Step-Audio-EditX
Step-Audio-EditX 是一款基于大语言模型架构的开源音频编辑工具,拥有 30 亿参数并采用强化学习技术优化。它专注于对语音进行精细化修改,能够灵活调整说话人的情感色彩、演绎风格以及呼吸、轻笑、清嗓子等副语言特征,同时也具备强大的零样本文本转语音能力,支持中文、英文及多种方言的高质量克隆。
这款工具主要解决了传统音频处理中难以自然修改语气细节或需要大量定制数据的痛点。用户无需重新录制,即可通过指令让现有音频呈现出截然不同的情绪状态或添加逼真的非语言声音,极大地提升了语音内容的表现力和编辑效率。
Step-Audio-EditX 非常适合 AI 研究人员、语音应用开发者以及需要制作高品质语音内容的创作者使用。其独特的技术亮点在于引入了丰富的副语言标签控制,并支持多语言(含日韩语)及多音字发音精准调控。此外,项目不仅开放了模型权重,还公布了包括 SFT、DPO 和 GRPO 在内的完整训练代码,并适配了 vLLM 加速推理,为社区提供了从研究到落地的全方位支持。
使用场景
某游戏本地化团队正在为一款悬疑冒险游戏制作多语言角色配音,需要将中文原声快速适配为带有特定情绪和非语言细节的日文与韩文版本。
没有 Step-Audio-EditX 时
- 情感调整成本高昂:若录音演员语气不够惊恐或悲伤,必须重新召集配音员进棚补录,耗时且协调困难。
- 非语言细节缺失:原声中缺乏喘息、轻笑或清嗓子等副语言特征,导致角色听起来像机器人在念稿,缺乏真实感。
- 多语种适配僵化:切换日语或韩语时,难以保留原角色的独特音色和说话风格,往往需要寻找新的配音演员,破坏角色一致性。
- 零样本克隆效果差:传统工具在未见过的方言或特定语调上表现生硬,无法自然迁移角色的说话习惯。
使用 Step-Audio-EditX 后
- 指令式情感重绘:只需输入文本指令(如“增加颤抖的恐惧感”),Step-Audio-EditX 即可基于强化学习直接修改音频情感,无需演员返场。
- 精细化副语言注入:利用新增的
exhale(呼气)、chuckle(轻笑)、clears throat(清嗓)等标签,一键为对话添加逼真的呼吸感和微表情声音。 - 跨语言风格保持:在生成日语和韩语配音时,Step-Audio-EditX 能完美锁定原角色的音色与说话风格,实现真正的“一人分饰多语”。
- 强大的零样本泛化:即使是复杂的四川话或粤语角色,也能通过零样本技术高质量克隆并迁移到新语言中,保持韵味不变。
Step-Audio-EditX 将原本需要数周协调的重录工作缩短为分钟级的指令编辑,彻底改变了音频后期制作的流程效率。
运行环境要求
未说明(模型为 3B 参数,支持 vLLM 推理及 Int4 量化版本,通常建议 NVIDIA GPU)
未说明
快速开始
Step-Audio-EditX







🔥🔥🔥 新闻!!!
- 2026年1月29日:
- 🧩 新模型发布:
- 性能更优,整体提升超过4%。
- 增加了更多超语言学标签,包括**
呼气、嗅鼻声、吸气、轻笑、清嗓、咯咯笑**。 - 欢迎前往StepFun音频工作室试用。
- 💻 我们发布了SFT、DPO和GRPO的训练代码。
- 🌟 现已支持使用vLLM进行训练和推理。感谢vLLM团队!
- 🧩 新模型发布:
- 2025年11月28日: 🚀 新模型发布:现已支持日语和韩语。
- 2025年11月23日: 📊 Step-Audio-Edit-Benchmark 发布!
- 2025年11月19日: ⚙️ 我们发布了模型的新版本,该版本支持多音字发音控制,并提升了情感、说话风格和超语言学编辑的表现。
- 2025年11月12日: 📦 我们发布了Step-Audio-EditX(HuggingFace;ModelScope)和Step-Audio-Tokenizer(HuggingFace;ModelScope)的优化推理代码和模型权重。
- 2025年11月7日: ✨ 演示页面;🎮 HF Space Playground
- 2025年11月6日: 👋 我们发布了[Step-Audio-EditX]的技术报告(arXiv)。
简介
我们开源了Step-Audio-EditX,这是一个基于3B参数大语言模型的强化学习音频模型,专长于富有表现力的迭代式音频编辑。它在情感、说话风格和超语言学特征的编辑方面表现出色,同时还具备强大的零样本文本转语音(TTS)能力。
 微信开发者群
微信开发者群
📑 开源计划
- 推理代码
- 在线演示(Gradio)
- Step-Audio-Edit-Benchmark
- 模型检查点
- Step-Audio-Tokenizer
- Step-Audio-EditX
- Step-Audio-EditX-Int4
- 训练代码
- SFT训练
- DPO训练
- GRPO训练
- PPO训练
- ⏳ 功能支持计划
- 编辑功能
- 多音字发音控制
- 更多超语言学标签(如咳嗽、哭泣、紧张等)
- 填充词去除
- 其他语言
- 日语、韩语
- 阿拉伯语、法语、俄语、西班牙语等
- 编辑功能
特性
零样本TTS
- 对普通话、英语、四川话和粤语具有出色的零样本TTS克隆效果。
- 如果需要使用方言或其他语言,只需在文本前加上**
[四川话]** /[粤语]/[日语]/ **[韩语]**标签即可。 - 🔥 支持多音字发音控制,只需将多音字替换为拼音即可。
- [我也想过过过儿过过的生活] -> [我也想guo4guo4guo1儿guo4guo4的生活]
情感与说话风格编辑
- 对情感和风格的迭代控制效果显著,支持数十种选项进行编辑。
- 情感编辑:[愤怒、快乐、悲伤、兴奋、恐惧、惊讶、厌恶等]
- 说话风格编辑:[娇嗔、年长、孩童、低语、严肃、慷慨、夸张等]
- 更多情感和说话风格的编辑功能正在开发中。敬请期待! 🚀
- 对情感和风格的迭代控制效果显著,支持数十种选项进行编辑。
超语言学编辑
- 可精确控制10种超语言学特征,使合成音频更加自然、人性化且富有表现力。
- 支持的标签包括:
- [呼吸、笑声、惊讶—哦、确认—嗯、嗯、惊讶—啊、惊讶—哇、叹息、疑问—诶、不满—哼]
可用标签
| 情绪 | happy | 表达快乐 | angry | 表达愤怒 | ||||||||||||||||||||||||||
| sad | 表达悲伤 | fear | 表达恐惧 | |||||||||||||||||||||||||||
| surprised | 表达惊讶 | confusion | 表达困惑 | |||||||||||||||||||||||||||
| empathy | 表达共情与理解 | embarrass | 表达尴尬 | |||||||||||||||||||||||||||
| excited | 表达兴奋和热情 | depressed | 表达沮丧或灰心的情绪 | |||||||||||||||||||||||||||
| admiration | 表达钦佩或尊敬 | coldness | 表达冷淡和漠不关心 | |||||||||||||||||||||||||||
| disgusted | 表达厌恶或反感 | humour | 表达幽默或俏皮 | |||||||||||||||||||||||||||
| 说话风格 | serious | 以严肃或庄重的方式说话 | arrogant | 以傲慢的方式说话 | ||||||||||||||||||||||||||
| child | 以孩子般的方式说话 | older | 以老年人的声音说话 | |||||||||||||||||||||||||||
| girl | 以轻快、青春的女性化方式说话 | pure | 以纯洁、天真的方式说话 | |||||||||||||||||||||||||||
| sister | 以成熟、自信的女性化方式说话 | sweet | 以甜美、可爱的方式说话 | |||||||||||||||||||||||||||
| exaggerated | 以夸张、戏剧化的方式说话 | ethereal | 以柔和、空灵、梦幻的方式说话 | |||||||||||||||||||||||||||
| whisper | 以低语、非常轻柔的方式说话 | generous | 以豪爽、外向、直率的方式说话 | |||||||||||||||||||||||||||
| recite | 以清晰、节奏感强、朗诵诗歌的方式说话 | act_coy | 以甜美、俏皮、惹人喜爱的方式说话 | |||||||||||||||||||||||||||
| warm | 以温暖、友好的方式说话 | shy | 以害羞、胆怯的方式说话 | |||||||||||||||||||||||||||
| comfort | 以安慰、令人安心的方式说话 | authority | 以权威、命令式的方式说话 | |||||||||||||||||||||||||||
| chat | 以随意、聊天般的方式说话 | radio | 以广播节目般的方式说话 | |||||||||||||||||||||||||||
| soulful | 以真挚、深情的方式说话 | gentle | story | 以叙述性、有声书风格的方式说话 | vivid | program | news | advertising | roar | murmur | shout | deeply | loudly | 副语言 | [sigh] | [inhale] | [laugh] | [chuckle] | [exhale] | [clears throat] | [snort] | [giggle] | [cough] | [breath] | [uhm] | [Confirmation-en] | [Surprise-oh] | 表达惊讶:“哦” | [Surprise-ah] | 表达惊讶:“啊” |
| [Surprise-wa] | 表达惊讶:“哇” | [Surprise-yo] | 表达惊讶:“哟” | |||||||||||||||||||||||||||
| [Dissatisfaction-hnn] | 不满的声音:“哼” | [Question-ei] | 疑问:“诶” | |||||||||||||||||||||||||||
| [Question-ah] | 疑问:“啊” | [Question-en] | 疑问:“嗯” | |||||||||||||||||||||||||||
| [Question-yi] | 疑问:“咦” | [Question-oh] | 疑问:“哦” |
功能请求与愿望清单
💡 我们欢迎所有关于新功能的想法!如果您希望在项目中添加某项功能,请在我们的讨论区发起讨论。
我们将在此处收集社区反馈,并将受欢迎的建议纳入未来的开发计划。感谢您的贡献!
演示
| 任务 | 文本 | 原始音频 | 编辑后音频 |
|---|---|---|---|
| 情感-恐惧 | 我总觉得,有人在跟着我,我能听到奇怪的脚步声。 | ||
| 风格-耳语 | 比如在工作间隙,做一些简单的伸展运动,放松一下身体,这样,会让你更有精力。 | ||
| 风格-娇羞 | 我今天想喝奶茶,可是不知道喝什么口味,你帮我选一下嘛,你选的都好喝~ | ||
| 言语副语言特征 | 你这次又忘记带钥匙了 [Dissatisfaction-hnn],真是拿你没办法。 | ||
| 去噪 | 此类立法随后不时得到澄清和延长。不,那人并没有喝醉,他只是纳闷我们怎么会和这个陌生人扯上关系。突然间,我的反应变得迟钝了。不用糖烹饪更健康。 | ||
| 语速-加快 | 上次你说鞋子有点磨脚,我给你买了一双软软的鞋垫。 |
更多示例,请参阅演示页面。
模型下载
| 模型 | 🤗 Hugging Face | ModelScope |
|---|---|---|
| Step-Audio-EditX | stepfun-ai/Step-Audio-EditX | stepfun-ai/Step-Audio-EditX |
| Step-Audio-EditX | stepfun-ai/Step-Audio-EditX-AWQ-4bit | stepfun-ai/Step-Audio-EditX-AWQ-4bit |
| Step-Audio-Tokenizer | stepfun-ai/Step-Audio-Tokenizer | stepfun-ai/Step-Audio-Tokenizer |
模型使用
📜 要求
下表列出了运行 Step-Audio-EditX 模型所需的要求(批量大小 = 1):
| 模型 | 参数量 | 设置 (采样频率) |
GPU 最佳显存 |
|---|---|---|---|
| Step-Audio-EditX | 3B | 41.6Hz | 12 GB |
- 需要支持 CUDA 的 NVIDIA 显卡。
- 该模型已在单个 L40S 显卡上测试过。
- 12GB 只是一个临界值,而 16GB 显存会更加安全。
- 测试的操作系统:Linux
🔧 依赖与安装
- Python >= 3.12
- PyTorch >= 2.9.1
- CUDA 工具包
git clone https://github.com/stepfun-ai/Step-Audio-EditX.git
cd Step-Audio-EditX
uv sync --refresh
source .venv/bin/activate
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
git clone https://huggingface.co/stepfun-ai/Step-Audio-EditX
git clone https://huggingface.co/stepfun-ai/Step-Audio-EditX-AWQ-4bit/
下载完模型后,您存放文件的目录应具有如下结构:
where_you_download_dir
├── Step-Audio-Tokenizer
├── Step-Audio-EditX
使用 Docker 运行
您可以使用提供的 Dockerfile 来设置运行 Step-Audio-EditX 所需的环境。
# 构建 Docker 镜像
docker build . -t step-audio-editx
# 运行 Docker 容器
docker run --rm --gpus all \
-v /your/code/path:/app \
-v /your/model/path:/model \
-p 7860:7860 \
step-audio-editx
本地推理演示
[!提示] 为获得最佳性能,每次推理的音频长度应控制在 30 秒以内。
# 零样本克隆
# 生成的音频文件路径为 output/fear_zh_female_prompt_cloned.wav
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-text "我总觉得,有人在跟着我,我能听到奇怪的脚步声。" \
--prompt-audio "examples/fear_zh_female_prompt.wav" \
--generated-text "可惜没有如果,已经发生的事情终究是发生了。" \
--edit-type "clone" \
--output-dir ./output
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-text "His political stance was conservative, and he was particularly close to margaret thatcher." \
--prompt-audio "examples/zero_shot_en_prompt.wav" \
--generated-text "Underneath the courtyard is a large underground exhibition room which connects the two buildings. " \
--edit-type "clone" \
--output-dir ./output
# 编辑
# 每次编辑迭代都会生成一个或多个波形文件,例如:output/fear_zh_female_prompt_edited_iter1.wav、output/fear_zh_female_prompt_edited_iter2.wav,等等。
# 情感;恐惧
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-text "我总觉得,有人在跟着我,我能听到奇怪的脚步声。" \
--prompt-audio "examples/fear_zh_female_prompt.wav" \
--edit-type "emotion" \
--edit-info "fear" \
--output-dir ./output
# 情感;快乐
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-text "You know, I just finished that big project and feel so relieved. Everything seems easier and more colorful, what a wonderful feeling!" \
--prompt-audio "examples/en_happy_prompt.wav" \
--edit-type "emotion" \
--edit-info "happy" \
--output-dir ./output
# 风格;耳语
# 对于耳语风格的编辑,建议将迭代次数设置为大于1,以获得更好的效果。
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-text "比如在工作间隙,做一些简单的伸展运动,放松一下身体,这样,会让你更有精力." \
--prompt-audio "examples/whisper_prompt.wav" \
--edit-type "style" \
--edit-info "whisper" \
--output-dir ./output
# 言语副语言特征
# 支持的标签包括:呼吸、笑声、惊讶-哦、确认-英、嗯、惊讶-啊、惊讶-哇、叹息、疑问-哎、不满-哼
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-text "我觉得这个计划大概是可行的,不过还需要再仔细考虑一下。" \
--prompt-audio "examples/paralingustic_prompt.wav" \
--generated-text "我觉得这个计划大概是可行的,[Uhm]不过还需要再仔细考虑一下。" \
--edit-type "paralinguistic" \
--output-dir ./output
# 去噪
# 不需要提示文本。
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-audio "examples/denoise_prompt.wav"\
--edit-type "denoise" \
--output-dir ./output
# VAD(语音活动检测)
# 不需要提示文本。
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-audio "examples/vad_prompt.wav" \
--edit-type "vad" \
--output-dir ./output
# 语速
# 支持的编辑信息包括:更快、更慢、更快一些、更慢一些
python3 tts_infer.py \
--model-path where_you_download_dir \
--tokenizer-path where_you_download_dir \
--prompt-text "上次你说鞋子有点磨脚,我给你买了一双软软的鞋垫。" \
--prompt-audio "examples/speed_prompt.wav" \
--edit-type "speed" \
--edit-info "more faster" \
--output-dir ./output
启动Web演示
启动本地服务器进行在线推理。 假设您有一块至少有12GB显存的GPU,并且已经下载了所有模型。
# 标准启动
python app.py --model-path where_you_download_dir --tokenizer-path where_you_download_dir --model-source local
# 使用预量化AWQ 4位模型,内存高效模式(适用于显存有限的情况,约6-8GB使用)
python app.py \
--model-path path/to/quantized/model \
--tokenizer-path where_you_download_dir \
--model-source local \
--gpu-memory-utilization 0.1 \
--enforce-eager \
--max-num-seqs 1 \
--cosyvoice-dtype bfloat16 \
--no-cosyvoice-cuda-graph
可用参数
| 参数 | 默认值 | 描述 |
|---|---|---|
--model-path |
(必填) | 模型目录路径 |
--model-source |
auto |
模型来源:auto、local、modelscope、huggingface |
--gpu-memory-utilization |
0.5 |
vLLM KV缓存使用的显存比例(0.0-1.0) |
--max-model-len |
3072 |
最大序列长度,影响KV缓存大小 |
--enforce-eager |
True |
禁用vLLM CUDA图(节省约0.5GB显存) |
--max-num-seqs |
1 |
最大并发序列数(vLLM默认:256,越小占用显存越少) |
--dtype |
bfloat16 |
模型数据类型:float16、bfloat16 |
--quantization |
None |
量化方法:awq、gptq、fp8 |
--cosyvoice-dtype |
bfloat16 |
CosyVoice声码器数据类型:float32、bfloat16、float16 |
--no-cosyvoice-cuda-graph |
False |
禁用CosyVoice CUDA图(节省显存) |
--enable-auto-transcribe |
False |
启用自动音频转录 |
显存使用指南
| 配置 | 估计显存用量 | 使用场景 |
|---|---|---|
| 标准(默认) | ~12-15 GB | 最佳质量和速度 |
| 内存高效 | ~6-8 GB | 显存有限,质量略有牺牲 |
| AWQ 4位量化 | ~8-10 GB | 质量和显存的良好平衡 |
训练
请参考script/ReadMe.md
🔄 模型量化(可选)
对于显存有限的用户,可以创建模型的量化版本以降低内存需求:
# 创建AWQ 4位量化模型
python quantization/awq_quantize.py --model_path path/to/Step-Audio-EditX
# 高级量化选项
python quantization/awq_quantize.py
有关详细的量化选项和参数,请参阅quantization/README.md。
技术细节
 Step-Audio-EditX由三个主要组件组成:
Step-Audio-EditX由三个主要组件组成:
- 一个双码本音频分词器,用于将参考或输入音频转换成离散的标记。
- 一个音频LLM,用于生成双码本标记序列。
- 一个音频解码器,通过流匹配方法将音频LLM预测的双码本标记序列重新转换回音频波形。
Audio-Edit能够在所有语音中实现对情感和说话风格的迭代控制,这得益于在SFT和PPO训练过程中使用的大规模数据集。
评估
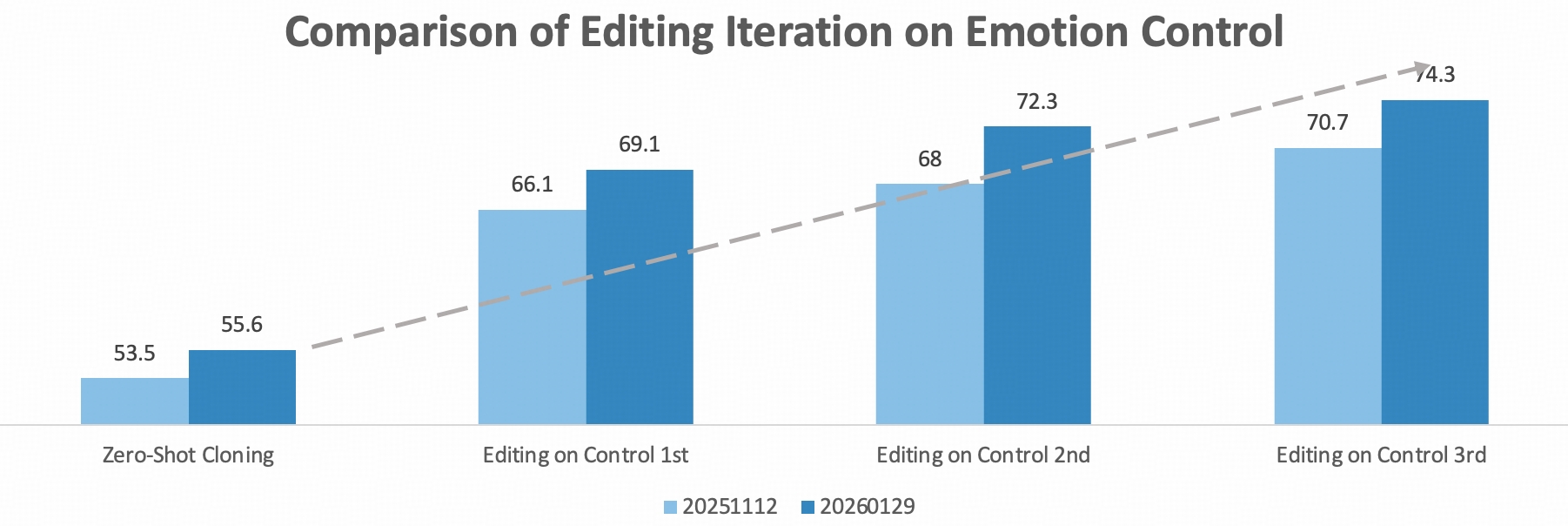
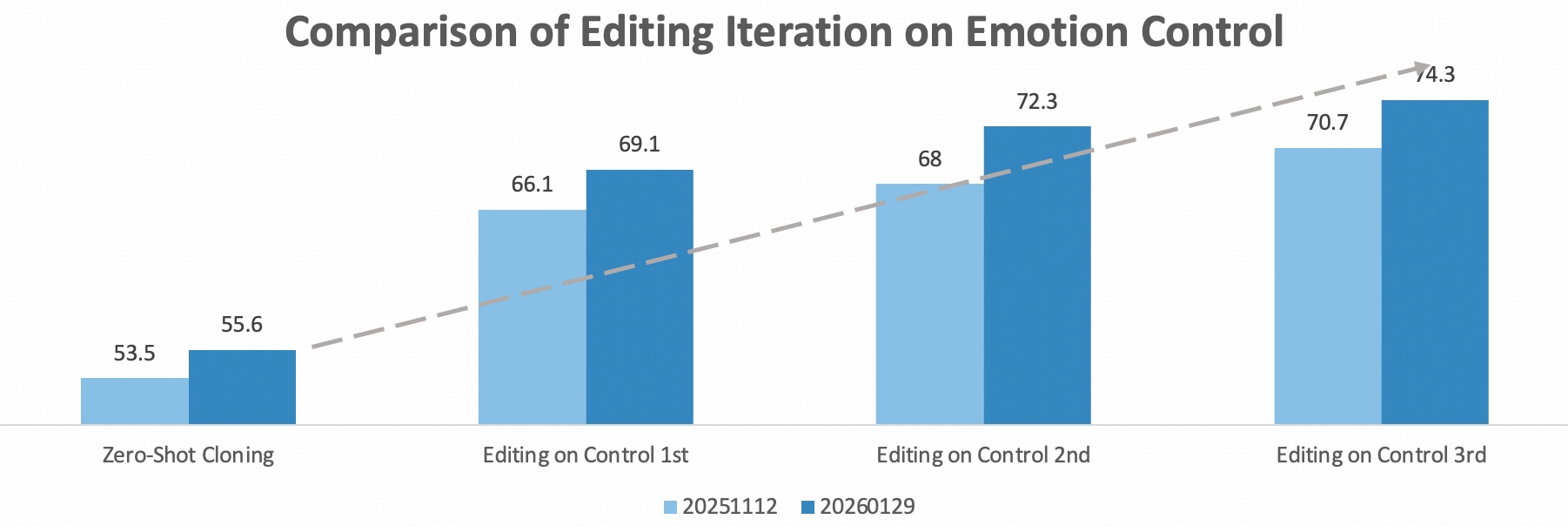
Step-Audio-EditX 与闭源模型的对比。
- 在零样本克隆和情感控制方面,Step-Audio-EditX 的表现均优于 Minimax 和 Doubao。
- 仅经过一轮迭代,Step-Audio-EditX 的情感编辑便显著提升了三款模型的情感可控音频输出质量。随着迭代次数的增加,其整体性能持续提升。
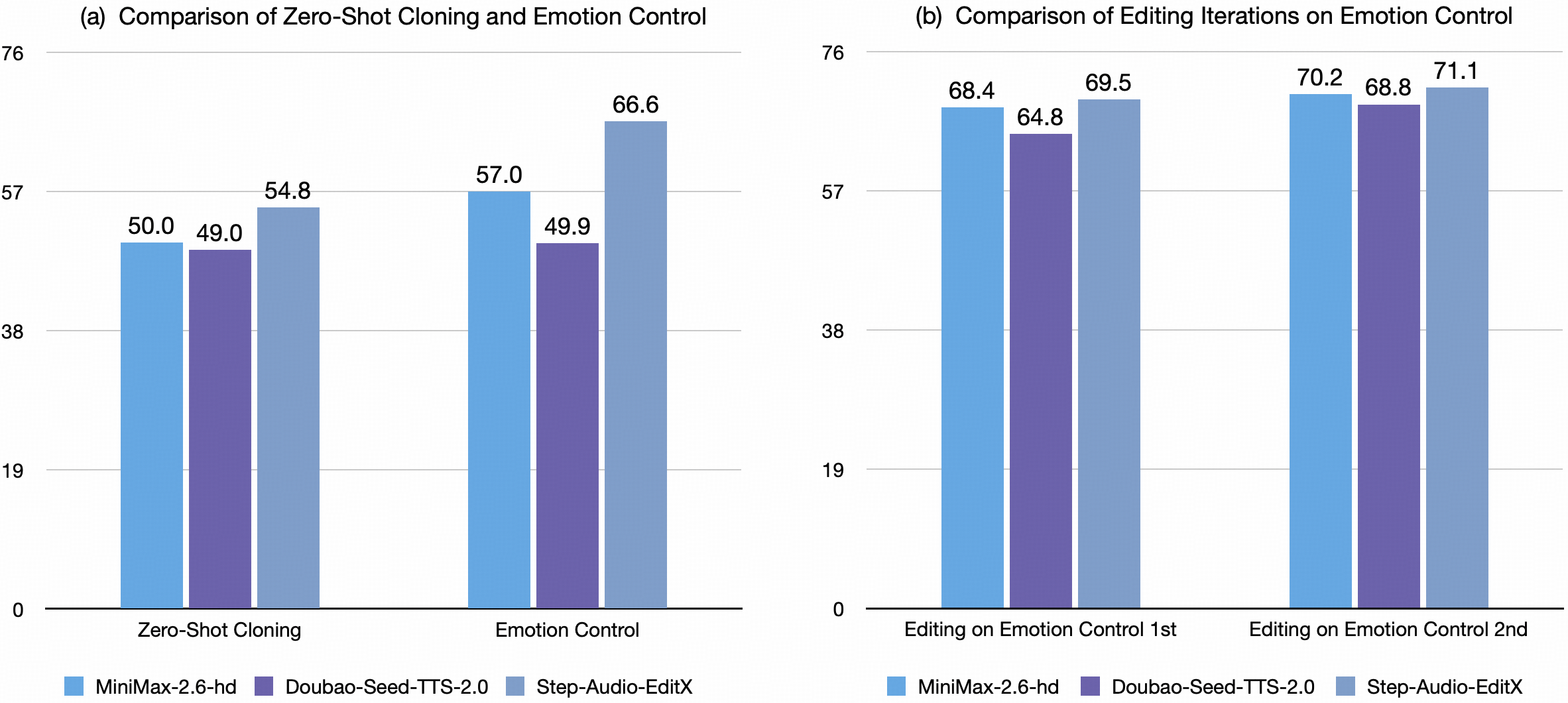
对闭源模型的泛化能力。
- 在情感和语调风格编辑方面,主流闭源系统的内置音色具备较强的上下文理解能力,能够在一定程度上传达文本中的情感。使用 Step-Audio-EditX 进行一轮编辑后,所有语音模型在情感和风格准确性上的表现均得到显著提升。随后的两轮迭代进一步优化了效果,充分证明了我们模型强大的泛化能力。
- 对于超语言特征编辑,经 Step-Audio-EditX 编辑后,其超语言特征的还原效果已可与闭源模型的内置音色直接合成原生超语言内容时的效果相媲美。(“sub” 表示用原生词汇替换超语言标记)
| 语言 | 模型 | 情感 ↑ | 语速风格 ↑ | 副语言 ↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Iter0 | Iter1 | Iter2 | Iter3 | Iter0 | Iter1 | Iter2 | Iter3 | Iter0 | sub | Iter1 | ||
| 中文 | MiniMax-2.6-hd | 71.6 | 78.6 | 81.2 | 83.4 | 1.73 | 2.80 | 2.90 | ||||
| Doubao-Seed-TTS-2.0 | 67.4 | 77.8 | 80.6 | 82.8 | 1.67 | 2.81 | 2.90 | |||||
| GPT-4o-mini-TTS | 62.6 | 76.0 | 77.0 | 81.8 | 1.71 | 2.88 | 2.93 | |||||
| ElevenLabs-v2 | 60.4 | 74.6 | 77.4 | 79.2 | 1.70 | 2.71 | 2.92 | |||||
| 英文 | MiniMax-2.6-hd | 55.0 | 64.0 | 64.2 | 66.4 | 1.72 | 2.87 | 2.88 | ||||
| Doubao-Seed-TTS-2.0 | 53.8 | 65.8 | 65.8 | 66.2 | 1.72 | 2.75 | 2.92 | |||||
| GPT-4o-mini-TTS | 56.8 | 61.4 | 64.8 | 65.2 | 1.90 | 2.90 | 2.88 | |||||
| ElevenLabs-v2 | 51.0 | 61.2 | 64.0 | 65.2 | 1.93 | 2.87 | 2.88 | |||||
| 平均 | MiniMax-2.6-hd | 63.3 | 71.3 | 72.7 | 74.9 | 44.2 | 59.6 | 62.7 | 65.8 | 1.73 | 2.84 | 2.89 |
| Doubao-Seed-TTS-2.0 | 60.6 | 71.8 | 73.2 | 74.5 | 42.6 | 61.1 | 63.9 | 63.6 | 1.70 | 2.78 | 2.91 | |
| GPT-4o-mini-TTS | 59.7 | 68.7 | 70.9 | 73.5 | 49.1 | 63.2 | 64.1 | 66.6 | 1.81 | 2.89 | 2.90 | |
| ElevenLabs-v2 | 55.7 | 67.9 | 70.7 | 72.2 | 47.4 | 62.7 | 66.1 | 67.4 | 1.82 | 2.79 | 2.90 | |
| 语言 | 模型 | 情感 ↑ | 语速风格 ↑ | 副语言 ↑ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Iter0 | Iter1 | Iter2 | Iter3 | Iter0 | Iter1 | Iter2 | Iter3 | Iter0 | Iter1 | ||
| 中文 | 20251112 | 57.0 | 71.7 | 74.5 | 77.7 | 41.6 | 62.1 | 65.8 | 69.2 | 1.80 | 2.89 |
| 20251128 | 58.7 | 73.6 | 75.1 | 77.8 | 40.4 | 62.1 | 65.3 | 68.0 | 1.80 | 2.89 | |
| 20260129 | 60.1 | 75.0 | 79.1 | 81.6 | 51.1 | 70.0 | 68.9 | 62.4 | 2.07 | 2.91 | |
| 英文 | 20251112 | 49.9 | 60.5 | 61.5 | 63.7 | 50.3 | 62.4 | 64.3 | 63.1 | 2.02 | 2.88 |
| 20251128 | 51.2 | 60.0 | 63.1 | 64.2 | 48.8 | 63.4 | 62.3 | 64.4 | 2.02 | 2.89 | |
| 20260129 | 51.0 | 63.1 | 65.5 | 67.0 | 43.3 | 60.4 | 66.5 | 69.6 | 2.18 | 2.93 | |
| 平均 | 20251112 | 53.5 | 66.1 | 68.0 | 70.7 | 46.0 | 62.3 | 65.1 | 66.2 | 1.91 | 2.89 |
| 20251128 | 55.0 | 66.8 | 69.1 | 71.0 | 44.6 | 62.8 | 63.8 | 66.2 | 1.91 | 2.89 | |
| 20260129 | 55.6 | 69.1 | 72.3 | 74.3 | 47.2 | 65.2 | 67.7 | 66.0 | 2.12 | 2.92 | |
致谢
本项目部分代码和数据来源于:
感谢所有开源项目对本项目的贡献!
许可协议
- 本开源仓库中的代码采用 Apache 2.0 许可证授权。
引用
@misc{yan2025stepaudioeditxtechnicalreport,
title={Step-Audio-EditX 技术报告},
author={Chao Yan 和 Boyong Wu 和 Peng Yang 和 Pengfei Tan 和 Guoqiang Hu 和 Yuxin Zhang 和 Xiangyu 和 Zhang 和 Fei Tian 和 Xuerui Yang 和 Xiangyu Zhang 和 Daxin Jiang 和 Gang Yu},
year={2025},
eprint={2511.03601},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2511.03601},
}
⚠️ 使用声明
- 请勿将本模型用于任何未经授权的活动,包括但不限于:
- 未经许可的语音克隆
- 冒充他人身份
- 欺诈行为
- 制作深度伪造内容或其他非法用途
- 使用本模型时,请确保遵守当地法律法规,并遵循相关伦理准则。
- 模型开发者对任何滥用或误用该技术的行为不承担任何责任。
我们倡导负责任的生成式人工智能研究,并呼吁社区在人工智能的开发与应用中坚持安全与伦理标准。如果您对使用本模型有任何疑虑,请随时与我们联系。
星标历史

常见问题
相似工具推荐
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
GPT-SoVITS
GPT-SoVITS 是一款强大的开源语音合成与声音克隆工具,旨在让用户仅需极少量的音频数据即可训练出高质量的个性化语音模型。它核心解决了传统语音合成技术依赖海量录音数据、门槛高且成本大的痛点,实现了“零样本”和“少样本”的快速建模:用户只需提供 5 秒参考音频即可即时生成语音,或使用 1 分钟数据进行微调,从而获得高度逼真且相似度极佳的声音效果。 该工具特别适合内容创作者、独立开发者、研究人员以及希望为角色配音的普通用户使用。其内置的友好 WebUI 界面集成了人声伴奏分离、自动数据集切片、中文语音识别及文本标注等辅助功能,极大地降低了数据准备和模型训练的技术门槛,让非专业人士也能轻松上手。 在技术亮点方面,GPT-SoVITS 不仅支持中、英、日、韩、粤语等多语言跨语种合成,还具备卓越的推理速度,在主流显卡上可实现实时甚至超实时的生成效率。无论是需要快速制作视频配音,还是进行多语言语音交互研究,GPT-SoVITS 都能以极低的数据成本提供专业级的语音合成体验。
MoneyPrinterTurbo
MoneyPrinterTurbo 是一款利用 AI 大模型技术,帮助用户一键生成高清短视频的开源工具。只需输入一个视频主题或关键词,它就能全自动完成从文案创作、素材匹配、字幕合成到背景音乐搭配的全过程,最终输出完整的竖屏或横屏短视频。 这款工具主要解决了传统视频制作流程繁琐、门槛高以及素材版权复杂等痛点。无论是需要快速产出内容的自媒体创作者,还是希望尝试视频生成的普通用户,无需具备专业的剪辑技能或昂贵的硬件配置(普通电脑即可运行),都能轻松上手。同时,其清晰的 MVC 架构和对多种主流大模型(如 DeepSeek、Moonshot、通义千问等)的广泛支持,也使其成为开发者进行二次开发或技术研究的理想底座。 MoneyPrinterTurbo 的独特亮点在于其高度的灵活性与本地化友好性。它不仅支持中英文双语及多种语音合成,允许用户精细调整字幕样式和画面比例,还特别优化了国内网络环境下的模型接入方案,让用户无需依赖 VPN 即可使用高性能国产大模型。此外,工具提供批量生成模式,可一次性产出多个版本供用户择优,极大地提升了内容创作的效率与质量。
oh-my-openagent
oh-my-openagent(简称 omo)是一款强大的开源智能体编排框架,前身名为 oh-my-opencode。它致力于打破单一模型供应商的生态壁垒,解决开发者在构建 AI 应用时面临的“厂商锁定”难题。不同于仅依赖特定模型的封闭方案,omo 倡导开放市场理念,支持灵活调度多种主流大模型:利用 Claude、Kimi 或 GLM 进行任务编排,调用 GPT 处理复杂推理,借助 Minimax 提升响应速度,或发挥 Gemini 的创意优势。 这款工具特别适合希望摆脱平台限制、追求极致性能与成本平衡的开发者及研究人员使用。通过统一接口,用户可以轻松组合不同模型的长处,构建更高效、更具适应性的智能体系统。其独特的技术亮点在于“全模型兼容”架构,让用户不再受制于某一家公司的策略变动或定价调整,真正实现对前沿模型资源的自由驾驭。无论是构建自动化编码助手,还是开发多步骤任务处理流程,oh-my-openagent 都能提供灵活且稳健的基础设施支持,助力用户在快速演进的 AI 生态中保持技术主动权。
TTS
🐸TTS 是一款功能强大的深度学习文本转语音(Text-to-Speech)开源库,旨在将文字自然流畅地转化为逼真的人声。它解决了传统语音合成技术中声音机械生硬、多语言支持不足以及定制门槛高等痛点,让高质量的语音生成变得触手可及。 无论是希望快速集成语音功能的开发者,还是致力于探索前沿算法的研究人员,亦或是需要定制专属声音的数据科学家,🐸TTS 都能提供得力支持。它不仅预置了覆盖全球 1100 多种语言的训练模型,让用户能够即刻上手,还提供了完善的工具链,支持用户利用自有数据训练新模型或对现有模型进行微调,轻松实现特定风格的声音克隆。 在技术亮点方面,🐸TTS 表现卓越。其最新的 ⓍTTSv2 模型支持 16 种语言,并在整体性能上大幅提升,实现了低于 200 毫秒的超低延迟流式输出,极大提升了实时交互体验。此外,它还无缝集成了 🐶Bark、🐢Tortoise 等社区热门模型,并支持调用上千个 Fairseq 模型,展现了极强的兼容性与扩展性。配合丰富的数据集分析与整理工具,🐸TTS 已成为科研与生产环境中备受信赖的语音合成解决方案。