PLMpapers
PLMpapers 是一个专注于预训练语言模型(PLM)的开源知识宝库,旨在为自然语言处理领域的探索者梳理必读经典论文。自 2018 年 PLM 技术爆发以来,相关研究层出不穷,初学者往往难以把握发展脉络。PLMpapers 通过精选代表性工作,并提供一张清晰的家族演进图谱,直观展示了从早期的 ELMo、ULMFiT 到 BERT、GPT 系列等关键模型的技术传承与演变关系,有效解决了文献检索困难和知识体系碎片化的问题。
除了论文清单,该项目还整理了清华大学团队开源的 CPM 系列等大型模型资源,并收录了关于预训练模型过去、现在与未来的权威综述,为深入理解技术全貌提供了坚实支撑。其独特的可视化图表不仅逻辑严密,还开放了 PPT 源文件,方便用户直接用于学术汇报或教学分享。
PLMpapers 特别适合 NLP 领域的研究人员、算法工程师以及高校师生使用。无论是希望快速入门的新手,还是需要追踪前沿动态的资深专家,都能从中高效获取核心资讯,构建系统的知识框架。作为一个由社区共同维护的项目,它始终以开放的态度欢迎修正与建议,是学习预训练语言模型不可或缺的指南针。
使用场景
某高校 NLP 实验室的研究生正在撰写关于“预训练语言模型演进”的综述论文,急需梳理从 ELMo 到 BERT 再到 CPM 的技术脉络。
没有 PLMpapers 时
- 文献检索零散低效:需要在 Google Scholar、arXiv 和各个会议官网间反复切换搜索,难以一次性找全从 2015 年半监督序列学习到最新大模型的关键论文。
- 技术演进关系模糊:面对海量独立论文,难以直观理清模型间的继承与改进关系(如 GPT 系列与 BERT 的区别,或 ERNIE 的不同版本),导致综述逻辑混乱。
- 资源获取成本高:找到论文后,还需单独寻找对应的开源代码、预训练模型权重或项目主页,常因链接失效或信息缺失而浪费数小时。
- 缺乏权威筛选:容易陷入非核心工作的细节中,难以快速识别出像 ULMFiT、BERT 这样真正具有里程碑意义的“必读”工作。
使用 PLMpapers 后
- 一站式核心库构建:直接利用整理好的清单,瞬间获取从早期 context2vec 到最新 CPM-2 的代表性论文列表,覆盖完整发展史。
- 可视化脉络梳理:借助仓库提供的家族图谱(PLMfamily)及 PPT 源文件,清晰掌握各模型间的演化逻辑,迅速搭建起论文的叙述框架。
- 资源链路直达:每个条目均附带论文 PDF、代码仓库及模型下载链接,实现了从理论阅读到复现实验的无缝衔接。
- 精准聚焦重点:基于清华 NLP 团队的专业筛选,直接锁定高价值文献,避免了在低质量研究中浪费时间,显著提升科研效率。
PLMpapers 将原本需要数天整理的碎片化信息浓缩为一张清晰的知识地图,让研究者能专注于创新而非资料搜集。
运行环境要求
未说明
未说明

快速开始
预训练语言模型(PLMs)必读论文
由 Xiaozhi Wang 和 Zhengyan Zhang 贡献。
简介
自2018年以来,预训练语言模型(PLM)在自然语言处理领域取得了巨大成功。在这个仓库中,我们列出了一些具有代表性的PLM相关工作,并通过一张图展示了它们之间的关系。欢迎大家分享或使用!这里可以获取该图的PPT源文件,以便在您的演示文稿中使用。
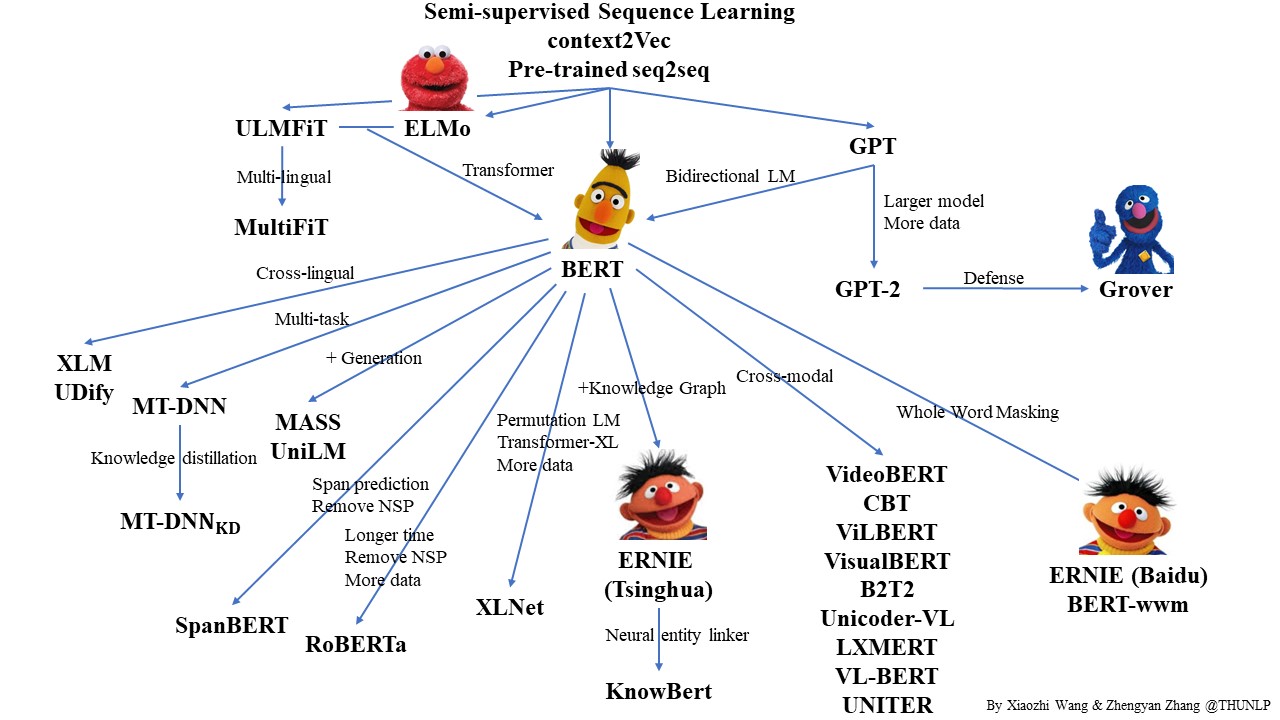
欢迎大家提出修正和建议。
开源PLMs
近年来,我们持续训练并发布了多个大规模PLM,具体如下。欢迎尝试使用!
- CPM-2。经济高效的预训练语言模型,2021年。[模型&代码]
- CPM-1。中文预训练语言模型,2020年。[模型&代码] [论文]
- OpenCLap。开源中文语言预训练模型库,2019年。[链接]
综述
预训练模型:过去、现在与未来。Xu Han, Zhengyan Zhang, Ning Ding, Yuxian Gu, Xiao Liu, Yuqi Huo, Jiezhong Qiu, Liang Zhang, Wentao Han, Minlie Huang, Qin Jin, Yanyan Lan, Yang Liu, Zhiyuan Liu, Zhiwu Lu, Xipeng Qiu, Ruihua Song, Jie Tang, Ji-Rong Wen, Jinhui Yuan, Wayne Xin Zhao, Jun Zhu。arXiv:2106.07139 2021年。[pdf]
PLMs相关论文
- 半监督序列学习。安德鲁·M·戴、阮文魁。NIPS 2015。[pdf]
- context2vec:使用双向LSTM学习通用上下文嵌入。奥伦·梅拉穆德、雅各布·戈德伯格、伊多·达甘。CoNLL 2016。[pdf] [项目] (context2vec)
- 面向序列到序列学习的无监督预训练。普拉吉特·拉马昌德兰、彼得·J·刘、阮文魁。EMNLP 2017。[pdf] (预训练seq2seq)
- 深度上下文化词表示。马修·E·彼得斯、马克·诺伊曼、莫希特·伊耶尔、马特·加德纳、克里斯托弗·克拉克、肯顿·李和卢克·泽特勒莫耶。NAACL 2018。[pdf] [项目] (ELMo)
- 用于文本分类的通用语言模型微调。杰里米·霍华德和塞巴斯蒂安·鲁德尔。ACL 2018。[pdf] [项目] (ULMFiT)
- 通过生成式预训练提升语言理解能力。亚历克·拉德福德、卡尔提克·纳拉西曼、蒂姆·萨利曼斯和伊利亚·苏茨克维尔。预印本。[pdf] [项目] (GPT)
- BERT:面向语言理解的深度双向Transformer预训练。雅各布·德夫林、明伟·张、肯顿·李和克里斯蒂娜·陶塔诺娃。NAACL 2019。[pdf] [代码与模型]
- 语言模型是无监督的多任务学习者。亚历克·拉德福德、杰弗里·吴、雷文·柴尔德、大卫·卢安、达里奥·阿莫迪和伊利亚·苏茨克维尔。预印本。[pdf] [代码] (GPT-2)
- ERNIE:融入信息实体的增强语言表示。郑燕章、许汉、智远刘、辛江、孙茂松和刘群。ACL 2019。[pdf] [代码与模型] (清华ERNIE)
- ERNIE:通过知识融合增强表示。孙宇、王书焕、李玉坤、冯世坤、陈旭义、张汉、田鑫、朱丹曦、田浩和吴华。预印本。[pdf] [代码] (百度ERNIE)
- 防御神经网络生成的假新闻。罗温·泽勒斯、阿里·霍尔茨曼、汉娜·拉什金、约纳坦·比斯克、阿里·法哈迪、弗兰齐斯卡·罗斯纳、叶津·崔。NeurIPS 2019。[pdf] [项目] (Grover)
- 跨语言语言模型预训练。纪尧姆·朗普尔、阿莱克西斯·孔纽。NeurIPS 2019。[pdf] [代码与模型] (XLM)
- 面向自然语言理解的多任务深度神经网络。刘晓东、何鹏程、陈维珠、高建峰。ACL 2019。[pdf] [代码与模型] (MT-DNN)
- MASS:面向语言生成的掩码序列到序列预训练。宋凯涛、谭旭、秦涛、陆建峰、刘铁岩。ICML 2019。[pdf] [代码与模型]
- 面向自然语言理解和生成的统一语言模型预训练。李东、南洋、王文辉、魏福如、刘晓东、王宇、高建峰、周明、韩锡文。预印本。[pdf] (UniLM)
- XLNet:面向语言理解的广义自回归预训练。杨志林、戴子航、杨一鸣、海梅·卡博内尔、鲁斯兰·萨拉胡丁诺夫、阮文魁。NeurIPS 2019。[pdf] [代码与模型]
- RoBERTa:稳健优化的BERT预训练方法。尹涵刘、迈尔·奥特、纳曼·戈亚尔、杜静菲、曼达尔·乔希、陈丹琪、奥默·列维、迈克·刘易斯、卢克·泽特勒莫耶、维塞林·斯托亚诺夫。预印本。[pdf] [代码与模型]
- SpanBERT:通过表示和预测跨度改进预训练。曼达尔·乔希、陈丹琪、尹涵刘、丹尼尔·S·韦尔德、卢克·泽特勒莫耶、奥默·列维。预印本。[pdf] [代码与模型]
- 知识增强的上下文词表示。马修·E·彼得斯、马克·诺伊曼、罗伯特·L·洛根四世、罗伊·施瓦茨、维杜尔·乔希、萨米尔·辛格、诺亚·A·史密斯。EMNLP 2019。[pdf] (KnowBert)
- VisualBERT:视觉与语言任务的简单高效基线。李云年·哈罗德·李、马克·亚茨卡尔、达·殷、谢志睿、常凯威。预印本。[pdf] [代码与模型]
- ViLBERT:面向视觉-语言任务的预训练无关任务视觉语言表示。陆嘉森、德拉夫·巴特拉、黛薇·帕里克、斯蒂芬·李。NeurIPS 2019。[pdf] [代码与模型]
- VideoBERT:视频与语言表示学习的联合模型。孙晨、奥斯汀·迈尔斯、卡尔·冯德里克、凯文·墨菲、科黛莉亚·施密德。ICCV 2019。[pdf]
- LXMERT:从Transformer中学习跨模态编码器表示。谭浩、莫希特·班萨尔。EMNLP 2019。[pdf] [代码与模型]
- VL-BERT:通用视觉-语言表示的预训练。苏伟杰、朱锡洲、曹岳、李彬、陆磊威、魏福如、戴继丰。预印本。[pdf]
- Unicoder-VL:通过跨模态预训练实现视觉与语言的通用编码器。李根、段楠、方跃坚、龚明、蒋大新、周明。预印本。[pdf]
- K-BERT:利用知识图谱实现语言表示。刘伟杰、周鹏、赵哲、王志若、鞠奇、邓浩唐、王平。预印本。[pdf]
- 用于视觉问答的文本中检测到的对象融合。克里斯·阿尔伯蒂、杰弗里·凌、迈克尔·柯林斯、大卫·赖特。EMNLP 2019。[pdf] (B2T2)
- 用于时间表示学习的对比双向Transformer。孙晨、法比安·巴拉德尔、凯文·墨菲、科黛莉亚·施密德。预印本。[pdf] (CBT)
- ERNIE 2.0:面向语言理解的持续预训练框架。孙宇、王书焕、李玉坤、冯世坤、田浩、吴华、王海峰。预印本。[pdf] [代码]
- 75种语言,1个模型:通用解析通用依存关系。丹·孔德拉秋克、米兰·斯特拉卡。EMNLP 2019。[pdf] [代码与模型] (UDify)
- 面向中文BERT的全词掩码预训练。崔一鸣、车万祥、刘婷、秦兵、杨子青、王士瑾、胡国平。预印本。[pdf] [代码与模型] (中文BERT-wwm)
- UNITER:学习通用图像-文本表示。陈彦纯、李林洁、于立成、艾哈迈德·埃尔·霍利、费萨尔·艾哈迈德、甘哲、程宇、刘晶晶。预印本。[pdf]
- MultiFiT:高效的多语言语言模型微调。朱利安·艾森施洛斯、塞巴斯蒂安·鲁德尔、皮奥特·查普拉、马尔钦·卡尔达斯、西尔万·古格尔、杰里米·霍华德。EMNLP 2019。[pdf] [代码与模型]
- 探索统一文本到文本Transformer的迁移学习极限。科林·拉菲尔、诺姆·沙泽尔、亚当·罗伯茨、凯瑟琳·李、沙兰·纳兰格、迈克尔·马特纳、颜琦周、李伟、彼得·J·刘。预印本。[pdf] [代码与模型] (T5)
- BART:面向自然语言生成、翻译和理解的去噪序列到序列预训练。迈克·刘易斯、尹涵刘、纳曼·戈亚尔、马尔詹·加兹维涅贾德、阿卜杜勒拉赫曼·穆罕默德、奥默·列维、维斯·斯托亚诺夫、卢克·泽特勒莫耶。ACL 2020。[pdf]
- ELECTRA:将文本编码器作为判别器而非生成器进行预训练。凯文·克拉克、明堂隆、阮文魁、克里斯托弗·D·曼宁。ICLR 2020。[pdf]
- 语言表示学习的互信息最大化视角。孔令鹏、西普里安·德·马松·达图姆、于雷、王玲、戴子航、尤加塔玛。ICLR 2020。[pdf]
- StructBERT:将语言结构融入预训练以实现深度语言理解。王伟、毕斌、严明、吴辰、夏江南、鲍祖义、彭立伟、罗思。ICLR 2020。[pdf]
- Poly-encoders:用于快速准确多句评分的架构和预训练策略。塞缪尔·于莫、库尔特·舒斯特、玛丽-安妮·拉绍、杰森·韦斯顿。ICLR 2020。[pdf]
- FreeLB:增强的语言理解对抗训练。朱晨、程宇、甘哲、孙思琪、托马斯·戈德斯坦、刘晶晶。ICLR 2020。[pdf]
- 上下文词表示的多语言对齐。史蒂文·曹、尼基塔·基塔耶夫、丹·克莱因。ICLR 2020。[pdf]
- TaBERT:面向文本和表格数据联合理解的预训练。尹鹏程、格雷厄姆·诺伊比格、易文涛、塞巴斯蒂安·里德尔。ACL 2020。[pdf] [代码]
- BERTRAM:改进的词嵌入对上下文化模型性能有重大影响。蒂莫·希克、欣里希·舒策。ACL 2020。[pdf]
- TAPAS:通过预训练实现弱监督的表格解析。乔纳森·赫尔齐格、帕韦乌·克日什托夫·诺瓦克、托马斯·穆勒、弗朗切斯科·皮奇诺、朱利安·马丁·艾森施洛斯。ACL 2020。[pdf]
- 关于预训练语言模型的句子嵌入。李波翰、周浩、何俊贤、王明轩、杨一鸣、李雷。EMNLP 2020。[pdf]
- 面向高效多领域语言模型预训练的实证研究。克里斯蒂安·阿鲁梅、孙清、帕尔敏德·巴蒂亚。EMNLP 2020。[pdf]
- 利用对齐信息进行多语言神经机器翻译的预训练。林泽辉、潘晓、王明轩、邱锡鹏、冯江涛、周浩、李雷。EMNLP 2020。[pdf]
- 将Transformer作为基于能量的完形填空模型进行预训练。凯文·克拉克、明堂隆、阮文魁、克里斯托弗·D·曼宁。EMNLP 2020。[pdf]
- PatchBERT:即时、词汇外补丁。文尚焕、冈崎直晃。EMNLP 2020。[pdf]
- 通过释义进行预训练。迈克·刘易斯、马尔詹·加兹维涅贾德、加尔吉·戈什、阿尔门·阿加贾尼扬、王思达、卢克·泽特勒莫耶。NeurIPS 2020。[pdf]
- ConvBERT:基于跨度的动态卷积改进BERT。蒋子航、于伟豪、周大泉、陈云鹏、冯家仕、严水成。NeurIPS 2020。[pdf]
模型压缩与加速相关论文
- TinyBERT:为自然语言理解蒸馏BERT。Xiaoqi Jiao、Yichun Yin、Lifeng Shang、Xin Jiang、Xiao Chen、Linlin Li、Fang Wang、Qun Liu。预印本。[pdf] [代码与模型]
- 将特定任务知识从BERT蒸馏到简单神经网络。Raphael Tang、Yao Lu、Linqing Liu、Lili Mou、Olga Vechtomova、Jimmy Lin。预印本。[pdf]
- 用于BERT模型压缩的耐心知识蒸馏。Siqi Sun、Yu Cheng、Zhe Gan、Jingjing Liu。EMNLP 2019。[pdf] [代码]
- 面向大规模问答系统的多任务知识蒸馏模型压缩。Ze Yang、Linjun Shou、Ming Gong、Wutao Lin、Daxin Jiang。预印本。[pdf]
- PANLP在MEDIQA 2019上的应用:预训练语言模型、迁移学习与知识蒸馏。Wei Zhu、Xiaofeng Zhou、Keqiang Wang、Xun Luo、Xiepeng Li、Yuan Ni、Guotong Xie。第18届BioNLP研讨会。[pdf]
- 通过知识蒸馏改进用于自然语言理解的多任务深度神经网络。Xiaodong Liu、Pengcheng He、Weizhu Chen、Jianfeng Gao。预印本。[pdf] [代码与模型]
- 学识渊博的学生学得更好:学生初始化对知识蒸馏的影响。Iulia Turc、Ming-Wei Chang、Kenton Lee、Kristina Toutanova。预印本。[pdf]
- 用于序列标注的小型实用BERT模型。Henry Tsai、Jason Riesa、Melvin Johnson、Naveen Arivazhagan、Xin Li、Amelia Archer。EMNLP 2019。[pdf]
- Q-BERT:基于Hessian矩阵的超低精度量化BERT。Sheng Shen、Zhen Dong、Jiayu Ye、Linjian Ma、Zhewei Yao、Amir Gholami、Michael W. Mahoney、Kurt Keutzer。预印本。[pdf]
- ALBERT:用于自监督语言表示学习的轻量级BERT。Zhenzhong Lan、Mingda Chen、Sebastian Goodman、Kevin Gimpel、Piyush Sharma、Radu Soricut。ICLR 2020。[pdf]
- 利用最优子词和共享投影实现极端的语言模型压缩。Sanqiang Zhao、Raghav Gupta、Yang Song、Denny Zhou。预印本。[pdf]
- DistilBERT:BERT的蒸馏版本——更小、更快、更便宜、更轻。Victor Sanh、Lysandre Debut、Julien Chaumond、Thomas Wolf。预印本。[pdf]
- 通过结构化Dropout按需减少Transformer深度。Angela Fan、Edouard Grave、Armand Joulin。ICLR 2020。[pdf]
- 芝麻街上的窃贼!基于BERT的API模型提取。Kalpesh Krishna、Gaurav Singh Tomar、Ankur P. Parikh、Nicolas Papernot、Mohit Iyyer。ICLR 2020。[pdf]
- DeeBERT:动态提前退出以加速BERT推理。Ji Xin、Raphael Tang、Jaejun Lee、Yaoliang Yu、Jimmy Lin。ACL 2020。[pdf]
- 针对语言模型压缩的中间表示对比蒸馏。Siqi Sun、Zhe Gan、Yuwei Fang、Yu Cheng、Shuohang Wang、Jingjing Liu。EMNLP 2020。[pdf]
- 忒修斯之船式的BERT:通过渐进式模块替换压缩BERT。Canwen Xu、Wangchunshu Zhou、Tao Ge、Furu Wei、Ming Zhou。EMNLP 2020。[pdf]
- TernaryBERT:感知蒸馏的超低比特BERT。Wei Zhang、Lu Hou、Yichun Yin、Lifeng Shang、Xiao Chen、Xin Jiang、Qun Liu。EMNLP 2020。[pdf]
- 当BERT参与彩票时,所有彩票都是中奖的。Sai Prasanna、Anna Rogers、Anna Rumshisky。EMNLP 2020。[pdf]
- Funnel-Transformer:过滤序列冗余以实现高效语言处理。Zihang Dai、Guokun Lai、Yiming Yang、Quoc Le。NeurIPS 2020。[pdf]
- DynaBERT:具有自适应宽度和深度的动态BERT。Lu Hou、Zhiqi Huang、Lifeng Shang、Xin Jiang、Xiao Chen、Qun Liu。NeurIPS 2020。[pdf]
- BERT失去耐心:通过提前退出实现快速且鲁棒的推理。Wangchunshu Zhou、Canwen Xu、Tao Ge、Julian McAuley、Ke Xu、Furu Wei。NeurIPS 2020。[pdf]
模型分析相关论文
- 揭示BERT的黑暗秘密。奥尔加·科瓦列娃、阿列克谢·罗曼诺夫、安娜·罗杰斯、安娜·鲁姆希斯基。EMNLP 2019。[pdf]
- BERT是如何回答问题的?对Transformer表示的逐层分析。贝蒂·范·阿肯、本杰明·温特、亚历山大·勒瑟、菲利克斯·A·格斯。CIKM 2019。[pdf]
- 十六个注意力头真的比一个更好吗?。保罗·米歇尔、奥默·列维、格雷厄姆·纽比。预印本。[pdf] [代码]
- BERT真的稳健吗?针对文本分类和蕴含任务的自然语言攻击强基准。季进、金志静、周天一、彼得·索洛维茨。预印本。[pdf] [代码]
- BERT有嘴巴,它必须说话:将BERT视为马尔可夫随机场语言模型。亚历克斯·王、权赫贤。NeuralGen 2019。[pdf] [代码]
- 上下文表示的语言学知识与迁移性。尼尔森·F·刘、马特·加德纳、约纳坦·贝林科夫、马修·E·彼得斯、诺亚·A·史密斯。NAACL 2019。[pdf]
- BERT在关注什么?对BERT注意力机制的分析。凯文·克拉克、乌尔瓦希·坎德尔瓦尔、奥默·列维、克里斯托弗·D·曼宁。BlackBoxNLP 2019。[pdf] [代码]
- 芝麻开门:深入BERT的语言学知识。林永杰、陈义琛、罗伯特·弗兰克。BlackBoxNLP 2019。[pdf] [代码]
- 分析Transformer语言模型中注意力结构。杰西·维格、约纳坦·贝林科夫。BlackBoxNLP 2019。[pdf]
- 黑盒遇见黑盒:神经语言模型与大脑的表征相似性和稳定性分析。萨米拉·阿布纳尔、丽莎·贝因博恩、罗谢尔·乔埃尼、威廉·祖伊德玛。BlackBoxNLP 2019。[pdf]
- BERT重新发现经典的NLP流水线。伊恩·滕尼、迪潘詹·达斯、艾莉·帕夫利克。ACL 2019。[pdf]
- 多语言BERT到底有多“多语言”?。泰尔莫·皮雷斯、伊娃·施林格、丹·加雷特。ACL 2019。[pdf]
- BERT学到了关于语言结构的哪些知识?。加内什·贾瓦哈尔、贝努瓦·萨戈、贾梅·塞达。ACL 2019。[pdf]
- Beto、Bentz、Becas:BERT令人惊讶的跨语言有效性。吴世杰、马克·德雷兹。EMNLP 2019。[pdf]
- 上下文化词表示究竟有多“上下文”?比较BERT、ELMo和GPT-2嵌入的几何特性。卡温·埃塔亚拉吉。EMNLP 2019。[pdf]
- 探测神经网络对自然语言论证的理解。蒂莫西·尼文、洪宇·考。ACL 2019。[pdf] [代码]
- 用于攻击和分析NLP的通用对抗触发器。埃里克·华莱士、石峰、尼基尔·坎德帕尔、马特·加德纳、萨米尔·辛格。EMNLP 2019。[pdf] [代码]
- Transformer中表示的自底向上演化:基于机器翻译和语言建模目标的研究。埃琳娜·沃伊塔、里科·森尼希、伊万·季托夫。EMNLP 2019。[pdf]
- NLP模型知道数字吗?嵌入中的数感能力探测。埃里克·华莱士、王一中、李素坚、萨米尔·辛格、马特·加德纳。EMNLP 2019。[pdf]
- 探究BERT的语言知识:使用NPIs的五种分析方法。亚历克斯·沃斯塔特、曹宇、伊欧娜·格罗苏、魏鹏、哈根·布利克斯、倪颖宁、安娜·阿尔索普、希卡·博尔迪亚、刘浩坤、艾丽西亚·帕里什、王圣富、杰森·庞、安哈德·莫哈内、蒲蒙·胡特、帕洛玛·耶雷蒂奇、塞缪尔·R·鲍曼。EMNLP 2019。[pdf] [代码]
- 可视化并理解BERT的有效性。郝雅茹、董丽、魏福儒、许科。EMNLP 2019。[pdf]
- BERT几何特性的可视化与度量。安迪·科嫩、艾米丽·赖夫、安妮·袁、彬·金、亚当·皮尔斯、费尔南达·维埃加斯、马丁·瓦滕伯格。NeurIPS 2019。[pdf]
- 作为Transformer模型解释的自注意力机制的有效性探讨。吉诺·布鲁纳、刘洋、达米安·帕斯夸尔、奥利弗·里希特、罗杰·瓦滕霍费尔。预印本。[pdf]
- Transformer剖析:通过核函数视角统一理解Transformer的注意力机制。姚宏·蔡、白绍杰、山田诚、路易斯-菲利普·莫伦西、鲁斯兰·萨拉胡丁诺夫。EMNLP 2019。[pdf]
- 语言模型能作为知识库吗? 法比奥·佩特罗尼、蒂姆·罗克塔谢尔、帕特里克·刘易斯、安东·巴赫京、吴宇翔、亚历山大·H·米勒、塞巴斯蒂安·里德尔。EMNLP 2019,[pdf] [代码]
- 微调还是不微调?将预训练表示适配到多样化任务。马修·E·彼得斯、塞巴斯蒂安·鲁德尔、诺亚·A·史密斯。RepL4NLP 2019,[pdf]
- 单语表示的跨语言迁移性研究。米克尔·阿特切、塞巴斯蒂安·鲁德尔、丹尼·约加塔马。预印本,[pdf] [数据集]
- 一种用于在词表示中寻找句法的结构性探针。约翰·休伊特、克里斯托弗·D·曼宁。NAACL 2019。[pdf]
- 评估BERT的句法能力。约阿夫·戈德堡。技术报告。[pdf]
- 从上下文中你能学到什么?对上下文化词表示中句子结构的探测。伊恩·滕尼、帕特里克·夏、柏林·陈、亚历克斯·王、亚当·波利亚克、R·托马斯·麦科伊、金娜琼、本杰明·范·杜尔梅、塞缪尔·R·鲍曼、迪潘詹·达斯和艾莉·帕夫利克。ICLR 2019。[pdf]
- 你能告诉我如何穿过芝麻街吗?超越语言建模的句子级预训练。亚历克斯·王、扬·胡拉、帕特里克·夏、拉格文德拉·帕帕加里、R·托马斯·麦科伊、罗马·帕特尔、金娜琼、伊恩·滕尼、黄英辉、于嘉婷、金淑宁、柏林·陈、本杰明·范·杜尔梅、爱德华·格雷夫、艾莉·帕夫利克、塞缪尔·R·鲍曼。ACL 2019。[pdf]
- BERT不是中间语,以及分词的偏差。贾斯迪普·辛格、布莱恩·麦肯、理查德·索彻和熊才明。DeepLo 2019。[pdf] [数据集]
- BERT并非如此:来自一套新的心理语言学诊断工具对语言模型的启示。艾莉森·埃廷格。预印本。[pdf] [代码]
- 多语言BERT到底有多“语言中性”?。金德里希·利博维茨基、鲁道夫·罗萨和亚历山大·弗雷泽。预印本。[pdf]
- 多语言BERT的跨语言能力:一项实证研究。卡尔提凯扬·K、王子涵、斯蒂芬·梅休、丹·罗斯。ICLR 2020。[pdf]
- 在多语言BERT中寻找通用语法关系。伊桑·A·奇、约翰·休伊特、克里斯托弗·D·曼宁。ACL 2020。[pdf]
- 针对预训练语言模型的否定式和误引导探针:鸟会说话,但不会飞。诺拉·卡斯纳、欣里希·舒策。ACL 2020。[pdf]
- 扰动掩码:无需参数的探针,用于分析和解释BERT。吴志勇、陈云、郭斌、刘群。ACL 2020。[pdf]
- 鸟有四条腿?!NumSense:探测预训练语言模型的数值常识知识。比尔·余晨林、李世妍、拉胡尔·坎纳和任翔。EMNLP 2020。[pdf]
- 识别BERT多语言能力的关键要素。菲利普·杜夫特、欣里希·舒策。EMNLP 2020。[pdf]
- AUTOPROMPT:利用自动生成的提示从语言模型中提取知识。泰勒·申、亚萨曼·拉泽吉、罗伯特·L·洛根四世、埃里克·华莱士、萨米尔·辛格。EMNLP 2020。[pdf]
- 预训练BERT网络的彩票假说。陈天龙、乔纳森·弗兰克尔、常诗宇、刘思佳、张阳、王章阳、迈克尔·卡宾。NeurIPS 2020。[pdf]
关于微调或适配的论文
- SMART:通过原则性正则化优化实现预训练自然语言模型的鲁棒高效微调。姜浩明、何鹏程、陈伟柱、刘晓东、高剑锋、赵拓。ACL 2020。[pdf]
- 你有合适的剪刀吗?基于蒙特卡洛方法裁剪预训练语言模型。苗宁、宋宇轩、周浩、李磊。ACL 2020。[pdf]
- ExpBERT:利用自然语言解释进行表征工程。希卡尔·穆尔蒂、庞伟科、珀西·梁。ACL 2020。[pdf]
- 不要停止预训练:将语言模型适配到特定领域和任务。苏钦·古鲁兰根、安娜·马拉索维奇、斯瓦巴·斯瓦扬迪普塔、凯尔·洛、伊兹·贝尔塔吉、道格·唐尼、诺亚·A·史密斯。ACL 2020。[pdf]
- 回忆与学习:减少遗忘的深度预训练语言模型微调方法。陈三元、侯宇泰、崔一鸣、车万祥、刘挺、于向展。EMNLP 2020。[pdf]
- 掩码机制:作为预训练语言模型微调的高效替代方案。赵孟杰、林涛、米飞、马丁·雅吉、欣里希·舒策。EMNLP 2020。[pdf]
- CogLTX:将BERT应用于长文本。丁明、周畅、杨红霞、唐杰。NeurIPS 2020。[pdf]
基于提示的微调相关论文
这是我们关于预训练语言模型基于提示微调的新论文列表。[repo]
教程与资源
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。