tau2-bench
tau2-bench 是一个专为评估现实世界中“工具 - 智能体 - 用户”交互性能而设计的仿真基准框架。它主要解决了当前 AI 客服智能体在复杂业务场景下缺乏标准化、高质量评估手段的难题,帮助开发者量化智能体在遵循业务政策、调用外部工具以及处理多轮对话时的真实表现。
该工具非常适合 AI 研究人员、大模型应用开发者以及企业级智能体构建者使用。通过模拟航空、零售、电信及银行业务等多种真实领域,tau2-bench 能够测试智能体是否能在严格约束下准确完成任务。其独特的技术亮点在于支持从传统的文本半双工(轮流对话)到先进的语音全双工(实时双向通话)评估模式,并集成了基于检索增强生成(RAG)的知识库查询能力。此外,最新版本还修复了大量任务逻辑缺陷,提供了包含实时语音交互和知识检索的综合排行榜,为优化智能体的协作能力提供了可靠的数据支撑。
使用场景
某金融科技团队正在开发一款能处理复杂银行业务的智能客服 Agent,需要在上线前验证其能否准确调用内部工具并遵守合规政策。
没有 tau2-bench 时
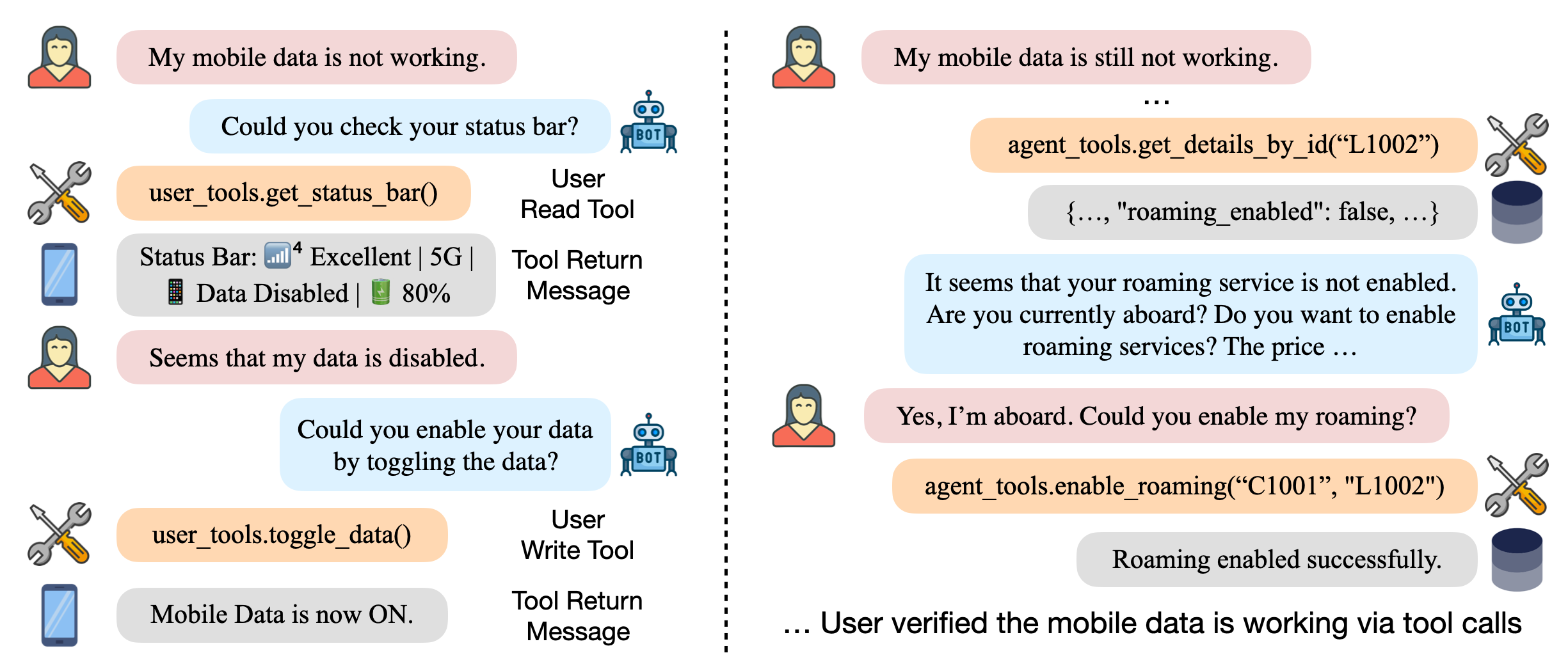
- 测试场景单一:仅能用简单的文本问答进行测试,无法模拟真实用户在电话中打断、插话的全双工语音交互场景。
- 知识检索黑盒:难以评估 Agent 在涉及具体银行条款(如利率政策、转账限额)时,是否能正确通过 RAG 检索文档而非胡乱编造。
- 规则遵循风险:缺乏系统化的方法验证 Agent 是否严格遵守“不得向未授权用户透露余额”等关键业务策略,容易埋下合规隐患。
- 反馈模糊低效:测试失败后只能看到最终结果错误,无法复现和分析 Agent 调用工具的具体轨迹,导致调试如同大海捞针。
使用 tau2-bench 后
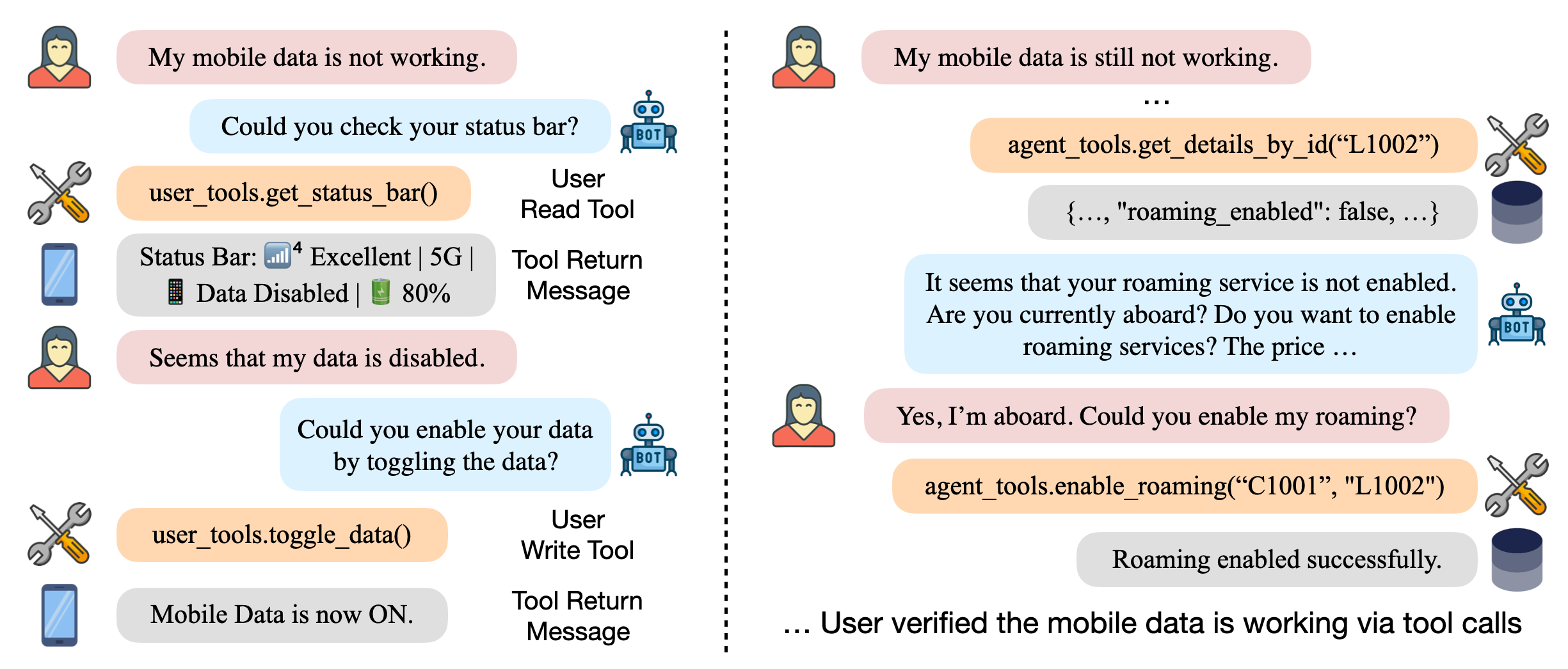
- 全真语音演练:利用
voice模块接入实时音频 API,直接在模拟用户随时插话的嘈杂环境中,压力测试 Agent 的响应稳定性。 - 知识能力量化:通过
banking_knowledge领域任务,精确测量 Agent 检索内部文档的准确率,确保回答有据可依。 - 策略执行可视:在
airline或retail等预设场景中,自动检测 Agent 是否越权操作,将隐性的合规风险转化为显性的评测分数。 - 轨迹深度诊断:借助详细的交互轨迹记录,快速定位是工具参数传错还是逻辑判断失误,将模型迭代周期从数天缩短至数小时。
tau2-bench 将原本依赖人工经验的模糊测试,转变为可量化、全覆盖的自动化评估体系,确保智能代理在真实世界中既聪明又守规矩。
运行环境要求
- macOS
- Linux
- Windows
未说明
未说明
快速开始
τ-基准:面向真实世界领域的工具-智能体-用户交互基准测试
![]()
![]()

τ³-基准怎么读? 我们就叫“塔乌三”,不过你怎么念都行!
τ³-基准的新特性
- 知识领域(
banking_knowledge) — 基于知识检索的客服领域,配备可配置的RAG管道、文档搜索、嵌入以及基于智能体外壳的搜索。了解更多 → - 语音全双工(音频原生) — 使用实时API(OpenAI、Gemini、xAI)进行端到端的语音评估。了解更多 →
- 任务质量(75+项修复) — 移除了不正确的预期动作,澄清了模糊的指令,修复了不可能的约束,并在航空、零售和银行领域中添加了缺失的回退行为。基于SABER(Cuadron等人,2025年)的分析。了解更多 →
- 更新后的排行榜 — 现在包括语音和知识评估结果。可在taubench.com上比较模型性能。提交你的结果 →
完整版本历史请参阅CHANGELOG.md。
向后兼容性说明:如果你只是评估智能体(而非训练),请使用
base任务划分来评估与原始τ-基准结构匹配的完整任务集。这是默认设置。
从τ²-基准升级吗? 安装现在使用
uv而不是pip install -e .,且需要Python>=3.12, <3.14(之前是>=3.10)。部分内部API已被重构——详情请参阅CHANGELOG.md。
概述
τ-基准是一个用于评估跨多个领域的客服智能体的仿真框架。它支持基于文本的半双工(轮流式)评估,以及使用实时音频API进行的语音全双工(同时进行)评估。
每个领域指定:
- 智能体必须遵循的策略
- 智能体可以使用的工具集合
- 用于评估智能体表现的任务集合
- 可选:用户模拟器的用户工具集合
可用领域:mock · airline · retail · telecom · banking_knowledge
| 模式 | 描述 |
|---|---|
| 文本(半双工) | 轮流式聊天并使用工具 |
| 语音(全双工) | 通过实时提供商(OpenAI、Gemini、xAI)进行端到端的音频 |
快速入门
1. 安装
git clone https://github.com/sierra-research/tau2-bench
cd tau2-bench
uv sync # 仅核心(文本模式:航空、零售、电信、mock)
可选扩展(按需安装):
uv sync --extra voice # + 语音/音频原生功能
uv sync --extra knowledge # + banking_knowledge领域(检索管道)
uv sync --extra gym # + gymnasium RL接口
uv sync --extra dev # + pytest、ruff、pre-commit(贡献时必需)
uv sync --all-extras # 全部
这需要uv。语音功能还需要系统依赖(macOS上需brew install portaudio ffmpeg)。详细信息请参阅完整安装指南。
2. 设置API密钥
cp .env.example .env
# 编辑.env文件,填入你的API密钥(使用LiteLLM — 任何支持的提供商均可)
3. 运行评估
tau2 run --domain airline --agent-llm gpt-4.1 --user-llm gpt-4.1 \
--num-trials 1 --num-tasks 5
结果会保存到data/simulations/目录下。使用tau2 view可以浏览这些结果。
提示:运行
tau2 intro可获得可用领域、命令和示例的概览。
文档
入门指南
| 文档 | 描述 |
|---|---|
| 入门指南 | 安装、API密钥、首次运行、输出结构、配置 |
| CLI参考 | 所有tau2命令和选项 |
核心概念
| 文档 | 描述 |
|---|---|
| 智能体开发者指南 | 构建并评估你自己的智能体 |
| 领域 | 领域结构、数据格式及可用领域 |
| 编排器与通信模式 | 半双工和全双工编排 |
知识检索
| 文档 | 描述 |
|---|---|
| 知识检索 | 检索管道配置、嵌入、RAG以及banking_knowledge领域的沙盒设置 |
语音与音频
| 文档 | 描述 |
|---|---|
| 语音(全双工) | 提供商、语音复杂度、CLI选项及语音评估的输出结构 |
| 音频原生架构 | 用于添加或修改实时提供商适配器的内部架构 |
RL与训练
| 文档 | 描述 |
|---|---|
| Gym接口 | 与Gymnasium兼容的环境、游玩模式、训练/测试划分 |
排行榜与实验
| 文档 | 描述 |
|---|---|
| 排行榜提交 | 如何将结果提交至 taubench.com |
| 实验 | 实验性功能和研究代码 |
项目
| 文档 | 描述 |
|---|---|
| 贡献指南 | 如何为 τ-bench 做出贡献 |
| 变更日志 | 版本历史与发布说明 |
贡献
我们欢迎各种形式的贡献!无论您是修复 bug、添加新功能、创建领域,还是贡献研究代码,请参阅我们的 贡献指南,以了解相关规范。
引用
如果您使用了 $\tau^3$-bench 的特定组件,请引用下方对应的论文。
知识领域 (banking_knowledge)
@article{shi2026tau,
title={$\tau$-Knowledge: Evaluating Conversational Agents over Unstructured Knowledge},
author={Shi, Quan and Zytek, Alexandra and Razavi, Pedram and Narasimhan, Karthik and Barres, Victor},
journal={arXiv preprint arXiv:2603.04370},
year={2026}
}
语音全双工基准测试
@misc{ray2026tauvoicebenchmarkingfullduplexvoice,
title={$\tau$-Voice: Benchmarking Full-Duplex Voice Agents on Real-World Domains},
author={Soham Ray and Keshav Dhandhania and Victor Barres and Karthik Narasimhan},
year={2026},
eprint={2603.13686},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.13686},
}
核心 $\tau$-Bench
@misc{barres2025tau2,
title={$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment},
author={Victor Barres and Honghua Dong and Soham Ray and Xujie Si and Karthik Narasimhan},
year={2025},
eprint={2506.07982},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2506.07982},
}
@misc{yao2024tau,
title={$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains},
author={Shunyu Yao and Noah Shinn and Pedram Razavi and Karthik Narasimhan},
year={2024},
eprint={2406.12045},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2406.12045},
}
任务修复
@inproceedings{cuadron2026saber,
title={{SABER}: Small Actions, Big Errors {\textemdash} Safeguarding Mutating Steps in {LLM} Agents},
author={Alejandro Cuadron and Pengfei Yu and Yang Liu and Arpit Gupta},
booktitle={ICLR 2026 Workshop on Memory for LLM-Based Agentic Systems},
year={2026},
url={https://openreview.net/forum?id=En2z9dckgP},
}
版本历史
v1.0.02026/03/18v0.2.02025/10/06v0.1.32025/08/26v0.1.22025/07/17常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。