crfasrnn
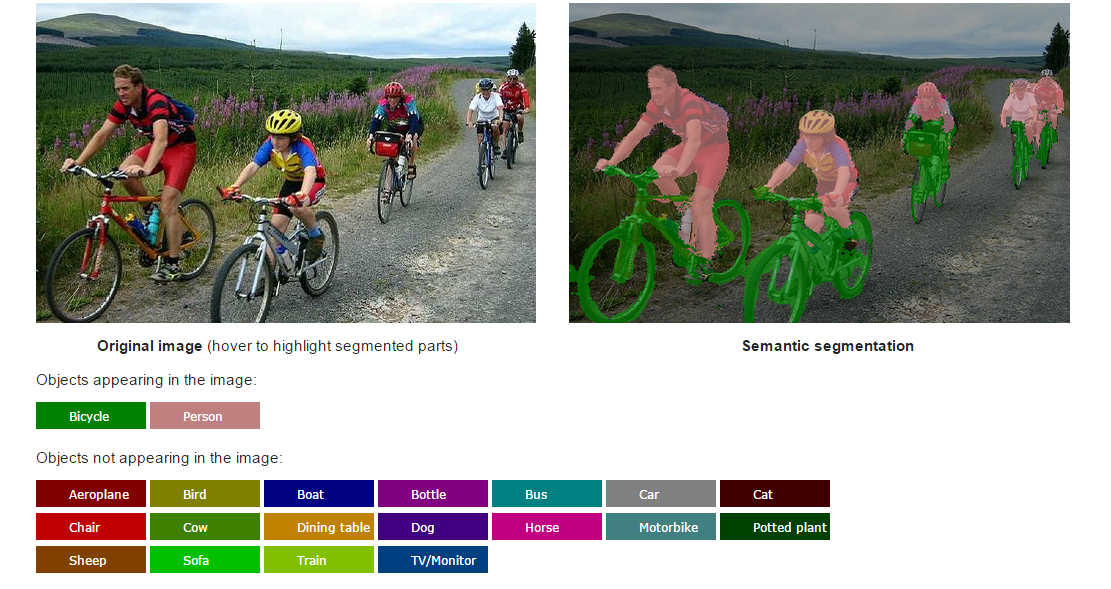
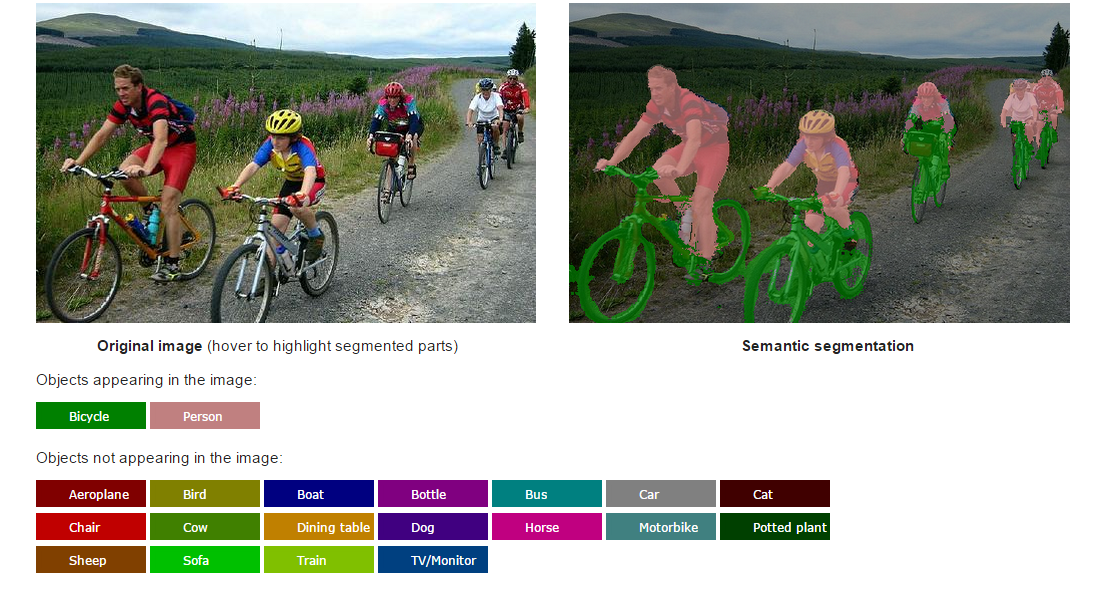
crfasrnn 是一款专注于语义图像分割的开源深度学习工具,源自牛津大学团队在 ICCV 2015 发表的著名论文《Conditional Random Fields as Recurrent Neural Networks》。它的核心任务不仅是识别图像中的物体类别,更能精准勾勒出物体的二维轮廓边界,从而生成细节丰富、边缘清晰的分割结果。
传统分割方法往往在物体边缘处理上较为模糊,而 crfasrnn 创造性地将条件随机场(CRF)建模为循环神经网络(RNN)的一个层级,成功将概率图模型的精细推理能力与深度学习的端到端训练优势相结合。这一独特的技术亮点使得模型能够有效优化分割图的局部一致性,显著提升了边缘定位的准确度。
该工具主要面向计算机视觉领域的研究人员和开发者。它基于 Caffe 框架开发,提供了自定义的"MultiStageMeanfield"网络层,方便用户将其集成到现有的全卷积网络(FCN)架构中进行二次开发或学术研究。此外,社区也衍生出了 PyTorch 和 TensorFlow/Keras 版本,降低了不同技术栈使用者的上手门槛。虽然其最初研发愿景是用于辅助视障人士的增强现实眼镜项目,但目前已成为图像分割领域经典的基准算法之一,适合需要高精度物体轮廓提取场景的技术人员探索使用。
使用场景
某医疗影像分析团队正在开发辅助诊断系统,需要从肺部 CT 扫描图中精确分割出肿瘤区域以计算体积。
没有 crfasrnn 时
- 仅依靠基础卷积神经网络(如 FCN)输出的分割结果边缘粗糙,呈现明显的锯齿状,无法贴合肿瘤的真实不规则轮廓。
- 模型容易将邻近的血管或正常组织误判为肿瘤的一部分,导致分割区域出现“粘连”现象,缺乏空间一致性。
- 后处理需要人工编写复杂的形态学算法来平滑边缘和去除噪点,不仅增加了开发工作量,还难以适应不同病例的多样性。
- 最终生成的 2D 轮廓精度不足,直接影响医生对肿瘤生长趋势的判断及手术方案的制定。
使用 crfasrnn 后
- crfasrnn 将条件随机场(CRF)作为循环神经网络层嵌入模型,自动优化像素间关系,生成的肿瘤边缘光滑且紧密贴合真实解剖结构。
- 利用高阶上下文信息有效区分了肿瘤与周围相似组织,显著减少了误检和区域粘连,提升了分割的逻辑一致性。
- 端到端的训练方式消除了对繁琐后处理算法的依赖,模型直接输出高质量掩码,大幅简化了工程落地流程。
- 精确恢复的 2D 轮廓使得肿瘤体积计算误差降低,为临床医生提供了更可靠的量化数据支持。
crfasrnn 的核心价值在于将深度学习的全局特征提取能力与传统概率图模型的细节优化能力完美结合,实现了像素级语义分割精度的质的飞跃。
运行环境要求
- Linux
可选(用于加速处理),需安装 NVIDIA 驱动及 CUDA SDK,具体版本未说明
未说明
快速开始
用于语义图像分割的CRF-RNN
在线演示: http://crfasrnn.torr.vision
PyTorch版本: http://github.com/sadeepj/crfasrnn_pytorch
TensorFlow/Keras版本: http://github.com/sadeepj/crfasrnn_keras
![]()
本软件包包含“CRF-RNN”语义图像分割方法的代码,该方法发表于ICCV 2015论文《条件随机场作为递归神经网络》(http://www.robots.ox.ac.uk/~szheng/papers/CRFasRNN.pdf)。该论文最初在一篇arXiv技术报告中有所介绍。基于此代码的在线演示荣获ICCV 2015最佳演示奖。我们的软件构建于Caffe深度学习框架之上。当前版本由以下人员开发:
Sadeep Jayasumana、 Shuai Zheng、 Bernardino Romera Paredes、 Anurag Arnab, 以及 Zhizhong Su。
指导教师:Philip Torr
我们的工作使计算机能够识别图像中的物体,而我们工作的独特之处在于,我们还能恢复物体的二维轮廓。目前,我们已训练该模型识别20个类别。该软件允许您在自己的图像上测试我们的算法——不妨试一试,看看是否能骗过它;如果您有好的示例,欢迎发送给我们。
我们为何要进行这项研究?这项工作是为部分失明人士开发增强现实眼镜项目的一部分。请在此处了解更多信息:smart-specs。
如需演示及更多关于CRF-RNN的信息,请访问项目官网:http://crfasrnn.torr.vision。
如果您在研究中使用此代码/模型,请引用以下论文:
@inproceedings{crfasrnn_ICCV2015,
author = {Shuai Zheng and Sadeep Jayasumana and Bernardino Romera-Paredes and Vibhav Vineet and
Zhizhong Su and Dalong Du and Chang Huang and Philip H. S. Torr},
title = {Conditional Random Fields as Recurrent Neural Networks},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2015}
}
@inproceedings{higherordercrf_ECCV2016,
author = {Anurag Arnab and Sadeep Jayasumana and Shuai Zheng and Philip H. S. Torr},
title = {Higher Order Conditional Random Fields in Deep Neural Networks},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2016}
}
如何使用CRF-RNN层
CRF-RNN被开发为一个名为MultiStageMeanfieldLayer的自定义Caffe层。在模型定义prototxt文件中使用该层的方式如下所示。更多详细示例请参阅matlab-scripts或python-scripts文件夹。
# 这是FCN的一部分,coarse是一个来自FCN的blob
layer { type: 'Crop' name: 'crop' bottom: 'bigscore' bottom: 'data' top: 'coarse' }
# 此层用于将FCN的输出拆分为两个。这是CRF-RNN所必需的。
layer { type: 'Split' name: 'splitting'
bottom: 'coarse' top: 'unary' top: 'Q0'
}
layer {
name: "inference1" # 保持名称“inference1”,以便从我们的caffemodel加载预训练参数。
type: "MultiStageMeanfield" # 此层的类型
bottom: "unary" # 来自FCN的一元输入
bottom: "Q0" # FCN一元输入的副本
bottom: "data" # 输入图像
top: "pred" # CRF-RNN的输出
param {
lr_mult: 10000 # W_G的学习率
}
param {
lr_mult: 10000 # W_B的学习率
}
param {
lr_mult: 1000 # 兼容性变换矩阵的学习率
}
multi_stage_meanfield_param {
num_iterations: 10 # CRF-RNN的迭代次数
compatibility_mode: POTTS # 使用对角线为-1的矩阵初始化兼容性变换矩阵
threshold: 2
theta_alpha: 160
theta_beta: 3
theta_gamma: 3
spatial_filter_weight: 3
bilateral_filter_weight: 5
}
}
安装指南
首先,通过运行以下命令克隆项目:
git clone --recursive https://github.com/torrvision/crfasrnn.git
您需要编译此仓库中修改过的Caffe库。以下是针对Ubuntu 14.04的说明。您也可以参考通用的Caffe安装指南,以获取更多帮助。
1.1 安装依赖项
一般依赖项
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-dev
CUDA(可选——仅当您计划使用GPU加速处理时才需要)
安装正确的CUDA驱动程序及其SDK。从Nvidia官网下载CUDA SDK。
您可能需要将某些模块列入黑名单,以免它们干扰驱动程序的安装。此外,您还需要先卸载默认的Nvidia驱动程序。
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
打开 /etc/modprobe.d/blacklist.conf 并添加:
blacklist amd76x_edac
blacklist vga16fb
blacklist nouveau
blacklist rivafb
blacklist nvidiafb
blacklist rivatv
sudo apt-get remove --purge nvidia*
重启电脑后,在登录之前,尝试按“Ctrl + Alt + F1”切换到文本模式登录。然后尝试:
sudo service lightdm stop
chmod +x cuda*.run
sudo ./cuda*.run
BLAS
安装ATLAS、OpenBLAS或MKL等BLAS库。安装BLAS:
sudo apt-get install libatlas-base-dev
Python
安装Anaconda Python发行版,或安装带有numpy、scipy等的默认Python发行版。
MATLAB(可选——仅当您计划使用MATLAB接口时才需要)
使用标准发行版安装MATLAB。
1.2 构建自定义Caffe版本
在Makefile.config中正确设置路径。您可以将Makefile.config.example重命名为Makefile.config,因为其中大部分内容已经填写完毕。根据您的环境,您可能需要稍作调整。
之后,在Ubuntu 14.04中,尝试:
make
如果没有错误信息,您可以继续编译并安装Python和Matlab封装器: 安装MATLAB封装器(可选):
make matcaffe
安装Python封装器(可选):
make pycaffe
好了!现在您可以享受我们的软件了!
1.3 运行演示
运行演示的 MATLAB 和 Python 脚本分别位于 matlab-scripts 和 python-scripts 目录中。这两个脚本的功能相同,您可以任选其一。
Python 用户:
切换到 python-scripts 目录。首先下载包含训练权重的模型。在 Linux 系统中,可以通过以下命令完成:
sh download_trained_model.sh
或者,您也可以直接点击 python-scripts/README.md 文件中的链接来获取模型。
要运行演示,请执行:
python crfasrnn_demo.py
您将得到一个名为 output.png 的输出图像。
如果您想使用自己的图像,只需在 crfasrnn_demo.py 文件中将 "input.jpg" 替换为您想要处理的图像文件名即可。
MATLAB 用户:
切换到 matlab-scripts 目录。首先下载包含训练权重的模型。在 Linux 系统中,可以通过以下命令完成:
sh download_trained_model.sh
或者,您也可以直接点击 matlab-scripts/README.md 文件中的链接来获取模型。
打开您的 MATLAB 应用程序并运行 crfrnn_demo.m 文件。
如果您想使用自己的图像,只需在 crfrnn_demo.m 文件中将 "input.jpg" 替换为您想要处理的图像文件名即可。
此外,您还可以在 MatConvNet 中找到我们模型的一部分。
关于 CRF-RNN 层的说明:
如果您希望尝试我们训练的 CRF-RNN 模型,务必保持层名称不变(即“inference1”),这样代码才能正确加载 caffemodel 中的参数。否则,参数将会被重新初始化。
您会发现,端到端训练的 CRF-RNN 模型性能优于其他方法。如果将 CRF-RNN 层的名称改为“inference2”,则会观察到较低的性能,因为此时 CNN 和 CRF 的参数并未进行联合优化。
在新数据集上训练 CRF-RNN:
如果您希望在其他数据集上训练 CRF-RNN,请按照我们论文中描述的分步训练方法进行。简而言之,您需要先训练一个强大的像素级 CNN 模型。随后,通过在 prototxt 文件中添加 MultiStageMeanfieldLayer,将我们的 CRF-RNN 层插入到该模型中。这样,您就可以对 CNN 和 CRF-RNN 部分进行端到端的联合训练。
请注意,我们目前提供的 deploy.prototxt 文件是为 PASCAL VOC 挑战赛量身定制的。该数据集包含 21 个类别标签,包括背景。如果您希望将我们的模型微调用于其他数据集,应相应地修改相应层的 num_output 参数。此外,当前代码中的反卷积层无法通过 prototxt 文件初始化参数。如果您更改了那里的 num_output 值,就需要手动重新初始化 caffemodel 文件中的参数。
更多详细信息请参阅 examples/segmentationcrfasrnn。
为什么预测结果全为黑色?
这可能是因为您在模型定义的 prototxt 文件中更改了层名称,导致权重未能正确加载。也可能是您在 prototxt 文件中修改了反卷积层的输出数量,但未正确初始化该层所致。
MultiStageMeanfield 导致段错误?
此错误通常发生在您未将 spatial.par 和 bilateral.par 文件放置在脚本运行路径中时。
第三方提供的 Python 训练脚本:
我们感谢 martinkersner 和 MasazI 提供的 CRF-RNN Python 训练脚本。
与上游 Caffe 合并
CRF-RNN 代码可以集成到上游 Caffe 中。然而,由于 crop 层的变化,我们提供的 caffemodel 可能需要额外的训练才能达到相同的精度。mtourne 友好地提供了一个将代码与上游 Caffe 合并的版本。
CRF-RNN 的 GPU 版本
hyenal 友好地提供了一个纯 GPU 版本的 CRF-RNN。这将显著加快训练和测试的速度。
CRF-as-RNN 作为 Lasagne 中的一层
包含 CPU/GPU CRF-RNN 的最新 Caffe
Keras/TensorFlow 版本的 CRF-RNN
如果您知道还有其他第三方的工作,请告知我们。
有关 CRF-RNN 的更多信息,请访问项目官网 http://crfasrnn.torr.vision。联系方式:crfasrnn@gmail.com
版本历史
0.22016/05/090.12015/10/01常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
tesseract
Tesseract 是一款历史悠久且备受推崇的开源光学字符识别(OCR)引擎,最初由惠普实验室开发,后由 Google 维护,目前由全球社区共同贡献。它的核心功能是将图片中的文字转化为可编辑、可搜索的文本数据,有效解决了从扫描件、照片或 PDF 文档中提取文字信息的难题,是数字化归档和信息自动化的重要基础工具。 在技术层面,Tesseract 展现了强大的适应能力。从版本 4 开始,它引入了基于长短期记忆网络(LSTM)的神经网络 OCR 引擎,显著提升了行识别的准确率;同时,为了兼顾旧有需求,它依然支持传统的字符模式识别引擎。Tesseract 原生支持 UTF-8 编码,开箱即用即可识别超过 100 种语言,并兼容 PNG、JPEG、TIFF 等多种常见图像格式。输出方面,它灵活支持纯文本、hOCR、PDF、TSV 等多种格式,方便后续数据处理。 Tesseract 主要面向开发者、研究人员以及需要构建文档处理流程的企业用户。由于它本身是一个命令行工具和库(libtesseract),不包含图形用户界面(GUI),因此最适合具备一定编程能力的技术人员集成到自动化脚本或应用程序中