FSA-Net
FSA-Net 是一款轻量级头部姿态估计开源模型,只需一张普通 RGB 照片就能实时输出人脸的俯仰、偏航、滚转三个角度。它摆脱了传统方法对关键点或深度图的依赖,把“精细结构聚合”思想引入特征融合:先按空间关系把特征图拆成若干局部区域,再动态加权汇总,既保留细节又大幅压缩计算量。实验显示,在公开数据集上其精度优于 Hopenet 等主流方案,而模型大小只有后者的 1/100,单张 GTX-1080Ti 即可跑 30 FPS 以上。
适合计算机视觉研究者、AR/VR 开发者、人机交互设计师以及想做人脸朝向检测的开发者快速集成;附带的 SSD/MTCNN 人脸检测 demo 也让普通用户能直接用摄像头体验。
使用场景
一家做线上少儿英语教育的初创公司,准备在 iPad 端推出“AI 纠音”功能:孩子对着摄像头朗读时,系统实时判断其头部朝向,若长时间低头或左顾右盼就弹出提醒,以保证注意力集中。
没有 FSA-Net 时
- 用传统人脸关键点 + 3D 姿态解算,iPad Air 2 上帧率只有 8 FPS,孩子一动就卡顿。
- 关键点抖动导致误判,孩子稍微低头 5° 就被系统判定“走神”,频繁弹窗打断课堂。
- 模型 120 MB,App Store 下载包体超标,用户投诉“更新一次 200 MB”。
- 多人课堂场景下,老师和孩子同框,算法把老师的姿态也算进去,界面乱成一团。
使用 FSA-Net 后
- 单帧 RGB 直接回归姿态,iPad Air 2 稳定 28 FPS,动画流畅无掉帧。
- 误差从 ±6° 降到 ±2°,只在真正偏头 15° 以上才提醒,误报率下降 80%。
- 模型仅 1.2 MB,整包瘦身 90%,4G 用户也能秒下。
- 内置 SSD 人脸检测,自动锁定最近一张儿童脸,老师入镜也不干扰。
FSA-Net 让“AI 纠音”在低端平板上也能低延迟、高精度地守护孩子的注意力。
运行环境要求
- Linux
需要 NVIDIA GPU,推荐 GTX-1080Ti 或更高,CUDA 8.0,cuDNN 7.1.3
未说明

快速开始
FSA-Net
[CVPR19] FSA-Net:基于单张图像的细粒度结构聚合学习,用于头部姿态估计
代码作者:杨孙毅
【更新信息】
- 2019年10月6日:再次向【Kapil Sachdeva】(https://github.com/ksachdeva)致以衷心的感谢!我们已成功替换 Keras 的 Lambda 层,并支持将 tf 预训练模型 转换为 TensorFlow 模型!
- 2019年9月27日:对模型代码进行了重构。由【Kapil Sachdeva】(https://github.com/ksachdeva)贡献了极其优美且简洁的代码。
- 2019年8月30日:演示版本更新!新增了鲁棒且高效的 SSD 人脸检测器!
对比视频
(基准方法 Hopenet:https://github.com/natanielruiz/deep-head-pose)

(全新!!!)快速且稳健的 SSD 人脸检测器演示(2019年8月30日)
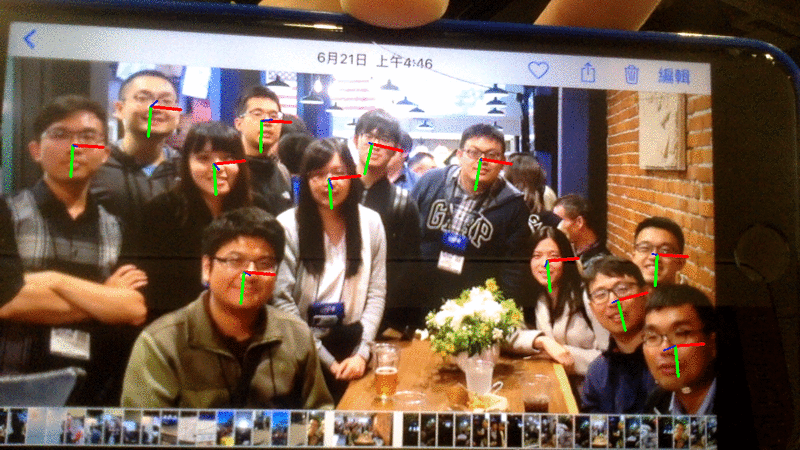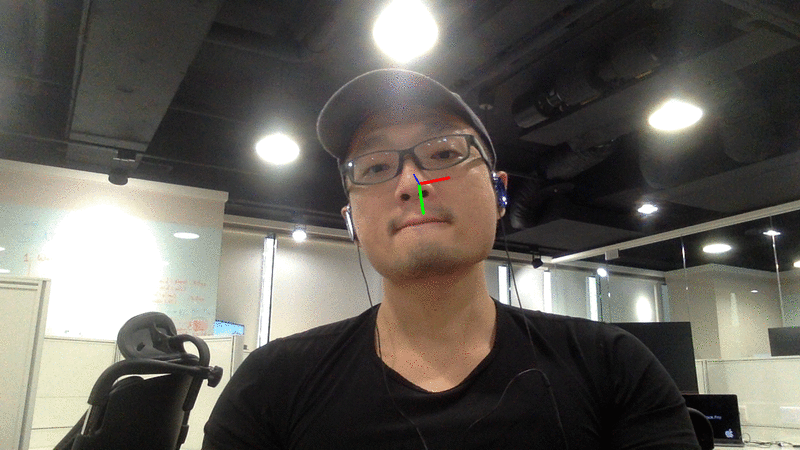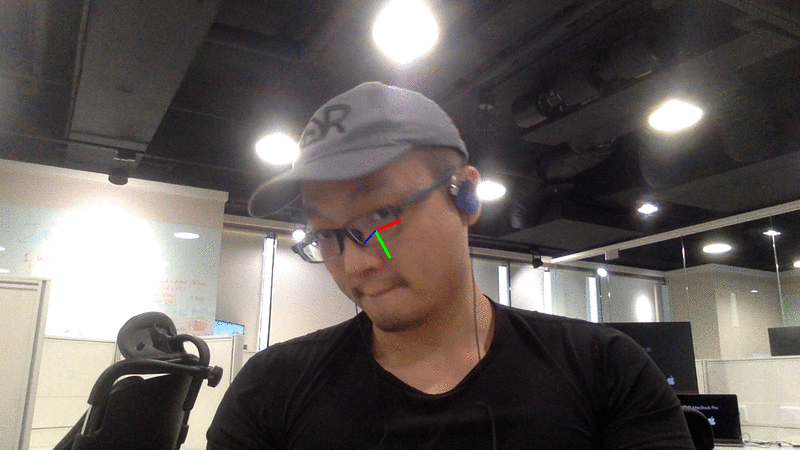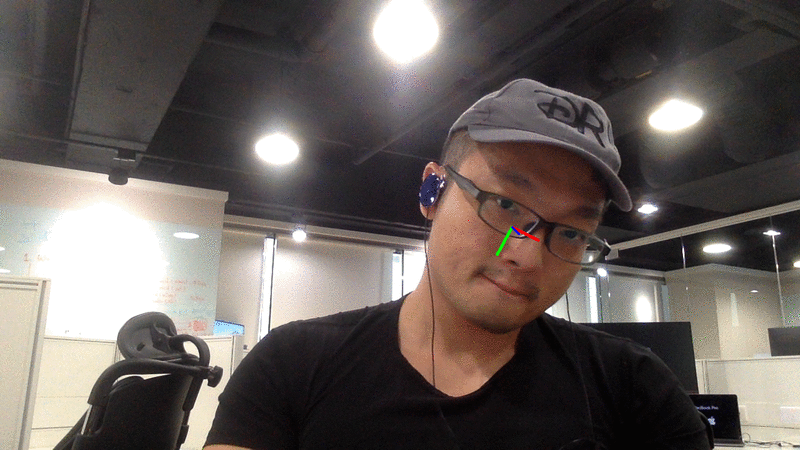
网络摄像头演示
| 单人场景(LBP) | 多人场景(MTCNN) |
|---|---|
 |
 |
| 时间序列 | 细粒度结构 |
|---|---|
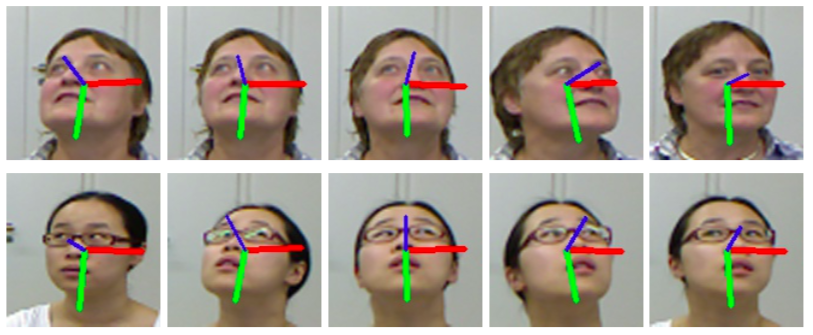 |
 |
结果
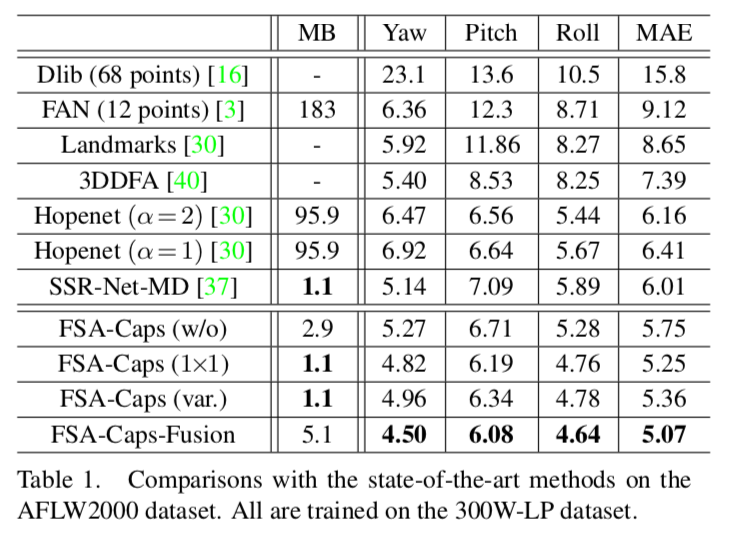
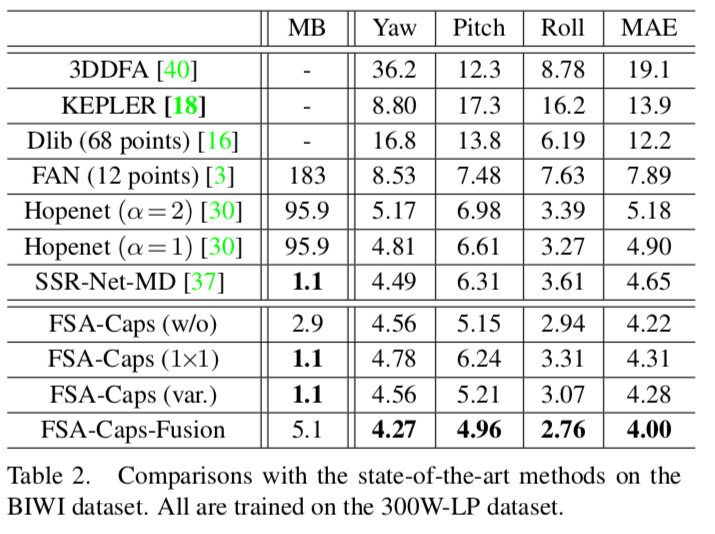
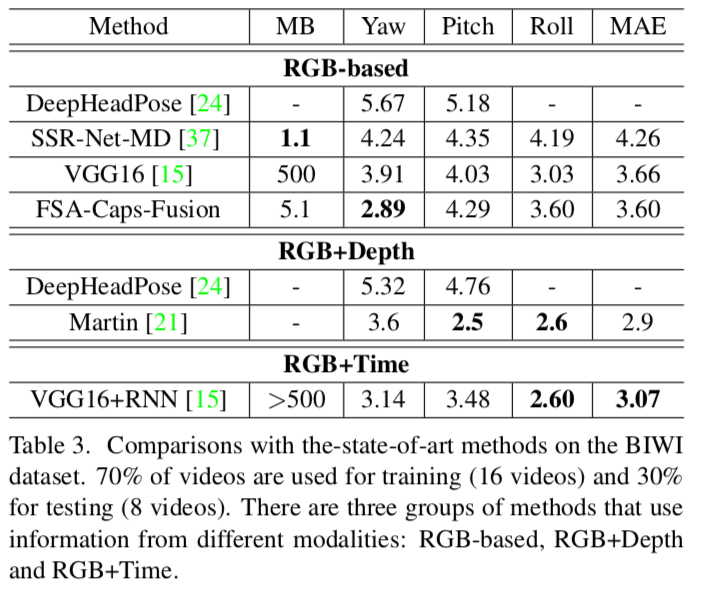
论文
https://github.com/shamangary/FSA-Net/blob/master/0191.pdf
论文作者
摘要
本文提出了一种基于单张图像进行头部姿态估计的方法。以往的方法往往通过地标或深度估计来预测头部姿态,而这些方法往往需要额外的计算资源,远超实际需求。我们的方法以回归和特征聚合为基础。为了构建一个更轻量化的模型,我们采用了软分段回归方案。现有的特征聚合方法通常将输入视为一组特征,因此忽略了特征图中各特征之间的空间关系。我们提出了一种学习细粒度结构映射的方法,通过在特征聚合前对特征进行空间分组。细粒度结构能够提供基于部分的信息以及聚合后的值。通过利用可学习与不可学习的权重,针对空间位置进行差异化设计,我们可以生成多种互补的模型组合。实验结果表明,我们的方法在性能上优于当前最先进的方法,包括无地标方法以及基于地标或深度估计的方法。仅使用一帧 RGB 图像作为输入,我们的方法在估计yaw角时甚至超越了采用多模态信息(RGB-D、RGB-Time)的方法。此外,所提出的模型的内存开销比以往方法减少了 100 倍。
平台
- Keras
- TensorFlow
- GTX-1080Ti
- Ubuntu
python 3.5.6 hc3d631a_0
keras-applications 1.0.4 py35_1 anaconda
keras-base 2.1.0 py35_0 anaconda
keras-gpu 2.1.0 0 anaconda
keras-preprocessing 1.0.2 py35_1 anaconda
tensorflow 1.10.0 mkl_py35heddcb22_0
tensorflow-base 1.10.0 mkl_py35h3c3e929_0
tensorflow-gpu 1.10.0 hf154084_0 anaconda
cudnn 7.1.3 cuda8.0_0
cuda80 1.0 0 soumith
numpy 1.15.2 py35_blas_openblashd3ea46f_0 [blas_openblas] conda-forge
numpy-base 1.14.3 py35h2b20989_0
依赖项
- 一份关于大部分依赖项的指南。(中文版) http://shamangary.logdown.com/posts/3009851
- Anaconda
- OpenCV
- MTCNN
pip3 install mtcnn
- Capsule:https://github.com/XifengGuo/CapsNet-Keras
- Loupe_Keras:https://github.com/shamangary/LOUPE_Keras
代码
本项目共分为三个主要部分:
- 数据预处理
- 训练与测试
- 演示
接下来,我们将逐一详细讲解各个部分的内容。
本仓库适用于 300W-LP、AFLW2000 和 BIWI 数据集。
1. 数据预处理
【献给像我这样懒惰的人】
如果你不想重新下载每一份数据集的图片并重复进行预处理,或者你甚至并不在意文件夹中的数据结构,只需从以下链接下载 data.zip 文件,并将数据文件夹替换为该文件即可。
现在,你可以直接跳转到“训练与测试”阶段。
【详细说明】
在论文中,我们定义了 协议 1 和 协议 2。
# 协议 1
训练:300W-LP(包含多个子集:{AFW.npz, AFW_Flip.npz, HELEN.npz, HELEN_Flip.npz, IBUG.npz, IBUG_Flip.npz, LFPW.npz, LFPW_Flip.npz})
测试:AFLW2000.npz 或 BIWI_noTrack.npz
# 协议 2
训练:BIWI(70%)→ BIWI_train.npz
测试:BIWI(30%)→ BIWI_test.npz
(请注意,类型 1(300W-LP、AFLW2000)的数据集图像排列方式相同,我将其归类为 类型 1。这与协议 1 或协议 2 无关。)
如果你想从头开始进行预处理,请先下载数据集。
下载数据集
- 【300W-LP、AFLW2000】(http://www.cbsr.ia.ac.cn/users/xiangyuzhu/projects/3DDFA/main.htm)
- 【BIWI】(https://data.vision.ee.ethz.ch/cvl/gfanelli/head_pose/head_forest.html)
将 300W-LP 和 AFLW2000 文件夹放置于 data/type1/ 目录下,将 BIWI 文件夹放置于 data/ 目录下。
运行预处理
# 对于 300W-LP 和 AFLW2000 数据集
cd data/type1
sh run_created_db_type1.sh
# 对于 BIWI 数据集
cd data
python TYY_create_db_biwi.py
python TYY_create_db_biwi_70_30.py
2. 训练与测试
# 训练
sh run_fsanet_train.sh
# 测试
# 请注意,我们分别计算 yaw、pitch、roll 的 MAE,然后将它们平均为单一的 MAE 以进行评估。
sh run_fsanet_test.sh
只需在 Shell 脚本中确认自己想要使用的模型类型,一切就绪。
3. 演示
要正确处理演示文件,您需要一台网络摄像头。
请注意,颜色轴的中心即为检测到的人脸中心。 理想情况下,每一张帧都应包含新的面部检测结果。 然而,如果面部检测失败,则会沿用之前的检测结果来估算人脸姿态。
LBP 在实时面部检测中速度足够快;而 MTCNN 虽然精度更高,但速度较慢。
(2019年8月30日更新!)SSD 面部检测既稳健又快速!我从 https://www.pyimagesearch.com 处借用了部分面部检测器代码。
# LBP 面部检测器(速度快,但往往容易漏检人脸)
cd demo
sh run_demo_FSANET.sh
# MTCNN 面部检测器(速度慢,但精度高)
cd demo
sh run_demo_FSANET_mtcnn.sh
# SSD 面部检测器(速度快且精度高)
cd demo
sh run_demo_FSANET_ssd.sh
4. 转换为 TensorFlow 模型图
cd training_and_testing
python keras_to_tf.py --trained-model-dir-path ../pre-trained/300W_LP_models/fsanet_var_capsule_3_16_2_21_5 --output-dir-path <your_output_dir>
上述命令会将 TensorFlow 模型图生成至 <your_output_dir>/converted-models/tf/fsanet_var_capsule_3_16_2_21_5.pb 目录下。
模块说明:
ssr_G_model: https://github.com/shamangary/FSA-Net/blob/master/lib/FSANET_model.py#L441
- 采用双流结构来提取特征。
ssr_feat_S_model: https://github.com/shamangary/FSA-Net/blob/master/lib/FSANET_model.py#L442
- 通过不同评分函数生成细粒度的结构映射。
- 将这些映射应用于特征,并生成主胶囊。
ssr_aggregation_model: https://github.com/shamangary/FSA-Net/blob/master/lib/FSANET_model.py#L443
- 将主胶囊输入胶囊层,输出最终的聚合胶囊特征,并将其划分为三个阶段。
ssr_F_model: https://github.com/shamangary/FSA-Net/blob/master/lib/FSANET_model.py#L444
- 以先前三个阶段的特征作为输入,进行软步进回归(SSR)模块的处理。每个阶段进一步拆分为三个子部分:预测、动态索引偏移以及动态缩放。如需了解更多细节,请参阅 '[IJCAI18] SSR-Net'。
SSRLayer: https://github.com/shamangary/FSA-Net/blob/master/lib/FSANET_model.py#L444
- 以预测、动态索引偏移和动态缩放作为最终回归输出的输入。 在本例中,共有三个输出值: yaw、pitch 和 roll。
第三方实现
使用 FSANet ONNX 格式打造的超棒 VR 飞行模拟
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。