OpenAlpha_Evolve
OpenAlpha_Evolve 是一款基于 Python 的开源框架,致力于利用大语言模型实现算法的自动化演进。受 DeepMind AlphaEvolve 研究启发,它模拟自然选择机制,通过“生成 - 测试 - 改进”的循环,自主发现并持续优化代码解决方案。
针对传统编程中人工调试效率低、复杂算法探索成本高的问题,OpenAlpha_Evolve 提供了一套完整的自动化流程。用户只需定义任务目标与测试用例,系统便会调度多个智能体协作,从初始代码生成到变异修复,再到性能评估,最终筛选出最优解。
OpenAlpha_Evolve 特别适合希望探索 AI 驱动编程、自动化问题解决的研究人员和开发者。其核心亮点在于模块化代理架构,涵盖提示词设计、代码生成、评估及选择控制器,并支持基于差异(diff)的代码迭代更新。这不仅降低了算法创新的门槛,也为构建更智能的自主编码系统提供了可扩展的基础设施,让 AI 真正参与到代码进化的过程中。
使用场景
某金融风控团队正在攻坚一个实时交易数据清洗模块,要求在毫秒级高并发下将处理延迟降低 50%。
没有 OpenAlpha_Evolve 时
- 资深工程师需反复手写不同策略,人工排查 Bug 效率低下且易疲劳出错。
- 传统单元测试难以覆盖所有极端输入,导致线上偶尔出现未预见的异常。
- 算法调优依赖直觉,缺乏量化指标来科学衡量每次改进的实际 fitness 值。
- 跨团队协作中,优化逻辑难以复现,新人接手维护成本极高。
使用 OpenAlpha_Evolve 后
- OpenAlpha_Evolve 根据任务定义自动生成多组候选代码并并行执行沙箱测试。
- 评估代理自动计算正确率与运行时间,精准淘汰低效方案并保留优质基因。
- 进化循环持续引入变异,逐步逼近最优解,大幅减少人为干预带来的盲区。
- 数据库完整保存演化谱系,确保任何阶段的代码变更都可解释且可回溯。
它将复杂的算法寻优工作转化为自动化、可量化的智能进化流程,显著提升研发效率。
运行环境要求
- Windows
- macOS
- Linux
未说明
未说明
快速开始
OpenAlpha_Evolve:贡献以改进此项目
OpenAlpha_Evolve 是一个开源 Python 框架,灵感来源于 DeepMind 的 AlphaEvolve 等自主编码智能体(autonomous coding agents)的前沿研究。它是对核心思想的再生:一个智能系统,通过 LiteLLM 利用大语言模型(Large Language Models,简称 LLMs),在进化原则的指导下,迭代地编写、测试和改进代码。
我们的使命是为研究人员、开发者和爱好者提供一个易于访问、理解且可扩展的平台,以探索人工智能、代码生成和自动化问题解决之间迷人的交叉领域。
![]()
目录
✨ 愿景:AI 驱动的算法创新
想象一个能够:
- 理解复杂的问题描述。
- 生成初始算法解决方案。
- 严格测试其自身代码。
- 从失败和成功中学习。
- 随时间进化出越来越复杂和高效的算法。
OpenAlpha_Evolve 是迈向这一愿景的一步。这不仅仅是关于生成代码;而是关于创建一个能够自主发现和优化解决方案的系统。
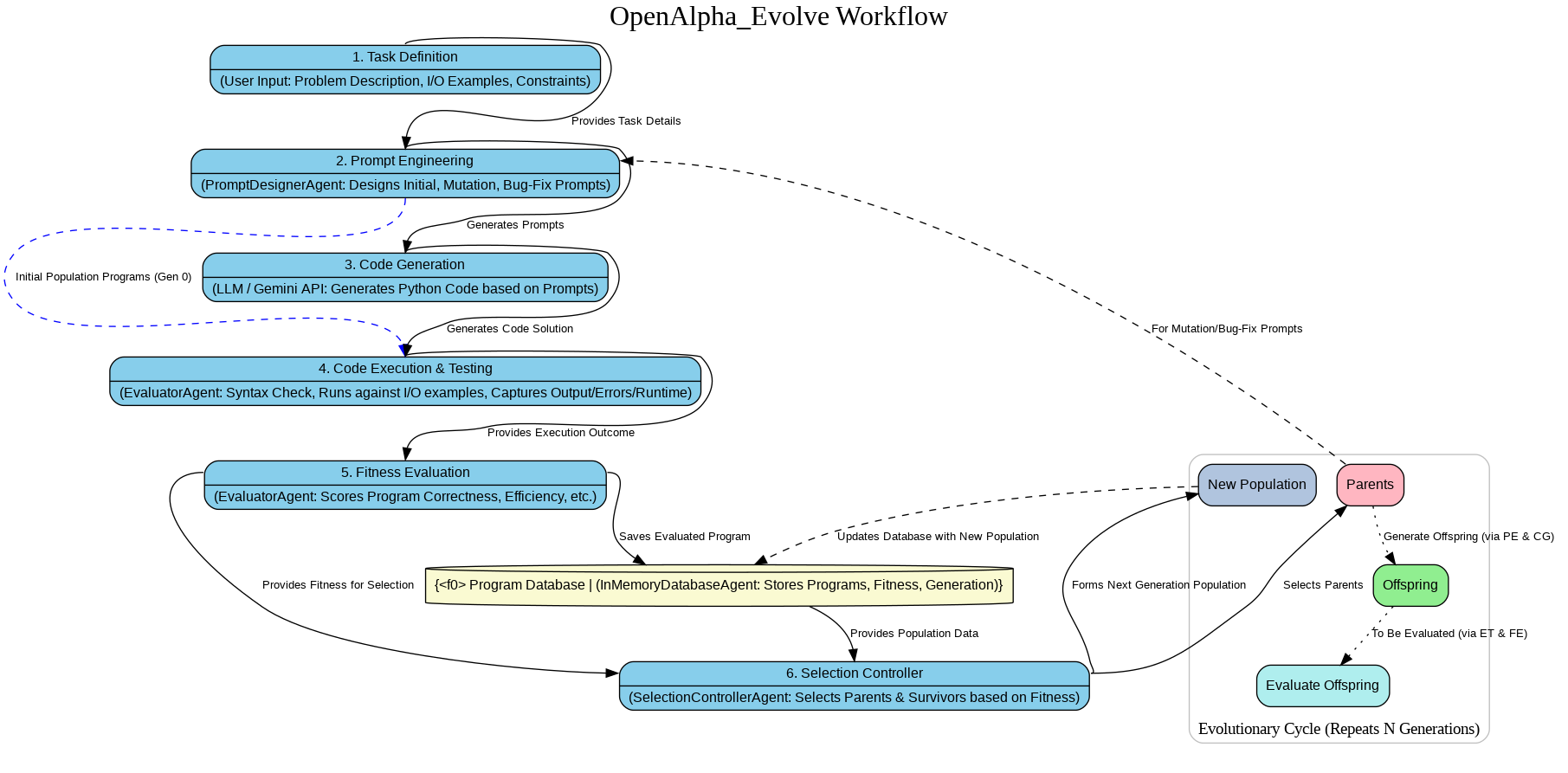
🧠 工作原理:进化循环
OpenAlpha_Evolve 采用模块化、基于智能体(agent-based)的架构来编排进化过程:
- 任务定义(Task Definition):您,即用户,定义算法“任务”——要解决的问题,包括输入和预期输出的示例。
- 提示词工程(Prompt Engineering)(
PromptDesignerAgent):此智能体为 LLM 制作智能提示词。它设计:- 初始提示词(Initial Prompts):用于生成第一组候选解决方案。
- 变异提示词(Mutation Prompts):用于引入现有解决方案的变体和改进,通常要求以“差异(diff)”格式提出更改。
- 错误修复提示词(Bug-Fix Prompts):引导 LLM 纠正先前尝试中的错误,通常也期望返回“差异”。
- 代码生成(Code Generation)(
CodeGeneratorAgent):由 LLM 驱动(当前配置为 Gemini),此智能体接收提示词并生成 Python 代码。如果请求并收到“差异”,它会尝试将更改应用到父代码中。 - 评估(Evaluation)(
EvaluatorAgent):生成的代码接受测试!- 语法检查(Syntax Check):代码是否为有效的 Python?
- 执行(Execution):代码在临时隔离环境中运行,针对任务中定义的输入/输出示例进行测试。
- 适应度评分(Fitness Scoring):程序根据正确性(通过多少测试用例)、效率(运行时间)和其他潜在指标进行评分。
- 数据库(Database)(
DatabaseAgent):所有程序(代码、适应度评分、生成记录、谱系)都被存储,创建进化历史记录(目前为内存中)。 - 选择(Selection)(
SelectionControllerAgent):“适者生存”原则的体现。此智能体选择:- 父代(Parents):来自当前世代有前途的程序,用于产生子代。
- 幸存者(Survivors):来自当前种群和新子代中最好的程序,以进入下一代。
- 迭代(Iteration):此循环重复定义的代数,每一代都旨在产生比上一代更好的解决方案。
- 编排(Orchestration)(
TaskManagerAgent):操作的大师,协调所有其他智能体并管理整体进化循环。
🚀 关键特性
- LLM 驱动的代码生成:利用最先进的 LLMs,通过 LiteLLM,支持多个提供商(OpenAI, Anthropic, Google 等)。
- 进化算法核心:通过选择、LLM 驱动的变异/错误修复(使用 diff)和生存来实现迭代改进。
- 模块化智能体架构:轻松扩展或替换各个组件(例如,使用不同的 LLM、数据库或评估策略)。
- 自动化程序评估:语法检查和针对用户提供的示例的功能测试。代码执行使用 Docker 容器进行沙箱化,以提高安全性和依赖管理,并配备可配置的超时机制。
- 配置管理:通过
config/settings.py和.env轻松调整参数,如种群大小、代数、LLM 模型、API 设置和 Docker 配置。 - 详细日志:全面的日志提供对进化过程每一步的洞察。
- 基于差异的变异:系统设计为使用差异进行变异和错误修复,允许 LLM 进行更有针对性的代码修改。
- 开源与可扩展:使用 Python 构建,专为实验和社区贡献而设计。
📂 项目结构
./
├── code_generator/ # Agent responsible for generating code using LLMs.
├── database_agent/ # Agent for managing the storage and retrieval of programs and their metadata.
├── evaluator_agent/ # Agent that evaluates the generated code for syntax, execution, and fitness.
├── prompt_designer/ # Agent that crafts prompts for the LLM for initial generation, mutation, and bug fixing.
├── selection_controller/ # Agent that implements the selection strategy for parent and survivor programs.
├── task_manager/ # Agent that orchestrates the overall evolutionary loop and coordinates other agents.
├── config/ # Holds configuration files, primarily `settings.py` for system parameters and API keys.
├── core/ # Defines core data structures and interfaces, like `Program` and `TaskDefinition`.
├── tests/ # Includes unit and integration tests to ensure code quality and correctness.
├── main.py # The main entry point to run the OpenAlpha_Evolve system and start an evolutionary run.
├── requirements.txt # Lists all Python package dependencies required to run the project.
├── .env.example # An example file showing the environment variables needed, such as API keys. Copy this to `.env` and fill in your values.
├── .gitignore # Specifies intentionally untracked files that Git should ignore (e.g., `.env`, `__pycache__/`).
├── LICENSE.md # Contains the full text of the MIT License under which the project is distributed.
└── README.md # This file! Provides an overview of the project, setup instructions, and documentation.
🏁 入门指南
前置条件:
- Python 3.10+
pip(包管理工具)git(版本控制工具)- Docker:用于沙箱代码评估。请确保已安装并运行 Docker Desktop(Windows/Mac)或 Docker Engine(Linux)。访问 docker.com 获取安装说明。
克隆仓库:
git clone https://github.com/shyamsaktawat/OpenAlpha_Evolve.git cd OpenAlpha_Evolve设置虚拟环境(推荐):
python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate安装依赖项:
pip install -r requirements.txt设置环境变量(对 API 密钥至关重要):
- 此步骤对于应用程序正确使用您的 API 密钥至关重要。
.env文件存储您的敏感凭据和配置,覆盖config/settings.py中的默认占位符。 - 通过复制示例创建您的个人环境文件:
cp .env_example .env
LLM 配置
Google Cloud 认证(例如,通过应用程序默认凭证 (ADC) 或由
GOOGLE_APPLICATION_CREDENTIALS指向的服务账号密钥)是使用 Google 大语言模型 (LLM) 的一种支持方法。要为 Google Cloud 设置环境变量,您可以使用以下任一方法。这些应添加到您的
.env文件中:# For Google Cloud (Vertex AI / AI Studio) # Option 1: Using Application Default Credentials (ADC) # Ensure you have authenticated via gcloud CLI: # gcloud auth application-default login # Or set the GOOGLE_APPLICATION_CREDENTIALS environment variable: # GOOGLE_APPLICATION_CREDENTIALS="/path/to/your/service-account-key.json" # Option 2: Directly using an API Key for specific Google services (e.g., Gemini API) # GEMINI_API_KEY="your_gemini_api_key"本项目使用 LiteLLM 来接口连接各种 LLM 提供商。对于 Google Cloud 以外的提供商(例如 OpenAI, Anthropic, Cohere),请参阅 LiteLLM 文档 以了解所需的具体环境变量。常见示例包括:
# OPENAI_API_KEY="your_openai_api_key" # ANTHROPIC_API_KEY="your_anthropic_api_key" # COHERE_API_KEY="your_cohere_api_key"将您选择的 LLM 提供商所需的必要 API 密钥变量添加到您的
.env文件中。- 此步骤对于应用程序正确使用您的 API 密钥至关重要。
运行 OpenAlpha_Evolve! 使用以下命令运行示例任务(Dijkstra 算法):
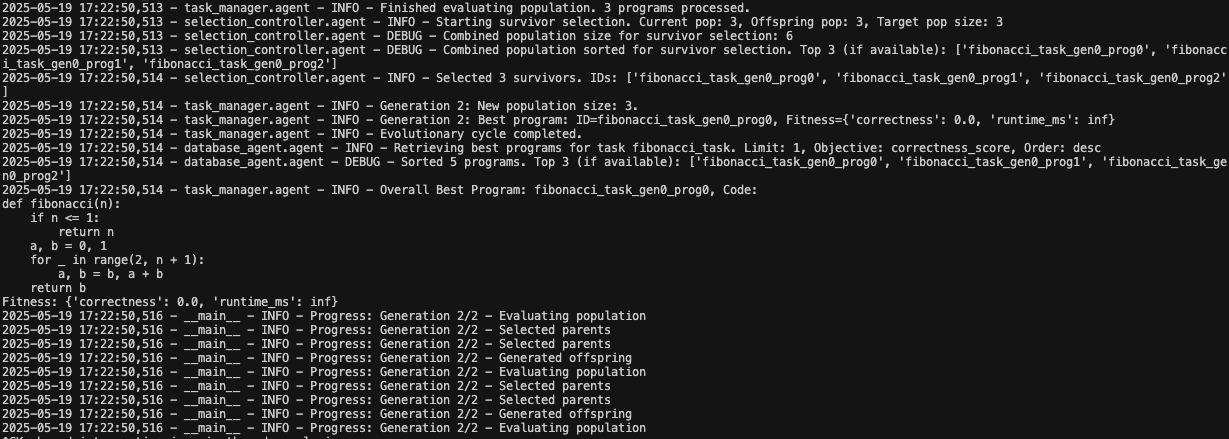
python -m main examples/shortest_path.yaml在终端中查看日志以观察进化过程的展开!日志文件也默认保存到
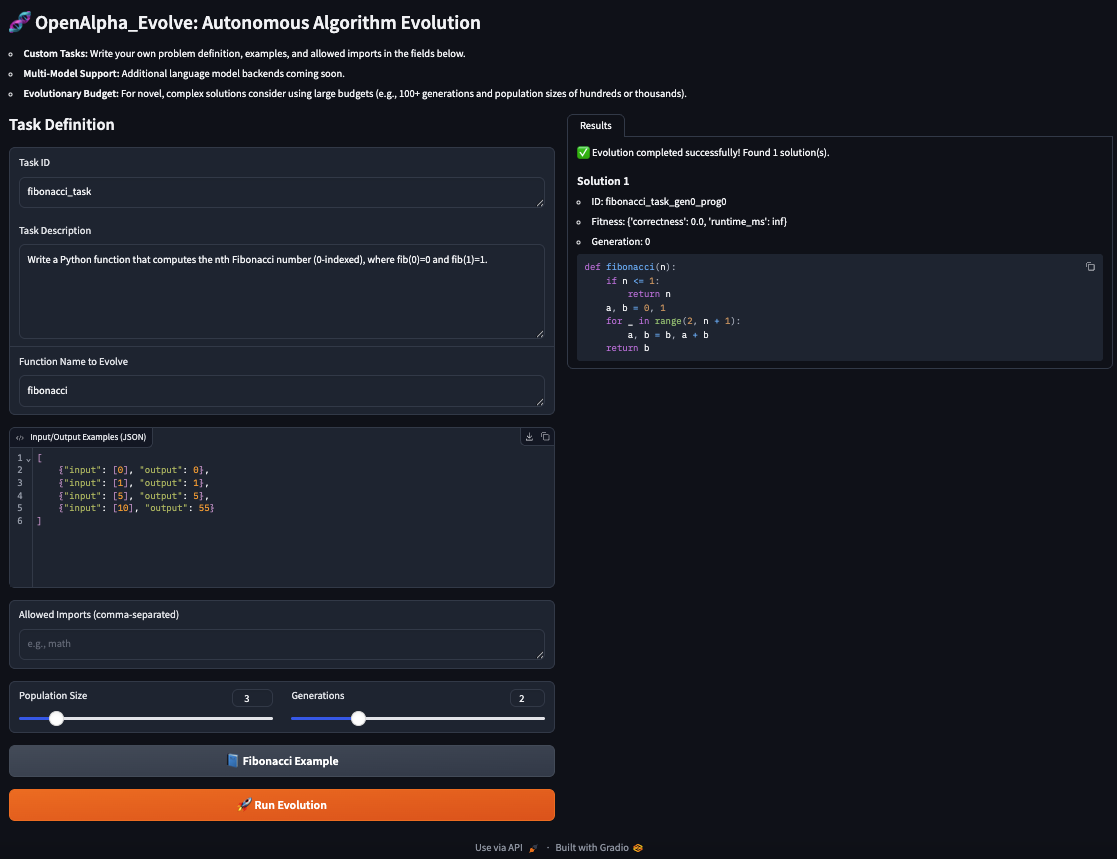
alpha_evolve.log。启动 Gradio Web 界面 通过 Web 用户界面 (Web UI) 与系统交互。要启动 Gradio 应用:
python app.pyGradio 将显示一个本地 URL(例如 http://127.0.0.1:7860)以及如果启用了公共分享链接。在浏览器中打开它以定义自定义任务并交互式地运行进化过程。
💡 定义您自己的算法挑战!
想用新问题挑战 OpenAlpha_Evolve 吗?这很简单!您可以通过两种方式定义您的任务:
1. 使用 YAML 文件(推荐)
在 examples 目录中创建一个具有以下结构的 YAML 文件:
task_id: "your_task_id"
task_description: |
Your detailed problem description here.
Be specific about function names, expected behavior, and constraints.
function_name: "your_function_name"
allowed_imports: ["module1", "module2"]
tests:
- description: "Test group description" # Describes a group of related tests
name: "Test group name" # A name for this test group
test_cases: # This should be a list of individual test cases
- input: [arg1, arg2] # First test case
output: expected_output # Expected result for this input
# Each test case uses either 'output' for direct comparison
# or 'validation_func' for more complex validation.
- input: [arg_for_validation_func_1, arg_for_validation_func_2] # Second test case
validation_func: |
def validate(output_from_function):
# Custom validation logic for this specific test case's output
# For example, check if output is within a certain range,
# or if it has specific properties.
return isinstance(output_from_function, bool) and output_from_function is True
参见 examples/shortest_path.yaml 中的示例
2. 使用 Python 代码(旧版)
您仍然可以使用 TaskDefinition 类以编程方式定义任务:
from core.task_definition import TaskDefinition
task = TaskDefinition(
id="your_task_id",
description="Your detailed problem description",
function_name_to_evolve="your_function_name",
input_output_examples=[
{"input": [arg1, arg2], "output": expected_output},
# More examples...
],
allowed_imports=["module1", "module2"]
)
任务定义的最佳实践
制定有效的任务定义是成功引导 OpenAlpha_Evolve 的关键。请考虑以下建议:
- 清晰且无歧义:撰写任务描述时,仿佛向另一位开发者解释问题一样。尽量避免行话,或者清晰地解释它们。
- 提供多样且全面的示例:测试用例是智能体 (Agent) 验证其生成代码的主要方式。
- 包含典型用例
- 覆盖边界情况(空输入、边界值等)
- 包含测试不同逻辑路径的示例
- 对于复杂检查使用验证函数
- 从简单开始,然后增加复杂度:首先将复杂问题分解为更简单的版本。
- 指定约束和边界情况:在描述中提及具体的约束和边界情况。
- 定义预期的函数签名 (Function Signature):清楚地说明预期的函数名称和参数。
- 迭代与优化:根据智能体 (Agent) 的表现审查并优化你的任务定义。
🔮 展望:未来演进
🤝 加入演进:贡献指南
这是一个开放的协作邀请!无论你是 AI 研究人员、Python 开发者,还是仅仅是一个爱好者,都欢迎你的贡献。
- 报告 Bug (缺陷):发现问题了吗?请在 GitHub 上创建一个 Issue (问题)!
- 建议功能:有让 OpenAlpha_Evolve 变得更好的想法吗?打开一个 Issue (问题) 来讨论它!
- 提交拉取请求 (Pull Requests):
- Fork (分叉) 仓库。
- 为你的功能或修复创建新分支(
git checkout -b feature/your-feature-name)。 - 编写清晰、文档完善的代码。
- 如果适用,为你的更改添加测试。
- 确保你的更改不会破坏现有功能。
- 提交一个带有清晰更改描述的拉取请求 (Pull Request)!
让我们一起进化这个智能体 (Agent)!
📜 许可证
本项目采用 MIT 许可证 授权。详细信息请参阅 LICENSE.md 文件。
🙏 致谢
OpenAlpha_Evolve 自豪地受到 Google DeepMind 团队在 AlphaEvolve 以及其他基于大语言模型 (LLM) 的代码生成和自动发现相关研究的开创性工作的启发。本项目旨在使核心概念更容易被广泛实验和学习。我们站在巨人的肩膀上。
免责声明:这是一个实验性项目。生成的代码可能并不总是最优、正确或安全的。请务必彻底审查和测试代码,特别是在将其用于生产环境之前。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。