spiceai
Spice 是一款基于 Rust 构建的便携式加速引擎,专为打造“数据驱动”的 AI 应用和智能体而设计。它巧妙地将 SQL 查询、语义搜索与大语言模型(LLM)推理能力融合在一个轻量级的运行环境中,帮助开发者轻松解决 AI 幻觉问题,确保生成的回答始终基于真实可靠的数据。
对于需要构建企业级 AI 助手或数据分析应用的开发者而言,Spice 极大地简化了技术架构。它支持跨数据库、数据仓库和数据湖的统一联邦查询,无需移动数据即可实现高效分析。其独特亮点在于“多合一”的 API 设计:不仅提供标准的 SQL 接口(如 ODBC/JDBC)和向量搜索功能,还原生兼容 OpenAI 协议,可直接作为本地模型的加速网关;同时支持 Iceberg 目录和 MCP 协议,便于与外部工具无缝集成。
凭借单二进制文件或容器的便携部署方式,以及 CUDA/Metal 硬件加速能力,Spice 让团队能专注于业务逻辑创新,而非繁琐的基础设施搭建。无论是初创公司的全栈工程师,还是大型企业的 AI 架构师,都能利用 Spice 快速构建出既聪明又可信的智能应用。
使用场景
某电商公司的数据团队正致力于构建一个能实时回答“上季度高价值客户流失原因”的智能分析助手,需要同时处理海量交易数据和非结构化客服记录。
没有 spiceai 时
- 数据孤岛严重:交易数据在 PostgreSQL,日志在 S3 数据湖,客服文本在 Elasticsearch,开发者需编写复杂的 ETL 脚本或维护多个连接才能聚合数据。
- 响应延迟高:传统跨库查询效率低下,且缺乏向量搜索能力,导致 AI 代理在检索相关客服对话时耗时数秒,无法实现实时交互。
- 架构臃肿:为了支持 SQL 查询、向量检索和 LLM 推理,团队不得不分别部署数据库中间件、向量数据库和本地模型服务,运维成本极高。
- 开发门槛高:前端工程师需学习多种协议(如 JDBC、REST、gRPC)来对接不同后端,难以快速将数据能力嵌入 AI 应用。
使用 spiceai 后
- 统一数据联邦:spiceai 通过单一 SQL 接口直接联邦查询 Postgres、S3 和 Elasticsearch,无需移动数据即可瞬间关联交易与客服记录。
- 加速智能检索:利用内置的
vector_searchUDTF 和 Rust 加速引擎,spiceai 将混合搜索(关键词 + 向量)延迟降低至毫秒级,让 AI 回答更即时。 - 极简运行时:仅需一个轻量级二进制文件或容器,spiceai 便同时提供了 SQL 查询、OpenAI 兼容的 LLM 推理网关及向量搜索能力,大幅简化架构。
- 标准化开发体验:开发者只需通过标准的 ODBC/JDBC 或 OpenAI SDK 即可调用所有能力,快速构建出数据驱动的分析 Agent。
spiceai 通过统一的加速引擎消除了数据与应用间的隔阂,让开发者能以最低成本构建真正“落地于数据”的 AI 应用。
运行环境要求
- Linux
- macOS
- Windows
- 可选
- 支持本地模型服务加速,需 NVIDIA GPU (CUDA) 或 Apple Silicon (Metal)
- 具体型号和显存大小取决于所加载的 LLM 模型大小,README 未指定最低硬性要求
未说明。内存需求取决于数据联邦、加速引擎(Arrow/DuckDB/SQLite)及加载的模型大小。
快速开始

![]()
![]()





)

Spice 是一款用 Rust 编写的 SQL 查询、搜索和 LLM 推理引擎,专为数据应用和智能代理设计。
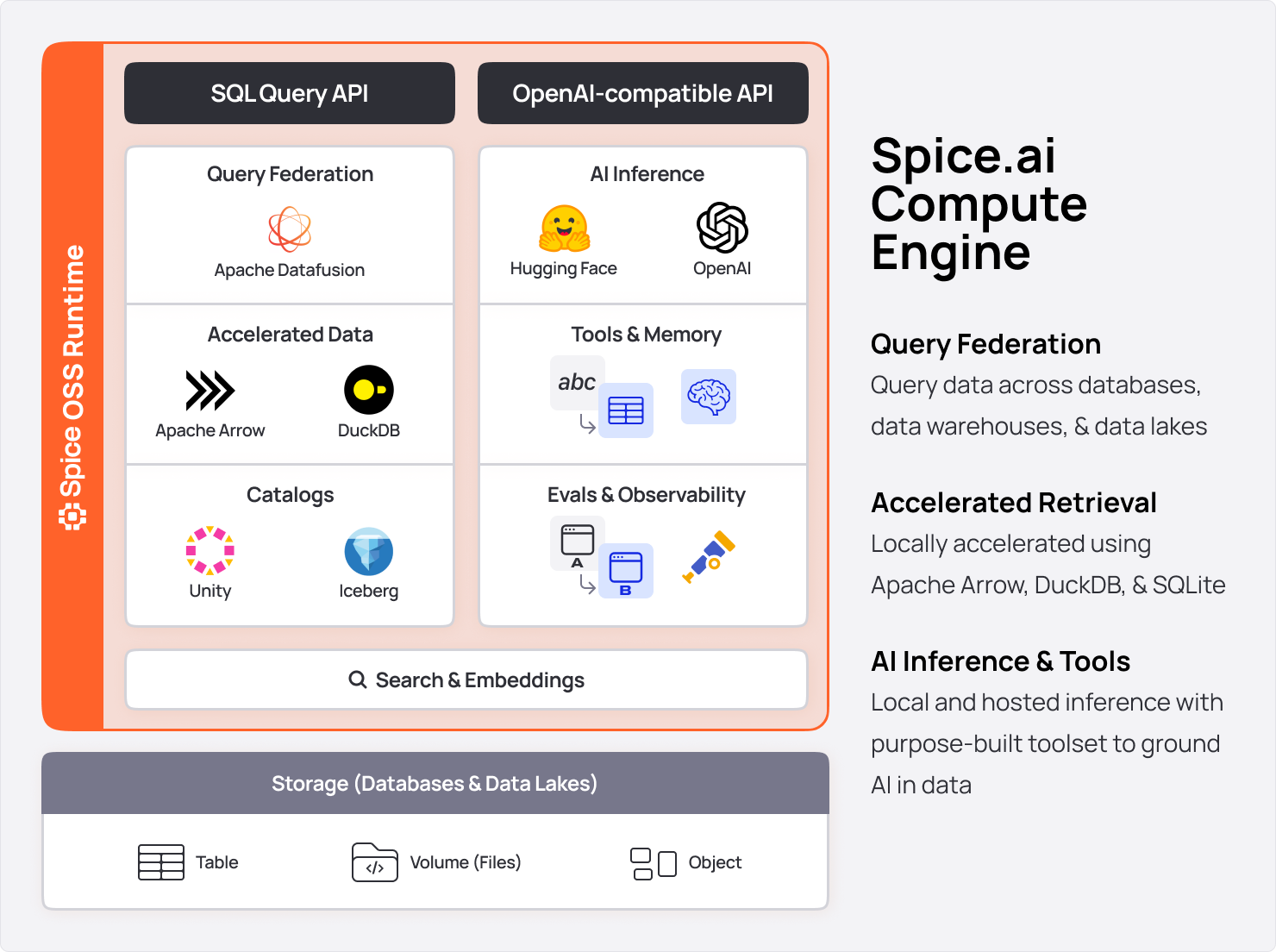
Spice 在一个轻量级、可移植的运行时(单个二进制文件或容器)中提供了四种行业标准 API:
- SQL 查询与搜索:HTTP、Arrow Flight、Arrow Flight SQL、ODBC、JDBC 和 ADBC API;
vector_search和text_searchUDTF。 - OpenAI 兼容 API:用于兼容 OpenAI SDK 的 HTTP API、本地模型服务(CUDA/Metal 加速)以及托管模型网关。
- Iceberg 目录 REST API:统一的 Iceberg REST 目录 API。
- MCP HTTP+SSE API:通过 Model Context Protocol (MCP) 使用 HTTP 和 Server-Sent Events (SSE) 与外部工具集成。
🎯 目标:开发者可以专注于构建数据应用和 AI 代理,同时确信其应用建立在可靠的数据基础之上。
Spice 的主要特性包括:
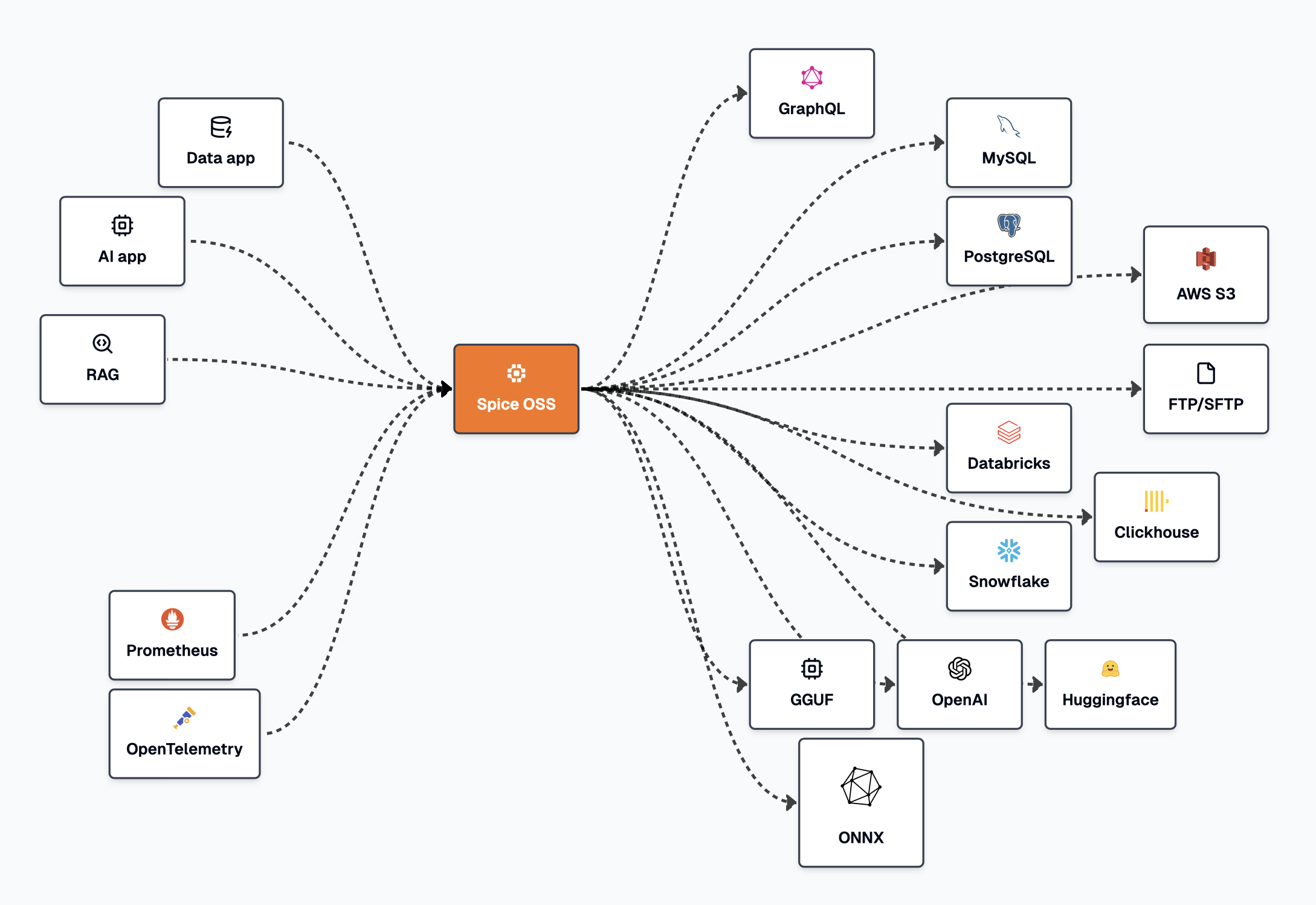
- 数据联邦:可在任何数据库、数据仓库或数据湖中执行 SQL 查询。支持从单节点到分布式多节点的查询执行。了解更多。
- 数据物化与加速:使用 Arrow、DuckDB、SQLite、PostgreSQL 或 Spice Cayenne (Vortex) 对数据库查询进行物化、加速和缓存。阅读 MaterializedView 采访——构建数据库 CDN
- 企业级搜索:基于 Tantivy 的 BM25 关键字、向量和全文搜索,以及通过 Amazon S3 Vectors 或 pgvector 实现的 PB 级向量相似性搜索,适用于结构化和非结构化数据。
- AI 应用与智能代理:一个结合了 OpenAI 兼容 API 和 MCP 集成的 AI 数据库,可驱动检索增强生成(RAG)和智能代理。了解更多。
如果您希望使用 DataFusion、DuckDB 或 Vortex 进行开发,Spice 提供了一个简单、灵活且适合生产环境的引擎,您可以直接使用。
📣 阅读 Spice.ai 1.0 稳定版公告。
Spice 基于业界领先的技术构建,包括 Apache DataFusion、Apache Arrow、Arrow Flight、SQLite 和 DuckDB。
🎥 观看 CMU 数据库如何利用 Spice.ai 开源技术加速数据与 AI
🎥 观看如何使用 Spice、OpenAI 和 MCP 查询数据
🎥 观看如何使用 Amazon S3 Vectors 进行搜索
为什么选择 Spice?
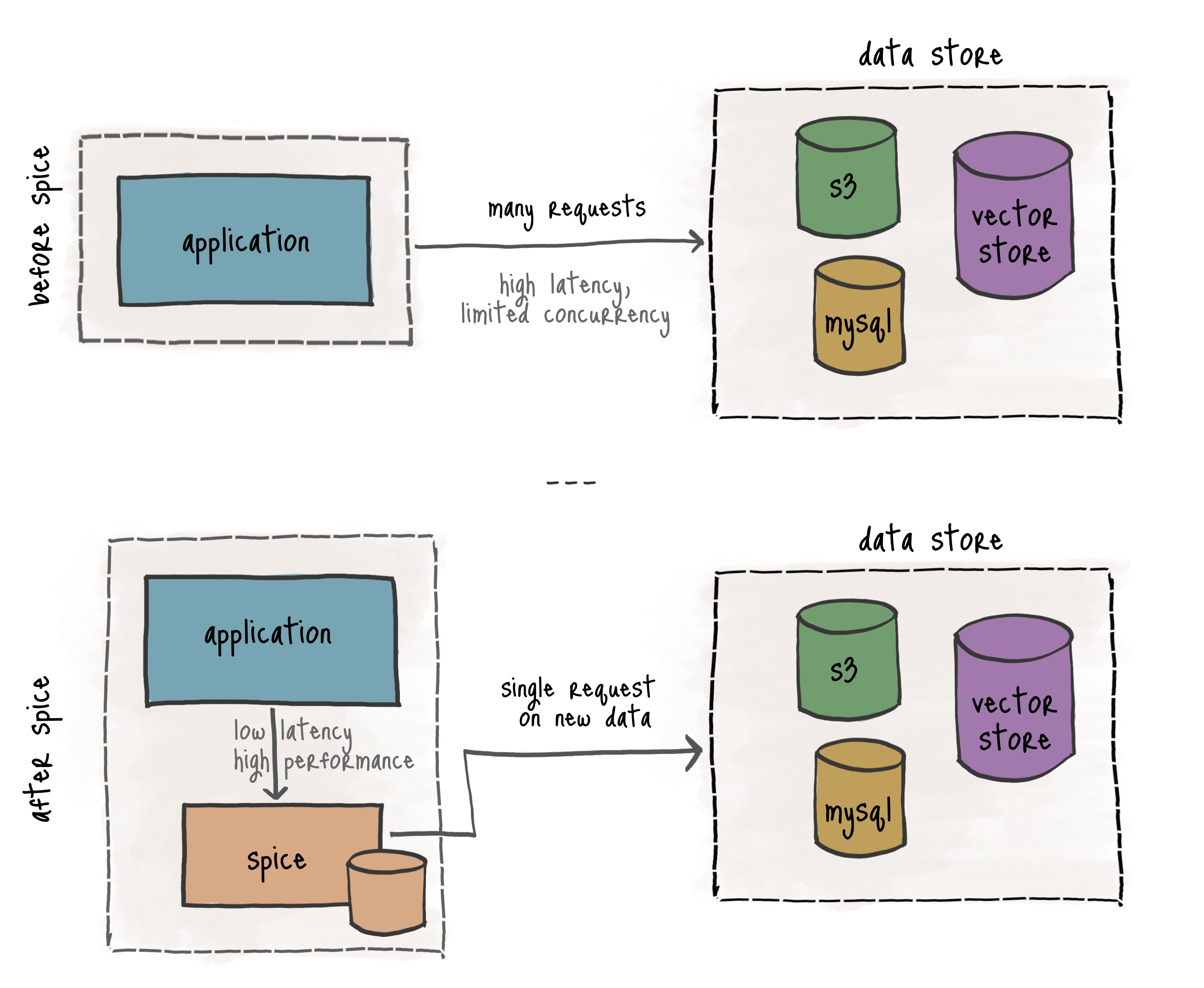
Spice 通过使用户能够使用 SQL 从一个或多个数据源快速、轻松地查询、联邦和加速数据,简化了数据驱动型 AI 应用和智能代理的构建过程,同时确保 AI 始终基于实时、可靠的数据。将数据集与应用和 AI 模型同地部署,以支持 AI 反馈循环、实现 RAG 和搜索,并提供快速、低延迟的数据查询与 AI 推理服务,同时完全掌控成本和性能。
最新功能
- Spice 辣椒数据加速器:使用Vortex 列式格式 + SQLite 元数据,简化多文件加速。提供与 DuckDB 相当的性能,同时不受单文件规模限制。
- 多节点分布式查询:通过集成 Apache Ballista,在多个节点上扩展查询执行,从而提升大规模数据集上的性能。
- 加速快照:从 S3 启动加速,实现快速冷启动(几秒而非几分钟)。支持临时存储,并具备持久化恢复能力。
- Iceberg 表写入:使用标准 SQL
INSERT INTO语句直接写入 Iceberg 表,完成数据摄取和转换——无需 Spark。 - PB 级向量搜索:原生集成 Amazon S3 Vectors,管理从数据摄取、嵌入到查询的完整向量生命周期。结合 RRF 的 SQL 集成混合搜索。
Spice 有何不同?
- AI 原生运行时:Spice 将数据查询与 AI 推理整合到一个引擎中,实现数据驱动的 AI 和精准的 AI 应用。
- 以应用为中心:专为在应用和代理级别进行分布式部署而设计,通常采用应用与 Spice 实例之间的 1:1 或 1:N 映射模式,不同于传统数据系统将多个应用集中部署在一个中央数据库上。常见做法是启动多个 Spice 实例,甚至为每个租户或客户单独部署一个实例。
- 双引擎加速:在数据集层面同时支持 OLAP(Arrow/DuckDB)和 OLTP(SQLite/PostgreSQL)引擎,灵活应对分析型和事务型工作负载。
- 分离式存储:计算与分离式存储解耦,将本地物化的工作数据集与应用程序、仪表板或 ML 流水线共置,同时访问原始存储中的源数据。
- 边缘到云端原生:可作为独立实例、Kubernetes Sidecar、微服务或集群部署,覆盖边缘/POP、本地数据中心及公有云环境。可通过串联多个 Spice 实例实现分层优化的分布式部署。
Spice 如何对比?
数据查询与分析
| 功能 | Spice | Trino / Presto | Dremio | ClickHouse | Materialize |
|---|---|---|---|---|---|
| 主要用例 | 数据与 AI 应用/代理 | 大数据分析 | 交互式分析 | 实时分析 | 实时分析 |
| 主要部署模式 | Sidecar | 集群 | 集群 | 集群 | 集群 |
| 联邦查询支持 | ✅ | ✅ | ✅ | ― | ― |
| 加速/物化 | ✅(Arrow、SQLite、DuckDB、PostgreSQL) | 中间存储 | 反射表(Iceberg) | 物化视图 | ✅(实时视图) |
| 元数据目录支持 | ✅(Iceberg、Unity Catalog、AWS Glue) | ✅ | ✅ | ― | ― |
| 查询结果缓存 | ✅ | ✅ | ✅ | ✅ | 有限 |
| 多模态加速 | ✅(OLAP + OLTP) | ― | ― | ― | ― |
| 变更数据捕获 (CDC) | ✅(Debezium) | ― | ― | ― | ✅(Debezium) |
AI 应用与代理
| 功能 | Spice | LangChain | LlamaIndex | AgentOps.ai | Ollama |
|---|---|---|---|---|---|
| 主要用例 | 数据与 AI 应用 | 代理式工作流 | RAG 应用 | 代理运营 | LLM 应用 |
| 编程语言 | 任意语言(HTTP 接口) | JavaScript、Python | Python | Python | 任意语言(HTTP 接口) |
| 统一的数据 + AI 运行时 | ✅ | ― | ― | ― | ― |
| 联邦数据查询 | ✅ | ― | ― | ― | ― |
| 加速数据访问 | ✅ | ― | ― | ― | ― |
| 工具/函数 | ✅(MCP HTTP+SSE) | ✅ | ✅ | 有限 | 有限 |
| LLM 内存 | ✅ | ✅ | ― | ✅ | ― |
| 混合搜索 | ✅(关键词、向量及全文检索) | ✅ | ✅ | 有限 | 有限 |
| 缓存 | ✅(查询及结果缓存) | 有限 | ― | ― | ― |
| 嵌入表示 | ✅(内置及可插拔模型/数据库) | ✅ | ✅ | 有限 | ― |
✅ = 完全支持
❌ = 不支持
有限 = 部分或受限支持
示例用例
基于数据的智能体AI应用
- OpenAI兼容API:通过支持OpenAI响应API的高级交互,连接托管模型(OpenAI、Anthropic、xAI、Amazon Bedrock)或在本地部署(Llama、NVIDIA NIM)。AI网关配方
- 联邦数据访问:使用SQL和NSQL(文本转SQL)跨数据库、数据仓库和数据湖进行查询,并借助高级查询下推实现快速检索。借助Apache Ballista扩展至分布式多节点查询执行。联邦SQL查询配方
- 搜索与RAG:利用加速嵌入技术进行搜索并检索上下文,用于检索增强生成(RAG)工作流。原生集成Amazon S3向量存储,支持PB级向量搜索。通过Tantivy驱动的BM25实现全文搜索(FTS),并通过
text_search和vector_searchUDTF将向量相似度搜索(VSS)集成到SQL中。采用互斥排名融合(RRF)实现混合搜索。Amazon S3向量 Cookbook配方 - LLM记忆与可观测性:为AI智能体存储和检索历史及上下文,同时深入洞察数据流、模型性能和追踪信息。LLM记忆配方 | 可观测性与监控功能文档
数据库CDN与查询网格
- 数据加速:将物化数据集与应用程序同地部署,采用Arrow、SQLite、DuckDB、PostgreSQL或Cayenne(Vortex+SQLite)格式,实现亚秒级查询。可通过存储在S3中的快照快速冷启动。使用标准SQL
INSERT INTO写入Iceberg表。DuckDB数据加速配方 - 容错与本地数据副本:通过维护关键数据集的本地副本,确保应用程序的可用性。在联邦源发生故障时,可利用加速快照进行恢复。本地数据副本配方
- 响应式仪表板:通过为前端和BI工具加速数据,并配置可调的刷新计划,实现快速的实时分析。销售BI仪表板演示
- 简化遗留系统迁移:使用单一端点统一遗留系统与现代基础设施,包括跨多个数据源的联邦SQL查询。联邦SQL查询配方
检索增强生成(RAG)
- 统一向量相似度搜索:通过原生集成Amazon S3向量存储,实现对结构化和非结构化数据源的高效向量相似度搜索,支持PB级向量存储与查询。Spice运行时管理向量生命周期:摄取数据、使用AWS Bedrock(Amazon Titan、Cohere)、HuggingFace模型或Model2Vec(静态嵌入速度快500倍)进行嵌入,并存储于S3向量桶或pgvector中。支持余弦相似度、欧几里得距离或点积计算。通过
vector_search和text_searchUDTF将搜索集成到SQL中,并利用互斥排名融合(RRF)实现混合搜索。示例:SELECT * FROM vector_search(my_table, '搜索查询', 10) WHERE condition ORDER BY _score;。Amazon S3向量 Cookbook配方 - 语义知识层:定义语义上下文模型,以丰富AI所需的数据。语义模型功能文档
- 文本转SQL:利用内置的NSQL和采样工具,将自然语言查询转换为SQL,确保查询准确性。文本转SQL配方
常见问题解答
Spice是缓存吗? 并不是严格意义上的缓存;你可以将其理解为一种“主动”缓存、物化或数据预取机制。缓存通常在缓存未命中时才获取数据,而Spice则会根据时间间隔、触发条件或通过CDC监听数据变化来预取和物化筛选后的数据。除了数据加速外,Spice还支持结果缓存。
Spice是数据库CDN吗? 是的,Spice的一个常见用法就是作为不同数据源的CDN。借鉴CDN的概念,Spice允许你将数据库(或数据湖、数据仓库)的工作集“运送”(加载)到最常被访问的位置,例如数据密集型应用或用于AI上下文的场景。
观看30秒BI仪表板加速演示
https://github.com/spiceai/spiceai/assets/80174/7735ee94-3f4a-4983-a98e-fe766e79e03a
更多演示请访问YouTube。
支持的数据连接器
| 名称 | 描述 | 状态 | 协议/格式 |
|---|---|---|---|
databricks (mode: delta_lake) |
Databricks | 稳定 | S3/Delta Lake |
delta_lake |
Delta Lake | 稳定 | Delta Lake |
dremio |
Dremio | 稳定 | Arrow Flight |
duckdb |
DuckDB | 稳定 | 嵌入式 |
file |
文件 | 稳定 | Parquet, CSV |
github |
GitHub | 稳定 | GitHub API |
postgres |
PostgreSQL | 稳定 | |
s3 |
S3 | 稳定 | Parquet, CSV |
mysql |
MySQL | 稳定 | |
spice.ai |
Spice.ai | 稳定 | Arrow Flight |
graphql |
GraphQL | 发布候选 | JSON |
dynamodb |
Amazon DynamoDB | 发布候选 | |
databricks (mode: spark_connect) |
Databricks | 测试版 | Spark Connect |
flightsql |
FlightSQL | 测试版 | Arrow Flight SQL |
iceberg |
Apache Iceberg | 测试版 | Parquet |
mssql |
Microsoft SQL Server | 测试版 | 表格数据流 (TDS) |
odbc |
ODBC | 测试版 | ODBC |
snowflake |
Snowflake | 测试版 | Arrow |
spark |
Spark | 测试版 | Spark Connect |
oracle |
Oracle | 开发中 | Oracle ODPI-C |
abfs |
Azure BlobFS | 开发中 | Parquet, CSV |
clickhouse |
Clickhouse | 开发中 | |
debezium |
Debezium CDC | 开发中 | Kafka + JSON |
gcs, gs |
Google Cloud Storage | 开发中 | Parquet, CSV, JSON |
kafka |
Kafka | 开发中 | Kafka + JSON |
ftp, sftp |
FTP/SFTP | 开发中 | Parquet, CSV |
glue |
AWS Glue | 开发中 | Iceberg、Parquet、CSV |
http, https |
HTTP(s) | 开发中 | Parquet、CSV、JSON |
imap |
IMAP | 开发中 | IMAP 邮件 |
localpod |
本地数据集复制 | 开发中 | |
mongodb |
MongoDB | 开发中 | |
sharepoint |
Microsoft SharePoint | 开发中 | 非结构化 UTF-8 文档 |
scylladb |
ScyllaDB | 开发中 | |
smb |
SMB(服务器消息块) | 开发中 | SMB |
elasticsearch |
ElasticSearch | 计划中 |
支持的数据加速器
| 名称 | 描述 | 状态 | 引擎模式 |
|---|---|---|---|
cayenne |
Spice Cayenne (Vortex) | 发布候选 | file |
arrow |
内存中的 Arrow 记录 | 稳定 | memory |
duckdb |
嵌入式 DuckDB | 稳定 | memory, file |
postgres |
附加的 PostgreSQL | 发布候选 | 不适用 |
sqlite |
嵌入式 SQLite | 发布候选 | memory, file |
支持的模型提供商
| 名称 | 描述 | 状态 | 机器学习格式 | 大语言模型格式 |
|---|---|---|---|---|
openai |
OpenAI(或兼容)大语言模型端点 | 发布候选版 | - | OpenAI 兼容的 HTTP 端点 |
file |
本地文件系统 | 发布候选版 | ONNX | GGUF、GGML、SafeTensor |
huggingface |
HuggingFace 上托管的模型 | 发布候选版 | ONNX | GGUF、GGML、SafeTensor |
spice.ai |
Spice.ai 云平台上托管的模型 | ONNX | OpenAI 兼容的 HTTP 端点 | |
azure |
Azure OpenAI | - | OpenAI 兼容的 HTTP 端点 | |
bedrock |
Amazon Bedrock(Nova 模型) | Alpha 版本 | - | OpenAI 兼容的 HTTP 端点 |
anthropic |
Anthropic 上托管的模型 | Alpha 版本 | - | OpenAI 兼容的 HTTP 端点 |
xai |
xAI 上托管的模型 | Alpha 版本 | - | OpenAI 兼容的 HTTP 端点 |
支持的嵌入提供商
| 名称 | 描述 | 状态 | 机器学习格式 | 大语言模型格式* |
|---|---|---|---|---|
openai |
OpenAI(或兼容)大语言模型端点 | 发布候选版 | - | OpenAI 兼容的 HTTP 端点 |
file |
本地文件系统 | 发布候选版 | ONNX | GGUF、GGML、SafeTensor |
huggingface |
HuggingFace 上托管的模型 | 发布候选版 | ONNX | GGUF、GGML、SafeTensor |
model2vec |
静态嵌入(快 500 倍) | 发布候选版 | Model2Vec | - |
azure |
Azure OpenAI | Alpha 版本 | - | OpenAI 兼容的 HTTP 端点 |
bedrock |
AWS Bedrock(例如 Titan、Cohere) | Alpha 版本 | - | OpenAI 兼容的 HTTP 端点 |
支持的向量存储
| 名称 | 描述 | 状态 |
|---|---|---|
s3_vectors |
Amazon S3 向量,用于 PB 级别的向量存储和查询 | Alpha |
pgvector |
PostgreSQL 配合 pgvector 扩展 | Alpha |
duckdb_vector |
DuckDB 配合向量扩展,用于高效向量存储与搜索 | Alpha |
sqlite_vec |
SQLite 配合 sqlite-vec 扩展,用于轻量级向量操作 | Alpha |
支持的目录
目录连接器可连接到外部目录提供商,并使其表在 Spice 中可供联邦 SQL 查询使用。目前不支持为外部目录中的表配置加速功能。外部目录的模式层次结构将在 Spice 中得以保留。
| 名称 | 描述 | 状态 | 协议/格式 |
|---|---|---|---|
spice.ai |
Spice.ai 云平台 | 稳定 | Arrow Flight |
unity_catalog |
Unity 目录 | 稳定 | Delta Lake |
databricks |
Databricks | 测试版 | Spark Connect、S3/Delta Lake |
iceberg |
Apache Iceberg | 测试版 | Parquet |
glue |
AWS Glue | Alpha | CSV、Parquet、Iceberg |
⚡️ 快速入门(本地机器)
https://github.com/spiceai/spiceai/assets/88671039/85cf9a69-46e7-412e-8b68-22617dcbd4e0
安装
安装 Spice CLI:
在 macOS、Linux 和 WSL 上:
curl https://install.spiceai.org | /bin/bash
或者使用 brew:
brew install spiceai/spiceai/spice
在 Windows 上使用 PowerShell:
iex ((New-Object System.Net.WebClient).DownloadString("https://install.spiceai.org/Install.ps1"))
使用方法
步骤 1. 使用 spice init 命令初始化一个新的 Spice 应用程序:
spice init spice_qs
在 spice_qs 目录中会创建一个 spicepod.yaml 文件。切换到该目录:
cd spice_qs
步骤 2. 启动 Spice 运行时:
spice run
示例输出如下:
2025/01/20 11:26:10 INFO Spice.ai 运行时启动中...
2025-01-20T19:26:10.679068Z INFO runtime::init::dataset: 未配置任何数据集。如果这不是预期行为,请检查 Spicepod 配置。
2025-01-20T19:26:10.679716Z INFO runtime::flight: Spice 运行时飞行服务正在监听 127.0.0.1:50051
2025-01-20T19:26:10.679786Z INFO runtime::metrics_server: Spice 运行时指标服务正在监听 127.0.0.1:9090
2025-01-20T19:26:10.680140Z INFO runtime::http: Spice 运行时 HTTP 服务正在监听 127.0.0.1:8090
2025-01-20T19:26:10.879126Z INFO runtime::init::results_cache: 已初始化 SQL 结果缓存;最大大小:128.00 MiB,条目 TTL:1s
此时运行时已启动并可接受查询。
步骤 3. 在一个新的终端窗口中,添加 spiceai/quickstart Spicepod。Spicepod 是一种包含数据集和机器学习模型配置的软件包。
spice add spiceai/quickstart
spicepod.yaml 文件将更新为包含 spiceai/quickstart 依赖项。
version: v1
kind: Spicepod
name: spice_qs
dependencies:
- spiceai/quickstart
spiceai/quickstart Spicepod 将向运行时添加一个 taxi_trips 数据表,现在可以通过 SQL 查询该表。
2025-01-20T19:26:30.011633Z INFO runtime::init::dataset: 数据集 taxi_trips 已注册(s3://spiceai-demo-datasets/taxi_trips/2024/),启用了加速(arrow)和结果缓存。
2025-01-20T19:26:30.013002Z INFO runtime::accelerated_table::refresh_task: 正在加载数据集 taxi_trips 的数据
2025-01-20T19:26:40.312839Z INFO runtime::accelerated_table::refresh_task: 已在 10 秒 299 毫秒内加载了 2,964,624 行数据(399.41 MiB)至数据集 taxi_trips
步骤 4. 启动 Spice SQL REPL:
spice sql
SQL REPL 界面将显示如下:
欢迎来到 Spice.ai SQL REPL!输入 'help' 获取帮助。
show tables; -- 列出可用表
sql>
输入 show tables; 以显示可供查询的表:
sql> show tables;
+---------------+--------------+---------------+------------+
| table_catalog | table_schema | table_name | table_type |
+---------------+--------------+---------------+------------+
| spice | public | taxi_trips | BASE TABLE |
| spice | runtime | query_history | BASE TABLE |
| spice | runtime | metrics | BASE TABLE |
+---------------+--------------+---------------+------------+
时间:0.022671708 秒。3 行。
输入查询语句以显示最长的出租车行程:
SELECT trip_distance, total_amount FROM taxi_trips ORDER BY trip_distance DESC LIMIT 10;
输出:
+---------------+--------------+
| trip_distance | total_amount |
+---------------+--------------+
| 312722.3 | 22.15 |
| 97793.92 | 36.31 |
| 82015.45 | 21.56 |
| 72975.97 | 20.04 |
| 71752.26 | 49.57 |
| 59282.45 | 33.52 |
| 59076.43 | 23.17 |
| 58298.51 | 18.63 |
| 51619.36 | 24.2 |
| 44018.64 | 52.43 |
+---------------+--------------+
时间:0.045150667 秒。10 行。
⚙️ 运行时容器部署
使用本地 Docker 镜像:
docker pull spiceai/spiceai
在 Dockerfile 中:
from spiceai/spiceai:latest
使用 Helm:
helm repo add spiceai https://helm.spiceai.org
helm install spiceai spiceai/spiceai
🏎️ 下一步
探索 Spice.ai 烹饪书
Spice.ai 烹饪书是一系列使用 Spice 的食谱和示例。可在 https://github.com/spiceai/cookbook 找到。
使用 Spice.ai 云平台
通过 Spice 运行时访问 Spice.ai 云平台上托管的即用型 Spicepod 和数据集。公共 Spicepod 列表可在 Spicerack 上找到:https://spicerack.org/。
要使用公共数据集,请在 Spice.ai 上创建一个免费账户:
访问 spice.ai 并点击 免费试用。
创建账户后,创建一个应用以生成 API 密钥。
设置完成后,即可访问包括数据集在内的即用型 Spicepod。在本演示中,使用来自 Spice.ai Quickstart 的 taxi_trips 数据集。
步骤 1. 初始化一个新项目。
# 初始化一个新的 Spice 应用程序
spice init spice_app
# 切换到应用目录
cd spice_app
步骤 2. 使用 spice login 命令从命令行登录并进行身份验证。系统将弹出浏览器窗口提示您进行身份验证:
spice login
步骤 3. 启动运行时:
# 启动运行时
spice run
步骤 4. 配置数据集:
在新的终端窗口中,使用 spice dataset configure 命令配置一个新的数据集:
spice dataset configure
输入一个将在查询中用于引用该数据集的名称。此名称不必与数据集源中的名称一致。
数据集名称:(spice_app) taxi_trips
输入数据集的描述:
描述:出租车行程数据集
输入数据集的位置:
来源:spice.ai/spiceai/quickstart/datasets/taxi_trips
当提示是否加速数据时,选择 y:
是否本地加速(y/n)? y
您应该会在运行时终端看到以下输出:
2024-12-16T05:12:45.803694Z INFO runtime::init::dataset: 数据集 taxi_trips 已注册 (spice.ai/spiceai/quickstart/datasets/taxi_trips), 加速方式 (arrow, 每10秒刷新), 结果缓存已启用。
2024-12-16T05:12:45.805494Z INFO runtime::accelerated_table::refresh_task: 正在加载数据集 taxi_trips 的数据
2024-12-16T05:13:24.218345Z INFO runtime::accelerated_table::refresh_task: 已为数据集 taxi_trips 加载 2,964,624 行数据(8.41 GiB),耗时 38 秒 412 毫秒。
步骤 5. 在新的终端窗口中,使用 Spice SQL REPL 查询数据集
spice sql
SELECT tpep_pickup_datetime, passenger_count, trip_distance from taxi_trips LIMIT 10;
输出将显示查询结果以及查询执行时间:
+----------------------+-----------------+---------------+
| tpep_pickup_datetime | passenger_count | trip_distance |
+----------------------+-----------------+---------------+
| 2024-01-11T12:55:12 | 1 | 0.0 |
| 2024-01-11T12:55:12 | 1 | 0.0 |
| 2024-01-11T12:04:56 | 1 | 0.63 |
| 2024-01-11T12:18:31 | 1 | 1.38 |
| 2024-01-11T12:39:26 | 1 | 1.01 |
| 2024-01-11T12:18:58 | 1 | 5.13 |
| 2024-01-11T12:43:13 | 1 | 2.9 |
| 2024-01-11T12:05:41 | 1 | 1.36 |
| 2024-01-11T12:20:41 | 1 | 1.11 |
| 2024-01-11T12:37:25 | 1 | 2.04 |
+----------------------+-----------------+---------------+
时间:0.00538925 秒。10 行。
您可以尝试使用未加速的数据集来体验查询生成所需的时间。您可以在 datasets.yaml 文件中将加速设置从 true 更改为 false。
📄 文档
完整的文档可在 spiceai.org/docs 上找到。
超过 45 个快速入门和示例可在 Spice Cookbook 中找到。
🔌 可扩展性
Spice.ai 被设计为可扩展的,并在 EXTENSIBILITY.md 中记录了扩展点。您可以构建自定义的 数据连接器、数据加速器、目录连接器、秘密存储、模型 或 嵌入。
🔨 即将推出的功能
🚀 请参阅 Roadmap 以了解即将推出的功能。
🤝 与我们联系
我们非常感谢并珍视您的支持!您可以通过多种方式帮助 Spice:
- 使用 Spice.ai 构建应用程序,并通过 hey@spice.ai 或在 Discord、X 或 LinkedIn 上向我们发送反馈和建议。
- 如果您发现某些功能未能正常工作,请 提交问题。
- 加入我们的团队 (我们正在招聘!)。
- 为项目贡献代码或文档(请参阅 CONTRIBUTING.md)。
- 关注我们的博客 spiceai.org/blog。
⭐️ 请给这个仓库加星标!感谢您的支持! 🙏
版本历史
v1.11.52026/04/01v1.11.42026/03/12v1.11.32026/03/09v2.0.0-rc.12026/03/04v1.11.22026/02/18v1.11.12026/02/10v1.11.02026/01/28v1.11.0-rc.32026/01/23v1.11.0-rc.22026/01/21v1.11.0-rc.12026/01/07v1.10.42026/01/05v1.10.32025/12/29v1.10.22025/12/22v1.10.12025/12/16v1.10.02025/12/09v1.10.0-rc.12025/12/03v1.9.2.d2541e82025/12/04v1.9.22025/11/26v1.9.12025/11/25v1.9.02025/11/19常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。