self-correction-llm-papers
self-correction-llm-papers 是一个专注于“大语言模型自我修正”领域的学术资源库,系统整理了利用自动化反馈机制提升模型准确性的前沿研究论文。当前大模型常面临幻觉、逻辑错误或事实不准确等挑战,而该资源库聚焦的核心问题正是如何让模型在生成内容后,能够像人类一样自动发现并修正这些错误,从而输出更可靠的结果。
这份合集特别适合 AI 研究人员、算法工程师以及对大模型对齐技术感兴趣的开发者使用。它不仅仅是一份简单的文献列表,更提供了一套清晰的概念框架,将复杂的自我修正策略科学地划分为三大类:训练时修正(如基于人类反馈的强化学习 RLHF)、生成时修正(如重排序与反馈引导)以及事后修正(如自我精炼与多模型辩论)。通过这种结构化的整理,用户可以快速定位到特定技术路线的最新进展,高效追踪从基础理论到具体算法的实现细节。对于希望深入理解如何让大模型具备“自省”能力,或正在寻找优化模型输出质量方案的专业人士而言,self-correction-llm-papers 是一份极具价值的入门指南与研究地图。
使用场景
某金融科技公司正在开发一款自动合规报告生成系统,要求模型输出的法律条款引用必须绝对准确且逻辑自洽。
没有 self-correction-llm-papers 时
- 模型在生成复杂法规分析时容易产生“幻觉”,编造不存在的法条编号,人工复核成本极高。
- 团队缺乏系统的自我修正理论指导,只能盲目尝试提示词工程,无法从根本上解决逻辑断裂问题。
- 面对生成错误,系统缺乏自动反馈机制,一旦输出错误内容便直接交付,导致合规风险不可控。
- 研发人员难以区分训练时修正与生成时修正的策略差异,导致技术选型混乱,资源浪费严重。
使用 self-correction-llm-papers 后
- 团队依据库中"Self-Refine Strategy"等论文实现了多轮自我反思机制,模型能主动识别并修正编造的法条,准确率提升 40%。
- 借助库中分类清晰的策略框架(如 RLHF、Feedback-guided),研发团队快速锁定了适合金融场景的“外部反馈修正”路径。
- 系统集成了自动化反馈闭环,模型在输出前能利用内部逻辑校验进行多次迭代,显著降低了人工复审压力。
- 通过参考库中关于“模型辩论策略”的研究,系统引入双模型互检机制,进一步消除了隐蔽的逻辑漏洞。
self-correction-llm-papers 为构建高可靠性大模型应用提供了从理论到策略的完整导航,将不可控的生成风险转化为可管理的修正流程。
运行环境要求
未说明
未说明

快速开始
自纠正大语言模型论文集
![]()


![]()
这是一个关于具有自动化反馈的自纠正大型语言模型的研究论文合集。
我们的综述论文:自动纠正大型语言模型:探索多样化的自纠正策略。作者:Liangming Pan、Michael Saxon、Wenda Xu、Deepak Nathani、Xinyi Wang、William Yang Wang
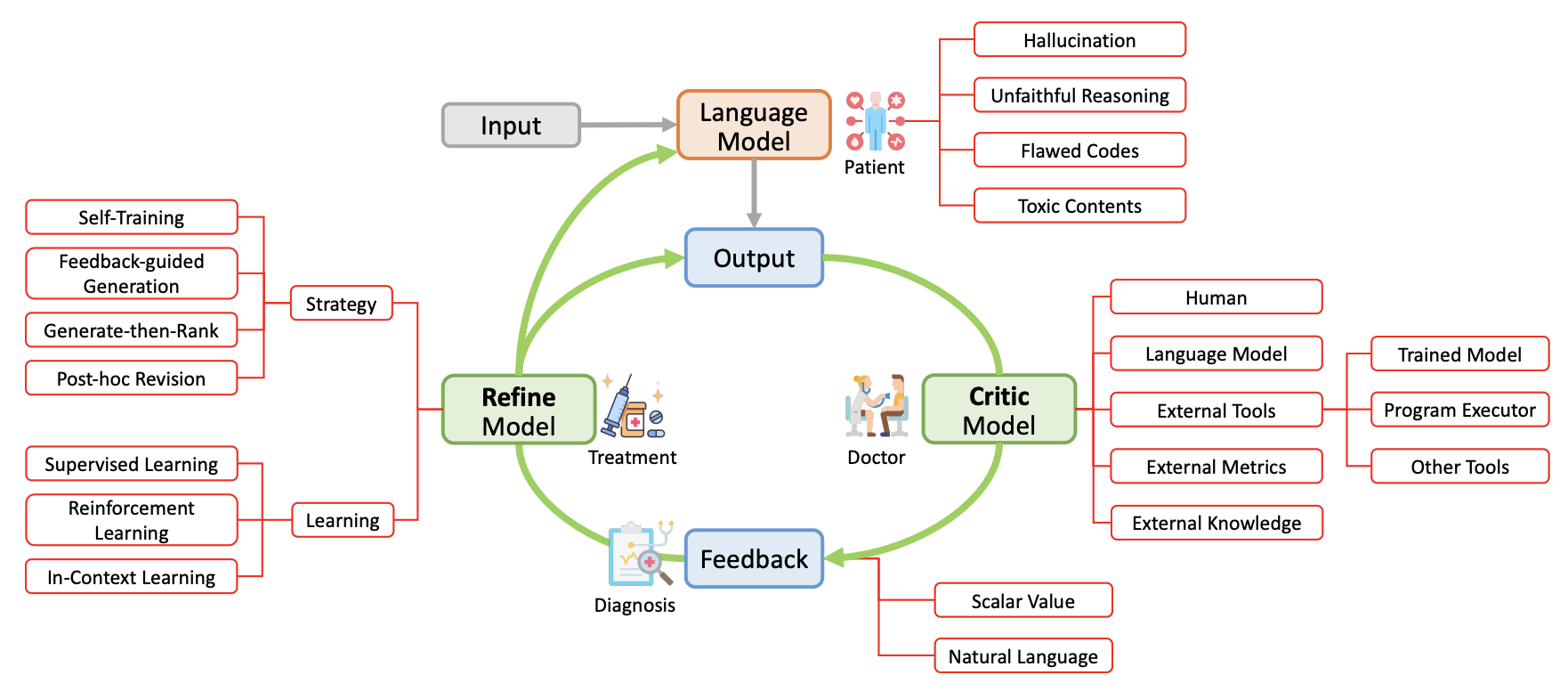
目录
| 1. 训练时纠正 | |
| 1.1 RLHF 策略 | 1.2 微调策略 |
| 1.3 自训练策略 | |
| 2. 生成时纠正 | |
| 2.1 重排序策略 | 2.2 反馈引导策略 |
| 3. 事后纠正 | |
| 3.1 自精炼策略 | 3.2 外部反馈策略 |
| 3.3 模型辩论策略 | |
训练时纠正
RLHF 策略
通过人类反馈训练语言模型遵循指令。 神经信息处理系统进展会议(NeurIPS),2022年。论文
Long Ouyang、Jeffrey Wu、Xu Jiang、Diogo Almeida、Carroll L. Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray、John Schulman、Jacob Hilton、Fraser Kelton、Luke Miller、Maddie Simens、Amanda Askell、Peter Welinder、Paul F. Christiano、Jan Leike、Ryan Lowe
细粒度的人类反馈为语言模型训练提供更好的奖励。 arXiv,2023年。论文
Zeqiu Wu、Yushi Hu、Weijia Shi、Nouha Dziri、Alane Suhr、Prithviraj Ammanabrolu、Noah A. Smith、Mari Ostendorf、Hannaneh Hajishirzi
通过来自人类反馈的强化学习训练一个有益且无害的助手。 arXiv,2022年。论文
Yuntao Bai、Andy Jones、Kamal Ndousse、Amanda Askell、Anna Chen、Nova DasSarma、Dawn Drain、Stanislav Fort、Deep Ganguli、Tom Henighan、Nicholas Joseph、Saurav Kadavath、Jackson Kernion、Tom Conerly、Sheer El-Showk、Nelson Elhage、Zac Hatfield-Dodds、Danny Hernandez、Tristan Hume、Scott Johnston、Shauna Kravec、Liane Lovitt、Neel Nanda、Catherine Olsson、Dario Amodei、Tom Brown、Jack Clark、Sam McCandlish、Chris Olah、Ben Mann、Jared Kaplan
通过有针对性的人类判断改进对话代理的一致性。 arXiv,2022年。论文
Amelia Glaese、Nat McAleese、Maja Trębacz、John Aslanides、Vlad Firoiu、Timo Ewalds、Maribeth Rauh、Laura Weidinger、Martin Chadwick、Phoebe Thacker、Lucy Campbell-Gillingham、Jonathan Uesato、Po-Sen Huang、Ramona Comanescu、Fan Yang、Abigail See、Sumanth Dathathri、Rory Greig、Charlie Chen、Doug Fritz、Jaume Sanchez Elias、Richard Green、Soňa Mokrá、Nicholas Fernando、Boxi Wu、Rachel Foley、Susannah Young、Iason Gabriel、William Isaac、John Mellor、Demis Hassabis、Koray Kavukcuoglu、Lisa Anne Hendricks、Geoffrey Irving
微调策略
大规模语言反馈下训练语言模型。 arXiv,2023年。论文
Jérémy Scheurer、Jon Ander Campos、Tomasz Korbak、Jun Shern Chan、Angelica Chen、Kyunghyun Cho、Ethan Perez
通过人类反馈持续改进抽取式问答。 arXiv,2023年。论文
Ge Gao、Hung-Ting Chen、Yoav Artzi、Eunsol Choi
事后链使语言模型与反馈对齐。 arXiv,2023年。论文
Hao Liu、Carmelo Sferrazza、Pieter Abbeel
QUARK:通过强化遗忘实现可控文本生成。 神经信息处理系统进展会议(NeurIPS),2022年。论文
Ximing Lu、Sean Welleck、Jack Hessel、Liwei Jiang、Lianhui Qin、Peter West、Prithviraj Ammanabrolu、Yejin Choi
SimCLS:抽象摘要对比学习的简单框架。 计算语言学协会年度会议(ACL),2021年。论文
Yixin Liu、Pengfei Liu
BERTTune:使用 BERTScore 对神经机器翻译进行微调。 计算语言学协会年度会议(ACL),2021年。论文
Inigo Jauregi Unanue、Jacob Parnell、Massimo Piccardi
自训练策略
STaR:通过推理进行推理的自举。 神经信息处理系统大会(NeurIPS),2022年。论文
埃里克·泽利克曼、吴宇怀、杰西·穆、诺亚·古德曼
SELF-INSTRUCT:利用自我生成的指令对齐语言模型。 计算语言学协会年会(ACL),2023年。论文
王一中、耶加内·科尔迪、斯瓦鲁普·米什拉、阿丽莎·刘、诺亚·A·史密斯、丹尼尔·卡沙比、汉娜内·哈吉希尔齐
宪法式AI:从AI反馈中实现无害性。 arXiv,2022年。论文
白云涛、索劳夫·卡达瓦特、桑迪潘·昆杜、阿曼达·阿斯克尔、杰克逊·科尼恩、安迪·琼斯、安娜·陈、安娜·戈尔迪、阿扎莉娅·米尔霍塞尼、卡梅伦·麦金农、卡罗尔·陈、凯瑟琳·奥尔森、克里斯托弗·奥拉、丹尼·埃尔南德斯、道恩·德雷恩、迪普·甘古利、达斯汀·李、伊莱·特兰-约翰逊、伊森·佩雷斯、杰米·克尔、贾雷德·穆勒、杰弗里·拉迪什、乔舒亚·兰道、卡马尔·恩多斯、卡米莱·卢科修特、莉安·洛维特、迈克尔·塞利托、尼尔森·埃尔哈格、尼古拉斯·希费尔、诺埃米·梅尔卡多、诺娃·达萨尔马、罗伯特·拉森比、罗宾·拉尔森、萨姆·林格、斯科特·约翰斯顿、绍娜·克拉韦克、希尔·埃尔·肖克、斯坦尼斯拉夫·福特、塔梅拉·兰厄姆、蒂莫西·泰林-劳顿、汤姆·科纳利、汤姆·赫尼根、特里斯坦·休姆、塞缪尔·R·鲍曼、扎克·哈特菲尔德-多兹、本·曼、达里奥·阿莫迪、尼古拉斯·约瑟夫、萨姆·麦坎德利什、汤姆·布朗、贾雷德·卡普兰
基于强化学习反思的语言模型自我改进。 arXiv,2023年。论文
庞景程、王鹏远、李开元、陈雄辉、徐嘉诚、张宗章、余洋
大型语言模型可以自我改进。 arXiv,2022年。论文
黄家欣、顾世翔、侯乐、吴悦鑫、王雪芝、于洪坤、韩佳伟
AlpacaFarm:用于学习人类反馈方法的仿真框架。 arXiv,2023年。论文
扬·杜布瓦、李雪晨、罗翰·陶里、张天义、伊尚·古尔拉贾尼、吉米·巴、卡洛斯·盖斯特林、珀西·梁、夏目隆则
生成时修正
重排序策略
大型语言模型通过自我验证成为更好的推理者。 arXiv,2023年。论文
翁毅轩、朱敏俊、夏飞、李斌、何仕柱、刘康、赵军
CodeT:利用生成的测试进行代码生成。 国际表征学习会议(ICLR),2023年。论文
陈贝、张凤吉、阮英、赞道光、林泽奇、楼建光、陈伟竹
LEVER:通过执行学习验证语言到代码的生成。 国际机器学习会议(ICML),2023年。论文
倪安松、斯里尼·艾耶尔、德拉戈米尔·拉德夫、韦斯·斯托亚诺夫、易文涛、王思达·I、林希·维多利亚
借助检索重新思考:忠实的大语言模型推理。 arXiv,2022年。论文
何航峰、张宏明、丹·罗斯
INSTRUCTSCORE:迈向具有自动反馈的可解释文本生成评估。 arXiv,2023年。论文
许文达、王丹青、潘良明、宋振桥、马库斯·弗赖塔格、威廉·杨·王、李磊
高质量而非高模型概率:基于神经度量的最小贝叶斯风险解码。 计算语言学协会期刊(TACL),2022年。论文
马库斯·弗赖塔格、大卫·格兰吉耶、谭启俊、梁博文
利用步骤感知验证器使语言模型成为更好的推理者。 计算语言学协会年会(ACL),2023年。论文
李一飞、林泽奇、张士卓、傅强、陈贝、楼建光、陈伟竹
反馈引导策略
让我们逐步验证。 arxiv,2023年。论文
亨特·莱特曼、维尼特·科萨拉朱、尤拉·伯达、哈里·爱德华兹、鲍文·贝克、泰迪·李、扬·莱克、约翰·舒尔曼、伊利亚·苏茨克维尔、卡尔·科布
扩散语言模型提升可控文本生成。 神经信息处理系统进展会议(NeurIPS),2022年。论文
李香丽莎、约翰·希克斯顿、伊沙恩·古尔拉贾尼、珀西·梁、夏目典则
FUDGE:利用未来判别器进行可控文本生成。 计算语言学协会北美分会:人类语言技术会议(NAACL),2021年。论文
凯文·杨、丹·克莱因
Entailer:以忠实且真实的理由链回答问题。 自然语言处理经验方法会议(EMNLP),2022年。论文
奥伊温德·塔夫乔德、巴瓦娜·达尔维·米什拉、彼得·克拉克
利用验证器引导搜索生成自然语言证明。 自然语言处理经验方法会议(EMNLP),2022年。论文
杨凯宇、邓佳、陈丹琪
判别器引导的多步推理与语言模型。 arxiv,2023年。论文
穆罕默德·哈利法、拉贾努根·洛格斯瓦兰、蒙泰·李、洪拉克·李、王璐
通过合作推理诱导的语言模型解决数学应用题。 计算语言学协会年会(ACL),2023年。论文
朱新宇、王俊杰、张林、张宇翔、黄永峰、甘如怡、张嘉兴、杨宇久
助产术提示:利用递归解释实现逻辑一致的推理。 自然语言处理经验方法会议(EMNLP),2022年。论文
郑在勋、秦连辉、肖恩·韦莱克、法泽·布拉赫曼、钱德拉·巴加瓦图拉、罗南·勒布拉斯、叶金·崔
使用大型语言模型进行忠实推理。 arxiv,2022年。论文
安东尼娅·克雷斯韦尔、默里·沙纳汉
利用语言模型进行推理即是在构建世界模型的基础上进行规划。 arxiv,2023年。论文
郝世博、顾毅、马浩迪、洪家华、王振、王哲黛西、胡志婷
分解增强推理:基于自我评估引导的解码。 arxiv,2023年。论文
谢宇曦、川口健二、赵一然、赵旭、简明彦、何俊贤、谢启哲
思维之树:利用大型语言模型进行深思熟虑的问题解决。 arxiv,2023年。论文
姚顺宇、于典、赵杰弗里、伊扎克·沙夫兰、托马斯·L·格里菲斯、曹源、卡蒂克·纳拉西曼
事后修正
自我精炼策略
自我精炼:基于自我反馈的迭代优化。 arxiv,2023年。论文
阿曼·马丹、尼凯特·坦东、普拉卡尔·古普塔、斯凯勒·哈利南、高露雨、萨拉·维格雷夫、乌里·阿隆、努哈·德齐里、施赖迈·普拉布莫耶、杨一鸣、沙尚克·古普塔、博迪萨特瓦·普拉萨德·马朱姆德尔、凯瑟琳·赫尔曼、肖恩·韦莱克、阿米尔·亚兹丹巴赫什、彼得·克拉克
自我验证提升少样本临床信息抽取。 arxiv,2023年。论文
泽拉莱姆·盖罗、钱丹·辛格、程浩、特里斯坦·诺曼、米歇尔·加利、高建峰、霍伊丰·普恩
反思:具有言语强化学习能力的语言代理。 arxiv,2023年。论文
诺亚·辛恩、费德里科·卡萨诺、贝克·拉巴什、阿什温·戈皮纳特、卡蒂克·纳拉西曼、姚顺宇
利用大型语言模型进行迭代翻译优化。 arxiv,2023年。论文
陈品珍、郭志成、巴里·哈道、肯尼思·希菲尔德
利用GPT-4进行自动翻译后编辑。 arxiv,2023年。论文
维卡斯·劳纳克、阿姆尔·沙拉夫、哈尼·哈桑·阿瓦达拉、阿鲁尔·梅内塞斯
语言模型可以解决计算机任务。 arxiv,2023年。论文
金根佑、皮埃尔·巴尔迪、斯蒂芬·麦卡利尔
SelFee:由自我反馈生成驱动的迭代式自我修订大型语言模型。 博客文章,2023年。网站
成贤叶、容来赵、斗荣金、成东金、贤彬黄、敏俊徐
SelfCheckGPT:面向生成式大型语言模型的零资源黑盒幻觉检测。 arxiv,2023年。论文
波特萨维·马纳库尔、阿迪安·刘西、马克·J·F·盖尔斯
CLOVA:具备工具使用与更新功能的闭环视觉助手。 arxiv,2023年。论文
高志、杜云涛、张欣彤、马晓健、韩文娟、朱松春、李青
外部反馈策略
Re3:通过递归式重提示与修订生成更长的故事。 自然语言处理中的经验方法会议(EMNLP),2022年。论文
凯文·杨、田元东、彭楠云、丹·克莱因
CodeRL:通过预训练模型和深度强化学习掌握代码生成。 神经信息处理系统大会(NeurIPS),2022年。论文
Hung Le、Yue Wang、Akhilesh Deepak Gotmare、Silvio Savarese、Steven C.H. Hoi
REFINER:基于中间表示的推理反馈。 arXiv,2023年。论文
Debjit Paul、Mete Ismayilzada、Maxime Peyrard、Beatriz Borges、Antoine Bosselut、Robert West、Boi Faltings
RL4F:利用强化学习生成自然语言反馈以修复模型输出。 计算语言学协会年度会议(ACL),2023年。论文
Afra Feyza Akyurek、Ekin Akyurek、Ashwin Kalyan、Peter Clark、Derry Tanti Wijaya、Niket Tandon
学习模拟自然语言反馈用于交互式语义解析。 计算语言学协会年度会议(ACL),2023年。论文
Hao Yan、Saurabh Srivastava、Yintao Tai、Sida I. Wang、Wen-tau Yih、Ziyu Yao
Baldur:利用大型语言模型进行全证明生成与修复。 arXiv,2023年。论文
Emily First、Markus N. Rabe、Talia Ringer、Yuriy Brun
CRITIC:大型语言模型可通过工具交互式批评实现自我修正。 arXiv,2023年。论文
Gou Zhibin、Shao Zhihong、Gong Yeyun、Shen Yelong、Yang Yujiu、Duan Nan、Chen Weizhu
FacTool:生成式AI中的事实性检测——一种面向多任务与多领域的工具增强框架。 arXiv,2023年。论文
I-Chun Chern、Steffi Chern、Chen Shiqi、Yuan Weizhe、Feng Kehua、Zhou Chunting、He Junxian、Graham Neubig、Liu Pengfei
RARR:利用语言模型研究并修订语言模型所说的内容。 计算语言学协会年度会议(ACL),2023年。论文
Gao Luyu、Dai Zhuyun、Pasupat Panupong、Anthony Chen、Chaganty Arun Tejasvi、Fan Yicheng、Zhao Vincent Y.、Lao Ni、Lee Hongrae、Juan Da-Cheng、Guu Kelvin
核对事实并再试一次:借助外部知识与自动化反馈改进大型语言模型。 arXiv,2023年。论文
Peng Baolin、Galley Michel、He Pengcheng、Cheng Hao、Xie Yujia、Hu Yu、Huang Qiuyuan、Liden Lars、Yu Zhou、Chen Weizhu、Gao Jianfeng
Self-Checker:用于大型语言模型事实核查的即插即用模块。 arXiv,2023年。论文
Li Miaoran、Peng Baolin、Zhang Zhu
通过即插即用的检索反馈改进语言模型。 arXiv,2023年。论文
Yu Wenhao、Zhang Zhihan、Liang Zhenwen、Jiang Meng、Sabharwal Ashish
揭秘GPT在代码生成中的自我修复机制。 arXiv,2023年。论文
Theo X. Olausson、Inala Jeevana Priya、Wang Chenglong、Gao Jianfeng、Solar-Lezama Armando
Self-Edit:面向代码生成的故障感知代码编辑器。 arXiv,2023年。论文
Zhang Kechi、Li Zhuo、Li Jia、Li Ge、Jin Zhi
教导大型语言模型进行自我调试。 arXiv,2023年。论文
Chen Xinyun、Lin Maxwell、Schärli Nathanael、Zhou Denny
SelfEvolve:基于大型语言模型的代码演化框架。 arXiv,2023年。论文
Jiang Shuyang、Wang Yuhao、Wang Yu
Logic-LM:通过符号求解器赋能大型语言模型,实现忠实的逻辑推理。 arXiv,2023年。论文
Pan Liangming、Albalak Alon、Wang Xinyi、Yang Wang William
用于辅助人类评估者的自我批评模型。 arXiv,2022年。论文
Saunders William、Yeh Catherine、Wu Jeff、Bills Steven、Ouyang Long、Ward Jonathan、Leike Jan
ALGO:利用生成的Oracle验证器合成算法程序。 arXiv,2023年。论文
Zhang Kexun、Wang Danqing、Xia Jingtao、Yang Wang William、Li Lei
软件安全的新时代:迈向通过大型语言模型与形式化验证实现自愈软件。 arXiv,2023年。论文
Charalambous Yiannis、Tihanyi Norbert、Jain Ridhi、Sun Youcheng、Ferrag Mohamed Amine、Cordeiro Lucas C.
通过学习自我修正来生成序列。 国际表征学习会议(ICLR),2023年。论文
Welleck Sean、Lu Ximing、West Peter、Brahman Faeze、Shen Tianxiao、Khashabi Daniel、Choi Yejin
MAF:用于改进大型语言模型推理的多方面反馈。 自然语言处理中的经验方法会议(EMNLP),2023年。论文
Nathani Deepak、Wang David、Pan Liangming、Yang Wang William
CLOVA:具有工具使用与更新功能的闭环视觉助手 arXiv,2023年 论文
Gao Zhi、Du Yuntao、Zhang Xintong、Ma Xiaojian、Han Wenjuan、Zhu Song-Chun、Li Qing
LLM自我修正:DeCRIM——分解、批评与精炼,以增强在多重约束下的指令遵循能力 自然语言处理中的经验方法会议(EMNLP),2024年。论文
Palmeira Ferraz Thomas、Mehta Kartik、Lin Yu-Hsiang、Chang Haw-Shiuan、Oraby Shereen、Liu Sijia、Subramanian Vivek、Chung Tagyoung、Bansal Mohit、Peng Nanyun
模型辩论策略
通过多智能体辩论提升语言模型的事实性和推理能力。 arxiv,2023年。论文
Yilun Du、Shuang Li、Antonio Torralba、Joshua B. Tenenbaum、Igor Mordatch
LM vs LM:通过交叉质询检测事实性错误。 arxiv,2023年。论文
Roi Cohen、May Hamri、Mor Geva、Amir Globerson
利用自我博弈和基于AI反馈的上下文学习改进语言模型谈判。 arxiv,2023年。论文
Yao Fu、Hao Peng、Tushar Khot、Mirella Lapata
PRD:同行排名与讨论提升基于大型语言模型的评估。 arxiv,2023年。论文
Ruosen Li、Teerth Patel、Xinya Du
贡献
贡献者

Liangming Pan |

Xinyuan Lu |
致谢
- 在本领域中,我们可能遗漏了一些重要工作,请大家为本仓库贡献力量!提前感谢您的努力。
- 如果您遇到任何问题,请直接联系Liangming Pan,或在GitHub仓库中提交issue。
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。