annoy
Annoy 是一个由 Spotify 开源的高效近似最近邻搜索库,提供 C++ 核心与 Python 接口。它主要用于在海量高维向量数据中,快速查找与目标点最相似的邻居节点,广泛应用于推荐系统、图像检索等场景。
面对传统算法在处理百万级数据时内存占用过高、多进程共享困难的问题,Annoy 给出了独特的解决方案。其核心亮点在于支持将索引构建为只读的静态文件,并通过内存映射(mmap)技术加载。这意味着索引只需构建一次,即可被多个进程同时共享读取,不仅极大降低了内存 footprint,还实现了毫秒级的启动速度。此外,Annoy 支持欧氏距离、余弦相似度等多种度量方式,即使在千维空间下也能保持优异的性能。
这款工具非常适合后端开发者、算法工程师及数据科学家使用。如果你需要在生产环境中部署大规模相似性搜索服务,或者希望在 Hadoop 等分布式任务中高效复用索引文件,Annoy 凭借其轻量、快速且易于集成的特性,将成为你值得信赖的技术选择。
使用场景
某大型电商平台的推荐系统团队需要为千万级商品库构建实时“猜你喜欢”功能,通过计算商品向量相似度来快速召回相关物品。
没有 annoy 时
- 内存爆炸:全量商品向量加载到内存后占用数十 GB,导致单台服务器无法承载,必须拆分服务或升级昂贵硬件。
- 启动缓慢:每次服务重启或扩容时,重新加载和构建索引耗时数分钟,无法满足弹性伸缩的秒级需求。
- 资源浪费:多进程部署模式下,每个进程独立复制一份索引数据,造成巨大的内存冗余和浪费。
- 更新僵化:难以在不中断服务的情况下动态切换新索引,迭代算法模型时运维风险极高。
使用 annoy 后
- 极致省存:annoy 将索引构建为紧凑的只读文件,内存占用降低一个数量级,普通实例即可轻松承载千万数据。
- 秒级加载:利用 mmap 技术直接将磁盘文件映射到内存,服务启动或扩容时索引加载几乎瞬间完成。
- 共享内存:多个工作进程可直接共享同一份 mmap 索引文件,彻底消除多进程间的内存重复开销。
- 平滑切换:索引构建与加载完全解耦,后台生成新文件后通过原子替换即可实现无感知的模型热更新。
annoy 通过基于磁盘文件的内存映射机制,以极低的内存成本实现了海量高维数据的毫秒级近似最近邻搜索,让大规模推荐系统在低成本硬件上也能高效运行。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明(特点为小内存占用,支持将索引构建在磁盘上以处理无法放入内存的大数据集)

快速开始
Annoy
.. figure:: https://raw.github.com/spotify/annoy/master/ann.png :alt: Annoy 示例 :align: center
{kind=link}
.. image:: https://github.com/spotify/annoy/actions/workflows/ci.yml/badge.svg :target: https://github.com/spotify/annoy/actions
{kind=link}
Annoy(近似最近邻 Oh Yeah)是一个 C++ 库,并带有 Python 绑定,用于在空间中搜索与给定查询点距离较近的点。它还可以创建大型只读的基于文件的数据结构,这些数据结构会被 mmap <https://en.wikipedia.org/wiki/Mmap>__ 映射到内存中,从而允许多个进程共享同一份数据。
安装
要安装,只需运行 pip install --user annoy,即可从 PyPI <https://pypi.python.org/pypi/annoy>_ 下载最新版本。
对于 C++ 版本,只需克隆仓库并 #include "annoylib.h" 即可。
背景
目前已有其他一些库可以进行最近邻搜索。Annoy 的速度几乎与最快的库相当(见下文),但真正让 Annoy 脱颖而出的是它的另一项特性:它能够 使用静态文件作为索引。具体来说,这意味着你可以 在多个进程之间共享索引。Annoy 还将索引的创建与加载分离,因此你可以将索引以文件形式传递,并快速将其映射到内存中。Annoy 的另一个优点是它会尽量减少内存占用,因此生成的索引文件通常非常小。
这有什么用呢?如果你需要查找最近邻,并且拥有多个 CPU 核心,那么你只需要构建一次索引即可。此外,你还可以将静态索引文件分发到生产环境、Hadoop 作业等场景中使用。任何进程都可以将索引文件通过 mmap 映射到内存中,然后立即进行查询。
我们在 Spotify <http://www.spotify.com/>__ 将其用于音乐推荐。在运行矩阵分解算法后,每个用户或物品都可以表示为 f 维空间中的一个向量。这个库帮助我们搜索相似的用户或物品。我们的高维空间中包含数百万首曲目,因此内存使用是一个首要考虑的问题。
Annoy 是由 Erik Bernhardsson <http://www.erikbern.com>__ 在一次 Hack Week <http://labs.spotify.com/2013/02/15/organizing-a-hack-week/>__ 的几个下午时间里开发出来的。
功能概览
欧几里得距离 <https://en.wikipedia.org/wiki/Euclidean_distance>、曼哈顿距离 <https://en.wikipedia.org/wiki/Taxicab_geometry>、余弦距离 <https://en.wikipedia.org/wiki/Cosine_similarity>、汉明距离 <https://en.wikipedia.org/wiki/Hamming_distance>或者点积距离 <https://en.wikipedia.org/wiki/Dot_product>__- 余弦距离等价于归一化向量之间的欧几里得距离 = sqrt(2-2*cos(u, v))
- 如果维度不太高(比如少于 100 维)效果更好,但即使高达 1,000 维也能表现出乎意料地好
- 内存占用小
- 允许多个进程共享内存
- 索引创建与查询分离(一旦树结构建立,就无法再添加新条目)
- 原生支持 Python,已在 2.7、3.6 和 3.7 上测试通过。
- 可以在磁盘上构建索引,从而支持无法完全放入内存的大规模数据集索引(由
Rene Hollander <https://github.com/ReneHollander>__ 贡献)
Python 代码示例
.. code-block:: python
from annoy import AnnoyIndex import random
f = 40 # 将被索引的向量长度
t = AnnoyIndex(f, 'angular') for i in range(1000): v = [random.gauss(0, 1) for z in range(f)] t.add_item(i, v)
t.build(10) # 10 棵树 t.save('test.ann')
...
u = AnnoyIndex(f, 'angular') u.load('test.ann') # 非常快速,直接通过 mmap 映射文件 print(u.get_nns_by_item(0, 1000)) # 找到最接近的 1000 个邻居
目前它只接受整数作为条目的标识符。请注意,它会为 max(id)+1 个条目分配内存,因为它假设你的条目编号是 0 … n-1。如果你需要其他类型的 ID,就需要自己维护一个映射表。
完整的 Python API
AnnoyIndex(f, metric)返回一个新的读写索引,存储 f 维的向量。度量方式可以是"angular"、"euclidean"、"manhattan"、"hamming"或"dot"。a.add_item(i, v)添加条目i(任意非负整数)及其对应的向量v。注意,它会为max(i)+1个条目分配内存。a.build(n_trees, n_jobs=-1)构建包含n_trees棵树的森林。树的数量越多,查询精度越高。调用build后,将不能再添加新的条目。n_jobs指定用于构建树的线程数量。n_jobs=-1表示使用所有可用的 CPU 核心。a.save(fn, prefault=False)将索引保存到磁盘,并加载它(参见下一个函数)。保存后,将不能再添加新的条目。a.load(fn, prefault=False)从磁盘加载(通过 mmap)索引。如果将prefault设置为True,它会预先将整个文件读入内存(使用带有MAP_POPULATE标志的 mmap)。默认值为False。a.unload()卸载索引。a.get_nns_by_item(i, n, search_k=-1, include_distances=False)返回最接近的n个条目。查询时会检查最多search_k个节点,默认值为n_trees * n。search_k提供了运行时的权衡:更高的精度和更快的速度之间的取舍。如果将include_distances设置为True,它将返回一个包含两个列表的元组:第二个列表包含所有对应的距离。a.get_nns_by_vector(v, n, search_k=-1, include_distances=False)类似,但通过向量v进行查询。a.get_item_vector(i)返回之前添加的条目i的向量。a.get_distance(i, j)返回条目i和j之间的距离。注意:此方法过去返回的是 平方 距离,但从 2016 年 8 月起已更改为返回实际距离。a.get_n_items()返回索引中的条目总数。a.get_n_trees()返回索引中的树的数量。a.on_disk_build(fn)准备 Annoy 在指定文件中而非内存中构建索引(在添加条目前执行,构建完成后无需保存)。a.set_seed(seed)使用给定的种子初始化随机数生成器。仅在构建树时使用,即只有在添加条目之前才需要设置。调用a.build(n_trees)或a.load(fn)后将不再生效。
注意事项:
- 对输入值没有进行边界检查,请务必小心。
- Annoy 的角距离实际上是归一化向量之间的欧几里得距离,对于两个向量 u 和 v,其值为
sqrt(2(1-cos(u,v)))
C++ API 非常类似:只需 #include "annoylib.h" 即可访问。
权衡
调整 Annoy 的主要参数只有两个:树的数量 n_trees 和查询时检查的节点数量 search_k。
n_trees在构建时指定,会影响构建时间和索引大小。较大的值会提高搜索精度,但也会导致索引变大。search_k在运行时指定,影响搜索性能。较大的值会提高搜索精度,但返回结果所需的时间也会更长。
如果未指定 search_k,它将默认为 n * n_trees,其中 n 是近似最近邻的数量。否则,search_k 和 n_trees 大致是独立的,即在 search_k 保持不变的情况下,n_trees 的值不会影响搜索时间,反之亦然。因此,建议在内存允许的情况下尽可能增大 n_trees;而在查询时间有限的情况下,则应尽可能增大 search_k。
你也可以选择接受较慢的搜索速度,以换取更快的加载速度、更低的内存占用和更少的磁盘 I/O。在支持的平台上,索引会在 load 和 save 时进行预取,从而提前将文件从磁盘读入内存。如果你将 prefault 设置为 False,则会按需从磁盘读取内存映射索引的页面,并将其缓存在内存中,直到完成一次搜索为止。这可能会显著增加首次搜索的时间,但对于内存容量远小于索引大小的系统、对已加载索引执行少量查询的情况,或者索引中大部分区域不太可能与搜索查询相关的情形,这种方式可能更为合适。
它是如何工作的
通过使用随机投影(random projections <http://en.wikipedia.org/wiki/Locality-sensitive_hashing#Random_projection>__)并构建一棵树来实现。在树的每个中间节点上,都会选择一个随机超平面,将空间划分为两个子空间。这个超平面是通过从子集中随机采样两点,并取这两点之间的等距超平面来确定的。
我们重复这一过程 k 次,从而得到一棵森林。k 的具体值需要根据你的需求进行调整,权衡精度和性能之间的折衷。
汉明距离(由 Martin Aumüller <https://github.com/maumueller>__ 贡献)会在底层将数据打包成 64 位整数,并利用内置的位计数原语,因此速度相当快。所有的分割都是轴对齐的。
点积距离(由 Peter Sobot <https://github.com/psobot>__ 和 Pavel Korobov <https://github.com/pkorobov>__ 贡献)使用微软研究院 Bachrach 等人在 2014 年发表的方法,将提供的向量从点积(或“内积”)空间转换为更适合查询的余弦空间:a method by Bachrach et al., at Microsoft Research, published in 2014 <https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/XboxInnerProduct.pdf>__。
更多信息
Dirk Eddelbuettel <https://github.com/eddelbuettel>__ 提供了Annoy 的 R 版本 <http://dirk.eddelbuettel.com/code/rcpp.annoy.html>__。Andy Sloane <https://github.com/a1k0n>__ 提供了Annoy 的 Java 版本 <https://github.com/spotify/annoy-java>__,不过目前仅支持余弦距离且为只读模式。Pishen Tsai <https://github.com/pishen>__ 提供了Annoy 的 Scala 封装 <https://github.com/pishen/annoy4s>__,该封装使用 JNA 调用 Annoy 的 C++ 库。Atsushi Tatsuma <https://github.com/yoshoku>__ 提供了Annoy 的 Ruby 绑定 <https://github.com/yoshoku/annoy.rb>__。Taneli Leppä <https://github.com/rosmo>__ 提供了Go 语言的实验性支持 <https://github.com/spotify/annoy/blob/master/README_GO.rst>__。Boris Nagaev <https://github.com/starius>__ 编写了Lua 绑定 <https://github.com/spotify/annoy/blob/master/README_Lua.md>__。- 在 Spotify Hack Week 2016 的部分时间里(以及之后的一段时间),
Jim Kang <https://github.com/jimkang>__ 为 Annoy 编写了Node.js 绑定 <https://github.com/jimkang/annoy-node>__。 Min-Seok Kim <https://github.com/mskimm>__ 构建了 Annoy 的Scala 版本 <https://github.com/mskimm/ann4s>__。hanabi1224 <https://github.com/hanabi1224>__ 构建了 Annoy 的只读Rust 版本 <https://github.com/hanabi1224/RuAnnoy>__,同时还提供了 dotnet、jvm 和 dart 的只读绑定。- 关于 Annoy 的
纽约机器学习聚会演讲 <http://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup>__。 - Annoy 可以作为
conda 包 <https://anaconda.org/conda-forge/python-annoy>__ 在 Linux、OS X 和 Windows 上使用。 ann-benchmarks <https://github.com/erikbern/ann-benchmarks>__ 是一个针对多种近似最近邻库的基准测试工具。Annoy 在其中表现相当有竞争力,尤其是在高精度场景下:
.. figure:: https://raw.githubusercontent.com/erikbern/ann-benchmarks/main/results/glove-100-angular.png :alt: ANN 基准测试结果 :align: center :target: https://github.com/erikbern/ann-benchmarks
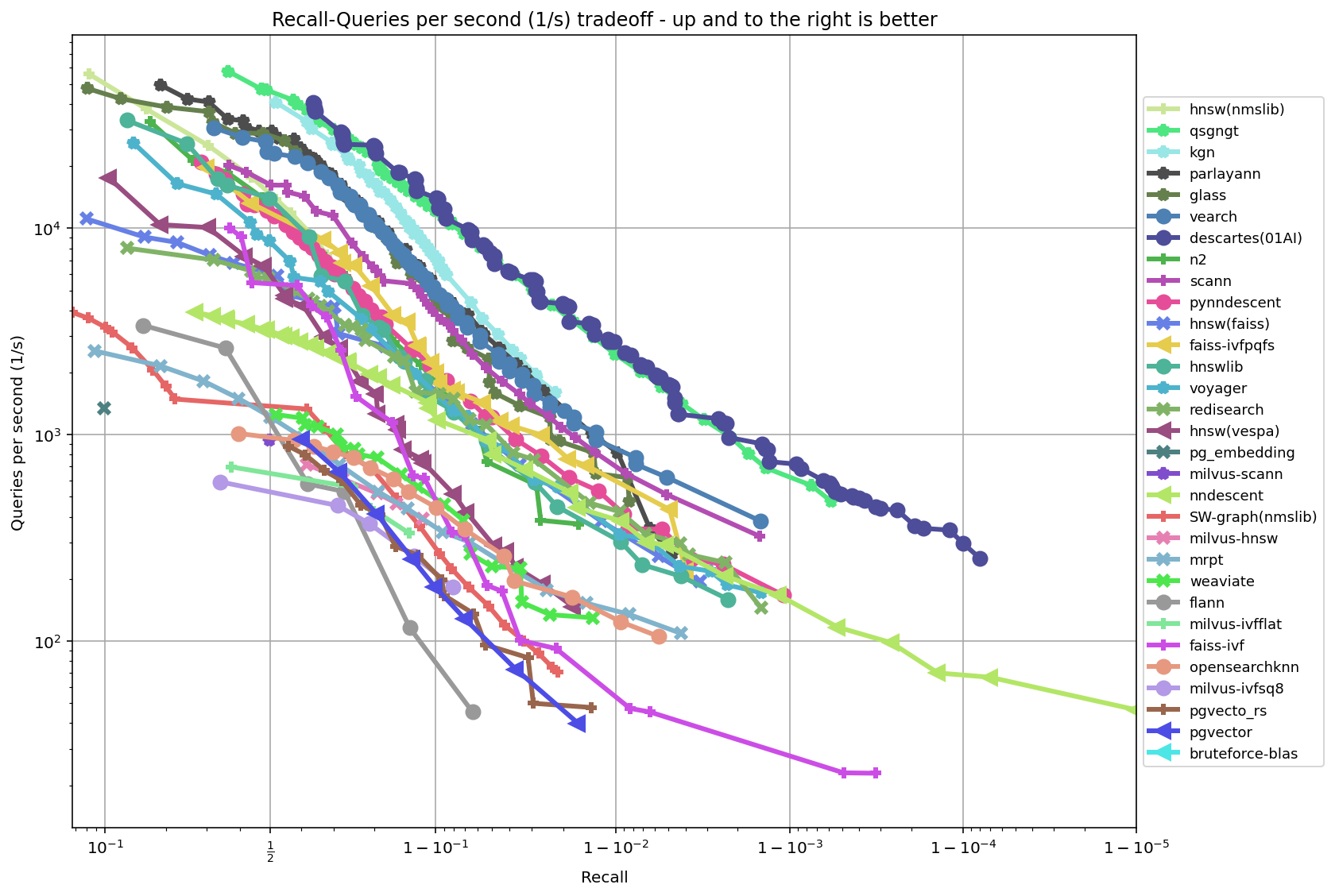{kind=link}
源代码
整个项目完全用 C++ 编写,并包含一些为了提升性能和减少内存占用而做的优化措施。请务必注意这一点 :)
感谢 Qiang Kou <https://github.com/thirdwing>__ 和 Timothy Riley <https://github.com/tjrileywisc>__ 的努力,代码现在也支持 Windows 系统。
要运行测试,请执行 python setup.py nosetests。测试套件中包含一个从互联网下载的大型真实世界数据集,因此执行起来可能需要几分钟时间。
讨论
欢迎随时在 annoy-user <https://groups.google.com/group/annoy-user>__ 论坛上提出问题或发表评论。我在 Twitter 上的账号是 @fulhack <https://twitter.com/fulhack>__。
版本历史
v1.17.32023/06/14v1.17.22023/04/10v1.17.12022/08/08v1.17.02020/09/18v1.16.32019/12/26v1.16.22019/10/11v1.16.12019/10/111.162019/07/09v1.15.22019/04/171.152019/04/17v1.15.12019/02/22v1.15.02018/12/10v1.14.02018/11/04v1.13.02018/08/31v1.12.02018/05/07v1.11.52018/03/31v1.11.42018/02/06v1.11.12018/01/20v1.10.02017/11/13v1.9.52017/09/30常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。