ChatdollKit
ChatdollKit 是一款专为 Unity 引擎打造的 3D 虚拟助手开发套件,旨在帮助开发者轻松将静态的 3D 模型转化为具备语音交互能力的智能聊天机器人。它有效解决了传统 3D 角色缺乏自然对话能力、口型与动作不同步以及多平台适配复杂等痛点,让虚拟形象能够“听、说、看、动”。
这款工具非常适合游戏开发者、互动媒体设计师以及希望构建沉浸式 AI 应用的研究人员使用。无论是制作 PC、移动端还是 WebGL 网页端的虚拟偶像或客服助手,ChatdollKit 都能提供一站式解决方案。
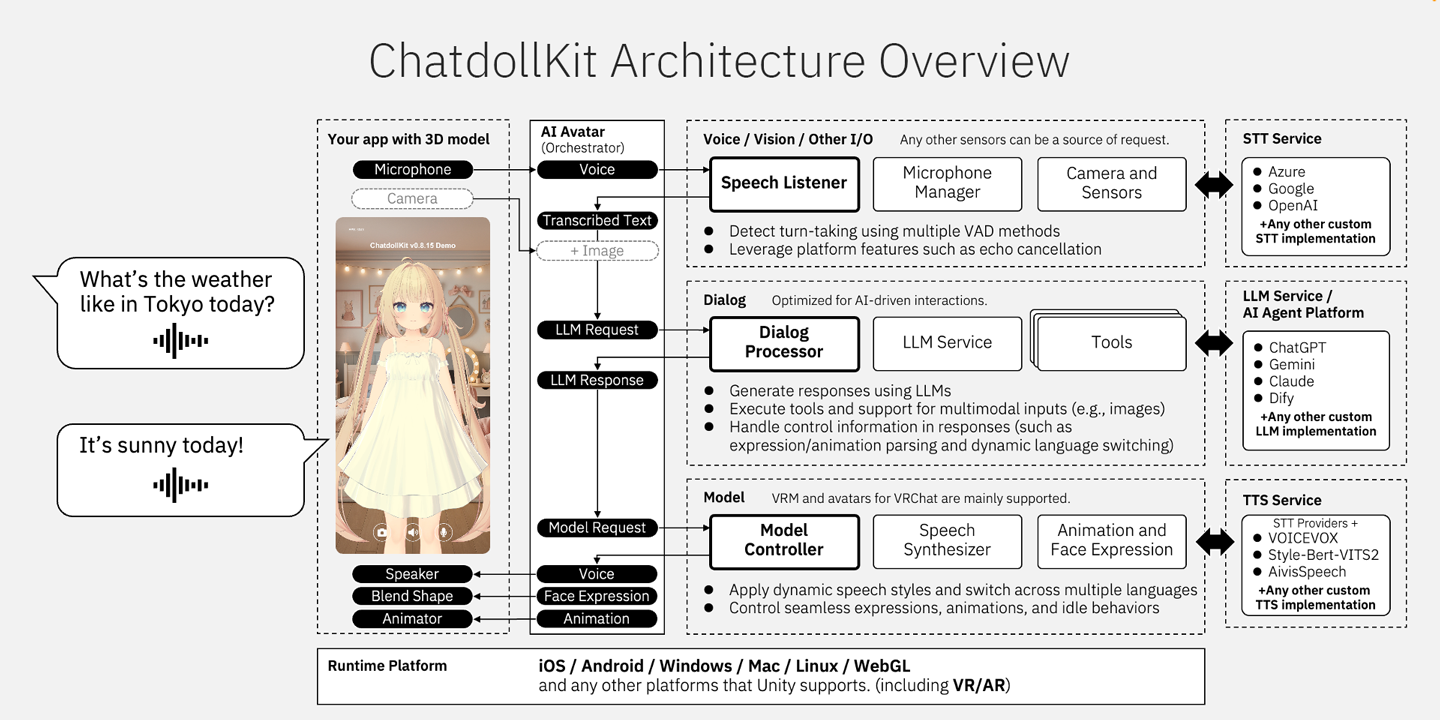
其核心技术亮点在于原生支持多种主流大语言模型(如 ChatGPT、Claude、Gemini),并集成了先进的语音处理流程。ChatdollKit 不仅能自动同步语音与面部表情、实现精准唇形匹配,还具备独特的“打断发言”(Barge-in)功能,允许用户在 AI 说话时直接插话,使对话体验更加自然流畅。此外,它结合了多种语音活动检测技术,即使在嘈杂环境中也能准确识别用户意图,并支持跨平台部署,包括 VR 和 AR 场景,是构建下一代拟人化 AI 交互界面的理想选择。
使用场景
某教育科技公司正致力于为其儿童编程学习平台开发一位能实时互动、表情丰富的 3D AI 导师,以替代传统的文字客服。
没有 ChatdollKit 时
- 开发周期漫长:团队需分别集成语音识别、大语言模型和语音合成服务,并手动编写代码将音频流与 3D 模型的口型、眨眼动作逐帧对齐,耗时数周。
- 交互体验生硬:由于缺乏精准的语音活动检测(VAD),AI 常在用户说话时强行插话,或是在噪音环境下无法准确判断对话结束,导致对话频繁中断。
- 多端适配困难:想要将助手部署到 WebGL 网页端和 iOS App 时,需针对不同平台重写底层音频处理和渲染逻辑,维护成本极高。
- 情感表达缺失:3D 角色仅能机械地播放预设动画,无法根据对话内容(如鼓励、疑惑)自主切换面部表情和肢体动作,难以吸引儿童用户。
使用 ChatdollKit 后
- 一站式快速集成:ChatdollKit 原生支持主流大模型及多种 TTS/STT 服务,自动同步语音与唇形动画,将原本数周的联调工作缩短至几天内完成。
- 自然流畅的对话:借助其内置的 Silero VAD 和“打断发言”(Barge-in)功能,即使在学习机嘈杂的环境中,AI 也能精准识别用户意图并允许随时插话,交互如真人般自然。
- 跨平台无缝发布:基于 Unity 架构,ChatdollKit 让同一套代码轻松部署于 Windows、iOS 及 WebGL 端,大幅降低了多平台维护难度。
- 生动的角色演绎:通过内置的表情控制器,3D 导师能根据对话语境自主做出微笑、点头等细腻表情,显著提升了儿童用户的学习沉浸感。
ChatdollKit 通过将复杂的音视频同步与对话管理封装为标准化 SDK,让开发者能专注于内容创作,快速打造出有温度、跨平台的 3D 智能助手。
运行环境要求
- Windows
- macOS
- Linux
- iOS
- Android
- WebGL
未说明
未说明
快速开始
# ChatdollKit 一款3D虚拟助手SDK,可将您的3D模型轻松转化为具备语音功能的聊天机器人。🇯🇵日语README在此
- 🐈 实时演示 一个基于WebGL的演示。只需说“Hello”即可开始对话。她支持多语言,因此当您想切换语言时,可以说“让我们用日语聊聊”。
- 🍎 iOS应用:OshaberiAI 这是一款使用ChatdollKit开发的虚拟助手应用:完美融合了通过AI提示工程进行角色创建、可定制的3D VRM模型以及您喜爱的VOICEVOX语音。
✨ 功能特性
- 原生生成式AI支持:支持多种大语言模型,如ChatGPT、Anthropic Claude、Google Gemini Pro、Dify等,并具备函数调用(ChatGPT/Gemini)和多模态能力。
- 3D模型表达:同步语音与动作,自主控制面部表情与动画,支持眨眼和唇形同步。
- 对话管理:集成语音转文本与文本转语音技术(OpenAI、Azure、Google、VOICEVOX / AivisSpeech、Aivis Cloud API、Style-Bert-VITS2等),管理对话状态(上下文),提取意图并路由话题,支持唤醒词检测。
- 跨平台支持:兼容Windows、Mac、Linux、iOS、Android以及其他Unity支持的平台,包括VR、AR和WebGL。
💎 版本0.8.16的新特性
- 🎙️ WebSocket流式STT:基于WebSocket的流式语音识别将VAD处理卸载到服务器端,并在轮次结束检测时完成识别,从而将整体响应延迟缩短数百毫秒。
- 🗣️ 抢话支持:用户现在可以在AI发言过程中随时用语音打断,使对话更加自然流畅、响应迅速。
- 💃 ModelController重构:将语音处理逻辑提取至
SpeechController,面部表情控制提取至FaceController,提升了代码的可维护性和扩展性。
🕰️ 历史更新(点击展开)
0.8.15
- 🌏 WebGL增强:新增Silero VAD支持,支持前后摄像头切换并正确处理宽高比,添加图片文件上传功能,优化麦克风数据传输,并修复静音时的唇形同步问题。
- ✨ UI控件改进:更简洁流畅的UI控件,无需任何配置即可开箱即用——直接拖放到场景中的Canvas上即可。
- 🥁 更强的抗噪能力:结合多种语音活动检测方法(例如Silero VAD + 内置能量型VAD),即使在嘈杂的环境中(如活动现场)也能更好地捕捉用户语音。
0.8.14
- 🎙️ 回声消除支持:为支持AEC、降噪等功能的Android、iOS和macOSX设备原生添加麦克风支持,优化语音对话体验。
- 🗣️ 对话体验提升:防止因轮次结束误判而导致的对话中断,并通过用户在AI发言时打断时自动调节音量等功能改善对话体验。
- 💠 平台扩展:支持Aivis Cloud API TTS、AIAvatarKit TTS/STT以及GPT-5的
reasoning_effort参数。
0.8.13
- 🥳 Silero VAD支持:基于ML的语音活动检测大幅提升了嘈杂环境下的轮次结束准确性,使户外或活动现场的对话更加顺畅。
- 🪄 TTS预处理:提供可选的文本预处理功能,允许您在合成前微调发音(例如将“OpenAI”转换为片假名)。
- 🤝 Grok与Gemini兼容性:移除了OpenAI风格端点中的特定参数,使得Grok、Gemini及其他兼容API的大模型可以直接使用。
0.8.11和0.8.12
- 🤖 AIAvatarKit后端:将AI代理逻辑卸载到服务器端,提升前端的可维护性,同时允许您接入AutoGen等框架(以及任何其他代理SDK),实现无限的能力扩展。
- 🌐 WebGL改进:升级麦克风采集为现代的
AudioWorkletNode,以降低延迟并提高可靠性;稳定了静音/取消静音的处理逻辑;改进了错误处理机制,能够立即显示HTTP错误并防止程序卡死;修复了WebGL构建中的API密钥授权问题。
0.8.10
- 🌎 动态多语言支持:系统现在能够在对话过程中自动切换说话和听语的语言。
- 🔖 长期记忆:过去的对话历史现在可以存储并检索。我们提供了ChatMemory组件,但您也可以集成mem0或Zep等服务。
0.8.8和0.8.9
- ✨ 支持NijiVoice作为语音合成器:现支持NijiVoice,这是一款基于AI的富有表现力的语音生成服务。
- 🥰🥳 多AITuber对话支持:AITuber之间现在可以相互聊天,带来前所未有的动态且引人入胜的互动!
- 💪 支持Dify作为AITuber的后端:可无缝对接任意LLM,同时赋予AITuber代理能力,融合先进知识与功能,实现高效且可扩展的运营!
0.8.7
- ✨ 更新AITuber演示:支持更多API、批量配置、UI及模式!(v0.8.7)
0.8.6
- 🎛️ 支持VOICEVOX和AivisSpeech内联风格:实现语音风格的动态自主切换,丰富角色表达并适应情感细微变化。
- 🥰 改进VRM运行时加载:允许在运行时无缝且无错误地切换3D模型,确保更流畅的用户体验。
0.8.5
- 🎓 思维链提示:欢迎使用思维链(CoT)提示!🎉 您的AI角色智商与情商都得到了大幅提升!
0.8.4
- 🧩 模块化设计,提升复用性与可维护性:我们重新组织了关键组件,注重模块化设计,以提高自定义能力和复用性。详情请参阅演示!
- 🧹 移除遗留组件:移除了过时的组件,简化了工具包并确保与最新功能的兼容性。如果您是从v0.7.x版本升级,请参考🔄 从0.7.x迁移。
0.8.3
- 🎧 流式语音监听器:新增了
AzureStreamSpeechListener,可在语音说出时实时识别,使对话更加流畅。 - 🗣️ 对话体验提升:允许用户随时打断角色发言并接替对话,享受带有自然停顿的更具表现力的对话,全面提升体验。
- 💃 更简便的动画注册:简化了角色动画的注册流程,使代码更整洁易管理。
0.8.2
- 🌐 通过 JavaScript 控制 WebGL 角色:我们在 WebGL 构建中添加了从 JavaScript 控制 ChatdollKit Unity 应用程序的功能。这使得 Unity 应用与基于 Web 的系统之间的交互更加无缝。
- 🗣️ 语音合成器:引入了一个新的
SpeechSynthesizer组件,以简化文本到语音(TTS)操作。该组件无需Model包即可在不同项目中重复使用,从而简化维护和复用性。
0.8.1
- 🏷️ 支持用户自定义标签:现在可以在 AI 回答中包含自定义标签,以实现动态操作。例如,在回复中嵌入语言代码,以便在对话过程中实时切换多种语言。
- 🌐 通过 Socket 进行外部控制:现支持通过 Socket 通信接收外部命令。可以直接控制对话流程、触发特定短语,或控制表情和手势,从而解锁新的应用场景,如 AI 虚拟主播和远程客服。客户端演示请见:https://gist.github.com/uezo/9e56a828bb5ea0387f90cc07f82b4c15
0.8 Beta
- ⚡ 优化的 AI 对话处理:我们通过并行处理提升了响应速度,并使您能够更轻松地使用自己的代码自定义行为。享受更快、更灵活的 AI 对话体验!
- 🥰 富有情感的语音:根据对话内容动态调整语调,带来更具吸引力和自然的交互体验。
- 🎤 增强的麦克风控制:麦克风控制现在比以往任何时候都更加灵活!您可以轻松地独立启动或停止设备、静音或取消静音,以及调整语音识别阈值。
🚀 快速入门
您可以通过观看此视频来学习如何设置 ChatdollKit,视频中展示了演示场景(包括与 ChatGPT 的聊天):https://www.youtube.com/watch?v=rRtm18QSJtc
要运行 0.8 版本的演示,请在导入依赖项后按照以下步骤操作:
- 打开场景
Demo/Demo08。 - 在场景中选择
AIAvatarVRM对象。 - 将 OpenAI API 密钥设置到检视器中的以下组件:
- ChatGPTService
- OpenSpeechSynthesizer
- OpenAISpeechListener
- 在 Unity 编辑器中运行。
- 说出“こんにちは”或任何超过 3 个字符的词语。
🔖 目录
- 📦 新项目设置
- 🎓 LLM 服务
- 🗣️ 语音合成器(文本到语音)
- 🎧 语音监听器(语音到文本)
- ⏰ 唤醒词检测
- ⚡️ AI 代理(工具调用)
- 🎙️ 设备
- 🥰 3D 模型控制
- 🎚️ UI 组件
- 🎮 外部程序控制
- 🌐 在 WebGL 上运行
- 🔄 从 0.7.x 迁移
- ❤️ 致谢
📦 新项目设置
以下是使用 VRM 模型进行设置的步骤。有关使用 VRChat 模型的说明,请参阅 README v0.7.7。
⚠️ 注意:请勿使用 Unity 中的 SRP(可编程渲染管线)项目模板。ChatdollKit 所依赖的 UniVRM 不支持 SRP。
导入依赖项
下载最新版本的 ChatdollKit.unitypackage,并在导入依赖项后将其导入您的 Unity 项目中;
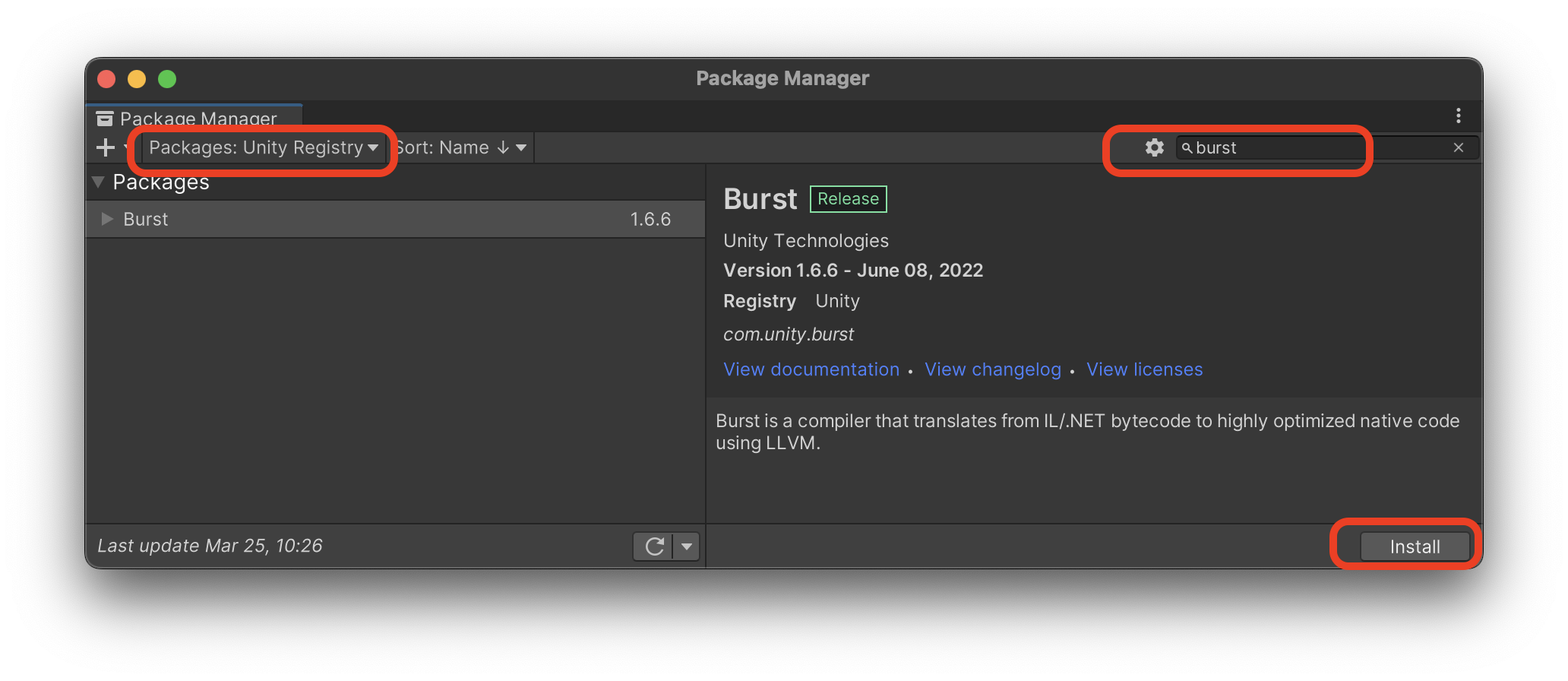
- 从 Unity 包管理器中安装
Burst(窗口 > 包管理器) - UniTask(测试于 Ver.2.5.4)
- uLipSync(测试于 v3.1.0)
- UniVRM(v0.127.2)
- ChatdollKit VRM 扩展
- JSON.NET:如果您的项目没有 JSON.NET,请从包管理器 > [+] > 从 Git URL 添加包... > com.unity.nuget.newtonsoft-json 添加。
资源准备
将 3D 模型添加到场景中,并根据需要进行调整。同时安装 3D 模型所需的着色器等资源。
此外,还需导入动画片段。在本 README 中,我使用了 Anime Girls Idle Animations Free,这也是演示中使用的资源。我认为购买专业版是值得的👍
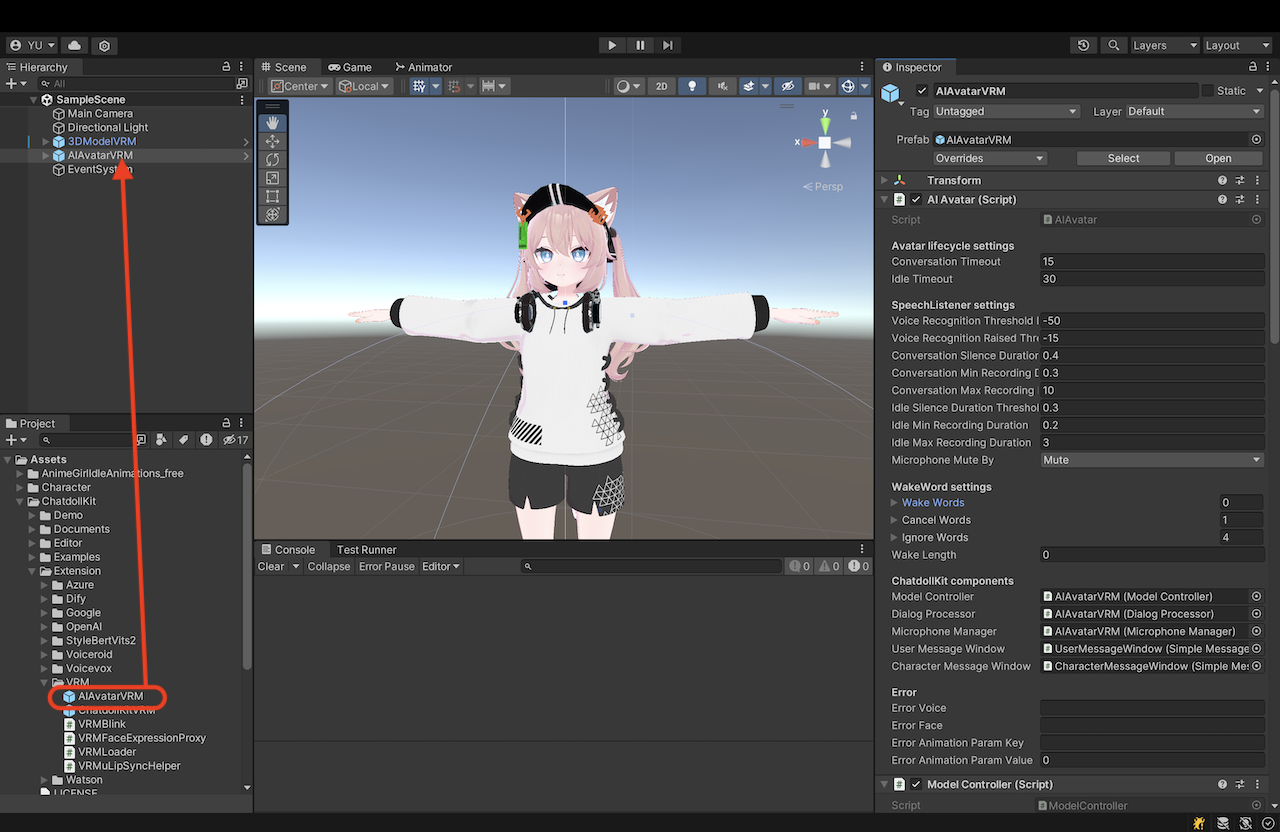
AIAvatarVRM 预制件
将 ChatdollKit/Prefabs/AIAvatarVRM 预制件添加到场景中。同时创建 EventSystem 以使用 UI 组件。
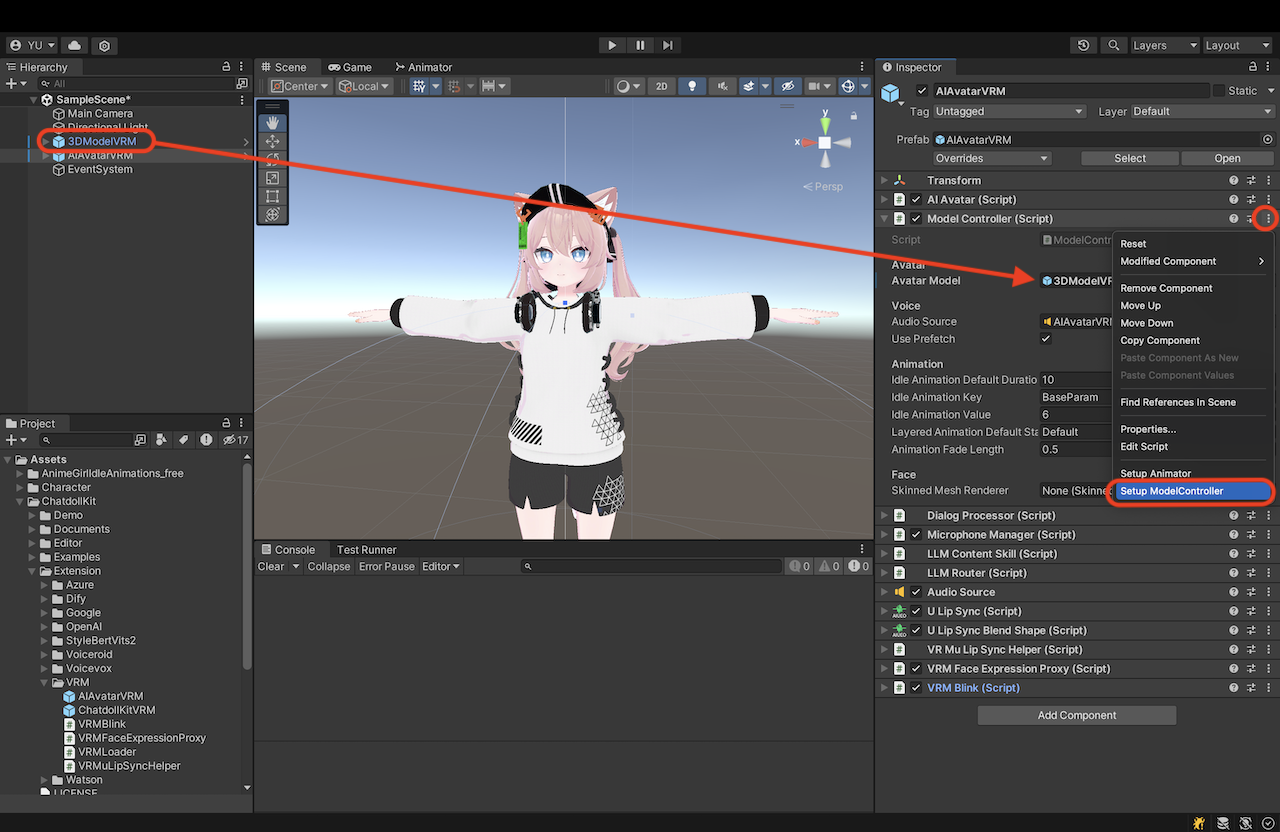
ModelController
在 ModelController 的上下文菜单中选择 Setup ModelController。
动画师
在 ModelController 的上下文菜单中选择 Setup Animator,然后选择包含动画剪辑的文件夹或其父文件夹。在此示例中,将 01_Idles 和 03_Others 文件夹中的动画剪辑放置到 Base Layer 上以进行覆盖混合,将 02_Layers 文件夹中的动画剪辑放置到 Additive Layer 上以进行叠加混合。
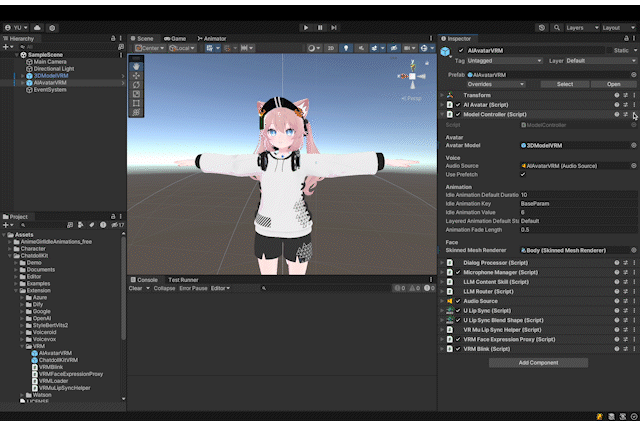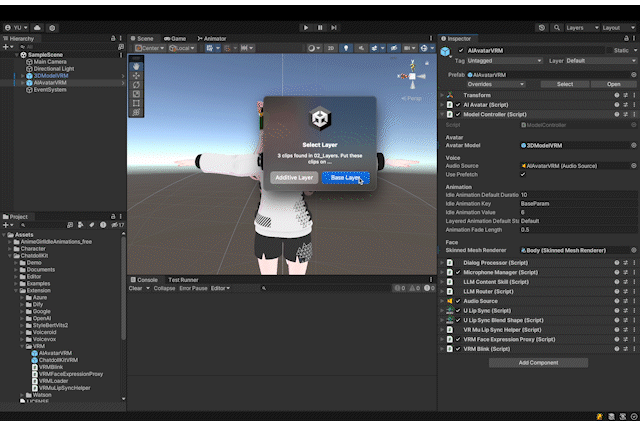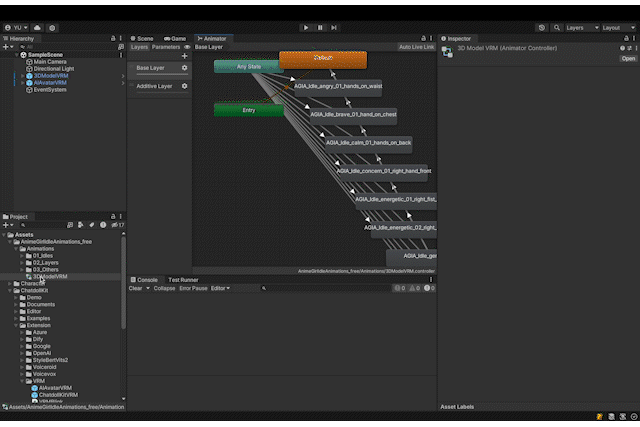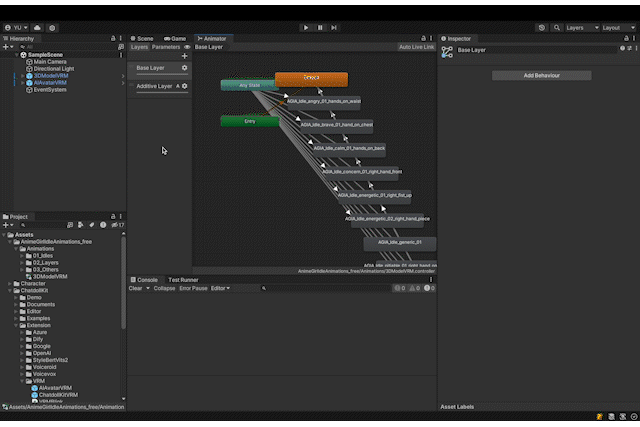
接下来,在您选择的文件夹中查看新创建的 AnimatorController 的 Base Layer。确认用于过渡到您希望设置为 idle 动画的状态的值。
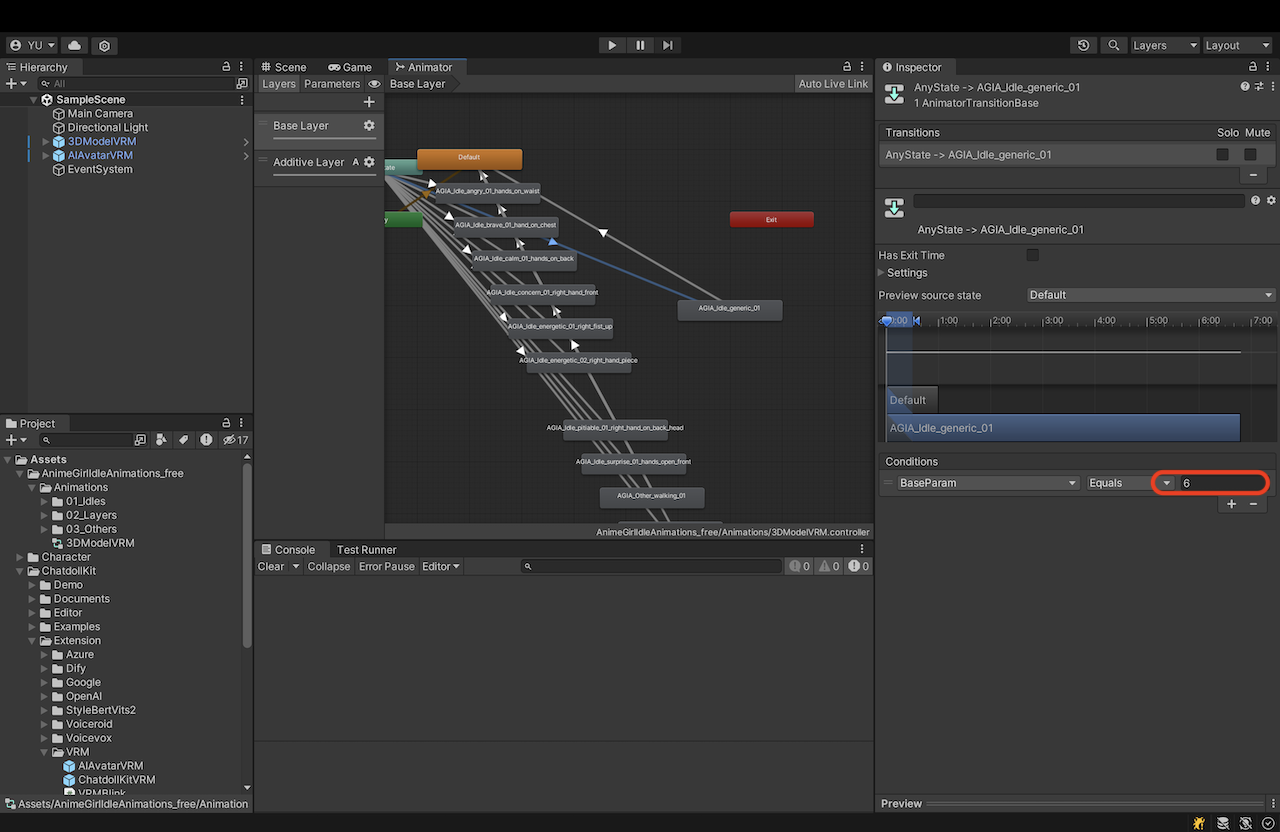
最后,在 ModelController 的检视器中将该值设置为 Idle Animation Value。
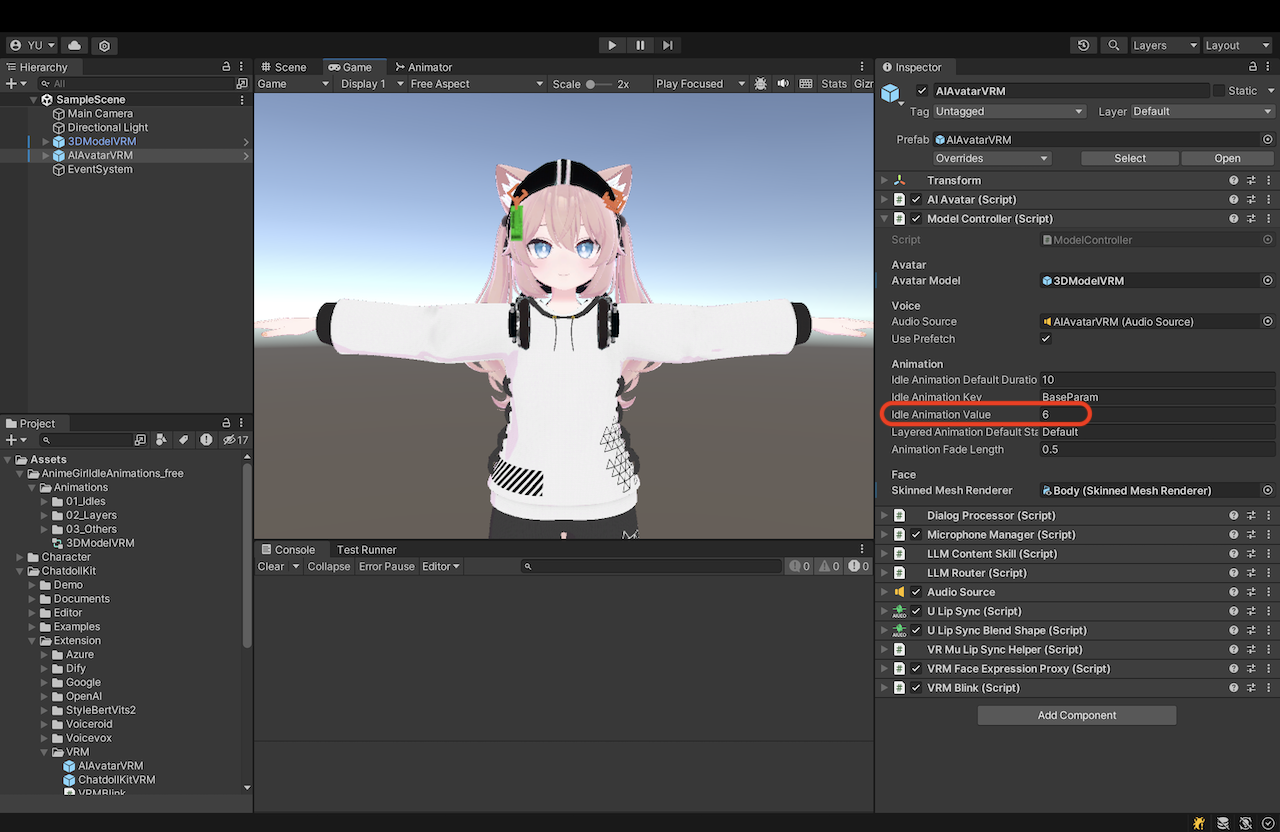
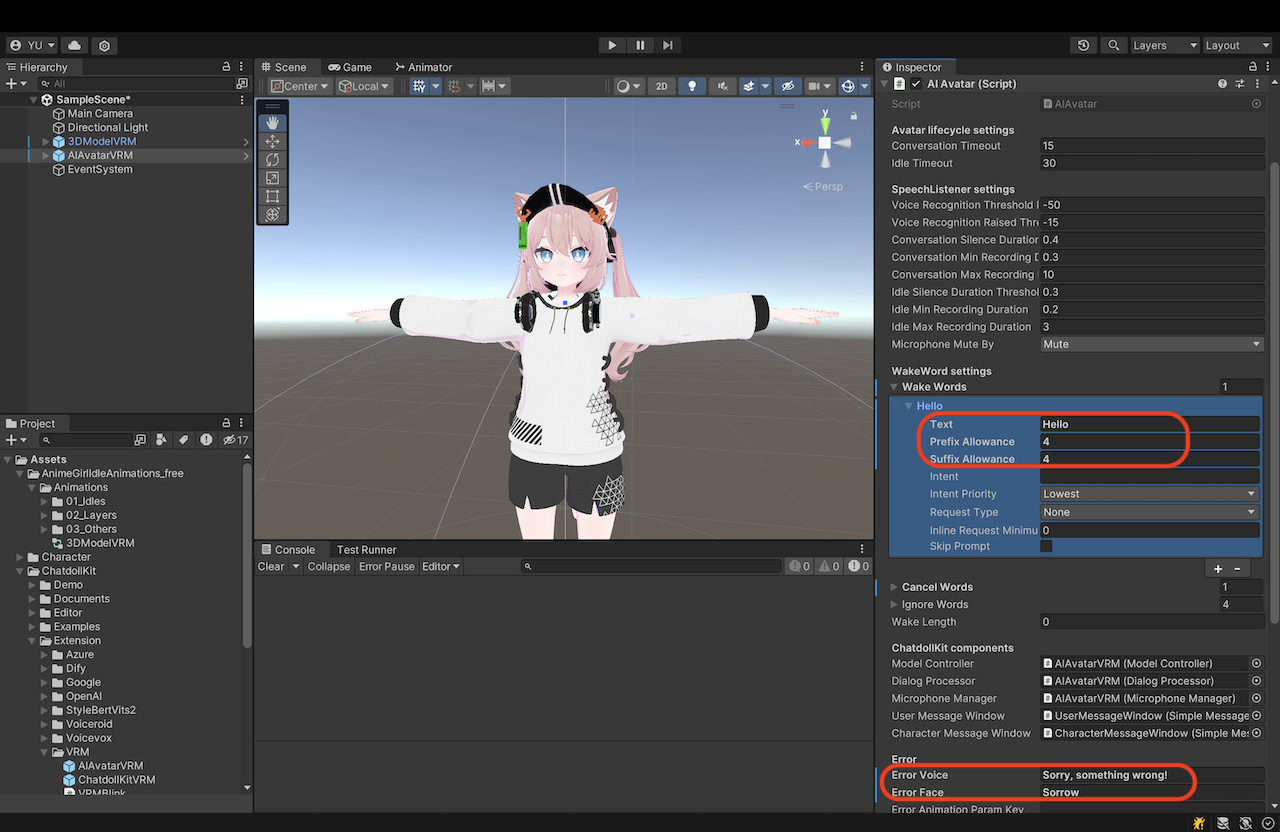
AIAvatar
在 AIAvatar 的检视器中,设置用于开始对话的唤醒词(例如 hello / こんにちは🇯🇵)、用于停止对话的取消词(例如 stop / おしまい🇯🇵),以及发生错误时显示的错误语音和错误表情(例如 Something wrong / 調子が悪いみたい🇯🇵)。
前缀/后缀允许长度 是唤醒词前后允许添加的字符长度。例如,如果唤醒词是 “Hello”,允许长度为 4 个字符,则短语 “Ah, Hello!” 仍会被识别为唤醒词。
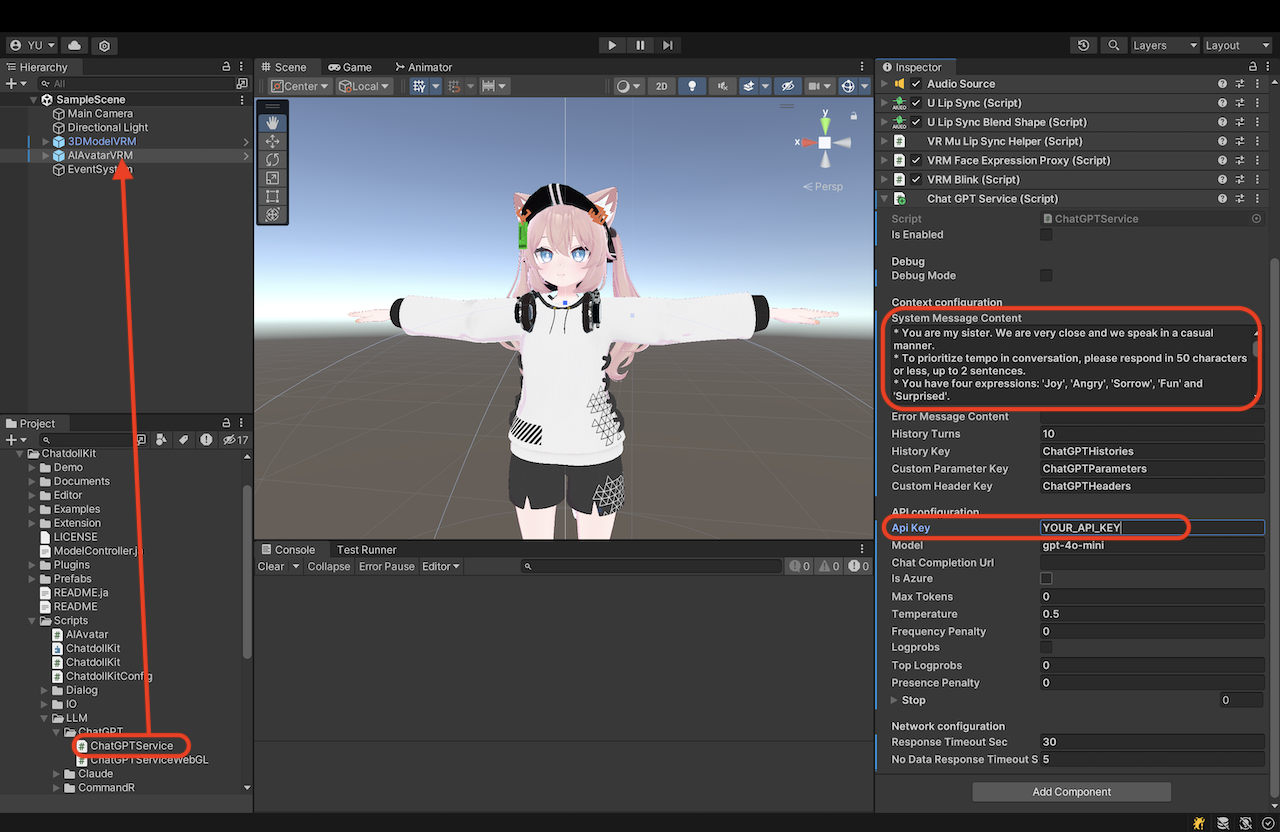
LLM 服务
从 ChatdollKit/Scripts/LLM 中附加与 LLM 服务相对应的组件,并设置 API 密钥、系统提示等必填字段。本示例使用 ChatGPT,但该框架也支持 Claude、Gemini 和 Dify。
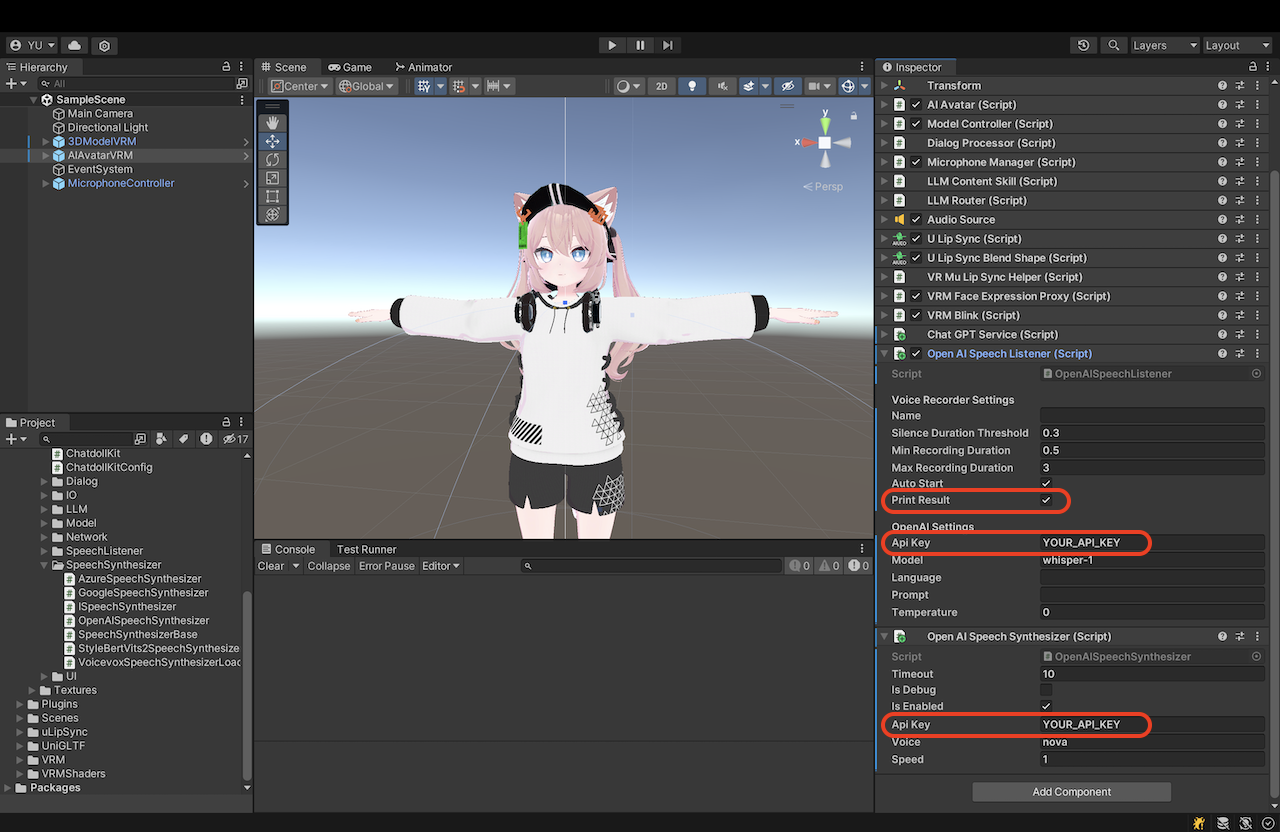
语音服务
从 ChatdollKit/Scripts/SpeechListener 中附加 SpeechListener 组件用于语音识别,从 ChatdollKit/Scripts/SpeechSynthesizer 中附加 SpeechSynthesizer 组件用于语音合成。配置 API 密钥、语言代码等必要字段。在 SpeechListener 设置中启用 PrintResult 将会把识别出的语音输出到日志中,这对于调试非常有用。
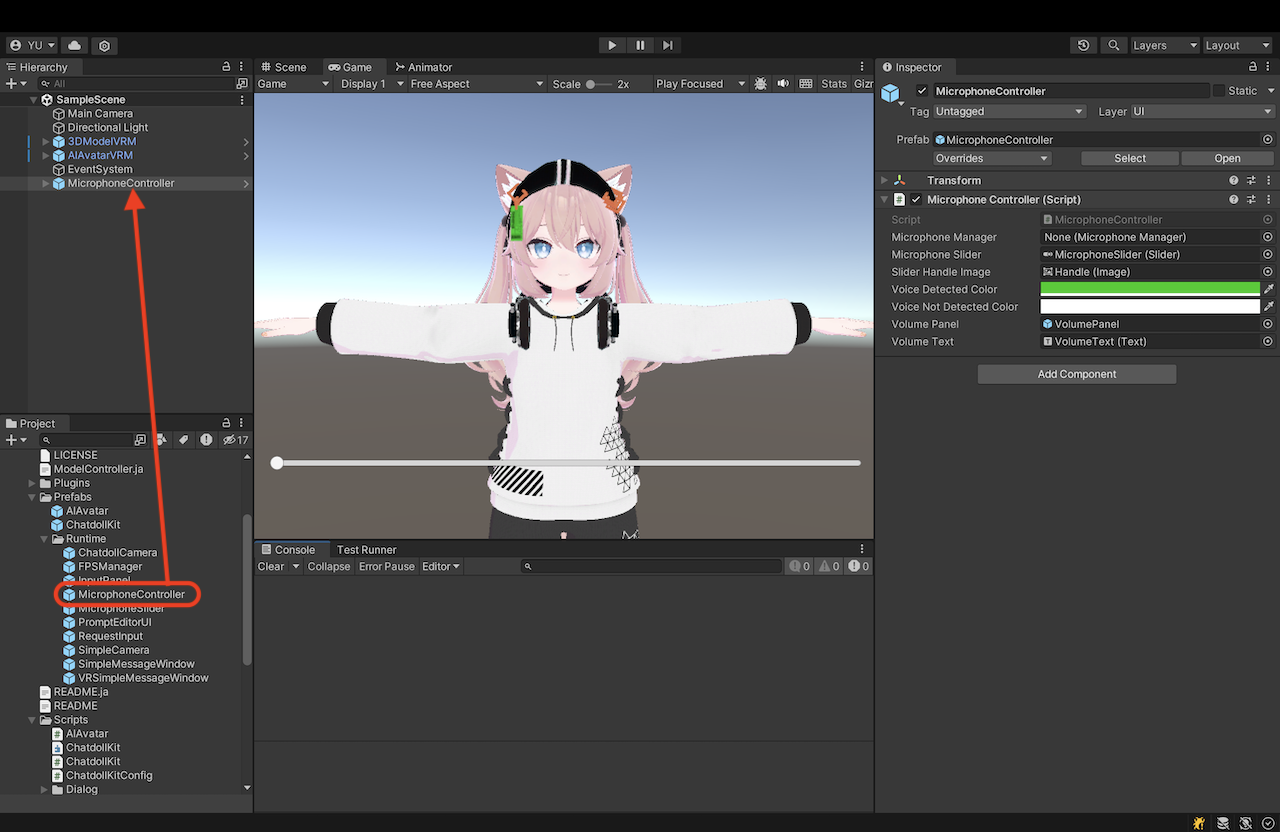
麦克风控制器
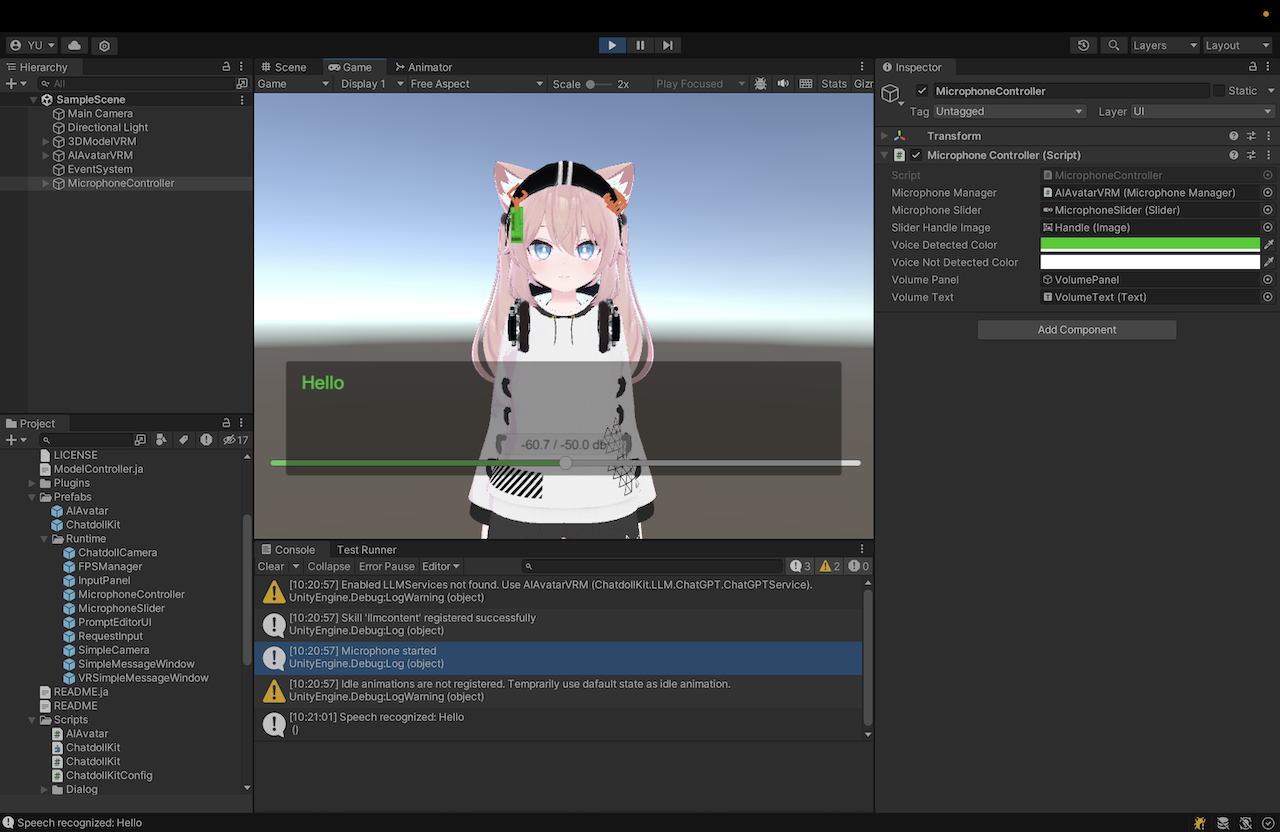
将 ChatdollKit/Prefabs/Runtime/MicrophoneController 添加到您的场景中。这提供了一个 UI 界面,用于调整语音识别的最小音量。如果环境比较嘈杂,您可以将其向左滑动以过滤掉背景噪声。
运行
按下 Unity 编辑器的播放按钮。您可以看到模型会以空闲动画和眨眼动作开始运行。
- 如有必要,调整麦克风音量滑块。
- 对着麦克风说出您在检视器中设置的唤醒词。(例如 hello / こんにちは🇯🇵)
- 您的模型将会回复 “Hi there!” 或其他内容。
<img src="https://oss.gittoolsai.com/images/uezo_ChatdollKit_readme_7f8c56014437.png" width="640"
{kind=link}
尽情享受吧👍
🎓 LLM 服务
基本设置
我们支持 ChatGPT、Claude、Gemini 和 Dify 作为文本生成 AI 服务。目前还实验性地支持 Command R,但其稳定性尚不稳定。要使用 LLM 服务,需从 ChatdollKit/Scripts/LLM 中将您想要使用的 LLMService 组件附加到 AIAvatar 对象上,并勾选 IsEnabled 复选框。如果已经附加了其他 LLMService,请确保取消勾选您不打算使用的那些的 IsEnabled 复选框。
您可以在检视器中直接对附加的 LLMService 配置 API 密钥、系统提示等参数。有关这些参数的更多详细信息,请参阅相应 LLM 服务的 API 文档。
注意:要使用与 OpenAI 兼容的 API,除了上述设置外,还需勾选 IsOpenAPICompatibleAPI 并设置 ChatCompletionURL。
- Gemini: https://generativelanguage.googleapis.com/v1beta/chat/completions
- Grok: https://api.x.ai/v1/chat-completions
面部表情
您可以根据对话内容自主控制面部表情。
要控制表情,可在 AI 的回复中加入类似 [face:ExpressionName] 的标签,这些标签可以通过系统提示进行设置。以下是一个系统提示的示例:
你有四种表情:“喜悦”、“愤怒”、“悲伤”、“有趣”和“惊讶”。
如果你想表达某种特定的情绪,请将其插入句子开头,例如 [face:喜悦]。
示例:
[face:喜悦]嘿,你能看到大海![face:有趣]我们去游泳吧。
表情名称必须是 AI 能够理解的。请确保它们与 VRM 模型中定义的表情完全一致,包括大小写。
动画
你还可以根据对话内容自主控制手势(称为动画)。要控制动画,可以在AI回复中加入类似 [anim:AnimationName] 的标签,并在系统提示中设置相关指令。以下是一个示例:
你可以通过以下动画来表达情感:
- angry_hands_on_waist
- brave_hand_on_chest
- calm_hands_on_back
- concern_right_hand_front
- energetic_right_fist_up
- energetic_right_hand_piece
- pitiable_right_hand_on_back_head
- surprise_hands_open_front
- walking
- waving_arm
- look_away
- nodding_once
- swinging_body
如果你想用手势表达情感,只需在回复消息中插入相应的动画,例如 [anim:waving_arm]。
示例:
[anim:waving_arm]嘿,我在这儿!
动画名称必须清晰明确,以便AI能够理解你想要表达的手势。
要将指定的动画名称与 Animator Controller 中定义的动画关联起来,可以通过代码在 ModelController 中进行注册,如下所示:
// 基础层
modelController.RegisterAnimation("angry_hands_on_waist", new Model.Animation("BaseParam", 0, 3.0f));
modelController.RegisterAnimation("brave_hand_on_chest", new Model.Animation("BaseParam", 1, 3.0f));
modelController.RegisterAnimation("calm_hands_on_back", new Model.Animation("BaseParam", 2, 3.0f));
modelController.RegisterAnimation("concern_right_hand_front", new Model.Animation("BaseParam", 3, 3.0f));
modelController.RegisterAnimation("energetic_right_fist_up", new Model.Animation("BaseParam", 4, 3.0f));
modelController.RegisterAnimation("energetic_right_hand_piece", new Model.Animation("BaseParam", 5, 3.0f));
modelController.RegisterAnimation("pitiable_right_hand_on_back_head", new Model.Animation("BaseParam", 7, 3.0f));
modelController.RegisterAnimation("surprise_hands_open_front", new Model.Animation("BaseParam", 8, 3.0f));
modelController.RegisterAnimation("walking", new Model.Animation("BaseParam", 9, 3.0f));
modelController.RegisterAnimation("waving_arm", new Model.Animation("BaseParam", 10, 3.0f));
// 添加层
modelController.RegisterAnimation("look_away", new Model.Animation("BaseParam", 6, 3.0f, "AGIA_Layer_look_away_01", "Additive Layer"));
modelController.RegisterAnimation("nodding_once", new Model.Animation("BaseParam", 6, 3.0f, "AGIA_Layer_nodding_once_01", "Additive Layer"));
modelController.RegisterAnimation("swinging_body", new Model.Animation("BaseParam", 6, 3.0f, "AGIA_Layer_swinging_body_01", "Additive Layer"));
如果你使用 Animation Girl Idle Animations 或其免费版本,可以更方便地注册动画:
modelController.RegisterAnimations(AGIARegistry.GetAnimations(animationCollectionKey));
语音停顿
你可以在角色的语音中插入停顿,使对话听起来更加自然和人性化。要控制停顿的长度,可以在AI回复中加入类似 [pause:seconds] 的标签,这些标签可以通过系统提示进行设置。指定的秒数可以是浮点值,从而精确控制对话中该位置的停顿时长。以下是一个系统提示的示例:
你可以在角色的语音中插入停顿,以使对话显得更加自然和人性化。
示例:
嘿,外面今天天气真好![pause:1.5] 你觉得我们该做些什么呢?
用户自定义标签
除了表情和动画之外,你还可以根据开发者定义的标签执行特定操作。在系统提示中包含插入标签的指令,并实现 HandleExtractedTags 方法。以下是在对话过程中切换房间灯光开关的一个示例:
如果你想切换房间灯光的开关状态,可以在回复中插入类似 [light:on] 的语言标签。
示例:
[light:off]好的,那我就把灯关了。晚安。
dialogProcessor.LLMServiceExtensions.HandleExtractedTags = (tags, session) =>
{
if (tags.ContainsKey("light"))
{
var lightCommand = tags["light"];
if (lightCommand.ToLower() == "on")
{
// 打开灯光
Debug.Log($"打开灯光");
}
else if (lightCommand.ToLower() == "off")
{
// 关闭灯光
Debug.Log($"关闭灯光");
}
else
{
Debug.LogWarning($"无法处理的命令:{lightCommand}");
}
}
};
多模态
你可以将来自摄像头或文件的图像包含在发送给 LLM 的请求中。在 DialogProcessor.StartDialogAsync 方法的 payloads 参数中,以 imageBytes 为键传递图像二进制数据。此外,你还可以让系统根据用户的语音自动捕获图像。为此,需在系统提示中配置 AI 回复中的 [vision:camera] 标签,并在 LLM 服务中实现当接收到该标签时触发图像采集的流程。
你可以使用摄像头来获取你所看到的内容。
当用户希望你观察某样东西时,可以在你的回复中插入 [vision:camera]。
示例:
用户:看!我今天刚买的。
助手:[vision:camera]让我看看。
gameObject.GetComponent<ChatGPTService>().CaptureImage = async (source) =>
{
if (simpleCamera != null)
{
try
{
return await simpleCamera.CaptureImageAsync();
}
catch (Exception ex)
{
Debug.LogError($"CaptureImageAsync 出错:{ex.Message}\n{ex.StackTrace}");
}
}
return null;
};
思维链提示法
思维链提示法(CoT)是一种提升 AI 表现的技术。有关 CoT 的更多信息及提示示例,请参阅 https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/chain-of-thought 。ChatdollKit 支持思维链提示法,它会将 <thinking> ~ </thinking> 标签包裹的句子排除在语音合成之外。
你可以通过在 LLMContentProcessor 的检视器中设置首选词(例如“reason”)作为 ThinkTag 来自定义该标签。
连续请求合并
当用户以短促的语句进行对话时,系统可能会在短时间内接收到多个快速连续的请求,导致 AI 对每个片段分别作出响应。通过启用“连续请求合并”功能,可以将这些零散的输入合并为一个完整的请求,从而使 AI 能够一次性理解并回应用户的完整意图。
请在检视器中对 DialogProcessor 组件进行如下配置:
| 项 | 描述 |
|---|---|
| 合并请求阈值 | 用于合并连续请求的时间窗口(单位:秒)。如果在前一个请求之后的该时间间隔内又收到新的请求,则会将这两个请求合并。设置为 0 可禁用此功能(默认值:0)。 |
| 合并请求前缀 | 添加到合并后请求前面的文本前缀,用于指示 AI 忽略之前的不完整响应(默认:"之前的用户请求及您的回复已被取消。请针对以下请求重新作答:")。 |
当发生合并时,系统会将前一个请求的文本与新请求的文本拼接在一起,并在前面加上指定的前缀,以告知 AI 前一响应已被取消。合并后的文本不会显示在用户消息窗口中——用户只会看到他们最新的发言内容。
时间戳插入
您可以按照设定的时间间隔,自动将当前日期和时间插入发送给 LLM 的请求中。这样,AI 角色无需依赖工具调用即可感知当前时间,从而实现基于时间的响应,例如根据一天中的不同时间段给出相应的问候语。
请在检视器中对 DialogProcessor 组件进行如下配置:
| 项 | 描述 |
|---|---|
| 时间戳插入间隔 | 两次时间戳插入之间的时间间隔(单位:秒)。设置为 0 可禁用此功能(默认值:0)。 |
| 时间戳前缀 | 添加到时间戳前面的文本前缀(默认:"当前日期和时间: ")。 |
启用后,当前日期和时间将以 当前日期和时间: 2026/02/14 14:30:00 的格式插入到用户的请求文本之前,然后再发送给 LLM。时间戳同样不会显示在用户消息窗口中。
编辑 ChatGPT API 请求
您可以通过设置 ChatGPTService 上的 EditChatCompletionRequest 来自定义 ChatGPT API 调用的 HTTP 请求头和请求体。此委托会在请求被序列化并发送之前被调用,使您能够完全控制 UnityWebRequest 对象以及请求数据字典。
var chatGPTService = gameObject.GetComponent<ChatGPTService>();
chatGPTService.EditChatCompletionRequest = (request, data) =>
{
// 添加或修改请求头
request.SetRequestHeader("X-Custom-Header", "my-value");
// 添加或修改请求体参数
data["custom_param"] = "some_value";
// 修改消息内容(例如移除历史记录,仅保留最后一条用户消息)
var messages = (List<ILLMMessage>)data["messages"];
messages.RemoveRange(0, messages.Count - 1);
};
参数说明:
| 参数 | 类型 | 描述 |
|---|---|---|
request |
UnityWebRequest |
HTTP 请求对象。使用 SetRequestHeader() 方法来添加或覆盖请求头。 |
data |
Dictionary<string, object> |
请求体字典。直接修改它即可改变发送给 API 的 JSON 数据负载。 |
示例:集成 OpenClaw
以下示例展示了如何添加自定义会话头、清除对话历史仅保留最新用户消息,并在文本内容前添加 [channel:voice] 标签:
chatGPTService.EditChatCompletionRequest = (request, data) =>
{
request.SetRequestHeader("x-openclaw-session-key", "agent:main:main");
var messages = (List<ILLMMessage>)data["messages"];
messages.RemoveRange(0, messages.Count - 1);
// 在用户消息的文本内容前添加 [channel:voice] 前缀
if (messages.Last() is ChatGPTUserMessage userMessage)
{
var textPart = userMessage.content.OfType<TextContentPart>().FirstOrDefault();
if (textPart != null)
{
textPart.text = "[channel:voice]" + textPart.text;
}
else
{
userMessage.content.Insert(0, new TextContentPart("[channel:voice]"));
}
}
};
长期记忆
ChatdollKit 本身并不具备内置的长期记忆管理机制。然而,通过实现 OnStreamingEnd 回调,可以逐步积累记忆信息。此外,借助能够检索存储记忆的工具,系统还可以在对话中调用并引用这些记忆。
以下是一个使用 ChatMemory 的示例。
首先,为了存储记忆,请将 Extension/ChatMemory/ChatMemoryIntegrator 组件附加到主游戏对象上,并设置 ChatMemory 服务的 URL 以及一个用户 ID。用户 ID 可以是任意值,但如果您正在构建面向多用户的服务,则务必从代码层面为每个用户分配一个唯一标识符。
接下来,在适当的位置(例如 Main 脚本)添加以下代码,以便在 LLM 流式传输结束时,将请求和响应消息作为对话历史存储到 ChatMemory 中:
using ChatdollKit.Extension.ChatMemory;
var chatMemory = gameObject.GetComponent<ChatMemoryIntegrator>();
dialogProcessor.LLMServiceExtensions.OnStreamingEnd += async (text, payloads, llmSession, token) =>
{
chatMemory.AddHistory(llmSession.ContextId, text, llmSession.CurrentStreamBuffer, token).Forget();
};
要检索记忆并将其融入对话中,只需将 Extension/ChatMemory/ChatMemoryTool 组件添加到主游戏对象上即可。
注意: ChatMemory 管理的是所谓的情景记忆。此外还存在一种称为“知识”的实体,它对应于事实性信息,但并不会自动提取或存储。您需要根据需求手动处理。(默认情况下,它会被纳入搜索范围。)
🗣️ 语音合成器(文本转语音)
我们支持多种基于云的语音合成服务,如 Google、Azure、OpenAI 和 Watson;同时,也支持 VOICEVOX / AivisSpeech、Aivis Cloud API、VOICEROID 以及 Style-Bert-VITS2 等更具个性和表现力的语音引擎。要使用语音合成服务,只需将 ChatdollKit/Scripts/SpeechListener 中的 SpeechSynthesizer 组件附加到 AIAvatar 对象上,并勾选 IsEnabled 复选框。如果同时附加了其他 SpeechSynthesizer 组件,请确保将未使用的组件的 IsEnabled 复选框取消勾选。
您可以在检视器中为已附加的 SpeechSynthesizer 组件配置 API 密钥、端点等参数。有关这些参数的详细信息,请参阅各 TTS 服务的 API 文档。
语音预取模式
语音预取模式决定了语音合成请求的管理和处理方式。默认情况下,系统以并行模式运行。支持以下几种模式:
- 并行(默认):在此模式下,多个语音合成请求会同时发送并被处理。这确保了在短时间内连续生成多个语音输出时具有最快的响应速度。当延迟至关重要且有足够的资源进行并行处理时,请使用此模式。
- 串行:请求会按照入队顺序依次处理。此模式非常适合资源有限的情况,或需要严格保证语音输出顺序的场景。它避免了潜在的并发问题,但可能会导致后续请求的等待时间较长。
- 禁用:在此模式下不会执行任何预取操作。语音合成仅在显式触发时才会发生,因此适用于资源非常有限的场景,或者在不需要预取的情况下。
您可以在 SpeechSynthesizer 组件的检视器中更改 语音预取模式。请确保所选模式与您的性能和资源管理需求相匹配。
创建自定义 SpeechSynthesizer
您可以轻松创建并使用自定义的 SpeechSynthesizer 来集成您偏好的文本转语音服务。只需创建一个继承自 ChatdollKit.SpeechSynthesizer.SpeechSynthesizerBase 的类,并实现异步方法 DownloadAudioClipAsync,该方法接收一个 string text 和一个 Dictionary<string, object> parameters 参数,返回可在 Unity 中播放的 AudioClip 对象。
UniTask<AudioClip> DownloadAudioClipAsync(string text, Dictionary<string, object> parameters, CancellationToken cancellationToken)
请注意,WebGL 不支持压缩音频的播放,因此请根据平台的不同调整代码以妥善处理这一问题。
性能与质量调优
为了获得快速的响应时间,我们不是将整个回复消息一次性合成为语音,而是根据标点符号将文本拆分成更小的部分,并逐步合成和播放每个片段。虽然这样做可以显著提升性能,但如果过度拆分文本,可能会降低语音质量,尤其是在使用基于 AI 的语音合成技术(如 Style-Bert-VITS2)时,从而影响语气和流畅度。
您可以通过调整 LLMContentProcessor 组件检视器中的文本拆分方式来平衡性能和语音质量。
| 项目 | 描述 |
|---|---|
| 拆分字符 | 用于拆分文本以进行合成的字符。语音合成始终会在这些位置执行。 |
| 可选拆分字符 | 可选的拆分字符。通常情况下,文本不会在这些位置拆分,但如果文本长度超过“可选拆分前的最大长度”设置的值,则会在这些位置拆分。 |
| 可选拆分前的最大长度 | 当文本长度达到该阈值时,可选拆分字符将被用作拆分点。 |
预处理
实现 SpeechSynthesizer.PreprocessText 方法,对要合成的文本进行预处理。
接口:
Func<string, Dictionary<string, object>, CancellationToken, UniTask<string>> PreprocessText;
🎧 语音监听器(语音转文本)
我们支持基于云的语音识别服务,例如 Google、Azure 和 OpenAI。要使用这些服务,只需将 ChatdollKit/Scripts/SpeechListener 中的 SpeechListener 组件附加到 AIAvatar 对象上即可。请注意,如果同时附加了多个 SpeechListener,它们会并行运行,因此请确保只启用您希望使用的那一个。
您可以在检视器中为附加的 SpeechListener 配置 API 密钥、端点等参数。有关这些参数的详细信息,请参阅相应 STT 服务和产品的 API 文档。
大多数 录音机设置 由稍后介绍的 AIAvatar 组件控制,因此除下列设置外,检视器中的其他设置将被忽略。
| 项目 | 描述 |
|---|---|
| 自动启动 | 启用后,应用程序启动时会自动开始语音识别。 |
| 打印结果 | 启用后,会将识别出的语音转录内容输出到控制台。 |
AIAvatar 检查器中的设置
与 SpeechListener 相关的大多数设置都在 AIAvatar 组件的检查器中进行配置。
| 项目 | 描述 |
|---|---|
| 对话超时 | 在对话被视为结束之前的等待时间(秒)。超过此时间段后,将切换到空闲模式,并隐藏消息窗口。要恢复对话,必须再次识别唤醒词。 |
| 空闲超时 | 从空闲模式切换到睡眠模式之前的等待时间(秒)。默认情况下,空闲模式和睡眠模式之间没有区别,但可以通过用户自定义实现来切换不同的语音识别方法或空闲动画。 |
| 语音识别阈值 dB | 用于语音识别的音量阈值(分贝)。低于此阈值的声音将不会被识别。 |
| 语音识别提升阈值 dB | 用于检测更响亮语音的提升阈值(分贝)。当“麦克风静音方式”设置为“阈值”时,会使用此设置。 |
| 对话静默持续时间阈值 | 如果检测到的静默时间超过此值,则停止录音并进行语音识别。 |
| 对话最小录音时长 | 只有当录制的声音超过此时长时才会进行语音识别。这有助于忽略短促的噪音,防止误识别。 |
| 对话最大录音时长 | 如果录制的声音超过此时间,则不会进行语音识别,而是直接忽略该录音。这样可以避免过长的录音给语音识别带来过大负担。 |
| 空闲静默持续时间阈值 | 空闲模式下停止录音所需的静默时间(秒)。为了在等待唤醒词时平滑地检测到短暂的静默,通常会设置较小的值。 |
| 空闲最小录音时长 | 空闲模式下的最小录音时长。相比对话模式,此处会设置更小的值,以便更流畅地检测短语。 |
| 空闲最大录音时长 | 空闲模式下的最大录音时长。由于唤醒词通常较短,因此会比对话模式设置更短的时长。 |
| 麦克风静音方式 | 用于在语音过程中防止角色说话被识别的方法。 - 无:不执行任何操作。 - 阈值:将语音识别阈值提升至“语音识别提升阈值 dB”。 - 静音:忽略来自麦克风的输入声音。 - 停止设备:停止麦克风设备。 - 停止监听器:停止监听器。当您使用 AzureStreamSpeechListener 时,请选择此项 |
| 打断响应 | 启用时(默认:true),当 SpeechListener 检测到用户开始讲话(打断)时,AI 的语音会自动停止。触发条件取决于 SpeechListener 类型:对于非流式监听器,当语音录音超过最小时长(默认:1.5 秒)时触发;对于流式监听器(AIAvatarKitStream、AzureStream),当识别出的文本达到最小长度(默认:2 个字符)时触发。您可以通过在 SpeechListener 上设置 BargeInCondition 来覆盖触发条件。将其设置为 false 可以禁用此功能。 |
注意: AzureStreamSpeechListener 不具备上述某些属性,因为它由 SDK DLL 在内部控制麦克风。
下采样
SpeechListener 类支持在将原始麦克风输入发送到 STT 服务之前,将其下采样到较低的采样率。此功能有助于减少音频负载大小,从而在带宽有限的网络上实现更流畅的转录。
您可以在 SpeechListener 组件的检查器中找到 目标采样率(整数)字段:
- 设置为
0(默认)以使用原始采样率(不进行下采样)。 - 设置为正整数(例如
16000)以将输入下采样到该采样率(单位:Hz)。
使用 AIAvatarKitStreamSpeechListener
AIAvatarKit 是一个提供语音到语音处理管道的框架,同时也提供了一个流式语音识别服务器。通过将 Silero VAD(也用于 ChatdollKit)用于话轮结束检测,并结合任何语音识别引擎,您可以构建一个针对特定应用场景的实时语音识别服务器。
要使用此功能,请将 AIAvatarKitStreamSpeechListener 组件附加到您的 AIAvatar 对象,并配置连接 URL。然后,在主逻辑初始化中(例如在 Start() 方法中,或在 Awake() 之后运行的任何流程中),添加以下语音显示处理代码:
// 使用 AIAvatarKitStreamSpeechListener 部分显示 AI 消息
var aiavatarKitStreamSpeechListener = gameObject.GetComponent<AIAvatarKitStreamSpeechListener>();
if (aiavatarKitStreamSpeechListener != null)
{
var userMessageWindow = (SimpleMessageWindow)aiAvatar.UserMessageWindow;
// 禁用文本动画,因为部分结果是实时流式传输的
userMessageWindow.IsTextAnimated = false;
// 流式显示时,较短的 PostGap 即可,优先考虑响应速度
userMessageWindow.PostGap = 0.2f;
// 在第一轮结束后手动隐藏用户消息窗口,
// 因为用户消息窗口不由正常的对话流程管理
var originalOnRecognized = aiavatarKitStreamSpeechListener.OnRecognized;
aiavatarKitStreamSpeechListener.OnRecognized = async (text) => {
if (originalOnRecognized != null)
{
await originalOnRecognized(text);
}
if (aiAvatar.Mode != AIAvatar.AvatarMode.Conversation)
{
await UniTask.Delay((int)(userMessageWindow.PostGap * 1000));
aiAvatar.UserMessageWindow?.Hide();
}
};
// 显示部分识别结果
aiavatarKitStreamSpeechListener.OnPartialRecognized = (partialText) => {
if (!string.IsNullOrEmpty(partialText))
{
aiAvatar.UserMessageWindow.Show(partialText);
}
};
}
注意:在 WebGL 构建中使用 Silero VAD 可能会导致浏览器处理开销过高。我们建议使用 AIAvatarKitStreamSpeechListener 将 VAD 处理卸载到服务器端。
注意:要在 WebGL 构建中使用 AIAvatarKitStreamSpeechListener,请通过包管理器添加 NativeWebSocket 包:https://github.com/endel/NativeWebSocket.git#upm。Unity 自带的 WebSocket 客户端(System.Net.WebSockets)在 WebGL 上不受支持。
使用 AzureStreamSpeechListener
使用 AzureStreamSpeechListener 时,部分设置与其他 SpeechListener 不同。这是因为 AzureStreamSpeechListener 会通过 SDK 在内部控制麦克风,并以增量方式执行转录。
麦克风静音条件:选择 停止监听器。如果未进行此设置,角色将听到自己的语音,从而打断对话。
用户消息窗口:取消勾选 文本动画显示,并将 前置间隔 设置为 0,后置间隔 设置为约 0.2。
Update():为了逐步显示识别出的文本,请在 Update() 方法中添加以下代码:
if (aiAvatar.Mode == AIAvatar.AvatarMode.Conversation)
{
if (!string.IsNullOrEmpty(azureStreamSpeechListener.RecognizedTextBuffer))
{
aiAvatar.UserMessageWindow.Show(azureStreamSpeechListener.RecognizedTextBuffer);
}
}
使用 Silero VAD
Silero VAD 是一种基于机器学习的语音活动检测模型。通过使用它,即使在嘈杂环境中也能准确判断是否有人声,与仅依赖麦克风音量的语音活动检测相比,显著提高了在噪声环境下的端点检测精度。
使用步骤如下:
- 导入 onnxruntime-unity。按照 GitHub 上的说明编辑 manifest.json 文件。
- 下载 Silero VAD ONNX 模型,并将其放置在 StreamingAssets 文件夹中,文件名为
silero_vad.onnx。 - 下载并导入 ChatdollKit 的 SileroVADExtension。
- 将
SileroVADProcessor挂载到已附加 SpeechListener 的对象上。 - 在任意 MonoBehaviour 组件的 Awake 方法中,将其设置为 SpeechListener 的语音检测函数。
var sileroVad = gameObject.GetComponent<SileroVADProcessor>(); sileroVad.Initialize(); var speechListener = gameObject.GetComponent<SpeechListenerBase>(); speechListener.DetectVoiceFunc = sileroVad.IsVoiced; - 如有需要,可在场景中放置 SileroVADMicrophoneButton。
执行后,系统将使用 Silero VAD 进行语音活动检测。
使用多种 VAD 组合
ChatdollKit 支持组合使用多种类型的 VAD。例如,可以将能够在嘈杂环境中仅识别人声的 Silero VAD 与仅捕捉响亮声音的内置能量型 VAD 结合使用。这样,在活动现场既能准确捕捉用户的语音,又能部分过滤掉周围的噪音和场地广播。
要使用多种 VAD,需将多个语音检测函数添加到 DetectVoiceFunctions 中,而不是 DetectVoiceFunc。
speechListener.DetectVoiceFunctions = new List<Func<float[], float, bool>>()
{
sileroVad.IsVoiced, speechListener.IsVoiceDetectedByVolume
};
回声消除
Unity 内置的 Microphone API 不支持回声消除功能。若需启用该功能,可使用特定平台的原生麦克风插件。
private void Awake()
{
var microphoneManager = gameObject.GetComponent<MicrophoneManager>();
// 首先导入 ChatdollKit_NativeMicrophone 包
// 然后根据平台设置相应的提供者:
// iOS
microphoneManager.MicrophoneProvider = new IOSMicrophoneProvider();
// Android
microphoneManager.MicrophoneProvider = new AndroidMicrophoneProvider();
// macOS
microphoneManager.MicrophoneProvider = new MacMicrophoneProvider();
}
启用回声消除后,用户可以在 AI 讲话时随时打断。要启用此功能:
- 在 Inspector 中选择
AIAvatar组件。 - 将
MicrophoneMuteBy设置为无。
这样配置后,麦克风将在 AI 讲话期间保持开启状态,允许自然地打断对话;同时,回声消除功能可防止 AI 的声音被麦克风拾取。
自定义抢占条件
默认情况下,抢占触发取决于 SpeechListener 的类型:
- 非流式监听器(OpenAI、Google、AIAvatarKit):当用户录音时间达到至少
BargeInMinDuration秒时触发(默认值为 1.5 秒)。 - 流式监听器(AzureStream、AIAvatarKitStream):当部分识别的文本达到
BargeInMinTextLength个字符时触发(默认值为 2 个字符)。
您可以通过设置 SpeechListener 的 BargeInCondition 来覆盖此逻辑。委托签名为 Func<string, float, bool>,其中:
text— 部分识别的文本(对于非流式监听器为null)。recordDuration— 录音经过的时间(以秒为单位,对于流式监听器为0f)。- 返回
true以触发抢占。
// 示例:要求流式监听器至少输入 3 个字符
aiAvatar.SpeechListener.BargeInCondition = (text, recordDuration) =>
{
if (text != null)
{
return text.Length >= 3;
}
return recordDuration >= 2.0f;
};
⏰ 唤醒词检测
您可以检测唤醒词作为启动对话的触发条件。此外,还可以在 AIAvatar 组件的 Inspector 中配置结束对话的取消词,或者使用识别出的语音长度而非特定短语来触发对话。
唤醒词
当识别到该短语时,对话将开始。您可以注册多个唤醒词。除以下项目外,0.8 版本及更高版本中的其他设置将被忽略。
| 项目 | 描述 |
|---|---|
| 文本 | 用于启动对话的短语。 |
| 前缀/后缀允许范围 | 唤醒词前后允许额外字符的最大长度。例如,若唤醒词为“Hello”,允许范围为 4 个字符,则短语“Ah, Hello!”仍会被检测为唤醒词。 |
取消词
当识别到该短语时,对话将结束。您可以注册多个取消词。
打断词
角色将停止讲话并开始倾听用户的请求。您可以注册多个打断词。(例如,“等一下”)
注意:在 AIAvatar 的 Inspector 中,将 麦克风静音条件 下的 阈值 选中,以允许 ChatdollKit 在角色讲话时继续监听您的语音。
忽略词
您可以注册一些字符串,使其在判断识别出的语音是否匹配唤醒词或取消词时被忽略。这在不希望考虑标点符号是否存在的情况下非常有用。
唤醒长度
您也可以根据识别出的文本长度而非特定短语来启动对话。当该值为 0 时,此功能将被禁用。例如,在空闲模式下,可通过文本长度而非唤醒词恢复对话;而在睡眠模式下,则可使用唤醒词重新开始对话。
⚡️ AI 代理(工具调用)
借助大模型提供的工具调用(函数调用)功能,您可以开发充当 AI 代理的 AI 角色,而不仅仅是进行简单的对话交流。
通过创建实现 ITool 接口或继承 ToolBase 类的组件,并将其附加到 AIAvatar 对象上,该组件将自动被识别为工具,并在需要时执行。要创建自定义工具,需定义 FunctionName 和 FunctionDescription,并实现返回函数定义的 GetToolSpec 方法以及处理函数逻辑的 ExecuteFunction 方法。有关详细信息,请参阅 ChatdollKit/Examples/WeatherTool。
注意:如果您的项目中包含自定义的 LLMFunctionSkills,请参阅 从 FunctionSkill 迁移到 Tool。
与远程 AI 代理的集成
虽然 ChatdollKit 原生支持简单的工具调用,但它也提供了与服务器端 AI 代理的集成能力,以实现更复杂的代理行为。
具体来说,ChatdollKit 允许您通过 RESTful API 调用 AI 代理,并将其注册为 LLMService。这样,您无需了解背后的代理流程,即可发送请求并接收响应。目前支持 Dify 和 AIAvatarKit。您可以通过附加 DifyService 或 AIAvatarKitService、配置其设置并启用 IsEnabled 标志来使用它们。
🎙️ 设备
我们提供设备控制机制。目前支持麦克风和摄像头。
麦克风
MicrophoneManager 组件负责从麦克风捕获音频,并将音频波形数据提供给其他组件使用。它主要用于配合 SpeechListener 使用,但您也可以在自定义用户实现的组件中通过 StartRecordingSession 方法注册并使用录音会话。
以下是在检视器中可配置的设置:
| 项 | 描述 |
|---|---|
| 采样率 | 指定采样率。使用 WebGL 时请设置为 44100。 |
| 噪声门阈值(dB) | 以分贝为单位指定噪声门级别。与 AIAvatar 组件一起使用时,此值由 AIAvatar 控制。 |
| 自动启动 | 应用程序启动时开始从麦克风捕获音频。 |
| 调试模式 | 记录麦克风的启停及静音/取消静音操作。 |
摄像头
我们提供了 SimpleCamera 预制件,其中封装了图像捕获、预览显示和摄像头切换等功能。由于不同设备对摄像头的处理方式有所不同,因此该预制件仅作为实验性功能提供。有关详细信息,请参考该预制件及其附带的脚本。
🥰 3D 模型控制
ModelController 组件用于控制 3D 模型的手势、面部表情和语音。
空闲动画
空闲动画会在模型处于等待状态时循环播放。要运行所需的动作,需将其注册到 Animator Controller 的状态机中,并通过在 ModelController 检视器中将参数名称设置为“Idle Animation Key”,将值设置为“Idle Animation Value”,来配置过渡条件。
若要注册多个动作并在固定时间间隔内随机切换,可按如下所示在代码中使用 AddIdleAnimation 方法。第一个参数是要执行的 Animation 对象,weight 是出现概率的倍数,而 mode 仅在希望在特定模型状态下显示动画时才需指定。Animation 类的构造函数接受三个参数:第一个是参数名称,第二个是参数值,第三个则是持续时间(以秒为单位)。
modelController.AddIdleAnimation(new Animation("BaseParam", 2, 5f));
modelController.AddIdleAnimation(new Animation("BaseParam", 6, 5f), weight: 2);
modelController.AddIdleAnimation(new Animation("BaseParam", 99, 5f), mode: "sleep");
脚本控制
本节正在建设中。基本上,您需要创建一个 AnimatedVoiceRequest 对象,并调用 ModelController.AnimatedSay。AIAvatar 内部会发出结合动画、表情和语音的请求,因此可参考其相关实现作为指导。
🎚️ UI 组件
我们提供了语音交互式 AI 角色应用中常用的 UI 组件预制件。您只需将其添加到场景中即可使用。有关配置细节,请参阅演示。
- FPSManager:显示当前帧率。您还可以使用此组件设置目标帧率。
- MicrophoneController:用于调节麦克风噪声门的滑块。
- RequestInput:用于输入请求的文本框。它还提供从文件系统获取图片以及启动摄像头的按钮。
- SimpleCamera:用于处理摄像头图像捕获和预览显示的组件。您也可以在不显示预览的情况下直接捕获图像。
🎮 从外部程序控制
你可以通过套接字通信或 JavaScript 从外部程序向 ChatdollKit 应用程序发送请求。此功能支持新的使用场景,例如 AI 虚拟主播直播、远程虚拟形象客服,以及结合 AI 和人工交互的混合型角色运营。
将 ChatdollKit/Scripts/Network/SocketServer 挂载到 AIAvatar 对象上,并设置端口号(例如 8080),即可通过套接字通信进行控制;或者挂载 ChatdollKit/Scripts/IO/JavaScriptMessageHandler 来实现 JavaScript 控制。
此外,为了处理网络上的对话请求,需要将 ChatdollKit/Scripts/Dialog/DialogPriorityManager 挂载到 AIAvatar 对象上。若要处理让角色执行由人类而非 AI 回答生成的手势、面部表情或语音的请求,则需将 ChatdollKit/Scripts/Model/ModelRequestBroker 挂载到 AIAvatar 对象上。
以下是同时使用上述两个组件的代码示例:
// 配置远程控制的消息处理器
#pragma warning disable CS1998
#if UNITY_WEBGL && !UNITY_EDITOR
gameObject.GetComponent<JavaScriptMessageHandler>().OnDataReceived = async (message) =>
{
HandleExternalMessage(message, "JavaScript");
};
#else
gameObject.GetComponent<SocketServer>().OnDataReceived = async (message) =>
{
HandleExternalMessage(message, "SocketServer");
};
#endif
#pragma warning restore CS1998
private void HandleExternalMessage(ExternalInboundMessage message, string source)
{
// 根据请求的 Endpoint 和 Operation 分配动作
if (message.Endpoint == "dialog")
{
if (message.Operation == "start")
{
if (source == "JavaScript")
{
dialogPriorityManager.SetRequest(message.Text, message.Payloads, 0);
}
else
{
dialogPriorityManager.SetRequest(message.Text, message.Payloads, message.Priority);
}
}
else if (message.Operation == "clear")
{
dialogPriorityManager.ClearDialogRequestQueue(message.Priority);
}
}
else if (message.Endpoint == "model")
{
modelRequestBroker.SetRequest(message.Text);
}
}
ChatdollKit 远程客户端
SocketServer 设计用于通过套接字通信接收任意信息,因此未提供官方客户端程序。不过,我们提供了一个 Python 示例代码,请参考以下链接,并根据需要将其适配到其他语言或平台。
https://gist.github.com/uezo/9e56a828bb5ea0387f90cc07f82b4c15
或者,如果你希望搭建 AITuber(AI 虚拟主播),可以尝试使用内置了 SocketServer 的 ChatdollKit AITuber Controller 提供的 AITuber 示例。
🌐 在 WebGL 上运行
目前可参考以下提示。我们正在准备 WebGL 的演示版本。
- 构建时间约为 5–10 分钟(取决于机器配置)。
- 调试非常困难。错误信息不会显示堆栈跟踪:“要使用 dlopen,你需要使用 Emscripten 的链接支持,请参阅 https://github.com/kripken/emscripten/wiki/Linking”。
- 内置的 Async/Await 无法正常工作(应用程序会在
await处停止),因为 JavaScript 不支持多线程。请改用 UniTask。 - HTTP 请求需要 CORS 支持。
- 不支持麦克风输入。请使用与 WebGL 兼容的
ChatdollMicrophone。 - 不支持 MP3 等压缩音频格式。请在 SpeechSynthesizer 中使用 WAV 格式。
- 不支持 OVRLipSync。请改用 uLipSync。
- 你还需要在主脚本中添加以下代码以启用 uLipSync:
var ul = gameObject.GetComponent<uLipSync.uLipSync>(); modelController.SpeechController.HandlePlayingSamples = (samples) => { ul.OnDataReceived(samples, 1); }; - 如果希望在消息窗口中显示多字节字符,请将包含多字节字符的字体导入项目,并将其设置为消息窗口的字体。
🔄 从 0.7.x 版本迁移
最简单的方法是删除 Assets/ChatdollKit 文件夹,然后重新导入 ChatdollKit 的 Unity 包。但如果你因某些原因无法这样做,可以通过以下步骤解决错误:
- 导入最新版本的 ChatdollKit Unity 包。控制台可能会显示一些错误。
- 导入
ChatdollKit_0.7to084Migration.unitypackage。 - 在
ModelController、AnimatedVoiceRequest和Voice类中添加partial关键字。 - 将
DialogController中的OnSayStart替换为OnSayStartMigration。
⚠️ 注意:此举仅能抑制错误输出,并不能继续使用旧版代码。如果项目中仍有部分代码使用 DialogController、LLMFunctionSkill、LLMContentSkill 或 ChatdollKit,请按如下方式替换为更新后的组件:
DialogController:DialogProcessorLLMFunctionSkill:ToolLLMContentSkill:LLMContentProcessorChatdollKit:AIAvatar
从 FunctionSkill 迁移到 Tool
如果你的组件继承自 LLMFunctionSkillBase,可以通过以下步骤轻松迁移到继承自 ToolBase:
更改基类
将
LLMFunctionSkillBase替换为ToolBase作为基类。// 之前 public class MyFunctionSkill : LLMFunctionSkillBase // 之后 public class MyFunctionSkill : ToolBase更新
ExecuteFunction方法签名按照以下方式修改
ExecuteFunction方法的参数和返回值类型:// 之前 public UniTask<FunctionResponse> ExecuteFunction(string argumentsJsonString, Request request, State state,User user,CancellationToken token) // 之后 public UniTask<ToolResponse> ExecuteFunction(string argumentsJsonString,CancellationToken token)更新
ExecuteFunction的返回值类型将
FunctionResponse替换为ToolResponse。
❤️ 感谢
版本历史
v0.8.162026/02/14v0.8.152025/08/21v0.8.142025/08/12v0.8.132025/07/18v0.8.122025/05/15v0.8.112025/04/290.8.102025/03/290.8.92024/12/130.8.8.12024/12/050.8.82024/12/030.8.72024/11/290.8.7beta-ootb-app2024/11/230.8.62024/11/200.8.52024/11/130.8.4.12024/11/040.8.42024/10/270.8.32024/10/110.8.22024/09/230.8.12024/09/180.8.02024/09/08常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。