alpaca_eval
AlpacaEval 是一款专为指令跟随型语言模型打造的自动评测工具。它利用大模型模拟人类偏好,替代了传统耗时、昂贵且难以复现的人工评估流程。对于致力于模型迭代的开发者和研究人员而言,这能极大提升效率。
相比其他基准测试,AlpacaEval 表现卓越:运行时间少于 3 分钟,成本低于 10 美元,且与权威的人类基准 ChatBot Arena 评分的相关性高达 0.98。其最新的 2.0 版本默认采用长度控制的胜率指标,不仅进一步提升了评估准确度,还有效防止了模型通过生成长文本“刷分”,确保结果公平可靠。
无论是验证微调效果、对比不同模型性能,还是构建自定义排行榜,AlpacaEval 都能提供快速、高质量且可复现的数据支持,是 AI 研发中值得信赖的自动化评估方案。
使用场景
某 AI 初创团队在微调开源大模型时,需要频繁对比多个检查点(checkpoint)的指令遵循能力,以便决定下一步优化方向。
没有 alpaca_eval 时
- 依赖人工标注或众包平台,评估一个版本耗时数天,严重拖慢迭代节奏。
- 聘请专业评测人员成本高昂,单次完整测试预算可能超过数百美元。
- 人工评分存在主观偏差,不同评审员对同一回答的打分差异较大,难以横向对比。
- 缺乏自动化基准,无法快速验证新策略是否真的提升了模型表现。
使用 alpaca_eval 后
- alpaca_eval 能在 3 分钟内自动完成全量测试,将评估周期从数天压缩至分钟级。
- 仅需少量 API 调用费用,单次运行成本低于 10 美元,极大降低了试错门槛。
- 其评分结果与 ChatBot Arena 的人类偏好相关性高达 0.98,数据可信度媲美人工。
- 内置长度控制机制,有效防止模型通过堆砌字数来刷高分,确保评估公平性。
alpaca_eval 以极低的成本和极高的效率,为模型开发提供了可信赖的自动化评估基准。
运行环境要求
- 未说明
未说明
未说明
快速开始
 AlpacaEval : 面向指令遵循语言模型的自动评估器
AlpacaEval : 面向指令遵循语言模型的自动评估器
![]()
![]()
![]()
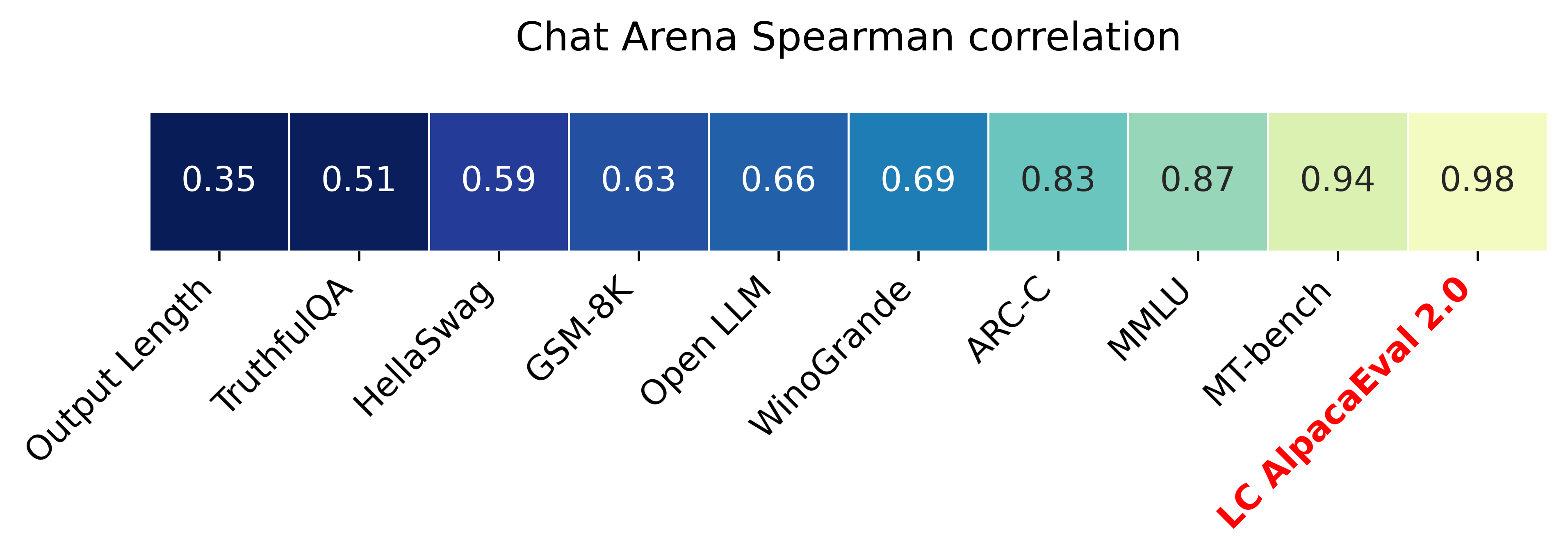
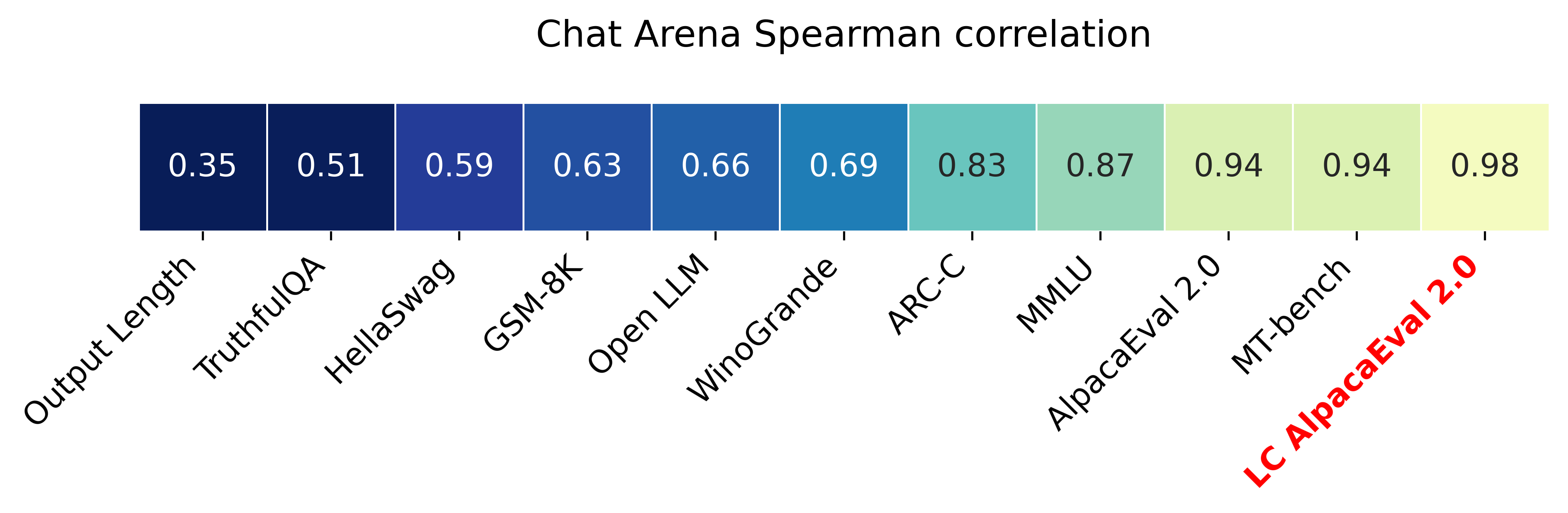
带有长度控制胜率(length-controlled win-rates)的 AlpacaEval 2.0(论文)与 ChatBot Arena 的 Spearman 相关系数达到 0.98,同时运行成本低于 10 美元 的 OpenAI 积分,且耗时少于 3 分钟。我们的目标是建立一个聊天大语言模型(chat LLMs)基准,具备:快速(< 5 分钟)、廉价(< 10 美元)以及与人类高度相关(0.98)的特点。以下是与其他基准的比较:
更新:
:tada: 长度控制胜率(Length-controlled Win Rates) 已发布并默认启用!这将与 ChatBot Arena 的相关性从 0.93 提高到 0.98,同时显著降低了长度操纵的可能性。原始胜率仍会在网站和命令行界面(CLI)中显示。更多详情 在此。
:tada: AlpacaEval 2.0 已发布并默认启用!我们改进了自动标注器(更好且更便宜),并使用 GPT-4 preview 作为基线。更多详情 在此。对于旧版本,请设置环境变量 IS_ALPACA_EVAL_2=False。
目录
概述
指令遵循模型(例如 ChatGPT)的评估通常需要人工交互。这既耗时又昂贵,且难以复现。AlpacaEval 是一种基于大语言模型(LLM)的自动评估方法,具有快速、廉价、可复现的特点,并经过 2 万条人工标注的验证。它特别适用于模型开发。尽管我们在之前的自动评估流程上有所改进,但仍存在基本的 局限性,例如对更长输出的偏好。AlpacaEval 提供以下内容:
- 排行榜:AlpacaEval 评估集上常见模型的排行榜。注意:自动评估器(例如 GPT-4)可能会偏向于生成更长输出和/或在评估器底层模型(例如 GPT-4)上微调过的模型。
- 自动评估器:一个与人类高度一致的自动评估器(在 2 万条标注上进行了验证)。我们通过测量强大的 LLM(例如 GPT-4)偏好该模型输出而非参考模型输出的频率来评估模型。我们的评估器默认启用了缓存和输出随机化功能。
- 构建自动评估器的工具包:用于构建高级自动评估器(例如带缓存、批处理或多标注者)并分析它们(质量、价格、速度、统计效力、偏差、方差等)的简单接口。
- 人工评估数据:AlpacaFarm 评估集上给定模型与参考模型之间的 2 万条人工偏好数据。其中 2500 条是交叉标注(4 名人类标注同一组 650 个示例)。
- AlpacaEval 数据集:AlpacaFarm 评估集的简化版,其中“指令”和“输入”合并为一个字段,且参考输出更长。详情在此。
何时使用和不使用 AlpacaEval?
何时使用 AlpacaEval? 我们的自动评估器是简单指令遵循任务的人工评估的快速且廉价的代理。如果您需要快速运行大量评估,例如在模型开发期间,它非常有用。
何时不使用 AlpacaEval? 像任何其他自动评估器一样,AlpacaEval 不应取代高风险决策中的人工评估,例如决定模型发布。特别是,AlpacaEval 受限于以下事实:(1) 评估集中的指令可能无法代表 LLM 的高级使用;(2) 自动评估器可能存在偏见,例如偏好回答的风格而非事实准确性;以及 (3) AlpacaEval 不衡量模型可能造成的风险。详情见 局限性。
快速开始
要安装稳定版,请运行
pip install alpaca-eval
要安装夜间版本(开发版),请运行
pip install git+https://github.com/tatsu-lab/alpaca_eval
然后你可以按如下方式使用:
export OPENAI_API_KEY=<your_api_key> # for more complex configs, e.g. using Azure or switching clients see client_configs/README.md
alpaca_eval --model_outputs 'example/outputs.json'
这将把排行榜 (leaderboard) 打印到控制台,并将排行榜和标注结果保存到与 model_outputs 文件相同的目录中。重要参数如下:
- model_outputs:要添加到排行榜的模型输出的 JSON 文件路径。每个字典 (dictionary) 应包含
instruction和output键。 - annotators_config:这是要使用的标注器 (annotator)。我们推荐使用
weighted_alpaca_eval_gpt4_turbo(AlpacaEval 2.0 的默认值),它与我们的人工标注数据有较高的一致性,上下文大小 (context size) 较大,且成本较低。关于所有标注器的比较,请参见 此处。 - reference_outputs:参考模型的输出。格式与
model_outputs相同。默认情况下,对于 AlpacaEval 2.0,这是gpt4_turbo。 - output_path:保存标注结果和排行榜的路径。
如果您没有模型输出,可以使用 evaluate_from_model,并传入本地路径或 HuggingFace 模型名称,或者来自标准 API (应用程序编程接口) 的模型(OpenAI、Anthropic、Cohere、Google 等)。其他命令:
>>> alpaca_eval -- --help
SYNOPSIS
alpaca_eval COMMAND
COMMANDS
COMMAND is one of the following:
evaluate
Evaluate a model based on its outputs. This is the default entrypoint if no command is specified.
evaluate_from_model
Evaluate a model from HuggingFace or an API provider. This is a wrapper around `evaluate` which includes generating from a desired model.
make_leaderboard
Precompute and save an entire leaderboard for a given dataset / evaluator / set of models generations.
analyze_evaluators
Analyze an evaluator and populates the evaluators leaderboard (agreement with human, speed, price,...).
有关每个函数的更多信息,请使用 alpaca_eval <command> -- --help。
排行榜及如何解读它们
模型
我们的排行榜是基于 AlpacaEval 数据集 计算的。
我们使用不同的基线(baseline)模型和自动标注器(autoannotators)预先计算了重要模型的排行榜。
我们的两个主要排行榜("AlpacaEval 2.0" 和 "AlpacaEval")可以在 此页面 找到。
"AlpacaEval 2.0" 使用 weighted_alpaca_eval_gpt4_turbo 作为标注器(annotator),使用 gpt4_turbo 作为基线(baseline)。
"AlpacaEval" 使用 alpaca_eval_gpt4 作为标注器(annotator),使用 text_davinci_003 作为基线(baseline)。
所有预计算的排行榜请参见 此处。
稍后我们还将展示如何 添加您的模型 到排行榜,以及如何为您的评估器/数据集创建一个 新的排行榜。
有关开箱即用(out of the box)的所有模型的配置,请参见 此处。
AlpacaEval 最小化排行榜:
| 胜率 (Win Rate) | 标准误 (Std Error) | |
|---|---|---|
| gpt4 | 95.3 | 0.7 |
| claude | 88.4 | 1.1 |
| chatgpt | 86.1 | 1.2 |
| guanaco-65b | 71.8 | 1.6 |
| vicuna-13b | 70.4 | 1.6 |
| text_davinci_003 | 50.0 | 0.0 |
| alpaca-farm-ppo-human | 41.2 | 1.7 |
| alpaca-7b | 26.5 | 1.5 |
| text_davinci_001 | 15.2 | 1.2 |
这些指标是如何精确计算的?
胜率(Win Rate):胜率衡量的是模型输出优于参考输出的频率(AlpacaEval 中为 test-davinci-003,AlpacaEval 2.0 中为 gpt4_turbo)。
更具体地说,为了计算胜率,我们从 AlpacaEval 数据集中收集目标模型在每个指令上的输出对。
然后我们将每个输出与参考模型(例如 text-davinci-003)在同一指令上的输出配对。
然后我们询问自动评估器它们更喜欢哪个输出。
请参阅 AlpacaEval 的 和 AlpacaEval 2.0 的 提示词(prompts)和配置,特别是我们会随机化输出的顺序以避免位置偏差。
然后我们对数据集中所有指令的偏好进行平均,以获得模型相对于基线(baseline)的胜率。
如果两个输出完全相同,我们为两个模型各计一半偏好。
标准误(Standard error):这是胜率的标准误(以 N-1 归一化),即跨不同指令的平均偏好。
关于我们的自动标注器(auto-annotator):alpaca_eval_gpt4 的详细信息
我们的 alpaca_eval_gpt4(见 配置)标注器会对偏好取平均,其中偏好获取方式如下:
- 它接收一个指令和一对输出(来自目标模型和参考模型)
- 如果该三元组(triple)的偏好已计算过,则返回它(即使用缓存)
- 它随机化输出的顺序以避免位置偏差
- 它将指令和输出格式化为 以下零样本提示词(zero-shot prompt),要求按偏好顺序排列输出
- 它使用
temperature=0通过 GPT4 完成提示词 - 它从补全结果中解析偏好并返回
该标注器是 AlpacaFarm 和 Aviary 评估器的混合体(并深受其影响)。 特别是,我们使用了与 AlpacaFarm 相同的代码(缓存/随机化/超参数),但使用了类似于 Aviary 的排序提示词。 我们对 Aviary 的提示词进行了修改,以减少对较长输出的偏差。 详情见 相关工作。
对于 AlpacaEval 2.0,我们使用 weighted_alpaca_eval_gpt4_turbo,它使用 logprobs(对数概率)来计算连续偏好,并使用 GPT4_turbo 作为模型(见 配置)。
评估器
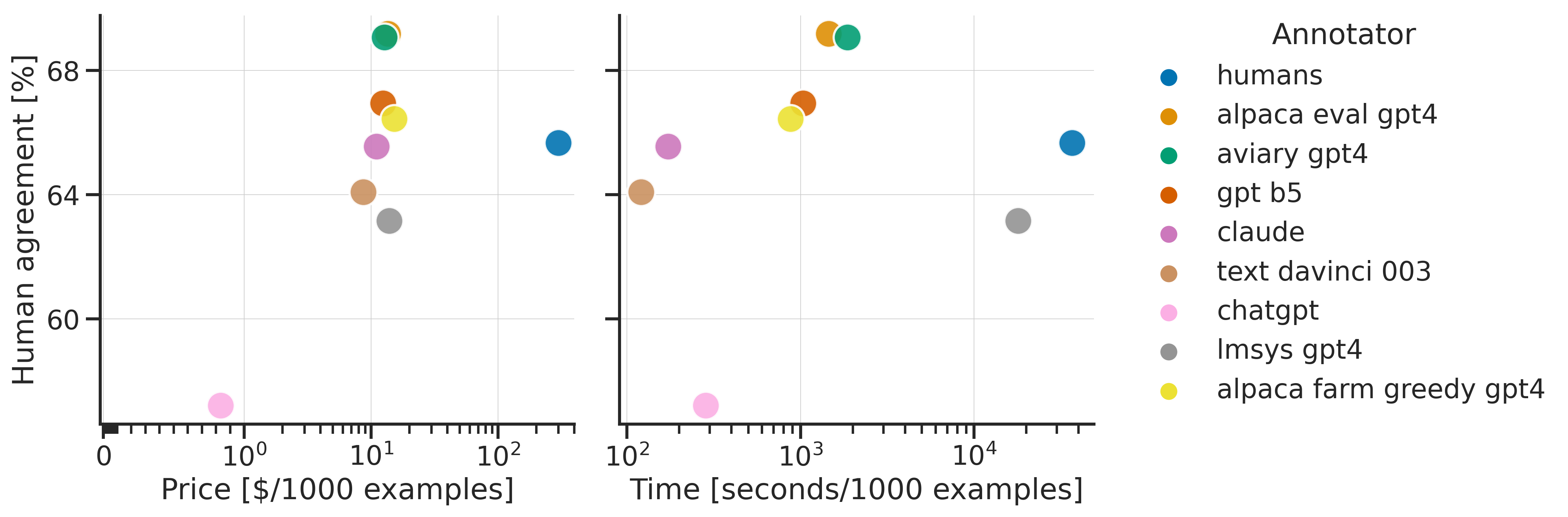
我们通过与我们收集的 2.5K 人工标注 进行比较,在 AlpacaEval 集上评估不同的自动标注器(~650 个指令,每个有 4 个人工标注)。
下面我们展示了我们建议的评估器(weighted_alpaca_eval_gpt4_turbo,alpaca_eval_gpt4)、先前自动评估器(alpaca_farm_greedy_gpt4,aviary_gpt4,lmsys_gpt4)、人类(humans)以及具有基本相同提示词的不同基础模型(gpt4,claude,text_davinci_003,chatgpt_fn,guanaco_33b, chatgpt)的指标。
有关开箱即用(out of the box)的所有评估器及其相关指标的配置,请参见 此处。
| 人类一致性 | 价格 [$/1000 示例] | 时间 [秒/1000 示例] | Spearman 相关系数 | Pearson 相关系数 | 偏差 | 方差 | 偏好更长回答的概率 | |
|---|---|---|---|---|---|---|---|---|
| alpaca_eval_gpt4 | 69.2 | 13.6 | 1455 | 0.97 | 0.93 | 28.4 | 14.6 | 0.68 |
| alpaca_eval_cot_gpt4_turbo_fn | 68.6 | 6.3 | 1989 | 0.97 | 0.90 | 29.3 | 18.4 | 0.67 |
| alpaca_eval_gpt4_turbo_fn | 68.1 | 5.5 | 864 | 0.93 | 0.82 | 30.2 | 15.6 | 0.65 |
| alpaca_eval_llama3_70b_fn | 67.5 | 0.4 | 209 | 0.90 | 0.86 | 32.3 | 8.2 | 0.79 |
| gpt4 | 66.9 | 12.5 | 1037 | 0.88 | 0.87 | 31.5 | 14.6 | 0.65 |
| alpaca_farm_greedy_gpt4 | 66.4 | 15.3 | 878 | 0.85 | 0.75 | 30.2 | 19.3 | 0.60 |
| alpaca_eval_cot_gpt4_turbo_fn | 65.7 | 4.3 | 228 | 0.78 | 0.77 | 33.9 | 23.7 | 0.61 |
| humans | 65.7 | 300.0 | 36800 | 1.00 | 1.00 | 0.0 | 34.3 | 0.64 |
| claude | 65.3 | 3.3 | 173 | 0.93 | 0.90 | 32.4 | 18.5 | 0.66 |
| lmsys_gpt4 | 65.3 | 13.9 | 17982 | 0.98 | 0.97 | 31.6 | 15.9 | 0.74 |
| text_davinci_003 | 64.1 | 8.7 | 121 | 0.85 | 0.83 | 33.8 | 22.7 | 0.70 |
| longest | 62.2 | 0.0 | 0 | 0.27 | 0.56 | 37.8 | 0.0 | 1.00 |
| chatgpt | 57.3 | 0.8 | 285 | 0.72 | 0.71 | 39.4 | 34.1 | 0.59 |
这些指标是如何精确计算的?
我们现在用文字说明如何计算上表中的指标。代码在此处。
人类一致性:这衡量了当前标注者与来自我们 交叉标注集 的约 650 条标注中人类多数偏好之间的一致性,该数据集每个示例包含 4 条人工标注。
为了估计单个标注者(上表中 humans 行)与人类多数之间的一致性,我们选取 4 条标注中的一条,并计算其在预测其余 3 条标注的众数 (mode) 时的准确率。
然后,我们在所有 4 条标注和 650 个指令上平均此准确率以获得人类一致性,即,我们计算期望(在人类和样本上)的留一法 (leave-one-out) 一致性。
如果众数不唯一,我们随机选择一个众数。
我们对自动标注器执行完全相同的计算,以便最终数字具有可比性。
价格 [$/1000 示例]:这是每 1000 次标注的平均价格。 对于人类,这是我们支付给 Mechanical Turkers (众包工人) 以收集这些标注的价格(每小时 21 美元)。 如果价格取决于用于计算标注的机器(例如 Guanaco),我们将其留空。
时间 [秒/1000 示例]:这是计算 1000 次标注所需的平均时间。 对于人类,这是每位 Mechanical Turker (众包工人) 标注 1000 个示例所花费的中位时间的估计值。 对于自动标注器,这是我们运行标注时花费的平均时间。请注意,这可能取决于不同用户不同的 API 限制以及集群正在处理的请求数量。
Spearman 相关系数:这衡量了使用自动标注器偏好计算的排行榜与使用人类偏好计算的排行榜之间的 Spearman 相关性 (Spearman correlation)。与人类一致性一样,我们使用来自 AlpacaFarm 的人工标注,但现在我们考虑的是方法级别的一致性,而不仅仅是与样本层面的一致性。请注意,我们仅使用了 9 个模型,因此相关性不太可靠。
Pearson 相关系数:与 Spearman 相关系数相同,但使用 Pearson 相关性 (Pearson correlation)。
偏差:最可能的人类标签与最可能的自动标签之间的一致性。 对于自动标注器,我们通过为每个示例采样 4 条不同的标注来估计它。 这里的随机性来自于提示词 (prompt) 中输出的顺序、从 LLM (大语言模型) 采样,以及如果适用的话,批次中指令的顺序和池中标注器的选择。 然后,我们取这 4 条标注的众数,并计算该众数在预测 4 条人类标注的众数时的准确率。 请注意,这可能是如果我们拥有“无限”数量的交叉标注时会得到的真实偏差的高估。 低偏差意味着标注者在期望上与人类具有相同的偏好。 对于人类的情况,根据定义偏差为零。 请注意,这与标准统计偏差相关但不等同,因为我们取众数而不是对标注求平均,并且我们考虑 0-1 损失 (0-1 loss) 而不是平方损失 (squared loss)。
Variance (方差):单个自动偏好与最可能偏好之间的预期一致性。 我们估算它的方式与估算人类的"人类一致性 (human agreement)"相同,即,在使用第 4 个标注预测 3 个标注的众数 (mode) 时,取留一法 (leave one out) 误差的期望值。 低方差意味着标注器 (annotator) 与其自身偏好一致,即,如果你用不同的种子 (seeds) 从它采样,它会给出相同的结果。 与偏差 (bias) 类似,这并非标准的统计方差,因为我们取的是标注的众数而非平均值,并且考虑的是 0-1 损失而非平方损失。
请注意,"人类一致性 (human agreement)"与偏差和方差密切相关。特别是,方差衡量了由于我们仅使用单个标注而产生的误差,而偏差旨在衡量当前标注器的不可约误差。
Proba. prefer longer (偏好更长概率):当两个输出中一个显著长于另一个(超过 30 个字符差异)时,标注器偏好较长输出的概率。
在 完整表格 中,我们还提供了以下指标:
Proba. prefer lists (偏好列表概率):当一个输出包含列表/项目符号而另一个不包含时,标注器偏好包含该输出的概率。
Proba. prefer 1 (偏好第一个概率):标注器偏好成对输出中第一个的概率。我们提出的所有标注器在提示词 (prompt) 中对输出进行了随机化,因此这应该是 0.5。先前的标注器,如 lmsys 和 aviary,则不是这样。
# parsed (解析数量):这是标注器能够解析的示例数量。
请注意,如果方差和偏差为空,这意味着由于资源(时间和价格)限制,每个 648 个示例仅执行了一次单次标注。这解释了为什么 #parsed 是 648,否则它应该是 2592。
Tips for choosing evaluators
总体而言,如果您希望与人类高度一致,建议使用 annotators_config=weighted_alpaca_eval_gpt4_turbo;如果您预算紧张,建议使用 annotators_config=chatgpt_fn。
在选择标注器时,我们建议您考虑以下几点(前三点显而易见):
"人类一致性 (%)""价格 [$/1000 个示例]""时间 [秒/1000 个示例]""* 相关性 (* corr.)"约 > 0.7。相关性不宜过低很重要,但我们不建议将其作为主要指标,因为相关性仅基于 9 个模型计算。"Proba. prefer longer (偏好更长概率)"约 < 0.7。确实,我们发现大多数人类标注者的偏好都强烈偏向更长的答案(正如始终偏好最长输出的"longest"评估器的 performance=62.2 所示)。这表明这可能是人类标注者的一种偏差。为了避免排行榜出现强烈的长度偏差,我们建议使用“偏好更长概率”低于 0.7 的自动标注器。"Variance (方差)"约 < 0.2。我们相信一个好的评估器 (evaluator) 应尽可能少方差,以便结果主要是可复现的。注意,在模拟人类的情况下(如 AlpacaFarm 所示),方差可能是可取的。
我们在上表中过滤了不满足这些要求的标注器(除了用于参考目的的人类 / ChatGPT / 003 / lmsys)。查看所有结果请参见 此处。
总体而言,我们发现 weighted_alpaca_eval_gpt4_turbo 在质量/价格/时间/方差/长度偏差之间是一个很好的权衡。
上述指标是基于众包工作者 (crowd-workers) 的标注计算的。虽然有用,但这些标注并不完美,例如,众包工作者往往更看重风格而非事实性 (factuality)。因此,我们建议用户在自己的指令和人类标注上验证自动评估器。详情见 局限性。
使用场景
评估模型
>>> alpaca_eval evaluate -- --help
NAME
alpaca_eval evaluate - Evaluate a model based on its outputs. This is the default entrypoint if no command is specified.
SYNOPSIS
alpaca_eval evaluate <flags>
DESCRIPTION
Evaluate a model based on its outputs. This is the default entrypoint if no command is specified.
标志位
--model_outputs=MODEL_OUTPUTS
类型:Optional[Union]
默认值:None
要添加到排行榜的模型输出。接受数据(字典列表、pd.dataframe、datasets.Dataset)或读取这些数据的路径(json, csv, tsv)或生成这些数据的函数。每个字典(或 DataFrame 的行)应包含在提示词中格式化的键。例如默认情况下为 instruction 和 output,可选 input。如果为 None,我们仅打印排行榜。
-r, --reference_outputs=REFERENCE_OUTPUTS
类型:Union
默认值:<func...
参考模型的输出。与 model_outputs 格式相同。如果为 None,参考输出是 AlpacaEval 集上的一组特定 Davinci 003 输出:
--annotators_config=ANNOTATORS_CONFIG
类型:Union
默认值:'alpaca_eval_gpt4_turbo_fn'
标注器配置文件的路径(或字典列表)。详情见 PairwiseAnnotator 的文档字符串。
-n, --name=NAME
类型:Optional[Optional]
默认值:None
要添加到排行榜的模型名称。如果为 None,我们检查 generator 是否在 model_outputs 中,否则使用 "Current model"。
-o, --output_path=OUTPUT_PATH
类型:Union
默认值:'auto'
存储新排行榜和标注结果的目录路径。如果为 None,我们不保存。如果为 auto,如果 model_outputs 是路径则使用它,否则使用调用脚本的目录。
-p, --precomputed_leaderboard=PRECOMPUTED_LEADERBOARD
类型:Union
默认值:'auto'
预计算的排行榜或其路径(json, csv, 或 tsv)。排行榜应至少包含列 win_rate。如果为 auto,我们将尝试使用对应于参考输出的排行榜(仅在 CORRESPONDING_OUTPUTS_LEADERBOARDS 中存在时)。如果为 None,我们不会添加排行榜中的其他模型。
--is_overwrite_leaderboard=IS_OVERWRITE_LEADERBOARD
类型:bool
默认值:False
如果模型已在排行榜中,是否覆盖排行榜。
-l, --leaderboard_mode_to_print=LEADERBOARD_MODE_TO_PRINT
类型:Optional
默认值:'minimal'
使用的排行榜模式。仅当预计算排行榜有 mode 列时使用,此时将按此模式过滤排行榜。如果为 None,保留所有。
-c, --current_leaderboard_mode=CURRENT_LEADERBOARD_MODE
类型:str
默认值:'community'
当前方法的排行榜模式。
--is_return_instead_of_print=IS_RETURN_INSTEAD_OF_PRINT
类型:bool
默认值:False
是否返回指标而不是打印结果。
-f, --fn_metric=FN_METRIC
类型:Union
默认值:'pairwise_to_winrate'
metrics.py 中将偏好转换为指标的函数或函数名。该函数应接受一个偏好序列(0 表示平局,1 表示基础模型获胜,2 表示要比较的模型获胜)并返回一个指标字典以及用于排序排行榜的键。
-s, --sort_by=SORT_BY
类型:str
默认值:'win_rate'
用于排序排行榜的键。
--is_cache_leaderboard=IS_CACHE_LEADERBOARD
类型:Optional[Optional]
默认值:None
是否将结果排行榜保存到 precomputed_leaderboard。如果为 None,仅当 max_instances 不为 None 时保存。向排行榜添加模型的首选方法是将 precomputed_leaderboard 设置为之前保存在 <output_path>/leaderboard.csv 的排行榜。
--max_instances=MAX_INSTANCES
类型:Optional[Optional]
默认值:None
要标注的最大实例数。用于测试。
--annotation_kwargs=ANNOTATION_KWARGS
类型:Optional[Optional]
默认值:None
传递给 PairwiseAnnotator.annotate_head2head 的其他参数。
-A, --Annotator=ANNOTATOR
默认值:<class 'alpaca_eval.annotators.pairwise_evaluator.PairwiseAn...
要使用的标注器类。
接受额外的标志。
传递给 PairwiseAnnotator 的其他参数。
</details>
<details>
<summary><code>>>> alpaca_eval evaluate_from_model -- --help</code></summary>
名称
alpaca_eval evaluate_from_model - 评估来自 HuggingFace 或 API 提供商的模型。这是 evaluate 的包装器,包括从所需模型生成内容。
概要 alpaca_eval evaluate_from_model MODEL_CONFIGS <标志>
描述
评估来自 HuggingFace 或 API 提供商的模型。这是 evaluate 的包装器,包括从所需模型生成内容。
位置参数
MODEL_CONFIGS
类型:Union
字典或路径(相对于 models_configs),指向包含解码模型配置的 yaml 文件。如果是目录,我们在其中搜索 'configs.yaml'。第一个字典中的键应为生成器的名称,值应为生成器配置的字典,该配置应具有
标志
-r, --reference_model_configs=REFERENCE_MODEL_CONFIGS
类型:Optional[Union]
默认值:None
与 model_configs 相同,但用于参考模型。如果为 None,我们使用默认的 Davinci003 输出。
-e, --evaluation_dataset=EVALUATION_DATASET
类型:Union
默认值:<func...
评估数据集的路径或返回 DataFrame 的函数。如果为 None,我们使用默认的评估
-a, --annotators_config=ANNOTATORS_CONFIG
类型:Union
默认值:'alpaca_eval_gpt4_turbo_fn'
标注器配置的路径或字典。如果为 None,我们使用默认的标注器配置。
-o, --output_path=OUTPUT_PATH
类型:Union
默认值:'auto'
保存生成内容、标注和排行榜的路径。如果 auto 则保存在 results/<model_name>
-m, --max_instances=MAX_INSTANCES
类型:Optional[int]
默认值:None
生成和评估的最大实例数。如果为 None,我们评估所有实例。
--is_strip_output=IS_STRIP_OUTPUT
类型:bool
默认值:True
是否去除输出尾部及首部的空白字符。
--is_load_outputs=IS_LOAD_OUTPUTS
类型:bool
默认值:True
是否尝试从输出路径加载输出。如果为 True 且输出存在,我们仅为尚未有输出的指令生成输出。
-c, --chunksize=CHUNKSIZE
类型:int
默认值:64
保存前生成的实例数。如果为 None,在所有生成完成后保存。
接受额外的标志。
传递给 evaluate 的其他关键字参数
备注 您也可以对位置参数使用标志语法
</details>
要评估模型,您需要:
1. 选择一个评估集并计算指定的 `model_outputs`(模型输出)。默认情况下,我们使用来自 [AlpacaEval](#data-release) 的 805 个示例。要在 AlpacaEval 上计算输出,请使用:
```python
import datasets
eval_set = datasets.load_dataset("tatsu-lab/alpaca_eval", "alpaca_eval")["eval"]
for example in eval_set:
# generate here is a placeholder for your models generations
example["output"] = generate(example["instruction"])
example["generator"] = "my_model" # name of your model
如果您的模型是 HuggingFace 模型或来自标准 API 提供商(OpenAI, Anthropic, Cohere),那么您可以直接使用 alpaca_eval evaluate_from_model 来处理生成输出的任务。
- 计算参考输出
reference_outputs(参考输出)。默认情况下,我们使用gpt4_turbo在 AlpacaEval 上的预计算输出。 如果您想使用不同的模型或不同的数据集,请遵循与 (1.) 相同的步骤。 - 通过
annotators_config(标注器配置)指定一个评估器。我们推荐使用alpaca_eval_gpt4_turbo_fn。对于其他选项和比较,请参阅 此表。根据评估器的不同,您可能需要在环境中设置适当的API_KEY,或者在 client_configs 中设置。
一起运行:
alpaca_eval --model_outputs 'example/outputs.json' \
--annotators_config 'alpaca_eval_gpt4_turbo_fn'
如果您没有解码后的输出,可以使用 evaluate_from_model,它将为您处理解码(模型和参考)工作。
这是一个示例:
# need a GPU for local models
alpaca_eval evaluate_from_model \
--model_configs 'oasst_pythia_12b' \
--annotators_config 'alpaca_eval_gpt4_turbo_fn'
这里 model_configs 和 reference_model_configs(可选)是指定 prompt(提示词)、模型提供商(此处为 HuggingFace)和解码参数的目录路径。
示例请参阅 此目录。
对于所有开箱即用的模型提供商,请参阅 此处。
关于标注者的信息
- 缓存(Caching):默认情况下,所有注释都缓存到磁盘上的
caching_path处。因此注释永远不会重新计算,这使得注释更快、更便宜,并允许可复现性。即使评估不同的模型也有帮助,因为许多模型具有相同的输出。 - 输出随机化(Output randomization):默认情况下,我们对输出示例进行随机打乱,因为我们发现标注者倾向于偏好他们看到的第一个示例。
- 批处理(Batching):我们提供代码和示例来批量处理注释,如果
prompt较长,这可以降低注释的成本和时间。例如参见 alpaca_farm_greedy_gpt4。 - 标注者池(Pool of annotators):我们提供代码和示例来使用自动标注者池进行评估,这对于复制 人类标注 的方差很有帮助。例如参见 alpaca_farm。
- 基于指令的种子设定(Seeding based on instructions):为了可复现性和模型之间更公平的比较,我们基于指令对所有随机性(输出顺序、批次中的顺序、池中每个标注者的示例)进行种子设定。
制作新的排行榜
>>> alpaca_eval make_leaderboard -- --help
NAME
alpaca_eval make_leaderboard - Precompute and save an entire leaderboard for a given dataset / evaluator / set of models generations.
SYNOPSIS
alpaca_eval make_leaderboard <flags>
DESCRIPTION
Precompute and save an entire leaderboard for a given dataset / evaluator / set of models generations.
FLAGS
--leaderboard_path=LEADERBOARD_PATH
Type: Optional[Union]
Default: None
The path to save the leaderboard to. The leaderboard will be saved as a csv file, if it already exists it will
--annotators_config=ANNOTATORS_CONFIG
Type: Union
Default: 'alpaca_eval_gpt4_turbo_fn'
The path the (or list of dict of) the annotator's config file.
--all_model_outputs=ALL_MODEL_OUTPUTS
Type: Union
Default: <fu...
The outputs of all models to add to the leaderboard. Accepts data (list of dictionary, pd.dataframe, datasets.Dataset) or a path to read those (json, csv, tsv potentially with globbing) or a function to generate those. If the path contains a globbing pattern, we will read all files matching the pattern and concatenate them. Each dictionary (or row of dataframe) should contain the keys that are formatted in the prompts. E.g. by default `instruction` and `output` with optional `input`. It should also contain a column `generator` with the name of the current model.
-r, --reference_outputs=REFERENCE_OUTPUTS
Type: Union
Default: <func...
The outputs of the reference model. Same format as `all_model_outputs` but without needing `generator`. By default, the reference outputs are the 003 outputs on AlpacaEval set.
-f, --fn_add_to_leaderboard=FN_ADD_TO_LEADERBOARD
Type: Callable
Default: 'evaluate'
The function to use to add a model to the leaderboard. If a string, it should be the name of a function in `main.py`. The function should take the arguments: `model_outputs`, `annotators_config`, `name`, `precomputed_leaderboard`, `is_return_instead_of_print`, `reference_outputs`.
--leaderboard_mode=LEADERBOARD_MODE
Type: str
Default: 'verified'
The mode of the leaderboard to save all new entries with.
-i, --is_return_instead_of_print=IS_RETURN_INSTEAD_OF_PRINT
Type: bool
Default: False
Whether to return the metrics instead of printing the results.
Additional flags are accepted.
Additional arguments to pass to `fn_add_to_leaderboard`.
如果您想使用单个命令(而不是多次 alpaca_eval 调用)为您的目标评估集和评估器制作新的排行榜,可以使用以下内容:
alpaca_eval make_leaderboard \
--leaderboard_path <path_to_save_leaderboard> \
--all_model_outputs <model_outputs_path> \
--reference_outputs <reference_outputs_path> \
--annotators_config <path_to_config.yaml>
其中:
leaderboard_path: 保存排行榜 (leaderboard) 的路径。排行榜将保存为 csv 文件,如果文件已存在则会追加内容。all_model_outputs:要添加到排行榜 (leaderboard) 的所有模型输出的 json 路径(可以是单个文件或通过通配符匹配多个文件)。每个字典应包含在提示词 (prompt) 中格式化的键 (instruction和output) 以及一个名为generator的列,其中包含当前模型的名字。例如请参见 此文件。reference_outputs:参考模型的输出路径。每个字典应包含在提示词 (prompt) 中格式化的键 (instruction和output)。默认情况下,参考输出是 AlpacaEval 集上的 003 输出。annotators_config:标注器 (annotator) 配置文件的路径。默认为alpaca_eval_gpt4。
创建新的评估器
>>> alpaca_eval analyze_evaluators -- --help
NAME
alpaca_eval analyze_evaluators - Analyze an evaluator and populates the evaluators leaderboard (agreement with human, speed, price,...).
SYNOPSIS
alpaca_eval analyze_evaluators <flags>
DESCRIPTION
Analyze an evaluator and populates the evaluators leaderboard (agreement with human, speed, price,...).
FLAGS
--annotators_config=ANNOTATORS_CONFIG
Type: Union
Default: 'alpaca_eval_gpt4_turbo_fn'
The path the (or list of dict of) the annotator's config file.
-A, --Annotator=ANNOTATOR
Default: <class 'alpaca_eval.annotators.pairwise_evaluator.PairwiseAn...
The annotator class to use.
--analyzer_kwargs=ANALYZER_KWARGS
Type: Optional[Optional]
Default: None
Additional arguments to pass to the analyzer.
-p, --precomputed_leaderboard=PRECOMPUTED_LEADERBOARD
Type: Union
Default: PosixPath('/Users/yanndubois/Desktop/GitHub/alpaca_eval/src/...
The precomputed (meta)leaderboard of annotators or a path to it (json, csv, or tsv).
--is_save_leaderboard=IS_SAVE_LEADERBOARD
Type: bool
Default: False
Whether to save the leaderboard (ie analyzed results).
--is_return_instead_of_print=IS_RETURN_INSTEAD_OF_PRINT
Type: bool
Default: False
Whether to return the leaderboard (ie analyzed results). If True, it will not print the results.
--is_overwrite_leaderboard=IS_OVERWRITE_LEADERBOARD
Type: bool
Default: False
Whether to overwrite the leaderboard if it already exists.
-m, --max_instances=MAX_INSTANCES
Type: Optional[Optional]
Default: None
The maximum number of instances to analyze.
--is_single_annotator=IS_SINGLE_ANNOTATOR
Type: bool
Default: False
Whether to analyze a single annotator. If True, will not be able to estimate the annotator's bias.
-l, --leaderboard_mode_to_print=LEADERBOARD_MODE_TO_PRINT
Type: str
Default: 'minimal'
The mode of the leaderboard to print.
-c, --current_leaderboard_mode=CURRENT_LEADERBOARD_MODE
Type: str
Default: 'minimal'
The mode of the leaderboard to save all new entries with.
-o, --output_path=OUTPUT_PATH
Type: Union
Default: 'auto'
Path to save the leaderboard and annotataions. If None, we don't save.
Additional flags are accepted.
Additional arguments to pass to `Annotator`.
AlpacaEval 提供了一种简单的方法来创建新的评估器 (evaluator)。你只需要创建一个新 的 configs.yaml 配置文件,然后将其作为 --annotators_config <path_to_config.yaml> 传递给 alpaca_eval。
以下是创建新评估器的几种方法:
- 更改提示词 (prompt):在文本文件中编写新提示词,并在配置文件的
prompt_template中指定路径。路径相对于配置文件。 - 更改解码参数:在配置文件的
completions_kwargs中指定所需的参数。有关所有可用参数的详细信息,请参阅由配置文件中fn_completions指定的对应函数的文档字符串 在此文件中。 - 更改模型:在
model_name中指定所需的模型,并在prompt_template中指定相应的提示词。如果模型来自其他提供商,你需要更改fn_completions,该函数映射到 此文件 中的相应函数。我们提供了用于使用 OpenAI、Anthropic、Cohere 或 HuggingFace 模型的fn_completions函数。要安装所有提供商所需的包,请使用pip install alpaca_eval[all]。
配置文件中的其他参数
最简单的方法是查看 SinglePairwiseAnnotator 的文档字符串。
这里有一些重要的参数:
Parameters
----------
prompt_template : path
A prompt that will be given to `fn_prompter` or path to the prompts. Path is relative to
`evaluators_configs/`
fn_completion_parser : callable or str
Function in `completion_parsers.py` to use for parsing the completions into preferences. For each completion,
the number of preferences should be equal to the batch_size if not we set all the preferences in that batch to
NaN.
completion_parser_kwargs : dict
Kwargs for fn_completion_parser.
fn_completions : callable or str
Function in `decoders.py` to use for decoding the output.
completions_kwargs : dict
kwargs for fn_completions. E.g. model_name, max_tokens, temperature, top_p, top_k, stop_seq.
is_randomize_output_order : bool
Whether to randomize output_1, output_2 when formatting.
batch_size : int
Number of examples that will be added in a single prompt.
创建好评估器后,你还可以分析它并使用以下命令将其添加到 评估器 的 排行榜 中:
alpaca_eval analyze_evaluators --annotators_config '<path_to_config.yaml>'
为了估计偏差 (bias) 和方差 (variance),此操作使用 4 个随机种子 (seeds) 评估每个示例,即 2.5K 次评估。
如果你想要更便宜的评价,可以使用 --is_single_annotator True 使用单个种子,这将跳过偏差和方差的估计。
参与贡献
我们接受针对新模型、评估器(Evaluator)和评估集(Eval Set)的 PR(拉取请求),以及错误修复。我们将定期更新 排行榜网站 以纳入新的社区贡献。我们还为 AlpacaEval 创建了一个 支持 Discord,如果您遇到任何问题并希望向社区寻求帮助,可以使用它。
要开始贡献,请先 fork 该仓库,并从源码安装包 pip install -e .。
贡献模型
首先,您需要在 models_configs 文件夹中添加一个模型配置定义。作为示例,您可以查看 falcon-7b-instruct yaml。请确保文件夹名称和 yaml 中的键名完全匹配。
然后,请按照 评估模型 中的步骤运行模型的推理(inference),在评估集上生成输出,并根据其中一个评估器对模型进行评分。示例命令可能如下所示:
alpaca_eval evaluate_from_model \
--model_configs 'falcon-7b-instruct'
运行此命令后,您应该生成了一个 outputs json 文件以及对应的 排行榜文件 中的新条目。请提交包含配置、输出文件和更新后的排行榜的 PR。
具体来说,您应该执行以下操作:
- 在 github 上 fork 仓库
- 克隆 fork 后的仓库
git clone <URL> - 在
src/alpaca_eval/models_configs/<model_name>处创建模型配置并对其进行评估evaluate_from_model --model_configs '<model_name>' - 将模型配置、输出和排行榜条目添加到 fork 后的仓库中
git add src/alpaca_eval/models_configs/<model_name> # add the model config
git add src/alpaca_eval/leaderboards/ # add the actual leaderboard entry
git add src/alpaca_eval/metrics/weights # add the weights for LC
git add -f results/<model_name>/model_outputs.json # force add the outputs on the dataset
git add -f results/<model_name>/*/annotations.json # force add the evaluations from the annotators
git commit -m "Add <model_name> to AlpacaEval"
git push
注意:如果您在 AlpacaEval 之外生成输出,您仍然需要添加模型配置,但使用 fn_completions: null。请参阅 此配置 作为示例。
获取您的模型验证
AlpacaEval 中的已验证结果表示核心维护者已解码模型的输出并执行了评估。不幸的是,我们 AlpacaEval 维护者缺乏资源来验证所有模型,因此我们仅会对排行榜前 5 名的模型进行验证。对于由此可能造成的任何不便我们深表歉意,感谢您的理解。若要验证您的模型,请遵循以下步骤:
- 通过 Discord 联系
@yann,或者如果您有我们的电子邮件,请给我们发邮件,简要说明为什么您的模型应该被验证。 - 等待我们的回复和批准后再继续。
- 准备一个从您的模型解码的脚本,该脚本不需要 GPU,通常与您贡献模型时使用的脚本相同。它应能在不使用本地 GPU 的情况下运行
alpaca_eval evaluate_from_model --model_configs '<your_model_name>'。 - 生成用于运行脚本的临时 API 密钥(API Keys)并与我们分享。具体来说,我们需要解码您的模型和进行评估所需的密钥(例如,OpenAI 或 Anthropic 密钥)。
- 我们将执行
alpaca_eval evaluate_from_model --model_configs '<your_model_name>',更新结果,并通知您以便您可以撤销临时密钥。
请注意,我们不会重新评估同一个模型。由于采样方差(Sampling Variance),结果可能与您的初始结果略有不同。我们将用已验证的结果替换您之前的社区结果。
贡献评估器
请首先遵循 制作新评估器 中的指示。一旦您创建了标注器(annotator)配置,我们要求您通过评估最小集合的模型为该标注器创建一个新的排行榜。这些模型的输出可以通过下载 alpaca_eval_all_outputs.json 找到。
alpaca_eval make_leaderboard \
--leaderboard_path src/alpaca_eval/leaderboards/data_AlpacaEval/<evaluator>_leaderboard.csv \
--all_model_outputs alpaca_eval_all_outputs.json \
--annotators_config <evaluator_config>
然后,请提交包含标注器配置和排行榜 csv 的 PR。
贡献评估集
要贡献新的评估集,您首先需要指定一组文本指令。然后,您需要指定一组参考输出(模型胜率是相对于此参考计算的)。为了方便使用,您可以使用默认的 text-davinci-003 参考配置。
将这些放在一起放入一个 json 文件中,其中每个条目指定 instruction、output 和 generator 字段。您可以参考 alpaca_eval.json 作为指南(dataset 字段不是必需的)。
最后,我们要求您在这个新的评估集上创建一个最小排行榜。您可以使用以下内容完成此操作:
alpaca_eval make_leaderboard \
--leaderboard_path <src/alpaca_eval/leaderboards/data_AlpacaEval/your_leaderboard_name.csv> \
--all_model_outputs alpaca_eval_all_outputs.json \
--reference_outputs <path_to_json_file>
请提交包含评估集 json 和相应排行榜 csv 的 PR。
贡献补全函数
目前,我们支持不同的补全函数(completion function),例如 openai, anthropic, huggingface_local, huggingface_hub_api ... 如果您想贡献一个新的补全函数/API 来进行推理(inference),请遵循以下步骤:
- 在 decoder 文件夹 中添加一个名为
<name>.py的文件,其中包含函数<name>_completions(prompts : Sequence[str], model_name :str, ... )。该函数应以 prompts 和 kwargs 作为参数并返回补全结果(completions)。请查看目录中的其他补全函数作为模板。例如 huggingface_local_completions 或 anthropic。 - 在 init 中添加
<name>_completions及其依赖项。同样您可以参考 huggingface_local_completions 的示例。 - 更新 setup.py 中的可选依赖项。
- 在 models configs 中添加您想要评估的模型。
- 使用
alpaca_eval evaluate_from_model --model_configs '<model_configs>'评估您的模型。 - (可选)按照 这些步骤 将上一个模型的结果推送到 AlpacaEval 排行榜。
随时可以尽早开始提交 PR (Pull Request),我们将能在过程中提供帮助!
局限性
AlpacaEval 评估流程与其他当前的评估器一样,存在重要的局限性,因此不应在重要场景中替代人工评估,例如决定模型是否准备好部署。这些局限性大致可分为三类:
指令可能无法代表真实使用情况:AlpacaEval 集包含来自各种数据集的示例(self-instruct, open-assistant, vicuna, koala, hh-rlhf),这些可能无法代表真实使用情况以及像 GPT4 这样更好模型的先进应用。这可能导致最好的闭源模型(GPT4 / Claude / ChatGPT / ...)看起来比实际情况更接近开源模型。事实上,这些闭源模型似乎是在更多样化的数据上预训练/微调的。例如参见 此博客 关于更复杂指令的初步结果。然而,请注意,在 AlpacaFarm 中,我们展示了我们在评估集上的胜率(win-rates)与 Alpaca Demo 用户交互指令的胜率高度相关(0.97 R2)。此外,AlpacaEval 排行榜显示的开源模型和 OpenAI 模型之间的差距比其他排行榜(例如 lmsys)更大。
自动标注者的偏见:原始自动标注者似乎存在隐性偏见。特别是,我们发现它们倾向于偏好更长的输出和包含列表的输出(例如
alpaca_eval_gpt4为 0.68 / 0.69,claude为 0.62 / 0.58)。虽然我们发现人类也有类似的偏见(0.64 / 0.61),但我们认为这可能更多是我们使用的人工标注流程的局限性,而非真正的人类偏见。更普遍地说,通过定性分析,我们发现自动标注者更重视输出的风格而非其内容(例如事实性)。最后,我们发现自动评估者倾向于偏好来自相似模型(很可能是在相同数据上训练的)的输出,正如claude和alpaca_eval_gpt4排行榜上 ChatGPT/GPT4 的巨大差异所表明的那样。注意,长度控制在我们的长度控制胜率中部分缓解了长度偏见。缺乏安全评估:重要的是,AlpacaEval 仅评估模型的指令遵循能力,而不是它们可能造成的危害(例如有毒行为或偏见)。因此,当前 ChatGPT 和最佳开源模型之间的小差距不应被解释为后者已准备好部署。
除了上述关于评估流程的局限性外,关于我们对评估器的验证以及我们 提出的方法 来选择评估集也存在局限性。
关于我们验证流程的局限性
首先,基于人工交叉标注的评估器验证存在以下局限性:(1) 我们定性发现,我们的众包工作者也倾向于偏好风格(如长度和列表的存在)而非事实性;(2) 这并不能首先验证针对参考模型的胜率是否是一种好的评估策略;(3) 16 名众包工作者的偏好不能代表所有人类的偏好。
其次,我们建议的基于统计功效选择评估集的方法存在以下局限性:(1) 统计功效不能确保正确的方向,例如,您可能有一组不自然的指令,其中 Alpaca 的表现“优于”更好的模型;(2) 这可能会促使用户选择数据以支持他们想要验证的假设。
额外分析和图表
长度控制的 AlpacaEval (LCAE)
长度控制的 AlpacaEval 可视化:
![]()
长度控制的 AlpacaEval 开发:
![]()
该笔记本展示了我们考虑过的用于减轻自动标注器长度偏差的不同选项。
在此我们简要总结主要结果。即:
- LCAE(长度控制版 AlpacaEval)将 AlpacaEval 2.0 与 Chat Arena 的相关性从 0.94 提高到了 0.98。这使得 LCAE 成为与 Chat Arena 相关性最高的基准,如下图所示。
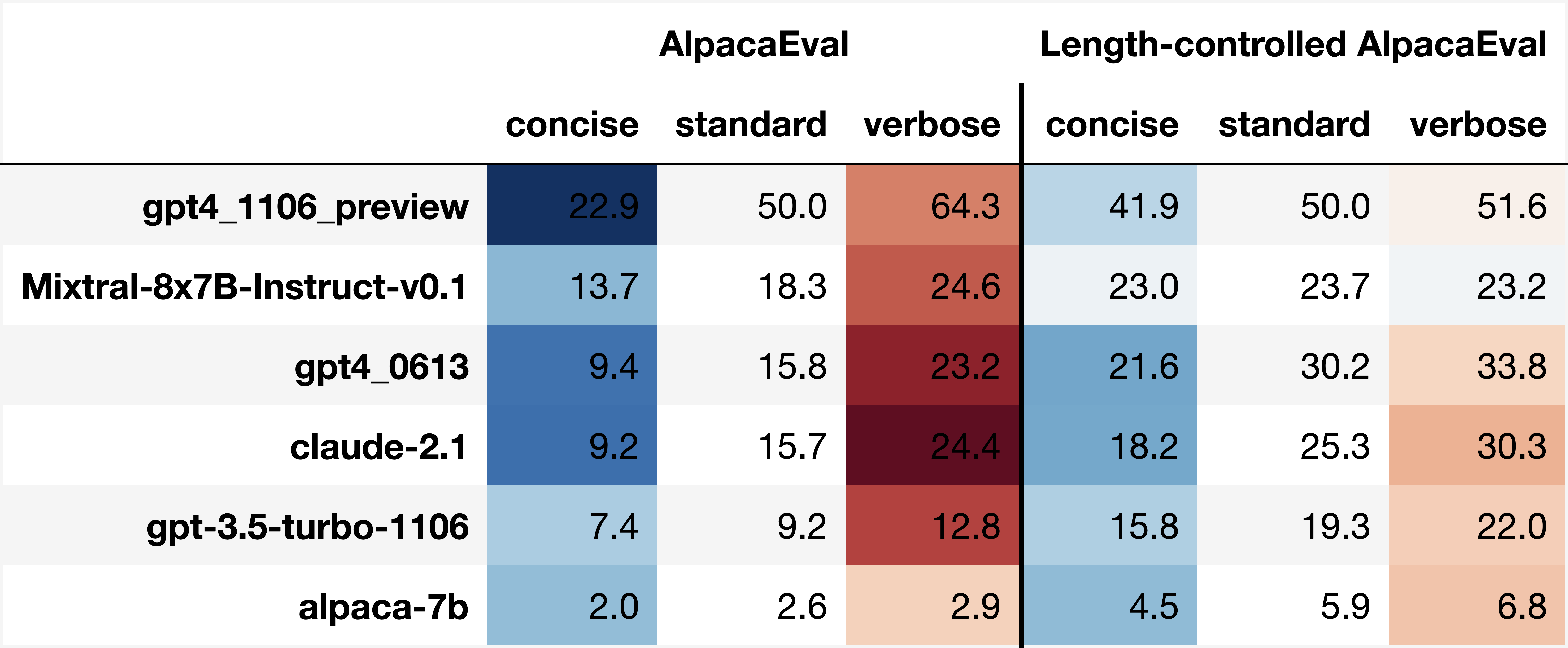
- LCAE 降低了长度可操纵性。AlpacaEval 的主要问题之一是,你可以通过增加输出长度来提高胜率。例如,在 AlpacaEval 2.0 中,当提示“尽可能提供详细信息”时,基线的胜率(50%)增加到 64%,而当提示“在提供回答问题所需的所有必要信息的同时尽可能简洁”时,胜率下降到 23%。更一般地说,AlpacaEval 的相对长度可操纵性约为 21%,而 LCAE 下降至约 6%,因此通过提示词长度进行操纵的可能性降低了 3 倍。如下图所示。
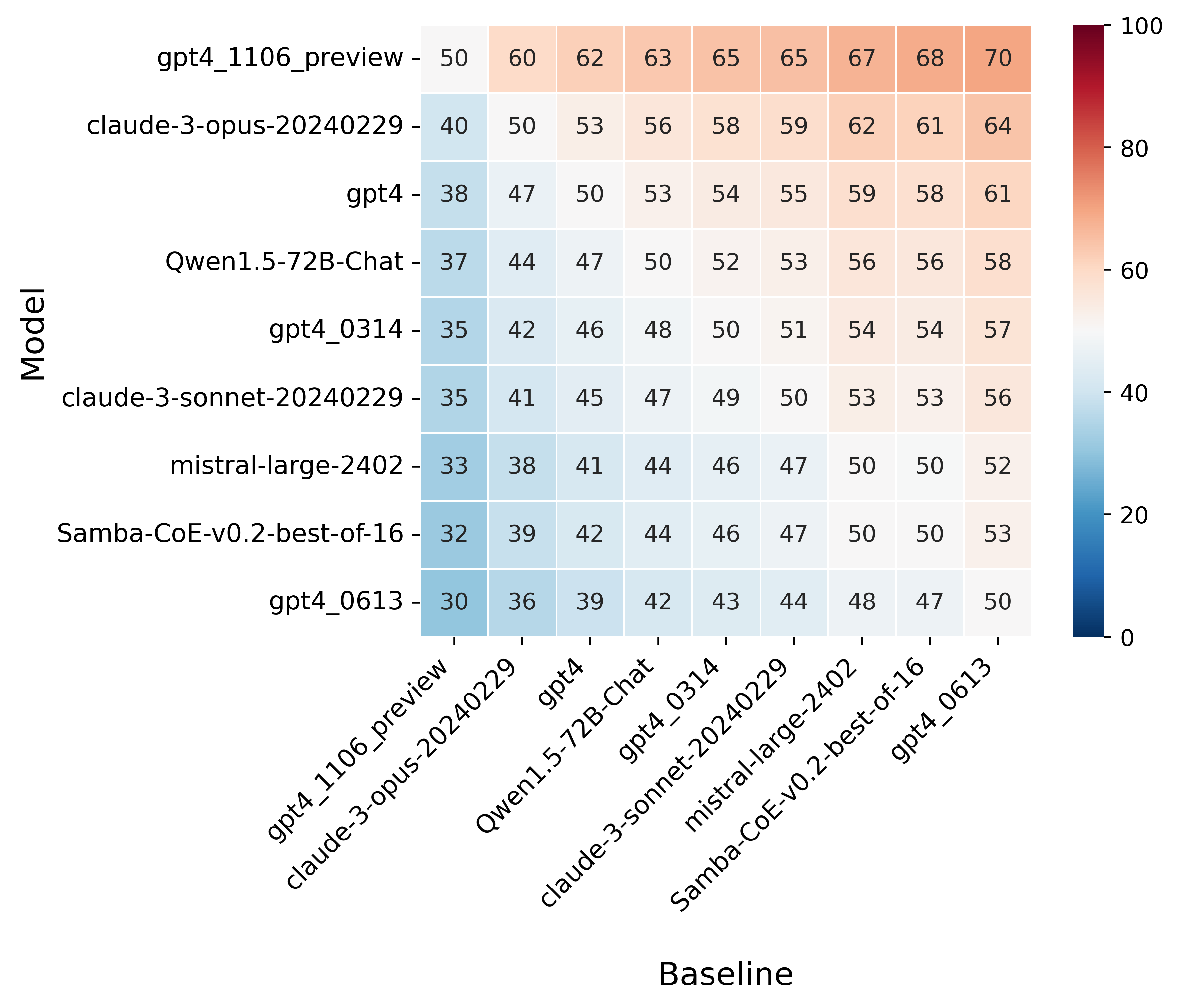
- 我们可以预测不同基线的性能。使用 GLM(广义线性模型)来控制长度偏差的另一个好处在于,我们现在拥有一个模型,可以预测模型在不同基线下的胜率。特别是,我们的 GLM 具有许多优良属性,例如
win_rate(m,b) = 1 - win_rate(b,m) \in [0,1]和win_rate(m,m) = 0.5。如下图所示。
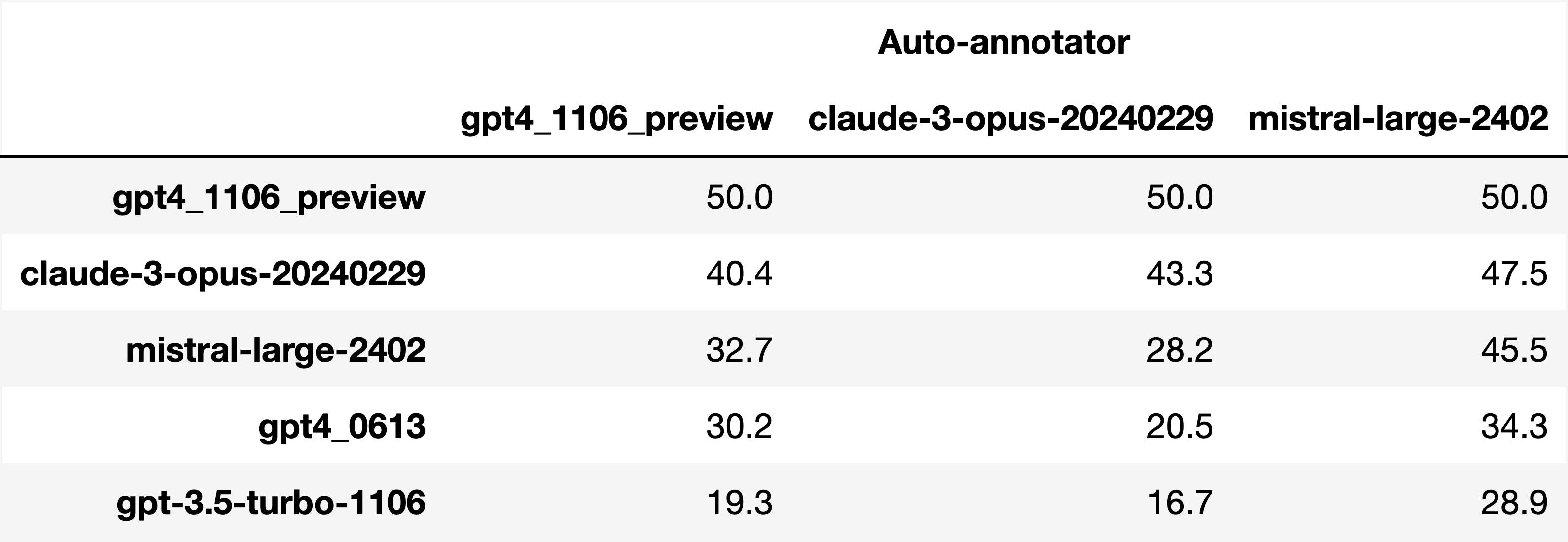
最后,请注意我们仅控制了长度偏差。还有其他已知的偏差我们没有控制,例如自动标注器倾向于偏好与其模型相似的输出。虽然我们可以控制这一点,但在实践中我们发现这不如长度偏差那么严重。原因有二:(1) 这主要是因为排行榜上主要是单个模型,因为在自动标注器的输出上进行微调似乎并没有像想象中那样显著影响胜率;(2) 这种偏差实际上比人们想象的要弱。例如,我们在下面展示了由三个不同模型自动标注的排行榜子集,我们看到模型的排名完全相同。特别是,claude-3-opus 偏好 gpt4_preview,而 mistral-large 偏好前两者。
分析评估器
注意:以下所有结果均关于 AlpacaEval 1.0,且此后未更新。
分析评估器:
![]()
正如我们在 评估器排行榜 中所见,在选择评估器时有许多指标需要考虑,例如质量、价格和速度。为了协助选择评估器,我们提供了一些函数来绘制这些指标。下图例如显示了不同评估器的价格/时间/一致性。
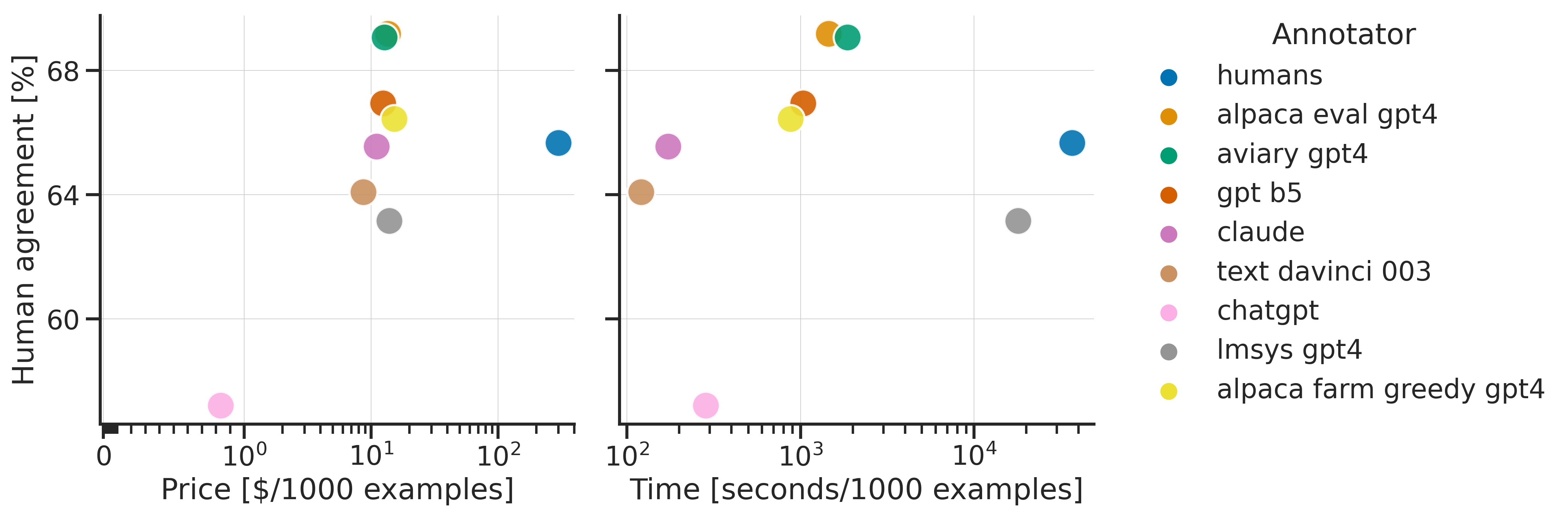
在这里我们看到 alpaca_eval_gpt4 表现非常好,在所有考虑的指标上都优于人类。
此前我们只考虑了与人类标注者的整体一致性。可以进行的额外验证是检查使用我们的自动标注器制作排行榜是否与人类制作的排行榜给出相似的结果。为了支持此类分析,我们发布了来自 AlpacaFarm 的 22 种方法的输出的 人类标注 => 22*805 = ~18K 标注。因此,我们可以测试 22 个模型的胜率在人类评估和我们自动标注器评估之间的相关性。请注意,这可以说是比使用“人类一致性 [%]"更好的选择自动评估器的方法,但由于需要 18K 标注,成本较高。下图显示了 alpaca_eval_gpt4 评估器的此类相关性。
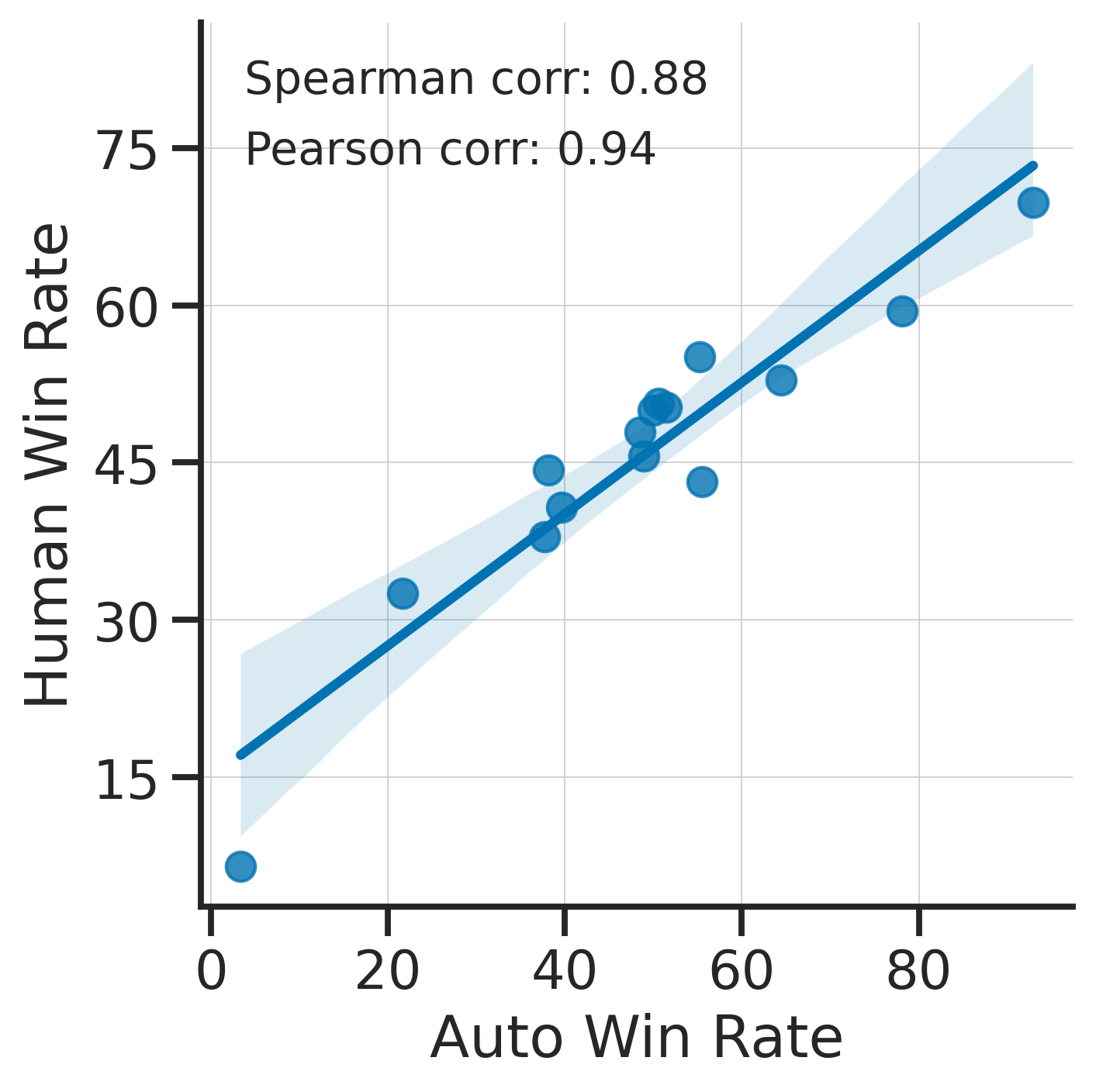
我们看到 alpaca_eval_gpt4 排行榜与人类排行榜高度相关(0.94 皮尔逊相关系数),这进一步表明自动评估是人类评估的良好代理。有关代码和更多分析,请参阅 此笔记本,或上面的 Colab 笔记本。
分析评估集
注意:以下所有结果均关于 AlpacaEval 1.0,且此后未更新。
制作评估集:
![]()
创建评估集时有两个主要因素需要考虑:使用多少数据?以及什么数据?
回答这些问题的一种方法是考虑一个你认为质量不同的模型排行榜,并检查需要多少数据才能在统计上显著地区分它们。我们将在下面使用配对 t 检验来测试每对模型之间的胜率差异是否具有统计学意义。
首先,让我们考虑使用多少数据的问题。下面我们展示了从 AlpacaEval 中需要的随机样本数量,以便在最小的 alpaca_eval_gpt4 排行榜中,每对模型的配对 t 检验给出 P 值 < 0.05。灰色单元格对应于在 805 个样本中没有显著差异的对。y 轴和 x 轴分别按第一个和第二个模型的胜率排序。
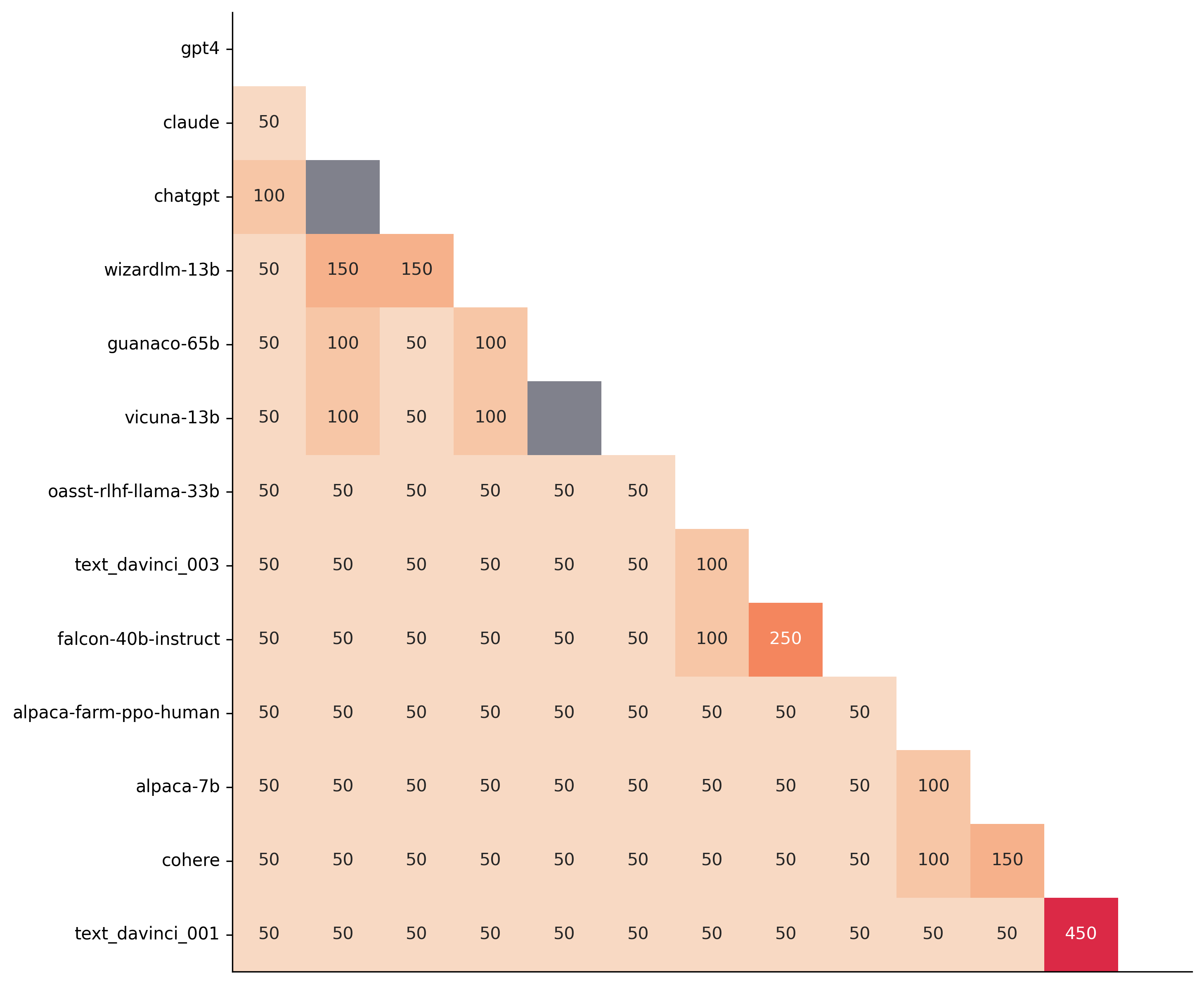
我们可以看到,大多数模型仅用 50 个样本即可区分,而 150 个样本允许区分绝大多数配对(78 对中的 74 对)。这表明在测试具有与最小 alpaca_eval_gpt4 排行榜 上相似性能差距的两个模型时,我们可以将评估集大小减少为原来的四分之一。
第二个问题是什么数据可以使用。同样,我们可以从统计功效 (statistical power) 的角度来回答这个问题:什么样的数据最能区分模型。让我们考虑 AlpacaEval 包含的所有数据集,但让我们控制评估集的大小,因为我们只关心数据的质量。下图显示了 AlpacaEval 每个子集的 80 个示例上,每对模型的成对 t 检验 (paired t-test) 的 P 值 (p-values)。
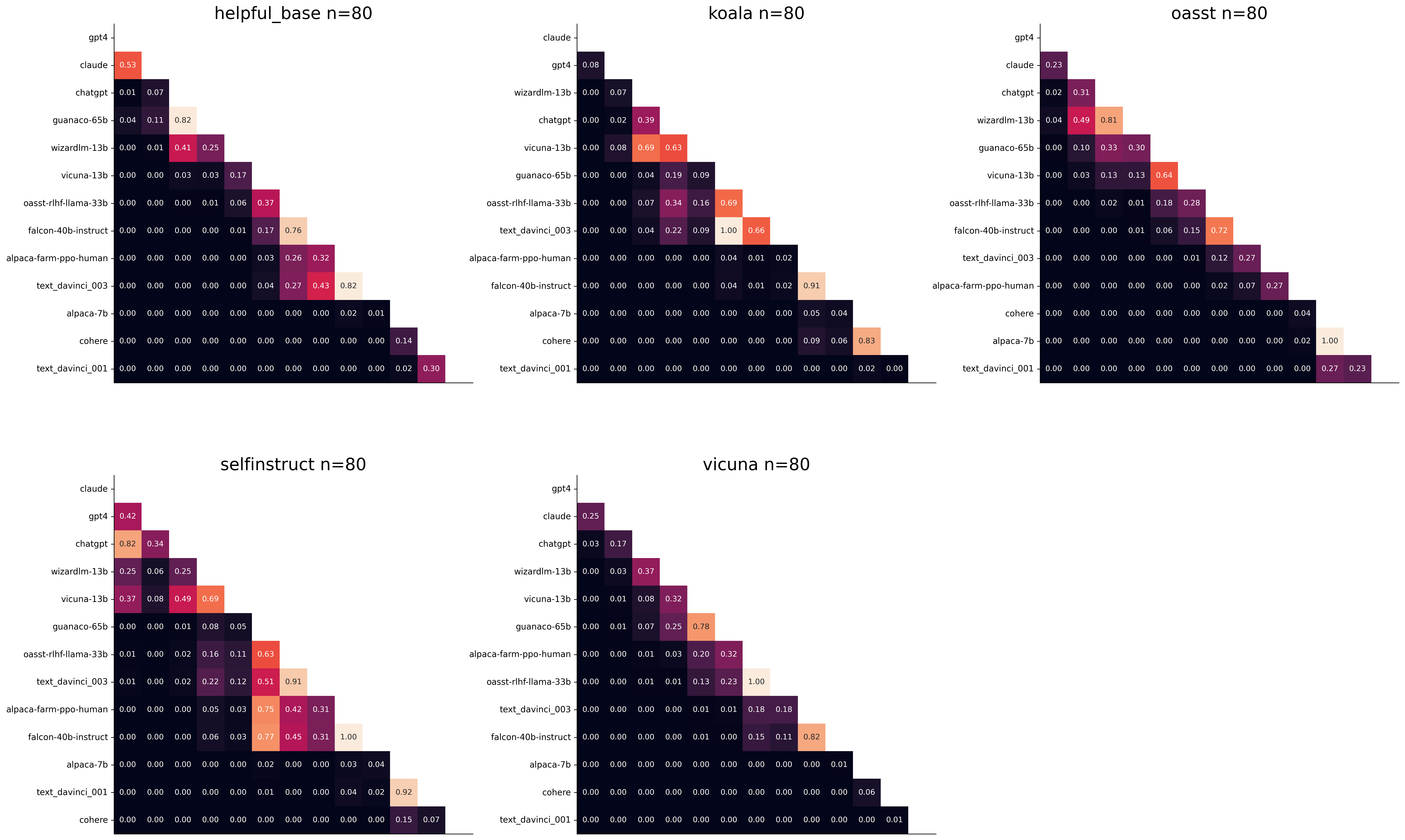
例如,我们看到 self-instruct 数据集产生的统计功效最低,这表明可以从评估集中移除该数据集。确切原因应在未来的工作中进行分析。关于代码和更多分析,请参阅 此笔记本,或上面的 colab 笔记本。
引用
请根据您使用的内容和引用的内容考虑引用以下内容:
- 代码、结果和通用基准:
alpaca_eval(本仓库)。指定您使用的是 AlpacaEval 还是 AlpacaEval 2.0。有关长度控制的胜率,见下文。 - 长度控制 (LC) 胜率:
alpaca_eval_length。 - 人工标注:
dubois2023alpacafarm(AlpacaFarm) - AlpacaEval 评估集:
alpaca_eval以及 self-instruct, open-assistant, vicuna, koala, hh-rlhf。
以下是 bibtex 条目:
@misc{alpaca_eval,
author = {Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {AlpacaEval: An Automatic Evaluator of Instruction-following Models},
year = {2023},
month = {5},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/alpaca_eval}}
}
@article{dubois2024length,
title={Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators},
author={Dubois, Yann and Galambosi, Bal{\'a}zs and Liang, Percy and Hashimoto, Tatsunori B},
journal={arXiv preprint arXiv:2404.04475},
year={2024}
}
@misc{dubois2023alpacafarm,
title={AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback},
author={Yann Dubois and Xuechen Li and Rohan Taori and Tianyi Zhang and Ishaan Gulrajani and Jimmy Ba and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto},
year={2023},
eprint={2305.14387},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
更多信息
长度控制胜率
长度控制 (LC) 胜率是胜率的去偏版本,它控制了输出的长度。
主要思想是,对于每个模型,我们将拟合一个逻辑回归 (logistic regression) 来预测自动标注器 (autoannotator) 的偏好,给定条件为:(1) 指令,(2) 模型,以及 (3) 基线 (baseline) 与模型输出之间的长度差异。
有了这样的逻辑回归,我们可以通过将长度差异设置为 0 来尝试预测反事实 (counterfactual) 情况:“如果模型的输出长度与基线相同,偏好会是多少”。
通过对这种长度控制的偏好进行平均,我们便得到了长度控制的胜率。
逻辑回归的确切形式被设定为使 LC 胜率的解释类似于原始胜率,例如对于任何模型 m1 和 m2,我们有 win_rate(m1, m2) = 1 - win_rate(m2, m1) \in [0,100] 且 win_rate(m1, m1) = 0.5。
长度控制胜率将 AlpacaEval 排行榜 (leaderboard) 与 Chat Arena 之间的相关性从 0.93 提高到 0.98 斯皮尔曼相关系数 (Spearman correlation),同时显著降低了标注器的长度可操纵性 (length gameability)。
有关长度控制胜率的更多信息和结果,请参阅 此笔记本。
这种通过预测结果并条件化于中介变量 (mediator)(长度差异)来估计受控直接效应 (controlled direct effect) 的想法,在统计推断中很常见。
要获取先前标注模型的 LC 胜率,您可以使用以下命令:
pip install -U alpaca_eval
alpaca_eval --model_outputs … --is_recompute_metrics_only True
AlpacaEval 2.0
AlpacaEval 2.0 是 AlpacaEval 的新版本。以下是区别:
- 参考模型:
gpt4_turbo:我们将基线 (baseline) 从text-davinci-003升级到gpt4_turbo,以使基准 (benchmark) 更具挑战性,并获得更能反映当前最先进水平 (state of the art) 的指标。 - 标注器:
weighted_alpaca_eval_gpt4_turbo:我们在质量和价格方面改进了标注器。首先,我们使用gpt4_turbo模型进行标注,其成本约为gpt4的一半。其次,我们更改了提示词,使模型输出单个 token,这进一步降低了成本并提高了速度。最后,我们没有使用二元偏好,而是使用了 logprobs (对数概率) 来计算连续偏好,从而得出最终的加权胜率。请注意,后两项变化产生了意想不到的效果,即减少了标注器的长度偏差。
默认情况下,pip install alpaca_eval==0.5 将使用 AlpacaEval 2.0。如果您希望默认使用旧配置,可以在环境中设置 IS_ALPACA_EVAL_2=False。
数据发布
作为 AlpacaEval 的一部分,我们发布以下数据:
- 人工标注数据(17701) 为了开发和理解自动评估器(automatic evaluators),我们发布了为 AlpacaFarm 收集的所有人类成对评估数据。这包含了在 AlpacaFarm 评估集上,22 个模型与
text-davinci-003参考模型之间的比较。标注来自 Amazon Mechanical Turk 上的 16 名众包工人池。涉及的模型包括:6 个来自 OpenAI,2 个来自 AlpacaFarm 的 SFT(监督微调)模型,13 个来自 AlpacaFarm 的 RLHF(基于人类反馈的强化学习)方法,以及 LLaMA 7B。 - 人工交叉标注(2596) 为了进一步分析自动评估器,我们从 AlpacaFarm 评估集中选择了 650 个示例(通过跨模型和数据层的分层采样),并为每个示例收集了 4 个人工标注。
- AlpacaEval 数据集(805) 我们对 AlpacaFarm 评估集进行了轻微的修改/简化。首先,我们将 instruction(指令)和 input(输入)字段合并为单个 instruction 字段。这影响了 AlpacaFarm 评估集中 1/4 的示例,这些示例全部来自 self-instruct 评估集。其次,我们重新生成了 text-davinci-003 参考输出,不再限制其输出长度。
关于人工标注的更多详情,请参阅 AlpacaFarm 论文。
与 AlpacaFarm 的区别
AlpacaEval 是对 AlpacaFarm 中的自动成对偏好模拟器的改进和简化。除了 AlpacaFarm 之外,你应该使用 AlpacaEval。主要区别如下:
- AlpacaEval 合并了指令和输入:AlpacaEval 评估与 AlpacaFarm 评估相同,只是 instruction(指令)和 input(输入)字段被合并为
{instruction}\n\n{input}。这影响了 AlpacaFarm 评估集中 1/4 的示例(self-instruct 子集)。这种简化为那些未通过区分这两个字段进行训练的模型提供了更公平的比较。 - AlpacaEval 处理更长的生成:AlpacaFarm 中的模型在生成时限制最大 token(词元)数为 300。我们将此数字更改为 AlpacaEval 的 2000。注意,这也影响了参考生成(
text-davinci-003),因此即使对于没有 input 字段的示例,AlpacaEval 上的结果也与 AlpacaFarm 上的结果不可比。 - AlpacaEval 消除了标注者内部和标注者之间的方差:AlpacaFarm 模拟器在模式行为和多样性方面复制了人工标注。特别是,AlpacaFarm 的模拟器使用模型池和提示词(prompt),并添加噪声以复制人工标注的内部和之间方差。如果目标是使用自动标注器进行评估或简单地训练更好的模型,那么这种方差可能并不理想。因此,AlpacaEval 的默认标注器没有这种方差。我们通过使用
--anotators_config 'alpaca_farm'和--p_label_flip 0.25创建评估器时,提供选项将其加回。
相关工作
已有几项工作提出了用于指令跟随模型的新自动标注器。这里我们列出我们所知的并讨论它们与我们的区别。我们在 我们的评估器排行榜 中评估了所有这些。
- Vicuna/lmsys lmsys 标注器(
lmsys_gpt4)通过询问标注器对每个输出的评分(1-10 分),然后选择得分最高的输出作为首选来评估成对输出。他们不对输出顺序进行随机化,并且在评分后要求解释。总体而言,我们发现该标注器对较长输出有强烈的 bias(偏差)(0.74),且与人工标注的 correlation(相关性)相对较低(63.2)。 - AlpacaFarm 最好的 AlpacaFarm 标注器(
alpaca_farm_greedy_gpt4)通过直接询问标注器它更喜欢哪个输出来评估成对输出。此外,它将 5 个示例 batch(批处理)在一起以分摊提示词的长度,并对输出顺序进行随机化。总体而言,我们发现该标注器对较长输出的 bias(偏差)较小(0.60),且比其他标注器更快(每 1000 个示例 878 秒)。它与大多数人工标注的 correlation(相关性)略高(66.4),高于人类本身(65.7)。然而,它的成本更高(每 1000 个示例 $15.3),并且由于 batching(批处理)原因无法处理非常长的输出。 - Aviary Aviary 标注器(
aviary_gpt4)要求标注器按偏好对输出进行排序,而不仅仅是选择首选输出。它不对输出顺序进行随机化,并使用较高的 temperature(温度参数)进行解码(0.9)。总体而言,我们发现该标注器对较长输出有相对较强的 bias(偏差)(0.70),且与人工标注的 correlation(相关性)非常高(69.1)。通过降低 temperature(温度参数)和随机化输出顺序,我们 进一步提高了 correlation(相关性)至 69.8(improved_aviary_gpt4),但这进一步将长度 bias(偏差)增加到了 0.73。
我们的 alpaca_eval_gpt4 是 AlpacaFarm 和 Aviary 标注器的混合体。它要求标注器按偏好对输出进行排序,但它使用 temperature(温度参数)0,对输出进行随机化,并对 prompt(提示词)进行了一些修改,将长度 bias(偏差)降低到 0.68。
其他相关工作包括最近分析自动评估器的论文。例如:
- AlpacaFarm Appx C 和 Large Language Models are not Fair Evaluators 都发现自动标注器存在 position bias(位置偏差)。
- AlpacaFarm Sec. 5.2. 和 The False Promise of Imitating Proprietary LLMs 都发现自动标注器偏爱 style(风格,例如列表的使用、语调、措辞、长度)而非 factuality(事实性)。
解读标注
对于所有模型,您可以在 results/<model_name>/*/annotations.json 下找到 auto-annotations(自动标注)。这些标注包含以下列:
instruction: prompt(提示词)generator_1: baseline model(基线模型)output_1: 基线模型的输出generator_2: 被评估的模型output_2: 被评估模型的输出annotator: auto-annotator(自动标注器)preference: auto-annotator(自动标注器)的结果。这是一个介于 1 和 2 之间的 float(浮点数)。越接近 1 表示 auto-annotator(自动标注器)更偏好output_1,越接近 2 表示它更偏好output_2。对于 AlpacaEval 2.0,preference-1对应于output_1被选中的概率。对于 AlpacaEval 1.0,如果output_1被偏好则preference为 1,如果output_2被偏好则为 2,如果两者相同则为 1.5。win rate(胜率)始终是(preference -1).mean()。raw_completion: auto-annotator(自动标注器)的原始输出。此字段包含在output_1和output_2顺序去随机化之前的补全内容!因此更难解读,详见下文。
Chain of thought(思维链)
对于某些标注器,例如 alpaca_eval_cot_gpt4_turbo_fn,我们使用 Chain of thought reasoning(思维链推理)使模型的偏好更具可解释性。这些内容可以在 concise_explanation 下找到。要解读它们,您还应该查看 referenced_models,它将临时模型名称(在提示词中)转换为实际输出。下面,我们将提供更多关于背后机制的解释。
您可以检查 annotations.json 中的 raw_annotations["concise_explanation] 列(例如 此处),其中包含自动标注器的 Chain of thought reasoning(思维链推理)。请注意,raw_annotations 不受输出顺序随机化的影响。特别是,"m" 和 "M" 有时指第一个模型(参考模型),有时指第二个模型(被评估模型)。要了解指的是哪个模型,您应该使用 preference 和 ordered_models 列。为了使其更容易理解,我们添加了一个 "referenced_models" 列,将模型名称映射到相应的输出。例如,在下面的标注中,我们看到偏好值为 1.0(即 output_1),并且对应于 concise_explanation 中的模型 M(参见 ordered_models)。
{
"instruction": "How did US states get their names?",
"output_1": "The names of U.S. states are derived from a variety of languages and sources, including indigenous American languages, European languages (primarily English, Spanish, and French), as well as other historical influences. Here is a brief overview of how some states got their names:\n\n1. **Indigenous American Languages**: Many state names come from Native American words or names of tribes, often from the languages of the indigenous peoples who lived in or near those areas.\n - **Alabama**: Possibly derived from the Choctaw language, meaning \"thicket clearers.\"\n - **Connecticut**: From a Mohegan-Pequot word meaning \"long tidal river.\"\n - **Massachusetts": [...]",
"generator_1": "gpt4_1106_preview",
"dataset": "helpful_base",
"output_2": "The names of the 50 U.S. states come from a variety of sources, including Native American languages, European languages, and historical figures. Here's a brief overview of how some states got their names:\n\n1. Native American origins: Many states have names derived from Native American languages. For example, Alabama comes from the Choctaw word \"Albah amo,\" meaning \"plant gatherers\" or \"herb gatherers.\" Similarly, the name Mississippi comes from the Ojibwe word \"Misi-ziibi,\" meaning \"great river.\"\n\n2. European languages: [...].",
"generator_2": "gpt4",
"annotator": "alpaca_eval_cot_gpt4_turbo_fn",
"preference": 1.0,
"raw_completion": {
"concise_explanation": "Model M provided a more detailed and structured response, including bold headings for each category and a wider range of examples. It also included additional categories such as 'Other European Languages' and 'Combination of Languages and Influences', which added depth to the explanation. Model m's response was accurate but less comprehensive and lacked the clear structure found in Model M's output.",
"ordered_models": [
{
"model": "M",
"rank": 1
},
{
"model": "m",
"rank": 2
}
]
},
"referenced_models": {
"M": "output_1",
"m": "output_2"
}
}
主要更新
- 2024 年 3 月 12 日:更新为使用 length-controlled (LC)(长度控制)win rates(胜率)。这是控制输出长度的 win-rates(胜率)的无偏版本。
- 2024 年 1 月 3 日:更新至 AlpacaEval 2.0,该版本使用 GPT4-turbo 作为 baseline(基线)和 annotator(标注器)。
- 2024 年 1 月 2 日:添加了 Azure API 以及更通用的客户端配置设置方式。参见 此处
- 2023 年 6 月 19 日:添加任何人都可以使用的排行榜
chatgpt_fn(无需等待列表)。 - 2023 年 6 月 19 日:更新以使用 OpenAI 的 function calling(函数调用)。示例:
chatgpt_fn或alpaca_eval_gpt4_fn。
版本历史
v0.6.62024/12/27v0.3.22023/11/08v0.3.12023/09/19v0.3.02023/09/01v0.2.92023/08/23v0.6.52024/08/17v0.6.42024/07/18v0.6.32024/06/24v0.6.22024/04/19v0.6.12024/04/13v0.62024/03/20v0.5.42024/02/24v0.5.32024/02/01v0.5.22024/01/10v0.5.12024/01/10v0.5.02024/01/10v0.3.62023/11/24v0.3.52023/11/16vv0.3.42023/11/16v0.3.32023/11/08常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。