Tensorflow-Cookbook
Tensorflow-Cookbook 是一个面向 TensorFlow 的开源代码库,旨在提供简单易用的构建模块,帮助开发者快速搭建深度学习模型。Tensorflow-Cookbook 汇集了常用的网络架构、函数和图像处理工具,有效解决了从零开始配置环境和高频调用底层 API 的繁琐问题。
Tensorflow-Cookbook 适合需要快速原型开发的深度学习工程师、计算机视觉研究人员以及希望简化 TensorFlow 学习曲线的学生。通过 ops.py 和 utils.py 等模块,用户可以直接调用卷积、图像预处理等操作,无需反复查阅文档。
Tensorflow-Cookbook 的独特亮点在于支持生成对抗网络(GAN)和分类任务的通用架构,内置了多种卷积变体(如部分卷积、空洞卷积),并集成了数据加载的 DatasetAPI 模板。此外,还提供了丰富的权重初始化和正则化选项,如谱归一化等高级功能。借助 Tensorflow-Cookbook,开发者可以大幅减少样板代码,将精力集中在核心算法的创新上。
使用场景
某医疗 AI 初创公司的算法工程师需要在两周内交付一个肺部 CT 影像分类原型系统。由于项目时间紧迫,团队对模型精度和开发效率都有极高要求。
没有 Tensorflow-Cookbook 时
- 需要从零手写卷积、池化等底层算子,代码冗余且容易在 padding 类型和 stride 参数上出现低级错误
- 数据预处理与加载流程繁琐,手动编写 tf.data 管道难以兼顾图像增强与多进程读取的效率平衡
- 网络权重初始化缺乏统一标准,常因初始值分布不当导致模型训练初期损失剧烈震荡,调试耗时
使用 Tensorflow-Cookbook 后
- 直接复用 ops.py 中的封装函数,一行代码即可配置包含谱归一化的高级卷积层,有效减少 Bug
- 通过 DatasetAPI 模块快速构建数据管道,自动处理图像尺寸调整与并行映射,大幅缩短数据准备周期
- 内置多种成熟的初始化策略(如 He、Xavier)及正则化选项,显著提升了模型收敛的稳定性与最终精度
核心价值:将重复性工程细节抽象为标准化组件,让开发者能专注于模型架构创新而非底层实现。
运行环境要求
- 未说明
未说明
未说明

快速开始

网页
TensorFlow 2 实战指南
贡献
目前,该仓库包含对生成对抗网络(GAN)和分类任务有用的通用架构和函数。
我将继续添加其他领域的有用内容。
同时,我们欢迎您的拉取请求(Pull Requests)和问题反馈(Issues)。
如果您想实现某些功能,请在 Issue 中写下您的需求,我会去实现它。
如何使用
导入
ops.py- 操作
- from ops import *
utils.py- 图像处理
- from utils import *
网络模板
def network(x, is_training=True, reuse=False, scope="network"):
with tf.variable_scope(scope, reuse=reuse):
x = conv(...)
...
return logit
使用 DatasetAPI(数据集 API)将数据插入网络
Image_Data_Class = ImageData(img_size, img_ch, augment_flag)
trainA_dataset = ['./dataset/cat/trainA/a.jpg',
'./dataset/cat/trainA/b.png',
'./dataset/cat/trainA/c.jpeg',
...]
trainA = tf.data.Dataset.from_tensor_slices(trainA_dataset)
trainA = trainA.map(Image_Data_Class.image_processing, num_parallel_calls=16)
trainA = trainA.shuffle(buffer_size=10000).prefetch(buffer_size=batch_size).batch(batch_size).repeat()
trainA_iterator = trainA.make_one_shot_iterator()
data_A = trainA_iterator.get_next()
logit = network(data_A)
- 更多信息请参见 此链接。
选项
padding='SAME'- pad = ceil[ (kernel - stride) / 2 ]
pad_type- 'zero' or 'reflect'
sn
注意
- 如果您不希望共享变量,请将所有作用域名称设置为不同。
权重
weight_init = tf.truncated_normal_initializer(mean=0.0, stddev=0.02)
weight_regularizer = tf.contrib.layers.l2_regularizer(0.0001)
weight_regularizer_fully = tf.contrib.layers.l2_regularizer(0.0001)
初始化
Xavier: tf.contrib.layers.xavier_initializer()USE """tf.contrib.layers.variance_scaling_initializer()""" if uniform : factor = gain * gain mode = 'FAN_AVG' else : factor = (gain * gain) / 1.3 mode = 'FAN_AVG'He: tf.contrib.layers.variance_scaling_initializer()if uniform : factor = gain * gain mode = 'FAN_IN' else : factor = (gain * gain) / 1.3 mode = 'FAN_OUT'Normal: tf.random_normal_initializer(mean=0.0, stddev=0.02)Truncated_normal: tf.truncated_normal_initializer(mean=0.0, stddev=0.02)Orthogonal: tf.orthogonal_initializer(1.0) / # if relu = sqrt(2), the others = 1.0
正则化
l2_decay: tf.contrib.layers.l2_regularizer(0.0001)orthogonal_regularizer: orthogonal_regularizer(0.0001) & orthogonal_regularizer_fully(0.0001)
卷积(Convolution)
基础卷积
x = conv(x, channels=64, kernel=3, stride=2, pad=1, pad_type='reflect', use_bias=True, sn=True, scope='conv')
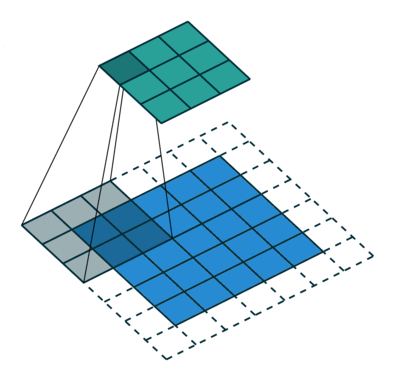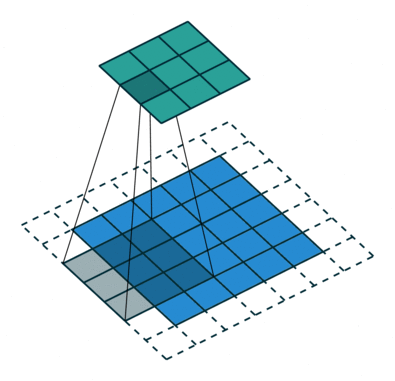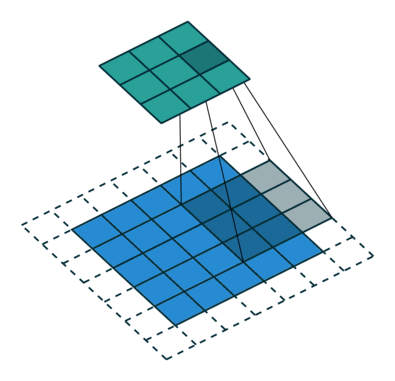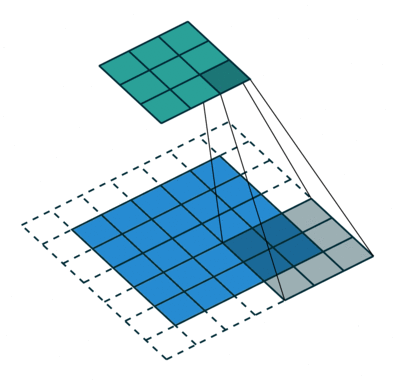
部分卷积(NVIDIA 部分卷积)
x = partial_conv(x, channels=64, kernel=3, stride=2, use_bias=True, padding='SAME', sn=True, scope='partial_conv')
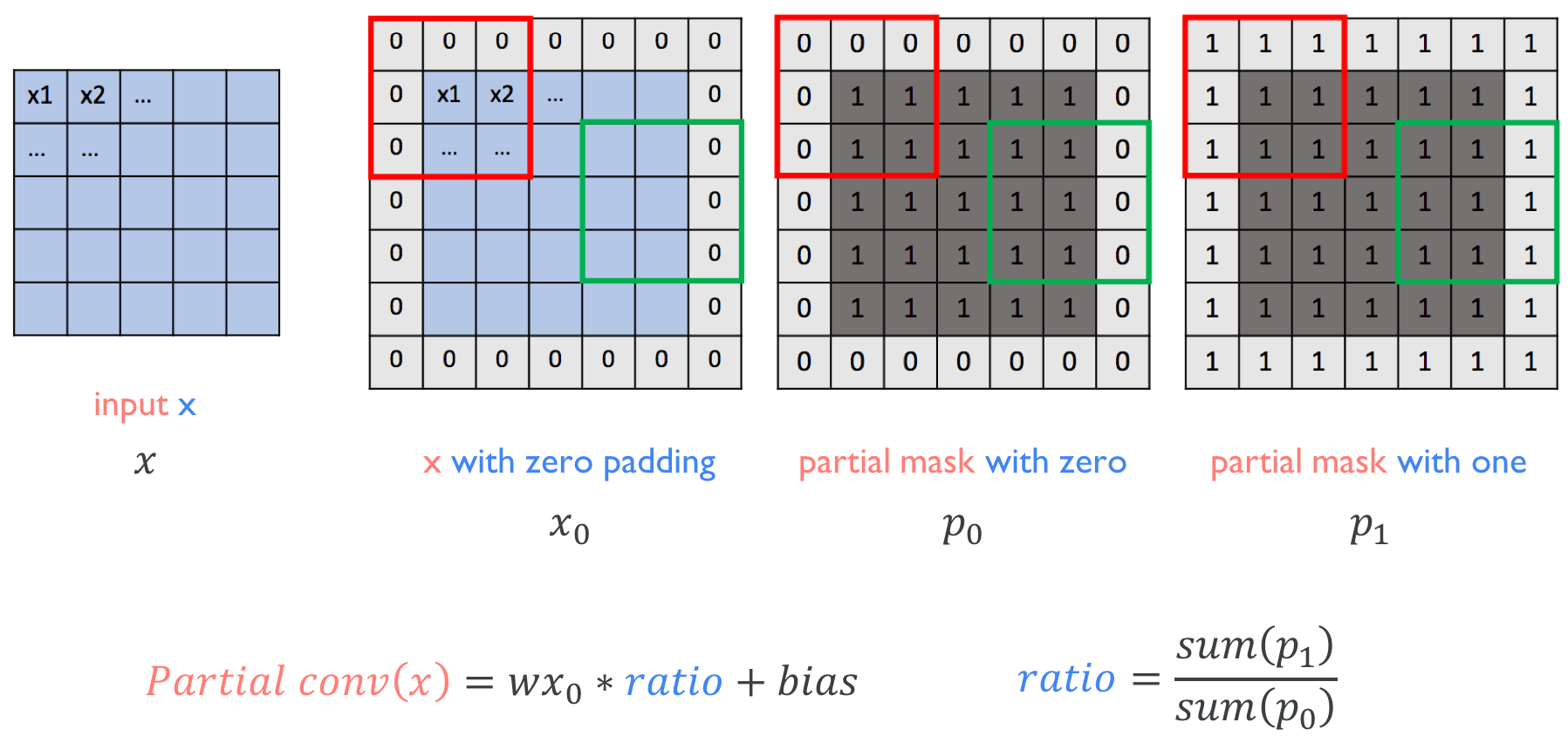
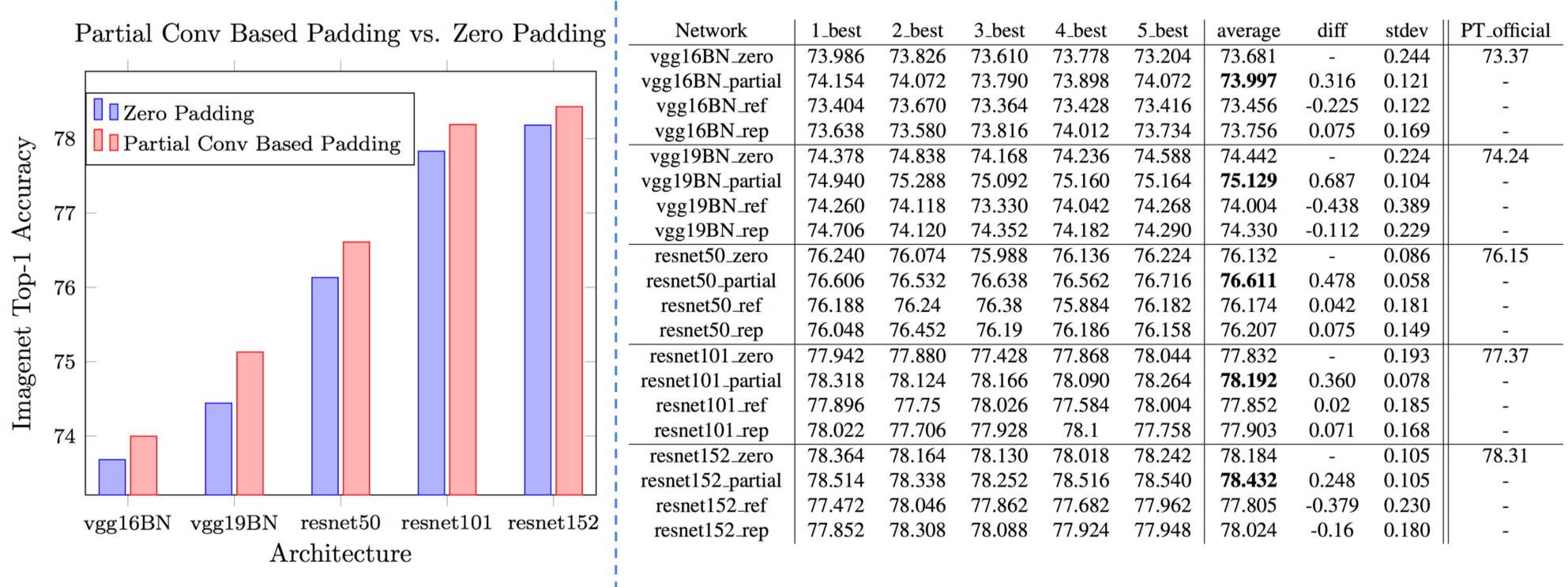
空洞卷积(Dilated Convolution)
x = dilate_conv(x, channels=64, kernel=3, rate=2, use_bias=True, padding='VALID', sn=True, scope='dilate_conv')
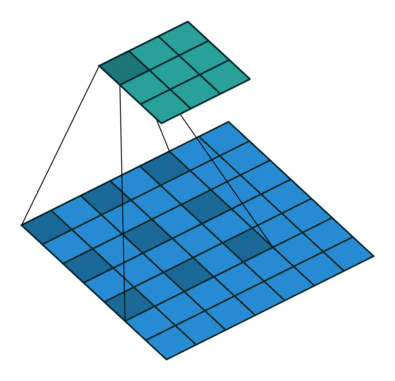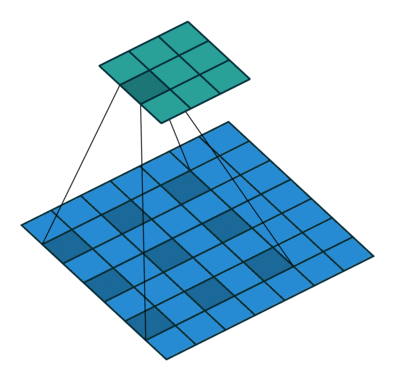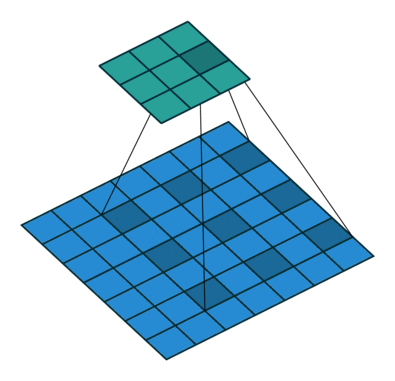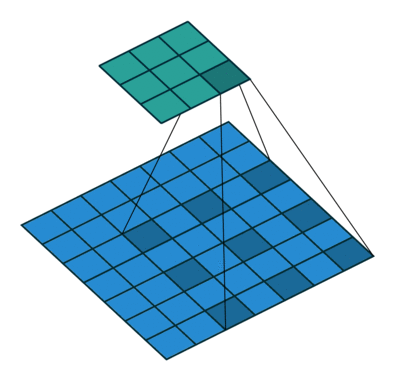
反卷积(Deconvolution)
基础反卷积
x = deconv(x, channels=64, kernel=3, stride=1, padding='SAME', use_bias=True, sn=True, scope='deconv')
全连接(Fully-connected)
x = fully_connected(x, units=64, use_bias=True, sn=True, scope='fully_connected')

像素洗牌(Pixel shuffle)
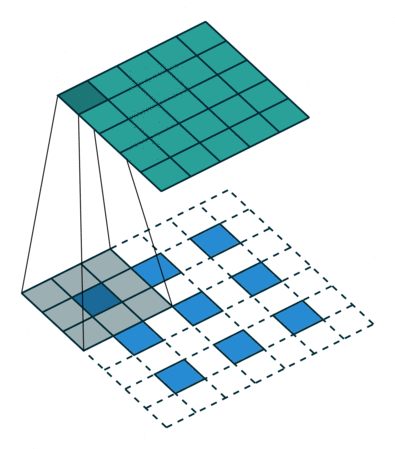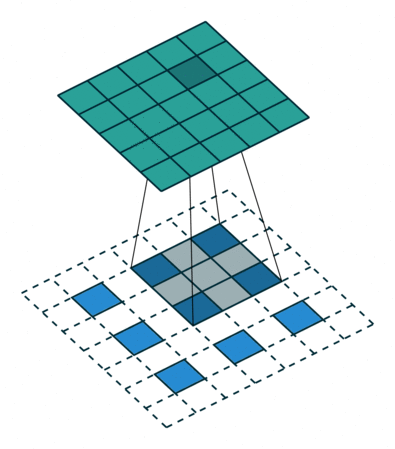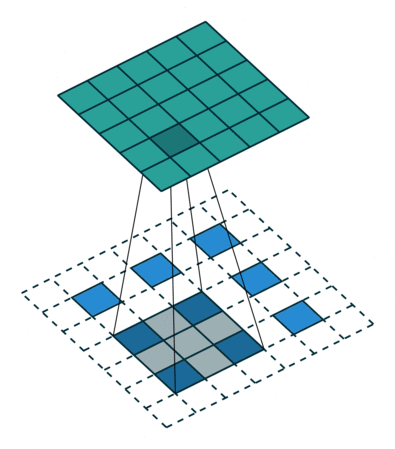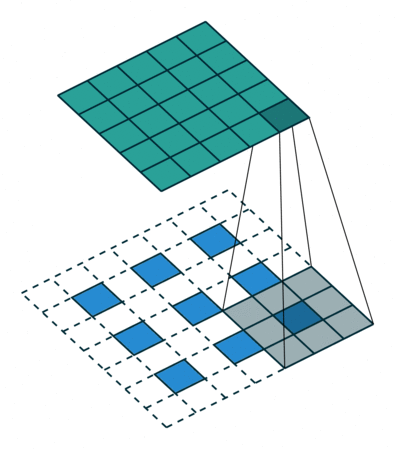
x = conv_pixel_shuffle_down(x, scale_factor=2, use_bias=True, sn=True, scope='pixel_shuffle_down')
x = conv_pixel_shuffle_up(x, scale_factor=2, use_bias=True, sn=True, scope='pixel_shuffle_up')
down===> [height, width] -> [height // scale_factor, width // scale_factor]up===> [height, width] -> [height * scale_factor, width * scale_factor]
模块(Block)
残差块(Residual block)
x = resblock(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block')
x = resblock_down(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block_down')
x = resblock_up(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block_up')
down===> [height, width] -> [height // 2, width // 2]up===> [height, width] -> [height * 2, width * 2]
密集块(Dense block)
x = denseblock(x, channels=64, n_db=6, is_training=is_training, use_bias=True, sn=True, scope='denseblock')
n_db===> 密集块的数量
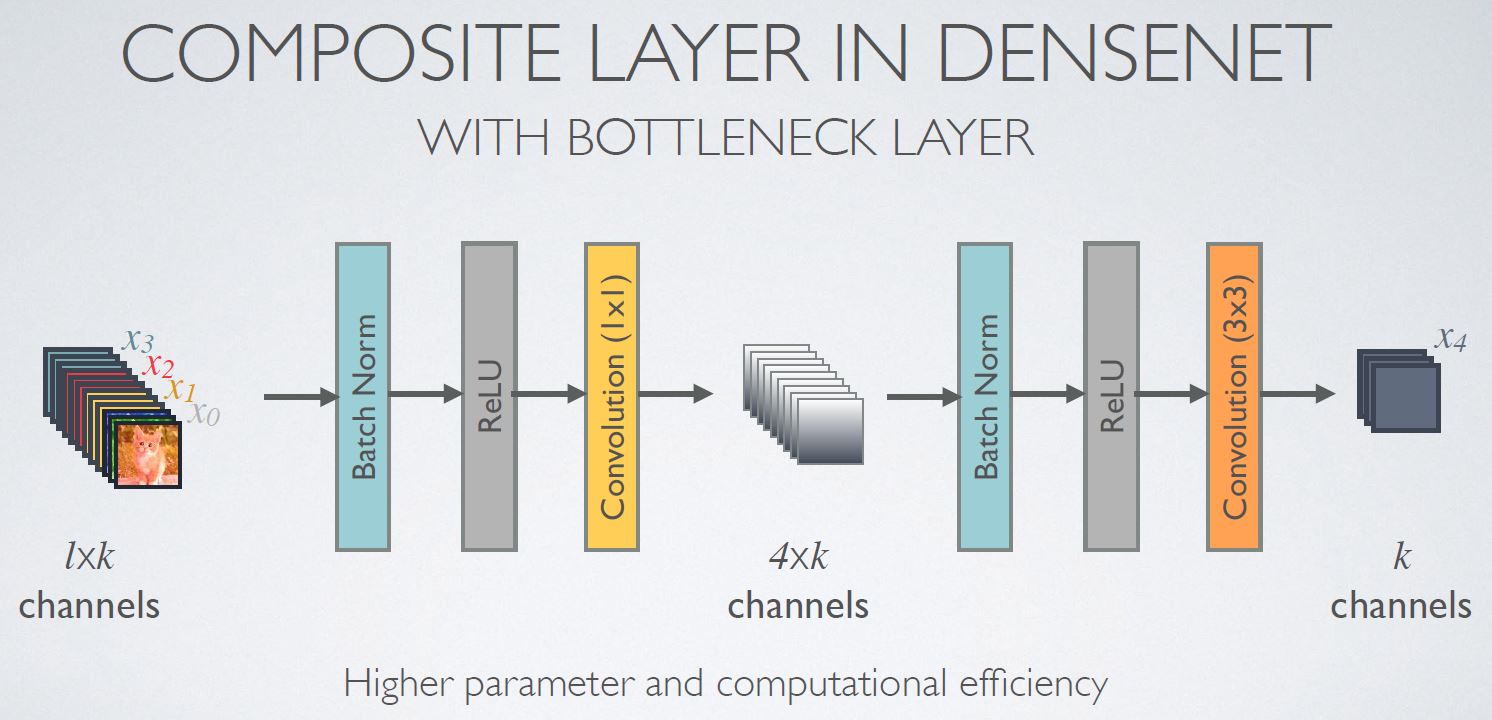
残差密集块(Residual-dense block)
x = res_denseblock(x, channels=64, n_rdb=20, n_rdb_conv=6, is_training=is_training, use_bias=True, sn=True, scope='res_denseblock')
n_rdb===> RDB 的数量n_rdb_conv===> 每个 RDB 的卷积层数



注意力模块
x = self_attention(x, use_bias=True, sn=True, scope='self_attention')
x = self_attention_with_pooling(x, use_bias=True, sn=True, scope='self_attention_version_2')
x = squeeze_excitation(x, ratio=16, use_bias=True, sn=True, scope='squeeze_excitation')
x = convolution_block_attention(x, ratio=16, use_bias=True, sn=True, scope='convolution_block_attention')
x = global_context_block(x, use_bias=True, sn=True, scope='gc_block')
x = srm_block(x, use_bias=False, is_training=is_training, scope='srm_block')
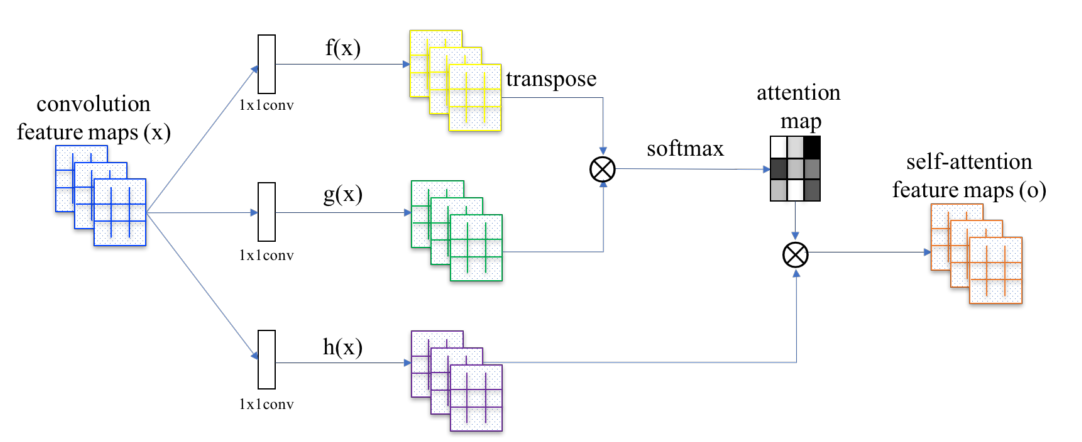
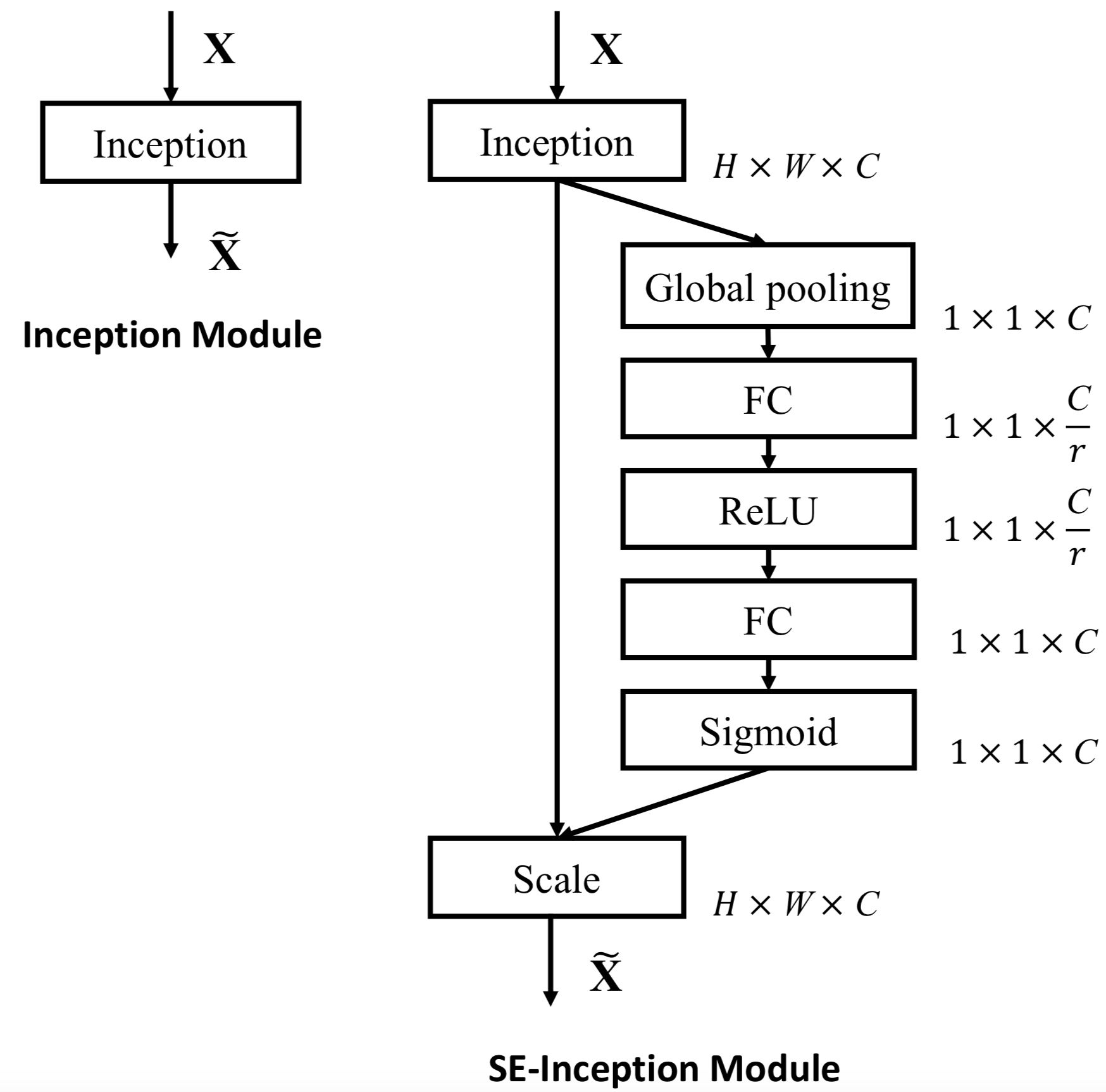
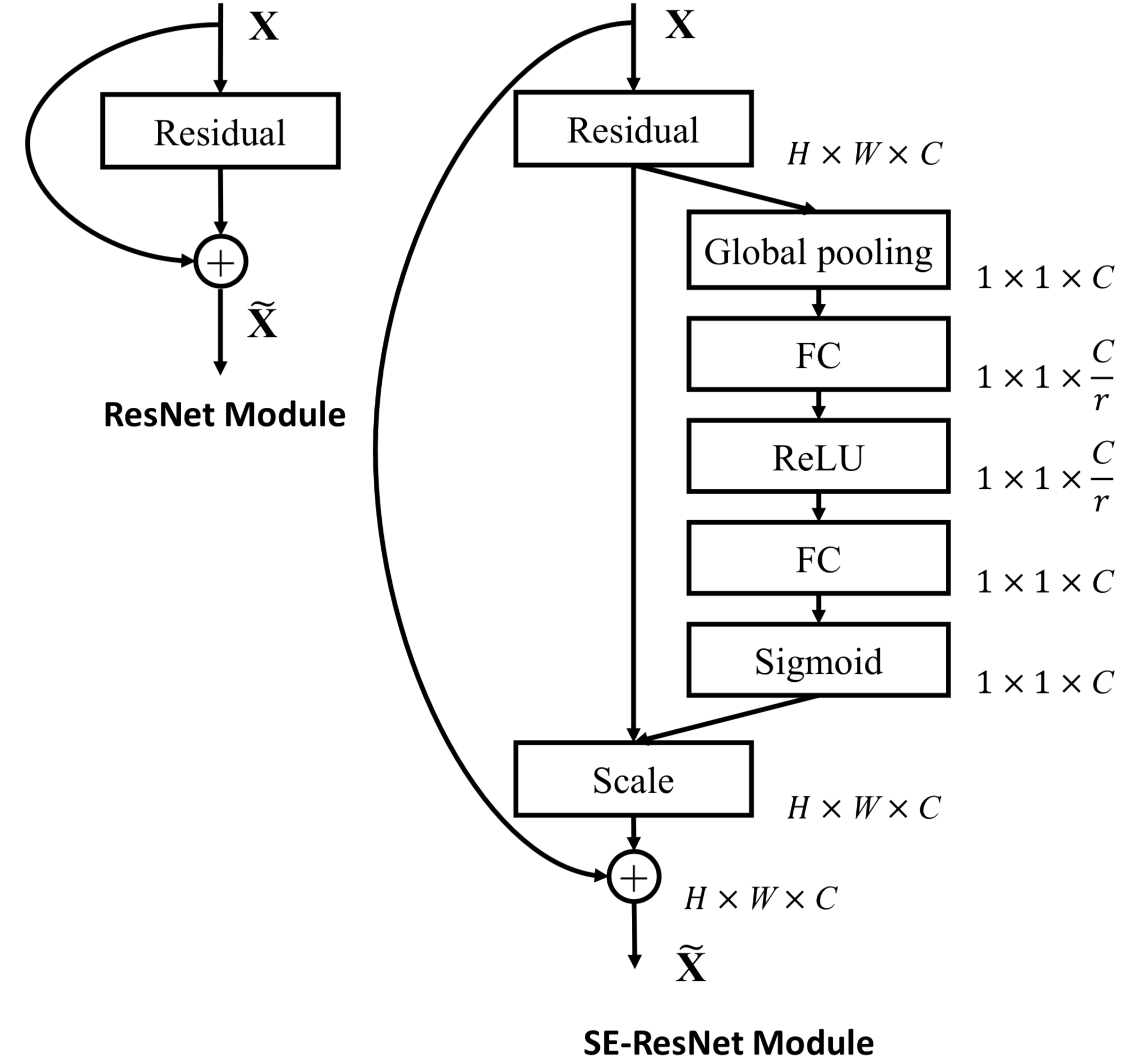
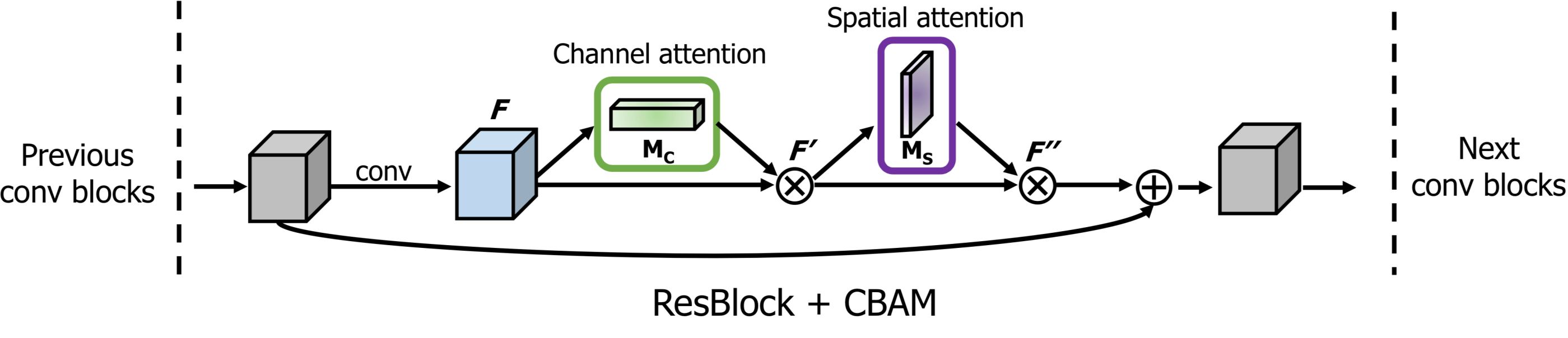
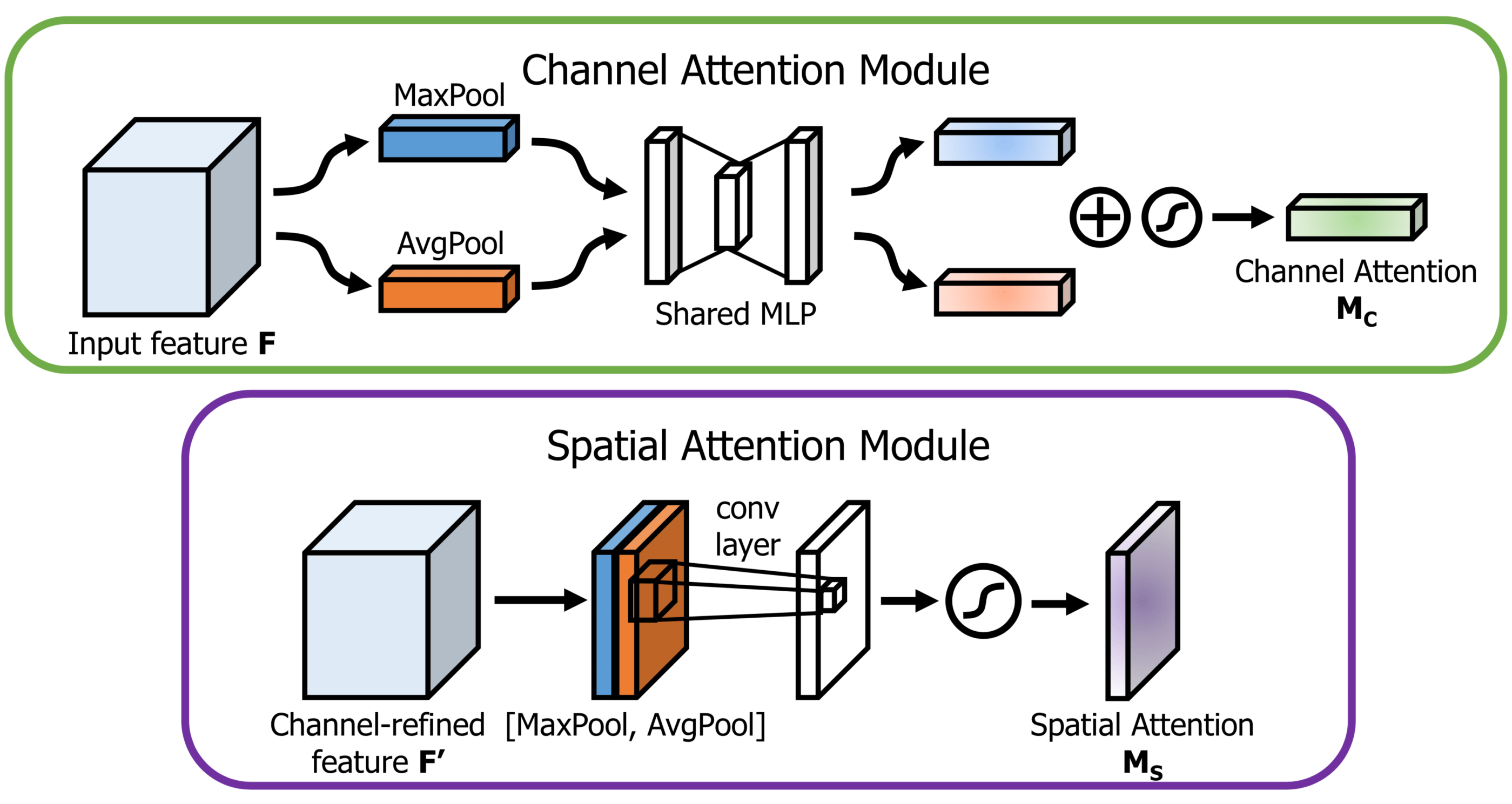


归一化
x = batch_norm(x, is_training=is_training, scope='batch_norm')
x = layer_norm(x, scope='layer_norm')
x = instance_norm(x, scope='instance_norm')
x = group_norm(x, groups=32, scope='group_norm')
x = pixel_norm(x)
x = batch_instance_norm(x, scope='batch_instance_norm')
x = layer_instance_norm(x, scope='layer_instance_norm')
x = switch_norm(x, scope='switch_norm')
x = condition_batch_norm(x, z, is_training=is_training, scope='condition_batch_norm'):
x = adaptive_instance_norm(x, gamma, beta)
x = adaptive_layer_instance_norm(x, gamma, beta, smoothing=True, scope='adaLIN')
- 查看 此链接 了解如何使用
condition_batch_norm - 查看 此链接 了解如何使用
adaptive_instance_norm - 查看 此链接 了解如何使用
adaptive_layer_instance_norm&layer_instance_norm
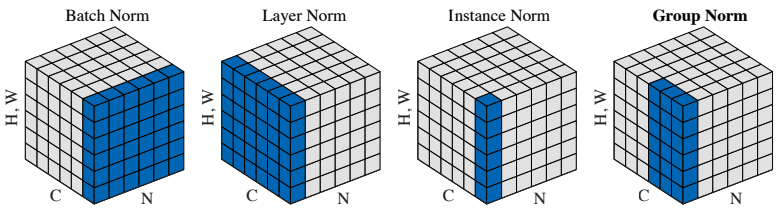
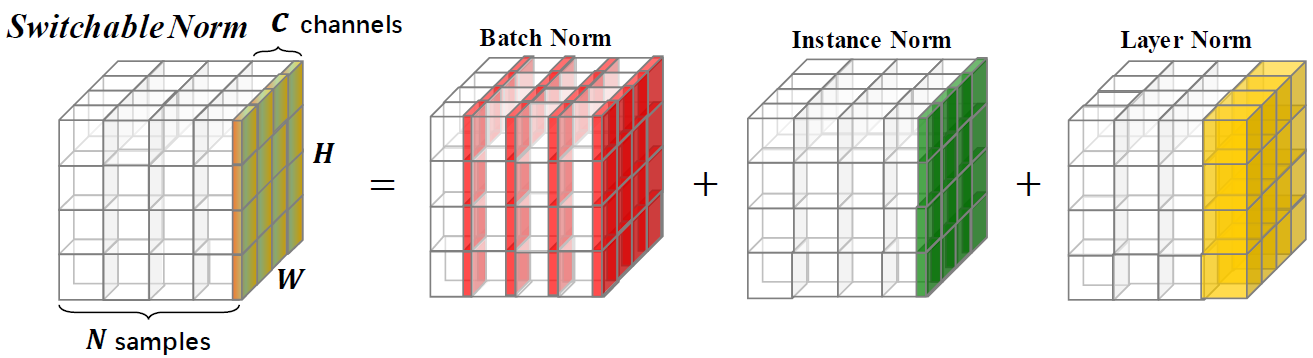
激活函数
x = relu(x)
x = lrelu(x, alpha=0.2)
x = tanh(x)
x = sigmoid(x)
x = swish(x)
x = elu(x)
池化与调整大小
x = nearest_up_sample(x, scale_factor=2)
x = bilinear_up_sample(x, scale_factor=2)
x = nearest_down_sample(x, scale_factor=2)
x = bilinear_down_sample(x, scale_factor=2)
x = max_pooling(x, pool_size=2)
x = avg_pooling(x, pool_size=2)
x = global_max_pooling(x)
x = global_avg_pooling(x)
x = flatten(x)
x = hw_flatten(x)
损失函数
分类损失
loss, accuracy = classification_loss(logit, label)
loss = dice_loss(n_classes=10, logit, label)
正则化损失
g_reg_loss = regularization_loss('generator')
d_reg_loss = regularization_loss('discriminator')
- 如果您想使用正则化器,则需要自行实现
像素损失
loss = L1_loss(x, y)
loss = L2_loss(x, y)
loss = huber_loss(x, y)
loss = histogram_loss(x, y)
loss = gram_style_loss(x, y)
loss = color_consistency_loss(x, y)
histogram_loss表示图像像素值颜色分布的差异。gram_style_loss表示使用格拉姆矩阵的风格差异。color_consistency_loss表示生成图像与输入图像之间的颜色差异。
GAN 损失
d_loss = discriminator_loss(Ra=True, loss_func='wgan-gp', real=real_logit, fake=fake_logit)
g_loss = generator_loss(Ra=True, loss_func='wgan-gp', real=real_logit, fake=fake_logit)
Raloss_func- gan
- lsgan
- hinge
- wgan-gp
- dragan
- 查看 此链接 了解如何使用
gradient_penalty

VDB 损失 (vdb loss)
d_bottleneck_loss = vdb_loss(real_mu, real_logvar, i_c) + vdb_loss(fake_mu, fake_logvar, i_c)
KL 散度 (kl-divergence) (z ~ N(0, 1))
loss = kl_loss(mean, logvar)
作者
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。