predrnn-pytorch
PredRNN-pytorch 是一个基于 PyTorch 实现的开源项目,专注于时空序列的预测学习。它的核心任务是通过分析历史视频帧或图像序列中的视觉动态变化,精准生成未来的图像内容。这一工具有效解决了传统模型在处理复杂时空依赖关系时难以捕捉长期动态特征的难题,特别适用于气象雷达回波预测、交通流量演变模拟以及机器人动作推演等场景。
该项目主要面向人工智能研究人员和深度学习开发者,为他们提供了复现经典论文算法及探索前沿技术的坚实基座。PredRNN-pytorch 不仅包含了 2017 年提出的初代 PredRNN 模型,还集成了 2022 年升级版的 PredRNN-V2。其独特的技术亮点包括:创新的“之字形”记忆流机制,实现了不同网络层间信息的双向高效沟通;PredRNN-V2 引入的记忆解耦损失函数,促使模型学习到更模块化的视觉动态结构;以及逆向课程采样策略,显著增强了模型从上下文推断长期规律的能力。此外,它还支持结合动作指令的视频预测,展现了在基于模型的视觉控制领域的巨大潜力。无论是学术研究还是工程落地,PredRNN-pytorch 都是处理时空预测任务的得力助手。
使用场景
某智慧城市交通管理中心正在构建一套短时交通流预测系统,旨在通过历史监控画面预判未来路网的拥堵演变趋势。
没有 predrnn-pytorch 时
- 时空特征割裂:传统 CNN 或普通 LSTM 模型难以同时捕捉车辆移动的空间形态与时间连续性,导致预测画面模糊,无法还原真实的交通动态。
- 长程依赖丢失:在预测超过 10 分钟的未来路况时,模型容易受误差累积影响,迅速退化为静态背景图,丢失关键的车流变化细节。
- 外部干预失效:模型仅能被动观察视频,无法融合“信号灯切换”或“事故疏导”等控制动作,难以支撑主动式的交通调控决策。
- 训练收敛困难:缺乏有效的课程学习策略,模型在面对复杂多变的早晚高峰数据时,训练不稳定且泛化能力差。
使用 predrnn-pytorch 后
- 时空动态解耦:利用 PredRNN-V2 的记忆解耦机制,模型成功分离并学习了车流的模块化运动规律,生成的未来帧清晰锐利,保留了车道和车型细节。
- 长期预测稳定:借助反向计划采样(Reverse Scheduled Sampling)策略,强制模型从真实上下文学习长时依赖,显著提升了 30 分钟以上长远路况的预测准确性。
- 支持动作条件预测:通过融合控制动作与隐藏状态,系统能模拟“若绿灯延长 10 秒”后的具体车流疏散效果,为智能信控提供量化依据。
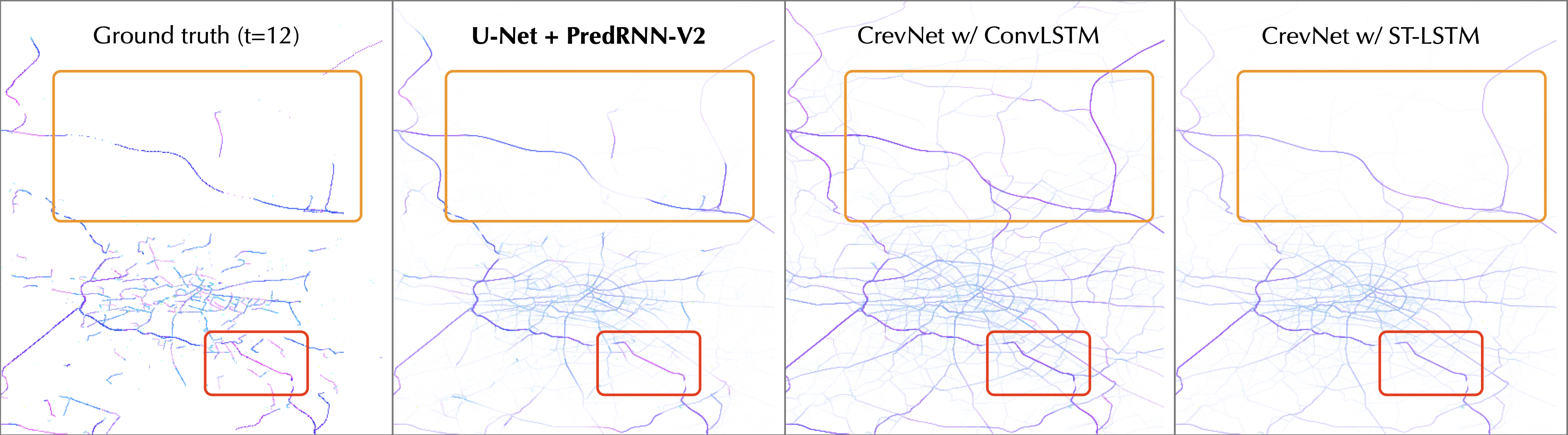
- 感知指标优化:在柏林 Traffic4Cast 实测中,结合 U-Net 的架构将均方误差(MSE)大幅降低至 5.135,视觉感知质量远超传统基线模型。
predrnn-pytorch 通过独特的时空记忆流与解耦学习机制,将交通预测从模糊的“看图猜谜”升级为可干预、高精度的动态推演引擎。
运行环境要求
- 未说明
未说明(基于 PyTorch 的时空预测模型通常建议配备 NVIDIA GPU 以加速训练)
未说明
快速开始
PredRNN:用于时空预测学习的循环神经网络(TPAMI 2022)
时空序列的预测学习旨在通过学习历史上下文来生成未来的图像,其中视觉动态被认为具有模块化的结构,可以通过组合式的子系统来学习。
初版于 NeurIPS 2017
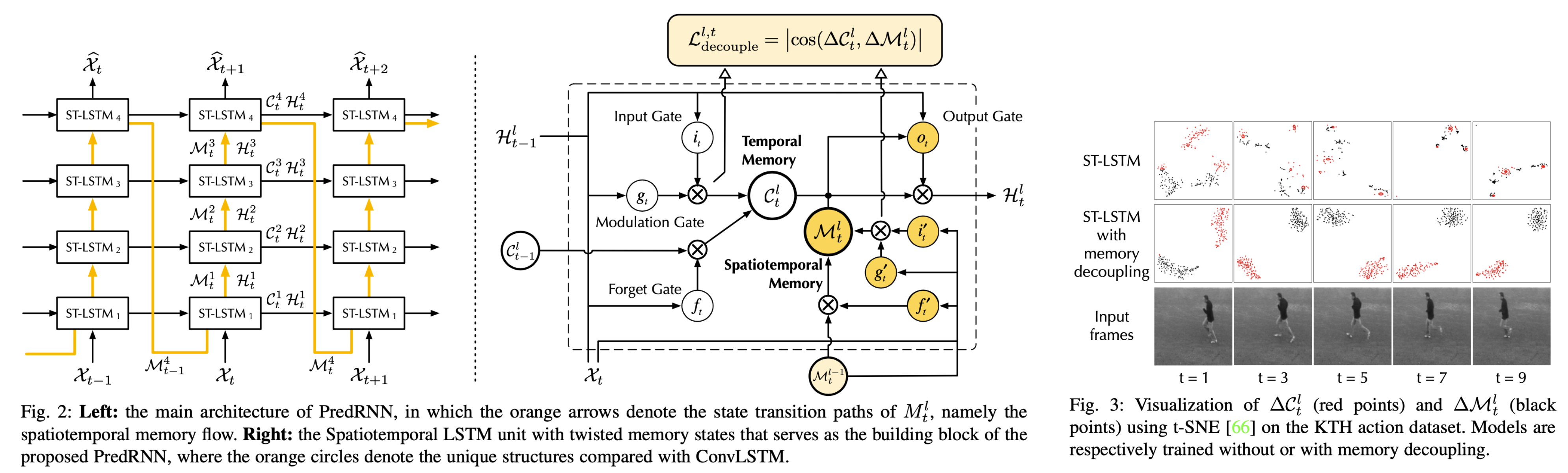
本仓库首先包含 PredRNN(2017)的 PyTorch 实现 [论文],这是一种具有两组记忆单元的循环网络,它们以几乎独立的方式进行状态转移,最终形成对复杂环境的统一表征。
具体而言,除了 LSTM 的原始记忆单元外,该网络还具有一个在所有层中自下而上和自上而下双向传播的锯齿形记忆流,从而使不同层次 RNN 学习到的视觉动态能够相互交流。
TPAMI 2022 版 PredRNN-V2 的新特性
本仓库还包括 PredRNN-V2 的实现 [论文],它在以下三个方面对 PredRNN 进行了改进。
1. 记忆解耦的 ST-LSTM
我们发现,PredRNN 中的两组记忆单元包含不必要的冗余特征,因此提出了一种记忆解耦损失,以鼓励它们学习视觉动态的模块化结构。
2. 反向调度采样
反向调度采样是一种针对序列到序列 RNN 的新型课程学习策略。与传统的调度采样相反,它逐渐将 PredRNN 编码器的训练过程从使用先前生成的帧切换为使用之前的真值帧。优点:这迫使模型从上下文帧中学习长期动态。
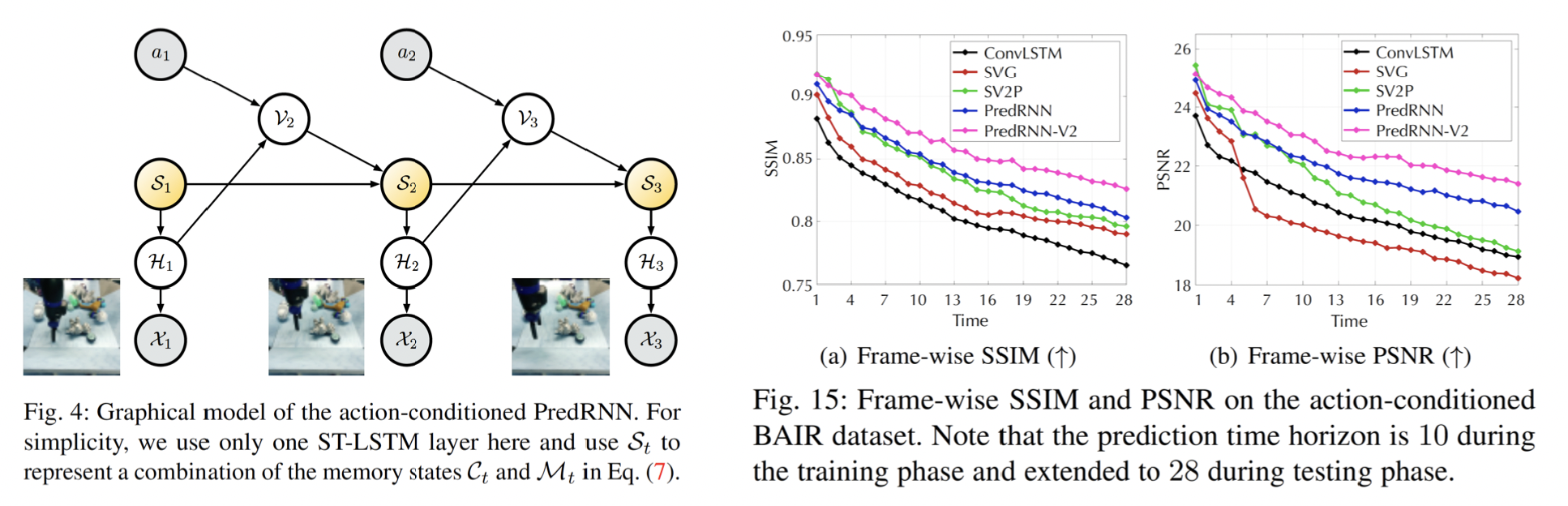
3. 动作条件下的视频预测
我们进一步将 PredRNN 扩展到动作条件下的视频预测任务。通过将动作与隐藏状态融合,PredRNN 和 PredRNN-V2 在长期预测方面表现出极高的竞争力,有望作为基于模型的视觉控制中的基础动力学模型。
我们在 BAIR 机器人推动物体数据集上展示了定量结果,该任务是从 2 个观测帧预测未来 28 帧。
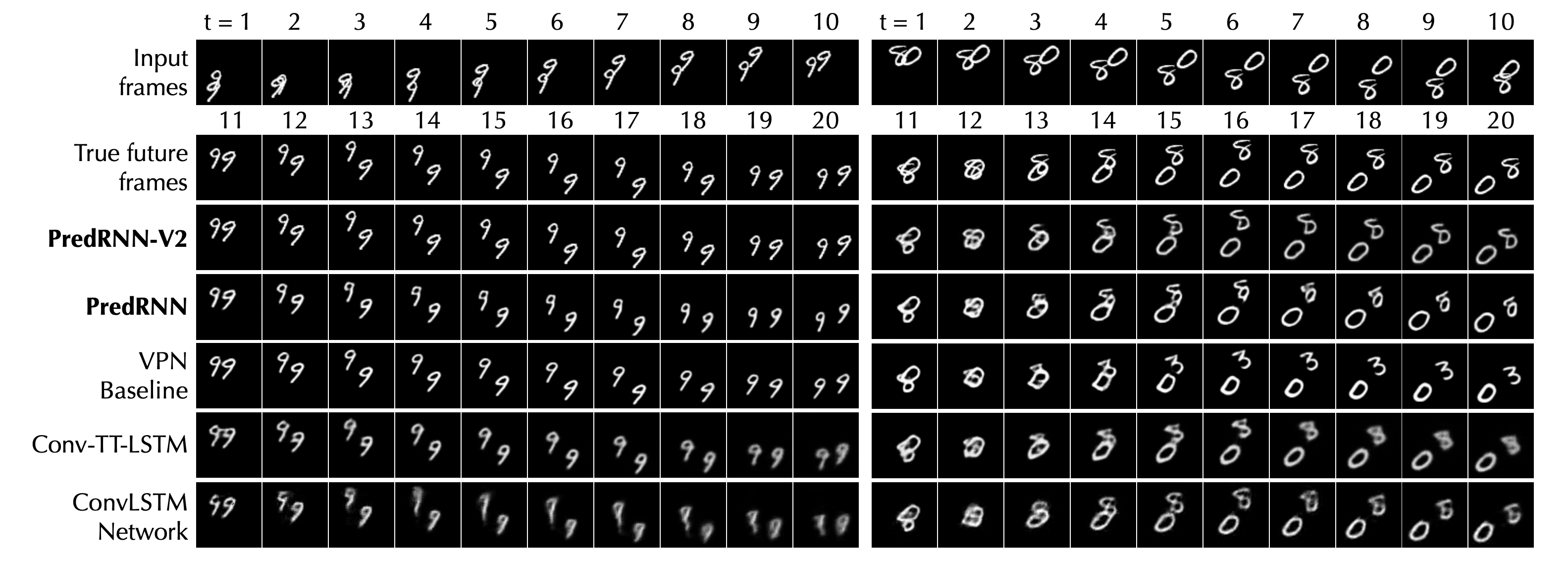
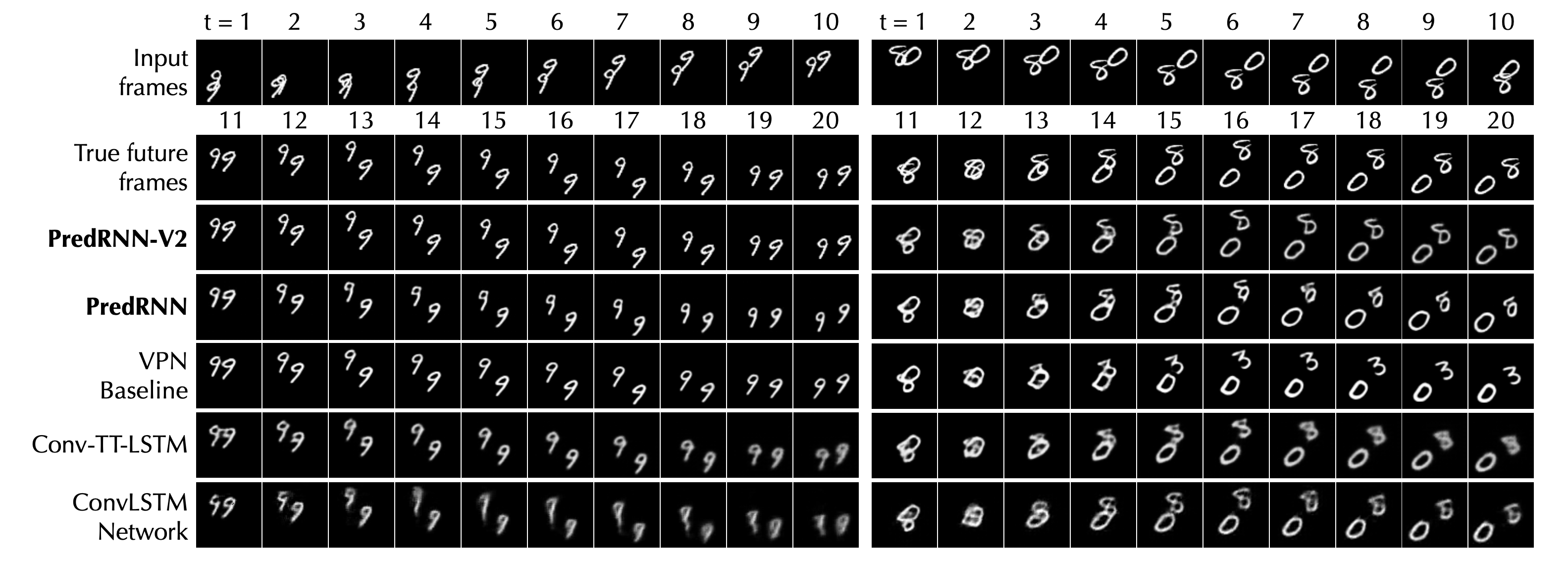
展示案例
移动 MNIST
KTH

BAIR(我们放大红色框内的区域)

Traffic4Cast
雷达回波
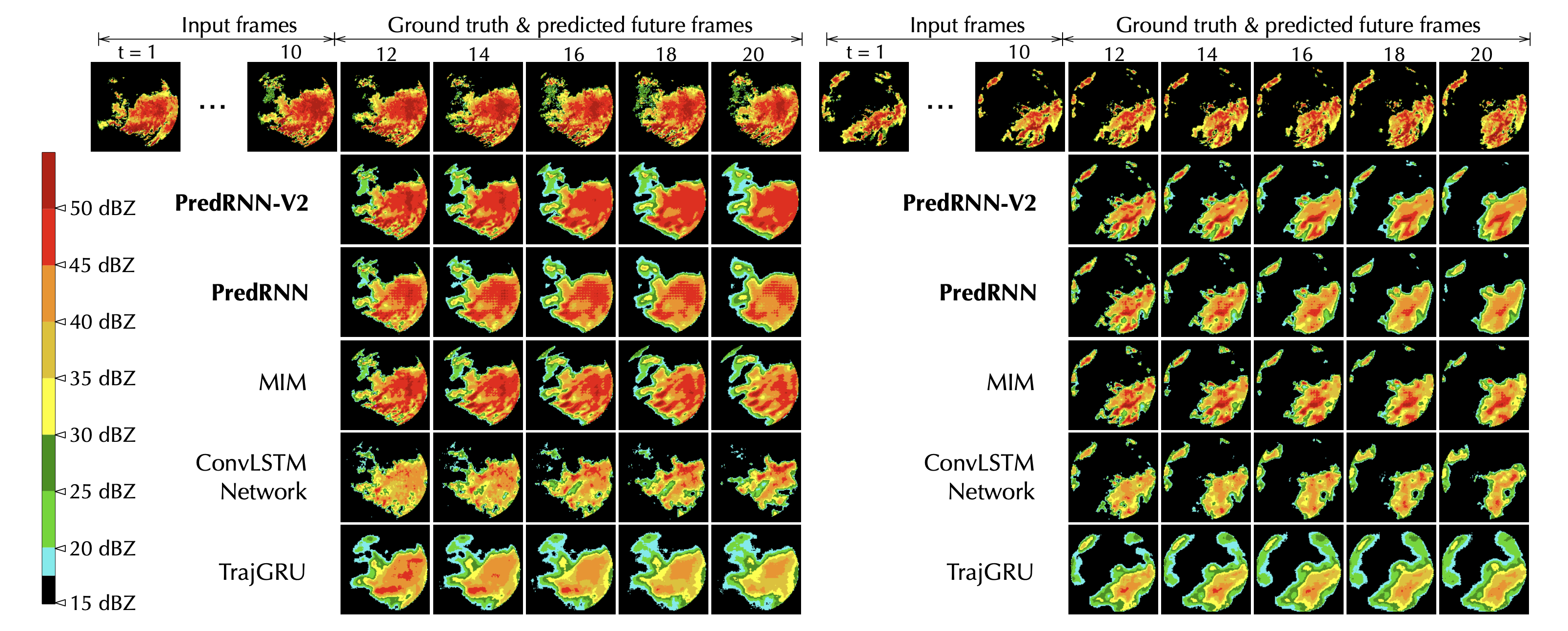
LPIPS 下移动 MNIST 和 KTH 的定量结果
LPIPS 对人类感知判断更为敏感,数值越低越好。
| 移动 MNIST | KTH 动作 | |
|---|---|---|
| PredRNN | 0.109 | 0.204 |
| PredRNN-V2 | 0.071 | 0.139 |
Traffic4Cast(柏林)的定量结果
| MSE (10^{-3}) | |
|---|---|
| U-Net | 6.992 |
| CrevNet | 6.789 |
| U-Net+PredRNN-V2 | 5.135 |
快速入门
安装 Python 3.6 和 PyTorch 1.9.0 以运行主代码。同时,安装 Tensorflow 2.1.0 用于 BAIR 数据加载器。
下载数据。本仓库包含三个数据集的代码:移动 MNIST 数据集、KTH 动作数据集,以及 BAIR 数据集(30.1GB),可通过以下命令获取:
wget http://rail.eecs.berkeley.edu/datasets/bair_robot_pushing_dataset_v0.tar训练模型。您可以使用以下 Bash 脚本来训练模型。训练好的模型将保存在
--save_dir文件夹中,生成的未来帧将保存在--gen_frm_dir文件夹中。您可以从 清华大学云 或 Google Drive 获取 预训练模型。
cd mnist_script/
sh predrnn_mnist_train.sh
sh predrnn_v2_mnist_train.sh
cd kth_script/
sh predrnn_kth_train.sh
sh predrnn_v2_kth_train.sh
cd bair_script/
sh predrnn_bair_train.sh
sh predrnn_v2_bair_train.sh
引用
如果您觉得本仓库有用,请引用以下论文。
@inproceedings{wang2017predrnn,
title={{PredRNN}: Recurrent Neural Networks for Predictive Learning Using Spatiotemporal {LSTM}s},
author={Wang, Yunbo and Long, Mingsheng and Wang, Jianmin and Gao, Zhifeng and Yu, Philip S},
booktitle={Advances in Neural Information Processing Systems},
pages={879--888},
year={2017}
}
@misc{wang2021predrnn,
title={{PredRNN}: A Recurrent Neural Network for Spatiotemporal Predictive Learning},
author={Wang, Yunbo and Wu, Haixu and Zhang, Jianjin and Gao, Zhifeng and Wang, Jianmin and Yu, Philip S and Long, Mingsheng},
year={2021},
eprint={2103.09504},
archivePrefix={arXiv},
}
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
MoneyPrinterTurbo
MoneyPrinterTurbo 是一款利用 AI 大模型技术,帮助用户一键生成高清短视频的开源工具。只需输入一个视频主题或关键词,它就能全自动完成从文案创作、素材匹配、字幕合成到背景音乐搭配的全过程,最终输出完整的竖屏或横屏短视频。 这款工具主要解决了传统视频制作流程繁琐、门槛高以及素材版权复杂等痛点。无论是需要快速产出内容的自媒体创作者,还是希望尝试视频生成的普通用户,无需具备专业的剪辑技能或昂贵的硬件配置(普通电脑即可运行),都能轻松上手。同时,其清晰的 MVC 架构和对多种主流大模型(如 DeepSeek、Moonshot、通义千问等)的广泛支持,也使其成为开发者进行二次开发或技术研究的理想底座。 MoneyPrinterTurbo 的独特亮点在于其高度的灵活性与本地化友好性。它不仅支持中英文双语及多种语音合成,允许用户精细调整字幕样式和画面比例,还特别优化了国内网络环境下的模型接入方案,让用户无需依赖 VPN 即可使用高性能国产大模型。此外,工具提供批量生成模式,可一次性产出多个版本供用户择优,极大地提升了内容创作的效率与质量。
oh-my-openagent
oh-my-openagent(简称 omo)是一款强大的开源智能体编排框架,前身名为 oh-my-opencode。它致力于打破单一模型供应商的生态壁垒,解决开发者在构建 AI 应用时面临的“厂商锁定”难题。不同于仅依赖特定模型的封闭方案,omo 倡导开放市场理念,支持灵活调度多种主流大模型:利用 Claude、Kimi 或 GLM 进行任务编排,调用 GPT 处理复杂推理,借助 Minimax 提升响应速度,或发挥 Gemini 的创意优势。 这款工具特别适合希望摆脱平台限制、追求极致性能与成本平衡的开发者及研究人员使用。通过统一接口,用户可以轻松组合不同模型的长处,构建更高效、更具适应性的智能体系统。其独特的技术亮点在于“全模型兼容”架构,让用户不再受制于某一家公司的策略变动或定价调整,真正实现对前沿模型资源的自由驾驭。无论是构建自动化编码助手,还是开发多步骤任务处理流程,oh-my-openagent 都能提供灵活且稳健的基础设施支持,助力用户在快速演进的 AI 生态中保持技术主动权。
onlook
Onlook 是一款专为设计师打造的开源 AI 优先设计工具,被誉为“设计师版的 Cursor”。它旨在打破设计与开发之间的壁垒,让用户能够以可视化的方式直接构建、样式化和编辑 React 应用。通过 Onlook,用户无需深入编写复杂代码,即可在类似 Figma 的直观界面中完成网页原型的搭建与调整,并实时预览最终效果。 这款工具主要解决了传统工作流中设计稿到代码转换效率低、沟通成本高的问题。以往,设计师使用 Figma 等工具完成设计后,需要开发人员手动将其转化为代码,过程繁琐且容易出错。Onlook 允许用户直接在浏览器 DOM 中进行可视化编辑,底层自动生成基于 Next.js 和 TailwindCSS 的高质量代码,实现了“所见即所得”的开发体验。它不仅支持从文本或图像快速生成应用,还具备分支管理、资源管理及一键部署等功能,极大地简化了从创意到成品的流程。 Onlook 特别适合前端开发者、UI/UX 设计师以及希望快速验证产品创意的独立开发者使用。对于设计师而言,它降低了参与前端开发的门槛;对于开发者来说,它提供了一个高效的视觉化调试和原型构建环境。其核心技术亮点在于
serena
Serena 是一款专为编程智能体(Coding Agent)打造的强大工具包,被誉为“智能体的集成开发环境(IDE)”。它通过模型上下文协议(MCP)与各类大语言模型及客户端无缝集成,旨在解决传统 AI 在复杂代码库中因依赖行号或简单文本搜索而导致的效率低下和准确性不足的问题。 与传统方法不同,Serena 采用“智能体优先”的设计理念,提供基于语义的代码检索、编辑和重构能力。它能像资深开发者使用 IDE 一样,深入理解代码的符号层级和关联结构,从而让智能体在大型项目中运行得更快、更稳、更可靠。无论是终端用户(如 Claude Code)、IDE 插件(VSCode、Cursor)还是桌面应用,都能轻松接入 Serena 以扩展功能。 Serena 特别适合需要处理大规模代码项目的开发者、研究人员以及希望提升 AI 编码能力的技术团队。其核心技术亮点在于灵活的后端支持:既默认集成了基于语言服务器协议(LSP)的开源方案,支持超过 40 种编程语言;也可选配强大的 JetBrains 插件,利用专业 IDE 的深度分析能力。这让 Serena 成为连接人工智能与复杂软件工程的高效桥
sam2
SAM 2 是 Meta 推出的新一代基础模型,旨在解决图像与视频中的“提示式视觉分割”难题。无论是静态图片还是动态视频,用户只需提供简单的点击、框选等提示,SAM 2 就能精准识别并分割出目标对象。它将单张图像视为单帧视频进行处理,成功打破了以往模型在视频理解上的局限。 这款工具特别适合计算机视觉开发者、AI 研究人员以及需要处理视频内容的设计师使用。对于希望探索多目标跟踪或构建交互式应用的技术团队,SAM 2 提供了强大的底层支持。其核心亮点在于采用了带有流式记忆机制的 Transformer 架构,能够实现实时的视频处理性能。此外,项目配套发布了迄今为止规模最大的视频分割数据集(SA-V),并通过“模型闭环数据引擎”不断自我进化。最新更新的 SAM 2.1 版本不仅提供了更优的预训练权重,还支持全模型编译加速及灵活的多目标独立追踪,让复杂场景下的视频分析变得更加高效与便捷。