storm
STORM 是一款由斯坦福大学研发的智能知识整理系统,能够像人类研究员一样,基于互联网搜索自动撰写带有引用来源的长篇专题报告。它主要解决了用户在面对海量信息时,难以高效完成深度调研、梳理逻辑框架及核实出处的痛点,将繁琐的资料搜集与初稿撰写过程自动化。
该系统特别适合需要快速掌握陌生领域全貌的研究人员、学生、内容创作者,以及希望构建定制化知识引擎的开发者使用。对于普通用户,它能提供结构清晰的百科式文章;对于开发者,其模块化的 Python 包支持灵活接入不同的语言模型和检索源。
STORM 的核心技术亮点在于其独特的“多视角提问”机制。不同于直接让大模型生成内容,STORM 会在预写作阶段模拟不同专家的视角,主动提出一系列深入且广泛的问题,并通过搜索引擎获取答案,从而构建出逻辑严密的详细大纲。在此基础上,系统再结合收集到的参考文献生成最终报告。此外,最新升级的 Co-STORM 版本还引入了人机协作模式,允许用户在调研过程中介入引导,使生成的内容更符合特定需求。无论是作为个人研究助手,还是作为二次开发的基础设施,STORM 都展现了强大的知识合成能力。
使用场景
某科技公司的行业分析师需要在两天内完成一份关于“固态电池技术突破与商业化路径”的深度调研报告,以供高层战略会议使用。
没有 storm 时
- 信息搜集碎片化:分析师需手动在多个搜索引擎和学术库中反复切换关键词,耗时数小时才能拼凑出零散的文献列表,极易遗漏关键视角。
- 大纲构建困难:面对海量杂乱信息,难以快速梳理出逻辑严密的多维度大纲,往往陷入“只见树木不见森林”的困境,导致报告结构松散。
- 引用核对繁琐:人工整理参考文献和对应引注极易出错,花费大量时间核对来源真实性,且容易因疲劳产生幻觉或张冠李戴。
- 视角单一局限:受限于个人知识边界,报告往往缺乏跨学科或多利益相关方(如政策、供应链、技术瓶颈)的深度追问,内容深度不足。
使用 storm 后
- 自动化全景调研:storm 自动基于互联网进行多轮检索,模拟不同专家视角主动提问,迅速覆盖技术原理、市场障碍及政策环境等全方位信息。
- 智能生成结构化大纲:系统先通过“预写作阶段”生成逻辑清晰的多级大纲,确保报告骨架严谨,分析师只需微调即可锁定核心叙事线。
- 一键生成带引注长文:storm 直接输出包含准确 citations 的完整长篇报告,所有论据均自动关联原始来源,大幅降低事实核查成本。
- 深度与广度兼备:借助多视角问答机制,报告自然融入了原本容易被忽视的边缘视角,显著提升了内容的专业深度和决策参考价值。
storm 将原本需要数天的人工调研与撰写过程压缩至小时级,让分析师从繁琐的信息搬运工转型为高价值的策略洞察者。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始
![]()
STORM:基于检索与多视角提问的主题大纲生成
| 研究预览 | STORM论文| Co-STORM论文 | 官网 |
**最新消息** 🔥[2025/01] 我们在
knowledge-stormv1.1.0中加入了对语言模型和嵌入模型的litellm(https://github.com/BerriAI/litellm)集成。[2024/09] Co-STORM代码库现已发布,并整合到
knowledge-stormPython包v1.0.0中。运行pip install knowledge-storm --upgrade即可体验。[2024/09] 我们推出了协作式STORM(Co-STORM),以支持人机协同的知识整理!Co-STORM论文已被EMNLP 2024主会接收。
[2024/07] 现在您可以通过
pip install knowledge-storm安装我们的软件包![2024/07] 我们新增了
VectorRM,用于支持基于用户提供的文档进行知识增强,补充了现有的搜索引擎支持(YouRM、BingSearch)。(参见#58)[2024/07] 我们发布了面向开发者的轻量级演示版——一个基于Python Streamlit框架构建的极简用户界面,便于本地开发和演示部署。(参见#54)
[2024/06] 我们将在NAACL 2024上展示STORM!请于6月17日莅临海报展示环节2,或查看我们的演示材料。
[2024/05] 我们在rm.py中增加了必应搜索支持。使用
GPT-4o测试STORM——我们现在已将演示中的文章生成部分配置为使用GPT-4o模型。[2024/04] 我们发布了重构后的STORM代码库!我们定义了STORM流水线的接口,并重新实现了STORM-wiki(参见
src/storm_wiki),以展示如何实例化该流水线。我们提供了API,支持自定义不同的语言模型以及检索/搜索集成。
![]()
概述 (立即试用STORM!)

尽管该系统目前还无法生成可以直接发表的文章——这类文章通常需要大量编辑——但经验丰富的维基百科编辑认为它在写作前的准备阶段非常有帮助。
已有超过7万人试用了我们的在线研究预览。快来体验STORM如何助力您的知识探索之旅,并欢迎提供反馈以帮助我们改进系统 🙏!
STORM与Co-STORM的工作原理
STORM
STORM将带有引用的长篇文章生成过程分解为两个步骤:
- 写作准备阶段:系统通过互联网调研收集参考资料,并生成文章大纲。
- 写作阶段:系统利用大纲和参考资料生成包含引用的完整文章。
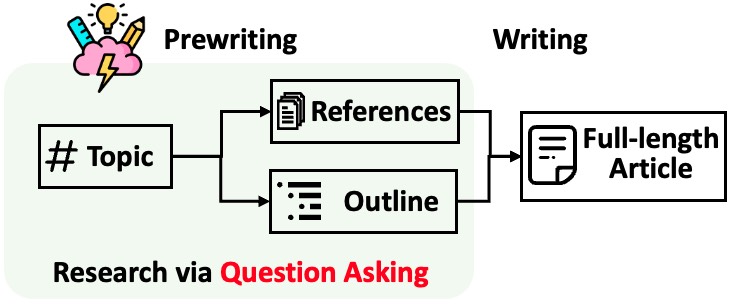
STORM认为,自动化研究过程的核心在于能够自动提出高质量的问题。直接让语言模型提问效果并不理想。为了提升问题的深度和广度,STORM采用了两种策略:
- 视角引导式提问:给定输入主题后,STORM会通过调研类似主题的现有文章来发现不同视角,并利用这些视角来指导提问过程。
- 模拟对话:STORM模拟一位维基百科作者与基于互联网资源的主题专家之间的对话,使语言模型能够不断更新对主题的理解,并提出后续问题。
CO-STORM
Co-STORM提出了一种协作式话语协议,通过实施轮次管理策略来支持以下角色之间的顺畅协作:
- Co-STORM LLM专家:此类代理会基于外部知识源生成答案,或根据对话历史提出后续问题。
- 主持人:该代理会根据检索器发现但尚未在先前轮次中使用的信息,生成具有启发性的提问。问题生成也可以基于知识来源。
- 人类用户:人类用户可以选择(1)观察对话以更深入地理解主题,或(2)主动参与对话,通过插入话语来引导讨论方向。
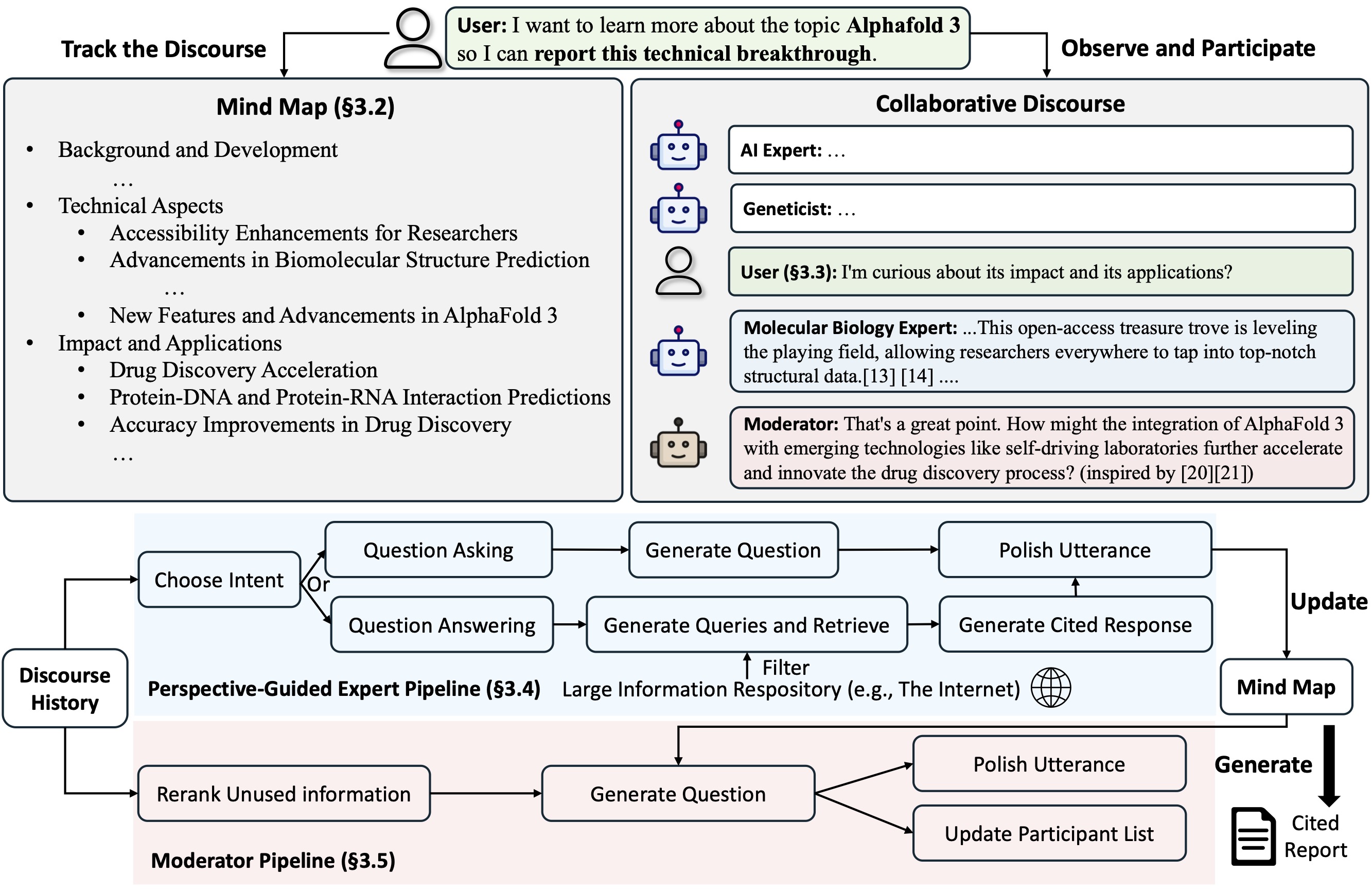
Co-STORM还会维护一张动态更新的思维导图,将收集到的信息组织成层次化的概念结构,旨在在人类用户和系统之间构建共享的概念空间。实践证明,当对话持续且深入时,思维导图有助于减轻认知负担。
STORM和Co-STORM均采用高度模块化的方式实现,使用了dspy框架。
安装
要安装knowledge storm库,请使用pip install knowledge-storm。
您也可以安装源代码,以便直接修改STORM引擎的行为。
克隆Git仓库。
git clone https://github.com/stanford-oval/storm.git cd storm安装所需依赖。
conda create -n storm python=3.11 conda activate storm pip install -r requirements.txt
API
目前,我们的软件包支持:
- 语言模型组件:所有由 litellm 支持的语言模型,详见 这里
- 嵌入模型组件:所有由 litellm 支持的嵌入模型,详见 这里
- 检索模块组件:
YouRM、BingSearch、VectorRM、SerperRM、BraveRM、SearXNG、DuckDuckGoSearchRM、TavilySearchRM、GoogleSearch和AzureAISearch等
:star2: 欢迎为将更多搜索引擎/检索器集成到 knowledge_storm/rm.py 中提交 PR!
STORM 和 Co-STORM 都工作在信息整理层,您需要分别设置信息检索模块和语言模型模块来创建它们的 Runner 类。
STORM
STORM 知识整理引擎被定义为一个简单的 Python STORMWikiRunner 类。以下是一个使用 You.com 搜索引擎和 OpenAI 模型的示例。
import os
from knowledge_storm import STORMWikiRunnerArguments, STORMWikiRunner, STORMWikiLMConfigs
from knowledge_storm.lm import LitellmModel
from knowledge_storm.rm import YouRM
lm_configs = STORMWikiLMConfigs()
openai_kwargs = {
'api_key': os.getenv("OPENAI_API_KEY"),
'temperature': 1.0,
'top_p': 0.9,
}
# STORM 是一个 LM 系统,因此不同的组件可以由不同的模型驱动,以在成本和质量之间取得良好平衡。
# 为了最佳实践,为用于拆分查询、在对话中综合答案的 `conv_simulator_lm` 选择更便宜/更快的模型。
# 为用于生成带有引用的可验证文本的 `article_gen_lm` 选择更强大的模型。
gpt_35 = LitellmModel(model='gpt-3.5-turbo', max_tokens=500, **openai_kwargs)
gpt_4 = LitellmModel(model='gpt-4o', max_tokens=3000, **openai_kwargs)
lm_configs.set_conv_simulator_lm(gpt_35)
lm_configs.set_question_asker_lm(gpt_35)
lm_configs.set_outline_gen_lm(gpt_4)
lm_configs.set_article_gen_lm(gpt_4)
lm_configs.set_article_polish_lm(gpt_4)
# 更多配置请参阅 STORMWikiRunnerArguments 类。
engine_args = STORMWikiRunnerArguments(...)
rm = YouRM(ydc_api_key=os.getenv('YDC_API_KEY'), k=engine_args.search_top_k)
runner = STORMWikiRunner(engine_args, lm_configs, rm)
可以通过简单的 run 方法调用 STORMWikiRunner 实例:
topic = input('主题: ')
runner.run(
topic=topic,
do_research=True,
do_generate_outline=True,
do_generate_article=True,
do_polish_article=True,
)
runner.post_run()
runner.summary()
do_research: 如果为 True,则模拟与不同观点的对话以收集关于该主题的信息;否则加载已有的结果。do_generate_outline: 如果为 True,则为该主题生成大纲;否则加载已有的结果。do_generate_article: 如果为 True,则根据大纲和收集到的信息生成该主题的文章;否则加载已有的结果。do_polish_article: 如果为 True,则通过添加总结部分并(可选)去除重复内容来润色文章;否则加载已有的结果。
Co-STORM
Co-STORM 知识整理引擎被定义为一个简单的 Python CoStormRunner 类。以下是一个使用 Bing 搜索引擎和 OpenAI 模型的示例。
from knowledge_storm.collaborative_storm.engine import CollaborativeStormLMConfigs, RunnerArgument, CoStormRunner
from knowledge_storm.lm import LitellmModel
from knowledge_storm.logging_wrapper import LoggingWrapper
from knowledge_storm.rm import BingSearch
# Co-STORM 采用与 STORM 相同的多 LM 系统范式
lm_config: CollaborativeStormLMConfigs = CollaborativeStormLMConfigs()
openai_kwargs = {
"api_key": os.getenv("OPENAI_API_KEY"),
"api_provider": "openai",
"temperature": 1.0,
"top_p": 0.9,
"api_base": None,
}
question_answering_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=1000, **openai_kwargs)
discourse_manage_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=500, **openai_kwargs)
utterance_polishing_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=2000, **openai_kwargs)
warmstart_outline_gen_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=500, **openai_kwargs)
question_asking_lm = LitellmModel(model=gpt_4o_model_name, max tokens=300, **openai_kwargs)
knowledge_base_lm = LitellmModel(model=gpt_4o_model_name, max tokens=1000, **openai_kwargs)
lm_config.set_question_answering_lm(question_answering_lm)
lm_config.set_discourse_manage_lm(discourse_manage_lm)
lm_config.set_utterance_polishing_lm(utterance_polishing_lm)
lm_config.set_warmstart_outline_gen_lm(warmstart_outline_gen_lm)
lm_config.set_question_asking_lm(question_asking_lm)
lm_config.set_knowledge_base_lm(knowledge_base_lm)
# 更多配置请参阅 Co-STORM 的 RunnerArguments 类。
topic = input('主题: ')
runner_argument = RunnerArgument(topic=topic, ...)
logging_wrapper = LoggingWrapper(lm_config)
bing_rm = BingSearch(bing_search_api_key=os.environ.get("BING_SEARCH_API_KEY"),
k=runner_argument.retrieve_top_k)
costorm_runner = CoStormRunner(lm_config=lm_config,
runner_argument=runner_argument,
logging_wrapper=logging_wrapper,
rm=bing_rm)
可以通过 warmstart() 和 step(...) 方法调用 CoStormRunner 实例。
# 热身系统,以在 Co-STORM 和用户之间建立共享的概念空间
costorm_runner.warm_start()
# 逐步推进协作性讨论
# 您可以按任意顺序运行下面任一代码片段,次数不限
# 要观察对话:
conv_turn = costorm_runner.step()
# 要主动引导对话,插入您的发言:
costorm_runner.step(user_utterance="您的发言")
# 根据协作性讨论生成报告
costorm_runner.knowledge_base.reorganize()
article = costorm_runner.generate_report()
print(article)
使用示例脚本快速入门
我们在 examples 文件夹 中提供了脚本,以便快速启动 STORM 和 Co-STORM,并使用不同的配置进行运行。
我们建议使用 secrets.toml 来设置 API 密钥。在根目录下创建一个 secrets.toml 文件,并添加以下内容:
# ============ 语言模型配置 ============
# 设置 OpenAI API 密钥。
OPENAI_API_KEY="your_openai_api_key"
# 如果您使用的是 OpenAI 提供的 API 服务,请包含以下行:
OPENAI_API_TYPE="openai"
# 如果您使用的是 Microsoft Azure 提供的 API 服务,请包含以下行:
OPENAI_API_TYPE="azure"
AZURE_API_BASE="your_azure_api_base_url"
AZURE_API_VERSION="your_azure_api_version"
# ============ 检索器配置 ============
BING_SEARCH_API_KEY="your_bing_search_api_key" # 如果使用 bing search
# ============ 编码器配置 ============
ENCODER_API_TYPE="openai" # 如果使用 OpenAI 编码器
STORM 示例
使用默认配置运行 STORM 与 gpt 系列模型:
运行以下命令。
python examples/storm_examples/run_storm_wiki_gpt.py \
--output-dir $OUTPUT_DIR \
--retriever bing \
--do-research \
--do-generate-outline \
--do-generate-article \
--do-polish-article
使用您喜爱的语言模型或基于您自己的语料库运行 STORM: 请查看 examples/storm_examples/README.md。
Co-STORM 示例
要使用默认配置运行 Co-STORM 与 gpt 系列模型,
- 在
secrets.toml中添加BING_SEARCH_API_KEY="xxx"和ENCODER_API_TYPE="xxx" - 运行以下命令
python examples/costorm_examples/run_costorm_gpt.py \
--output-dir $OUTPUT_DIR \
--retriever bing
流水线的定制化
STORM
如果您已安装源代码,可以根据自己的使用场景对 STORM 进行定制。STORM 引擎由 4 个模块组成:
- 知识整理模块:收集关于给定主题的广泛信息。
- 大纲生成模块:通过为整理后的知识生成层次化的大纲来组织收集到的信息。
- 文章生成模块:将收集到的信息填充到生成的大纲中。
- 文章润色模块:对撰写的文章进行优化和提升,以获得更好的呈现效果。
每个模块的接口在 knowledge_storm/interface.py 中定义,其实现则在 knowledge_storm/storm_wiki/modules/* 中实例化。这些模块可以根据您的具体需求进行定制(例如,生成项目符号格式的章节而不是完整的段落)。
Co-STORM
如果您已安装源代码,可以根据自己的使用场景对 Co-STORM 进行定制。
- Co-STORM 引入了多种 LLM 代理类型(即 Co-STORM 专家和主持人)。LLM 代理的接口在
knowledge_storm/interface.py中定义,其实现在knowledge_storm/collaborative_storm/modules/co_storm_agents.py中实例化。可以自定义不同的 LLM 代理策略。 - Co-STORM 引入了一种协作性话语协议,其核心功能在于轮次策略管理。我们在
knowledge_storm/collaborative_storm/engine.py中提供了通过DiscourseManager实现轮次策略管理的示例。该部分可以进一步定制和改进。
数据集
为了促进自动知识整理和复杂信息检索的研究,我们的项目发布了以下数据集:
FreshWiki
FreshWiki 数据集是一组包含 100 篇高质量维基百科文章的集合,重点涵盖了 2022 年 2 月至 2023 年 9 月期间编辑次数最多的页面。更多详情请参阅 STORM 论文 的第 2.1 节。
您可以直接从 huggingface 下载该数据集。为避免数据污染问题,我们还存档了用于构建数据的 源代码,以便在未来重复使用。
WildSeek
为了研究用户在真实环境中对复杂信息检索任务的兴趣,我们利用网络研究预览中收集的数据创建了 WildSeek 数据集。我们对数据进行了下采样,以确保主题的多样性和数据的质量。每个数据点都是一对内容,包括一个主题以及用户针对该主题进行深度搜索的目标。更多详情请参阅 Co-STORM 论文 的第 2.2 节和附录 A。
WildSeek 数据集可在 这里 获取。
复现 STORM 和 Co-STORM 论文结果
对于 STORM 论文实验,请切换到分支 NAACL-2024-code-backup 这里。
对于 Co-STORM 论文实验,目前暂用分支 EMNLP-2024-code-backup(即将更新)。
路线图与贡献
我们的团队正在积极开发:
- 人机协作功能:支持用户参与知识整理过程。
- 信息抽象:为整理后的信息开发抽象表示,以支持除维基百科式报告之外的其他呈现形式。
如果您有任何问题或建议,请随时提交问题或拉取请求。我们欢迎任何有助于改进系统和代码库的贡献!
联系人:Yijia Shao 和 Yucheng Jiang
致谢
我们感谢维基百科提供的优秀开源内容。FreshWiki 数据集来源于维基百科,采用知识共享署名-相同方式共享(CC BY-SA)许可协议。
我们非常感谢 Michelle Lam 为本项目设计的标志,以及 Dekun Ma 主导的 UI 开发工作。
同时感谢 Vercel 对 开源软件 的支持。
引用
如果您在工作中使用了本代码或其中的一部分,请引用我们的论文:
@inproceedings{jiang-etal-2024-unknown,
title = "进入未知的未知:通过参与语言模型代理对话实现主动式人类学习",
author = "Jiang, Yucheng and
Shao, Yijia and
Ma, Dekun and
Semnani, Sina and
Lam, Monica",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "2024 年自然语言处理经验方法会议论文集",
month = nov,
year = "2024",
address = "迈阿密,佛罗里达州,美国",
publisher = "计算语言学协会",
url = "https://aclanthology.org/2024.emnlp-main.554/",
doi = "10.18653/v1/2024.emnlp-main.554",
pages = "9917--9955",
}
@inproceedings{shao-etal-2024-assisting,
title = "借助大型语言模型从零开始协助撰写类似维基百科的文章",
author = "Shao, Yijia and
Jiang, Yucheng and
Kanell, Theodore and
Xu, Peter and
Khattab, Omar and
Lam, Monica",
editor = "Duh, Kevin and
Gomez, Helena and
Bethard, Steven",
booktitle = "2024 年北美计算语言学协会人类语言技术会议论文集(第一卷:长篇论文)",
month = jun,
year = "2024",
address = "墨西哥城,墨西哥",
publisher = "计算语言学协会",
url = "https://aclanthology.org/2024.naacl-long.347/",
doi = "10.18653/v1/2024.naacl-long.347",
pages = "6252--6278",
}
版本历史
v1.1.02025/01/23v1.0.02024/09/25v0.2.42024/08/09v0.2.32024/07/18v0.2.02024/07/08v0.1.02024/04/23常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。