summarize
Summarize 是一个开源的智能摘要工具,支持通过命令行(CLI)或浏览器扩展(Chrome 侧边栏 / Firefox 侧边栏)快速提取网页、PDF、视频、播客、YouTube 等内容的核心信息。它能自动识别内容类型——比如检测到 YouTube 视频时,会抓取幻灯片截图、结合 OCR 文字识别与字幕生成带时间戳的摘要卡片,并支持点击跳转播放位置。
Summarize 解决了用户面对大量文本或音视频内容时“抓不住重点”的问题,尤其适合需要高效获取信息但不想手动整理的场景。普通用户可通过浏览器一键总结当前页面;研究人员、学生或知识工作者能快速处理论文、讲座或播客;开发者则可利用其 CLI 灵活集成到工作流中。
技术上,它融合了多种能力:优先使用官方字幕,缺失时调用 Whisper、Gemini 或 OpenAI 等模型进行语音转写;支持本地、免费(如 OpenRouter)及付费模型;输出支持 Markdown、JSON 等格式,并具备缓存感知与成本估算。浏览器扩展依赖本地后台服务(daemon)处理 heavy lifting(如 ffmpeg、OCR),兼顾速度与隐私,所有通信仅限本机。
使用场景
一位高校研究生正在撰写文献综述,需要快速消化大量学术论文(PDF)、在线讲座视频(YouTube)和播客访谈内容。
没有 summarize 时
- 面对几十页的 PDF 论文,只能逐字阅读或手动高亮重点,耗时且容易遗漏核心结论。
- YouTube 上的技术讲座动辄一小时以上,没有字幕或幻灯片索引,回看查找关键观点极其低效。
- 播客访谈内容密集但无文字稿,无法快速定位专家提到的具体方法或数据。
- 不同来源的内容格式割裂,缺乏统一入口进行信息提炼,整理笔记过程繁琐混乱。
- 若想提取视频中的图表或公式,需手动截图+OCR,操作复杂且准确率低。
使用 summarize 后
- 在终端输入
summarize paper.pdf,几秒内获得结构化摘要,保留研究问题、方法与结论。 - 浏览 YouTube 讲座时打开 Chrome Side Panel,自动提取带时间戳的幻灯片卡片,点击即可跳转视频对应位置。
- 对播客链接执行
summarize https://example.podcast.mp3,自动调用本地 Whisper 模型生成文字摘要,关键论点一目了然。 - 无论网页、PDF、音频还是视频,均通过同一命令或侧边栏界面处理,输出统一为 Markdown,便于整合进笔记系统。
- 视频中的幻灯片经 OCR 识别后,公式与图表文字可直接复制,大幅提升信息复用效率。
summarize 将多模态内容转化为可检索、可交互的结构化知识,让研究者从“信息搬运”转向“深度思考”。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
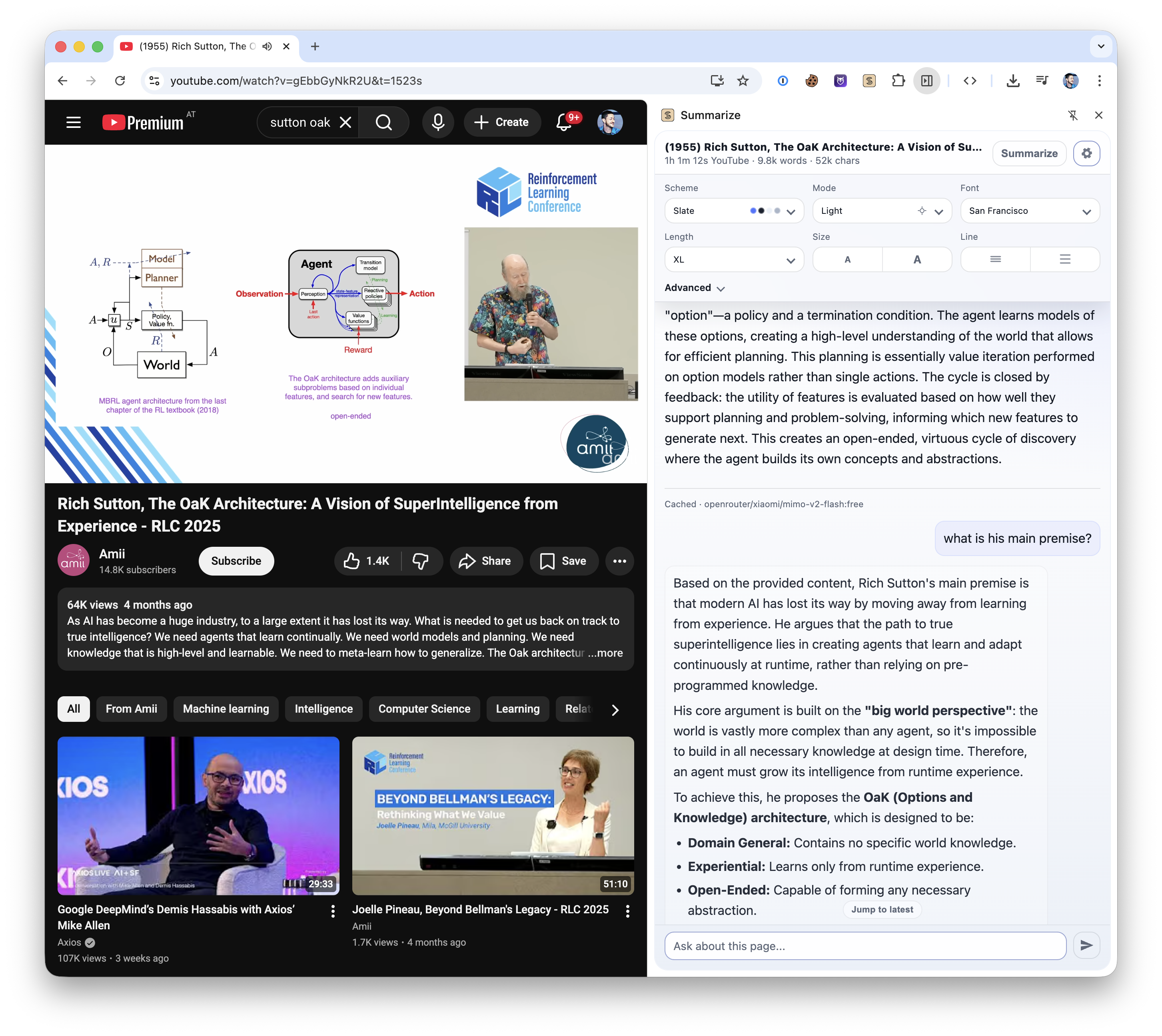
快速开始
Summarize 📝 — Chrome 侧边栏 + CLI
快速从 URL、文件和媒体中生成摘要。支持终端、Chrome 侧边栏(Side Panel)和 Firefox 侧边栏(Sidebar)。
亮点功能
- Chrome 侧边栏内置 聊天 功能(流式代理 + 历史记录)。
- YouTube 幻灯片:截图 + OCR(光学字符识别)+ 字幕卡片,带时间戳跳转,支持 OCR/字幕切换。
- 媒体感知摘要:自动检测视频/音频内容 vs 网页内容。
- 流式 Markdown 输出 + 指标 + 缓存状态提示。
- CLI 支持 URL、文件、播客、YouTube、音视频、PDF 等多种输入。
功能概览
- 支持多种输入源:网页、PDF、图片、音视频、YouTube、播客、RSS。
- 视频源(YouTube/直接媒体)的幻灯片提取,结合 OCR 与带时间戳的卡片。
- 优先使用已发布的字幕;若无,则回退至 Groq/ONNX/whisper.cpp/AssemblyAI/Gemini/OpenAI/FAL 进行转录。
- 流式输出,支持 Markdown 渲染、指标展示和缓存状态提示。
- 支持本地、付费和免费模型:兼容 OpenAI 的本地端点、付费服务商,以及 OpenRouter 提供的免费预设。
- 多种输出模式:Markdown/纯文本、JSON 诊断信息、仅提取内容、指标、耗时和成本估算。
- 智能默认行为:若内容长度小于请求的摘要长度,则直接返回原文(使用
--force-summary可强制摘要)。
获取扩展程序(推荐)
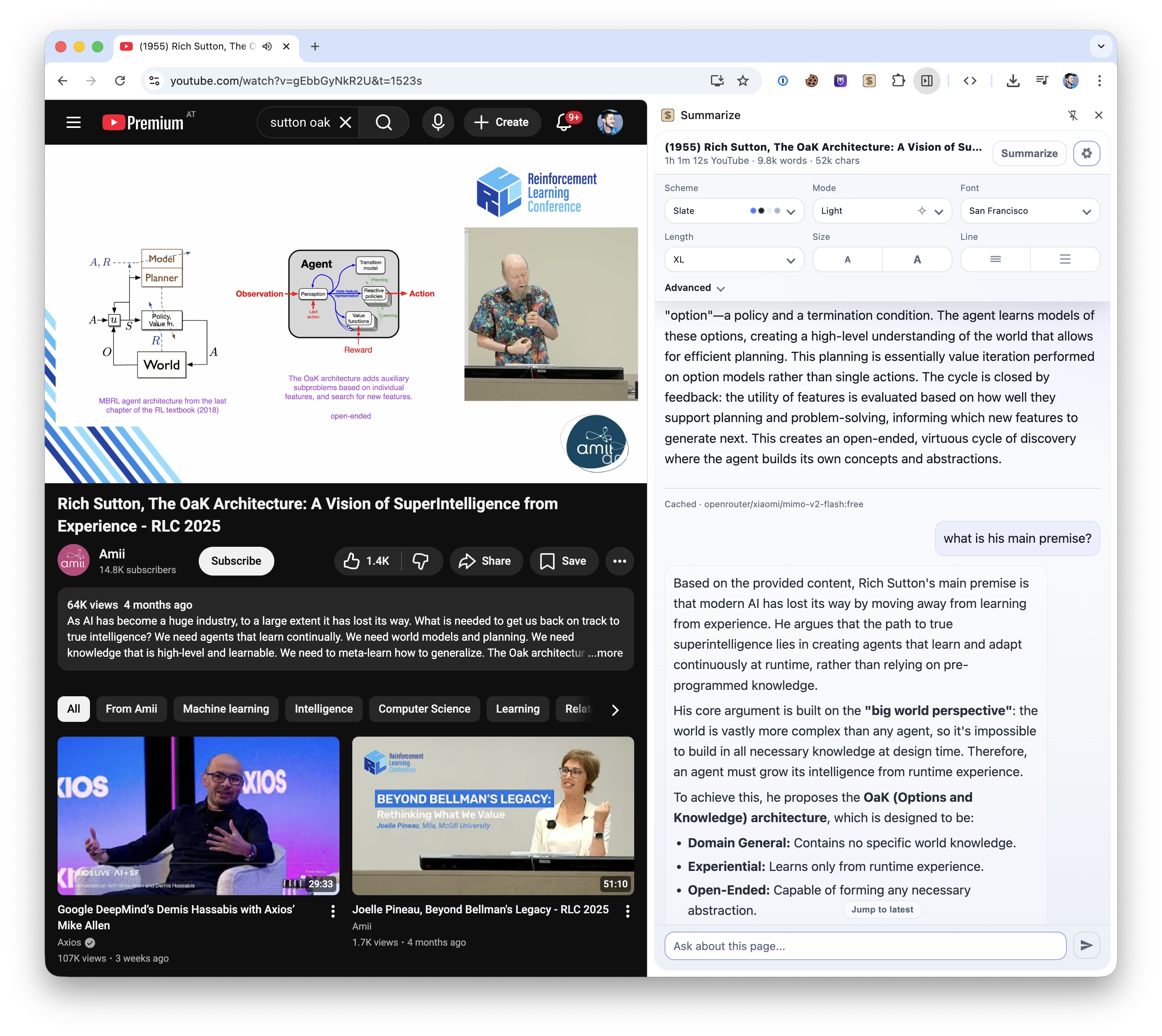
一键为当前标签页生成摘要。支持 Chrome 侧边栏、Firefox 侧边栏及本地守护进程(daemon),用于流式 Markdown 输出。
Chrome 网上应用店: Summarize Side Panel
浏览器中的 YouTube 幻灯片截图:
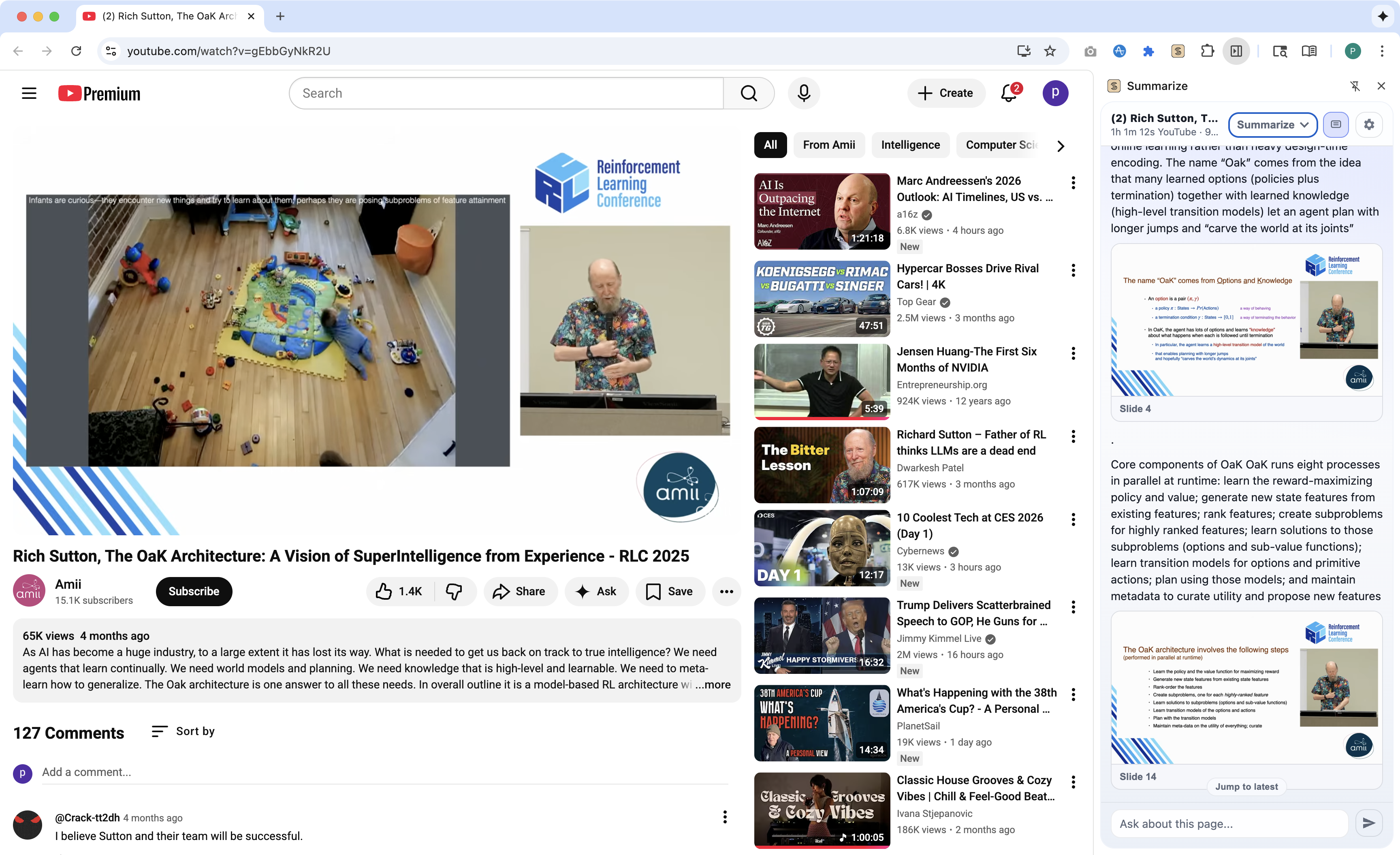
初学者快速入门(扩展程序)
- 安装 CLI(任选其一):
- npm(跨平台):
npm i -g @steipete/summarize - Homebrew(macOS arm64):
brew install steipete/tap/summarize
- npm(跨平台):
- 安装上述扩展程序,并打开侧边栏。
- 面板会显示一个 token 和安装命令。在终端中运行:
summarize daemon install --token <TOKEN>
为何需要守护进程(daemon)?
- 扩展程序无法在浏览器内执行重型提取任务。它通过本地后台服务(运行于
127.0.0.1)实现快速流式处理和媒体工具调用(如 yt-dlp、ffmpeg、OCR、转录)。 - 该服务会自动启动(通过 launchd/systemd/计划任务),确保侧边栏随时可用。
如果你只需要 CLI,完全可以跳过守护进程的安装。
注意事项:
- 摘要仅在侧边栏打开时运行。
- 自动模式会在页面导航时(包括 SPA)自动摘要;否则请手动点击按钮。
- 守护进程仅限本地回环地址(localhost),需共享 token;再次运行
summarize daemon install --token <TOKEN>会新增一个配对 token,而非使旧 token 失效。 - 自启机制:macOS(launchd)、Linux(systemd 用户级)、Windows(计划任务)。
- 提示:通过
summarize refresh-free配置free模型(需设置OPENROUTER_API_KEY)。添加--set-default可将模型设为free。
更多详情:
- 分步安装指南:apps/chrome-extension/README.md
- 架构与故障排查:docs/chrome-extension.md
- Firefox 兼容性说明:apps/chrome-extension/docs/firefox.md
幻灯片功能(扩展程序)
- 在 Summarize 选择器中选择 Video + Slides。
- 幻灯片显示在顶部;可展开为全宽卡片并附带时间戳。
- 点击幻灯片可跳转视频;当 OCR 内容显著时,可切换 Transcript/OCR。
- 依赖项:
yt-dlp+ffmpeg用于提取;tesseract用于 OCR。缺少工具时,面板内会显示提示。
高级用法(未打包 / 开发模式)
- 构建并加载扩展程序(未打包):
- Chrome:
pnpm -C apps/chrome-extension build- 访问
chrome://extensions→ 启用开发者模式 → 加载已解压的扩展程序 - 选择路径:
apps/chrome-extension/.output/chrome-mv3
- 访问
- Firefox:
pnpm -C apps/chrome-extension build:firefox- 访问
about:debugging#/runtime/this-firefox→ 加载临时附加组件 - 选择文件:
apps/chrome-extension/.output/firefox-mv3/manifest.json
- 访问
- Chrome:
- 打开侧边栏 → 复制 token。
- 以开发模式安装守护进程:
pnpm summarize daemon install --token <TOKEN> --dev
CLI
安装
需要 Node 22+。
- npx(无需安装):
npx -y @steipete/summarize "https://example.com"
- npm(全局安装):
npm i -g @steipete/summarize
- npm(作为库 / 最小依赖):
npm i @steipete/summarize-core
import { createLinkPreviewClient } from "@steipete/summarize-core/content";
- Homebrew(自定义 tap):
brew install steipete/tap/summarize
Homebrew 的可用性取决于当前 tap 中针对你架构的 formula。
如果在 Intel/x64 上 Homebrew 安装失败,请使用上方的 npm 全局安装方式。
可选的本地依赖
如需重度媒体功能,请安装以下工具:
ffmpeg:--slides及许多本地媒体/转录流程必需yt-dlp:YouTube 幻灯片提取及部分远程媒体流程必需tesseract:--slides-ocr的可选 OCR 工具- 可选的云端转录服务提供商:
GROQ_API_KEYASSEMBLYAI_API_KEYGEMINI_API_KEY/GOOGLE_GENERATIVE_AI_API_KEY/GOOGLE_API_KEYOPENAI_API_KEYFAL_KEY
macOS(通过 Homebrew):
brew install ffmpeg yt-dlp
brew install tesseract # 可选,用于 --slides-ocr
若启用 --slides 但缺少上述工具,Summarize 会发出警告并继续运行(不生成幻灯片)。
CLI 与扩展程序对比
- 仅 CLI:只需通过 npm/Homebrew 安装并运行
summarize ...(无需守护进程)。 - Chrome/Firefox 扩展程序:需安装 CLI 并运行
summarize daemon install --token <TOKEN>,以便侧边栏能流式接收结果并使用本地工具。
快速入门
summarize "https://example.com"
输入源
支持 URL 或本地路径:
summarize "/path/to/file.pdf" --model google/gemini-3-flash
summarize "https://example.com/report.pdf" --model google/gemini-3-flash
summarize "/path/to/audio.mp3"
summarize "/path/to/video.mp4"
标准输入(通过 - 管道传入内容):
echo "content" | summarize -
pbpaste | summarize -
二进制标准输入也支持(PDF/图像/音频/视频字节流)
cat /path/to/file.pdf | summarize -
注意事项:
- 标准输入(stdin)有 50MB 大小限制
-参数告诉summarize从标准输入读取内容- 文本标准输入被视为 UTF-8 文本(仅包含空白字符的输入会被视为为空而拒绝)
- 二进制标准输入会保留为原始字节,文件类型会在可能的情况下自动检测
- 适用于管道传递剪贴板内容或命令输出
YouTube(支持 youtube.com 和 youtu.be):
summarize "https://youtu.be/dQw4w9WgXcQ" --youtube auto
播客 RSS(转录最新一期的 enclosure):
summarize "https://feeds.npr.org/500005/podcast.xml"
Apple Podcasts 节目页面:
summarize "https://podcasts.apple.com/us/podcast/2424-jelly-roll/id360084272?i=1000740717432"
Spotify 节目页面(尽力而为;独家内容可能失败):
summarize "https://open.spotify.com/episode/5auotqWAXhhKyb9ymCuBJY"
输出长度
--length 控制我们请求的输出量(仅为指导值),并非硬性上限。
summarize "https://example.com" --length long
summarize "https://example.com" --length 20k
- 预设值:
short|medium|long|xl|xxl - 字符目标值:
1500、20k、20000 - 可选硬性上限:
--max-output-tokens <count>(例如2000、2k)- 提供商/模型 API 仍会强制执行其自身的最大输出限制。
- 如果省略,则不会发送最大 token 参数(使用提供商默认值)。
- 除非需要硬性上限,否则建议优先使用
--length。
- 短内容:当提取的内容比请求的长度更短时,CLI 会原样返回该内容。
- 使用
--force-summary可强制始终运行 LLM。
- 使用
- 最小值限制:
--length的数值必须 ≥ 50 个字符;--max-output-tokens必须 ≥ 16。 - 预设目标值(权威来源:
packages/core/src/prompts/summary-lengths.ts):- short: 目标约 900 字符(范围 600–1,200)
- medium: 目标约 1,800 字符(范围 1,200–2,500)
- long: 目标约 4,200 字符(范围 2,500–6,000)
- xl: 目标约 9,000 字符(范围 6,000–14,000)
- xxl: 目标约 17,000 字符(范围 14,000–22,000)
支持哪些文件类型?
尽力支持,具体取决于提供商。以下类型通常效果良好:
text/*及常见结构化文本(.txt、.md、.json、.yaml、.xml等)- 类文本文件会被内联到提示中,以提高与提供商的兼容性。
- PDF:
application/pdf(提供商支持情况各异;Google 在此最为可靠) - 图像:
image/jpeg、image/png、image/webp、image/gif - 音频/视频:
audio/*、video/*(本地音频/视频文件如 MP3/WAV/M4A/OGG/FLAC/MP4/MOV/WEBM 会在模型支持时自动转录)
注意事项:
- 如果提供商拒绝某种媒体类型,CLI 会快速失败并给出友好提示。
- xAI 模型不支持通过 AI SDK 附加通用文件(如 PDF);此类场景请使用 Google/OpenAI/Anthropic。
模型 ID
使用网关风格的 ID:<provider>/<model>。
示例:
openai/gpt-5-minianthropic/claude-sonnet-4-5xai/grok-4-fast-non-reasoninggoogle/gemini-3-flashzai/glm-4.7openrouter/openai/gpt-5-mini(强制使用 OpenRouter)
注意:某些模型/提供商不支持流式输出或特定文件媒体类型。发生这种情况时,CLI 会打印友好错误(或在提供商支持的情况下自动为该模型禁用流式输出)。
限制
- 超过 10 MB 的文本输入会在分词前被拒绝。
- 文本提示会通过 GPT 分词器预先检查是否超出模型输入限制(基于 LiteLLM 目录)。
常用标志
summarize <input> [flags]
使用 summarize --help 或 summarize help 查看完整帮助信息。
--model <provider/model>:指定使用的模型(默认为auto)--model auto:自动选择模型并启用备选方案(默认)--model <name>:使用配置中定义的模型(参见 Configuration)--timeout <duration>:超时时间,如30s、2m、5000ms(默认2m)--retries <count>:LLM 超时时的重试次数(默认1)--length short|medium|long|xl|xxl|s|m|l|<chars>--language, --lang <language>:输出语言(auto= 与源语言一致)--max-output-tokens <count>:LLM 输出 token 的硬性上限--cli [provider]:使用 CLI 提供商(--model cli/<provider>)。支持claude、gemini、codex、agent。若省略,则启用 CLI 并自动选择提供商。--stream auto|on|off:流式输出 LLM 结果(auto= 仅在 TTY 中启用;在--json模式下禁用)--plain:保留原始输出(不进行 ANSI/OSC Markdown 渲染)--no-color:禁用 ANSI 颜色--theme <name>:CLI 主题(aurora、ember、moss、mono)--format md|text:网站/文件内容格式(默认text)--markdown-mode off|auto|llm|readability:HTML → Markdown 转换模式(默认readability)--preprocess off|auto|always:控制uvx markitdown的使用(默认auto)- 安装
uvx:brew install uv(或 https://astral.sh/uv/)
- 安装
--extract:打印提取的内容并退出(仅适用于 URL;不支持标准输入-)- 已弃用的别名:
--extract-only
- 已弃用的别名:
--slides:为 YouTube/直接视频 URL 提取幻灯片,并在摘要叙述中内联渲染(在支持的终端中自动内联显示)--slides-ocr:对提取的幻灯片运行 OCR(需安装tesseract)--slides-dir <dir>:幻灯片图像的基础输出目录(默认./slides)--slides-scene-threshold <value>:场景检测阈值(0.1–1.0)--slides-max <count>:最多提取的幻灯片数量(默认6)--slides-min-duration <seconds>:幻灯片之间的最小间隔秒数--json:机器可读的输出,包含诊断信息、提示、metrics和可选摘要--verbose:在 stderr 输出调试/诊断信息--metrics off|on|detailed:指标输出(默认on)
编码 CLI(Codex、Claude、Gemini、Agent)
Summarize 可以使用常见的编码 CLI 作为本地模型后端:
codex->--cli codex/--model cli/codex/<model>claude->--cli claude/--model cli/claude/<model>gemini->--cli gemini/--model cli/gemini/<model>agent(Cursor Agent CLI)->--cli agent/--model cli/agent/<model>
要求:
- 二进制文件已安装并位于
PATH中(或设置CODEX_PATH、CLAUDE_PATH、GEMINI_PATH、AGENT_PATH) - 提供商已完成身份验证(
codex login、claude auth、gemini登录流程、agent login或CURSOR_API_KEY)
快速冒烟测试:
printf "Summarize CLI smoke input.\nOne short paragraph. Reply can be brief.\n" >/tmp/summarize-cli-smoke.txt
summarize --cli codex --plain --timeout 2m /tmp/summarize-cli-smoke.txt
summarize --cli claude --plain --timeout 2m /tmp/summarize-cli-smoke.txt
summarize --cli gemini --plain --timeout 2m /tmp/summarize-cli-smoke.txt
summarize --cli agent --plain --timeout 2m /tmp/summarize-cli-smoke.txt
设置显式的 CLI 白名单/顺序:
{
"cli": { "enabled": ["codex", "claude", "gemini", "agent"] }
}
配置隐式自动 CLI 回退:
{
"cli": {
"autoFallback": {
"enabled": true,
"onlyWhenNoApiKeys": true,
"order": ["claude", "gemini", "codex", "agent"]
}
}
}
更多详情:docs/cli.md
自动模型排序
--model auto 会根据内置规则(或你自定义的 model.rules 覆盖)构建候选尝试列表。
当满足以下任一条件时,CLI 尝试会被前置:
- 设置了
cli.enabled(显式白名单/顺序),或 - 启用了隐式自动选择且
cli.autoFallback已启用。
默认回退行为:仅在未配置任何 API 密钥时触发,顺序为 claude, gemini, codex, agent,并记住/优先使用上次成功的提供商(记录于 ~/.summarize/cli-state.json)。
设置显式的 CLI 尝试:
{
"cli": { "enabled": ["gemini"] }
}
禁用隐式自动 CLI 回退:
{
"cli": { "autoFallback": { "enabled": false } }
}
注意:显式使用 --model auto 不会触发隐式自动 CLI 回退,除非设置了 cli.enabled。
网站内容提取(Firecrawl + Markdown)
非 YouTube URL 会经过 fetch -> extract 流程。当直接抓取/提取被阻止或内容过少时,
若已配置,--firecrawl auto 会回退到 Firecrawl。
--firecrawl off|auto|always(默认auto)--extract --format md|text(默认text;若省略--format,则对非 YouTube URL 默认使用md)--markdown-mode off|auto|llm|readability(默认readability)auto:在配置了 LLM 转换器时使用;可能回退到uvx markitdownllm:强制使用 LLM 转换(需要配置模型密钥)off:禁用 LLM 转换(但若已配置 Firecrawl,仍可能返回其生成的 Markdown)
- 纯文本模式:使用
--format text。
YouTube 字幕转录
--youtube auto 首先尝试尽力而为的网页字幕端点。当字幕不可用时,会按以下顺序回退:
- Apify(若设置了
APIFY_API_TOKEN):使用爬虫 Actor (faVsWy9VTSNVIhWpR) - yt-dlp + Whisper(若
yt-dlp可用):下载音频,若已安装则使用本地whisper.cpp进行转录(优先),否则依次回退至 Groq (GROQ_API_KEY)、AssemblyAI (ASSEMBLYAI_API_KEY)、Gemini (GEMINI_API_KEY/ Google 别名)、OpenAI (OPENAI_API_KEY),最后是 FAL (FAL_KEY)
yt-dlp 模式环境变量:
YT_DLP_PATH- yt-dlp 二进制文件的可选路径(否则通过PATH解析)SUMMARIZE_WHISPER_CPP_MODEL_PATH- 本地whisper.cpp模型文件的可选覆盖路径SUMMARIZE_WHISPER_CPP_BINARY- 本地二进制文件的可选覆盖路径(默认:whisper-cli)SUMMARIZE_DISABLE_LOCAL_WHISPER_CPP=1- 禁用本地 whisper.cpp(强制使用远程服务)GROQ_API_KEY- Groq Whisper 转录ASSEMBLYAI_API_KEY- AssemblyAI 转录GEMINI_API_KEY- Gemini 转录(GOOGLE_GENERATIVE_AI_API_KEY/GOOGLE_API_KEY同样有效)OPENAI_API_KEY- OpenAI Whisper 转录OPENAI_WHISPER_BASE_URL- 可选的 OpenAI 兼容 Whisper 端点覆盖FAL_KEY- FAL AI Whisper 回退方案
Apify 需付费,但在字幕存在时通常更可靠。
幻灯片提取(YouTube + 直接视频链接)
提取幻灯片截图(通过 ffmpeg 进行场景检测)并可选 OCR:
依赖项:
ffmpeg:用于场景检测和帧提取yt-dlp:用于 YouTube 视频下载/流解析tesseract:仅在使用--slides-ocr时需要
summarize "https://www.youtube.com/watch?v=..." --slides
summarize "https://www.youtube.com/watch?v=..." --slides --slides-ocr
输出写入 ./slides/<sourceId>/(或通过 --slides-dir 指定)。OCR 结果包含在 JSON 输出中(--json),并存储在幻灯片目录内的 slides.json 文件中。当场景检测过于稀疏时,提取器还会以固定间隔采样以提高覆盖率。
使用 --slides 时,支持的终端(kitty/iTerm/Konsole)会在摘要叙述中自动渲染内联缩略图(模型插入 [slide:N] 标记)。当终端支持 OSC-8 时,时间戳链接可点击(适用于 YouTube/Vimeo/Loom/Dropbox)。若不支持内联图像,Summarize 会打印一条提示,说明磁盘上的幻灯片目录位置。
使用 --slides --extract 可打印完整的时间戳转录,并在匹配的时间点内联插入幻灯片图像。
通过 LLM 将提取的转录格式化为 Markdown(标题 + 段落):
summarize "https://www.youtube.com/watch?v=..." --extract --format md --markdown-mode llm
媒体转录(Whisper)
本地音视频文件会先进行转录,再进行摘要。--video-mode transcript 强制将直接媒体 URL(及嵌入媒体)先通过 Whisper 处理。优先使用本地 whisper.cpp(若可用);否则需要配置以下任一密钥:GROQ_API_KEY、ASSEMBLYAI_API_KEY、GEMINI_API_KEY(或 Google 别名)、OPENAI_API_KEY 或 FAL_KEY。
本地 ONNX 转录(Parakeet/Canary)
Summarize 可通过你提供的本地 CLI 使用 NVIDIA Parakeet/Canary ONNX 模型。自动选择(默认)在配置后优先使用 ONNX。
- 设置助手:
summarize transcriber setup - 从上游二进制文件/构建安装
sherpa-onnx(Homebrew 可能没有公式) - 自动选择:设置
SUMMARIZE_ONNX_PARAKEET_CMD或SUMMARIZE_ONNX_CANARY_CMD(无需额外标志) - 强制指定模型:
--transcriber parakeet|canary|whisper|auto - 文档:
docs/nvidia-onnx-transcription.md
已验证的播客服务(截至 2025-12-25)
运行:summarize <url>
- Apple Podcasts
- Spotify
- Amazon Music / Audible 播客页面
- Podbean
- Podchaser
- RSS 订阅源(若有 Podcasting 2.0 转录则优先使用)
- 嵌入式 YouTube 播客页面(例如 JREPodcast)
转录:若已安装,优先使用本地 whisper.cpp;否则在设置了密钥的情况下,依次使用 Groq、AssemblyAI、Gemini、OpenAI 或 FAL。
翻译路径
--language/--lang 控制摘要(及其他 LLM 生成文本)的输出语言,默认为 auto。
当输入为音频/视频时,CLI 需要先获取转录文本。转录文本来自以下路径之一:
- 已有转录文本(优先)
- YouTube:在可用时使用
youtubei/captionTracks。 - 播客(Podcasts):当 RSS 订阅源发布时,使用 Podcasting 2.0 标准中的
<podcast:transcript>(JSON/VTT 格式)。
- YouTube:在可用时使用
- Whisper 转录(后备方案)
- YouTube:在配置后,若无现成字幕,则回退到 yt-dlp(音频下载)+ Whisper 转录;Apify 是最后的选择。
- 若已安装本地
whisper.cpp且模型可用,则优先使用。 - 否则按以下顺序使用云端转录服务:Groq (
GROQ_API_KEY) → AssemblyAI (ASSEMBLYAI_API_KEY) → Gemini (GEMINI_API_KEY或 Google 别名) → OpenAI (OPENAI_API_KEY) → FAL (FAL_KEY)。
对于直接媒体 URL,可使用 --video-mode transcript 强制执行“转录 → 摘要”流程:
summarize https://example.com/file.mp4 --video-mode transcript --lang en
配置
单一配置位置:
~/.summarize/config.json
当前支持的键:
{
"model": { "id": "openai/gpt-5-mini" },
"env": { "OPENAI_API_KEY": "sk-..." },
"ui": { "theme": "ember" }
}
简写形式(等效):
{
"model": "openai/gpt-5-mini"
}
其他支持项:
model: { "mode": "auto" }(自动选择模型并回退;详见 docs/model-auto.md)model.rules(自定义候选模型及排序)models(定义可通过--model <preset>选择的预设)env(通用环境变量默认值;进程环境变量仍优先)apiKeys(旧版快捷方式,映射为环境变量名;新配置建议使用env)cache.media(媒体下载缓存:默认 TTL 7 天,上限 2048 MB;--no-media-cache可禁用)media.videoMode: "auto"|"transcript"|"understand"slides.enabled/slides.max/slides.ocr/slides.dir(--slides的默认值)ui.theme: "aurora"|"ember"|"moss"|"mono"openai.useChatCompletions: true(强制使用 OpenAI 兼容的聊天补全接口)
注意:配置文件采用宽松解析(JSON5),但不允许注释。未知键将被忽略。
媒体缓存默认值:
{
"cache": {
"media": { "enabled": true, "ttlDays": 7, "maxMb": 2048, "verify": "size" }
}
}
注意:--no-cache 仅跳过摘要缓存(LLM 输出),提取/转录缓存仍生效。使用 --no-media-cache 可跳过媒体文件缓存。
模型优先级顺序:
--modelSUMMARIZE_MODEL~/.summarize/config.json- 默认值 (
auto)
主题(theme)优先级顺序:
--themeSUMMARIZE_THEME~/.summarize/config.json(ui.theme)- 默认值 (
aurora)
环境变量优先级顺序:
- 进程环境变量
~/.summarize/config.json(env)~/.summarize/config.json(apiKeys,旧版)
环境变量
设置与所选 --model 对应的密钥:
可选的回退默认值可存储在配置中:
~/.summarize/config.json→"env": { "OPENAI_API_KEY": "sk-..." }- 进程环境变量始终优先
- 旧版
"apiKeys"仍有效(映射为环境变量名)
OPENAI_API_KEY(用于openai/...)NVIDIA_API_KEY(用于nvidia/...)ANTHROPIC_API_KEY(用于anthropic/...)XAI_API_KEY(用于xai/...)Z_AI_API_KEY(用于zai/...;支持别名ZAI_API_KEY)GEMINI_API_KEY(用于google/...)- 同时接受别名
GOOGLE_GENERATIVE_AI_API_KEY和GOOGLE_API_KEY
- 同时接受别名
OpenAI 兼容聊天补全开关:
OPENAI_USE_CHAT_COMPLETIONS=1(或在配置中设置openai.useChatCompletions)
UI 主题:
SUMMARIZE_THEME=aurora|ember|moss|monoSUMMARIZE_TRUECOLOR=1(强制启用 24-bit ANSI)SUMMARIZE_NO_TRUECOLOR=1(禁用 24-bit ANSI)
OpenRouter(OpenAI 兼容):
- 设置
OPENROUTER_API_KEY=... - 建议通过模型 ID 显式指定 OpenRouter:
--model openrouter/<author>/<slug> - 内置预设:
--model free(使用一组默认的 OpenRouter:free模型)
summarize refresh-free
快速开始:将 free 设为默认(同时保留 auto 可用)
summarize refresh-free --set-default
summarize "https://example.com"
summarize "https://example.com" --model auto
该命令会重新生成 free 预设(即 ~/.summarize/config.json 中的 models.free),具体步骤如下:
- 获取 OpenRouter
/models接口数据,筛选出:free模型 - 默认跳过明显较小的模型(根据模型 ID/名称推断参数量 <27B)
- 并发测试(并发数 4,超时 10 秒)哪些模型能返回非空文本
- 混合选择“较智能”(上下文长度/输出上限更大)和“较快”的模型
- 优化响应时间并写回排序后的列表
如果 --model free 停止工作,请运行:
summarize refresh-free
参数说明:
--runs 2(默认):对每个选定模型额外进行 N 次计时测试(总次数 = 1 + runs)--smart 3(默认):优先选择多少个“较智能”的模型(其余由最快模型填充)--min-params 27b(默认):忽略推断参数量小于 N 十亿的模型--max-age-days 180(默认):忽略超过 N 天未更新的模型(设为 0 可禁用)--set-default:同时在~/.summarize/config.json中设置"model": "free"
示例:
OPENROUTER_API_KEY=sk-or-... summarize "https://example.com" --model openrouter/meta-llama/llama-3.1-8b-instruct:free
OPENROUTER_API_KEY=sk-or-... summarize "https://example.com" --model openrouter/minimax/minimax-m2.5
如果你的 OpenRouter 账户设置了允许的提供商列表,请确保所选模型至少有一个提供商被允许。路由失败时,summarize 会打印出需要允许的具体提供商。
旧版兼容:设置 OPENAI_BASE_URL=https://openrouter.ai/api/v1(并提供 OPENAI_API_KEY 或 OPENROUTER_API_KEY)也可工作。
NVIDIA API Catalog(OpenAI 兼容;提供免费额度):
- 设置
NVIDIA_API_KEY=... - 可选:
NVIDIA_BASE_URL=https://integrate.api.nvidia.com/v1 - 免费额度:注册后 API Catalog 试用账户初始赠送 1000 点免费 API 积分(通过 API Catalog 个人资料页的 “Request More” 最多可增至 5000 点)
- 从
/v1/models中选择模型 ID(例如:快速模型stepfun-ai/step-3.5-flash,较强但较慢的z-ai/glm5)
export NVIDIA_API_KEY="nvapi-..."
summarize "https://example.com" --model nvidia/stepfun-ai/step-3.5-flash
Z.AI(OpenAI 兼容):
Z_AI_API_KEY=...(或ZAI_API_KEY=...)- 可选基础 URL 覆盖:
Z_AI_BASE_URL=...
可选服务:
FIRECRAWL_API_KEY(网站内容提取后备)YT_DLP_PATH(用于音频提取的 yt-dlp 二进制路径)GROQ_API_KEY(Groq Whisper 转录)ASSEMBLYAI_API_KEY(AssemblyAI 转录)GEMINI_API_KEY/GOOGLE_GENERATIVE_AI_API_KEY/GOOGLE_API_KEY(Gemini 转录)OPENAI_API_KEY/OPENAI_WHISPER_BASE_URL(OpenAI Whisper 转录)FAL_KEY(通过 FAL AI API 使用 Whisper 进行音频转录)APIFY_API_TOKEN(YouTube 转录后备)
模型限制(Model limits)
CLI 使用 LiteLLM 模型目录来获取模型限制(例如最大输出 token 数):
- 下载自:
https://raw.githubusercontent.com/BerriAI/litellm/main/model_prices_and_context_window.json - 缓存位置:
~/.summarize/cache/
库的使用方式(可选)
推荐(依赖最少):
@steipete/summarize-core/content@steipete/summarize-core/prompts
兼容性版本(会引入 CLI 的依赖):
@steipete/summarize/content@steipete/summarize/prompts
开发
pnpm install
pnpm check
更多内容
- 文档索引:docs/README.md
- CLI 提供商与配置:docs/cli.md
- 自动模型规则:docs/model-auto.md
- 网站内容提取:docs/website.md
- YouTube 处理:docs/youtube.md
- 媒体处理流水线:docs/media.md
- 配置结构与优先级:docs/config.md
故障排查
- “Receiving end does not exist”(接收端不存在):Chrome 尚未注入内容脚本(content script)。
- 扩展详情 -> 站点访问权限 -> 设置为“在所有站点上”(或允许当前域名)
- 刷新一次页面标签页。
- “Failed to fetch”(获取失败)/ 守护进程(daemon)不可达:
- 执行命令:
summarize daemon status - 日志位置:
~/.summarize/logs/daemon.err.log
- 执行命令:
许可证:MIT
版本历史
v0.12.02026/03/12v0.11.12026/02/14v0.10.02026/01/22v0.9.02025/12/31v0.8.22025/12/28v0.7.12025/12/26v0.6.12025/12/25v0.6.02025/12/25v0.5.02025/12/24v0.4.02025/12/21v0.3.02025/12/20v0.2.02025/12/20v0.1.22025/12/19v0.1.12025/12/19v0.1.02025/12/19常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。