skfolio
skfolio 是一款基于 Python 的开源库,专为投资组合优化和风险管理设计。它巧妙地将现代机器学习理念引入金融领域,构建在广泛使用的 scikit-learn 框架之上。
许多量化从业者常面临模型接口不统一、策略验证繁琐的痛点。skfolio 通过提供与 scikit-learn 完全兼容的统一接口,简化了投资组合模型的构建、微调、交叉验证及压力测试流程。用户无需学习全新的 API,即可利用熟悉的机器学习工作流来管理金融资产。
skfolio 非常适合量化研究员、数据科学家、金融工程师以及致力于探索机器学习在资产配置中应用的开发者。其独特优势在于深度整合了 scikit-learn 生态,支持多种先进的优化算法和风险度量方法,同时保持代码的规范性与可维护性。无论是进行学术探索还是开发企业级交易系统,skfolio 都能提供稳定可靠的底层支持,助力实现更科学的资产配置决策。
使用场景
某中型资产管理公司的量化研究员负责管理一个包含股票、债券和商品的混合投资组合,需每周根据市场数据动态调整权重。
没有 skfolio 时
- 需要从零编写凸优化求解代码,数学公式实现复杂且极易引入数值误差
- 风险模型与预期收益的整合缺乏统一框架,不同策略间难以横向对比
- 策略参数调整依赖手动循环脚本,无法利用 scikit-learn 生态的并行计算加速
- 缺乏内置的压力测试模块,难以在极端行情下快速评估组合的稳健性
使用 skfolio 后
- 采用类似 scikit-learn 的统一 estimator 接口,快速搭建从数据清洗到优化的完整管道
- 内置多种成熟的风险估计器和优化器,大幅减少底层数学库的重复开发工作
- 支持 GridSearchCV 等标准方法,自动化筛选最优策略参数并验证泛化能力
- 提供便捷的应力测试模块,一键模拟市场崩盘情景并可视化风险敞口变化
skfolio 通过将复杂的金融工程问题转化为标准化的机器学习流程,显著提升了投资组合管理的研发效率与可靠性。
运行环境要求
- 未说明
未说明
未说明
快速开始
.. -- mode: rst --
|Licence| |Codecov| |Black| |PythonVersion| |PyPi| |CI/CD| |Downloads| |Ruff| |Contribution| |Website| |JupyterLite| |Discord| |DOI|
.. |Licence| image:: https://img.shields.io/badge/License-BSD%203--Clause-blue.svg :target: https://github.com/skfolio/skfolio/blob/main/LICENSE
{kind=link}
.. |Codecov| image:: https://codecov.io/gh/skfolio/skfolio/graph/badge.svg?token=KJ0SE4LHPV :target: https://codecov.io/gh/skfolio/skfolio
{kind=link}
.. |PythonVersion| image:: https://img.shields.io/badge/python-3.10%20%7C%203.11%20%7C%203.12%20%7C%203.13-blue.svg :target: https://pypi.org/project/skfolio/
{kind=link}
.. |PyPi| image:: https://img.shields.io/pypi/v/skfolio :target: https://pypi.org/project/skfolio
.. |Black| image:: https://img.shields.io/badge/code%20style-black-000000.svg :target: https://github.com/psf/black
{kind=link}
.. |CI/CD| image:: https://img.shields.io/github/actions/workflow/status/skfolio/skfolio/release.yml.svg?logo=github :target: https://github.com/skfolio/skfolio/raw/main/LICENSE
{kind=link}
.. |Downloads| image:: https://static.pepy.tech/badge/skfolio :target: https://pepy.tech/project/skfolio
.. |Ruff| image:: https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json :target: https://github.com/astral-sh/ruff
.. |Contribution| image:: https://img.shields.io/badge/Contributions-Welcome-blue :target: https://github.com/skfolio/skfolio/blob/main/CONTRIBUTING.md
.. |Website| image:: https://img.shields.io/website.svg?down_color=red&down_message=down&up_color=53cc0d&up_message=up&url=https://skfolio.org :target: https://skfolio.org
{kind=link}
.. |JupyterLite| image:: https://jupyterlite.rtfd.io/en/latest/_static/badge.svg :target: https://skfolio.org/lite
{kind=link}
.. |Discord| image:: https://img.shields.io/badge/Discord-Join%20Chat-5865F2?logo=discord&logoColor=white :target: https://discord.gg/Bu7EtNYugS
.. |DOI| image:: https://zenodo.org/badge/731792488.svg :target: https://doi.org/10.5281/zenodo.16148630
{kind=link}
.. |PythonMinVersion| replace:: 3.10 .. |NumpyMinVersion| replace:: 1.23.4 .. |ScipyMinVersion| replace:: 1.8.0 .. |PandasMinVersion| replace:: 1.4.1 .. |CvxpyBaseMinVersion| replace:: 1.5.0 .. |ClarabelMinVersion| replace:: 0.9.0 .. |SklearnMinVersion| replace:: 1.6.0 .. |JoblibMinVersion| replace:: 1.3.2 .. |PlotlyMinVersion| replace:: 5.22.0
=============== |icon| skfolio
.. |icon| image:: https://raw.githubusercontent.com/skfolio/skfolio/master/docs/_static/logo_animate.svg :width: 100 :alt: skfolio documentation :target: https://skfolio.org/
{kind=link}
skfolio 是一个基于 scikit-learn(一个流行的 Python 机器学习库)构建的投资组合优化和风险管理 Python 库。它提供与 scikit-learn 兼容的统一接口和工具,用于构建、微调、交叉验证和压力测试投资组合模型。
该项目采用开源的 3-Clause BSD 许可证分发。
skfolio 由 Skfolio Labs <https://skfoliolabs.com>_ 支持,后者为机构提供企业支持和 SLA(服务等级协议)。
.. image:: https://raw.githubusercontent.com/skfolio/skfolio/master/docs/_static/expo.jpg :target: https://skfolio.org/auto_examples/ :alt: examples
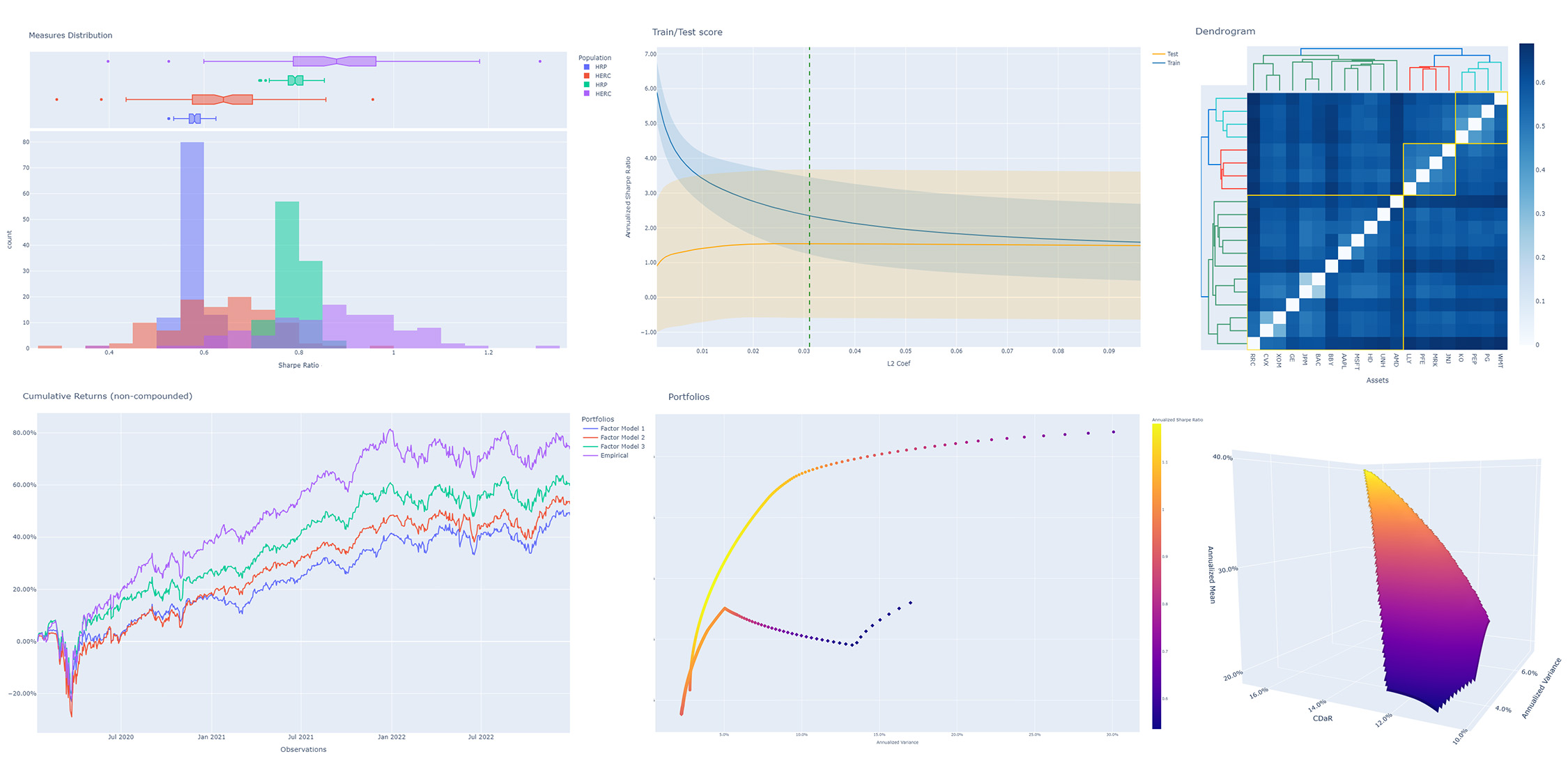{kind=link}
重要链接
- `文档 <https://skfolio.org/>`_
- `示例 <https://skfolio.org/auto_examples/>`_
- `用户指南 <https://skfolio.org/user_guide/>`_
- `GitHub 仓库 <https://github.com/skfolio/skfolio>`_
- `企业支持 <https://skfoliolabs.com>`_
收录于
~~~~~~~~~~~
* Daniel P. Palomar 所著的《投资组合优化:理论与实践》(`Portfolio Optimization: Theory and Application <https://portfoliooptimizationbook.com/>`_),其中包含使用 skfolio 的 Python 代码示例。
安装
~~~~~~~~~~~~
`skfolio` 可在 PyPI 上获取,并使用以下命令安装:::
pip install -U skfolio
依赖项
~~~~~~~~~~~~
`skfolio` 需要:
- python (>= |PythonMinVersion|)
- numpy (>= |NumpyMinVersion|)
- scipy (>= |ScipyMinVersion|)
- pandas (>= |PandasMinVersion|)
- cvxpy-base (>= |CvxpyBaseMinVersion|)
- clarabel (>= |ClarabelMinVersion|)
- scikit-learn (>= |SklearnMinVersion|)
- joblib (>= |JoblibMinVersion|)
- plotly (>= |PlotlyMinVersion|)
Docker
~~~~~~
您还可以使用 Docker 启动可复现的 JupyterLab 环境:
构建镜像:::
docker build -t skfolio-jupyterlab .
运行容器:::
docker run -p 8888:8888 -v <path-to-your-folder-containing-data>:/app/data -it skfolio-jupyterlab
浏览:
打开 localhost:8888/lab 并开始使用 `skfolio`
核心概念
~~~~~~~~~~~~
自 Markowitz(1952)提出现代投资组合理论以来,均值 - 方差优化(MVO)受到了广泛关注。
不幸的是,它面临许多缺点,包括对输入参数(预期收益和协方差)的高度敏感性、权重集中、高换手率以及样本外表现不佳。
众所周知,朴素配置(如 1/N、反波动率等)往往在样本外优于 MVO(DeMiguel, 2007)。
为了缓解这些缺点,人们开发了许多方法(收缩估计、额外约束、正则化、不确定性集、高阶矩、贝叶斯方法、相干风险度量、左尾风险优化、分布鲁棒优化、因子模型、风险平价、层次聚类、集成方法、预筛选等)。
鉴于方法数量众多,且它们可以组合使用,因此需要一个统一的框架,采用机器学习方法进行模型选择、验证和参数调优,同时降低数据泄露和过拟合的风险。
该框架建立在 scikit-learn 的应用程序接口(API)之上。
可用模型
投资组合优化:
- 朴素:
- 等权重
- 反波动率
- 随机(狄利克雷)
- 凸优化:
- 均值 - 风险
- 风险预算
- 最大分散化
- 分布鲁棒条件风险价值(CVaR)
- 基准跟踪
- 聚类:
- 层次风险平价
- 层次等风险贡献
- 舒尔补分配
- 嵌套簇优化
- 集成方法:
- 堆叠优化
- 朴素:
预期收益估计器:
- 经验估计
- 指数加权
- 均衡
- 收缩
协方差估计器:
- 经验估计
- Gerber
- 去噪
- Detoning
- 指数加权
- Ledoit-Wolf
- Oracle 近似收缩
- 收缩协方差
- Graphical Lasso CV
- 隐含协方差
距离估计器:
- 皮尔逊距离
- 肯德尔距离
- 斯皮尔曼距离
- 协方差距离(基于上述任意一种协方差估计器)
- 距离相关系数
- 信息变异
分布估计器:
- 单变量:
- 高斯
- 学生 t
- Johnson Su
- 正态逆高斯
- 二元 Copula(相依结构)
- 高斯 Copula
- 学生 t Copula
- Clayton Copula
- Gumbel Copula
- Joe Copula
- 独立 Copula
- 多变量
- Vine Copula(藤结构 Copula)(规则、中心化、聚类、条件采样)
- 单变量:
先验估计器:
- 经验估计
- Black & Litterman
- 因子模型
- 合成数据(压力测试、因子压力测试)
- 熵池法
- 意见池法
不确定性集估计器:
- 关于预期收益:
- 经验估计
- 循环 Bootstrap(自助法)
- 关于协方差:
- 经验估计
- 循环 Bootstrap(自助法)
- 关于预期收益:
预选择转换器:
- 非支配选择
- 选择 K 个极值(最佳或最差)
- 剔除高相关性资产
- 选择不即将到期的资产
- 选择完整资产(处理晚成立、退市等)
- 剔除零方差
交叉验证与模型选择:
- 兼容所有
sklearn方法(如 KFold 等) - 向前滚动
- 组合净化交叉验证
- 多次随机交叉验证
- 兼容所有
超参数调优:
- 兼容所有
sklearn方法(如 GridSearchCV、RandomizedSearchCV)
- 兼容所有
风险度量:
- 方差
- 半方差
- 平均绝对偏差
- 一阶下偏矩
- CVaR(条件在险价值)
- EVaR(熵在险价值)
- 最差实现
- CDaR(条件回撤风险)
- 最大回撤
- 平均回撤
- EDaR(熵回撤风险)
- 溃疡指数
- 基尼平均差
- 在险价值 (VaR)
- 回撤风险
- 熵风险度量
- 四阶中心矩
- 四阶下偏矩
- 偏度
- 峰度
优化特性:
- 最小化风险
- 最大化收益
- 最大化效用
- 最大化比率
- 交易成本
- 管理费
- L1 和 L2 正则化
- 权重约束
- 组约束
- 预算约束
- 跟踪误差约束
- 换手率约束
- 基数和组基数约束
- 阈值(做多和做空)约束
快速开始
以下代码片段旨在介绍 `skfolio` 的功能,以便您能快速开始使用。它遵循与 scikit-learn 相同的 API。
导入
-------
.. code-block:: python
from sklearn import set_config
from sklearn.model_selection import (
GridSearchCV,
KFold,
RandomizedSearchCV,
train_test_split,
)
from sklearn.pipeline import Pipeline
from scipy.stats import loguniform
from skfolio import RatioMeasure, RiskMeasure
from skfolio.datasets import load_factors_dataset, load_sp500_dataset
from skfolio.distribution import VineCopula
from skfolio.model_selection import (
CombinatorialPurgedCV,
WalkForward,
cross_val_predict,
)
from skfolio.moments import (
DenoiseCovariance,
DetoneCovariance,
EWMu,
GerberCovariance,
ShrunkMu,
)
from skfolio.optimization import (
MeanRisk,
HierarchicalRiskParity,
NestedClustersOptimization,
ObjectiveFunction,
RiskBudgeting,
)
from skfolio.pre_selection import SelectKExtremes
from skfolio.preprocessing import prices_to_returns
from skfolio.prior import (
BlackLitterman,
EmpiricalPrior,
EntropyPooling,
FactorModel,
OpinionPooling,
SyntheticData,
)
from skfolio.uncertainty_set import BootstrapMuUncertaintySet
加载数据集
------------
.. code-block:: python
prices = load_sp500_dataset()
训练/测试集划分
----------------
.. code-block:: python
X = prices_to_returns(prices)
X_train, X_test = train_test_split(X, test_size=0.33, shuffle=False)
最小方差
----------------
.. code-block:: python
model = MeanRisk()
在训练集上拟合
-------------------
.. code-block:: python
model.fit(X_train)
print(model.weights_)
在测试集上预测
-------------------
.. code-block:: python
portfolio = model.predict(X_test)
print(portfolio.annualized_sharpe_ratio)
print(portfolio.summary())
最大索提诺比率
---------------------
.. code-block:: python
model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
risk_measure=RiskMeasure.SEMI_VARIANCE,
)
去噪协方差与收缩预期收益
---------------------------------------------
.. code-block:: python
model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
prior_estimator=EmpiricalPrior(
mu_estimator=ShrunkMu(), covariance_estimator=DenoiseCovariance()
),
)
预期收益的不确定性集
-----------------------------------
.. code-block:: python
model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
mu_uncertainty_set_estimator=BootstrapMuUncertaintySet(),
)
权重约束与交易成本
--------------------------------------
.. code-block:: python
model = MeanRisk(
min_weights={"AAPL": 0.10, "JPM": 0.05},
max_weights=0.8,
transaction_costs={"AAPL": 0.0001, "RRC": 0.0002},
groups=[
["Equity"] * 3 + ["Fund"] * 5 + ["Bond"] * 12,
["US"] * 2 + ["Europe"] * 8 + ["Japan"] * 10,
],
linear_constraints=[
"Equity <= 0.5 * Bond",
"US >= 0.1",
"Europe >= 0.5 * Fund",
"Japan <= 1",
],
)
model.fit(X_train)
基于 CVaR 的风险平价
-------------------
.. code-block:: python
model = RiskBudgeting(risk_measure=RiskMeasure.CVAR)
风险平价与 Gerber 协方差
-------------------------------
.. code-block:: python
model = RiskBudgeting(
prior_estimator=EmpiricalPrior(covariance_estimator=GerberCovariance())
)
带交叉验证和平行化的嵌套聚类优化
---------------------------------------------------------------------
.. code-block:: python
model = NestedClustersOptimization(
inner_estimator=MeanRisk(risk_measure=RiskMeasure.CVAR),
outer_estimator=RiskBudgeting(risk_measure=RiskMeasure.VARIANCE),
cv=KFold(),
n_jobs=-1,
)
L2 范数的随机搜索
--------------------------------
.. code-block:: python
randomized_search = RandomizedSearchCV(
estimator=MeanRisk(),
cv=WalkForward(train_size=252, test_size=60),
param_distributions={
"l2_coef": loguniform(1e-3, 1e-1),
},
)
randomized_search.fit(X_train)
best_model = randomized_search.best_estimator_
print(best_model.weights_)
嵌入参数的网格搜索
----------------------------------
.. code-block:: python
model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
risk_measure=RiskMeasure.VARIANCE,
prior_estimator=EmpiricalPrior(mu_estimator=EWMu(alpha=0.2)),
)
print(model.get_params(deep=True))
gs = GridSearchCV(
estimator=model,
cv=KFold(n_splits=5, shuffle=False),
n_jobs=-1,
param_grid={
"risk_measure": [
RiskMeasure.VARIANCE,
RiskMeasure.CVAR,
RiskMeasure.VARIANCE.CDAR,
],
"prior_estimator__mu_estimator__alpha": [0.05, 0.1, 0.2, 0.5],
},
)
gs.fit(X)
best_model = gs.best_estimator_
print(best_model.weights_)
Black & Litterman 模型
-----------------------
.. code-block:: python
views = ["AAPL - BBY == 0.03 ", "CVX - KO == 0.04", "MSFT == 0.06 "]
model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
prior_estimator=BlackLitterman(views=views),
)
因子模型
------------
.. code-block:: python
factor_prices = load_factors_dataset()
X, factors = prices_to_returns(prices, factor_prices)
X_train, X_test, factors_train, factors_test = train_test_split(
X, factors, test_size=0.33, shuffle=False
)
model = MeanRisk(prior_estimator=FactorModel())
model.fit(X_train, factors_train)
print(model.weights_)
portfolio = model.predict(X_test)
print(portfolio.calmar_ratio)
print(portfolio.summary())
因子模型与协方差去噪
----------------------------------
.. code-block:: python
model = MeanRisk(
prior_estimator=FactorModel(
factor_prior_estimator=EmpiricalPrior(covariance_estimator=DetoneCovariance())
)
)
Black & Litterman 因子模型
------------------------------
.. code-block:: python
factor_views = ["MTUM - QUAL == 0.03 ", "VLUE == 0.06"]
model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
prior_estimator=FactorModel(
factor_prior_estimator=BlackLitterman(views=factor_views),
),
)
预选择管道
----------------------
.. code-block:: python
set_config(transform_output="pandas")
model = Pipeline(
[
("pre_selection", SelectKExtremes(k=10, highest=True)),
("optimization", MeanRisk()),
]
)
model.fit(X_train)
portfolio = model.predict(X_test)
K 折交叉验证
-----------------------
.. code-block:: python
model = MeanRisk()
mmp = cross_val_predict(model, X_test, cv=KFold(n_splits=5))
# mmp is the predicted MultiPeriodPortfolio object composed of 5 Portfolios (1 per testing fold)
mmp.plot_cumulative_returns()
print(mmp.summary())
组合净化交叉验证
-------------------------------------
.. code-block:: python
model = MeanRisk()
cv = CombinatorialPurgedCV(n_folds=10, n_test_folds=2)
print(cv.summary(X_train))
population = cross_val_predict(model, X_train, cv=cv)
population.plot_distribution(
measure_list=[RatioMeasure.SHARPE_RATIO, RatioMeasure.SORTINO_RATIO]
)
population.plot_cumulative_returns()
print(population.summary())
合成收益上的最小 CVaR 优化
----------------------------------------------
.. code-block:: python
vine = VineCopula(log_transform=True, n_jobs=-1)
prior = SyntheticData(distribution_estimator=vine, n_samples=2000)
model = MeanRisk(risk_measure=RiskMeasure.CVAR, prior_estimator=prior)
model.fit(X)
print(model.weights_)
压力测试
-----------
.. code-block:: python
vine = VineCopula(log_transform=True, central_assets=["BAC"], n_jobs=-1)
vine.fit(X)
X_stressed = vine.sample(n_samples=10_000, conditioning = {"BAC": -0.2})
ptf_stressed = model.predict(X_stressed)
合成因子上的最小 CVaR 优化
----------------------------------------------
.. code-block:: python
vine = VineCopula(central_assets=["QUAL"], log_transform=True, n_jobs=-1)
factor_prior = SyntheticData(
distribution_estimator=vine,
n_samples=10_000,
sample_args=dict(conditioning={"QUAL": -0.2}),
)
factor_model = FactorModel(factor_prior_estimator=factor_prior)
model = MeanRisk(risk_measure=RiskMeasure.CVAR, prior_estimator=factor_model)
model.fit(X, factors)
print(model.weights_)
因子压力测试
------------------
.. code-block:: python
factor_model.set_params(factor_prior_estimator__sample_args=dict(
conditioning={"QUAL": -0.5}
))
factor_model.fit(X, factors)
stressed_dist = factor_model.return_distribution_
stressed_ptf = model.predict(stressed_dist)
熵池
---------------
.. code-block:: python
entropy_pooling = EntropyPooling(
mean_views=[
"JPM == -0.002",
"PG >= LLY",
"BAC >= prior(BAC) * 1.2",
],
cvar_views=[
"GE == 0.08",
],
)
entropy_pooling.fit(X)
print(entropy_pooling.relative_entropy_)
print(entropy_pooling.effective_number_of_scenarios_)
print(entropy_pooling.return_distribution_.sample_weight)
基于熵池的 CVaR 层次风险平价优化
-------------------------------------------------------------
.. code-block:: python
entropy_pooling = EntropyPooling(cvar_views=["GE == 0.08"])
model = HierarchicalRiskParity(
risk_measure=RiskMeasure.CVAR,
prior_estimator=entropy_pooling
)
model.fit(X)
print(model.weights_)
基于因子合成数据的熵池压力测试
---------------------------------------------------------
.. code-block:: python
# Regular Vine Copula and sampling of 100,000 synthetic factor returns
factor_synth = SyntheticData(
n_samples=100_000,
distribution_estimator=VineCopula(log_transform=True, n_jobs=-1, random_state=0)
)
# Entropy Pooling by imposing a CVaR-95% of 10% on the Quality factor
factor_entropy_pooling = EntropyPooling(
prior_estimator=factor_synth,
cvar_views=["QUAL == 0.10"],
)
factor_entropy_pooling.fit(X, factors)
# We retrieve the stressed distribution:
stressed_dist = factor_model.return_distribution_
# We stress-test our portfolio:
stressed_ptf = model.predict(stressed_dist)
意见池化
---------------
.. code-block:: python
# We consider two expert opinions, each generated via Entropy Pooling with
# user-defined views.
# We assign probabilities of 40% to Expert 1, 50% to Expert 2, and by default
# the remaining 10% is allocated to the prior distribution:
opinion_1 = EntropyPooling(cvar_views=["AMD == 0.10"])
opinion_2 = EntropyPooling(
mean_views=["AMD >= BAC", "JPM <= prior(JPM) * 0.8"],
cvar_views=["GE == 0.12"],
)
opinion_pooling = OpinionPooling(
estimators=[("opinion_1", opinion_1), ("opinion_2", opinion_2)],
opinion_probabilities=[0.4, 0.5],
)
opinion_pooling.fit(X)
致谢
我们要感谢所有直接依赖项(dependencies)的贡献者,例如
scikit-learn <https://github.com/scikit-learn/scikit-learn>_ 和 cvxpy <https://github.com/cvxpy/cvxpy>_,以及以下资源的贡献者:
* PyPortfolioOpt
* Riskfolio-Lib
* scikit-portfolio
* statsmodels
* rsome
* `Microprediction <https://github.com/microprediction>`_ (Peter Cotton)
* `Portfolio Optimization Book <https://portfoliooptimizationbook.com/>`_ (Daniel P. Palomar)
* `quantresearch.org <https://quantresearch.org>`_ (Marcos López de Prado)
* gautier.marti.ai (Gautier Marti)
引用
如果您在科学出版物中使用 `skfolio`,我们将感激您的引用:
**该库:**
.. code-block:: bibtex
@software{skfolio,
title = {skfolio},
author = {Delatte, Hugo and Nicolini, Carlo and Manzi, Matteo},
year = {2024},
doi = {10.5281/zenodo.16148630},
url = {https://doi.org/10.5281/zenodo.16148630}
}
上述使用了 DOI(数字对象标识符)概念,它始终解析为最新版本。
如果您需要精确的可复现性(reproducibility),特别是对于要求此特性的期刊或会议,您可以引用您所用确切版本的特定版本 DOI。要查找它,
请访问我们的 `Zenodo 项目页面 <https://doi.org/10.5281/zenodo.16148630>`_,找到您希望引用的版本(例如 "v0.10.2"),并复制该版本旁边列出的 DOI。
**论文:**
.. code-block:: bibtex
@article{nicolini2025skfolio,
title = {skfolio: Portfolio Optimization in Python},
author = {Nicolini, Carlo and Manzi, Matteo and Delatte, Hugo},
journal = {arXiv preprint arXiv:2507.04176},
year = {2025},
eprint = {2507.04176},
archivePrefix = {arXiv},
url = {https://arxiv.org/abs/2507.04176}
}
版本历史
v0.17.02026/04/05v0.16.12026/03/24v0.16.02026/03/22v0.15.72026/03/14v0.15.62026/03/08v0.15.52026/02/10v0.15.42026/01/29v0.15.32025/12/19v0.15.22025/12/02v0.15.12025/12/02v0.15.02025/11/20v0.14.32025/11/12v0.14.22025/10/21v0.14.12025/10/14v0.14.02025/10/09v0.13.02025/09/08v0.12.02025/09/06v0.11.02025/07/26v0.10.22025/07/19v0.10.12025/06/17常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。