gpt-load
gpt-load 是一款专为高并发生产环境打造的高性能 AI API 透明代理工具。它核心解决了企业在整合多个 AI 服务时面临的密钥管理混乱、单点故障风险高以及负载均衡复杂等痛点。通过智能密钥轮询机制,gpt-load 能自动在多个 API 密钥间切换,并在检测到故障时迅速隔离与恢复,确保服务持续稳定运行,同时支持 OpenAI、Google Gemini 和 Anthropic Claude 等多种主流模型格式的原生兼容。
这款工具非常适合需要大规模集成 AI 能力的开发者、技术团队及企业用户。无论是构建复杂的 AI 应用,还是管理庞大的密钥池,gpt-load 都能提供企业级的架构支持。其独特的技术亮点包括基于 Go 语言实现的零拷贝流式传输与连接池复用,确保了极致的响应速度;支持配置热更新,无需重启即可调整策略;此外,还配备了基于 Vue 3 的现代化管理后台,提供实时监控、健康检查及细粒度的权限控制,让复杂的分布式部署变得直观易用。借助 gpt-load,用户可以轻松实现横向扩展,以低成本构建高可用的 AI 服务网关。
使用场景
某中型电商公司正在开发智能客服系统,需同时调用 OpenAI、Claude 和 Gemini 多个模型以应对不同场景,且要求服务在促销高峰期保持 99.9% 可用性。
没有 gpt-load 时
- 密钥管理混乱:开发团队需在代码中硬编码多个 API Key,一旦某个密钥配额耗尽或失效,整个服务立即中断,人工轮换耗时且易出错。
- 单点故障风险:直接连接单一上游服务商,若某家厂商接口波动或限流,缺乏自动熔断与切换机制,导致用户请求大量报错。
- 运维监控盲区:无法统一查看各渠道的实时用量、延迟和错误率,排查问题时需在多个厂商后台来回切换,效率极低。
- 架构扩展困难:每次新增模型供应商或调整负载均衡策略,都必须修改代码并重新部署服务,无法适应快速变化的业务需求。
使用 gpt-load 后
- 智能密钥轮询:gpt-load 接管所有 API Key,自动检测配额状态并进行毫秒级无缝轮换,即使个别密钥失效,前端服务也完全无感知。
- 高可用负载均衡:通过加权轮询机制将流量智能分发至多个上游节点,当某渠道异常时自动剔除并尝试恢复,确保服务持续在线。
- 统一可观测性:内置的 Web 管理面板实时展示全链路监控数据,包括各模型组的 QPS、响应时间及健康状态,故障定位从小时级缩短至分钟级。
- 动态热配置:运营人员可在不重启服务的情况下,通过界面动态调整路由策略或添加新模型通道,轻松支撑业务快速迭代。
gpt-load 将复杂的多模型调度转化为稳定的基础设施能力,让团队专注于业务逻辑而非底层运维。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
快速开始
GPT-Load

![]()
![]()
一款高性能、企业级的AI API透明代理服务,专为需要集成多种AI服务的企业和开发者设计。基于Go语言构建,具备智能密钥管理、负载均衡和全面监控能力,适用于高并发生产环境。
如需详细文档,请访问官方文档


特性
- 透明代理:完整保留原生API格式,支持OpenAI、Google Gemini、Anthropic Claude等多种格式
- 智能密钥管理:高性能密钥池,支持分组管理、自动轮换及故障恢复
- 负载均衡:多上游端点加权负载均衡,提升服务可用性
- 智能故障处理:自动密钥黑名单管理与恢复机制,确保服务连续性
- 动态配置:系统设置和分组配置支持热加载,无需重启
- 企业级架构:分布式主从部署,支持水平扩展与高可用性
- 现代化管理:基于Vue 3的Web管理界面,直观易用
- 全面监控:实时统计、健康检查及详细请求日志记录
- 高性能设计:零拷贝流式传输、连接池复用及原子操作
- 生产就绪:优雅关闭、错误恢复及全面的安全机制
- 双重认证:管理与代理分开认证,代理认证支持全局与分组级别密钥
支持的AI服务
GPT-Load作为透明代理服务,完全保留各AI服务商的原生API格式:
- OpenAI格式:官方OpenAI API、Azure OpenAI及其他兼容OpenAI的服务
- Google Gemini格式:Gemini Pro、Gemini Pro Vision等模型的原生API
- Anthropic Claude格式:Claude系列模型,支持高质量对话与文本生成
快速入门
系统要求
- Go 1.24+(用于源码构建)
- Docker(用于容器化部署)
- MySQL、PostgreSQL或SQLite(用于数据库存储)
- Redis(用于缓存及分布式协调,可选)
方法1:Docker快速启动
docker run -d --name gpt-load \
-p 3001:3001 \
-e AUTH_KEY=your-secure-key-here \
-v "$(pwd)/data":/app/data \
ghcr.io/tbphp/gpt-load:latest
请将
your-secure-key-here替换为强密码(切勿使用默认值),随后即可登录管理界面:http://localhost:3001
方法2:使用Docker Compose(推荐)
安装命令:
# 创建目录
mkdir -p gpt-load && cd gpt-load
# 下载配置文件
wget https://raw.githubusercontent.com/tbphp/gpt-load/refs/heads/main/docker-compose.yml
wget -O .env https://raw.githubusercontent.com/tbphp/gpt-load/refs/heads/main/.env.example
# 编辑.env文件,将AUTH_KEY修改为强密码。切勿使用默认或简单密钥,如sk-123456。
# 启动服务
docker compose up -d
部署前,务必更改默认管理员密钥(AUTH_KEY)。推荐格式为:sk-prod-[32位随机字符串]。
默认安装使用SQLite版本,适合轻量级单实例应用。
如需安装MySQL、PostgreSQL及Redis,请在docker-compose.yml文件中取消注释相关服务,配置相应环境变量并重启。
其他命令:
# 查看服务状态
docker compose ps
# 查看日志
docker compose logs -f
# 重启服务
docker compose down && docker compose up -d
# 更新至最新版本
docker compose pull && docker compose down && docker compose up -d
部署完成后:
- 访问Web管理界面:http://localhost:3001
- API代理地址:http://localhost:3001/proxy
请使用您修改后的AUTH_KEY登录管理界面。
方法3:源码构建
源码构建需要本地安装数据库(SQLite、MySQL或PostgreSQL)以及Redis(可选)。
# 克隆并构建
git clone https://github.com/tbphp/gpt-load.git
cd gpt-load
go mod tidy
# 创建配置
cp .env.example .env
# 编辑.env文件,将AUTH_KEY修改为强密码。切勿使用默认或简单密钥,如sk-123456。
# 修改.env中的DATABASE_DSN和REDIS_DSN配置
# REDIS_DSN为可选项;若未配置,则启用内存存储
# 运行
make run
部署完成后:
- 访问Web管理界面:http://localhost:3001
- API代理地址:http://localhost:3001/proxy
请使用您修改后的AUTH_KEY登录管理界面。
方法4:集群部署
集群部署要求所有节点连接到同一套MySQL(或PostgreSQL)和Redis,其中Redis为必选项。建议使用统一的分布式MySQL和Redis集群。
部署要求:
- 所有节点必须配置相同的
AUTH_KEY、DATABASE_DSN、REDIS_DSN - 主从架构下,从节点需配置环境变量:
IS_SLAVE=true
详情请参阅集群部署文档
配置体系
配置架构概述
GPT-Load采用双层配置架构:
1. 静态配置(环境变量)
- 特点:应用启动时读取,运行期间不可更改,需重启应用才能生效
- 用途:基础设施配置,如数据库连接、服务器端口、认证密钥等
- 管理:通过
.env文件或系统环境变量设置
2. 动态配置(热加载)
- 系统设置:存储在数据库中,为整个应用提供统一的行为标准
- 分组配置:针对特定分组自定义的行为参数,可以覆盖系统设置
- 配置优先级:分组配置 > 系统设置 > 环境配置
- 特点:支持热加载,修改后立即生效,无需重启应用
静态配置(环境变量)
服务器配置:
| 设置 | 环境变量 | 默认 | 描述 |
|---|---|---|---|
| 服务端口 | PORT |
3001 | HTTP服务器监听端口 |
| 服务地址 | HOST |
0.0.0.0 | HTTP服务器绑定地址 |
| 读取超时 | SERVER_READ_TIMEOUT |
60 | HTTP服务器读取超时(秒) |
| 写入超时 | SERVER_WRITE_TIMEOUT |
600 | HTTP服务器写入超时(秒) |
| 空闲超时 | SERVER_IDLE_TIMEOUT |
120 | HTTP连接空闲超时(秒) |
| 优雅关闭超时 | SERVER_GRACEFUL_SHUTDOWN_TIMEOUT |
10 | 服务优雅关闭等待时间(秒) |
| 从属模式 | IS_SLAVE |
false | 集群部署中的从属节点标识符 |
| 时区 | TZ |
Asia/Shanghai |
指定时区 |
安全配置:
| 设置 | 环境变量 | 默认 | 描述 |
|---|---|---|---|
| 管理员密钥 | AUTH_KEY |
- | 管理端的访问认证密钥,请将其更改为强密码 |
| 加密密钥 | ENCRYPTION_KEY |
- | 对API密钥进行静态加密。支持任意字符串,或留空以禁用加密。参见数据加密迁移 |
数据库配置:
| 设置 | 环境变量 | 默认 | 描述 |
|---|---|---|---|
| 数据库连接 | DATABASE_DSN |
./data/gpt-load.db |
数据库连接字符串(DSN)或文件路径 |
| Redis连接 | REDIS_DSN |
- | Redis连接字符串,为空时使用内存存储 |
性能与CORS配置:
| 设置 | 环境变量 | 默认 | 描述 |
|---|---|---|---|
| 最大并发请求数 | MAX_CONCURRENT_REQUESTS |
100 | 系统允许的最大并发请求数 |
| 启用CORS | ENABLE_CORS |
false | 是否启用跨域资源共享 |
| 允许的源 | ALLOWED_ORIGINS |
- | 全部来源,逗号分隔 |
| 允许的方法 | ALLOWED_METHODS |
GET,POST,PUT,DELETE,OPTIONS |
允许的HTTP方法 |
| 允许的头 | ALLOWED_HEADERS |
* |
允许的请求头,逗号分隔 |
| 允许凭证 | ALLOW_CREDENTIALS |
false | 是否允许发送凭据 |
日志配置:
| 设置 | 环境变量 | 默认 | 描述 |
|---|---|---|---|
| 日志级别 | LOG_LEVEL |
info |
日志级别:debug、info、warn、error |
| 日志格式 | LOG_FORMAT |
text |
日志格式:文本、json |
| 启用文件日志 | LOG_ENABLE_FILE |
false | 是否启用文件日志输出 |
| 日志文件路径 | LOG_FILE_PATH |
./data/logs/app.log |
日志文件存储路径 |
代理配置:
GPT-Load会自动从环境变量中读取代理设置,以便向上游AI提供商发起请求。
| 设置 | 环境变量 | 默认 | 描述 |
|---|---|---|---|
| HTTP代理 | HTTP_PROXY |
- | HTTP请求的代理服务器地址 |
| HTTPS代理 | HTTPS_PROXY |
- | HTTPS请求的代理服务器地址 |
| 不使用代理 | NO_PROXY |
- | 需要绕过代理的主机或域名列表,逗号分隔 |
支持的代理协议格式:
- HTTP:
http://user:pass@host:port - HTTPS:
https://user:pass@host:port - SOCKS5:
socks5://user:pass@host:port
动态配置(热加载)
基础设置:
| 设置 | 字段名称 | 默认 | 分组覆盖 | 描述 |
|---|---|---|---|---|
| 项目URL | app_url |
http://localhost:3001 |
❌ | 项目基础URL |
| 全局代理密钥 | proxy_keys |
初始值来自 AUTH_KEY |
❌ | 全局生效的代理密钥,逗号分隔 |
| 日志保留天数 | request_log_retention_days |
7 | ❌ | 请求日志保留天数,0表示不清理 |
| 日志写入间隔 | request_log_write_interval_minutes |
1 | ❌ | 日志写入数据库的周期(分钟) |
| 启用请求体日志记录 | enable_request_body_logging |
false | ✅ | 是否在请求日志中记录完整的请求体内容 |
请求设置:
| 设置 | 字段名称 | 默认值 | 组级覆盖 | 描述 |
|---|---|---|---|---|
| 请求超时时间 | request_timeout |
600 | ✅ | 转发请求完整生命周期的超时时间(秒) |
| 连接超时时间 | connect_timeout |
15 | ✅ | 与上游服务建立连接的超时时间(秒) |
| 空闲连接超时时间 | idle_conn_timeout |
120 | ✅ | HTTP 客户端空闲连接的超时时间(秒) |
| 响应头超时时间 | response_header_timeout |
600 | ✅ | 等待上游响应头的超时时间(秒) |
| 最大空闲连接数 | max_idle_conns |
100 | ✅ | 连接池中允许的最大空闲连接总数 |
| 每个主机最大空闲连接数 | max_idle_conns_per_host |
50 | ✅ | 每个上游主机允许的最大空闲连接数 |
| 代理 URL | proxy_url |
- | ✅ | 用于转发请求的 HTTP/HTTPS 代理,若为空则使用环境变量代理 |
关键配置:
| 设置 | 字段名称 | 默认值 | 组级覆盖 | 描述 |
|---|---|---|---|---|
| 最大重试次数 | max_retries |
3 | ✅ | 单次请求使用不同密钥的最大重试次数 |
| 黑名单阈值 | blacklist_threshold |
3 | ✅ | 密钥连续失败达到此次数后将进入黑名单 |
| 密钥验证周期 | key_validation_interval_minutes |
60 | ✅ | 后台定时执行密钥验证的周期(分钟) |
| 密钥验证并发数 | key_validation_concurrency |
10 | ✅ | 后台对无效密钥进行验证时的并发数量 |
| 密钥验证超时时间 | key_validation_timeout_seconds |
20 | ✅ | 后台验证单个密钥时的 API 请求超时(秒) |
数据加密迁移
GPT-Load 支持以加密方式存储 API 密钥。您可以随时启用、禁用或更换加密密钥。
查看数据加密迁移详情
迁移场景
- 启用加密:将明文数据加密存储 - 使用
--to <new-key> - 禁用加密:将加密数据解密为明文 - 使用
--from <current-key> - 更换加密密钥:替换加密密钥 - 使用
--from <current-key> --to <new-key>
操作步骤
Docker Compose 部署
# 1. 更新镜像(确保使用最新版本)
docker compose pull
# 2. 停止服务
docker compose down
# 3. 备份数据库(强烈建议)
# 在迁移之前,您必须手动备份数据库或导出您的密钥,以免因操作或异常导致密钥丢失。
# 4. 执行迁移命令
# 启用加密(your-32-char-secret-key 是您的密钥,建议使用 32 位以上的随机字符串)
docker compose run --rm gpt-load migrate-keys --to "your-32-char-secret-key"
# 禁用加密
docker compose run --rm gpt-load migrate-keys --from "your-current-key"
# 更换加密密钥
docker compose run --rm gpt-load migrate-keys --from "old-key" --to "new-32-char-secret-key"
# 5. 更新配置文件
# 编辑 .env 文件,将 ENCRYPTION_KEY 设置为与 --to 参数一致的值。
# 如果禁用加密,则移除 ENCRYPTION_KEY 或将其设置为空。
vim .env
# 添加或修改:ENCRYPTION_KEY=your-32-char-secret-key
# 6. 重启服务
docker compose up -d
源码构建部署
# 1. 停止服务
# 停止正在运行的服务进程(Ctrl+C 或终止进程)
# 2. 备份数据库(强烈建议)
# 在迁移之前,您必须手动备份数据库或导出您的密钥,以免因操作或异常导致密钥丢失。
# 3. 执行迁移命令
# 启用加密
make migrate-keys ARGS="--to your-32-char-secret-key"
# 禁用加密
make migrate-keys ARGS="--from your-current-key"
# 更换加密密钥
make migrate-keys ARGS="--from old-key --to new-32-char-secret-key"
# 4. 更新配置文件
# 编辑 .env 文件,将 ENCRYPTION_KEY 设置为与 --to 参数一致的值。
echo "ENCRYPTION_KEY=your-32-char-secret-key" >> .env
# 5. 重启服务
make run
重要提示
⚠️ 重要提醒:
- 一旦丢失 ENCRYPTION_KEY,加密数据将无法恢复! 请务必安全备份此密钥。建议使用密码管理器或安全的密钥管理系统。
- 迁移前必须停止服务,以避免数据不一致。
- 强烈建议在迁移前 备份数据库,以便在迁移失败时进行恢复。
- 密钥应使用 32 位或更长的随机字符串 以确保安全性。
- 迁移完成后,请确保
.env文件中的ENCRYPTION_KEY与--to参数一致。 - 如果禁用加密,则需移除或清空
ENCRYPTION_KEY配置。
密钥生成示例
# 生成安全随机密钥(32 位)
openssl rand -base64 32 | tr -d "=+/" | cut -c1-32
Web 管理界面
访问管理控制台地址: http://localhost:3001(默认地址)
界面概览
Web 管理界面提供以下功能:
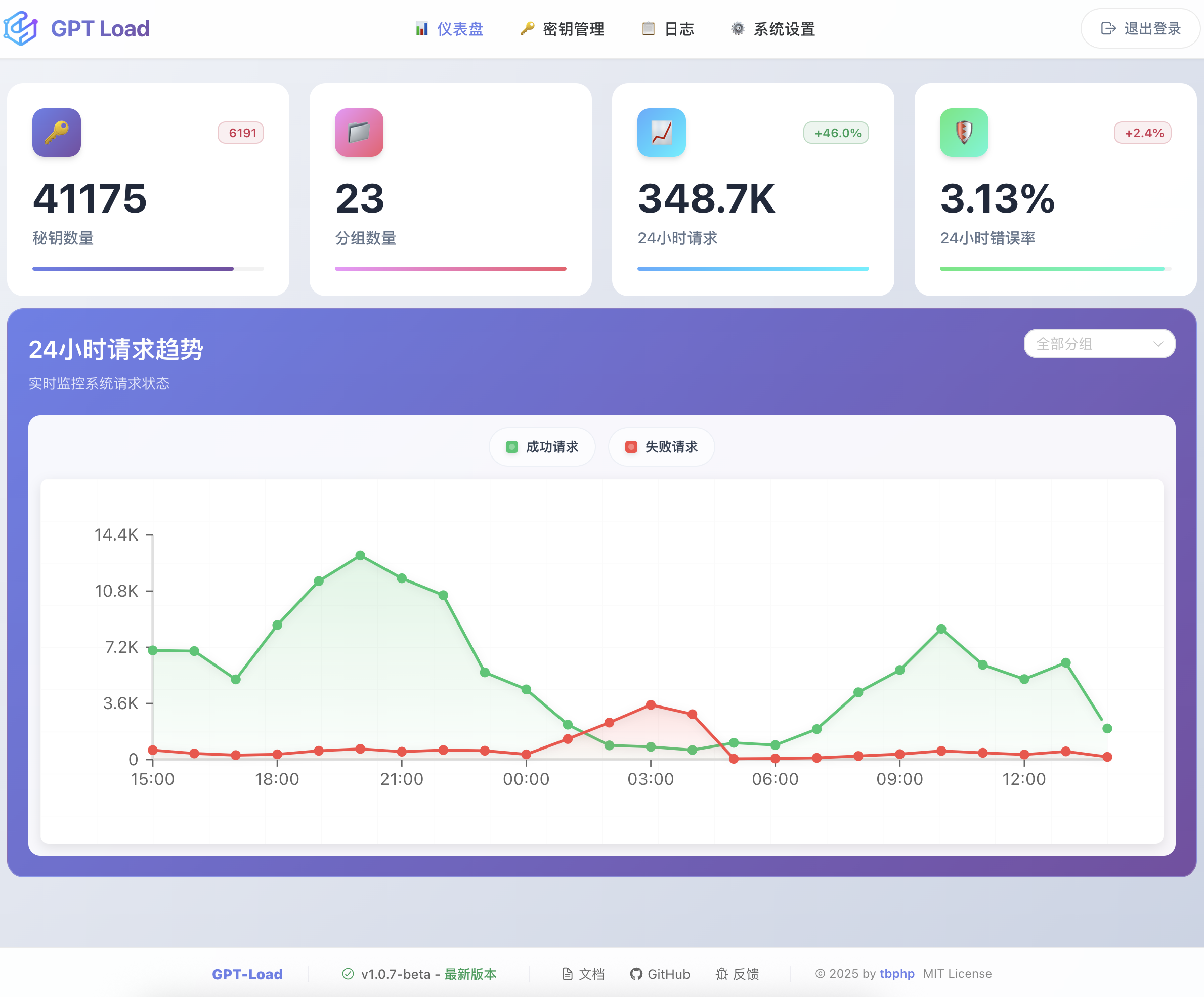
- 仪表盘:实时统计信息和系统状态概览
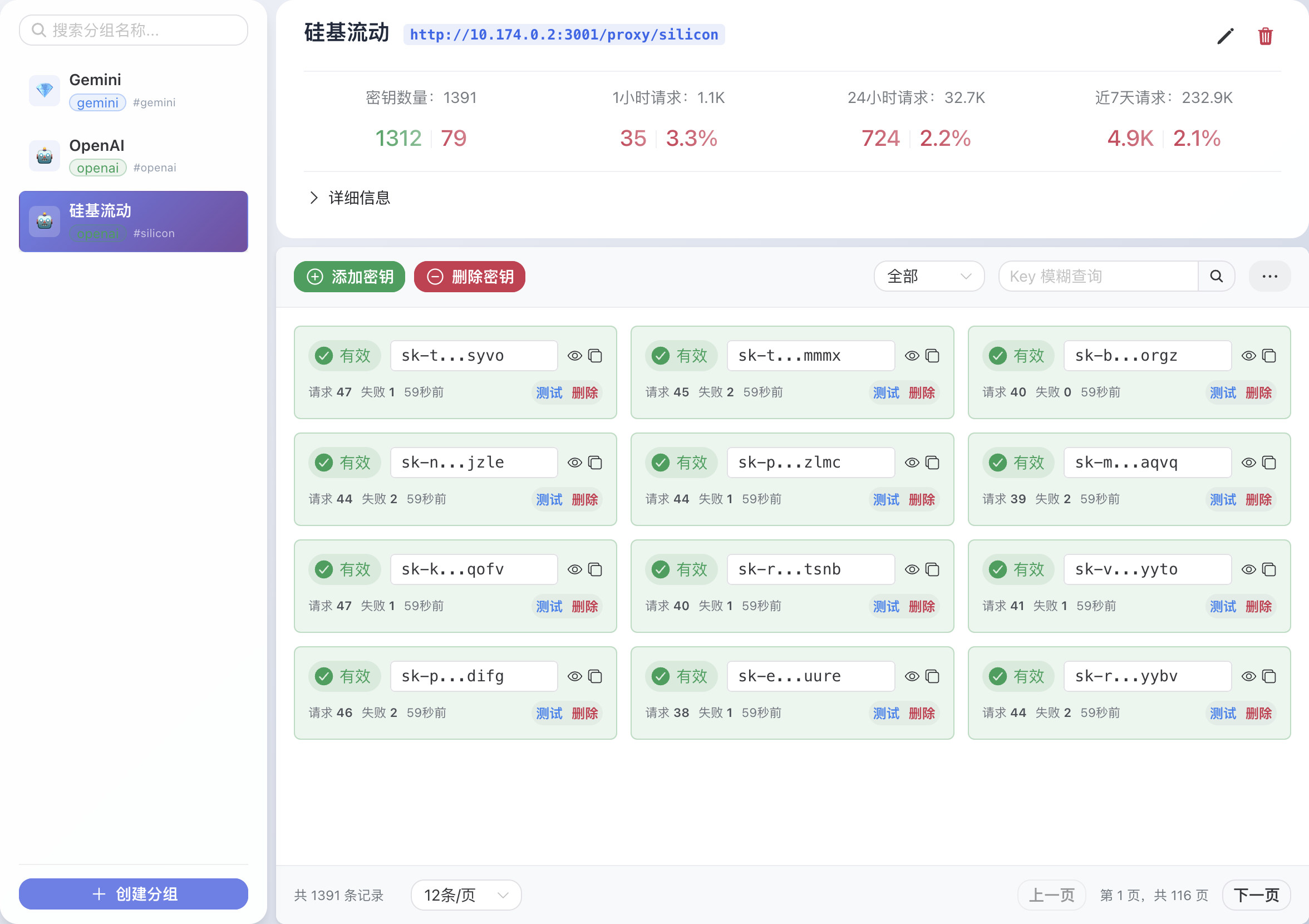
- 密钥管理:创建和配置 AI 服务提供商组,添加、删除和监控 API 密钥
- 请求日志:详细的请求历史记录和调试信息
- 系统设置:全局配置管理和热加载
API 使用指南
代理接口调用
GPT-Load 通过分组名称将请求路由到不同的 AI 服务。使用方法如下:
1. 代理端点格式
http://localhost:3001/proxy/{group_name}/{original_api_path}
{group_name}:在管理界面中创建的分组名称{original_api_path}:与原始 AI 服务路径保持完全一致
2. 认证方式
在Web管理界面中配置代理密钥,支持系统级和组级代理密钥。
- 认证方法:与原生API一致,但需将原始密钥替换为已配置的代理密钥。
- 密钥作用范围:在系统设置中配置的全局代理密钥可在所有组中使用。而在某个组中配置的组代理密钥仅对该组有效。
- 格式:多个密钥之间用逗号分隔。
3. OpenAI接口示例
GPT-Load目前支持两种兼容OpenAI的组类型:
openai(OpenAI聊天完成格式)openai-response(OpenAI响应格式)
假设已创建一个名为openai的组:
原始调用:
curl -X POST https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer sk-your-openai-key" \
-H "Content-Type: application/json" \
-d '{"model": "gpt-4.1-mini", "messages": [{"role": "user", "content": "Hello"}]}'
代理调用:
curl -X POST http://localhost:3001/proxy/openai/v1/chat/completions \
-H "Authorization: Bearer your-proxy-key" \
-H "Content-Type: application/json" \
-d '{"model": "gpt-4.1-mini", "messages": [{"role": "user", "content": "Hello"}]}'
需要更改的内容:
- 将
https://api.openai.com替换为http://localhost:3001/proxy/openai - 将原始API密钥替换为代理密钥
OpenAI响应格式示例(openai-response组):
curl -X POST http://localhost:3001/proxy/openai-response/v1/responses \
-H "Authorization: Bearer your-proxy-key" \
-H "Content-Type: application/json" \
-d '{"model": "gpt-4.1-mini", "input": "Hello"}'
4. Gemini接口示例
假设已创建一个名为gemini的组:
原始调用:
curl -X POST https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-pro:generateContent?key=your-gemini-key \
-H "Content-Type: application/json" \
-d '{"contents": [{"parts": [{"text": "Hello"}]}]}'
代理调用:
curl -X POST http://localhost:3001/proxy/gemini/v1beta/models/gemini-2.5-pro:generateContent?key=your-proxy-key \
-H "Content-Type: application/json" \
-d '{"contents": [{"parts": [{"text": "Hello"}]}]}'
需要更改的内容:
- 将
https://generativelanguage.googleapis.com替换为http://localhost:3001/proxy/gemini - 将URL参数中的
key=your-gemini-key替换为代理密钥
5. Anthropic接口示例
假设已创建一个名为anthropic的组:
原始调用:
curl -X POST https://api.anthropic.com/v1/messages \
-H "x-api-key: sk-ant-api03-your-anthropic-key" \
-H "anthropic-version: 2023-06-01" \
-H "Content-Type: application/json" \
-d '{"model": "claude-sonnet-4-20250514", "messages": [{"role": "user", "content": "Hello"}]}'
代理调用:
curl -X POST http://localhost:3001/proxy/anthropic/v1/messages \
-H "x-api-key: your-proxy-key" \
-H "anthropic-version: 2023-06-01" \
-H "Content-Type: application/json" \
-d '{"model": "claude-sonnet-4-20250514", "messages": [{"role": "user", "content": "Hello"}]}'
需要更改的内容:
- 将
https://api.anthropic.com替换为http://localhost:3001/proxy/anthropic - 将
x-api-key头中的原始API密钥替换为代理密钥
6. 支持的接口
OpenAI聊天完成格式(openai):
/v1/chat/completions- 聊天对话/v1/completions- 文本补全/v1/embeddings- 文本嵌入/v1/models- 模型列表- 以及其他所有兼容OpenAI的接口
OpenAI响应格式(openai-response):
/v1/responses- 统一响应生成/v1/models- 模型列表- 以及其他所有兼容OpenAI响应格式的接口
Gemini格式:
/v1beta/models/*/generateContent- 内容生成/v1beta/models- 模型列表- 以及其他所有Gemini原生接口
Anthropic格式:
/v1/messages- 消息对话/v1/models- 模型列表(如有)- 以及其他所有Anthropic原生接口
7. 客户端SDK配置
OpenAI Python SDK:
from openai import OpenAI
client = OpenAI(
api_key="your-proxy-key", # 使用代理密钥
base_url="http://localhost:3001/proxy/openai" # 使用代理端点
)
response = client.chat.completions.create(
model="gpt-4.1-mini",
messages=[{"role": "user", "content": "Hello"}]
)
Google Gemini SDK(Python):
import google.generativeai as genai
# 配置API密钥和基础URL
genai.configure(
api_key="your-proxy-key", # 使用代理密钥
client_options={"api_endpoint": "http://localhost:3001/proxy/gemini"}
)
model = genai.GenerativeModel('gemini-2.5-pro')
response = model.generate_content("Hello")
Anthropic SDK(Python):
from anthropic import Anthropic
client = Anthropic(
api_key="your-proxy-key", # 使用代理密钥
base_url="http://localhost:3001/proxy/anthropic" # 使用代理端点
)
response = client.messages.create(
model="claude-sonnet-4-20250514",
messages=[{"role": "user", "content": "Hello"}]
)
重要提示:作为透明代理服务,GPT-Load完全保留了各类AI服务的原生API格式和认证方式。您只需替换端点地址,并使用管理界面中配置的代理密钥,即可实现无缝迁移。
相关项目
- New API - 优秀的AI模型聚合管理和分发系统
贡献
感谢所有为GPT-Load做出贡献的开发者!

支持者
非常感谢LINUX DO社区的支持!
本项目由DigitalOcean提供支持。

许可证
MIT许可证 - 详情请参阅LICENSE文件。
星标历史

版本历史
v1.4.62026/03/29v1.4.52026/03/29v1.4.42026/02/16v1.4.32026/02/10v1.4.22026/01/25v1.4.12025/11/23v1.4.02025/11/09v1.4.0-beta.22025/11/09v1.4.0-beta.12025/11/08v1.3.22025/10/19v1.3.12025/10/13v1.3.02025/10/08v1.3.0-beta.62025/10/07v1.3.0-beta.52025/10/04v1.3.0-beta.42025/10/02v1.3.0-beta.32025/10/01v1.3.0-beta.22025/10/01v1.3.0-beta.12025/09/30v1.2.12025/09/21v1.2.02025/09/14常见问题
相似工具推荐
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
gstack
gstack 是 Y Combinator CEO Garry Tan 亲自开源的一套 AI 工程化配置,旨在将 Claude Code 升级为你的虚拟工程团队。面对单人开发难以兼顾产品战略、架构设计、代码审查及质量测试的挑战,gstack 提供了一套标准化解决方案,帮助开发者实现堪比二十人团队的高效产出。 这套配置特别适合希望提升交付效率的创始人、技术负责人,以及初次尝试 Claude Code 的开发者。gstack 的核心亮点在于内置了 15 个具有明确职责的 AI 角色工具,涵盖 CEO、设计师、工程经理、QA 等职能。用户只需通过简单的斜杠命令(如 `/review` 进行代码审查、`/qa` 执行测试、`/plan-ceo-review` 规划功能),即可自动化处理从需求分析到部署上线的全链路任务。 所有操作基于 Markdown 和斜杠命令,无需复杂配置,完全免费且遵循 MIT 协议。gstack 不仅是一套工具集,更是一种现代化的软件工厂实践,让单人开发者也能拥有严谨的工程流程。
codex
Codex 是 OpenAI 推出的一款轻量级编程智能体,专为在终端环境中高效运行而设计。它允许开发者直接在命令行界面与 AI 交互,完成代码生成、调试、重构及项目维护等任务,无需频繁切换至浏览器或集成开发环境,从而显著提升了编码流程的连贯性与专注度。 这款工具主要解决了传统 AI 辅助编程中上下文割裂的问题。通过将智能体本地化运行,Codex 能够更紧密地结合当前工作目录的文件结构,提供更具针对性的代码建议,同时支持以自然语言指令驱动复杂的开发操作,让“对话即编码”成为现实。 Codex 非常适合习惯使用命令行的软件工程师、全栈开发者以及技术研究人员。对于追求极致效率、偏好键盘操作胜过图形界面的极客用户而言,它更是理想的结对编程伙伴。 其独特亮点在于灵活的部署方式:既可作为全局命令行工具通过 npm 或 Homebrew 一键安装,也能无缝对接现有的 ChatGPT 订阅计划(如 Plus 或 Pro),直接复用账户权益。此外,它还提供了从纯文本终端到桌面应用的多形态体验,并支持基于 API 密钥的深度定制,充分满足不同场景下的开发需求。