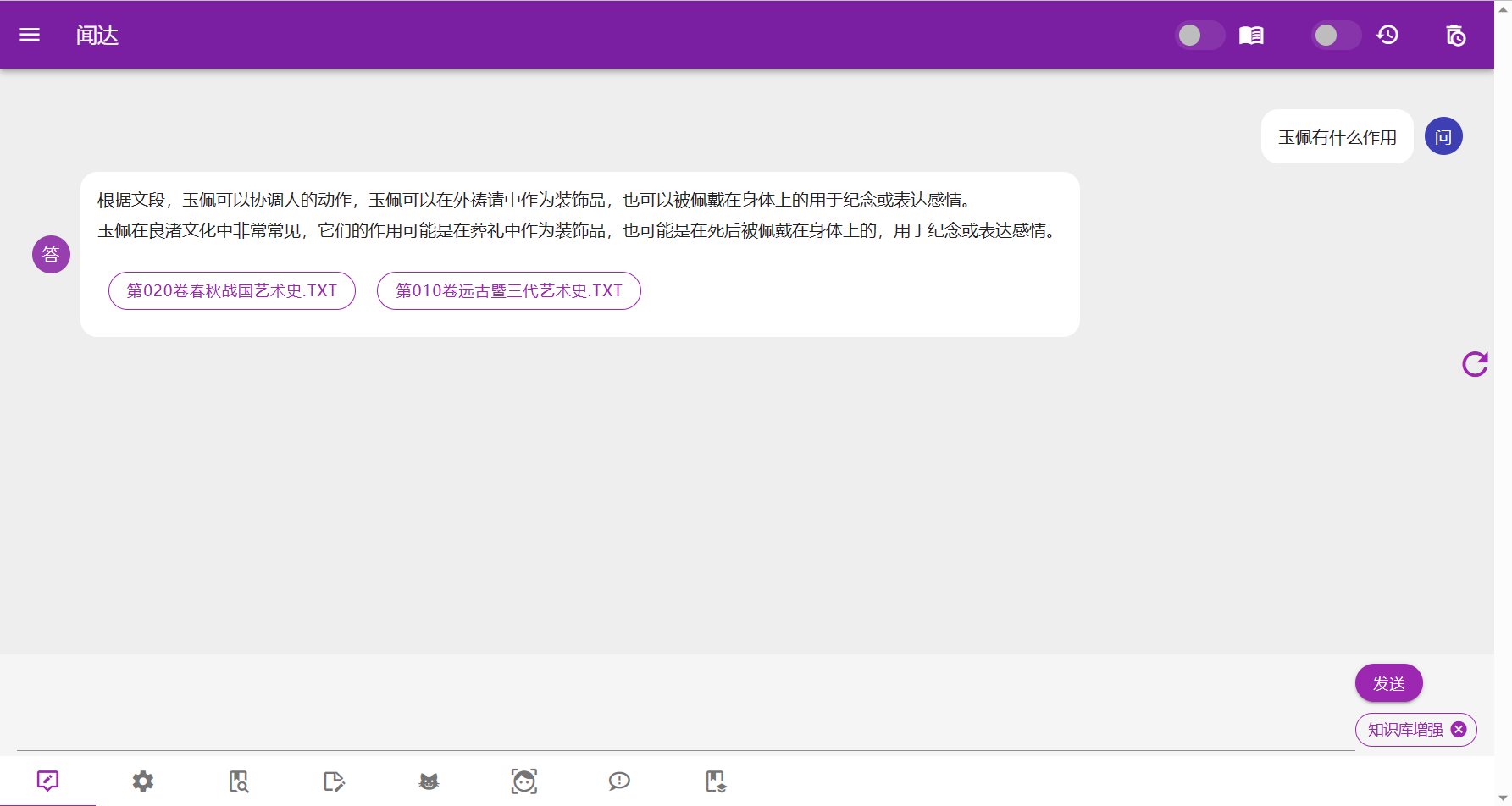
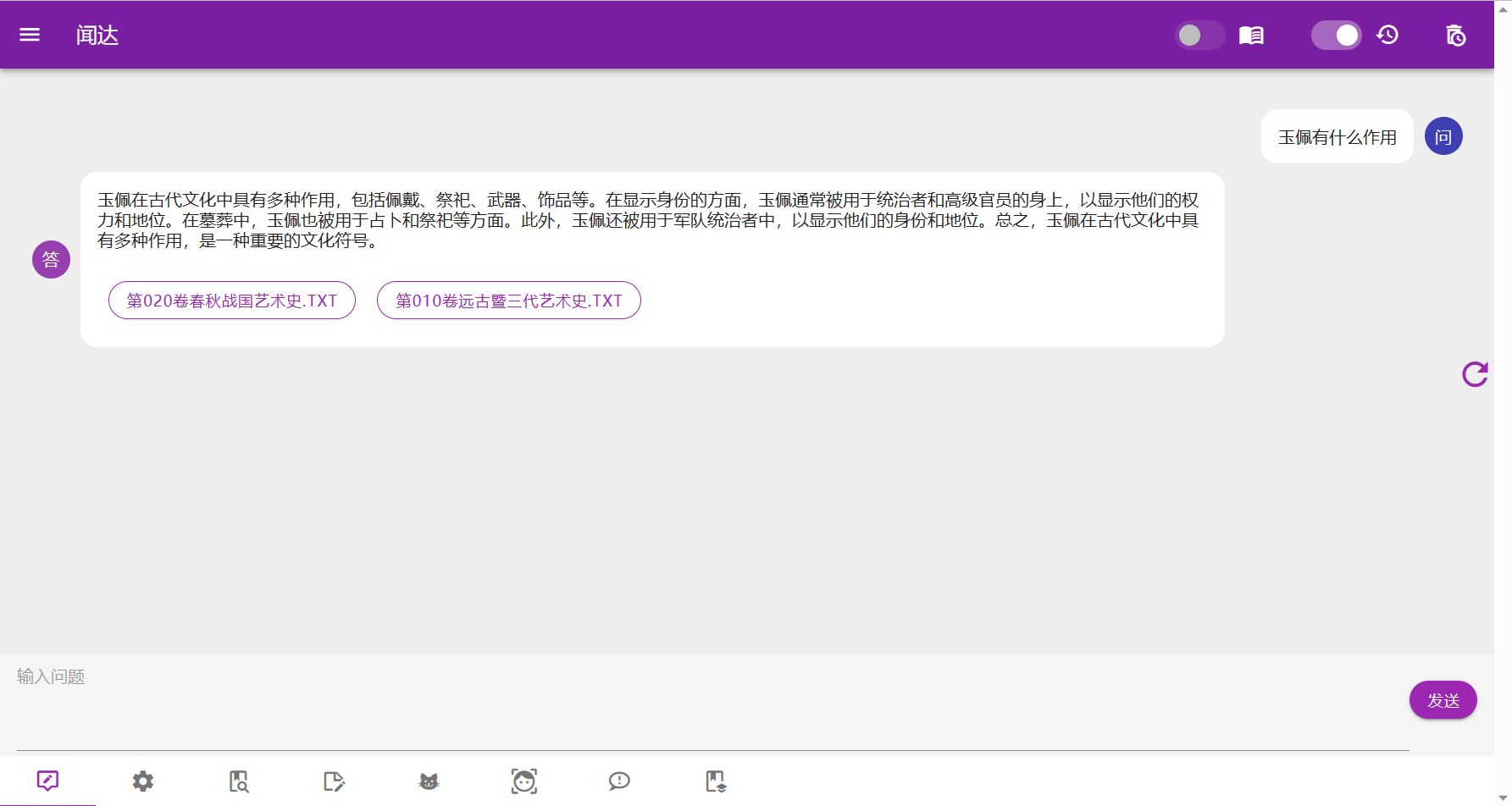
知识库
知识库原理是在搜索后,生成一些提示信息插入到对话里面,知识库的数据就被模型知道了。rtst模式计算语义并在本地数据库中匹配;fess模式(相当于本地搜索引擎)、bing模式均调用搜索引擎搜索获取答案。
为防止爆显存和受限于模型理解能力,插入的数据不能太长,所以有字数和条数限制,这一问题可通过知识库增强Auto解决。
正常使用中,勾选右上角知识库即开启知识库。
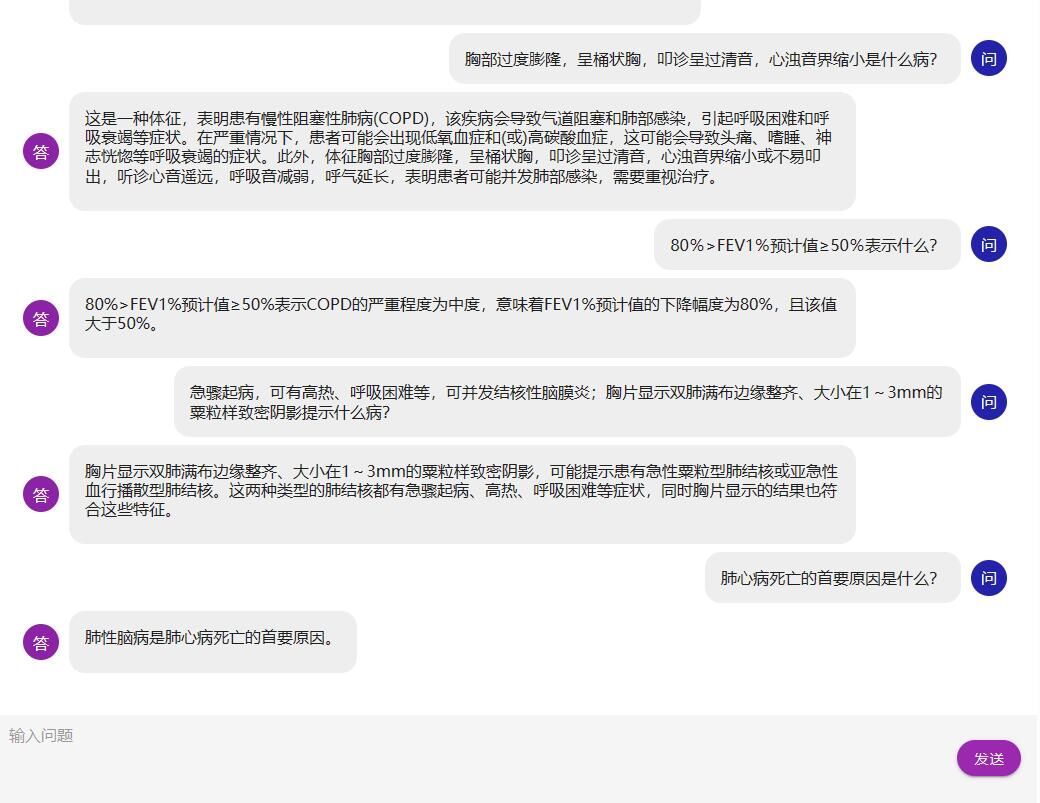
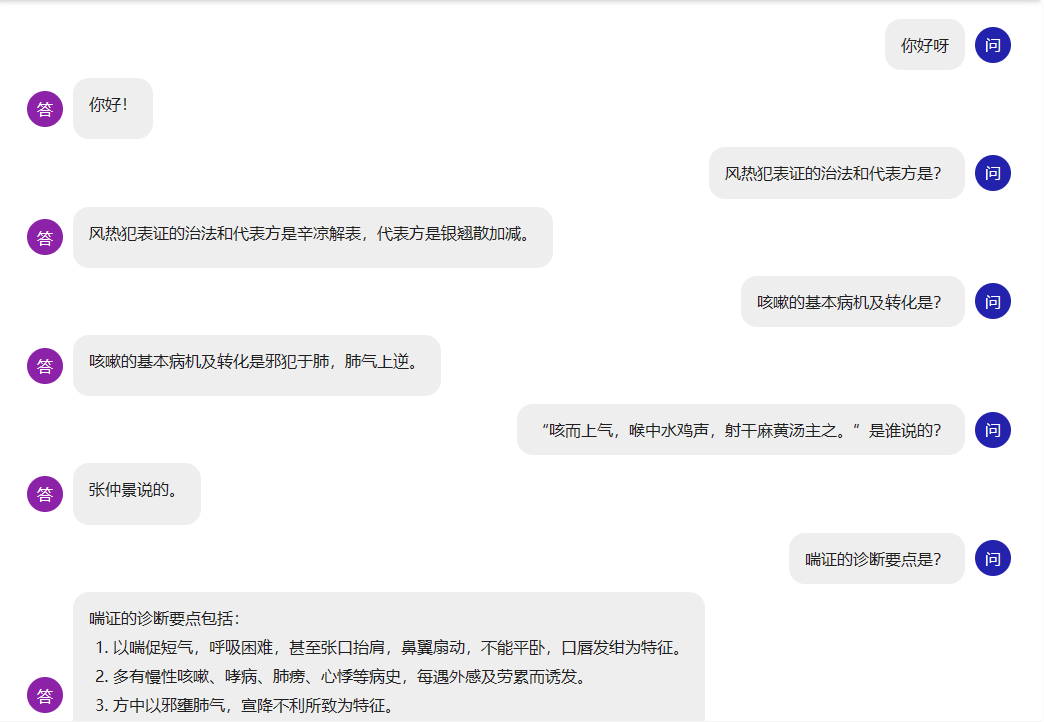
有以下几种方案:
- rtst模式,sentence_transformers+faiss进行索引,支持预先构建索引和运行中构建。
- bing模式,cn.bing搜索,仅国内可用
- bingsite模式,cn.bing站内搜索,仅国内可用
- fess模式,本地部署的fess搜索,并进行关键词提取
rtst模式
sentence_transformers+faiss进行索引、匹配,并连同上下文返回。目前支持txt和pdf格式。
支持预先构建索引和运行中构建,其中,预先构建索引强制使用cuda,运行中构建根据config.yml(复制example.config.yml)中rtst段的device(embedding运行设备)决定,对于显存小于12G的用户建议使用CPU。
Windows预先构建索引运行:plugins/buils_rtst_default_index.bat。
Linux直接使用wenda环境执行 python plugins/gen_data_st.py
需下载模型置于model文件夹,并将txt格式语料置于txt文件夹。
使用微调模型提高知识库回答准确性
闻达用户“帛凡”,训练并提供的权重合并模型和lora权重文件,详细信息见https://huggingface.co/fb700/chatglm-fitness-RLHF ,使用该模型或者lora权重文件,对比hatglm-6b、chatglm2-6b、百川等模型,在闻达知识库平台中,总结能力可获得显著提升。
模型
- GanymedeNil/text2vec-large-chinese 不再推荐,不支持英文且显存占用高
- moka-ai/m3e-base 推荐
fess模式
在本机使用默认端口安装fess后可直接运行。否则需修改config.yml(复制example.config.yml)中fess_host的127.0.0.1:8080为相应值。FESS安装教程
知识库调试
清洗知识库文件
安装 utool 工具,uTools 是一个极简、插件化的桌面软件,可以安装各种使用 nodejs 开发的插件。您可以使用插件对闻达的知识库进行数据清洗。请自行安装以下推荐插件:
- 插件“解散文件夹”,用于将子目录的文件移动到根目录,并删除所有子目录。
- 插件“重复文件查找”,用于删除目录中的重复文件,原理是对比文件 md5。
- 插件“文件批量重命名”,用于使用正则匹配和修改文件名,并将分类后的文件名进行知识库的分区操作。
模型配置
chatGLM-6B/chatGLM2-6B
运行:run_GLM6B.bat。
模型位置等参数:修改config.yml(复制example.config.yml)。
默认参数在GTX1660Ti(6G显存)上运行良好。
chatRWKV
支持torch和cpp两种后端实现,运行:run_rwkv.bat。
模型位置等参数:见config.yml(复制example.config.yml)。
torch
可使用内置脚本对模型量化,运行:cov_torch_rwkv.bat。此操作可以加快启动速度。
在安装vc后支持一键启动CUDA加速,运行:run_rwkv_with_vc.bat。强烈建议安装!!!
cpp
可使用内置脚本对torch版模型转换和量化。 运行:cov_ggml_rwkv.bat。
设置strategy诸如"Q8_0->8"即支持量化在cpu运行,速度较慢,没有显卡或者没有nvidia显卡的用户使用。
注意:默认windows版本文件为AVX2,默认Liunx版本文件是在debian sid编译的,其他linux发行版本未知。
可以查看:saharNooby/rwkv.cpp,下载其他版本,或者自行编译。
Aquila-7B
- 运行
pip install FlagAI。注意FlagAI依赖很多旧版本的包,需要自己编译,所以如果想基于python3.11运行或者想在一个环境同时跑其他模型,建议去下懒人包 - 运行:
run_Aquila.bat。
模型位置等参数:见config.yml(复制example.config.yml)。注意模型要在这里下:https://model.baai.ac.cn/model-detail/100101
基于本项目的二次开发
wenda-webui
项目调用闻达的 api 接口实现类似于 new bing 的功能。 技术栈:vue3 + element-plus + ts
接入Word文档软件
通过宏,调用闻达HTTP API

常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。