DoLa
DoLa 是一款专注于提升大语言模型事实准确性的开源解码策略。针对当前大模型普遍存在的“幻觉”问题——即生成偏离预训练事实的内容,DoLa 提供了一种无需外部知识检索或额外微调的解决方案。
其核心原理在于利用 Transformer 层中事实知识局部化的特性。DoLa 通过对比模型深层与浅层投影到词汇空间后的 Logits 差异,动态调整下一个词的生成概率。这种“分层对比解码”方法能有效抑制错误信息的生成,同时保留模型的流畅度。实验数据显示,应用在 LLaMA 系列模型上时,DoLa 能在 TruthfulQA 等基准测试中带来 12-17% 的绝对性能提升。
DoLa 基于 Hugging Face Transformers 实现,支持 MIT 协议。它非常适合大模型研究人员及开发者,尤其是那些希望在保持原有模型架构不变的前提下,低成本优化生成内容真实性的团队。通过简单的参数配置,即可在推理阶段直接应用,为构建更可靠的大模型应用提供了有力支持。
使用场景
某互联网医疗团队基于开源 LLaMA-7B 模型开发智能问诊系统,核心需求是确保生成的医学建议严格符合事实,避免误导患者造成严重后果,因此对准确性要求极高。
没有 DoLa 时
- 模型频繁出现幻觉,编造不存在的药物配伍禁忌或具体剂量建议,直接威胁患者安全。
- 对罕见病症的描述往往混淆概念,缺乏权威医学文献依据支撑,显得不够专业。
- 生成内容存在潜在安全风险,必须依赖昂贵且低效的人工审核流程才能发布。
- 用户因多次收到错误建议而流失,导致产品口碑严重受损且难以挽回信任。
使用 DoLa 后
- DoLa 通过对比早期与晚期层的 Logits 差异,有效抑制了模型的虚构倾向,无需额外训练。
- 输出的药物信息和治疗方案更贴近真实医学文献数据,逻辑链条更严密且可追溯。
- 事实性错误率大幅降低,显著提升了回答的可信度和专业度表现,用户满意度提高。
- 减少了对人工复核的依赖,加快了产品上线迭代速度并大幅降低运营成本。
DoLa 以零微调成本有效解决了大模型在垂直领域的事实性幻觉问题,让生成内容更加安全可靠,为高敏感场景落地提供了可行方案。
运行环境要求
- 未说明
需要 NVIDIA GPU,建议 32G 显存(V100),默认分配 27GiB
未说明

快速开始
DoLa:通过对比层解码提升大型语言模型的事实性
![]()


![]()
ICLR 2024 论文 "DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models" 的代码
论文:https://arxiv.org/abs/2309.03883
作者:Yung-Sung Chuang $^\dagger$, Yujia Xie $^\ddagger$, Hongyin Luo $^\dagger$, Yoon Kim $^\dagger$, James Glass $^\dagger$, Pengcheng He $^\ddagger$
$^\dagger$ 麻省理工学院,$^\ddagger$ 微软
概述
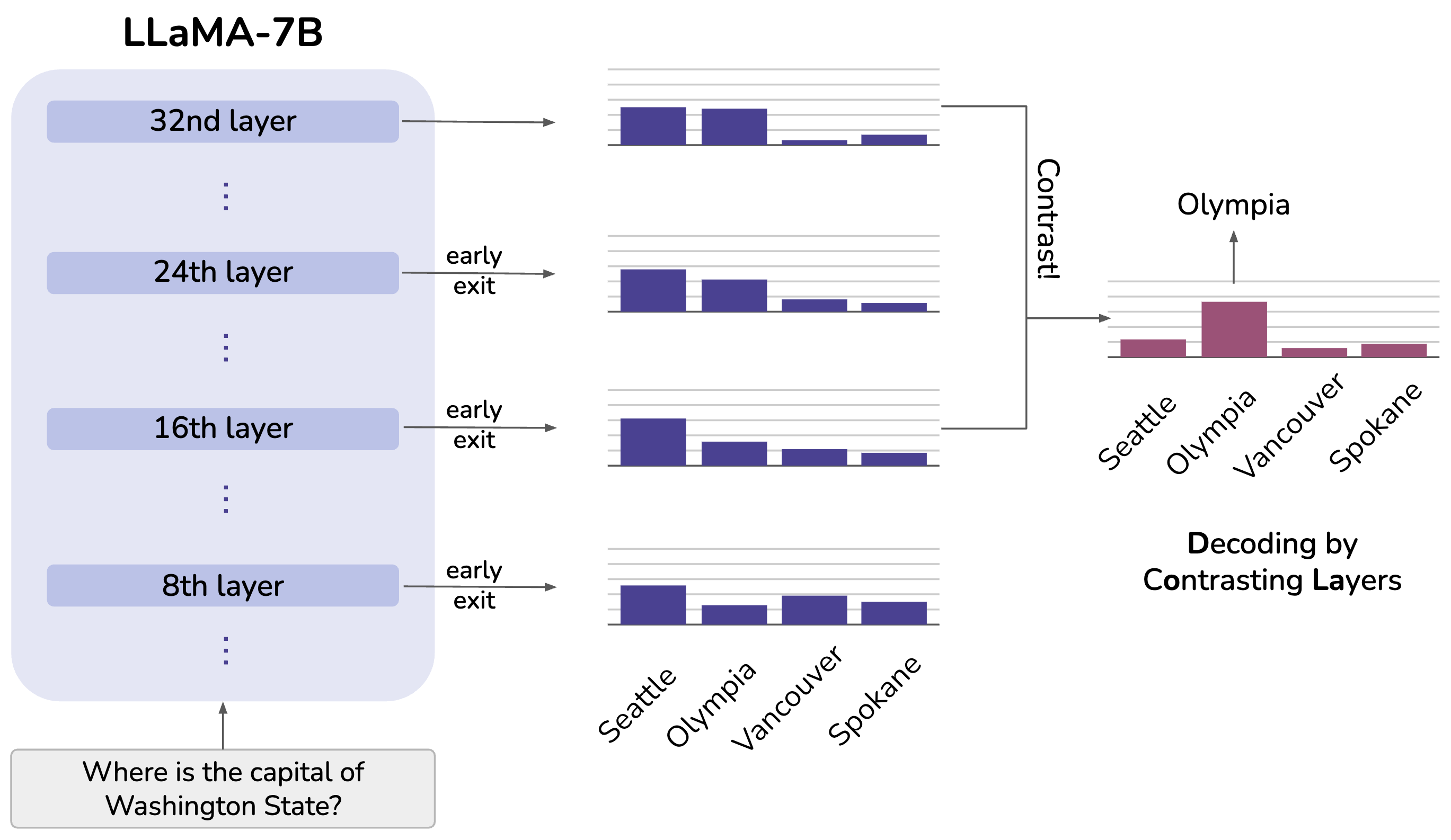
尽管大型语言模型(Large Language Models, LLMs)具有令人印象深刻的功能,但它们容易产生幻觉(hallucinations),即生成与预训练期间看到的事实不符的内容。我们提出了一种简单的解码策略,用于减少预训练 LLM 的幻觉,该策略不需要依赖检索到的外部知识进行条件控制,也不需要额外的微调。我们的方法通过对比将较深层和较浅层投影到词汇空间后获得的 logits(未归一化的对数概率)差异来获取下一个 token 的分布,利用了 LLM 中的事实性知识通常被证明局限于特定 Transformer 层这一事实。我们发现这种通过对比层进行解****码(DoLA)的方法能够更好地呈现事实性知识并减少错误事实的生成。DoLA 在多项选择题任务和开放式生成任务上持续提高了真实性,例如将 LLaMA 系列模型在 TruthfulQA 上的性能提升了 12-17 个绝对百分点,展示了其在使 LLM 可靠地生成真实事实方面的潜力。
环境配置
pip install -e transformers-4.28.1
pip install datasets
pip install accelerate
pip install openai # -> only for truthfulqa and gpt4_eval
实验
参数
| 参数 | 示例 | 描述 |
|---|---|---|
--model-name |
huggyllama/llama-7b |
指定要使用的模型,目前我们仅支持 LLaMA-v1。 |
--data-path |
/path/to/dataset |
数据集文件或文件夹的路径。 |
--output-path |
output-path.json |
存储输出结果的位置。 |
--num-gpus |
1 |
使用的 GPU 数量,分别对应 7B/13B/30B/65B 模型大小的 1/2/4/8。 |
--max_gpu_memory |
27 |
分配的最大 GPU 内存大小(单位 GiB)。默认值为 27(适用于 32G V100)。 |
理解 --early-exit-layers
--early-exit-layers 参数接受一个包含由逗号分隔的层号序列的字符串,中间没有空格。通过指定不同数量的层,我们可以让模型以不同的模式进行解码。
| 指定层数 | 示例 (字符串) | 解码模式描述 |
|---|---|---|
| 1 | -1 |
来自最终层输出的朴素解码。 |
| 2 | 16,32 |
DoLa 静态解码,将第二个指定的层(即 32)作为 mature_layer(成熟层),第一个指定的层(即 16)作为 premature_layer(早期层)。 |
| >2 | 0,2,4,6,8,10,12,14,32 |
DoLa 解码,将最后一个指定的层(即 32)作为 mature_layer(成熟层),所有前面的层(即 0,2,4,6,8,10,12,14)作为 candidate_premature_layers(候选早期层)。 |
FACTOR(多项选择题)
请从 https://github.com/AI21Labs/factor 下载数据文件 wiki_factor.csv
基线
python factor_eval.py --model-name huggyllama/llama-7b --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 1
python factor_eval.py --model-name huggyllama/llama-13b --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 2
python factor_eval.py --model-name huggyllama/llama-30b --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 4
python factor_eval.py --model-name huggyllama/llama-65b --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 8
DoLa
python factor_eval.py --model-name huggyllama/llama-7b --early-exit-layers 0,2,4,6,8,10,12,14,32 --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 1
python factor_eval.py --model-name huggyllama/llama-13b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,40 --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 2
python factor_eval.py --model-name huggyllama/llama-30b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,60 --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 4
python factor_eval.py --model-name huggyllama/llama-65b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,80 --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 8
TruthfulQA(多项选择)
--data-path 参数应指向一个包含 TruthfulQA.csv 的文件夹。如果文件不存在,系统将自动下载。
基线模型
python tfqa_mc_eval.py --model-name huggyllama/llama-7b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python tfqa_mc_eval.py --model-name huggyllama/llama-13b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python tfqa_mc_eval.py --model-name huggyllama/llama-30b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python tfqa_mc_eval.py --model-name huggyllama/llama-65b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
DoLa
python tfqa_mc_eval.py --model-name huggyllama/llama-7b --early-exit-layers 16,18,20,22,24,26,28,30,32 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python tfqa_mc_eval.py --model-name huggyllama/llama-13b --early-exit-layers 20,22,24,26,28,30,32,34,36,38,40 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python tfqa_mc_eval.py --model-name huggyllama/llama-30b --early-exit-layers 40,42,44,46,48,50,52,54,56,58,60 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python tfqa_mc_eval.py --model-name huggyllama/llama-65b --early-exit-layers 60,62,64,66,68,70,72,74,76,78,80 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
TruthfulQA
为了评估 TruthfulQA 的开放式生成结果,我们需要通过 OpenAI API 微调两个 GPT-3 curie 模型:
openai api fine_tunes.create -t finetune_truth.jsonl -m curie --n_epochs 5 --batch_size 21 --learning_rate_multiplier 0.1
openai api fine_tunes.create -t finetune_info.jsonl -m curie --n_epochs 5 --batch_size 21 --learning_rate_multiplier 0.1
微调完成后,可以通过运行 openai api fine_tunes.list | grep fine_tuned_model 来获取微调后的模型名称。
创建一个名为 gpt3.config.json 的配置文件,内容如下:
{"gpt_info": "curie:ft-xxxxxxxxxx",
"gpt_truth": "curie:ft-xxxxxxxxxx",
"api_key": "xxxxxxx"}
为 GPT-3 评估添加参数 --do-rating --gpt3-config gpt3.config.json。
基线模型
python tfqa_eval.py --model-name huggyllama/llama-7b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-13b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-30b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-65b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8 --do-rating --gpt3-config /path/to/gpt3.config.json
DoLa
python tfqa_eval.py --model-name huggyllama/llama-7b --early-exit-layers 16,18,20,22,24,26,28,30,32 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-13b --early-exit-layers 20,22,24,26,28,30,32,34,36,38,40 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-30b --early-exit-layers 40,42,44,46,48,50,52,54,56,58,60 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-65b --early-exit-layers 60,62,64,66,68,70,72,74,76,78,80 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8 --do-rating --gpt3-config /path/to/gpt3.config.json
GSM8K
我们使用 GSM8K 训练集的一个随机采样子集作为 StrategyQA 和 GSM8K 的验证集。该文件可以在 此处 下载。
--data-path 参数应为以下之一:
- 一个包含
gsm8k_test.jsonl的文件夹,否则文件将自动下载到指定文件夹中。 - (仅限 GSM8K)上述链接可下载的
gsm8k-train-sub.jsonl的路径。
基线模型
python gsm8k_eval.py --model-name huggyllama/llama-7b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python gsm8k_eval.py --model-name huggyllama/llama-13b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python gsm8k_eval.py --model-name huggyllama/llama-30b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python gsm8k_eval.py --model-name huggyllama/llama-65b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
DoLa
python gsm8k_eval.py --model-name huggyllama/llama-7b --early-exit-layers 0,2,4,6,8,10,12,14,32 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python gsm8k_eval.py --model-name huggyllama/llama-13b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,40 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python gsm8k_eval.py --model-name huggyllama/llama-30b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,60 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python gsm8k_eval.py --model-name huggyllama/llama-65b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,80 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
StrategyQA
--data-path 参数应为一个包含 strategyqa_train.json 的文件夹,否则文件将自动下载到您指定的文件夹中。
Baseline
python strqa_eval.py --model-name huggyllama/llama-7b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python strqa_eval.py --model-name huggyllama/llama-13b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python strqa_eval.py --model-name huggyllama/llama-30b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python strqa_eval.py --model-name huggyllama/llama-65b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
DoLa
python strqa_eval.py --model-name huggyllama/llama-7b --early-exit-layers 0,2,4,6,8,10,12,14,32 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python strqa_eval.py --model-name huggyllama/llama-13b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,40 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python strqa_eval.py --model-name huggyllama/llama-30b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,60 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python strqa_eval.py --model-name huggyllama/llama-65b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,80 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
GPT-4 评估(Vicuna QA 基准)
在 GPT-4 评估中,我们需要来自 FastChat 的问题文件。在以下命令中,我们假设您的 FastChat 仓库路径为 $fastchat。
Baseline
python gpt4_judge_eval.py --model-name huggyllama/llama-7b --model-id llama-7b-baseline --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 1
python gpt4_judge_eval.py --model-name huggyllama/llama-13b --model-id llama-13b-baseline --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 2
python gpt4_judge_eval.py --model-name huggyllama/llama-30b --model-id llama-30b-baseline --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 4
python gpt4_judge_eval.py --model-name huggyllama/llama-65b --model-id llama-65b-baseline --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 8
DoLa
python gpt4_judge_eval.py --model-name huggyllama/llama-7b --early-exit-layers 0,2,4,6,8,10,12,14,32 --model-id llama-7b-dola --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 1
python gpt4_judge_eval.py --model-name huggyllama/llama-13b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,40 --model-id llama-13b-dola --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 2
python gpt4_judge_eval.py --model-name huggyllama/llama-30b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,60 --model-id llama-30b-dola --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 4
python gpt4_judge_eval.py --model-name huggyllama/llama-65b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,80 --model-id llama-65b-dola --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 8
运行上述命令生成模型响应后,我们需要 OpenAI API 密钥来对不同解码结果生成的响应进行成对比较。
python $fastchat/eval/eval_gpt_review.py -q $fastchat/eval/table/question.jsonl -a output-answer-1.jsonl output-answer-2.jsonl -p $fastchat/eval/table/prompt.jsonl -r $fastchat/eval/table/reviewer.jsonl -o output-review-path.jsonl -k openai_api_key
有关 GPT-4 评估的更多详细信息,请查看 vicuna-blog-eval。
参考仓库
- FastChat: https://github.com/lm-sys/FastChat
- ContrastiveDecoding: https://github.com/XiangLi1999/ContrastiveDecoding
- TruthfulQA: https://github.com/sylinrl/TruthfulQA
- zero_shot_cot: https://github.com/kojima-takeshi188/zero_shot_cot
- FederatedScope: https://github.com/alibaba/FederatedScope
引用
如果对我们的工作有帮助,请引用我们的论文!
@inproceedings{chuang2024dola,
title={DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models},
author={Yung-Sung Chuang and Yujia Xie and Hongyin Luo and Yoon Kim and James R. Glass and Pengcheng He},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=Th6NyL07na}
}
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。